本篇论文主要基于 IPL 的思想实现,并做出了一定的修改与补充。
感谢 IPL 作者的开源,BibTeX 引用如下:
@InProceedings{Guo_2023_CVPR,
author = {Guo, Jiayi and Wang, Chaofei and Wu, You and Zhang, Eric and Wang, Kai and Xu, Xingqian and Song, Shiji and Shi, Humphrey and Huang, Gao},
title = {Zero-Shot Generative Model Adaptation via Image-Specific Prompt Learning},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {11494-11503}
}conda create -n ipl python=3.8
conda activate ipl请确保 NVIDIA 驱动、CUDA 以及 PyTorch 之间版本互相匹配。
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install ftfy regex tqdm ninja
pip install git+https://github.com/openai/CLIP.git预训练的源域生成器可以通过 Google Drive 或者 Tsinghua Cloud 下载,并将其置于 ./pre_stylegan 文件夹中。
运行 web_ui/app.py,默认端口设置为 3000。
使用图像反演功能可以将用户自主选择的图像反演至 W 空间,进一步地可以进行为用户提供两个图像反演接口,反演编码器分别使用 e4e 和 pSp。
- e4e Encoder:运行
./inference_e4e.py - pSp Encoder:运行
./inference_psp.py
根据网络具体设置运行 ./train.py 或 ./train_improved.py 训练自己的零样本生成模型。
在第一阶段 batch_size 设置为 32、iteration 为 300,第二阶段 batch_size 设置为 2,iteration 为 300的情况下,使用以下移动端显卡训练耗时大致为 12 小时。
NVIDIA GeForce RTX 3060 Laptop GPU
驱动程序版本: 32.0.15.5585
驱动程序日期: 2024/5/13
DirectX 版本: 12 (FL 12.1)
物理位置: PCI 总线 1、设备 0、功能 0
专用 GPU 内存:6.0 GB
共享 GPU 内存:15.9 GB
一种可能的训练脚本参数如下所示:
--frozen_gen_ckpt
./pre_stylegan/stylegan2-ffhq-config-f.pt
--source_model_type
"ffhq"
--output_interval
100
--save_interval
100
--auto_compute
--source_class
"photo"
--target_class
"disney"
--batch_mapper
32
--lr_mapper
0.05
--iter_mapper
300
--ctx_init
"a photo of a"
--n_ctx
4
--lambda_l
1
--run_stage1
--run_stage2
--batch
2
--lr
0.002
--iter
300
--output_dir
./output/disney_improved注意,用户可能需要根据自己的需求更改部分参数,以及提示词模板(utils/text_templates.py)。
提供测试以及对比图生成脚本:
