
在AI学习的漫漫长路上,理解不同文章中的模型与方法是每个人的必经之路,偶尔见到Fjodor van Veen所作的A mostly complete chart of Neural Networks 和 FeiFei Li AI课程中对模型的画法,大为触动。决定将深度神经网络中的一些模型 进行统一的图示,便于大家对模型的理解。
从AI研究的角度来说,AI的学习和跟进是有偏向性的,更多的精英是擅长相关的一到两个领域,在这个领域做到更好。而从AI应用工程师的角度来说,每一个工程都可能涉及很多个AI的方向,而他们需要了解掌握不同的方向才能更好的开发和设计。但是AI中每一个领域都在日新月异的成长。而每一位研究人员写paper的风格都不一样,相似的模型,为了突出不同的改进点,他们对模型的描述和图示都可能大不相同。为了帮助更多的人在不同领域能够快速跟进前沿技术,我们构建了“AlphaTree计划”,每一篇文章都会对应文章,代码,然后进行图示输出。
图示工作主要完成了object classification部分,部分还使用PlotNeuralNet link进行了更精美的绘制。 而其他的很多任务是基于object classification 去迁移的,因此不是每一个都需要模型绘制。
由于GAN工作的进展,使得相关工作达到可以进行总结的阶段,于是在2019年开启了GAN工作的总结。参考Mohammad KHalooei的教程,将GAN的发展分为四个level, 详细可见分目录 https://github.com/weslynn/AlphaTree-graphic-deep-neural-network/tree/master/GAN%E5%AF%B9%E6%8A%97%E7%94%9F%E6%88%90%E7%BD%91%E7%BB%9C
-
- level0 GAN的定义
- level1 GAN训练上的改进
- level2 那些优秀的GAN
- [level3 GAN不同方向的应用]
在了解这个计划之前,我们先了解一下各个方向的发展情况,用地铁图的形式绘制了第一个版本。第一个版本主要包括了图像方向的十二个子方向,里面列的模型,除了商业化的部分外,其他则选择了一些应用方向使用较多的开源模型。也许还有遗漏与不完善的地方,大家一起来更新吧。
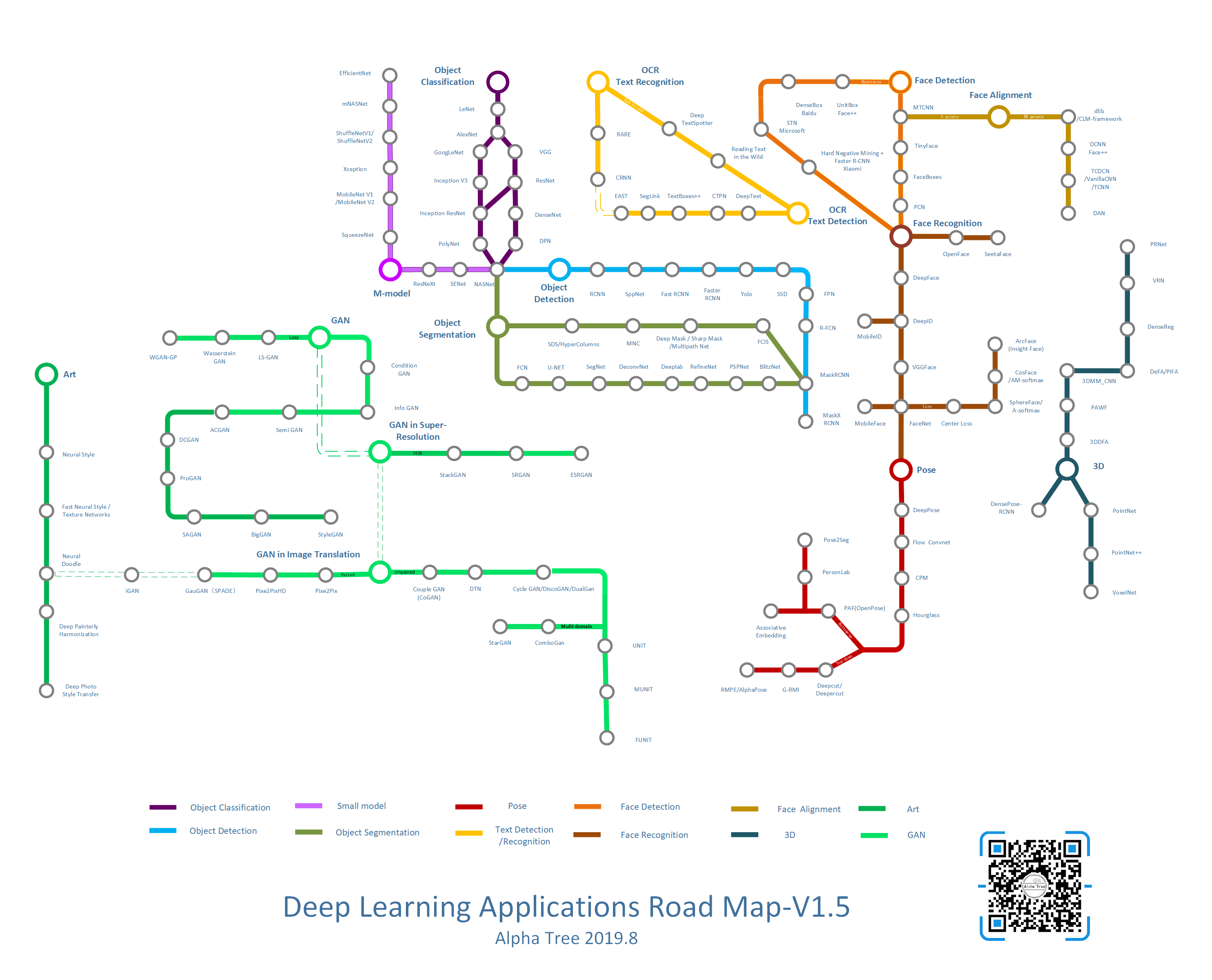
现在主要有如下方向

每个方向上都记录了一些比较重要的模型结构。为了方便理解模型的变化,我们对模型进行统一的图示
一个常用的神经网络结构可以进行如下的等价变换。每个圆圈上的数字代表这一层有多少个神经元。

图像的深度卷积网络 每一层的卷积核大小也是大家感兴趣的,因此会在简化结构中,加上卷积核大小。这个可以写在圆圈中,也可以写在圆圈下方。
如 LeNet网络

模型中用到的图标规定如下:

当大家描述网络结构时,常常会将卷积层和maxpooling层画在一起,我们也提供了这样的简化方法

一个具体的问题是否能用人工智能,或者更进一步说用深度学习某个算法解决,首先需要人对问题进行分解,提炼成可以用机器解决的问题,譬如说分类问题,回归问题,聚类问题等。
PS:
简单3d神经网络数据变化 : ConvNetDraw(Cédric cbovar) :https://cbovar.github.io/ConvNetDraw/
3d 神经网络数据变化绘制 :PlotNeuralNet https://github.com/HarisIqbal88/PlotNeuralNet
caffe 模型可视化网址 http://ethereon.github.io/netscope/#/editor
论文查询网址 :https://www.semanticscholar.org/
深度学习在解决分类问题上非常厉害。让它声名大噪的也是对于图像分类问题的解决。也产生了很多很经典的模型。其他方向的模型发展很多都是源于这各部分,它是很多模型的基础工作。因此我们首先了解一下它们。

从模型的发展过程中,随着准确率的提高,网络结构也在不断的进行改进,现在主要是两个方向,一是深度,二是复杂度。此外还有卷积核的变换等等。
深度神经网络的发展要从经典的LeNet模型说起,那是1998年提出的一个模型,在手写数字识别上达到商用标准。之后神经网络的发展就由于硬件和数据的限制,调参的难度等各种因素进入沉寂期。
到了2012年,Alex Krizhevsky 设计了一个使用ReLu做激活函数的AlexNet 在当年的ImageNet图像分类竞赛中(ILSVRC 2012),以top-5错误率15.3%拿下第一。 他的top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。而且网络针对多GPU训练进行了优化设计。从此开始了深度学习的黄金时代。
大家发表的paper一般可以分为两大类,一类是网络结构的改进,一类是训练过程的改进,如droppath,loss改进等。
之后网络结构设计发展主要有两条主线,一条是Inception系列(即上面说的复杂度),从GoogLeNet 到Inception V2 V3 V4,Inception ResNet。 Inception module模块在不断变化,一条是VGG系列(即深度),用简单的结构,尽可能的使得网络变得更深。从VGG 发展到ResNet ,再到DenseNet ,DPN等。
最终Google Brain用500块GPU训练出了比人类设计的网络结构更优的网络NASNet,最近训出了mNasNet。
此外,应用方面更注重的是,如何将模型设计得更小,这中间就涉及到很多卷积核的变换。这条路线则包括 SqueezeNet,MobileNet V1 V2 Xception shuffleNet等。
ResNet的变种ResNeXt 和SENet 都是从小模型的设计思路发展而来。
输入:图片 输出:类别标签

| 模型名 | AlexNet | ZFNet | VGG | GoogLeNet | ResNet |
|---|---|---|---|---|---|
| 初入江湖 | 2012 | 2013 | 2014 | 2014 | 2015 |
| 层数 | 8 | 8 | 19 | 22 | 152 |
| Top-5错误 | 16.4% | 11.2% | 7.3% | 6.7% | 3.57% |
| Data Augmentation | + | + | + | + | + |
| Inception(NIN) | – | – | – | + | – |
| 卷积层数 | 5 | 5 | 16 | 21 | 151 |
| 卷积核大小 | 11,5,3 | 7,5,3 | 3 | 7,1,3,5 | 7,1,3 |
| 全连接层数 | 3 | 3 | 3 | 1 | 1 |
| 全连接层大小 | 4096,4096,1000 | 4096,4096,1000 | 4096,4096,1000 | 1000 | 1000 |
| Dropout | + | + | + | + | + |
| Local Response Normalization | + | + | – | + | – |
| Batch Normalization | – | – | – | – | + |
ILSVRC2016 2016 年的 ILSVRC,来自中国的团队大放异彩:
CUImage(商汤和港中文),Trimps-Soushen(公安部三所),CUvideo(商汤和港中文),HikVision(海康威视),SenseCUSceneParsing(商汤和香港城市大学),NUIST(南京信息工程大学)包揽了各个项目的冠军。
CUImage(商汤科技和港中文):目标检测第一; Trimps-Soushen(公安部三所):目标定位第一; CUvideo(商汤和港中文):视频中物体检测子项目第一; NUIST(南京信息工程大学):视频中的物体探测两个子项目第一; HikVision(海康威视):场景分类第一; SenseCUSceneParsing(商汤和港中文):场景分析第一。
其中,Trimps-Soushen 以 2.99% 的 Top-5 分类误差率和 7.71% 的定位误差率赢得了 ImageNet 分类任务的胜利。该团队使用了分类模型的集成(即 Inception、Inception-ResNet、ResNet 和宽度残差网络模块的平均结果)和基于标注的定位模型 Faster R-CNN 来完成任务。训练数据集有 1000 个类别共计 120 万的图像数据,分割的测试集还包括训练未见过的 10 万张测试图像。
ILSVRC 2017 Momenta 提出的SENet 获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军, 2.251% Top-5 错误率
LeNet 详解 detail Yann LeCun
-
LeNet 最经典的CNN网络



