{kind=link}
{kind=link}
A PyTorch implementation of Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis. Audio samples can be found here. Colab demo can be found here.
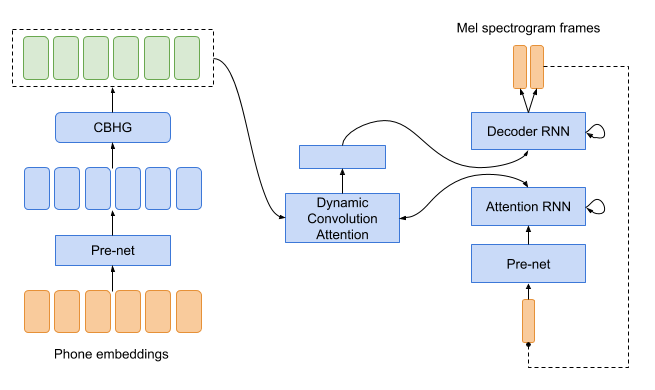
Fig 1:Tacotron (with Dynamic Convolution Attention).

Fig 2:Example Mel-spectrogram and attention plot.
Ensure you have Python 3.6 and PyTorch 1.7 or greater installed. Then install this package (along with the univoc vocoder):
pip install tacotron univoc
import torch
import soundfile as sf
from univoc import Vocoder
from tacotron import load_cmudict, text_to_id, Tacotron
# download pretrained weights for the vocoder (and optionally move to GPU)
vocoder = Vocoder.from_pretrained(
"https://github.com/bshall/UniversalVocoding/releases/download/v0.2/univoc-ljspeech-7mtpaq.pt"
).cuda()
# download pretrained weights for tacotron (and optionally move to GPU)
tacotron = Tacotron.from_pretrained(
"https://github.com/bshall/Tacotron/releases/download/v0.1/tacotron-ljspeech-yspjx3.pt"
).cuda()
# load cmudict and add pronunciation of PyTorch
cmudict = load_cmudict()
cmudict["PYTORCH"] = "P AY1 T AO2 R CH"
text = "A PyTorch implementation of Location-Relative Attention Mechanisms For Robust Long-Form Speech Synthesis."
# convert text to phone ids
x = torch.LongTensor(text_to_id(text, cmudict)).unsqueeze(0).cuda()
# synthesize audio
with torch.no_grad():
mel, _ = tacotron.generate(x)
wav, sr = vocoder.generate(mel.transpose(1, 2))
# save output
sf.write("location_relative_attention.wav", wav, sr)- Clone the repo:
git clone https://github.com/bshall/Tacotron
cd ./Tacotron
- Install requirements:
pipenv install
- Download and extract the LJ-Speech dataset:
wget https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2
tar -xvjf LJSpeech-1.1.tar.bz2
- Download the train split here and extract it in the root directory of the repo.
- Extract Mel spectrograms and preprocess audio:
pipenv run python preprocess.py path/to/LJSpeech-1.1 datasets/LJSpeech-1.1
usage: preprocess.py [-h] in_dir out_dir
Preprocess an audio dataset.
positional arguments:
in_dir Path to the dataset directory
out_dir Path to the output directory
optional arguments:
-h, --help show this help message and exit
- Train the model:
pipenv run python train.py ljspeech path/to/LJSpeech-1.1/metadata.csv datasets/LJSpeech-1.1
usage: train.py [-h] [--resume RESUME] checkpoint_dir text_path dataset_dir
Train Tacotron with dynamic convolution attention.
positional arguments:
checkpoint_dir Path to the directory where model checkpoints will be saved
text_path Path to the dataset transcripts
dataset_dir Path to the preprocessed data directory
optional arguments:
-h, --help show this help message and exit
--resume RESUME Path to the checkpoint to resume from
Pretrained weights for the LJSpeech model are available here.
- Trained using a batch size of 64 on a single GPU (using automatic mixed precision).
- Used a gradient clipping threshold of 0.05 as it seems to stabilize the alignment with the smaller batch size.
- Used a different learning rate schedule (again to deal with smaller batch size).
- Used 80-bin (instead of 128 bin) log-Mel spectrograms.