DataHarmonizer Templates OLD data.js version
This documentation is for DataHarmonizer 0.15.5 and earlier. For version 1.0.0 and later, see the DataHarmonizer LinkML Templates.
Spreadsheet templates are located under the /templates/ folder, one subfolder per template. A template typically includes:
| file | description |
|---|---|
| data.tsv | A text file containing a specification for a spreadsheet template, which handles all columns and sections of columns for the spreadsheet. This can be a direct copy of a google spreadsheet for example, for easy workgroup management of template content. |
| data.js | A file containing the spreadsheet template in json format which DataHarmonizer main.html loads directly. Run the command-line /script/make_data.py program within the template folder to create or update the data.js file. Example MacOS/Linux: python ../../script/make_data.py
|
| reference.html | An HTML page that provides template column documentation in readable report format. The DataHarmonizer template menu system has a link to this. |
| reference_template.html | An HTML formatted page template which is used by make_data.py to generate reference.html. Title, descriptive text and styling (via doc.css) can all be customized for this report. The "{html}" search and replace expressing is all that make_data.py adjusts. There is a generic /template/reference_template.html that can be copied into a new template and modified. |
| doc.css | An HTML style sheet (css) used to style reference.html |
| export.js | There are inevitably export data transformation cases that DataHarmonizer's generic field export options can't handle. For this custom coding in an export.js file is required. |
Other files can be included the template folder as desired. DataHarmonizer software is not involved in the creation of these files, so they must be manually updated as the template evolves. For example:
| file | description |
|---|---|
| SOP.pdf | Statement of Procedure document. |
| exampleInput/ | A folder containing spreadsheet data that tests validation success or failure cases. |
data.tsv template columns provide DataHarmonizer with all the textual, datatype and other information used to compose each column of a user-editable spreadsheet. This file can be a bit delicate in terms of certain character content:
- Ensure that column fields of data.tsv don't have extra carriage returns as these likely will cause errors by make_data.py in converting to data.js json file. These can be detected when viewing data.tsv by seeing if text from one row appears on next row even when "word wrap" feature is turned off in a text editor - an indication that a carriage return is in content of a spreadsheet cell text value.
- As well, although UTF8 characters are generally acceptable, it helps to normalize any quotes or dashes in column header or field text to basic - and " quotes.
- The data.tsv template's first row contains DataHarmonizer column names.
- Optional: the second row contains Robot template commands that enable the template to be compiled into an ontology .owl format as a possibly useful data product.
- No values need to be in this row if no .owl output is needed.
- If an .owl file is generated by running Robot on data.tsv, note that Robot will only include fields and terms that have rows that have an Ontology ID column field value.
- Remaining rows detail spreadsheet template column specifications, or categorical selection list items within those columns.
These are currently a custom set of fields specific to DataHarmonizer, but DataHarmonizer will be upgraded to use the LinkML specification in the near future
Note column field help info provided by some fields below (which includes description, guidance, and examples) is available when user double clicks on column header.