[1] LeCun, Yann; Léon Bottou; Yoshua Bengio; Patrick Haffner (1998). "Gradient-based learning applied to document recognition" pdf
tf code https://github.com/tensorflow/models/blob/master/research/slim/nets/lenet.py
pytorch code https://github.com/pytorch/examples/blob/master/mnist/main.py
caffe code https://github.com/BVLC/caffe/blob/master/examples/mnist/lenet.prototxt
PyTorch定义了常用模型,并且提供了预训练版本: AlexNet: AlexNet variant from the “One weird trick” paper. VGG: VGG-11, VGG-13, VGG-16, VGG-19 (with and without batch normalization) ResNet: ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152 SqueezeNet: SqueezeNet 1.0, and SqueezeNet 1.1 其中ImageNet比赛中相关的网络,可参见 https://github.com/pytorch/examples/tree/master/imagenet 另外也可以参考https://github.com/aaron-xichen/pytorch-playground.git 里面各种网络结构写法 (非官方)
AlexNet 详解 detail Alex Krizhevsky, Geoffrey Hinton
-
AlexNet 2012年,Alex Krizhevsky用AlexNet 在当年的ImageNet图像分类竞赛中(ILSVRC 2012),以top-5错误率15.3%拿下第一。 他的top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。



[2] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012. pdf
tensorflow 源码 https://github.com/tensorflow/models/blob/master/research/slim/nets/alexnet.py
caffe https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/train_val.prototxt
GoogLeNet 详解 detail Christian Szegedy / Google
-
GoogLeNet 采用InceptionModule和全局平均池化层,构建了一个22层的深度网络,使得很好地控制计算量和参数量的同时( AlexNet 参数量的1/12),获得了非常好的分类性能. 它获得2014年ILSVRC挑战赛冠军,将Top5 的错误率降低到6.67%. GoogLeNet名字将L大写,是为了向开山鼻祖的LeNet网络致敬.


[3] Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.pdf
tensorflow 源码 https://github.com/tensorflow/models/blob/master/research/slim/nets/inception_v1.py
caffe https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/train_val.prototxt
Inception V3 详解 detail Christian Szegedy / Google
-
Inception V3,GoogLeNet的改进版本,采用InceptionModule和全局平均池化层,v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),ILSVRC 2012 Top-5错误率降到3.58% test error


[4] Szegedy, Christian, et al. “Rethinking the inception architecture for computer vision.” arXiv preprint arXiv:1512.00567 (2015). pdf
tensorflow 源码 https://github.com/tensorflow/models/blob/master/research/slim/nets/inception_v3.py
VGG 详解 detail Karen Simonyan , Andrew Zisserman / Visual Geometry Group(VGG)Oxford
-
VGG
VGG-Net是2014年ILSVRC classification第二名(第一名是GoogLeNet),ILSVRC localization 第一名。VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3


单独看VGG19的模型:

[5] Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014). pdf
tensorflow 源码: https://github.com/tensorflow/models/blob/master/research/slim/nets/vgg.py
caffe :
ResNet and ResNeXt详解 detail 何凯明 He Kaiming
-
ResNet ResNet,深度残差网络,通过shortcut( skip connection )的设计,打破了深度神经网络深度的限制,使得网络深度可以多达到1001层。 它构建的152层深的神经网络,在ILSVRC2015获得在ImageNet的classification、detection、localization以及COCO的detection和segmentation上均斩获了第一名的成绩,其中classificaiton 取得3.57%的top-5错误率,


 [6] He, Kaiming, et al. "Deep residual learning for image recognition." arXiv preprint arXiv:1512.03385 (2015). pdf (ResNet,Very very deep networks, CVPR best paper)
[6] He, Kaiming, et al. "Deep residual learning for image recognition." arXiv preprint arXiv:1512.03385 (2015). pdf (ResNet,Very very deep networks, CVPR best paper)tensorflow 源码 https://github.com/tensorflow/models/tree/master/research/slim/nets/resnet_v1.py
https://github.com/tensorflow/models/tree/master/research/slim/nets/resnet_v2.py
-
ResNeXt
结构采用grouped convolutions,减少了超参数的数量(子模块的拓扑结构一样),不增加参数复杂度,提高准确率。


[7] He, Kaiming, et al. "Aggregated Residual Transformations for Deep Neural Networks." arXiv preprint arXiv:1611.05431 . [pdf](https://arxiv.org/pdf/1611.05431.pdf) (ResNet,Very very deep networks, CVPR best paper)
torch https://github.com/facebookresearch/ResNeXt
Inception-Resnet-V2详解 detail Christian Szegedy / Google
Inception Resnet V2是基于Inception V3 和 ResNet结构发展而来的一个网络。在这篇paper中,还同期给出了Inception V4.


[8] Christian Szegedy, et al. “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning” arXiv preprint arXiv:1602.07261 (2015). pdf
github链接: https://github.com/tensorflow/models/blob/master/research/slim/nets/inception_resnet_v2.py
DenseNet详解 detail 黄高Gao Huang, 刘壮Zhuang Liu
作者发现(Deep networks with stochastic depth)通过类似Dropout的方法随机扔掉一些层,能够提高ResNet的泛化能力。于是设计了DenseNet。 DenseNet 将ResNet的residual connection 发挥到了极致,它做了两个重要的设计,一是网络的每一层都直接与其前面层相连,实现特征的重复利用,第二是网络的每一层都很窄,达到降低冗余性的目的。
DenseNet很容易训练,但是它有很多数据需要重复使用,因此显存占用很大。不过现在的更新版本,已经通过用时间换空间的方法,将DenseLayer(Contact-BN-Relu_Conv)中部分数据使用完就释放,而在需要的时候重新计算。这样增加少部分计算量,节约大量内存空间。


 [9] Gao Huang,Zhuang Liu, et al. DenseNet:2016,Densely Connected Convolutional Networks arXiv preprint arXiv:1608.06993 . pdf CVPR 2017 Best Paper
[10]Geoff Pleiss, Danlu Chen, Gao Huang, et al.Memory-Efficient Implementation of DenseNets. pdf
[9] Gao Huang,Zhuang Liu, et al. DenseNet:2016,Densely Connected Convolutional Networks arXiv preprint arXiv:1608.06993 . pdf CVPR 2017 Best Paper
[10]Geoff Pleiss, Danlu Chen, Gao Huang, et al.Memory-Efficient Implementation of DenseNets. pdf
github链接: torch https://github.com/liuzhuang13/DenseNet
pytorch https://github.com/gpleiss/efficient_densenet_pytorch
caffe https://github.com/liuzhuang13/DenseNetCaffe
DPN详解 detail 颜水成
之前我们已经了解了ResNet 和 DenseNet,ResNet使用的是相加(element-wise adding),DenseNet则使用的是拼接(concatenate)。
DPN把DenseNet和ResNet联系到了一起,该神经网络结合ResNet和DenseNet的长处,共享公共特征,并且通过双路径架构保留灵活性以探索新的特征。在设计上,采用了和ResNeXt一样的group操作。
它在在图像分类、目标检测还是语义分割领域都有极大的优势,可以去看2017 ImageNet NUS-Qihoo_DPNs 的表现。


 [11]Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng.Dual Path Networks pdf
[11]Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng.Dual Path Networks pdf
github链接:
MxNet https://github.com/cypw/DPNs (官方)
caffe:https://github.com/soeaver/caffe-model
PolyNet [Xingcheng Zhang] 林达华[Dahua Lin] / CUHK-MMLAB & 商汤科技 详解 detail
这个模型在Inception_ResNet_v2 的基础上,替换了之前的Inception module,改用 PolyInception module 作为基础模块,然后通过数学多项式来组合设计每一层网络结构。因此结构非常复杂。

PolyNet在ImageNet大规模图像分类测试集上获得了single-crop错误率4.25%和multi-crop错误率3.45%。在ImageNet2016的比赛中商汤科技与香港中大-商汤科技联合实验室在多项比赛中选用了这种网络结构并取得了三个单项第一的优异成绩。
提供了caffe的proto 和模型。 caffe:https://github.com/CUHK-MMLAB/polynet
模型结构图 (官方) http://ethereon.github.io/netscope/#/gist/b22923712859813a051c796b19ce5944 https://raw.githubusercontent.com/CUHK-MMLAB/polynet/master/polynet.png
[12] Xingcheng Zhang, Zhizhong Li, ChenChange Loy, Dahua Lin,PolyNet: A Pursuit of Structural Diversity in Very Deep Networks.2017 pdf
SENet 详解 detail
Momenta 提出的SENet 获得了最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军。 它在结构中增加了一个se模块,通过Squeeze 和 Excitation 的操作,学习自动获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。




[13] Squeeze-and-Excitation Networks pdf
caffe:https://github.com/hujie-frank/SENet
这是谷歌用AutoML(Auto Machine Learning)在500块GPU上自行堆砌convolution cell(有两种cell )设计的网络。性能各种战胜人类设计。