- ./eval.py
- ./comparison.py
ctx_init 参数用于初始化 prompts,官方提供的演示 context 是a photo of a。
source_prompts = [prompt_prefix + " " + args.source_class]
target_prompts = [prompt_prefix + " " + args.target_class]源域的初始提示词 source_prompts 是 ctx_init 与源域标签的组合。若源域标签为 photo,则源域的初始提示词是 a photo of a photo。目标域的初始提示词同理。
源域以及目标域的初始提示词接下来会进行 tokenize:
source_tokenized_prompts = torch.cat([clip.tokenize(p) for p in source_prompts]).to(device)
# (1, 77) 'sot a photo of a photo eot' 在经过tokenize后为tensor [[49406, 320, 1125, 539, 320, 1125, 49407, etc]]
# 77是CLIP在tokenize方法中缺省的context_length,超过context_length将被truncate,不足的将用0补齐
target_tokenized_prompts = torch.cat([clip.tokenize(p) for p in target_prompts]).to(device)
# (1, 77) 'sot a photo of a disney' 在经过tokenize后为tensor [[49406, 320, 1125, 539, 320, 4696, 49407, etc]]
# 77是CLIP在tokenize方法中缺省的context_length,超过context_length将被truncate,不足的将用0补齐tokenize 是 CLIP 对送入的 prompt 字符串进行标记化处理,在头部和尾部添加 startoftext 以及 endoftext 标记,最终为两个首尾标记和全部单词生成 int 标记。其中 CLIP 模型缺省的 context_length 是77,若 prompt 大于 77 会进行截断(truncate),若小于 77 会进行补零,因此 source_tokenized_prompts 与 target_tokenized_prompts 的形状均为 (1, 77)。
在提示词标记化之后,将进行嵌入表示 embedding:
source_embedding = clip_model.token_embedding(source_tokenized_prompts).type(clip_model.dtype)
# (1, 77, 512) 其中512是CLIP中的n_dim,token_embedding层的词嵌入的维度
target_embedding = clip_model.token_embedding(target_tokenized_prompts).type(clip_model.dtype)
# (1, 77, 512) 其中512是CLIP中的n_dim,token_embedding层的词嵌入的维度在 Mapper 生成 prompts 后进行 prompts 的特征提取时,需要传入 tokenize 之后的人工初始化 prompt(‘a photo of a photo.’或‘a photo of a disney.’),用于选择 eot 符号对应的维度来进行特征投影(因为 eot 作为整个句子的结尾,被认为该维度包含更多的信息。具体做法:由于在 tokenize 之后,eot 符号对应的维度的值最大,因此可使用 argmax 来定位),以保证最后得到的特征形状与图像特征提取的输出形状相同,使得后续可以进行对比学习的损失计算。
# Z空间到W空间的变换
sample_z = mixing_noise(args.batch_mapper, 512, args.mixing, device)
