
Run ILGPU C# kernels on WebGPU, WebGL, Wasm, Cuda, OpenCL, and CPU — from a single codebase.
Write parallel compute code in C# and let the library pick the best available backend automatically. In the browser, three backends (WebGPU, WebGL, Wasm) bring GPU-accelerated compute to virtually every modern browser. On desktop and server, ILGPU's native Cuda and OpenCL backends are available alongside CPU. The same async extension methods work everywhere.
Your existing ILGPU kernels run in the browser with zero changes to the kernel code — and the same code runs on desktop too.
- Wasm RadixSort — ILGPU's RadixSort algorithm now works on the Wasm backend with full multi-worker parallelism. Fixed 7 codegen and dispatch bugs including struct-with-view serialization, view field mapping, local alloca addressing, and barrier synchronization
- Wasm barrier kernel improvements — Per-thread scratch memory prevents cross-worker data races. Post-helper barriers ensure correct scan/reduce synchronization across parallel workers. Atomic loads/stores for cross-worker memory visibility
- WebGPU backend refactor — Extracted
SharedMemoryResolverandUniformityAnalyzersubsystems. Per-function emulation library trimming. Dead variable elimination. i64 constant hoisting. Pre-compiled regex patterns. WGSL pre-validation - WebGPU RadixSort — All RadixSort variants passing (including 4M+ element sorts, pairs, descending). Fixed shared memory sizing, scan barriers, range checks, and alignment padding
- Device loss detection — WebGPU monitors
device.lostpromise; WebGL monitorswebglcontextlostevent.IsDeviceLost/IsContextLostproperties and events enable fail-fast error handling - Unified test infrastructure —
PlaywrightMultiTestruns all 1500+ tests (desktop + browser) in a singledotnet testinvocation. 153 Wasm tests, 0 failures
