diff --git a/week2_model_based/practice_vi.ipynb b/week2_model_based/practice_vi.ipynb
index e510370ba..973579327 100644
--- a/week2_model_based/practice_vi.ipynb
+++ b/week2_model_based/practice_vi.ipynb
@@ -1 +1,909 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_vi.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"dDQKDe_d4TAR"},"source":["### Markov decision process\n","\n","This week methods are all built to solve __M__arkov __D__ecision __P__rocesses. In the broadest sense, the MDP is defined by how it changes the states and how rewards are computed.\n","\n","State transition is defined by $P(s' |s,a)$ - how likely you are to end at the state $s'$ if you take an action $a$ from the state $s$. Now there's more than one way to define rewards, but for convenience we'll use $r(s,a,s')$ function.\n","\n","_This notebook is inspired by the awesome_ [CS294](https://github.com/berkeleydeeprlcourse/homework/blob/36a0b58261acde756abd55306fbe63df226bf62b/hw2/HW2.ipynb) _by Berkeley_"]},{"cell_type":"markdown","metadata":{"id":"G793b49v4TAa"},"source":["For starters, let's define a simple MDP from this picture:\n","\n",""]},{"cell_type":"code","metadata":{"id":"JokMVpgS4TAb"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/submit.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/mdp.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Q7psltI74TAc"},"source":["transition_probs = {\n"," 's0': {\n"," 'a0': {'s0': 0.5, 's2': 0.5},\n"," 'a1': {'s2': 1}\n"," },\n"," 's1': {\n"," 'a0': {'s0': 0.7, 's1': 0.1, 's2': 0.2},\n"," 'a1': {'s1': 0.95, 's2': 0.05}\n"," },\n"," 's2': {\n"," 'a0': {'s0': 0.4, 's2': 0.6},\n"," 'a1': {'s0': 0.3, 's1': 0.3, 's2': 0.4}\n"," }\n","}\n","rewards = {\n"," 's1': {'a0': {'s0': +5}},\n"," 's2': {'a1': {'s0': -1}}\n","}\n","\n","from mdp import MDP\n","mdp = MDP(transition_probs, rewards, initial_state='s0')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"aptlOq3-4TAc"},"source":["We can now use the MDP just as any other gym environment:"]},{"cell_type":"code","metadata":{"id":"1P4Z0nyM4TAd","outputId":"adcd0062-07be-4233-ae0d-0bd5a3e3e3d0"},"source":["print('initial state =', mdp.reset())\n","next_state, reward, done, info = mdp.step('a1')\n","print('next_state = %s, reward = %s, done = %s' % (next_state, reward, done))"],"execution_count":null,"outputs":[{"output_type":"stream","text":["initial state = s0\n","next_state = s2, reward = 0.0, done = False\n"],"name":"stdout"}]},{"cell_type":"markdown","metadata":{"id":"LGRFfXCx4TAj"},"source":["but it also has other methods that you'll need for Value Iteration:"]},{"cell_type":"code","metadata":{"id":"m7HkluEM4TAj","outputId":"834673c1-4e15-4203-9332-d485169af928"},"source":["print(\"mdp.get_all_states =\", mdp.get_all_states())\n","print(\"mdp.get_possible_actions('s1') = \", mdp.get_possible_actions('s1'))\n","print(\"mdp.get_next_states('s1', 'a0') = \", mdp.get_next_states('s1', 'a0'))\n","print(\"mdp.get_reward('s1', 'a0', 's0') = \", mdp.get_reward('s1', 'a0', 's0'))\n","print(\"mdp.get_transition_prob('s1', 'a0', 's0') = \", mdp.get_transition_prob('s1', 'a0', 's0'))"],"execution_count":null,"outputs":[{"output_type":"stream","text":["mdp.get_all_states = ('s0', 's1', 's2')\n","mdp.get_possible_actions('s1') = ('a0', 'a1')\n","mdp.get_next_states('s1', 'a0') = {'s0': 0.7, 's1': 0.1, 's2': 0.2}\n","mdp.get_reward('s1', 'a0', 's0') = 5\n","mdp.get_transition_prob('s1', 'a0', 's0') = 0.7\n"],"name":"stdout"}]},{"cell_type":"markdown","metadata":{"id":"_5b-S1za4TAk"},"source":["### Optional: Visualizing MDPs\n","\n","You can also visualize any MDP with the drawing fuction donated by [neer201](https://github.com/neer201).\n","\n","You have to install graphviz for system and for python. \n","\n","1. * For ubuntu just run: `sudo apt-get install graphviz` \n"," * For OSX: `brew install graphviz`\n","2. `pip install graphviz`\n","3. restart the notebook\n","\n","__Note:__ Installing graphviz on some OS (esp. Windows) may be tricky. However, you can ignore this part alltogether and use the standart vizualization."]},{"cell_type":"code","metadata":{"id":"e8cTCCsw4TAl","outputId":"f64e32db-5e61-40b2-b6d2-0ac66ed70a91"},"source":["from mdp import has_graphviz\n","from IPython.display import display\n","print(\"Graphviz available:\", has_graphviz)"],"execution_count":null,"outputs":[{"output_type":"stream","text":["Graphviz available: True\n"],"name":"stdout"}]},{"cell_type":"code","metadata":{"id":"u6eXD2VV4TAn","outputId":"b51aaf24-875c-483e-bf12-fdd03290c716"},"source":["if has_graphviz:\n"," from mdp import plot_graph, plot_graph_with_state_values, plot_graph_optimal_strategy_and_state_values\n"," display(plot_graph(mdp))"],"execution_count":null,"outputs":[{"output_type":"display_data","data":{"image/svg+xml":"\n\n\n\n\n","text/plain":[""]},"metadata":{"tags":[]}}]},{"cell_type":"markdown","metadata":{"id":"rjmj8HqP4TAp"},"source":["### Value Iteration\n","\n","Now let's build something to solve this MDP. The simplest algorithm so far is __V__alue __I__teration\n","\n","Here's the pseudo-code for VI:\n","\n","---\n","\n","`1.` Initialize $V^{(0)}(s)=0$, for all $s$\n","\n","`2.` For $i=0, 1, 2, \\dots$\n"," \n","`3.` $ \\quad V_{(i+1)}(s) = \\max_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')]$, for all $s$\n","\n","---"]},{"cell_type":"markdown","metadata":{"id":"wjdZyDdo4TAs"},"source":["First, let's write a function to compute the state-action value function $Q^{\\pi}$, defined as follows:\n","\n","$$Q_i(s, a) = \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')].$$\n"]},{"cell_type":"code","metadata":{"id":"2Nol2GMV4TAu"},"source":["def get_action_value(mdp, state_values, state, action, gamma):\n"," \"\"\" Computes Q(s,a) according to the formula above \"\"\"\n","\n"," \n","\n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"fpSRbBKd4TAu"},"source":["import numpy as np\n","test_Vs = {s: i for i, s in enumerate(sorted(mdp.get_all_states()))}\n","assert np.isclose(get_action_value(mdp, test_Vs, 's2', 'a1', 0.9), 0.69)\n","assert np.isclose(get_action_value(mdp, test_Vs, 's1', 'a0', 0.9), 3.95)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"qlU2gcRJ4TAw"},"source":["Using $Q(s,a)$ we now can define the \"next\" V(s) for value iteration.\n"," $$V_{(i+1)}(s) = \\max_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')] = \\max_a Q_i(s,a)$$"]},{"cell_type":"code","metadata":{"id":"2-N2MI_64TAx"},"source":["def get_new_state_value(mdp, state_values, state, gamma):\n"," \"\"\" Computes the next V(s) according to the formula above. Please do not change state_values in process. \"\"\"\n"," if mdp.is_terminal(state):\n"," return 0\n","\n"," \n"," \n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ltxcMRsf4TAx"},"source":["test_Vs_copy = dict(test_Vs)\n","assert np.isclose(get_new_state_value(mdp, test_Vs, 's0', 0.9), 1.8)\n","assert np.isclose(get_new_state_value(mdp, test_Vs, 's2', 0.9), 1.08)\n","assert np.isclose(get_new_state_value(mdp, {'s0': -1e10, 's1': 0, 's2': -2e10}, 's0', 0.9), -13500000000.0), \\\n"," \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\"\n","assert test_Vs == test_Vs_copy, \"Please do not change state_values in get_new_state_value\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"MOgbwGgX4TAy"},"source":["Finally, let's combine everything we wrote into a working value iteration algo."]},{"cell_type":"code","metadata":{"id":"2dc-cvDu4TAy"},"source":["# parameters\n","gamma = 0.9 # discount for the MDP\n","num_iter = 100 # maximum iterations, excluding initialization\n","# stop VI if new values are as close to old values (or closer)\n","min_difference = 0.001\n","\n","# initialize V(s)\n","state_values = {s: 0 for s in mdp.get_all_states()}\n","\n","if has_graphviz:\n"," display(plot_graph_with_state_values(mdp, state_values))\n","\n","for i in range(num_iter):\n","\n"," # Compute new state values using the functions you defined above.\n"," # It must be a dict {state : float V_new(state)}\n"," new_state_values = \n","\n"," assert isinstance(new_state_values, dict)\n","\n"," # Compute difference\n"," diff = max(abs(new_state_values[s] - state_values[s])\n"," for s in mdp.get_all_states())\n"," print(\"iter %4i | diff: %6.5f | \" % (i, diff), end=\"\")\n"," print(' '.join(\"V(%s) = %.3f\" % (s, v) for s, v in state_values.items()))\n"," state_values = new_state_values\n","\n"," if diff < min_difference:\n"," print(\"Terminated\")\n"," break"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"P3vdbCLH4TAy"},"source":["if has_graphviz:\n"," display(plot_graph_with_state_values(mdp, state_values))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"i5vAfode4TAz"},"source":["print(\"Final state values:\", state_values)\n","\n","assert abs(state_values['s0'] - 3.781) < 0.01\n","assert abs(state_values['s1'] - 7.294) < 0.01\n","assert abs(state_values['s2'] - 4.202) < 0.01"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"7igSDGQD4TAz"},"source":["Now let's use those $V^{*}(s)$ to find optimal actions in each state:\n","\n"," $$\\pi^*(s) = argmax_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')] = argmax_a Q_i(s,a).$$\n"," \n","The only difference vs V(s) is that here instead of max we take argmax: find the action that leads to the maximum of Q(s,a)."]},{"cell_type":"code","metadata":{"id":"DcXjiEqr4TAz"},"source":["def get_optimal_action(mdp, state_values, state, gamma=0.9):\n"," \"\"\" Finds optimal action using formula above. \"\"\"\n"," if mdp.is_terminal(state):\n"," return None\n","\n"," \n","\n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"VQp_e_V_4TAz"},"source":["assert get_optimal_action(mdp, state_values, 's0', gamma) == 'a1'\n","assert get_optimal_action(mdp, state_values, 's1', gamma) == 'a0'\n","assert get_optimal_action(mdp, state_values, 's2', gamma) == 'a1'\n","\n","assert get_optimal_action(mdp, {'s0': -1e10, 's1': 0, 's2': -2e10}, 's0', 0.9) == 'a0', \\\n"," \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\"\n","assert get_optimal_action(mdp, {'s0': -2e10, 's1': 0, 's2': -1e10}, 's0', 0.9) == 'a1', \\\n"," \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\""],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"-NiKxKkU4TA0"},"source":["if has_graphviz:\n"," display(plot_graph_optimal_strategy_and_state_values(mdp, state_values, get_action_value))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"DIaa_EG64TA1"},"source":["# Measure agent's average reward\n","\n","s = mdp.reset()\n","rewards = []\n","for _ in range(10000):\n"," s, r, done, _ = mdp.step(get_optimal_action(mdp, state_values, s, gamma))\n"," rewards.append(r)\n","\n","print(\"average reward: \", np.mean(rewards))\n","\n","assert(0.40 < np.mean(rewards) < 0.55)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"5r8aWg-M4TA2"},"source":["### Frozen lake"]},{"cell_type":"code","metadata":{"id":"lu4XMKab4TA2"},"source":["from mdp import FrozenLakeEnv\n","mdp = FrozenLakeEnv(slip_chance=0)\n","\n","mdp.render()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"xheVP-IK4TA2"},"source":["def value_iteration(mdp, state_values=None, gamma=0.9, num_iter=1000, min_difference=1e-5):\n"," \"\"\" performs num_iter value iteration steps starting from state_values. The same as before but in a function \"\"\"\n"," state_values = state_values or {s: 0 for s in mdp.get_all_states()}\n"," for i in range(num_iter):\n","\n"," # Compute new state values using the functions you defined above. It must be a dict {state : new_V(state)}\n"," new_state_values = \n","\n"," assert isinstance(new_state_values, dict)\n","\n"," # Compute the difference\n"," diff = max(abs(new_state_values[s] - state_values[s])\n"," for s in mdp.get_all_states())\n","\n"," print(\"iter %4i | diff: %6.5f | V(start): %.3f \" %\n"," (i, diff, new_state_values[mdp._initial_state]))\n","\n"," state_values = new_state_values\n"," if diff < min_difference:\n"," break\n","\n"," return state_values"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"YpUiTG0V4TA2"},"source":["state_values = value_iteration(mdp)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"e853Et3q4TA3"},"source":["s = mdp.reset()\n","mdp.render()\n","for t in range(100):\n"," a = get_optimal_action(mdp, state_values, s, gamma)\n"," print(a, end='\\n\\n')\n"," s, r, done, _ = mdp.step(a)\n"," mdp.render()\n"," if done:\n"," break"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"HK8PwJd54TA3"},"source":["### Let's visualize!\n","\n","It's usually interesting to see, what your algorithm actually learned under the hood. To do so, we'll plot the state value functions and optimal actions at each VI step."]},{"cell_type":"code","metadata":{"id":"PdHigU9R4TA3"},"source":["import matplotlib.pyplot as plt\n","%matplotlib inline\n","\n","\n","def draw_policy(mdp, state_values):\n"," plt.figure(figsize=(3, 3))\n"," h, w = mdp.desc.shape\n"," states = sorted(mdp.get_all_states())\n"," V = np.array([state_values[s] for s in states])\n"," Pi = {s: get_optimal_action(mdp, state_values, s, gamma) for s in states}\n"," plt.imshow(V.reshape(w, h), cmap='gray', interpolation='none', clim=(0, 1))\n"," ax = plt.gca()\n"," ax.set_xticks(np.arange(h)-.5)\n"," ax.set_yticks(np.arange(w)-.5)\n"," ax.set_xticklabels([])\n"," ax.set_yticklabels([])\n"," Y, X = np.mgrid[0:4, 0:4]\n"," a2uv = {'left': (-1, 0), 'down': (0, -1), 'right': (1, 0), 'up': (0, 1)}\n"," for y in range(h):\n"," for x in range(w):\n"," plt.text(x, y, str(mdp.desc[y, x].item()),\n"," color='g', size=12, verticalalignment='center',\n"," horizontalalignment='center', fontweight='bold')\n"," a = Pi[y, x]\n"," if a is None:\n"," continue\n"," u, v = a2uv[a]\n"," plt.arrow(x, y, u*.3, -v*.3, color='m',\n"," head_width=0.1, head_length=0.1)\n"," plt.grid(color='b', lw=2, ls='-')\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"j5plpt_64TA4"},"source":["state_values = {s: 0 for s in mdp.get_all_states()}\n","\n","for i in range(10):\n"," print(\"after iteration %i\" % i)\n"," state_values = value_iteration(mdp, state_values, num_iter=1)\n"," draw_policy(mdp, state_values)\n","# please ignore iter 0 at each step"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"rSIcOqdZ4TA4"},"source":["from IPython.display import clear_output\n","from time import sleep\n","mdp = FrozenLakeEnv(map_name='8x8', slip_chance=0.1)\n","state_values = {s: 0 for s in mdp.get_all_states()}\n","\n","for i in range(30):\n"," clear_output(True)\n"," print(\"after iteration %i\" % i)\n"," state_values = value_iteration(mdp, state_values, num_iter=1)\n"," draw_policy(mdp, state_values)\n"," sleep(0.5)\n","# please ignore iter 0 at each step"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"M5h0nvn14TA4"},"source":["Massive tests"]},{"cell_type":"code","metadata":{"id":"wmd8w9va4TA4"},"source":["mdp = FrozenLakeEnv(slip_chance=0)\n","state_values = value_iteration(mdp)\n","\n","total_rewards = []\n","for game_i in range(1000):\n"," s = mdp.reset()\n"," rewards = []\n"," for t in range(100):\n"," s, r, done, _ = mdp.step(\n"," get_optimal_action(mdp, state_values, s, gamma))\n"," rewards.append(r)\n"," if done:\n"," break\n"," total_rewards.append(np.sum(rewards))\n","\n","print(\"average reward: \", np.mean(total_rewards))\n","assert(1.0 <= np.mean(total_rewards) <= 1.0)\n","print(\"Well done!\")"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"UO53Ys_64TA5"},"source":["# Measure agent's average reward\n","mdp = FrozenLakeEnv(slip_chance=0.1)\n","state_values = value_iteration(mdp)\n","\n","total_rewards = []\n","for game_i in range(1000):\n"," s = mdp.reset()\n"," rewards = []\n"," for t in range(100):\n"," s, r, done, _ = mdp.step(\n"," get_optimal_action(mdp, state_values, s, gamma))\n"," rewards.append(r)\n"," if done:\n"," break\n"," total_rewards.append(np.sum(rewards))\n","\n","print(\"average reward: \", np.mean(total_rewards))\n","assert(0.8 <= np.mean(total_rewards) <= 0.95)\n","print(\"Well done!\")"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ZpN6kg2a4TA6"},"source":["# Measure agent's average reward\n","mdp = FrozenLakeEnv(slip_chance=0.25)\n","state_values = value_iteration(mdp)\n","\n","total_rewards = []\n","for game_i in range(1000):\n"," s = mdp.reset()\n"," rewards = []\n"," for t in range(100):\n"," s, r, done, _ = mdp.step(\n"," get_optimal_action(mdp, state_values, s, gamma))\n"," rewards.append(r)\n"," if done:\n"," break\n"," total_rewards.append(np.sum(rewards))\n","\n","print(\"average reward: \", np.mean(total_rewards))\n","assert(0.6 <= np.mean(total_rewards) <= 0.7)\n","print(\"Well done!\")"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"qgcjyhTR4TA6"},"source":["# Measure agent's average reward\n","mdp = FrozenLakeEnv(slip_chance=0.2, map_name='8x8')\n","state_values = value_iteration(mdp)\n","\n","total_rewards = []\n","for game_i in range(1000):\n"," s = mdp.reset()\n"," rewards = []\n"," for t in range(100):\n"," s, r, done, _ = mdp.step(\n"," get_optimal_action(mdp, state_values, s, gamma))\n"," rewards.append(r)\n"," if done:\n"," break\n"," total_rewards.append(np.sum(rewards))\n","\n","print(\"average reward: \", np.mean(total_rewards))\n","assert(0.6 <= np.mean(total_rewards) <= 0.8)\n","print(\"Well done!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"LnVRYtE64TA7"},"source":["### Submit to coursera\n","\n","If your submission doesn't finish in 30 seconds, set `verbose=True` and try again."]},{"cell_type":"code","metadata":{"id":"QW3Cft5w4TA7"},"source":["from submit import submit_assigment\n","submit_assigment(\n"," get_action_value,\n"," get_new_state_value,\n"," get_optimal_action,\n"," value_iteration,\n"," 'your.email@example.com',\n"," 'YourAssignmentToken',\n"," verbose=False,\n",")"],"execution_count":null,"outputs":[]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Markov decision process\n",
+ "\n",
+ "This week methods are all built to solve __M__arkov __D__ecision __P__rocesses. In the broadest sense, the MDP is defined by how it changes the states and how rewards are computed.\n",
+ "\n",
+ "State transition is defined by $P(s' |s,a)$ - how likely you are to end at the state $s'$ if you take an action $a$ from the state $s$. Now there's more than one way to define rewards, but for convenience we'll use $r(s,a,s')$ function.\n",
+ "\n",
+ "_This notebook is inspired by the awesome_ [CS294](https://github.com/berkeleydeeprlcourse/homework/blob/36a0b58261acde756abd55306fbe63df226bf62b/hw2/HW2.ipynb) _by Berkeley_"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For starters, let's define a simple MDP from this picture:\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/mdp.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transition_probs = {\n",
+ " 's0': {\n",
+ " 'a0': {'s0': 0.5, 's2': 0.5},\n",
+ " 'a1': {'s2': 1}\n",
+ " },\n",
+ " 's1': {\n",
+ " 'a0': {'s0': 0.7, 's1': 0.1, 's2': 0.2},\n",
+ " 'a1': {'s1': 0.95, 's2': 0.05}\n",
+ " },\n",
+ " 's2': {\n",
+ " 'a0': {'s0': 0.4, 's2': 0.6},\n",
+ " 'a1': {'s0': 0.3, 's1': 0.3, 's2': 0.4}\n",
+ " }\n",
+ "}\n",
+ "rewards = {\n",
+ " 's1': {'a0': {'s0': +5}},\n",
+ " 's2': {'a1': {'s0': -1}}\n",
+ "}\n",
+ "\n",
+ "from mdp import MDP\n",
+ "mdp = MDP(transition_probs, rewards, initial_state='s0')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now use the MDP just as any other gym environment:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "initial state = s0\n",
+ "next_state = s2, reward = 0.0, done = False\n"
+ ]
+ }
+ ],
+ "source": [
+ "print('initial state =', mdp.reset())\n",
+ "next_state, reward, done, info = mdp.step('a1')\n",
+ "print('next_state = %s, reward = %s, done = %s' % (next_state, reward, done))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "but it also has other methods that you'll need for Value Iteration:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "mdp.get_all_states = ('s0', 's1', 's2')\n",
+ "mdp.get_possible_actions('s1') = ('a0', 'a1')\n",
+ "mdp.get_next_states('s1', 'a0') = {'s0': 0.7, 's1': 0.1, 's2': 0.2}\n",
+ "mdp.get_reward('s1', 'a0', 's0') = 5\n",
+ "mdp.get_transition_prob('s1', 'a0', 's0') = 0.7\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(\"mdp.get_all_states =\", mdp.get_all_states())\n",
+ "print(\"mdp.get_possible_actions('s1') = \", mdp.get_possible_actions('s1'))\n",
+ "print(\"mdp.get_next_states('s1', 'a0') = \", mdp.get_next_states('s1', 'a0'))\n",
+ "print(\"mdp.get_reward('s1', 'a0', 's0') = \", mdp.get_reward('s1', 'a0', 's0'))\n",
+ "print(\"mdp.get_transition_prob('s1', 'a0', 's0') = \", mdp.get_transition_prob('s1', 'a0', 's0'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Optional: Visualizing MDPs\n",
+ "\n",
+ "You can also visualize any MDP with the drawing fuction donated by [neer201](https://github.com/neer201).\n",
+ "\n",
+ "You have to install graphviz for system and for python. \n",
+ "\n",
+ "1. * For ubuntu just run: `sudo apt-get install graphviz` \n",
+ " * For OSX: `brew install graphviz`\n",
+ "2. `pip install graphviz`\n",
+ "3. restart the notebook\n",
+ "\n",
+ "__Note:__ Installing graphviz on some OS (esp. Windows) may be tricky. However, you can ignore this part alltogether and use the standart vizualization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Graphviz available: True\n"
+ ]
+ }
+ ],
+ "source": [
+ "from mdp import has_graphviz\n",
+ "from IPython.display import display\n",
+ "print(\"Graphviz available:\", has_graphviz)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/svg+xml": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "if has_graphviz:\n",
+ " from mdp import plot_graph, plot_graph_with_state_values, plot_graph_optimal_strategy_and_state_values\n",
+ " display(plot_graph(mdp))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Value Iteration\n",
+ "\n",
+ "Now let's build something to solve this MDP. The simplest algorithm so far is __V__alue __I__teration\n",
+ "\n",
+ "Here's the pseudo-code for VI:\n",
+ "\n",
+ "---\n",
+ "\n",
+ "`1.` Initialize $V^{(0)}(s)=0$, for all $s$\n",
+ "\n",
+ "`2.` For $i=0, 1, 2, \\dots$\n",
+ " \n",
+ "`3.` $ \\quad V_{(i+1)}(s) = \\max_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')]$, for all $s$\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "First, let's write a function to compute the state-action value function $Q^{\\pi}$, defined as follows:\n",
+ "\n",
+ "$$Q_i(s, a) = \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')].$$\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_action_value(mdp, state_values, state, action, gamma):\n",
+ " \"\"\" Computes Q(s,a) according to the formula above \"\"\"\n",
+ "\n",
+ " \n",
+ "\n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "test_Vs = {s: i for i, s in enumerate(sorted(mdp.get_all_states()))}\n",
+ "assert np.isclose(get_action_value(mdp, test_Vs, 's2', 'a1', 0.9), 0.69)\n",
+ "assert np.isclose(get_action_value(mdp, test_Vs, 's1', 'a0', 0.9), 3.95)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Using $Q(s,a)$ we now can define the \"next\" V(s) for value iteration.\n",
+ " $$V_{(i+1)}(s) = \\max_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')] = \\max_a Q_i(s,a)$$"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_new_state_value(mdp, state_values, state, gamma):\n",
+ " \"\"\" Computes the next V(s) according to the formula above. Please do not change state_values in process. \"\"\"\n",
+ " if mdp.is_terminal(state):\n",
+ " return 0\n",
+ "\n",
+ " \n",
+ " \n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_Vs_copy = dict(test_Vs)\n",
+ "assert np.isclose(get_new_state_value(mdp, test_Vs, 's0', 0.9), 1.8)\n",
+ "assert np.isclose(get_new_state_value(mdp, test_Vs, 's2', 0.9), 1.08)\n",
+ "assert np.isclose(get_new_state_value(mdp, {'s0': -1e10, 's1': 0, 's2': -2e10}, 's0', 0.9), -13500000000.0), \\\n",
+ " \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\"\n",
+ "assert test_Vs == test_Vs_copy, \"Please do not change state_values in get_new_state_value\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Finally, let's combine everything we wrote into a working value iteration algo."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# parameters\n",
+ "gamma = 0.9 # discount for the MDP\n",
+ "num_iter = 100 # maximum iterations, excluding initialization\n",
+ "# stop VI if new values are as close to old values (or closer)\n",
+ "min_difference = 0.001\n",
+ "\n",
+ "# initialize V(s)\n",
+ "state_values = {s: 0 for s in mdp.get_all_states()}\n",
+ "\n",
+ "if has_graphviz:\n",
+ " display(plot_graph_with_state_values(mdp, state_values))\n",
+ "\n",
+ "for i in range(num_iter):\n",
+ "\n",
+ " # Compute new state values using the functions you defined above.\n",
+ " # It must be a dict {state : float V_new(state)}\n",
+ " new_state_values = \n",
+ "\n",
+ " assert isinstance(new_state_values, dict)\n",
+ "\n",
+ " # Compute difference\n",
+ " diff = max(abs(new_state_values[s] - state_values[s])\n",
+ " for s in mdp.get_all_states())\n",
+ " print(\"iter %4i | diff: %6.5f | \" % (i, diff), end=\"\")\n",
+ " print(' '.join(\"V(%s) = %.3f\" % (s, v) for s, v in state_values.items()))\n",
+ " state_values = new_state_values\n",
+ "\n",
+ " if diff < min_difference:\n",
+ " print(\"Terminated\")\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if has_graphviz:\n",
+ " display(plot_graph_with_state_values(mdp, state_values))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Final state values:\", state_values)\n",
+ "\n",
+ "assert abs(state_values['s0'] - 3.781) < 0.01\n",
+ "assert abs(state_values['s1'] - 7.294) < 0.01\n",
+ "assert abs(state_values['s2'] - 4.202) < 0.01"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now let's use those $V^{*}(s)$ to find optimal actions in each state:\n",
+ "\n",
+ " $$\\pi^*(s) = argmax_a \\sum_{s'} P(s' | s,a) \\cdot [ r(s,a,s') + \\gamma V_{i}(s')] = argmax_a Q_i(s,a).$$\n",
+ " \n",
+ "The only difference vs V(s) is that here instead of max we take argmax: find the action that leads to the maximum of Q(s,a)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_optimal_action(mdp, state_values, state, gamma=0.9):\n",
+ " \"\"\" Finds optimal action using formula above. \"\"\"\n",
+ " if mdp.is_terminal(state):\n",
+ " return None\n",
+ "\n",
+ " \n",
+ "\n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "assert get_optimal_action(mdp, state_values, 's0', gamma) == 'a1'\n",
+ "assert get_optimal_action(mdp, state_values, 's1', gamma) == 'a0'\n",
+ "assert get_optimal_action(mdp, state_values, 's2', gamma) == 'a1'\n",
+ "\n",
+ "assert get_optimal_action(mdp, {'s0': -1e10, 's1': 0, 's2': -2e10}, 's0', 0.9) == 'a0', \\\n",
+ " \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\"\n",
+ "assert get_optimal_action(mdp, {'s0': -2e10, 's1': 0, 's2': -1e10}, 's0', 0.9) == 'a1', \\\n",
+ " \"Please ensure that you handle negative Q-values of arbitrary magnitude correctly\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if has_graphviz:\n",
+ " display(plot_graph_optimal_strategy_and_state_values(mdp, state_values, get_action_value))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Measure agent's average reward\n",
+ "\n",
+ "s = mdp.reset()\n",
+ "rewards = []\n",
+ "for _ in range(10000):\n",
+ " s, r, done, _ = mdp.step(get_optimal_action(mdp, state_values, s, gamma))\n",
+ " rewards.append(r)\n",
+ "\n",
+ "print(\"average reward: \", np.mean(rewards))\n",
+ "\n",
+ "assert(0.40 < np.mean(rewards) < 0.55)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Frozen lake"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from mdp import FrozenLakeEnv\n",
+ "mdp = FrozenLakeEnv(slip_chance=0)\n",
+ "\n",
+ "mdp.render()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def value_iteration(mdp, state_values=None, gamma=0.9, num_iter=1000, min_difference=1e-5):\n",
+ " \"\"\" performs num_iter value iteration steps starting from state_values. The same as before but in a function \"\"\"\n",
+ " state_values = state_values or {s: 0 for s in mdp.get_all_states()}\n",
+ " for i in range(num_iter):\n",
+ "\n",
+ " # Compute new state values using the functions you defined above. It must be a dict {state : new_V(state)}\n",
+ " new_state_values = \n",
+ "\n",
+ " assert isinstance(new_state_values, dict)\n",
+ "\n",
+ " # Compute the difference\n",
+ " diff = max(abs(new_state_values[s] - state_values[s])\n",
+ " for s in mdp.get_all_states())\n",
+ "\n",
+ " print(\"iter %4i | diff: %6.5f | V(start): %.3f \" %\n",
+ " (i, diff, new_state_values[mdp._initial_state]))\n",
+ "\n",
+ " state_values = new_state_values\n",
+ " if diff < min_difference:\n",
+ " break\n",
+ "\n",
+ " return state_values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "state_values = value_iteration(mdp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s = mdp.reset()\n",
+ "mdp.render()\n",
+ "for t in range(100):\n",
+ " a = get_optimal_action(mdp, state_values, s, gamma)\n",
+ " print(a, end='\\n\\n')\n",
+ " s, r, done, _ = mdp.step(a)\n",
+ " mdp.render()\n",
+ " if done:\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Let's visualize!\n",
+ "\n",
+ "It's usually interesting to see, what your algorithm actually learned under the hood. To do so, we'll plot the state value functions and optimal actions at each VI step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "\n",
+ "\n",
+ "def draw_policy(mdp, state_values):\n",
+ " plt.figure(figsize=(3, 3))\n",
+ " h, w = mdp.desc.shape\n",
+ " states = sorted(mdp.get_all_states())\n",
+ " V = np.array([state_values[s] for s in states])\n",
+ " Pi = {s: get_optimal_action(mdp, state_values, s, gamma) for s in states}\n",
+ " plt.imshow(V.reshape(w, h), cmap='gray', interpolation='none', clim=(0, 1))\n",
+ " ax = plt.gca()\n",
+ " ax.set_xticks(np.arange(h)-.5)\n",
+ " ax.set_yticks(np.arange(w)-.5)\n",
+ " ax.set_xticklabels([])\n",
+ " ax.set_yticklabels([])\n",
+ " Y, X = np.mgrid[0:4, 0:4]\n",
+ " a2uv = {'left': (-1, 0), 'down': (0, -1), 'right': (1, 0), 'up': (0, 1)}\n",
+ " for y in range(h):\n",
+ " for x in range(w):\n",
+ " plt.text(x, y, str(mdp.desc[y, x].item()),\n",
+ " color='g', size=12, verticalalignment='center',\n",
+ " horizontalalignment='center', fontweight='bold')\n",
+ " a = Pi[y, x]\n",
+ " if a is None:\n",
+ " continue\n",
+ " u, v = a2uv[a]\n",
+ " plt.arrow(x, y, u*.3, -v*.3, color='m',\n",
+ " head_width=0.1, head_length=0.1)\n",
+ " plt.grid(color='b', lw=2, ls='-')\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "state_values = {s: 0 for s in mdp.get_all_states()}\n",
+ "\n",
+ "for i in range(10):\n",
+ " print(\"after iteration %i\" % i)\n",
+ " state_values = value_iteration(mdp, state_values, num_iter=1)\n",
+ " draw_policy(mdp, state_values)\n",
+ "# please ignore iter 0 at each step"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "from time import sleep\n",
+ "mdp = FrozenLakeEnv(map_name='8x8', slip_chance=0.1)\n",
+ "state_values = {s: 0 for s in mdp.get_all_states()}\n",
+ "\n",
+ "for i in range(30):\n",
+ " clear_output(True)\n",
+ " print(\"after iteration %i\" % i)\n",
+ " state_values = value_iteration(mdp, state_values, num_iter=1)\n",
+ " draw_policy(mdp, state_values)\n",
+ " sleep(0.5)\n",
+ "# please ignore iter 0 at each step"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Massive tests"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mdp = FrozenLakeEnv(slip_chance=0)\n",
+ "state_values = value_iteration(mdp)\n",
+ "\n",
+ "total_rewards = []\n",
+ "for game_i in range(1000):\n",
+ " s = mdp.reset()\n",
+ " rewards = []\n",
+ " for t in range(100):\n",
+ " s, r, done, _ = mdp.step(\n",
+ " get_optimal_action(mdp, state_values, s, gamma))\n",
+ " rewards.append(r)\n",
+ " if done:\n",
+ " break\n",
+ " total_rewards.append(np.sum(rewards))\n",
+ "\n",
+ "print(\"average reward: \", np.mean(total_rewards))\n",
+ "assert(1.0 <= np.mean(total_rewards) <= 1.0)\n",
+ "print(\"Well done!\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Measure agent's average reward\n",
+ "mdp = FrozenLakeEnv(slip_chance=0.1)\n",
+ "state_values = value_iteration(mdp)\n",
+ "\n",
+ "total_rewards = []\n",
+ "for game_i in range(1000):\n",
+ " s = mdp.reset()\n",
+ " rewards = []\n",
+ " for t in range(100):\n",
+ " s, r, done, _ = mdp.step(\n",
+ " get_optimal_action(mdp, state_values, s, gamma))\n",
+ " rewards.append(r)\n",
+ " if done:\n",
+ " break\n",
+ " total_rewards.append(np.sum(rewards))\n",
+ "\n",
+ "print(\"average reward: \", np.mean(total_rewards))\n",
+ "assert(0.8 <= np.mean(total_rewards) <= 0.95)\n",
+ "print(\"Well done!\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Measure agent's average reward\n",
+ "mdp = FrozenLakeEnv(slip_chance=0.25)\n",
+ "state_values = value_iteration(mdp)\n",
+ "\n",
+ "total_rewards = []\n",
+ "for game_i in range(1000):\n",
+ " s = mdp.reset()\n",
+ " rewards = []\n",
+ " for t in range(100):\n",
+ " s, r, done, _ = mdp.step(\n",
+ " get_optimal_action(mdp, state_values, s, gamma))\n",
+ " rewards.append(r)\n",
+ " if done:\n",
+ " break\n",
+ " total_rewards.append(np.sum(rewards))\n",
+ "\n",
+ "print(\"average reward: \", np.mean(total_rewards))\n",
+ "assert(0.6 <= np.mean(total_rewards) <= 0.7)\n",
+ "print(\"Well done!\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Measure agent's average reward\n",
+ "mdp = FrozenLakeEnv(slip_chance=0.2, map_name='8x8')\n",
+ "state_values = value_iteration(mdp)\n",
+ "\n",
+ "total_rewards = []\n",
+ "for game_i in range(1000):\n",
+ " s = mdp.reset()\n",
+ " rewards = []\n",
+ " for t in range(100):\n",
+ " s, r, done, _ = mdp.step(\n",
+ " get_optimal_action(mdp, state_values, s, gamma))\n",
+ " rewards.append(r)\n",
+ " if done:\n",
+ " break\n",
+ " total_rewards.append(np.sum(rewards))\n",
+ "\n",
+ "print(\"average reward: \", np.mean(total_rewards))\n",
+ "assert(0.6 <= np.mean(total_rewards) <= 0.8)\n",
+ "print(\"Well done!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to coursera\n",
+ "\n",
+ "If your submission doesn't finish in 30 seconds, set `verbose=True` and try again."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_assigment\n",
+ "submit_assigment(\n",
+ " get_action_value,\n",
+ " get_new_state_value,\n",
+ " get_optimal_action,\n",
+ " value_iteration,\n",
+ " 'your.email@example.com',\n",
+ " 'YourAssignmentToken',\n",
+ " verbose=False,\n",
+ ")"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week3_model_free/experience_replay.ipynb b/week3_model_free/experience_replay.ipynb
index 9825360a2..5aa6a5b75 100644
--- a/week3_model_free/experience_replay.ipynb
+++ b/week3_model_free/experience_replay.ipynb
@@ -1 +1,345 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"experience_replay.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"YPdtIpBDdi4x"},"source":["### Honor Track: experience replay\n","\n","There's a powerful technique that you can use to improve the sample efficiency for off-policy algorithms: [spoiler] Experience replay :)\n","\n","The catch is that you can train Q-learning and EV-SARSA on `` tuples even if they aren't sampled under the current agent's policy. So here's what we're gonna do:\n","\n","\n","\n","#### Training with experience replay\n","1. Play game, sample ``.\n","2. Update q-values based on ``.\n","3. Store `` transition in a buffer. \n"," 3. If buffer is full, delete the earliest data.\n","4. Sample K such transitions from that buffer and update the q-values based on them.\n","\n","\n","To enable such training, first, we must implement a memory structure, that would act as this buffer."]},{"cell_type":"code","metadata":{"id":"_u_E2KS8di4z"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"W6kAYyMZdi40"},"source":["import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline\n","\n","from IPython.display import clear_output"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"NQ1f7TzOdi40"},"source":[""],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"JFyXjhEbdi41"},"source":["import random\n","\n","\n","class ReplayBuffer(object):\n"," def __init__(self, size):\n"," \"\"\"\n"," Create Replay buffer.\n"," Parameters\n"," ----------\n"," size: int\n"," Max number of transitions to store in the buffer. When the buffer is\n"," overflowed, the old memories are dropped.\n","\n"," Note: for this assignment you can pick any data structure you want.\n"," If you want to keep it simple, you can store a list of tuples of (s, a, r, s') in self._storage\n"," However you may find, that there are faster and/or more memory-efficient ways to do so.\n"," \"\"\"\n"," self._storage = []\n"," self._maxsize = size\n","\n"," # OPTIONAL: YOUR CODE\n","\n"," def __len__(self):\n"," return len(self._storage)\n","\n"," def add(self, obs_t, action, reward, obs_tp1, done):\n"," '''\n"," Make sure, _storage will not exceed _maxsize. \n"," Make sure, FIFO rule is being followed: the oldest examples have to be removed earlier\n"," '''\n"," data = (obs_t, action, reward, obs_tp1, done)\n","\n"," # add data to storage\n"," \n","\n"," def sample(self, batch_size):\n"," \"\"\"Sample a batch of experiences.\n"," Parameters\n"," ----------\n"," batch_size: int\n"," How many transitions to sample.\n"," Returns\n"," -------\n"," obs_batch: np.array\n"," batch of observations\n"," act_batch: np.array\n"," batch of actions executed given obs_batch\n"," rew_batch: np.array\n"," rewards received as the results of executing act_batch\n"," next_obs_batch: np.array\n"," next set of observations, seen after executing act_batch\n"," done_mask: np.array\n"," done_mask[i] = 1 if executing act_batch[i] resulted in\n"," the end of an episode and 0 otherwise.\n"," \"\"\"\n"," idxes = \n","\n"," # collect for each index\n"," \n","\n"," return (\n"," np.array( ),\n"," np.array( ),\n"," np.array( ),\n"," np.array( ),\n"," np.array( ,\n"," )"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ptoGh7Epdi46"},"source":["Some tests to make sure your buffer works right"]},{"cell_type":"code","metadata":{"id":"spzmuisddi47"},"source":["def obj2arrays(obj):\n"," for x in obj:\n"," yield np.array([x])\n","\n","def obj2sampled(obj):\n"," return tuple(obj2arrays(obj))\n","\n","replay = ReplayBuffer(2)\n","obj1 = (0, 1, 2, 3, True)\n","obj2 = (4, 5, 6, 7, False)\n","replay.add(*obj1)\n","assert replay.sample(1) == obj2sampled(obj1), \\\n"," \"If there's just one object in buffer, it must be retrieved by buf.sample(1)\"\n","replay.add(*obj2)\n","assert len(replay) == 2, \"Please make sure __len__ methods works as intended.\"\n","replay.add(*obj2)\n","assert len(replay) == 2, \"When buffer is at max capacity, replace objects instead of adding new ones.\"\n","assert tuple(np.unique(a) for a in replay.sample(100)) == obj2sampled(obj2)\n","replay.add(*obj1)\n","assert max(len(np.unique(a)) for a in replay.sample(100)) == 2\n","replay.add(*obj1)\n","assert tuple(np.unique(a) for a in replay.sample(100)) == obj2sampled(obj1)\n","print(\"Success!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Yaush3KHdi47"},"source":["Now let's use this buffer to improve the training:"]},{"cell_type":"code","metadata":{"id":"zlRq2M57di47"},"source":["import gym\n","env = gym.make(\"Taxi-v3\")\n","n_actions = env.action_space.n"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"tRIymZTLdi48"},"source":["def play_and_train_with_replay(env, agent, replay=None,\n"," t_max=10**4, replay_batch_size=32):\n"," \"\"\"\n"," This function should \n"," - run a full game, actions given by agent.getAction(s)\n"," - train agent using agent.update(...) whenever possible\n"," - return total reward\n"," :param replay: ReplayBuffer where agent can store and sample (s,a,r,s',done) tuples.\n"," If None, do not use an experience replay\n"," \"\"\"\n"," total_reward = 0.0\n"," s = env.reset()\n","\n"," for t in range(t_max):\n"," # get agent to pick action given state s\n"," a = \n","\n"," next_s, r, done, _ = env.step(a)\n","\n"," # update agent on current transition. Use agent.update\n"," \n","\n"," if replay is not None:\n"," # store current transition in buffer\n"," \n","\n"," # sample replay_batch_size random transitions from replay,\n"," # then update the agent on each of them in a loop\n"," s_, a_, r_, next_s_, done_ = replay.sample(replay_batch_size)\n"," for i in range(replay_batch_size):\n"," \n","\n"," s = next_s\n"," total_reward += r\n"," if done:\n"," break\n","\n"," return total_reward"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ybT9zIbSdi48"},"source":["# Create two agents: first will use the experience replay, second will not.\n","\n","agent_baseline = QLearningAgent(\n"," alpha=0.5, epsilon=0.25, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))\n","\n","agent_replay = QLearningAgent(\n"," alpha=0.5, epsilon=0.25, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))\n","\n","replay = ReplayBuffer(1000)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"lQGmiCpwdi49"},"source":["from IPython.display import clear_output\n","import pandas as pd\n","\n","def moving_average(x, span=100):\n"," return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values\n","\n","rewards_replay, rewards_baseline = [], []\n","\n","for i in range(1000):\n"," rewards_replay.append(\n"," play_and_train_with_replay(env, agent_replay, replay))\n"," rewards_baseline.append(\n"," play_and_train_with_replay(env, agent_baseline, replay=None))\n","\n"," agent_replay.epsilon *= 0.99\n"," agent_baseline.epsilon *= 0.99\n","\n"," if i % 100 == 0:\n"," clear_output(True)\n"," print('Baseline : eps =', agent_replay.epsilon,\n"," 'mean reward =', np.mean(rewards_baseline[-10:]))\n"," print('ExpReplay: eps =', agent_baseline.epsilon,\n"," 'mean reward =', np.mean(rewards_replay[-10:]))\n"," plt.plot(moving_average(rewards_replay), label='exp. replay')\n"," plt.plot(moving_average(rewards_baseline), label='baseline')\n"," plt.grid()\n"," plt.legend()\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"rhfZcfMYdi4-"},"source":["### Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"O6wLlXi4di4-"},"source":["from submit import submit_experience_replay\n","submit_experience_replay(rewards_replay, rewards_baseline, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ZYLLK5o8di4-"},"source":["#### What to expect:\n","\n","Experience replay, if implemented correctly, will improve algorithm's initial convergence a lot, but it shouldn't affect the final performance.\n","\n","### Outro\n","\n","We will use the code you just wrote extensively in the next week of our course. If you're feeling, that you need more examples to understand how the experience replay works, try using it for binarized state spaces (CartPole or other __[classic control envs](https://gym.openai.com/envs/#classic_control)__).\n","\n","__Next week__ we're gonna explore how q-learning and similar algorithms can be applied for large state spaces, with deep learning models to approximate the Q function.\n","\n","However, __the code you've written__ this week is already capable to solve many RL problems, and as an added benifit - it is very easy to detach. You can use Q-learning, SARSA and Experience Replay for any RL problems you want to solve - just throw them into a file and import the stuff you need."]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Honor Track: experience replay\n",
+ "\n",
+ "There's a powerful technique that you can use to improve the sample efficiency for off-policy algorithms: [spoiler] Experience replay :)\n",
+ "\n",
+ "The catch is that you can train Q-learning and EV-SARSA on `` tuples even if they aren't sampled under the current agent's policy. So here's what we're gonna do:\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Training with experience replay\n",
+ "1. Play game, sample ``.\n",
+ "2. Update q-values based on ``.\n",
+ "3. Store `` transition in a buffer. \n",
+ " 3. If buffer is full, delete the earliest data.\n",
+ "4. Sample K such transitions from that buffer and update the q-values based on them.\n",
+ "\n",
+ "\n",
+ "To enable such training, first, we must implement a memory structure, that would act as this buffer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "\n",
+ "from IPython.display import clear_output"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import random\n",
+ "\n",
+ "\n",
+ "class ReplayBuffer(object):\n",
+ " def __init__(self, size):\n",
+ " \"\"\"\n",
+ " Create Replay buffer.\n",
+ " Parameters\n",
+ " ----------\n",
+ " size: int\n",
+ " Max number of transitions to store in the buffer. When the buffer is\n",
+ " overflowed, the old memories are dropped.\n",
+ "\n",
+ " Note: for this assignment you can pick any data structure you want.\n",
+ " If you want to keep it simple, you can store a list of tuples of (s, a, r, s') in self._storage\n",
+ " However you may find, that there are faster and/or more memory-efficient ways to do so.\n",
+ " \"\"\"\n",
+ " self._storage = []\n",
+ " self._maxsize = size\n",
+ "\n",
+ " # OPTIONAL: YOUR CODE\n",
+ "\n",
+ " def __len__(self):\n",
+ " return len(self._storage)\n",
+ "\n",
+ " def add(self, obs_t, action, reward, obs_tp1, done):\n",
+ " '''\n",
+ " Make sure, _storage will not exceed _maxsize. \n",
+ " Make sure, FIFO rule is being followed: the oldest examples have to be removed earlier\n",
+ " '''\n",
+ " data = (obs_t, action, reward, obs_tp1, done)\n",
+ "\n",
+ " # add data to storage\n",
+ " \n",
+ "\n",
+ " def sample(self, batch_size):\n",
+ " \"\"\"Sample a batch of experiences.\n",
+ " Parameters\n",
+ " ----------\n",
+ " batch_size: int\n",
+ " How many transitions to sample.\n",
+ " Returns\n",
+ " -------\n",
+ " obs_batch: np.array\n",
+ " batch of observations\n",
+ " act_batch: np.array\n",
+ " batch of actions executed given obs_batch\n",
+ " rew_batch: np.array\n",
+ " rewards received as the results of executing act_batch\n",
+ " next_obs_batch: np.array\n",
+ " next set of observations, seen after executing act_batch\n",
+ " done_mask: np.array\n",
+ " done_mask[i] = 1 if executing act_batch[i] resulted in\n",
+ " the end of an episode and 0 otherwise.\n",
+ " \"\"\"\n",
+ " idxes = \n",
+ "\n",
+ " # collect for each index\n",
+ " \n",
+ "\n",
+ " return (\n",
+ " np.array( ),\n",
+ " np.array( ),\n",
+ " np.array( ),\n",
+ " np.array( ),\n",
+ " np.array( ,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Some tests to make sure your buffer works right"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def obj2arrays(obj):\n",
+ " for x in obj:\n",
+ " yield np.array([x])\n",
+ "\n",
+ "def obj2sampled(obj):\n",
+ " return tuple(obj2arrays(obj))\n",
+ "\n",
+ "replay = ReplayBuffer(2)\n",
+ "obj1 = (0, 1, 2, 3, True)\n",
+ "obj2 = (4, 5, 6, 7, False)\n",
+ "replay.add(*obj1)\n",
+ "assert replay.sample(1) == obj2sampled(obj1), \\\n",
+ " \"If there's just one object in buffer, it must be retrieved by buf.sample(1)\"\n",
+ "replay.add(*obj2)\n",
+ "assert len(replay) == 2, \"Please make sure __len__ methods works as intended.\"\n",
+ "replay.add(*obj2)\n",
+ "assert len(replay) == 2, \"When buffer is at max capacity, replace objects instead of adding new ones.\"\n",
+ "assert tuple(np.unique(a) for a in replay.sample(100)) == obj2sampled(obj2)\n",
+ "replay.add(*obj1)\n",
+ "assert max(len(np.unique(a)) for a in replay.sample(100)) == 2\n",
+ "replay.add(*obj1)\n",
+ "assert tuple(np.unique(a) for a in replay.sample(100)) == obj2sampled(obj1)\n",
+ "print(\"Success!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now let's use this buffer to improve the training:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "env = gym.make(\"Taxi-v3\")\n",
+ "n_actions = env.action_space.n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def play_and_train_with_replay(env, agent, replay=None,\n",
+ " t_max=10**4, replay_batch_size=32):\n",
+ " \"\"\"\n",
+ " This function should \n",
+ " - run a full game, actions given by agent.getAction(s)\n",
+ " - train agent using agent.update(...) whenever possible\n",
+ " - return total reward\n",
+ " :param replay: ReplayBuffer where agent can store and sample (s,a,r,s',done) tuples.\n",
+ " If None, do not use an experience replay\n",
+ " \"\"\"\n",
+ " total_reward = 0.0\n",
+ " s = env.reset()\n",
+ "\n",
+ " for t in range(t_max):\n",
+ " # get agent to pick action given state s\n",
+ " a = \n",
+ "\n",
+ " next_s, r, done, _ = env.step(a)\n",
+ "\n",
+ " # update agent on current transition. Use agent.update\n",
+ " \n",
+ "\n",
+ " if replay is not None:\n",
+ " # store current transition in buffer\n",
+ " \n",
+ "\n",
+ " # sample replay_batch_size random transitions from replay,\n",
+ " # then update the agent on each of them in a loop\n",
+ " s_, a_, r_, next_s_, done_ = replay.sample(replay_batch_size)\n",
+ " for i in range(replay_batch_size):\n",
+ " \n",
+ "\n",
+ " s = next_s\n",
+ " total_reward += r\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " return total_reward"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Create two agents: first will use the experience replay, second will not.\n",
+ "\n",
+ "agent_baseline = QLearningAgent(\n",
+ " alpha=0.5, epsilon=0.25, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))\n",
+ "\n",
+ "agent_replay = QLearningAgent(\n",
+ " alpha=0.5, epsilon=0.25, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))\n",
+ "\n",
+ "replay = ReplayBuffer(1000)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "import pandas as pd\n",
+ "\n",
+ "def moving_average(x, span=100):\n",
+ " return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values\n",
+ "\n",
+ "rewards_replay, rewards_baseline = [], []\n",
+ "\n",
+ "for i in range(1000):\n",
+ " rewards_replay.append(\n",
+ " play_and_train_with_replay(env, agent_replay, replay))\n",
+ " rewards_baseline.append(\n",
+ " play_and_train_with_replay(env, agent_baseline, replay=None))\n",
+ "\n",
+ " agent_replay.epsilon *= 0.99\n",
+ " agent_baseline.epsilon *= 0.99\n",
+ "\n",
+ " if i % 100 == 0:\n",
+ " clear_output(True)\n",
+ " print('Baseline : eps =', agent_replay.epsilon,\n",
+ " 'mean reward =', np.mean(rewards_baseline[-10:]))\n",
+ " print('ExpReplay: eps =', agent_baseline.epsilon,\n",
+ " 'mean reward =', np.mean(rewards_replay[-10:]))\n",
+ " plt.plot(moving_average(rewards_replay), label='exp. replay')\n",
+ " plt.plot(moving_average(rewards_baseline), label='baseline')\n",
+ " plt.grid()\n",
+ " plt.legend()\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to Coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_experience_replay\n",
+ "submit_experience_replay(rewards_replay, rewards_baseline, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### What to expect:\n",
+ "\n",
+ "Experience replay, if implemented correctly, will improve algorithm's initial convergence a lot, but it shouldn't affect the final performance.\n",
+ "\n",
+ "### Outro\n",
+ "\n",
+ "We will use the code you just wrote extensively in the next week of our course. If you're feeling, that you need more examples to understand how the experience replay works, try using it for binarized state spaces (CartPole or other __[classic control envs](https://gym.openai.com/envs/#classic_control)__).\n",
+ "\n",
+ "__Next week__ we're gonna explore how q-learning and similar algorithms can be applied for large state spaces, with deep learning models to approximate the Q function.\n",
+ "\n",
+ "However, __the code you've written__ this week is already capable to solve many RL problems, and as an added benifit - it is very easy to detach. You can use Q-learning, SARSA and Experience Replay for any RL problems you want to solve - just throw them into a file and import the stuff you need."
