Home
Trabajar en equipo siempre ha sido complicado. Bueno. Trabajar en general. Después de ponerse de acuerdo quién hace qué, lo más difícil de trabajar en equipo es hacer el trabajo.
¿Quién ha tenido un proyecto que se ve algo así?

¿Y por qué tenemos que recurrir a esto? ¿Qué pasaría si trabajáramos en una sola carpeta del proyecto? La ventaja de manejar el proyecto por versiones es que si haces algún cambio que rompe todo, puedes simplemente tomar la versión anterior y empezar a trabajar desde ahí. Además, puedes trabajar en paralelo con tus compañeros. Pero, ¿qué pasa cuando todos trabajan en hacer cambios en sobre el mismo archivo y lo tienen que juntar para entregarlo?
Y este es un problema que no solo aplica al desarrollo de software. Prácticamente todas las profesiones que trabajen en una computadora son propensas a sufrir de este problema.
Es por esto que, desde los 70s, los desarrolladores empezaron a trabajar en herramientas para simplificar estos flujos de trabajo.
En 1991, un joven finlandés llamado Linus Torvalds empezó a trabajar en un proyecto que publicaría en 1994 conocido como Linux. El kernel de Linux es el proyecto open source más exitoso de la historia, y, naturalmente, un proyecto así de grande es complejo de manejar.
Hasta 2002, todos los cambios hechos al kernel se mantenían en parches y archivos separados. Durante 3 años, la comunidad que desarrollaba el kernel utilizó un sistema propietario llamado BitKeeper, sin embargo, en 2005 la relación entre la comunidad y la empresa que desarrollaba BitKeeper se rompió y les revocaron el status de free-of-charge.
Fue entonces que Linus decidió hacer su propio software de control de versiones (VCS).

El objetivo de este proyecto era tener un VCS:
- Rápido
- Diseño simple
- Énfasis en el soporte para muchos desarrolladores en paralelo
- Totalmente distribuido
- Soporte eficiente para proyectos grandes (como el kernel de Linux)
Y es así como, en 2005, nació Git.
Un software de control de versiones puede ser centralizado o distribuido.
Un CVCS (Centralized Version Control Software) depende de un repositorio centralizado, a donde todos los desarrolladores contribuyen. Los desarrolladores descargan los cambios del servidor central, realizan sus cambios, y los suben al servidor. Sin embargo, este flujo tiene varias desventajas: los desarrolladores están obligados a mantener su código actualizado antes de subir sus cambios al servidor, dependen de una sola copia para mantener su código, y si no tienen conexión, no pueden subir sus cambios al servidor.
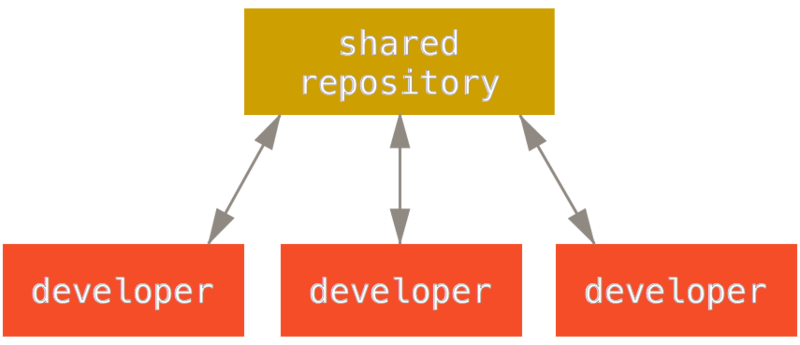
Los DVCS (Distributed Version Control Software) no dependen de un servidor central para registrar los cambios. Cada desarrollador tiene una copia completa del historial del repositorio en su computadora, y los cambios se registran en este repositorio. Puede sonar poco práctico, sin embargo, los proyectos de software generalmente consisten de archivos de texto, los cuales se pueden comprimir de manera que prácticamente no ocupen espacio. Un no puede tener, por definición, un servidor central. Puede existir una copia “central” (blessed repository en la jerga de git) a donde todos los desarrolladores contribuyen, sin embargo, no estás obligado a contribuir tus cambios a ese repositorio
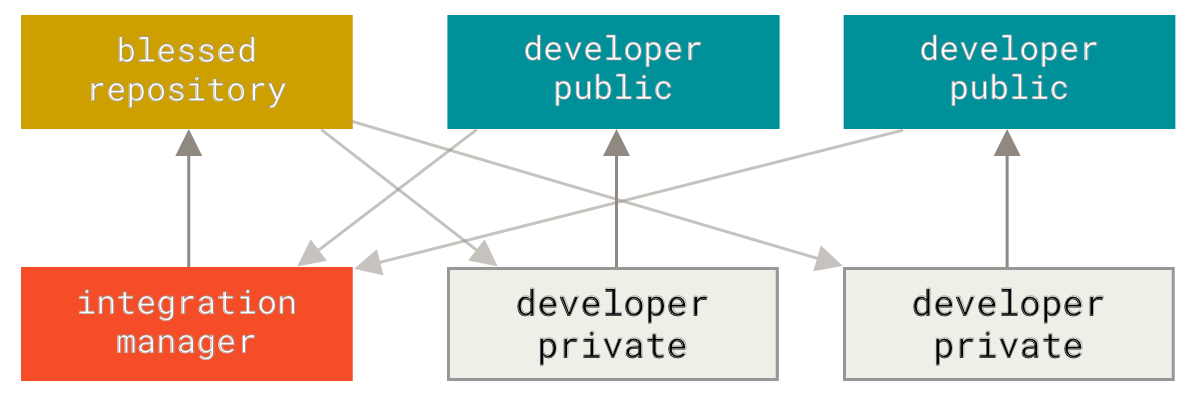
Volviendo al tema de Git…
Git trabaja sobre snapshots. Esto significa que cada que guardas tus cambios en el repositorio, git almacena una copia de todo el repositorio, y no únicamente el set de cambios hechos. Para hacer eficiente este método, git no almacena los archivos que no han sido cambiados, únicamente hace que el archivo en ese snapshot apunte a la última versión modificada.
