[06] Caso de Uso: Detalhes do Coletor
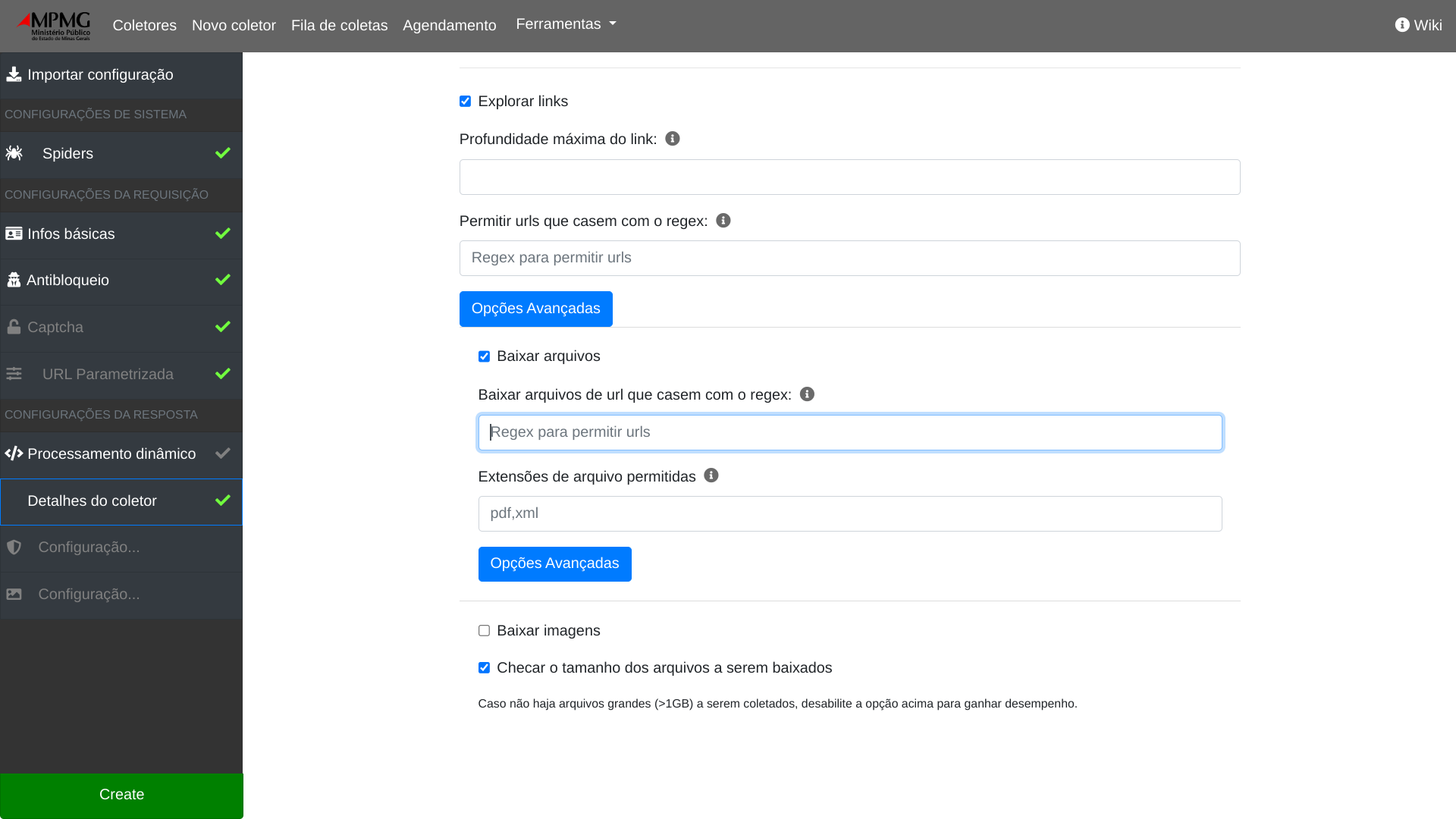
Detalhes do coletor é a tela de configuração em que indicamos as páginas e os documentos que devem ser coletados. Através de URLs, expressões regulares e itens HTML, é possível especificar a exploração de links e escolher os formatos dos arquivos que serão buscados pelo coletor.
Pre-requisitos: para completo entendimento das configurações dessa documentação, é necessário algum conhecimento nos itens abaixo. Para cada um deles, indicamos materiais de referência.
- Regex (expressões regulares);
- HTML;
- Ferramenta de inspeção de navegadores web (Mozilla Firefox, Google Chrome, entre outros).
Nas próximas seções, detalhamos os campos e botões disponíveis. Observação: as Opções Avançadas podem ser aplicadas à coleta de páginas e ao download de arquivos. Serão explicadas juntamente, por serem semelhantes em ambos os casos.
Nesta seção, especificamos e filtramos as URLs para as páginas a serem coletadas:
-
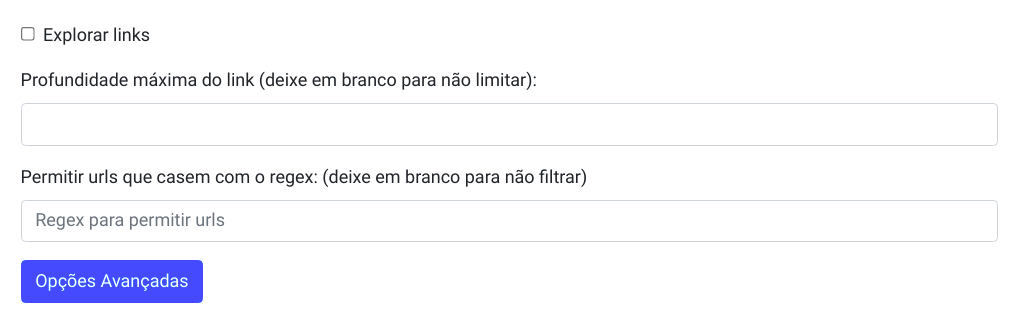
Explorar links: checkbox - indica se o coletor deve ou não buscar por URLs nas páginas a serem visitadas. Default: não.
-