Browser backends (Blazor WebAssembly) — auto-selected: WebGPU → WebGL → Wasm
| WebGPU | WebGL | Wasm | |
|---|---|---|---|
| Compiles to | WGSL | GLSL ES 3.0 | Wasm binary |
| Runs on | GPU | GPU | Web Workers |
Desktop backends (Console, WPF, ASP.NET) — auto-selected: Cuda → OpenCL → CPU
| Cuda | OpenCL | CPU | |
|---|---|---|---|
| Compiles to | PTX | OpenCL C | — |
| Runs on | NVIDIA GPU | Any GPU | CPU cores (multi-threaded) |
The Live Demo source is in SpawnDev.ILGPU.Demo:
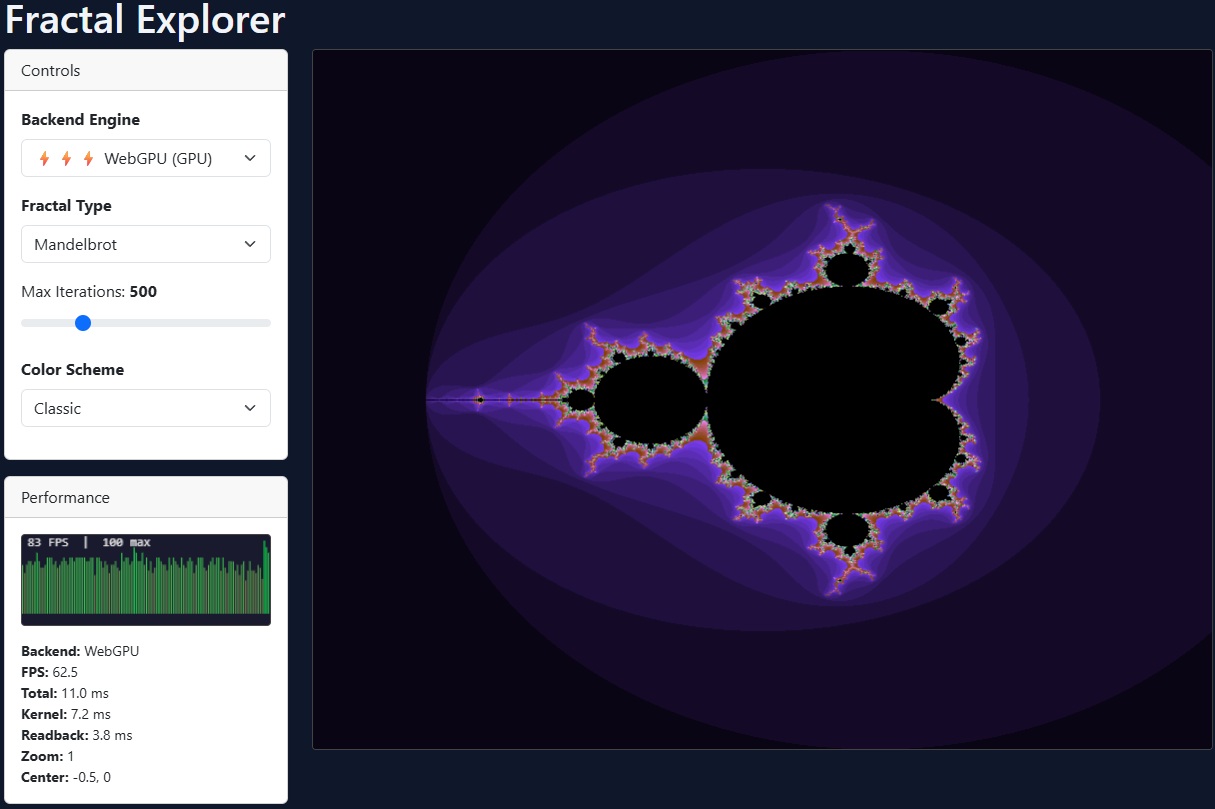
- Fractal Explorer — Interactive Mandelbrot / Multi-fractal Explorer with double-precision zoom
- 3D Raymarching — Real-time GPU raymarched scenes
- GPU Boids — 3D flocking simulation with GPU physics
- Game of Life — Conway's Game of Life on the GPU
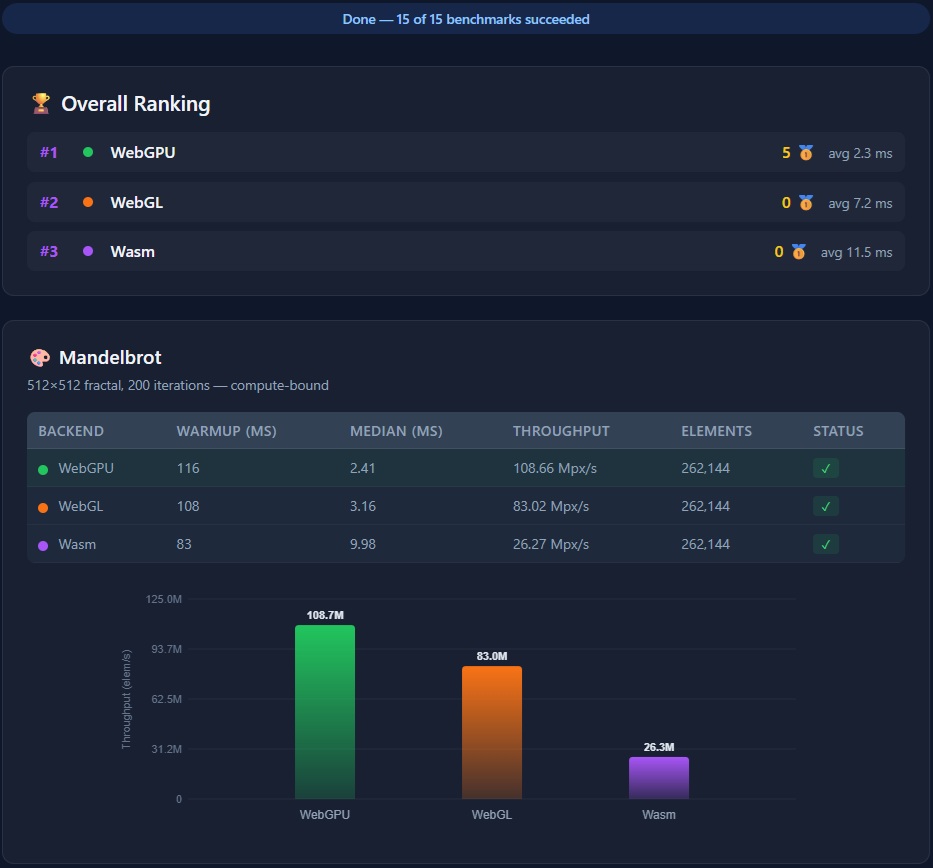
- Benchmarks — Performance comparison across all backends
- Unit Tests — Comprehensive test suite for all backends
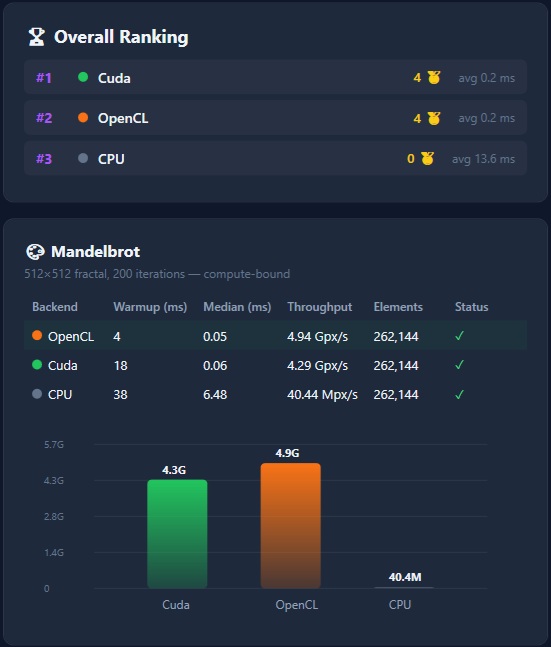
The WPF Demo runs the same shared kernels on CUDA, OpenCL, and CPU with live backend switching:
- Fractal Explorer — Interactive Mandelbrot / Multi-fractal Explorer with double-precision zoom
- 3D Raymarching — Real-time GPU raymarched scenes
- GPU Boids — 3D flocking simulation with GPU physics
- Benchmarks — Performance comparison across CUDA, OpenCL, and CPU backends
Comprehensive documentation is available in the Docs folder:
- Getting Started — Installation, setup, first kernel
- Backends — WebGPU, WebGL, Wasm, Cuda, OpenCL, CPU setup & configuration
- Writing Kernels — Kernel rules, index types, math functions, shared memory
- Memory & Buffers — Allocation, async readback, zero-allocation patterns
- Canvas Rendering —
