Stitching Directives #2227
Stitching Directives #2227
Conversation
🦋 Changeset detectedLatest commit: b79c572 The changes in this PR will be included in the next version bump. This PR includes changesets to release 5 packages
Not sure what this means? Click here to learn what changesets are. Click here if you're a maintainer who wants to add another changeset to this PR |
|
The latest changes of this PR are not available as alpha, since there are no linked |
|
graphql/graphql-js#2606 (comment) We can use custom scalars as directive arguments, but no point in building validation into their parse function as directive arguments are never type-checked (!!!), see comment above. We can just look up the directive arguments on our own and validate them outside graphql. This is a larger deficiency within the current API, as referenced in the comment above, and we should not reinvent our own workaround at this point. |
|
@gmac @Urigo @dotansimha @kamilkisiela @ardatan @tvvignesh This is ready for a look. To get validation working from subschema end you need to add to makeExecutableSchema arguments when building subschema. Add the exported typeDefs SDL within typeDefs argument and to pass the stitchingDirectivedValidator to schemaTransform argument. To use on gateway, pass the stitchingDirectivesTransform to the subschemaConfigTransformer argument within stitchSchemas. Once this is working correctly, we can add these as default transforms... May have time to set up a more elaborate example later over the weekend. But it is ready to start playing around with. I want to discuss the directive syntax. I implemented a default simple approach and the argsExpr that allows the most complex option. @gmac suggestions in linked discussion is somewhere in between and I am planning on adding in those options as well. but I want to broaden the discussion to more people to make sure that we come up with the right specification and not too many confusing options... |
|
Also definitely open to improvements within the implementation! So, implementation and specifications are open for discussion, as is everything else in between. ;) |
|
Note that in the examples above by used an argument of type _Key. That was just to save time, as the sub schema can rely on the fact that the gateway will send the correct argument without any need for coercion. This could be specified within the sub schema as a properly typed input object. |
|
@yaacovCR Thanks. I am just trying to get my head around this 😅 Is this still applicable for the latest updates you have made here?: #2022 (reply in thread) There I see that something like I did see a test condition having this SDL (has args become argsExpr?): scalar _Key
type Query {
_user(key: _Key): [User] @merge(argsExpr: "key: [[$key]]")
}
type User @base(selectionSet: "{ id }") {
id: ID
name: String
}I am trying to get my head around how this will look like for me coming from federation. # Accounts - Federation
extend type Query {
me: User
}
type User @key(fields: "id") {
id: ID!
username: String!
}
# Accounts - Stitching (As proposed in https://github.com/ardatan/graphql-tools/discussions/2022#discussioncomment-125866)
type Query {
me: User
_users(ids: [ID]): [User] @merge(args: "ids: [[$key.id]]")
}
type User {
id: ID!
username: String!
}
# Accounts - Latest Type Merging PR (Not sure)
scalar _Key
type Query {
me: User
_users(key: _Key): [User] @merge
}
type User @base(selectionSet: "{ id }") {
id: ID!
username: String!