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week3_model_free/qlearning.ipynb b/week3_model_free/qlearning.ipynb
index b46c02ee4..6b5e0d15d 100644
--- a/week3_model_free/qlearning.ipynb
+++ b/week3_model_free/qlearning.ipynb
@@ -1 +1,535 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"qlearning.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"ZOEn26uI2H8Y"},"source":["## Q-learning\n","\n","This notebook will guide you through the implementation of vanilla Q-learning algorithm.\n","\n","You need to implement QLearningAgent (follow instructions for each method) and use it in a number of tests below."]},{"cell_type":"code","metadata":{"id":"Q9pgNnPI2H8e"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display for drawing game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"uKEoikh_2H8f"},"source":["import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"rf4KxZHu2H8f"},"source":["from collections import defaultdict\n","import random\n","import math\n","import numpy as np\n","\n","\n","class QLearningAgent:\n"," def __init__(self, alpha, epsilon, discount, get_legal_actions):\n"," \"\"\"\n"," Q-Learning Agent\n"," based on https://inst.eecs.berkeley.edu/~cs188/sp19/projects.html\n"," Instance variables you have access to:\n"," - self.epsilon (exploration prob)\n"," - self.alpha (learning rate)\n"," - self.discount (discount rate aka gamma)\n","\n"," Functions that you should use:\n"," - self.get_legal_actions(state) {state, hashable -> list of actions, each is hashable}\n"," which returns legal actions for a state\n"," - self.get_qvalue(state,action)\n"," which returns Q(state,action)\n"," - self.set_qvalue(state,action,value)\n"," which sets Q(state,action) := value\n"," !!!Important!!!\n"," Note: please avoid using self._qValues directly. \n"," There's a special self.get_qvalue/set_qvalue for that.\n"," \"\"\"\n","\n"," self.get_legal_actions = get_legal_actions\n"," self._qvalues = defaultdict(lambda: defaultdict(lambda: 0))\n"," self.alpha = alpha\n"," self.epsilon = epsilon\n"," self.discount = discount\n","\n"," def get_qvalue(self, state, action):\n"," \"\"\" Returns Q(state,action) \"\"\"\n"," return self._qvalues[state][action]\n","\n"," def set_qvalue(self, state, action, value):\n"," \"\"\" Sets the Qvalue for [state,action] to the given value \"\"\"\n"," self._qvalues[state][action] = value\n","\n"," #---------------------BEGINNING OF YOUR CODE---------------------#\n","\n"," def get_value(self, state):\n"," \"\"\"\n"," Compute your agent's estimate of V(s) using current q-values\n"," V(s) = max_over_action Q(state,action) over possible actions.\n"," Note: please take into account that q-values can be negative.\n"," \"\"\"\n"," possible_actions = self.get_legal_actions(state)\n","\n"," # If there are no legal actions, return 0.0\n"," if len(possible_actions) == 0:\n"," return 0.0\n","\n"," \n","\n"," return value\n","\n"," def update(self, state, action, reward, next_state):\n"," \"\"\"\n"," You should do your Q-Value update here:\n"," Q(s,a) := (1 - alpha) * Q(s,a) + alpha * (r + gamma * V(s'))\n"," \"\"\"\n","\n"," # agent parameters\n"," gamma = self.discount\n"," learning_rate = self.alpha\n","\n"," \n","\n"," self.set_qvalue(state, action, )\n","\n"," def get_best_action(self, state):\n"," \"\"\"\n"," Compute the best action to take in the state (using current q-values). \n"," \"\"\"\n"," possible_actions = self.get_legal_actions(state)\n","\n"," # If there are no legal actions, return None\n"," if len(possible_actions) == 0:\n"," return None\n","\n"," \n","\n"," return best_action\n","\n"," def get_action(self, state):\n"," \"\"\"\n"," Compute the action to take in the current state, including exploration. \n"," With probability self.epsilon, we should take a random action.\n"," otherwise - the best policy action (self.get_best_action).\n","\n"," Note: To pick randomly from a list, use random.choice(list). \n"," To pick True or False with a given probablity, generate a uniform number in [0, 1]\n"," and compare it with your probability\n"," \"\"\"\n","\n"," # Pick Action\n"," possible_actions = self.get_legal_actions(state)\n"," action = None\n","\n"," # If there are no legal actions, return None\n"," if len(possible_actions) == 0:\n"," return None\n","\n"," # agent parameters:\n"," epsilon = self.epsilon\n","\n"," \n","\n"," return chosen_action"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"q3lBMWha2H8g"},"source":["### Try it on taxi\n","\n","Here we use the qlearning agent on taxi env from openai gym.\n","You will need to add a few agent functions here."]},{"cell_type":"code","metadata":{"id":"C0H8mqeQ2H8g"},"source":["import gym\n","env = gym.make(\"Taxi-v3\")\n","\n","n_actions = env.action_space.n"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"zGW_cZXo2H8h"},"source":["agent = QLearningAgent(\n"," alpha=0.5, epsilon=0.25, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"8QcjHKlj2H8h"},"source":["def play_and_train(env, agent, t_max=10**4):\n"," \"\"\"\n"," This function should \n"," - run a full game, actions given by agent's e-greedy policy\n"," - train agent using agent.update(...) whenever it is possible\n"," - return the total reward\n"," \"\"\"\n"," total_reward = 0.0\n"," s = env.reset()\n","\n"," for t in range(t_max):\n"," # get an agent to pick action given state s.\n"," a = \n","\n"," next_s, r, done, _ = env.step(a)\n","\n"," # train (update) an agent for state s\n"," \n","\n"," s = next_s\n"," total_reward += r\n"," if done:\n"," break\n","\n"," return total_reward"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"azqGhPFm2H8h","outputId":"28d6f635-0544-4a52-c610-f2dff88e45d4"},"source":["from IPython.display import clear_output\n","\n","rewards = []\n","for i in range(1000):\n"," rewards.append(play_and_train(env, agent))\n"," agent.epsilon *= 0.99\n","\n"," if i % 100 == 0:\n"," clear_output(True)\n"," plt.title('eps = {:e}, mean reward = {:.1f}'.format(agent.epsilon, np.mean(rewards[-10:])))\n"," plt.plot(rewards)\n"," plt.show()\n"," "],"execution_count":null,"outputs":[{"output_type":"display_data","data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAAAX8AAAEICAYAAAC3Y/QeAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO2deXhU1fnHP28mG4FAwk4IEJYAAgJCFBFRcANX6lJFrWKrte4/W1vFfSsttbZW60rValstdRcVRVFxRzaVHY2ALLKHNYGQZM7vj3tncmcyM5k1y8z7eZ48mXvOufe8986d73nve849R4wxKIqiKKlFWmMboCiKojQ8Kv6KoigpiIq/oihKCqLiryiKkoKo+CuKoqQgKv6KoigpiIq/oihNChGZIyKXNbYdyY6KfwoiIveLyHcisldEVorIxSHKiojcKiLrRGSPiEwXkdaO/HNF5HMRqRCROQH2P11ElorIPrvcAEfeIBGZJSLbRaTOCyci0lZEXhWRchH5QUQuCNeuKK5JkYh8aJ/HShE5wZF3iYjU2Ofg+RsTbV1KwyMib/t9fwdFZEmI8sfb90GFfV/0aEh7GwIV/9SkHDgdaANMAh4UkaOClL0YuAgYBRQALYC/O/LLgL8BU/13FJFi4DngCiAPeAOYISLpdpEq4AXg0iB1PwIcBDoBFwKPicjAMO2KlP8CXwHtgFuBl0SkgyP/C2NMK8ffnBjqanI4vpOGrFNEpEE0yBhzsvP7Az4HXgxiV3vgFeB2oC2wAPhfQ9jZoBhj9C8Bf1iC9DKwDVgDXOfIuwt4CeuG2gssAoY48m8CNtp5q4DjE2zrDOCGIHkvAb9zbB8FHABy/MpdBszxS7sGeMuxnQbs9z8foI91K/qktcQS/r6OtH8DU8OxC6thewrYZF/L3wOuIOfYF6gEch1pnwBX2J8vAT6N8tpeAnwGPADsAlbbtl4CrAe2ApMc5bOA+4F1wBbgcaCFnZcPvGnfUzvtz4WOfecA99r17QXeBdoHsWsMsMG+1zbb1zYNmAx8D+zAapjb2uWf9dwjQFfAAFfb272xnIC0MG2cYtu43/7uTwRWAruBh4GPgMsSeL8XATVAUZD8y4HP/e7F/UD/RP4OG/pPPf8EYHszbwDfYP1QjgeuF5FxjmITsDyPtsDzwGsikiEi/bBE83BjTC4wDlgbpJ7JIrIr2F+YtrYADgeWhSrm9zkLKA7n+AH2FWBQGPv1BaqNMd860r4BBjq2Q9n1DFCNJS6HASdhNVCBGAisNsbsDVHXYXZ46lsRuT1CT3kEsBjrqeJ5YDrWNe8D/Ax4WERa2WWnYp37UDu/K3CHnZcG/BPoAXTHEqSH/eq6APg50BHIBH4bwq7OWPdfDyzBuxb4CXAslvOyE+vpCyxBHmN/PharETvGsf2JMcYdpo0X2fXlYgn+K8BtQHushmdUMINF5IJQ97yIdA9xvh4utu1dGyR/INb3D4Axpty2a2CQ8s2Txm59kvEP68e+zi/tZuCf9ue7gLmOvDQsD3U01g9+K3ACkNEAtj4LvANIkPzLgG+xvKU2WE8JBhgZoNwcv7T+WCGmMVhCdDvgBm72KxfI8x8NbPZL+6WnjlB2YYWJKrE9Zrv8+cCHQc7xIuf3YadNAZ6xP/cCetrf06HAcv9zCHF9LwG+c2wfatvZyZG2A0vsxb5evR15I4E1QY49FNjp2J4D3ObYvgp4J8i+Y7CerLIdaStwPJUBXbBCc+lY3v1O+xo8DvwK2OC4h34TgY33OLYv9vstCNYTSSI9/1LgkhD5T2E/YTrSPgu1T3P8U88/MfQACvy88FuwRMnDes8HY3lMG4ACY0wpcD1WA7HV7sgsSISRIvJnLC/8XGPf4QF4GisePgfr6eBDO31Dfcc3xqzE6lN4GKtxa48lnPXuC+wD/DtwW2OFM+qzqweQAWxyXP8nsLxhRGSZo+NvdH11GWNWG2PWGGPcxpglwD3AOWGcg4ctjs/77WP6p7UCOgA5wEKH3e/Y6YhIjog8YXd+7wE+BvJExOU41mbH5wr7uMHYZow54NjuAbzqqHsFVnikkzHme6yGaShWw/wm8KP9pHos1pNBuDaud3wuwPe3YPzy44qIHI31xPNSiGL13XtJgYp/YliP5a3lOf5yjTGnOMp083yww0SFwI8AxpjnjTFHY/0YDfCnQJWIyC1+Ixh8/kIZKCJ3AycDJxlj9gQrZwvencaYImNMIZbQbrT/6sUY85IxZpAxph1wJ5anPj+MXb8F0u1OYw9D7Prrs2s9luff3nH9WxtjBtr7DjS1nX+f2Pv2EpHcQHUFOi18Q07xYjtWQzDQYXcbY3VQAtwA9ANGGGNaUxt2idYW/wZ/PXCy332bbYzxfNcfYTV6mXbaR1iNez7wdQQ2OuvdhO9vQZzb/ojIhaHu+TDCPpOAV4wxoX4fy7C+f0+dLbGefEKFRpsdKv6JYR6wV0RuEpEWIuISa1jj4Y4yw0XkLDt2fD2WWM0VkX4icpyIZGF1YO7HCpXUwRjzB+M7AsXnL5hxInIzVmz4BGPMjlAnItZwy972yIwBwF+xHtvddr5LRLKxQgNpIpItIhmO/YfbZToA04AZ9hOBZ7RHNlZICHvfLPvcyrFiwfeISEsRGYXVT/Lv+uwyxmzC6uz8i4i0FpE0u+yxQa7jt1jidadtw5nAYKwOe0TkZBHpZH/ujxW+et1xjnNE5K5Q1zEc7Gv6D+ABEfE8pXSV2r6iXKz7YZeItMVqTOPJ48AUsYc1ikgHEZngyP8Iqz/qY3t7jr39qTGmJkob3wIGOn4L12F55gExxjwX6p43xqwLtq9Y/VvnYvUHheJVYJCInG3fn3cAiz33bbKg4p8A7B/CaViPyGuwPLonsWLTHl4HzsOKo14EnGWMqcLqtJxq77MZK1Rxc5xN/ANWZ1ypw2O6xZPpCIeAFaqZifXI/zbwtDFmmuNYF2H92B/DCgfsxxIwDw9ijXJZZZ/rLx15PezyHo9qv13Ow1VYQzi3YoV4rjTGeMrWZ9fFWI3Kcrvel7Bi2MGYCJTYZacC5xhjttl5xwOLRaTcrvMVrGvooRtWTDge3IQVk55rh01mY3nSYA2pbYF1b8zFCgnFkwex+k7eFZG9dh0jHPkfYYm7R/w/xQpTfewoE5GNxpjtwE+xrvkOrA77eF1Lf36CdS9+6J9hhwIvtG3aBpyN1e+zE+saTEyQTY2GBA/1KonC9hL7GGN+1ti2KLEhIoXAC8aYYO9JKEqTpMFf7FCUZMIYswFr3L6iNCs07KMoipKCaNhHURQlBVHPX1EUJQVpFjH/9u3bm6KiosY2Q1EUpVmxcOHC7caYDoHymoX4FxUVsWDBgsY2Q1EUpVkhIj8Ey9Owj6IoSgqi4q8oipKCqPgriqKkICr+iqIoKYiKv6IoSgqi4q8oipKCqPgriqKkICr+TYwat2FXxcGAeQeqath7oMq7XVXj5oX563G7g0/RUVZ+0LMMHW63YdveypD1G2PYuvdAwLyqGjd7HPVHQln5QaprAi5LEBXGGLbv8z0X/+vjpKrGzaJ1O3lz8Y/etK17D/D2kk1R21Bd42b6vHUcrA59Xjv2VdIQ06gYY9ixL/T36+FgtZvd+8P/LsvKD4a8z5ys3V7Ohyu3hn3spsCa7eV89O22+gtGif+92hRQ8W8k7nx9KRc+OZf73lnJmY9a05d/Vrqd8574gqH3vBdQxM574gsOvetd7/YjH5Zy48uLecMhaB52VRykaPJbDLv3PabPt1bFu+31pRz5x/f5at3OoHZ9sXoHR0x5n//MrftuyJX/Wcjgu95l0bqdfLN+F2634Ycd5Rhj2LLnAP+bX3cdjd37q9iy5wDD7n2P66Z/FbRh8Wd9WQUvLQy82uPa7eXc8+ZySn4/m8+/305Z+UG276tk/N8+5rB73gu4z29e+IazHv2ca57/ytsIXfmfRVz53CK276vkhx3l/G/+Ol5csJ6qGjf/+Hg176/Ywp4DVT6CumTDbt5esonNuw8wc+lmJr+yhKueW+QV9zXby3nmszV8/O027p+1ir/N/pbhv5/NeU/M5X/z19UR0B937ad061427669Li8v3MDiDbtYX1bBxl37uemlxVzyz3lcP/0rLn1mvreu8spqzn38C95abDVgt722lOG/n82m3fvZV1nNj7v2M29NGWc9+hlzV+9g0+79HKiqoeJgNedN+4Ihd79LeWU1a7aX89pXG9lzoIpzn/iCZT/uZsmG3fywo5x3lm7inaWbGHbvezww+1t2V1Tx1Kdr+GrdTlZtDryq4Zj75/DzZ+YHbRTXl1X4XK+qGjfrdljnunt/FffPWsWUt5b77FNeWc3WPaHvne37Kus0aG63Yd2OCu/2roqD/OPj1dS4Dau31S7mNfb+OUx6eh77D9b4fBc1bsOTn6xmxaY9XPP8In76+OdM+/h7b94363fx5CereeazNcxcsokPV9U2egvWlvH61xv5z9wfKPn9bOatKQto94ertrLI8Ztct6OCNdvLqXEb1pdVUBVHp8lJs3jDNxl59gtLXD8rtRbSMsZw4ZNfevP3HqgmN9u7IBZl5Qf5ZsNuwPJYO+Zms3HnfsDyeP1xejEff7uN84/ozswlm6hxG5Zu3E27lllc+ux8fnlML578ZDU3je/P8Yd0YleF9eN5bM73nHlYV655fhGHdGnNjeP7M3uFdWOf9ejnAJxyaGdmLtnM1LMO5dWvNvLlmjJWbNpLhkv4Zv1u/nTOYE576BPKD1r2zVyymZlLNvPpTWMpzM8B4Icd5fy46wDfbtnLEx99T4tMFy9dcRSj77PW22iV5eKkAZ158tPVHNe/E3//4Dte/7q2sbvgH7XXzMO4Bz7mgfOGUuM2DOraGhHhjW9q91lXVkF5ZQ0Lf7B+cHe+voy3HE8Av3tpcZ1jHt2nPWu2l7Nx1/46ebNXbOHyfy/krjMGct87K3l76eY6ZeatLWPe2jJuenkJlxxVxKmDu/DLfy3wXu+8nAy+vuMkVm7eww0vflNnfyezlm3hsO55nPb3T9m2t5J5a8v477z2fFq6HYDrp3/Nl35CM3HaXO9nV5pQYzdCA++cVef4pz70acB6//5BKf+dtz5sL7bvbW9z4oBOHNmrHa9/vZEtew6Qk5nOmu3lPuVG9mrHF6vrLiiXl5PJiQM6ce4TX3ivE8AFI7pzXom10mOH3CxyMl08+P53/POztQwpbMMlo4po3yqLjrnZnPb3T6iqMfzqmF488fFq7zGe+nQNm/cc4LELh/l8p4fcUbv2zKmHdsFgmLnE9/ucv3Ynqzbv4+VFgZ2TId3y+Gb9rjrp5z7xBbedegiXHt2TZz5fy/R568nLyajzXXlo2zKTsvKDXHd8Mb85sW/AMrHQaLN6ish4rJWDXMCTxpipwcqWlJSYZJveoWjyWz7b3//hFHrfMtO7/fnk4yjIa+HdvmvGMp75fC0A71w/mv6dW3PN84t4c/EmHpw4lJ7tWwIwuDAPgF/+awHvLbfWCB8/sDOPXzScwXfNYs+Ban59Ql8emP0tADmZLioO1tAhN4tteyu58/QB3P2G5XUN657HonXWTXz3GQO5c0bgJUzPHlZI6bZ9dW74rPQ0KoN4f2unnkpVjZviW9+u91odXpTP/LXBn1ZCMapPO649rthH/BSlOXFs3w48+4sjotpXRBYaY0oC5TVK2EdEXMAjWAuIDwDOt9dhTVnc9TTC+TmZ3s8Hq91U1biZaXurWekuznj4M8542AofGWO8wg+wbV8lRZPfYs+BasDytj1U2F65py9gif10AXiFHwgq/AAvL9rA0o2766QHE36wGr9zn/giaL6TaIUfrCercIW/dXbtg/CQbnn06tAy6noBjihq6/38/g3HUtyxFYX5LchwxW/t96vG9ObSo3sGzHvgvCFMGFoQ9rFKeuRzWZBjtWuZ6bM9sKA1H/52DFPOHMQFI3zXTO/tuG6BzrVLm+yANnd1ODuh0uJBmsBffjqk/oLA0G55SD1f2SVHFQVMnzC0gA65WRFa50ui3PPGCvscAZQaY1YDiMh0rMW5l4fcq5mxr7KaVll1L3GgGJ6/+Pt/4V3aZHs/v7Vkk1foAa74z0Kfsje/ssRne11Zhc/2K19tDGqzKy0yYSrpkc+CH3Z6wwiR8NU63yeF4/p35ANHR+HAgtZs21vJVr9O6lZZ6bzwq5Gc8tAnEdX3syO70yorg8c/+j5g/sLbT/Q+ibx21VGICJf/awHvLt/CX88dwr/n/lDH5lA8MHEod76+jNkrttCuZSZvXWcti7x+ZwUPf1DK4UVtueXVJXX2G9S1Nf+4uISRf/wAgDOGFFBjDG8t3sQxfTvw8bfb+PM5gzl9SAHZGS6+XL2Dpz5dQ//Oucy8bjS/ffEbXvlqI4d2bcOZhxXyl58O4ZPS7fRq35KD1W5OfMBacreoXQ6vXjWKD1dtRQROG1xAhiuN347rR2WVmwmPfMraHRWMLm7Pvy8dwcIfyjj7MavB/s+lI8hvmel94jx5UGd27DvIkb3akd8yg8UbdtO5dTZd81rQy36ifXDiUP5v+td0bpPN7acN4PbTBjBq6gds3LWfrPQ0BhS0ZuOu/eTlZPDxjWNpmZmOK004UFXDwRo3rbMzuO+dlTw6x/r+vrzleHIyXcxbU8bhPduSne6i723W9/fZ5ONYsmE3FQer+c0LVhjt29+fjMFQXWPIyXQhIizZuJv3V27hT2cP9oYQ/3jWoXzy3TZaZaVzdHEHzhhSwOINuzjj4c/46fBCBhe2oWt+C/YeqGZ9WQUXH1VE6+wMxvTrQKusdLbvO8gbi3/k3gmDaGs3mnNX76Bb2xxGTf3Ae/36dc7l8CmzAXj96lG8uHA9k08+hNXb9rF2RwVnDCng3jeXex20eNNY4t8VWO/Y3oDvQtGIyOXA5QDdu/t6Fs2BN775kWv/+xVvXns0g7q28ckLFKO/K4RnDWAczcHrX9Xt4PVQ4zbeDl4PGREIenoEXukJh3TiD2cO4oYXv+GT77aHvV8wrh7bh7tOH8gxf7bi/c/+4ghq3Ibxf/uY/JxMVtux4m5tcxhQ0Npn3wtGdGfh2p2s3VHO6OIOzF6xpc7xM1xp3DS+H6cP6cLSjbu56WVLeIf3yKddy0wyXGk8dP5hVFW7EdvVG1zYhneXb6FXh1b8blw/LvjHl1wwojs/GdrV++TSOjuddq2y6sSy83MyeHDiUJZv2kOe48mtd4dWPHDeUADeWbaZj/1GmeRmZdDS4TQ8dP5hADxygdWBmeb3febbApObnU5amjD17MGcOawrfTrmApDuSmNsv46A7733whUjyW+ZyVnDCn2Ol53hIjvDxezfHMsf317JpJFF9vnU1pPv9yQwuth31uDDHU891jml076V5QF3yq11ZDwe9eM/G07fzrkUtMnm1lMHkJleG5Tw2ANw5ZjevL9iK2P7d6RTa+s4xx/SyVt26d3jWLFpD13zWnifGob3yKfabbzHdPpjd55uNUJOB+n8I7pz/hG+mjO4MI/nLxtBSVFbH9ucjLGvMcD4QZ198o7s1Q6At647mg6tsujYOtsnf0i3PIZ0y/PW5Qnf3n5a4gIiTbbD1xgzDZgGVsy/kc3xYc32crq3zQnpJXs6XJdv2sOgrm146tM1zFq2mRd+NZL9AcT/v/PW10lz4nSsA+0fKu9APUMRnUTi+T85yQolBhv1EYgzD+vKqwGePG44sS/De+T7jKzJa5FBuiuNr+44iQfe+5YH3/8OwNv5deWY3ryzdDPP/PxwerSzPFBjDJ+V7ggo/oIgIgwsaIPbcUlevrJ2Cd4zhviGSa4c04fRxR28P8y1U0+tc9xFt59IuivN24/z4MShbN1TSU6m9fPyF0IngdrazPQ0WmYG/mn6Cz9AccdW/ObEvpw9vNC7v78Ye/CI6JDCNnTMzQ5YxkO6K81HfDwNWEGbyEIxH/1uDC2z0snPyeSasX24ZFSRN89zv+Vmp9M1rwV3TxgU8li52RnM+vUxQfNbZaXXud6eeyMQIoJLoF2rzKBlPBzVp329ZepjYIGvI/i384bGHBaKlsYS/41AN8d2oZ3WZFlfVkF2houKg9WMvX8OV43pzY3j+4e9/71v1ka0DhyMfOiWMyxUWR1c/KcFCGnsj+Cx0VVfcDMAbVtm1gnNBGNAl9YBxb+VHW93erzprloPq7394zxneCEnDrA8vZvG9+cmv+9ARMJ6eilqn8Ogrq25ZmyfkOVcaeIV/mA47QTrBz5haKt6bbCOX9eLbJHhiqgRFhGuO7447PKfTz6ONi0y6i/oR9uWmdz7k0Ec179j/YUdOMX3t+P6+eR57rdW2Y3rh+YGCM82BD85rGuj1AuNN85/PlAsIj1FJBOYCMxoJFvCYvR9H3L4lNlekQs2ZtdDqP7bUJ57MJye/4Gq4I3HQx+UxlTf1wGGqNXHoxcOC7tsIM8VakU/K8gj9ZnDChnTr0PQjjUnzk7Ghy84zPvZGTrLzc7gzWtHM35Ql3DMDkgwW1tkusI+hqfdGF1c61UWta8VS2d6vCjIa+HTyEbCRUf2iGsnrOd+SIvC6YgnIsI5wwt5cOLQRrWjIWkU8TfGVAPXALOAFcALxpjQQe8mQqQjYwPd0p63ZAvaBH/s9uxnjOFAVU2DvCEKeN8liISiEI/Vd/jFLP21/7DullftSZYgItAqK51nfn5Enf6TQKQ7vOnTBhdw26mH1LtPNLx/w7E8/8sRddJzMsIX/z4drSeEq8b0Yd6txzN+YGeuOLYXACvuGc/TlxweH2ObKI9cMIyzhnWlV/vYRlbFg/t/OoQJQxvPE29oGu1ZyxgzE5hZb8EmhkeE63NUnF7mWr+OwB/tl0qK2rfkx92h31p89vO13PXG8piHHcaLqWcdymS/0UTBvHmo6wX7hzNG9mrHV+t2sa+yOm42RtJpHQuF+Tnel9WcROL5X39CX0p6tGVkb6tD8PGLhkd1nOZKv865/PXc1PG2mxJNtsO3qSOI91XyUPFTEWHM/XN80jbYb+b2bN+Sz7+v+2YjwB/fXklxx1bejsvV28oDlouFKWcO4tZXl0a0T++O4cWyPaT7ib3z8f5v5w3lhAGdOFDl5tyS2i6g+84e7POCW6Rk+MXge3ewbD6kS+tAxeNGiwwX+6tqgoaDApHhSmNshDF0RYkHKv4R4gy+DLnbmmfHMwLk2c/Xclz/jnRrW9cbdLKr4iDZGWneMcCB8ExH0L9zbti2Fea38DYs4RAqXBOMnAi9UX8hdop/ZnoarbLSueN039DQuYd3Ixb8G5yx/Tsy87rRHNIl/GsZDW9cO4ov15QFDV0pSlNCJ3aLEE/o3f/3va+ymjtnLKv3bVK32+A2Vlw6lPh7iGRSp6H1jErxJ9IXuoCAL60FwuP9+odgnG2Bf8MQLwIdd0BB64SLcp+OuVw4okdC61CUeKHiHyGeWL6/jniGYtY3TW6NMbiNQQTvSy+hqKoJv6M32MsnwfD3kMMh3FEiHqvT/YYyip/nnwgaKuavKM0ZFf9ICaLFztE5oahxG4yxwh/hvFgSieeflR5ZSMaVJsz+zbERdSZnBxnJ0ql1FoML2/Der4/hghHd6ZZvxez953ZxvkcQzzlunPg3OIqi1EV/JRHikXbxG8Tp8WgNULp1H68sCvzOWrXb8vzThLiHfSLpaARLJPt0bMXzlx0ZdsgoM0io5stbTmDGNUdT3CmXP5x5qFeA/V+AcoaaIrU3XBLVqChKMqHiHyXBwsfGwN8/+K62nF9+jVf8JSxPPdTMmP5EGkbxCHHnNtncfcbAsPYJV1g91ycjTZh/6wkMKWzjk24dK1FhH72tFaU+9FcSIcGiOp6Yv8GEfFuxxu7wFZGwPN+9B3zHv4cK00fs+TuEPNzO30g7TdNdaXTIzaKrHQZy1pMw8Y+iL0NRUg0V/wgJ1uHraRSM8c3zL2fF/K0O32g6PEOJdLCQTDCcIhlM028+Ofz5i5x4Ggn/zldnuCxRHb6JalQUJZnQX0mEeId6+gd0TO2/OnkOatwGt9vy4KOJeYfqT86IIubvIVij4pzuN9iiIYHwHC2UFx5pYxUu0QxhVZRUQ1/yihBvh28d7a9V5VDaU+12e0ND0Xi+ocYSRdqYuBxeebBQldNGz/S+d54+oN4XxMKJDiXK81cUpX5U/OthfVkFhfn1TzXgnXXThJ6h0O22yqaJROX5hhpKGo6YpqcJ1baxTq88mM2BGpSfj6r/CcBzvJBPKhqeUZRGQ8U/BJ5l66aedag3LZj4GkeHbyivt9rt9r7kFc0bp6E8/3Aak7Q08bZUztqDPa1EG5rxnFpIexPo+d93zmAODWMGUEVJVVT8Q7B8k7VC1WLH4uS1YR9ftXSKXChRd5val7yiIZQnHY6Yemo9rn9Hn6XkgsXJQ83YGU49oZ5UEjke3zlRnKIoddHn7hActMfY+6yB6+3w9cU71NP4etH+Gu98ySveBGtQzi0pZNJIa84Zz8RsPzvSd43SeC+m8cezBnNs3w511tp1kqgOX0VR6kc9/xB4xN+51F6woZ4+o31ChX1qjDfmH2+Cjay54/SBtMx0ccuph3DsfXOAqgBvKMfXlgEFrXn2F0eELKOzXypK46GuVwg8Uys4x6qbAJ6/2228yzsa4/uSl7/Iuh0Tu8WbYCGaNPG8VOaqrdevqA6PVJTUQsU/BLWef11hdHqt1//va077+6eA5fk7xf+A3/q51fZLXp4yZzvG0cdKsMXXAz1l+KfV9yQSyboCiqI0fTTsE4LKaku4neGUQP2XM+yFVwLl/232dz7bbu9LXtYxJwwt4OVFG+JirytIB2rAxstvO5T4f3HzcbTODr5amaIozQ8V/xB4PH/nm7Cejt1QfvLc1bVLM27e47tGr6fD16O18Yr9d8jNCur5B0r3TwoV9enSJvolFRVFaZqo+IfgYICYv+dlrlALjq/cvDdonhXzrxX9eIXa/37+YdS4Aw+rDNQX4N/oNGTMf85vx7B9X2WD1acoSl1U/EPgmU7ZKZQez//LNWVRHfP215by/bZyBtpDIOM14iVNhAM1vv0L4wd25rLRgd/G9a+1IUfeFLVvSVH7yNcPVou46bsAABlNSURBVBQlfsTU4SsiPxWRZSLiFpESv7ybRaRURFaJyDhH+ng7rVREJsdSf6LxLKFY466dU98d6i2rMPh+WzkQf8/flQZb9/h603k5GZQUtfVJkzofPPvraB9FSSViHe2zFDgL+NiZKCIDgInAQGA88KiIuETEBTwCnAwMAM63yzZJPG+nOtfRDRJZiRiP1kb7Bq0/IsLovu3DfnGq7mgf3/xrj+tDSY/8uNimKErTI6awjzFmBQQMGUwAphtjKoE1IlIKeN74KTXGrLb3m26XXR6LHYnCo/POWHp9a/SGS7zDLILVMbvsnnEU3/p2WOWd+DcGN5zUL37GAdceV8yyH/dwdJ/2cT2uoijRkahx/l2B9Y7tDXZasPQ6iMjlIrJARBZs27YtQWaGxuv5xzHs48HjaQfrpI38eOLzH0K/tev/xJGIN46dHNKlNR/9bixtcnTIqKI0Ber1/EVkNtA5QNatxpjX42+ShTFmGjANoKSkJE7BlkhtsP4vWLvTm+YOf0ndkHjE1h138Q+vfF3PPy5mKIrSTKhX/I0xJ0Rx3I2Ac1rFQjuNEOlNDo+Xv/CHWvGviZvnL2Efr1VWesihpVDr5TvDSaEO7e/oa4evoqQWiQr7zAAmikiWiPQEioF5wHygWER6ikgmVqfwjATZEDOBnPL4xfyt/+GEfTq3ya63TKRRG/8+BxFh7dRTIzuIoijNlliHep4pIhuAkcBbIjILwBizDHgBqyP3HeBqY0yNMaYauAaYBawAXrDLNkkC6Xz8RvvYYZ8oG5NHLxwW8Hjhon6+oqQ2sY72eRV4NUjeFGBKgPSZwMxY6m046gpz3Dp87Wa3Jso+BP/pm8MVf4/Hr9MpK0pqo7N6+rHwhzJ+3LUfCOzlx9vzDyfsEyjUlO7yD9tEWn9k5RVFSS5U/P04+7EvGH3fh0BgLz/e4/wPLQxvndmPfzeWd399jHfbOdkcBBbzUA2C/zoDiqKkFjq3TwA83nggnY/fuHzrf9e8FrjSpN7jdm+X47Nd1/OvK+aRjPZRFCW1UM8/BIG0M15hn3VlFTHtX9fzj7DDV8VfUVIaFf8QBArxRBP2GdGzbZ20NdvLo7LJg/+4/Ei1XMM+ipLaqPiHIFDMP5rRPmcPr7tUYySHCVQ0Kz02zz9Nv3lFSWlUAkIQr3H+LTNDd61E44P7i3/EL3mp568oKY2KfwgCi3/k6u8v1PEgK93lsx35G75xNEZRlGaHin8IAg/1jPw4Mc+bE6DOzFjDPir+ipLSqPiHIJD4RzPUMxFedjjif8moohBHUPVXlFRGx/mHIJDQRxP2iXWu/PA6fOuW6d+5dZ202tk/A9f1zvWj2bHvYIQWKorS3FDxD0Fg8Y/8OPWJfzRtg7/nH6kjH8ymQA2GoijJh4p/CALNtR/NOP86Qh0HQk3s9ua1R9O2ZWbI/TXooyipjYp/CALNuBlN2CdW8Q/U4PhP5+AU/0Fd658vSEf7KEpqox2+IagJsGZjNGGfRAz19Eff8FUUJRJU/EMQMOYfhfoH8vyHdMsLe/9wakz0AuyKoiQXGvYJQeD5/GN/yWvp3ePIdNWmWV54bDPGiTbjiqJEgIp/CAJ5/pXVkS+95e/5t8qK/2VXz19RlEhQfzEEgbz8f33xQ8TH8Z+KwZ/fjusbMj/Yw8bkk/t7P4cr/dpGKIoCKv4hidOiXfV2+F5+TG8K81uEdaxcx1PDFcf29n5Wz19RlEjQsE8D4IzvByPchuazm4+jsqpu6Em1X1GUSFDxD0G81utNC2MWtVB1GUdncOvsDMiuWyZS8TcxdjAritK80bBPCBpSHmOtS8M+iqJEQkziLyJ/FpGVIrJYRF4VkTxH3s0iUioiq0RknCN9vJ1WKiKTY6k/0cQr5g9w4/h+EZV3TgMdjh0q/oqiREKsnv97wCBjzGDgW+BmABEZAEwEBgLjgUdFxCUiLuAR4GRgAHC+XbZJEs/QyFVj+oSuy6+qSOfbD7e8vtmrKArEKP7GmHeNMdX25lzAs1jtBGC6MabSGLMGKAWOsP9KjTGrjTEHgel22SZJPD3/+vAfVhqpSPvP9ROMDrlZAKSH0QmtKEryEs8O318A/7M/d8VqDDxssNMA1vuljwh0MBG5HLgcoHv37nE0M3waNebv0PJ4NkKP/2w4H67cSte88IaWKoqSnNQr/iIyG+gcIOtWY8zrdplbgWrguXgZZoyZBkwDKCkpaZShKYnw/I/r3zGsuhIVnOmQm8W5h3dL0NEVRWku1Cv+xpgTQuWLyCXAacDxpna84kbAqTCFdhoh0psczuGXWelpUU3t4OS7KSfjChqe8Qv7aGheUZQEEuton/HAjcAZxpgKR9YMYKKIZIlIT6AYmAfMB4pFpKeIZGJ1Cs+IxYZ48e6yzazdXu6T5pTjo/u0j7mODFda0DH/dT1/VX9FURJHrDH/h4Es4D27w3GuMeYKY8wyEXkBWI4VDrraGFMDICLXALMAF/C0MWZZjDbEhcv/vbCOt+30/MN5USsWQkWY8ltmJLRuRVFSj5jE3xgTdPyiMWYKMCVA+kxgZiz1Jgp/79u5GTxcE6+6fSt3tjVPTTo8oXUripJ66Hi/EDj1OC3BV8rf8/cM3ezVviWdWgeYz0FRFCUGVPxD4BP2Sbjn77utEX9FURKJin8IfMI+iY75+6n/xUf1SGh9iqKkNir+oXDoccJj/n7bZw0rDFhOURQlHqj4h8ApyIke7aMzLCuK0pDofP4hcIZiGtrzL8xvQf/Oudx+WpOd905RlGaMin8IGtLz79upFYvW7fJuZ6W7eOf6YxJap6IoqUvKh32qatwcqKqpk75p934qDtamJ3oSzKcvOZznLgs4x52iKErcSXnP/6xHP2fJxt110k958BOf7fQwB/o/OHEo/zf964jtyMvJZFSf9jw4cShZ6a6I91cURYmElBf/QMIPsLOiymc7PYywT35OBicO6BSTPROGdq2/kIOrxvTmveVbYqpTUZTUI+XFP1xcrvBi/g29nOKN4/tz4/j+DVqnoijNn5SP+YdLRqLnd1AURWlAVNHCJD0Mz19EdB5+RVGaBSr+YRJOzF9o+LCPoihKNKj4h4lzwfMXrxjJlDMHBSyn0q8oSnNAO3zDxOn5F+S1ICcz8HBM9fwVRWkOqOcfJuIQ9WARoG5tczTmryhKs0DFP0yc/b3OeX4K2tQutPLUpBKfRkJRFKWpouIfJs75/EXEu8B66xa16+u2a5XV4HYpiqJEg4p/mDgndkv07M6KoiiJRsU/TJyhnkSv6qUoipJoVPzDJM0v7KMoitKciUn8ReReEVksIl+LyLsiUmCni4g8JCKldv4wxz6TROQ7+29SrCfQUDg9fxF0VI+iKM2aWD3/PxtjBhtjhgJvAnfY6ScDxfbf5cBjACLSFrgTGAEcAdwpIvkx2tAg6NQ+iqIkEzFJmjFmj2OzJbWLX00A/mUs5gJ5ItIFGAe8Z4wpM8bsBN4DxsdiQ7T86t8L+HDV1rDLi9+7u564f1a6tgqKojQ/Yn7DV0SmABcDu4GxdnJXYL2j2AY7LVh6oONejvXUQPfu3WM10wdjDLOWbWHWsvrnwT+uf0dG9mrnE+ZpnZ1BblY61x1fzLklhRz9pw/jap+iKEqiqddtFZHZIrI0wN8EAGPMrcaYbsBzwDXxMswYM80YU2KMKenQoUO8DmsfO/yy/Trn8stjenk7eU8b3AWwOn1/c2JfCvNz4mqboihKQ1Cv52+MOSHMYz0HzMSK6W8EujnyCu20jcAYv/Q5YR4/bkSg/V48jn8kDYeiKEpTJdbRPsWOzQnASvvzDOBie9TPkcBuY8wmYBZwkojk2x29J9lpDYqJQME9RT1hHxOg6XjruqN57epR3u33fn0ML14xMiYbFUVREkmsMf+pItIPcAM/AFfY6TOBU4BSoAL4OYAxpkxE7gXm2+XuMcaUxWhDveyrrCYnw+Udqx+N8+6ZrdPtrps3sKCNz3Zxp9woalAURWk4YhJ/Y8zZQdINcHWQvKeBp2OpNxJ2769iyN3vcvXY3vxuXH/bhvD393j6aSE8f0VRlOZG0o9T3FVxEIA3vtnkTYtOwG3PP4Jd27fK5LZTD4miLkVRlMSSkou5RNRp6x/zj2DfBbedGEFFiqIoDUfSe/7xGp1TO8xfwz6KojR/kl78PThf0oqmQfB0+OpQT0VRkoGkF/9AWh1JzN9T0tN4uFX9FUVJApJe/D04Z+aJRr8HF+YBcMmonvExSFEUpRFJzQ7fSMraLUWH3CzWTj01MQYpiqI0MCnj+TuJ5A1fRVGUZCTpxT+Q0Efm+cfPFkVRlKZC0ou/B+fSiyroiqKkOikj/gBLN+7m5Ac/obyyurFNURRFaVRSSvynvr2SFZv2sPCHnY1tiqIoSqOSUuLvIYrZHRRFUZKKpBf/gC95adBfUZQUJ+nF34PUX0RRFCVlSBnxdxLRfP76kKAoShKSmuKvkXxFUVKcpBf/QJ57NCt5KYqiJBNJL/5eYpzSWVEUJZlIAfHX6R0URVH8SXrx96y56zulsyq6oiipTdKLf8CYf8OboSiK0qRIfvEPJPWq/oqipDhxEX8RuUFEjIi0t7dFRB4SkVIRWSwiwxxlJ4nId/bfpHjUH4rAnn8EyzhqiEhRlCQk5pW8RKQbcBKwzpF8MlBs/40AHgNGiEhb4E6gBMv/XigiM4wxCZtpLdahnoqiKMlIPDz/B4Ab8Q2mTAD+ZSzmAnki0gUYB7xnjCmzBf89YHwcbAiKZ8F153z+VW5Vf0VRUpuYxF9EJgAbjTHf+GV1BdY7tjfYacHSAx37chFZICILtm3bFouZdbj9taVxPZ6iKEpzo96wj4jMBjoHyLoVuAUr5BN3jDHTgGkAJSUlUbvqGuJRFEWpS73ib4w5IVC6iBwK9AS+sUMqhcAiETkC2Ah0cxQvtNM2AmP80udEYXfYxDo9g7YdiqIkI1GHfYwxS4wxHY0xRcaYIqwQzjBjzGZgBnCxPernSGC3MWYTMAs4SUTyRSQf66lhVuynEcrORB5dURSleRLzaJ8gzAROAUqBCuDnAMaYMhG5F5hvl7vHGFOWIBuAWs892vn8tfFQFCUZiZv4296/57MBrg5S7mng6XjVWx+1o30aqkZFUZSmT/K/4Ruj565TOiuKkowkvfhrl62iKEpdkl78o/H8Ref+VxQlyUl+8Y9inzTtIFAUJclJevF321M5SATjfVwO8T9hQKe426QoitLYJL34R+P5e7T/pvH9GduvY1ztURRFaQokv/hHof6uNEv9a9zuOFujKIrSNEh+8Xf4/uGG8j1hn2qd/VNRlCQl6cXfGfcJ9ykgzfb83Sr+iqIkKYma3qHJ4NHvjbv2s2rL3rD28YR91PNXFCVZSXrP3xP22VdZHfY+tvZTo4P8FUVJUpJf/KPQb884fw37KIqSrCS/+EexT262FQ1rkeGKrzGKoihNhKSP+ZswXX+R2qeEc4Z3I01g0lFFiTNMURSlEUl+8Y9inzSBXx3bO+62KIqiNBWSP+wTRdBfI/2KoiQ7KSD+4ZVzvv+lg3wURUl2VPwD7aO+v6IoSU7yi3+Y5USncVYUJYVIfvEPd7SPzz6JsUVRFKWpkPTiH+57Wur4K4qSSiS9+EczdieaEUKKoijNiZjEX0TuEpGNIvK1/XeKI+9mESkVkVUiMs6RPt5OKxWRybHUHw6q44qiKHWJx0teDxhj7ncmiMgAYCIwECgAZotIXzv7EeBEYAMwX0RmGGOWx8GOgETW4WuV1gZDUZRkJ1Fv+E4AphtjKoE1IlIKHGHnlRpjVgOIyHS7bOLEP5px/gmxRFEUpekQj5j/NSKyWESeFpF8O60rsN5RZoOdFiy9DiJyuYgsEJEF27Zti9q4cMfsOzt81fNXFCXZqVf8RWS2iCwN8DcBeAzoDQwFNgF/iZdhxphpxpgSY0xJhw4doj5OuKN9VPAVRUkl6g37GGNOCOdAIvIP4E17cyPQzZFdaKcRIj0hRDe3j7YEiqIkN7GO9uni2DwTWGp/ngFMFJEsEekJFAPzgPlAsYj0FJFMrE7hGbHYEC/SHHEffQpQFCXZibXD9z4RGYrVR7oW+BWAMWaZiLyA1ZFbDVxtjKkBEJFrgFmAC3jaGLMsRhtCEq6Qt2mRwf6qGqB2MRdFUZRkJSaVM8ZcFCJvCjAlQPpMYGYs9UZCuCGcy0b39H7WRVwURUl2kt7FdbvDK5eeJlwyqmf9BRVFUZKApJ/eQcP3iqIodUl+8dfeW0VRlDokv/iHWU7n81cUJZVIevHXuI+iKEpdkl789YUtRVGUuiS9+K/YtDescto3oChKKpH04v/M52sb2wRFUZQmR9KLv6IoilKXpBb/g9VhvuGFjvZRFCW1SGrx37X/YGOboCiK0iRJavHvmJvN2qmnNrYZiqIoTY6kFn9FURQlMCr+iqIoKYiKv4329yqKkkqo+CuKoqQgST+fv5NJI3vgSkujc5ssNu+u5OnP1njz9AVfRVFSidQS/6OK6NWhFQB7DlT5iL+iKEoqkVJhH1dabWDfpUF+RVFSmJQS/zSH4DsbAkVRlFQjtcTfIfhpfp6/PggoipJKpJT4O0M9/o7/wII2DWyNoihK4xGz+IvItSKyUkSWich9jvSbRaRURFaJyDhH+ng7rVREJsdafyS0yHB5PzvDPt/ccRLDe+Q3pCmKoiiNSkyjfURkLDABGGKMqRSRjnb6AGAiMBAoAGaLSF97t0eAE4ENwHwRmWGMWR6LHeGSnVnb1jln8WyTk9EQ1SuKojQZYh3qeSUw1RhTCWCM2WqnTwCm2+lrRKQUOMLOKzXGrAYQkel22QYR/0xX3QedG07sG6CkoihKchOr+PcFRovIFOAA8FtjzHygKzDXUW6DnQaw3i99RIw2hI3/nP0646eiKKlKveIvIrOBzgGybrX3bwscCRwOvCAiveJhmIhcDlwO0L1793gcUlEURbGpV/yNMScEyxORK4FXjLX6+TwRcQPtgY1AN0fRQjuNEOn+9U4DpgGUlJTo5AuKoihxJNbRPq8BYwHsDt1MYDswA5goIlki0hMoBuYB84FiEekpIplYncIzYrRBURRFiZBYY/5PA0+LyFLgIDDJfgpYJiIvYHXkVgNXG2NqAETkGmAW4AKeNsYsi9EGRVEUJULENIPpLEtKSsyCBQui3v/9FVuoqnEzflCXOFqlKIrStBGRhcaYkkB5KTGr5/GHdGpsExRFUZoUKTW9g6IoimKh4q8oipKCqPgriqKkICr+iqIoKYiKv6IoSgqi4q8oipKCqPgriqKkICr+iqIoKUizeMNXRLYBP8RwiPZYcw4pei380evhi16PWpLhWvQwxnQIlNEsxD9WRGRBsFecUw29Fr7o9fBFr0ctyX4tNOyjKIqSgqj4K4qipCCpIv7TGtuAJoReC1/0evii16OWpL4WKRHzVxRFUXxJFc9fURRFcaDiryiKkoIktfiLyHgRWSUipSIyubHtaQhEpJuIfCgiy0VkmYj8n53eVkTeE5Hv7P/5drqIyEP2NVosIsMa9wzij4i4ROQrEXnT3u4pIl/a5/w/ez1p7DWn/2enfykiRY1pdyIQkTwReUlEVorIChEZmar3hoj82v6NLBWR/4pIdirdG0kr/iLiAh4BTgYGAOeLyIDGtapBqAZuMMYMAI4ErrbPezLwvjGmGHjf3gbr+hTbf5cDjzW8yQnn/4AVju0/AQ8YY/oAO4FL7fRLgZ12+gN2uWTjQeAdY0x/YAjWdUm5e0NEugLXASXGmEFYa4pPJJXuDWNMUv4BI4FZju2bgZsb265GuA6vAycCq4AudloXYJX9+QngfEd5b7lk+AMKsQTtOOBNQLDe2kz3v0+AWcBI+3O6XU4a+xzieC3aAGv8zykV7w2gK7AeaGt/128C41Lp3khaz5/aL9fDBjstZbAfTQ8DvgQ6GWM22VmbAc/Cxsl+nf4G3Ai47e12wC5jTLW97Txf77Ww83fb5ZOFnsA24J92GOxJEWlJCt4bxpiNwP3AOmAT1ne9kBS6N5JZ/FMaEWkFvAxcb4zZ48wzlvuS9GN8ReQ0YKsxZmFj29JESAeGAY8ZYw4DyqkN8QApdW/kAxOwGsQCoCUwvlGNamCSWfw3At0c24V2WtIjIhlYwv+cMeYVO3mLiHSx87sAW+30ZL5Oo4AzRGQtMB0r9PMgkCci6XYZ5/l6r4Wd3wbY0ZAGJ5gNwAZjzJf29ktYjUEq3hsnAGuMMduMMVXAK1j3S8rcG8ks/vOBYrv3PhOrM2dGI9uUcEREgKeAFcaYvzqyZgCT7M+TsPoCPOkX2yM7jgR2O0IAzRpjzM3GmEJjTBHW9/+BMeZC4EPgHLuY/7XwXKNz7PJJ4wUbYzYD60Wkn510PLCcFLw3sMI9R4pIjv2b8VyL1Lk3GrvTIZF/wCnAt8D3wK2NbU8DnfPRWI/ti4Gv7b9TsOKT7wPfAbOBtnZ5wRoV9T2wBGv0Q6OfRwKuyxjgTftzL2AeUAq8CGTZ6dn2dqmd36ux7U7AdRgKLLDvj9eA/FS9N4C7gZXAUuDfQFYq3Rs6vYOiKEoKksxhH0VRFCUIKv6KoigpiIq/oihKCqLiryiKkoKo+CuKoqQgKv6KoigpiIq/oihKCvL/cUAkcW6+f1kAAAAASUVORK5CYII=\n","text/plain":[""]},"metadata":{"tags":[]}}]},{"cell_type":"markdown","metadata":{"id":"oWnYtC0H2H8j"},"source":["### Submit to Coursera I: Preparation"]},{"cell_type":"code","metadata":{"id":"BUvKTulc2H8j"},"source":["submit_rewards1 = rewards.copy()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"XahXevMw2H8j"},"source":["# Binarized state spaces\n","\n","Use an agent to train efficiently on `CartPole-v0`. This environment has a continuous set of possible states, so you will have to group them somwhow into bins.\n","\n","The simplest way is to use `round(x, n_digits)` (or `np.round`) to round the real number to a given amount of digits. The tricky part is to get the `n_digits` right for each state to train effectively.\n","\n","Note that you don't need to convert a state to integers, but to __tuples__ for any kind of values."]},{"cell_type":"code","metadata":{"id":"FtvMgGrq2H8k"},"source":["def make_env():\n"," return gym.make('CartPole-v0').env # .env unwraps the TimeLimit wrapper\n","\n","env = make_env()\n","n_actions = env.action_space.n\n","\n","print(\"first state: %s\" % (env.reset()))\n","plt.imshow(env.render('rgb_array'))"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"5wBpnGdO2H8k"},"source":["### Play a few games\n","\n","We need to estimate observation distributions. To do so, we'll play a few games and record all states."]},{"cell_type":"code","metadata":{"id":"A1RQwyEU2H8k"},"source":["def visualize_cartpole_observation_distribution(seen_observations):\n"," seen_observations = np.array(seen_observations)\n"," \n"," # The meaning of the observations is documented in\n"," # https://github.com/openai/gym/blob/master/gym/envs/classic_control/cartpole.py\n","\n"," f, axarr = plt.subplots(2, 2, figsize=(16, 9), sharey=True)\n"," for i, title in enumerate(['Cart Position', 'Cart Velocity', 'Pole Angle', 'Pole Velocity At Tip']):\n"," ax = axarr[i // 2, i % 2]\n"," ax.hist(seen_observations[:, i], bins=20)\n"," ax.set_title(title)\n"," xmin, xmax = ax.get_xlim()\n"," ax.set_xlim(min(xmin, -xmax), max(-xmin, xmax))\n"," ax.grid()\n"," f.tight_layout()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"D9n3xz312H8k","outputId":"0ce0fe3c-9908-41cd-9bed-9fff39942bf2"},"source":["seen_observations = []\n","for _ in range(1000):\n"," seen_observations.append(env.reset())\n"," done = False\n"," while not done:\n"," s, r, done, _ = env.step(env.action_space.sample())\n"," seen_observations.append(s)\n","\n","visualize_cartpole_observation_distribution(seen_observations)"],"execution_count":null,"outputs":[{"output_type":"display_data","data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAABHgAAAKACAYAAADn488NAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzde7hlV1kn6t8n4RIpSILBEpJIoURsIC0NZYgHj1aMHQKIiTYgdIREI2mOoNimWwOi0Fw02tAIrcCJIU0QmkAjSCRgiEhJ04cACbdwkU4RgqmQECEhUIBo4Xf+WLN0987eVfu29l6z9vs+z35qrTHHHHOsMWftGvVb81LdHQAAAADG69s2ugMAAAAArI6ABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMwT1Xtqarv2c/yT1TVjnXsEgCwiVXVq6vqBats41lVdcFa9QmYPQIeYE1V1b+tqiuHkOTGqnpHVf3wKtrrqrrffpafWVXfGrb3lar6SFX9xEq3lyTdvaW7rx3av92Eqrsf2N07V7MNAGBjreecpapOqKqvVdWWBZZ9uKqevtLtLlV3/3Z3/8KwzW1Dfw+Z9naB9SPgAdZMVf1qkt9P8ttJtib57iQvT3LqCtpazoTjfd29JcnhSV6V5I1VdcRytwkAbA7rPWfp7iuS7E7y2HnrPijJA5K8frnbBZhPwAOsiao6LMnzkjytu9/c3V/r7n/o7j/r7v841Dm+qt5XVV8evin7g6q605w2uqqeVlXXJLmmqt4zLPro8O3az+yvD939j0kuTHJoku+tqsOq6jVV9bdV9bmqenZVfduwrftV1V9V1W1V9cWqesO8ftyvqs5OcnqSXxu2/2fD8uuq6seH13euqt+vqs8PP79fVXcelu2oqt1VdU5V3Tx85p9bkwEHAFZkA+csFyV58ryyJyd5e3d/qaq+v6our6pbqurTVfX4/XyGp1TVrqHuJVV17znLHjinnS9U1bOG8udW1WuHavv6++Whvz861D9uTjvfWVVfr6p7LmVcgY0n4AHWyg8luUuSt+ynzreS/PskRw71T0ryi/PqnJbkYUke0N0/MpT9wHDZ1BuyH8M3aL+QZE+Sa5L81ySHJfmeJD+aySRqX8Dy/CTvTHJEkqOHuv+H7j4/yeuS/N6w/ccssNnfSHJCkgcn+YEkxyd59pzl3zX04agkZyX5Q2cXAcCG2qg5yx8n+ZGqOiZJhi+d/m2Si6rqrkkuT/Lfk3xnkickeXlVPWB+I1X1Y0l+J8njk9wryeeSXDwsu1uSv0jy50nuneR+Sd61QF/29ffwob9/NbTxs3PqPDHJu7r7bxdYH5hBAh5grXxHki92997FKnT3Vd19RXfv7e7rkvy/mQQvc/1Od9/S3d9YxrZPqKovJ7kpk8nIT2US8jwhyTO7+6vD9l6c5EnDOv+Q5D5J7t3df9fd713G9uY6PcnzuvvmYQL0n+ZsY992njd8M/j2oV/3X+G2AIDV25A5S3dfn2Rn/nmecFKSOye5NMlPJLmuu//bsM0PJ/mTJI9boKnTk1zY3R/q7m8meWaSH6qqbUM7N3X3i4f5zVe7+/1L6V8mZxg9sapqeP+kTEIpYCQEPMBa+VKSI/d3HXpVfV9Vva2qbqqqr2Ry3fuR86pdv4JtX9Hdh3f3kd19Qnf/xdDuHTP5Vmufz2VyJk2S/FqSSvKBmjwV6+dXsN1k8u3Y/G3ce877L82bQH49ye1usAgArJuNnLNclH8OeJ6U5OLu3vel08OGS8K+PHxxdXomZwLP93/MPbp7z/CZjkpyTJLPrKBfGYKgryfZUVXfn8nZP5espC1gYwh4gLXyviTfzOR05cW8IslfJzm2u++e5FmZhCxz9Rr154v557N09vnuJDckSXff1N1P6e57J/l3mZwGvdCTLw7Un88vsI3Pr7jXAMC0beSc5c1Jjq6qE5P8dCaBTzIJi/5q+MJq38+W7v5/Fmjj/5h7DJd3fUcmc5zrM7k0/UAW6/tFmVym9aQkb+ruv1vKhwJmg4AHWBPdfVuS38rkHjOnVdW3V9Udq+qRVfV7Q7W7JflKkj3DN0MLTVrm+0KWNlGZ359vJXljkhdW1d2q6j5JfjXJa5Okqh5XVUcP1W/NZKLzjyvY/uuTPLuq7llVR2YyBq/dT30AYANt5Jylu7+W5E1J/luSz3X3lcOityX5vqp60tCXO1bVD1bVv1igmdcn+bmqevDwYIffTvL+4VKytyW5V1X9yvAgiLtV1cMWaONvM5n3zO/vazO51P1nk7xmCZ8ZmCECHmDNdPeLMwlRnp3JxOH6JE9P8qdDlf+Qyc0Ev5rkj5Ls96bJg+dmcvPBL+/vaRKL+KUkX0tybZL3ZnLjwguHZT+Y5P1VtSeT04+f0d3XLtDGq5I8YNj+ny6w/AVJrkzysSRXJ/nQUAYAzKgNnrNclMkZOP8UoHT3V5OcnMn9Az+fyX0FfzeTe/TM7/tfJPnNTO7Rc2OS7x3W29fOv07ymKGNa5KcuEAbX0/ywiT/a+jvCUP59ZnMZTrJ/1zCZwZmSHWv1dUQAAAAjFlVXZjk89397ANWBmbKojcWAwAAYPMYnsT100n+1cb2BFgJl2gBAABsclX1/CQfT/Kfu/uzG90fYPlcogUAAAAwcs7gAQAAABi50d6D58gjj+x73vOeuetd77rRXTmofe1rXzPGU2aMp8v4Tp8xnj5jPF37xveqq676Ynffcy3bPvLII3vbtm1r2eRBwTE9O+yL2WFfzA77YnbYFwtbbM4y2oBn27ZtedGLXpQdO3ZsdFcOajt37jTGU2aMp8v4Tp8xnj5jPF37xreqPrfWbW/bti1XXnnlWjc7eo7p2WFfzA77YnbYF7PDvljYYnMWl2gBAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjd8hGdwBgObade+my6p9z3N6ceYB1rjvv0avpEgAAwIZzBg8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkTtgwFNVF1bVzVX18QWWnVNVXVVHDu+rql5WVbuq6mNV9ZA5dc+oqmuGnzPmlD+0qq4e1nlZVdVafTgAAACAzWApZ/C8Oskp8wur6pgkJyf5mznFj0xy7PBzdpJXDHXvkeQ5SR6W5Pgkz6mqI4Z1XpHkKXPWu922AAAAAFjcAQOe7n5PklsWWPSSJL+WpOeUnZrkNT1xRZLDq+peSR6R5PLuvqW7b01yeZJThmV37+4ruruTvCbJaav7SAAAAACby4ruwVNVpya5obs/Om/RUUmun/N+91C2v/LdC5QDAAAAsESHLHeFqvr2JM/K5PKsdVVVZ2dy6Ve2bt2aPXv2ZOfOnevdjU3FGE+fMV6ec47bu6z6Ww898DrGf3Ucw9NnjKdrrcd3/nzFvrs9x/TssC9mh30xO+yL2WFfLM+yA54k35vkvkk+OtwP+egkH6qq45PckOSYOXWPHspuSLJjXvnOofzoBeovqLvPT3J+kmzfvr23bNmSHTt2LFadNbBz505jPGXGeHnOPPfSZdU/57i9efHV+/9Vd93pO1bRIxzD02eMp2utx3f+fMW+uz3H9OywL2aHfTE77IvZYV8sz7Iv0eruq7v7O7t7W3dvy+Syqod0901JLkny5OFpWickua27b0xyWZKTq+qI4ebKJye5bFj2lao6YXh61pOTvHWNPhsAAADAprCUx6S/Psn7kty/qnZX1Vn7qf72JNcm2ZXkj5L8YpJ09y1Jnp/kg8PP84ayDHUuGNb5TJJ3rOyjAAAAAGxOB7xEq7ufeIDl2+a87iRPW6TehUkuXKD8yiQPOlA/AAAAAFjYip6iBQAAAMDsEPAAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkDhjwVNWFVXVzVX18Ttl/rqq/rqqPVdVbqurwOcueWVW7qurTVfWIOeWnDGW7qurcOeX3rar3D+VvqKo7reUHBAAAADjYLeUMnlcnOWVe2eVJHtTd/zLJ/07yzCSpqgckeUKSBw7rvLyq7lBVd0jyh0kemeQBSZ441E2S303yku6+X5Jbk5y1qk8EAAAAsMkcMODp7vckuWVe2Tu7e+/w9ookRw+vT01ycXd/s7s/m2RXkuOHn13dfW13/32Si5OcWlWV5MeSvGlY/6Ikp63yMwEAAABsKoesQRs/n+QNw+ujMgl89tk9lCXJ9fPKH5bkO5J8eU5YNLf+7VTV2UnOTpKtW7dmz5492blz52r7z34Y4+kzxstzznF7D1xpjq2HHngd4786juHpM8bTtdbjO3++Yt/dnmN6dtgXs8O+mB32xeywL5ZnVQFPVf1Gkr1JXrc23dm/7j4/yflJsn379t6yZUt27NixHpvetHbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWXHAU1VnJvmJJCd1dw/FNyQ5Zk61o4eyLFL+pSSHV9Uhw1k8c+sDAAAAsAQrekx6VZ2S5NeS/GR3f33OokuSPKGq7lxV901ybJIPJPlgkmOHJ2bdKZMbMV8yBEPvTvLYYf0zkrx1ZR8FAAAAYHNaymPSX5/kfUnuX1W7q+qsJH+Q5G5JLq+qj1TVK5Okuz+R5I1JPpnkz5M8rbu/NZyd8/QklyX5VJI3DnWT5NeT/GpV7crknjyvWtNPCAAAAHCQO+AlWt39xAWKFw1huvuFSV64QPnbk7x9gfJrM3nKFgAAAAArsKJLtAAAAACYHQIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJE7YMBTVRdW1c1V9fE5Zfeoqsur6prhzyOG8qqql1XVrqr6WFU9ZM46Zwz1r6mqM+aUP7Sqrh7WeVlV1Vp/SAAAAICD2VLO4Hl1klPmlZ2b5F3dfWySdw3vk+SRSY4dfs5O8opkEggleU6ShyU5Pslz9oVCQ52nzFlv/rYAAAAA2I8DBjzd/Z4kt8wrPjXJRcPri5KcNqf8NT1xRZLDq+peSR6R5PLuvqW7b01yeZJThmV37+4ruruTvGZOWwAAAAAswSErXG9rd984vL4pydbh9VFJrp9Tb/dQtr/y3QuUL6iqzs7kzKBs3bo1e/bsyc6dO1f4EVgKYzx9xnh5zjlu77Lqbz30wOsY/9VxDE+fMZ6utR7f+fMV++72HNOzw76YHfbF7LAvZod9sTwrDXj+SXd3VfVadGYJ2zo/yflJsn379t6yZUt27NixHpvetHbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWelTtL4wXF6V4c+bh/Ibkhwzp97RQ9n+yo9eoBwAAACAJVppwHNJkn1PwjojyVvnlD95eJrWCUluGy7luizJyVV1xHBz5ZOTXDYs+0pVnTA8PevJc9oCAAAAYAkOeIlWVb0+yY4kR1bV7kyehnVekjdW1VlJPpfk8UP1tyd5VJJdSb6e5OeSpLtvqarnJ/ngUO953b3vxs2/mMmTug5N8o7hBwAAAIAlOmDA091PXGTRSQvU7SRPW6SdC5NcuED5lUkedKB+AAAAALCwlV6iBQAAAMCMEPAAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjNyqAp6q+vdV9Ymq+nhVvb6q7lJV962q91fVrqp6Q1Xdaah75+H9rmH5tjntPHMo/3RVPWJ1HwkAAABgc1lxwFNVRyX55STbu/tBSe6Q5AlJfjfJS7r7fkluTXLWsMpZSW4dyl8y1EtVPWBY74FJTkny8qq6w0r7BQAAALDZrPYSrUOSHFpVhyT59iQ3JvmxJG8all+U5LTh9anD+wzLT6qqGsov7u5vdvdnk+xKcvwq+wUAAACwaVR3r3zlqmckeWGSbyR5Z5JnJLliOEsnVXVMknd094Oq6uNJTunu3cOyzyR5WJLnDuu8dih/1bDOmxbY3tlJzk6SrVu3PvSCCy7Ili1bVtx/DmzPnj3GeMqM8fJcfcNty6q/9dDkC9/Yf53jjjpsFT3CMTx9xni69o3viSeeeFV3b19te/PnKxdffPGq+3iwcUzPDvtidtgXs8O+mB32xcIWm7McstIGq+qITM6+uW+SLyf5H5lcYjU13X1+kvOTZPv27b1ly5bs2LFjmpvc9Hbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWc0lWj+e5LPd/bfd/Q9J3pzk4UkOHy7ZSpKjk9wwvL4hyTFJMiw/LMmX5pYvsA4AAAAAB7CagOdvkpxQVd8+3EvnpCSfTPLuJI8d6pyR5K3D60uG9xmW/2VPrg+7JMkThqds3TfJsUk+sIp+AQAAAGwqK75Eq7vfX1VvSvKhJHuTfDiT05EvTXJxVb1gKHvVsMqrkvxxVe1KcksmT85Kd3+iqt6YSTi0N8nTuvtbK+0XAAAAwGaz4oAnSbr7OUmeM6/42izwFKzu/rskj1uknRdmcrNmAAAAAJZptY9JBwAAAGCDCXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARm5VAU9VHV5Vb6qqv66qT1XVD1XVParq8qq6ZvjziKFuVdXLqmpXVX2sqh4yp50zhvrXVNUZq/1QAAAAAJvJas/geWmSP+/u70/yA0k+leTcJO/q7mOTvGt4nySPTHLs8HN2klckSVXdI8lzkjwsyfFJnrMvFAIAAADgwFYc8FTVYUl+JMmrkqS7/767v5zk1CQXDdUuSnLa8PrUJK/piSuSHF5V90ryiCSXd/ct3X1rksuTnLLSfgEAAABsNtXdK1ux6sFJzk/yyUzO3rkqyTOS3NDdhw91Ksmt3X14Vb0tyXnd/d5h2buS/HqSHUnu0t0vGMp/M8k3uvtFC2zz7EzO/snWrVsfesEFF2TLli0r6j9Ls2fPHmM8ZcZ4ea6+4bZl1d96aPKFb+y/znFHHbaKHuEYnj5jPF37xvfEE0+8qru3r7a9+fOViy++eNV9PNg4pmeHfTE77IvZYV/MDvtiYYvNWQ5ZRZuHJHlIkl/q7vdX1Uvzz5djJUm6u6tqZQnSArr7/ExCpWzfvr23bNmSHTt2rFXzLGDnzp3GeMqM8fKcee6ly6p/znF78+Kr9/+r7rrTd6yiRziGp88YT9daj+/8+Yp9d3uO6dlhX8wO+2J22Bezw75YntXcg2d3kt3d/f7h/ZsyCXy+MFx6leHPm4flNyQ5Zs76Rw9li5UDAAAAsAQrDni6+6Yk11fV/YeikzK5XOuSJPuehHVGkrcOry9J8uThaVonJLmtu29MclmSk6vqiOHmyicPZQAAAAAswWou0UqSX0ryuqq6U5Jrk/xcJqHRG6vqrCSfS/L4oe7bkzwqya4kXx/qprtvqarnJ/ngUO953X3LKvsFAAAAsGmsKuDp7o8kWehmhCctULeTPG2Rdi5McuFq+gIAAACwWa3mHjwAAAAAzAABDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACN3yEZ3AAAAYNZtO/fSqbZ/znF7c+YUt3HdeY+eWtvAbHAGDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgdstEdANho2869dCrtXnfeo6fSLgAAwHzO4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkVh3wVNUdqurDVfW24f19q+r9VbWrqt5QVXcayu88vN81LN82p41nDuWfrqpHrLZPAAAAAJvJWpzB84wkn5rz/neTvKS775fk1iRnDeVnJbl1KH/JUC9V9YAkT0jywCSnJHl5Vd1hDfoFAAAAsCmsKuCpqqOTPDrJBcP7SvJjSd40VLkoyWnD61OH9xmWnzTUPzXJxd39ze7+bJJdSY5fTb8AAAAANpPq7pWvXPWmJL+T5G5J/kOSM5NcMZylk6o6Jsk7uvtBVfXxJKd09+5h2WeSPCzJc4d1XjuUv2pY503zNpeqOjvJ2UmydevWh15wwQXZsmXLivvPge3Zs8cYT5kxXp6rb7htWfW3Hpp84RtT6swBHHfUYRuz4XXmGJ4+Yzxd+8b3xBNPvKq7t6+2vfnzlYsvvnjVfTzYOKZnh32xdMudgyzXtOcsm2Veshb8vZgd9sXCFpuzHLLSBqvqJ5Lc3N1XVdWO1XRuqbr7/CTnJ8n27dt7y5Yt2bFjXTa9ae3cudMYT5kxXp4zz710WfXPOW5vXnz1in/Vrcp1p+/YkO2uN8fw9Bnj6Vrr8Z0/X7Hvbs8xPTvsi6Vb7hxkuaY9Z9ks85K14O/F7LAvlmc1v0EenuQnq+pRSe6S5O5JXprk8Ko6pLv3Jjk6yQ1D/RuSHJNkd1UdkuSwJF+aU77P3HUAAAAAOIAV34Onu5/Z3Ud397ZMbpL8l919epJ3J3nsUO2MJG8dXl8yvM+w/C97cn3YJUmeMDxl675Jjk3ygZX2CwAAAGCzmcY5gL+e5OKqekGSDyd51VD+qiR/XFW7ktySSSiU7v5EVb0xySeT7E3ytO7+1hT6BQAAAHBQWpOAp7t3Jtk5vL42CzwFq7v/LsnjFln/hUleuBZ9AQAAANhsVvWYdAAAAAA2noAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABG7pCN7gBwcNp27qUb3QUAAIBNwxk8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGzk2WAQAADnLr8QCM68579NS3ASzOGTwAAAAAIyfgAQAAABg5l2gBAACjth6XHwHMOmfwAAAAAIycgAcAAABg5AQ8AAAAACO34oCnqo6pqndX1Ser6hNV9Yyh/B5VdXlVXTP8ecRQXlX1sqraVVUfq6qHzGnrjKH+NVV1xuo/FgAAAMDmsZozePYmOae7H5DkhCRPq6oHJDk3ybu6+9gk7xreJ8kjkxw7/Jyd5BXJJBBK8pwkD0tyfJLn7AuFAAAAADiwFQc83X1jd39oeP3VJJ9KclSSU5NcNFS7KMlpw+tTk7ymJ65IcnhV3SvJI5Jc3t23dPetSS5PcspK+wUAAACw2VR3r76Rqm1J3pPkQUn+prsPH8orya3dfXhVvS3Jed393mHZu5L8epIdSe7S3S8Yyn8zyTe6+0ULbOfsTM7+ydatWx96wQUXZMuWLavuP4vbs2ePMZ6yg3WMr77hto3uQpJk66HJF76xMds+7qjDNmbD6+xgPYZniTGern3je+KJJ17V3dtX2978+crFF1+86j4ebBzTs+Ng2RezMu9YjY2cs6yVg2Xuc7D8vTgY2BcLW2zOcshqG66qLUn+JMmvdPdXJpnORHd3Va0+Qfrn9s5Pcn6SbN++vbds2ZIdO3asVfMsYOfOncZ4yg7WMT7z3Es3ugtJknOO25sXX73qX3Urct3pOzZku+vtYD2GZ4kxnq61Ht/58xX77vYc07PjYNkXszLvWI2NnLOslYNl7nOw/L04GNgXy7Oqp2hV1R0zCXde191vHoq/MFx6leHPm4fyG5IcM2f1o4eyxcoBAAAAWIIVR8TD5VevSvKp7v4vcxZdkuSMJOcNf751TvnTq+riTG6ofFt331hVlyX57Tk3Vj45yTNX2i8AAADW37Ypn0l13XmPnmr7MHarOQfw4UmelOTqqvrIUPasTIKdN1bVWUk+l+Txw7K3J3lUkl1Jvp7k55Kku2+pqucn+eBQ73ndfcsq+gUAAACwqaw44BlullyLLD5pgfqd5GmLtHVhkgtX2hcAAGB2TfvMDgBWeQ8eAAAAADaegAcAAABg5AQ8AAAAACMn4AEAAAAYudU8RQsAAADWhceww/4JeAAAYJPzlCuA8XOJFgAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAA8oKzcAACAASURBVIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjNwhG90BAABgcdvOvXRqbZ9z3N6cOcX2YUz2/V2b5t+L68579FTahcQZPAAAAACjJ+ABAAAAGDmXaAFMyTROqXdaLwAAsBABD2xy07yuHwAAgPXhEi0AAACAkRPwAAAAAIzczFyiVVWnJHlpkjskuaC7z9vgLgEAwAG53BlYqmn/vnC/xs1tJgKeqrpDkj9M8q+T7E7ywaq6pLs/ubE9g9liAsm0jgGTAQCA8RMgbW4zEfAkOT7Jru6+Nkmq6uIkpyYR8DBKy/nFes5xe3Om4IYNtprJwGLHsAkAMCt8QQLAZlDdvdF9SFU9Nskp3f0Lw/snJXlYdz99Xr2zk5w9vL1/ki8l+eJ69nUTOjLGeNqM8XQZ3+kzxtNnjKdr3/jep7vvudrGFpivfHq1bR6EHNOzw76YHfbF7LAvZod9sbAF5yyzcgbPknT3+UnO3/e+qq7s7u0b2KWDnjGePmM8XcZ3+ozx9Bnj6Vrr8Z0/X+H2HNOzw76YHfbF7LAvZod9sTyz8hStG5IcM+f90UMZAAAAAAcwKwHPB5McW1X3rao7JXlCkks2uE8AAAAAozATl2h1996qenqSyzJ5TPqF3f2JJazq9OfpM8bTZ4yny/hOnzGePmM8XcZ3/Rnz2WFfzA77YnbYF7PDvliGmbjJMgAAAAArNyuXaAEAAACwQgIeAAAAgJEbVcBTVY+rqk9U1T9W1aKPSquq66rq6qr6SFVduZ59HLtljPEpVfXpqtpVVeeuZx/HrqruUVWXV9U1w59HLFLvW8Mx/JGqctPxAzjQMVlVd66qNwzL319V29a/l+O2hDE+s6r+ds5x+wsb0c+xqqoLq+rmqvr4Isurql42jP/Hquoh693HsVvCGO+oqtvmHMO/td593Eyq6j9X1V8Px/Nbqurwje7TZrXU+R/TYV49Ow707wTro6qOqap3V9Unh99Nz9joPo3FqAKeJB9P8tNJ3rOEuid294O72z9Sy3PAMa6qOyT5wySPTPKAJE+sqgesT/cOCucmeVd3H5vkXcP7hXxjOIYf3N0/uX7dG58lHpNnJbm1u++X5CVJfnd9ezluy/h7/4Y5x+0F69rJ8Xt1klP2s/yRSY4dfs5O8op16NPB5tXZ/xgnyf+ccww/bx36tJldnuRB3f0vk/zvJM/c4P5sZsuZY7OGzKtnzqtz4H8nmL69Sc7p7gckOSHJ0/y9WJpRBTzd/anu/vRG9+NgtsQxPj7Jru6+trv/PsnFSU6dfu8OGqcmuWh4fVGS0zawLweLpRyTc8f9TUlOqqpaxz6Onb/3U9bd70lyy36qnJrkNT1xRZLDq+pe69O7g8MSxph11N3v7O69w9srkhy9kf3ZzMyxN5R/X2eIfydmQ3ff2N0fGl5/Ncmnkhy1sb0ah1EFPMvQSd5ZVVdV1dkb3ZmD0FFJrp/zfnf8hVuOrd194/D6piRbF6l3l6q6sqquqCoh0P4t5Zj8pzrDfyhuS/Id69K7g8NS/97/m+FyizdV1THr07VNw+/e9fFDVfXRqnpHVT1wozuzifx8kndsdCdgA/jdDvsx3FbhXyV5/8b2ZBwO2egOzFdVf5HkuxZY9Bvd/dYlNvPD3X1DVX1nksur6q+HNJas2RizH/sb47lvururqhdp5j7Dcfw9Sf6yqq7u7s+sdV9hDf1Zktd39zer6t9lcsbUj21wn2A5PpTJ7949VfWoJH+aySVxrNBS5hxV9RuZnI7/uvXs22Zj/geMTVVtSfInSX6lu7+y0f0Zg5kLeLr7x9egjRuGP2+uqrdkcuqjgGewBmN8Q5K538wfPZQx2N8YV9UXqupe3X3jcHnFzYu0se84vraqdmaSXAt4FraUY3Jfnd1VdUiSw5J8aX26d1A44Bh399zxvCDJ761DvzYTv3unbO7ksbvfXlUvr6oju/uLG9mvMTvQnKOqzkzyE0lO6u7FvvBgDazFHJup8LsdFlBVd8wk3Hldd795o/szFgfdJVpVddequtu+10lOzuTGcaydDyY5tqruW1V3SvKEJJ7ytHSXJDljeH1Gktt9a1ZVR1TVnYfXRyZ5eJJPrlsPx2cpx+TccX9skr/0n4llOeAYz7sfzE9mcr00a+eSJE8enqZ1QpLb5lzuyRqoqu/ad2+uqjo+k3mSIHhKquqUJL+W5Ce7++sb3R/YIObVMM/wb/Grknyqu//LRvdnTEYV8FTVT1XV7iQ/lOTSqrpsKL93Vb19qLY1yXur6qNJPpDk0u7+843p8fgsZYyH+5c8PcllmfwH7o3d/YmN6vMInZfkX1fVNUl+fHifqtpeVfueOvQvklw5HMfvTnJedwt4FrHYMVlVz6uqfU8ge1WS76iqXUl+NYs/vYwFLHGMf3l4lOVHk/xykjM3prfjVFWvT/K+JPevqt1VdVZVPbWqnjpUeXuSa5PsSvJHSX5xg7o6WksY48cm+fhwDL8syRMEwVP1B0nulsnl9B+pqldudIc2q8Xmf0yfefVsWejfiY3u0yb18CRPSvJjw78PHxkuneYAyrwFAAAAYNxGdQYPAAAAALcn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAPMtKq6rqp+fKP7MV9V7ayqX9jofgAA+7cRc4mqem5VvXaVbZxeVe9cqz5NU1W9sqp+c6P7AZudgAdYF8Pk6htVtaeqvlBVr66qLeuw3ftW1T9W1SumvS0AYHrWcy5RVUdV1d6q+t4Flr2lql40je3O1d2v6+6T52y3q+p+q2lzsXlRVe2oqt37We8dw7jvqap/qKq/n/P+ld391O5+/mr6BqyegAdYT4/p7i1JHpJke5Jnr8M2n5zk1iQ/U1V3XoftAQDTsy5zie6+Icm7kjxpbnlV3SPJo5JcNI3troMVzYu6+5HdvWUY+9cl+b1977v7qdPqLLA8Ah5g3Q2TpnckeVCSVNVPVtUnqurLw6VP/2Kh9arq26rq3Kr6TFV9qareOEy0FlRVlclE5tlJ/iHJY+Yt76p6alVdM2z7D4d1UlV3qKoXV9UXq+qzVfX0of4hi2zr56vqU1V1a1VdVlX3WcnYAAAHtk5ziYsyL+BJ8oQkn+zuq6vq3lX1J1X1t8Nc4ZcX6+/++ldVx1TVm4d2vlRVfzCUn1lV7x1ev2eo/tHhrJmfqaqPV9Vj5rRzx2He8q8W6cOC86Kquuswlveec1bOvRf7LIu0/eqqesHwekdV7a6qZw39ua6qTl9Oe8DKCHiAdVdVx2Ty7deHq+r7krw+ya8kuWeStyf5s6q60wKr/lKS05L8aJJ7Z/IN1B/uZ1M/nOToJBcneWOSMxao8xNJfjDJv0zy+CSPGMqfkuSRSR6cybeEp+3n85ya5FlJfnr4DP9z+EwAwBSs01ziLUmOrKofnlP2pCQXVdW3JfmzJB9NclSSk5L8SlU9Yn4j++tfVd0hyduSfC7JtqGti+e30d0/Mrz8geGsmTckeU2Sn51T7VFJbuzuDy/yeRacF3X31zKZ83x+zlk5n1+kjaX6riRHDp/njCTnV9X9V9kmcAACHmA9/WlVfTnJe5P8VZLfTvIzSS7t7su7+x+SvCjJoUn+rwXWf2qS3+ju3d39zSTPTfLYxc6qyWRC8Y7uvjXJf09ySlV957w653X3l7v7b5K8O5NAJ5mEPS8dtnVrkvP287memuR3uvtT3b13+FwPdhYPAKy5dZtLdPc3kvyPTM56SVUdm+ShmcwpfjDJPbv7ed399919bZI/yuQMn/n217/jMwma/mN3f627/66737vEsXhtkkdV1d2H909K8sf7qb+UedFa+s3u/mZ3/1WSSzOZWwFTJOAB1tNp3X14d9+nu39xmDjdO5NvrZIk3f2PSa7P5Buf+e6T5C3D6c1fTvKpJN9KsnV+xao6NMnjMrlOPN39viR/k+Tfzqt605zXX0+y72aN9x76sc/c1wv166Vz+nVLklrkMwAAK7duc4nBRUkeV1V3ySRAuay7bx7aufe+doa2nrVIO/vr3zFJPjd8QbQsw1k2/yvJv6mqwzM5C+d1C9Vdxrxordw6nBm0z+cyGQdgigQ8wEb7fCaTpCT/dH34MUluWKDu9UkeOUzs9v3cZbgOf76fSnL3JC+vqpuq6qb882nCS3FjJqcx73PMfupen+TfzevXod39/y1xWwDAyk1rLpFMzhS6JcmpmVwOddGcdj47r527dfejltm/65N8937ORj6Qi4Z+PS7J+/bzOQ40L+oVbn8xRwz39tnnuzMZB2CKBDzARntjkkdX1UlVdcck5yT5ZpKFwpFXJnnhvkufquqew/1vFnJGkguTHJfJZVcPTvLwJD9QVcctsV/PqMljUg9P8uv7qfvKJM+sqgcO/Tqsqh63hG0AAKs3rblEurszudfN7yY5PJP77iTJB5J8tap+vaoOrcnDGR5UVT+4zP59IJMvlc6rqrtW1V2q6uGLdOcLSb5nXtmfZnKvwGcM/VzMgeZFX0jyHVV12H7aWK7/NNxn6P/O5J6H/2MN2wYWIOABNlR3fzqTb57+a5IvZvJEh8d0998vUP2lSS5J8s6q+mqSK5I8bH6lqtp3s8Pf7+6b5vxcleTPs7SzeP4oyTuTfCzJhzO5IeLeTE7jnv8Z3pLJxO/iqvpKko9ncpo0ADBl05hLzPOaTM5AecNw355097cyCS0enOSzw3YvSHK7gGR//RvaeUyS+2VyydTuTO7Zs5DnZnKD5y9X1eOHtr+R5E+S3DfJmxdaaSnzou7+60xuBH3t0P5qL6e6KZMbWH8+k8vCnjpsA5iimoTSAOxPVT0yySu7242TAYCZUVW/leT7uvtnD1h5HVTVjiSv7e6jD1QXWFvO4AFYwHC69aOq6pDhm6/nZPK4VACAmVBV90hyVpLzN7ovwMYT8AAsrJL8p0xOL/5wJk/Z+K0N7REAwKCqnpLJTZrf0d3v2ej+ABvPJVoAAAAAI+cMHgAAAICRO2SjO7BSRx55ZG/btm2ju3FQ+drXvpa73vWuG92NTcFYrx9jvb6M9/ox1mvvqquu+mJ333Mt2xzrfMXxtTTGaWmM09IYp6UxTktjnJZmrOO02JxltAHPtm3bcuWVV250Nw4qO3fuzI4dOza6G5uCsV4/xnp9Ge/1Y6zXXlV9bq3bHOt8xfG1NMZpaYzT0hinpTFOS2Oclmas47TYnMUlWgAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQOGPBU1YVVdXNVfXyBZedUVVfVkcP7qqqXVdWuqvpYVT1kTt0zquqa4eeMOeUPraqrh3VeVlW1Vh8OAAAAYDNYyhk8r05yyvzCqjomyclJ/mZO8SOTHDv8nJ3kFUPdeyR5TpKHJTk+yXOq6ohhnVckecqc9W63LQAAAAAWd8CAp7vfk+SWBRa9JMmvJek5ZacmeU1PXJHk8Kq6V5JHJLm8u2/p7luTXJ7klGHZ3bv7iu7uJK9JctrqPhIAAADA5nLISlaqqlOT3NDdH513RdVRSa6f8373ULa/8t0LlC+23bMzOTMoW7duzc6dO1fSfRaxZ88eY7pOjPX6Mdbry3ivH2M9uw6G+Yrja2mM09IYp6UxTktjnJbGOC3NwTZOyw54qurbkzwrk8uz1lV3n5/k/CTZvn1779ixY727cFDbuXNnjOn6MNbrx1ivL+O9foz17DoY5iuOr6UxTktjnJbGOC2NcVoa47Q0B9s4reQpWt+b5L5JPlpV1yU5OsmHquq7ktyQ5Jg5dY8eyvZXfvQC5QAAAAAs0bIDnu6+uru/s7u3dfe2TC6rekh335TkkiRPHp6mdUKS27r7xiSXJTm5qo4Ybq58cpLLhmVfqaoThqdnPTnJW9foswEAAABsCkt5TPrrk7wvyf2randVnbWf6m9Pcm2SXUn+KMkvJkl335Lk+Uk+OPw8byjLUOeCYZ3PJHnHyj4KAAAAwOZ0wHvwdPcTD7B825zXneRpi9S7MMmFC5RfmeRBB+oHAAAAAAtbyT14AAAAAJghAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+Dh/2/v/oM1q+v7gL8/A0FNaARNZmuBBmZkzCAYE7dIx06ySCKrZoR2jMWxcUlImUwxNQ0zEeKktCozWJMYbZO0TCDB1LpSEgdGSZAgd0xmAhKVqoCGDf6CoqSCmh2N6ZpP/7iHeLve3T3cH89zz3Nfr5k79znf8+N+7mfPvc/Z9z0/AAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmLgjBjxVdW1VPVJVn1gx9paq+mRVfayq3lNVx62Yd3lV7auqT1XVuSvGdw9j+6rqshXjp1TVncP4u6vqmI38BgEAAAAW3ZgzeH43ye6Dxm5Ncnp3PyfJXyS5PEmq6rQkFyR59rDOb1bVUVV1VJLfSPLiJKcleeWwbJK8Oclbu/uZSR5LctG6viMAAACAbeaIAU93fzDJoweNvb+7DwyTdyQ5cXh9XpK93f2N7v50kn1Jzhw+9nX3A939t0n2JjmvqirJC5PcMKx/XZLz1/k9AQAAAGwrR2/ANn46ybuH1ydkOfB53IPDWJJ8/qDx5yd5epIvrwiLVi7/barq4iQXJ8mOHTuytLS03tpZYf/+/Xo6I3o9O3o9W/o9O3q9dS3C8Yr9axx9GkefxtGncfRpHH0aZ9H6tK6Ap6pen+RAknduTDmH191XJ7k6SXbu3Nm7du2axZfdNpaWlqKns6HXs6PXs6Xfs6PXW9ciHK/Yv8bRp3H0aRx9GkefxtGncRatT2sOeKrqwiQ/nuSc7u5h+KEkJ61Y7MRhLIcY/1KS46rq6OEsnpXLAwAAADDCmh6TXlW7k/xikpd199dWzLopyQVV9aSqOiXJqUk+lOSuJKcOT8w6Jss3Yr5pCIZuT/LyYf09SW5c27cCAAAAsD2NeUz6u5L8WZJnVdWDVXVRkv+S5B8kubWq7q6q/5ok3X1PkuuT3Jvkj5Jc0t3fHM7OeU2SW5Lcl+T6YdkkeV2SX6iqfVm+J881G/odAgAAACy4I16i1d2vXGX4kCFMd1+Z5MpVxm9OcvMq4w9k+SlbAAAAAKzBmi7RAgAAAGDrEPAAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATNwRA56quraqHqmqT6wYe1pV3VpV9w+fjx/Gq6reXlX7qupjVfVDK9bZMyx/f1XtWTH+vKr6+LDO26uqNvqbBAAAAFhkY87g+d0kuw8auyzJbd19apLbhukkeXGSU4ePi5P8VrIcCCW5Isnzk5yZ5IrHQ6FhmX+9Yr2DvxYAAAAAh3HEgKe7P5jk0YOGz0ty3fD6uiTnrxh/Ry+7I8lxVfWMJOcmubW7H+3ux5LcmmT3MO+7u/uO7u4k71ixLQAAAABGOHqN6+3o7oeH119IsmN4fUKSz69Y7sFh7HDjD64yvqqqujjLZwZlx44dWVpaWmP5rGb//v16OiN6PTt6PVv6PTt6vXUtwvGK/WscfRpHn8bRp3H0aRx9GmfR+rTWgOfvdXdXVW9EMSO+1tVJrk6SnTt39q5du2bxZbeNpaWl6Ols6PXs6PVs6ffs6PXWtQjHK/avcfRpHH0aR5/G0adx9GmcRevTWp+i9cXh8qoMnx8Zxh9KctKK5U4cxg43fuIq4wAAAACMtNaA56Ykjz8Ja0+SG1eMv3p4mtZZSb4yXMp1S5IXVdXxw82VX5TklmHeV6vqrOHpWa9esS0AAAAARjjiJVpV9a4ku5J8T1U9mOWnYV2V5PqquijJZ5O8Ylj85iQvSbIvydeS/FSSdPejVfXGJHcNy72hux+/cfO/yfKTup6S5A+HDwAAAABGOmLA092vPMSsc1ZZtpNccojtXJvk2lXG/zzJ6UeqAwAAAIDVrfUSLQAAAAC2CAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMStK+Cpqn9XVfdU1Seq6l1V9eSqOqWq7qyqfVX17qo6Zlj2ScP0vmH+ySu2c/kw/qmqOnd93xIAAADA9rLmgKeqTkjyb5Ps7O7TkxyV5IIkb07y1u5+ZpLHklw0rHJRkseG8bcOy6WqThvWe3aS3Ul+s6qOWmtdAAAAANvNei/ROjrJU6rq6CTfmeThJC9McsMw/7ok5w+vzxumM8w/p6pqGN/b3d/o7k8n2ZfkzHXWBQAAALBtVHevfeWq1ya5MsnXk7w/yWuT3DGcpZOqOinJH3b36VX1iSS7u/vBYd5fJnl+kv8wrPPfh/FrhnVuWOXrXZzk4iTZsWPH8/bu3bvm2vl2+/fvz7HHHjvvMrYFvZ4dvZ4t/Z4dvd54Z5999oe7e+d6t7MIxyv2r3H0aRx9GkefxtGncfRpnKn26VDHLEevdYNVdXyWz745JcmXk/zPLF9itWm6++okVyfJzp07e9euXZv55badpaWl6Ols6PXs6PVs6ffs6PXWtQjHK/avcfRpHH0aR5/G0adx9GmcRevTei7R+tEkn+7uv+ru/5vkD5K8IMlxwyVbSXJikoeG1w8lOSlJhvlPTfKlleOrrAMAAADAEawn4PlckrOq6juHe+mck+TeJLcnefmwzJ4kNw6vbxqmM8z/QC9fH3ZTkguGp2ydkuTUJB9aR10AAAAA28qaL9Hq7jur6oYkH0lyIMlHs3w68vuS7K2qNw1j1wyrXJPk96pqX5JHs/zkrHT3PVV1fZbDoQNJLunub661LgAAAIDtZs0BT5J09xVJrjho+IGs8hSs7v6bJD9xiO1cmeWbNQMAAADwBK33MekAAAAAzJmABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDi1hXwVNVxVXVDVX2yqu6rqn9aVU+rqlur6v7h8/HDslVVb6+qfVX1sar6oRXb2TMsf39V7VnvNwUAAACwnaz3DJ63Jfmj7v7+JD+Q5L4klyW5rbtPTXLbMJ0kL05y6vBxcZLfSpKqelqSK5I8P8mZSa54PBQCAAAA4MjWHPBU1VOT/HCSa5Kku/+2u7+c5Lwk1w2LXZfk/OH1eUne0cvuSHJcVT0jyblJbu3uR7v7sSS3Jtm91roAAAAAtpv1nMFzSpK/SvI7VfXRqvrtqvquJDu6++FhmS8k2TG8PiHJ51es/+AwdqhxAAAAAEao7l7bilU7k9yR5AXdfWdVvS3JV5P8XHcft2K5x7r7+Kp6b5KruvtPh/Hbkrwuya4kT+7uNw3jv5zk6939K6t8zYuzfHlXduzY8by9e/euqXZWt3///hx77LHzLmNb0OvZ0evZ0u/Z0euNd/bZZ3+4u3eudzuLcLxi/xpHn8bRp3H0aRx9Gkefxplqnw51zHL0Orb5YJIHu/vOYfqGLN9v54tV9Yzufni4BOuRYf5DSU5asf6Jw9hDWQ55Vo4vrfYFu/vqJFcnyc6dO3vXrl2rLcYaLS0tRU9nQ69nR69nS79nR6+3rkU4XrF/jaNP4+jTOPo0jj6No0/jLFqf1nyJVnd/Icnnq+pZw9A5Se5NclOSx5+EtSfJjcPrm5K8enia1llJvjJcynVLkhdV1fHDzZVfNIwBAAAAMMJ6zuBJkp9L8s6qOibJA0l+Ksuh0fVVdVGSzyZ5xbDszUlekmRfkq8Ny6a7H62qNya5a1juDd396DrrAgAAANg21hXwdPfdSVa7Vv2cVZbtJJccYjvXJrl2PbUAAAAAbFfreYoWAAAAAFuAgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAXQQFsQAADzFJREFUAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEzc0fMuAAAAYBGcfNn71rzupWccyIWHWf8zV710zdsGtod1n8FTVUdV1Uer6r3D9ClVdWdV7auqd1fVMcP4k4bpfcP8k1ds4/Jh/FNVde56awIAAADYTjbiEq3XJrlvxfSbk7y1u5+Z5LEkFw3jFyV5bBh/67Bcquq0JBckeXaS3Ul+s6qO2oC6AAAAALaFdQU8VXVikpcm+e1hupK8MMkNwyLXJTl/eH3eMJ1h/jnD8ucl2dvd3+juTyfZl+TM9dQFAAAAsJ2s9wyeX0/yi0n+bph+epIvd/eBYfrBJCcMr09I8vkkGeZ/ZVj+78dXWQcAAACAI1jzTZar6seTPNLdH66qXRtX0mG/5sVJLk6SHTt2ZGlpaRZfdtvYv3+/ns6IXs+OXs+Wfs+OXm9di3C8Yv8aR5/G2U59uvSMA0de6BB2POXw62+XHh7Jdtqf1kOfxlm0Pq3nKVovSPKyqnpJkicn+e4kb0tyXFUdPZylc2KSh4blH0pyUpIHq+roJE9N8qUV449buc7/p7uvTnJ1kuzcubN37dq1jvI52NLSUvR0NvR6dvR6tvR7dvR661qE4xX71zj6NM526tPhnoJ1JJeecSC/+vFD//fsM6/ateZtL5LttD+thz6Ns2h9WvMlWt19eXef2N0nZ/kmyR/o7lcluT3Jy4fF9iS5cXh90zCdYf4HuruH8QuGp2ydkuTUJB9aa10AAAAA2816zuA5lNcl2VtVb0ry0STXDOPXJPm9qtqX5NEsh0Lp7nuq6vok9yY5kOSS7v7mJtQFAAAAsJA2JODp7qUkS8PrB7LKU7C6+2+S/MQh1r8yyZUbUQsAAADAdrPep2gBAAAAMGcCHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAE7cZj0kHAADYck6+7H3zLgFg0ziDBwAAAGDiBDwAAAAAE+cSLQAAgC1usy8v+8xVL93U7QObzxk8AAAAABMn4AEAAACYOAEPAAAAwMS5Bw+wsE6+7H259IwDuXATr1l3vToAALAVCHiAudnsmwUCAABsFy7RAgAAAJg4AQ8AAADAxAl4AAAAACbOPXgA1mGz7yPkJs4AAMAYzuABAAAAmDhn8ACH5ClXAAAA0yDgAQAAtgR/XAJYO5doAQAAAEycM3gAAAC2uc08e8pDI2A2nMEDAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDi1hzwVNVJVXV7Vd1bVfdU1WuH8adV1a1Vdf/w+fhhvKrq7VW1r6o+VlU/tGJbe4bl76+qPev/tgAAAAC2j/WcwXMgyaXdfVqSs5JcUlWnJbksyW3dfWqS24bpJHlxklOHj4uT/FayHAgluSLJ85OcmeSKx0MhAAAAAI5szQFPdz/c3R8ZXv91kvuSnJDkvCTXDYtdl+T84fV5Sd7Ry+5IclxVPSPJuUlu7e5Hu/uxJLcm2b3WugAAAAC2m+ru9W+k6uQkH0xyepLPdfdxw3gleay7j6uq9ya5qrv/dJh3W5LXJdmV5Mnd/aZh/JeTfL27f2WVr3Nxls/+yY4dO563d+/eddfOt+zfvz/HHnvsvMvYFqbS648/9JV5l7BuO56SfPHr865i7c444anzLuEJmcq+vQj0euOdffbZH+7unevdziIcr9i/xtGncZ5Inxbh2GOtpn7McjgbeTzj524cfRpnqn061DHL0evdcFUdm+T3k/x8d391OdNZ1t1dVetPkL61vauTXJ0kO3fu7F27dm3UpkmytLQUPZ2NqfT6wsveN+8S1u3SMw7kVz++7l91c/OZV+2adwlPyFT27UWg11vXIhyv2L/G0adxnkifFuHYY62mfsxyOBt5POPnbhx9GmfR+rSup2hV1XdkOdx5Z3f/wTD8xeHSqwyfHxnGH0py0orVTxzGDjUOAAAAwAjreYpWJbkmyX3d/WsrZt2U5PEnYe1JcuOK8VcPT9M6K8lXuvvhJLckeVFVHT/cXPlFwxgAAAAAI6znHMAXJPnJJB+vqruHsV9KclWS66vqoiSfTfKKYd7NSV6SZF+SryX5qSTp7ker6o1J7hqWe0N3P7qOugAAAAC2lTUHPMPNkusQs89ZZflOcskhtnVtkmvXWgsAAADAdraYd/ECAAA2xclP8EbIl55xYFvfPJknvs8czmr702eueumGbR+mbF03WQYAAABg/pzBAxO2kX8NAQAAYLoEPABb2GaHeE5pBgCAxeASLQAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAE+cmy7BJDndz3EvPOJALPQELAACADSLgAdjGNvopXQeHl57SBQBsNk8dhWUCHratzX4jAAAAgFkR8AAAwALxRyyA7clNlgEAAAAmzhk8AGyaWfwV2XXxAADgDB4AAACAyXMGD1uW68eBMTw5AwAAnMEDAAAAMHnO4GHNnGEDbAfOEAKA7W0zjwUcB7CRBDwLai2/hC4940AuFNoAAADA5Ah4AGCO1vpXwbGhvL8MwtbkTGgANpp78AAAAABMnIAHAAAAYOJcojUnTssFYBZm8X7jMjAAgPkT8AAAAMAcbNYfYh6/V58/wmwvAh4AADjImP90eQIpAFuJe/AAAAAATNyWOYOnqnYneVuSo5L8dndfNeeSAAAAYLI28158Lv/aerZEwFNVRyX5jSQ/luTBJHdV1U3dfe98KwMAYKvy0AoA+JYtEfAkOTPJvu5+IEmqam+S85LMLeBxwAAA42z2e6a/EE6X4ymAxeX9f+up7p53DamqlyfZ3d0/M0z/ZJLnd/drDlru4iQXD5PPSvKpmRa6+L4nyf+ZdxHbhF7Pjl7Pln7Pjl5vvO/r7u9d70YW5HjF/jWOPo2jT+Po0zj6NI4+jTPVPq16zLJVzuAZpbuvTnL1vOtYVFX15929c951bAd6PTt6PVv6PTt6vXUtwvGK/WscfRpHn8bRp3H0aRx9GmfR+rRVnqL1UJKTVkyfOIwBAAAAcARbJeC5K8mpVXVKVR2T5IIkN825JgAAAIBJ2BKXaHX3gap6TZJbsvyY9Gu7+545l7UdTfp08onR69nR69nS79nRazaT/WscfRpHn8bRp3H0aRx9Gmeh+rQlbrIMAAAAwNptlUu0AAAAAFgjAQ8AAADAxAl4trGqelpV3VpV9w+fj19lmedW1Z9V1T1V9bGq+pfzqHXqxvR6WO6PqurLVfXeWdc4dVW1u6o+VVX7quqyVeY/qarePcy/s6pOnn2Vi2FEr3+4qj5SVQeq6uXzqHGRjOj3L1TVvcPv6Nuq6vvmUSeLp6reOOxXd1fV+6vqH827pq2oqt5SVZ8cevWeqjpu3jVtRVX1E8Px5N9V1cI8kngjHOn3PMuq6tqqeqSqPjHvWraqqjqpqm4fjgvuqarXzrumraiqnlxVH6qq/zX06T/Ou6aNIuDZ3i5Lclt3n5rktmH6YF9L8urufnaS3Ul+3YHLmozpdZK8JclPzqyqBVFVRyX5jSQvTnJakldW1WkHLXZRkse6+5lJ3prkzbOtcjGM7PXnklyY5H/MtrrFM7LfH02ys7ufk+SGJP9ptlWywN7S3c/p7ucmeW+Sfz/vgraoW5OcPvwM/kWSy+dcz1b1iST/IskH513IVjLy9zzLfjfL/x/h0A4kubS7T0tyVpJL7E+r+kaSF3b3DyR5bpLdVXXWnGvaEAKe7e28JNcNr69Lcv7BC3T3X3T3/cPr/53kkSTfO7MKF8cRe50k3X1bkr+eVVEL5Mwk+7r7ge7+2yR7s9zzlVb+G9yQ5JyqqhnWuCiO2Ovu/kx3fyzJ382jwAUzpt+3d/fXhsk7kpw44xpZUN391RWT35XEkzlW0d3v7+4Dw6SfwUPo7vu6+1PzrmMLGnMMQ5Lu/mCSR+ddx1bW3Q9390eG13+d5L4kJ8y3qq2nl+0fJr9j+FiI9zgBz/a2o7sfHl5/IcmOwy1cVWcmOSbJX252YQvoCfWaJ+yEJJ9fMf1gvv3N7O+XGQ7Ev5Lk6TOpbrGM6TUb54n2+6Ikf7ipFbGtVNWVVfX5JK+KM3jG+On4GeSJ8b7KphhuR/CDSe6cbyVbU1UdVVV3Z/kEhlu7eyH6dPS8C2BzVdUfJ/mHq8x6/cqJ7u6qOmRqWVXPSPJ7SfZ0t7/Kr2Kjeg2wFlX1r5LsTPIj866F6Tjce1d339jdr0/y+qq6PMlrklwx0wK3iCP1aVjm9Vm+POKds6xtKxnTJ2DzVdWxSX4/yc8fdDYmg+7+ZpLnDrcfeU9Vnd7dk7+/k4BnwXX3jx5qXlV9saqe0d0PDwHOI4dY7ruTvC/Lb853bFKpk7cRvWbNHkpy0orpE4ex1ZZ5sKqOTvLUJF+aTXkLZUyv2Tij+l1VP5rlMPlHuvsbM6qNBXC4966DvDPJzdmmAc+R+lRVFyb58STndPe2/SPOE9if+Bbvq2yoqvqOLIc77+zuP5h3PVtdd3+5qm7P8v2dJh/wuERre7spyZ7h9Z4k3/aXlao6Jsl7kryju2+YYW2L5oi9Zl3uSnJqVZ0y7LMXZLnnK638N3h5kg9s54PwdRjTazbOEftdVT+Y5L8leVl3C4/ZMFV16orJ85J8cl61bGVVtTvJL2b5Z/BrR1oeDuJ9lQ0z3F/ymiT3dfevzbueraqqvvfxBwdV1VOS/FgW5D2u/P9m+6qqpye5Psk/TvLZJK/o7keHR1f+bHf/zHDK/+8kuWfFqhd2992zr3i6xvR6WO5Pknx/kmOzfHbJRd19y5zKnpSqekmSX09yVJJru/vKqnpDkj/v7puq6slZvszwB7N8g74LuvuB+VU8XSN6/U+yHAwfn+RvknxheBIfazCi33+c5Iwkj9/n63Pd/bI5lcsCqarfT/KsLN8w/bNZfr9yZsFBqmpfkiflW2eF3tHdPzvHkrakqvrnSf5zlh/W8eUkd3f3ufOtamtY7ff8nEvakqrqXUl2JfmeJF9MckV3XzPXoraYqvpnSf4kycfzrYdd/FJ33zy/qraeqnpOlh++clSWT3q5vrvfMN+qNoaABwAAAGDiXKIFAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxP0/v9BVMKnnwScAAAAASUVORK5CYII=\n","text/plain":[""]},"metadata":{"tags":[],"needs_background":"light"}}]},{"cell_type":"markdown","metadata":{"id":"FYIIo16N2H8l"},"source":["## Binarize environment"]},{"cell_type":"code","metadata":{"id":"3JNQZonz2H8l"},"source":["from gym.core import ObservationWrapper\n","\n","\n","class Binarizer(ObservationWrapper):\n"," def observation(self, state):\n"," # Hint: you can do that with round(x, n_digits).\n"," # You may pick a different n_digits for each dimension.\n"," state = \n","\n"," return tuple(state)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"vM24Nzn32H8l"},"source":["env = Binarizer(make_env())"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"yQjvWM2Z2H8l"},"source":["seen_observations = []\n","for _ in range(1000):\n"," seen_observations.append(env.reset())\n"," done = False\n"," while not done:\n"," s, r, done, _ = env.step(env.action_space.sample())\n"," seen_observations.append(s)\n"," if done:\n"," break\n","\n","visualize_cartpole_observation_distribution(seen_observations)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"SN_4cfi02H8l"},"source":["## Learn binarized policy\n","\n","Now let's train a policy, that uses binarized state space.\n","\n","__Tips:__\n","\n","* Note, that increasing the number of digits for one dimension of the observations increases your state space by a factor of $10$.\n","* If your binarization is too fine-grained, your agent will take much longer than 10000 steps to converge. You can either increase the number of iterations and reduce epsilon decay or change binarization. In practice we found, that this mistake is rather frequent.\n","* If your binarization is too coarse, your agent may fail to find the optimal policy. In practice we found, that in this particular environment this kind of mistake is rare.\n","* **Start with a coarse binarization** and make it more fine-grained if that seems necessary.\n","* Having $10^3$–$10^4$ distinct states is recommended (`len(agent._qvalues)`), but not required.\n","* If things don't work without annealing $\\varepsilon$, consider adding that, but make sure, that it doesn't go to zero too quickly.\n","\n","A reasonable agent should attain an average reward of at least 50."]},{"cell_type":"code","metadata":{"id":"0l6dcGdE2H8m"},"source":["import pandas as pd\n","\n","def moving_average(x, span=100):\n"," return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"nU4miZle2H8m"},"source":["agent = QLearningAgent(\n"," alpha=0.5, epsilon=0.25, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Uk5D4fNp2H8m"},"source":["rewards = []\n","epsilons = []\n","\n","for i in range(10000):\n"," reward = play_and_train(env, agent)\n"," rewards.append(reward)\n"," epsilons.append(agent.epsilon)\n"," \n"," # OPTIONAL: \n","\n"," if i % 100 == 0:\n"," rewards_ewma = moving_average(rewards)\n"," \n"," clear_output(True)\n"," plt.plot(rewards, label='rewards')\n"," plt.plot(rewards_ewma, label='rewards ewma@100')\n"," plt.legend()\n"," plt.grid()\n"," plt.title('eps = {:e}, rewards ewma@100 = {:.1f}'.format(agent.epsilon, rewards_ewma[-1]))\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"GV1Jcr2h2H8m"},"source":["### Submit to Coursera II: Submission"]},{"cell_type":"code","metadata":{"id":"vKf_kF772H8m"},"source":["submit_rewards2 = rewards.copy()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"kk0r4DYl2H8n"},"source":["from submit import submit_qlearning\n","submit_qlearning(submit_rewards1, submit_rewards2, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Q-learning\n",
+ "\n",
+ "This notebook will guide you through the implementation of vanilla Q-learning algorithm.\n",
+ "\n",
+ "You need to implement QLearningAgent (follow instructions for each method) and use it in a number of tests below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display for drawing game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import defaultdict\n",
+ "import random\n",
+ "import math\n",
+ "import numpy as np\n",
+ "\n",
+ "\n",
+ "class QLearningAgent:\n",
+ " def __init__(self, alpha, epsilon, discount, get_legal_actions):\n",
+ " \"\"\"\n",
+ " Q-Learning Agent\n",
+ " based on https://inst.eecs.berkeley.edu/~cs188/sp19/projects.html\n",
+ " Instance variables you have access to:\n",
+ " - self.epsilon (exploration prob)\n",
+ " - self.alpha (learning rate)\n",
+ " - self.discount (discount rate aka gamma)\n",
+ "\n",
+ " Functions that you should use:\n",
+ " - self.get_legal_actions(state) {state, hashable -> list of actions, each is hashable}\n",
+ " which returns legal actions for a state\n",
+ " - self.get_qvalue(state,action)\n",
+ " which returns Q(state,action)\n",
+ " - self.set_qvalue(state,action,value)\n",
+ " which sets Q(state,action) := value\n",
+ " !!!Important!!!\n",
+ " Note: please avoid using self._qValues directly. \n",
+ " There's a special self.get_qvalue/set_qvalue for that.\n",
+ " \"\"\"\n",
+ "\n",
+ " self.get_legal_actions = get_legal_actions\n",
+ " self._qvalues = defaultdict(lambda: defaultdict(lambda: 0))\n",
+ " self.alpha = alpha\n",
+ " self.epsilon = epsilon\n",
+ " self.discount = discount\n",
+ "\n",
+ " def get_qvalue(self, state, action):\n",
+ " \"\"\" Returns Q(state,action) \"\"\"\n",
+ " return self._qvalues[state][action]\n",
+ "\n",
+ " def set_qvalue(self, state, action, value):\n",
+ " \"\"\" Sets the Qvalue for [state,action] to the given value \"\"\"\n",
+ " self._qvalues[state][action] = value\n",
+ "\n",
+ " #---------------------BEGINNING OF YOUR CODE---------------------#\n",
+ "\n",
+ " def get_value(self, state):\n",
+ " \"\"\"\n",
+ " Compute your agent's estimate of V(s) using current q-values\n",
+ " V(s) = max_over_action Q(state,action) over possible actions.\n",
+ " Note: please take into account that q-values can be negative.\n",
+ " \"\"\"\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ "\n",
+ " # If there are no legal actions, return 0.0\n",
+ " if len(possible_actions) == 0:\n",
+ " return 0.0\n",
+ "\n",
+ " \n",
+ "\n",
+ " return value\n",
+ "\n",
+ " def update(self, state, action, reward, next_state):\n",
+ " \"\"\"\n",
+ " You should do your Q-Value update here:\n",
+ " Q(s,a) := (1 - alpha) * Q(s,a) + alpha * (r + gamma * V(s'))\n",
+ " \"\"\"\n",
+ "\n",
+ " # agent parameters\n",
+ " gamma = self.discount\n",
+ " learning_rate = self.alpha\n",
+ "\n",
+ " \n",
+ "\n",
+ " self.set_qvalue(state, action, )\n",
+ "\n",
+ " def get_best_action(self, state):\n",
+ " \"\"\"\n",
+ " Compute the best action to take in the state (using current q-values). \n",
+ " \"\"\"\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ "\n",
+ " # If there are no legal actions, return None\n",
+ " if len(possible_actions) == 0:\n",
+ " return None\n",
+ "\n",
+ " \n",
+ "\n",
+ " return best_action\n",
+ "\n",
+ " def get_action(self, state):\n",
+ " \"\"\"\n",
+ " Compute the action to take in the current state, including exploration. \n",
+ " With probability self.epsilon, we should take a random action.\n",
+ " otherwise - the best policy action (self.get_best_action).\n",
+ "\n",
+ " Note: To pick randomly from a list, use random.choice(list). \n",
+ " To pick True or False with a given probablity, generate a uniform number in [0, 1]\n",
+ " and compare it with your probability\n",
+ " \"\"\"\n",
+ "\n",
+ " # Pick Action\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ " action = None\n",
+ "\n",
+ " # If there are no legal actions, return None\n",
+ " if len(possible_actions) == 0:\n",
+ " return None\n",
+ "\n",
+ " # agent parameters:\n",
+ " epsilon = self.epsilon\n",
+ "\n",
+ " \n",
+ "\n",
+ " return chosen_action"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Try it on taxi\n",
+ "\n",
+ "Here we use the qlearning agent on taxi env from openai gym.\n",
+ "You will need to add a few agent functions here."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "env = gym.make(\"Taxi-v3\")\n",
+ "\n",
+ "n_actions = env.action_space.n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent = QLearningAgent(\n",
+ " alpha=0.5, epsilon=0.25, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def play_and_train(env, agent, t_max=10**4):\n",
+ " \"\"\"\n",
+ " This function should \n",
+ " - run a full game, actions given by agent's e-greedy policy\n",
+ " - train agent using agent.update(...) whenever it is possible\n",
+ " - return the total reward\n",
+ " \"\"\"\n",
+ " total_reward = 0.0\n",
+ " s = env.reset()\n",
+ "\n",
+ " for t in range(t_max):\n",
+ " # get an agent to pick action given state s.\n",
+ " a = \n",
+ "\n",
+ " next_s, r, done, _ = env.step(a)\n",
+ "\n",
+ " # train (update) an agent for state s\n",
+ " \n",
+ "\n",
+ " s = next_s\n",
+ " total_reward += r\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " return total_reward"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAX8AAAEICAYAAAC3Y/QeAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nO2deXhU1fnHP28mG4FAwk4IEJYAAgJCFBFRcANX6lJFrWKrte4/W1vFfSsttbZW60rValstdRcVRVFxRzaVHY2ALLKHNYGQZM7vj3tncmcyM5k1y8z7eZ48mXvOufe8986d73nve849R4wxKIqiKKlFWmMboCiKojQ8Kv6KoigpiIq/oihKCqLiryiKkoKo+CuKoqQgKv6KoigpiIq/oihNChGZIyKXNbYdyY6KfwoiIveLyHcisldEVorIxSHKiojcKiLrRGSPiEwXkdaO/HNF5HMRqRCROQH2P11ElorIPrvcAEfeIBGZJSLbRaTOCyci0lZEXhWRchH5QUQuCNeuKK5JkYh8aJ/HShE5wZF3iYjU2Ofg+RsTbV1KwyMib/t9fwdFZEmI8sfb90GFfV/0aEh7GwIV/9SkHDgdaANMAh4UkaOClL0YuAgYBRQALYC/O/LLgL8BU/13FJFi4DngCiAPeAOYISLpdpEq4AXg0iB1PwIcBDoBFwKPicjAMO2KlP8CXwHtgFuBl0SkgyP/C2NMK8ffnBjqanI4vpOGrFNEpEE0yBhzsvP7Az4HXgxiV3vgFeB2oC2wAPhfQ9jZoBhj9C8Bf1iC9DKwDVgDXOfIuwt4CeuG2gssAoY48m8CNtp5q4DjE2zrDOCGIHkvAb9zbB8FHABy/MpdBszxS7sGeMuxnQbs9z8foI91K/qktcQS/r6OtH8DU8OxC6thewrYZF/L3wOuIOfYF6gEch1pnwBX2J8vAT6N8tpeAnwGPADsAlbbtl4CrAe2ApMc5bOA+4F1wBbgcaCFnZcPvGnfUzvtz4WOfecA99r17QXeBdoHsWsMsMG+1zbb1zYNmAx8D+zAapjb2uWf9dwjQFfAAFfb272xnIC0MG2cYtu43/7uTwRWAruBh4GPgMsSeL8XATVAUZD8y4HP/e7F/UD/RP4OG/pPPf8EYHszbwDfYP1QjgeuF5FxjmITsDyPtsDzwGsikiEi/bBE83BjTC4wDlgbpJ7JIrIr2F+YtrYADgeWhSrm9zkLKA7n+AH2FWBQGPv1BaqNMd860r4BBjq2Q9n1DFCNJS6HASdhNVCBGAisNsbsDVHXYXZ46lsRuT1CT3kEsBjrqeJ5YDrWNe8D/Ax4WERa2WWnYp37UDu/K3CHnZcG/BPoAXTHEqSH/eq6APg50BHIBH4bwq7OWPdfDyzBuxb4CXAslvOyE+vpCyxBHmN/PharETvGsf2JMcYdpo0X2fXlYgn+K8BtQHushmdUMINF5IJQ97yIdA9xvh4utu1dGyR/INb3D4Axpty2a2CQ8s2Txm59kvEP68e+zi/tZuCf9ue7gLmOvDQsD3U01g9+K3ACkNEAtj4LvANIkPzLgG+xvKU2WE8JBhgZoNwcv7T+WCGmMVhCdDvgBm72KxfI8x8NbPZL+6WnjlB2YYWJKrE9Zrv8+cCHQc7xIuf3YadNAZ6xP/cCetrf06HAcv9zCHF9LwG+c2wfatvZyZG2A0vsxb5evR15I4E1QY49FNjp2J4D3ObYvgp4J8i+Y7CerLIdaStwPJUBXbBCc+lY3v1O+xo8DvwK2OC4h34TgY33OLYv9vstCNYTSSI9/1LgkhD5T2E/YTrSPgu1T3P8U88/MfQACvy88FuwRMnDes8HY3lMG4ACY0wpcD1WA7HV7sgsSISRIvJnLC/8XGPf4QF4GisePgfr6eBDO31Dfcc3xqzE6lN4GKtxa48lnPXuC+wD/DtwW2OFM+qzqweQAWxyXP8nsLxhRGSZo+NvdH11GWNWG2PWGGPcxpglwD3AOWGcg4ctjs/77WP6p7UCOgA5wEKH3e/Y6YhIjog8YXd+7wE+BvJExOU41mbH5wr7uMHYZow54NjuAbzqqHsFVnikkzHme6yGaShWw/wm8KP9pHos1pNBuDaud3wuwPe3YPzy44qIHI31xPNSiGL13XtJgYp/YliP5a3lOf5yjTGnOMp083yww0SFwI8AxpjnjTFHY/0YDfCnQJWIyC1+Ixh8/kIZKCJ3AycDJxlj9gQrZwvencaYImNMIZbQbrT/6sUY85IxZpAxph1wJ5anPj+MXb8F0u1OYw9D7Prrs2s9luff3nH9WxtjBtr7DjS1nX+f2Pv2EpHcQHUFOi18Q07xYjtWQzDQYXcbY3VQAtwA9ANGGGNaUxt2idYW/wZ/PXCy332bbYzxfNcfYTV6mXbaR1iNez7wdQQ2OuvdhO9vQZzb/ojIhaHu+TDCPpOAV4wxoX4fy7C+f0+dLbGefEKFRpsdKv6JYR6wV0RuEpEWIuISa1jj4Y4yw0XkLDt2fD2WWM0VkX4icpyIZGF1YO7HCpXUwRjzB+M7AsXnL5hxInIzVmz4BGPMjlAnItZwy972yIwBwF+xHtvddr5LRLKxQgNpIpItIhmO/YfbZToA04AZ9hOBZ7RHNlZICHvfLPvcyrFiwfeISEsRGYXVT/Lv+uwyxmzC6uz8i4i0FpE0u+yxQa7jt1jidadtw5nAYKwOe0TkZBHpZH/ujxW+et1xjnNE5K5Q1zEc7Gv6D+ABEfE8pXSV2r6iXKz7YZeItMVqTOPJ48AUsYc1ikgHEZngyP8Iqz/qY3t7jr39qTGmJkob3wIGOn4L12F55gExxjwX6p43xqwLtq9Y/VvnYvUHheJVYJCInG3fn3cAiz33bbKg4p8A7B/CaViPyGuwPLonsWLTHl4HzsOKo14EnGWMqcLqtJxq77MZK1Rxc5xN/ANWZ1ypw2O6xZPpCIeAFaqZifXI/zbwtDFmmuNYF2H92B/DCgfsxxIwDw9ijXJZZZ/rLx15PezyHo9qv13Ow1VYQzi3YoV4rjTGeMrWZ9fFWI3Kcrvel7Bi2MGYCJTYZacC5xhjttl5xwOLRaTcrvMVrGvooRtWTDge3IQVk55rh01mY3nSYA2pbYF1b8zFCgnFkwex+k7eFZG9dh0jHPkfYYm7R/w/xQpTfewoE5GNxpjtwE+xrvkOrA77eF1Lf36CdS9+6J9hhwIvtG3aBpyN1e+zE+saTEyQTY2GBA/1KonC9hL7GGN+1ti2KLEhIoXAC8aYYO9JKEqTpMFf7FCUZMIYswFr3L6iNCs07KMoipKCaNhHURQlBVHPX1EUJQVpFjH/9u3bm6KiosY2Q1EUpVmxcOHC7caYDoHymoX4FxUVsWDBgsY2Q1EUpVkhIj8Ey9Owj6IoSgqi4q8oipKCqPgriqKkICr+iqIoKYiKv6IoSgqi4q8oipKCqPgriqKkICr+TYwat2FXxcGAeQeqath7oMq7XVXj5oX563G7g0/RUVZ+0LMMHW63YdveypD1G2PYuvdAwLyqGjd7HPVHQln5QaprAi5LEBXGGLbv8z0X/+vjpKrGzaJ1O3lz8Y/etK17D/D2kk1R21Bd42b6vHUcrA59Xjv2VdIQ06gYY9ixL/T36+FgtZvd+8P/LsvKD4a8z5ys3V7Ohyu3hn3spsCa7eV89O22+gtGif+92hRQ8W8k7nx9KRc+OZf73lnJmY9a05d/Vrqd8574gqH3vBdQxM574gsOvetd7/YjH5Zy48uLecMhaB52VRykaPJbDLv3PabPt1bFu+31pRz5x/f5at3OoHZ9sXoHR0x5n//MrftuyJX/Wcjgu95l0bqdfLN+F2634Ycd5Rhj2LLnAP+bX3cdjd37q9iy5wDD7n2P66Z/FbRh8Wd9WQUvLQy82uPa7eXc8+ZySn4/m8+/305Z+UG276tk/N8+5rB73gu4z29e+IazHv2ca57/ytsIXfmfRVz53CK276vkhx3l/G/+Ol5csJ6qGjf/+Hg176/Ywp4DVT6CumTDbt5esonNuw8wc+lmJr+yhKueW+QV9zXby3nmszV8/O027p+1ir/N/pbhv5/NeU/M5X/z19UR0B937ad061427669Li8v3MDiDbtYX1bBxl37uemlxVzyz3lcP/0rLn1mvreu8spqzn38C95abDVgt722lOG/n82m3fvZV1nNj7v2M29NGWc9+hlzV+9g0+79HKiqoeJgNedN+4Ihd79LeWU1a7aX89pXG9lzoIpzn/iCZT/uZsmG3fywo5x3lm7inaWbGHbvezww+1t2V1Tx1Kdr+GrdTlZtDryq4Zj75/DzZ+YHbRTXl1X4XK+qGjfrdljnunt/FffPWsWUt5b77FNeWc3WPaHvne37Kus0aG63Yd2OCu/2roqD/OPj1dS4Dau31S7mNfb+OUx6eh77D9b4fBc1bsOTn6xmxaY9XPP8In76+OdM+/h7b94363fx5CereeazNcxcsokPV9U2egvWlvH61xv5z9wfKPn9bOatKQto94ertrLI8Ztct6OCNdvLqXEb1pdVUBVHp8lJs3jDNxl59gtLXD8rtRbSMsZw4ZNfevP3HqgmN9u7IBZl5Qf5ZsNuwPJYO+Zms3HnfsDyeP1xejEff7uN84/ozswlm6hxG5Zu3E27lllc+ux8fnlML578ZDU3je/P8Yd0YleF9eN5bM73nHlYV655fhGHdGnNjeP7M3uFdWOf9ejnAJxyaGdmLtnM1LMO5dWvNvLlmjJWbNpLhkv4Zv1u/nTOYE576BPKD1r2zVyymZlLNvPpTWMpzM8B4Icd5fy46wDfbtnLEx99T4tMFy9dcRSj77PW22iV5eKkAZ158tPVHNe/E3//4Dte/7q2sbvgH7XXzMO4Bz7mgfOGUuM2DOraGhHhjW9q91lXVkF5ZQ0Lf7B+cHe+voy3HE8Av3tpcZ1jHt2nPWu2l7Nx1/46ebNXbOHyfy/krjMGct87K3l76eY6ZeatLWPe2jJuenkJlxxVxKmDu/DLfy3wXu+8nAy+vuMkVm7eww0vflNnfyezlm3hsO55nPb3T9m2t5J5a8v477z2fFq6HYDrp3/Nl35CM3HaXO9nV5pQYzdCA++cVef4pz70acB6//5BKf+dtz5sL7bvbW9z4oBOHNmrHa9/vZEtew6Qk5nOmu3lPuVG9mrHF6vrLiiXl5PJiQM6ce4TX3ivE8AFI7pzXom10mOH3CxyMl08+P53/POztQwpbMMlo4po3yqLjrnZnPb3T6iqMfzqmF488fFq7zGe+nQNm/cc4LELh/l8p4fcUbv2zKmHdsFgmLnE9/ucv3Ynqzbv4+VFgZ2TId3y+Gb9rjrp5z7xBbedegiXHt2TZz5fy/R568nLyajzXXlo2zKTsvKDXHd8Mb85sW/AMrHQaLN6ish4rJWDXMCTxpipwcqWlJSYZJveoWjyWz7b3//hFHrfMtO7/fnk4yjIa+HdvmvGMp75fC0A71w/mv6dW3PN84t4c/EmHpw4lJ7tWwIwuDAPgF/+awHvLbfWCB8/sDOPXzScwXfNYs+Ban59Ql8emP0tADmZLioO1tAhN4tteyu58/QB3P2G5XUN657HonXWTXz3GQO5c0bgJUzPHlZI6bZ9dW74rPQ0KoN4f2unnkpVjZviW9+u91odXpTP/LXBn1ZCMapPO649rthH/BSlOXFs3w48+4sjotpXRBYaY0oC5TVK2EdEXMAjWAuIDwDOt9dhTVnc9TTC+TmZ3s8Hq91U1biZaXurWekuznj4M8542AofGWO8wg+wbV8lRZPfYs+BasDytj1U2F65py9gif10AXiFHwgq/AAvL9rA0o2766QHE36wGr9zn/giaL6TaIUfrCercIW/dXbtg/CQbnn06tAy6noBjihq6/38/g3HUtyxFYX5LchwxW/t96vG9ObSo3sGzHvgvCFMGFoQ9rFKeuRzWZBjtWuZ6bM9sKA1H/52DFPOHMQFI3zXTO/tuG6BzrVLm+yANnd1ODuh0uJBmsBffjqk/oLA0G55SD1f2SVHFQVMnzC0gA65WRFa50ui3PPGCvscAZQaY1YDiMh0rMW5l4fcq5mxr7KaVll1L3GgGJ6/+Pt/4V3aZHs/v7Vkk1foAa74z0Kfsje/ssRne11Zhc/2K19tDGqzKy0yYSrpkc+CH3Z6wwiR8NU63yeF4/p35ANHR+HAgtZs21vJVr9O6lZZ6bzwq5Gc8tAnEdX3syO70yorg8c/+j5g/sLbT/Q+ibx21VGICJf/awHvLt/CX88dwr/n/lDH5lA8MHEod76+jNkrttCuZSZvXWcti7x+ZwUPf1DK4UVtueXVJXX2G9S1Nf+4uISRf/wAgDOGFFBjDG8t3sQxfTvw8bfb+PM5gzl9SAHZGS6+XL2Dpz5dQ//Oucy8bjS/ffEbXvlqI4d2bcOZhxXyl58O4ZPS7fRq35KD1W5OfMBacreoXQ6vXjWKD1dtRQROG1xAhiuN347rR2WVmwmPfMraHRWMLm7Pvy8dwcIfyjj7MavB/s+lI8hvmel94jx5UGd27DvIkb3akd8yg8UbdtO5dTZd81rQy36ifXDiUP5v+td0bpPN7acN4PbTBjBq6gds3LWfrPQ0BhS0ZuOu/eTlZPDxjWNpmZmOK004UFXDwRo3rbMzuO+dlTw6x/r+vrzleHIyXcxbU8bhPduSne6i723W9/fZ5ONYsmE3FQer+c0LVhjt29+fjMFQXWPIyXQhIizZuJv3V27hT2cP9oYQ/3jWoXzy3TZaZaVzdHEHzhhSwOINuzjj4c/46fBCBhe2oWt+C/YeqGZ9WQUXH1VE6+wMxvTrQKusdLbvO8gbi3/k3gmDaGs3mnNX76Bb2xxGTf3Ae/36dc7l8CmzAXj96lG8uHA9k08+hNXb9rF2RwVnDCng3jeXex20eNNY4t8VWO/Y3oDvQtGIyOXA5QDdu/t6Fs2BN775kWv/+xVvXns0g7q28ckLFKO/K4RnDWAczcHrX9Xt4PVQ4zbeDl4PGREIenoEXukJh3TiD2cO4oYXv+GT77aHvV8wrh7bh7tOH8gxf7bi/c/+4ghq3Ibxf/uY/JxMVtux4m5tcxhQ0Npn3wtGdGfh2p2s3VHO6OIOzF6xpc7xM1xp3DS+H6cP6cLSjbu56WVLeIf3yKddy0wyXGk8dP5hVFW7EdvVG1zYhneXb6FXh1b8blw/LvjHl1wwojs/GdrV++TSOjuddq2y6sSy83MyeHDiUJZv2kOe48mtd4dWPHDeUADeWbaZj/1GmeRmZdDS4TQ8dP5hADxygdWBmeb3febbApObnU5amjD17MGcOawrfTrmApDuSmNsv46A7733whUjyW+ZyVnDCn2Ol53hIjvDxezfHMsf317JpJFF9vnU1pPv9yQwuth31uDDHU891jml076V5QF3yq11ZDwe9eM/G07fzrkUtMnm1lMHkJleG5Tw2ANw5ZjevL9iK2P7d6RTa+s4xx/SyVt26d3jWLFpD13zWnifGob3yKfabbzHdPpjd55uNUJOB+n8I7pz/hG+mjO4MI/nLxtBSVFbH9ucjLGvMcD4QZ198o7s1Q6At647mg6tsujYOtsnf0i3PIZ0y/PW5Qnf3n5a4gIiTbbD1xgzDZgGVsy/kc3xYc32crq3zQnpJXs6XJdv2sOgrm146tM1zFq2mRd+NZL9AcT/v/PW10lz4nSsA+0fKu9APUMRnUTi+T85yQolBhv1EYgzD+vKqwGePG44sS/De+T7jKzJa5FBuiuNr+44iQfe+5YH3/8OwNv5deWY3ryzdDPP/PxwerSzPFBjDJ+V7ggo/oIgIgwsaIPbcUlevrJ2Cd4zhviGSa4c04fRxR28P8y1U0+tc9xFt59IuivN24/z4MShbN1TSU6m9fPyF0IngdrazPQ0WmYG/mn6Cz9AccdW/ObEvpw9vNC7v78Ye/CI6JDCNnTMzQ5YxkO6K81HfDwNWEGbyEIxH/1uDC2z0snPyeSasX24ZFSRN89zv+Vmp9M1rwV3TxgU8li52RnM+vUxQfNbZaXXud6eeyMQIoJLoF2rzKBlPBzVp329ZepjYIGvI/i384bGHBaKlsYS/41AN8d2oZ3WZFlfVkF2houKg9WMvX8OV43pzY3j+4e9/71v1ka0DhyMfOiWMyxUWR1c/KcFCGnsj+Cx0VVfcDMAbVtm1gnNBGNAl9YBxb+VHW93erzprloPq7394zxneCEnDrA8vZvG9+cmv+9ARMJ6eilqn8Ogrq25ZmyfkOVcaeIV/mA47QTrBz5haKt6bbCOX9eLbJHhiqgRFhGuO7447PKfTz6ONi0y6i/oR9uWmdz7k0Ec179j/YUdOMX3t+P6+eR57rdW2Y3rh+YGCM82BD85rGuj1AuNN85/PlAsIj1FJBOYCMxoJFvCYvR9H3L4lNlekQs2ZtdDqP7bUJ57MJye/4Gq4I3HQx+UxlTf1wGGqNXHoxcOC7tsIM8VakU/K8gj9ZnDChnTr0PQjjUnzk7Ghy84zPvZGTrLzc7gzWtHM35Ql3DMDkgwW1tkusI+hqfdGF1c61UWta8VS2d6vCjIa+HTyEbCRUf2iGsnrOd+SIvC6YgnIsI5wwt5cOLQRrWjIWkU8TfGVAPXALOAFcALxpjQQe8mQqQjYwPd0p63ZAvaBH/s9uxnjOFAVU2DvCEKeN8liISiEI/Vd/jFLP21/7DullftSZYgItAqK51nfn5Enf6TQKQ7vOnTBhdw26mH1LtPNLx/w7E8/8sRddJzMsIX/z4drSeEq8b0Yd6txzN+YGeuOLYXACvuGc/TlxweH2ObKI9cMIyzhnWlV/vYRlbFg/t/OoQJQxvPE29oGu1ZyxgzE5hZb8EmhkeE63NUnF7mWr+OwB/tl0qK2rfkx92h31p89vO13PXG8piHHcaLqWcdymS/0UTBvHmo6wX7hzNG9mrHV+t2sa+yOm42RtJpHQuF+Tnel9WcROL5X39CX0p6tGVkb6tD8PGLhkd1nOZKv865/PXc1PG2mxJNtsO3qSOI91XyUPFTEWHM/XN80jbYb+b2bN+Sz7+v+2YjwB/fXklxx1bejsvV28oDlouFKWcO4tZXl0a0T++O4cWyPaT7ib3z8f5v5w3lhAGdOFDl5tyS2i6g+84e7POCW6Rk+MXge3ewbD6kS+tAxeNGiwwX+6tqgoaDApHhSmNshDF0RYkHKv4R4gy+DLnbmmfHMwLk2c/Xclz/jnRrW9cbdLKr4iDZGWneMcCB8ExH0L9zbti2Fea38DYs4RAqXBOMnAi9UX8hdop/ZnoarbLSueN039DQuYd3Ixb8G5yx/Tsy87rRHNIl/GsZDW9cO4ov15QFDV0pSlNCJ3aLEE/o3f/3va+ymjtnLKv3bVK32+A2Vlw6lPh7iGRSp6H1jErxJ9IXuoCAL60FwuP9+odgnG2Bf8MQLwIdd0BB64SLcp+OuVw4okdC61CUeKHiHyGeWL6/jniGYtY3TW6NMbiNQQTvSy+hqKoJv6M32MsnwfD3kMMh3FEiHqvT/YYyip/nnwgaKuavKM0ZFf9ICaLFztE5oahxG4yxwh/hvFgSieeflR5ZSMaVJsz+zbERdSZnBxnJ0ql1FoML2/Der4/hghHd6ZZvxez953ZxvkcQzzlunPg3OIqi1EV/JRHikXbxG8Tp8WgNULp1H68sCvzOWrXb8vzThLiHfSLpaARLJPt0bMXzlx0ZdsgoM0io5stbTmDGNUdT3CmXP5x5qFeA/V+AcoaaIrU3XBLVqChKMqHiHyXBwsfGwN8/+K62nF9+jVf8JSxPPdTMmP5EGkbxCHHnNtncfcbAsPYJV1g91ycjTZh/6wkMKWzjk24dK1FhH72tFaU+9FcSIcGiOp6Yv8GEfFuxxu7wFZGwPN+9B3zHv4cK00fs+TuEPNzO30g7TdNdaXTIzaKrHQZy1pMw8Y+iL0NRUg0V/wgJ1uHraRSM8c3zL2fF/K0O32g6PEOJdLCQTDCcIhlM028+Ofz5i5x4Ggn/zldnuCxRHb6JalQUJZnQX0mEeId6+gd0TO2/OnkOatwGt9vy4KOJeYfqT86IIubvIVij4pzuN9iiIYHwHC2UFx5pYxUu0QxhVZRUQ1/yihBvh28d7a9V5VDaU+12e0ND0Xi+ocYSRdqYuBxeebBQldNGz/S+d54+oN4XxMKJDiXK81cUpX5U/OthfVkFhfn1TzXgnXXThJ6h0O22yqaJROX5hhpKGo6YpqcJ1baxTq88mM2BGpSfj6r/CcBzvJBPKhqeUZRGQ8U/BJ5l66aedag3LZj4GkeHbyivt9rt9r7kFc0bp6E8/3Aak7Q08bZUztqDPa1EG5rxnFpIexPo+d93zmAODWMGUEVJVVT8Q7B8k7VC1WLH4uS1YR9ftXSKXChRd5val7yiIZQnHY6Yemo9rn9Hn6XkgsXJQ83YGU49oZ5UEjke3zlRnKIoddHn7hActMfY+6yB6+3w9cU71NP4etH+Gu98ySveBGtQzi0pZNJIa84Zz8RsPzvSd43SeC+m8cezBnNs3w511tp1kqgOX0VR6kc9/xB4xN+51F6woZ4+o31ChX1qjDfmH2+Cjay54/SBtMx0ccuph3DsfXOAqgBvKMfXlgEFrXn2F0eELKOzXypK46GuVwg8Uys4x6qbAJ6/2228yzsa4/uSl7/Iuh0Tu8WbYCGaNPG8VOaqrdevqA6PVJTUQsU/BLWef11hdHqt1//va077+6eA5fk7xf+A3/q51fZLXp4yZzvG0cdKsMXXAz1l+KfV9yQSyboCiqI0fTTsE4LKaku4neGUQP2XM+yFVwLl/232dz7bbu9LXtYxJwwt4OVFG+JirytIB2rAxstvO5T4f3HzcbTODr5amaIozQ8V/xB4PH/nm7Cejt1QfvLc1bVLM27e47tGr6fD16O18Yr9d8jNCur5B0r3TwoV9enSJvolFRVFaZqo+IfgYICYv+dlrlALjq/cvDdonhXzrxX9eIXa/37+YdS4Aw+rDNQX4N/oNGTMf85vx7B9X2WD1acoSl1U/EPgmU7ZKZQez//LNWVRHfP215by/bZyBtpDIOM14iVNhAM1vv0L4wd25rLRgd/G9a+1IUfeFLVvSVH7yNcPVou46bsAABlNSURBVBQlfsTU4SsiPxWRZSLiFpESv7ybRaRURFaJyDhH+ng7rVREJsdSf6LxLKFY466dU98d6i2rMPh+WzkQf8/flQZb9/h603k5GZQUtfVJkzofPPvraB9FSSViHe2zFDgL+NiZKCIDgInAQGA88KiIuETEBTwCnAwMAM63yzZJPG+nOtfRDRJZiRiP1kb7Bq0/IsLovu3DfnGq7mgf3/xrj+tDSY/8uNimKErTI6awjzFmBQQMGUwAphtjKoE1IlIKeN74KTXGrLb3m26XXR6LHYnCo/POWHp9a/SGS7zDLILVMbvsnnEU3/p2WOWd+DcGN5zUL37GAdceV8yyH/dwdJ/2cT2uoijRkahx/l2B9Y7tDXZasPQ6iMjlIrJARBZs27YtQWaGxuv5xzHs48HjaQfrpI38eOLzH0K/tev/xJGIN46dHNKlNR/9bixtcnTIqKI0Ber1/EVkNtA5QNatxpjX42+ShTFmGjANoKSkJE7BlkhtsP4vWLvTm+YOf0ndkHjE1h138Q+vfF3PPy5mKIrSTKhX/I0xJ0Rx3I2Ac1rFQjuNEOlNDo+Xv/CHWvGviZvnL2Efr1VWesihpVDr5TvDSaEO7e/oa4evoqQWiQr7zAAmikiWiPQEioF5wHygWER6ikgmVqfwjATZEDOBnPL4xfyt/+GEfTq3ya63TKRRG/8+BxFh7dRTIzuIoijNlliHep4pIhuAkcBbIjILwBizDHgBqyP3HeBqY0yNMaYauAaYBawAXrDLNkkC6Xz8RvvYYZ8oG5NHLxwW8Hjhon6+oqQ2sY72eRV4NUjeFGBKgPSZwMxY6m046gpz3Dp87Wa3Jso+BP/pm8MVf4/Hr9MpK0pqo7N6+rHwhzJ+3LUfCOzlx9vzDyfsEyjUlO7yD9tEWn9k5RVFSS5U/P04+7EvGH3fh0BgLz/e4/wPLQxvndmPfzeWd399jHfbOdkcBBbzUA2C/zoDiqKkFjq3TwA83nggnY/fuHzrf9e8FrjSpN7jdm+X47Nd1/OvK+aRjPZRFCW1UM8/BIG0M15hn3VlFTHtX9fzj7DDV8VfUVIaFf8QBArxRBP2GdGzbZ20NdvLo7LJg/+4/Ei1XMM+ipLaqPiHIFDMP5rRPmcPr7tUYySHCVQ0Kz02zz9Nv3lFSWlUAkIQr3H+LTNDd61E44P7i3/EL3mp568oKY2KfwgCi3/k6u8v1PEgK93lsx35G75xNEZRlGaHin8IAg/1jPw4Mc+bE6DOzFjDPir+ipLSqPiHIJD4RzPUMxFedjjif8moohBHUPVXlFRGx/mHIJDQRxP2iXWu/PA6fOuW6d+5dZ202tk/A9f1zvWj2bHvYIQWKorS3FDxD0Fg8Y/8OPWJfzRtg7/nH6kjH8ymQA2GoijJh4p/CALNtR/NOP86Qh0HQk3s9ua1R9O2ZWbI/TXooyipjYp/CALNuBlN2CdW8Q/U4PhP5+AU/0Fd658vSEf7KEpqox2+IagJsGZjNGGfRAz19Eff8FUUJRJU/EMQMOYfhfoH8vyHdMsLe/9wakz0AuyKoiQXGvYJQeD5/GN/yWvp3ePIdNWmWV54bDPGiTbjiqJEgIp/CAJ5/pXVkS+95e/5t8qK/2VXz19RlEhQfzEEgbz8f33xQ8TH8Z+KwZ/fjusbMj/Yw8bkk/t7P4cr/dpGKIoCKv4hidOiXfV2+F5+TG8K81uEdaxcx1PDFcf29n5Wz19RlEjQsE8D4IzvByPchuazm4+jsqpu6Em1X1GUSFDxD0G81utNC2MWtVB1GUdncOvsDMiuWyZS8TcxdjAritK80bBPCBpSHmOtS8M+iqJEQkziLyJ/FpGVIrJYRF4VkTxH3s0iUioiq0RknCN9vJ1WKiKTY6k/0cQr5g9w4/h+EZV3TgMdjh0q/oqiREKsnv97wCBjzGDgW+BmABEZAEwEBgLjgUdFxCUiLuAR4GRgAHC+XbZJEs/QyFVj+oSuy6+qSOfbD7e8vtmrKArEKP7GmHeNMdX25lzAs1jtBGC6MabSGLMGKAWOsP9KjTGrjTEHgel22SZJPD3/+vAfVhqpSPvP9ROMDrlZAKSH0QmtKEryEs8O318A/7M/d8VqDDxssNMA1vuljwh0MBG5HLgcoHv37nE0M3waNebv0PJ4NkKP/2w4H67cSte88IaWKoqSnNQr/iIyG+gcIOtWY8zrdplbgWrguXgZZoyZBkwDKCkpaZShKYnw/I/r3zGsuhIVnOmQm8W5h3dL0NEVRWku1Cv+xpgTQuWLyCXAacDxpna84kbAqTCFdhoh0psczuGXWelpUU3t4OS7KSfjChqe8Qv7aGheUZQEEuton/HAjcAZxpgKR9YMYKKIZIlIT6AYmAfMB4pFpKeIZGJ1Cs+IxYZ48e6yzazdXu6T5pTjo/u0j7mODFda0DH/dT1/VX9FURJHrDH/h4Es4D27w3GuMeYKY8wyEXkBWI4VDrraGFMDICLXALMAF/C0MWZZjDbEhcv/vbCOt+30/MN5USsWQkWY8ltmJLRuRVFSj5jE3xgTdPyiMWYKMCVA+kxgZiz1Jgp/79u5GTxcE6+6fSt3tjVPTTo8oXUripJ66Hi/EDj1OC3BV8rf8/cM3ezVviWdWgeYz0FRFCUGVPxD4BP2Sbjn77utEX9FURKJin8IfMI+iY75+6n/xUf1SGh9iqKkNir+oXDoccJj/n7bZw0rDFhOURQlHqj4h8ApyIke7aMzLCuK0pDofP4hcIZiGtrzL8xvQf/Oudx+WpOd905RlGaMin8IGtLz79upFYvW7fJuZ6W7eOf6YxJap6IoqUvKh32qatwcqKqpk75p934qDtamJ3oSzKcvOZznLgs4x52iKErcSXnP/6xHP2fJxt110k958BOf7fQwB/o/OHEo/zf964jtyMvJZFSf9jw4cShZ6a6I91cURYmElBf/QMIPsLOiymc7PYywT35OBicO6BSTPROGdq2/kIOrxvTmveVbYqpTUZTUI+XFP1xcrvBi/g29nOKN4/tz4/j+DVqnoijNn5SP+YdLRqLnd1AURWlAVNHCJD0Mz19EdB5+RVGaBSr+YRJOzF9o+LCPoihKNKj4h4lzwfMXrxjJlDMHBSyn0q8oSnNAO3zDxOn5F+S1ICcz8HBM9fwVRWkOqOcfJuIQ9WARoG5tczTmryhKs0DFP0yc/b3OeX4K2tQutPLUpBKfRkJRFKWpouIfJs75/EXEu8B66xa16+u2a5XV4HYpiqJEg4p/mDgndkv07M6KoiiJRsU/TJyhnkSv6qUoipJoVPzDJM0v7KMoitKciUn8ReReEVksIl+LyLsiUmCni4g8JCKldv4wxz6TROQ7+29SrCfQUDg9fxF0VI+iKM2aWD3/PxtjBhtjhgJvAnfY6ScDxfbf5cBjACLSFrgTGAEcAdwpIvkx2tAg6NQ+iqIkEzFJmjFmj2OzJbWLX00A/mUs5gJ5ItIFGAe8Z4wpM8bsBN4DxsdiQ7T86t8L+HDV1rDLi9+7u564f1a6tgqKojQ/Yn7DV0SmABcDu4GxdnJXYL2j2AY7LVh6oONejvXUQPfu3WM10wdjDLOWbWHWsvrnwT+uf0dG9mrnE+ZpnZ1BblY61x1fzLklhRz9pw/jap+iKEqiqddtFZHZIrI0wN8EAGPMrcaYbsBzwDXxMswYM80YU2KMKenQoUO8DmsfO/yy/Trn8stjenk7eU8b3AWwOn1/c2JfCvNz4mqboihKQ1Cv52+MOSHMYz0HzMSK6W8EujnyCu20jcAYv/Q5YR4/bkSg/V48jn8kDYeiKEpTJdbRPsWOzQnASvvzDOBie9TPkcBuY8wmYBZwkojk2x29J9lpDYqJQME9RT1hHxOg6XjruqN57epR3u33fn0ML14xMiYbFUVREkmsMf+pItIPcAM/AFfY6TOBU4BSoAL4OYAxpkxE7gXm2+XuMcaUxWhDveyrrCYnw+Udqx+N8+6ZrdPtrps3sKCNz3Zxp9woalAURWk4YhJ/Y8zZQdINcHWQvKeBp2OpNxJ2769iyN3vcvXY3vxuXH/bhvD393j6aSE8f0VRlOZG0o9T3FVxEIA3vtnkTYtOwG3PP4Jd27fK5LZTD4miLkVRlMSSkou5RNRp6x/zj2DfBbedGEFFiqIoDUfSe/7xGp1TO8xfwz6KojR/kl78PThf0oqmQfB0+OpQT0VRkoGkF/9AWh1JzN9T0tN4uFX9FUVJApJe/D04Z+aJRr8HF+YBcMmonvExSFEUpRFJzQ7fSMraLUWH3CzWTj01MQYpiqI0MCnj+TuJ5A1fRVGUZCTpxT+Q0Efm+cfPFkVRlKZC0ou/B+fSiyroiqKkOikj/gBLN+7m5Ac/obyyurFNURRFaVRSSvynvr2SFZv2sPCHnY1tiqIoSqOSUuLvIYrZHRRFUZKKpBf/gC95adBfUZQUJ+nF34PUX0RRFCVlSBnxdxLRfP76kKAoShKSmuKvkXxFUVKcpBf/QJ57NCt5KYqiJBNJL/5eYpzSWVEUJZlIAfHX6R0URVH8SXrx96y56zulsyq6oiipTdKLf8CYf8OboSiK0qRIfvEPJPWq/oqipDhxEX8RuUFEjIi0t7dFRB4SkVIRWSwiwxxlJ4nId/bfpHjUH4rAnn8EyzhqiEhRlCQk5pW8RKQbcBKwzpF8MlBs/40AHgNGiEhb4E6gBMv/XigiM4wxCZtpLdahnoqiKMlIPDz/B4Ab8Q2mTAD+ZSzmAnki0gUYB7xnjCmzBf89YHwcbAiKZ8F153z+VW5Vf0VRUpuYxF9EJgAbjTHf+GV1BdY7tjfYacHSAx37chFZICILtm3bFouZdbj9taVxPZ6iKEpzo96wj4jMBjoHyLoVuAUr5BN3jDHTgGkAJSUlUbvqGuJRFEWpS73ib4w5IVC6iBwK9AS+sUMqhcAiETkC2Ah0cxQvtNM2AmP80udEYXfYxDo9g7YdiqIkI1GHfYwxS4wxHY0xRcaYIqwQzjBjzGZgBnCxPernSGC3MWYTMAs4SUTyRSQf66lhVuynEcrORB5dURSleRLzaJ8gzAROAUqBCuDnAMaYMhG5F5hvl7vHGFOWIBuAWs892vn8tfFQFCUZiZv4296/57MBrg5S7mng6XjVWx+1o30aqkZFUZSmT/K/4Ruj565TOiuKkowkvfhrl62iKEpdkl78o/H8Ref+VxQlyUl+8Y9inzTtIFAUJclJevF321M5SATjfVwO8T9hQKe426QoitLYJL34R+P5e7T/pvH9GduvY1ztURRFaQokv/hHof6uNEv9a9zuOFujKIrSNEh+8Xf4/uGG8j1hn2qd/VNRlCQl6cXfGfcJ9ykgzfb83Sr+iqIkKYma3qHJ4NHvjbv2s2rL3rD28YR91PNXFCVZSXrP3xP22VdZHfY+tvZTo4P8FUVJUpJf/KPQb884fw37KIqSrCS/+EexT262FQ1rkeGKrzGKoihNhKSP+ZswXX+R2qeEc4Z3I01g0lFFiTNMURSlEUl+8Y9inzSBXx3bO+62KIqiNBWSP+wTRdBfI/2KoiQ7KSD+4ZVzvv+lg3wURUl2VPwD7aO+v6IoSU7yi3+Y5USncVYUJYVIfvEPd7SPzz6JsUVRFKWpkPTiH+57Wur4K4qSSiS9+EczdieaEUKKoijNiZjEX0TuEpGNIvK1/XeKI+9mESkVkVUiMs6RPt5OKxWRybHUHw6q44qiKHWJx0teDxhj7ncmiMgAYCIwECgAZotIXzv7EeBEYAMwX0RmGGOWx8GOgETW4WuV1gZDUZRkJ1Fv+E4AphtjKoE1IlIKHGHnlRpjVgOIyHS7bOLEP5px/gmxRFEUpekQj5j/NSKyWESeFpF8O60rsN5RZoOdFiy9DiJyuYgsEJEF27Zti9q4cMfsOzt81fNXFCXZqVf8RWS2iCwN8DcBeAzoDQwFNgF/iZdhxphpxpgSY0xJhw4doj5OuKN9VPAVRUkl6g37GGNOCOdAIvIP4E17cyPQzZFdaKcRIj0hRDe3j7YEiqIkN7GO9uni2DwTWGp/ngFMFJEsEekJFAPzgPlAsYj0FJFMrE7hGbHYEC/SHHEffQpQFCXZibXD9z4RGYrVR7oW+BWAMWaZiLyA1ZFbDVxtjKkBEJFrgFmAC3jaGLMsRhtCEq6Qt2mRwf6qGqB2MRdFUZRkJSaVM8ZcFCJvCjAlQPpMYGYs9UZCuCGcy0b39H7WRVwURUl2kt7FdbvDK5eeJlwyqmf9BRVFUZKApJ/eQcP3iqIodUl+8dfeW0VRlDokv/iHWU7n81cUJZVIevHXuI+iKEpdkl789YUtRVGUuiS9+K/YtDescto3oChKKpH04v/M52sb2wRFUZQmR9KLv6IoilKXpBb/g9VhvuGFjvZRFCW1SGrx37X/YGOboCiK0iRJavHvmJvN2qmnNrYZiqIoTY6kFn9FURQlMCr+iqIoKYiKv4329yqKkkqo+CuKoqQgST+fv5NJI3vgSkujc5ssNu+u5OnP1njz9AVfRVFSidQS/6OK6NWhFQB7DlT5iL+iKEoqkVJhH1dabWDfpUF+RVFSmJQS/zSH4DsbAkVRlFQjtcTfIfhpfp6/PggoipJKpJT4O0M9/o7/wII2DWyNoihK4xGz+IvItSKyUkSWich9jvSbRaRURFaJyDhH+ng7rVREJsdafyS0yHB5PzvDPt/ccRLDe+Q3pCmKoiiNSkyjfURkLDABGGKMqRSRjnb6AGAiMBAoAGaLSF97t0eAE4ENwHwRmWGMWR6LHeGSnVnb1jln8WyTk9EQ1SuKojQZYh3qeSUw1RhTCWCM2WqnTwCm2+lrRKQUOMLOKzXGrAYQkel22QYR/0xX3QedG07sG6CkoihKchOr+PcFRovIFOAA8FtjzHygKzDXUW6DnQaw3i99RIw2hI3/nP0646eiKKlKveIvIrOBzgGybrX3bwscCRwOvCAiveJhmIhcDlwO0L1793gcUlEURbGpV/yNMScEyxORK4FXjLX6+TwRcQPtgY1AN0fRQjuNEOn+9U4DpgGUlJTo5AuKoihxJNbRPq8BYwHsDt1MYDswA5goIlki0hMoBuYB84FiEekpIplYncIzYrRBURRFiZBYY/5PA0+LyFLgIDDJfgpYJiIvYHXkVgNXG2NqAETkGmAW4AKeNsYsi9EGRVEUJULENIPpLEtKSsyCBQui3v/9FVuoqnEzflCXOFqlKIrStBGRhcaYkkB5KTGr5/GHdGpsExRFUZoUKTW9g6IoimKh4q8oipKCqPgriqKkICr+iqIoKYiKv6IoSgqi4q8oipKCqPgriqKkICr+iqIoKUizeMNXRLYBP8RwiPZYcw4pei380evhi16PWpLhWvQwxnQIlNEsxD9WRGRBsFecUw29Fr7o9fBFr0ctyX4tNOyjKIqSgqj4K4qipCCpIv7TGtuAJoReC1/0evii16OWpL4WKRHzVxRFUXxJFc9fURRFcaDiryiKkoIktfiLyHgRWSUipSIyubHtaQhEpJuIfCgiy0VkmYj8n53eVkTeE5Hv7P/5drqIyEP2NVosIsMa9wzij4i4ROQrEXnT3u4pIl/a5/w/ez1p7DWn/2enfykiRY1pdyIQkTwReUlEVorIChEZmar3hoj82v6NLBWR/4pIdirdG0kr/iLiAh4BTgYGAOeLyIDGtapBqAZuMMYMAI4ErrbPezLwvjGmGHjf3gbr+hTbf5cDjzW8yQnn/4AVju0/AQ8YY/oAO4FL7fRLgZ12+gN2uWTjQeAdY0x/YAjWdUm5e0NEugLXASXGmEFYa4pPJJXuDWNMUv4BI4FZju2bgZsb265GuA6vAycCq4AudloXYJX9+QngfEd5b7lk+AMKsQTtOOBNQLDe2kz3v0+AWcBI+3O6XU4a+xzieC3aAGv8zykV7w2gK7AeaGt/128C41Lp3khaz5/aL9fDBjstZbAfTQ8DvgQ6GWM22VmbAc/Cxsl+nf4G3Ai47e12wC5jTLW97Txf77Ww83fb5ZOFnsA24J92GOxJEWlJCt4bxpiNwP3AOmAT1ne9kBS6N5JZ/FMaEWkFvAxcb4zZ48wzlvuS9GN8ReQ0YKsxZmFj29JESAeGAY8ZYw4DyqkN8QApdW/kAxOwGsQCoCUwvlGNamCSWfw3At0c24V2WtIjIhlYwv+cMeYVO3mLiHSx87sAW+30ZL5Oo4AzRGQtMB0r9PMgkCci6XYZ5/l6r4Wd3wbY0ZAGJ5gNwAZjzJf29ktYjUEq3hsnAGuMMduMMVXAK1j3S8rcG8ks/vOBYrv3PhOrM2dGI9uUcEREgKeAFcaYvzqyZgCT7M+TsPoCPOkX2yM7jgR2O0IAzRpjzM3GmEJjTBHW9/+BMeZC4EPgHLuY/7XwXKNz7PJJ4wUbYzYD60Wkn510PLCcFLw3sMI9R4pIjv2b8VyL1Lk3GrvTIZF/wCnAt8D3wK2NbU8DnfPRWI/ti4Gv7b9TsOKT7wPfAbOBtnZ5wRoV9T2wBGv0Q6OfRwKuyxjgTftzL2AeUAq8CGTZ6dn2dqmd36ux7U7AdRgKLLDvj9eA/FS9N4C7gZXAUuDfQFYq3Rs6vYOiKEoKksxhH0VRFCUIKv6KoigpiIq/oihKCqLiryiKkoKo+CuKoqQgKv6KoigpiIq/oihKCvL/cUAkcW6+f1kAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "\n",
+ "rewards = []\n",
+ "for i in range(1000):\n",
+ " rewards.append(play_and_train(env, agent))\n",
+ " agent.epsilon *= 0.99\n",
+ "\n",
+ " if i % 100 == 0:\n",
+ " clear_output(True)\n",
+ " plt.title('eps = {:e}, mean reward = {:.1f}'.format(agent.epsilon, np.mean(rewards[-10:])))\n",
+ " plt.plot(rewards)\n",
+ " plt.show()\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to Coursera I: Preparation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "submit_rewards1 = rewards.copy()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Binarized state spaces\n",
+ "\n",
+ "Use an agent to train efficiently on `CartPole-v0`. This environment has a continuous set of possible states, so you will have to group them somwhow into bins.\n",
+ "\n",
+ "The simplest way is to use `round(x, n_digits)` (or `np.round`) to round the real number to a given amount of digits. The tricky part is to get the `n_digits` right for each state to train effectively.\n",
+ "\n",
+ "Note that you don't need to convert a state to integers, but to __tuples__ for any kind of values."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def make_env():\n",
+ " return gym.make('CartPole-v0').env # .env unwraps the TimeLimit wrapper\n",
+ "\n",
+ "env = make_env()\n",
+ "n_actions = env.action_space.n\n",
+ "\n",
+ "print(\"first state: %s\" % (env.reset()))\n",
+ "plt.imshow(env.render('rgb_array'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Play a few games\n",
+ "\n",
+ "We need to estimate observation distributions. To do so, we'll play a few games and record all states."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def visualize_cartpole_observation_distribution(seen_observations):\n",
+ " seen_observations = np.array(seen_observations)\n",
+ " \n",
+ " # The meaning of the observations is documented in\n",
+ " # https://github.com/openai/gym/blob/master/gym/envs/classic_control/cartpole.py\n",
+ "\n",
+ " f, axarr = plt.subplots(2, 2, figsize=(16, 9), sharey=True)\n",
+ " for i, title in enumerate(['Cart Position', 'Cart Velocity', 'Pole Angle', 'Pole Velocity At Tip']):\n",
+ " ax = axarr[i // 2, i % 2]\n",
+ " ax.hist(seen_observations[:, i], bins=20)\n",
+ " ax.set_title(title)\n",
+ " xmin, xmax = ax.get_xlim()\n",
+ " ax.set_xlim(min(xmin, -xmax), max(-xmin, xmax))\n",
+ " ax.grid()\n",