ICanvasRenderer, zero-copy GPU→canvas blitting, per-backend details - Advanced Patterns — Device sharing, external buffers, GPU intrinsics, render loops
- Limitations — Blazor WASM constraints, browser compatibility
- API Reference — Public API surface by namespace
| 🎮 WebGPU | 🖼️ WebGL | 🧊 Wasm | |
|---|---|---|---|
| Executes on | GPU | GPU | Web Workers |
| Transpiles to | WGSL | GLSL ES 3.0 | WebAssembly binary |
| Technique | Compute shader | Transform Feedback | Multi-worker |
| Blocking | Non-blocking | Non-blocking | Non-blocking |
| SharedArrayBuffer | Not required | Not required | Required for multi-worker |
| Shared Memory | ✅ | ❌ | ✅ |
| Group.Barrier() | ✅ | ❌ | ✅ |
| Dynamic Shared Memory | ✅ | ❌ | ✅ |
| ILGPU Algorithms | ✅ RadixSort, Scan, Reduce, etc. | ❌ | ✅ Scan, Reduce; RadixSort (≤64 elements) |
| Atomics | ✅ | ❌ | ✅ |
| 64-bit (f64/i64) | ✅ Emulated | ✅ Emulated | ✅ Native |
| Browser support | Chrome/Edge 113+ | All modern browsers | All modern browsers |
| Best for | GPU compute (modern) | GPU compute (universal) | General compute |
Auto-selection priority: WebGPU → WebGL → Wasm
SpawnDev.ILGPU bundles ILGPU's native backends, so the same NuGet package works on desktop and server too.
| 🚀 Cuda | 🔧 OpenCL | 🐢 CPU | |
|---|---|---|---|
| Executes on | NVIDIA GPU | NVIDIA/AMD/Intel GPU | CPU cores |
| Transpiles to | PTX | OpenCL C | — (interpreted) |
| Shared Memory | ✅ | ✅ | ✅ |
| Atomics | ✅ | ✅ | ✅ |
| 64-bit | ✅ Native | ✅ Native | ✅ Native |
| Requirement | NVIDIA GPU + driver | OpenCL 2.0+ or 3.0 GPU | None |
OpenCL 3.0 support: NVIDIA GPUs with OpenCL 3.0 drivers are now supported. The
GenericAddressSpacerequirement that previously blocked these devices has been relaxed, significantly increasing OpenCL device compatibility.
