Home
A text mining and language exploration workbench in Java. Primarily designed for event extraction and text-based event forecasting for interactive narrative applications, the workbench is a generic text and language machine learning sandbox that can be adopted to a wide variety of tasks. Hoop is composed of a collection of modules (hoops) each of which can take linguistic input from one, process it and pass it onto another. Combining those modules or hoops allows you to create complex analysis systems.
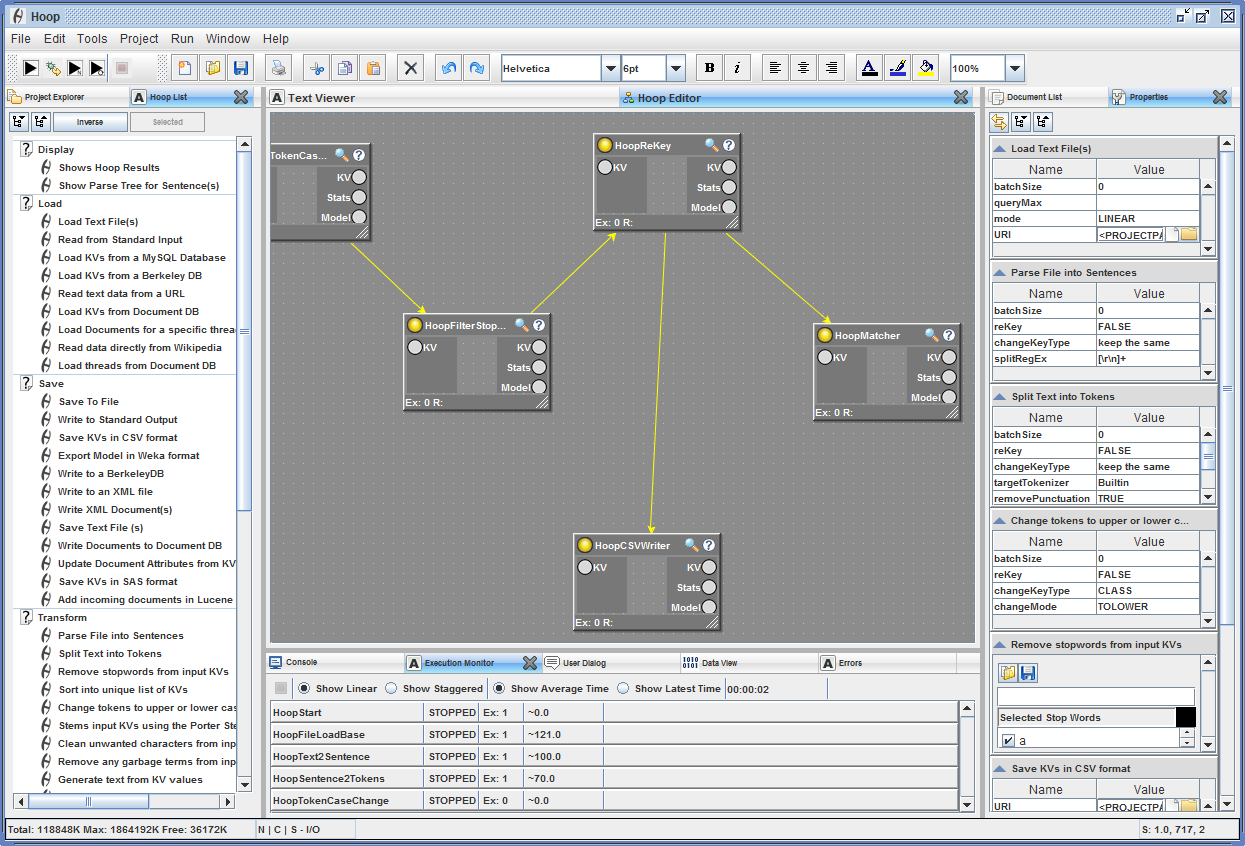
Within large complex language analysis systems we often focus on analyzing our results statistically without examining the correctness of the individual steps. Even worse, we tend to not look at those cases that get rejected by parsers or have been mis-classified by machine learning classifiers. Hoop attempts to provide a means whereby each hoop in a transformation process or analysis step can be examined and interrogated as it is doing its job. All in all Hoop attempts to provide:
- Inspectability
Most systems allow you to do an after-action review of a completed pipeline (a CPE in UIMA terms). This makes it very difficult to inspect what data was produced in each step (CASes) and what data was discarded. Hoop integrates an inspection system which can be activated at any time during or after the running of a Hoop sequence. By clicking on the magnifying glass in a selected Hoop panel you can see the data that was created in that step and you can also inspect what data was discarded.