# (batch_size, 512)
sample_w = net.generator_frozen.style(sample_z)
# (batch_size, 512)Z 空间和 W 空间是 StyleGAN 模型中两种不同的隐变量空间,分别用于控制生成图像的随机特征和样式信息。W 空间通过对 Z 空间的映射得到。
-
Z 空间(Latent Space Z):
- Z 空间是随机噪声空间,通常由随机噪声向量组成,表示了图像的随机特征。
- 在 StyleGAN 中,Z 空间的维度通常为 512 维。这意味着一个 Z 向量由 512 个数字组成,每个数字表示了图像的一个随机特征的强度或者方向。
-
W 空间(Style Space W):
-
W 空间经过特征解耦的隐空间,与 Z 空间相比更加解耦合。
-
在 StyleGAN 中,W 空间的维度也通常为 512 维,是通过mapping network进行映射得到的,mapping network 由 PixelNorm 层与 EqualLinear 层构成。以下代码节选自
sg2_model.py:'''mapping network''' layers = [PixelNorm()] for i in range(n_mlp): layers.append( EqualLinear( style_dim, style_dim, lr_mul=lr_mlp, activation="fused_lrelu" ) ) self.style = nn.Sequential(*layers)
-
-
Z 空间与 W 空间的关系:
- 在 StyleGAN 中,通常会先将一个 Z 向量映射到 W 空间,然后再将 W 向量输入到生成器网络中生成图像。
- Z 空间提供了初始随机噪声,而 W 空间则通过特征解耦提供更多控制图像风格的灵活性。通过对 Z 和 W 之间的映射以及 W 在生成器中的应用,StyleGan 实现了高度可控且具有良好生成效果的图像合成。
在代码中,stage 1 的损失函数是 global_clip_loss,该损失由三部分组成:
- 对比学习损失:Mapper 生成的源域 prompts 的特征**(注意,这里的 prompts 特征是与人工初始化的 prompts 的特征做过 element-wise 相加后的特征)**与源域图像特征的余弦相似度组成的对比学习损失;
- 目标域正则化损失:Mapper 生成的目标域 prompts 的特征与目标域文本标签特征的余弦相似度,这里生成的目标域 prompts 特征同样也是与人工初始化的 prompts 做过加法的。注意该损失有权重
lambda_l。 - 源域正则化:计算生成的源域prompts与源域标签之间的余弦相似度,由
lambda_src控制,默认是 0。
在训练的第二阶段进行前向传播时,需要先对目标域生成器(generator_trainable)的所有层进行 unfreeze,然后对更新哪些层做出选择,承担选择任务的功能函数:model.ZSSGAN.ZSSGAN.determine_opt_layers,最后 freeze 所有层后再 unfreeze 选择的网络层。
if self.training and self.auto_layer_iters > 0:
self.generator_trainable.unfreeze_layers() # unfreeze
