In this project we had to implement 3 different methods of finding the probability and compare them. The algorithms we had to implement are:
- Simple deduction
- Variable elimination (where the elimination order is alphabetically)
- Variable elimination (where the elimination order is according the the sum of all factors that a variable is found in)
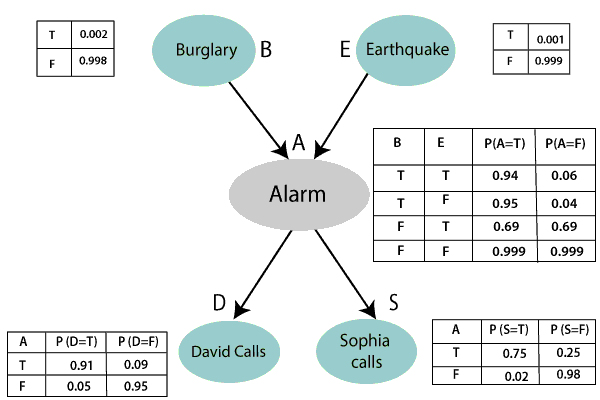
In this part we had to first create CPTs and simplify all query according to the bellow example (going through all possible outcomes for the hidden and calulating them).
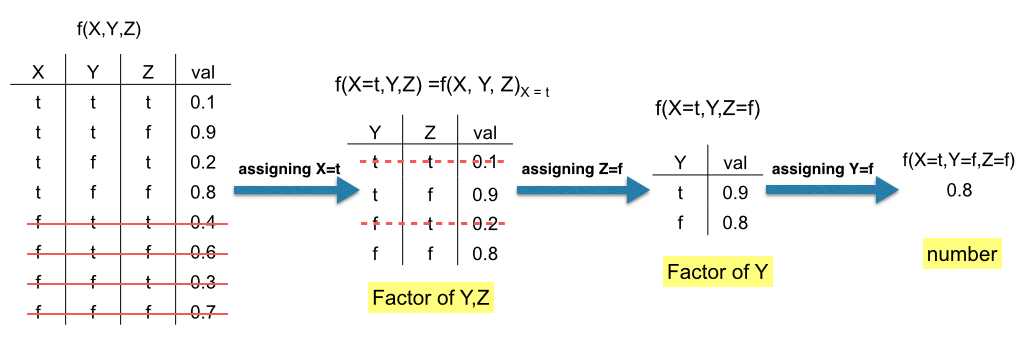
The variable elimination algorithm is called that as ut eliminate variables one by one and by that decreases the number of caculations being done. The process includes a few simple steps:
- Turn CPTs into factors, this is done by deleting all irrelevant rows and columns.
- If one of the factors is one valued we can disregard it.
- Go over hiddens: 3.1 Pick hidden H 3.2 Join all factors that contain H 3.3 Eliminate H by summing out the rows and deleting its column 3.4 If factor becomes one value disregard it.
We were given an XML file which we had to read the network from (an example is also found in this project). After having read the XML the next step was creating the network and connecting all nodes and then implementing all 3 algorithms.
As well as printing the probability of a given query we also had to print the number of additions and multiplications that took place in the calculation. Note that if the query is found as is in the CPTs (meaning that the event and givens are all found in the same CTP) we had to return it instantly without doing any caloculations. When printing the outcomes we note a great decrease between the first and second algorithm, between the second and third there was also a decrease in number of calculations however, since it was a heuristic algorithm sometimes it did better than algo 2 and sometimes worst.
The third algorithm could've been better if when there are two variables of tables the same size it would eliminate them alphabetically and not randomly as I did.