


TsFile是一种为时间序列数据设计的列式存储文件格式,它支持高效压缩、高读写吞吐量,并且兼容多种框架,如Spark和Flink。TsFile很容易集成到物联网大数据处理框架中。
时序数据即时间序列数据,是指带时间标签(按照时间的顺序变化,即时间序列化)的数据,其来源多元、数据量庞大,可广泛应用于物联网、智能制造、金融分析等领域。在数据驱动的当下,时序数据的重要性不言而喻。
尽管时序数据如此普遍且重要,但长期以来,时序数据的管理都缺乏标准化的文件格式。TsFile 的出现为用户管理时序数据提供了统一的文件格式。
TsFile 通过自研实现了时序数据高效率管理、高灵活传输,并支持多类软件深度集成。其特性包括:
-
时序模型:专门为物联网设计的数据模型,每个时间序列与特定设备相关联,所有设备通过分层结构相互连接;
-
跨语言独立使用:可以使用多种语言的 SDK 直接读写 TsFile,使得一些轻量级的数据读写场景成为可能。
-
高效写入和压缩:为时间序列量身定制的列式存储格式,将数据按设备进行组织,并保证每个序列的数据连续存储,最小化存储空间。相比 CSV,压缩比可提升 90% 以上。
-
高查询性能:通过设备、物理量和时间维度索引,TsFile 实现了基于特定时间范围的时序数据快速过滤和查询。相比通用文件格式,查询吞吐可提升 2-10 倍。
-
开放集成:TsFile 是时序数据库 IoTDB 的底层存储文件格式,可与 IoTDB 形成可插拔的存算分离架构。TsFile 支持与 Spark、Flink 等大数据软件建立无缝生态集成,从而确保跨不同数据处理环境的兼容性和互操作性,实现时序数据跨生态深度分析。
TsFile 可管理多个设备的时序数据。每个设备可具有不同的物理量。
每个设备的每个物理量对应一条时间序列。
TsFile 数据模型(Schema)定义了所有设备物理量的集合,如下表所示(m1 ~ m5)
| Time | deviceId | m1 | m2 | m3 | m4 | m5 |
|---|---|---|---|---|---|---|
| 1 | device1 | 1 | 2 | 3 | ||
| 2 | device1 | 1 | 2 | 3 | ||
| 3 | device2 | 1 | 3 | 4 | 5 | |
| 4 | device2 | 1 | 3 | 4 | 5 | |
| 5 | device3 | 1 | 2 | 3 | 4 | 5 |
其中 Time 和 deviceId 为内置字段,无需定义,可直接写入。
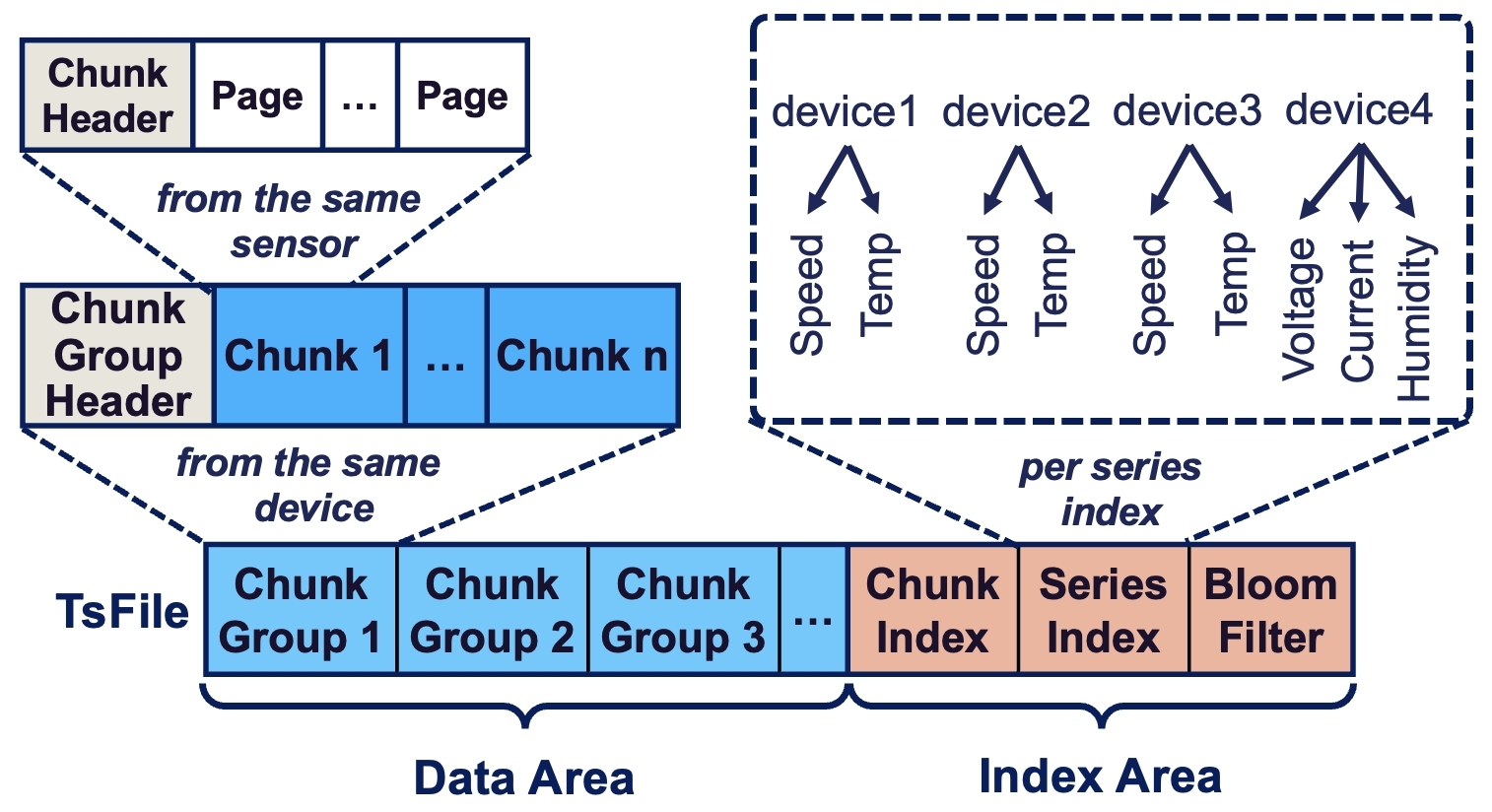
下为 Apache TsFile 的文件结构。
-
Page:一段连续的时序数据,存储的基本单元,按时间升序排序,时间戳和值各有单独的列进行存储。
-
Chunk:由同一序列的多个连续的 Page 组成,一个文件同一个序列可以存储多个 Chunk。