train_layers = self.determine_opt_layers() # layer to train
if not isinstance(train_layers, list):
train_layers = [train_layers]
self.generator_trainable.freeze_layers()
self.generator_trainable.unfreeze_layers(train_layers) # unfreeze具体选择带更新网络层的策略:
将 W 空间的隐向量送入目标域生成器(SG2Generator)中,并进行反向传播,此时可以通过反向传播后 W 空间隐向量不同维度的更新幅度来衡量不同网络层的影响力,因此选出更新幅度最大的维度就可以确定在 Model Adaption 中需要更新的网络层。
之所以 W 空间编码在 n_latent 维度上的序号就代表着对应的网络层数的序号,是因为 StyleGAN 生成器的结构决定了这一点:StyleGAN 生成器中,W 空间编码的不同维度会被送入生成器网络的不同层,控制这些层的特征映射 (feature mapping)。具体来说,W 空间编码的每个维度会被重复 n_latent 次,作为该层的风格向量 (style vector),通过 AdaIN (Adaptive Instance Normalization) 层控制该层的特征映射。因此,W 空间编码的第 i 个维度会影响生成器网络中第 i 层的特征映射。当某个维度的 W 值被更新的程度较大时,就意味着该维度对应的层在生成目标图像时起到了重要作用,需要被优化。
stage 2 的损失函数是 CLIP Loss 类中的 clip_directional_loss,该损失函数由两部分组成:
edit_direciton:源域生成器与目标域生成器生成的图片在经过 image encdoer 后做 element-wise 的相减,最后除以自身的 L2 Norm 方便后续与 target_direction 计算余弦相似度。target_direction:Mapper 产生的源域和目标域 prompts 的 text_features 做element-wise相减后,最后初一自身的 L2 Norm 以便后续与 edit_direction 计算余弦相似度。
测试所用 nada 权重 Google Drive 链接:StyleGAN-NADA Models
参考文献:GAN 的几种评价指标
-
Inception Score(IS)
评估图像的质量和多样性
质量:把生成的图片
$x$ 输入 Inception V3 中,得到输出 1000 维的向量$y$ ,向量的每个维度的值对应图片属于某类的概率。对于一个清晰的图片,它属于某一类的概率应该非常大,而属于其它类的概率应该很小。用专业术语说,$p(y|x)$ 的熵应该很小(熵代表混乱度,均匀分布的混乱度最大,熵最大)。多样性: 如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的,假设生成了 10000 张图片,那么最理想的情况是,1000 类中每类生成了 10 张。转换成术语,就是生成图片在所有类别概率的边缘分布
$p(y)$ 熵很大(均匀分布)。因此,对于 IS 我们需要求的两个量就是
$p(y|x)$ 和$p(y)$ 。实际中,选取大量生成样本,用经验分布模拟$p(y)$ :$$\hat{p}(y)=\frac{1}{N}\sum_{i=1}^{N}p(y|\mathbf{x}^{(i)})$$ Inception Score 的完整公式如下:
$$IS=\exp\left(\mathbb{E}_x[KL(p(y|x)||p(y))]\right)$$ 其中
