
Upstage OCR API로부터 추출한 OCR 정보를 알맞게 분류하는 Post OCR Parsing Task
* OCR (Optical Character Recognition) : 텍스트 이미지를 기계가 읽을 수 있는 문자로 변환하는 과정입니다.
* Post OCR Parsing : 텍스트 이미지의 OCR 결과를 기반으로, 해당 이미지 내에서 얻고자 하는 정보를 추출하는 과정입니다.
Dataset
개인정보가 포함된 명함 인쇄물의 특성상, 크롤링하여 수집할 경우 개인정보 보호 이슈가 발생할 것이라고 생각했습니다.
또한, 직접 수집할 경우, 모델이 학습하기에 충분한 양의 데이터를 구축하기 어려울 것이라고 판단하여 데이터를 직접 생성하는 것으로 결정했습니다.
Feature Engineering
OCR API로부터 전달받은 결과로부터, 명함 이미지 특성에 맞는 feature들을 생성해주는 작업이 필요했습니다.
받은 정보인 bounding box 좌표와 해당 text 정보를 이용해 feature들을 생성해주었습니다.
Model
- CNN (image data) + MLP (tabular data)
실제 명함 이미지를 조사한 결과, 명함 내 정보 위치와 글자 크기가 특정한 정보를 강조하기 위한 형태를 이루고 있다고 판단했습니다.
이를 토대로 Computer Vision 관점에서 명함 Image data와 함께, 명함 내 정보의 위치관계와 같은 Tabular data를 이용한 모델을 적용했습니다.
- NER
명함 정보 분류를 위해 자연어 처리의 개체명 인식 task 를 적용하면 성능 향상이 있을 것이라고 판단하여 NER Model 을 사용하였습니다.
한국어를 위한 KoBERT 모델에 Conditional Random Field (CRF) Layer가 추가된 KoBERT + CRF 기반의 Opensource NER Model 을 사용하였습니다.
한국어 개체명 태깅이 되어있는 Open dataset 을 통해 학습을 진행하였으며, 해당 Dataset은 사람 이름, 기관명, 시간, 날짜, 통화를 포함한 8개 category 가 존재하는 Dataset 이었습니다.
이 중에서 명함 정보 분류에 적용할 수 있는 사람 이름, 기관명 category에 대한 inference 결과값 만을 추출하고 적용하여 모델 성능을 향상시켰습니다.
기본적으로 추출해야 하는 이름/전화번호/이메일주소/직책의 4가지 카테고리를 포함하여, 총 10가지 (UNKNOWN 포함 11가지) 의 카테고리를 분류할 수 있습니다.
Accuracy
정보를 가진 모든 bounding box에 대해서 카테고리를 맞춘 비율로 평가 metric을 설정했습니다.
Result
train accuracy : 1
validation accuracy : 0.9945| Task | Description |
|---|---|
| Data Generation | 학습에 사용할 명함 이미지 데이터 + json 파일 생성 |
| Data Pre-processing | OCR API로부터 나온 결과를 모델이 학습하기에 적합하도록 전처리 |
| Model - CNN + MLP | Image data (CNN) 와 Tabular data (MLP) 를 모두 고려하여 학습하는 모델 |
| Model - NER | 학습된 모델을 통해 일부 feature의 category 분류 |
| Feature Engineering | 데이터의 특성을 고려한 feature 생성 |
| Frontend | Auto fix / Fix input 기능이 추가된, Streamlit으로 구현한 프로토타입 |
| Backend | FastAPI를 이용하여 3개의 분리된 모듈로 구현한 Backend(OCR API / CNN + MLP / NER) |

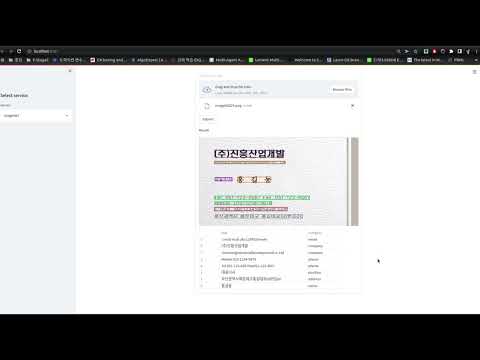
Demo Front-end는 Streamlit을 통해 구현하였습니다. Streamlit Front-end는 FastAPI 기반의 Back-end를 통해 출력물을 사용자에게 제공합니다.

- Data Pre-processing
사용자가 이미지를 제출하면, 가능한 경우 Back-end 서버에서 이미지의 각도와 범위를 보정합니다. 해당 이미지를 OCR API 서버로 요청하여 json output을 응답으로 받고, 출력된 정보를 조건에 따라 줄 단위로 변경합니다. - 전처리된 정보가 각 조건에 따라 모델 및 rule-base기반으로 처리되고, 출력값에 따라 각 항목의 category를 제공합니다.
- TBA
Learn More에 기록한 각 README 파일을 참고하여 필요한 라이브러리를 설치해주시면 됩니다.
ConVinsight(CV-05)는 Computer Vision의 이니셜인 'CV'와,
'이용자의 Convenience(편리)를 찾는 insight(통찰력)' 을 의미합니다.
| Member | Role | Github |
|---|---|---|
| 김나영 | OCR Output 전처리 / 데이터 생성 | Github |
| 신규범 | PM / 모델 설계 및 구현 / OCR Output 전처리 / 서비스 구현 | Github |
| 이정수 | Feature 설계 / 모델 학습 / Test 데이터셋 구현 | Github |
| 이현홍 | 데이터 생성 / 이미지 전처리 | Github |
| 전수민 | Feature 설계 / 모델 구현 및 모델 학습 / Test 데이터셋 구현 | Github |