[14]Learning Transferable Architectures for Scalable Image Recognitionpdf
github链接: https://github.com/tensorflow/models/blob/master/research/slim/nets/nasnet/nasnet.py
随着模型结构的发展,在很多机器智能领域,深度神经网络都展现出了超人的能力。但是,随着准确率的提升,这些网络也需要更多的计算资源和运行时的内存,这些需求使得高精度的大型网络无法在移动设备或者嵌入式系统上运行。
于是从应用角度发展了另外一条支线,着重在于轻量化模型的设计与发展。它的主要思想在于从卷积层的设计来构建更高效的网络计算方式,从而使网络参数减少的同时,不损失网络性能。
除了模型的设计,还有Deep Compression ,剪枝等多种方法将模型小型化。
SqueezeNet使用bottleneck方法设计一个非常小的网络,使用不到1/50的参数(125w --- 1.25million)在ImageNet上实现AlexNet级别的准确度。 MobileNetV1使用深度可分离卷积来构建轻量级深度神经网络,其中MobileNet-160(0.5x),和SqueezeNet大小差不多,但是在ImageNet上的精度提高4%。 ShuffleNet利用pointwise group卷积和channel shuffle来减少计算成本并实现比MobileNetV1更高的准确率。 MobileNetV2基于inverted residual structure with linear bottleneck,改善了移动模型在多个任务和基准测试中的最新性能。mNASNet是和NASNet一样强化学习的构造结果,准确性略优于MobileNetV2,在移动设备上具有比MobileNetV1,ShuffleNet和MobileNetV2更复杂的结构和更多的实际推理时间。(总结出自MobileFaceNets)
“ With the same accuracy, our MnasNet model runs 1.5x faster than the hand-crafted state-of-the-art MobileNetV2, and 2.4x faster than NASNet, which also used architecture search. After applying the squeeze-and-excitation optimization, our MnasNet+SE models achieve ResNet-50 level top-1 accuracy at 76.1%, with 19x fewer parameters and 10x fewer multiply-adds operations. On COCO object detection, our model family achieve both higher accuracy and higher speed over MobileNet, and achieves comparable accuracy to the SSD300 model with 35x less computation cost.
在相同的准确率下,MnasNet 模型的速度比手工调参得到的当前最佳模型 MobileNet V2 快 1.5 倍,并且比 NASNet 快 2.4 倍,它也是使用架构搜索的算法。在应用压缩和激活(squeeze-and-excitation)优化方法后,MnasNet+SE 模型获得了 76.1% 的 ResNet 级别的 top-1 准确率,其中参数数量是 ResNet 的 1/19,且乘法-加法运算量是它的 1/10。在 COCO 目标检测任务上,我们的MnasNet模型系列获得了比 MobileNet 更快的速度和更高的准确率,并在 1/35 的计算成本下获得了和 SSD300 相当的准确率。” https://ai.googleblog.com/2018/08/mnasnet-towards-automating-design-of.html

| 网络名称 | 最早公开日期 | 发表情况 | 作者团队 | 链接 |
|---|---|---|---|---|
| SqueezeNet | 2016.02 | ICLR2017 | Berkeley&Stanford | codepdf |
| MobileNet | 2016.04 | CVPR2017 | code code | |
| ShuffleNet | 2016.06 | CVPR2017 | Face++ | code |
| Xception | 2016.10 | ---- | ||
| MobileNetV2 | 2018.01 | ---- | code | |
| ShuffleNet V2 | 2018.07 | ECCV2018 | Face++ | |
| MorphNet | 2018.04 | ---- | code | |
| MnasNet | 2018.07 | ---- | ||
| EfficientNet | 2019.06 | ICML2019 | code |
ShuffleNet 论文中引用了 SqueezeNet;Xception 论文中引用了 MobileNet
CNN网络时间消耗分析
对于一个卷积层,假设其大小为 h \times w \times c \times n (其中c为#input channel, n为#output channel),输出的feature map尺寸为 H' \times W' ,则该卷积层的
paras = n \times (h \times w \times c + 1) FLOPS= H' \times W' \times n \times(h \times w \times c + 1) 即#FLOPS= H' \times W' \times #paras
但是虽然Conv等计算密集型操作占了其时间的绝大多数,但其它像Elemwise/Data IO等内存读写密集型操作也占了相当比例的时间
ShuffleNet_V1与MobileNet_V2上的时间消耗分析
从上图中可看出,因此像以往那样一味以FLOPs来作为指导准则来设计CNN网络是不完备的,虽然它可以反映出占大比例时间的Conv操作。 --------此处来自shufflenet v2
SqueezeNet 的核心在于 Fire module,Fire module 由两层构成,分别是 squeeze 层+expand 层,squeeze 层是一个 1×1 卷积核的卷积层,对上一层 feature map 进行卷积,主要目的是减少 feature map 的维数,expand 层是 1×1 和 3×3 卷积核的卷积层,expand 层中,把 1×1 和 3×3 得到的 feature map 进行 concat。


[1]AlexNet-level accuracy with 50x fewer parameters and <0.5MBpdf
github链接: caffe: https://github.com/DeepScale/SqueezeNet
MobileNet 详解 detail Google
MobileNet 顾名思义,可以用在移动设备上的网络,性能和效率取得了很好平衡。它发展了两个版本,第一个版本基本结构和VGG类似,主要通过 depthwise separable convolution 来减少参数和提升计算速度。 第二代结合了ResNet的特性,提出了一种新的 Inverted Residuals and Linear Bottleneck。性能优于对应的NasNet。

MobileNet v1:2017,MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications


MobileNet v2:2018,Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation


TensorFlow实现:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.py
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet_v2.py
caffe实现:https://github.com/pby5/MobileNet_Caffe
手机端caffe实现:https://github.com/HolmesShuan/ShuffleNet-An-Extremely-Efficient-CNN-for-Mobile-Devices-Caffe-Reimplementation caffe实现:https://github.com/camel007/Caffe-ShuffleNet
shufflenet v2
https://arxiv.org/abs/1807.11164
NasNet和 AdaNet 等方法会通过搜索从零开始设计一个网络,但是考虑到搜索需要的计算资源和时间,成本太昂贵的。如何利用现有架构来进行优化, 谷歌研究人员提出一种神经网络模型改进的复杂方法 MorphNet。 MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks, MorphNet 将现有神经网络作为输入,为新问题生成规模更小、速度更快、性能更好的新神经网络。
https://github.com/google-research/morph-net
MorphNet 通过收缩和扩展阶段的循环来优化神经网络。在收缩阶段,MorphNet 通过稀疏性正则化项(sparsifying regularizer)识别出效率低的神经元,并将它们从网络中去除,因而该网络的总损失函数包含每一神经元的成本。但是对于所有神经元,MorphNet 没有采用统一的成本度量,而是计算神经元相对于目标资源的成本。随着训练的继续进行,优化器在计算梯度时是了解资源成本信息的,从而得知哪些神经元的资源效率高,哪些神经元可以去除。
[5]MnasNet: Platform-Aware Neural Architecture Search for Mobilepdf
使用一个简单而高效的复合系数来以更结构化的方式放大 CNNs。 不像传统的方法那样任意缩放网络维度,如宽度,深度和分辨率,该论文的方法用一系列固定的尺度缩放系数来统一缩放网络维度。 通过使用这种新颖的缩放方法和 AutoML技术,最高达10倍的效率(更小、更快)。 https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
pytorch pretrained-model https://github.com/Cadene/pretrained-models.pytorch
概述 :https://arxiv.org/pdf/1804.06655.pdf


人脸检测与识别是一个研究很久的课题。传统方法之前也有了很多稳定可行的方法。而深度学习的出现,无论对检测还是识别又有了很大的提升。随着算法和代码的开源,现在很多公司都可以自己搭建一套自己的人脸检测识别系统。那么下面几篇经典论文,都是会需要接触到的。
在了解深度学习算法之前,也要了解一下传统的方法:如 harr特征( 2004 Viola和Jones的《Robust Real-Time Face Detection》),LAP(Locally Assembled Binary)等。LAP是结合haar特征和LBP(local binary pattern)特征,把不同块的haar特征按照lbp的编码方法形成一个编码。
常见的人脸检测开源算法可以使用 opencv dlib seetaface等。seetafce采用了多种特征(LAB、SURF、SIFT)和多种分类器(boosted、MLP)的结合。
深度学习最早的代表作之一是2015年CVPR的 CascadeCNN 。
CascadeCNN详解 detail
H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neuralnetwork cascade for face detection,” in IEEE Conference on ComputerVision and Pattern Recognition, 2015, pp. 5325-5334. 这篇文章保留了传统人脸检测方法中Cascade的概念,级联了6个CNN,使用3种输入大小分别为12、24、48的浅层网络,一类为分类网络(12-net,24...):2分类,判断是不是人脸,同时产生候选框,一类是矫正网络(12-Calibration-net,24...)它们是45分类(当时训练的时候将每一个正样本进行scale、x轴、y轴变换(共45种变换),生成45张图片)对候选框进行位置矫正。在每个分类网络之后接一个矫正网络用于回归人脸框的位置。
对比传统人脸检测方法,CascadeCNN将Cascade级联结构中每个stage中CNN的分类器代替了传统的分类器;2. 每个分类stage之后应用了一个矫正网络使得人脸框的位置更为精确。该论文是当时基于CNN的人脸检测方法中速度最快的


MTCNN 详解 detail zhang kaipeng 乔宇 Qiao Yu / CUHK-MMLAB & SIAT
- MTCNN MTCNN 将人脸检测与关键点检测放到了一起来完成。整个任务分解后让三个子网络来完成。每个网络都很浅,使用多个小网络级联,较好的完成任务。


[1] [ECCV2016] Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks pdf
Caffe 源码:https://github.com/kpzhang93/MTCNN_face_detection_alignment 官方
tensorflow 源码 : https://github.com/davidsandberg/facenet/tree/master/src/align
从技术实现上可将人脸关键点检测分为2大类:生成式方法(Generative methods) 和 判别式方法(Discriminative methods)。 Generative methods 构建人脸shape和appearance的生成模型。这类方法将人脸对齐看作是一个优化问题,来寻找最优的shape和appearance参数,使得appearance模型能够最好拟合输入的人脸。这类方法包括:
ASM(Active Shape Model) 1995 AAM (Active Appearnce Model) 1998
Discriminative methods直接从appearance推断目标位置。这类方法通常通过学习独立的局部检测器或回归器来定位每个面部关键点,然后用一个全局的形状模型对预测结果进行调整,使其规范化。或者直接学习一个向量回归函数来推断整个脸部的形状。这类方法包括传统的方法以及最新的深度学习方法:
Constrained local models (CLMs) 2006 https://github.com/TadasBaltrusaitis/CLM-framework Deformable part models (DPMs) 基于级联形状回归的方法(Cascaded regression) 2010 CPR(Cascaded Pose Regression) ESR https://github.com/soundsilence/FaceAlignment ERT(Ensemble of Regression Trees) dlib: One Millisecond Face Alignment with an Ensemble of Regression Trees. http://www.csc.kth.se/~vahidk/papers/KazemiCVPR14.pdf https://github.com/davisking/dlib Face Alignment at 3000 FPS cvpr2013, https://github.com/yulequan/face-alignment-in-3000fps