$\mathbb{E}_x$ 表示对所有图像的期望,$KL(p(y|x)||p(y))$ 表示每张图像的 KL 散度,$\exp$ 表示取指数。通常计算 Inception Score 时,会生成 50000 个图片,然后把它分成 10 份,每份 5000 个,分别代入公式计算 10 次 Inception Score,再计算均值和方差,作为最终的衡量指标(均值±方差)。但是 5000 个样本往往不足以得到准确的边缘分布
$p(y)$ ,尤其是像 ImageNet 这种包含 1000 个类的数据集。StyleGAN-nada 以及 IPL 在经过 batch_size 为 2,iteration 为 300 的训练后(其中 IPL 的 Mapper 是以 batch_size 为 32,iteration 为 300 进行训练的),二者的 IS 分别为
(2.2960, 0.2042)以及(2.6420, 0.1959)。 -
Fréchet Inception Distance(FID)
评估目标域的风格
计算 IS 时只考虑了生成样本,没有考虑真实数据,即 IS 无法反映真实数据和样本之间的距离,IS 判断数据真实性的依据,源于 Inception V3 的训练集 ImageNet,在 Inception V3 的“世界观”下,凡是不像 ImageNet 的数据,都是不真实的,都不能保证输出一个 sharp 的 predition distribution。因此,要想更好地评价生成网络,就要使用更加有效的方法计算真实分布与生成样本之间的距离。
FID 距离计算真实样本,生成样本在特征空间之间的距离。首先利用 Inception 网络来提取特征,然后使用高斯模型对特征空间进行建模,再去求解两个特征之间的距离,较低的 FID 意味着较高图片的质量和多样性。
-
Single Image Fréchet Inception Score(SIFID)
FID 测量生成的图像的深层特征分布与真实图像的分布之间的偏差。在 ICCV 2019 Best Paper 中提出了 SIFID,只使用一张真实目标域的图像。与 FID 不同,SFID 不使用 Inception Network 中最后一个池化层之后的激活矢量(每个图像一个向量),而是在第二个池层之前的卷积层输出处使用深层特征的内部分布(feature map 中每个位置一个向量)。最终 SIFID 是真实图像和生成的样本中这些特征的统计数据之间的 FID。
-
Structural Consistency Score(SCS)
评估图像的结构保存能力
-
Identity Similarity(ID)
评估图像的特征保存能力
IS(Inception Score)↑
| 数据集 | 源域→目标域 | NADA | IPL | IPL* |
|---|---|---|---|---|
| FFHQ | Photo→Disney | |||
| FFHQ | Photo→Anime Painting | |||
| FFHQ | Photo→Wall painting | |||
| FFHQ | Photo→Ukiyo-e | |||
| FFHQ | Photo→Pixar character | |||
| FFHQ | Photo→Tolkien elf | |||
| FFHQ | Photo→Werewolf | |||
| AFHQ | Photo→Cartoon | |||
| AFHQ | Photo→Pointillism | |||
| AFHQ | Photo→Cubism |
SFID(Single Fréchet Inception Distance)↓
| 数据集 | 源域→目标域 | NADA | IPL | IPL* |
|---|---|---|---|---|
| FFHQ | Photo→Disney | |||
| FFHQ | Photo→Anime Painting | |||