+ " f.tight_layout()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAABHgAAAKACAYAAADn488NAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4yLjEsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+j8jraAAAgAElEQVR4nOzde7hlV1kn6t8n4RIpSILBEpJIoURsIC0NZYgHj1aMHQKIiTYgdIREI2mOoNimWwOi0Fw02tAIrcCJIU0QmkAjSCRgiEhJ04cACbdwkU4RgqmQECEhUIBo4Xf+WLN0987eVfu29l6z9vs+z35qrTHHHHOsMWftGvVb81LdHQAAAADG69s2ugMAAAAArI6ABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMwT1Xtqarv2c/yT1TVjnXsEgCwiVXVq6vqBats41lVdcFa9QmYPQIeYE1V1b+tqiuHkOTGqnpHVf3wKtrrqrrffpafWVXfGrb3lar6SFX9xEq3lyTdvaW7rx3av92Eqrsf2N07V7MNAGBjreecpapOqKqvVdWWBZZ9uKqevtLtLlV3/3Z3/8KwzW1Dfw+Z9naB9SPgAdZMVf1qkt9P8ttJtib57iQvT3LqCtpazoTjfd29JcnhSV6V5I1VdcRytwkAbA7rPWfp7iuS7E7y2HnrPijJA5K8frnbBZhPwAOsiao6LMnzkjytu9/c3V/r7n/o7j/r7v841Dm+qt5XVV8evin7g6q605w2uqqeVlXXJLmmqt4zLPro8O3az+yvD939j0kuTHJoku+tqsOq6jVV9bdV9bmqenZVfduwrftV1V9V1W1V9cWqesO8ftyvqs5OcnqSXxu2/2fD8uuq6seH13euqt+vqs8PP79fVXcelu2oqt1VdU5V3Tx85p9bkwEHAFZkA+csFyV58ryyJyd5e3d/qaq+v6our6pbqurTVfX4/XyGp1TVrqHuJVV17znLHjinnS9U1bOG8udW1WuHavv6++Whvz861D9uTjvfWVVfr6p7LmVcgY0n4AHWyg8luUuSt+ynzreS/PskRw71T0ryi/PqnJbkYUke0N0/MpT9wHDZ1BuyH8M3aL+QZE+Sa5L81ySHJfmeJD+aySRqX8Dy/CTvTHJEkqOHuv+H7j4/yeuS/N6w/ccssNnfSHJCkgcn+YEkxyd59pzl3zX04agkZyX5Q2cXAcCG2qg5yx8n+ZGqOiZJhi+d/m2Si6rqrkkuT/Lfk3xnkickeXlVPWB+I1X1Y0l+J8njk9wryeeSXDwsu1uSv0jy50nuneR+Sd61QF/29ffwob9/NbTxs3PqPDHJu7r7bxdYH5hBAh5grXxHki92997FKnT3Vd19RXfv7e7rkvy/mQQvc/1Od9/S3d9YxrZPqKovJ7kpk8nIT2US8jwhyTO7+6vD9l6c5EnDOv+Q5D5J7t3df9fd713G9uY6PcnzuvvmYQL0n+ZsY992njd8M/j2oV/3X+G2AIDV25A5S3dfn2Rn/nmecFKSOye5NMlPJLmuu//bsM0PJ/mTJI9boKnTk1zY3R/q7m8meWaSH6qqbUM7N3X3i4f5zVe7+/1L6V8mZxg9sapqeP+kTEIpYCQEPMBa+VKSI/d3HXpVfV9Vva2qbqqqr2Ry3fuR86pdv4JtX9Hdh3f3kd19Qnf/xdDuHTP5Vmufz2VyJk2S/FqSSvKBmjwV6+dXsN1k8u3Y/G3ce877L82bQH49ye1usAgArJuNnLNclH8OeJ6U5OLu3vel08OGS8K+PHxxdXomZwLP93/MPbp7z/CZjkpyTJLPrKBfGYKgryfZUVXfn8nZP5espC1gYwh4gLXyviTfzOR05cW8IslfJzm2u++e5FmZhCxz9Rr154v557N09vnuJDckSXff1N1P6e57J/l3mZwGvdCTLw7Un88vsI3Pr7jXAMC0beSc5c1Jjq6qE5P8dCaBTzIJi/5q+MJq38+W7v5/Fmjj/5h7DJd3fUcmc5zrM7k0/UAW6/tFmVym9aQkb+ruv1vKhwJmg4AHWBPdfVuS38rkHjOnVdW3V9Udq+qRVfV7Q7W7JflKkj3DN0MLTVrm+0KWNlGZ359vJXljkhdW1d2q6j5JfjXJa5Okqh5XVUcP1W/NZKLzjyvY/uuTPLuq7llVR2YyBq/dT30AYANt5Jylu7+W5E1J/luSz3X3lcOityX5vqp60tCXO1bVD1bVv1igmdcn+bmqevDwYIffTvL+4VKytyW5V1X9yvAgiLtV1cMWaONvM5n3zO/vazO51P1nk7xmCZ8ZmCECHmDNdPeLMwlRnp3JxOH6JE9P8qdDlf+Qyc0Ev5rkj5Ls96bJg+dmcvPBL+/vaRKL+KUkX0tybZL3ZnLjwguHZT+Y5P1VtSeT04+f0d3XLtDGq5I8YNj+ny6w/AVJrkzysSRXJ/nQUAYAzKgNnrNclMkZOP8UoHT3V5OcnMn9Az+fyX0FfzeTe/TM7/tfJPnNTO7Rc2OS7x3W29fOv07ymKGNa5KcuEAbX0/ywiT/a+jvCUP59ZnMZTrJ/1zCZwZmSHWv1dUQAAAAjFlVXZjk89397ANWBmbKojcWAwAAYPMYnsT100n+1cb2BFgJl2gBAABsclX1/CQfT/Kfu/uzG90fYPlcogUAAAAwcs7gAQAAABi50d6D58gjj+x73vOeuetd77rRXTmofe1rXzPGU2aMp8v4Tp8xnj5jPF37xveqq676Ynffcy3bPvLII3vbtm1r2eRBwTE9O+yL2WFfzA77YnbYFwtbbM4y2oBn27ZtedGLXpQdO3ZsdFcOajt37jTGU2aMp8v4Tp8xnj5jPF37xreqPrfWbW/bti1XXnnlWjc7eo7p2WFfzA77YnbYF7PDvljYYnMWl2gBAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjd8hGdwBgObade+my6p9z3N6ceYB1rjvv0avpEgAAwIZzBg8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkTtgwFNVF1bVzVX18QWWnVNVXVVHDu+rql5WVbuq6mNV9ZA5dc+oqmuGnzPmlD+0qq4e1nlZVdVafTgAAACAzWApZ/C8Oskp8wur6pgkJyf5mznFj0xy7PBzdpJXDHXvkeQ5SR6W5Pgkz6mqI4Z1XpHkKXPWu922AAAAAFjcAQOe7n5PklsWWPSSJL+WpOeUnZrkNT1xRZLDq+peSR6R5PLuvqW7b01yeZJThmV37+4ruruTvCbJaav7SAAAAACby4ruwVNVpya5obs/Om/RUUmun/N+91C2v/LdC5QDAAAAsESHLHeFqvr2JM/K5PKsdVVVZ2dy6Ve2bt2aPXv2ZOfOnevdjU3FGE+fMV6ec47bu6z6Ww898DrGf3Ucw9NnjKdrrcd3/nzFvrs9x/TssC9mh30xO+yL2WFfLM+yA54k35vkvkk+OtwP+egkH6qq45PckOSYOXWPHspuSLJjXvnOofzoBeovqLvPT3J+kmzfvr23bNmSHTt2LFadNbBz505jPGXGeHnOPPfSZdU/57i9efHV+/9Vd93pO1bRIxzD02eMp2utx3f+fMW+uz3H9OywL2aHfTE77IvZYV8sz7Iv0eruq7v7O7t7W3dvy+Syqod0901JLkny5OFpWickua27b0xyWZKTq+qI4ebKJye5bFj2lao6YXh61pOTvHWNPhsAAADAprCUx6S/Psn7kty/qnZX1Vn7qf72JNcm2ZXkj5L8YpJ09y1Jnp/kg8PP84ayDHUuGNb5TJJ3rOyjAAAAAGxOB7xEq7ufeIDl2+a87iRPW6TehUkuXKD8yiQPOlA/AAAAAFjYip6iBQAAAMDsEPAAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkDhjwVNWFVXVzVX18Ttl/rqq/rqqPVdVbqurwOcueWVW7qurTVfWIOeWnDGW7qurcOeX3rar3D+VvqKo7reUHBAAAADjYLeUMnlcnOWVe2eVJHtTd/zLJ/07yzCSpqgckeUKSBw7rvLyq7lBVd0jyh0kemeQBSZ441E2S303yku6+X5Jbk5y1qk8EAAAAsMkcMODp7vckuWVe2Tu7e+/w9ookRw+vT01ycXd/s7s/m2RXkuOHn13dfW13/32Si5OcWlWV5MeSvGlY/6Ikp63yMwEAAABsKoesQRs/n+QNw+ujMgl89tk9lCXJ9fPKH5bkO5J8eU5YNLf+7VTV2UnOTpKtW7dmz5492blz52r7z34Y4+kzxstzznF7D1xpjq2HHngd4786juHpM8bTtdbjO3++Yt/dnmN6dtgXs8O+mB32xeywL5ZnVQFPVf1Gkr1JXrc23dm/7j4/yflJsn379t6yZUt27NixHpvetHbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWXHAU1VnJvmJJCd1dw/FNyQ5Zk61o4eyLFL+pSSHV9Uhw1k8c+sDAAAAsAQrekx6VZ2S5NeS/GR3f33OokuSPKGq7lxV901ybJIPJPlgkmOHJ2bdKZMbMV8yBEPvTvLYYf0zkrx1ZR8FAAAAYHNaymPSX5/kfUnuX1W7q+qsJH+Q5G5JLq+qj1TVK5Okuz+R5I1JPpnkz5M8rbu/NZyd8/QklyX5VJI3DnWT5NeT/GpV7crknjyvWtNPCAAAAHCQO+AlWt39xAWKFw1huvuFSV64QPnbk7x9gfJrM3nKFgAAAAArsKJLtAAAAACYHQIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJE7YMBTVRdW1c1V9fE5Zfeoqsur6prhzyOG8qqql1XVrqr6WFU9ZM46Zwz1r6mqM+aUP7Sqrh7WeVlV1Vp/SAAAAICD2VLO4Hl1klPmlZ2b5F3dfWySdw3vk+SRSY4dfs5O8opkEggleU6ShyU5Pslz9oVCQ52nzFlv/rYAAAAA2I8DBjzd/Z4kt8wrPjXJRcPri5KcNqf8NT1xRZLDq+peSR6R5PLuvqW7b01yeZJThmV37+4ruruTvGZOWwAAAAAswSErXG9rd984vL4pydbh9VFJrp9Tb/dQtr/y3QuUL6iqzs7kzKBs3bo1e/bsyc6dO1f4EVgKYzx9xnh5zjlu77Lqbz30wOsY/9VxDE+fMZ6utR7f+fMV++72HNOzw76YHfbF7LAvZod9sTwrDXj+SXd3VfVadGYJ2zo/yflJsn379t6yZUt27NixHpvetHbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWelTtL4wXF6V4c+bh/Ibkhwzp97RQ9n+yo9eoBwAAACAJVppwHNJkn1PwjojyVvnlD95eJrWCUluGy7luizJyVV1xHBz5ZOTXDYs+0pVnTA8PevJc9oCAAAAYAkOeIlWVb0+yY4kR1bV7kyehnVekjdW1VlJPpfk8UP1tyd5VJJdSb6e5OeSpLtvqarnJ/ngUO953b3vxs2/mMmTug5N8o7hBwAAAIAlOmDA091PXGTRSQvU7SRPW6SdC5NcuED5lUkedKB+AAAAALCwlV6iBQAAAMCMEPAAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjNyqAp6q+vdV9Ymq+nhVvb6q7lJV962q91fVrqp6Q1Xdaah75+H9rmH5tjntPHMo/3RVPWJ1HwkAAABgc1lxwFNVRyX55STbu/tBSe6Q5AlJfjfJS7r7fkluTXLWsMpZSW4dyl8y1EtVPWBY74FJTkny8qq6w0r7BQAAALDZrPYSrUOSHFpVhyT59iQ3JvmxJG8all+U5LTh9anD+wzLT6qqGsov7u5vdvdnk+xKcvwq+wUAAACwaVR3r3zlqmckeWGSbyR5Z5JnJLliOEsnVXVMknd094Oq6uNJTunu3cOyzyR5WJLnDuu8dih/1bDOmxbY3tlJzk6SrVu3PvSCCy7Ili1bVtx/DmzPnj3GeMqM8fJcfcNty6q/9dDkC9/Yf53jjjpsFT3CMTx9xni69o3viSeeeFV3b19te/PnKxdffPGq+3iwcUzPDvtidtgXs8O+mB32xcIWm7McstIGq+qITM6+uW+SLyf5H5lcYjU13X1+kvOTZPv27b1ly5bs2LFjmpvc9Hbu3GmMp8wYL8+Z5166rPrnHLc3L756/7/qrjt9xyp6hGN4+ozxdK31+M6fr9h3t+eYnh32xeywL2aHfTE77IvlWc0lWj+e5LPd/bfd/Q9J3pzk4UkOHy7ZSpKjk9wwvL4hyTFJMiw/LMmX5pYvsA4AAAAAB7CagOdvkpxQVd8+3EvnpCSfTPLuJI8d6pyR5K3D60uG9xmW/2VPrg+7JMkThqds3TfJsUk+sIp+AQAAAGwqK75Eq7vfX1VvSvKhJHuTfDiT05EvTXJxVb1gKHvVsMqrkvxxVe1KcksmT85Kd3+iqt6YSTi0N8nTuvtbK+0XAAAAwGaz4oAnSbr7OUmeM6/42izwFKzu/rskj1uknRdmcrNmAAAAAJZptY9JBwAAAGCDCXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARm5VAU9VHV5Vb6qqv66qT1XVD1XVParq8qq6ZvjziKFuVdXLqmpXVX2sqh4yp50zhvrXVNUZq/1QAAAAAJvJas/geWmSP+/u70/yA0k+leTcJO/q7mOTvGt4nySPTHLs8HN2klckSVXdI8lzkjwsyfFJnrMvFAIAAADgwFYc8FTVYUl+JMmrkqS7/767v5zk1CQXDdUuSnLa8PrUJK/piSuSHF5V90ryiCSXd/ct3X1rksuTnLLSfgEAAABsNtXdK1ux6sFJzk/yyUzO3rkqyTOS3NDdhw91Ksmt3X14Vb0tyXnd/d5h2buS/HqSHUnu0t0vGMp/M8k3uvtFC2zz7EzO/snWrVsfesEFF2TLli0r6j9Ls2fPHmM8ZcZ4ea6+4bZl1d96aPKFb+y/znFHHbaKHuEYnj5jPF37xvfEE0+8qru3r7a9+fOViy++eNV9PNg4pmeHfTE77IvZYV/MDvtiYYvNWQ5ZRZuHJHlIkl/q7vdX1Uvzz5djJUm6u6tqZQnSArr7/ExCpWzfvr23bNmSHTt2rFXzLGDnzp3GeMqM8fKcee6ly6p/znF78+Kr9/+r7rrTd6yiRziGp88YT9daj+/8+Yp9d3uO6dlhX8wO+2J22Bezw75YntXcg2d3kt3d/f7h/ZsyCXy+MFx6leHPm4flNyQ5Zs76Rw9li5UDAAAAsAQrDni6+6Yk11fV/YeikzK5XOuSJPuehHVGkrcOry9J8uThaVonJLmtu29MclmSk6vqiOHmyicPZQAAAAAswWou0UqSX0ryuqq6U5Jrk/xcJqHRG6vqrCSfS/L4oe7bkzwqya4kXx/qprtvqarnJ/ngUO953X3LKvsFAAAAsGmsKuDp7o8kWehmhCctULeTPG2Rdi5McuFq+gIAAACwWa3mHjwAAAAAzAABDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACN3yEZ3AAAAYNZtO/fSqbZ/znF7c+YUt3HdeY+eWtvAbHAGDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgdstEdANho2869dCrtXnfeo6fSLgAAwHzO4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkVh3wVNUdqurDVfW24f19q+r9VbWrqt5QVXcayu88vN81LN82p41nDuWfrqpHrLZPAAAAAJvJWpzB84wkn5rz/neTvKS775fk1iRnDeVnJbl1KH/JUC9V9YAkT0jywCSnJHl5Vd1hDfoFAAAAsCmsKuCpqqOTPDrJBcP7SvJjSd40VLkoyWnD61OH9xmWnzTUPzXJxd39ze7+bJJdSY5fTb8AAAAANpPq7pWvXPWmJL+T5G5J/kOSM5NcMZylk6o6Jsk7uvtBVfXxJKd09+5h2WeSPCzJc4d1XjuUv2pY503zNpeqOjvJ2UmydevWh15wwQXZsmXLivvPge3Zs8cYT5kxXp6rb7htWfW3Hpp84RtT6swBHHfUYRuz4XXmGJ4+Yzxd+8b3xBNPvKq7t6+2vfnzlYsvvnjVfTzYOKZnh32xdMudgyzXtOcsm2Veshb8vZgd9sXCFpuzHLLSBqvqJ5Lc3N1XVdWO1XRuqbr7/CTnJ8n27dt7y5Yt2bFjXTa9ae3cudMYT5kxXp4zz710WfXPOW5vXnz1in/Vrcp1p+/YkO2uN8fw9Bnj6Vrr8Z0/X7Hvbs8xPTvsi6Vb7hxkuaY9Z9ks85K14O/F7LAvlmc1v0EenuQnq+pRSe6S5O5JXprk8Ko6pLv3Jjk6yQ1D/RuSHJNkd1UdkuSwJF+aU77P3HUAAAAAOIAV34Onu5/Z3Ud397ZMbpL8l919epJ3J3nsUO2MJG8dXl8yvM+w/C97cn3YJUmeMDxl675Jjk3ygZX2CwAAAGCzmcY5gL+e5OKqekGSDyd51VD+qiR/XFW7ktySSSiU7v5EVb0xySeT7E3ytO7+1hT6BQAAAHBQWpOAp7t3Jtk5vL42CzwFq7v/LsnjFln/hUleuBZ9AQAAANhsVvWYdAAAAAA2noAHAAAAYOQEPAAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABG7pCN7gBwcNp27qUb3QUAAIBNwxk8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGzk2WAQAADnLr8QCM68579NS3ASzOGTwAAAAAIyfgAQAAABg5l2gBAACjth6XHwHMOmfwAAAAAIycgAcAAABg5AQ8AAAAACO34oCnqo6pqndX1Ser6hNV9Yyh/B5VdXlVXTP8ecRQXlX1sqraVVUfq6qHzGnrjKH+NVV1xuo/FgAAAMDmsZozePYmOae7H5DkhCRPq6oHJDk3ybu6+9gk7xreJ8kjkxw7/Jyd5BXJJBBK8pwkD0tyfJLn7AuFAAAAADiwFQc83X1jd39oeP3VJJ9KclSSU5NcNFS7KMlpw+tTk7ymJ65IcnhV3SvJI5Jc3t23dPetSS5PcspK+wUAAACw2VR3r76Rqm1J3pPkQUn+prsPH8orya3dfXhVvS3Jed393mHZu5L8epIdSe7S3S8Yyn8zyTe6+0ULbOfsTM7+ydatWx96wQUXZMuWLavuP4vbs2ePMZ6yg3WMr77hto3uQpJk66HJF76xMds+7qjDNmbD6+xgPYZniTGern3je+KJJ17V3dtX2978+crFF1+86j4ebBzTs+Ng2RezMu9YjY2cs6yVg2Xuc7D8vTgY2BcLW2zOcshqG66qLUn+JMmvdPdXJpnORHd3Va0+Qfrn9s5Pcn6SbN++vbds2ZIdO3asVfMsYOfOncZ4yg7WMT7z3Es3ugtJknOO25sXX73qX3Urct3pOzZku+vtYD2GZ4kxnq61Ht/58xX77vYc07PjYNkXszLvWI2NnLOslYNl7nOw/L04GNgXy7Oqp2hV1R0zCXde191vHoq/MFx6leHPm4fyG5IcM2f1o4eyxcoBAAAAWIIVR8TD5VevSvKp7v4vcxZdkuSMJOcNf751TvnTq+riTG6ofFt331hVlyX57Tk3Vj45yTNX2i8AAADW37Ypn0l13XmPnmr7MHarOQfw4UmelOTqqvrIUPasTIKdN1bVWUk+l+Txw7K3J3lUkl1Jvp7k55Kku2+pqucn+eBQ73ndfcsq+gUAAACwqaw44BlullyLLD5pgfqd5GmLtHVhkgtX2hcAAGB2TfvMDgBWeQ8eAAAAADaegAcAAABg5AQ8AAAAACMn4AEAAAAYudU8RQsAAADWhceww/4JeAAAYJPzlCuA8XOJFgAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAA8oKzcAACAASURBVIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjNwhG90BAABgcdvOvXRqbZ9z3N6cOcX2YUz2/V2b5t+L68579FTahcQZPAAAAACjJ+ABAAAAGDmXaAFMyTROqXdaLwAAsBABD2xy07yuHwAAgPXhEi0AAACAkRPwAAAAAIzczFyiVVWnJHlpkjskuaC7z9vgLgEAwAG53BlYqmn/vnC/xs1tJgKeqrpDkj9M8q+T7E7ywaq6pLs/ubE9g9liAsm0jgGTAQCA8RMgbW4zEfAkOT7Jru6+Nkmq6uIkpyYR8DBKy/nFes5xe3Om4IYNtprJwGLHsAkAMCt8QQLAZlDdvdF9SFU9Nskp3f0Lw/snJXlYdz99Xr2zk5w9vL1/ki8l+eJ69nUTOjLGeNqM8XQZ3+kzxtNnjKdr3/jep7vvudrGFpivfHq1bR6EHNOzw76YHfbF7LAvZod9sbAF5yyzcgbPknT3+UnO3/e+qq7s7u0b2KWDnjGePmM8XcZ3+ozx9Bnj6Vrr8Z0/X+H2HNOzw76YHfbF7LAvZod9sTyz8hStG5IcM+f90UMZAAAAAAcwKwHPB5McW1X3rao7JXlCkks2uE8AAAAAozATl2h1996qenqSyzJ5TPqF3f2JJazq9OfpM8bTZ4yny/hOnzGePmM8XcZ3/Rnz2WFfzA77YnbYF7PDvliGmbjJMgAAAAArNyuXaAEAAACwQgIeAAAAgJEbVcBTVY+rqk9U1T9W1aKPSquq66rq6qr6SFVduZ59HLtljPEpVfXpqtpVVeeuZx/HrqruUVWXV9U1w59HLFLvW8Mx/JGqctPxAzjQMVlVd66qNwzL319V29a/l+O2hDE+s6r+ds5x+wsb0c+xqqoLq+rmqvr4Isurql42jP/Hquoh693HsVvCGO+oqtvmHMO/td593Eyq6j9X1V8Px/Nbqurwje7TZrXU+R/TYV49Ow707wTro6qOqap3V9Unh99Nz9joPo3FqAKeJB9P8tNJ3rOEuid294O72z9Sy3PAMa6qOyT5wySPTPKAJE+sqgesT/cOCucmeVd3H5vkXcP7hXxjOIYf3N0/uX7dG58lHpNnJbm1u++X5CVJfnd9ezluy/h7/4Y5x+0F69rJ8Xt1klP2s/yRSY4dfs5O8op16NPB5tXZ/xgnyf+ccww/bx36tJldnuRB3f0vk/zvJM/c4P5sZsuZY7OGzKtnzqtz4H8nmL69Sc7p7gckOSHJ0/y9WJpRBTzd/anu/vRG9+NgtsQxPj7Jru6+trv/PsnFSU6dfu8OGqcmuWh4fVGS0zawLweLpRyTc8f9TUlOqqpaxz6Onb/3U9bd70lyy36qnJrkNT1xRZLDq+pe69O7g8MSxph11N3v7O69w9srkhy9kf3ZzMyxN5R/X2eIfydmQ3ff2N0fGl5/Ncmnkhy1sb0ah1EFPMvQSd5ZVVdV1dkb3ZmD0FFJrp/zfnf8hVuOrd194/D6piRbF6l3l6q6sqquqCoh0P4t5Zj8pzrDfyhuS/Id69K7g8NS/97/m+FyizdV1THr07VNw+/e9fFDVfXRqnpHVT1wozuzifx8kndsdCdgA/jdDvsx3FbhXyV5/8b2ZBwO2egOzFdVf5HkuxZY9Bvd/dYlNvPD3X1DVX1nksur6q+HNJas2RizH/sb47lvururqhdp5j7Dcfw9Sf6yqq7u7s+sdV9hDf1Zktd39zer6t9lcsbUj21wn2A5PpTJ7949VfWoJH+aySVxrNBS5hxV9RuZnI7/uvXs22Zj/geMTVVtSfInSX6lu7+y0f0Zg5kLeLr7x9egjRuGP2+uqrdkcuqjgGewBmN8Q5K538wfPZQx2N8YV9UXqupe3X3jcHnFzYu0se84vraqdmaSXAt4FraUY3Jfnd1VdUiSw5J8aX26d1A44Bh399zxvCDJ761DvzYTv3unbO7ksbvfXlUvr6oju/uLG9mvMTvQnKOqzkzyE0lO6u7FvvBgDazFHJup8LsdFlBVd8wk3Hldd795o/szFgfdJVpVddequtu+10lOzuTGcaydDyY5tqruW1V3SvKEJJ7ytHSXJDljeH1Gktt9a1ZVR1TVnYfXRyZ5eJJPrlsPx2cpx+TccX9skr/0n4llOeAYz7sfzE9mcr00a+eSJE8enqZ1QpLb5lzuyRqoqu/ad2+uqjo+k3mSIHhKquqUJL+W5Ce7++sb3R/YIObVMM/wb/Grknyqu//LRvdnTEYV8FTVT1XV7iQ/lOTSqrpsKL93Vb19qLY1yXur6qNJPpDk0u7+843p8fgsZYyH+5c8PcllmfwH7o3d/YmN6vMInZfkX1fVNUl+fHifqtpeVfueOvQvklw5HMfvTnJedwt4FrHYMVlVz6uqfU8ge1WS76iqXUl+NYs/vYwFLHGMf3l4lOVHk/xykjM3prfjVFWvT/K+JPevqt1VdVZVPbWqnjpUeXuSa5PsSvJHSX5xg7o6WksY48cm+fhwDL8syRMEwVP1B0nulsnl9B+pqldudIc2q8Xmf0yfefVsWejfiY3u0yb18CRPSvJjw78PHxkuneYAyrwFAAAAYNxGdQYPAAAAALcn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAPMtKq6rqp+fKP7MV9V7ayqX9jofgAA+7cRc4mqem5VvXaVbZxeVe9cqz5NU1W9sqp+c6P7AZudgAdYF8Pk6htVtaeqvlBVr66qLeuw3ftW1T9W1SumvS0AYHrWcy5RVUdV1d6q+t4Flr2lql40je3O1d2v6+6T52y3q+p+q2lzsXlRVe2oqt37We8dw7jvqap/qKq/n/P+ld391O5+/mr6BqyegAdYT4/p7i1JHpJke5Jnr8M2n5zk1iQ/U1V3XoftAQDTsy5zie6+Icm7kjxpbnlV3SPJo5JcNI3troMVzYu6+5HdvWUY+9cl+b1977v7qdPqLLA8Ah5g3Q2TpnckeVCSVNVPVtUnqurLw6VP/2Kh9arq26rq3Kr6TFV9qareOEy0FlRVlclE5tlJ/iHJY+Yt76p6alVdM2z7D4d1UlV3qKoXV9UXq+qzVfX0of4hi2zr56vqU1V1a1VdVlX3WcnYAAAHtk5ziYsyL+BJ8oQkn+zuq6vq3lX1J1X1t8Nc4ZcX6+/++ldVx1TVm4d2vlRVfzCUn1lV7x1ev2eo/tHhrJmfqaqPV9Vj5rRzx2He8q8W6cOC86Kquuswlveec1bOvRf7LIu0/eqqesHwekdV7a6qZw39ua6qTl9Oe8DKCHiAdVdVx2Ty7deHq+r7krw+ya8kuWeStyf5s6q60wKr/lKS05L8aJJ7Z/IN1B/uZ1M/nOToJBcneWOSMxao8xNJfjDJv0zy+CSPGMqfkuSRSR6cybeEp+3n85ya5FlJfnr4DP9z+EwAwBSs01ziLUmOrKofnlP2pCQXVdW3JfmzJB9NclSSk5L8SlU9Yn4j++tfVd0hyduSfC7JtqGti+e30d0/Mrz8geGsmTckeU2Sn51T7VFJbuzuDy/yeRacF3X31zKZ83x+zlk5n1+kjaX6riRHDp/njCTnV9X9V9kmcAACHmA9/WlVfTnJe5P8VZLfTvIzSS7t7su7+x+SvCjJoUn+rwXWf2qS3+ju3d39zSTPTfLYxc6qyWRC8Y7uvjXJf09ySlV957w653X3l7v7b5K8O5NAJ5mEPS8dtnVrkvP287memuR3uvtT3b13+FwPdhYPAKy5dZtLdPc3kvyPTM56SVUdm+ShmcwpfjDJPbv7ed399919bZI/yuQMn/n217/jMwma/mN3f627/66737vEsXhtkkdV1d2H909K8sf7qb+UedFa+s3u/mZ3/1WSSzOZWwFTJOAB1tNp3X14d9+nu39xmDjdO5NvrZIk3f2PSa7P5Buf+e6T5C3D6c1fTvKpJN9KsnV+xao6NMnjMrlOPN39viR/k+Tfzqt605zXX0+y72aN9x76sc/c1wv166Vz+nVLklrkMwAAK7duc4nBRUkeV1V3ySRAuay7bx7aufe+doa2nrVIO/vr3zFJPjd8QbQsw1k2/yvJv6mqwzM5C+d1C9Vdxrxordw6nBm0z+cyGQdgigQ8wEb7fCaTpCT/dH34MUluWKDu9UkeOUzs9v3cZbgOf76fSnL3JC+vqpuq6qb882nCS3FjJqcx73PMfupen+TfzevXod39/y1xWwDAyk1rLpFMzhS6JcmpmVwOddGcdj47r527dfejltm/65N8937ORj6Qi4Z+PS7J+/bzOQ40L+oVbn8xRwz39tnnuzMZB2CKBDzARntjkkdX1UlVdcck5yT5ZpKFwpFXJnnhvkufquqew/1vFnJGkguTHJfJZVcPTvLwJD9QVcctsV/PqMljUg9P8uv7qfvKJM+sqgcO/Tqsqh63hG0AAKs3rblEurszudfN7yY5PJP77iTJB5J8tap+vaoOrcnDGR5UVT+4zP59IJMvlc6rqrtW1V2q6uGLdOcLSb5nXtmfZnKvwGcM/VzMgeZFX0jyHVV12H7aWK7/NNxn6P/O5J6H/2MN2wYWIOABNlR3fzqTb57+a5IvZvJEh8d0998vUP2lSS5J8s6q+mqSK5I8bH6lqtp3s8Pf7+6b5vxcleTPs7SzeP4oyTuTfCzJhzO5IeLeTE7jnv8Z3pLJxO/iqvpKko9ncpo0ADBl05hLzPOaTM5AecNw355097cyCS0enOSzw3YvSHK7gGR//RvaeUyS+2VyydTuTO7Zs5DnZnKD5y9X1eOHtr+R5E+S3DfJmxdaaSnzou7+60xuBH3t0P5qL6e6KZMbWH8+k8vCnjpsA5iimoTSAOxPVT0yySu7242TAYCZUVW/leT7uvtnD1h5HVTVjiSv7e6jD1QXWFvO4AFYwHC69aOq6pDhm6/nZPK4VACAmVBV90hyVpLzN7ovwMYT8AAsrJL8p0xOL/5wJk/Z+K0N7REAwKCqnpLJTZrf0d3v2ej+ABvPJVoAAAAAI+cMHgAAAICRO2SjO7BSRx55ZG/btm2ju3FQ+drXvpa73vWuG92NTcFYrx9jvb6M9/ox1mvvqquu+mJ333Mt2xzrfMXxtTTGaWmM09IYp6UxTktjnJZmrOO02JxltAHPtm3bcuWVV250Nw4qO3fuzI4dOza6G5uCsV4/xnp9Ge/1Y6zXXlV9bq3bHOt8xfG1NMZpaYzT0hinpTFOS2Oclmas47TYnMUlWgAAAAAjJ+ABAAAAGDkBDwAAAMDICXgAAAAARk7AAwAAADByAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQOGPBU1YVVdXNVfXyBZedUVVfVkcP7qqqXVdWuqvpYVT1kTt0zquqa4eeMOeUPraqrh3VeVlW1Vh8OAAAAYDNYyhk8r05yyvzCqjomyclJ/mZO8SOTHDv8nJ3kFUPdeyR5TpKHJTk+yXOq6ohhnVckecqc9W63LQAAAAAWd8CAp7vfk+SWBRa9JMmvJek5ZacmeU1PXJHk8Kq6V5JHJLm8u2/p7luTXJ7klGHZ3bv7iu7uJK9JctrqPhIAAADA5nLISlaqqlOT3NDdH513RdVRSa6f8373ULa/8t0LlC+23bMzOTMoW7duzc6dO1fSfRaxZ88eY7pOjPX6Mdbry3ivH2M9uw6G+Yrja2mM09IYp6UxTktjnJbGOC3NwTZOyw54qurbkzwrk8uz1lV3n5/k/CTZvn1779ixY727cFDbuXNnjOn6MNbrx1ivL+O9foz17DoY5iuOr6UxTktjnJbGOC2NcVoa47Q0B9s4reQpWt+b5L5JPlpV1yU5OsmHquq7ktyQ5Jg5dY8eyvZXfvQC5QAAAAAs0bIDnu6+uru/s7u3dfe2TC6rekh335TkkiRPHp6mdUKS27r7xiSXJTm5qo4Ybq58cpLLhmVfqaoThqdnPTnJW9foswEAAABsCkt5TPrrk7wvyf2randVnbWf6m9Pcm2SXUn+KMkvJkl335Lk+Uk+OPw8byjLUOeCYZ3PJHnHyj4KAAAAwOZ0wHvwdPcTD7B825zXneRpi9S7MMmFC5RfmeRBB+oHAAAAAAtbyT14AAAAAJghAh4AAACAkRPwAAAAAIycgAcAAABg5AQ8AAAAACMn4AEAAAAYOQEPAAAAwMgJeAAAAABGTsADAAAAMHICHgAAAICRE/AAAAAAjJyABwAAAGDkBDwAAAAAIyfgAQAAABg5AQ8AAADAyAl4AAAAAEZOwAMAAAAwcgIeAAAAgJET8AAAAACMnIAHAAAAYOQEPAAAAAAjJ+Dh/2/v/oM1q+v7gL8/A0FNaARNZmuBBmZkzCAYE7dIx06ySCKrZoR2jMWxcUlImUwxNQ0zEeKktCozWJMYbZO0TCDB1LpSEgdGSZAgd0xmAhKVqoCGDf6CoqSCmh2N6ZpP/7iHeLve3T3cH89zz3Nfr5k79znf8+N+7mfPvc/Z9z0/AAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmLgjBjxVdW1VPVJVn1gx9paq+mRVfayq3lNVx62Yd3lV7auqT1XVuSvGdw9j+6rqshXjp1TVncP4u6vqmI38BgEAAAAW3ZgzeH43ye6Dxm5Ncnp3PyfJXyS5PEmq6rQkFyR59rDOb1bVUVV1VJLfSPLiJKcleeWwbJK8Oclbu/uZSR5LctG6viMAAACAbeaIAU93fzDJoweNvb+7DwyTdyQ5cXh9XpK93f2N7v50kn1Jzhw+9nX3A939t0n2JjmvqirJC5PcMKx/XZLz1/k9AQAAAGwrR2/ANn46ybuH1ydkOfB53IPDWJJ8/qDx5yd5epIvrwiLVi7/barq4iQXJ8mOHTuytLS03tpZYf/+/Xo6I3o9O3o9W/o9O3q9dS3C8Yr9axx9GkefxtGncfRpHH0aZ9H6tK6Ap6pen+RAknduTDmH191XJ7k6SXbu3Nm7du2axZfdNpaWlqKns6HXs6PXs6Xfs6PXW9ciHK/Yv8bRp3H0aRx9GkefxtGncRatT2sOeKrqwiQ/nuSc7u5h+KEkJ61Y7MRhLIcY/1KS46rq6OEsnpXLAwAAADDCmh6TXlW7k/xikpd199dWzLopyQVV9aSqOiXJqUk+lOSuJKcOT8w6Jss3Yr5pCIZuT/LyYf09SW5c27cCAAAAsD2NeUz6u5L8WZJnVdWDVXVRkv+S5B8kubWq7q6q/5ok3X1PkuuT3Jvkj5Jc0t3fHM7OeU2SW5Lcl+T6YdkkeV2SX6iqfVm+J881G/odAgAAACy4I16i1d2vXGX4kCFMd1+Z5MpVxm9OcvMq4w9k+SlbAAAAAKzBmi7RAgAAAGDrEPAAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATNwRA56quraqHqmqT6wYe1pV3VpV9w+fjx/Gq6reXlX7qupjVfVDK9bZMyx/f1XtWTH+vKr6+LDO26uqNvqbBAAAAFhkY87g+d0kuw8auyzJbd19apLbhukkeXGSU4ePi5P8VrIcCCW5Isnzk5yZ5IrHQ6FhmX+9Yr2DvxYAAAAAh3HEgKe7P5jk0YOGz0ty3fD6uiTnrxh/Ry+7I8lxVfWMJOcmubW7H+3ux5LcmmT3MO+7u/uO7u4k71ixLQAAAABGOHqN6+3o7oeH119IsmN4fUKSz69Y7sFh7HDjD64yvqqqujjLZwZlx44dWVpaWmP5rGb//v16OiN6PTt6PVv6PTt6vXUtwvGK/WscfRpHn8bRp3H0aRx9GmfR+rTWgOfvdXdXVW9EMSO+1tVJrk6SnTt39q5du2bxZbeNpaWl6Ols6PXs6PVs6ffs6PXWtQjHK/avcfRpHH0aR5/G0adx9GmcRevTWp+i9cXh8qoMnx8Zxh9KctKK5U4cxg43fuIq4wAAAACMtNaA56Ykjz8Ja0+SG1eMv3p4mtZZSb4yXMp1S5IXVdXxw82VX5TklmHeV6vqrOHpWa9esS0AAAAARjjiJVpV9a4ku5J8T1U9mOWnYV2V5PqquijJZ5O8Ylj85iQvSbIvydeS/FSSdPejVfXGJHcNy72hux+/cfO/yfKTup6S5A+HDwAAAABGOmLA092vPMSsc1ZZtpNccojtXJvk2lXG/zzJ6UeqAwAAAIDVrfUSLQAAAAC2CAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMStK+Cpqn9XVfdU1Seq6l1V9eSqOqWq7qyqfVX17qo6Zlj2ScP0vmH+ySu2c/kw/qmqOnd93xIAAADA9rLmgKeqTkjyb5Ps7O7TkxyV5IIkb07y1u5+ZpLHklw0rHJRkseG8bcOy6WqThvWe3aS3Ul+s6qOWmtdAAAAANvNei/ROjrJU6rq6CTfmeThJC9McsMw/7ok5w+vzxumM8w/p6pqGN/b3d/o7k8n2ZfkzHXWBQAAALBtVHevfeWq1ya5MsnXk7w/yWuT3DGcpZOqOinJH3b36VX1iSS7u/vBYd5fJnl+kv8wrPPfh/FrhnVuWOXrXZzk4iTZsWPH8/bu3bvm2vl2+/fvz7HHHjvvMrYFvZ4dvZ4t/Z4dvd54Z5999oe7e+d6t7MIxyv2r3H0aRx9GkefxtGncfRpnKn26VDHLEevdYNVdXyWz745JcmXk/zPLF9itWm6++okVyfJzp07e9euXZv55badpaWl6Ols6PXs6PVs6ffs6PXWtQjHK/avcfRpHH0aR5/G0adx9GmcRevTei7R+tEkn+7uv+ru/5vkD5K8IMlxwyVbSXJikoeG1w8lOSlJhvlPTfKlleOrrAMAAADAEawn4PlckrOq6juHe+mck+TeJLcnefmwzJ4kNw6vbxqmM8z/QC9fH3ZTkguGp2ydkuTUJB9aR10AAAAA28qaL9Hq7jur6oYkH0lyIMlHs3w68vuS7K2qNw1j1wyrXJPk96pqX5JHs/zkrHT3PVV1fZbDoQNJLunub661LgAAAIDtZs0BT5J09xVJrjho+IGs8hSs7v6bJD9xiO1cmeWbNQMAAADwBK33MekAAAAAzJmABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEycgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDi1hXwVNVxVXVDVX2yqu6rqn9aVU+rqlur6v7h8/HDslVVb6+qfVX1sar6oRXb2TMsf39V7VnvNwUAAACwnaz3DJ63Jfmj7v7+JD+Q5L4klyW5rbtPTXLbMJ0kL05y6vBxcZLfSpKqelqSK5I8P8mZSa54PBQCAAAA4MjWHPBU1VOT/HCSa5Kku/+2u7+c5Lwk1w2LXZfk/OH1eUne0cvuSHJcVT0jyblJbu3uR7v7sSS3Jtm91roAAAAAtpv1nMFzSpK/SvI7VfXRqvrtqvquJDu6++FhmS8k2TG8PiHJ51es/+AwdqhxAAAAAEao7l7bilU7k9yR5AXdfWdVvS3JV5P8XHcft2K5x7r7+Kp6b5KruvtPh/Hbkrwuya4kT+7uNw3jv5zk6939K6t8zYuzfHlXduzY8by9e/euqXZWt3///hx77LHzLmNb0OvZ0evZ0u/Z0euNd/bZZ3+4u3eudzuLcLxi/xpHn8bRp3H0aRx9Gkefxplqnw51zHL0Orb5YJIHu/vOYfqGLN9v54tV9Yzufni4BOuRYf5DSU5asf6Jw9hDWQ55Vo4vrfYFu/vqJFcnyc6dO3vXrl2rLcYaLS0tRU9nQ69nR69nS79nR6+3rkU4XrF/jaNP4+jTOPo0jj6No0/jLFqf1nyJVnd/Icnnq+pZw9A5Se5NclOSx5+EtSfJjcPrm5K8enia1llJvjJcynVLkhdV1fHDzZVfNIwBAAAAMMJ6zuBJkp9L8s6qOibJA0l+Ksuh0fVVdVGSzyZ5xbDszUlekmRfkq8Ny6a7H62qNya5a1juDd396DrrAgAAANg21hXwdPfdSVa7Vv2cVZbtJJccYjvXJrl2PbUAAAAAbFfreYoWAAAAAFuAgAcAAABg4gQ8AAAAABMn4AEAAACYOAEPAAAAwMQJeAAAAAAmTsADAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxAl4AAAAACZOwAMAXQQFsQAADzFJREFUAAAwcQIeAAAAgIkT8AAAAABMnIAHAAAAYOIEPAAAAAATJ+ABAAAAmDgBDwAAAMDECXgAAAAAJk7AAwAAADBxAh4AAACAiRPwAAAAAEzc0fMuAAAAYBGcfNn71rzupWccyIWHWf8zV710zdsGtod1n8FTVUdV1Uer6r3D9ClVdWdV7auqd1fVMcP4k4bpfcP8k1ds4/Jh/FNVde56awIAAADYTjbiEq3XJrlvxfSbk7y1u5+Z5LEkFw3jFyV5bBh/67Bcquq0JBckeXaS3Ul+s6qO2oC6AAAAALaFdQU8VXVikpcm+e1hupK8MMkNwyLXJTl/eH3eMJ1h/jnD8ucl2dvd3+juTyfZl+TM9dQFAAAAsJ2s9wyeX0/yi0n+bph+epIvd/eBYfrBJCcMr09I8vkkGeZ/ZVj+78dXWQcAAACAI1jzTZar6seTPNLdH66qXRtX0mG/5sVJLk6SHTt2ZGlpaRZfdtvYv3+/ns6IXs+OXs+Wfs+OXm9di3C8Yv8aR5/G2U59uvSMA0de6BB2POXw62+XHh7Jdtqf1kOfxlm0Pq3nKVovSPKyqnpJkicn+e4kb0tyXFUdPZylc2KSh4blH0pyUpIHq+roJE9N8qUV449buc7/p7uvTnJ1kuzcubN37dq1jvI52NLSUvR0NvR6dvR6tvR7dvR661qE4xX71zj6NM526tPhnoJ1JJeecSC/+vFD//fsM6/ateZtL5LttD+thz6Ns2h9WvMlWt19eXef2N0nZ/kmyR/o7lcluT3Jy4fF9iS5cXh90zCdYf4HuruH8QuGp2ydkuTUJB9aa10AAAAA2816zuA5lNcl2VtVb0ry0STXDOPXJPm9qtqX5NEsh0Lp7nuq6vok9yY5kOSS7v7mJtQFAAAAsJA2JODp7qUkS8PrB7LKU7C6+2+S/MQh1r8yyZUbUQsAAADAdrPep2gBAAAAMGcCHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAE7cZj0kHAADYck6+7H3zLgFg0ziDBwAAAGDiBDwAAAAAE+cSLQAAgC1usy8v+8xVL93U7QObzxk8AAAAABMn4AEAAACYOAEPAAAAwMS5Bw+wsE6+7H259IwDuXATr1l3vToAALAVCHiAudnsmwUCAABsFy7RAgAAAJg4AQ8AAADAxAl4AAAAACbOPXgA1mGz7yPkJs4AAMAYzuABAAAAmDhn8ACH5ClXAAAA0yDgAQAAtgR/XAJYO5doAQAAAEycM3gAAAC2uc08e8pDI2A2nMEDAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDi1hzwVNVJVXV7Vd1bVfdU1WuH8adV1a1Vdf/w+fhhvKrq7VW1r6o+VlU/tGJbe4bl76+qPev/tgAAAAC2j/WcwXMgyaXdfVqSs5JcUlWnJbksyW3dfWqS24bpJHlxklOHj4uT/FayHAgluSLJ85OcmeSKx0MhAAAAAI5szQFPdz/c3R8ZXv91kvuSnJDkvCTXDYtdl+T84fV5Sd7Ry+5IclxVPSPJuUlu7e5Hu/uxJLcm2b3WugAAAAC2m+ru9W+k6uQkH0xyepLPdfdxw3gleay7j6uq9ya5qrv/dJh3W5LXJdmV5Mnd/aZh/JeTfL27f2WVr3Nxls/+yY4dO563d+/eddfOt+zfvz/HHnvsvMvYFqbS648/9JV5l7BuO56SfPHr865i7c444anzLuEJmcq+vQj0euOdffbZH+7unevdziIcr9i/xtGncZ5Inxbh2GOtpn7McjgbeTzj524cfRpnqn061DHL0evdcFUdm+T3k/x8d391OdNZ1t1dVetPkL61vauTXJ0kO3fu7F27dm3UpkmytLQUPZ2NqfT6wsveN+8S1u3SMw7kVz++7l91c/OZV+2adwlPyFT27UWg11vXIhyv2L/G0adxnkifFuHYY62mfsxyOBt5POPnbhx9GmfR+rSup2hV1XdkOdx5Z3f/wTD8xeHSqwyfHxnGH0py0orVTxzGDjUOAAAAwAjreYpWJbkmyX3d/WsrZt2U5PEnYe1JcuOK8VcPT9M6K8lXuvvhJLckeVFVHT/cXPlFwxgAAAAAI6znHMAXJPnJJB+vqruHsV9KclWS66vqoiSfTfKKYd7NSV6SZF+SryX5qSTp7ker6o1J7hqWe0N3P7qOugAAAAC2lTUHPMPNkusQs89ZZflOcskhtnVtkmvXWgsAAADAdraYd/ECAAA2xclP8EbIl55xYFvfPJknvs8czmr702eueumGbR+mbF03WQYAAABg/pzBAxO2kX8NAQAAYLoEPABb2GaHeE5pBgCAxeASLQAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAE+cmy7BJDndz3EvPOJALPQELAACADSLgAdjGNvopXQeHl57SBQBsNk8dhWUCHratzX4jAAAAgFkR8AAAwALxRyyA7clNlgEAAAAmzhk8AGyaWfwV2XXxAADgDB4AAACAyXMGD1uW68eBMTw5AwAAnMEDAAAAMHnO4GHNnGEDbAfOEAKA7W0zjwUcB7CRBDwLai2/hC4940AuFNoAAADA5Ah4AGCO1vpXwbGhvL8MwtbkTGgANpp78AAAAABMnIAHAAAAYOJcojUnTssFYBZm8X7jMjAAgPkT8AAAAMAcbNYfYh6/V58/wmwvAh4AADjImP90eQIpAFuJe/AAAAAATNyWOYOnqnYneVuSo5L8dndfNeeSAAAAYLI28158Lv/aerZEwFNVRyX5jSQ/luTBJHdV1U3dfe98KwMAYKvy0AoA+JYtEfAkOTPJvu5+IEmqam+S85LMLeBxwAAA42z2e6a/EE6X4ymAxeX9f+up7p53DamqlyfZ3d0/M0z/ZJLnd/drDlru4iQXD5PPSvKpmRa6+L4nyf+ZdxHbhF7Pjl7Pln7Pjl5vvO/r7u9d70YW5HjF/jWOPo2jT+Po0zj6NI4+jTPVPq16zLJVzuAZpbuvTnL1vOtYVFX15929c951bAd6PTt6PVv6PTt6vXUtwvGK/WscfRpHn8bRp3H0aRx9GmfR+rRVnqL1UJKTVkyfOIwBAAAAcARbJeC5K8mpVXVKVR2T5IIkN825JgAAAIBJ2BKXaHX3gap6TZJbsvyY9Gu7+545l7UdTfp08onR69nR69nS79nRazaT/WscfRpHn8bRp3H0aRx9Gmeh+rQlbrIMAAAAwNptlUu0AAAAAFgjAQ8AAADAxAl4trGqelpV3VpV9w+fj19lmedW1Z9V1T1V9bGq+pfzqHXqxvR6WO6PqurLVfXeWdc4dVW1u6o+VVX7quqyVeY/qarePcy/s6pOnn2Vi2FEr3+4qj5SVQeq6uXzqHGRjOj3L1TVvcPv6Nuq6vvmUSeLp6reOOxXd1fV+6vqH827pq2oqt5SVZ8cevWeqjpu3jVtRVX1E8Px5N9V1cI8kngjHOn3PMuq6tqqeqSqPjHvWraqqjqpqm4fjgvuqarXzrumraiqnlxVH6qq/zX06T/Ou6aNIuDZ3i5Lclt3n5rktmH6YF9L8urufnaS3Ul+3YHLmozpdZK8JclPzqyqBVFVRyX5jSQvTnJakldW1WkHLXZRkse6+5lJ3prkzbOtcjGM7PXnklyY5H/MtrrFM7LfH02ys7ufk+SGJP9ptlWywN7S3c/p7ucmeW+Sfz/vgraoW5OcPvwM/kWSy+dcz1b1iST/IskH513IVjLy9zzLfjfL/x/h0A4kubS7T0tyVpJL7E+r+kaSF3b3DyR5bpLdVXXWnGvaEAKe7e28JNcNr69Lcv7BC3T3X3T3/cPr/53kkSTfO7MKF8cRe50k3X1bkr+eVVEL5Mwk+7r7ge7+2yR7s9zzlVb+G9yQ5JyqqhnWuCiO2Ovu/kx3fyzJ382jwAUzpt+3d/fXhsk7kpw44xpZUN391RWT35XEkzlW0d3v7+4Dw6SfwUPo7vu6+1PzrmMLGnMMQ5Lu/mCSR+ddx1bW3Q9390eG13+d5L4kJ8y3qq2nl+0fJr9j+FiI9zgBz/a2o7sfHl5/IcmOwy1cVWcmOSbJX252YQvoCfWaJ+yEJJ9fMf1gvv3N7O+XGQ7Ev5Lk6TOpbrGM6TUb54n2+6Ikf7ipFbGtVNWVVfX5JK+KM3jG+On4GeSJ8b7KphhuR/CDSe6cbyVbU1UdVVV3Z/kEhlu7eyH6dPS8C2BzVdUfJ/mHq8x6/cqJ7u6qOmRqWVXPSPJ7SfZ0t7/Kr2Kjeg2wFlX1r5LsTPIj866F6Tjce1d339jdr0/y+qq6PMlrklwx0wK3iCP1aVjm9Vm+POKds6xtKxnTJ2DzVdWxSX4/yc8fdDYmg+7+ZpLnDrcfeU9Vnd7dk7+/k4BnwXX3jx5qXlV9saqe0d0PDwHOI4dY7ruTvC/Lb853bFKpk7cRvWbNHkpy0orpE4ex1ZZ5sKqOTvLUJF+aTXkLZUyv2Tij+l1VP5rlMPlHuvsbM6qNBXC4966DvDPJzdmmAc+R+lRVFyb58STndPe2/SPOE9if+Bbvq2yoqvqOLIc77+zuP5h3PVtdd3+5qm7P8v2dJh/wuERre7spyZ7h9Z4k3/aXlao6Jsl7kryju2+YYW2L5oi9Zl3uSnJqVZ0y7LMXZLnnK638N3h5kg9s54PwdRjTazbOEftdVT+Y5L8leVl3C4/ZMFV16orJ85J8cl61bGVVtTvJL2b5Z/BrR1oeDuJ9lQ0z3F/ymiT3dfevzbueraqqvvfxBwdV1VOS/FgW5D2u/P9m+6qqpye5Psk/TvLZJK/o7keHR1f+bHf/zHDK/+8kuWfFqhd2992zr3i6xvR6WO5Pknx/kmOzfHbJRd19y5zKnpSqekmSX09yVJJru/vKqnpDkj/v7puq6slZvszwB7N8g74LuvuB+VU8XSN6/U+yHAwfn+RvknxheBIfazCi33+c5Iwkj9/n63Pd/bI5lcsCqarfT/KsLN8w/bNZfr9yZsFBqmpfkiflW2eF3tHdPzvHkrakqvrnSf5zlh/W8eUkd3f3ufOtamtY7ff8nEvakqrqXUl2JfmeJF9MckV3XzPXoraYqvpnSf4kycfzrYdd/FJ33zy/qraeqnpOlh++clSWT3q5vrvfMN+qNoaABwAAAGDiXKIFAAAAMHECHgAAAICJE/AAAAAATJyABwAAAGDiBDwAAAAAEyfgAQAAAJg4AQ8AAADAxP0/v9BVMKnnwScAAAAASUVORK5CYII=\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "needs_background": "light",
+ "tags": []
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "seen_observations = []\n",
+ "for _ in range(1000):\n",
+ " seen_observations.append(env.reset())\n",
+ " done = False\n",
+ " while not done:\n",
+ " s, r, done, _ = env.step(env.action_space.sample())\n",
+ " seen_observations.append(s)\n",
+ "\n",
+ "visualize_cartpole_observation_distribution(seen_observations)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Binarize environment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gym.core import ObservationWrapper\n",
+ "\n",
+ "\n",
+ "class Binarizer(ObservationWrapper):\n",
+ " def observation(self, state):\n",
+ " # Hint: you can do that with round(x, n_digits).\n",
+ " # You may pick a different n_digits for each dimension.\n",
+ " state = \n",
+ "\n",
+ " return tuple(state)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env = Binarizer(make_env())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "seen_observations = []\n",
+ "for _ in range(1000):\n",
+ " seen_observations.append(env.reset())\n",
+ " done = False\n",
+ " while not done:\n",
+ " s, r, done, _ = env.step(env.action_space.sample())\n",
+ " seen_observations.append(s)\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ "visualize_cartpole_observation_distribution(seen_observations)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Learn binarized policy\n",
+ "\n",
+ "Now let's train a policy, that uses binarized state space.\n",
+ "\n",
+ "__Tips:__\n",
+ "\n",
+ "* Note, that increasing the number of digits for one dimension of the observations increases your state space by a factor of $10$.\n",
+ "* If your binarization is too fine-grained, your agent will take much longer than 10000 steps to converge. You can either increase the number of iterations and reduce epsilon decay or change binarization. In practice we found, that this mistake is rather frequent.\n",
+ "* If your binarization is too coarse, your agent may fail to find the optimal policy. In practice we found, that in this particular environment this kind of mistake is rare.\n",
+ "* **Start with a coarse binarization** and make it more fine-grained if that seems necessary.\n",
+ "* Having $10^3$–$10^4$ distinct states is recommended (`len(agent._qvalues)`), but not required.\n",
+ "* If things don't work without annealing $\\varepsilon$, consider adding that, but make sure, that it doesn't go to zero too quickly.\n",
+ "\n",
+ "A reasonable agent should attain an average reward of at least 50."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pandas as pd\n",
+ "\n",
+ "def moving_average(x, span=100):\n",
+ " return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent = QLearningAgent(\n",
+ " alpha=0.5, epsilon=0.25, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "rewards = []\n",
+ "epsilons = []\n",
+ "\n",
+ "for i in range(10000):\n",
+ " reward = play_and_train(env, agent)\n",
+ " rewards.append(reward)\n",
+ " epsilons.append(agent.epsilon)\n",
+ " \n",
+ " # OPTIONAL: \n",
+ "\n",
+ " if i % 100 == 0:\n",
+ " rewards_ewma = moving_average(rewards)\n",
+ " \n",
+ " clear_output(True)\n",
+ " plt.plot(rewards, label='rewards')\n",
+ " plt.plot(rewards_ewma, label='rewards ewma@100')\n",
+ " plt.legend()\n",
+ " plt.grid()\n",
+ " plt.title('eps = {:e}, rewards ewma@100 = {:.1f}'.format(agent.epsilon, rewards_ewma[-1]))\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to Coursera II: Submission"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "submit_rewards2 = rewards.copy()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_qlearning\n",
+ "submit_qlearning(submit_rewards1, submit_rewards2, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week3_model_free/sarsa.ipynb b/week3_model_free/sarsa.ipynb
index 83ae1530b..5c8494c6d 100644
--- a/week3_model_free/sarsa.ipynb
+++ b/week3_model_free/sarsa.ipynb
@@ -1 +1,414 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"sarsa.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"mtwUPz_BM_jd"},"source":["## On-policy learning and SARSA\n","\n","_This notebook builds upon `qlearning.ipynb`, or to be exact your implementation of QLearningAgent._\n","\n","The policy we're gonna use is epsilon-greedy policy, where an agent takes the optimal action with probability $(1-\\epsilon)$, otherwise samples an action at random. Note, that agent __can__ occasionally samples the optimal action during the random sampling by pure chance."]},{"cell_type":"code","metadata":{"id":"AfaASWYgM_js"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"fLprTJNMM_jt"},"source":["import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"xW1gQG1CM_ju"},"source":["You can copy your `QLearningAgent` implementation from the previous notebook."]},{"cell_type":"code","metadata":{"id":"AIsn_iVwM_ju"},"source":["from collections import defaultdict\n","import random\n","import math\n","import numpy as np\n","\n","\n","class QLearningAgent:\n"," def __init__(self, alpha, epsilon, discount, get_legal_actions):\n"," \"\"\"\n"," Q-Learning Agent\n"," based on https://inst.eecs.berkeley.edu/~cs188/sp19/projects.html\n"," Instance variables you have access to\n"," - self.epsilon (exploration prob)\n"," - self.alpha (learning rate)\n"," - self.discount (discount rate aka gamma)\n","\n"," Functions you should use\n"," - self.get_legal_actions(state) {state, hashable -> list of actions, each is hashable}\n"," which returns legal actions for a state\n"," - self.get_qvalue(state,action)\n"," which returns Q(state,action)\n"," - self.set_qvalue(state,action,value)\n"," which sets Q(state,action) := value\n","\n"," !!!Important!!!\n"," Note: please avoid using self._qValues directly. \n"," There's a special self.get_qvalue/set_qvalue for that.\n"," \"\"\"\n","\n"," self.get_legal_actions = get_legal_actions\n"," self._qvalues = defaultdict(lambda: defaultdict(lambda: 0))\n"," self.alpha = alpha\n"," self.epsilon = epsilon\n"," self.discount = discount\n","\n"," def get_qvalue(self, state, action):\n"," \"\"\" Returns Q(state,action) \"\"\"\n"," return self._qvalues[state][action]\n","\n"," def set_qvalue(self, state, action, value):\n"," \"\"\" Sets the Qvalue for [state,action] to the given value \"\"\"\n"," self._qvalues[state][action] = value\n","\n"," #---------------------START OF YOUR CODE---------------------#\n","\n"," def get_value(self, state):\n"," \"\"\"\n"," Compute your agent's estimate of V(s) using current q-values\n"," V(s) = max_over_action Q(state,action) over all possible actions.\n"," Note: please take into account, that q-values can be negative.\n"," \"\"\"\n"," possible_actions = self.get_legal_actions(state)\n","\n"," # If there are no legal actions, return 0.0\n"," if len(possible_actions) == 0:\n"," return 0.0\n","\n"," \n","\n"," return value\n","\n"," def update(self, state, action, reward, next_state):\n"," \"\"\"\n"," You should do your Q-Value update here:\n"," Q(s,a) := (1 - alpha) * Q(s,a) + alpha * (r + gamma * V(s'))\n"," \"\"\"\n","\n"," # agent parameters\n"," gamma = self.discount\n"," learning_rate = self.alpha\n","\n"," \n","\n"," self.set_qvalue(state, action, )\n","\n"," def get_best_action(self, state):\n"," \"\"\"\n"," Compute the best action to take in a state (using current q-values). \n"," \"\"\"\n"," possible_actions = self.get_legal_actions(state)\n","\n"," # If there are no legal actions, return None\n"," if len(possible_actions) == 0:\n"," return None\n","\n"," \n","\n"," return best_action\n","\n"," def get_action(self, state):\n"," \"\"\"\n"," Compute the action to take in the current state, including exploration. \n"," With probability self.epsilon, we should take a random action.\n"," otherwise - the best policy action (self.getPolicy).\n","\n"," Note: To pick randomly from a list, use random.choice(list). \n"," To pick True or False with a given probablity, generate uniform number in [0, 1]\n"," and compare it with your probability\n"," \"\"\"\n","\n"," # Pick Action\n"," possible_actions = self.get_legal_actions(state)\n"," action = None\n","\n"," # If there are no legal actions, return None\n"," if len(possible_actions) == 0:\n"," return None\n","\n"," # agent parameters:\n"," epsilon = self.epsilon\n","\n"," \n","\n"," return chosen_action"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"4U6lzfgZM_jw"},"source":["Now we gonna to implement Expected Value SARSA on top of it."]},{"cell_type":"code","metadata":{"id":"mvD_kRipM_jx"},"source":["class EVSarsaAgent(QLearningAgent):\n"," \"\"\" \n"," An agent, that changes some of q-learning functions to implement Expected Value SARSA. \n"," Note: this demo assumes, that your implementation of QLearningAgent.update uses get_value(next_state).\n"," If it doesn't, please add\n"," def update(self, state, action, reward, next_state):\n"," and implement it for Expected Value SARSA's V(s')\n"," \"\"\"\n","\n"," def get_value(self, state):\n"," \"\"\" \n"," Returns Vpi for current state under epsilon-greedy policy:\n"," V_{pi}(s) = sum _{over a_i} {pi(a_i | s) * Q(s, a_i)}\n","\n"," Hint: all other methods from QLearningAgent are still accessible.\n"," \"\"\"\n"," epsilon = self.epsilon\n"," possible_actions = self.get_legal_actions(state)\n","\n"," # If there are no legal actions, return 0.0\n"," if len(possible_actions) == 0:\n"," return 0.0\n","\n"," \n","\n"," return state_value"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"0yxGfMVOM_jx"},"source":["### Cliff World\n","\n","Let's now see, how our algorithm compares against q-learning in case, where we force an agent to explore all the time.\n","\n","\n","
image by cs188
"]},{"cell_type":"code","metadata":{"id":"k49cw1iBM_jy"},"source":["import gym\n","import gym.envs.toy_text\n","env = gym.envs.toy_text.CliffWalkingEnv()\n","n_actions = env.action_space.n\n","\n","print(env.__doc__)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"up2zGpvxM_jz"},"source":["# Our cliffworld has one difference from what's on the image: there is no wall.\n","# Agent can choose to go as close to the cliff as it wishes. x:start, T:exit, C:cliff, o: flat ground\n","env.render()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"VGwHXDjCM_jz"},"source":["def play_and_train(env, agent, t_max=10**4):\n"," \"\"\"This function should \n"," - run a full game, actions given by agent.getAction(s)\n"," - train agent using agent.update(...) whenever possible\n"," - return total reward\"\"\"\n"," total_reward = 0.0\n"," s = env.reset()\n","\n"," for t in range(t_max):\n"," a = agent.get_action(s)\n","\n"," next_s, r, done, _ = env.step(a)\n"," agent.update(s, a, r, next_s)\n","\n"," s = next_s\n"," total_reward += r\n"," if done:\n"," break\n","\n"," return total_reward"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"WNMrPJfcM_j1"},"source":["agent_sarsa = EVSarsaAgent(alpha=0.25, epsilon=0.2, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))\n","\n","agent_ql = QLearningAgent(alpha=0.25, epsilon=0.2, discount=0.99,\n"," get_legal_actions=lambda s: range(n_actions))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Gidy-DAYM_j1"},"source":["from IPython.display import clear_output\n","import pandas as pd\n","\n","def moving_average(x, span=100):\n"," return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values\n","\n","rewards_sarsa, rewards_ql = [], []\n","\n","for i in range(5000):\n"," rewards_sarsa.append(play_and_train(env, agent_sarsa))\n"," rewards_ql.append(play_and_train(env, agent_ql))\n"," # Note: agent.epsilon stays constant\n","\n"," if i % 100 == 0:\n"," clear_output(True)\n"," print('EVSARSA mean reward =', np.mean(rewards_sarsa[-100:]))\n"," print('QLEARNING mean reward =', np.mean(rewards_ql[-100:]))\n"," plt.title(\"epsilon = %s\" % agent_ql.epsilon)\n"," plt.plot(moving_average(rewards_sarsa), label='ev_sarsa')\n"," plt.plot(moving_average(rewards_ql), label='qlearning')\n"," plt.grid()\n"," plt.legend()\n"," plt.ylim(-500, 0)\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"VE3SUE38M_j2"},"source":["Let's now see, what did the algorithms learn by visualizing their actions at every state."]},{"cell_type":"code","metadata":{"id":"IFne8ZddM_j2"},"source":["def draw_policy(env, agent):\n"," \"\"\" Prints CliffWalkingEnv policy with arrows. Hard-coded. \"\"\"\n"," n_rows, n_cols = env._cliff.shape\n","\n"," actions = '^>v<'\n","\n"," for yi in range(n_rows):\n"," for xi in range(n_cols):\n"," if env._cliff[yi, xi]:\n"," print(\" C \", end='')\n"," elif (yi * n_cols + xi) == env.start_state_index:\n"," print(\" X \", end='')\n"," elif (yi * n_cols + xi) == n_rows * n_cols - 1:\n"," print(\" T \", end='')\n"," else:\n"," print(\" %s \" %\n"," actions[agent.get_best_action(yi * n_cols + xi)], end='')\n"," print()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"AVbIp67CM_j5"},"source":["print(\"Q-Learning\")\n","draw_policy(env, agent_ql)\n","\n","print(\"SARSA\")\n","draw_policy(env, agent_sarsa)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"KmqEe6HPM_j6"},"source":["### Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"a2nSddoxM_j7"},"source":["from submit import submit_sarsa\n","submit_sarsa(rewards_ql, rewards_sarsa, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"KtYN2NBoM_j7"},"source":["### More\n","\n","Here are some of the things you can do if you feel like it:\n","\n","* Play with an epsilon. See how learned policies change if you set an epsilon to the higher/lower values (e.g. 0.75).\n","* Expected Value SASRSA for softmax policy:\n","$$ \\pi(a_i|s) = softmax({Q(s,a_i) \\over \\tau}) = {e ^ {Q(s,a_i)/ \\tau} \\over {\\sum_{a_j} e ^{Q(s,a_j) / \\tau }}} $$\n","* Implement N-step algorithms and TD($\\lambda$): see [Sutton's book](http://incompleteideas.net/book/bookdraft2018jan1.pdf) chapter 7 and chapter 12.\n","* Use those algorithms to train on CartPole in previous / next assignment for this week."]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## On-policy learning and SARSA\n",
+ "\n",
+ "_This notebook builds upon `qlearning.ipynb`, or to be exact your implementation of QLearningAgent._\n",
+ "\n",
+ "The policy we're gonna use is epsilon-greedy policy, where an agent takes the optimal action with probability $(1-\\epsilon)$, otherwise samples an action at random. Note, that agent __can__ occasionally samples the optimal action during the random sampling by pure chance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week3_model_free/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can copy your `QLearningAgent` implementation from the previous notebook."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import defaultdict\n",
+ "import random\n",
+ "import math\n",
+ "import numpy as np\n",
+ "\n",
+ "\n",
+ "class QLearningAgent:\n",
+ " def __init__(self, alpha, epsilon, discount, get_legal_actions):\n",
+ " \"\"\"\n",
+ " Q-Learning Agent\n",
+ " based on https://inst.eecs.berkeley.edu/~cs188/sp19/projects.html\n",
+ " Instance variables you have access to\n",
+ " - self.epsilon (exploration prob)\n",
+ " - self.alpha (learning rate)\n",
+ " - self.discount (discount rate aka gamma)\n",
+ "\n",
+ " Functions you should use\n",
+ " - self.get_legal_actions(state) {state, hashable -> list of actions, each is hashable}\n",
+ " which returns legal actions for a state\n",
+ " - self.get_qvalue(state,action)\n",
+ " which returns Q(state,action)\n",
+ " - self.set_qvalue(state,action,value)\n",
+ " which sets Q(state,action) := value\n",
+ "\n",
+ " !!!Important!!!\n",
+ " Note: please avoid using self._qValues directly. \n",
+ " There's a special self.get_qvalue/set_qvalue for that.\n",
+ " \"\"\"\n",
+ "\n",
+ " self.get_legal_actions = get_legal_actions\n",
+ " self._qvalues = defaultdict(lambda: defaultdict(lambda: 0))\n",
+ " self.alpha = alpha\n",
+ " self.epsilon = epsilon\n",
+ " self.discount = discount\n",
+ "\n",
+ " def get_qvalue(self, state, action):\n",
+ " \"\"\" Returns Q(state,action) \"\"\"\n",
+ " return self._qvalues[state][action]\n",
+ "\n",
+ " def set_qvalue(self, state, action, value):\n",
+ " \"\"\" Sets the Qvalue for [state,action] to the given value \"\"\"\n",
+ " self._qvalues[state][action] = value\n",
+ "\n",
+ " #---------------------START OF YOUR CODE---------------------#\n",
+ "\n",
+ " def get_value(self, state):\n",
+ " \"\"\"\n",
+ " Compute your agent's estimate of V(s) using current q-values\n",
+ " V(s) = max_over_action Q(state,action) over all possible actions.\n",
+ " Note: please take into account, that q-values can be negative.\n",
+ " \"\"\"\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ "\n",
+ " # If there are no legal actions, return 0.0\n",
+ " if len(possible_actions) == 0:\n",
+ " return 0.0\n",
+ "\n",
+ " \n",
+ "\n",
+ " return value\n",
+ "\n",
+ " def update(self, state, action, reward, next_state):\n",
+ " \"\"\"\n",
+ " You should do your Q-Value update here:\n",
+ " Q(s,a) := (1 - alpha) * Q(s,a) + alpha * (r + gamma * V(s'))\n",
+ " \"\"\"\n",
+ "\n",
+ " # agent parameters\n",
+ " gamma = self.discount\n",
+ " learning_rate = self.alpha\n",
+ "\n",
+ " \n",
+ "\n",
+ " self.set_qvalue(state, action, )\n",
+ "\n",
+ " def get_best_action(self, state):\n",
+ " \"\"\"\n",
+ " Compute the best action to take in a state (using current q-values). \n",
+ " \"\"\"\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ "\n",
+ " # If there are no legal actions, return None\n",
+ " if len(possible_actions) == 0:\n",
+ " return None\n",
+ "\n",
+ " \n",
+ "\n",
+ " return best_action\n",
+ "\n",
+ " def get_action(self, state):\n",
+ " \"\"\"\n",
+ " Compute the action to take in the current state, including exploration. \n",
+ " With probability self.epsilon, we should take a random action.\n",
+ " otherwise - the best policy action (self.getPolicy).\n",
+ "\n",
+ " Note: To pick randomly from a list, use random.choice(list). \n",
+ " To pick True or False with a given probablity, generate uniform number in [0, 1]\n",
+ " and compare it with your probability\n",
+ " \"\"\"\n",
+ "\n",
+ " # Pick Action\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ " action = None\n",
+ "\n",
+ " # If there are no legal actions, return None\n",
+ " if len(possible_actions) == 0:\n",
+ " return None\n",
+ "\n",
+ " # agent parameters:\n",
+ " epsilon = self.epsilon\n",
+ "\n",
+ " \n",
+ "\n",
+ " return chosen_action"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we gonna to implement Expected Value SARSA on top of it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EVSarsaAgent(QLearningAgent):\n",
+ " \"\"\" \n",
+ " An agent, that changes some of q-learning functions to implement Expected Value SARSA. \n",
+ " Note: this demo assumes, that your implementation of QLearningAgent.update uses get_value(next_state).\n",
+ " If it doesn't, please add\n",
+ " def update(self, state, action, reward, next_state):\n",
+ " and implement it for Expected Value SARSA's V(s')\n",
+ " \"\"\"\n",
+ "\n",
+ " def get_value(self, state):\n",
+ " \"\"\" \n",
+ " Returns Vpi for current state under epsilon-greedy policy:\n",
+ " V_{pi}(s) = sum _{over a_i} {pi(a_i | s) * Q(s, a_i)}\n",
+ "\n",
+ " Hint: all other methods from QLearningAgent are still accessible.\n",
+ " \"\"\"\n",
+ " epsilon = self.epsilon\n",
+ " possible_actions = self.get_legal_actions(state)\n",
+ "\n",
+ " # If there are no legal actions, return 0.0\n",
+ " if len(possible_actions) == 0:\n",
+ " return 0.0\n",
+ "\n",
+ " \n",
+ "\n",
+ " return state_value"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Cliff World\n",
+ "\n",
+ "Let's now see, how our algorithm compares against q-learning in case, where we force an agent to explore all the time.\n",
+ "\n",
+ "\n",
+ "
image by cs188
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "import gym.envs.toy_text\n",
+ "env = gym.envs.toy_text.CliffWalkingEnv()\n",
+ "n_actions = env.action_space.n\n",
+ "\n",
+ "print(env.__doc__)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Our cliffworld has one difference from what's on the image: there is no wall.\n",
+ "# Agent can choose to go as close to the cliff as it wishes. x:start, T:exit, C:cliff, o: flat ground\n",
+ "env.render()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def play_and_train(env, agent, t_max=10**4):\n",
+ " \"\"\"This function should \n",
+ " - run a full game, actions given by agent.getAction(s)\n",
+ " - train agent using agent.update(...) whenever possible\n",
+ " - return total reward\"\"\"\n",
+ " total_reward = 0.0\n",
+ " s = env.reset()\n",
+ "\n",
+ " for t in range(t_max):\n",
+ " a = agent.get_action(s)\n",
+ "\n",
+ " next_s, r, done, _ = env.step(a)\n",
+ " agent.update(s, a, r, next_s)\n",
+ "\n",
+ " s = next_s\n",
+ " total_reward += r\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " return total_reward"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent_sarsa = EVSarsaAgent(alpha=0.25, epsilon=0.2, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))\n",
+ "\n",
+ "agent_ql = QLearningAgent(alpha=0.25, epsilon=0.2, discount=0.99,\n",
+ " get_legal_actions=lambda s: range(n_actions))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "import pandas as pd\n",
+ "\n",
+ "def moving_average(x, span=100):\n",
+ " return pd.DataFrame({'x': np.asarray(x)}).x.ewm(span=span).mean().values\n",
+ "\n",
+ "rewards_sarsa, rewards_ql = [], []\n",
+ "\n",
+ "for i in range(5000):\n",
+ " rewards_sarsa.append(play_and_train(env, agent_sarsa))\n",
+ " rewards_ql.append(play_and_train(env, agent_ql))\n",
+ " # Note: agent.epsilon stays constant\n",
+ "\n",
+ " if i % 100 == 0:\n",
+ " clear_output(True)\n",
+ " print('EVSARSA mean reward =', np.mean(rewards_sarsa[-100:]))\n",
+ " print('QLEARNING mean reward =', np.mean(rewards_ql[-100:]))\n",
+ " plt.title(\"epsilon = %s\" % agent_ql.epsilon)\n",
+ " plt.plot(moving_average(rewards_sarsa), label='ev_sarsa')\n",
+ " plt.plot(moving_average(rewards_ql), label='qlearning')\n",
+ " plt.grid()\n",
+ " plt.legend()\n",
+ " plt.ylim(-500, 0)\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's now see, what did the algorithms learn by visualizing their actions at every state."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def draw_policy(env, agent):\n",
+ " \"\"\" Prints CliffWalkingEnv policy with arrows. Hard-coded. \"\"\"\n",
+ " n_rows, n_cols = env._cliff.shape\n",
+ "\n",
+ " actions = '^>v<'\n",
+ "\n",
+ " for yi in range(n_rows):\n",
+ " for xi in range(n_cols):\n",
+ " if env._cliff[yi, xi]:\n",
+ " print(\" C \", end='')\n",
+ " elif (yi * n_cols + xi) == env.start_state_index:\n",
+ " print(\" X \", end='')\n",
+ " elif (yi * n_cols + xi) == n_rows * n_cols - 1:\n",
+ " print(\" T \", end='')\n",
+ " else:\n",
+ " print(\" %s \" %\n",
+ " actions[agent.get_best_action(yi * n_cols + xi)], end='')\n",
+ " print()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Q-Learning\")\n",
+ "draw_policy(env, agent_ql)\n",
+ "\n",
+ "print(\"SARSA\")\n",
+ "draw_policy(env, agent_sarsa)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to Coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_sarsa\n",
+ "submit_sarsa(rewards_ql, rewards_sarsa, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### More\n",
+ "\n",
+ "Here are some of the things you can do if you feel like it:\n",
+ "\n",
+ "* Play with an epsilon. See how learned policies change if you set an epsilon to the higher/lower values (e.g. 0.75).\n",
+ "* Expected Value SASRSA for softmax policy:\n",
+ "$$ \\pi(a_i|s) = softmax({Q(s,a_i) \\over \\tau}) = {e ^ {Q(s,a_i)/ \\tau} \\over {\\sum_{a_j} e ^{Q(s,a_j) / \\tau }}} $$\n",
+ "* Implement N-step algorithms and TD($\\lambda$): see [Sutton's book](http://incompleteideas.net/book/bookdraft2018jan1.pdf) chapter 7 and chapter 12.\n",
+ "* Use those algorithms to train on CartPole in previous / next assignment for this week."