深度学习:
2013 香港中文大学汤晓欧,SunYi等人作品,首次将CNN用于人脸关键点检测。总体思想是由粗到细,实现5个人脸关键点的精确定位。网络结构分为3层:level 1、level 2、level 3。每层都包含多个独立的CNN模型,负责预测部分或全部关键点位置,在此基础上平均来得到该层最终的预测结果。
TCDCN Facial Landmark Detection by Deep Multi-task Learning http://mmlab.ie.cuhk.edu.hk/projects/TCDCN.html VanillaCNN
https://github.com/MarekKowalski/DeepAlignmentNetwork
##LAB (LAB-Look at Boundary A Boundary-Aware Face Alignment Algorithm ) 2018cvpr 清华&商汤作品。借鉴人体姿态估计,将边界信息引入关键点回归上。网络包含3个部分:边界热度图估计模块(Boundary heatmap estimator),基于边界的关键点定位模块( Boundary-aware landmarks regressor )和边界有效性判别模块(Boundary effectiveness discriminator)
过去二十年来,人脸识别要解决的关键问题还是如何寻找合适特征的算法,主要经过了四个阶段。
第一个阶段Holistci Learning,通过对图片进行空间转换,得到满足假设的一定分布的低维表示 ,如线性子空间,稀疏表示等等。这个想法在20世纪90年代占据了FR的主导地位 2000年。
然而,一个众所周知的问题是这些理论上合理的算法无法解决很多异常的问题,当人脸变化偏离了先前的假设,算法就失效了。 在21世纪初,这个问题引起了以Local handcraft算子为主的研讨。 出现了Gabor 算子和LBP算子,及它们的多层和高维扩展。局部算子的一些不变属性表现出了强大的性能。
不幸的是,手工设计的算子缺乏独特性和紧凑性,在海量数据处理表现出局限性。 在2010年初,基于浅层学习的算法被引入,尝试用两层网络来学习,之后,出现了深度学习的方法,使用多层神经网络来进行特征提取和转换。
Osadchy, Margarita, Yann Le Cun, and Matthew L. Miller. "Synergistic face detection and pose estimation with energy-based models." The Journal of Machine Learning Research 8 (2007): 1197- 1215.
2014年,DeepFace 和DeepID第一次在不受约束的情景超越了人类的表现。从那时起,研究 重点已转向基于深度学习的方法。


DeepFace是FaceBook提出来的,后续有DeepID和FaceNet出现。DeepFace是第一个真正将大数据和深度神经网络应用于人脸识别和验证的方法,人脸识别精度接近人类水平,可以谓之CNN在人脸识别的奠基之作
之后Facenet跳出了分类问题的限制,而是构建了一种框架,通过已有的深度模型,训练一个人脸特征。然后用这个人脸特征来完成人脸识别,人脸验证和人脸聚类。
DeepFace 在算法上并没有什么特别的创新,它的改进在于对前面人脸预处理对齐的部分做了精细的调整,结果显示会有一定的帮助,但是也有一些疑问,因为你要用 3D Alignment(对齐),在很多情况下,尤其是极端情况下,可能会失败。
DeepFace: Closing the Gap to Human-Level Performance in Face Verification



DeepID 还是将人脸作为一个分类问题来解决,而从facenet开始,则是通过设计不同的loss,端对端去学习一个人脸的特征。这个特征 在欧式空间 或者高维空间,能够用距离来代表人脸的相似性。

Facenet 详解 detail
和物体分类这种分类问题不同,Facenet是构建了一种框架,通过已有的深度模型,结合不同loss,训练一个很棒的人脸特征。它直接使用端对端的方法去学习一个人脸图像到欧式空间的编码,这样构建的映射空间里的距离就代表了人脸图像的相似性。然后基于这个映射空间,就可以轻松完成人脸识别,人脸验证和人脸聚类。
[CVPR2015] Schroff F, Kalenichenko D, Philbin J. Facenet: A unified embedding for face recognition and clustering[J]. arXiv preprint arXiv:1503.03832, 2015.pdf
Model name LFW accuracy Training dataset Architecture
20170511-185253 0.987 CASIA-WebFace Inception ResNet v1
20170512-110547 0.992 MS-Celeb-1M Inception ResNet v1

它使用现有的模型结构,然后将卷积神经网络去掉sofmax后,经过L2的归一化,然后得到特征表示,之后基于这个特征表示计算Loss。文章中使用的结构是ZFNet,GoogLeNet,tf代码是改用了Inception_resnet_v1。
Loss的发展: 文中使用的Loss 是 triplet loss。后来相应的改进有ECCV2016的 center loss,SphereFace,2018年的AMSoftmax和ArchFace(InsightFace),现在效果最好的是ArchFace(InsightFace)。