| field | description |
|---|---|
| Ontology ID | Optional ontology term identifier, if available, for the column field or select value. Can be a long purl, or in short form as prefix:ID, which the robot command can handle if it is in this OBO Foundry friendly list. |
| parent class | A textual name which is a section name for a spreadsheet column, or parent term of a select list item |
| label | 1) The name of a section - if the term has no parent class; 2) the name of a column field / header, if the parent class is a section; 3) the label of a select field value. |
| datatype | The acceptable data entry type for this field. See datatypes below. |
| source | Used to name a select list field that row's select list should be replicated from. For example, a "citizenship" select field sourced from a "country of birth" select list of countries. |
| data status | A customizable list of additional metadata select options to include with given (select or numeric or text) input field to indicate if a value was missing, not collected, etc. Format: semicolon separated list of options. Options are also displayed in column help info. |
| requirement | Indicates data entry recommended or required status for field, which also controls colour coding and visibility options of column header Options: "required" (header shown in yellow) or "recommended" (header shown in purple). |
| min value | Minimum value to validate numeric or date field entry by. See max value description for special {term} substitution tests. |
| max value | Maximum value to validate numeric or date field entry by. For both min and max value, a special "{today}" entry will on validation have entered date compare to the current day. For max value, if date is after current day, validation will fail. Similarly, one can test against another field's date content by entering {date field name} i.e. a date field name in set brackets, and this field's entry will be validated as greater or less than given field's value, if any. |
| capitalize | On data entry or validation, capitalize field content according to setting. Leaves text unchanged when no value is provided. Options: lower / UPPER / Title |
| pattern | A regular expression to validate a field's textual content by. Include ^ and $ start and end of line qualifiers for full string match. Example simple email validation: ^\S+@\S+.\S+$ |
| description | Helpful description of what field is about. Available in column help info. |
| guidance | Data entry guidance for a field. Available in column help info. |
| examples | Data entry examples. Available in column help info. |
| EXPORT_[export format keyword] | Any field that begins with "EXPORT_" prefix supplies information about an [export format keyword] format that DataHarmonizer can export the template's data to. Details below. |
| remaining fields ... | DataHarmonizer does not use any other fields, but template managers may include them for the robot .owl output content or other purposes. |
The datatype column mentioned above accepts the following values:
| datatype | description |
|---|---|
| xs:token | An XML string |
| xs:unique | A xs:token which should be unique in a dataset. Good for validating sample identifiers for example |
| xs:date | An XML date |
| select | A field with a pulldown menu of selection options. This will appear as a hierarchy if each selection option listed later in sheet has a parent term in the same list. |
| multiple | A field with a popup menu allowing multiple selection/deselection of items in a given hierarchy of terms. |
| xs:nonNegativeInteger | An integer >= 0 |
| xs:decimal | A decimal number |
| provenance | Marks a field that when validated, automatically receives a prefix of "DataHarmonizer provenance: vX.Y.Z" in addition to its existing content. |
Often the date or date and time of an event such as sample collection is recorded to some degree of precision. However database date and datetime types usually don't have any formal way of incorporating that precision information. We have provided one way of enabling precision to be specified which also causes entered dates to be normalized to some extent on loading of a dataset. The mechanism is fairly simple: if a specification supplies an ISO 8601 date field, like "sample collection date" then if one also includes the same field with a " unit" suffix, i.e. "sample collection date unit", then DH will take this as a signal to apply the following normalization mechanism:
The image below shows that date formatting is being normalized row-by-row to the YYYY-01-01 or YYYY-MM-01 or YYYY-MM-DD degree of precision based on other field's " precision" setting. This approach supports dates destined for database date fields, that need date comparison for order at least, and in a sense matching granularity, e.g. year entries will match perfectly, month ones will too, etc.
Here is the spreadsheet data before it gets opened in DataHarmonizer:
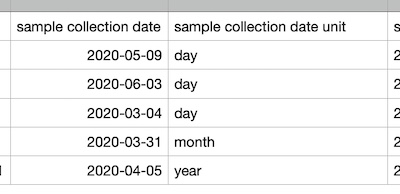
When it is opened in DH, the dates get adjusted to match granularity:
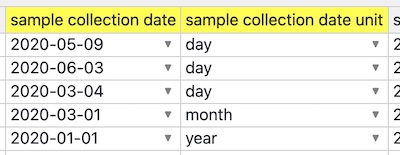
As well if some dates can't be matched to granularity (say month is missing but that's the granularity set) then DH will currently put an "__" underscore value in appropriate position in date so that validation trips and user is drawn to specify the desired granularity. For example if "month" is granularity unit, but given date is just year "2020", then entry will be converted to "2020-__-01", thus triggering validation error.