} |
8a7a028 to
15e24e7
Compare
|
@yaacovCR Just saw that you pushed some updates here: 15e24e7#diff-20430c9c75aa9f36d08da2f7bce0ac3e50f1be693465cd085186b981252a8394 I guess that might help. Will try going through it again. |
|
@yaacovCR Had a look at it properly. While this can be good to start with, to be honest I kind of find Federation SDL more explanatory (maybe due to the lack of complicated expressions). I am trying to get a similar experience in stitching (though I understand, this is the first step and I am totally fine with this as a start since these complexity won't be exposed to the clients consuming the schema anyways). There is only one thing which I feel is kind of complicated for me to digest in the entire SDL:
By seeing this directive:
|
|
Guys, some honest feedback again here. Kindly excuse me cause I know I am sharing this without helping you guys in any way. I spent almost a day trying to understand Type Merging (not this PR but the TS implementation itself as documented here: https://www.graphql-tools.com/docs/stitch-type-merging) and I should honestly say that its very difficult for beginners like me to understand what is happening even when it is documented well. Rest of the GraphQL Tools and the guild stack is easy to understand. Leaving this feedback here cause, if this has to actually get some mainstream usage amongst the community, it might need some good quality video tutorial or blogs or something like that since it takes a very different approach to merging schemas unlike normal stitching. I can help, but the problem is I am myself confused with it 😂 After reading the same page multiple times, I have the feeling of understanding it but not understanding it 😅 I hope you got what I mean. Also, there are a few confusing parts. If you see this, import { stitchSchemas } from '@graphql-tools/stitch';
const gatewaySchema = stitchSchemas({
subschemas: [
{
schema: postsSchema,
merge: {
User: {
fieldName: 'postUserById',
selectionSet: '{ id }',
args: (originalObject) => ({ id: originalObject.id }),
}
}
},
{
schema: usersSchema,
merge: {
User: {
fieldName: 'userById',
selectionSet: '{ id }',
args: (originalObject) => ({ id: originalObject.id }),
}
}
},
],
mergeTypes: true // << optional in v7
});Also, I feel most of the confusion would be reduced if better naming convention is chosen. For eg. the name The reason it feels probably difficult is cause a lot of things are stacking together:
I don't know if any of these can be changed since it would lead to breaking changes I guess, but still I thought I should let you know. This is the final piece of the puzzle I am yet to solve with GraphQL and the Guild stack. Have handled the rest on my end. PS: I will try again tomorrow and update this thread if I manage to understand it. And if I do manage to understand this, I will make a tutorial for this right away myself. Thanks. |
|
@tvvignesh thanks for the feedback, that’s all reasonable stuff. A lot of us on stitching started using it many years ago when it was Apollo Stitching, and it was an utter mess; however, that background makes type merging pretty intuitive. I totally hear you that starting with zero background makes stitching pretty opaque, though I don’t think it’s any worse than coming fresh to Federation (which I did earlier this year). All that is to say, a few points:
Sorry that’s not super helpful, and your feedback is all very valid, so thanks for sharing. |
|
@gmac Thanks for your response on the same. Actually, I did use stitching before but not microservices with Apollo where it was as simple as doing I understand what you are saying. @yaacovCR is doing an amazing job with this actively maintaining the lib. I just probably have to get the basics right to work on this. Will try again. Planning to get myself properly first well settled with the JS implementation and once I understand it, I will come and try out the directives as well. |
|
Ah, if you weren’t doing manual delegation before, then you weren’t using all of stitching features. If you have no crossover type associations, then everything in modern stitching is still as simple as it was before, and you really don’t need anything beyond the “combining multiple schemas” page. If you’ve moved up to crossover types in Federation, then yeah, merging features now apply to what youre doing. The good news is though, that if you understand how Federation works under the hood then you may be surprised to realize how fundamentally simpler merging is; albeit, you have to write the config versus federation that sets up a mess of complexity for you to make extremely basic things work. At the end of the day, merging is kind of two step process:
|
|
@tvvignesh – you inspired me to draw a picture to go with the "basic example" on the Type Merging docs page... does this help explain what's going on...?