https://github.com/davidsandberg/facenet/blob/master/src/models/inception_resnet_v1.py
tensorflow 源码 :https://github.com/davidsandberg/facenet
caffe center loss:https://github.com/kpzhang93/caffe-face
mxnet center loss :https://github.com/pangyupo/mxnet_center_loss
caffe sphereface: https://github.com/wy1iu/sphereface
deepinsight: https://github.com/deepinsight/insightface
AMSoftmax :https://github.com/happynear/AMSoftmax
github:https://github.com/cmusatyalab/openface 基于谷歌的文章《FaceNet: A Unified Embedding for Face Recognition and Clustering》。openface是卡内基梅隆大学的 Brandon Amos主导的。 B. Amos, B. Ludwiczuk, M. Satyanarayanan, "Openface: A general-purpose face recognition library with mobile applications," CMU-CS-16-118, CMU School of Computer Science, Tech. Rep., 2016.
Detection: Funnel-Structured Cascade for Multi-View Face Detection with Alignment-Awareness
2016
中科院山世光老师开源的人脸识别引擎—SeetafaceEngine,主要实现下面三个功能: SeetaFace Detection SeetaFace Alignment SeetaFace Identification
github:https://github.com/seetaface/SeetaFaceEngine
主要在Landmark Detection,Landmark and head pose tracking,Facial Action Unit Recognition等,其中Facial Action Unit Recognition是个比较有意思的点,该项目给出一个脸部的每个AU的回归分数和分类结果。
Detect faces with a pre-trained models from dlib or OpenCV. Transform the face for the neural network. This repository uses dlib's real-time pose estimation with OpenCV's affine transformation to try to make the eyes and bottom lip appear in the same location on each image.
github:https://github.com/TadasBaltrusaitis/OpenFace
这个研究得比较少,主要是分两个方面:
一种是设计一个小型网络,从头开始训。这种包括LmobileNetE(112M),lightCNN (A light cnn for deep face representation with noisy labels. arXiv preprint), ShiftFaceNet(性能能有点差 LFW 96%),MobileFaceNet等
一种是从大模型进行knowledge distillation 知识蒸馏得到小模型。包括从DeepID2 进行teacher-student训练得到MobileID,从FaceNet预训练模型继续训MobileNetV1等。
这个模型主要就是用类MobileNet V2的结构,加上ArcFace的loss进行训练。
3D人脸重建主要有两种方式,一种是通过多摄像头或者多帧图像的关键点匹配(Stereo matching),重建人脸的深度信息,或者深度相机,从而得到模型,另一种是通过预先训练好的人脸模型(3d morphable model),拟合单帧或多帧RGB图像或深度图像,从而得到3d人脸模型的个性化参数。
深度学习在3d face的研究着重在第二个。
由于Blanz和Vetter在1999年提出3D Morphable Model(3DMM)(Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. international conference on computer graphics and interactive techniques (1999)),成为最受欢迎的单图3D面部重建方法。早期是针对特殊点的对应关系(可以是关键点 也可以是局部特征点)来解非线性优化函数,得到3DMM系数。然而,这些方法严重依赖于高精度手工标记或者特征。
首先,2016年左右,CNN的尝试主要是用级联CNN结构来回归准确3DMM系数,解决大姿态下面部特征点定位问题。但迭代会花费大量时间
http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm
自动化所作品, 解决极端姿态下(如侧脸),一些特征点变了不可见,不同姿态下的人脸表观也存在巨大差异使得关键点定位困难等问题
本文提出一种基于3D人脸形状的定位方法3DDFA,算法框架为: (1) 输入为100x100的RGB图像和PNCC (Projected Normalized Coordinate Code) 特征,PNCC特征的计算与当前形状相关,可以反映当前形状的信息;算法的输出为3D人脸形状模型参数 (2) 使用卷积神经网络拟合从输入到输出的映射函数,网络包含4个卷积层,3个pooling层和2个全连接层 通过级联多个卷积神经网络直至在训练集上收敛,PNCC特征会根据当前预测的人脸形状更新,并作为下一级卷积神经网络的输入。 (3) 此外,卷积神经网络的损失函数也做了精心的设计,通过引入权重,让网络优先拟合重要的形状参数,如尺度、旋转和平移;当人脸形状接近ground truth时,再考虑拟合其他形状参数 实验证明该损失函数可以提升定位模型的精度。由于参数化形状模型会限制人脸形状变形的能力,作者在使用3DDFA拟合之后,抽取HOG特征作为输入,使用线性回归来进一步提升2D特征点的定位精度。
训练3DDFA模型,需要大量的多姿态人脸样本。为此,作者基于已有的数据集如300W,利用3D信息虚拟生成不同姿态下的人脸图像,核心思想为:先预测人脸图像的深度信息,通过3D旋转来生成不同姿态下的人脸图像
这篇文章是来自密西根州立大学的Amin Jourabloo和Xiaoming Liu的工作。 2D的人脸形状U可以看成是3D人脸形状A通过投影变化m得到,如下图所示: 3D人脸形状模型可以表示为平均3D人脸形状 A 0 与若干表征身份、表情的基向量 A id 和 A exp 通过p参数组合而成 面部特征点定位问题(预测U)可以转变为同时预测投影矩阵m和3D人脸形状模型参数p
算法的整体框架通过级联6个卷积神经网络来完成这一任务: (1) 首先以整张人脸图像作为输入,来预测投影矩阵的更新 (2) 使用更新后的投影矩阵计算当前的2D人脸形状,基于当前的2D人脸形状抽取块特征作为下一级卷积神经网络的输入,下一级卷积神经网络用于更新3D人脸形状 (3) 基于更新后的3D人脸形状,计算可得当前2D人脸形状的预测 (4) 根据新的2D人脸形状预测,抽取块特征输入到卷积神经网络中来更新投影矩阵,交替迭代优化求解投影矩阵m和3D人脸形状模型参数p,直到在训练集收敛
值得一提的是,该方法在预测3D人脸形状和投影矩阵的同时也考虑到计算每一个特征点是否可见。如果特征点不可见,则不使用该特征点上的块特征作为输入,这是普通2D人脸对齐方法难以实现的 此外,作者提出两种pose-invariant的特征Piecewise Affine-Warpped Feature (PAWF)和Direct 3D Projected Feature (D3PF),可以进一步提升特征点定位的精度
End to end 的方法,将输入图片转换为3DMM参数
Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network 2016 https://github.com/anhttran/3dmm_cnn
密集人脸对齐 用cnn学习2d图像与3d图像之间的密集对应关系 然后使用预测的密集约束计算3DMM参数。
http://cvlab.cse.msu.edu/project-pifa.html
密西根州立大学的Amin Jourabloo和Xiaoming Liu等人的工作,该组其他人脸对齐的工作可参见其项目主页。
摘要: 在人脸对齐方法中,以前的算法主要集中在特定数量的人脸特征点检测,比如5、34或者68个特征点,这些方法都属于稀疏的人脸对齐算法。在本文中,我们提出了一种针对大角度人脸图像的一种3D密集人脸对齐算法。在该模型中,我们通过训练CNN模型利用人脸图像来估计3D人脸shape,利用该shape来fitting相应的3D人脸模型,不仅能够检测到人脸特征点,还能匹配人脸轮廓和SIFT特征点。此外还解决了不同数据库中由于包含不同数量的特征点(5、34或68)而不能交叉验证的问题。可以实时运行
原文: CVPR 2017 https://github.com/ralpguler/DenseReg 摘要: 在本文中,我们提出通过完全卷积网络学习从图像像素到密集模板网格的映射。我们将此任务作为一个回归问题,并利用手动注释的面部标注来训练我们的网络。我们使用这样的标注,在三维对象模板和输入图像之间,建立密集的对应领域,然后作为训练我们的回归系统的基础。我们表明,我们可以将来自语义分割的想法与回归网络相结合,产生高精度的“量化回归”架构。我们的系统叫DenseReg,可以让我们以全卷积的方式估计密集的图像到模板的对应关系。因此,我们的网络可以提供有用的对应信息,而当用作统计可变形模型的初始化时,我们获得了标志性的本地化结果,远远超过当前最具挑战性的300W基准的最新技术。我们对大量面部分析任务的方法进行了全面评估,并且还展示了其用于其他估计任务的用途,如人耳建模。
诺丁汉大学和金斯顿大学 用CNN Regression的方法解决大姿态下的三维人脸重建问题。 ICCV论文:《Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression》
Volumetric Regression Network(VRN) 本文作者使用的模型,由多个沙漏模型组合在一起形成。
- VRN模型使用两个沙漏模块堆积而成,并且没有使用hourglass的间接监督结构。
- VRN-guided 模型是使用了Stacked Hourglass Networks for Human Pose Estimation 的工作作为基础,在前半部分使用两个沙漏模块用来获取68个标记点,后半部分使用两个沙漏模块,以一张RGB图片和68个通道(每个通道一个标记点)的标记点作为输入数据。
- VRN-Multitask 模型,用了三个沙漏模块,第一个模块后分支两个沙漏模块,一个生成三维模型,一个生成68个标记点。
github:https://github.com/AaronJackson/vrn
原文: CVPR 2017 摘要: 本文提出了一个强有力的方法来同时实现3D人脸重构和密集人脸对齐。为实现该目标,我们设计了一个UV位置图,来达到用2D图表示UV 空间内完整人脸的3D形状特征。然后训练了一个简单的CNN来通过单张2D图像回归得到UV图。我们的方法不需要任何先验人脸模型,就可以重构出完整的面部结构。速度9.8ms/帧。
https://github.com/YadiraF/PRNet
PRNet 简单来说,就是以前的一张图片三通道是RGB,表达的是二维的图片, 有没有什么方法简单的将三维问题,转换成和现有解决方案相似的问题来处理。作者将一个三维的人脸,投影到x y z 三个平面上,改用xyz作为三个通道,于是 三维的人脸 就可以还是变成三个通道来进行处理。 简单有效。
PS: 个人用CAS-PEAL-R1数据集测试了作者给的模型,人脸角度偏差在5°以内,胜过其他二维图片68个特征点很多算法的效果。
HPEN High-Fidelity Pose and Expression Normalization for Face Recognition in the Wild
表情相关 ExpNet: Landmark-Free, Deep, 3D Facial Expressions
Expression-Net https://github.com/fengju514/Expression-Net
数据集
UMDFace
MTFL(TCDCN所用)
[300W-3D]: The fitted 3D Morphable Model (3DMM) parameters of 300W samples.
[300W-3D-Face]: The fitted 3D mesh, which is needed if you do not have Basel Face Model (BFM)
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks) ICCV2017 直接使用CNN预测heatmap以获得3D face landmark
两个github项目,在做同一件事,2d和3d的人脸对齐问题,区别在于前者是Pytorch 的代码,后者是Torch7的。 github:https://github.com/1adrianb/face-alignment github: https://github.com/1adrianb/2D-and-3D-face-alignment
2D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-FAN-300W.t7
3D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN.t7
2D-to-3D FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-to-3D-FAN.tar.gz
3D-FAN-depth:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN-depth
other
综述A 2019 guide to Human Pose Estimation with Deep Learning
https://github.com/peterljq/OpenMMD
https://shunsukesaito.github.io/PIFu/

传统的文本文字检测识别,有了很好的商用。但是场景文字检测识别一直没有很好的被解决。随着深度学习的发展,近年来相应工作了有了较好的进展,其主要分为两个步骤:
1.文字定位(Text Detection),即找到单词或文本行(word/linelevel)的边界框(bounding box),近些年的难点主要针对场景内的倾斜文字检测。
2.文字识别(Text Recognition)
将这两个步骤合在一起就能得到文字的端到端检测(End-to-end Recognition)
传统常用的方法有:
MSER(Maximally Stable Extremal Regions)最大稳定极值区域
Chen H, Tsai S S, Schroth G, et al. Robust text detection in natural images with edge-enhanced maximally stable extremal regions[C]//Image Processing (ICIP), 2011 18th IEEE International Conference on. IEEE, 2011: 2609-2612.
通过MSER得到文本候选区域,再通过几何和笔划宽度信息滤掉非文本区域, 剩余的文本信息形成文本直线,最终可被切分为单个文字。
Matlab code:http://cn.mathworks.com/help/vision/examples/automatically-detect-and-recognize-text-in-natural-images.html
此外Google DeepMind提出了一种新的网络结构,叫做STN(Spatial Transformer Networks) ,可以用在文字校正方面:
STN可以被安装在任意CNN的任意一层中,相当于在传统Convolution中间,装了一个“插件”,可以使得传统的卷积带有了[裁剪]、[平移]、[缩放]、[旋转]等特性。
[1] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[C]//Advances in Neural Information Processing Systems. 2015: 2017-2025.
https://github.com/skaae/recurrent-spatial-transformer-code
google 的表格检测 tabel detection in heterogeneous documents
常用的开源 tesseract https://github.com/tesseract-ocr/tesseract Combined Script and Page Orientation Estimation using the Tesseract OCR engine An Overview of the Tesseract OCR Engine 后来加上lstm之后,效果有了更好的改善
文字定位分为 如下几类:Proposal-based method ,Segmantation-based method , Part-based method 和 Hybrid method
DeepText(此方法不是Google的DeepText哦),对fasterRCNN进行改进用在文字检测上,先用Inception-RPN提取候选的单词区域,再利用一个text-detection网络过滤候选区域中的噪声区域,最后对重叠的box进行投票和非极大值抑制
Deep Matching Prior Network 金连文教授发表在 CVPR2017 上的工作提出了一个重要观点:在生成 proposal 时回归矩形框不如回归一个任意多边形。
理由:这是因为文本在图像中更多的是具有不规则多边形的轮廓。他们在SSD(Single ShotMultiBox Detector)的检测框架基础上,将回归边界框的过程和匹配的过程都加入到网络结构中,取得了较好的识别效果并且兼顾了速度。
现在的方法越来越倾向于从整体上自动处理文本行或者边界框,如 arXiv上的一篇文章就将 Faster R-CNN中的RoI pooling替换为可以快速计算任意方向的操作来对文本进行自动处理。
Arbitrary Oriented Scene Text Detection via Rotation Proposals
TextProposals: a Text-specific Selective Search Algorithm for Word Spotting in the Wild.
这篇文章针对文本的特殊属性,将object proposal 的方法用在了文本检测中,形成了text-proposal。
text-proposal也是基于联通区域的组合,但又与之前的方法有所不同:初始化的区域并不对应单个字符,也不需要知道里面的字符数。
代码见:https://github.com/lluisgomez/TextProposals
Gupta A, et al. Synthetic data for text localisation in natural images. CVPR, 2016.
-
CTPN 使用CNN + RNN 进行文本检测与定位。

作者caffe中模型结构如图:

[1] [ECCV2016] Detecting Text in Natural Image with Connectionist Text Proposal Network pdf
Caffe 源码:https://github.com/tianzhi0549/CTPN 官方
TextBoxes 详解 detail 白翔 Xiang Bai/Media and Communication Lab, HUST
- TextBoxes,一个端到端的场景文本检测模型。这个算法是基于SSD来实现的,解决水平文字检测问题,将原来3×3的kernel改成了更适应文字的long conv kernels 3×3 -> 1×5。default boxes 也做了修改。


作者caffe中模型结构如图:

[2] M. Liao et al. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. AAAI, 2017. pdf
Caffe 源码:https://github.com/MhLiao/TextBoxes 官方
TextBoxes++ 详解 detail 白翔 Xiang Bai/Media and Communication Lab, HUST
-
TextBoxes++ 这个算法也是基于SSD来实现的,实现了对多方向文字的检测。boundingbox的输出从4维的水平的boundingbox扩展到4+8=12维的输出。long conv kernels 从 1×5 改成了 3×5。default boxes 也做了修改。