Auto-selection: Cuda → OpenCL → CPU (via CreatePreferredAcceleratorAsync)
- Cross-platform — Same kernel code runs in browser (WebGPU, WebGL, Wasm) and desktop (Cuda, OpenCL, CPU) from one NuGet package
- Automatic backend selection —
CreatePreferredAcceleratorAsync()picks the best backend on any platform (browser or desktop) - Unified async API —
SynchronizeAsync()andCopyToHostAsync()work everywhere, falling back to synchronous calls on desktop - ILGPU-compatible — Use familiar APIs (
ArrayView,Index1D/2D/3D, math intrinsics, etc.) - WGSL transpilation — C# kernels automatically compiled to WebGPU Shading Language
- GLSL transpilation — C# kernels compiled to GLSL ES 3.0 vertex shaders with Transform Feedback for GPU compute
- Wasm compilation — C# kernels compiled to native WebAssembly binary modules
- 64-bit emulation —
long/ulong(i64) always emulated viavec2<u32>(required by ILGPU IR).double(f64) emulation configurable viaF64EmulationMode: fast Dekker (vec2<f32>, default), precise Ozaki (vec4<f32>), or Disabled (promoted to f32) - WebGPU extension auto-detection — Probes adapter for
shader-f16,subgroups,timestamp-query, and other features; conditionally enables them on the device - Subgroup operations —
Group.BroadcastandWarp.Shuffleare supported on the WebGPU backend when the browser supports thesubgroupsextension - Multi-worker dispatch — Wasm backend distributes work across all available CPU cores via SharedArrayBuffer; falls back to a single off-thread worker when SAB is unavailable
- Zero-copy canvas rendering —
ICanvasRendererpresents pixel buffers to HTML canvases without CPU readback on GPU backends: WebGPU uses a fullscreen-triangle render pass reading directly from GPU storage; WebGL transfers anImageBitmapfrom its worker and draws synchronously; Wasm reuses a cachedImageData. One API, all backends:CanvasRendererFactory.Create(accelerator) - Blazor WebAssembly — Seamless integration via SpawnDev.BlazorJS
- Shared memory & barriers — Static and dynamic workgroup memory with
Group.Barrier()synchronization (WebGPU, Wasm, Cuda, OpenCL) - ILGPU Algorithms — RadixSort, Scan, Reduce, Histogram, and other algorithm extensions are fully supported on WebGPU (including large-scale sorts up to 4M+ elements) and Wasm (with multi-worker barrier synchronization), tested in-browser across all backends
- Broadcast —
Group.Broadcastfor intra-group value sharing (WebGPU, Wasm) - Device loss handling — WebGPU monitors
device.lostand WebGL monitorswebglcontextlost;IsDeviceLost/IsContextLostproperties andDeviceLost/ContextLostevents enable applications to detect GPU device loss and fail fast with clear errors instead of silent corruption - GpuMatrix4x4 — GPU-friendly 4×4 matrix struct that auto-transposes from .NET's row-major
Matrix4x4to GPU column-major order. UseTransformPointandTransformDirectiondirectly inside kernels for 3D transformations - No native dependencies — Entirely written in C#
dotnet add package SpawnDev.ILGPUSpawnDev.ILGPU requires SpawnDev.BlazorJS for browser interop.