| FFHQ | Photo→Wall painting | |||
| FFHQ | Photo→Ukiyo-e | |||
| FFHQ | Photo→Pixar character | |||
| FFHQ | Photo→Tolkien elf | |||
| FFHQ | Photo→Werewolf | |||
| AFHQ | Photo→Cartoon | |||
| AFHQ | Photo→Pointillism | |||
| AFHQ | Photo→Cubism |
新增了对自定义图像进行风格迁移的功能。
HyperStyle 中的 e4e encoder 将自定义的真实图像编码至 StyleGAN2 中的 W 空间生成 latent codes,再将其分别输入至源域生成器以及目标域生成器以代替原始的从正态分布中 sample 出的随机向量生成的 w_codes,从而得到相应的图片。其中 e4e encoder 来源于 HyperStyle 提供的预训练 checkpoint。
使用方法:运行 inference.py,设置对应的参数,如生成器以及 e4e encoder 的路径、图像路径等,最后运行即可。
- 第一次尝试只加载了
w_encoder类及其对应 checkpoint 参数,导致并未将真实图片编码到 StyleGAN 的 W 空间中,没有 inversion 出合理的结果。 - 第二次尝试使用了
restyle_e4e_encoder,但是没有使用 dlib 进行 alignment,也没有使用 restyle 模型在反演时使用的多次进行前向传播来修正 latent code 的策略。此次尝试虽然反演出了合理的人像,但是人像的特征保存能力非常弱。 - 第三次尝试解决了上一次发现的问题,加入 dlib 提供的 landmark 检测以实现 alignment,并且使用
run_loop函数在 restyle_e4e_encoder 中进行多次前向传播以修正得到的 W 空间的 latent code,效果较好。 - 对比 pSp 和 e4e encoder,pSp 对人脸图像的还原能力较强,但是会导致目标域图像具有随机的彩色光晕。
参考 MIT 开源项目 pytorch-deployment 进行生成模型的 Web UI 部署。参考项目使用的是 StarGANv2 模型,对其进行优化使得其可以部署 StyleGAN 模型。
分别对人像和宠物图像生成了两个单独的卡片和 HTML 网页,网页可以完成两种功能:
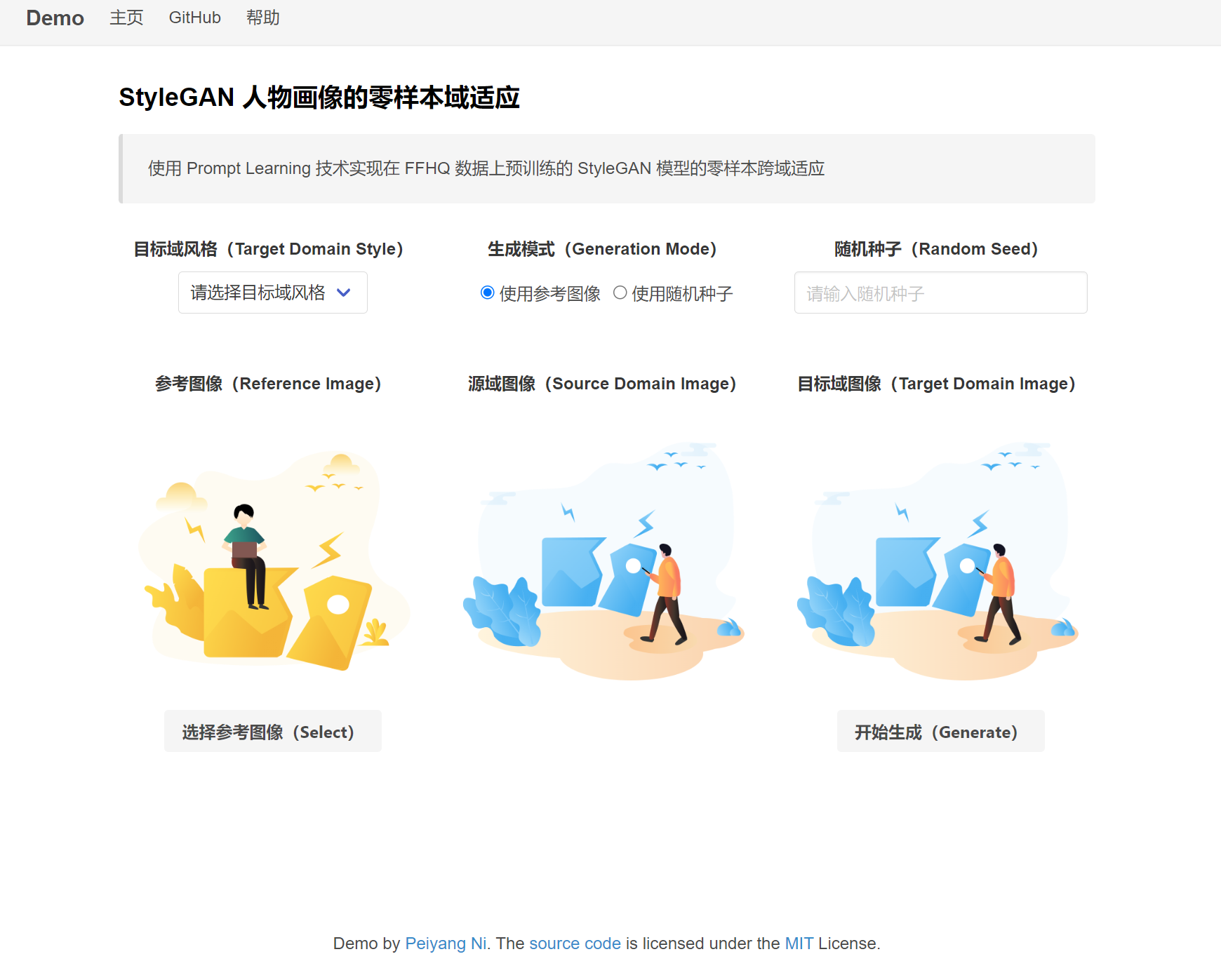
- 使用参考图像进行零样本跨域适应,同时可以在网页下拉框中选择预期的目标域风格(由于没有合适的 restyle encoder,宠物图像不支持选择参考图像)
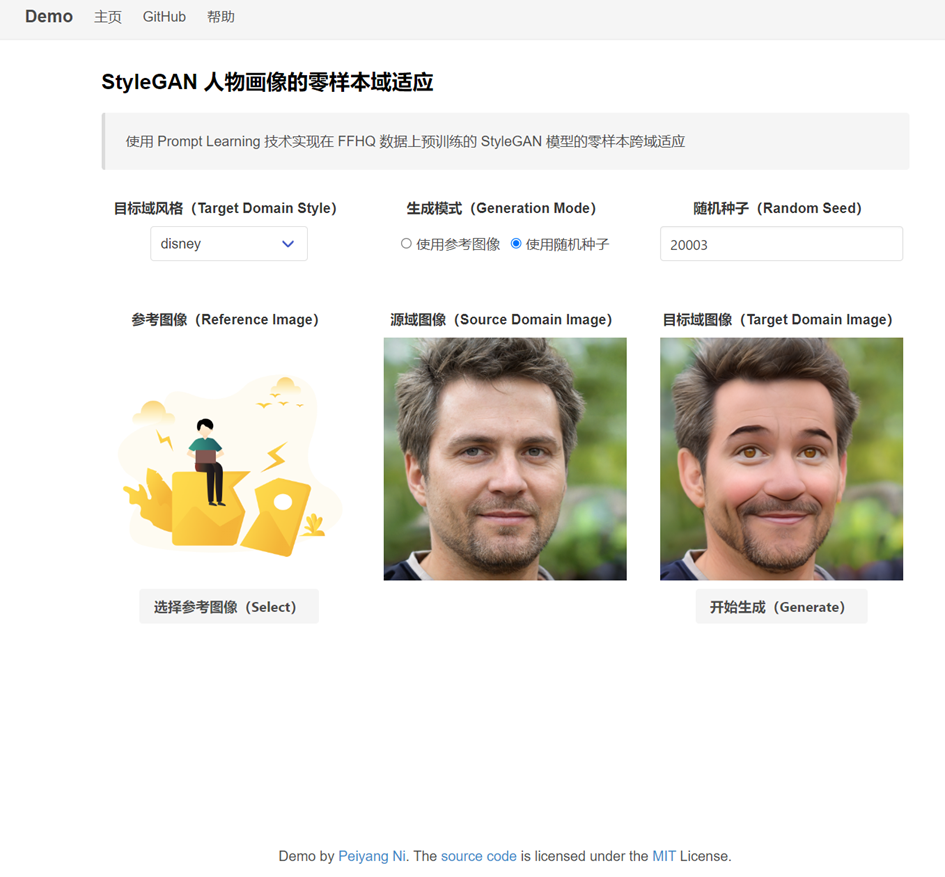
- 直接使用随机数生成源域图像并进行零样本跨域适应
UI 独立代码可以参考本人仓库 stylegan-ui,但功能有限,完整的 UI 代码已经合并到主程序中,请参考 ./web_ui 中的具体代码。
主页:
人物画像的零样本域适应(初始状态):
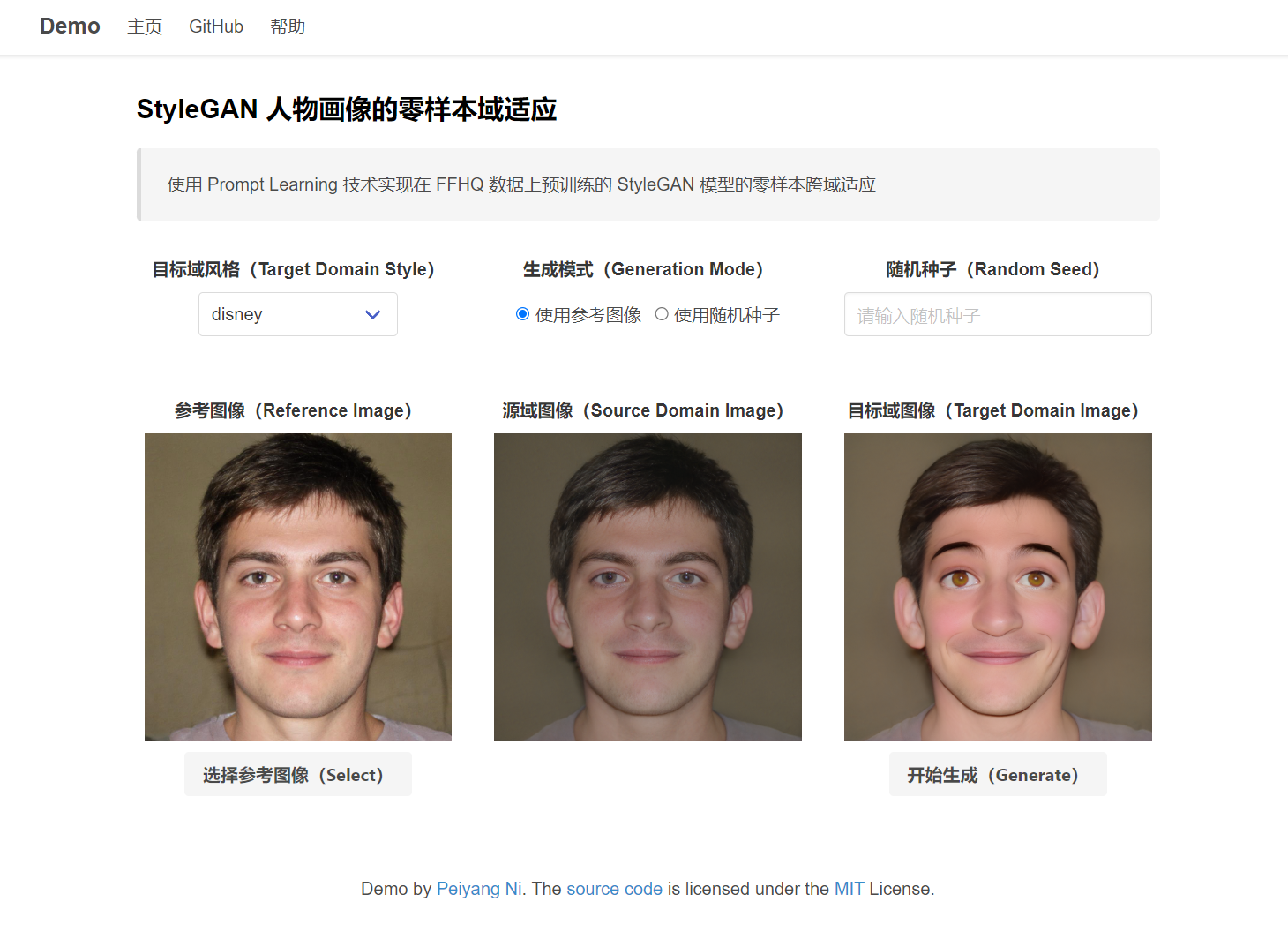
人物画像的零样本域适应(使用参考图像生成状态):
人物画像的零样本域适应(使用随机数生成效果):
宠物画像的零样本域适应(初始状态):
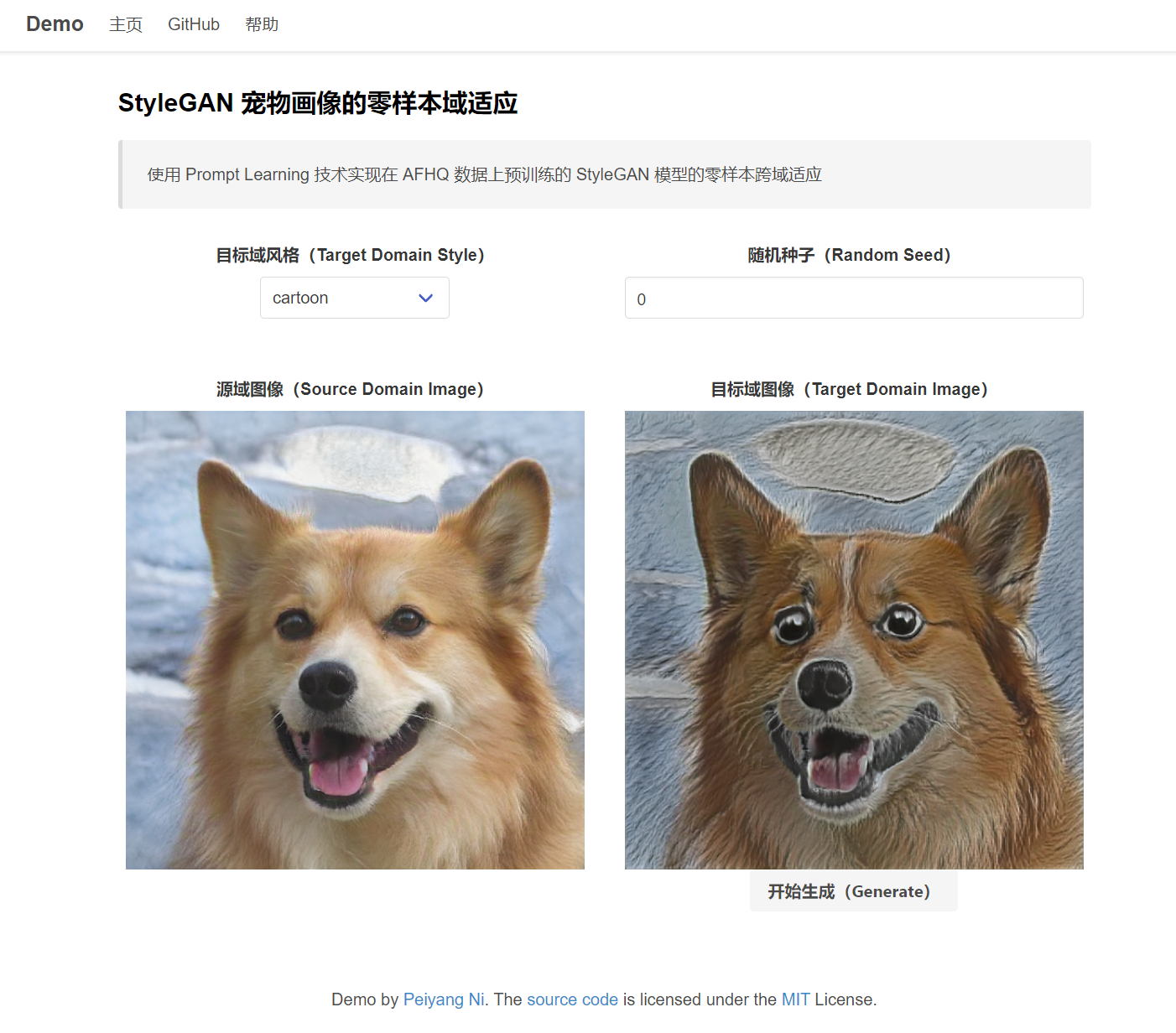
宠物画像的零样本域适应(使用随机数生成状态):
Mapper 的作用是从 W 空间的隐式代码中学习出符合源域图片特征以及符合目标域文字特征的 prompts。
改进后的 Mapper 结构:
class TransformerMapperV2(nn.Module):