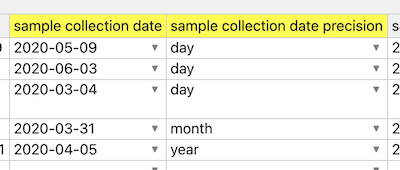
If one simply name the "date ... unit" field to have a different suffix, like "... precision", then the whole automatic normalization (to first day of month, or first month) process is skipped:
Code portions of this solution involve the setDateChange() function. This doesn't currently handle time precision however.
Often there is a need to specify a number specifically, such as an age at time of sample collection, but at the same time offer a range of bin entries for the same datum, for data normalization between databases or for preserving privacy through aggregation. DataHarmonizer has a mechanism for simplifying the data entry involved in such work by allowing a numeric field, such as "age", to be followed by an optional "unit" (such as a pulldown menu including "month" and "year"), followed by a select menu of numeric ranges, each of which is a string of text containing leading and tailing integers that can be parsed into the ranges that the single numeric field can be validated within. On dataset load, and on data entry, the bin will be updated in accordance with the numeric field and unit field entries automatically.
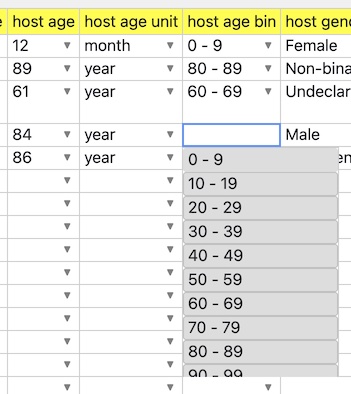
The key to activating this functionality is in the field names. Given a field name "X", having special field names "X unit", and "X bin" will trigger this function. The unit field is optional, and is a bit of a hack. If one includes "month" in it, then the numeric field entry will be multiplied by 12 (months) in order to find the right bin to fit it in. In the future a better way of providing semantics and field connectivity will be offered.
Template specification columns that are named EXPORT_[export format keyword] (e.g. EXPORT_GSAID) get translated into a simple export format data structure associated with each applicable template column field in data.js.
If the export format keyword is listed in main.js at top in the TEMPLATES dictionary, its dictionary key becomes a menu option under the DataHarmonizer "Export To ..." menu list.
- For DataHarmonizer template column field specifications, a value in an EXPORT_[export format keyword] column field is treated as an export format column name to export the template spreadsheet's column field data to.
- Similarly, for template select and multiple select values, a value in an EXPORT_[export format keyword] will cause a source field to be transformed into given target export field.
Two additional features enable many common transform tasks:
- A semicolon ";" symbol existing in an EXPORT_ field value will cause the source template's field value to be channeled to the multiple export fields separated by the semicolon. If an export field target is mentioned on multiple field specification rows of the template, then the values of the source fields, if any, will be concatenated into the export target field, in order (with delimiters as placeholders for any empty component values).
- In addition, if a targeted export field is specified as a key:value pair, i.e. "[export field name]:[string]" format, then the input field value will be transformed to the given export string value. This allows conversion of values from source to export, and is pertinent to selection lists choices that vary across systems but which are semantically equivalent.
There are inevitably export data transformation cases that the above functionality can't handle. For this custom coding in an export.js file is required. Documentation on this coming soon!
A number of templates are hard-coded into the DataHarmonizer menu system (see TEMPLATE dictionary at top of main.js), but one can load a template that is not in the menu by using the following URL pattern with "template" parameter:
//[path to DataHarmonizer app folder]/DataHarmonizer/main.html?template=[template folder name]
For example, local file reference
file:///Users/[path to DataHarmonizer app folder]/DataHarmonizer/main.html?template=gisaid
or web URL
http://genepio.org/DataHarmonizer/main.html?template=gisaid
can be used to access the GISAID template (currently in ALPHA version) in the DataHarmonizer /template/gisaid/ folder.
This enables development and use of customized or new templates.