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week4_approx/dqn_atari_pytorch.ipynb b/week4_approx/dqn_atari_pytorch.ipynb
index 9ca050fdb..cf5305745 100644
--- a/week4_approx/dqn_atari_pytorch.ipynb
+++ b/week4_approx/dqn_atari_pytorch.ipynb
@@ -1 +1,1261 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"dqn_atari_pytorch.ipynb","provenance":[],"collapsed_sections":["MmXm5C2VgGhy","okmpBFKGgGiW"]}},"cells":[{"cell_type":"markdown","metadata":{"id":"RQxyK5KQgGhS"},"source":["# Deep Q-Network implementation.\n","\n","This homework shamelessly demands you to implement a DQN - an approximate q-learning algorithm with experience replay and target networks - and see if it works better this way.\n","\n","Original paper:\n","https://arxiv.org/pdf/1312.5602.pdf"]},{"cell_type":"code","metadata":{"id":"_1Wrwaq5gGhe","outputId":"ca1a7238-207b-49c3-ca1b-d6932158ecc8"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n"," \n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/submit.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/framebuffer.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/replay_buffer.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/atari_wrappers.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/utils.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[{"output_type":"stream","text":["Starting virtual X frame buffer: Xvfb.\n"],"name":"stdout"}]},{"cell_type":"markdown","metadata":{"id":"CscvZpD8gGhj"},"source":["__Frameworks__ - we'll accept this homework in any deep learning framework. This particular notebook was designed for pytoch, but you find it easy to adapt it to almost any python-based deep learning framework."]},{"cell_type":"code","metadata":{"id":"JBn2y003gGhl"},"source":["import random\n","import numpy as np\n","import torch\n","import utils"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"YXglEOD7gGhm"},"source":["import gym\n","import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"K2Em9YNdgGhn"},"source":["### Let's play some old videogames\n","\n","\n","This time we're going to apply the approximate q-learning to an Atari game called Breakout. It's not the hardest thing out there, but it's definitely way more complex, than anything we tried before.\n"]},{"cell_type":"code","metadata":{"id":"5D4obeQVgGho"},"source":["ENV_NAME = \"BreakoutNoFrameskip-v4\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"1M8B7tJLgGhp"},"source":["## Preprocessing"]},{"cell_type":"markdown","metadata":{"id":"gIAQ3p9CgGhq"},"source":["Let's see what observations look like."]},{"cell_type":"code","metadata":{"id":"elZb5Os-gGhq","outputId":"09af73aa-778e-4e40-ff68-7233ba1cd964"},"source":["env = gym.make(ENV_NAME)\n","env.reset()\n","\n","n_cols = 5\n","n_rows = 2\n","fig = plt.figure(figsize=(16, 9))\n","\n","for row in range(n_rows):\n"," for col in range(n_cols):\n"," ax = fig.add_subplot(n_rows, n_cols, row * n_cols + col + 1)\n"," ax.imshow(env.render('rgb_array'))\n"," env.step(env.action_space.sample())\n","plt.show()"],"execution_count":null,"outputs":[{"output_type":"display_data","data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAAA6UAAAH3CAYAAABD+PmTAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjMsIGh0\ndHA6Ly9tYXRwbG90bGliLm9yZy+AADFEAAAgAElEQVR4nO3dbazkd3nf/8/1twMPNlQ2N7Us29SG\nOqmgah1YuVYL/GlpyGJFMfQBtVUFJ0VdkEBK5FSVCVJBlSK1aTASaupoEdaaKjHQOgSrclwcNwqq\nUhPWxDHmxtgmRni12AVXQJYIYvvbB+e3MFl295w9c/Od+Z7XSxqdOb+ZOXNZ+/bRXmfm/LZaawEA\nAIAe/r/eAwAAALB3WUoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG6WtpRW1YGqeqiqHqmq\nG5f1PNCDvhmdxhmdxhmdxtkktYx/p7Sqzkny5SQ/neTxJJ9Jcl1r7QsLfzJYMX0zOo0zOo0zOo2z\naZb1SumVSR5prX2ltfb9JB9Jcs2SngtWTd+MTuOMTuOMTuNslHOX9HUvSvK1mc8fT/IPZu9QVQeT\nHJw+feWS5oBZ32itvWgBX2fbvhON04XGGd3KGtc3HSyq70TjrKfTNr6spXRbrbVDSQ4lSVUt/j3E\n8KO+uson0zgdaJzRraxxfdOB7+GM7rSNL+vtu0eTXDLz+cXTMRiBvhmdxhmdxhmdxtkoy1pKP5Pk\n8qq6rKqek+TaJHcs6blg1fTN6DTO6DTO6DTORlnK23dba09X1TuT/I8k5yS5pbX2+WU816LddNNN\nO77vDTfcsOvHnvz4eR47r57PfbKTZ1nmc+3WJvedaHzVz30yjS+fxlf73CfT+HLpe7XPfbJN6DvR\n+G4er/EtvRpf2u+UttbuTHLnsr4+9KRvRqdxRqdxRqdxNkm3Ex1tgkX+9OVsHz/vc89jXX/qx+Jp\nnNFpnJHpm9FpfO9Y1u+UAgAAwLa8UsqP2O4nQXvxpzeMReOMTuOMTN+Mbi827pVSAAAAuvFKKdv+\ntGWV76GHZdA4o9M4I9M3o9O4V0oBAADoyCulZzDvTyXmefwqfyKyF376wqlpnNFpnJHpm9FpfO+o\n1lrvGVJV/YdgL7ivtba/xxNrnBXROKPr0ri+WRHfwxndaRv39l0AAAC6WYu371588cVDntqY9dKz\nMY2zChpndL0a0zer4Hs4oztTY14pBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC62fVSWlWX\nVNUfVtUXqurzVfVL0/H3VtXRqrp/uly9uHFhdTTO6DTOyPTN6DTOSOb5J2GeTvIrrbXPVtXzktxX\nVXdPt72/tfYb848HXWmc0Wmckemb0WmcYex6KW2tHUtybLr+nar6YpKLFjUY9KZxRqdxRqZvRqdx\nRrKQ3ymtqkuT/FSST0+H3llVD1TVLVV1/mkec7CqjlTVkePHjy9iDFgajTM6jTMyfTM6jbPp5l5K\nq+rHk9ye5Jdba99OcnOSlya5Ils/vXnfqR7XWjvUWtvfWtu/b9++eceApdE4o9M4I9M3o9M4I5hr\nKa2qH8vW/wS/3Vr73SRprT3RWnumtfZskg8muXL+MaEPjTM6jTMyfTM6jTOKec6+W0k+lOSLrbWb\nZo5fOHO3NyV5cPfjQT8aZ3QaZ2T6ZnQaZyTznH33HyX5+SSfq6r7p2O/muS6qroiSUvyWJK3zTUh\n9KNxRqdxRqZvRqdxhjHP2Xf/V5I6xU137n4cWB8aZ3QaZ2T6ZnQaZyTzvFK6MjfccEPvEdgAN910\n0/Z3WlMaZyc0zug2tXF9sxOb2neicXZmnsYX8k/CAAAAwG5YSgEAAOjGUgoAAEA3llIAAAC6sZQC\nAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUU\nAACAbs6d9wtU1WNJvpPkmSRPt9b2V9Xzk3w0yaVJHkvy5tba/533uWDV9M3oNM7oNM7I9M0oFvVK\n6T9urV3RWts/fX5jkntaa5cnuWf6HDaVvhmdxhmdxhmZvtl4y3r77jVJbp2u35rkjUt6HuhB34xO\n44xO44xM32ycRSylLcknq+q+qjo4HbugtXZsuv71JBec/KCqOlhVR6rqyPHjxxcwBizFrvpONM7G\n0Dij8/cURuZ7OEOY+3dKk7yqtXa0qv5mkrur6kuzN7bWWlW1kx/UWjuU5FCSXHLJJT9yO6yJXfU9\n3aZxNoHGGZ2/pzAy38MZwtyvlLbWjk4fn0zy8SRXJnmiqi5Mkunjk/M+D/Sgb0ancUancUamb0Yx\n11JaVfuq6nknrid5fZIHk9yR5Prpbtcn+cQ8zwM96JvRaZzRaZyR6ZuRzPv23QuSfLyqTnyt32mt\n3VVVn0nysap6a5KvJnnznM8DPeib0Wmc0WmckembYcy1lLbWvpLk75/i+DeTvG6erw296ZvRaZzR\naZyR6ZuRLOJER0t374EDvUdgA/xx7wHmoHF2QuOMblMb1zc7sal9JxpnZ+ZpfFn/TikAAABsy1IK\nAABAN5ZSAAAAurGUAgAA0I2lFAAAgG424uy7z/7tb/ceAZZK44xO44xM34xO4yybV0oBAADoxlIK\nAABAN5ZSAAAAurGUAgAA0I2lFAAAgG424uy7T/2N7/YeAZZK44xO44xM34xO4yybV0oBAADoxlIK\nAABAN7t++25V/WSSj84cekmSf5vkvCT/Ksn/mY7/amvtzl1PCJ1onNFpnNFpnJHpm5HseiltrT2U\n5IokqapzkhxN8vEkv5jk/a2131jIhNCJxhmdxhmdxhmZvhnJok509Lokj7bWvlpVC/qSP/TU3/n+\nwr8mA/rGUr+6xulP44xuQxvXNzuyoX0nGmeH5mh8Ub9Tem2S22Y+f2dVPVBVt1TV+Qt6DuhJ44xO\n44xO44xM32y0uZfSqnpOkp9L8l+nQzcneWm23k5wLMn7TvO4g1V1pKqOHD9+fN4xYGk0zug0zuh2\n07i+2RS+hzOCRbxS+oYkn22tPZEkrbUnWmvPtNaeTfLBJFee6kGttUOttf2ttf379u1bwBiwNBpn\ndBpndGfduL7ZIL6Hs/EWsZRel5m3C1TVhTO3vSnJgwt4DuhJ44xO44xO44xM32y8uU50VFX7kvx0\nkrfNHP71qroiSUvy2Em3wUbROKPTOKPTOCPTN6OYayltrR1P8oKTjv38XBOdwu88++JFf0kG9Pol\nfE2Ns040zug2tXF9sxOb2neicXZmnsYXdfZdAAAAOGuWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0\nM9fZd1fl+x95b+8R2ASv/+PeE+yaxtkRjTO6DW1c3+zIhvadaJwdmqNxr5QCAADQjaUUAACAbiyl\nAAAAdGMpBQAAoBtLKQAAAN1sxNl3/+ddV/UegQ3ws6+/qfcIu6ZxdkLjjG5TG9c3O7GpfScaZ2fm\nadwrpQAAAHRjKQUAAKAbSykAAADd7GgprapbqurJqnpw5tjzq+ruqnp4+nj+dLyq6gNV9UhVPVBV\nr1jW8LAI+mZ0Gmd0Gmdk+mYv2OkrpYeTHDjp2I1J7mmtXZ7knunzJHlDksuny8EkN88/JizV4eib\nsR2Oxhnb4WiccR2OvhncjpbS1tqnkjx10uFrktw6Xb81yRtnjn+4bbk3yXlVdeEihoVl0Dej0zij\n0zgj0zd7wTy/U3pBa+3YdP3rSS6Yrl+U5Gsz93t8OgabRN+MTuOMTuOMTN8MZSEnOmqttSTtbB5T\nVQer6khVHTl+/PgixoCl2E3ficbZHBpndP6ewsh8D2cE8yylT5x4O8D08cnp+NEkl8zc7+Lp2F/T\nWjvUWtvfWtu/b9++OcaApZir70TjrD2NMzp/T2FkvoczlHmW0juSXD9dvz7JJ2aOv2U6+9dVSb41\n8/YC2BT6ZnQaZ3QaZ2T6Zijn7uROVXVbktcmeWFVPZ7kPUn+fZKPVdVbk3w1yZunu9+Z5OokjyT5\nbpJfXPDMsFD6ZnQaZ3QaZ2T6Zi/Y0VLaWrvuNDe97hT3bUneMc9QsEr6ZnQaZ3QaZ2T6Zi9YyImO\nAAAAYDcspQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG4s\npQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAutl2Ka2qW6rqyap6cObYf6yqL1XV\nA1X18ao6bzp+aVX9ZVXdP11+a5nDwyJofL3ce+BA7j1woPcYQ9E4I9M3o9M4e8FOXik9nOTkvyHe\nneTvttb+XpIvJ3nXzG2PttaumC5vX8yYsFSHo3HGdjgaXwt+6LIUh6NvxnY4Gmdw2y6lrbVPJXnq\npGOfbK09PX16b5KLlzAbrITGGZ3GGZm+14MfuCyPxtkLFvE7pf8yye/PfH5ZVf1pVf1RVb16AV8f\netM4o9M4I9M3o9P4kvmhy/KdO8+Dq+rdSZ5O8tvToWNJXtxa+2ZVvTLJ71XVy1tr3z7FYw8mOZgk\n559//jxjwNJofPWuuuuu3iPsKRpnZPpmdBpnFLt+pbSqfiHJzyb5F621liStte+11r45Xb8vyaNJ\nfuJUj2+tHWqt7W+t7d+3b99ux4Cl0Tij0/jqXXXXXX7wsiL6ZnQaZyS7eqW0qg4k+TdJ/v/W2ndn\njr8oyVOttWeq6iVJLk/ylYVMCiukcUancUam79Xzw5bV0jij2XYprarbkrw2yQur6vEk78nWGb6e\nm+TuqkqSe6eze70myb+rqr9K8mySt7fWnjrlF4Y1oXFGp3FGpm9Gp/H+/NBl+bZdSltr153i8IdO\nc9/bk9w+71CwShpndBpnZPpmdBpnL1jE2XcBAABgVyylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjG\nUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3\nllIAAAC6sZQCAADQzbZLaVXdUlVPVtWDM8feW1VHq+r+6XL1zG3vqqpHquqhqvqZZQ0Oi6JxRqdx\nRqdxRqZv9oKdvFJ6OMmBUxx/f2vtiulyZ5JU1cuSXJvk5dNj/nNVnbOoYWFJDkfjjO1wNM7YDkfj\njOtw9M3gtl1KW2ufSvLUDr/eNUk+0lr7Xmvtz5M8kuTKOeaDpdM4o9M4o9M4I9M3e8E8v1P6zqp6\nYHpLwfnTsYuSfG3mPo9Px35EVR2sqiNVdeT48eNzjAFLo3FGp3FGt+vG9c0G8D2cYex2Kb05yUuT\nXJHkWJL3ne0XaK0daq3tb63t37dv3y7HgKXROKPTOKObq3F9s+Z8D2cou1pKW2tPtNaeaa09m+SD\n+eHbAo4muWTmrhdPx2CjaJzRaZzRaZyR6ZvR7GopraoLZz59U5ITZwO7I8m1VfXcqrosyeVJ/mS+\nEWH1NM7oNM7oNM7I9M1ozt3uDlV1W5LXJnlhVT2e5D1JXltVVyRpSR5L8rYkaa19vqo+luQLSZ5O\n8o7W2jPLGR0WQ+OMTuOMTuOMTN/sBdsupa21605x+ENnuP+vJfm1eYaCVdI4o9M4o9M4I9M3e8E8\nZ98FAACAuVhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0YykFAACgG0spAAAA\n3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0s+1SWlW3VNWTVfXgzLGPVtX9\n0+Wxqrp/On5pVf3lzG2/tczhYRE0zug0zsj0zeg0zl5w7g7uczjJf0ry4RMHWmv//MT1qnpfkm/N\n3P/R1toVixoQVuBwNM7YDkfjjOtw9M3YDkfjDG7bpbS19qmquvRUt1VVJXlzkn+y2LFgdTTO6DTO\nyPTN6DTOXjDv75S+OskTrbWHZ45dVlV/WlV/VFWvPt0Dq+pgVR2pqiPHjx+fcwxYGo0zOo0zMn0z\nOo0zhJ28ffdMrkty28znx5K8uLX2zap6ZZLfq6qXt9a+ffIDW2uHkhxKkksuuaTNOQcsi8YZncYZ\nmb4ZncYZwq5fKa2qc5P8syQfPXGstfa91to3p+v3JXk0yU/MOyT0oHFGp3FGpm9Gp3FGMs/bd/9p\nki+11h4/caCqXlRV50zXX5Lk8iRfmW9E6EbjjE7jjEzfjE7jDGMn/yTMbUn+d5KfrKrHq+qt003X\n5q+/XSBJXpPkgem01P8tydtba08tcmBYNI0zOo0zMn0zOo2zF+zk7LvXneb4L5zi2O1Jbp9/LFgd\njTM6jTMyfTM6jbMXzHv2XQAAANg1SykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAA\ngG62/XdKV+Fb5zyb/37eX/QeY0+698CBuR5/1V13LWiS+f3DT36y9winpfF+NL4aGu9H48un7370\nvRoa70fjW7xSCgAAQDeWUgAAALqxlAIAANDNWvxOKf2s0/vQYRk0zug0zsj0zeg0vsVSyjD8T83o\nNM7oNM7I9M3o5mm8WmsLHGWXQ1T1H4K94L7W2v4eT6xxVkTjjK5L4/pmRXwPZ3SnbdzvlAIAANDN\ntktpVV1SVX9YVV+oqs9X1S9Nx59fVXdX1cPTx/On41VVH6iqR6rqgap6xbL/I2AeGmd0Gmdk+mZ0\nGmcv2MkrpU8n+ZXW2suSXJXkHVX1siQ3JrmntXZ5knumz5PkDUkuny4Hk9y88KlhsTTO6DTOyPTN\n6DTO8LZdSltrx1prn52ufyfJF5NclOSaJLdOd7s1yRun69ck+XDbcm+S86rqwoVPDguicUancUam\nb0ancfaCs/qd0qq6NMlPJfl0kgtaa8emm76e5ILp+kVJvjbzsMenYyd/rYNVdaSqjpzlzLA0Gmd0\nGmdk+mZ0GmdUO15Kq+rHk9ye5Jdba9+eva1tncL3rM7a1Vo71Frb3+ssY3AyjTM6jTMyfTM6jTOy\nHS2lVfVj2fqf4Ldba787HX7ixFsBpo9PTsePJrlk5uEXT8dgbWmc0Wmckemb0Wmc0e3k7LuV5ENJ\nvthau2nmpjuSXD9dvz7JJ2aOv2U689dVSb4189YCWDsaZ3QaZ2T6ZnQaZ09orZ3xkuRV2Xo7wANJ\n7p8uVyd5QbbO9PVwkj9I8vzp/pXkN5M8muRzSfbv4Dmai8sKLkc07jL4ReMuo19+pPHo22Wci+/h\nLqNfTtl4ay01hdhVVfUfgr3gvl6/N6FxVkTjjK5L4/pmRXwPZ3Snbfyszr4LAAAAi2QpBQAAoBtL\nKQAAAN2c23uAyTeSHJ8+bqoXxvw97WT+v7WKQU5D4/3thfl7Nv4XSR7q+Pzz2gt9rLt1btz38P72\nwvz+njKfvdDIOpur8bU40VGSVNWRTf7He83f1ybMvwkznon5+1r3+dd9vu2Yv791/29Y9/m2Y/6+\nNmH+TZjxTMzf17zze/suAAAA3VhKAQAA6GadltJDvQeYk/n72oT5N2HGMzF/X+s+/7rPtx3z97fu\n/w3rPt92zN/XJsy/CTOeifn7mmv+tfmdUgAAAPaedXqlFAAAgD3GUgoAAEA33ZfSqjpQVQ9V1SNV\ndWPveXaiqh6rqs9V1f1VdWQ69vyquruqHp4+nt97zllVdUtVPVlVD84cO+XMteUD05/JA1X1in6T\n/2DWU83/3qo6Ov053F9VV8/c9q5p/oeq6mf6TP2DWTS+ZPruS+PLp/F+NrHvROOrpvHV2rS+E41v\n+wSttW6XJOckeTTJS5I8J8mfJXlZz5l2OPdjSV540rFfT3LjdP3GJP+h95wnzfeaJK9I8uB2Mye5\nOsnvJ6kkVyX59JrO/94k//oU933Z1NJzk1w2NXZOp7k13q8Pfa9mdo33a0Tjy597I/ueZtd4//k1\nvry5N6rvMzSi8enS+5XSK5M80lr7Smvt+0k+kuSazjPt1jVJbp2u35rkjR1n+RGttU8leeqkw6eb\n+ZokH25b7k1yXlVduJpJT+0085/ONUk+0lr7Xmvtz5M8kq3WetD4Cui7W9+JxldC476HL4jGl0Tj\na2Ft+040nm0a772UXpTkazOfPz4dW3ctySer6r6qOjgdu6C1dmy6/vUkF/QZ7aycbuZN+nN55/S2\nhltm3qaxTvOv0yxnY4TG9b0a6zbPTml8Pax74+s0y9nS+HrQ+HKM0Hei8R/ovZRuqle11l6R5A1J\n3lFVr5m9sW29br1R/9bOJs6c5OYkL01yRZJjSd7Xd5yhDNX4ps070fdyabw/jS+XxvvT+PIM1Xey\nmTNngY33XkqPJrlk5vOLp2NrrbV2dPr4ZJKPZ+vl6CdOvKw+fXyy34Q7drqZN+LPpbX2RGvtmdba\ns0k+mB++LWCd5l+nWXZskMb1vRrrNs+OaLy/DWl8nWY5KxrvT+PLM0jficZ/oPdS+pkkl1fVZVX1\nnCTXJrmj80xnVFX7qup5J64neX2SB7M19/XT3a5P8ok+E56V0818R5K3TGf+uirJt2beWrA2Tnpv\n/Zuy9eeQbM1/bVU9t6ouS3J5kj9Z9XwTjfej79XQeD8aX76N6zvR+LrQ+HIM1Hei8R8601mQVnHJ\n1tmlvpytszK9u/c8O5j3Jdk6m9SfJfn8iZmTvCDJPUkeTvIHSZ7fe9aT5r4tWy+r/1W23tf91tPN\nnK0zff3m9GfyuST713T+/zLN98AU/4Uz93/3NP9DSd7QeXaN9+lD36ubX+N9GtH4ambfqL6nmTW+\nHvNrfDnzblzfZ2hE49OlpgcBAADAyvV++y4AAAB7mKUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1Y\nSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjG\nUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3\nllIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6\nsZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQ\njaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN0sbSmtqgNV9VBVPVJVNy7reaAHfTM6jTM6jTM6jbNJ\nqrW2+C9adU6SLyf56SSPJ/lMkutaa19Y+JPBiumb0Wmc0Wmc0WmcTbOsV0qvTPJIa+0rrbXvJ/lI\nkmuW9FywavpmdBpndBpndBpno5y7pK97UZKvzXz+eJJ/MHuHqjqY5OD06SuXNAfM+kZr7UUL+Drb\n9p1onC40zuhW1ri+6WBRfScaZz2dtvFlLaXbaq0dSnIoSapq8e8hhh/11VU+mcbpQOOMbmWN65sO\nfA9ndKdtfFlv3z2a5JKZzy+ejsEI9M3oNM7oNM7oNM5GWdZS+pkkl1fVZVX1nCTXJrljSc8Fq6Zv\nRqdxRqdxRqdxNspS3r7bWnu6qt6Z5H8kOSfJLa21zy/juRbtpptu2vF9b7jhhl0/9uTHz/PYefV8\n7pOdPMsyn2u3NrnvROOrfu6TaXz5NL7a5z6ZxpdL36t97pNtQt+JxnfzeI1v6dX40n6ntLV2Z5I7\nl/X1oSd9MzqNMzqNMzqNs0m6nehoEyzypy9n+/h5n3se6/pTPxZP44xO44xM34xO43vHsn6nFAAA\nALbllVJ+xHY/CdqLP71hLBpndBpnZPpmdHuxca+UAgAA0I1XStn2py2rfA89LIPGGZ3GGZm+GZ3G\nvVIKAABAR14pPYN5fyoxz+NX+RORvfDTF05N44xO44xM34xO43tHtdZ6z5Cq6j8Ee8F9rbX9PZ5Y\n46yIxhldl8b1zYr4Hs7oTtu4t+8CAADQzVq8fffiiy8e8tTGrJeejWmcVdA4o+vVmL5ZBd/DGd2Z\nGvNKKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQza6X0qq6pKr+sKq+UFWfr6pfmo6/t6qO\nVtX90+XqxY0Lq6NxRqdxRqZvRqdxRjLPPwnzdJJfaa19tqqel+S+qrp7uu39rbXfmH886ErjjE7j\njEzfjE7jDGPXS2lr7ViSY9P171TVF5NctKjBoDeNMzqNMzJ9MzqNM5KF/E5pVV2a5KeSfHo69M6q\neqCqbqmq80/zmINVdaSqjhw/fnwRY8DSaJzRaZyR6ZvRaZxNN/dSWlU/nuT2JL/cWvt2kpuTvDTJ\nFdn66c37TvW41tqh1tr+1tr+ffv2zTsGLI3GGZ3GGZm+GZ3GGcFcS2lV/Vi2/if47dba7yZJa+2J\n1tozrbVnk3wwyZXzjwl9aJzRaZyR6ZvRaZxRzHP23UryoSRfbK3dNHP8wpm7vSnJg7sfD/rROKPT\nOCPTN6PTOCOZ5+y7/yjJzyf5XFXdPx371STXVdUVSVqSx5K8ba4JoR+NMzqNMzJ9MzqNM4x5zr77\nv5LUKW66c/fjwPrQOKPTOCPTN6PTOCOZ55XSlbnhhht6j8AGuOmmm7a/05rSODuhcUa3qY3rm53Y\n1L4TjbMz8zS+kH8SBgAAAHbDUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtL\nKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdHPuvF+gqh5L8p0kzyR5\nurW2v6qen+SjSS5N8liSN7fW/u+8zwWrpm9Gp3FGp3FGpm9GsahXSv9xa+2K1tr+6fMbk9zTWrs8\nyT3T57Cp9M3oNM7oNM7I9M3GW9bbd69Jcut0/dYkb1zS80AP+mZ0Gmd0Gmdk+mbjLGIpbUk+WVX3\nVdXB6dgFrbVj0/WvJ7ng5AdV1cGqOlJVR44fP76AMWApdtV3onE2hsYZnb+nMDLfwxnC3L9TmuRV\nrbWjVfU3k9xdVV+avbG11qqqnfyg1tqhJIeS5JJLLvmR22FN7Krv6TaNswk0zuj8PYWR+R7OEOZ+\npbS1dnT6+GSSjye5MskTVXVhkkwfn5z3eaAHfTM6jTM6jTMyfTOKuZbSqtpXVc87cT3J65M8mOSO\nJNdPd7s+ySfmeR7oQd+MTmOrsbMAABLfSURBVOOMTuOMTN+MZN63716Q5ONVdeJr/U5r7a6q+kyS\nj1XVW5N8Ncmb53we6EHfjE7jjE7jjEzfDGOupbS19pUkf/8Ux7+Z5HXzfG3oTd+MTuOMTuOMTN+M\nZBEnOlq6ew8c6D0CG+CPew8wB42zExpndJvauL7ZiU3tO9E4OzNP48v6d0oBAABgW5ZSAAAAurGU\nAgAA0I2lFAAAgG4spQAAAHSzEWffffZvf7v3CLBUGmd0Gmdk+mZ0GmfZvFIKAABAN5ZSAAAAurGU\nAgAA0I2lFAAAgG4spQAAAHSzEWfffepvfLf3CLBUGmd0Gmdk+mZ0GmfZvFIKAABAN5ZSAAAAutn1\n23er6ieTfHTm0EuS/Nsk5yX5V0n+z3T8V1trd+56QuhE44xO44xO44xM34xk10tpa+2hJFckSVWd\nk+Roko8n+cUk72+t/cZCJoRONM7oNM7oNM7I9M1IFnWio9clebS19tWqWtCX/KGn/s73F/41GdA3\nlvrVNU5/Gmd0G9q4vtmRDe070Tg7NEfji/qd0muT3Dbz+Tur6oGquqWqzj/VA6rqYFUdqaojx48f\nX9AYsDQaZ3QaZ3Rn1bi+2TC+h7PR5l5Kq+o5SX4uyX+dDt2c5KXZejvBsSTvO9XjWmuHWmv7W2v7\n9+3bN+8YsDQaZ3QaZ3S7aVzfbArfwxnBIl4pfUOSz7bWnkiS1toTrbVnWmvPJvlgkisX8BzQk8YZ\nncYZncYZmb7ZeItYSq/LzNsFqurCmdvelOTBBTwH9KRxRqdxRqdxRqZvNt5cJzqqqn1JfjrJ22YO\n/3pVXZGkJXnspNtgo2ic0Wmc0WmckembUcy1lLbWjid5wUnHfn6uiU7hd5598aK/JAN6/RK+psZZ\nJxpndJvauL7ZiU3tO9E4OzNP44s6+y4AAACcNUspAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqZ6+y7\nq/L9j7y39whsgtf/ce8Jdk3j7IjGGd2GNq5vdmRD+040zg7N0bhXSgEAAOjGUgoAAEA3llIAAAC6\nsZQCAADQjaUUAACAbjbi7Lv/866reo/ABvjZ19/Ue4Rd0zg7oXFGt6mN65ud2NS+E42zM/M07pVS\nAAAAurGUAgAA0I2lFAAAgG52tJRW1S1V9WRVPThz7PlVdXdVPTx9PH86XlX1gap6pKoeqKpXLGt4\nWAR9MzqNMzqNMzJ9sxfs9JXSw0kOnHTsxiT3tNYuT3LP9HmSvCHJ5dPlYJKb5x8Tlupw9M3YDkfj\njO1wNM64DkffDG5HS2lr7VNJnjrp8DVJbp2u35rkjTPHP9y23JvkvKq6cBHDwjLom9FpnNFpnJHp\nm71gnt8pvaC1dmy6/vUkF0zXL0rytZn7PT4d+2uq6mBVHamqI8ePH59jDFiKufpONM7a0zij8/cU\nRuZ7OENZyImOWmstSTvLxxxqre1vre3ft2/fIsaApdhN39PjNM5G0Dij8/cURuZ7OCOYZyl94sTb\nAaaPT07Hjya5ZOZ+F0/HYJPom9FpnNFpnJHpm6HMs5TekeT66fr1ST4xc/wt09m/rkryrZm3F8Cm\n0Dej0zij0zgj0zdDOXcnd6qq25K8NskLq+rxJO9J8u+TfKyq3prkq0nePN39ziRXJ3kkyXeT/OKC\nZ4aF0jej0zij0zgj0zd7wY6W0tbadae56XWnuG9L8o55hoJV0jej0zij0zgj0zd7wUJOdAQAAAC7\nYSkFAACgG0spAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0YykFAACg\nG0spAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANDNtktpVd1SVU9W1YMzx/5jVX2pqh6oqo9X\n1XnT8Uur6i+r6v7p8lvLHB4WQeOMTuOMTN+MTuPsBTt5pfRwkgMnHbs7yd9trf29JF9O8q6Z2x5t\nrV0xXd6+mDFhqQ5H44ztcDTOuA5H34ztcDTO4LZdSltrn0ry1EnHPtlae3r69N4kFy9hNlgJjTM6\njTMyfTM6jbMXLOJ3Sv9lkt+f+fyyqvrTqvqjqnr1Ar4+9KZxRqdxRqZvRqdxNt658zy4qt6d5Okk\nvz0dOpbkxa21b1bVK5P8XlW9vLX27VM89mCSg0ly/vnnzzPG0O49sPVujavuuqvzJHuTxhmdxhmZ\nvhmdxhnFrl8prapfSPKzSf5Fa60lSWvte621b07X70vyaJKfONXjW2uHWmv7W2v79+3bt9sxYGk0\nvnz3Hjjwgx+8sHoaZ2T6ZnQaZyS7Wkqr6kCSf5Pk51pr3505/qKqOme6/pIklyf5yiIGhVXSOKPT\n+PL5oUs/+mZ0Gmc02759t6puS/LaJC+sqseTvCdbZ/h6bpK7qypJ7p3O7vWaJP+uqv4qybNJ3t5a\ne+qUXxjWhMYZncYZmb5Xz68WrZbG2Qu2XUpba9ed4vCHTnPf25PcPu9Q/JBv+MuncUancUamb0an\n8dXyQ5c+5jrREcA8fMMHAMBSCgBL4IcuALAzllIAAHbMD1yARbOUAgAAxA9detn1v1MKAAAA87KU\nAgAA0I2lFAAAgG4spQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2l\nFAAAgG62XUqr6paqerKqHpw59t6qOlpV90+Xq2due1dVPVJVD1XVzyxrcFgUjTM6jTM6jTMyfbMX\n7OSV0sNJDpzi+Ptba1dMlzuTpKpeluTaJC+fHvOfq+qcRQ0LS3I4Gmdsh6NxxnY4Gmdch6NvBrft\nUtpa+1SSp3b49a5J8pHW2vdaa3+e5JEkV84xHyydxhmdxhmdxhmZvtkL5vmd0ndW1QPTWwrOn45d\nlORrM/d5fDoGm0jjjE7jjE7jjEzfDGO3S+nNSV6a5Iokx5K872y/QFUdrKojVXXk+PHjuxwDlkbj\njE7jjG6uxvXNmvM9nKHsailtrT3RWnumtfZskg/mh28LOJrkkpm7XjwdO9XXONRa299a279v377d\njAFLo3FGp3FGN2/j+mad+R7OaHa1lFbVhTOfvinJibOB3ZHk2qp6blVdluTyJH8y34iwehpndBpn\ndBpnZPpmNOdud4equi3Ja5O8sKoeT/KeJK+tqiuStCSPJXlbkrTWPl9VH0vyhSRPJ3lHa+2Z5YwO\ni6FxRqdxRqdxRqZv9oJtl9LW2nWnOPyhM9z/15L82jxDwSppnNFpnNFpnJHpm71gnrPvAgAAwFws\npQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG4spQAAAHRj\nKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAutl2Ka2qW6rqyap6cObYR6vq/unyWFXdPx2/\ntKr+cua231rm8LAIGmd0Gmdk+mZ0GmcvOHcH9zmc5D8l+fCJA621f37ielW9L8m3Zu7/aGvtikUN\nCCtwOBpnbIejccZ1OPpmbIejcQa37VLaWvtUVV16qtuqqpK8Ock/WexYsDoaZ3QaZ2T6ZnQaZy+Y\n93dKX53kidbawzPHLquqP62qP6qqV8/59aE3jTM6jTMyfTM6jTOEnbx990yuS3LbzOfHkry4tfbN\nqnplkt+rqpe31r598gOr6mCSg0ly/vnnzzkGLI3GGZ3GGZm+GZ3GGcKuXymtqnOT/LMkHz1xrLX2\nvdbaN6fr9yV5NMlPnOrxrbVDrbX9rbX9+/bt2+0YsDQaZ3QaZ2T6ZnQaZyTzvH33nyb5Umvt8RMH\nqupFVXXOdP0lSS5P8pX5RoRuNM7oNM7I9M3oNM4wdvJPwtyW5H8n+cmqeryq3jrddG3++tsFkuQ1\nSR6YTkv935K8vbX21CIHhkXTOKPTOCPTN6PTOHvBTs6+e91pjv/CKY7dnuT2+ceC1dE4o9M4I9M3\no9M4e8G8Z98FAACAXbOUAgAA0I2lFAAAgG4spQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABA\nN+f2HiBJvnXOs/nv5/1F7zH2jHsPHJjr8VfdddeCJlmsf/jJT/Ye4bQ0vjqj9p1onLH7Tta3cX2v\nhr770fhqaPz0vFIKAABAN5ZSAAAAurGUAgAA0M1a/E4pq7Xu70eHeeibkembkemb0Wn89CylDMP/\n6IxO44xO44xM34xunsartbbAUXY5RFX/IdgL7mut7e/xxBpnRTTO6Lo0rm9WxPdwRnfaxrf9ndKq\nuqSq/rCqvlBVn6+qX5qOP7+q7q6qh6eP50/Hq6o+UFWPVNUDVfWKxf63wGJpnNFpnJHpm9FpnL1g\nJyc6ejrJr7TWXpbkqiTvqKqXJbkxyT2ttcuT3DN9niRvSHL5dDmY5OaFTw2LpXFGp3FGpm9Gp3GG\nt+1S2lo71lr77HT9O0m+mOSiJNckuXW6261J3jhdvybJh9uWe5OcV1UXLnxyWBCNMzqNMzJ9MzqN\nsxec1T8JU1WXJvmpJJ9OckFr7dh009eTXDBdvyjJ12Ye9vh0DNaexhmdxhmZvhmdxhnVjs++W1U/\nnuT2JL/cWvt2Vf3gttZaO9tfkK6qg9l6SwGsBY0zOo0zMn0zOo0zsh29UlpVP5at/wl+u7X2u9Ph\nJ068FWD6+OR0/GiSS2YefvF07K9prR1qre3vdZYxmKVxRqdxRqZvRqdxRreTs+9Wkg8l+WJr7aaZ\nm+5Icv10/fokn5g5/pbpzF9XJfnWzFsLYO1onNFpnJHpm9FpnD2htXbGS5JXJWlJHkhy/3S5OskL\nsnWmr4eT/EGS50/3ryS/meTRJJ9Lsn8Hz9FcXFZwOaJxl8EvGncZ/fIjjUffLuNcfA93Gf1yysZb\na6kpxK7O9j3wsEv+UWpGp3FG16VxfbMivoczutM2flZn3wUAAIBFspQCAADQjaUUAACAbiylAAAA\ndHNu7wEm30hyfPq4qV4Y8/e0k/n/1ioGOQ2N97cX5u/Z+F8keajj889rL/Sx7ta5cd/D+9sL8/t7\nynz2QiPrbK7G1+Lsu0lSVUc2+R/vNX9fmzD/Jsx4Jubva93nX/f5tmP+/tb9v2Hd59uO+fvahPk3\nYcYzMX9f887v7bsAAAB0YykFAACgm3VaSg/1HmBO5u9rE+bfhBnPxPx9rfv86z7fdszf37r/N6z7\nfNsxf1+bMP8mzHgm5u9rrvnX5ndKAQAA2HvW6ZVSAAAA9hhLKQAAAN10X0qr6kBVPVRVj1TVjb3n\n2YmqeqyqPldV91fVkenY86vq7qp6ePp4fu85Z1XVLVX1ZFU9OHPslDPXlg9MfyYPVNUr+k3+g1lP\nNf97q+ro9Odwf1VdPXPbu6b5H6qqn+kz9Q9m0fiS6bsvjS+fxvvZxL4Tja+axldr0/pONL7tE7TW\nul2SnJPk0SQvSfKcJH+W5GU9Z9rh3I8leeFJx349yY3T9RuT/Ifec54032uSvCLJg9vNnOTqJL+f\npJJcleTTazr/e5P861Pc92VTS89NctnU2Dmd5tZ4vz70vZrZNd6vEY0vf+6N7HuaXeP959f48ube\nqL7P0IjGp0vvV0qvTPJIa+0rrbXvJ/lIkms6z7Rb1yS5dbp+a5I3dpzlR7TWPpXkqZMOn27ma5J8\nuG25N8l5VXXhaiY9tdPMfzrXJPlIa+17rbU/T/JItlrrQeMroO9ufScaXwmN+x6+IBpfEo2vhbXt\nO9F4tmm891J6UZKvzXz++HRs3bUkn6yq+6rq4HTsgtbasen615Nc0Ge0s3K6mTfpz+Wd09sabpl5\nm8Y6zb9Os5yNERrX92qs2zw7pfH1sO6Nr9MsZ0vj60HjyzFC34nGf6D3UrqpXtVae0WSNyR5R1W9\nZvbGtvW69Ub9WzubOHOSm5O8NMkVSY4leV/fcYYyVOObNu9E38ul8f40vlwa70/jyzNU38lmzpwF\nNt57KT2a5JKZzy+ejq211trR6eOTST6erZejnzjxsvr08cl+E+7Y6WbeiD+X1toTrbVnWmvPJvlg\nfvi2gHWaf51m2bFBGtf3aqzbPDui8f42pPF1muWsaLw/jS/PIH0nGv+B3kvpZ5JcXlWXVdVzklyb\n5I7OM51RVe2rqueduJ7k9UkezNbc1093uz7JJ/pMeFZON/MdSd4ynfnrqiTfmnlrwdo46b31b8rW\nn0OyNf+1VfXcqrosyeVJ/mTV80003o++V0Pj/Wh8+Tau70Tj60LjyzFQ34nGf+hMZ0FaxSVbZ5f6\ncrbOyvTu3vPsYN6XZOtsUn+W5PMnZk7ygiT3JHk4yR8keX7vWU+a+7Zsvaz+V9l6X/dbTzdzts70\n9ZvTn8nnkuxf0/n/yzTfA1P8F87c/93T/A8leUPn2TXepw99r25+jfdpROOrmX2j+p5m1vh6zK/x\n5cy7cX2foRGNT5eaHgQAAAAr1/vtuwAAAOxhllIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAA\noBtLKQAAAN38P4MFx8hKCA3KAAAAAElFTkSuQmCC\n","text/plain":[""]},"metadata":{"tags":[]}}]},{"cell_type":"markdown","metadata":{"id":"tQUICeKQgGhs"},"source":["**Let's play a little.**\n","\n","Pay attention to zoom and fps args of the play function. Control: A, D, space."]},{"cell_type":"code","metadata":{"id":"y69dTrTygGhv"},"source":["# # does not work in Colab.\n","# # make keyboard interrupt to continue\n","\n","# from gym.utils.play import play\n","\n","# play(env=gym.make(ENV_NAME), zoom=5, fps=30)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"hj1LfEQ3gGhv"},"source":["### Processing game image \n","\n","Raw Atari images are large, 210x160x3 by default. However, we don't need that level of detail in order to learn from them.\n","\n","We can thus save a lot of time by preprocessing game image, including\n","* Resizing to a smaller shape, 64 x 64\n","* Converting to grayscale\n","* Cropping irrelevant image parts (top, bottom and edges)\n","\n","Also please keep one dimension for channel so that final shape would be 1 x 64 x 64.\n","\n","Tip: You can implement your own grayscale converter and assign a huge weight to the red channel. This dirty trick is not necessary but it will speed up the learning."]},{"cell_type":"code","metadata":{"id":"XBaN3hjGgGhw"},"source":["from gym.core import ObservationWrapper\n","from gym.spaces import Box\n","\n","\n","class PreprocessAtariObs(ObservationWrapper):\n"," def __init__(self, env):\n"," \"\"\"A gym wrapper that crops, scales an image into the desired shapes and grayscales it.\"\"\"\n"," ObservationWrapper.__init__(self, env)\n","\n"," self.img_size = (1, 64, 64)\n"," self.observation_space = Box(0.0, 1.0, self.img_size)\n","\n","\n"," def _to_gray_scale(self, rgb, channel_weights=[0.8, 0.1, 0.1]):\n"," \n","\n","\n"," def observation(self, img):\n"," \"\"\"what happens to each observation\"\"\"\n","\n"," # Here's what you need to do:\n"," # * crop image, remove irrelevant parts\n"," # * resize image to self.img_size\n"," # (use imresize from any library you want,\n"," # e.g. opencv, skimage, PIL, keras)\n"," # * cast image to grayscale\n"," # * convert image pixels to (0,1) range, float32 type\n"," \n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"pjcDs0Y0gGhy"},"source":["import gym\n","# spawn game instance for tests\n","env = gym.make(ENV_NAME) # create raw env\n","env = PreprocessAtariObs(env)\n","observation_shape = env.observation_space.shape\n","n_actions = env.action_space.n\n","env.reset()\n","obs, _, _, _ = env.step(env.action_space.sample())\n","\n","# test observation\n","assert obs.ndim == 3, \"observation must be [channel, h, w] even if there's just one channel\"\n","assert obs.shape == observation_shape\n","assert obs.dtype == 'float32'\n","assert len(np.unique(obs)) > 2, \"your image must not be binary\"\n","assert 0 <= np.min(obs) and np.max(\n"," obs) <= 1, \"convert image pixels to [0,1] range\"\n","\n","assert np.max(obs) >= 0.5, \"It would be easier to see a brighter observation\"\n","assert np.mean(obs) >= 0.1, \"It would be easier to see a brighter observation\"\n","\n","print(\"Formal tests seem fine. Here's an example of what you'll get.\")\n","\n","n_cols = 5\n","n_rows = 2\n","fig = plt.figure(figsize=(16, 9))\n","obs = env.reset()\n","for row in range(n_rows):\n"," for col in range(n_cols):\n"," ax = fig.add_subplot(n_rows, n_cols, row * n_cols + col + 1)\n"," ax.imshow(obs[0, :, :], interpolation='none', cmap='gray')\n"," obs, _, _, _ = env.step(env.action_space.sample())\n","plt.show()\n"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"MmXm5C2VgGhy"},"source":["### Wrapping."]},{"cell_type":"markdown","metadata":{"id":"VCDgNDMXgGh1"},"source":["**About the game:** You have 5 lives and get points for breaking the wall. Higher bricks cost more than the lower ones. There are 4 actions: start game (should be called at the beginning and after each life is lost), move left, move right and do nothing. There are some common wrappers used for Atari environments."]},{"cell_type":"code","metadata":{"id":"qH-P2OmFgGh1"},"source":["%load_ext autoreload\n","%autoreload 2\n","import atari_wrappers\n","\n","def PrimaryAtariWrap(env, clip_rewards=True):\n"," assert 'NoFrameskip' in env.spec.id\n","\n"," # This wrapper holds the same action for frames and outputs\n"," # the maximal pixel value of 2 last frames (to handle blinking\n"," # in some envs)\n"," env = atari_wrappers.MaxAndSkipEnv(env, skip=4)\n","\n"," # This wrapper sends done=True when each life is lost\n"," # (not all the 5 lives that are givern by the game rules).\n"," # It should make easier for the agent to understand that losing is bad.\n"," env = atari_wrappers.EpisodicLifeEnv(env)\n","\n"," # This wrapper laucnhes the ball when an episode starts.\n"," # Without it the agent has to learn this action, too.\n"," # Actually it can but learning would take longer.\n"," env = atari_wrappers.FireResetEnv(env)\n","\n"," # This wrapper transforms rewards to {-1, 0, 1} according to their sign\n"," if clip_rewards:\n"," env = atari_wrappers.ClipRewardEnv(env)\n","\n"," # This wrapper is yours :)\n"," env = PreprocessAtariObs(env)\n"," return env"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Nscq92jKgGh3"},"source":["**Let's see if the game is still playable after applying the wrappers.**\n","At playing the EpisodicLifeEnv wrapper seems not to work but actually it does (because after when life finishes a new ball is dropped automatically - it means that FireResetEnv wrapper understands that a new episode began)."]},{"cell_type":"code","metadata":{"id":"vtyQpBzwgGh4"},"source":["# # does not work in Colab.\n","# # make keyboard interrupt to continue\n","\n","# from gym.utils.play import play\n","\n","# def make_play_env():\n","# env = gym.make(ENV_NAME)\n","# env = PrimaryAtariWrap(env)\n","# # in torch imgs have shape [c, h, w] instead of common [h, w, c]\n","# env = atari_wrappers.AntiTorchWrapper(env)\n","# return env\n","\n","# play(make_play_env(), zoom=10, fps=3)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"hv6VPgtqgGh5"},"source":["### Frame buffer\n","\n","Our agent can only process one observation at a time, so we have to make sure it has enough information to find the optimal actions. For instance, agent has to react to moving objects so he must be able to measure an object's velocity.\n","\n","To do so, we introduce a buffer, that stores 4 last images. This time everything is pre-implemented for you, not really by the staff of the course :)"]},{"cell_type":"code","metadata":{"id":"Qx-QxYhLgGh6"},"source":["from framebuffer import FrameBuffer\n","\n","def make_env(clip_rewards=True, seed=None):\n"," env = gym.make(ENV_NAME) # create raw env\n"," if seed is not None:\n"," env.seed(seed)\n"," env = PrimaryAtariWrap(env, clip_rewards)\n"," env = FrameBuffer(env, n_frames=4, dim_order='pytorch')\n"," return env\n","\n","env = make_env()\n","env.reset()\n","n_actions = env.action_space.n\n","state_shape = env.observation_space.shape"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"9kcv7ZmqgGh7"},"source":["for _ in range(12):\n"," obs, _, _, _ = env.step(env.action_space.sample())\n","\n","plt.figure(figsize=[12,10])\n","plt.title(\"Game image\")\n","plt.imshow(env.render(\"rgb_array\"))\n","plt.show()\n","\n","plt.figure(figsize=[15,15])\n","plt.title(\"Agent observation (4 frames top to bottom)\")\n","plt.imshow(utils.img_by_obs(obs, state_shape), cmap='gray')\n","plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"0ESiBgkigGh7"},"source":["## DQN as it is"]},{"cell_type":"markdown","metadata":{"id":"tNiepFoWgGh8"},"source":["### Building a network\n","\n","We now need to build a neural network, that can map images to state q-values. This network will be called on every agent's step so it is better not to be the resnet-152, unless you have an array of GPUs. Instead, you can use strided convolutions with a small number of features to save time and memory.\n","\n","You can build any architecture you want, but for reference, here's something, that will more or less work:"]},{"cell_type":"markdown","metadata":{"id":"5d1c2LxcgGh9"},"source":[""]},{"cell_type":"code","metadata":{"id":"ZmVDC3UOgGh9"},"source":["import torch\n","import torch.nn as nn\n","device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n","# those, who have a GPU but feel unfair to use it can uncomment:\n","# device = torch.device('cpu')\n","device"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"-giTXP4mgGh-"},"source":["def conv2d_size_out(size, kernel_size, stride):\n"," \"\"\"\n"," common use case:\n"," cur_layer_img_w = conv2d_size_out(cur_layer_img_w, kernel_size, stride)\n"," cur_layer_img_h = conv2d_size_out(cur_layer_img_h, kernel_size, stride)\n"," to understand the shape for dense layer's input\n"," \"\"\"\n"," return (size - (kernel_size - 1) - 1) // stride + 1\n"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"5amV9IiBgGh-"},"source":["class DQNAgent(nn.Module):\n"," def __init__(self, state_shape, n_actions, epsilon=0):\n","\n"," super().__init__()\n"," self.epsilon = epsilon\n"," self.n_actions = n_actions\n"," self.state_shape = state_shape\n","\n"," # Define your network body here. Please, make sure agent is fully contained here\n"," # nn.Flatten() can be useful\n"," \n"," \n","\n"," def forward(self, state_t):\n"," \"\"\"\n"," takes agent's observation (tensor), returns qvalues (tensor)\n"," :param state_t: a batch of 4-frame buffers, shape = [batch_size, 4, h, w]\n"," \"\"\"\n"," # Use your network to compute qvalues for a given state\n"," qvalues = \n","\n"," assert qvalues.requires_grad, \"qvalues must be a torch tensor with grad\"\n"," assert len(\n"," qvalues.shape) == 2 and qvalues.shape[0] == state_t.shape[0] and qvalues.shape[1] == n_actions\n","\n"," return qvalues\n","\n"," def get_qvalues(self, states):\n"," \"\"\"\n"," like forward, but works on numpy arrays, not tensors\n"," \"\"\"\n"," model_device = next(self.parameters()).device\n"," states = torch.tensor(states, device=model_device, dtype=torch.float)\n"," qvalues = self.forward(states)\n"," return qvalues.data.cpu().numpy()\n","\n"," def sample_actions(self, qvalues):\n"," \"\"\"pick actions given qvalues. Uses epsilon-greedy exploration strategy. \"\"\"\n"," epsilon = self.epsilon\n"," batch_size, n_actions = qvalues.shape\n","\n"," random_actions = np.random.choice(n_actions, size=batch_size)\n"," best_actions = qvalues.argmax(axis=-1)\n","\n"," should_explore = np.random.choice(\n"," [0, 1], batch_size, p=[1-epsilon, epsilon])\n"," return np.where(should_explore, random_actions, best_actions)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"G-IpGUemgGh_"},"source":["agent = DQNAgent(state_shape, n_actions, epsilon=0.5).to(device)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"KI3vzhgIgGh_"},"source":["Now let's try out our agent to see if the code raises any errors."]},{"cell_type":"code","metadata":{"id":"tvoEdYA3gGh_"},"source":["def evaluate(env, agent, n_games=1, greedy=False, t_max=10000):\n"," \"\"\" Plays n_games full games. If greedy, picks actions as argmax(qvalues). Returns the mean reward. \"\"\"\n"," rewards = []\n"," for _ in range(n_games):\n"," s = env.reset()\n"," reward = 0\n"," for _ in range(t_max):\n"," qvalues = agent.get_qvalues([s])\n"," action = qvalues.argmax(axis=-1)[0] if greedy else agent.sample_actions(qvalues)[0]\n"," s, r, done, _ = env.step(action)\n"," reward += r\n"," if done:\n"," break\n","\n"," rewards.append(reward)\n"," return np.mean(rewards)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ZYojdTpzgGiA"},"source":["evaluate(env, agent, n_games=1)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"vVLhLr5BgGiA"},"source":["### Experience replay\n","\n",""]},{"cell_type":"markdown","metadata":{"id":"IHwxsw2ugGiB"},"source":["#### The interface is fairly simple:\n","* `exp_replay.add(obs, act, rw, next_obs, done)` - saves (s,a,r,s',done) tuple into the buffer;\n","* `exp_replay.sample(batch_size)` - returns observations, actions, rewards, next_observations and is_done for `batch_size` random samples.\n","* `len(exp_replay)` - returns the number of elements stored in replay buffer."]},{"cell_type":"code","metadata":{"id":"d0Mw3GYygGiF"},"source":["from replay_buffer import ReplayBuffer\n","exp_replay = ReplayBuffer(10)\n","\n","for _ in range(30):\n"," exp_replay.add(env.reset(), env.action_space.sample(),\n"," 1.0, env.reset(), done=False)\n","\n","obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n"," 5)\n","\n","assert len(exp_replay) == 10, \"experience replay size should be 10 because that's what the maximum capacity is\""],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"BDRmvWBNgGiH"},"source":["def play_and_record(initial_state, agent, env, exp_replay, n_steps=1):\n"," \"\"\"\n"," Play the game for exactly n steps, record every (s,a,r,s', done) to replay buffer. \n"," Whenever game ends, add record with done=True and reset the game.\n"," It is guaranteed, that env has done=False when passed to this function.\n","\n"," PLEASE DO NOT RESET ENV UNLESS IT IS \"DONE\"\n","\n"," :returns: return sum of rewards over time and the state, in which the env stays\n"," \"\"\"\n"," s = initial_state\n"," sum_rewards = 0\n","\n"," # Play the game for n_steps as per instructions above\n"," \n","\n"," return sum_rewards, s"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"B0zanhnygGiH"},"source":["# testing your code.\n","exp_replay = ReplayBuffer(2000)\n","\n","state = env.reset()\n","play_and_record(state, agent, env, exp_replay, n_steps=1000)\n","\n","# if you're using your own experience replay buffer, some of those tests may need several corrections.\n","# just make sure you know, what your code does\n","assert len(exp_replay) == 1000, \"play_and_record should have added exactly 1000 steps, \"\\\n"," \"but instead added %i\" % len(exp_replay)\n","is_dones = list(zip(*exp_replay._storage))[-1]\n","\n","assert 0 < np.mean(is_dones) < 0.1, \"Please, make sure you restart the game whenever it is 'done' and record the is_done correctly into the buffer.\"\\\n"," \"Got %f is_done rate over %i steps. [If you think it's your tough luck, just re-run the test]\" % (\n"," np.mean(is_dones), len(exp_replay))\n","\n","for _ in range(100):\n"," obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n"," 10)\n"," assert obs_batch.shape == next_obs_batch.shape == (10,) + state_shape\n"," assert act_batch.shape == (\n"," 10,), \"actions batch should have shape (10,) but is instead %s\" % str(act_batch.shape)\n"," assert reward_batch.shape == (\n"," 10,), \"rewards batch should have shape (10,) but is instead %s\" % str(reward_batch.shape)\n"," assert is_done_batch.shape == (\n"," 10,), \"is_done batch should have shape (10,) but is instead %s\" % str(is_done_batch.shape)\n"," assert [int(i) in (0, 1)\n"," for i in is_dones], \"is_done should be strictly True or False\"\n"," assert [\n"," 0 <= a < n_actions for a in act_batch], \"actions should be within [0, n_actions)\"\n","\n","print(\"Well done!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"nKsbZDeQgGiH"},"source":["### Target networks\n","\n","We also employ the so called \"target network\" - a copy of neural network weights to be used for reference Q-values:\n","\n","The network itself is an exact copy of agent network, but its parameters are not trained. Instead, they are moved here from agent's actual network from time to time.\n","\n","$$ Q_{reference}(s,a) = r + \\gamma \\cdot \\max _{a'} Q_{target}(s',a') $$\n","\n",""]},{"cell_type":"code","metadata":{"id":"O7BRmZUBgGiI"},"source":["target_network = DQNAgent(agent.state_shape, agent.n_actions, epsilon=0.5).to(device)\n","# This is how you can load the weights from agent into target network\n","target_network.load_state_dict(agent.state_dict())"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"uuw73E0BgGiI"},"source":["### Learning with... Q-learning\n","Here we write a function similar to `agent.update` from tabular q-learning."]},{"cell_type":"markdown","metadata":{"id":"9718KlpRgGiI"},"source":["Compute Q-learning TD error:\n","\n","$$ L = { 1 \\over N} \\sum_i [ Q_{\\theta}(s,a) - Q_{reference}(s,a) ] ^2 $$\n","\n","With Q-reference defined as\n","\n","$$ Q_{reference}(s,a) = r(s,a) + \\gamma \\cdot max_{a'} Q_{target}(s', a') $$\n","\n","Where:\n","* $Q_{target}(s',a')$ denotes q-value of next state and next action predicted by __target_network__;\n","* $s, a, r, s'$ are current state, action, reward and next state respectively;\n","* $\\gamma$ is a discount factor defined two cells above.\n","\n","\n","__Note 1:__ there's an example input below. Feel free to experiment with it before you write the function.\n","\n","__Note 2:__ compute_td_loss is a source of 99% of bugs in this homework. If reward doesn't improve, it often helps to go through it line by line [with a rubber duck](https://rubberduckdebugging.com/)."]},{"cell_type":"code","metadata":{"id":"2nm5qqZvgGiI"},"source":["def compute_td_loss(states, actions, rewards, next_states, is_done,\n"," agent, target_network,\n"," gamma=0.99,\n"," check_shapes=False,\n"," device=device):\n"," \"\"\" Compute td loss using torch operations only. Use the formula above. \"\"\"\n"," states = torch.tensor(states, device=device, dtype=torch.float) # shape: [batch_size, *state_shape]\n","\n"," # for some torch reason should not make actions a tensor\n"," actions = torch.tensor(actions, device=device, dtype=torch.long) # shape: [batch_size]\n"," rewards = torch.tensor(rewards, device=device, dtype=torch.float) # shape: [batch_size]\n"," # shape: [batch_size, *state_shape]\n"," next_states = torch.tensor(next_states, device=device, dtype=torch.float)\n"," is_done = torch.tensor(\n"," is_done.astype('float32'),\n"," device=device,\n"," dtype=torch.float\n"," ) # shape: [batch_size]\n"," is_not_done = 1 - is_done\n","\n"," # get q-values for all actions in current states\n"," predicted_qvalues = agent(states)\n","\n"," # compute q-values for all actions in next states\n"," predicted_next_qvalues = target_network(next_states)\n"," \n"," # select q-values for chosen actions\n"," predicted_qvalues_for_actions = predicted_qvalues[range(\n"," len(actions)), actions]\n","\n"," # compute V*(next_states) using predicted next q-values\n"," next_state_values = \n","\n"," assert next_state_values.dim(\n"," ) == 1 and next_state_values.shape[0] == states.shape[0], \"must predict one value per state\"\n","\n"," # compute \"target q-values\" for loss - that is what's inside the square parentheses in the formula above.\n"," # at the last state use the simplified formula: Q(s,a) = r(s,a) since s' doesn't exist\n"," # you can multiply next state values by is_not_done to achieve this.\n"," target_qvalues_for_actions = \n","\n"," # mean squared error loss to minimize\n"," loss = torch.mean((predicted_qvalues_for_actions -\n"," target_qvalues_for_actions.detach()) ** 2)\n","\n"," if check_shapes:\n"," assert predicted_next_qvalues.data.dim(\n"," ) == 2, \"make sure you predicted q-values for all actions in next state\"\n"," assert next_state_values.data.dim(\n"," ) == 1, \"make sure you computed V(s') as the maximum over just the actions axis and not all axes\"\n"," assert target_qvalues_for_actions.data.dim(\n"," ) == 1, \"there's something wrong with target q-values, they must be a vector\"\n","\n"," return loss"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"xwR5NPYwgGiJ"},"source":["Sanity checks"]},{"cell_type":"code","metadata":{"id":"oEa_v166gGiJ"},"source":["obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n"," 10)\n","\n","loss = compute_td_loss(obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch,\n"," agent, target_network,\n"," gamma=0.99, check_shapes=True)\n","loss.backward()\n","\n","assert loss.requires_grad and tuple(loss.data.size()) == (\n"," ), \"you must return scalar loss - mean over batch\"\n","assert np.any(next(agent.parameters()).grad.data.cpu().numpy() !=\n"," 0), \"loss must be differentiable w.r.t. network weights\"\n","assert np.all(next(target_network.parameters()).grad is None), \"target network should not have grads\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"bo55W0h2gGiJ"},"source":["## Main loop\n","\n","\n","It's time to put everything together and see if it learns something."]},{"cell_type":"code","metadata":{"id":"Wag3R7TqgGiK"},"source":["from tqdm import trange\n","from IPython.display import clear_output\n","import matplotlib.pyplot as plt"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"2zqr0XOCgGiK"},"source":["seed = \n","random.seed(seed)\n","np.random.seed(seed)\n","torch.manual_seed(seed)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Oy9NjDZrgGiK"},"source":["env = make_env(seed)\n","state_shape = env.observation_space.shape\n","n_actions = env.action_space.n\n","state = env.reset()\n","\n","agent = DQNAgent(state_shape, n_actions, epsilon=1).to(device)\n","target_network = DQNAgent(state_shape, n_actions).to(device)\n","target_network.load_state_dict(agent.state_dict())"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ehAUylGwgGiK"},"source":["Buffer of size $10^4$ fits into 5 Gb RAM.\n","\n","Larger sizes ($10^5$ and $10^6$ are common) can be used. It can improve the learning, but $10^4$ is quiet enough. $10^2$ will probably fail learning."]},{"cell_type":"code","metadata":{"id":"pQzM-hW9gGiL"},"source":["exp_replay = ReplayBuffer(10**4)\n","for i in range(100):\n"," if not utils.is_enough_ram(min_available_gb=0.1):\n"," print(\"\"\"\n"," Less than 100 Mb RAM available. \n"," Make sure the buffer size in not too large.\n"," Also check, whether other processes consume RAM heavily.\n"," \"\"\"\n"," )\n"," break\n"," play_and_record(state, agent, env, exp_replay, n_steps=10**2)\n"," if len(exp_replay) == 10**4:\n"," break\n","print(len(exp_replay))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"oC5eGLUSgGiL"},"source":["timesteps_per_epoch = 1\n","batch_size = 16\n","total_steps = 3 * 10**6\n","decay_steps = 10**6\n","\n","opt = torch.optim.Adam(agent.parameters(), lr=1e-4)\n","\n","init_epsilon = 1\n","final_epsilon = 0.1\n","\n","loss_freq = 50\n","refresh_target_network_freq = 5000\n","eval_freq = 5000\n","\n","max_grad_norm = 50\n","\n","n_lives = 5"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"AraYlYDJgGiM"},"source":["mean_rw_history = []\n","td_loss_history = []\n","grad_norm_history = []\n","initial_state_v_history = []\n","step = 0"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"5DGyLVGJgGiM"},"source":["state = env.reset()\n","for step in trange(step, total_steps + 1):\n"," if not utils.is_enough_ram():\n"," print('less that 100 Mb RAM available, freezing')\n"," print('make sure, that everything is ok and make KeyboardInterrupt to continue')\n"," try:\n"," while True:\n"," pass\n"," except KeyboardInterrupt:\n"," pass\n","\n"," agent.epsilon = utils.linear_decay(init_epsilon, final_epsilon, step, decay_steps)\n","\n"," # play\n"," _, state = play_and_record(state, agent, env, exp_replay, timesteps_per_epoch)\n","\n"," # train\n"," \n","\n"," loss = \n","\n"," loss.backward()\n"," grad_norm = nn.utils.clip_grad_norm_(agent.parameters(), max_grad_norm)\n"," opt.step()\n"," opt.zero_grad()\n","\n"," if step % loss_freq == 0:\n"," td_loss_history.append(loss.data.cpu().item())\n"," grad_norm_history.append(grad_norm)\n","\n"," if step % refresh_target_network_freq == 0:\n"," # Load agent weights into target_network\n"," \n","\n"," if step % eval_freq == 0:\n"," mean_rw_history.append(evaluate(\n"," make_env(clip_rewards=True, seed=step), agent, n_games=3 * n_lives, greedy=True)\n"," )\n"," initial_state_q_values = agent.get_qvalues(\n"," [make_env(seed=step).reset()]\n"," )\n"," initial_state_v_history.append(np.max(initial_state_q_values))\n","\n"," clear_output(True)\n"," print(\"buffer size = %i, epsilon = %.5f\" %\n"," (len(exp_replay), agent.epsilon))\n","\n"," plt.figure(figsize=[16, 9])\n","\n"," plt.subplot(2, 2, 1)\n"," plt.title(\"Mean reward per life\")\n"," plt.plot(mean_rw_history)\n"," plt.grid()\n","\n"," assert not np.isnan(td_loss_history[-1])\n"," plt.subplot(2, 2, 2)\n"," plt.title(\"TD loss history (smoothened)\")\n"," plt.plot(utils.smoothen(td_loss_history))\n"," plt.grid()\n","\n"," plt.subplot(2, 2, 3)\n"," plt.title(\"Initial state V\")\n"," plt.plot(initial_state_v_history)\n"," plt.grid()\n","\n"," plt.subplot(2, 2, 4)\n"," plt.title(\"Grad norm history (smoothened)\")\n"," plt.plot(utils.smoothen(grad_norm_history))\n"," plt.grid()\n","\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"LEMDs-F-gGiM"},"source":["Agent is evaluated for 1 life, not for the whole episode of 5 lives. Rewards in evaluation are also truncated. Because this is the environment the agent is learning in and this way the mean rewards per life can be compared to initial state value.\n","\n","**The goal is to get 10 points in the real env**. So 3 or more points in the preprocessed one will probably be enough. You can interrupt the learning then."]},{"cell_type":"markdown","metadata":{"id":"ejLEk8ikgGiN"},"source":["Final scoring is done on a whole episode with all 5 lives."]},{"cell_type":"code","metadata":{"id":"R8DcuWKogGiN"},"source":["final_score = evaluate(\n"," make_env(clip_rewards=False, seed=9),\n"," agent, n_games=30, greedy=True, t_max=10 * 1000\n",") * n_lives\n","print('final score:', final_score)\n","assert final_score >= 10, 'not as cool as DQN can'\n","print('Cool!')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"FIM9n3cIgGiN"},"source":["## How to interpret plots:\n","\n","This is not the supervised learning so don't expect anything to improve monotonously. \n","* **TD loss** is the MSE between agent's current Q-values and target Q-values. It may slowly increase or decrease, it's ok. The \"not ok\" behavior includes going NaN or staying at the exact zero before agent has perfect the performance.\n","* **grad norm** just shows the intensivity of training. Not ok is growing to values of about 100 (or maybe even 50), though it depends on the network architecture.\n","* **mean reward** is the expected sum of r(s,a) agent gets over the full game session. It will oscillate, but on average it should get higher over time (after a few thousand of iterations...). \n"," * In basic q-learning implementation it takes about 40k steps to \"warm up\" agent before it starts to get better.\n","* **Initial state V** is the expected discounted reward for an episode in the oppinion of the agent. It should behave more smoothly than **mean reward**. It should get higher over time, but sometimes can experience drawdowns, because of the agent's overestimates.\n","* **buffer size** - this one is simple. It should go up and cap at max size.\n","* **epsilon** - agent's willingness to explore. If you see, that agent's already at 0.01 epsilon before its average reward is above 0 - it means, that you need to increase the epsilon. Set it back to 0.2 - 0.5 and decrease the pace, at which it goes down.\n","* Smoothing of plots is done with a gaussian kernel.\n","\n","At first, your agent will lose quickly. Then it will learn to suck less and at least hit the ball a few times before it loses. Finally, it will learn to actually score some points.\n","\n","**Training will take time.** A lot of it, actually. Probably you will not see any improvment during first **150k** time steps (note, that by default in this notebook agent is evaluated every 5000 time steps).\n","\n","But hey, long training time isn't _that_ bad:\n",""]},{"cell_type":"markdown","metadata":{"id":"qO1wiCCngGiO"},"source":["## About hyperparameters:\n","\n","The task has something in common with the supervised learning: loss is optimized through the buffer (instead of Train dataset). But the distribution of states and actions in the buffer **is not stationary** and depends on the policy, that generated it. It can even happen, that the mean TD error across the buffer is very low, but the performance is extremely poor (imagine the agent collects data to the buffer and always manages to avoid the ball).\n","\n","* Total timesteps and training time: It seems to be huge, but actually it is normal for RL.\n","\n","* $\\epsilon$ decay shedule was taken from the original paper and is traditional for epsilon-greedy policies. At the beginning of the training the agent's greedy policy is poor so many random actions should be made.\n","\n","* Optimizer: In the original paper RMSProp was used (they did not have Adam in 2013) and it can work as good as Adam. For us Adam was a default and it worked.\n","\n","* lr: $10^{-3}$ would probably be too huge\n","\n","* batch size: This one can be very important: if it is too small the agent can fail to learn. Huge batch takes more time to process. If batch of size 8 can not be processed on the hardware you use, take 2 (or even 4) batches of size 4, divide the loss on them by 2 (or 4) and make an optimization step after both backward() calls in torch.\n","\n","* target network update frequency: has something in common with the learning rate. Too frequent updates can lead to divergence. Too rare can lead to slow learning. For millions of total timesteps thousands of inner steps seem ok. One iteration of target network updating is an iteration of (this time approximate) $\\gamma$-compression, that stands behind Q-learning. The more inner steps it makes the more accurate is the compression.\n","* max_grad_norm - just huge enough. In torch clip_grad_norm also evaluates the norm before clipping and it can be convenient for logging."]},{"cell_type":"markdown","metadata":{"id":"GkiBGeOAgGiQ"},"source":["### Video"]},{"cell_type":"code","metadata":{"id":"nuqN7g88gGiQ"},"source":["# Record sessions\n","\n","import gym.wrappers\n","\n","with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n"," sessions = [evaluate(env_monitor, agent, n_games=n_lives, greedy=True) for _ in range(10)]"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"TsxIwpT4gGiR"},"source":["# Show video. This may not work in some setups. If it doesn't\n","# work for you, you can download the videos and view them locally.\n","\n","from pathlib import Path\n","from IPython.display import HTML\n","\n","video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n","\n","HTML(\"\"\"\n","\n","\"\"\".format(video_names[-1])) # You can also try other indices"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"KuHR0WnFgGiR"},"source":["## Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"LAo10sXqgGiU"},"source":["from submit import submit_breakout\n","env = make_env()\n","submit_breakout(agent, env, evaluate, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"d3kjL0EWgGiV"},"source":["```\n","```\n","```\n","```\n","```\n","```\n","\n","\n","\n","\n","\n","\n","## Let's have a closer look at this.\n","\n","If average episode score is below 200 using all 5 lives, then probably DQN has not converged fully. But anyway let's make a more complete record of an episode."]},{"cell_type":"code","metadata":{"id":"txUTyivxgGiV"},"source":["eval_env = make_env(clip_rewards=False)\n","record = utils.play_and_log_episode(eval_env, agent)\n","print('total reward for life:', np.sum(record['rewards']))\n","for key in record:\n"," print(key)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ITK4axr9gGiV"},"source":["fig = plt.figure(figsize=(5, 5))\n","ax = fig.add_subplot(1, 1, 1)\n","\n","ax.scatter(record['v_mc'], record['v_agent'])\n","ax.plot(sorted(record['v_mc']), sorted(record['v_mc']),\n"," 'black', linestyle='--', label='x=y')\n","\n","ax.grid()\n","ax.legend()\n","ax.set_title('State Value Estimates')\n","ax.set_xlabel('Monte-Carlo')\n","ax.set_ylabel('Agent')\n","\n","plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"_mbH8w20gGiW"},"source":["$\\hat V_{Monte-Carlo}(s_t) = \\sum_{\\tau=0}^{episode~end} \\gamma^{\\tau-t}r_t$"]},{"cell_type":"markdown","metadata":{"id":"qNlIlPRAgGiW"},"source":["Is there a big bias? It's ok, anyway it works."]},{"cell_type":"markdown","metadata":{"id":"cTB6Ik93gGiW"},"source":["## More\n","\n","If you want to play with DQN a bit more, here's a list of things you can try with it:\n","\n","### Easy:\n","* Implementing __double q-learning__ shouldn't be a problem, if you already have target networks in place.\n"," * You will probably need `tf.argmax` to select best actions\n"," * Here's an original [article](https://arxiv.org/abs/1509.06461)\n","\n","* __Dueling__ architecture is also quite straightforward, if you have standard DQN.\n"," * You will need to change network architecture, namely the q-values layer\n"," * It must now contain two heads: V(s) and A(s,a), both dense layers\n"," * You should then add them up via elemwise sum layer.\n"," * Here's an [article](https://arxiv.org/pdf/1511.06581.pdf)"]},{"cell_type":"markdown","metadata":{"id":"okmpBFKGgGiW"},"source":["### Hard: Prioritized experience replay\n","\n","In this section, you're invited to implement prioritized experience replay:\n","\n","* You will probably need to provide a custom data structure;\n","* Once pool.update is called, collect the pool.experience_replay.observations, actions, rewards and is_alive and store them in your data structure;\n","* You can now sample such transitions in proportion to the error (see [article](https://arxiv.org/abs/1511.05952)) for training.\n","\n","It's probably more convenient to explicitly declare inputs for \"sample observations\", \"sample actions\" and so on to plug them into q-learning.\n","\n","Prioritized (and even normal) experience replay should greatly reduce an amount of game sessions you need to play in order to achieve good performance. \n","\n","While its effect on runtime is limited for atari, more complicated envs (further in the course) will certainly benefit for it.\n","\n","There is even more out there - see this [overview article](https://arxiv.org/abs/1710.02298)."]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Deep Q-Network implementation.\n",