"""
改良版transformer mapper,增加多头注意力,减小transformer encoder的层数,防止学习到的源域图像细节过拟合
同时去掉开头的PixelNorm,防止与transformer中的layer normalization冲突
并在transformer encoder之后加入Pixel Norm以及全连接层
"""
def __init__(self, opts, n_dim):
super(TransformerMapperV2, self).__init__()
self.opts = opts
self.n_dim = n_dim
layers = [] # transformer中有layer normalization,不需要进行PixelNorm
# 自定义Transformer编码器层配置
transformer_layer = TransformerEncoderLayer(d_model=512, nhead=4, dim_feedforward=1024, dropout=0.1)
# 构建Transformer编码器
self.transformer_encoder = TransformerEncoder(transformer_layer, num_layers=2)
layers.append(self.transformer_encoder)
# 再过一次PixelNorm以及全连接层,将每个点归一化(除以模长),避免输入noise的极端权重,改善稳定性
layers.append(PixelNorm())
self.linear = EqualLinear(512, 512, lr_mul=0.01, activation='fused_lrelu')
layers.append(self.linear)
# 最后一个全连接层,输出维度保持不变
self.final_linear = EqualLinear(512, n_dim * opts.n_ctx, lr_mul=0.01, activation='fused_lrelu')
layers.append(self.final_linear)
self.mapping = nn.Sequential(*layers).to(device)在 IPL 的官方代码实现中,人工设计的 prompts 有两处,一是 ctx_init,由命令行参数赋值,即 "a photo of a",另一处是 utils/text_templates.py 中的 templates,下面分别分析这两处的具体作用。
-
ctx_init在compute_text_features函数中用于定位eot层符号所表示的维度来进行投影,使得文字特征与图像特征维度相同,并不参与text_features的实际计算。但是在该函数中,Mapper 输出的 image-specific prompts 已经与域标签的嵌入表示进行了 concat。 -
在 stage 1 训练 Mapper 损失函数中,Mapper 学习到的 image-specific prompts 在与源域标签进行 concat 并得到文字编码后,会与 ctx_init 的文字编码进行 element-wise 的相加,最后再与源域生成器输出的图片的图像编码进行对比损失计算;
同理,在 stage 2 训练目标域生成器时,Mapper 输出的 image-specific prompts 在分别与源域、目标域标签 concat 后送入文字编码器得到文字特征,再与 ctx_init 的文字特征进行 element-wise 相加,最后二者相减得到 text_direction。
templates 是提前准备好的一系列字符串,其中字符串的格式全部类似于 a photo of a {}.