|

|
Thanks a ton @gmac This really helps a lot. I used your diagram to jot down the inference I have as I see it. Kindly correct me if I am wrong. A diagram like this with an explainer to the same in the docs can help a lot in the docs. Inferences (Marked against step nos. as in the diagram):
Questions here:
Questions here:
The field
Some other questions:
The reason I guess federation kind of feels easier for me is cause it uses But after seeing this diagram, I can get some real clarity into the execution phase of GQL. And as far as the stitching phase goes, I feel that some inline comments at every step to the Sorry for the long text. Just wanted to take you all through my thoughts. Thanks again. CC: @yaacovCR |
|
The answers to your questions about selectionSet and fieldName are yes. Access to subschemas is serial in example above as depicted. Although types are not owned by services in our model (as opposed to Federation), root fields (and regular fields) are. So first subservice entry must occur initially separate from rest, but rest can occur in parallel. This i believe is similar to Federation. You can, however add a local root field on the gateway so that the initial entry happens on the gateway with all remaining subservices in parallel. That I believe is unique to our model. I am not sure why you think on the subservices level easier to code with resolveReference. In our model, each subschema is just a regular GraphQL server. Thanks for joining the discussion! |
|
@tvvignesh I’m still not entirely happy with this diagram, and will be expanding it with a step in the current 3.5 position that explains how fieldName + originalObject are used to generate the query in step 4. Then to your question of why originalObject is needed before performing subsequent queries in step 4: that makes the bold assumption that the inputs are the same. The posts service could very well require one or more fields that are not the same as the id in the initial query; the fact that the initial query has enough information to make the second query is just luck. Then @yaacovCR - I’m surprised that you’re saying merger requests are parallel after the first original object. I was under the impression that it would be serial, and that steps 3.5, 4, and 5 would repeat sequentially for each subservice with originalObject growing each time as the aggregate of mergers... thus, a service could require an aggregate of keys from two previous services (versus federation which can only utilize keys from the origin service) |
|
It should be parallel if no additional inputs are required. Say you have resolved the user from from an account service and now you want to grab additional details about the user from the user service and post service and billing service and what have you serviced and all you need is the ID that you now have from the account service. Those should all be in parallel. If one of those services requires additional fields from so we're not resolvable from the account service, an additional round will be triggered. |
|
Super smart! I love the algorithm design. Just a crazy idea to the point @tvvignesh raised earlier: could initial query arguments seed original object to potentially advance the process one step ahead, when possible? It’s not uncommon that the IDs will match. I suppose it does conflate an input field with an object field, which are definitely not the same, although it could be a manual option to say initial arguments work as the original object... just thinking out loud. |
|
Yes, as above, should work transparently if you add a resolver on gateway itself that returns the stub. |
|
I only half understand... could you provide an example in the context of
the diagrammed queries? I sort of get what you’re saying and it’s
diabolically clever, although I can’t picture how it’s written.
Would it just be that the gateway has to define “userById” as a local schema that returns “{ id: 23 }”...? Then I assume you’d need to take some steps in mergedTypeOptions to assure that the local gateway version of the field gets used?
|
True. And thats exactly what I like about stitching. The only reason I feel
@gmac No issues. This is definitely a great start. Diagrams like this definitely help in making people understand. Its just that since there are 2 phases in stitching - The phase where you stitch everything together based on various parameters, and then the execution phase itself - I am not sure if it will be easy for you to represent both in the same diagram. @yaacovCR While I get your point regarding parallel queries to some extent, is there some way you would recommend to write queries to establish maximum parallelism with stitching? Or is it something which I should not worry about much and rely on the gateway to do the job for me? To be honest, this is not my concern at this point since I am just starting off, but thought I would understand this so that I can reduce the roundtrips made between the services and gateway. Thanks again. |
|
@tvvignesh — you don’t need to work too hard to maximize parallelism. It mostly just works efficiently these days. The exchange Yaacov and I had above is getting into power-user optimizations. I wouldn’t worry about trying to short-cut request cycles until you know exactly how everything works and you are doing fine performance tuning on your stack. Regarding “phases”, I’ll also add an expression of that into the diagram as well. I think you may have oversimplified a bit in your description. There’s really three phases: 1) the original object phase where an initial representation is resolved, 2) the merger phase where all merged objects are resolved in parallel based on the original object (this step is repeatable), and 3) the final return phase where the original object and all mergers are returned as the final response. I appreciate that you’re trying to understand the stack top to bottom, although don’t overlook the value of just building on code samples either. We’re getting into a lot of minutia here that you don’t actually need to know the full internals on to use. |
| @@ -0,0 +1,32 @@ | |||
| { | |||
| "name": "@graphql-tools/type-merging-directives", | |||
There was a problem hiding this comment.