For more information see the main page for Inspectability
- Explainability
In a complex system that runs on a cluster in which essentially all the steps happen in a parallel fashion, it can be difficult if not impossible to understand what exactly is happening to the system and the data is processes. Hoop aims to provide both visualization tools to understand how data is managed, manipulated and pushed through the pipeline, as well as make the results comprehensible through enhanced text visualizations (e.g. a document wall showing text highlighting based on likelihood estimates)
For more information see the main page for Explainability
- Repeatability
Initially the Hoop code should make it possible to repeat an experiment hundreds or thousands of times, perhaps in such a way that each time different permutations are tried of a pipeline. However the ultimate goal is to create system that can be run indefinitely akin to online learning but with a strong feedback loop that can integrate previously discarded data if the system detects faults in previously used assumptions.
For more information see the main page for Repeatability
1. User Documentation 2. Developer Documentation Workbench GUI Documentation Execution Module Documentation Hoop and Graph
1. Drag and Drop editor allowing you to stitch together custom tools and applications
2. Rich API and developer support for rapid text analysis prototyping
3. Large set of language oriented and related libraries with comprehensible API, see below
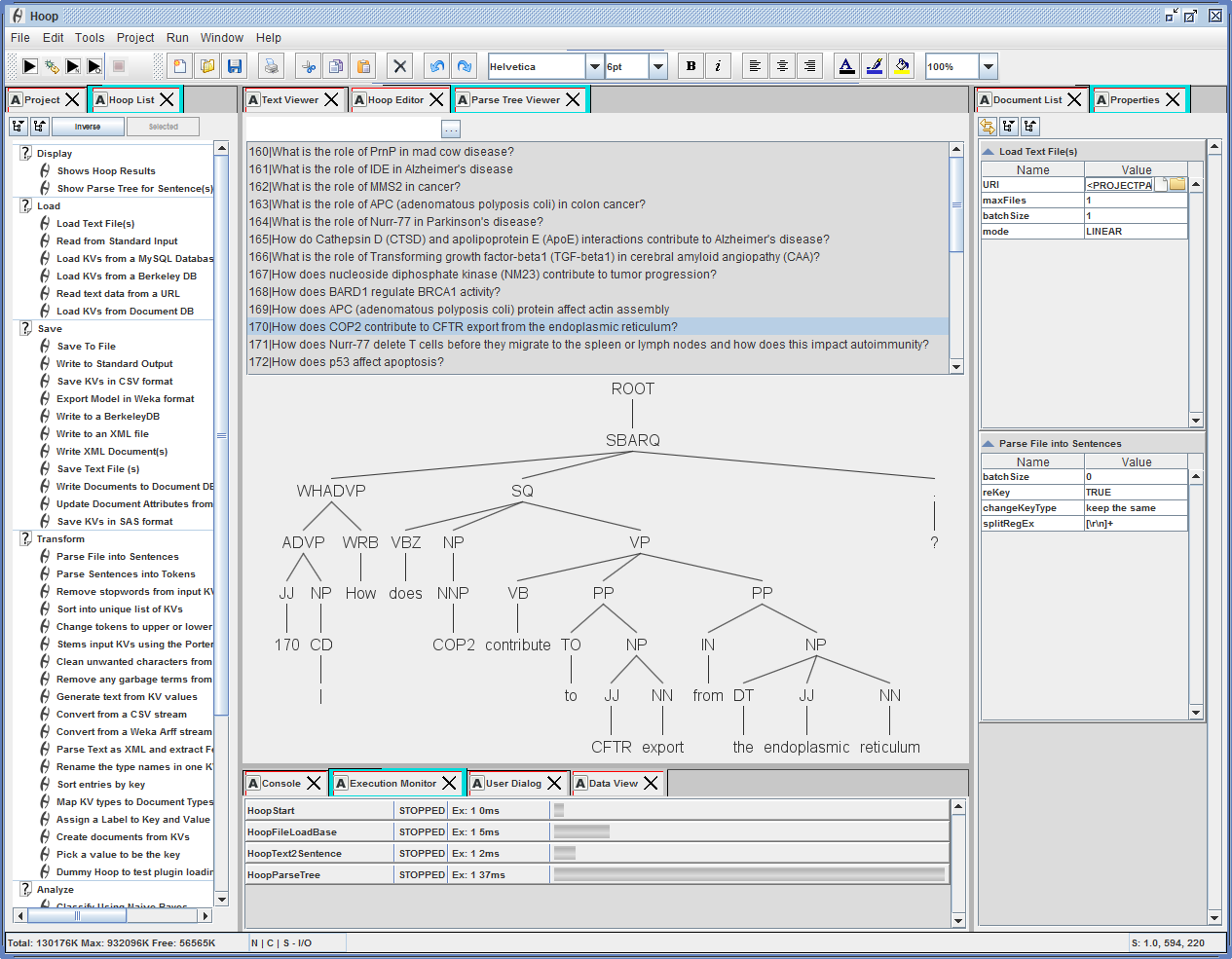
Many of the popular language processing tools are natively available directly from within the IDE. For example, shown below is a Hoop graph in which the last hoop is a visualization wrapper for the Standford NLP parse tree visualization panel. Below is an example of a graph that parses and shows a text file containing TREC questions.
1. Van Velsen, M., Williams J., Verhulsdonck G., Narrative Concepts for AI Driven Digital Interactive Story Telling, in proceedings of the 2009 ICIDS conference