Profundidade máxima do link: o campo pode ser preenchido com valor numérico inteiro positivo que indica a profundidade da exploração de links. (Por exemplo, inserindo o número
1, o coletor acessará apenas URLs encontradas na página correspondente à URL base.) Default: vazio - não há restrição de profundidade. -
Permitir urls que casem com o regex: essa opção permite filtrar os links de interesse, considerando apenas as URLs que casem com o Regex especificado. Default: vazio - não há restrição de URLs a partir de expressões regulares.
Esta seção é referente às especificações dos arquivos que devem ser coletados.
Os campos abaixo são relativos à extração e filtragem dos links dos arquivos encontrados:
-
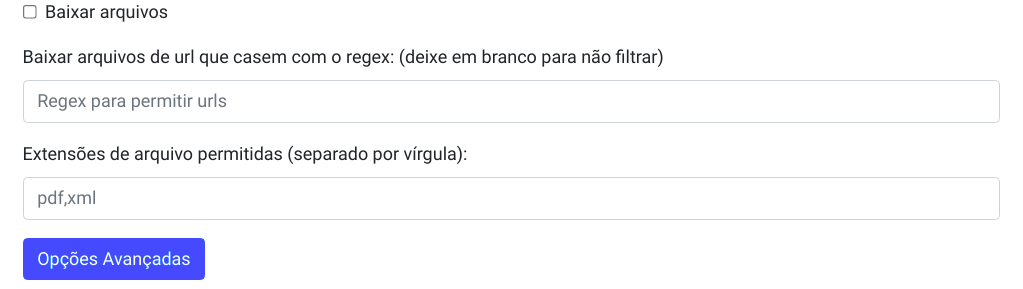
Baixar arquivos: checkbox - indica se arquivos devem ou não serem procurados e baixados. Default: não.
-
Baixar arquivos de url que casem com o regex: devem ser baixados apenas os arquivos cujas URLs casem com a expressão regular indicada. Default: vazio - não há restrição de download por essa ferramenta.
-
Extensões de arquivo permitidas: baixar apenas arquivos com as extensões especificadas. Default: vazio - permite todos os tipos de arquivo.
Outras configurações relacionadas à coleta de arquivos:

- Baixar imagens: checkbox - especifica se imagens encontradas nas páginas acessadas devem ser baixadas. Default: não coletar imagens.
Atenção: A opção de baixar imagens diz respeito às imagens que estão no código-fonte, no leiaute do site. O download de arquivos com extensões de imagem é configurado através das ferramentas de download de arquivos vistos anteriormente.
- Checar o tamanho dos arquivos a serem baixados: Dentre os documentos encontrados pelo coletor, podem existir arquivos "grandes" (maiores que 1GB), que exigem um tratamento especial pelo coletor. A coleta de um site pode ser seriamente comprometida quando o coletor lida com esses arquivos da maneira incorreta. Desta forma, por default, essa opção está habilitada.
As Opções Avançadas são configurações adicionais para extração e tratamento de links.
Primeiramente, vamos tratar das opções que são comuns entre arquivos e páginas:

-
Permitir só urls dos domínios: campo para especificar a URL dos domínios de interesse. Default: vazio - a coleta de páginas ou arquivos será feita, independentemente do site em que foram encontrados.
-
Extrair links do tipo: o campo pode ser preenchido com tags HTML que devem ser consideradas pelo coletor para obter URLs. Default: vazio - buscar links em tags
a. -
Extrair urls dos atributos: o coletor irá extrair links dos atributos HTML cujas tags foram explicitadas no campo acima. Defaul: vazio - acessar atributo
href. -
Função python para processar os atributos: às vezes, a URL de interesse não é exatamente o valor do atributo especificado acima, mas sim alguma string que pode ser construída a partir dele. Nesse caso, é possível especificar uma função lambda para realizar um processamento desse atributo. Default:
lambda x: x- não há transformação do atributo para a construção dos links.
Além dessas opções, existem algumas configurações que são específicas do processamento das páginas (ou seja, referentes ao primeiro botão):
- Codificação das páginas:

- Checar tipo da página:

Com o objetivo de exemplificar as funcionalidades da tela de Detalhes do Coletor, criamos dois casos de uso: no primeiro exemplo, vamos focar nas ferramentas relacionadas à extração de links; no segundo exemplo, usaremos as Opções Avançadas para coletar arquivos.
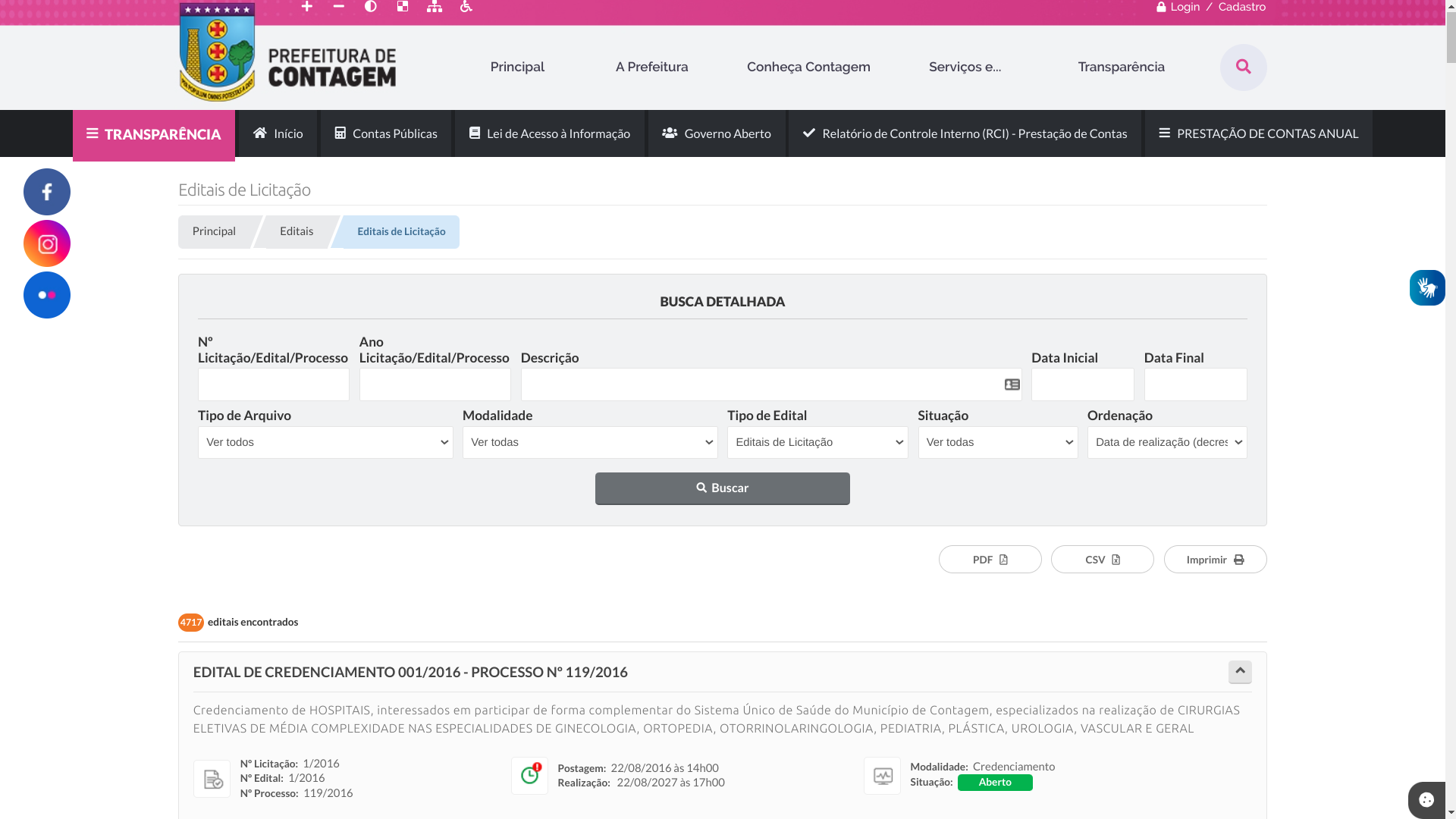
O objetivo deste coletor é salvar as páginas que detalham as licitações disponíveis nesta página:
Abaixo, clicando nos links de cada edital, eis um exemplo do tipo de página que vamos coletar:

Podemos notar que URLs dessas páginas são da forma https://www.portal.contagem.mg.gov.br/portal/editais/0/1/N/, em que N é o identificador da licitação.
Disponibilizamos o JSON de configuração deste coletor, que pode ser importado e testando, seguindo as orientações desta página. Neste estudo, vamos nos ater apenas à especificação dos detalhes do coletor. Você pode consultar esta documentação caso tenha dúvidas em outra seção.
Abaixo, a tela de detalhes deste coletor.

Considerações:
-
Habilitamos a opção de explorar links, para buscar as URLs das licitações;
-
Desejamos coletar páginas que podem ser acessadas diretamente a partir da URL base (
https://www.portal.contagem.mg.gov.br/portal/editais/1/), portanto, a profundidade máxima desejada é1; -
Podemos filtrar as URLs de interesse, utilizando a informação de que elas possuem o formato que observamos na seção anterior. Essa filtragem será feita usando expressões regulares:
^(https:\/\/www.portal\.contagem\.mg\.gov\.br\/portal\/editais\/0\/1\/.*) -
Nos outros campos, podemos manter as opções default: não desejamos baixar arquivos ou precisaremos das outras ferramentas para atingir nossos objetivos.
Ao executar o coletor instanciado, podemos verificar que os códigos-fonte das páginas desejadas estão salvos na pasta de destino especificada (no caso, diretório \data\casodeuso1).
Neste caso de uso, vamos coletar a página de Editais de Licitação de São Lourenço. O objetivo é salvar as página e baixar todos os documentos PDFs contidos nelas e que podem ser acessados estaticamente. Exemplo de página abaixo: os arquivos estão nos links dos textos marcados em vermelho.

Novamente, focaremos apenas na tela Detalhes do Coletor. O JSON de configuração deste coletor pode ser importado através da interface para que você possa testá-lo.

Considerações:
-
Para este exemplo, precisamos de habilitar o "Explorar Links", porque queremos buscar outras páginas de licitações do site. Não precisamos especificar profundidade máxima: os links serão filtrados pela RegEx dada, obedecendo o formato das páginas de licitações.
-
Para baixar os arquivos da página, habilitamos essa opção na interface. Também especificamos o RegEx que o link dos arquivos deve seguir.
Agora, clicamos no botão de "Opções Avançadas" correspondente às opções para extração de links (primeiro botão azul).

- Deixamos o modo padrão de codificação das páginas, não é necessário trocar.
- Para garantirmos que a busca de arquivos não fuja do domínio, especificamos que desejamos nos manter apenas no site da Prefeitura de São Lourenço.
- Não precisamos especificar tags e atributos diferentes de
aehrefporque os links dos arquivos são encontrados nessas propriedades. Da mesma forma, não é necessário usar alguma função lambda para processar as URLs: elas já estão no formato desejado. - Não checamos tipos de páginas, pois esse coletor funciona adequadamente sem conferir a tipagem.
Terminamos, assim, a configuração deste coletor. É possível importar essa configuração do coletor navegando até a página de "Novo Coletor" e, em seguida, abrindo a seção "Importar configuração". Use o seletor de arquivo para encontrar a configuração baixada em seu sistema e as configurações da coleta serão automaticamente preenchidas. Você pode encontrar o resultado de sua execução em \data\casodeuso2