Does this mean that “@computed” will also go through the extra package, then? I actually like this from the doc standpoint. The main type merging page can just focus on static config with links over to an SDL page explaining how each static config translates to SDL.
|
@yaacovCR – is this revision of the diagram accurate to your eye? The idea is that steps 4-7 are a repeatable sequence for each type merger beyond the original object. I this looks sufficiently accurate, I'll write up some supporting narrative and include it in merging docs.
@tvvignesh – more insightful? |
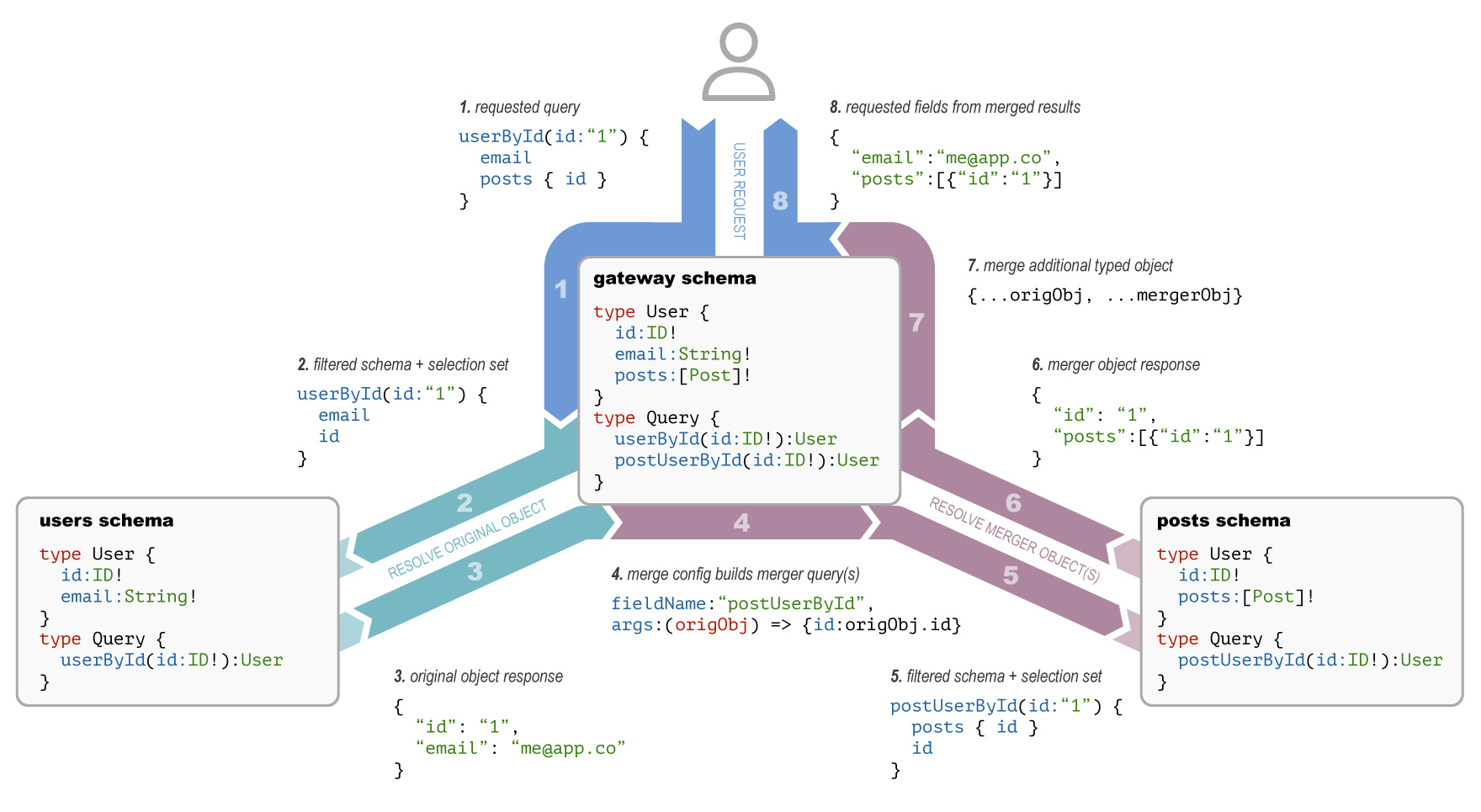
|
Looks good to me.