原始 hhfq 数据集的模板共有 79 个字符串。
与 ctx_init 起作用的函数不同,templates 在第一阶段的训练的 domain regularization loss 中使用到的 get_text_features 函数起作用,用于与目标域标签进行格式化连接后成为 image-specific prompts 向目标域靠近的方向。即 domain loss 使学习到的 prompts 向以目标域标签为中心的字符串对齐。
IPL 方法对 Mapper 学习到的 prompts 除了(1)使用对比学习使 prompts 学习到源域图片的特征以及(2)使用域正则化使得 prompts 向目标域标签对齐之外,并没有使用其他与人工设计的 prompts 有关的正则化方式来约束 prompts 的学习,因此人工设计的 prompts 可能并没有起到太大的约束作用。
如果对比学习损失是为了让 Mapper 自监督学习到图片的特征外,那么是否可以对域正则化损失进行改进,约束学习到的 prompts 向人工设计的初始化 prompts 对齐,以实现类似于 Stable Diffusion 类似的 prompts 控制图像生成的效果。
对第一阶段的损失函数做出修改,更新domain loss,将原始 domain loss 中使用的以目标域标签为中心的模板更换成自定义模板,使目标域的image-specific prompts与自定义模板对齐。
经过多次实验和分析,刻意让 Mapper 输出的image-specific prompts 去逼近用户设置的 prompts,会产生一些隐式细节的丢失。因为 Mapper 本身存在的目的就是学习出人工无法准确描述的细节(包括源域图像的自身细节以及目标域风格的细节),如果对 Mapper 的损失函数中加上太多人为设计的限制,很显然会造成细节的丢失并且出现同质的现象。
因此,为了达到既使用精心设计的 prompts 来优化域适应,同时又不影响 Mapper 自主学习双域特征,在原有两个损失函数的基础上,新增一个权重较小的损失函数,用于将 Mapper 学习到的目标域 prompts 向自定义模板对齐。
中文提示词:
针对将普通人像转换成迪士尼风格人物画像的任务,给出60个描述迪士尼人像特有特征的文字prompt。
将上述生成的60个prompts放在同一个Python列表中,即每一个prompt作为该列表的字符串元素,输出整个Python列表。
英文提示词:
For the task of converting a {source_class} photo into a {target_class} photo, provide 60 text prompts describing the distinctive features of {target_class} photos. Put the generated 60 prompts into the same Python list, with each prompt as a string element of the list, and output the entire Python list.
IPL 训练第一阶段的损失函数除了源域 prompts 与源域图像之间的对比学习损失函数外,还有将目标域 prompts 与目标域标签计算余弦相似度的 domain regularization。
对 domain regularization 进行改进,引入开发者自定义的 prompts,约束 Mapper 学习到的目标域 prompts 向开发者自定义的 prompts 对齐,以此来进行 prompt tuning,发挥 prompt learning 的更大优势,并增强自定义性。
IPL 训练第二阶段的损失函数,使用 criteria.clip_loss.CLIPLoss.clip_directional_loss。
致谢节选自大论文谢辞,此件非个人主动公开件,只部分节选以表谢意。
“孩儿立志出乡关,学不成名誓不还”。此语既是我求学生涯的初心,亦是我今日站在本科学习生活的最后一个台阶上、准备迈入研究生科研生活大门时,回首过往岁月的感慨与对未来的期许。此心既始,满腔热忱与展望。
“岁月不居,时节如流”。四年本科时光瞬息而深长,此行路上,幸蒙导师悉心指导、精心引路,与同窗并肩奋斗、携手前进,家人的温暖挚友的支持如影随形。
对于那些在我生命中留下灿烂痕迹的挚友们以及朝夕相伴的室友们,你们的友情如同星辰,照亮了我在困惑与挫败中的道路,让成功与喜悦之时更加沉稳而深刻。我们的欢笑与泪水,交织成这段青春岁月中最绚烂的篇章。
回望来时路,深深感谢三院大学生科技协会的朋友们,科协历届相传的“传帮带”精神帮助我一步步建立起对计算机科学的认知。同时,在科协任职副主席的这一年是我承担过的工作量最大,但同时也是最意义深远的一段学生工作。“木起青绿,梦绘初蓝”,希望科协能恒守初衷,为桂电培养更多优秀的电子科技人才,让科协的光,照亮未来的每一个梦想。
最深沉的感恩还要献给我的家人,血浓于水,感谢你们成为我最坚实的后盾,不仅教会了我责任和担当,更为我在这四年的成长、求学和推免之路中的每一步注入无尽的勇气与鼓励。
本文之作与设计,实乃诸多智者启迪之果,离不开文末各参考文献的启发和帮助,感谢国内外学者的精研实证,为本文注入理论精髓与实验根基,其贡献铭记于心。此外,本设计的完成更离不开互联网上的浩渺资源与教程,由于篇幅限制,学生无法在参考文献中一一列举所有资料,谨在此向网络彼端的知识贡献者以及GitHub开源社区对本设计的帮助和指导深表谢忱。“饮水思源,缘木思本”,为了支持互联网精神和回馈开源社群,本文实现的基于Prompt Learning方法的零样本图像风格迁移算法以及设计的Web UI系统已根据MIT协议开源,训练、推理以及Web UI系统等相关代码已悉数托管于GitHub仓库:https://github.com/bonjour-npy/UndergraduateDissertation
恭敬在心,不在虚文,敬意非言语所能全表。每一份感激,皆化作行动的力量,无声却坚定地践行着这份敬意。