2. Van Velsen, M., Williams J., Verhulsdonck, G., Concepts for Interactive Digital Storytelling: From Table-top to Game-AI, in proceedings of the fifth conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE), 2009
3. Jhala, A., Velsen, M., Challenges in Development and Design of Interactive Narrative Authoring Systems, a Panel, in proceedings of the 2009 AAAI Spring Symposium
4. Van Velsen, M., Towards Real-time Authoring of Believable Agents in Interactive Narrative, in proceedings of the 8th International Conference on Intelligent Virtual Agents (IVA-08), 2008
1. Forster, F. (1985). Aspects of the Novel. San Diego: Harcourt Brace Jovanovich
2. Gee, J. (2005). An Introduction to Discourse Analysis. New York: Routledge
3. Bal, M. (1997). Narratology : introduction to the theory of narrative. Toronto Buffalo: University of Toronto Press
4. Chatman, S. (1980). Story and discourse: narrative structure in fiction and film. Ithaca, N.Y: Cornell University Press
5. Genette, . Narrative discourse : an essay in method. Ithaca, N.Y: Cornell University Press, 1983
6. Auerbach, E. (2003). Mimesis : the representation of reality in Western literature. Princeton, N.J: Princeton University Press
7. Wood, J. (2008). How fiction works. New York: Picador
8. Bal, M. (1997). Narratology : introduction to the theory of narrative. Toronto Buffalo: University of Toronto Press
9. Leitch, T. (1986). What stories are : narrative theory and interpretation. University Park Pa: Pennsylvania State University Press
Initially written as a set of support code for graduate classes and smaller narrative projects, the code is slowly growing to encompass a larger text-based data mining framework.
This source set includes code written for other various graduate courses and is part of a larger research effort in the field of interactive narrative (IN). Language Technologies (CMU, LTI http://www.lti.cs.cmu.edu/) Courses that have contribute to this source base are