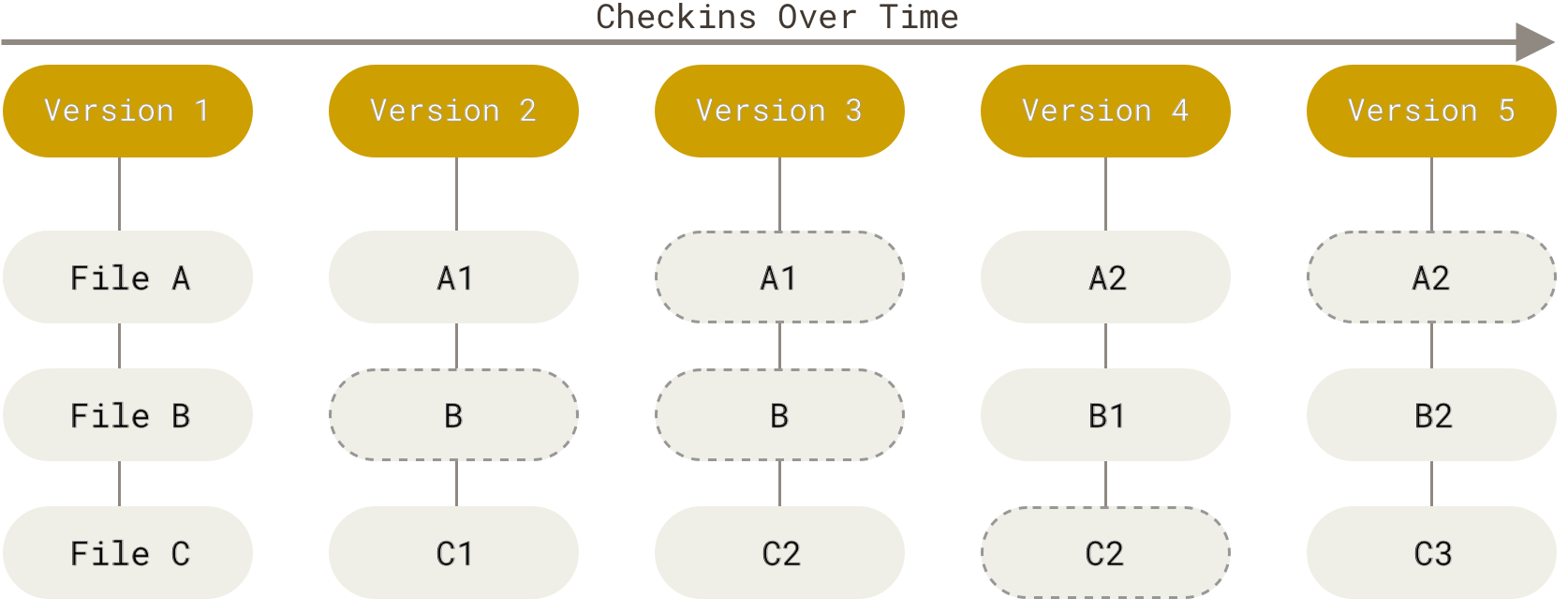
Todos los cambios hechos con git se almacenan en la base de datos local, esto significa que, contrario a los CVCS, no depende de la red para revisar el historial de cambios o hacer cualquier otra acción. Esto te permite trabajar aunque no tengas internet.
Todo en git tiene un checksum. En términos prácticos, esto significa que no se puede alterar ningún archivo o directorio pasado sin que git te avise. Para hacer el checksum, git usa el algoritmo de SHA-1, el cual genera una cadena de texto hexadecimal de 40 caracteres.
Casi todas las operaciones de git añaden a la base de datos, son muy pocas las que eliminan o modifican la historia. Prácticamente todas las operaciones se pueden deshacer o hay una forma de revertirlas.
Un archivo de git puede estar en uno de los siguientes estados:
- Committed: Los cambios están guardados en la base de datos.