using SpawnDev.BlazorJS;
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.RootComponents.Add<App>("#app");
builder.RootComponents.Add<HeadOutlet>("head::after");
// Add BlazorJS services
builder.Services.AddBlazorJSRuntime();
await builder.Build().BlazorJSRunAsync();The library discovers all available browser backends and picks the best one (WebGPU → WebGL → Wasm):
using global::ILGPU;
using global::ILGPU.Runtime;
using SpawnDev.ILGPU;
// Initialize context with all available backends
using var context = await Context.CreateAsync(builder => builder.AllAcceleratorsAsync());
// Create the best available accelerator (WebGPU > WebGL > Wasm)
using var accelerator = await context.CreatePreferredAcceleratorAsync();
// Allocate buffers and run a kernel — same API regardless of backend
int length = 256;
using var bufA = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i).ToArray());
using var bufB = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i * 2f).ToArray());
using var bufC = accelerator.Allocate1D<float>(length);
var kernel = accelerator.LoadAutoGroupedStreamKernel<Index1D, ArrayView<float>, ArrayView<float>, ArrayView<float>>(VectorAddKernel);
kernel((Index1D)length, bufA.View, bufB.View, bufC.View);
await accelerator.SynchronizeAsync();
var results = await bufC.CopyToHostAsync<float>();
// The kernel — runs on GPU or Wasm transparently
static void VectorAddKernel(Index1D index, ArrayView<float> a, ArrayView<float> b, ArrayView<float> c)
{
c[index] = a[index] + b[index];
}// WebGPU — GPU compute via WGSL
using var context = await Context.CreateAsync(builder => builder.WebGPU());
var device = context.GetWebGPUDevices()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);// WebGL — GPU compute via GLSL ES 3.0 + Transform Feedback (works on virtually all browsers)
using var context = await Context.CreateAsync(builder => builder.WebGL());
var device = context.GetWebGLDevices()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);// Wasm — native WebAssembly binary
using var context = await Context.CreateAsync(builder => builder.Wasm());
var device = context.GetDevices<WasmILGPUDevice>()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);SpawnDev.ILGPU also works in console, WPF, ASP.NET, and other .NET apps. The same async pattern used in Blazor WASM works on desktop too:
using global::ILGPU;
using global::ILGPU.Runtime;
using SpawnDev.ILGPU;
// SAME code as Blazor WASM — AllAcceleratorsAsync auto-detects the environment
// Browser: registers WebGPU, WebGL, Wasm
// Desktop: registers Cuda, OpenCL, CPU (browser backends are skipped)
using var context = await Context.CreateAsync(builder => builder.AllAcceleratorsAsync());
using var accelerator = await context.CreatePreferredAcceleratorAsync();
Console.WriteLine($"Using: {accelerator.Name} ({accelerator.AcceleratorType})");
// Same kernel code, same async extensions
int length = 256;
using var bufA = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i).ToArray());
using var bufB = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i * 2f).ToArray());
using var bufC = accelerator.Allocate1D<float>(length);
var kernel = accelerator.LoadAutoGroupedStreamKernel<Index1D, ArrayView<float>, ArrayView<float>, ArrayView<float>>(VectorAddKernel);
kernel((Index1D)length, bufA.View, bufB.View, bufC.View);
// SynchronizeAsync/CopyToHostAsync fall back to synchronous calls on desktop
await accelerator.SynchronizeAsync();
var results = await bufC.CopyToHostAsync<float>();
Console.WriteLine($"result[0]={results[0]}, result[255]={results[255]}");
static void VectorAddKernel(Index1D index, ArrayView<float> a, ArrayView<float> b, ArrayView<float> c)
{
c[index] = a[index] + b[index];
}Same kernel, any platform. The
VectorAddKernelabove is identical in both examples. Write once, run on WebGPU, WebGL, Wasm, Cuda, OpenCL, or CPU.
Why async? Browser backends require async — Blazor WASM's single-threaded environment will deadlock on synchronous calls. Desktop backends support both sync and async, with async extensions gracefully falling back to synchronous ILGPU calls. Therefore, the async pattern is always recommended for maximum portability.
All desktop and browser tests run in a single dotnet test invocation via the PlaywrightMultiTest NUnit project:
# Run all tests (desktop + browser) with timestamped results
timestamp=$(date +%Y%m%d_%H%M%S) && dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--logger "trx;LogFileName=results_${timestamp}.trx" \
--results-directory PlaywrightMultiTest/TestResults
# Run only WebGPU tests
dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--filter "FullyQualifiedName~WebGPUTests."