+ "\n",
+ "This homework shamelessly demands you to implement a DQN - an approximate q-learning algorithm with experience replay and target networks - and see if it works better this way.\n",
+ "\n",
+ "Original paper:\n",
+ "https://arxiv.org/pdf/1312.5602.pdf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Starting virtual X frame buffer: Xvfb.\n"
+ ]
+ }
+ ],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ " \n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/framebuffer.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/replay_buffer.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/atari_wrappers.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/utils.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Frameworks__ - we'll accept this homework in any deep learning framework. This particular notebook was designed for pytoch, but you find it easy to adapt it to almost any python-based deep learning framework."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import random\n",
+ "import numpy as np\n",
+ "import torch\n",
+ "import utils"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Let's play some old videogames\n",
+ "\n",
+ "\n",
+ "This time we're going to apply the approximate q-learning to an Atari game called Breakout. It's not the hardest thing out there, but it's definitely way more complex, than anything we tried before.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ENV_NAME = \"BreakoutNoFrameskip-v4\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's see what observations look like."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAA6UAAAH3CAYAAABD+PmTAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjMsIGh0\ndHA6Ly9tYXRwbG90bGliLm9yZy+AADFEAAAgAElEQVR4nO3dbazkd3nf/8/1twMPNlQ2N7Us29SG\nOqmgah1YuVYL/GlpyGJFMfQBtVUFJ0VdkEBK5FSVCVJBlSK1aTASaupoEdaaKjHQOgSrclwcNwqq\nUhPWxDHmxtgmRni12AVXQJYIYvvbB+e3MFl295w9c/Od+Z7XSxqdOb+ZOXNZ+/bRXmfm/LZaawEA\nAIAe/r/eAwAAALB3WUoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG6WtpRW1YGqeqiqHqmq\nG5f1PNCDvhmdxhmdxhmdxtkktYx/p7Sqzkny5SQ/neTxJJ9Jcl1r7QsLfzJYMX0zOo0zOo0zOo2z\naZb1SumVSR5prX2ltfb9JB9Jcs2SngtWTd+MTuOMTuOMTuNslHOX9HUvSvK1mc8fT/IPZu9QVQeT\nHJw+feWS5oBZ32itvWgBX2fbvhON04XGGd3KGtc3HSyq70TjrKfTNr6spXRbrbVDSQ4lSVUt/j3E\n8KO+uson0zgdaJzRraxxfdOB7+GM7rSNL+vtu0eTXDLz+cXTMRiBvhmdxhmdxhmdxtkoy1pKP5Pk\n8qq6rKqek+TaJHcs6blg1fTN6DTO6DTO6DTORlnK23dba09X1TuT/I8k5yS5pbX2+WU816LddNNN\nO77vDTfcsOvHnvz4eR47r57PfbKTZ1nmc+3WJvedaHzVz30yjS+fxlf73CfT+HLpe7XPfbJN6DvR\n+G4er/EtvRpf2u+UttbuTHLnsr4+9KRvRqdxRqdxRqdxNkm3Ex1tgkX+9OVsHz/vc89jXX/qx+Jp\nnNFpnJHpm9FpfO9Y1u+UAgAAwLa8UsqP2O4nQXvxpzeMReOMTuOMTN+Mbi827pVSAAAAuvFKKdv+\ntGWV76GHZdA4o9M4I9M3o9O4V0oBAADoyCulZzDvTyXmefwqfyKyF376wqlpnNFpnJHpm9FpfO+o\n1lrvGVJV/YdgL7ivtba/xxNrnBXROKPr0ri+WRHfwxndaRv39l0AAAC6WYu371588cVDntqY9dKz\nMY2zChpndL0a0zer4Hs4oztTY14pBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC62fVSWlWX\nVNUfVtUXqurzVfVL0/H3VtXRqrp/uly9uHFhdTTO6DTOyPTN6DTOSOb5J2GeTvIrrbXPVtXzktxX\nVXdPt72/tfYb848HXWmc0Wmckemb0WmcYex6KW2tHUtybLr+nar6YpKLFjUY9KZxRqdxRqZvRqdx\nRrKQ3ymtqkuT/FSST0+H3llVD1TVLVV1/mkec7CqjlTVkePHjy9iDFgajTM6jTMyfTM6jbPp5l5K\nq+rHk9ye5Jdba99OcnOSlya5Ils/vXnfqR7XWjvUWtvfWtu/b9++eceApdE4o9M4I9M3o9M4I5hr\nKa2qH8vW/wS/3Vr73SRprT3RWnumtfZskg8muXL+MaEPjTM6jTMyfTM6jTOKec6+W0k+lOSLrbWb\nZo5fOHO3NyV5cPfjQT8aZ3QaZ2T6ZnQaZyTznH33HyX5+SSfq6r7p2O/muS6qroiSUvyWJK3zTUh\n9KNxRqdxRqZvRqdxhjHP2Xf/V5I6xU137n4cWB8aZ3QaZ2T6ZnQaZyTzvFK6MjfccEPvEdgAN910\n0/Z3WlMaZyc0zug2tXF9sxOb2neicXZmnsYX8k/CAAAAwG5YSgEAAOjGUgoAAEA3llIAAAC6sZQC\nAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUU\nAACAbs6d9wtU1WNJvpPkmSRPt9b2V9Xzk3w0yaVJHkvy5tba/533uWDV9M3oNM7oNM7I9M0oFvVK\n6T9urV3RWts/fX5jkntaa5cnuWf6HDaVvhmdxhmdxhmZvtl4y3r77jVJbp2u35rkjUt6HuhB34xO\n44xO44xM32ycRSylLcknq+q+qjo4HbugtXZsuv71JBec/KCqOlhVR6rqyPHjxxcwBizFrvpONM7G\n0Dij8/cURuZ7OEOY+3dKk7yqtXa0qv5mkrur6kuzN7bWWlW1kx/UWjuU5FCSXHLJJT9yO6yJXfU9\n3aZxNoHGGZ2/pzAy38MZwtyvlLbWjk4fn0zy8SRXJnmiqi5Mkunjk/M+D/Sgb0ancUancUamb0Yx\n11JaVfuq6nknrid5fZIHk9yR5Prpbtcn+cQ8zwM96JvRaZzRaZyR6ZuRzPv23QuSfLyqTnyt32mt\n3VVVn0nysap6a5KvJnnznM8DPeib0Wmc0WmckembYcy1lLbWvpLk75/i+DeTvG6erw296ZvRaZzR\naZyR6ZuRLOJER0t374EDvUdgA/xx7wHmoHF2QuOMblMb1zc7sal9JxpnZ+ZpfFn/TikAAABsy1IK\nAABAN5ZSAAAAurGUAgAA0I2lFAAAgG424uy7z/7tb/ceAZZK44xO44xM34xO4yybV0oBAADoxlIK\nAABAN5ZSAAAAurGUAgAA0I2lFAAAgG424uy7T/2N7/YeAZZK44xO44xM34xO4yybV0oBAADoxlIK\nAABAN7t++25V/WSSj84cekmSf5vkvCT/Ksn/mY7/amvtzl1PCJ1onNFpnNFpnJHpm5HseiltrT2U\n5IokqapzkhxN8vEkv5jk/a2131jIhNCJxhmdxhmdxhmZvhnJok509Lokj7bWvlpVC/qSP/TU3/n+\nwr8mA/rGUr+6xulP44xuQxvXNzuyoX0nGmeH5mh8Ub9Tem2S22Y+f2dVPVBVt1TV+Qt6DuhJ44xO\n44xO44xM32y0uZfSqnpOkp9L8l+nQzcneWm23k5wLMn7TvO4g1V1pKqOHD9+fN4xYGk0zug0zuh2\n07i+2RS+hzOCRbxS+oYkn22tPZEkrbUnWmvPtNaeTfLBJFee6kGttUOttf2ttf379u1bwBiwNBpn\ndBpndGfduL7ZIL6Hs/EWsZRel5m3C1TVhTO3vSnJgwt4DuhJ44xO44xO44xM32y8uU50VFX7kvx0\nkrfNHP71qroiSUvy2Em3wUbROKPTOKPTOCPTN6OYayltrR1P8oKTjv38XBOdwu88++JFf0kG9Pol\nfE2Ns040zug2tXF9sxOb2neicXZmnsYXdfZdAAAAOGuWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0\nM9fZd1fl+x95b+8R2ASv/+PeE+yaxtkRjTO6DW1c3+zIhvadaJwdmqNxr5QCAADQjaUUAACAbiyl\nAAAAdGMpBQAAoBtLKQAAAN1sxNl3/+ddV/UegQ3ws6+/qfcIu6ZxdkLjjG5TG9c3O7GpfScaZ2fm\nadwrpQAAAHRjKQUAAKAbSykAAADd7GgprapbqurJqnpw5tjzq+ruqnp4+nj+dLyq6gNV9UhVPVBV\nr1jW8LAI+mZ0Gmd0Gmdk+mYv2OkrpYeTHDjp2I1J7mmtXZ7knunzJHlDksuny8EkN88/JizV4eib\nsR2Oxhnb4WiccR2OvhncjpbS1tqnkjx10uFrktw6Xb81yRtnjn+4bbk3yXlVdeEihoVl0Dej0zij\n0zgj0zd7wTy/U3pBa+3YdP3rSS6Yrl+U5Gsz93t8OgabRN+MTuOMTuOMTN8MZSEnOmqttSTtbB5T\nVQer6khVHTl+/PgixoCl2E3ficbZHBpndP6ewsh8D2cE8yylT5x4O8D08cnp+NEkl8zc7+Lp2F/T\nWjvUWtvfWtu/b9++OcaApZir70TjrD2NMzp/T2FkvoczlHmW0juSXD9dvz7JJ2aOv2U6+9dVSb41\n8/YC2BT6ZnQaZ3QaZ2T6Zijn7uROVXVbktcmeWFVPZ7kPUn+fZKPVdVbk3w1yZunu9+Z5OokjyT5\nbpJfXPDMsFD6ZnQaZ3QaZ2T6Zi/Y0VLaWrvuNDe97hT3bUneMc9QsEr6ZnQaZ3QaZ2T6Zi9YyImO\nAAAAYDcspQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG4s\npQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAutl2Ka2qW6rqyap6cObYf6yqL1XV\nA1X18ao6bzp+aVX9ZVXdP11+a5nDwyJofL3ce+BA7j1woPcYQ9E4I9M3o9M4e8FOXik9nOTkvyHe\nneTvttb+XpIvJ3nXzG2PttaumC5vX8yYsFSHo3HGdjgaXwt+6LIUh6NvxnY4Gmdw2y6lrbVPJXnq\npGOfbK09PX16b5KLlzAbrITGGZ3GGZm+14MfuCyPxtkLFvE7pf8yye/PfH5ZVf1pVf1RVb16AV8f\netM4o9M4I9M3o9P4kvmhy/KdO8+Dq+rdSZ5O8tvToWNJXtxa+2ZVvTLJ71XVy1tr3z7FYw8mOZgk\n559//jxjwNJofPWuuuuu3iPsKRpnZPpmdBpnFLt+pbSqfiHJzyb5F621liStte+11r45Xb8vyaNJ\nfuJUj2+tHWqt7W+t7d+3b99ux4Cl0Tij0/jqXXXXXX7wsiL6ZnQaZyS7eqW0qg4k+TdJ/v/W2ndn\njr8oyVOttWeq6iVJLk/ylYVMCiukcUancUam79Xzw5bV0jij2XYprarbkrw2yQur6vEk78nWGb6e\nm+TuqkqSe6eze70myb+rqr9K8mySt7fWnjrlF4Y1oXFGp3FGpm9Gp/H+/NBl+bZdSltr153i8IdO\nc9/bk9w+71CwShpndBpnZPpmdBpnL1jE2XcBAABgVyylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjG\nUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3\nllIAAAC6sZQCAADQzbZLaVXdUlVPVtWDM8feW1VHq+r+6XL1zG3vqqpHquqhqvqZZQ0Oi6JxRqdx\nRqdxRqZv9oKdvFJ6OMmBUxx/f2vtiulyZ5JU1cuSXJvk5dNj/nNVnbOoYWFJDkfjjO1wNM7YDkfj\njOtw9M3gtl1KW2ufSvLUDr/eNUk+0lr7Xmvtz5M8kuTKOeaDpdM4o9M4o9M4I9M3e8E8v1P6zqp6\nYHpLwfnTsYuSfG3mPo9Px35EVR2sqiNVdeT48eNzjAFLo3FGp3FGt+vG9c0G8D2cYex2Kb05yUuT\nXJHkWJL3ne0XaK0daq3tb63t37dv3y7HgKXROKPTOKObq3F9s+Z8D2cou1pKW2tPtNaeaa09m+SD\n+eHbAo4muWTmrhdPx2CjaJzRaZzRaZyR6ZvR7GopraoLZz59U5ITZwO7I8m1VfXcqrosyeVJ/mS+\nEWH1NM7oNM7oNM7I9M1ozt3uDlV1W5LXJnlhVT2e5D1JXltVVyRpSR5L8rYkaa19vqo+luQLSZ5O\n8o7W2jPLGR0WQ+OMTuOMTuOMTN/sBdsupa21605x+ENnuP+vJfm1eYaCVdI4o9M4o9M4I9M3e8E8\nZ98FAACAuVhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0YykFAACgG0spAAAA\n3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0s+1SWlW3VNWTVfXgzLGPVtX9\n0+Wxqrp/On5pVf3lzG2/tczhYRE0zug0zsj0zeg0zl5w7g7uczjJf0ry4RMHWmv//MT1qnpfkm/N\n3P/R1toVixoQVuBwNM7YDkfjjOtw9M3YDkfjDG7bpbS19qmquvRUt1VVJXlzkn+y2LFgdTTO6DTO\nyPTN6DTOXjDv75S+OskTrbWHZ45dVlV/WlV/VFWvPt0Dq+pgVR2pqiPHjx+fcwxYGo0zOo0zMn0z\nOo0zhJ28ffdMrkty28znx5K8uLX2zap6ZZLfq6qXt9a+ffIDW2uHkhxKkksuuaTNOQcsi8YZncYZ\nmb4ZncYZwq5fKa2qc5P8syQfPXGstfa91to3p+v3JXk0yU/MOyT0oHFGp3FGpm9Gp3FGMs/bd/9p\nki+11h4/caCqXlRV50zXX5Lk8iRfmW9E6EbjjE7jjEzfjE7jDGMn/yTMbUn+d5KfrKrHq+qt003X\n5q+/XSBJXpPkgem01P8tydtba08tcmBYNI0zOo0zMn0zOo2zF+zk7LvXneb4L5zi2O1Jbp9/LFgd\njTM6jTMyfTM6jbMXzHv2XQAAANg1SykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAA\ngG62/XdKV+Fb5zyb/37eX/QeY0+698CBuR5/1V13LWiS+f3DT36y9winpfF+NL4aGu9H48un7370\nvRoa70fjW7xSCgAAQDeWUgAAALqxlAIAANDNWvxOKf2s0/vQYRk0zug0zsj0zeg0vsVSyjD8T83o\nNM7oNM7I9M3o5mm8WmsLHGWXQ1T1H4K94L7W2v4eT6xxVkTjjK5L4/pmRXwPZ3SnbdzvlAIAANDN\ntktpVV1SVX9YVV+oqs9X1S9Nx59fVXdX1cPTx/On41VVH6iqR6rqgap6xbL/I2AeGmd0Gmdk+mZ0\nGmcv2MkrpU8n+ZXW2suSXJXkHVX1siQ3JrmntXZ5knumz5PkDUkuny4Hk9y88KlhsTTO6DTOyPTN\n6DTO8LZdSltrx1prn52ufyfJF5NclOSaJLdOd7s1yRun69ck+XDbcm+S86rqwoVPDguicUancUam\nb0ancfaCs/qd0qq6NMlPJfl0kgtaa8emm76e5ILp+kVJvjbzsMenYyd/rYNVdaSqjpzlzLA0Gmd0\nGmdk+mZ0GmdUO15Kq+rHk9ye5Jdba9+eva1tncL3rM7a1Vo71Frb3+ssY3AyjTM6jTMyfTM6jTOy\nHS2lVfVj2fqf4Ldba787HX7ixFsBpo9PTsePJrlk5uEXT8dgbWmc0Wmckemb0Wmc0e3k7LuV5ENJ\nvthau2nmpjuSXD9dvz7JJ2aOv2U689dVSb4189YCWDsaZ3QaZ2T6ZnQaZ09orZ3xkuRV2Xo7wANJ\n7p8uVyd5QbbO9PVwkj9I8vzp/pXkN5M8muRzSfbv4Dmai8sKLkc07jL4ReMuo19+pPHo22Wci+/h\nLqNfTtl4ay01hdhVVfUfgr3gvl6/N6FxVkTjjK5L4/pmRXwPZ3Snbfyszr4LAAAAi2QpBQAAoBtL\nKQAAAN2c23uAyTeSHJ8+bqoXxvw97WT+v7WKQU5D4/3thfl7Nv4XSR7q+Pzz2gt9rLt1btz38P72\nwvz+njKfvdDIOpur8bU40VGSVNWRTf7He83f1ybMvwkznon5+1r3+dd9vu2Yv791/29Y9/m2Y/6+\nNmH+TZjxTMzf17zze/suAAAA3VhKAQAA6GadltJDvQeYk/n72oT5N2HGMzF/X+s+/7rPtx3z97fu\n/w3rPt92zN/XJsy/CTOeifn7mmv+tfmdUgAAAPaedXqlFAAAgD3GUgoAAEA33ZfSqjpQVQ9V1SNV\ndWPveXaiqh6rqs9V1f1VdWQ69vyquruqHp4+nt97zllVdUtVPVlVD84cO+XMteUD05/JA1X1in6T\n/2DWU83/3qo6Ov053F9VV8/c9q5p/oeq6mf6TP2DWTS+ZPruS+PLp/F+NrHvROOrpvHV2rS+E41v\n+wSttW6XJOckeTTJS5I8J8mfJXlZz5l2OPdjSV540rFfT3LjdP3GJP+h95wnzfeaJK9I8uB2Mye5\nOsnvJ6kkVyX59JrO/94k//oU933Z1NJzk1w2NXZOp7k13q8Pfa9mdo33a0Tjy597I/ueZtd4//k1\nvry5N6rvMzSi8enS+5XSK5M80lr7Smvt+0k+kuSazjPt1jVJbp2u35rkjR1n+RGttU8leeqkw6eb\n+ZokH25b7k1yXlVduJpJT+0085/ONUk+0lr7Xmvtz5M8kq3WetD4Cui7W9+JxldC476HL4jGl0Tj\na2Ft+040nm0a772UXpTkazOfPz4dW3ctySer6r6qOjgdu6C1dmy6/vUkF/QZ7aycbuZN+nN55/S2\nhltm3qaxTvOv0yxnY4TG9b0a6zbPTml8Pax74+s0y9nS+HrQ+HKM0Hei8R/ovZRuqle11l6R5A1J\n3lFVr5m9sW29br1R/9bOJs6c5OYkL01yRZJjSd7Xd5yhDNX4ps070fdyabw/jS+XxvvT+PIM1Xey\nmTNngY33XkqPJrlk5vOLp2NrrbV2dPr4ZJKPZ+vl6CdOvKw+fXyy34Q7drqZN+LPpbX2RGvtmdba\ns0k+mB++LWCd5l+nWXZskMb1vRrrNs+OaLy/DWl8nWY5KxrvT+PLM0jficZ/oPdS+pkkl1fVZVX1\nnCTXJrmj80xnVFX7qup5J64neX2SB7M19/XT3a5P8ok+E56V0818R5K3TGf+uirJt2beWrA2Tnpv\n/Zuy9eeQbM1/bVU9t6ouS3J5kj9Z9XwTjfej79XQeD8aX76N6zvR+LrQ+HIM1Hei8R8601mQVnHJ\n1tmlvpytszK9u/c8O5j3Jdk6m9SfJfn8iZmTvCDJPUkeTvIHSZ7fe9aT5r4tWy+r/1W23tf91tPN\nnK0zff3m9GfyuST713T+/zLN98AU/4Uz93/3NP9DSd7QeXaN9+lD36ubX+N9GtH4ambfqL6nmTW+\nHvNrfDnzblzfZ2hE49OlpgcBAADAyvV++y4AAAB7mKUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1Y\nSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjG\nUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3\nllIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6\nsZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQ\njaUUAACAbiylAAAAdGMpBQAAoBtLKQAAAN0sbSmtqgNV9VBVPVJVNy7reaAHfTM6jTM6jTM6jbNJ\nqrW2+C9adU6SLyf56SSPJ/lMkutaa19Y+JPBiumb0Wmc0Wmc0WmcTbOsV0qvTPJIa+0rrbXvJ/lI\nkmuW9FywavpmdBpndBpndBpno5y7pK97UZKvzXz+eJJ/MHuHqjqY5OD06SuXNAfM+kZr7UUL+Drb\n9p1onC40zuhW1ri+6WBRfScaZz2dtvFlLaXbaq0dSnIoSapq8e8hhh/11VU+mcbpQOOMbmWN65sO\nfA9ndKdtfFlv3z2a5JKZzy+ejsEI9M3oNM7oNM7oNM5GWdZS+pkkl1fVZVX1nCTXJrljSc8Fq6Zv\nRqdxRqdxRqdxNspS3r7bWnu6qt6Z5H8kOSfJLa21zy/juRbtpptu2vF9b7jhhl0/9uTHz/PYefV8\n7pOdPMsyn2u3NrnvROOrfu6TaXz5NL7a5z6ZxpdL36t97pNtQt+JxnfzeI1v6dX40n6ntLV2Z5I7\nl/X1oSd9MzqNMzqNMzqNs0m6nehoEyzypy9n+/h5n3se6/pTPxZP44xO44xM34xO43vHsn6nFAAA\nALbllVJ+xHY/CdqLP71hLBpndBpnZPpmdHuxca+UAgAA0I1XStn2py2rfA89LIPGGZ3GGZm+GZ3G\nvVIKAABAR14pPYN5fyoxz+NX+RORvfDTF05N44xO44xM34xO43tHtdZ6z5Cq6j8Ee8F9rbX9PZ5Y\n46yIxhldl8b1zYr4Hs7oTtu4t+8CAADQzVq8fffiiy8e8tTGrJeejWmcVdA4o+vVmL5ZBd/DGd2Z\nGvNKKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQza6X0qq6pKr+sKq+UFWfr6pfmo6/t6qO\nVtX90+XqxY0Lq6NxRqdxRqZvRqdxRjLPPwnzdJJfaa19tqqel+S+qrp7uu39rbXfmH886ErjjE7j\njEzfjE7jDGPXS2lr7ViSY9P171TVF5NctKjBoDeNMzqNMzJ9MzqNM5KF/E5pVV2a5KeSfHo69M6q\neqCqbqmq80/zmINVdaSqjhw/fnwRY8DSaJzRaZyR6ZvRaZxNN/dSWlU/nuT2JL/cWvt2kpuTvDTJ\nFdn66c37TvW41tqh1tr+1tr+ffv2zTsGLI3GGZ3GGZm+GZ3GGcFcS2lV/Vi2/if47dba7yZJa+2J\n1tozrbVnk3wwyZXzjwl9aJzRaZyR6ZvRaZxRzHP23UryoSRfbK3dNHP8wpm7vSnJg7sfD/rROKPT\nOCPTN6PTOCOZ5+y7/yjJzyf5XFXdPx371STXVdUVSVqSx5K8ba4JoR+NMzqNMzJ9MzqNM4x5zr77\nv5LUKW66c/fjwPrQOKPTOCPTN6PTOCOZ55XSlbnhhht6j8AGuOmmm7a/05rSODuhcUa3qY3rm53Y\n1L4TjbMz8zS+kH8SBgAAAHbDUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAAoBtL\nKQAAAN1YSgEAAOjGUgoAAEA3llIAAAC6sZQCAADQjaUUAACAbiylAAAAdHPuvF+gqh5L8p0kzyR5\nurW2v6qen+SjSS5N8liSN7fW/u+8zwWrpm9Gp3FGp3FGpm9GsahXSv9xa+2K1tr+6fMbk9zTWrs8\nyT3T57Cp9M3oNM7oNM7I9M3GW9bbd69Jcut0/dYkb1zS80AP+mZ0Gmd0Gmdk+mbjLGIpbUk+WVX3\nVdXB6dgFrbVj0/WvJ7ng5AdV1cGqOlJVR44fP76AMWApdtV3onE2hsYZnb+nMDLfwxnC3L9TmuRV\nrbWjVfU3k9xdVV+avbG11qqqnfyg1tqhJIeS5JJLLvmR22FN7Krv6TaNswk0zuj8PYWR+R7OEOZ+\npbS1dnT6+GSSjye5MskTVXVhkkwfn5z3eaAHfTM6jTM6jTMyfTOKuZbSqtpXVc87cT3J65M8mOSO\nJNdPd7s+ySfmeR7oQd+MTmOrsbMAABLfSURBVOOMTuOMTN+MZN63716Q5ONVdeJr/U5r7a6q+kyS\nj1XVW5N8Ncmb53we6EHfjE7jjE7jjEzfDGOupbS19pUkf/8Ux7+Z5HXzfG3oTd+MTuOMTuOMTN+M\nZBEnOlq6ew8c6D0CG+CPew8wB42zExpndJvauL7ZiU3tO9E4OzNP48v6d0oBAABgW5ZSAAAAurGU\nAgAA0I2lFAAAgG4spQAAAHSzEWffffZvf7v3CLBUGmd0Gmdk+mZ0GmfZvFIKAABAN5ZSAAAAurGU\nAgAA0I2lFAAAgG4spQAAAHSzEWfffepvfLf3CLBUGmd0Gmdk+mZ0GmfZvFIKAABAN5ZSAAAAutn1\n23er6ieTfHTm0EuS/Nsk5yX5V0n+z3T8V1trd+56QuhE44xO44xO44xM34xk10tpa+2hJFckSVWd\nk+Roko8n+cUk72+t/cZCJoRONM7oNM7oNM7I9M1IFnWio9clebS19tWqWtCX/KGn/s73F/41GdA3\nlvrVNU5/Gmd0G9q4vtmRDe070Tg7NEfji/qd0muT3Dbz+Tur6oGquqWqzj/VA6rqYFUdqaojx48f\nX9AYsDQaZ3QaZ3Rn1bi+2TC+h7PR5l5Kq+o5SX4uyX+dDt2c5KXZejvBsSTvO9XjWmuHWmv7W2v7\n9+3bN+8YsDQaZ3QaZ3S7aVzfbArfwxnBIl4pfUOSz7bWnkiS1toTrbVnWmvPJvlgkisX8BzQk8YZ\nncYZncYZmb7ZeItYSq/LzNsFqurCmdvelOTBBTwH9KRxRqdxRqdxRqZvNt5cJzqqqn1JfjrJ22YO\n/3pVXZGkJXnspNtgo2ic0Wmc0WmckembUcy1lLbWjid5wUnHfn6uiU7hd5598aK/JAN6/RK+psZZ\nJxpndJvauL7ZiU3tO9E4OzNP44s6+y4AAACcNUspAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqZ6+y7\nq/L9j7y39whsgtf/ce8Jdk3j7IjGGd2GNq5vdmRD+040zg7N0bhXSgEAAOjGUgoAAEA3llIAAAC6\nsZQCAADQjaUUAACAbjbi7Lv/866reo/ABvjZ19/Ue4Rd0zg7oXFGt6mN65ud2NS+E42zM/M07pVS\nAAAAurGUAgAA0I2lFAAAgG52tJRW1S1V9WRVPThz7PlVdXdVPTx9PH86XlX1gap6pKoeqKpXLGt4\nWAR9MzqNMzqNMzJ9sxfs9JXSw0kOnHTsxiT3tNYuT3LP9HmSvCHJ5dPlYJKb5x8Tlupw9M3YDkfj\njO1wNM64DkffDG5HS2lr7VNJnjrp8DVJbp2u35rkjTPHP9y23JvkvKq6cBHDwjLom9FpnNFpnJHp\nm71gnt8pvaC1dmy6/vUkF0zXL0rytZn7PT4d+2uq6mBVHamqI8ePH59jDFiKufpONM7a0zij8/cU\nRuZ7OENZyImOWmstSTvLxxxqre1vre3ft2/fIsaApdhN39PjNM5G0Dij8/cURuZ7OCOYZyl94sTb\nAaaPT07Hjya5ZOZ+F0/HYJPom9FpnNFpnJHpm6HMs5TekeT66fr1ST4xc/wt09m/rkryrZm3F8Cm\n0Dej0zij0zgj0zdDOXcnd6qq25K8NskLq+rxJO9J8u+TfKyq3prkq0nePN39ziRXJ3kkyXeT/OKC\nZ4aF0jej0zij0zgj0zd7wY6W0tbadae56XWnuG9L8o55hoJV0jej0zij0zgj0zd7wUJOdAQAAAC7\nYSkFAACgG0spAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANCNpRQAAIBuLKUAAAB0YykFAACg\nG0spAAAA3VhKAQAA6MZSCgAAQDeWUgAAALqxlAIAANDNtktpVd1SVU9W1YMzx/5jVX2pqh6oqo9X\n1XnT8Uur6i+r6v7p8lvLHB4WQeOMTuOMTN+MTuPsBTt5pfRwkgMnHbs7yd9trf29JF9O8q6Z2x5t\nrV0xXd6+mDFhqQ5H44ztcDTOuA5H34ztcDTO4LZdSltrn0ry1EnHPtlae3r69N4kFy9hNlgJjTM6\njTMyfTM6jbMXLOJ3Sv9lkt+f+fyyqvrTqvqjqnr1Ar4+9KZxRqdxRqZvRqdxNt658zy4qt6d5Okk\nvz0dOpbkxa21b1bVK5P8XlW9vLX27VM89mCSg0ly/vnnzzPG0O49sPVujavuuqvzJHuTxhmdxhmZ\nvhmdxhnFrl8prapfSPKzSf5Fa60lSWvte621b07X70vyaJKfONXjW2uHWmv7W2v79+3bt9sxYGk0\nvnz3Hjjwgx+8sHoaZ2T6ZnQaZyS7Wkqr6kCSf5Pk51pr3505/qKqOme6/pIklyf5yiIGhVXSOKPT\n+PL5oUs/+mZ0Gmc02759t6puS/LaJC+sqseTvCdbZ/h6bpK7qypJ7p3O7vWaJP+uqv4qybNJ3t5a\ne+qUXxjWhMYZncYZmb5Xz68WrZbG2Qu2XUpba9ed4vCHTnPf25PcPu9Q/JBv+MuncUancUamb0an\n8dXyQ5c+5jrREcA8fMMHAMBSCgBL4IcuALAzllIAAHbMD1yARbOUAgAAxA9detn1v1MKAAAA87KU\nAgAA0I2lFAAAgG4spQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2l\nFAAAgG62XUqr6paqerKqHpw59t6qOlpV90+Xq2due1dVPVJVD1XVzyxrcFgUjTM6jTM6jTMyfbMX\n7OSV0sNJDpzi+Ptba1dMlzuTpKpeluTaJC+fHvOfq+qcRQ0LS3I4Gmdsh6NxxnY4Gmdch6NvBrft\nUtpa+1SSp3b49a5J8pHW2vdaa3+e5JEkV84xHyydxhmdxhmdxhmZvtkL5vmd0ndW1QPTWwrOn45d\nlORrM/d5fDoGm0jjjE7jjE7jjEzfDGO3S+nNSV6a5Iokx5K872y/QFUdrKojVXXk+PHjuxwDlkbj\njE7jjG6uxvXNmvM9nKHsailtrT3RWnumtfZskg/mh28LOJrkkpm7XjwdO9XXONRa299a279v377d\njAFLo3FGp3FGN2/j+mad+R7OaHa1lFbVhTOfvinJibOB3ZHk2qp6blVdluTyJH8y34iwehpndBpn\ndBpnZPpmNOdud4equi3Ja5O8sKoeT/KeJK+tqiuStCSPJXlbkrTWPl9VH0vyhSRPJ3lHa+2Z5YwO\ni6FxRqdxRqdxRqZv9oJtl9LW2nWnOPyhM9z/15L82jxDwSppnNFpnNFpnJHpm71gnrPvAgAAwFws\npQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAurGUAgAA0I2lFAAAgG4spQAAAHRj\nKQUAAKAbSykAAADdWEoBAADoxlIKAABAN5ZSAAAAutl2Ka2qW6rqyap6cObYR6vq/unyWFXdPx2/\ntKr+cua231rm8LAIGmd0Gmdk+mZ0GmcvOHcH9zmc5D8l+fCJA621f37ielW9L8m3Zu7/aGvtikUN\nCCtwOBpnbIejccZ1OPpmbIejcQa37VLaWvtUVV16qtuqqpK8Ock/WexYsDoaZ3QaZ2T6ZnQaZy+Y\n93dKX53kidbawzPHLquqP62qP6qqV8/59aE3jTM6jTMyfTM6jTOEnbx990yuS3LbzOfHkry4tfbN\nqnplkt+rqpe31r598gOr6mCSg0ly/vnnzzkGLI3GGZ3GGZm+GZ3GGcKuXymtqnOT/LMkHz1xrLX2\nvdbaN6fr9yV5NMlPnOrxrbVDrbX9rbX9+/bt2+0YsDQaZ3QaZ2T6ZnQaZyTzvH33nyb5Umvt8RMH\nqupFVXXOdP0lSS5P8pX5RoRuNM7oNM7I9M3oNM4wdvJPwtyW5H8n+cmqeryq3jrddG3++tsFkuQ1\nSR6YTkv935K8vbX21CIHhkXTOKPTOCPTN6PTOHvBTs6+e91pjv/CKY7dnuT2+ceC1dE4o9M4I9M3\no9M4e8G8Z98FAACAXbOUAgAA0I2lFAAAgG4spQAAAHRjKQUAAKAbSykAAADdWEoBAADoxlIKAABA\nN+f2HiBJvnXOs/nv5/1F7zH2jHsPHJjr8VfdddeCJlmsf/jJT/Ye4bQ0vjqj9p1onLH7Tta3cX2v\nhr770fhqaPz0vFIKAABAN5ZSAAAAurGUAgAA0M1a/E4pq7Xu70eHeeibkembkemb0Wn89CylDMP/\n6IxO44xO44xM34xunsartbbAUXY5RFX/IdgL7mut7e/xxBpnRTTO6Lo0rm9WxPdwRnfaxrf9ndKq\nuqSq/rCqvlBVn6+qX5qOP7+q7q6qh6eP50/Hq6o+UFWPVNUDVfWKxf63wGJpnNFpnJHpm9FpnL1g\nJyc6ejrJr7TWXpbkqiTvqKqXJbkxyT2ttcuT3DN9niRvSHL5dDmY5OaFTw2LpXFGp3FGpm9Gp3GG\nt+1S2lo71lr77HT9O0m+mOSiJNckuXW6261J3jhdvybJh9uWe5OcV1UXLnxyWBCNMzqNMzJ9MzqN\nsxec1T8JU1WXJvmpJJ9OckFr7dh009eTXDBdvyjJ12Ye9vh0DNaexhmdxhmZvhmdxhnVjs++W1U/\nnuT2JL/cWvt2Vf3gttZaO9tfkK6qg9l6SwGsBY0zOo0zMn0zOo0zsh29UlpVP5at/wl+u7X2u9Ph\nJ068FWD6+OR0/GiSS2YefvF07K9prR1qre3vdZYxmKVxRqdxRqZvRqdxRreTs+9Wkg8l+WJr7aaZ\nm+5Icv10/fokn5g5/pbpzF9XJfnWzFsLYO1onNFpnJHpm9FpnD2htXbGS5JXJWlJHkhy/3S5OskL\nsnWmr4eT/EGS50/3ryS/meTRJJ9Lsn8Hz9FcXFZwOaJxl8EvGncZ/fIjjUffLuNcfA93Gf1yysZb\na6kpxK7O9j3wsEv+UWpGp3FG16VxfbMivoczutM2flZn3wUAAIBFspQCAADQjaUUAACAbiylAAAA\ndHNu7wEm30hyfPq4qV4Y8/e0k/n/1ioGOQ2N97cX5u/Z+F8keajj889rL/Sx7ta5cd/D+9sL8/t7\nynz2QiPrbK7G1+Lsu0lSVUc2+R/vNX9fmzD/Jsx4Jubva93nX/f5tmP+/tb9v2Hd59uO+fvahPk3\nYcYzMX9f887v7bsAAAB0YykFAACgm3VaSg/1HmBO5u9rE+bfhBnPxPx9rfv86z7fdszf37r/N6z7\nfNsxf1+bMP8mzHgm5u9rrvnX5ndKAQAA2HvW6ZVSAAAA9hhLKQAAAN10X0qr6kBVPVRVj1TVjb3n\n2YmqeqyqPldV91fVkenY86vq7qp6ePp4fu85Z1XVLVX1ZFU9OHPslDPXlg9MfyYPVNUr+k3+g1lP\nNf97q+ro9Odwf1VdPXPbu6b5H6qqn+kz9Q9m0fiS6bsvjS+fxvvZxL4Tja+axldr0/pONL7tE7TW\nul2SnJPk0SQvSfKcJH+W5GU9Z9rh3I8leeFJx349yY3T9RuT/Ifec54032uSvCLJg9vNnOTqJL+f\npJJcleTTazr/e5P861Pc92VTS89NctnU2Dmd5tZ4vz70vZrZNd6vEY0vf+6N7HuaXeP959f48ube\nqL7P0IjGp0vvV0qvTPJIa+0rrbXvJ/lIkms6z7Rb1yS5dbp+a5I3dpzlR7TWPpXkqZMOn27ma5J8\nuG25N8l5VXXhaiY9tdPMfzrXJPlIa+17rbU/T/JItlrrQeMroO9ufScaXwmN+x6+IBpfEo2vhbXt\nO9F4tmm891J6UZKvzXz++HRs3bUkn6yq+6rq4HTsgtbasen615Nc0Ge0s3K6mTfpz+Wd09sabpl5\nm8Y6zb9Os5yNERrX92qs2zw7pfH1sO6Nr9MsZ0vj60HjyzFC34nGf6D3UrqpXtVae0WSNyR5R1W9\nZvbGtvW69Ub9WzubOHOSm5O8NMkVSY4leV/fcYYyVOObNu9E38ul8f40vlwa70/jyzNU38lmzpwF\nNt57KT2a5JKZzy+ejq211trR6eOTST6erZejnzjxsvr08cl+E+7Y6WbeiD+X1toTrbVnWmvPJvlg\nfvi2gHWaf51m2bFBGtf3aqzbPDui8f42pPF1muWsaLw/jS/PIH0nGv+B3kvpZ5JcXlWXVdVzklyb\n5I7OM51RVe2rqueduJ7k9UkezNbc1093uz7JJ/pMeFZON/MdSd4ynfnrqiTfmnlrwdo46b31b8rW\nn0OyNf+1VfXcqrosyeVJ/mTV80003o++V0Pj/Wh8+Tau70Tj60LjyzFQ34nGf+hMZ0FaxSVbZ5f6\ncrbOyvTu3vPsYN6XZOtsUn+W5PMnZk7ygiT3JHk4yR8keX7vWU+a+7Zsvaz+V9l6X/dbTzdzts70\n9ZvTn8nnkuxf0/n/yzTfA1P8F87c/93T/A8leUPn2TXepw99r25+jfdpROOrmX2j+p5m1vh6zK/x\n5cy7cX2foRGNT5eaHgQAAAAr1/vtuwAAAOxhllIAAAC6sZQCAADQjaUUAACAbiylAAAAdGMpBQAA\noBtLKQAAAN38P4MFx8hKCA3KAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "env = gym.make(ENV_NAME)\n",
+ "env.reset()\n",
+ "\n",
+ "n_cols = 5\n",
+ "n_rows = 2\n",
+ "fig = plt.figure(figsize=(16, 9))\n",
+ "\n",
+ "for row in range(n_rows):\n",
+ " for col in range(n_cols):\n",
+ " ax = fig.add_subplot(n_rows, n_cols, row * n_cols + col + 1)\n",
+ " ax.imshow(env.render('rgb_array'))\n",
+ " env.step(env.action_space.sample())\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Let's play a little.**\n",
+ "\n",
+ "Pay attention to zoom and fps args of the play function. Control: A, D, space."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# # does not work in Colab.\n",
+ "# # make keyboard interrupt to continue\n",
+ "\n",
+ "# from gym.utils.play import play\n",
+ "\n",
+ "# play(env=gym.make(ENV_NAME), zoom=5, fps=30)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Processing game image \n",
+ "\n",
+ "Raw Atari images are large, 210x160x3 by default. However, we don't need that level of detail in order to learn from them.\n",
+ "\n",
+ "We can thus save a lot of time by preprocessing game image, including\n",
+ "* Resizing to a smaller shape, 64 x 64\n",
+ "* Converting to grayscale\n",
+ "* Cropping irrelevant image parts (top, bottom and edges)\n",
+ "\n",
+ "Also please keep one dimension for channel so that final shape would be 1 x 64 x 64.\n",
+ "\n",
+ "Tip: You can implement your own grayscale converter and assign a huge weight to the red channel. This dirty trick is not necessary but it will speed up the learning."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gym.core import ObservationWrapper\n",
+ "from gym.spaces import Box\n",
+ "\n",
+ "\n",
+ "class PreprocessAtariObs(ObservationWrapper):\n",
+ " def __init__(self, env):\n",
+ " \"\"\"A gym wrapper that crops, scales an image into the desired shapes and grayscales it.\"\"\"\n",
+ " ObservationWrapper.__init__(self, env)\n",
+ "\n",
+ " self.img_size = (1, 64, 64)\n",
+ " self.observation_space = Box(0.0, 1.0, self.img_size)\n",
+ "\n",
+ "\n",
+ " def _to_gray_scale(self, rgb, channel_weights=[0.8, 0.1, 0.1]):\n",
+ " \n",
+ "\n",
+ "\n",
+ " def observation(self, img):\n",
+ " \"\"\"what happens to each observation\"\"\"\n",
+ "\n",
+ " # Here's what you need to do:\n",
+ " # * crop image, remove irrelevant parts\n",
+ " # * resize image to self.img_size\n",
+ " # (use imresize from any library you want,\n",
+ " # e.g. opencv, skimage, PIL, keras)\n",
+ " # * cast image to grayscale\n",
+ " # * convert image pixels to (0,1) range, float32 type\n",
+ " \n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "# spawn game instance for tests\n",
+ "env = gym.make(ENV_NAME) # create raw env\n",
+ "env = PreprocessAtariObs(env)\n",
+ "observation_shape = env.observation_space.shape\n",
+ "n_actions = env.action_space.n\n",
+ "env.reset()\n",
+ "obs, _, _, _ = env.step(env.action_space.sample())\n",
+ "\n",
+ "# test observation\n",
+ "assert obs.ndim == 3, \"observation must be [channel, h, w] even if there's just one channel\"\n",
+ "assert obs.shape == observation_shape\n",
+ "assert obs.dtype == 'float32'\n",
+ "assert len(np.unique(obs)) > 2, \"your image must not be binary\"\n",
+ "assert 0 <= np.min(obs) and np.max(\n",
+ " obs) <= 1, \"convert image pixels to [0,1] range\"\n",
+ "\n",
+ "assert np.max(obs) >= 0.5, \"It would be easier to see a brighter observation\"\n",
+ "assert np.mean(obs) >= 0.1, \"It would be easier to see a brighter observation\"\n",
+ "\n",
+ "print(\"Formal tests seem fine. Here's an example of what you'll get.\")\n",
+ "\n",
+ "n_cols = 5\n",
+ "n_rows = 2\n",
+ "fig = plt.figure(figsize=(16, 9))\n",
+ "obs = env.reset()\n",
+ "for row in range(n_rows):\n",
+ " for col in range(n_cols):\n",
+ " ax = fig.add_subplot(n_rows, n_cols, row * n_cols + col + 1)\n",
+ " ax.imshow(obs[0, :, :], interpolation='none', cmap='gray')\n",
+ " obs, _, _, _ = env.step(env.action_space.sample())\n",
+ "plt.show()\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Wrapping."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**About the game:** You have 5 lives and get points for breaking the wall. Higher bricks cost more than the lower ones. There are 4 actions: start game (should be called at the beginning and after each life is lost), move left, move right and do nothing. There are some common wrappers used for Atari environments."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext autoreload\n",
+ "%autoreload 2\n",
+ "import atari_wrappers\n",
+ "\n",
+ "def PrimaryAtariWrap(env, clip_rewards=True):\n",
+ " assert 'NoFrameskip' in env.spec.id\n",
+ "\n",
+ " # This wrapper holds the same action for frames and outputs\n",
+ " # the maximal pixel value of 2 last frames (to handle blinking\n",
+ " # in some envs)\n",
+ " env = atari_wrappers.MaxAndSkipEnv(env, skip=4)\n",
+ "\n",
+ " # This wrapper sends done=True when each life is lost\n",
+ " # (not all the 5 lives that are givern by the game rules).\n",
+ " # It should make easier for the agent to understand that losing is bad.\n",
+ " env = atari_wrappers.EpisodicLifeEnv(env)\n",
+ "\n",
+ " # This wrapper laucnhes the ball when an episode starts.\n",
+ " # Without it the agent has to learn this action, too.\n",
+ " # Actually it can but learning would take longer.\n",
+ " env = atari_wrappers.FireResetEnv(env)\n",
+ "\n",
+ " # This wrapper transforms rewards to {-1, 0, 1} according to their sign\n",
+ " if clip_rewards:\n",
+ " env = atari_wrappers.ClipRewardEnv(env)\n",
+ "\n",
+ " # This wrapper is yours :)\n",
+ " env = PreprocessAtariObs(env)\n",
+ " return env"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Let's see if the game is still playable after applying the wrappers.**\n",
+ "At playing the EpisodicLifeEnv wrapper seems not to work but actually it does (because after when life finishes a new ball is dropped automatically - it means that FireResetEnv wrapper understands that a new episode began)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# # does not work in Colab.\n",
+ "# # make keyboard interrupt to continue\n",
+ "\n",
+ "# from gym.utils.play import play\n",
+ "\n",
+ "# def make_play_env():\n",
+ "# env = gym.make(ENV_NAME)\n",
+ "# env = PrimaryAtariWrap(env)\n",
+ "# # in torch imgs have shape [c, h, w] instead of common [h, w, c]\n",
+ "# env = atari_wrappers.AntiTorchWrapper(env)\n",
+ "# return env\n",
+ "\n",
+ "# play(make_play_env(), zoom=10, fps=3)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Frame buffer\n",
+ "\n",
+ "Our agent can only process one observation at a time, so we have to make sure it has enough information to find the optimal actions. For instance, agent has to react to moving objects so he must be able to measure an object's velocity.\n",
+ "\n",
+ "To do so, we introduce a buffer, that stores 4 last images. This time everything is pre-implemented for you, not really by the staff of the course :)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from framebuffer import FrameBuffer\n",
+ "\n",
+ "def make_env(clip_rewards=True, seed=None):\n",
+ " env = gym.make(ENV_NAME) # create raw env\n",
+ " if seed is not None:\n",
+ " env.seed(seed)\n",
+ " env = PrimaryAtariWrap(env, clip_rewards)\n",
+ " env = FrameBuffer(env, n_frames=4, dim_order='pytorch')\n",
+ " return env\n",
+ "\n",
+ "env = make_env()\n",
+ "env.reset()\n",
+ "n_actions = env.action_space.n\n",
+ "state_shape = env.observation_space.shape"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for _ in range(12):\n",
+ " obs, _, _, _ = env.step(env.action_space.sample())\n",
+ "\n",
+ "plt.figure(figsize=[12,10])\n",
+ "plt.title(\"Game image\")\n",
+ "plt.imshow(env.render(\"rgb_array\"))\n",
+ "plt.show()\n",
+ "\n",
+ "plt.figure(figsize=[15,15])\n",
+ "plt.title(\"Agent observation (4 frames top to bottom)\")\n",
+ "plt.imshow(utils.img_by_obs(obs, state_shape), cmap='gray')\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## DQN as it is"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Building a network\n",
+ "\n",
+ "We now need to build a neural network, that can map images to state q-values. This network will be called on every agent's step so it is better not to be the resnet-152, unless you have an array of GPUs. Instead, you can use strided convolutions with a small number of features to save time and memory.\n",
+ "\n",
+ "You can build any architecture you want, but for reference, here's something, that will more or less work:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n",
+ "# those, who have a GPU but feel unfair to use it can uncomment:\n",
+ "# device = torch.device('cpu')\n",
+ "device"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def conv2d_size_out(size, kernel_size, stride):\n",
+ " \"\"\"\n",
+ " common use case:\n",
+ " cur_layer_img_w = conv2d_size_out(cur_layer_img_w, kernel_size, stride)\n",
+ " cur_layer_img_h = conv2d_size_out(cur_layer_img_h, kernel_size, stride)\n",
+ " to understand the shape for dense layer's input\n",
+ " \"\"\"\n",
+ " return (size - (kernel_size - 1) - 1) // stride + 1\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class DQNAgent(nn.Module):\n",
+ " def __init__(self, state_shape, n_actions, epsilon=0):\n",
+ "\n",
+ " super().__init__()\n",
+ " self.epsilon = epsilon\n",
+ " self.n_actions = n_actions\n",
+ " self.state_shape = state_shape\n",
+ "\n",
+ " # Define your network body here. Please, make sure agent is fully contained here\n",
+ " # nn.Flatten() can be useful\n",
+ " \n",
+ " \n",
+ "\n",
+ " def forward(self, state_t):\n",
+ " \"\"\"\n",
+ " takes agent's observation (tensor), returns qvalues (tensor)\n",
+ " :param state_t: a batch of 4-frame buffers, shape = [batch_size, 4, h, w]\n",
+ " \"\"\"\n",
+ " # Use your network to compute qvalues for a given state\n",
+ " qvalues = \n",
+ "\n",
+ " assert qvalues.requires_grad, \"qvalues must be a torch tensor with grad\"\n",
+ " assert len(\n",
+ " qvalues.shape) == 2 and qvalues.shape[0] == state_t.shape[0] and qvalues.shape[1] == n_actions\n",
+ "\n",
+ " return qvalues\n",
+ "\n",
+ " def get_qvalues(self, states):\n",
+ " \"\"\"\n",
+ " like forward, but works on numpy arrays, not tensors\n",
+ " \"\"\"\n",
+ " model_device = next(self.parameters()).device\n",
+ " states = torch.tensor(states, device=model_device, dtype=torch.float)\n",
+ " qvalues = self.forward(states)\n",
+ " return qvalues.data.cpu().numpy()\n",
+ "\n",
+ " def sample_actions(self, qvalues):\n",
+ " \"\"\"pick actions given qvalues. Uses epsilon-greedy exploration strategy. \"\"\"\n",
+ " epsilon = self.epsilon\n",
+ " batch_size, n_actions = qvalues.shape\n",
+ "\n",
+ " random_actions = np.random.choice(n_actions, size=batch_size)\n",
+ " best_actions = qvalues.argmax(axis=-1)\n",
+ "\n",
+ " should_explore = np.random.choice(\n",
+ " [0, 1], batch_size, p=[1-epsilon, epsilon])\n",
+ " return np.where(should_explore, random_actions, best_actions)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent = DQNAgent(state_shape, n_actions, epsilon=0.5).to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now let's try out our agent to see if the code raises any errors."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def evaluate(env, agent, n_games=1, greedy=False, t_max=10000):\n",
+ " \"\"\" Plays n_games full games. If greedy, picks actions as argmax(qvalues). Returns the mean reward. \"\"\"\n",
+ " rewards = []\n",
+ " for _ in range(n_games):\n",
+ " s = env.reset()\n",
+ " reward = 0\n",
+ " for _ in range(t_max):\n",
+ " qvalues = agent.get_qvalues([s])\n",
+ " action = qvalues.argmax(axis=-1)[0] if greedy else agent.sample_actions(qvalues)[0]\n",
+ " s, r, done, _ = env.step(action)\n",
+ " reward += r\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " rewards.append(reward)\n",
+ " return np.mean(rewards)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "evaluate(env, agent, n_games=1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Experience replay\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### The interface is fairly simple:\n",
+ "* `exp_replay.add(obs, act, rw, next_obs, done)` - saves (s,a,r,s',done) tuple into the buffer;\n",
+ "* `exp_replay.sample(batch_size)` - returns observations, actions, rewards, next_observations and is_done for `batch_size` random samples.\n",
+ "* `len(exp_replay)` - returns the number of elements stored in replay buffer."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from replay_buffer import ReplayBuffer\n",
+ "exp_replay = ReplayBuffer(10)\n",
+ "\n",
+ "for _ in range(30):\n",
+ " exp_replay.add(env.reset(), env.action_space.sample(),\n",
+ " 1.0, env.reset(), done=False)\n",
+ "\n",
+ "obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n",
+ " 5)\n",
+ "\n",
+ "assert len(exp_replay) == 10, \"experience replay size should be 10 because that's what the maximum capacity is\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def play_and_record(initial_state, agent, env, exp_replay, n_steps=1):\n",
+ " \"\"\"\n",
+ " Play the game for exactly n steps, record every (s,a,r,s', done) to replay buffer. \n",
+ " Whenever game ends, add record with done=True and reset the game.\n",
+ " It is guaranteed, that env has done=False when passed to this function.\n",
+ "\n",
+ " PLEASE DO NOT RESET ENV UNLESS IT IS \"DONE\"\n",
+ "\n",
+ " :returns: return sum of rewards over time and the state, in which the env stays\n",
+ " \"\"\"\n",
+ " s = initial_state\n",
+ " sum_rewards = 0\n",
+ "\n",
+ " # Play the game for n_steps as per instructions above\n",
+ " \n",
+ "\n",
+ " return sum_rewards, s"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# testing your code.\n",
+ "exp_replay = ReplayBuffer(2000)\n",
+ "\n",
+ "state = env.reset()\n",
+ "play_and_record(state, agent, env, exp_replay, n_steps=1000)\n",
+ "\n",
+ "# if you're using your own experience replay buffer, some of those tests may need several corrections.\n",
+ "# just make sure you know, what your code does\n",
+ "assert len(exp_replay) == 1000, \"play_and_record should have added exactly 1000 steps, \"\\\n",
+ " \"but instead added %i\" % len(exp_replay)\n",
+ "is_dones = list(zip(*exp_replay._storage))[-1]\n",
+ "\n",
+ "assert 0 < np.mean(is_dones) < 0.1, \"Please, make sure you restart the game whenever it is 'done' and record the is_done correctly into the buffer.\"\\\n",
+ " \"Got %f is_done rate over %i steps. [If you think it's your tough luck, just re-run the test]\" % (\n",
+ " np.mean(is_dones), len(exp_replay))\n",
+ "\n",
+ "for _ in range(100):\n",
+ " obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n",
+ " 10)\n",
+ " assert obs_batch.shape == next_obs_batch.shape == (10,) + state_shape\n",
+ " assert act_batch.shape == (\n",
+ " 10,), \"actions batch should have shape (10,) but is instead %s\" % str(act_batch.shape)\n",
+ " assert reward_batch.shape == (\n",
+ " 10,), \"rewards batch should have shape (10,) but is instead %s\" % str(reward_batch.shape)\n",
+ " assert is_done_batch.shape == (\n",
+ " 10,), \"is_done batch should have shape (10,) but is instead %s\" % str(is_done_batch.shape)\n",
+ " assert [int(i) in (0, 1)\n",
+ " for i in is_dones], \"is_done should be strictly True or False\"\n",
+ " assert [\n",
+ " 0 <= a < n_actions for a in act_batch], \"actions should be within [0, n_actions)\"\n",
+ "\n",
+ "print(\"Well done!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Target networks\n",
+ "\n",
+ "We also employ the so called \"target network\" - a copy of neural network weights to be used for reference Q-values:\n",
+ "\n",
+ "The network itself is an exact copy of agent network, but its parameters are not trained. Instead, they are moved here from agent's actual network from time to time.\n",
+ "\n",
+ "$$ Q_{reference}(s,a) = r + \\gamma \\cdot \\max _{a'} Q_{target}(s',a') $$\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "target_network = DQNAgent(agent.state_shape, agent.n_actions, epsilon=0.5).to(device)\n",
+ "# This is how you can load the weights from agent into target network\n",
+ "target_network.load_state_dict(agent.state_dict())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Learning with... Q-learning\n",
+ "Here we write a function similar to `agent.update` from tabular q-learning."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Compute Q-learning TD error:\n",
+ "\n",
+ "$$ L = { 1 \\over N} \\sum_i [ Q_{\\theta}(s,a) - Q_{reference}(s,a) ] ^2 $$\n",
+ "\n",
+ "With Q-reference defined as\n",
+ "\n",
+ "$$ Q_{reference}(s,a) = r(s,a) + \\gamma \\cdot max_{a'} Q_{target}(s', a') $$\n",
+ "\n",
+ "Where:\n",
+ "* $Q_{target}(s',a')$ denotes q-value of next state and next action predicted by __target_network__;\n",
+ "* $s, a, r, s'$ are current state, action, reward and next state respectively;\n",
+ "* $\\gamma$ is a discount factor defined two cells above.\n",
+ "\n",
+ "\n",
+ "__Note 1:__ there's an example input below. Feel free to experiment with it before you write the function.\n",
+ "\n",
+ "__Note 2:__ compute_td_loss is a source of 99% of bugs in this homework. If reward doesn't improve, it often helps to go through it line by line [with a rubber duck](https://rubberduckdebugging.com/)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def compute_td_loss(states, actions, rewards, next_states, is_done,\n",
+ " agent, target_network,\n",
+ " gamma=0.99,\n",
+ " check_shapes=False,\n",
+ " device=device):\n",
+ " \"\"\" Compute td loss using torch operations only. Use the formula above. \"\"\"\n",
+ " states = torch.tensor(states, device=device, dtype=torch.float) # shape: [batch_size, *state_shape]\n",
+ "\n",
+ " # for some torch reason should not make actions a tensor\n",
+ " actions = torch.tensor(actions, device=device, dtype=torch.long) # shape: [batch_size]\n",
+ " rewards = torch.tensor(rewards, device=device, dtype=torch.float) # shape: [batch_size]\n",
+ " # shape: [batch_size, *state_shape]\n",
+ " next_states = torch.tensor(next_states, device=device, dtype=torch.float)\n",
+ " is_done = torch.tensor(\n",
+ " is_done.astype('float32'),\n",
+ " device=device,\n",
+ " dtype=torch.float\n",
+ " ) # shape: [batch_size]\n",
+ " is_not_done = 1 - is_done\n",
+ "\n",
+ " # get q-values for all actions in current states\n",
+ " predicted_qvalues = agent(states)\n",
+ "\n",
+ " # compute q-values for all actions in next states\n",
+ " predicted_next_qvalues = target_network(next_states)\n",
+ " \n",
+ " # select q-values for chosen actions\n",
+ " predicted_qvalues_for_actions = predicted_qvalues[range(\n",
+ " len(actions)), actions]\n",
+ "\n",
+ " # compute V*(next_states) using predicted next q-values\n",
+ " next_state_values = \n",
+ "\n",
+ " assert next_state_values.dim(\n",
+ " ) == 1 and next_state_values.shape[0] == states.shape[0], \"must predict one value per state\"\n",
+ "\n",
+ " # compute \"target q-values\" for loss - that is what's inside the square parentheses in the formula above.\n",
+ " # at the last state use the simplified formula: Q(s,a) = r(s,a) since s' doesn't exist\n",
+ " # you can multiply next state values by is_not_done to achieve this.\n",
+ " target_qvalues_for_actions = \n",
+ "\n",
+ " # mean squared error loss to minimize\n",
+ " loss = torch.mean((predicted_qvalues_for_actions -\n",
+ " target_qvalues_for_actions.detach()) ** 2)\n",
+ "\n",
+ " if check_shapes:\n",
+ " assert predicted_next_qvalues.data.dim(\n",
+ " ) == 2, \"make sure you predicted q-values for all actions in next state\"\n",
+ " assert next_state_values.data.dim(\n",
+ " ) == 1, \"make sure you computed V(s') as the maximum over just the actions axis and not all axes\"\n",
+ " assert target_qvalues_for_actions.data.dim(\n",
+ " ) == 1, \"there's something wrong with target q-values, they must be a vector\"\n",
+ "\n",
+ " return loss"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Sanity checks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch = exp_replay.sample(\n",
+ " 10)\n",
+ "\n",
+ "loss = compute_td_loss(obs_batch, act_batch, reward_batch, next_obs_batch, is_done_batch,\n",
+ " agent, target_network,\n",
+ " gamma=0.99, check_shapes=True)\n",
+ "loss.backward()\n",
+ "\n",
+ "assert loss.requires_grad and tuple(loss.data.size()) == (\n",
+ " ), \"you must return scalar loss - mean over batch\"\n",
+ "assert np.any(next(agent.parameters()).grad.data.cpu().numpy() !=\n",
+ " 0), \"loss must be differentiable w.r.t. network weights\"\n",
+ "assert np.all(next(target_network.parameters()).grad is None), \"target network should not have grads\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Main loop\n",
+ "\n",
+ "\n",
+ "It's time to put everything together and see if it learns something."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from tqdm import trange\n",
+ "from IPython.display import clear_output\n",
+ "import matplotlib.pyplot as plt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "seed = \n",
+ "random.seed(seed)\n",
+ "np.random.seed(seed)\n",
+ "torch.manual_seed(seed)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env = make_env(seed)\n",
+ "state_shape = env.observation_space.shape\n",
+ "n_actions = env.action_space.n\n",
+ "state = env.reset()\n",
+ "\n",
+ "agent = DQNAgent(state_shape, n_actions, epsilon=1).to(device)\n",
+ "target_network = DQNAgent(state_shape, n_actions).to(device)\n",
+ "target_network.load_state_dict(agent.state_dict())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Buffer of size $10^4$ fits into 5 Gb RAM.\n",
+ "\n",
+ "Larger sizes ($10^5$ and $10^6$ are common) can be used. It can improve the learning, but $10^4$ is quiet enough. $10^2$ will probably fail learning."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "exp_replay = ReplayBuffer(10**4)\n",
+ "for i in range(100):\n",
+ " if not utils.is_enough_ram(min_available_gb=0.1):\n",
+ " print(\"\"\"\n",
+ " Less than 100 Mb RAM available. \n",
+ " Make sure the buffer size in not too large.\n",
+ " Also check, whether other processes consume RAM heavily.\n",
+ " \"\"\"\n",
+ " )\n",
+ " break\n",
+ " play_and_record(state, agent, env, exp_replay, n_steps=10**2)\n",
+ " if len(exp_replay) == 10**4:\n",
+ " break\n",
+ "print(len(exp_replay))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "timesteps_per_epoch = 1\n",
+ "batch_size = 16\n",
+ "total_steps = 3 * 10**6\n",
+ "decay_steps = 10**6\n",
+ "\n",
+ "opt = torch.optim.Adam(agent.parameters(), lr=1e-4)\n",
+ "\n",
+ "init_epsilon = 1\n",
+ "final_epsilon = 0.1\n",
+ "\n",
+ "loss_freq = 50\n",
+ "refresh_target_network_freq = 5000\n",
+ "eval_freq = 5000\n",
+ "\n",
+ "max_grad_norm = 50\n",
+ "\n",
+ "n_lives = 5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mean_rw_history = []\n",
+ "td_loss_history = []\n",
+ "grad_norm_history = []\n",
+ "initial_state_v_history = []\n",
+ "step = 0"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "state = env.reset()\n",
+ "for step in trange(step, total_steps + 1):\n",
+ " if not utils.is_enough_ram():\n",
+ " print('less that 100 Mb RAM available, freezing')\n",
+ " print('make sure, that everything is ok and make KeyboardInterrupt to continue')\n",
+ " try:\n",
+ " while True:\n",
+ " pass\n",
+ " except KeyboardInterrupt:\n",
+ " pass\n",
+ "\n",
+ " agent.epsilon = utils.linear_decay(init_epsilon, final_epsilon, step, decay_steps)\n",
+ "\n",
+ " # play\n",
+ " _, state = play_and_record(state, agent, env, exp_replay, timesteps_per_epoch)\n",
+ "\n",
+ " # train\n",
+ " \n",
+ "\n",
+ " loss = \n",
+ "\n",
+ " loss.backward()\n",
+ " grad_norm = nn.utils.clip_grad_norm_(agent.parameters(), max_grad_norm)\n",
+ " opt.step()\n",
+ " opt.zero_grad()\n",
+ "\n",
+ " if step % loss_freq == 0:\n",
+ " td_loss_history.append(loss.data.cpu().item())\n",
+ " grad_norm_history.append(grad_norm)\n",
+ "\n",
+ " if step % refresh_target_network_freq == 0:\n",
+ " # Load agent weights into target_network\n",
+ " \n",
+ "\n",
+ " if step % eval_freq == 0:\n",
+ " mean_rw_history.append(evaluate(\n",
+ " make_env(clip_rewards=True, seed=step), agent, n_games=3 * n_lives, greedy=True)\n",
+ " )\n",
+ " initial_state_q_values = agent.get_qvalues(\n",
+ " [make_env(seed=step).reset()]\n",
+ " )\n",
+ " initial_state_v_history.append(np.max(initial_state_q_values))\n",
+ "\n",
+ " clear_output(True)\n",
+ " print(\"buffer size = %i, epsilon = %.5f\" %\n",
+ " (len(exp_replay), agent.epsilon))\n",
+ "\n",
+ " plt.figure(figsize=[16, 9])\n",
+ "\n",
+ " plt.subplot(2, 2, 1)\n",
+ " plt.title(\"Mean reward per life\")\n",
+ " plt.plot(mean_rw_history)\n",
+ " plt.grid()\n",
+ "\n",
+ " assert not np.isnan(td_loss_history[-1])\n",
+ " plt.subplot(2, 2, 2)\n",
+ " plt.title(\"TD loss history (smoothened)\")\n",
+ " plt.plot(utils.smoothen(td_loss_history))\n",
+ " plt.grid()\n",
+ "\n",
+ " plt.subplot(2, 2, 3)\n",
+ " plt.title(\"Initial state V\")\n",
+ " plt.plot(initial_state_v_history)\n",
+ " plt.grid()\n",
+ "\n",
+ " plt.subplot(2, 2, 4)\n",
+ " plt.title(\"Grad norm history (smoothened)\")\n",
+ " plt.plot(utils.smoothen(grad_norm_history))\n",
+ " plt.grid()\n",
+ "\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Agent is evaluated for 1 life, not for the whole episode of 5 lives. Rewards in evaluation are also truncated. Because this is the environment the agent is learning in and this way the mean rewards per life can be compared to initial state value.\n",
+ "\n",
+ "**The goal is to get 10 points in the real env**. So 3 or more points in the preprocessed one will probably be enough. You can interrupt the learning then."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Final scoring is done on a whole episode with all 5 lives."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "final_score = evaluate(\n",
+ " make_env(clip_rewards=False, seed=9),\n",
+ " agent, n_games=30, greedy=True, t_max=10 * 1000\n",
+ ") * n_lives\n",
+ "print('final score:', final_score)\n",
+ "assert final_score >= 10, 'not as cool as DQN can'\n",
+ "print('Cool!')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## How to interpret plots:\n",
+ "\n",
+ "This is not the supervised learning so don't expect anything to improve monotonously. \n",
+ "* **TD loss** is the MSE between agent's current Q-values and target Q-values. It may slowly increase or decrease, it's ok. The \"not ok\" behavior includes going NaN or staying at the exact zero before agent has perfect the performance.\n",
+ "* **grad norm** just shows the intensivity of training. Not ok is growing to values of about 100 (or maybe even 50), though it depends on the network architecture.\n",
+ "* **mean reward** is the expected sum of r(s,a) agent gets over the full game session. It will oscillate, but on average it should get higher over time (after a few thousand of iterations...). \n",
+ " * In basic q-learning implementation it takes about 40k steps to \"warm up\" agent before it starts to get better.\n",
+ "* **Initial state V** is the expected discounted reward for an episode in the oppinion of the agent. It should behave more smoothly than **mean reward**. It should get higher over time, but sometimes can experience drawdowns, because of the agent's overestimates.\n",
+ "* **buffer size** - this one is simple. It should go up and cap at max size.\n",
+ "* **epsilon** - agent's willingness to explore. If you see, that agent's already at 0.01 epsilon before its average reward is above 0 - it means, that you need to increase the epsilon. Set it back to 0.2 - 0.5 and decrease the pace, at which it goes down.\n",
+ "* Smoothing of plots is done with a gaussian kernel.\n",
+ "\n",
+ "At first, your agent will lose quickly. Then it will learn to suck less and at least hit the ball a few times before it loses. Finally, it will learn to actually score some points.\n",
+ "\n",
+ "**Training will take time.** A lot of it, actually. Probably you will not see any improvment during first **150k** time steps (note, that by default in this notebook agent is evaluated every 5000 time steps).\n",
+ "\n",
+ "But hey, long training time isn't _that_ bad:\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## About hyperparameters:\n",
+ "\n",
+ "The task has something in common with the supervised learning: loss is optimized through the buffer (instead of Train dataset). But the distribution of states and actions in the buffer **is not stationary** and depends on the policy, that generated it. It can even happen, that the mean TD error across the buffer is very low, but the performance is extremely poor (imagine the agent collects data to the buffer and always manages to avoid the ball).\n",
+ "\n",
+ "* Total timesteps and training time: It seems to be huge, but actually it is normal for RL.\n",
+ "\n",
+ "* $\\epsilon$ decay shedule was taken from the original paper and is traditional for epsilon-greedy policies. At the beginning of the training the agent's greedy policy is poor so many random actions should be made.\n",
+ "\n",
+ "* Optimizer: In the original paper RMSProp was used (they did not have Adam in 2013) and it can work as good as Adam. For us Adam was a default and it worked.\n",
+ "\n",
+ "* lr: $10^{-3}$ would probably be too huge\n",
+ "\n",
+ "* batch size: This one can be very important: if it is too small the agent can fail to learn. Huge batch takes more time to process. If batch of size 8 can not be processed on the hardware you use, take 2 (or even 4) batches of size 4, divide the loss on them by 2 (or 4) and make an optimization step after both backward() calls in torch.\n",
+ "\n",
+ "* target network update frequency: has something in common with the learning rate. Too frequent updates can lead to divergence. Too rare can lead to slow learning. For millions of total timesteps thousands of inner steps seem ok. One iteration of target network updating is an iteration of (this time approximate) $\\gamma$-compression, that stands behind Q-learning. The more inner steps it makes the more accurate is the compression.\n",