- Modified: El archivo fue modificado y aún no se agrega a la base de datos.
- Staged: El archivo está marcado para ir a la base de datos en el siguiente commit.
Todos los repositorios de git tienen un directorio .git (Git directory) en donde se almacenan todos los metadatos de repositorio. Esta es la parte más importante del repositorio, ya que contiene toda la historia de versiones y es lo que se descarga cuando se clona un repositorio.
El working tree es el directorio actual, son los archivos tal cual que están actualmente dentro de la carpeta del repositorio. Estos archivos se extraen de las revisiones guardadas en la base de datos (en el Git directory) y se guardan en el disco para su modificación.
La staging area es un archivo (.git/index) dentro del Git directory que tiene almacenados los archivos marcados como staged.

A veces hay archivos que no queremos o no deberían estar registrados por git, por ejemplo, los archivos compilados de un proyecto, archivos con credenciales o configuraciones específicas de un IDE (.project y .classpath de Eclipse, .idea de IntelliJ o .DS_Store en las Mac). Los motivos para querer ignorar estos archivos son diferentes, pero la forma es la misma: un .gitignore. El gitignore es un archivo en la raíz del repositorio en donde cada línea representa un archivo, un directorio o una extensión que ignorar.
Para entender el modelo de branching de Git, primero necesitamos entender qué es lo que pasa detrás cuando se crean commits.
Como había mencionado, cada que se realiza una acción, git calcula el checksum de el o los objetos que se están agregando. Esto crea una nueva entrada en .git/objects por cada uno de los objetos que se van a agregar.
Si un archivo cambió, aunque sea el mismo archivo, como el contenido cambió, el checksum cambia y se genera una nueva entrada en la base de datos para ese objeto.
Cuando creas un commit, git añade una entrada con un apuntador (la referencia) al snapshot (tree) del contenido que estaba en staging. Cada commit que se agrega tiene la referencia del commit anterior (parent).
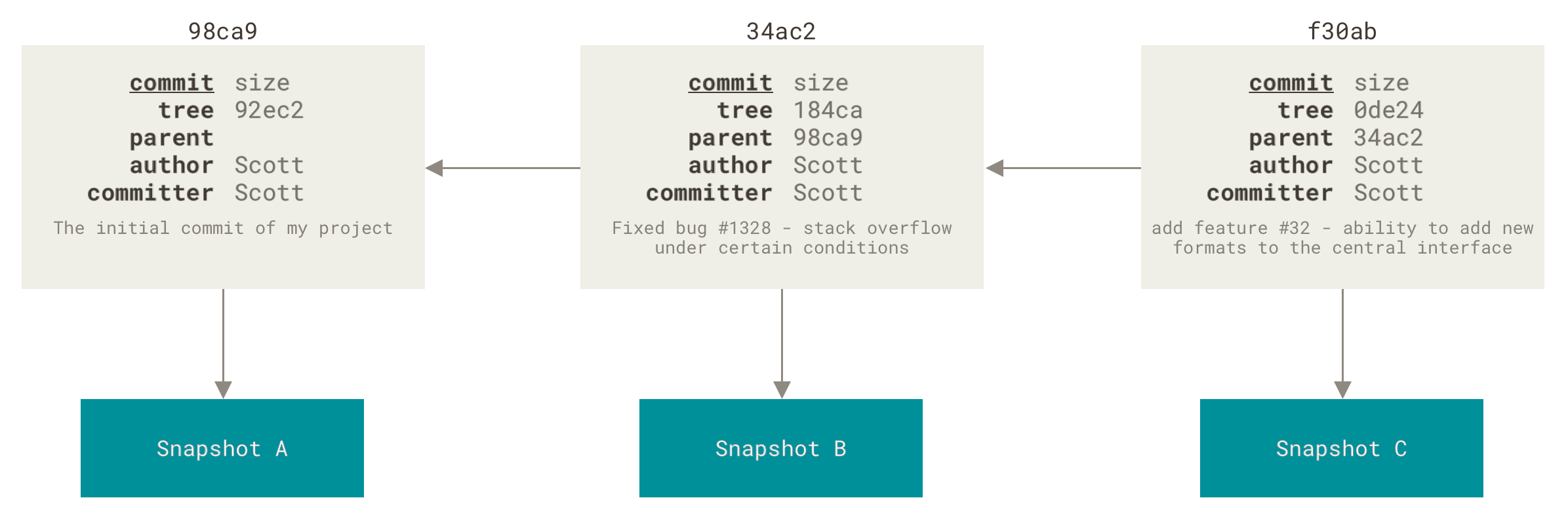
Después de tanto rollo, un branch no es más que un apuntador a un commit. El apuntador del branch actual va avanzando según se van agregando commits.
Para poder saber en qué branch estás actualmente, git tiene un apuntador especial llamado HEAD, el cual no es más que el apuntador al branch en el que estás trabajando.