[3] M. Liao et al. TextBoxes++: Multi-oriented text detection pdf
Caffe 源码:https://github.com/MhLiao/TextBoxes_plusplus 官方

基于分割的方法,使用FCN来做, 将文本行视为一个需要分割的目标,通过分割得到文字的显著性图像(salience map),这样就能得到文字的大概位置、整体方向及排列方式,再结合其他的特征进行高效的文字检测。
[CVPR2016]Zhang Z, et al.Multi-Oriented Text Detection with Fully Convolutional Networks,CVPR, 2016. pdf
caffe torch code :https://github.com/stupidZZ/FCN_Text
这篇文章将局部和全局信息结合,使用了一种coarse-to-fine的方法来定位自然场景中的文本。首先,使用了全卷积的神经网络来训练和预测文字区域的显著图;然后,结合显著图和文字元素来估计文字所在的直线;最后,另一个全卷积模型的分类器用来估计每个字符的中心,从而去掉误检区域。这个系统能够处理不同方向、语言、字体的文本检测,在MSRA-TD500, ICDAR2015和ICDAR2013的评测集上都取得了state-of-the-art的结果。
发现在卷积神经网络中可以同时预测字符的位置及字符之间的连接关系,这些特征对定位文字具有很好的帮助。其过程如下:
得到文字文本行的分割结果;
得到字符中心的预测结果;
得到文字的连接方向。
通过得到的这三种特征构造连通图(graph),然后对图进行逐边裁剪来得到文字位置。
对于多方向文字检测的问题,回归或直接逼近bounding box的方法难度都比较大,所以考虑使用 part-based model 对多方向文字进行处理。
将文字视为小块单元。对文字小块同时进行旋转和回归。并且通过对文字小块之间的方向性进行计算来学习文字之间的联系,最后通过简单的后处理就能得到任意形状甚至具有形变的文字检测结果。
例如,对于那些很长的文本行,其卷积核的尺寸难以控制,但是如果将其分解为局部的文字单元之后就能较好地解决。
SegLink+ CRNN 在ICDAR 2015上得到了当时最好的端到端识别效果。
B. Shi et al. Detecting Oriented Text in Natural Images by Linking Segments. IEEE CVPR, 2017.
Code: https://github.com/bgshih/seglink
最近有些方法同时使用分割(segmentation)和边界框回归(bounding box regression)的方式对场景文字进行检测。
如 CVPR2017 上的一篇文章使用PVANet对网络进行优化、加速,并输出三种不同的结果:
边缘部分分割的得分(score)结果;
可旋转的边界框(rotated bounding boxes)的回归结果;
多边形bounding boxes(quadrangle bounding boxes)的结果。
同时对非极大值抑制(NMS)进行改进,得到了很好的效果。
He W, et al. Deep Direct Regression for Multi-Oriented Scene Text Detection. ICCV, 2017
arXiv上的一篇文章使用了相似的思想:一个分支对图像分割进行预测,另一个分支对边界框(bounding box)进行预测,最后利用经过改进的非极大抑制(Refined NMS)进行融合。
###Word/Char Lever 通过多类分类器,如word 分类器,char 分类器 来判断。每一类都是一个word 或者char。
M. Jaderberg et al. Reading text in the wild with convolutional neural networks. IJCV, 2016.
从图片获取Sequence feature,然后通过RNN + CTC B. Su et al. Accurate scene text recognition based on recurrent neural network. ACCV, 2014.
He et al. Reading Scene Text in Deep Convolutional Sequences. AAAI, 2016.
CRNN 详解 detail 白翔 Xiang Bai/Media and Communication Lab, HUST
-
CRNN 将特征提取CNN,序列建模 RNN 和转录 CTC 整合到统一框架,完成端对端的识别任务.

[1] [2015-CoRR] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition pdf
code: http://mclab.eic.hust.edu.cn/~xbai/CRNN/crnn_code.zip
Torch 源码:https://github.com/bgshih/crnn Torch7 官方 pytorch https://github.com/meijieru/crnn.pytorch
用STN 加上 SRN 解决弯曲形变的文字识别问题
SRN: an attention-based encoder-decoder framework
Encoder: ConvNet + Bi-LSTM
Decoder: Attention-based character generator
[2]Shi B, Wang X, Lv P, et al. Robust Scene Text Recognition with Automatic Rectification[J]. arXiv preprint arXiv:1603.03915, 2016. paper
[2016-IJCV]Reading Text in the Wild with Convolutional Neural Networks pdf 较早的端到端识别研究是VGG 组发表在 IJCV2016中的一篇文章,其识别效果很好,并且在两年内一直保持领先地位。
这篇文章针对文字检测问题对R-CNN进行了改造:
通过edge box或其他的handcraft feature来计算proposal;
然后使用分类器对文本框进行分类,去掉非文本区域;
再使用 CNN对文本框进行回归来得到更为精确的边界框(bounding box regression);
最后使用一个文字识别算法进一步滤除非文本区域。
VGG组在CVPR2016上又提出了一个很有趣的工作。文章提出文本数据非常难以标注,所以他们通过合成的方法生成了很多含有文本信息的样本。虽然图像中存在合成的文字,但是依然能得到很好的效果。
[ICCV2017] Lukas Neumann ,Deep TextSpotter:An End-to-End Trainable Scene Text Localization and Recognition Framework pdf
https://github.com/MichalBusta/DeepTextSpotter
该方法将文字检测和识别整合到一个端到端的网络中。检测使用YOLOv2+RPN,并利用双线性采样将文字区域统一为高度一致的变长特征序列,再使用RNN+CTC进行识别。
文档矫正
DocUNet: Document Image Unwarping via A Stacked U-Net face++

物体分类(物体识别)解决的是这个东西是什么的问题(What)。而物体检测则是要解决这个东西是什么,具体位置在哪里(What and Where)。 物体分割则将物体和背景进行区分出来,譬如人群,物体分割中的实例分割则将人群中的每个人都分割出来。 输入:图片 输出:类别标签和bbox(x,y,w,h)

这里借用一张图,展示Object Detection 基础算法的发展

其中RCNN FastRCNN FasterRCNN为一脉相承。另外两个方向为Yolo 和SSD。Yolo迭代到Yolo V3,SSD的设计也让它后来在很多方向都有应用。
Christian Szegedy / Google 用AlexNet也做过物体检测的尝试。
[1] Szegedy, Christian, Alexander Toshev, and Dumitru Erhan. "Deep neural networks for object detection." Advances in Neural Information Processing Systems. 2013. pdf
不过真正取得巨大突破,引发基于深度学习目标检测的热潮的还是RCNN
但是如果将如何检测出区域,按照回归问题的思路去解决,预测出(x,y,w,h)四个参数的值,从而得出方框的位置。回归问题的训练参数收敛时间要长很多,于是将回归问题转成分类问题来解决。总共两个步骤:
第一步:将图片转换成不同大小的框, 第二步:对框内的数据进行特征提取,然后通过分类器判定,选区分最高的框作为物体定位框。


评价标准: IoU(Intersection over Union); mAP(Mean Average Precision) 速度:帧率FPS


RCNN Ross B. Girshick(RBG) link / UC-Berkeley
- RCNN R-CNN框架,取代传统目标检测使用的滑动窗口+手工设计特征,而使用CNN来进行特征提取。这是深度神经网络的应用。
Traditional region proposal methods + CNN classifier
也就是将第二步改成了深度神经网络提取特征。 然后通过线性svm分类器识别对象的的类别,再通过回归模型用于收紧边界框; 创新点:将CNN用在物体检测上,提高了检测率。 缺点: 基于选择性搜索算法为每个图像提取2,000个候选区域,使用CNN为每个图像区域提取特征,重复计算,速度慢,40-50秒。
R-CNN在PASCAL VOC2007上的检测结果提升到66%(mAP)

[2] SGirshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. pdf
github: https://github.com/rbgirshick/rcnn
SPPNet 何凯明 He Kaiming /MSRA
- SPPNet Spatial Pyramid Pooling(空间金字塔池化) [3] He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." European Conference on Computer Vision. Springer International Publishing, 2014. pdf
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的提出,将金字塔思想加入到CNN,实现了数据的多尺度输入。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。

这样打破了之前大家认为需要先提出检测框,然后resize到一个固定尺寸再通过CNN的模式,而可以图片先通过CNN获取到特征后,在特征图上使用不同的检测框提取特征。之后pooling到同样尺寸进行后续步骤。这样可以提高物体检测速度。
- intro: ECCV 2014 / TPAMI 2015
- keywords: SPP-Net
- arxiv: http://arxiv.org/abs/1406.4729
- github: https://github.com/ShaoqingRen/SPP_net
- notes: http://zhangliliang.com/2014/09/13/paper-note-sppnet/
- Fast RCNN [4] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015.
如果RCNN的卷积计算只需要计算一次,那么速度就可以很快降下来了。
Ross Girshick将SPPNet的方法应用到RCNN中,提出了一个可以看做单层sppnet的网络层,叫做ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量.将图像输出到CNN生成卷积特征映射。使用这些特征图结合候选区域算法提取候选区域。然后,使用RoI池化层将所有可能的区域重新整形为固定大小,以便将其馈送到全连接网络中。
1.首先将图像作为输入; 2.将图像传递给卷积神经网络,计算卷积后的特征。 3.然后通过之前proposal的方法提取ROI,在所有的感兴趣的区域上应用RoI池化层,并调整区域的尺寸。然后,每个区域被传递到全连接层的网络中; 4.softmax层用于全连接网以输出类别。与softmax层一起,也并行使用线性回归层,以输出预测类的边界框坐标。

github: https://github.com/rbgirshick/fast-rcnn
Faster RCNN 何凯明 He Kaiming
- Faster RCNN Fast RCNN的区域提取还是使用的传统方法,而Faster RCNN将Region Proposal Network和特征提取、目标分类和边框回归统一到了一个框架中。
Faster R-CNN = Region Proposal Network +Fast R-CNN



将区域提取通过一个CNN完成。这个CNN叫做Region Proposal Network,RPN的运用使得region proposal的额外开销就只有一个两层网络。关于RPN可以参考link

Faster R-CNN设计了提取候选区域的网络RPN,代替了费时的Selective Search(选择性搜索),使得检测速度大幅提升,下表对比了R-CNN、Fast R-CNN、Faster R-CNN的检测速度:

[5] Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
github: caffe https://github.com/rbgirshick/py-faster-rcnn/
-
Yolo(You only look once)
YOLO的检测思想不同于R-CNN系列的思想,它将目标检测作为回归任务来解决。YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。


[6] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:1506.02640 (2015). pdfYOLO,Oustanding Work, really practical PPT


c 官方: https://pjreddie.com/darknet/yolo/ v3 https://pjreddie.com/darknet/yolov2/ v2 https://pjreddie.com/darknet/yolov1/ v1
pytorch (tencent) v1, v2, v3 :https://github.com/TencentYoutuResearch/ObjectDetection-OneStageDet
yolo 介绍 可以参考介绍
SSD(The Single Shot Detector) 详解 detail
-
SSD SSD是一种直接预测bounding box的坐标和类别的object detection算法,没有生成proposal的过程。它使用object classification的模型作为base network,如VGG16网络,


[7] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015). pdf
tensorflow 源码 https://github.com/balancap/SSD-Tensorflow/blob/master/nets/ssd_vgg_300.py

FPN(feature pyramid networks)特征金字塔,是一种融合了多层特征信息的特征提取方法,可以结合各种深度神经网络使用。 SSD的多尺度特征融合的方式,没有上采样过程,没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3)

Feature Pyramid Networks for Object Detection pdf
-
R-FCN R-FCN是对faster rcnn的改进。因为Faster RCNN的roi pooling中的全连接层计算量大,但是丢弃全连接层(起到了融合特征和特征映射的作用),直接将roi pooling的生成的feature map 连接到最后的分类和回归层检测结果又很差,《Deep residual learning for image recognition》认为:图像分类具有图像移动不敏感性;而目标检测领域是图像移动敏感的,因此在roi pooling中加入位置相关性设计。

[8] Dai, Jifeng, et al. "R-FCN: Object Detection via Region-based Fully Convolutional Networks." arXiv preprint arXiv:1605.06409 (2016). pdf

{kind=link}
{kind=link}
{kind=link}
{kind=link}
-arxiv: http://arxiv.org/abs/1605.06409 -github: https://github.com/daijifeng001/R-FCN -github(MXNet): https://github.com/msracver/Deformable-ConvNets/tree/master/rfcn -github: https://github.com/Orpine/py-R-FCN -github: https://github.com/PureDiors/pytorch_RFCN -github: https://github.com/bharatsingh430/py-R-FCN-multiGPU -github: https://github.com/xdever/RFCN-tensorflow
R-FCN-3000 at 30fps: Decoupling Detection and Classification
https://arxiv.org/abs/1712.01802
- Mask R-CNN
ICCV 2017的最佳论文,在Mask R-CNN的工作中,它主要完成了三件事情:目标检测,目标分类,像素级分割。它在Faster R-CNN的结构基础上加上了Mask预测分支,并且改良了ROI Pooling,提出了ROI Align。这是第一次将目标检测和目标分割任务统一起来。

[9] He, Gkioxari, et al. "Mask R-CNN" arXiv preprint arXiv:1703.06870 (2017). [pdf]
目标识别网络(分类网络)尽管表面上来看可以接受任意尺寸的图片作为输入,但是由于网络结构最后全连接层的存在,使其丢失了输入的空间信息,因此,这些网络并没有办法直接用于解决诸如分割等稠密估计的问题。于是FCN用卷积层和池化层替代了分类网络中的全连接层,从而使得网络结构可以适应像素级的稠密估计任务。该工作被视为里程碑式的进步,因为它阐释了CNN如何可以在语义分割问题上被端对端的训练,而且高效的学习了如何基于任意大小的输入来为语义分割问题产生像素级别的标签预测。
在深度学习统治计算机视觉领域之前,有Texton Forests和Random Forest based classifiers等方法来进行语义分割。
FCN(Fully Convolutional Networks for Semantic Segmentation)成为了深度学习技术应用于语义分割问题的基石:
它利用了现存的CNN网络作为其模块之一来产生层次化的特征。作者将现存的知名的分类模型包括AlexNet、VGG-16、GoogLeNet和ResNet等转化为全卷积模型:将其全连接层均替换为卷积层,输出空间映射而不是分类分数。这些映射由小步幅卷积上采样(又称反卷积)得到,来产生密集的像素级别的标签。


输入:整幅图像。 输出:空间尺寸与输入图像相同,通道数等于全部类别个数。 真值:通道数为1(或2)的分割图像。
[1] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation.” in CVPR, 2015. pp. 3431-3440 pdf CVPR 2015 Best paper


caffe https://github.com/shelhamer/fcn.berkeleyvision.org 官方
tf : https://github.com/shekkizh/FCN.tensorflow
尽管FCN模型强大而普适,它任然有着多个缺点从而限制其对于某些问题的应用:
1 固有的空间不变性导致其没有考虑到有用的全局上下文信息,
2 并没有默认考虑对实例的辨识,
3 效率在高分辨率场景下还远达不到实时操作的能力,
4 不完全适合非结构性数据如3D点云,或者非结构化模型。
参考给出了这个综述的总结,他们所基于的架构、主要的贡献、以及基于其任务目标的分级:准确率、效率、训练难度、序列数据处理、多模式输入以及3D数据处理能力等。每个目标分为3个等级,依赖于对应工作对该目标的专注程度,叉号则代表该目标问题并没有被该工作考虑进来。


UNET 2005 UNet 思想来源于图像压缩和去噪的一个思想:将图像编码成一个小图,之后再解码回实际大图。
Unet的主要结构: 下采样 上采样 skip connection
降采样的理论意义:增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。

paper: http://www.arxiv.org/pdf/1505.04597.pdf
UNet++ 2017
就像Densnet 对Resnet的改进一样,Unet++ 通过将Unet中长连接拆成 短连接和长连接的组合,提升了效果
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
paper: http://www.http://arxiv.org/abs/1807.10165
Zongwei Zhou | 周纵苇

Github:https://github.com/MrGiovanni/Nested-UNet
Dilated Convolutions
DeepLab (v1 & v2)
http://liangchiehchen.com/projects/DeepLab.html RefineNet
ParseNet PSPNet
Large Kernel Matters
DeepLab v3
https://github.com/facebookresearch/deepmask
MS R-CNN对Mask R-CNN进行了修正,在结构中添加了Mask-IoU。Mask R-CNN的评价函数只对目标检测的候选框进行打分,而不是分割模板打分,所以会出现分割模板效果很差但是打分很高的情况。所以增加了对模板进行打分的Mask-IoU Head


参考Mohammad KHalooei的教程,我也将GAN分为4个level,第四个level将按照应用层面进行拓展。 这里先列出0,1,2,具体可以参见 GAN 对抗生成网络发展总览
| Level | Title | Co-authors | Publication | Links |
|---|---|---|---|---|
| Beginner | GAN : Generative Adversarial Nets | Goodfellow & et al. | NeurIPS (NIPS) 2014 | link |
| Beginner | GAN : Generative Adversarial Nets (Tutorial) | Goodfellow & et al. | NeurIPS (NIPS) 2016 Tutorial | link |
| Beginner | CGAN : Conditional Generative Adversarial Nets | Mirza & et al. | -- 2014 | link |
| Beginner | InfoGAN : Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets | Chen & et al. | NeuroIPS (NIPS) 2016 |
模型结构的发展:

[1411.1784]Mirza M, Osindero S,Conditional Generative Adversarial Nets pdf
通过GAN可以生成想要的样本,以MNIST手写数字集为例,可以任意生成0-9的数字。
但是如果我们想指定生成的样本呢?譬如指定生成1,或者2,就可以通过指定C condition来完成。
条件BN首先出现在文章 Modulating early visual processing by language 中,后来又先后被用在 cGANs With Projection Discriminator 中,目前已经成为了做条件 GAN(cGAN)的标准方案,包括 SAGAN、BigGAN 都用到了它。
https://github.com/znxlwm/tensorflow-MNIST-cGAN-cDCGAN

应用方向 数字生成, 图像自动标注等
Emily Denton & Soumith Chintala, arxiv: 1506.05751
是第一篇将层次化或者迭代生成的思想运用到 GAN 中的工作。在原始 GAN和后来的 CGAN中,GAN 还只能生成32X32 这种低像素小尺寸的图片。而这篇工作[16] 是首次成功实现 64X64 的图像生成。思想就是,与其一下子生成这么大的(包含信息量这么多),不如一步步由小转大,这样每一步生成的时候,可以基于上一步的结果,而且还只需要“填充”和“补全”新大小所需要的那些信息。这样信息量就会少很多,而为了进一步减少信息量,他们甚至让 G 每次只生成“残差”图片,生成后的插值图片与上一步放大后的图片做加法,就得到了这一步生成的图片。
Invertible Conditional GANs for image editing
通常GAN的生成网络输入为一个噪声向量z,IcGAN是对cGAN的z的解释。
利用一个encoder网络,对输入图像提取得到一个特征向量z,将特征向量z,以及需要转换的目标attribute向量y串联输入生成网络,得到生成图像,网络结构如下,

https://arxiv.org/pdf/1611.06355.pdf https://github.com/Guim3/IcGAN
为了提供更多的辅助信息并允许半监督学习,可以向判别器添加额外的辅助分类器,以便在原始任务以及附加任务上优化模型。
和CGAN不同的是,C不直接输入D。D不仅需要判断每个样本的真假,还需要完成一个分类任务即预测C
添加辅助分类器允许我们使用预先训练的模型(例如,在ImageNet上训练的图像分类器),并且在ACGAN中的实验证明这种方法可以帮助生成更清晰的图像以及减轻模式崩溃问题。 使用辅助分类器还可以应用在文本到图像合成和图像到图像的转换。

Salimans, Tim, et al. “Improved techniques for training gans.” Advances in Neural Information Processing Systems. 2016.