+ "* max_grad_norm - just huge enough. In torch clip_grad_norm also evaluates the norm before clipping and it can be convenient for logging."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Video"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Record sessions\n",
+ "\n",
+ "import gym.wrappers\n",
+ "\n",
+ "with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n",
+ " sessions = [evaluate(env_monitor, agent, n_games=n_lives, greedy=True) for _ in range(10)]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Show video. This may not work in some setups. If it doesn't\n",
+ "# work for you, you can download the videos and view them locally.\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n",
+ "\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-1])) # You can also try other indices"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Submit to Coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_breakout\n",
+ "env = make_env()\n",
+ "submit_breakout(agent, env, evaluate, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "```\n",
+ "```\n",
+ "```\n",
+ "```\n",
+ "```\n",
+ "```\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "## Let's have a closer look at this.\n",
+ "\n",
+ "If average episode score is below 200 using all 5 lives, then probably DQN has not converged fully. But anyway let's make a more complete record of an episode."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "eval_env = make_env(clip_rewards=False)\n",
+ "record = utils.play_and_log_episode(eval_env, agent)\n",
+ "print('total reward for life:', np.sum(record['rewards']))\n",
+ "for key in record:\n",
+ " print(key)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fig = plt.figure(figsize=(5, 5))\n",
+ "ax = fig.add_subplot(1, 1, 1)\n",
+ "\n",
+ "ax.scatter(record['v_mc'], record['v_agent'])\n",
+ "ax.plot(sorted(record['v_mc']), sorted(record['v_mc']),\n",
+ " 'black', linestyle='--', label='x=y')\n",
+ "\n",
+ "ax.grid()\n",
+ "ax.legend()\n",
+ "ax.set_title('State Value Estimates')\n",
+ "ax.set_xlabel('Monte-Carlo')\n",
+ "ax.set_ylabel('Agent')\n",
+ "\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "$\\hat V_{Monte-Carlo}(s_t) = \\sum_{\\tau=0}^{episode~end} \\gamma^{\\tau-t}r_t$"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Is there a big bias? It's ok, anyway it works."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## More\n",
+ "\n",
+ "If you want to play with DQN a bit more, here's a list of things you can try with it:\n",
+ "\n",
+ "### Easy:\n",
+ "* Implementing __double q-learning__ shouldn't be a problem, if you already have target networks in place.\n",
+ " * You will probably need `tf.argmax` to select best actions\n",
+ " * Here's an original [article](https://arxiv.org/abs/1509.06461)\n",
+ "\n",
+ "* __Dueling__ architecture is also quite straightforward, if you have standard DQN.\n",
+ " * You will need to change network architecture, namely the q-values layer\n",
+ " * It must now contain two heads: V(s) and A(s,a), both dense layers\n",
+ " * You should then add them up via elemwise sum layer.\n",
+ " * Here's an [article](https://arxiv.org/pdf/1511.06581.pdf)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Hard: Prioritized experience replay\n",
+ "\n",
+ "In this section, you're invited to implement prioritized experience replay:\n",
+ "\n",
+ "* You will probably need to provide a custom data structure;\n",
+ "* Once pool.update is called, collect the pool.experience_replay.observations, actions, rewards and is_alive and store them in your data structure;\n",
+ "* You can now sample such transitions in proportion to the error (see [article](https://arxiv.org/abs/1511.05952)) for training.\n",
+ "\n",
+ "It's probably more convenient to explicitly declare inputs for \"sample observations\", \"sample actions\" and so on to plug them into q-learning.\n",
+ "\n",
+ "Prioritized (and even normal) experience replay should greatly reduce an amount of game sessions you need to play in order to achieve good performance. \n",
+ "\n",
+ "While its effect on runtime is limited for atari, more complicated envs (further in the course) will certainly benefit for it.\n",
+ "\n",
+ "There is even more out there - see this [overview article](https://arxiv.org/abs/1710.02298)."
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week4_approx/practice_approx_qlearning_pytorch.ipynb b/week4_approx/practice_approx_qlearning_pytorch.ipynb
index 12beac6fd..e6f5934fb 100644
--- a/week4_approx/practice_approx_qlearning_pytorch.ipynb
+++ b/week4_approx/practice_approx_qlearning_pytorch.ipynb
@@ -1 +1,403 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_approx_qlearning_pytorch.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"aPN2oBWR2TgO"},"source":["# Approximate q-learning\n","\n","In this notebook you will teach a __PyTorch__ neural network to do Q-learning."]},{"cell_type":"code","metadata":{"id":"OBekm_922Tga"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"zftcYyMf2Tgc"},"source":["import gym\n","import numpy as np\n","import pandas as pd\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"PWidR5VX2Tgd"},"source":["env = gym.make(\"CartPole-v0\").env\n","env.reset()\n","n_actions = env.action_space.n\n","state_dim = env.observation_space.shape\n","\n","plt.imshow(env.render(\"rgb_array\"))\n","env.close()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"nFFNF7eQ2Tgd"},"source":["# Approximate Q-learning: building the network\n","\n","To train a neural network policy one must have a neural network policy. Let's build it.\n","\n","\n","Since we're working with a pre-extracted features (cart positions, angles and velocities), we don't need a complicated network yet. In fact, let's build something like this for starters:\n","\n","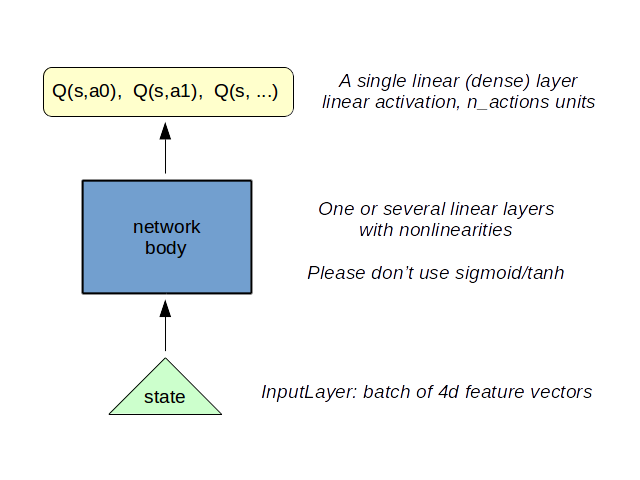\n","\n","For your first run, please, only use linear layers (`nn.Linear`) and activations. Stuff like batch normalization or dropout may ruin everything if used haphazardly. \n","\n","Also, please, avoid using nonlinearities like sigmoid & tanh: since agent's observations are not normalized, sigmoids might be saturated at initialization. Instead, use non-saturating nonlinearities like ReLU.\n","\n","Ideally you should start small, with maybe 1-2 hidden layers with < 200 neurons and then increase the network size, if agent doesn't beat the target score."]},{"cell_type":"code","metadata":{"id":"uBBktLrw2Tgf"},"source":["import torch\n","import torch.nn as nn\n","import torch.nn.functional as F"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"xCrXDvCB2Tgf"},"source":["network = nn.Sequential()\n","\n","network.add_module('layer1', )\n","\n","\n","\n","# hint: use state_dim[0] as input size"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ydDh_xL-2Tgg"},"source":["def get_action(state, epsilon=0):\n"," \"\"\"\n"," sample actions with epsilon-greedy policy\n"," recap: with p = epsilon pick random action, else pick action with highest Q(s,a)\n"," \"\"\"\n"," state = torch.tensor(state[None], dtype=torch.float32)\n"," q_values = network(state).detach().numpy()\n","\n"," \n","\n"," return int( )"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"RgToYvqR2Tgg"},"source":["s = env.reset()\n","assert tuple(network(torch.tensor([s]*3, dtype=torch.float32)).size()) == (\n"," 3, n_actions), \"please, make sure your model maps state s -> [Q(s,a0), ..., Q(s, a_last)]\"\n","assert isinstance(list(network.modules(\n","))[-1], nn.Linear), \"please, make sure you predict q-values without nonlinearity (ignore, if you know, what you're doing)\"\n","assert isinstance(get_action(\n"," s), int), \"get_action(s) must return int, not %s. try int(action)\" % (type(get_action(s)))\n","\n","# test epsilon-greedy exploration\n","for eps in [0., 0.1, 0.5, 1.0]:\n"," state_frequencies = np.bincount(\n"," [get_action(s, epsilon=eps) for i in range(10000)], minlength=n_actions)\n"," best_action = state_frequencies.argmax()\n"," assert abs(state_frequencies[best_action] -\n"," 10000 * (1 - eps + eps / n_actions)) < 200\n"," for other_action in range(n_actions):\n"," if other_action != best_action:\n"," assert abs(state_frequencies[other_action] -\n"," 10000 * (eps / n_actions)) < 200\n"," print('e=%.1f tests passed' % eps)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"2RoJ4wr_2Tgh"},"source":["### Q-learning via gradient descent\n","\n","Now we shall train our agent's Q-function by minimizing the TD loss:\n","$$ L = { 1 \\over N} \\sum_i (Q_{\\theta}(s,a) - [r(s,a) + \\gamma \\cdot max_{a'} Q_{-}(s', a')]) ^2 $$\n","\n","\n","Where\n","* $s, a, r, s'$ are current state, action, reward and next state respectively;\n","* $\\gamma$ is the discount factor defined two cells above.\n","\n","The tricky part is with $Q_{-}(s',a')$. From an engineering standpoint, it's the same as $Q_{\\theta}$ - the output of your neural network policy. However, when doing gradient descent, __we won't propagate gradients through it__ to make training more stable (see lectures).\n","\n","To do so, we shall use `x.detach()` function, which basically says \"consider this thing constant when doing backprop\"."]},{"cell_type":"code","metadata":{"id":"f8GMT3uJ2Tgi"},"source":["def compute_td_loss(states, actions, rewards, next_states, is_done, gamma=0.99, check_shapes=False):\n"," \"\"\" Compute td loss using torch operations only. Use the formula above. \"\"\"\n"," states = torch.tensor(\n"," states, dtype=torch.float32) # shape: [batch_size, state_size]\n"," actions = torch.tensor(actions, dtype=torch.long) # shape: [batch_size]\n"," rewards = torch.tensor(rewards, dtype=torch.float32) # shape: [batch_size]\n"," # shape: [batch_size, state_size]\n"," next_states = torch.tensor(next_states, dtype=torch.float32)\n"," is_done = torch.tensor(is_done, dtype=torch.uint8) # shape: [batch_size]\n","\n"," # get q-values for all actions in current states\n"," predicted_qvalues = network(states)\n","\n"," # select q-values for chosen actions\n"," predicted_qvalues_for_actions = predicted_qvalues[\n"," range(states.shape[0]), actions\n"," ]\n","\n"," # compute q-values for all actions in next states\n"," predicted_next_qvalues = \n","\n"," # compute V*(next_states) using predicted next q-values\n"," next_state_values = \n"," assert next_state_values.dtype == torch.float32\n","\n"," # compute \"target q-values\" for loss - it's what's inside square parentheses in the above formula.\n"," target_qvalues_for_actions = \n","\n"," # at the last state we shall use simplified formula: Q(s,a) = r(s,a) since s' doesn't exist\n"," target_qvalues_for_actions = torch.where(\n"," is_done, rewards, target_qvalues_for_actions)\n","\n"," # mean squared error loss to minimize\n"," loss = torch.mean((predicted_qvalues_for_actions -\n"," target_qvalues_for_actions.detach()) ** 2)\n","\n"," if check_shapes:\n"," assert predicted_next_qvalues.data.dim(\n"," ) == 2, \"make sure, that you predicted q-values for all actions in next state\"\n"," assert next_state_values.data.dim(\n"," ) == 1, \"make sure, that you computed V(s') as maximum over just the actions axis and not all axes\"\n"," assert target_qvalues_for_actions.data.dim(\n"," ) == 1, \"there's something wrong with target q-values, they must be a vector\"\n","\n"," return loss"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"mxwxB5Ri2Tgj"},"source":["# sanity checks\n","s = env.reset()\n","a = env.action_space.sample()\n","next_s, r, done, _ = env.step(a)\n","loss = compute_td_loss([s], [a], [r], [next_s], [done], check_shapes=True)\n","loss.backward()\n","\n","assert len(loss.size()) == 0, \"you must return scalar loss - mean over batch\"\n","assert np.any(next(network.parameters()).grad.detach().numpy() !=\n"," 0), \"loss must be differentiable w.r.t. network weights\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"0vAarxzd2Tgm"},"source":["### Playing the game"]},{"cell_type":"code","metadata":{"id":"t2Ym4rWK2Tgn"},"source":["opt = torch.optim.Adam(network.parameters(), lr=1e-4)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"yuIOB39j2Tgs"},"source":["def generate_session(env, t_max=1000, epsilon=0, train=False):\n"," \"\"\"play env with an approximate q-learning agent and train it at the same time\"\"\"\n"," total_reward = 0\n"," s = env.reset()\n","\n"," for t in range(t_max):\n"," a = get_action(s, epsilon=epsilon)\n"," next_s, r, done, _ = env.step(a)\n","\n"," if train:\n"," opt.zero_grad()\n"," compute_td_loss([s], [a], [r], [next_s], [done]).backward()\n"," opt.step()\n","\n"," total_reward += r\n"," s = next_s\n"," if done:\n"," break\n","\n"," return total_reward"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"kF4blQ1c2Tgt"},"source":["epsilon = 0.5"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"4KSiZ7ww2Tgu"},"source":["for i in range(1000):\n"," session_rewards = [generate_session(env, epsilon=epsilon, train=True) for _ in range(100)]\n"," print(\"epoch #{}\\tmean reward = {:.3f}\\tepsilon = {:.3f}\".format(i, np.mean(session_rewards), epsilon))\n","\n"," epsilon *= 0.99\n"," assert epsilon >= 1e-4, \"Make sure epsilon is always nonzero during training\"\n","\n"," if np.mean(session_rewards) > 300:\n"," print(\"You Win!\")\n"," break"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ebxGOO-82Tgu"},"source":["### How to interpret the results\n","\n","\n","Welcome to the f.. world of deep f...n reinforcement learning. Don't expect agent's reward to go up smoothly. Hope for it to increase eventually. If it deems you worthy.\n","\n","Seriously though,\n","* __ mean reward__ is the average reward per game. For the correct implementation it may stay low for some 10 epochs, then start growing, while oscilating insanely and converges by ~50-100 steps depending on the network architecture. \n","* If it never reaches target score by the end of for loop, try increasing the number of hidden neurons or look at the epsilon.\n","* __ epsilon__ - agent's willingness to explore. If you see, that agent's already at < 0.01 epsilon before it's is at least 200, just reset it back to 0.1 - 0.5."]},{"cell_type":"markdown","metadata":{"id":"VEbqShOd2Tgu"},"source":["### Record videos\n","\n","As usual, we now use `gym.wrappers.Monitor` to record the video of our agent playing the game. Unlike our previous attempts with state binarization, this time we expect our agent to act ~~(or fail)~~ more smoothly since there's no more binarization error at play.\n","\n","As you already did with tabular q-learning, we set epsilon=0 for final evaluation to prevent agent from exploring himself to death."]},{"cell_type":"code","metadata":{"id":"w0QmWMYt2Tgv"},"source":["# Record sessions\n","\n","import gym.wrappers\n","\n","with gym.wrappers.Monitor(gym.make(\"CartPole-v0\"), directory=\"videos\", force=True) as env_monitor:\n"," sessions = [generate_session(env_monitor, epsilon=0, train=False) for _ in range(100)]"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"IqQR973j2Tgv"},"source":["# Show video. This may not work in some setups. If it doesn't\n","# work for you, you can download the videos and view them locally.\n","\n","from pathlib import Path\n","from IPython.display import HTML\n","\n","video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n","\n","HTML(\"\"\"\n","\n","\"\"\".format(video_names[-1])) # You can also try other indices"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"1q-z8EaL2Tgw"},"source":["## Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"gdv8BSJm2Tgx"},"source":["from submit import submit_cartpole\n","submit_cartpole(generate_session, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Approximate q-learning\n",
+ "\n",
+ "In this notebook you will teach a __PyTorch__ neural network to do Q-learning."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week4_approx/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env = gym.make(\"CartPole-v0\").env\n",
+ "env.reset()\n",
+ "n_actions = env.action_space.n\n",
+ "state_dim = env.observation_space.shape\n",
+ "\n",
+ "plt.imshow(env.render(\"rgb_array\"))\n",
+ "env.close()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Approximate Q-learning: building the network\n",
+ "\n",
+ "To train a neural network policy one must have a neural network policy. Let's build it.\n",
+ "\n",
+ "\n",
+ "Since we're working with a pre-extracted features (cart positions, angles and velocities), we don't need a complicated network yet. In fact, let's build something like this for starters:\n",
+ "\n",
+ "\n",
+ "\n",
+ "For your first run, please, only use linear layers (`nn.Linear`) and activations. Stuff like batch normalization or dropout may ruin everything if used haphazardly. \n",
+ "\n",
+ "Also, please, avoid using nonlinearities like sigmoid & tanh: since agent's observations are not normalized, sigmoids might be saturated at initialization. Instead, use non-saturating nonlinearities like ReLU.\n",
+ "\n",
+ "Ideally you should start small, with maybe 1-2 hidden layers with < 200 neurons and then increase the network size, if agent doesn't beat the target score."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "network = nn.Sequential()\n",
+ "\n",
+ "network.add_module('layer1', )\n",
+ "\n",
+ "\n",
+ "\n",
+ "# hint: use state_dim[0] as input size"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_action(state, epsilon=0):\n",
+ " \"\"\"\n",
+ " sample actions with epsilon-greedy policy\n",
+ " recap: with p = epsilon pick random action, else pick action with highest Q(s,a)\n",
+ " \"\"\"\n",
+ " state = torch.tensor(state[None], dtype=torch.float32)\n",
+ " q_values = network(state).detach().numpy()\n",
+ "\n",
+ " \n",
+ "\n",
+ " return int( )"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s = env.reset()\n",
+ "assert tuple(network(torch.tensor([s]*3, dtype=torch.float32)).size()) == (\n",
+ " 3, n_actions), \"please, make sure your model maps state s -> [Q(s,a0), ..., Q(s, a_last)]\"\n",
+ "assert isinstance(list(network.modules(\n",
+ "))[-1], nn.Linear), \"please, make sure you predict q-values without nonlinearity (ignore, if you know, what you're doing)\"\n",
+ "assert isinstance(get_action(\n",
+ " s), int), \"get_action(s) must return int, not %s. try int(action)\" % (type(get_action(s)))\n",
+ "\n",
+ "# test epsilon-greedy exploration\n",
+ "for eps in [0., 0.1, 0.5, 1.0]:\n",
+ " state_frequencies = np.bincount(\n",
+ " [get_action(s, epsilon=eps) for i in range(10000)], minlength=n_actions)\n",
+ " best_action = state_frequencies.argmax()\n",
+ " assert abs(state_frequencies[best_action] -\n",
+ " 10000 * (1 - eps + eps / n_actions)) < 200\n",
+ " for other_action in range(n_actions):\n",
+ " if other_action != best_action:\n",
+ " assert abs(state_frequencies[other_action] -\n",
+ " 10000 * (eps / n_actions)) < 200\n",
+ " print('e=%.1f tests passed' % eps)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Q-learning via gradient descent\n",
+ "\n",
+ "Now we shall train our agent's Q-function by minimizing the TD loss:\n",
+ "$$ L = { 1 \\over N} \\sum_i (Q_{\\theta}(s,a) - [r(s,a) + \\gamma \\cdot max_{a'} Q_{-}(s', a')]) ^2 $$\n",
+ "\n",
+ "\n",
+ "Where\n",
+ "* $s, a, r, s'$ are current state, action, reward and next state respectively;\n",
+ "* $\\gamma$ is the discount factor defined two cells above.\n",
+ "\n",
+ "The tricky part is with $Q_{-}(s',a')$. From an engineering standpoint, it's the same as $Q_{\\theta}$ - the output of your neural network policy. However, when doing gradient descent, __we won't propagate gradients through it__ to make training more stable (see lectures).\n",
+ "\n",
+ "To do so, we shall use `x.detach()` function, which basically says \"consider this thing constant when doing backprop\"."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def compute_td_loss(states, actions, rewards, next_states, is_done, gamma=0.99, check_shapes=False):\n",
+ " \"\"\" Compute td loss using torch operations only. Use the formula above. \"\"\"\n",
+ " states = torch.tensor(\n",
+ " states, dtype=torch.float32) # shape: [batch_size, state_size]\n",
+ " actions = torch.tensor(actions, dtype=torch.long) # shape: [batch_size]\n",
+ " rewards = torch.tensor(rewards, dtype=torch.float32) # shape: [batch_size]\n",
+ " # shape: [batch_size, state_size]\n",
+ " next_states = torch.tensor(next_states, dtype=torch.float32)\n",
+ " is_done = torch.tensor(is_done, dtype=torch.uint8) # shape: [batch_size]\n",
+ "\n",
+ " # get q-values for all actions in current states\n",
+ " predicted_qvalues = network(states)\n",
+ "\n",
+ " # select q-values for chosen actions\n",
+ " predicted_qvalues_for_actions = predicted_qvalues[\n",
+ " range(states.shape[0]), actions\n",
+ " ]\n",
+ "\n",
+ " # compute q-values for all actions in next states\n",
+ " predicted_next_qvalues = \n",
+ "\n",
+ " # compute V*(next_states) using predicted next q-values\n",
+ " next_state_values = \n",
+ " assert next_state_values.dtype == torch.float32\n",
+ "\n",
+ " # compute \"target q-values\" for loss - it's what's inside square parentheses in the above formula.\n",
+ " target_qvalues_for_actions = \n",
+ "\n",
+ " # at the last state we shall use simplified formula: Q(s,a) = r(s,a) since s' doesn't exist\n",
+ " target_qvalues_for_actions = torch.where(\n",
+ " is_done, rewards, target_qvalues_for_actions)\n",
+ "\n",
+ " # mean squared error loss to minimize\n",
+ " loss = torch.mean((predicted_qvalues_for_actions -\n",
+ " target_qvalues_for_actions.detach()) ** 2)\n",
+ "\n",
+ " if check_shapes:\n",
+ " assert predicted_next_qvalues.data.dim(\n",
+ " ) == 2, \"make sure, that you predicted q-values for all actions in next state\"\n",
+ " assert next_state_values.data.dim(\n",
+ " ) == 1, \"make sure, that you computed V(s') as maximum over just the actions axis and not all axes\"\n",
+ " assert target_qvalues_for_actions.data.dim(\n",
+ " ) == 1, \"there's something wrong with target q-values, they must be a vector\"\n",
+ "\n",
+ " return loss"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sanity checks\n",
+ "s = env.reset()\n",
+ "a = env.action_space.sample()\n",
+ "next_s, r, done, _ = env.step(a)\n",
+ "loss = compute_td_loss([s], [a], [r], [next_s], [done], check_shapes=True)\n",
+ "loss.backward()\n",
+ "\n",
+ "assert len(loss.size()) == 0, \"you must return scalar loss - mean over batch\"\n",
+ "assert np.any(next(network.parameters()).grad.detach().numpy() !=\n",
+ " 0), \"loss must be differentiable w.r.t. network weights\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Playing the game"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "opt = torch.optim.Adam(network.parameters(), lr=1e-4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def generate_session(env, t_max=1000, epsilon=0, train=False):\n",
+ " \"\"\"play env with an approximate q-learning agent and train it at the same time\"\"\"\n",
+ " total_reward = 0\n",
+ " s = env.reset()\n",
+ "\n",
+ " for t in range(t_max):\n",
+ " a = get_action(s, epsilon=epsilon)\n",
+ " next_s, r, done, _ = env.step(a)\n",
+ "\n",
+ " if train:\n",
+ " opt.zero_grad()\n",
+ " compute_td_loss([s], [a], [r], [next_s], [done]).backward()\n",
+ " opt.step()\n",
+ "\n",
+ " total_reward += r\n",
+ " s = next_s\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " return total_reward"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "epsilon = 0.5"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(1000):\n",
+ " session_rewards = [generate_session(env, epsilon=epsilon, train=True) for _ in range(100)]\n",
+ " print(\"epoch #{}\\tmean reward = {:.3f}\\tepsilon = {:.3f}\".format(i, np.mean(session_rewards), epsilon))\n",
+ "\n",
+ " epsilon *= 0.99\n",
+ " assert epsilon >= 1e-4, \"Make sure epsilon is always nonzero during training\"\n",
+ "\n",
+ " if np.mean(session_rewards) > 300:\n",
+ " print(\"You Win!\")\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### How to interpret the results\n",
+ "\n",
+ "\n",
+ "Welcome to the f.. world of deep f...n reinforcement learning. Don't expect agent's reward to go up smoothly. Hope for it to increase eventually. If it deems you worthy.\n",
+ "\n",
+ "Seriously though,\n",
+ "* __ mean reward__ is the average reward per game. For the correct implementation it may stay low for some 10 epochs, then start growing, while oscilating insanely and converges by ~50-100 steps depending on the network architecture. \n",
+ "* If it never reaches target score by the end of for loop, try increasing the number of hidden neurons or look at the epsilon.\n",
+ "* __ epsilon__ - agent's willingness to explore. If you see, that agent's already at < 0.01 epsilon before it's is at least 200, just reset it back to 0.1 - 0.5."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Record videos\n",
+ "\n",
+ "As usual, we now use `gym.wrappers.Monitor` to record the video of our agent playing the game. Unlike our previous attempts with state binarization, this time we expect our agent to act ~~(or fail)~~ more smoothly since there's no more binarization error at play.\n",
+ "\n",
+ "As you already did with tabular q-learning, we set epsilon=0 for final evaluation to prevent agent from exploring himself to death."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Record sessions\n",
+ "\n",
+ "import gym.wrappers\n",
+ "\n",
+ "with gym.wrappers.Monitor(gym.make(\"CartPole-v0\"), directory=\"videos\", force=True) as env_monitor:\n",
+ " sessions = [generate_session(env_monitor, epsilon=0, train=False) for _ in range(100)]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Show video. This may not work in some setups. If it doesn't\n",
+ "# work for you, you can download the videos and view them locally.\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n",
+ "\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-1])) # You can also try other indices"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Submit to Coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_cartpole\n",
+ "submit_cartpole(generate_session, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week5_policy_based/practice_actorcritic_pytorch.ipynb b/week5_policy_based/practice_actorcritic_pytorch.ipynb
index 25fdf2eb9..e8836449a 100644
--- a/week5_policy_based/practice_actorcritic_pytorch.ipynb
+++ b/week5_policy_based/practice_actorcritic_pytorch.ipynb
@@ -1 +1,716 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"accelerator":"GPU","language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_actorcritic_pytorch.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"Mm0nB7a4bSlJ"},"source":["### Deep Kung-Fu with advantage actor-critic\n","\n","In this notebook you'll build a deep reinforcement learning agent for Atari [Kung-Fu Master](https://gym.openai.com/envs/KungFuMaster-v0/) and train it with Advantage Actor-Critic.\n","\n","Note that, strictly speaking, this will be neither [A3C](https://arxiv.org/abs/1602.01783) nor [A2C](https://openai.com/blog/baselines-acktr-a2c/), but rather a simplified version of the latter.\n","\n","Special thanks to Jesse Grabowski for making an [initial version](https://www.coursera.org/learn/practical-rl/discussions/all/threads/6iDjkbhPQoGg45G4T7KBHQ/replies/5eM_hA7vEeuoKgpcLmLqdw) of the PyTorch port of this assignment.\n","\n",""]},{"cell_type":"code","metadata":{"id":"Z7OIPx9GbSlQ"},"source":["import sys, os\n","if 'google.colab' in sys.modules:\n"," %tensorflow_version 1.x\n"," \n"," if not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/submit.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/atari_util.py\n","\n"," !touch .setup_complete\n","\n","# If you are running on a server, launch xvfb to record game videos\n","# Please make sure you have xvfb installed\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"uSQO0FVvbSlR"},"source":["import numpy as np\n","\n","import matplotlib.pyplot as plt\n","%matplotlib inline\n","\n","from IPython.display import display"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Wf9JwXT4bSlS"},"source":["For starters, let's take a look at the game itself:\n","\n","* Image resized to 42x42 and converted to grayscale to run faster\n","* Agent sees last 4 frames of game to account for object velocity"]},{"cell_type":"code","metadata":{"id":"GUrCxRPRbSlS"},"source":["import gym\n","from atari_util import PreprocessAtari\n","\n","def make_env():\n"," env = gym.make(\"KungFuMasterDeterministic-v0\")\n"," env = PreprocessAtari(\n"," env, height=42, width=42,\n"," crop=lambda img: img[60:-30, 5:],\n"," dim_order='pytorch',\n"," color=False, n_frames=4)\n"," return env\n","\n","env = make_env()\n","\n","obs_shape = env.observation_space.shape\n","n_actions = env.action_space.n\n","\n","print(\"Observation shape:\", obs_shape)\n","print(\"Num actions:\", n_actions)\n","print(\"Action names:\", env.env.env.get_action_meanings())"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"nJOIOd5JbSlS"},"source":["s = env.reset()\n","for _ in range(100):\n"," s, _, _, _ = env.step(env.action_space.sample())\n","\n","plt.title('Game image')\n","plt.imshow(env.render('rgb_array'))\n","plt.show()\n","\n","plt.title('Agent observation (4-frame buffer)')\n","plt.imshow(s.transpose([1, 0, 2]).reshape([42, -1]), cmap='gray')\n","plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"6X5IlFzFbSlT"},"source":["### Build a network\n","\n","We now have to build an agent for actor-critic training — a convolutional neural network, that converts states into action probabilities $\\pi$ and state values $V$.\n","\n","Your assignment here is to build and apply the neural network. You can use any framework you want, but in this notebook we prepared for you a template in PyTorch.\n","\n","For starters, we want you to implement this architecture:\n","\n","\n","\n","Notes:\n","* This diagram was originally made for Tensorflow. In PyTorch, the input shape is `[batch_size, 4, 42, 42]`.\n","* Use convolution kernel size 3x3 throughout.\n","* After your agent gets mean reward above 5000, we encourage you to experiment with the model architecture to score even better."]},{"cell_type":"code","metadata":{"id":"RstULNJjbSlT"},"source":["import torch\n","import torch.nn as nn\n","import torch.nn.functional as F"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"9Tf7mmE7bSlT"},"source":["device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\n","device"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"GxJtaFdMbSlU"},"source":["def conv2d_size_out(size, kernel_size, stride):\n"," \"\"\"\n"," Helper function to compute the spatial dimensions of the output\n"," of a convolutional layer, copied from Week 4.\n","\n"," Common use case:\n"," cur_layer_img_w = conv2d_size_out(cur_layer_img_w, kernel_size, stride)\n"," cur_layer_img_h = conv2d_size_out(cur_layer_img_h, kernel_size, stride)\n"," This can be used to understand the shape for the dense layer's input.\n"," \"\"\"\n"," return (size - (kernel_size - 1) - 1) // stride + 1"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"bef67TYWbSlU"},"source":["class Agent(nn.Module):\n"," def __init__(self, input_dims, n_actions, lr):\n"," super(Agent, self).__init__()\n"," \n"," self.input_dims = input_dims\n","\n"," # Initialize layers as shown in the image above\n"," \n","\n"," self.optimizer = torch.optim.Adam(self.parameters(), lr=lr)\n"," self.device = device\n"," self.to(self.device)\n"," \n"," def forward(self, state):\n"," # Compute logits and values using network.\n"," # Note, that if you do so naively, your state_values will have shape\n"," # ending in 1, since they come from a Linear(..., 1) layer. It is useful\n"," # to .squeeze(dim=-1) them, since this will help to avoid shape conflicts\n"," # in the loss function part, after we add multiple environments.\n"," # If you don't do this here, don't forget to do that in the\n"," # loss function!\n"," \n"," \n","\n"," return logits, state_values\n","\n"," def choose_action(self, observation):\n"," # PyTorch wants a batch dimension, so if we feed only a single observation we need to wrap it with an extra layer.\n"," # This line will allow the network to handle both single and multi-environment tests.\n"," if observation.ndim == 3:\n"," observation = [observation]\n","\n"," observation = torch.tensor(observation, dtype=torch.float32, device=device)\n"," # Pass states into the agent network and get back logits and states\n"," logits, _ = \n"," \n"," policy = F.softmax(logits, dim=-1)\n","\n"," actions = np.array([np.random.choice(len(p), p=p) for p in policy.detach().cpu().numpy()])\n"," return actions"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"slAvbUZ-bSlW"},"source":["# Test network\n","\n","agent = Agent(input_dims=obs_shape, n_actions=n_actions, lr=1e-4)\n","state = env.reset()\n","state = torch.tensor([state], dtype=torch.float32, device=device)\n","logits, state_values = agent(state)\n","\n","assert isinstance(logits, torch.Tensor) and len(logits.shape) == 2, \\\n"," \"Please return a 2D Torch tensor of logits with shape (batch_size, n_actions). You returned %s\" % repr(logits)\n","assert isinstance(state_values, torch.Tensor) and len(state_values.shape) == 1, \\\n"," \"Please return a 1D Torch tensor of state values with shape (batch_size,). You returned %s\" % repr(state_values)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Jj5OOiklbSlW"},"source":["###Actor-Critic\n","\n","Here we define loss functions and learning algorithms as usual."]},{"cell_type":"code","metadata":{"id":"QDpaAgeebSlX"},"source":["def compute_actor_critic_loss(agent, state, action, reward, next_state, done,\n"," gamma=0.99):\n"," # Infer batch_size from shape of state tensor:\n"," batch_size = state.shape[0]\n","\n"," # Convert everything to a tensor, send to GPU if available\n"," state = torch.tensor(state, dtype=torch.float32, device=device)\n"," next_state = torch.tensor(next_state, dtype=torch.float32, device=device)\n"," reward = torch.tensor(reward, dtype=torch.float32, device=device)\n"," done = torch.tensor(done, dtype=torch.bool, device=device)\n","\n"," # logits[n_envs, n_actions] and state_values[n_envs, n_actions]\n"," logits, state_value = agent(state)\n"," next_logits, next_state_value = agent(next_state)\n","\n"," # Probabilities and log-probabilities for all actions\n"," probs = F.softmax(logits, dim=-1) #[n_envs, n_actions]\n"," logprobs = F.log_softmax(logits, dim=-1) #[n_envs, n_actions]\n","\n"," # Set new state values with done == 1 to be 0.0 (no future rewards if done!)\n"," next_state_value[done] = 0.0\n","\n"," # Compute target state values using temporal difference formula.\n"," # Use reward, gamma, and next_state_value.\n"," target_state_value = \n","\n"," # Compute advantage using reward, gamma, state_value, and next_state_value.\n"," advantage = \n","\n"," # We need to slice out only the actions we took for actor loss -- we can use\n"," # the actions themselves as indexes, but we also need indexes on the batch dim\n"," batch_idx = np.arange(batch_size)\n"," logp_actions = logprobs[batch_idx, action]\n","\n"," # Compute policy entropy given logits_seq. Mind the \"-\" sign!\n"," entropy = \n","\n"," actor_loss = -(logp_actions * advantage.detach()).mean() - 0.001 * entropy.mean()\n"," critic_loss = F.mse_loss(target_state_value.detach(), state_value)\n","\n"," total_loss = actor_loss + critic_loss\n","\n"," # Never forget to zero grads in PyTorch!\n"," agent.optimizer.zero_grad()\n"," total_loss.backward()\n"," agent.optimizer.step()\n","\n"," return actor_loss.cpu().detach().numpy(), critic_loss.cpu().detach().numpy(), entropy.cpu().detach().numpy()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Gj5NAU2sbSlX"},"source":["state = env.reset()\n","state = torch.tensor([state], dtype=torch.float32).to(device)\n","logits, value = agent(state)\n","print(\"action logits:\\n\", logits)\n","print(\"state values:\\n\", value)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"MkxuaHr7bSlY"},"source":["### Let's play!\n","Let's build a function, that measures the agent's average reward."]},{"cell_type":"code","metadata":{"id":"7aQverLSbSlZ"},"source":["def evaluate(agent, env, n_games=1):\n"," \"\"\"Plays the game from start till done, returns per-game rewards \"\"\"\n","\n"," game_rewards = []\n"," for _ in range(n_games):\n"," state = env.reset()\n","\n"," total_reward = 0\n"," while True:\n"," action = agent.choose_action(state)\n"," state, reward, done, info = env.step(action)\n"," total_reward += reward\n"," if done:\n"," break\n","\n"," game_rewards.append(total_reward)\n"," return game_rewards"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"IT7qKpXTbSlZ"},"source":["import gym.wrappers\n","\n","with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n"," rewards = evaluate(agent, env_monitor, n_games=3)\n","\n","print(rewards)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"RWGFQv1mbSlZ"},"source":["# Show video. This may not work in some setups. If it doesn't\n","# work for you, you can download the videos and view them locally.\n","\n","from pathlib import Path\n","from IPython.display import HTML\n","\n","video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n","\n","HTML(\"\"\"\n","\n","\"\"\".format(video_names[-1])) # You can also try other indices"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ExJcWIKhbSlZ"},"source":["### Training on parallel games\n","\n","\n","\n","\n","To make actor-critic training more stable, we shall play several games in parallel. This means you'll have to initialize several parallel gym envs, send agent's actions there and .reset() each env if it becomes terminated. To minimize learner brain damage, we've taken care of them for you - just make sure you read it before you use it."]},{"cell_type":"code","metadata":{"id":"hPetUzY0bSla"},"source":["class EnvBatch:\n"," def __init__(self, n_envs = 10):\n"," \"\"\" Creates n_envs environments and babysits them for ya' \"\"\"\n"," self.envs = [make_env() for _ in range(n_envs)]\n"," \n"," def reset(self):\n"," \"\"\" Reset all games and return [n_envs, *obs_shape] observations \"\"\"\n"," return np.array([env.reset() for env in self.envs])\n"," \n"," def step(self, actions):\n"," \"\"\"\n"," Send a vector[batch_size] of actions into respective environments\n"," :returns: observations[n_envs, *obs_shape], rewards[n_envs], done[n_envs,], info[n_envs]\n"," \"\"\"\n"," results = [env.step(a) for env, a in zip(self.envs, actions)]\n"," new_obs, rewards, done, infos = map(np.array, zip(*results))\n"," \n"," # reset environments automatically\n"," for i in range(len(self.envs)):\n"," if done[i]:\n"," new_obs[i] = self.envs[i].reset()\n"," \n"," return new_obs, rewards, done, infos"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"jRwbjXSRbSla"},"source":["__Let's try it out:__"]},{"cell_type":"code","metadata":{"id":"NEdl1FfGbSla"},"source":["env_batch = EnvBatch(10)\n","\n","batch_states = env_batch.reset()\n","batch_actions = agent.choose_action(batch_states)\n","batch_next_states, batch_rewards, batch_done, _ = env_batch.step(batch_actions)\n","\n","print(\"State shape:\", batch_states.shape)\n","print(\"Actions:\", batch_actions)\n","print(\"Rewards:\", batch_rewards)\n","print(\"Done:\", batch_done)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"rougcG6FbSla"},"source":["# Sanity Check"]},{"cell_type":"code","metadata":{"id":"C-egoaOubSlb"},"source":["agent = Agent(lr=1e-4, n_actions=n_actions, input_dims=obs_shape)\n","\n","state = env_batch.reset()\n","action = agent.choose_action(state)\n","\n","next_state, reward, done, info = env_batch.step(action)\n","\n","l_act, l_crit, ent = compute_actor_critic_loss(agent, state, action, reward, next_state, done)\n","\n","assert abs(l_act) < 100 and abs(l_crit) < 100, \"losses seem abnormally large\"\n","assert 0 <= ent.mean() <= np.log(n_actions), \"impossible entropy value, double-check the formula pls\"\n","if ent.mean() < np.log(n_actions) / 2:\n"," print(\"Entropy is too low for an untrained agent\")\n","print(\"You just might be fine!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"rgjO_IzubSlb"},"source":["# Train \n","\n","Just the usual - play a bit, compute loss, follow the graidents, repeat a few million times.\n","\n",""]},{"cell_type":"code","metadata":{"id":"D9871CnZbSlb"},"source":["import pandas as pd\n","\n","def ewma(x, span=100):\n"," return pd.DataFrame({'x':np.asarray(x)}).x.ewm(span=span).mean().values\n","\n","env_batch = EnvBatch(10)\n","batch_states = env_batch.reset()\n","\n","rewards_history = []\n","entropy_history = []"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"P6J4LMv1bSlb"},"source":["Please pay extra attention to how we scale rewards in training. We do that for multiple reasons.\n","\n","1. All rewards are multiples of 100, and even an untrained agent can get a score of 800. Therefore, even in the beginning of training, the critic will have to predict pretty large numbers. Neural networks require extra tinkering to output large numbers reliably. In this case, the easiest workaround is just to scale back those numbers.\n","2. We have already tweaked the hyperparameters (loss coefficients) to work well with this scaling.\n","\n","Please note, that we would not need to do this in plain REINFORCE without entropy regularization but with Adam optimizer.\n","\n","In REINFORCE, there is only actor and no critic. Without entropy regularization, actor loss is just policy gradient. It is proportional to rewards, but it only affects the scale of the gradient. However, Adam maintains a running average of the variance of the gradient for each parameter it optimizes, and normalizes the gradient by its variance in each optimization step. This will negate any scaling of the gradient.\n","\n","If your implementation works correctly, you can comment out the `batch_rewards = batch_rewards * 0.01` line, restart training, and see it explode."]},{"cell_type":"code","metadata":{"id":"_4REqfQ0bSlc"},"source":["import tqdm\n","from IPython.display import clear_output\n","\n","with tqdm.trange(len(entropy_history), 100000) as progress_bar:\n"," for i in progress_bar:\n"," batch_actions = agent.choose_action(batch_states)\n"," batch_next_states, batch_rewards, batch_done, _ = env_batch.step(batch_actions)\n","\n"," # Reward scaling. See above for explanation.\n"," batch_rewards = batch_rewards * 0.01\n","\n"," agent_loss, critic_loss, entropy = compute_actor_critic_loss(\n"," agent, batch_states, batch_actions, batch_rewards, batch_next_states, batch_done)\n"," entropy_history.append(np.mean(entropy))\n","\n"," batch_states = batch_next_states\n","\n"," if i % 500 == 0:\n"," if i % 2500 == 0:\n"," rewards_history.append(np.mean(evaluate(agent, env, n_games=3)))\n"," if rewards_history[-1] >= 5000:\n"," print(\"Your agent has earned the yellow belt\")\n","\n"," clear_output(True)\n","\n"," plt.figure(figsize=[8, 4])\n"," plt.subplot(1, 2, 1)\n"," plt.plot(rewards_history, label='rewards')\n"," plt.plot(ewma(np.array(rewards_history), span=10), marker='.', label='rewards ewma@10')\n"," plt.title(\"Session rewards\")\n"," plt.grid()\n"," plt.legend()\n","\n"," plt.subplot(1, 2, 2)\n"," plt.plot(entropy_history, label='entropy')\n"," plt.plot(ewma(np.array(entropy_history), span=1000), marker='.', label='entropy ewma@1000')\n"," plt.title(\"Policy entropy\")\n"," plt.grid()\n"," plt.legend()\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"71xBEODDbSlc"},"source":["Relax and grab some refreshments while your agent is locked in an infinite loop of violence and death.\n","\n","__How to interpret plots:__\n","\n","The session reward is the easy thing: it should in general go up over time, but it's okay, if it fluctuates ~~like crazy~~. It's also OK, if it doesn't increase substantially before 10-20k initial steps, and some people, who tried this assignment [told us](https://www.coursera.org/learn/practical-rl/discussions/all/threads/3OnFNVxEEemLZA644RFX2A) they didn't see improvements until approximately 60k steps. However, if reward reaches zero and doesn't seem to get up over 2-3 evaluations, something wrong is happening.\n","\n","Since we use a policy-based method, we also keep track of __policy entropy__ — the same one you used as a regularizer. The only important thing about it is that your entropy shouldn't drop too low (`< 0.1`) before your agent gets the yellow belt. Or at least it can drop there, but _it shouldn't stay there for long_.\n","\n","If it does, the likely culprit is:\n","* Some bug in entropy computation. Remember, that it is $-\\sum p(a_i) \\cdot \\log p(a_i)$.\n","* Your model architecture is broken in some way: for example, if you create layers in `Agent.symbolic_step()` rather than in `Agent.__init__()`, then effectively you will be training two separate agents: one for `logits, state_values` and another one for `next_logits, next_state_values`.\n","* Your architecture is different from the one we suggest and it converges too quickly. Change your architecture or increase the entropy coefficient in actor loss. \n","* Gradient explosion: just [clip gradients](https://stackoverflow.com/a/43486487) and maybe use a smaller network.\n","* Us. Or TF developers. Or aliens. Or lizardfolk. Contact us on forums before it's too late!\n","\n","If you're debugging, just run `logits, values = agent.step(batch_states)` and manually look into logits and values. This will reveal the problem 9 times out of 10: you are likely to see some NaNs or insanely large numbers or zeros. Try to catch the moment, when this happens for the first time and investigate from there."]},{"cell_type":"markdown","metadata":{"id":"KXHwWnoEbSlc"},"source":["### \"Final\" evaluation"]},{"cell_type":"code","metadata":{"id":"6ZW3yJ0cbSlc"},"source":["import gym.wrappers\n","\n","with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n"," final_rewards = evaluate(agent, env_monitor, n_games=3)\n","\n","print(\"Final mean reward:\", np.mean(final_rewards))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Yn_1oCyybSlc"},"source":["# Show video. This may not work in some setups. If it doesn't\n","# work for you, you can download the videos and view them locally.\n","\n","from pathlib import Path\n","from IPython.display import HTML\n","\n","video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n","\n","HTML(\"\"\"\n","\n","\"\"\".format(video_names[-1]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"mO4tPWwzbSld"},"source":["HTML(\"\"\"\n","\n","\"\"\".format(video_names[-2])) # You can also try other indices"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"x1iOB6t5bSld"},"source":["If you don't see videos above, just navigate to `./videos` and download `.mp4` files from there."]},{"cell_type":"code","metadata":{"id":"E1o0ulgsbSld"},"source":["from submit import submit_kungfu\n","env = make_env()\n","submit_kungfu(agent, env, evaluate, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ZuTYMSLrbSld"},"source":["### Now what?\n","Well, 5k reward is [just the beginning](https://www.buzzfeed.com/mattjayyoung/what-the-color-of-your-karate-belt-actually-means-lg3g). Can you get past 200? With recurrent neural network memory, chances are you can even beat 400!\n","\n","* Try n-step advantage and \"lambda\"-advantage (aka GAE) - see [this article](https://arxiv.org/abs/1506.02438)\n"," * This change should improve the early convergence a lot\n","* Try recurrent a neural network \n"," * RNN memory will slow things down initially, but it will reach better final reward at this game\n","* Implement asynchronuous version\n"," * Remember [A3C](https://arxiv.org/abs/1602.01783)? The first \"A\" stands for asynchronuous. It means there are several parallel actor-learners out there.\n"," * You can write the custom code for synchronization, but we recommend using [redis](https://redis.io/)\n"," * You can store full parameter set in redis, along with any other metadate\n"," * Here's a _quick_ way to (de)serialize parameters for redis\n"," ```\n"," import joblib\n"," from six import BytesIO\n","```\n","```\n"," def dumps(data):\n"," \"converts whatever to string\"\n"," s = BytesIO()\n"," joblib.dump(data,s)\n"," return s.getvalue()\n","``` \n","```\n"," def loads(string):\n"," \"converts string to whatever was dumps'ed in it\"\n"," return joblib.load(BytesIO(string))\n","```"]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Deep Kung-Fu with advantage actor-critic\n",
+ "\n",
+ "In this notebook you'll build a deep reinforcement learning agent for Atari [Kung-Fu Master](https://gym.openai.com/envs/KungFuMaster-v0/) and train it with Advantage Actor-Critic.\n",
+ "\n",
+ "Note that, strictly speaking, this will be neither [A3C](https://arxiv.org/abs/1602.01783) nor [A2C](https://openai.com/blog/baselines-acktr-a2c/), but rather a simplified version of the latter.\n",
+ "\n",
+ "Special thanks to Jesse Grabowski for making an [initial version](https://www.coursera.org/learn/practical-rl/discussions/all/threads/6iDjkbhPQoGg45G4T7KBHQ/replies/5eM_hA7vEeuoKgpcLmLqdw) of the PyTorch port of this assignment.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules:\n",
+ " %tensorflow_version 1.x\n",
+ " \n",
+ " if not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/atari_util.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# If you are running on a server, launch xvfb to record game videos\n",
+ "# Please make sure you have xvfb installed\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "\n",
+ "from IPython.display import display"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For starters, let's take a look at the game itself:\n",
+ "\n",
+ "* Image resized to 42x42 and converted to grayscale to run faster\n",
+ "* Agent sees last 4 frames of game to account for object velocity"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "from atari_util import PreprocessAtari\n",
+ "\n",
+ "def make_env():\n",
+ " env = gym.make(\"KungFuMasterDeterministic-v0\")\n",
+ " env = PreprocessAtari(\n",
+ " env, height=42, width=42,\n",
+ " crop=lambda img: img[60:-30, 5:],\n",
+ " dim_order='pytorch',\n",
+ " color=False, n_frames=4)\n",
+ " return env\n",
+ "\n",
+ "env = make_env()\n",
+ "\n",
+ "obs_shape = env.observation_space.shape\n",
+ "n_actions = env.action_space.n\n",
+ "\n",
+ "print(\"Observation shape:\", obs_shape)\n",
+ "print(\"Num actions:\", n_actions)\n",
+ "print(\"Action names:\", env.env.env.get_action_meanings())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s = env.reset()\n",
+ "for _ in range(100):\n",
+ " s, _, _, _ = env.step(env.action_space.sample())\n",
+ "\n",
+ "plt.title('Game image')\n",
+ "plt.imshow(env.render('rgb_array'))\n",
+ "plt.show()\n",
+ "\n",
+ "plt.title('Agent observation (4-frame buffer)')\n",
+ "plt.imshow(s.transpose([1, 0, 2]).reshape([42, -1]), cmap='gray')\n",
+ "plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Build a network\n",
+ "\n",
+ "We now have to build an agent for actor-critic training — a convolutional neural network, that converts states into action probabilities $\\pi$ and state values $V$.\n",
+ "\n",
+ "Your assignment here is to build and apply the neural network. You can use any framework you want, but in this notebook we prepared for you a template in PyTorch.\n",
+ "\n",
+ "For starters, we want you to implement this architecture:\n",
+ "\n",
+ "\n",
+ "\n",
+ "Notes:\n",
+ "* This diagram was originally made for Tensorflow. In PyTorch, the input shape is `[batch_size, 4, 42, 42]`.\n",
+ "* Use convolution kernel size 3x3 throughout.\n",
+ "* After your agent gets mean reward above 5000, we encourage you to experiment with the model architecture to score even better."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\n",
+ "device"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def conv2d_size_out(size, kernel_size, stride):\n",
+ " \"\"\"\n",
+ " Helper function to compute the spatial dimensions of the output\n",
+ " of a convolutional layer, copied from Week 4.\n",
+ "\n",
+ " Common use case:\n",
+ " cur_layer_img_w = conv2d_size_out(cur_layer_img_w, kernel_size, stride)\n",
+ " cur_layer_img_h = conv2d_size_out(cur_layer_img_h, kernel_size, stride)\n",
+ " This can be used to understand the shape for the dense layer's input.\n",
+ " \"\"\"\n",
+ " return (size - (kernel_size - 1) - 1) // stride + 1"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Agent(nn.Module):\n",