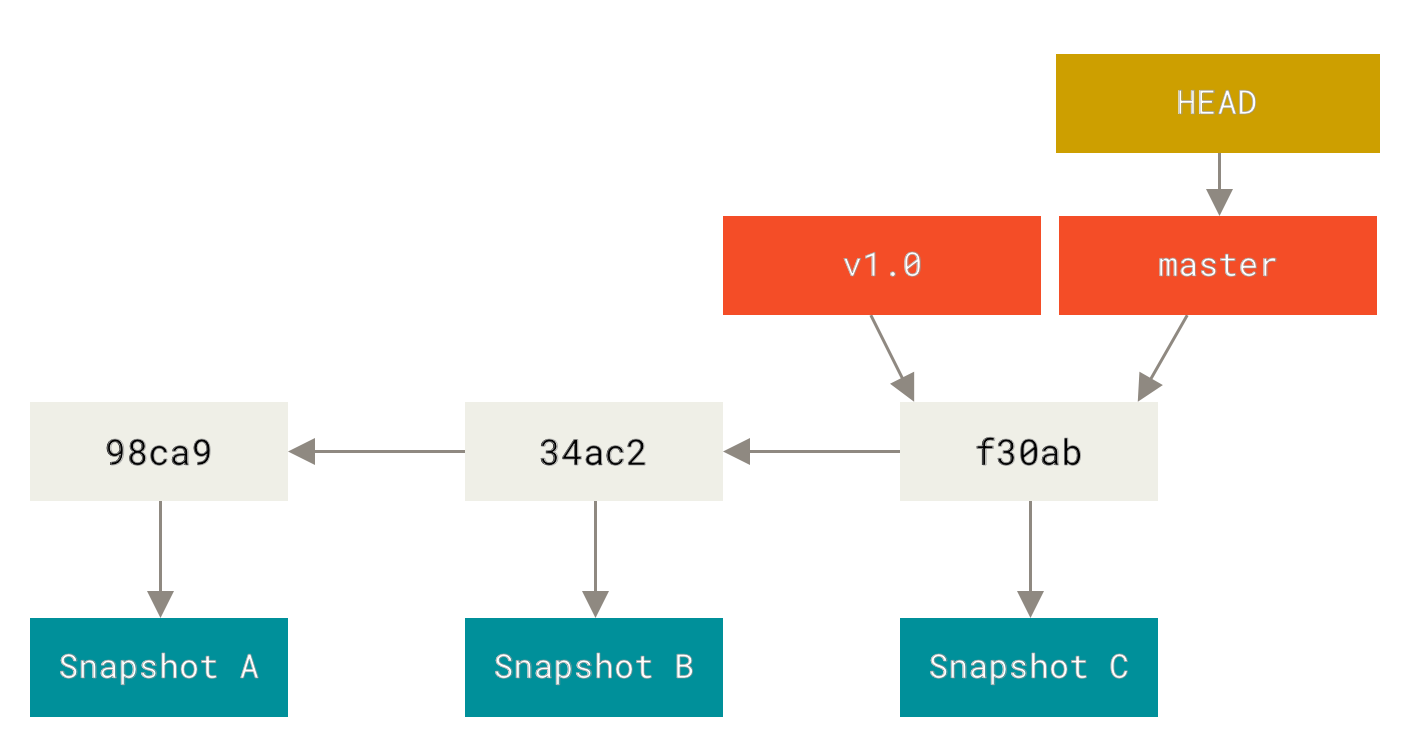
Cuando se crea un nuevo branch, este apunta al mismo commit que está apuntando el branch actual.
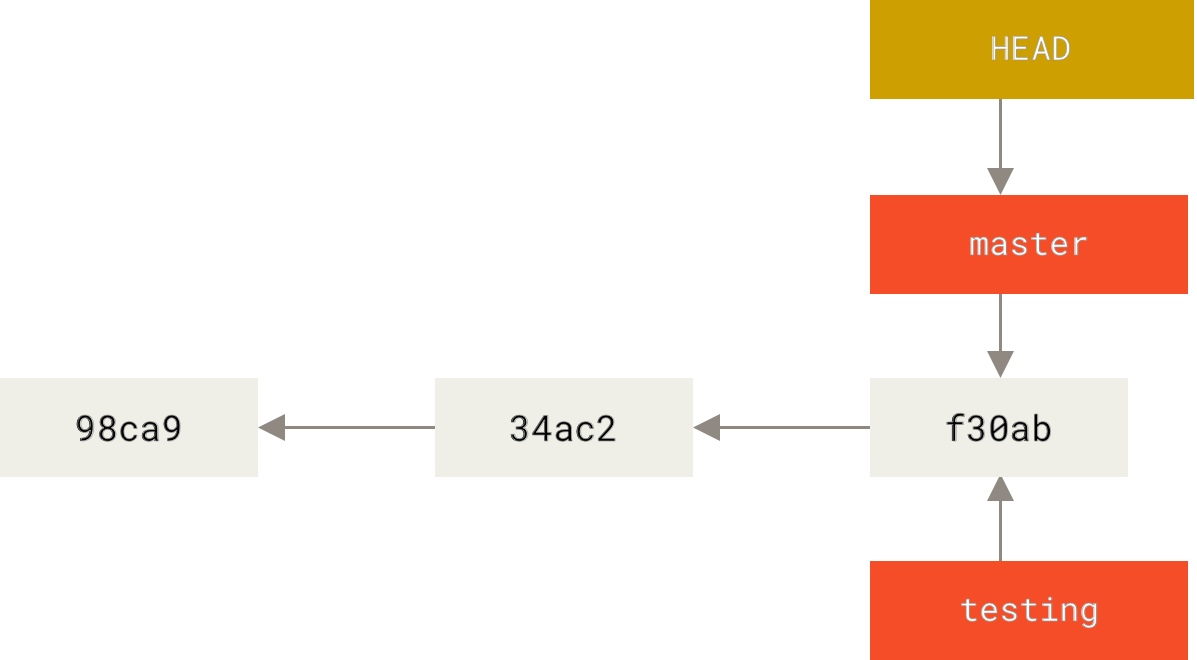
Cuando te cambias de branch, la referencia de HEAD apunta al nuevo branch que seleccionaste, pero, ¿qué pasa cuando empiezas a hacer cambios? El apuntador de HEAD se va a seguir moviendo con la referencia del branch. Puedes estar cambiando entre branches (siempre y cuando los cambios estén committeados) y cada branch tendrá su propia historia, es por eso que los commits almacenan la información de cuál es su commit padre.
