⚠️ Alert: If you are using this code with Keras v3, make sure you are using Keras ≥ 3.6.0. Earlier versions of Keras v3 do not honortrainable=False, which will result in training hand-crafted filters in LITEMV and H-Inception unexpectedly.
| Overview | |
|---|---|
| CI/CD | |
| Code |    |
| Community |   |
Authors: Ali Ismail-Fawaz1,†, Maxime Devanne1,†, Stefano Berreti2, Jonathan Weber1 and Germain Forestier1,3
† These authors contributed equally to this work
1 IRIMAS, Universite de Haute-Alsace, France
2 MICC, University of Florence, Italy
3 DSAI, Monash University, Australia
This repository is the source code of the article titled "Deep Learning for Skeleton Based Human Motion Rehabilitation Assessment: A Benchmark". In this article, we present a benchmark comparison between nine different deep learning architectures on for Skeleton Based Human Rehabilitation Assessment. This archive contains 39 classification datasets and 21 extrinsic regression datasets. More details about the dataset information is available on the article webpage.
Automated assessment of human motion plays a vital role in rehabilitation, enabling objective evaluation of patient performance and progress. Unlike general human activity recognition, rehabilitation motion assessment focuses on analyzing the quality of movement within the same action class, requiring the detection of subtle deviations from ideal motion. Recent advances in deep learning and video-based skeleton extraction have opened new possibilities for accessible, scalable motion assessment using affordable devices such as smartphones or webcams. However, the field lacks standardized benchmarks, consistent evaluation protocols, and reproducible methodologies, limiting progress and comparability across studies. In this work, we address these gaps by (i) aggregating existing rehabilitation datasets into a unified archive, (ii) proposing a general benchmarking framework for evaluating deep learning methods in this domain, and (iii) conducting extensive benchmarking of multiple architectures across classification and regression tasks. All datasets and implementations are released to the community to support transparency and reproducibility. This paper aims to establish a solid foundation for future research in automated rehabilitation assessment and foster the development of reliable, accessible, and personalized rehabilitation solutions.
In order to download the 60 datasets of our archive simply use the two following commands when in the root directory of this repository:
cd datasets
chmod +x get_datasets.sh
./get_datasets.shThis will create two sub-folders under the datasets folder: datasets/classification/ and datasets/regression/ where the datasets are stored inside.
For each dataset sub-folder, there exists a single json file containing the informaiton of the datasets alongside k folders for each fold (train-test split) on this specific dataset, where k is the number of folds which varries from dataset to another.
This repository supports the usage of docker. In order to create the docker image using the dockerfile, simply run the following command (assuming you have docker installed and nvidia cuda container as well):
docker build --build-arg USER_ID=$(id -u) --build-arg GROUP_ID=$(id -g) -t deep-rehab-pile-image .After the image has been successfully built, you can create the docker container using the following command:
docker run --gpus all -it --name deep-rehab-pile-container -v "$(pwd):/home/myuser/code" --user $(id -u):$(id -g) deep-rehab-pile-image bashThe code will be stored under the directory /home/myuser/code/ inside the docker container. This will allow you to use GPU acceleration.
If you do not want to use docker, simply install the project using the following command:
python3 -m venv ./deep-rehab-pile-venv
source ./deep-rehab-pile-venv/bin/activate
pip install --upgrade pip
pip install -e .[dev]Make sure you have jq installed on your system. This project supports python>=3.11 only.
numpy==1.26.4
scikit-learn==1.4.2
aeon==1.0.1
keras==3.6.0
tensorflow==2.16.1
hydra-core==1.3.2
omegaconf==2.3.0
pandas==2.0.3
matplotlib==3.9.0
For each experiment, our code runs multiple initialization (default 5) of a model on a single fold of a single dataset, reports the evaluation metrics on each initialization, as well as the ensemble performance of all initializations. The results reported in our article are of the ensemble performance.
If you wish to run a single experiment on a single dataset, on a single fold of this dataset, using a single model then first you have to execute your docker container to open a terminal inside if you're not inside the container:
docker exec -it deep-rehab-pile-container bashThen you can run the following command for example top run LITEMV on the IRDS_clf_bn_EFL classification dataset on fold number 0:
python3 main.py task=classification dataset_name=IRDS_clf_bn_EFL fold_number=0 estimator=LITEMVThe code uses hydra for the parameter configuration, simply see the hydra configuration file for a detailed view on the parameters of our experiments.