# Run a specific test
dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--filter "FullyQualifiedName~WebGPUTests.AlgorithmRadixSortPairsTest"How it works:
- Publishes Blazor WASM and Console projects automatically
- Launches Chromium via Playwright for browser tests (with
--enable-unsafe-webgpu) - Runs desktop tests as individual subprocesses
- Detects Blazor error UI during tests and captures browser console errors/warnings
- All results surfaced as standard NUnit test cases with
.trxoutput
Start the demo app and navigate to /tests to run the browser test suite interactively:
dotnet run --project SpawnDev.ILGPU.Demo1518 tests across eight test suites covering all core features on both browser and desktop. All tests are run via the unified PlaywrightMultiTest runner in a single dotnet test invocation.
| Suite | Backend | What's Tested |
|---|---|---|
| WebGPUTests | WebGPU | Full ILGPU feature set on GPU via WGSL, including RadixSort, Scan, Reduce |
| WebGPUNoSubgroupsTests | WebGPU (no subgroups) | Same tests with subgroups force-disabled to verify shared-memory emulation |
| WebGLTests | WebGL | GPU compute via GLSL ES 3.0, f64/i64 emulation |
| WasmTests | Wasm | Native WebAssembly binary dispatch to workers, shared memory, barriers |
| DefaultTests | Auto | Device enumeration, preferred backend, kernel execution |
| Suite | Backend | What's Tested |
|---|---|---|
| CudaTests | CUDA | Full ILGPU feature set on NVIDIA GPU |
| OpenCLTests | OpenCL | GPU compute on NVIDIA/AMD/Intel, dynamic subgroup feature detection |
| CPUTests | CPU | Multi-threaded CPU accelerator (Nvidia preset: warp=32, warps=32) |
| Area | What's Tested | Status |
|---|---|---|
| Memory | Allocation, transfer, copy, views | ✅ |
| Indexing | 1D, 2D, 3D kernels, boundary conditions | ✅ |
| Arithmetic | +, -, *, /, %, negation, complex expressions | ✅ |
| Bitwise | AND, OR, XOR, NOT, shifts (<<, >>) | ✅ |
| Math Functions | sin, cos, tan, exp, log, sqrt, pow, abs, min, max | ✅ |
| Atomics | Add, Min, Max, CompareExchange, Xor | ✅ |
| Control Flow | if/else, loops, nested, short-circuit | ✅ |
| Structs | Simple, nested, with arrays | ✅ |
| Type Casting | float↔int, uint, mixed precision | ✅ |
| 64-bit Emulation | double and long via software emulation (WebGPU, WebGL) |
✅ |
| GPU Patterns | Stencil, reduction, matrix multiply, lerp, smoothstep | ✅ |
| Shared Memory | Static and dynamic workgroup memory with Group.Barrier() |
✅ |
| Broadcast & Subgroups | Group.Broadcast, Warp.Shuffle (WebGPU with subgroups extension) |
✅ |
| Dynamic Shared Memory | Runtime-sized workgroup memory via SharedMemory.GetDynamic() |
✅ |
| ILGPU Algorithms | RadixSort (pairs, non-pow2, descending, large), Scan, Reduce, Histogram | ✅ WebGPU, Wasm (RadixSort excluded on Wasm) |
| Special Values | NaN, Infinity detection | ✅ |
| Backend Selection | Auto-discovery, priority, cross-backend kernel execution | ✅ |
| GpuMatrix4x4 | Identity, translation, LookAt transforms across all backends | ✅ |
| Backend | Browser Support |
|---|---|
| WebGPU | Chrome/Edge 113+, Firefox Nightly (dom.webgpu.enabled) |
| WebGL | ✅ All modern browsers (Chrome, Edge, Firefox, Safari, mobile browsers) |
| Wasm | All modern browsers (compatible with every browser that supports Blazor WASM) |
GPU on every device: WebGL support means GPU-accelerated compute works on virtually every browser and device — including mobile phones, tablets, and older desktops without WebGPU support.
Note: For multi-worker SharedArrayBuffer support (used by the Wasm backend for parallel dispatch), the page must be cross-origin isolated (COOP/COEP headers). The demo includes a service worker (
coi-serviceworker.js) that handles this automatically. Without SharedArrayBuffer, the Wasm backend falls back to single-worker mode — still running off the main thread to keep the UI responsive.