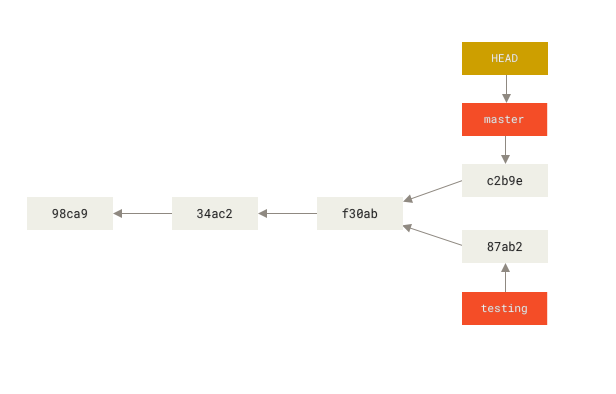
¿Y luego? ¿Cómo juntamos nuestras partes del proyecto?
En términos prácticos, el merge une dos sets de cambios diferentes en un mismo branch.
En términos técnicos, hace que dos branches diferentes combinen sus cambios (sin mezclar sus commits o sus historias) y apunten al mismo commit.
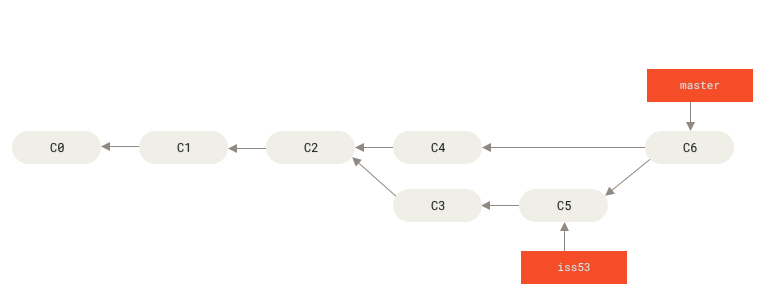
Un merge generalmente sigue una de las siguientes dos estrategias:
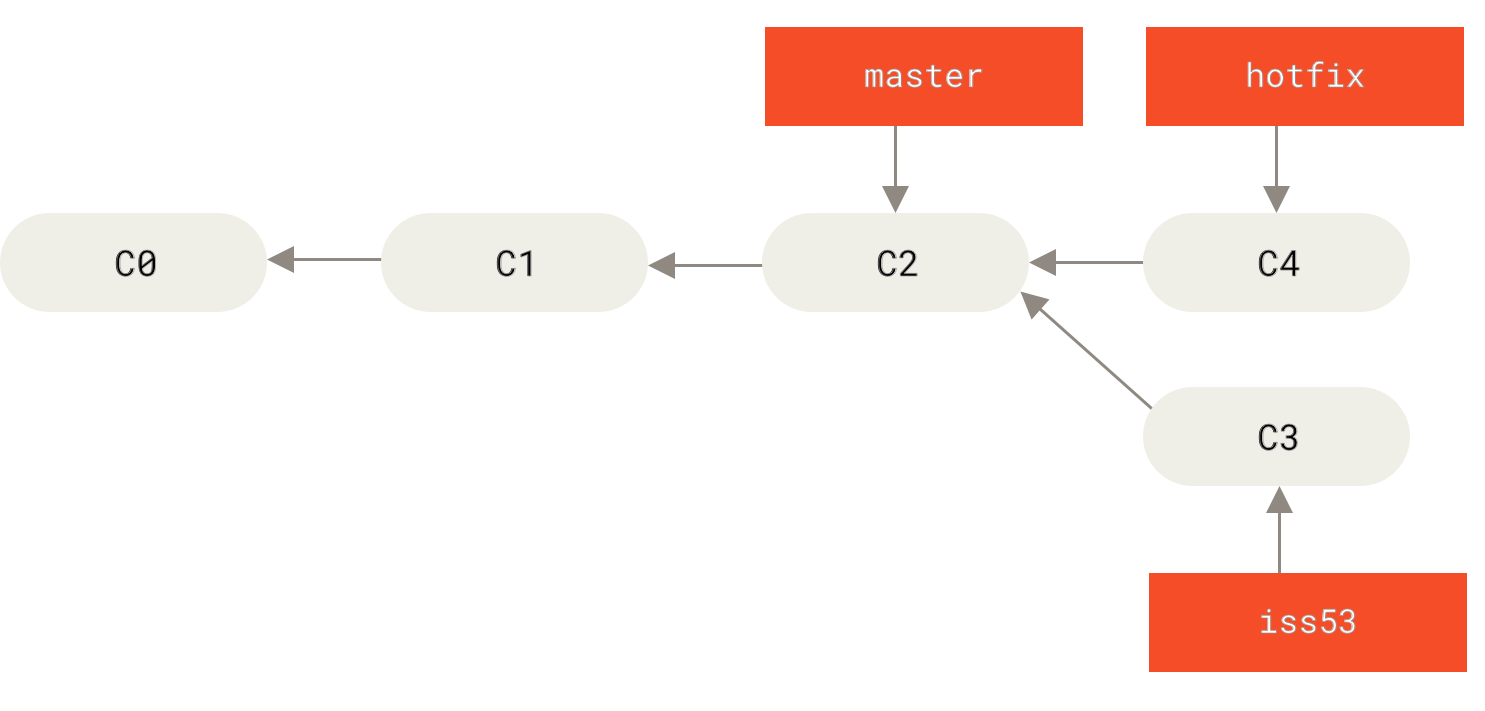
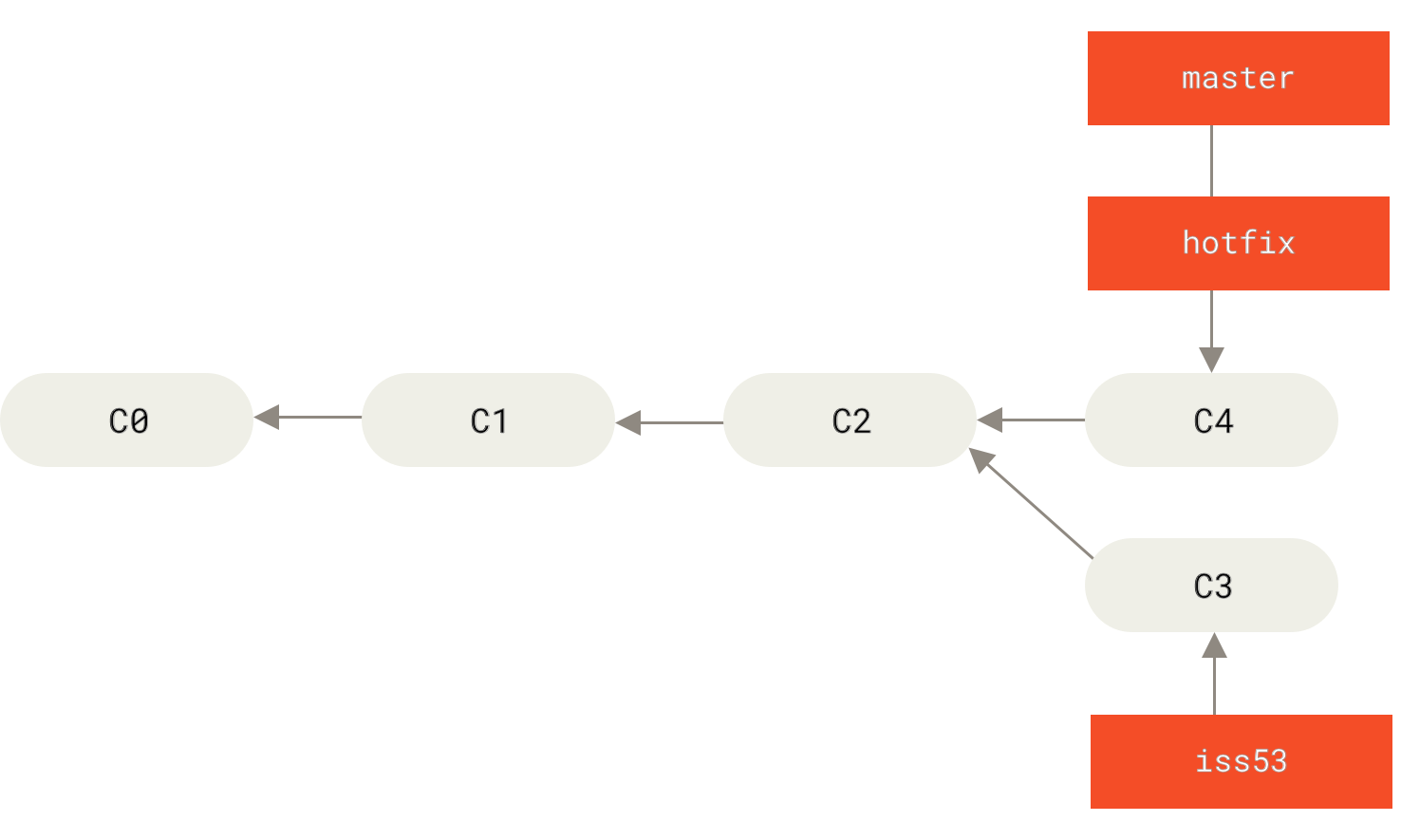
- Fast-forward: se utiliza cuando la historia de commits no diverge del branch al que se está haciendo el merge y el apuntador únicamente se tiene que mover hacia adelante.
