- Shows how to install auto-sklearn on an Azure Databricks cluster
- https://automl.github.io/auto-sklearn/stable/
- You can use an existing Databricks workspace, but make sure you do not have lots of Libraries attached to your cluster. It is usually best to test this in a clean workspace. You can click on a cluster and click on Libraries to see what is attached. To clean up lots of libraries on your cluster see the bottom of this page.
- https://docs.databricks.com/user-guide/dev-tools/databricks-cli.html
- I perfer using the CLI since you do not need a cluster running to upload init scripts. You can create init scripts with a notebook, but sometimes this apporach creates a malformed file.
- You do not need a cluster running, start a command prompt
databricks configure --token {PLACE YOUR TOKEN HERE}
dbfs mkdirs dbfs:/databricks/init/{clusterName-case-sensitive}
dbfs cp autosklearn.sh dbfs:/databricks/init/{clusterName-case-sensitive}/autosklearn.sh
dbfs ls dbfs:/databricks/init/{clusterName-case-sensitive}/
- Must match the name that you just uploaded the script {clusterName-case-sensitive}
- Select Python version 3
- Start the cluster
- The init script will run when the cluster starts. The cluster will take longer to provision since all the auto-sklearn dependencies will be installed.
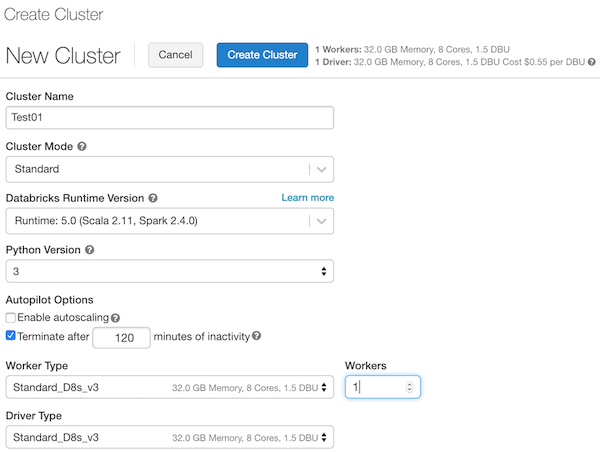
- Once the cluster has started
- Go to your workspace and add the library
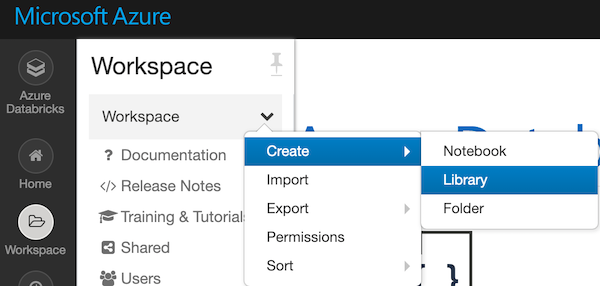
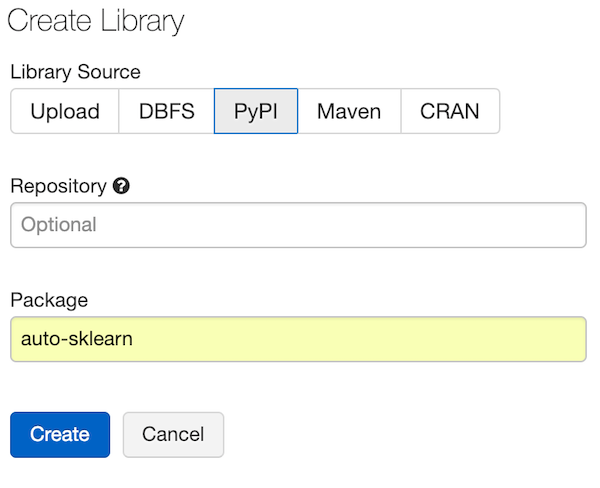
- Create a notebook (Python)
- In the first cell
import sklearn.model_selection import sklearn.datasets import sklearn.metrics import autosklearn.regression - In the second cell
X, y = sklearn.datasets.load_boston(return_X_y=True) feature_types = (['numerical'] * 3) + ['categorical'] + (['numerical'] * 9) X_train, X_test, y_train, y_test = \ sklearn.model_selection.train_test_split(X, y, random_state=1) - In the thrid cell
automl = autosklearn.regression.AutoSklearnRegressor( time_left_for_this_task=120, per_run_time_limit=30, tmp_folder='autosklearn_regression_example_tmp', output_folder='autosklearn_regression_example_out', ) automl.fit(X_train, y_train, dataset_name='boston', feat_type=feature_types)
-
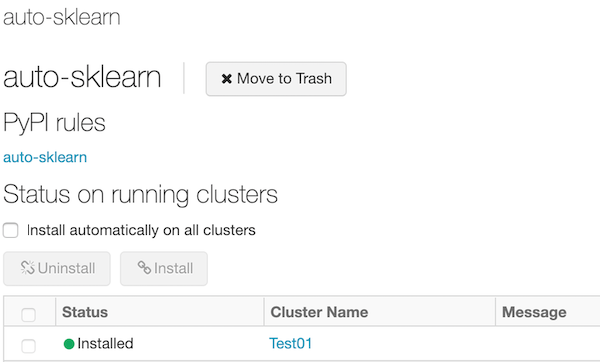
To cleanly install a Library
- If you install a Databricks Library the defualt says "Install automatically on all clusters". This can cause issues like slow startup times and libraries failing to install properly due to conflicts. You should only install libraries on the clusters that you need them.
- To cleanly install a library, start a cluster, then install the library and check-off the cluster. Do not use the "Install automatically on all clusters"
-
To clean up libraries
- Go to each Cluster
- Click on Libraries tab
- Check to see if you can uninstall the library (you would check-off the library then click Unistall)
- What if you cannot uninstall
- Go to the library
- If the library is missing (removed), you just need to add again and do not check "Install automatically on all clusters"
- Uncheck "Install automatically on all clusters"
- Go to the library
- Then go to EACH cluster and click on Libraries tab, select (checkbox) the library and click Uninstall
- If you no longer need the library then you can move to the trash