Log structured caching explained
To explain the principle of log-structured caching, the best way is to use little maths.
The current state of the storage is given by the following equation. The InitState is the initial state of the backing store when you started the writeboost'd device. It's an accumulation of side-effects of logs from the beginning to the present (CID means Current ID).
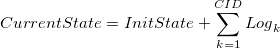
The second term of the rhs can be decomposed into three terms and the equation becomes
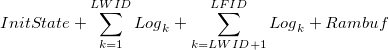
where LWID means Last Writeback ID and LFID means Last Flushed ID. And the Rambuf is side-effects that is still in volatile rambuf but not flushed to the caching device yet. Writeboost is designed to follow this equation by writing back the logs from the older one and never write back any newer side-effects before older logs is finished written back.
Now let's think about the situation that we've accidentally lost the caching device. This is a situation which should be carefully considered when it comes to production use. Losing caching device means losing side-effects after LWID so the CurrentState becomes
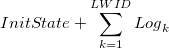
The point is, the CurrentState left is some kind of snapshot of older time when the CID was the LWID. Therefore, the filesystem or database using the writeboost'd device doesn't corrupt (precisely, it may corrupt due to the log boundary) but forgot some newer memories.
This property is quite helpful in the production use case and may let you reduce the extra costs to protect the caching device by using RAID, depending on the use case.
Each log is 512KB in size. The first 4KB is used as metadata and the last 127 4KB blocks are used for the data. The metadata section has CRC32 checksum to validate the log. Without the checksum, we can't protect the data from so-called partial write, the data is partially written in the caching device when sudden power fault's happened on the previous run.
Writeboost copies the in-coming write data to the rambuf and builds a log with the metadata at the start 4KB section. And then it flushes the log to the caching device sequentially. This way, the random 4KB writes submitted to the writeboost'd device are finally written in 512KB sequential writes. This sounds like a magic but it's seriously real. As a result, the random write 4KB throughput is close to the 512KB sequential write to the caching device because the overhead of writing to the rambuf is trivial.
This strategy is also advantageous to the lifetime of the SSD caching device. With the property that writeboost'd device only goes back the older time like snapshotting, this gives users more chance to eliminate extra cost for caching device redundancy.
The purity described in the Math section leads to one limitation that we can't implement write bypassing. Write bypassing is a method that writes larger than some threshold bypass the caching device but goes to the backing store directly. This is because the equation presumes that all side-effects are once written to the caching device and then written back to the backing store, they aren't allowed to bypass the caching device.
But I think this doesn't matter so much in reality because if the workload is helped by the bypassing, it means SSD caching device doesn't do any help in the first place, at least for the write-caching.
For workloads that write bypassing helps, I recommend write-around caching by setting write_around_mode to 1 and read_cache_threshold to non-zero. Unlike write-caching, read-caching is implemented bypassing with the threshold value.
Or you can keep the write-caching enabled because the lifetime of the caching device reduced by the extra writes that should be bypassed is eased because lifetime is maximized by the log-structured nature. In addition, writeboost implements sophisticated writeback optimization algorithm to efficiently writeback the written data, therefore the performance benefit of bypassing is not remarkable.