| title | description | author |
|---|---|---|
Exploring Interpersonal Relationships in the Bible |
Learn how to visualize family trees and work with live data using Memgraph and Cypher |
Mislav Vuletić |
Exploring the Hebrew Bible relationships with Memgraph
Reading the Bible everyone struggles to remember relationships between persons and where to find references to them in the Bible. That keeps us from being immersed in the story as it's common to find oneself guessing who is who to whom. Recently, we've discovered this gem of a dataset and wanted to explore it. Memgraph turned out to be a great fit for analysing the data.
In the first part of this article we'll answer some commonly asked questions using a graph database. In the second part you can find the step by step process of how to explore your own datasets; from idea to results.
The data collected by Brady Stephenson contains information about persons in the Bible and the relationships between them. Warning: the dataset is incomplete! At the time of writing the data is collected up to the second book of Chronicles, verse 20. If you want to know more about the format of input data and how we imported it into Memgraph, hop over to the second part of this article.
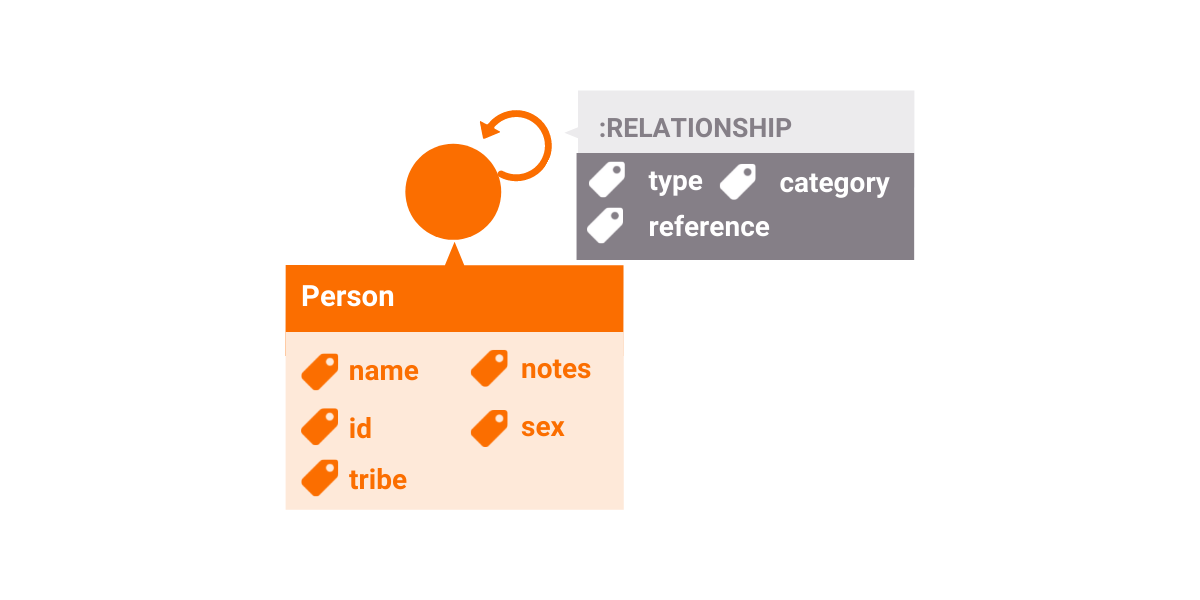
![Graph Data Model] (https://public-assets.memgraph.com/exploring_interpersonal_relationships_in_the_bible/graph_data_model.png)
Person:
- id ["Adam_1", "Jotham_2", "Jotham_3", ...]
- name ["Adam", "Eve", "Jacob", ...]
- notes
- sex ["male", "female"]
- tribe ["Judah", "Levi", "Manasseh", "Ammonite", ...]
RELATIONSHIP:
- type ["father", "half-brother", "killer", "killed by", ...]
- category ["logical", "explicit", "implicit"]
- reference ["GEN 4:19", "2KI 15:13", ...]
Every question in this section will be followed by:
- a short description
- an image from MemgraphLab (Memgraph's default data browser)
- a cypher query (SQL-like declarative query language for graph databases)
In the Bible, family and tribal membership appears to be transmitted through the father.
