학습 성능
- 사용된 데이터셋 수 (Train, Validation, Test)
- 전체 클래스 분포
- 적용된 하이퍼파라미터
- epochs, learning rate, confidence, batch size, input size 등
- Validation 결과
| 전체 이미지 | OK 이미지 | NG 이미지 |
|---|---|---|
| 5243 | 4944 | 299 |
| 결함 유형 | 이미지 |
|---|---|
| 기포 |  |
| 모서리 결함 |  |
| 절단면 | |
| 잔재 |  |
| 패임 |  |
| 라인 |  |
| 이물질 |  |
| 결함 유형 | 이미지 |
|---|---|
| inner defect |  |
| outer defect |  |
| 단계 | 이미지 |
|---|---|
| 색공간 |  |
| 대비 조정 |   |
| 임계값 설정 및 컨투어 추출 |    |
- 2 class (inner defect, outer defect) 640sz, 1389sz
- 7 class (bubble, chip, cut, debris, dent, line, spot) 640sz, 1389sz
- 7 class (bubble, chip, cut, debris, dent, line, spot) 640sz 하단 두 세트는 기포 라벨링 방식에 차이를 둠.
Latency T4 TensorRT10 FP16 (ms/img): T4 GPU에서 TensorRT 10 및 FP16 최적화를 적용한 모델이 한 이미지를 처리하는 데 평균적으로 걸리는 ms를 의미합니다.
T4 TensorRT10은 NVIDIA Tesla T4 GPU를 사용한 딥러닝 추론 최적화 환경입니다.
Tesla T4 GPU를 사용하는 AWS EC2 인스턴스는 g4dn 시리즈 인스턴스입니다.
제한된 데이터셋 규모와 실시간 추론의 필요성을 고려할 때, 모델의 계산 효율성과 성능 간 최적의 균형점을 찾는 것이 핵심 과제였습니다. 큰 모델은 작은 데이터셋에서 오히려 과적합 위험이 높고 일반화 성능이 떨어질 수 있어, 이러한 요구사항에 가장 적합한 모델로 YOLOv11s를 채택하였습니다. 이 모델은 경량 아키텍처를 통해 빠른 처리 속도와 제한된 데이터 환경에서도 안정적인 성능을 동시에 제공합니다.
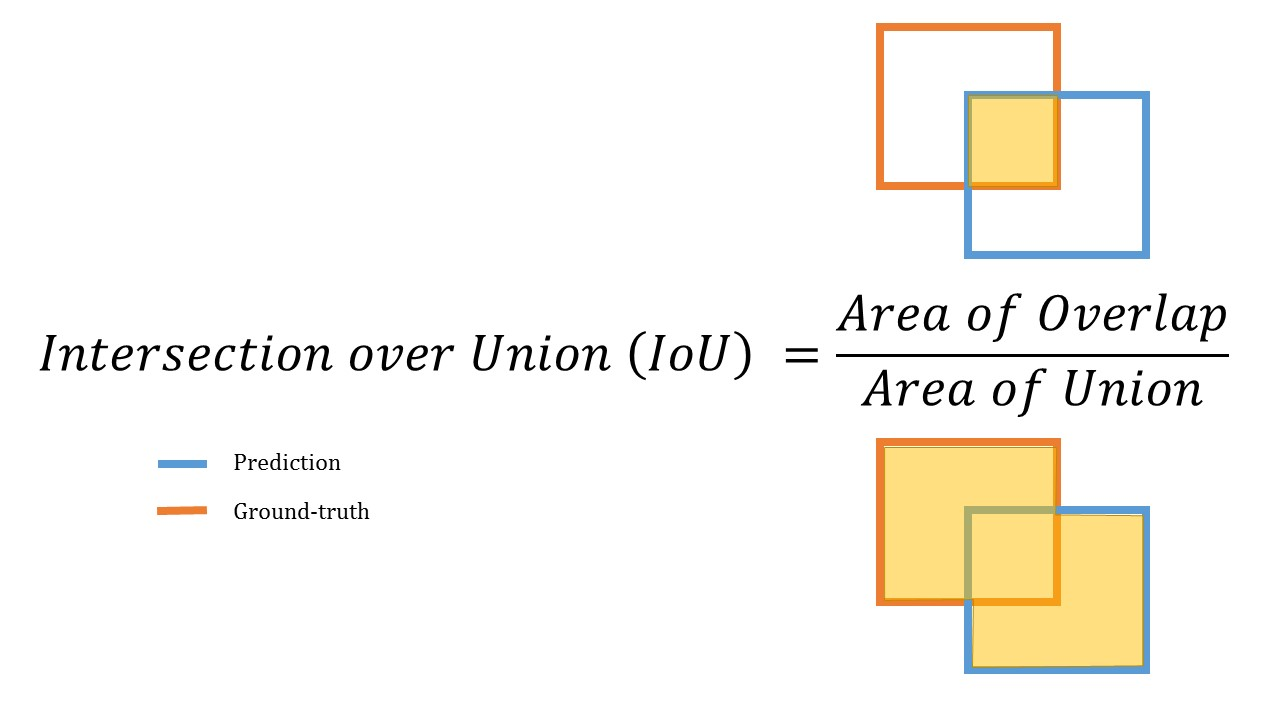
IoU(Intersection over Union) : 두 영역의 겹치는 영역을 두 영역의 합으로 나눈 값
Recall(재현율) : 실제 정답값 True 중 True라고 예측한 비율

