1. 소개
2. 프로젝트 최종 결과
3. 프로젝트 기획 배경 & 문제 인식
4. 진행 순서
5. 진행 순서별 상세 설명
6. 추후 보완점
7. 멤버 & 수행업무
8. 참고 자료
- 자율주행 시각 엔진 (Vision Engine)* 구현
※ 시각 엔진: 이미지에 담긴 다양한 정보를 인식 및 분석하여 이미지를 이해하는 엔진. 얼굴 인식, 유사 상품 추천 등에 사용 가능.
(출처: 카카오엔터프라이즈 홈페이지)
[시각 엔진 활용 예시]

- 운전 시 사람이 시각 정보를 수집하는 과정을 모방, 자율주행 시각엔진을 간단한 수준에서 구현해보고자 함
- 우수한 객체 탐지 (Object Detection) 성능과 거리 추정 정확도 확보
- 위 내용을 기반으로 한 다양한 적용 (Applications)
- 라이브러리: tensorflow-gpu 2.3.0
- 알고리즘: Yolo v3, v4, Deep SORT
- Tool: Google Colaboratory, LabelImg, Yololabel, Iriun
- YOLO v4를 사용한 다중 객체 탐지(Multi-Object Detection) 및 거리 추정, 그리고 트래킹(Tracking) & 카운팅(Counting)까지 구현 성공
[최종 결과 테스트 영상]

(원본 영상 링크)
- 사람이 운전 시 어떠한 상황에 어떠한 판단을 내리는지, 그리고 그 판단이 어떤 의미를 내포하고 있는지에 대해 고민, 아래와 같은 답을 얻음
* 내 앞 '가까이'에 갑자기 무언가가 나타났다 → 무엇인지는 모르지만 일단 급정거한다
: 거리를 인지하였음을 보여준다. (거리 인지)
* 내 시야 '멀리'에 무언가가 있다 → 위협이 되지 않는다면 무시, 피해야 한다면 그 대상과의 거리에 따라 적절하게 대응한다
(ex. '공사중' 바리케이드를 보면 우회하며, 그 거리가 가깝다면 급히 유턴, 멀다면 더 여유를 가지고 우회로 탐색)
: 발견한 것의 종류를 인지하였음을 보여준다 (객체 탐지)
* 한편, '가까워지기' 위해 쫓아가는 경우도 있다 (ex. 앞차를 따라갈 때)
: 눈에 보이는 다양한 대상들 중에서 하나의 고유한 대상을 인지하고 추적함을 보여준다 (트래킹)
- 위 모든 판단들에는 공통적으로 원근, 즉 '거리'에 대한 인지가 기반이 되며, '거리'란 반대편의 '객체 탐지'를 전제로 함
그리고 이 둘이 충족될 때, 트래킹 등 확장 적용 가능
- 그러나, 위의 내용을 구현하기 위해 '지상에서 거리를 추정하기'에는 두 가지 문제가 있음을 발견함
* '지상에서' : 사람의 얼굴이 분간 가능하기 때문에 초상권 등의 이슈 발생 가능
* '거리를 추정하기' : 사진 속 객체와 촬영 근원지(카메라) 간 거리 추정이 기존 모듈이나 라이브러리 등의 형식으로 존재하지 않는다
- 따라서, '공중에서', '직접 실측하고 맞춤화된 거리 추정 함수를 도출하기'로 결정함
- 위 배경 및 문제인식에 따라 다음과 같이 프로젝트 진행 순서를 구성하였음
(1) ‘공중’에서 촬영한 이미지/영상 데이터 수집
(2) 해당 이미지/영상 내 객체의 위치 좌표를 입력받아, 카메라와의 거리를 출력하는 함수식 도출 및 적용
(3) ‘거리 측정’을 위해 전제되어야 하는 객체 탐지 (Object Detection) 구현
(4) Tracking 및 Counting 등 추가 application 구현
(5) flags를 통해 코드 일부 수정
- 지상 8층 높이의 건물에서 삼각대로 카메라 고정 후 촬영
- Iriun을 사용하여 휴대폰 카메라를 웹캠으로 활용
- 유동인구가 많은 점심시간대인 11~14시 동안 2천 장의 이미지 수집 (이미지 자동저장 코드)