Antes del merge:
Después del merge:
- Recursive: Cuando dos branches divergen en su historia, se combinan en un nuevo commit donde se unen los cambios hechos en los últimos snapshots de cada branch.
Antes del merge:
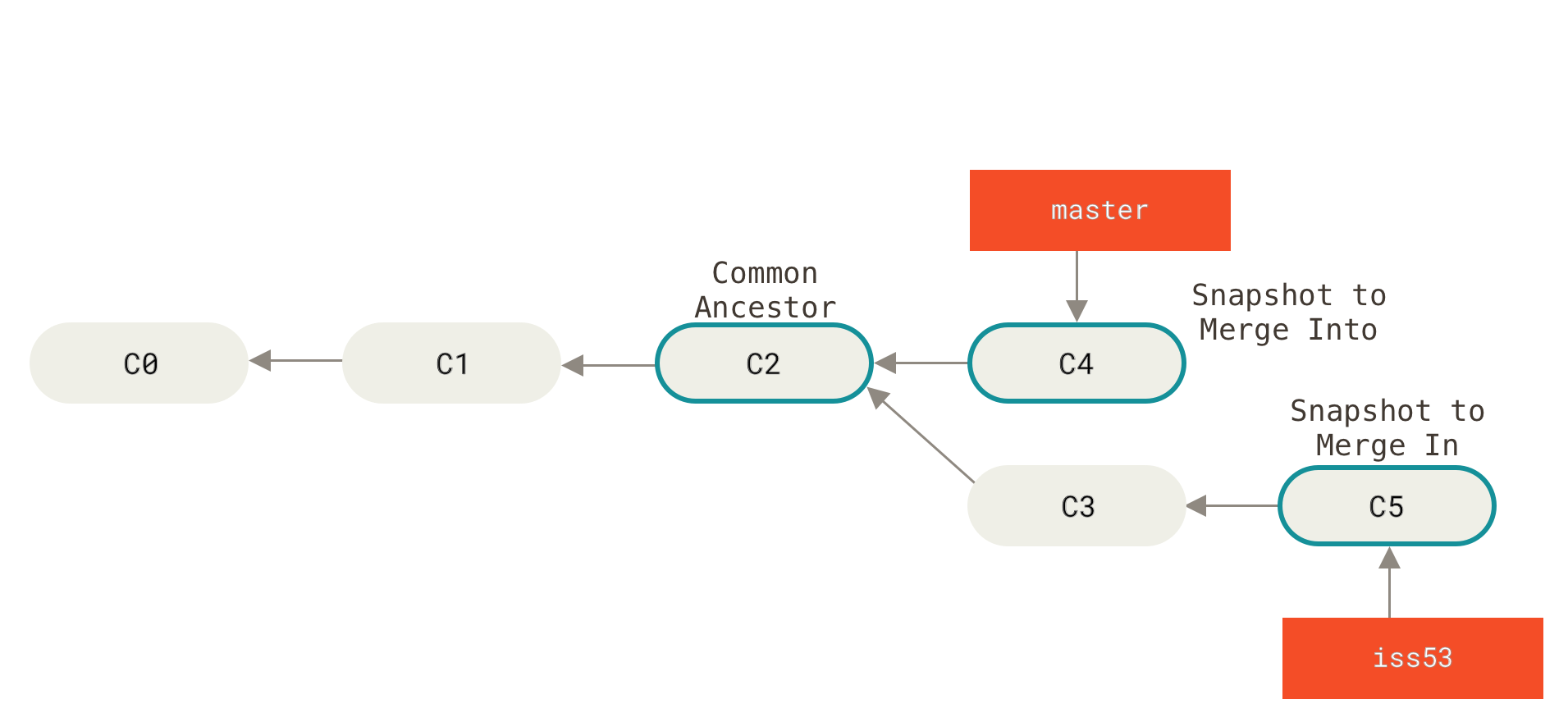
Después del merge:
Tristemente, no todo es miel sobre hojuelas. Cuando dos branches modificaron la misma parte del archivo, git indica que hubo problemas al hacer merge:
$ git merge branch1
Auto-merging index.html
CONFLICT (content): Merge conflict in index.html
Automatic merge failed; fix conflicts and then commit the result.Y en el archivo se marcan las secciones en donde se presentó el conflicto:
<<<<<<< HEAD:index.html
<div id="footer">contact : [email protected]</div>
=======
<div id="footer">
please contact us at [email protected]
</div>
>>>>>>> iss53:index.htmlEn donde la parte superior es lo que contiene el branch a donde queremos hacer el merge, y la parte inferior tiene el contenido del branch que se quiere unir. Para resolver el conflicto, hay que eliminar los marcadores que creó git y corregir el archivo a la versión deseada.