GPU hardware typically only supports 32-bit operations. Both GPU backends (WebGPU and WebGL) provide software emulation for 64-bit types.
i64 emulation (long/ulong) is always enabled — ILGPU's IR uses Int64 for ArrayView.Length and indices, so i64 emulation via vec2<u32> is required for correctness.
f64 emulation (double) is configurable via F64EmulationMode:
| Dekker (Default) | Ozaki | Disabled | |
|---|---|---|---|
| Representation | vec2<f32> (high + low) |
vec4<f32> (quad-float) |
Native f32 |
| Precision | ~48–53 bits of mantissa | Strict IEEE 754 double precision | 32-bit only |
| Memory | 8 bytes per value | 16 bytes per value | 4 bytes per value |
| Performance | ⚡ Fast | 🐢 ~2× slower | ⚡⚡ Fastest |
| Best for | General compute, fractals | Scientific, financial | Rendering, max perf |
using SpawnDev.ILGPU;
using SpawnDev.ILGPU.WebGPU.Backend;
// Default: Dekker double-float emulation (good precision, fast)
var options = new WebGPUBackendOptions();
// Ozaki quad-float emulation (strict IEEE 754 precision)
var options = new WebGPUBackendOptions { F64Emulation = F64EmulationMode.Ozaki };
// Disable f64 emulation (double promoted to float for max performance)
var options = new WebGPUBackendOptions { F64Emulation = F64EmulationMode.Disabled };
using var accelerator = await device.CreateAcceleratorAsync(context, options);The Wasm backend compiles ILGPU kernels to native WebAssembly binary modules and dispatches them to Web Workers for parallel execution. This provides near-native performance for compute-intensive workloads.
- Kernels are compiled to
.wasmbinary format (not text) - Compiled modules are cached and reused across dispatches
- Shared memory uses
SharedArrayBufferfor zero-copy data sharing
// Synchronize() — flushes queued commands to the backend (non-blocking, safe in WASM)
accelerator.Synchronize();
// SynchronizeAsync() — flushes AND waits for GPU completion
await accelerator.SynchronizeAsync();
// CopyToHostAsync() — the ONLY way to read GPU data back to CPU
var results = await buffer.CopyToHostAsync<float>();Note:
Synchronize()does not block in Blazor WASM — it flushes commands without waiting.SynchronizeAsync()flushes and waits for completion. Neither transfers data; useCopyToHostAsync()for GPU→CPU readback.
All backends include verbose debug logging, disabled by default. Enable per-backend when needed:
using SpawnDev.ILGPU.WebGPU.Backend;
using SpawnDev.ILGPU.WebGL.Backend;
using SpawnDev.ILGPU.Wasm.Backend;
WebGPUBackend.VerboseLogging = true; // WebGPU backend
WebGLBackend.VerboseLogging = true; // WebGL backend
WasmBackend.VerboseLogging = true; // Wasm backendWhen publishing, specific MSBuild properties are required:
<PropertyGroup>
<!-- Disable IL trimming to preserve ILGPU kernel methods and reflection metadata -->
<PublishTrimmed>false</PublishTrimmed>
<!-- Disable AOT compilation - ILGPU requires IL reflection -->
<RunAOTCompilation>false</RunAOTCompilation>
</PropertyGroup>If SpawnDev.ILGPU has been useful to you, please consider sponsoring me on GitHub! Your support directly helps me continue developing and maintaining this library and my other open-source projects.
I'm currently working on a modest development machine with only 16 GB of DDR5 RAM, which makes building, testing, and debugging across multiple GPU backends genuinely painful — especially when running the browser demo, CUDA/OpenCL tests, and the IDE simultaneously.
Any sponsorship — big or small — goes toward upgrading my development hardware so I can keep pushing this project forward:
| Priority | Upgrade | Why It Matters |
|---|---|---|
| 🔴 Critical | RAM (64–128 GB DDR5) | 16 GB is not enough for multi-backend testing + browser debugging |
| 🟡 High | High-end NVIDIA GPU (RTX 5090) | Faster CUDA compute, larger VRAM for AI/ML workloads and testing |
| 🟢 Dream | NVIDIA RTX 6000 | The ultimate card for AI compute and open-source GPU development |
Every contribution — whether it's a one-time donation or a monthly sponsorship — is deeply appreciated and makes a real difference. Thank you! 🙏
This project is licensed under the same terms as ILGPU. See LICENSE for details.
SpawnDev.ILGPU is built upon the excellent ILGPU library. We would like to thank the original authors and contributors of ILGPU for their hard work in providing a high-performance, robust IL-to-GPU compiler for the .NET ecosystem.
- ILGPU Project: https://github.com/m4rs-mt/ILGPU
- ILGPU Authors: Marcel Koester and the ILGPU contributors