-
ChunkGroup:由一个设备的一至多个 Chunk 组成,多个 Chunk 可共享一列时间存储(多值模型)。
-
Index:TsFile 末尾的元数据文件包含序列内部时间维度的索引和序列间的索引信息。
TsFile 通过采用二阶差分编码、游程编码(RLE)、位压缩和 Snappy 等先进的编码和压缩技术,优化时序数据的存储和访问,并支持对时间戳列和数据值列进行单独编码,以实现更好的数据处理效能。
其独特之处在于编码算法专为时序数据特性设计,聚焦在时间属性和数据之间的相关性。
TsFile、CSV 和 Parquet 三种文件格式的比较
| 维度 | TsFile | CSV | Parquet |
|---|---|---|---|
| 数据模型 | 物联网时序 | 无 | 嵌套 |
| 写入模式 | 批, 行 | 行 | 行 |
| 压缩 | 有 | 无 | 有 |
| 读取模式 | 查询, 扫描 | 扫描 | 查询 |
| 序列索引 | 有 | 无 | 无 |
| 时间索引 | 有 | 无 | 无 |
基于对时序数据应用需求的深刻理解,TsFile 有助于实现时序数据高压缩比和实时访问速度,并为企业进一步构建高效、可扩展、灵活的数据分析平台提供底层文件技术支撑。
| 数据类型 | 推荐编码 | 推荐压缩算法 |
|---|---|---|
| INT32 | TS_2DIFF | LZ4 |
| INT64 | TS_2DIFF | LZ4 |
| FLOAT | GORILLA | LZ4 |
| DOUBLE | GORILLA | LZ4 |
| BOOLEAN | RLE | LZ4 |
| TEXT | DICTIONARY | LZ4 |
更多类型的编码和压缩方式参见文档
Apache TsFile 提供了命令行工具 tsfile-cli,这是一个单文件、对管道友好的工具,可直接在
shell 中查看并导入 .tsfile 文件。读取类命令
(ls、meta、schema、stats、count、head、cat、sample)将数据输出到 stdout、
诊断信息输出到 stderr,因此可与 awk、jq、sort 等工具组合使用;write 命令则将 CSV/TSV
导入为新的 .tsfile。支持的输出格式:csv、tsv、json(NDJSON)、table。
| 命令 | 作用 |
|---|---|
ls |
列出文件中的表(表模型)或设备(树模型),每行一个名称 |
meta |
文件概览:数据模型、表 / 设备 / 序列数量、时间范围、文件大小 |
schema |
每条序列的数据类型、编码、压缩方式 |
stats |
每条序列的统计信息:行数、时间范围、最小 / 最大值、首 / 末值、求和 |
count |
每条序列的行数及总计 —— 直接读取统计信息,不扫描数据页 |