Hasta ahora, hemos visto qué es git y por qué necesitamos usarlo, cuáles son sus características y cómo funciona. Sin embargo, no hemos visto cómo podemos usarlo para trabajar en un proyecto de verdad (con o sin un equipo). Es aquí cuando aparece…
GitHub es un servicio de almacenamiento de repositorios de git. Con más de 31 millones de usuarios, es el principal servicio en donde los desarrolladores almacenan sus repositorios.
Entre otras cosas, GitHub tiene un componente social, que permite interactuar directamente con otros miembros de la comunidad. Esto pone el escenario para que sea la opción must-go para los proyectos open source. Además, cuenta con una plataforma que permite tener integraciones con diferentes aplicaciones y servicios para complementar el ciclo de desarrollo del software.
GitHub cuenta también con un programa para estudiantes, GitHub Education, el cual agrupa a diferentes empresas que te dan beneficios por el simple hecho de ser estudiante: repositorios privados ilimitados en GitHub, un dominio .me gratis con NameCheap por un año, crédito en diferentes cloud providers, etc.
GitHub es para los desarrolladores el equivalente a un portafolio para un diseñador. Tu actividad y tus contribuciones a proyectos de GitHub siempre son bien vistos por las empresas. Esto les demuestra que, además de que dominas git, sabes trabajar en proyectos organizados y colaborar en equipo.
Para empezar a integrar nuestro flujo de git con GitHub, necesitamos un concepto de git más (el último, lo prometo). Un remote no es más una url a donde el repositorio remoto está almacenado. Puede ser un directorio local o puede ser en un servidor remoto (como GitHub).
La interacción con un remote tiene tres elementos principales:
- Fetch: descarga la información que existe en el remote y no en el servidor local.
- Pull: descarga los cambios del branch remoto y los combina en el branch actual (pueden ocurrir conflictos de merge).
- Push: sube los cambios hechos localmente al remote. Únicamente permite hacerlo cuando tu local está al corriente con los cambios hechos en el remote.
Para GitHub, un fork es una copia de un repo que tú manejas. Cuando un usuario crea un repositorio en GitHub, ese usuario es quien lo administra. Un fork es una copia de ese repo administrada por quien lo forkeó. Cabe resaltar que todos estos detalles son a nivel GitHub, no git. Para git, un repositorio forkeado es simplemente un repositorio con un remote a tú repositorio en GitHub, sin embargo, GitHub nos da superpoderes para poder trabajar en equipo.
Cuando tienes un equipo definido para trabajar en un proyecto, como en proyectos escolares o proyectos profesionales más serios, conviene agregar a los miembros como colaboradores más que hacerlos crear forks.
Sin embargo, el verdadero poder de los forks viene con el open source. Si quieres contribuir a un proyecto open source, es muy poco probable que la comunidad te quiera incluir como colaborador, y para esto están los forks. Tú puedes crear tu propia copia del proyecto, hacer los cambios que quieras y luego crear un pull request para incluir tus cambios en el proyecto original.
Espera, ¿un pull requién?
El Pull Request (PR) es la base de la colaboración en proyectos de GitHub. El nombre puede ser un poco engañoso y confuso, pero GitLab (otro servicio de almacenamiento de repos) tiene un nombre más preciso: Merge Request (por cuestiones de convención con GitHub seguiré mencionando los Pull Requests).
Un PR es una solicitud para combinar un branch en otro. Este branch puede ser dentro del mismo repo o puede ser un fork. Como ya mencioné, GitHub nos da superpoderes para la colaboración, y el PR es donde se aprecian mejor. Dentro de un PR puedes comentar secciones específicas del código, dejar reseñas de si el código funciona o solicitar cambios, solicitar la aprobación de uno o varios colaboradores del repo para poder hacer el merge, etc…

Una vez que el PR se aprueba y se hace merge de los cambios, el branch base (al que se le hizo merge) tiene todos los cambios del branch a comparar.
El mundo de git (y no se diga GitHub) da para escribir y hablar indefinidamente. En mi experiencia, la mejor forma de aprender es romper. Mucho de lo que he aprendido sobre git lo aprendí descomponiendo repos una y otra vez, y obligándome a buscar la solución para mi desastre. Hay una infinidad de recursos que pueden ayudarles en este camino, y siempre habrá alguien dispuesto a ayudar.