Precision(정밀도) : True라고 예측한 것 중 실제 True인 비율

P-R Curve(Precision-Recall Curve) : Recall과 Precision을 x축과 y축으로 하여 분류기의 양성 클래스 성능을 분석하는 시각화 도구입니다. TP, FP, FN 메트릭을 기반으로 계산되며, 임계값 변화에 따른 두 지표의 트레이드오프 관계를 보여줍니다. TN에 의존하지 않아 불균형 데이터셋 평가에 적합하며, 곡선이 왼쪽 위 모서리(1,1)에 가까울수록 우수한 성능을 의미합니다. 곡선 아래 면적(AUC)으로 전반적 성능을 단일 값으로 평가할 수 있어 정확도보다 신뢰성 있는 평가가 가능합니다.
AP(Average Precision) : Precision-Recall Curve 아래 면적을 계산하여 모델의 전반적인 성능을 0에서 1 사이의 단일 값으로 요약하는 지표
mAP(mean Average Precision) : AP를 계산한 후 그 평균을 내는 것으로, 모델이 얼마나 다양한 클래스를 정확하게 탐지하는지를 종합적으로 보여주는 지표
NMS(Non-Maximum Suppression) : 객체 탐지(Object Detection) 알고리즘에서 중복된 경계 상자(Bounding Box)를 제거하고 가장 적합한 경계 상자를 선택하는 후처리 기법
주요 작동 원리:
- 모든 경계 상자를 confidence score 기준으로 정렬합니다.
- 가장 높은 confidence score를 가진 상자를 선택합니다.
- 선택된 상자와 IoU(Intersection over Union)가 특정 임계값 이상인 다른 상자들을 제거합니다.
- 남은 상자들 중 다음으로 높은 confidence score를 가진 상자를 선택하고 과정을 반복합니다.
mAP는 재현율(Recall)과 정밀도(Precision)의 균형을 종합적으로 평가하는 지표입니다. 단순히 한 가지 메트릭에 의존하지 않고, 모델이 얼마나 정확하게(Precision) 그리고 얼마나 빠짐없이(Recall) 객체를 탐지하는지를 동시에 고려합니다. 이를 통해 모델의 성능을 보다 균형 잡히고 신뢰성 있게 측정할 수 있어, 이 지표를 선택하였습니다.
mAP@50: IoU 0.5 이상일 때의 정확도
mAP@75: IoU 0.75 이상일 때의 정확도
mAP@50:95: IoU 0.5에서 0.95까지 0.05 단위로 평균낸 정확도
mAP@50와 mAP@50:95를 최우선으로 고려했습니다. 결함의 정확한 위치보다 존재 여부가 더 중요하기 때문입니다.