If you wish to run all the experiments to reproduce the results of our article simply run the following for classification experiments:
chmod +x run_classification_experiments.sh
nohup ./run_classification_experiments.sh &and the following for regression:
chmod +x run_regression_experiments.sh
nohup ./run_regression_experiments.sh &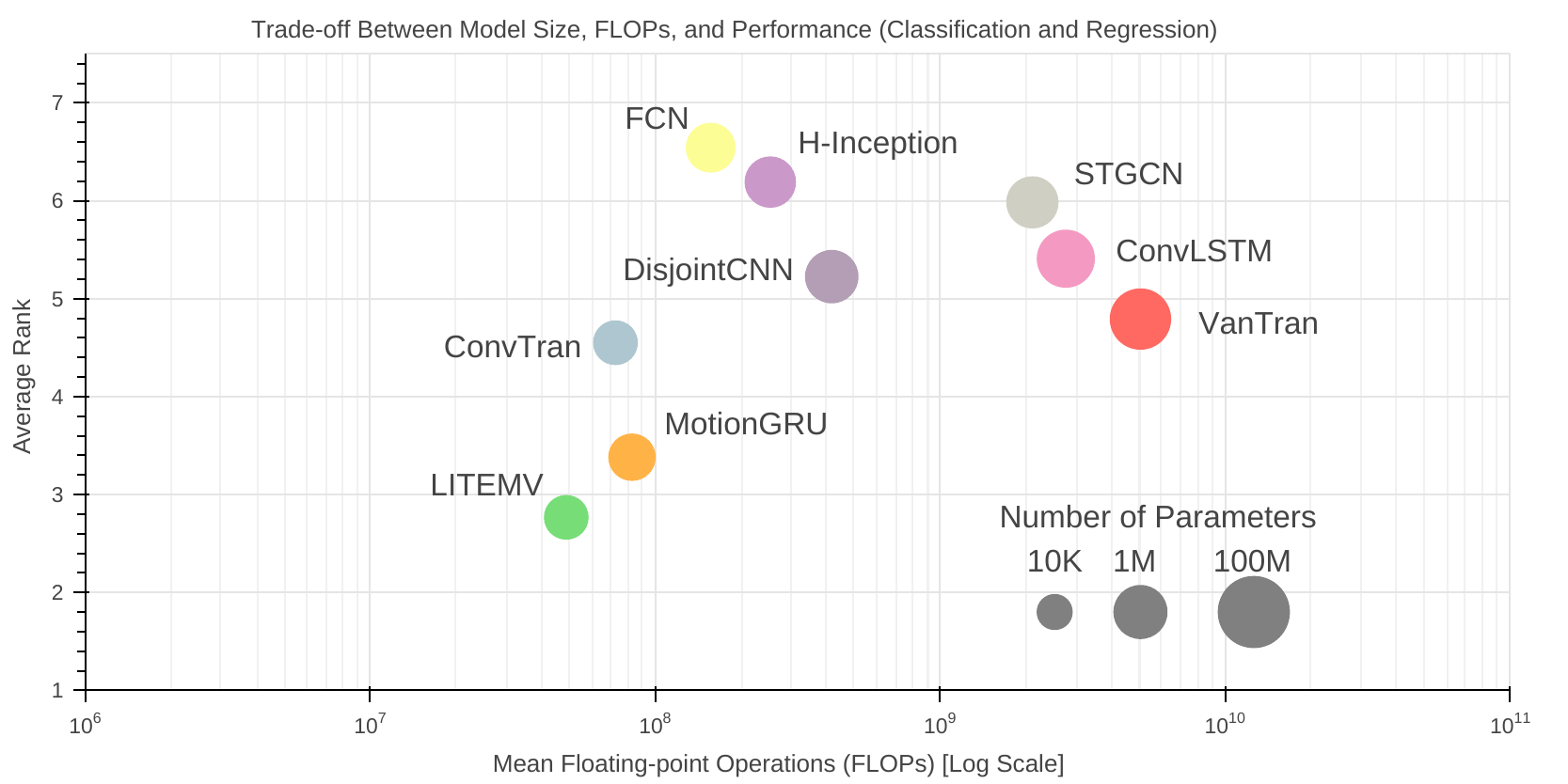
If you use this work please cite the following:
@article{ismail-fawaz2025DeepRehabPile,
author = {Ismail-Fawaz, Ali and Devanne, Maxime and Berretti, Sefano and Weber, Jonathan and Forestier, Germain},
title = {Deep Learning for Skeleton Based Human Motion Rehabilitation Assessment: A Benchmark},
journal={arxiv preprint arXiv:2507.21018},
year = {2025}
}This work was supported by the ANR DELEGATION project (grant ANR-21-CE23-0014) of the French Agence Nationale de la Recherche. The authors would like to acknowledge the High Performance Computing Center of the University of Strasbourg for supporting this work by providing scientific support and access to computing resources. Part of the computing resources were funded by the Equipex Equip@Meso project (Programme Investissements d'Avenir) and the CPER Alsacalcul/Big Data. The authors would also like to thank the creators and providers of the original datasets in our archive.