Which is why this seems like a sane question to ask.
The image shows the longest agnatic kinship path from Adam (created by G-d) all the way to Jotham, the son of Azariah.
Here the incompleteness of our dataset becomes obvious since the family tree of Uzziah, son of Amaziah, should be longer than of his brother Azariah (all the way to Yeshua).
The Amaziah -> Uzziah relationship is first noted in the second book of Chronicles 26:1, which is why it is not included.
This is one of the charms of dealing with live data.

MATCH path = ({name: "Adam"})
-[* {type: "father"} ]->
()
RETURN path
ORDER BY size(path) DESC
LIMIT 1Drawing the whole family tree from the Bible would be a hefty job. Since only the tribe of Israel is covered so far we can make a cut-off there and see what the family tree looked like in the book of Genesis. The image shows Adams family tree up to Jacob, the son of Isaac, grandson of Abram. Do note that apart from the families of Jacob; Moabites, Ammonites (sons of Lot), and other tribes were also present in later parts of the old testament. Female nodes in the graph are coloured orange, and male nodes are coloured red.

MATCH path = ({id: "Adam_1"})-[* bfs (
e, v | v.id != "Jacob_1" AND e.type = "father"
)]->()
RETURN pathJacob had twelve sons, all of whom became the heads of their own family groups, later known as the Twelve Tribes of Israel.
The tribe of Joseph split into two half-tribes: the tribe of Manasseh and the tribe of Ephraim.
In the following table we can see the size of each tribe up to the second book of Chronicles.
size_by_blood is calculated by counting all the nodes we can reach from the sons of Jacob using only the father relationships.
size_by_marriage is calculated by counting all the instances in the Bible where a person is explicitly noted to be a part of a certain tribe.
| tribe | size_by_blood | size_by_marriage |
|---|---|---|
| Judah | 163 | 294 |
| Levi | 110 | 323 |
| Benjamin | 101 | 189 |
| Joseph | 49 | 95 |
| Asher | 41 | 47 |
| Issachar | 17 | 26 |
| Simeon | 15 | 38 |
| Reuben | 9 | 34 |
| Gad | 8 | 44 |
| Naphtali | 5 | 13 |
| Zebulun | 4 | 13 |
| Dan | 2 | 14 |
MATCH ({id: "Jacob_1"})<-[{type: "son"}]-(son)
MATCH path = (son)-[* bfs (e, v | e.type = "father")]->(a)
WITH son.name as tribe, count(a) + 1 AS size_by_blood
OPTIONAL MATCH (person)
WHERE person.tribe IN
CASE tribe
WHEN "Joseph" THEN ["Manasseh", "Ephraim"]
ELSE [tribe]
END
RETURN tribe, size_by_blood, count(person) AS size_by_marriage
ORDER BY size_by_blood DESC, size_by_marriage DESCThe image shows the spear side of the Twelve Tribes of Israel up to 2CH 20:1. Can you guess which family tree belongs to whom? Help yourself with the table provided above!