YOLO의 자동 최적화 모드를 사용해서 데이터셋과 모델 구조에 최적화된 옵티마이저를 선택하도록 하였습니다. 이를 통해 학습률, momentum, 레이어별 weight decay를 자동으로 결정되게 하여 수동 설정 대비 더욱 안정적인 학습이 진행되도록 하였습니다.
| 2class yolov11s 50epoch img1389 | 2class yolov11s 50epoch img640 |
|---|---|
 |
 |
640으로 정규화된 이미지로 학습한 결과가 원본 이미지로 학습한 것보다 높은 mAP 값을 갖는 것을 확인하였습니다.
| 2class yolov11s 50epoch | 7class yolov11s 50epoch |
|---|---|
 |
 |
7class로 분류된 라벨로 학습한 결과가 2class로 분류된 라벨로 학습한 것보다 높은 mAP 값을 갖는 것을 확인하였습니다.
| Overall distribution labeling | Individual bubble labeling |
|---|---|
|
 |
각각의 기포에 대한 어노테이션으로 학습한 결과가 전반적인 기포에 대한 어노테이션을 학습한 것보다 높은 mAP 값을 갖는 것을 확인하였습니다.

| original_map_results | CLAHE2.0_map_results | CLAHE4.0_map_results |
|---|---|---|
 |
 |
 |
| PR_curve_original | PR_curve_CLAHE2.0 | PR_curve_CLAHE4.0 |
|---|---|---|
 |
 |
 |
분석 결과, CLAHE 2.0과 4.0은 mAP@50에서 각각 0.65, 0.61로 original의 0.60보다 약간 높은 성능을 보였으나, 클래스별 성능의 표준편차(original: 0.284, CLAHE 2.0: 0.292, CLAHE 4.0: 0.293)를 고려할 때 original이 더 균형 잡힌 성능을 보여주었습니다. CLAHE의 대비 강조는 일부 클래스에서는 성능을 향상시키지만 다른 클래스에서는 노이즈로 인한 성능 저하를 초래하기에, 학습에 대비 조정을 하지 않은 original 이미지를 사용하기로 결정했습니다.
성능 균형 분석:
Original: 표준편차 0.284 (가장 낮음)
CLAHE2.0: 표준편차 0.292
CLAHE4.0: 표준편차 0.293 (가장 높음)
7개 클래스에 대한 개별 기포 라벨링과 640 크기의 이미지를 사용한 실험에서는 최적의 파라미터를 찾기 위해 batch size(8, 16, 32)와 epochs(40, 50, 60, 70, 80)를 다양하게 조정하여 총 15가지 조건에서 실험을 수행했습니다. 각 조건별로 mAP(mean Average Precision) 값을 측정하여 모델의 성능을 평가했으며, 이를 통해 결함 검출에 가장 효과적인 학습 파라미터 조합을 도출했습니다.
실험 결과, batch size 32와 epoch 40에서 가장 우수한 성능을 보였습니다.
이 조합에서 mAP@50은 0.74, mAP@75는 0.17, mAP@50:95는 0.35를 기록했습니다. 특히 더 큰 batch size(32)가 일관되게 더 나은 성능을 보였으며, 더 많은 epoch 수가 반드시 성능 향상으로 이어지지는 않았습니다. 결함 탐지에서 중요한 지표인 mAP@50이 최고값을 기록했고, 전체 범위 평균인 mAP@50:95도 가장 높아 안정적인 성능을 보장하는 것으로 판단했습니다.
| Batch Size \ Epoch | 40 | 50 | 60 | 70 | 80 |
|---|---|---|---|---|---|
| 8 |  |
 |
 |
 |
 |
| 16 |  |
 |
 |
 |
 |
| 32 |  |
 |
 |
 |
|
