{kind=link}
Jupyter/IPython Extension for Sparql Pandas dataframe queries.
Via pip:
pip install ipython-sparql-pandasLoad the extension:
%load_ext ipython_sparql_pandas
Query:
%%sparql http://dbpedia.org/sparql/ -qs foo
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX dcb: <http://dbpedia.org/resource/Category:>
PREFIX dbp: <http://dbpedia.org/property/>
SELECT DISTINCT ?name ?capital ?populationTotal WHERE {
?capital dct:subject dcb:Capitals_in_Europe ;
dbp:populationTotal ?populationTotal ;
foaf:name ?name.
}
ORDER BY DESC(?populationTotal)
LIMIT 5The variable foo is now a Pandas dataframe of SPARQL results:
foo.plot.barh('name', 'populationTotal').invert_yaxis()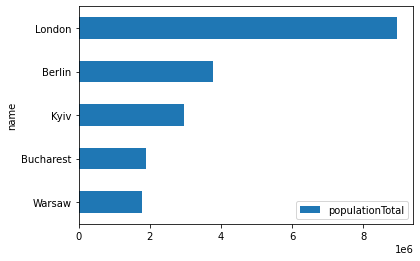
This package is inspired by ipython_sparql.