head |
输出前 N 行(默认 10,可用 -n 调整) |
cat |
流式输出所有匹配的行 |
sample |
对行做可复现的蓄水池采样(-n、--seed) |
write |
将 CSV/TSV 导入为新的表模型 .tsfile |
其中元数据类命令(ls、meta、schema、stats、count)无需解码数据页即可回答大部分问题,
而 head、cat、sample 则会读取真实的行数据。
tsfile-cli ls data.tsfile # 列出表 / 设备
tsfile-cli meta data.tsfile # 文件概览(模型、数量、时间范围、大小)
tsfile-cli head -n 20 data.tsfile # 前 20 行
tsfile-cli cat -m temp,humidity -f csv data.tsfile # 以 CSV 流式输出指定列
# 将 CSV/TSV 导入为新的表模型 .tsfile
printf 'time,id1,s1\n0,dev,0\n1,dev,10\n' \
| tsfile-cli write --table t1 --columns "id1:STRING:tag,s1:INT64:field" -o out.tsfile -平台支持。 目前
tsfile-cli仅支持在 Linux 和 macOS 上从源码编译。后续我们会单独 发布该工具的预编译版本。
tsfile-cli 随 C++ 模块一起构建,因此在仓库根目录用 Maven 编译 C++ 模块时,它会一并包含在产物中:
./mvnw clean package -P with-cpp生成的可执行文件位于 cpp/target/build/bin/tsfile-cli,它所依赖的共享库 libtsfile 位于
cpp/target/build/lib/(Linux 为 libtsfile.so,macOS 为 libtsfile.dylib)。tsfile-cli
在运行时会加载 libtsfile,因此使用时需要让动态链接器能找到该库 —— 可以把它保留在
cpp/target/build/lib 下并将该目录加入库搜索路径,或把 libtsfile 复制到可执行文件旁边(或系统库目录):
# Linux
export LD_LIBRARY_PATH=cpp/target/build/lib:$LD_LIBRARY_PATH
# macOS
export DYLD_LIBRARY_PATH=cpp/target/build/lib:$DYLD_LIBRARY_PATH
cpp/target/build/bin/tsfile-cli --version
cpp/target/build/bin/tsfile-cli --help完整的命令与选项说明见 cpp/tools/README.md。