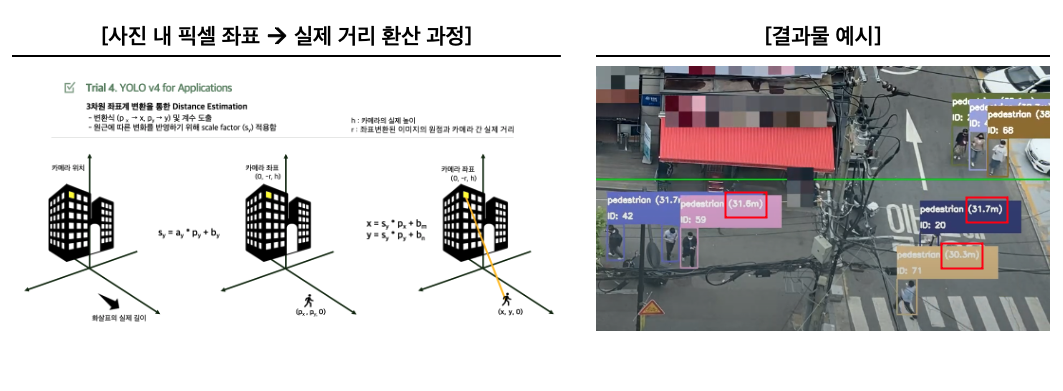
- 사진 내 픽셀 단위의 위치 좌표를 좌표 변환(coordinate transformation) 후, 변환된 픽셀 단위 좌표를 실제 길이 (미터 단위) 기준 좌표(x, y, 0)로 환산
- 같은 수의 픽셀이라도 원근에 따라 그 실제 길이는 달라지며, 이를 반영하기 위해 scale factor (Sy)를 적용하여 변환식 도출
- 변환식 도출 후 이미지 내 특정 물체들의 실제 길이를 실측하였고, 이를 바탕으로 유사 역행렬 연산을 통해 변환식의 계수들을 구함
- 변환식을 통해 얻은 실제 길이 기준 좌표와 카메라 위치 좌표 간 거리를 유클리드 거리로 산출
- 결과: 거리 추정치와 실제값 (네이버 지도상 거리)의 오차율이 1% 내외로, 우수한 정확도를 보임
(함수식 도출 전체 과정 보기)
- YOLO v3와 v4를 활용하여 총 3번의 객체 탐지 모델을 구현
- YOLO가 오류 없이 정상 작동하는지 테스트해보기 위한 시도
- 198장 랜덤 추출 및 라벨링
- 1개 클래스 (person)
- 라벨링 기준: 사람 형상 전체가 다 나온 경우 위주, 보행자 간에 겹친 경우 겹친 부분도 포함
- 훈련: 1000 epochs 후 중지
- 결과: 훈련을 도중 중지하였음에도 양호한 성능을 보였으나 (confidence: 주로 0.6 ~ 0.7), 오토바이 하나를 오인지하는 경우 발생


(1차 결과물 원본 영상 링크)
※ 가게 상호명들은 추후 문제 발생을 방지하기 위해 모자이크하였음
- YOLO 정상 작동 여부 확인 완료, 본격적인 테스트
- 500장 랜덤 추출 및 라벨링
- 3개 클래스 (pedestrian, bike, person on bike)
- 라벨링 기준: 신체 일부만 보이는 경우도 라벨링, 보행자 간에 겹친 경우 중 일부는 보이는 부분만 라벨링
- 훈련: 6000 epochs (약 12시간 소요)
- 결과: 클래스 수가 증가했음에도 불구, 객체를 더 잘 탐지하며 confidence도 향상 (주로 0.8~0.9)
그러나 여전히 오토바이 하나를 오인지하며, 요구르트 카트도 보행자로 인지하는 경우 발생


(2차 결과물 원본 영상 링크)
- YOLO v3를 통한 트래킹 레퍼런스를 찾는 데 어려움이 있어, 비교적 레퍼런스가 풍부한 v4를 활용하기로 결정
- 훈련: 6000 epochs (약 30시간 소요)
Google Colaboratory의 제약 조건 (12시간, GPU 제한)이 있어, 학습 중 백업되는 weights 파일을 복수의 계정들로 이어서 학습을 진행하였음 - 결과: confidence가 소폭 상승했으나 (0.9 이상) 전반적인 탐지 성능은 YOLO v3와 유사하며,
오토바이 하나를 오인지하는 현상 지속. 사람 실루엣의 형상이 잡혀서 그런 것으로 추정됨


(3차 결과물 원본 영상 링크)
- Deep SORT 알고리즘을 적용하여 Tracking 구현
- 특정 구역에 대한 누적/실시간 Counting 구현
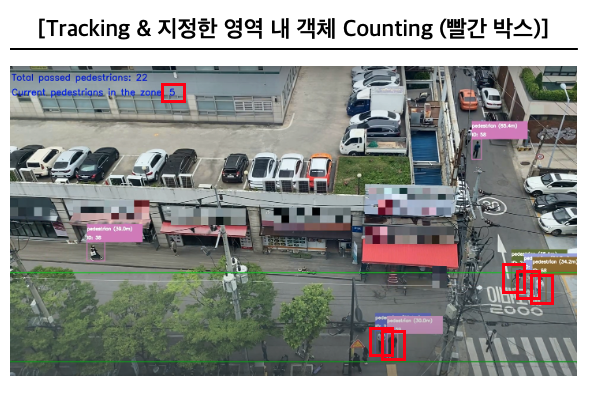
(최종 결과물 원본 영상 링크)
- counting과 거리 추정을 사용자마다 옵션으로 선택할 수 있도록 코드 수정

- 추후 성능 개선 여부를 논의하기 위해서는 정량 지표가 필요
- 라벨링된 테스트 데이터를 준비, mAP 등 정량 지표를 기준으로 성과 측정 필요
1) 임현수
- 일정 관리: 일자별 업무 기획 및 분배
- 데이터 수집: 이미지 데이터 수집, 거리 실측
- 라벨링
- YOLO 및 Deep SORT 알고리즘 학습 및 적용
- 거리 추정: Ideation 및 피드백
- 발표 및 문서화 (Github)
2) 정민주
- 데이터 수집: 거리 실측
- 라벨링
- 거리 추정: Ideation 및 변환식 도출, 함수화
- 문서화 (PT 자료)
- YOLO v3 및 Deep SORT, Counting: eMaster Class Academy
- YOLO v4: The AI Guy
본 프로젝트는 패스트캠퍼스 데이터사이언스 취업스쿨 16th 딥러닝 프로젝트로 진행되었습니다.