Theano+Lasagne https://github.com/openai/improved-gan
tf: https://github.com/gitlimlab/SSGAN-Tensorflow
https://blog.csdn.net/shenxiaolu1984/article/details/75736407
InfoGAN - Xi Chen, arxiv: 1606.03657
提出了latent code。
单一的噪声z,使得人们无法通过控制z的某些维度来控制生成数据的语义特征,也就是说,z是不可解释的。
以MNIST手写数字集为例,每个数字可以分解成多个维度特征:数字的类别、倾斜度、粗细度等等,在标准GAN的框架下,是无法在维度上具体指定生成什么样的数字。但是Info Gan 通过latent code的设定成功让网络学习到了可解释的特征表示(interpretable representation)
把原来的噪声z分解成两部分:一是原来的z;二是由若干个latent variables拼接而成的latent code c,这些latent variables会有一个先验的概率分布,且可以是离散的或连续的,用于代表生成数据的不同特征维度,如数字类别(离散),倾斜度(连续),粗细度(连续)等。通过找到对信息影响最大的c,来得到数据中最重要的特征。
InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets,NIPS 2016。

https://arxiv.org/abs/1606.03657
https://github.com/openai/InfoGAN
然后看看 loss、参数、权重的改进:
| Level | Title | Co-authors | Publication | Links |
|---|---|---|---|---|
| Beginner | LSGAN : Least Squares Generative Adversarial Networks | Mao & et al. | ICCV 2017 | link |
| Advanced | Improved Techniques for Training GANs | Salimans & et al. | NeurIPS (NIPS) 2016 | link |
| Advanced | WGAN : Wasserstein GAN | Arjovsky & et al. | ICML 2017 | link |
| Advanced | WGAN-GP : improved Training of Wasserstein GANs | 2017 | link | |
| Advanced | Certifying Some Distributional Robustness with Principled Adversarial Training | Sinha & et al. | ICML 2018 | link code |
Loss Functions:
LS-GAN - Guo-Jun Qi, arxiv: 1701.06264
[2] Mao et al., 2017.4 pdf
https://github.com/hwalsuklee/tensorflow-generative-model-collections https://github.com/guojunq/lsgan
用了最小二乘损失函数代替了GAN的损失函数,缓解了GAN训练不稳定和生成图像质量差多样性不足的问题。
但缺点也是明显的, LSGAN对离离群点的过度惩罚, 可能导致样本生成的'多样性'降低, 生成样本很可能只是对真实样本的简单模仿和细微改动.
WGAN - Martin Arjovsky, arXiv:1701.07875v1
WGAN: 在初期一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
为啥难训练? 令人拍案叫绝的Wasserstein GAN 中做了如下解释 : 原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
https://zhuanlan.zhihu.com/p/25071913
WGAN 针对loss改进 只改了4点: 1.判别器最后一层去掉sigmoid 2.生成器和判别器的loss不取log 3.每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c 4.不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
https://github.com/martinarjovsky/WassersteinGAN
Regularization and Normalization of the Discriminator:

WGAN-GP:
WGAN的作者Martin Arjovsky不久后就在reddit上表示他也意识到没能完全解决GAN训练稳定性,认为关键在于原设计中Lipschitz限制的施加方式不对,并在新论文中提出了相应的改进方案--WGAN-GP ,从weight clipping到gradient penalty,提出具有梯度惩罚的WGAN(WGAN with gradient penalty)替代WGAN判别器中权重剪枝的方法(Lipschitz限制):
[1704.00028] Gulrajani et al., 2017,improved Training of Wasserstein GANspdf
Tensorflow实现:https://github.com/igul222/improved_wgan_training
pytorch https://github.com/caogang/wgan-gp
GAN的实现
| Title | Co-authors | Publication | Links | size | FID/IS |
|---|---|---|---|---|---|
| Keras Implementation of GANs | Linder-Norén | Github | link | ||
| GAN implementation hacks | Salimans paper & Chintala | World research | link paper | ||
| DCGAN : Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks | Radford & et al. | ICLR 2016 | link paper | 64x64 human | |
| ProGAN:Progressive Growing of GANs for Improved Quality, Stability, and Variation | Tero Karras | 2017 | paper link | 1024x1024 human | 8.04 |
| SAGAN:Self-Attention Generative Adversarial Networks | Han Zhang & Ian Goodfellow | 2018.05 | paper link | 128x128 obj | 18.65/52.52 |
| BigGAN:Large Scale GAN Training for High Fidelity Natural Image Synthesis | Brock et al. | ICLR 2019 | demo paper link | 512x512 obj | 9.6/166.3 |
| StyleGAN:A Style-Based Generator Architecture for Generative Adversarial Networks | Tero Karras | 2018 | paper link | 1024x1024 human | 4.04 |
指标:
1 Inception Score (IS,越大越好) IS用来衡量GAN网络的两个指标:1. 生成图片的质量 和2. 多样性
2 Fréchet Inception Distance (FID,越小越好) 在FID中我们用相同的inception network来提取中间层的特征。然后我们使用一个均值为 μμ 方差为 ΣΣ 的正态分布去模拟这些特征的分布。较低的FID意味着较高图片的质量和多样性。FID对模型坍塌更加敏感。
FID和IS都是基于特征提取,也就是依赖于某些特征的出现或者不出现。但是他们都无法描述这些特征的空间关系。
物体的数据在Imagenet数据库上比较,人脸的 progan 和stylegan 在CelebA-HQ和FFHQ上比较。上表列的为FFHQ指标。
具体可以参见 GAN 对抗生成网络发展总览
人脸数据库 详解 detail
目前人脸识别领域常用的人脸数据库主要有:
-
WebFaces,Caltech, 10k+人,约500K张图片,非限制场景, http://www.vision.caltech.edu/Image_Datasets/Caltech_10K_WebFaces/#Download
-
CelebA,Multimedia Laboratory The Chinese University of Hong Kong 汤晓鸥,10K 名人,202K 脸部图像,每个图像40余标注属性 http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html 该数据集为香港中文大学汤晓鸥老师组开源的数据集,主要包含了5个关键点,40个属性值等,包含了202599张图片,图片都是高清的名人图片,可以用于人脸检测,5点训练,人脸头部姿势的训练等。
-
MSRA-CFW,MSRA,202792 张, 1583人 Data Set of Celebrity Faces on the Web http://research.microsoft.com/en-us/projects/msra-cfw/CASIA
-
CASIA-WebFace,李子青 Center for Biometrics and Security Research, 500k图片,10k个人 http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html 该数据集为中科院自动化所,李子青老师组开源的数据集,包含了10575个人,一共494414张图片,其中有3个人和lfw中的一样。该数据集主要用于人脸识别。图像都是著名电影中crop而出的,每个图片的大小都是250×250,每个类下面都有3张以上的图片,非常适合做人脸识别的训练。需要邮箱申请
-
MegaFace,华盛顿大学百万人脸MegaFace数据集 MegaFace资料集包含一百万张图片,代表690000个独特的人。所有数据都是华盛顿大学从Flickr(雅虎旗下图片分享网站)组织收集的。这是第一个在一百万规模级别的面部识别算法测试基准。 现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在去年年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。需要邮箱申请才可以下载,下载链接为http://megaface.cs.washington.edu/dataset/download.html
-
IMDB-WIKI 20k+个名人的460k+张图片 和维基百科62k+张图片, 总共: 523k+张图片,名人年龄、性别 https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
-
CACD2000 2k名人160k张人脸图片 http://bcsiriuschen.github.io/CARC/
-
AFLW(Annotated Facial Landmarks in the Wild)
AFLW人脸数据库是一个包括多姿态、多视角的大规模人脸数据库,而且每个人脸都被标注了21个特征点。此数据库信息量非常大,包括了各种姿态、表情、光照、种族等因素影响的图片。AFLW人脸数据库大约包括25000万已手工标注的人脸图片,其中59%为女性,41%为男性,大部分的图片都是彩色,只有少部分是灰色图片。该数据库非常适合用于人脸识别、人脸检测、人脸对齐等方面的研究,具有很高的研究价值。图像如下图所示,需要申请帐号才可以下载,下载链接为http://lrs.icg.tugraz.at/research/aflw/
-
WIDER FACE WIDER FACE是香港中文大学的一个提供更广泛人脸数据的人脸检测基准数据集,由YangShuo, Luo Ping ,Loy ,Chen Change ,Tang Xiaoou收集。它包含32203个图像和393703个人脸图像,在尺度,姿势,闭塞,表达,装扮,关照等方面表现出了大的变化。WIDER FACE是基于61个事件类别组织的,对于每一个事件类别,选取其中的40%作为训练集,10%用于交叉验证(cross validation),50%作为测试集。和PASCAL VOC数据集一样,该数据集也采用相同的指标。和MALF和Caltech数据集一样,对于测试图像并没有提供相应的背景边界框。图像如下图所示,下载链接为http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/
-
300W
300W数据集是由AFLW,AFW,Helen,IBUG,LFPW,LFW等数据集组成的数据库。需要邮箱申请才可以下载,下载链接为http://ibug.doc.ic.ac.uk/resources/300-W/
-
VGG Face dataset 该数据集包含了2622个不同的人,每个人包含1000张图片,是一个训练人脸识别的大的数据集,官网提供了每个图片的URL,需要自己解析下载,当然有些链接是需要翻墙的。下载链接:http://www.robots.ox.ac.uk/~vgg/data/vgg_face/
如果想做出贡献的话,你可以:
帮忙对没有收录的paper进行模型绘制
帮忙进行模型校对等
提出修改建议
进度:
2018/05/30 目前object classification 主干部分基本完成 包括 LeNet, AlexNet, GoogLeNet, Inception V3,Inception-Resnet-V2, VGG, ResNet ,ResNext, DenseNet ,DPN等。
2018/06/15 完成 MobileNet 与 MobileNet V2.
2018/07/04 完成FaceNet系列,修正地图上facenet loss部分,将二维距离(center loss) 到 球面角度距离SphereFace之后的发展 区分开
2018/08/10 图上加入MnasNet ,人脸部分加入 mobilefacenet mobileID
2018/09/04 修正3D人脸部分,整理16 17年的部分知名开源成果 将加入密集人脸对齐部分的算法 和 之前的cnn获取3dmm参数算法分开 。18年开始 主要研究在gan对侧脸部分的正脸生成,暂未整理 可看后续发展。
2019/06/30 完成GAN基本路线
其他: Face : mtcnn
OCR : CRNN CTPN Textboxes Textboxes++
Object Detection:ssd
一树一获者,谷也;一树十获者,木也;一树百获者;人也。 希望我们每一个人的努力,能够建立一片森林,为后人投下一片树荫。
每一位加入的作者,都可以选取植物的名称来表示自己,然后logo和名字将会作为自己的署名。
我希望,这终将成为一片森林。
此外,关于深度学习系统中模型结构要怎样设计,特定的任务要不要加入特定的结构和方法,Yann LeCun 和 Christopher Manning 有一个讨论 ,大家可以看一看 https://youtu.be/fKk9KhGRBdI 雷锋网有介绍 https://www.leiphone.com/news/201804/6l2mAsZQCQG2qYbi.html