MATCH ({id: "Jacob_1"})<-[{type: "son"}]-(son)
MATCH path = (son)-[* bfs (e, v | e.type = "father")]->(a)
RETURN pathEach line in the raw dataset by Brady Stephenson contains information about the relationship between two persons and the reference to the Bible verse. Here we show a cleaned dataset excerpt:
person_id_1,relationship,person_id_2,reference
G-d_1,Creator,Adam_1,GEN 2:7
Adam_1,husband,Eve_1,GEN 3:6
Eve_1,wife,Adam_1,GEN 2:25
Adam_1,father,Cain_1,GEN 4:1
Cain_1,son,Adam_1,GEN 4:1
We want to turn that data into a graph, where nodes of the graph represent persons from the Bible and edges represent relationships between them. In the image below we can see the graph of the excerpt given above:

{kind=link}
To do that we need to translate each line in the file into a cypher query. In pseudo-code that would be:
create PERSON "G-d_1" if it doesn't exist
create PERSON "Adam_1" if it doesn't exist
create RELATIONSHIP "Creator" between them
In cypher that looks like this:
MERGE (a: Person {id: "G-d_1"})
MERGE (b: Person {id: "Adam_1"})
CREATE (a)-[r: RELATIONSHIP {type: "Creator"}]->(b)In reality the data is a little more complex. Which is a good thing, since we can gather more information out of it. Here is an excerpt of the original data:
person_relationship_id,person_relationship_sequence,person_id_1,relationship_type,person_id_2,relationship_category,reference_id,relationship_notes
G-d_1:Adam_1:1,1,G-d_1,Creator,Adam_1,explicit,GEN 2:7,
Adam_1:Eve_1:2,2,Adam_1,husband,Eve_1,explicit,GEN 3:6,
Eve_1:Adam_1:3,3,Eve_1,wife,Adam_1,explicit,GEN 2:25,
Adam_1:Cain_1:4,4,Adam_1,father,Cain_1,explicit,GEN 4:1,
Cain_1:Adam_1:5,5,Cain_1,son,Adam_1,explicit,GEN 4:1,
The preferred way of loading such data into Memgraph is using a LOAD CSV expression.
LOAD CSV FROM '/relationship.csv' WITH HEADER AS row
MERGE (a: Person {id: row.person_id_1})
MERGE (b: Person {id: row.person_id_2})
CREATE (a)-[:RELATIONSHIP {
type: row.relationship_type,
category: row.relationship_category,
notes: row.relationship_notes,
reference: row.reference_id
}]->(b)Additionally we can add name, sex, tribe and other meta data to each person using the persons dataset.
LOAD CSV FROM "/person.csv" WITH HEADER AS row
MERGE (node: Person {id: row.person_id})
SET node += {
name: row.person_name,
sex: row.sex,
tribe: row.tribe,
notes: row.person_notes
}This brings us to the data model described at the beginning of the article. A step beyond would be modelling the data into nodes of type Person,Reference and Relationship with appropriate edges between them. That way we could add cross reference relationships and possibly have a better chance of extracting implicit relationships programmatically.
Without domain specific knowledge we can notice that every outgoing edge has to be paired with a matching incoming edge. We can check if every father and mother relationship has a son or daughter matching relationship. We can do the same for wives and husbands, brothers and sisters, etc. The following query returns all Persons that have an unequal amount of incoming versus outgoing edges:
MATCH (person)
OPTIONAL MATCH ()-[incoming]->(person)
WITH person, count(incoming) as ins
OPTIONAL MATCH (person)-[outgoing]->()
WITH person, ins, count(outgoing) as outs
WHERE outs != ins
RETURN person.nameResult:
G-d_1, Naamah_16, Naamah_1, Eve_3, Eve_1, Adam_1
Upon closer inspection we can see that Adam_1 is missing a created by edge towards G-d_1, and that Naamah_16 and Naamah_1 are the same person (same goes for Eve's). We've reported the errors to the author but in the mean time we can make these changes ourselves. We can do that with cypher or change the data directly in the CSV file.
MATCH (g {id: "G-d_1"})-[relationship]->(adam {id: "Adam_1"})
CREATE (adam)-[new_relationship: RELATIONSHIP]->(g)
SET new_relationship=relationship
SET new_relationship.type="created by";On the other side we can analyze the data using domain specific knowledge. If you have read the Bible some things might come out to you as odd straight away. For example, when we were executing the queries in the first part of the article we noticed that Benjamin was the son of Joseph and Rachel, but that can't be right since Joseph was the brother of Benjamin. Also, we have noticed that Nahshon_1 and Nahshon_2 must be the same person as there was no clear bloodline from Adam to David! In general for these kinds of observations you will usually need someone who is an expert in the field. These methods won't work well if the number of entries is too big. In those cases you'll have to accept small discrepancies between the data and the truth.
This has been a concise how-to guide on exploring real world data with all the charms that go with it. We hope you enjoyed reading it as much as we enjoyed writing it. The dataset will continue to be expanded. Download the latest version and you might get better results. Head over to the download page to start exploring your own data or play with a plethora of datasets we provide. Good luck and stay sharp!