Cantor is a global sequence generator service, which is distributed, stateless and high available.
Cantor generates unique, relatively orderly and inverse decodable 64-bit integer IDs.
This project provides a easy way to use it in your docker environment. In fact, you can only use a few commands to start up all the components the service depends on and the tools, such like monitors and load testing.
This project contains several components:
- Cantor service: the maintain service of the project
- Redis: one of the storage Cantor can depends on, optioanl in runtime
- HBase: one of the storage Cantor can depends on, optioanl in runtime
- Grafana: used for monitoring Cantor instances
- InfluxDB: storage Grafana depends on
- JMXTrans: used for collecting the monitor data of Cantor
Protocol of ID
| 1 bit | 2 bit | 2 bit | 7 bit | 3 bit | 28 bit | 21 bit |
|---|---|---|---|---|---|---|
| Sign bit as 0, never used | Protocol version, supporting 4 versions most | Generation sources descriptor, 4 in most | Custom spaces, 128 spaces most | Cantor service instance number, supporting 4 instances online most | Timestamp, which can be used in 8 years from 2018-01-01 00:00:00 | Sequence, about 13k ids generated per seconds |
In short, Cantor service guarantees that all unique IDs are generated based on its logic clock and a persistent sequence consuming state. When persistence service is down, Cantor service can downgrade to generate ID in local.
All components are dockerized and we can starts up all the components by docker-compose.
Deployment demonstration:
- Build Java project
$ cd $PROJECT_ROOT$ mvn clean install -N && cd http && mvn clean install && cd ../service && mvn clean package
- Build Docker images and deploy to docker swarm:
$ cd $PROJECT_ROOT$ docker-compose build$ docker stack deploy -c docker-compose.yml cantor
Service RESTful API:
| API | HTTP Method | Parameters | Request example | Return |
|---|---|---|---|---|
/id |
GET | cate: Custom category, range: How many IDs do you want return in a batch | http://localhost:8080/id?cate=0&range=100 |
{"start": "18446744073709551616", "range":"100"} |
/info |
GET | id: The ID to decode | http://127.0.0.1:8080/info?id=36313111556915201 |
{"sequence": 1,"descriptor": 1,"category": 2,"timestamp": 21664133} |
A Java SDK to improve the productivity of interacting with Cantor service.
- Design for thread safety
- Cache the IDs in memory with a TTL. When IDs are expired or out of stock, SDK will retrieve a new batch from Cantor service.
Monitoring by jmxtrans & influxdb & grafana
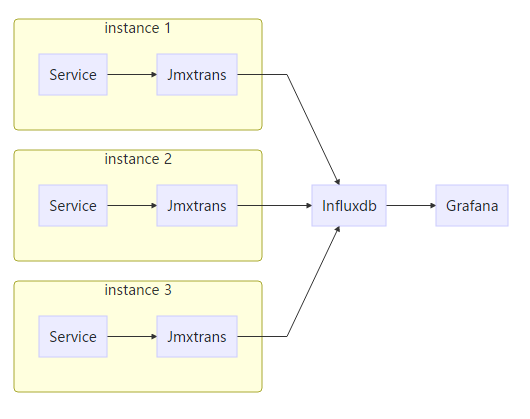
- Build and deploy the docker images
- Open grafana
http://localhost:3000 - Add data source in grafana
- Name: influxdb
- Type: InfluxDB
- URL: http://influxdb:8086
- Database: jmxdb
- User: admin
- Password: 123456
- Import
grafana.jsonin grafana
Uses apache-jmeter as performance test client. Jmeter version: apache-jmeter-4.0.
-
Script
- cantor_sc_100.jmx
- cantor_sc_200.jmx
- cantor_sc_400.jmx
- cantor_sc_1000.jmx
- cantor_sc_5000.jmx
- cantor_sc_5000_10.jmx
- cantor_sc_10000.jmx
- cantor_sc_10000_10.jmx
- cantor_sc_10000_300.jmx
-
Start Jmeter
docker exec -it <CONTAINER> /jmeter/apache-jmeter-4.0/bin/jmeter -n -t <Script>
-
Jmeter result
docker exec -it <CONTAINER> sort r.csv | uniq -c | awk '{print $1}'|sort|uniq -c