I thought more also about using gateway to avoid making first service call
sequential. This probably would not work with current algorithm, because to
call resolveExternalValue and kick off the type merging process, the
algorithm does not inspect the initial object, so as to avoid repeating
that check for every member of an array. Rather, it checks the initial sub
schema to see what fields were available, and then memoizes that result.
It's easy to returning an initial object that matches the argument on the
gateway, but because there is no actual initial sub schema, the algorithm
will probably fail.
The way to do it I suppose is to include on the gateway a local GraphQL
schema within the merged schemas. Whatever resolvers are in that local
schema will be executed locally and then merge with all the remotes.
…On Mon, Nov 23, 2020, 6:18 AM Greg MacWilliam ***@***.***> wrote:
@yaacovCR <https://github.com/yaacovCR> – is this revision of the diagram
accurate to your eye? The idea is that steps 4-7 are a repeatable sequence
for each type merger beyond the original object. I this looks sufficiently
accurate, I'll write up some supporting narrative and include it in merging
docs.
[image: stitching-flow]
<https://user-images.githubusercontent.com/727224/99928808-b55a6f80-2d18-11eb-8df6-7a409baa8718.jpg>
@tvvignesh <https://github.com/tvvignesh> – more insightful?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#2227 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AA7LAYHPFPFEXEB3K6S4WODSRHPB5ANCNFSM4TX7VKAQ>
.
|
Sure. Thanks for the clarity.
Definitely. This is even more clear. This diagram definitely clarifies the basics very well. I also tried extending the schema adding some more types like this and tried using the same diagram to validate the same and that works well too: # User service
type User {
id: ID!
email: String!
contactInfo: [Contact]
}
# Contact service
type Contact {
phone: String
address: String
}
# Post service
type Post {
id: ID!
message: String!
author: User!
comments: [Comment]
}
type Comment {
commentID: ID!
comment: String
}One more thing which I was trying to understand while doing this is how typemerging works with different types in the same microservice vs different types in different microservices. For eg. in the above SDL, both Thanks. |
…th unqualified and qualified keys note that you can use whatever you want as the initial variable name that begins in this examples as $key
BROKEN
type-merging-directives => stitching-directives
cannot use schema.getImplementations yet
this works for complex keys formatted just like the selection set, the default todo: [ ] add keyField argument to pick a simple key out of the selection set [ ] add key argument to build a custom complex key in any pattern
when computed fields are used, the key is supplemented with additional selection sets. but base is too non-descriptive....
7117b46 to
45ef617
Compare
|
Ok, pretty much done. For integration test, comparison with Federation, see: https://github.com/ardatan/graphql-tools/blob/45ef6175f65e9930038a4e9eb9583e1e96c9bd39/packages/stitch/tests/typeMergingWithDirectives.test.ts Note the pretty straightforward API with use of IMPORTANT: Most users will probably require zero arguments, as they can just rely on the default settings, also demonstrated in that example, or just use the |
|
@yaacovCR Just went through it. This is way more cleaner and descriptive than how it started off 👍 I don't see |
|
@ardatan @kamilkisiela I think canary release failed, did I break something? |
See #2022
To do:
[x] 1. create helper functions for parsing mergeArgsExpr values that allow flexible declaration of keys
[x] 2. create helpers that transform the more generic args/key/keyArg arguments proposed by @gmac into the more generic mergeArgsExpr
[x] 3. create helpers that use
@baseand@computeddirectives to automatically expand use of a "whole" key into the required selections[x] 4. create schema transformer for individual subschemas that validates arguments, as outlined below
[x] 5. create subschema transformer that performs same validation and also generates the transformed subschema