+ " def __init__(self, input_dims, n_actions, lr):\n",
+ " super(Agent, self).__init__()\n",
+ " \n",
+ " self.input_dims = input_dims\n",
+ "\n",
+ " # Initialize layers as shown in the image above\n",
+ " \n",
+ "\n",
+ " self.optimizer = torch.optim.Adam(self.parameters(), lr=lr)\n",
+ " self.device = device\n",
+ " self.to(self.device)\n",
+ " \n",
+ " def forward(self, state):\n",
+ " # Compute logits and values using network.\n",
+ " # Note, that if you do so naively, your state_values will have shape\n",
+ " # ending in 1, since they come from a Linear(..., 1) layer. It is useful\n",
+ " # to .squeeze(dim=-1) them, since this will help to avoid shape conflicts\n",
+ " # in the loss function part, after we add multiple environments.\n",
+ " # If you don't do this here, don't forget to do that in the\n",
+ " # loss function!\n",
+ " \n",
+ " \n",
+ "\n",
+ " return logits, state_values\n",
+ "\n",
+ " def choose_action(self, observation):\n",
+ " # PyTorch wants a batch dimension, so if we feed only a single observation we need to wrap it with an extra layer.\n",
+ " # This line will allow the network to handle both single and multi-environment tests.\n",
+ " if observation.ndim == 3:\n",
+ " observation = [observation]\n",
+ "\n",
+ " observation = torch.tensor(observation, dtype=torch.float32, device=device)\n",
+ " # Pass states into the agent network and get back logits and states\n",
+ " logits, _ = \n",
+ " \n",
+ " policy = F.softmax(logits, dim=-1)\n",
+ "\n",
+ " actions = np.array([np.random.choice(len(p), p=p) for p in policy.detach().cpu().numpy()])\n",
+ " return actions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Test network\n",
+ "\n",
+ "agent = Agent(input_dims=obs_shape, n_actions=n_actions, lr=1e-4)\n",
+ "state = env.reset()\n",
+ "state = torch.tensor([state], dtype=torch.float32, device=device)\n",
+ "logits, state_values = agent(state)\n",
+ "\n",
+ "assert isinstance(logits, torch.Tensor) and len(logits.shape) == 2, \\\n",
+ " \"Please return a 2D Torch tensor of logits with shape (batch_size, n_actions). You returned %s\" % repr(logits)\n",
+ "assert isinstance(state_values, torch.Tensor) and len(state_values.shape) == 1, \\\n",
+ " \"Please return a 1D Torch tensor of state values with shape (batch_size,). You returned %s\" % repr(state_values)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "###Actor-Critic\n",
+ "\n",
+ "Here we define loss functions and learning algorithms as usual."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def compute_actor_critic_loss(agent, state, action, reward, next_state, done,\n",
+ " gamma=0.99):\n",
+ " # Infer batch_size from shape of state tensor:\n",
+ " batch_size = state.shape[0]\n",
+ "\n",
+ " # Convert everything to a tensor, send to GPU if available\n",
+ " state = torch.tensor(state, dtype=torch.float32, device=device)\n",
+ " next_state = torch.tensor(next_state, dtype=torch.float32, device=device)\n",
+ " reward = torch.tensor(reward, dtype=torch.float32, device=device)\n",
+ " done = torch.tensor(done, dtype=torch.bool, device=device)\n",
+ "\n",
+ " # logits[n_envs, n_actions] and state_values[n_envs, n_actions]\n",
+ " logits, state_value = agent(state)\n",
+ " next_logits, next_state_value = agent(next_state)\n",
+ "\n",
+ " # Probabilities and log-probabilities for all actions\n",
+ " probs = F.softmax(logits, dim=-1) #[n_envs, n_actions]\n",
+ " logprobs = F.log_softmax(logits, dim=-1) #[n_envs, n_actions]\n",
+ "\n",
+ " # Set new state values with done == 1 to be 0.0 (no future rewards if done!)\n",
+ " next_state_value[done] = 0.0\n",
+ "\n",
+ " # Compute target state values using temporal difference formula.\n",
+ " # Use reward, gamma, and next_state_value.\n",
+ " target_state_value = \n",
+ "\n",
+ " # Compute advantage using reward, gamma, state_value, and next_state_value.\n",
+ " advantage = \n",
+ "\n",
+ " # We need to slice out only the actions we took for actor loss -- we can use\n",
+ " # the actions themselves as indexes, but we also need indexes on the batch dim\n",
+ " batch_idx = np.arange(batch_size)\n",
+ " logp_actions = logprobs[batch_idx, action]\n",
+ "\n",
+ " # Compute policy entropy given logits_seq. Mind the \"-\" sign!\n",
+ " entropy = \n",
+ "\n",
+ " actor_loss = -(logp_actions * advantage.detach()).mean() - 0.001 * entropy.mean()\n",
+ " critic_loss = F.mse_loss(target_state_value.detach(), state_value)\n",
+ "\n",
+ " total_loss = actor_loss + critic_loss\n",
+ "\n",
+ " # Never forget to zero grads in PyTorch!\n",
+ " agent.optimizer.zero_grad()\n",
+ " total_loss.backward()\n",
+ " agent.optimizer.step()\n",
+ "\n",
+ " return actor_loss.cpu().detach().numpy(), critic_loss.cpu().detach().numpy(), entropy.cpu().detach().numpy()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "state = env.reset()\n",
+ "state = torch.tensor([state], dtype=torch.float32).to(device)\n",
+ "logits, value = agent(state)\n",
+ "print(\"action logits:\\n\", logits)\n",
+ "print(\"state values:\\n\", value)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Let's play!\n",
+ "Let's build a function, that measures the agent's average reward."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def evaluate(agent, env, n_games=1):\n",
+ " \"\"\"Plays the game from start till done, returns per-game rewards \"\"\"\n",
+ "\n",
+ " game_rewards = []\n",
+ " for _ in range(n_games):\n",
+ " state = env.reset()\n",
+ "\n",
+ " total_reward = 0\n",
+ " while True:\n",
+ " action = agent.choose_action(state)\n",
+ " state, reward, done, info = env.step(action)\n",
+ " total_reward += reward\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " game_rewards.append(total_reward)\n",
+ " return game_rewards"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym.wrappers\n",
+ "\n",
+ "with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n",
+ " rewards = evaluate(agent, env_monitor, n_games=3)\n",
+ "\n",
+ "print(rewards)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Show video. This may not work in some setups. If it doesn't\n",
+ "# work for you, you can download the videos and view them locally.\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n",
+ "\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-1])) # You can also try other indices"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Training on parallel games\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "To make actor-critic training more stable, we shall play several games in parallel. This means you'll have to initialize several parallel gym envs, send agent's actions there and .reset() each env if it becomes terminated. To minimize learner brain damage, we've taken care of them for you - just make sure you read it before you use it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EnvBatch:\n",
+ " def __init__(self, n_envs = 10):\n",
+ " \"\"\" Creates n_envs environments and babysits them for ya' \"\"\"\n",
+ " self.envs = [make_env() for _ in range(n_envs)]\n",
+ " \n",
+ " def reset(self):\n",
+ " \"\"\" Reset all games and return [n_envs, *obs_shape] observations \"\"\"\n",
+ " return np.array([env.reset() for env in self.envs])\n",
+ " \n",
+ " def step(self, actions):\n",
+ " \"\"\"\n",
+ " Send a vector[batch_size] of actions into respective environments\n",
+ " :returns: observations[n_envs, *obs_shape], rewards[n_envs], done[n_envs,], info[n_envs]\n",
+ " \"\"\"\n",
+ " results = [env.step(a) for env, a in zip(self.envs, actions)]\n",
+ " new_obs, rewards, done, infos = map(np.array, zip(*results))\n",
+ " \n",
+ " # reset environments automatically\n",
+ " for i in range(len(self.envs)):\n",
+ " if done[i]:\n",
+ " new_obs[i] = self.envs[i].reset()\n",
+ " \n",
+ " return new_obs, rewards, done, infos"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Let's try it out:__"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env_batch = EnvBatch(10)\n",
+ "\n",
+ "batch_states = env_batch.reset()\n",
+ "batch_actions = agent.choose_action(batch_states)\n",
+ "batch_next_states, batch_rewards, batch_done, _ = env_batch.step(batch_actions)\n",
+ "\n",
+ "print(\"State shape:\", batch_states.shape)\n",
+ "print(\"Actions:\", batch_actions)\n",
+ "print(\"Rewards:\", batch_rewards)\n",
+ "print(\"Done:\", batch_done)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Sanity Check"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "agent = Agent(lr=1e-4, n_actions=n_actions, input_dims=obs_shape)\n",
+ "\n",
+ "state = env_batch.reset()\n",
+ "action = agent.choose_action(state)\n",
+ "\n",
+ "next_state, reward, done, info = env_batch.step(action)\n",
+ "\n",
+ "l_act, l_crit, ent = compute_actor_critic_loss(agent, state, action, reward, next_state, done)\n",
+ "\n",
+ "assert abs(l_act) < 100 and abs(l_crit) < 100, \"losses seem abnormally large\"\n",
+ "assert 0 <= ent.mean() <= np.log(n_actions), \"impossible entropy value, double-check the formula pls\"\n",
+ "if ent.mean() < np.log(n_actions) / 2:\n",
+ " print(\"Entropy is too low for an untrained agent\")\n",
+ "print(\"You just might be fine!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Train \n",
+ "\n",
+ "Just the usual - play a bit, compute loss, follow the graidents, repeat a few million times.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pandas as pd\n",
+ "\n",
+ "def ewma(x, span=100):\n",
+ " return pd.DataFrame({'x':np.asarray(x)}).x.ewm(span=span).mean().values\n",
+ "\n",
+ "env_batch = EnvBatch(10)\n",
+ "batch_states = env_batch.reset()\n",
+ "\n",
+ "rewards_history = []\n",
+ "entropy_history = []"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Please pay extra attention to how we scale rewards in training. We do that for multiple reasons.\n",
+ "\n",
+ "1. All rewards are multiples of 100, and even an untrained agent can get a score of 800. Therefore, even in the beginning of training, the critic will have to predict pretty large numbers. Neural networks require extra tinkering to output large numbers reliably. In this case, the easiest workaround is just to scale back those numbers.\n",
+ "2. We have already tweaked the hyperparameters (loss coefficients) to work well with this scaling.\n",
+ "\n",
+ "Please note, that we would not need to do this in plain REINFORCE without entropy regularization but with Adam optimizer.\n",
+ "\n",
+ "In REINFORCE, there is only actor and no critic. Without entropy regularization, actor loss is just policy gradient. It is proportional to rewards, but it only affects the scale of the gradient. However, Adam maintains a running average of the variance of the gradient for each parameter it optimizes, and normalizes the gradient by its variance in each optimization step. This will negate any scaling of the gradient.\n",
+ "\n",
+ "If your implementation works correctly, you can comment out the `batch_rewards = batch_rewards * 0.01` line, restart training, and see it explode."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import tqdm\n",
+ "from IPython.display import clear_output\n",
+ "\n",
+ "with tqdm.trange(len(entropy_history), 100000) as progress_bar:\n",
+ " for i in progress_bar:\n",
+ " batch_actions = agent.choose_action(batch_states)\n",
+ " batch_next_states, batch_rewards, batch_done, _ = env_batch.step(batch_actions)\n",
+ "\n",
+ " # Reward scaling. See above for explanation.\n",
+ " batch_rewards = batch_rewards * 0.01\n",
+ "\n",
+ " agent_loss, critic_loss, entropy = compute_actor_critic_loss(\n",
+ " agent, batch_states, batch_actions, batch_rewards, batch_next_states, batch_done)\n",
+ " entropy_history.append(np.mean(entropy))\n",
+ "\n",
+ " batch_states = batch_next_states\n",
+ "\n",
+ " if i % 500 == 0:\n",
+ " if i % 2500 == 0:\n",
+ " rewards_history.append(np.mean(evaluate(agent, env, n_games=3)))\n",
+ " if rewards_history[-1] >= 5000:\n",
+ " print(\"Your agent has earned the yellow belt\")\n",
+ "\n",
+ " clear_output(True)\n",
+ "\n",
+ " plt.figure(figsize=[8, 4])\n",
+ " plt.subplot(1, 2, 1)\n",
+ " plt.plot(rewards_history, label='rewards')\n",
+ " plt.plot(ewma(np.array(rewards_history), span=10), marker='.', label='rewards ewma@10')\n",
+ " plt.title(\"Session rewards\")\n",
+ " plt.grid()\n",
+ " plt.legend()\n",
+ "\n",
+ " plt.subplot(1, 2, 2)\n",
+ " plt.plot(entropy_history, label='entropy')\n",
+ " plt.plot(ewma(np.array(entropy_history), span=1000), marker='.', label='entropy ewma@1000')\n",
+ " plt.title(\"Policy entropy\")\n",
+ " plt.grid()\n",
+ " plt.legend()\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Relax and grab some refreshments while your agent is locked in an infinite loop of violence and death.\n",
+ "\n",
+ "__How to interpret plots:__\n",
+ "\n",
+ "The session reward is the easy thing: it should in general go up over time, but it's okay, if it fluctuates ~~like crazy~~. It's also OK, if it doesn't increase substantially before 10-20k initial steps, and some people, who tried this assignment [told us](https://www.coursera.org/learn/practical-rl/discussions/all/threads/3OnFNVxEEemLZA644RFX2A) they didn't see improvements until approximately 60k steps. However, if reward reaches zero and doesn't seem to get up over 2-3 evaluations, something wrong is happening.\n",
+ "\n",
+ "Since we use a policy-based method, we also keep track of __policy entropy__ — the same one you used as a regularizer. The only important thing about it is that your entropy shouldn't drop too low (`< 0.1`) before your agent gets the yellow belt. Or at least it can drop there, but _it shouldn't stay there for long_.\n",
+ "\n",
+ "If it does, the likely culprit is:\n",
+ "* Some bug in entropy computation. Remember, that it is $-\\sum p(a_i) \\cdot \\log p(a_i)$.\n",
+ "* Your model architecture is broken in some way: for example, if you create layers in `Agent.symbolic_step()` rather than in `Agent.__init__()`, then effectively you will be training two separate agents: one for `logits, state_values` and another one for `next_logits, next_state_values`.\n",
+ "* Your architecture is different from the one we suggest and it converges too quickly. Change your architecture or increase the entropy coefficient in actor loss. \n",
+ "* Gradient explosion: just [clip gradients](https://stackoverflow.com/a/43486487) and maybe use a smaller network.\n",
+ "* Us. Or TF developers. Or aliens. Or lizardfolk. Contact us on forums before it's too late!\n",
+ "\n",
+ "If you're debugging, just run `logits, values = agent.step(batch_states)` and manually look into logits and values. This will reveal the problem 9 times out of 10: you are likely to see some NaNs or insanely large numbers or zeros. Try to catch the moment, when this happens for the first time and investigate from there."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### \"Final\" evaluation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym.wrappers\n",
+ "\n",
+ "with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n",
+ " final_rewards = evaluate(agent, env_monitor, n_games=3)\n",
+ "\n",
+ "print(\"Final mean reward:\", np.mean(final_rewards))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Show video. This may not work in some setups. If it doesn't\n",
+ "# work for you, you can download the videos and view them locally.\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n",
+ "\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-1]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-2])) # You can also try other indices"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If you don't see videos above, just navigate to `./videos` and download `.mp4` files from there."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_kungfu\n",
+ "env = make_env()\n",
+ "submit_kungfu(agent, env, evaluate, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Now what?\n",
+ "Well, 5k reward is [just the beginning](https://www.buzzfeed.com/mattjayyoung/what-the-color-of-your-karate-belt-actually-means-lg3g). Can you get past 200? With recurrent neural network memory, chances are you can even beat 400!\n",
+ "\n",
+ "* Try n-step advantage and \"lambda\"-advantage (aka GAE) - see [this article](https://arxiv.org/abs/1506.02438)\n",
+ " * This change should improve the early convergence a lot\n",
+ "* Try recurrent a neural network \n",
+ " * RNN memory will slow things down initially, but it will reach better final reward at this game\n",
+ "* Implement asynchronuous version\n",
+ " * Remember [A3C](https://arxiv.org/abs/1602.01783)? The first \"A\" stands for asynchronuous. It means there are several parallel actor-learners out there.\n",
+ " * You can write the custom code for synchronization, but we recommend using [redis](https://redis.io/)\n",
+ " * You can store full parameter set in redis, along with any other metadate\n",
+ " * Here's a _quick_ way to (de)serialize parameters for redis\n",
+ " ```\n",
+ " import joblib\n",
+ " from six import BytesIO\n",
+ "```\n",
+ "```\n",
+ " def dumps(data):\n",
+ " \"converts whatever to string\"\n",
+ " s = BytesIO()\n",
+ " joblib.dump(data,s)\n",
+ " return s.getvalue()\n",
+ "``` \n",
+ "```\n",
+ " def loads(string):\n",
+ " \"converts string to whatever was dumps'ed in it\"\n",
+ " return joblib.load(BytesIO(string))\n",
+ "```"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week5_policy_based/practice_reinforce_pytorch.ipynb b/week5_policy_based/practice_reinforce_pytorch.ipynb
index ef8fe9925..6588d93a2 100644
--- a/week5_policy_based/practice_reinforce_pytorch.ipynb
+++ b/week5_policy_based/practice_reinforce_pytorch.ipynb
@@ -1 +1,460 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_reinforce_pytorch.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"vnDLy-e1UHVr"},"source":["# REINFORCE in PyTorch\n","\n","Just like we did before for Q-learning, this time we'll design a PyTorch network to learn `CartPole-v0` via policy gradient (REINFORCE).\n","\n","Most of the code in this notebook is taken from approximate Q-learning, so you'll find it more or less familiar and even simpler."]},{"cell_type":"code","metadata":{"id":"vyMZrpn3UHVx"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"nBGVMOmsUHVy"},"source":["import gym\n","import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"lBHkg_NCUHVy"},"source":["A caveat: with some versions of `pyglet`, the following cell may crash with `NameError: name 'base' is not defined`. The corresponding bug report is [here](https://github.com/pyglet/pyglet/issues/134). If you see this error, try restarting the kernel."]},{"cell_type":"code","metadata":{"id":"Q6_v-NWpUHVz"},"source":["env = gym.make(\"CartPole-v0\")\n","\n","# gym compatibility: unwrap TimeLimit\n","if hasattr(env, '_max_episode_steps'):\n"," env = env.env\n","\n","env.reset()\n","n_actions = env.action_space.n\n","state_dim = env.observation_space.shape\n","\n","plt.imshow(env.render(\"rgb_array\"))"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"viDiK4NvUHVz"},"source":["# Building the network for REINFORCE"]},{"cell_type":"markdown","metadata":{"id":"hRoL2689UHVz"},"source":["For REINFORCE algorithm, we'll need a model, that predicts action probabilities given states.\n","\n","For numerical stability, please, __do not include the softmax layer into your network architecture__.\n","We'll use softmax or log-softmax, where appropriate."]},{"cell_type":"code","metadata":{"id":"folSPW6AUHV0"},"source":["import torch\n","import torch.nn as nn"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"HyXtbSVyUHV0"},"source":["# Build a simple neural network, that predicts policy logits. \n","# Keep it simple: CartPole isn't worth deep architectures.\n","model = nn.Sequential(\n"," \n",")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"8gm_HEo2UHV0"},"source":["#### Prediction function"]},{"cell_type":"markdown","metadata":{"id":"Qfsr_zLCUHV0"},"source":["Note: output value of this function is not a torch tensor, it's a numpy array.\n","So, here the gradient calculation is not needed.\n"," \n","Use [no_grad](https://pytorch.org/docs/stable/autograd.html#torch.autograd.no_grad)\n","to suppress gradient calculation.\n"," \n","Also, `.detach()` (or legacy `.data` property) can be used instead, but there is a difference:\n"," \n","With `.detach()` computational graph is built but then disconnected from a particular tensor,\n","so `.detach()` should be used if that graph is needed for backprop via some other (not detached) tensor;\n"," \n","In contrast, no graph is built by any operation in `no_grad()` context, thus, it's preferable here."]},{"cell_type":"code","metadata":{"id":"2ZyCXS0rUHV1"},"source":["def predict_probs(states):\n"," \"\"\" \n"," Predict action probabilities given states.\n"," :param states: numpy array of shape [batch, state_shape]\n"," :returns: numpy array of shape [batch, n_actions]\n"," \"\"\"\n"," # convert states, compute logits, use softmax to get probability\n"," \n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"zdQsUjNZUHV1"},"source":["test_states = np.array([env.reset() for _ in range(5)])\n","test_probas = predict_probs(test_states)\n","assert isinstance(test_probas, np.ndarray), \\\n"," \"you must return np array and not %s\" % type(test_probas)\n","assert tuple(test_probas.shape) == (test_states.shape[0], env.action_space.n), \\\n"," \"wrong output shape: %s\" % np.shape(test_probas)\n","assert np.allclose(np.sum(test_probas, axis=1), 1), \"probabilities do not sum to 1\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"mSauJO3FUHV1"},"source":["### Play the game\n","\n","We can now use our newly built agent to play the game."]},{"cell_type":"code","metadata":{"id":"6AWbDIpHUHV1"},"source":["def generate_session(env, t_max=1000):\n"," \"\"\" \n"," Play a full session with REINFORCE agent.\n"," Returns sequences of states, actions, and rewards.\n"," \"\"\"\n"," # arrays to record session\n"," states, actions, rewards = [], [], []\n"," s = env.reset()\n","\n"," for t in range(t_max):\n"," # action probabilities array aka pi(a|s)\n"," action_probs = predict_probs(np.array([s]))[0]\n","\n"," # Sample action with given probabilities.\n"," a = \n"," new_s, r, done, info = env.step(a)\n","\n"," # record session history to train later\n"," states.append(s)\n"," actions.append(a)\n"," rewards.append(r)\n","\n"," s = new_s\n"," if done:\n"," break\n","\n"," return states, actions, rewards"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"v1kjy0e2UHV2"},"source":["# test it\n","states, actions, rewards = generate_session(env)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"iS_nFgXqUHV2"},"source":["### Computing cumulative rewards\n","\n","$$\n","\\begin{align*}\n","G_t &= r_t + \\gamma r_{t + 1} + \\gamma^2 r_{t + 2} + \\ldots \\\\\n","&= \\sum_{i = t}^T \\gamma^{i - t} r_i \\\\\n","&= r_t + \\gamma * G_{t + 1}\n","\\end{align*}\n","$$"]},{"cell_type":"code","metadata":{"id":"kVNEk0--UHV2"},"source":["def get_cumulative_rewards(rewards, # rewards at each step\n"," gamma=0.99 # discount for the reward\n"," ):\n"," \"\"\"\n"," Take a list of immediate rewards r(s,a) for the whole session \n"," and compute cumulative returns (a.k.a. G(s,a) in Sutton '16).\n"," \n"," G_t = r_t + gamma*r_{t+1} + gamma^2*r_{t+2} + ...\n","\n"," A simple way to compute cumulative rewards is to iterate from the last\n"," to the first timestep and compute G_t = r_t + gamma*G_{t+1} recurrently\n","\n"," You must return an array/list of cumulative rewards with as many elements as in the initial rewards.\n"," \"\"\"\n"," \n"," return "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"NUwayVIKUHV7"},"source":["get_cumulative_rewards(rewards)\n","assert len(get_cumulative_rewards(list(range(100)))) == 100\n","assert np.allclose(\n"," get_cumulative_rewards([0, 0, 1, 0, 0, 1, 0], gamma=0.9),\n"," [1.40049, 1.5561, 1.729, 0.81, 0.9, 1.0, 0.0])\n","assert np.allclose(\n"," get_cumulative_rewards([0, 0, 1, -2, 3, -4, 0], gamma=0.5),\n"," [0.0625, 0.125, 0.25, -1.5, 1.0, -4.0, 0.0])\n","assert np.allclose(\n"," get_cumulative_rewards([0, 0, 1, 2, 3, 4, 0], gamma=0),\n"," [0, 0, 1, 2, 3, 4, 0])\n","print(\"looks good!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"8b2RAp-pUHV8"},"source":["#### Loss function and updates\n","\n","We now need to define objective and update over the policy gradient.\n","\n","Our objective function is:\n","\n","$$ J \\approx { 1 \\over N } \\sum_{s_i,a_i} G(s_i,a_i) $$\n","\n","REINFORCE defines the way to compute the gradient of the expected reward with respect to policy parameters. The formula is as follows:\n","\n","$$ \\nabla_\\theta \\hat J(\\theta) \\approx { 1 \\over N } \\sum_{s_i, a_i} \\nabla_\\theta \\log \\pi_\\theta (a_i \\mid s_i) \\cdot G_t(s_i, a_i) $$\n","\n","We can abuse PyTorch's capabilities for automatic differentiation by defining our objective function as follows:\n","\n","$$ \\hat J(\\theta) \\approx { 1 \\over N } \\sum_{s_i, a_i} \\log \\pi_\\theta (a_i \\mid s_i) \\cdot G_t(s_i, a_i) $$\n","\n","When you compute the gradient of this function with respect to the network weights $\\theta$, it will become exactly the policy gradient."]},{"cell_type":"code","metadata":{"id":"ocoK5HBwUHV8"},"source":["def to_one_hot(y_tensor, ndims):\n"," \"\"\" helper: take an integer vector and convert it to 1-hot matrix. \"\"\"\n"," y_tensor = y_tensor.type(torch.LongTensor).view(-1, 1)\n"," y_one_hot = torch.zeros(\n"," y_tensor.size()[0], ndims).scatter_(1, y_tensor, 1)\n"," return y_one_hot"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"9TWILUKuUHV9"},"source":["# Your code: define the optimizers\n","optimizer = torch.optim.Adam(model.parameters(), 1e-3)\n","\n","\n","def train_on_session(states, actions, rewards, gamma=0.99, entropy_coef=1e-2):\n"," \"\"\"\n"," Takes a sequence of states, actions and rewards produced by generate_session.\n"," Updates agent's weights by following the policy gradient above.\n"," Please use Adam optimizer with the default parameters.\n"," \"\"\"\n","\n"," # cast everything into torch tensors\n"," states = torch.tensor(states, dtype=torch.float32)\n"," actions = torch.tensor(actions, dtype=torch.int32)\n"," cumulative_returns = np.array(get_cumulative_rewards(rewards, gamma))\n"," cumulative_returns = torch.tensor(cumulative_returns, dtype=torch.float32)\n","\n"," # predict logits, probas and log-probas using an agent.\n"," logits = model(states)\n"," probs = nn.functional.softmax(logits, -1)\n"," log_probs = nn.functional.log_softmax(logits, -1)\n","\n"," assert all(isinstance(v, torch.Tensor) for v in [logits, probs, log_probs]), \\\n"," \"please use compute with torch tensors and don't use predict_probs function\"\n","\n"," # select log-probabilities for chosen actions, log pi(a_i|s_i)\n"," log_probs_for_actions = torch.sum(\n"," log_probs * to_one_hot(actions, env.action_space.n), dim=1)\n"," \n"," # Compute loss here. Don't forget the entropy regularization with `entropy_coef` \n"," entropy = \n"," loss = \n","\n"," # Gradient descent step\n"," \n","\n"," # technical: return session rewards to print them later\n"," return np.sum(rewards)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"W46b5195UHV9"},"source":["### The actual training"]},{"cell_type":"code","metadata":{"id":"tIdl4EhaUHV9"},"source":["for i in range(100):\n"," rewards = [train_on_session(*generate_session(env)) for _ in range(100)] # generate new sessions\n"," \n"," print(\"mean reward:%.3f\" % (np.mean(rewards)))\n"," \n"," if np.mean(rewards) > 300:\n"," print(\"You Win!\") # but you can train even further\n"," break"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"J3geFGEQUHV-"},"source":["### Results & video"]},{"cell_type":"code","metadata":{"id":"pmoYpXoLUHV-"},"source":["# Record sessions\n","\n","import gym.wrappers\n","\n","with gym.wrappers.Monitor(gym.make(\"CartPole-v0\"), directory=\"videos\", force=True) as env_monitor:\n"," sessions = [generate_session(env_monitor) for _ in range(100)]"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"PXZtjoyxUHV-"},"source":["# Show video. This may not work in some setups. If it doesn't\n","# work for you, you can download the videos and view them locally.\n","\n","from pathlib import Path\n","from IPython.display import HTML\n","\n","video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n","\n","HTML(\"\"\"\n","\n","\"\"\".format(video_names[-1])) # You can also try other indices"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ayCWz8YzUHV_"},"source":["from submit import submit_cartpole\n","submit_cartpole(generate_session, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"StOnKxTUUHV_"},"source":["That's all, thank you for your attention!\n","\n","Not having enough? There's an actor-critic waiting for you in the honor section. But make sure you've seen the videos first."]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# REINFORCE in PyTorch\n",
+ "\n",
+ "Just like we did before for Q-learning, this time we'll design a PyTorch network to learn `CartPole-v0` via policy gradient (REINFORCE).\n",
+ "\n",
+ "Most of the code in this notebook is taken from approximate Q-learning, so you'll find it more or less familiar and even simpler."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week5_policy_based/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "A caveat: with some versions of `pyglet`, the following cell may crash with `NameError: name 'base' is not defined`. The corresponding bug report is [here](https://github.com/pyglet/pyglet/issues/134). If you see this error, try restarting the kernel."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env = gym.make(\"CartPole-v0\")\n",
+ "\n",
+ "# gym compatibility: unwrap TimeLimit\n",
+ "if hasattr(env, '_max_episode_steps'):\n",
+ " env = env.env\n",
+ "\n",
+ "env.reset()\n",
+ "n_actions = env.action_space.n\n",
+ "state_dim = env.observation_space.shape\n",
+ "\n",
+ "plt.imshow(env.render(\"rgb_array\"))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Building the network for REINFORCE"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For REINFORCE algorithm, we'll need a model, that predicts action probabilities given states.\n",
+ "\n",
+ "For numerical stability, please, __do not include the softmax layer into your network architecture__.\n",
+ "We'll use softmax or log-softmax, where appropriate."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Build a simple neural network, that predicts policy logits. \n",
+ "# Keep it simple: CartPole isn't worth deep architectures.\n",
+ "model = nn.Sequential(\n",
+ " \n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Prediction function"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note: output value of this function is not a torch tensor, it's a numpy array.\n",
+ "So, here the gradient calculation is not needed.\n",
+ " \n",
+ "Use [no_grad](https://pytorch.org/docs/stable/autograd.html#torch.autograd.no_grad)\n",
+ "to suppress gradient calculation.\n",
+ " \n",
+ "Also, `.detach()` (or legacy `.data` property) can be used instead, but there is a difference:\n",
+ " \n",
+ "With `.detach()` computational graph is built but then disconnected from a particular tensor,\n",
+ "so `.detach()` should be used if that graph is needed for backprop via some other (not detached) tensor;\n",
+ " \n",
+ "In contrast, no graph is built by any operation in `no_grad()` context, thus, it's preferable here."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def predict_probs(states):\n",
+ " \"\"\" \n",
+ " Predict action probabilities given states.\n",
+ " :param states: numpy array of shape [batch, state_shape]\n",
+ " :returns: numpy array of shape [batch, n_actions]\n",
+ " \"\"\"\n",
+ " # convert states, compute logits, use softmax to get probability\n",
+ " \n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_states = np.array([env.reset() for _ in range(5)])\n",
+ "test_probas = predict_probs(test_states)\n",
+ "assert isinstance(test_probas, np.ndarray), \\\n",
+ " \"you must return np array and not %s\" % type(test_probas)\n",
+ "assert tuple(test_probas.shape) == (test_states.shape[0], env.action_space.n), \\\n",
+ " \"wrong output shape: %s\" % np.shape(test_probas)\n",
+ "assert np.allclose(np.sum(test_probas, axis=1), 1), \"probabilities do not sum to 1\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Play the game\n",
+ "\n",
+ "We can now use our newly built agent to play the game."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def generate_session(env, t_max=1000):\n",
+ " \"\"\" \n",
+ " Play a full session with REINFORCE agent.\n",
+ " Returns sequences of states, actions, and rewards.\n",
+ " \"\"\"\n",
+ " # arrays to record session\n",
+ " states, actions, rewards = [], [], []\n",
+ " s = env.reset()\n",
+ "\n",
+ " for t in range(t_max):\n",
+ " # action probabilities array aka pi(a|s)\n",
+ " action_probs = predict_probs(np.array([s]))[0]\n",
+ "\n",
+ " # Sample action with given probabilities.\n",
+ " a = \n",
+ " new_s, r, done, info = env.step(a)\n",
+ "\n",
+ " # record session history to train later\n",
+ " states.append(s)\n",
+ " actions.append(a)\n",
+ " rewards.append(r)\n",
+ "\n",
+ " s = new_s\n",
+ " if done:\n",
+ " break\n",
+ "\n",
+ " return states, actions, rewards"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# test it\n",
+ "states, actions, rewards = generate_session(env)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Computing cumulative rewards\n",
+ "\n",
+ "$$\n",
+ "\\begin{align*}\n",
+ "G_t &= r_t + \\gamma r_{t + 1} + \\gamma^2 r_{t + 2} + \\ldots \\\\\n",
+ "&= \\sum_{i = t}^T \\gamma^{i - t} r_i \\\\\n",
+ "&= r_t + \\gamma * G_{t + 1}\n",
+ "\\end{align*}\n",
+ "$$"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def get_cumulative_rewards(rewards, # rewards at each step\n",
+ " gamma=0.99 # discount for the reward\n",
+ " ):\n",
+ " \"\"\"\n",
+ " Take a list of immediate rewards r(s,a) for the whole session \n",
+ " and compute cumulative returns (a.k.a. G(s,a) in Sutton '16).\n",
+ " \n",
+ " G_t = r_t + gamma*r_{t+1} + gamma^2*r_{t+2} + ...\n",
+ "\n",
+ " A simple way to compute cumulative rewards is to iterate from the last\n",
+ " to the first timestep and compute G_t = r_t + gamma*G_{t+1} recurrently\n",
+ "\n",
+ " You must return an array/list of cumulative rewards with as many elements as in the initial rewards.\n",
+ " \"\"\"\n",
+ " \n",
+ " return "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "get_cumulative_rewards(rewards)\n",
+ "assert len(get_cumulative_rewards(list(range(100)))) == 100\n",
+ "assert np.allclose(\n",
+ " get_cumulative_rewards([0, 0, 1, 0, 0, 1, 0], gamma=0.9),\n",
+ " [1.40049, 1.5561, 1.729, 0.81, 0.9, 1.0, 0.0])\n",
+ "assert np.allclose(\n",
+ " get_cumulative_rewards([0, 0, 1, -2, 3, -4, 0], gamma=0.5),\n",
+ " [0.0625, 0.125, 0.25, -1.5, 1.0, -4.0, 0.0])\n",
+ "assert np.allclose(\n",
+ " get_cumulative_rewards([0, 0, 1, 2, 3, 4, 0], gamma=0),\n",
+ " [0, 0, 1, 2, 3, 4, 0])\n",
+ "print(\"looks good!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Loss function and updates\n",
+ "\n",
+ "We now need to define objective and update over the policy gradient.\n",
+ "\n",
+ "Our objective function is:\n",
+ "\n",
+ "$$ J \\approx { 1 \\over N } \\sum_{s_i,a_i} G(s_i,a_i) $$\n",
+ "\n",
+ "REINFORCE defines the way to compute the gradient of the expected reward with respect to policy parameters. The formula is as follows:\n",
+ "\n",
+ "$$ \\nabla_\\theta \\hat J(\\theta) \\approx { 1 \\over N } \\sum_{s_i, a_i} \\nabla_\\theta \\log \\pi_\\theta (a_i \\mid s_i) \\cdot G_t(s_i, a_i) $$\n",
+ "\n",
+ "We can abuse PyTorch's capabilities for automatic differentiation by defining our objective function as follows:\n",
+ "\n",
+ "$$ \\hat J(\\theta) \\approx { 1 \\over N } \\sum_{s_i, a_i} \\log \\pi_\\theta (a_i \\mid s_i) \\cdot G_t(s_i, a_i) $$\n",
+ "\n",
+ "When you compute the gradient of this function with respect to the network weights $\\theta$, it will become exactly the policy gradient."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def to_one_hot(y_tensor, ndims):\n",
+ " \"\"\" helper: take an integer vector and convert it to 1-hot matrix. \"\"\"\n",
+ " y_tensor = y_tensor.type(torch.LongTensor).view(-1, 1)\n",
+ " y_one_hot = torch.zeros(\n",
+ " y_tensor.size()[0], ndims).scatter_(1, y_tensor, 1)\n",
+ " return y_one_hot"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Your code: define the optimizers\n",
+ "optimizer = torch.optim.Adam(model.parameters(), 1e-3)\n",
+ "\n",
+ "\n",
+ "def train_on_session(states, actions, rewards, gamma=0.99, entropy_coef=1e-2):\n",
+ " \"\"\"\n",
+ " Takes a sequence of states, actions and rewards produced by generate_session.\n",
+ " Updates agent's weights by following the policy gradient above.\n",
+ " Please use Adam optimizer with the default parameters.\n",
+ " \"\"\"\n",
+ "\n",
+ " # cast everything into torch tensors\n",
+ " states = torch.tensor(states, dtype=torch.float32)\n",
+ " actions = torch.tensor(actions, dtype=torch.int32)\n",
+ " cumulative_returns = np.array(get_cumulative_rewards(rewards, gamma))\n",
+ " cumulative_returns = torch.tensor(cumulative_returns, dtype=torch.float32)\n",
+ "\n",
+ " # predict logits, probas and log-probas using an agent.\n",
+ " logits = model(states)\n",
+ " probs = nn.functional.softmax(logits, -1)\n",
+ " log_probs = nn.functional.log_softmax(logits, -1)\n",
+ "\n",
+ " assert all(isinstance(v, torch.Tensor) for v in [logits, probs, log_probs]), \\\n",
+ " \"please use compute with torch tensors and don't use predict_probs function\"\n",
+ "\n",
+ " # select log-probabilities for chosen actions, log pi(a_i|s_i)\n",
+ " log_probs_for_actions = torch.sum(\n",
+ " log_probs * to_one_hot(actions, env.action_space.n), dim=1)\n",
+ " \n",
+ " # Compute loss here. Don't forget the entropy regularization with `entropy_coef` \n",
+ " entropy = \n",
+ " loss = \n",
+ "\n",
+ " # Gradient descent step\n",
+ " \n",
+ "\n",
+ " # technical: return session rewards to print them later\n",
+ " return np.sum(rewards)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### The actual training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(100):\n",
+ " rewards = [train_on_session(*generate_session(env)) for _ in range(100)] # generate new sessions\n",
+ " \n",
+ " print(\"mean reward:%.3f\" % (np.mean(rewards)))\n",
+ " \n",
+ " if np.mean(rewards) > 300:\n",
+ " print(\"You Win!\") # but you can train even further\n",
+ " break"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Results & video"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Record sessions\n",
+ "\n",
+ "import gym.wrappers\n",
+ "\n",
+ "with gym.wrappers.Monitor(gym.make(\"CartPole-v0\"), directory=\"videos\", force=True) as env_monitor:\n",
+ " sessions = [generate_session(env_monitor) for _ in range(100)]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Show video. This may not work in some setups. If it doesn't\n",
+ "# work for you, you can download the videos and view them locally.\n",
+ "\n",
+ "from pathlib import Path\n",
+ "from IPython.display import HTML\n",
+ "\n",
+ "video_names = sorted([s for s in Path('videos').iterdir() if s.suffix == '.mp4'])\n",
+ "\n",
+ "HTML(\"\"\"\n",
+ "\n",
+ "\"\"\".format(video_names[-1])) # You can also try other indices"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_cartpole\n",
+ "submit_cartpole(generate_session, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "That's all, thank you for your attention!\n",
+ "\n",
+ "Not having enough? There's an actor-critic waiting for you in the honor section. But make sure you've seen the videos first."
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week6_outro/bandits.ipynb b/week6_outro/bandits.ipynb
index b1e1a2f1f..aff24bff3 100644
--- a/week6_outro/bandits.ipynb
+++ b/week6_outro/bandits.ipynb
@@ -1 +1,368 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"bandits.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"code","metadata":{"id":"_NQ6R6KO9iav"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Frz6nw8T9ia3"},"source":["from abc import ABCMeta, abstractmethod, abstractproperty\n","import enum\n","\n","import numpy as np\n","np.set_printoptions(precision=3)\n","np.set_printoptions(suppress=True)\n","\n","import pandas\n","\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"PntdIxpF9ia3"},"source":["## Bernoulli Bandit\n","\n","We are going to implement several exploration strategies for simplest problem - bernoulli bandit.\n","\n","The bandit has $K$ actions. Action produce 1.0 reward $r$ with probability $0 \\le \\theta_k \\le 1$, which is unknown to the agent, but fixed over time. Agent's objective is to minimize the regret over fixed number $T$ of action selections:\n","\n","$$\\rho = T\\theta^* - \\sum_{t=1}^T r_t$$\n","\n","Where $\\theta^* = \\max_k\\{\\theta_k\\}$\n","\n","**Real-world analogy:**\n","\n","Clinical trials - we have $K$ pills and ill patient $T$. After taking the pill, a patient is cured with the probability $\\theta_k$. Task is to find the most efficient pill.\n","\n","A research on clinical trials - https://arxiv.org/pdf/1507.08025.pdf"]},{"cell_type":"code","metadata":{"id":"6VAy7fRl9ia4"},"source":["class BernoulliBandit:\n"," def __init__(self, n_actions=5):\n"," self._probs = np.random.random(n_actions)\n","\n"," @property\n"," def action_count(self):\n"," return len(self._probs)\n","\n"," def pull(self, action):\n"," if np.any(np.random.random() > self._probs[action]):\n"," return 0.0\n"," return 1.0\n","\n"," def optimal_reward(self):\n"," \"\"\" Used for regret calculation\n"," \"\"\"\n"," return np.max(self._probs)\n","\n"," def step(self):\n"," \"\"\" Used in nonstationary version\n"," \"\"\"\n"," pass\n","\n"," def reset(self):\n"," \"\"\" Used in nonstationary version\n"," \"\"\""],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"uCV1mHis9ia4"},"source":["class AbstractAgent(metaclass=ABCMeta):\n"," def init_actions(self, n_actions):\n"," self._successes = np.zeros(n_actions)\n"," self._failures = np.zeros(n_actions)\n"," self._total_pulls = 0\n","\n"," @abstractmethod\n"," def get_action(self):\n"," \"\"\"\n"," Get current best action\n"," :rtype: int\n"," \"\"\"\n"," pass\n","\n"," def update(self, action, reward):\n"," \"\"\"\n"," Observe reward from action and update agent's internal parameters\n"," :type action: int\n"," :type reward: int\n"," \"\"\"\n"," self._total_pulls += 1\n"," if reward == 1:\n"," self._successes[action] += 1\n"," else:\n"," self._failures[action] += 1\n","\n"," @property\n"," def name(self):\n"," return self.__class__.__name__\n","\n","\n","class RandomAgent(AbstractAgent):\n"," def get_action(self):\n"," return np.random.randint(0, len(self._successes))"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"rGUPT9PT9ia4"},"source":["### Epsilon-greedy agent\n","\n","**for** $t = 1,2,...$ **do**\n","\n"," **for** $k = 1,...,K$ **do**\n","\n"," $\\hat\\theta_k \\leftarrow \\alpha_k / (\\alpha_k + \\beta_k)$\n","\n"," **end for** \n","\n"," $x_t \\leftarrow argmax_{k}\\hat\\theta$ with the probability $1 - \\epsilon$ or random action with the probability $\\epsilon$\n","\n"," Apply $x_t$ and observe $r_t$\n","\n"," $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n","\n","**end for**\n","\n","Implement the algorithm above in the cell below:"]},{"cell_type":"code","metadata":{"id":"oRPirwR49ia5"},"source":["class EpsilonGreedyAgent(AbstractAgent):\n"," def __init__(self, epsilon=0.01):\n"," self._epsilon = epsilon\n","\n"," def get_action(self):\n"," \n","\n"," @property\n"," def name(self):\n"," return self.__class__.__name__ + \"(epsilon={})\".format(self._epsilon)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"BY4vvDYR9ia7"},"source":["### UCB Agent\n","Epsilon-greedy strategy heve no preference for actions. It would be better to select among actions, that are uncertain or have potential to be optimal. One can come up with an idea of index for each action, that represents optimality and uncertainty at the same time. One efficient way to do it is to use UCB1 algorithm:\n","\n","**for** $t = 1,2,...$ **do**\n","\n"," **for** $k = 1,...,K$ **do**\n","\n"," $w_k \\leftarrow \\alpha_k / (\\alpha_k + \\beta_k) + \\sqrt{2log\\ t \\ / \\ (\\alpha_k + \\beta_k)}$\n","\n"," **end for** \n","\n"," **end for** \n"," $x_t \\leftarrow argmax_{k}w$\n","\n"," Apply $x_t$ and observe $r_t$\n","\n"," $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n","\n","**end for**\n","\n","__Note:__ in practice, one can multiply $\\sqrt{2log\\ t \\ / \\ (\\alpha_k + \\beta_k)}$ by some tunable parameter to regulate the agent's optimism and wilingness to abandon non-promising actions.\n","\n","More versions and optimality analysis - https://homes.di.unimi.it/~cesabian/Pubblicazioni/ml-02.pdf"]},{"cell_type":"code","metadata":{"id":"-DJIamXz9ia7"},"source":["class UCBAgent(AbstractAgent):\n"," def get_action(self):\n"," "],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Oa-SHgJt9ia8"},"source":["### Thompson sampling\n","\n","UCB1 algorithm does not take into account the actual distribution of rewards. If we know the distribution - we can do much better by using Thompson sampling:\n","\n","**for** $t = 1,2,...$ **do**\n","\n"," **for** $k = 1,...,K$ **do**\n","\n"," Sample $\\hat\\theta_k \\sim beta(\\alpha_k, \\beta_k)$\n","\n"," **end for** \n","\n"," $x_t \\leftarrow argmax_{k}\\hat\\theta$\n","\n"," Apply $x_t$ and observe $r_t$\n","\n"," $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n","\n","**end for**\n"," \n","\n","More on Thompson Sampling:\n","https://web.stanford.edu/~bvr/pubs/TS_Tutorial.pdf"]},{"cell_type":"code","metadata":{"id":"j24FHjrV9ia8"},"source":["class ThompsonSamplingAgent(AbstractAgent):\n"," def get_action(self):\n"," \n"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"kYA1jX5E9ia9"},"source":["from collections import OrderedDict\n","\n","def get_regret(env, agents, n_steps=5000, n_trials=50):\n"," scores = OrderedDict({\n"," agent.name: [0.0 for step in range(n_steps)] for agent in agents\n"," })\n","\n"," for trial in range(n_trials):\n"," env.reset()\n","\n"," for a in agents:\n"," a.init_actions(env.action_count)\n","\n"," for i in range(n_steps):\n"," optimal_reward = env.optimal_reward()\n","\n"," for agent in agents:\n"," action = agent.get_action()\n"," reward = env.pull(action)\n"," agent.update(action, reward)\n"," scores[agent.name][i] += optimal_reward - reward\n","\n"," env.step() # change bandit's state if it is unstationary\n","\n"," for agent in agents:\n"," scores[agent.name] = np.cumsum(scores[agent.name]) / n_trials\n","\n"," return scores\n","\n","def plot_regret(agents, scores):\n"," for agent in agents:\n"," plt.plot(scores[agent.name])\n","\n"," plt.legend([agent.name for agent in agents])\n","\n"," plt.ylabel(\"regret\")\n"," plt.xlabel(\"steps\")\n","\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ju8zERpl9ia9","outputId":"6b08a064-7449-4228-b1c2-341f57fc2efe"},"source":["# Uncomment agents\n","agents = [\n"," # EpsilonGreedyAgent(),\n"," # UCBAgent(),\n"," # ThompsonSamplingAgent()\n","]\n","\n","regret = get_regret(BernoulliBandit(), agents, n_steps=10000, n_trials=10)\n","plot_regret(agents, regret)"],"execution_count":null,"outputs":[{"output_type":"display_data","data":{"image/png":"iVBORw0KGgoAAAANSUhEUgAAA+4AAAHjCAYAAAC95UVJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAIABJREFUeJzs3Xd0VVXexvHvSe+FNEoIJHREWgLSRTojCowoIirYKGLDCo7DgMqIwviiOOjgoKJiAJGiOBQZDIrUhE4oIRAgIQmQ3ts97x+BqxlCJySE57MWy3vP2Wef373JdeW5e599DNM0EREREREREZGqyaayCxARERERERGRC1NwFxEREREREanCFNxFREREREREqjAFdxEREREREZEqTMFdREREREREpApTcBcRERERERGpwhTcRURERERERKowBXcRERERERGRKkzBXURERERERKQKs6vsAq6Fr6+vWb9+/couQ0REREREROSKRUVFnTFN0+9S7W7q4F6/fn0iIyMruwwRERERERGRK2YYxrHLaaep8iIiIiIiIiJVmIK7iIiIiIiISBWm4C4iIiIiIiJShd3U17iXp6ioiPj4ePLz8yu7FJGbmpOTE4GBgdjb21d2KSIiIiIit7RqF9zj4+Nxd3enfv36GIZR2eWI3JRM0yQlJYX4+HiCg4MruxwRERERkVtatZsqn5+fj4+Pj0K7yDUwDAMfHx/NXBERERERqQKqXXAHFNpFrgN9jkREREREqoZqGdxFREREREREqgsF9wpga2tL69atrf+mTZt2xX1ERkby3HPPAfDFF1/wzDPPXHU9MTExDBgwgAYNGhAaGspdd93FL7/8ctX9XczkyZOZMWPGJdudOXMGe3t7PvnkkwqpIz09ndmzZ5fZlpiYyIABA67reSZNmsTatWsB6N69O5GRkde1/z+aN28ejRo1olGjRsybN6/cNqmpqfTu3ZtGjRrRu3dv0tLSADhw4AAdO3bE0dGxzM+nsLCQbt26UVxcXGF1i4iIiIjItVFwrwDOzs7s3LnT+m/ChAlX3EdYWBgffvjhNdeSn5/P3XffzahRo4iNjSUqKopZs2Zx5MiR89reyPD27bff0qFDB8LDwyuk//KC+/vvv89TTz11Xc/z5ptv0qtXr+vaZ3lSU1OZMmUKW7ZsYevWrUyZMsUayv9o2rRp9OzZk5iYGHr27Gn90qhGjRp8+OGHvPzyy2XaOzg40LNnTxYuXFjhr0FERERERK5OtVtV/o+m/LCP6JOZ17XP5rU9+Ns9t13VsfXr1+eBBx5g5cqVODs7880339CwYUO+/fZbpkyZgq2tLZ6envzyyy9EREQwY8YMVqxYUaaPuLg4Hn/8cc6cOYOfnx+ff/45QUFBjBw5Eg8PDyIjI0lKSuK9995jyJAhzJ8/n44dO3Lvvfda+2jRogUtWrQASkfIY2NjOXLkCEFBQXz99ddMmDCBiIgICgoKGDduHKNHjwZg+vTpLFq0iIKCAgYPHsyUKVMAmDp1KvPmzcPf35+6desSGhpKbGws999/P9u3bwdKR/2HDh1qfR4eHs4//vEPHnroIeLj4wkMDARg7ty5vPvuu3h5edGqVSscHR356KOPOH36NGPGjOH48eMAzJw5k86dOzN58mSOHz/OkSNHOH78OC+88ALPPfccEyZMIDY2ltatW9O7d2+mT5/Od999x9tvvw1ASUlJua8zIiKCSZMm4e7uzuHDh7nrrruYPXs2pmnyxBNPEBkZiWEYPP7444wfP56RI0cyYMAAhgwZUubnFB4ezt///ndM0+Tuu+/m3XffBcDNzY3nn3+eFStW4OzszPLlywkICLjk787q1avp3bs3NWrUAKB3796sWrWKYcOGlWm3fPlyIiIiABgxYgTdu3fn3Xffxd/fH39/f3788cfz+h40aBATJ05k+PDhl6xDRERERERuvGod3CtLXl4erVu3tj6fOHEiQ4cOBcDT05M9e/bw5Zdf8sILL7BixQrefPNNVq9eTZ06dUhPT79o388++ywjRoxgxIgRfPbZZzz33HMsW7YMKJ0KvmHDBg4cOMC9997LkCFD2LdvH23btr1on9HR0WzYsAFnZ2fmzJmDp6cn27Zto6CggM6dO9OnTx9iYmKIiYlh69atmKbJvffeyy+//IKrqysLFixg586dFBcX07ZtW0JDQ2nQoAGenp7s3LmT1q1b8/nnn/PYY48BcOLECRITE2nfvj0PPPAACxcu5KWXXuLkyZO89dZbbN++HXd3d3r06EGrVq0AeP755xk/fjxdunTh+PHj9O3bl/379wOl08B//vlnsrKyaNKkCWPHjmXatGns3buXnTt3AnD06FG8vb1xdHQESr8gKO91AmzdupXo6Gjq1atHv379WLJkCcHBwSQkJLB3716Ai/6cTp48yWuvvUZUVBTe3t706dOHZcuWMWjQIHJycujQoQNTp07l1Vdf5dNPP+WNN95g/vz5TJ8+/by+GjZsyOLFi0lISKBu3brW7YGBgSQkJJzXPjk5mVq1agFQs2ZNkpOTL/qzh9IvcrZt23bJdiIiIiIiUjmqdXC/2pHxa3Vuqnx5zo2QDhs2jPHjxwPQuXNnRo4cyQMPPMCf//zni/a9adMmlixZAsAjjzzCq6++at03aNAgbGxsaN68+QUD2+DBg4mJiaFx48bWfu69916cnZ0BWLNmDbt372bx4sUAZGRkEBMTw5o1a1izZg1t2rQBIDs7m5iYGLKyshg8eDAuLi7Wvs558skn+fzzz3n//fdZuHAhW7duBWDhwoU88MADADz44IM8/vjjvPTSS2zdupU777zTOqp8//33c+jQIQDWrl1LdHS0te/MzEyys7MBuPvuu3F0dMTR0RF/f/9yX3tiYiJ+fn7W5xd6nQ4ODrRv356QkBCg9Oe0YcMGevbsyZEjR3j22We5++67rSG/PNu2baN79+7W8w0fPpxffvmFQYMG4eDgYL3OPjQ0lJ9++sna5nqPeBuGcVkrw9va2uLg4EBWVhbu7u7XtQYREREREbl21Tq4V0V/DFLnHn/yySds2bKFH3/8kdDQUKKioq6q73OjyQCmaQJw2223lVmIbunSpURGRpa51tnV1bXMcbNmzaJv375l+l69ejUTJ060Tps/Z+bMmRes57777mPKlCn06NGD0NBQfHx8gNJp5ElJScyfPx8oHaGOiYm56GuzWCxs3rwZJyeni75uW1vbcq/Vd3Z2LnNP8gu9zoiIiPPCrmEYeHt7s2vXLlavXs0nn3zCokWL+Oyzzy5ac3ns7e2t/f+x1kuNuNepU8c6BR4gPj6e7t27n9c+ICCAxMREatWqRWJiIv7+/pdVV0FBQbnvrYiIiIiIVD4tTneDnVsEbOHChXTs2BGA2NhY7rjjDt588038/Pw4ceLEBY/v1KkTCxYsAErDXteuXS96voceeojffvuN77//3rotNzf3gu379u3Lxx9/TFFREQCHDh0iJyeHvn378tlnn1lHuRMSEjh16hTdunVj2bJl5OXlkZWVxQ8//GDty8nJib59+zJ27FjrNPlDhw6RnZ1NQkICcXFxxMXFMXHiRMLDw2nXrh3r168nLS2N4uJivvvuO2tfffr0YdasWdbnF5rRcI67uztZWVnW540bNyYuLu6SrxNKp8ofPXoUi8XCwoUL6dKlC2fOnMFisXDffffx9ttvW6/VL0/79u1Zv349Z86coaSkhPDwcO68886L1jt8+PAyCxqe+3duRkDfvn1Zs2YNaWlppKWlsWbNmvO+dIDSGQ/nVpyfN28eAwcOvOh5AVJSUvD19cXe3v6SbUVERERE5MbTiHsF+N9r3Pv162dd3TstLY2WLVvi6OhoXVH9lVdeISYmBtM06dmzJ61atWL9+vXl9j1r1iwee+wxpk+fbl2c7mKcnZ1ZsWIFL774Ii+88AIBAQG4u7vzxhtvlNv+ySefJC4ujrZt22KaJn5+fixbtow+ffqwf/9+65cNbm5ufP3117Rt25ahQ4fSqlUr/P39adeuXZn+hg8fztKlS61Ty8PDwxk8eHCZNvfddx9Dhw5l0qRJvP7667Rv354aNWrQtGlTPD09Afjwww8ZN24cLVu2pLi4mG7dul30VnI+Pj507tyZFi1a0L9/f6ZPn06DBg04fPgwDRs2vODrBGjXrh3PPPOMdXG6wYMHs2fPHh577DEsFgsA77zzzgXPXatWLaZNm8Zdd91lXZzucgL0xdSoUYO//vWv1vd30qRJ1ksKnnzyScaMGUNYWBgTJkzggQceYO7cudSrV49FixYBkJSURFhYGJmZmdjY2DBz5kyio6Px8PDg559/5u67776m+kREREREpOIY56ZU34zCwsLM/71v9v79+2nWrFklVXRx9evXJzIyEl9f38ou5YaZMWMGGRkZvPXWW5fVPjs7Gzc3N4qLixk8eDCPP/74eUH/ai1dupSoqCjryvLludBq/tXZn//8Z6ZNm0bjxo3P21eVP08iIiIicusxTRPDMLBYTGxsLr2eU1VnGEaUaZphl2qnEXepMIMHDyY2NpZ169Zd9jGTJ09m7dq15Ofn06dPHwYNGnRd60lJSblu/VUHhYWFDBo0qNzQLiIiIiJSVeQWFvPgnM0cPpVNbmGJdXvPpv5sOpJC05ruNK3lwfhejfFzd7xITzcnjbiLyAXp8yQiIiIiN1JiRh49ZqxnzqOhNKnpzq4TGXyyPpaoY2mX3cfHw9vS//ZaFVjl9aMRdxEREREREamyEjPyeGPpXup4OzOxfzP2nszg/k82AfDI3K3ntW8V6MmycZ0pKjExDCgqsbDzRDpO9rYs25FAUYmF7cfSuSPE50a/lAqn4C4iIiIiIiKXLTO/iPjUPJIy89gWl8bHEbE0CXAnr6iE4hILJzPy6dXMn9NZBTzWOZiiEgsTl+yh2FI62/uprsHkFJbwzZbj1j6/3HTM+riGqwPt6ntz9EwO7k72BHo783CHeoTV88YwDBzsSq9tt7e1oVOD0vXD2gZ538B34MZTcBcREREREZHLsnRHPOMX7iqzzcvFnoPJWWW2rd1/CoAXFp5/G+dPfz1qfdyrmT9t63nzwdoYCootPNU1mNf/1AzDuPkXnrueFNxFRERERERuEefWOCsqMbGYJoeSs3jnPwc4k11AZn4Rf24biLeLPT2bBbDjeDovf1sa0kffGcK/1h8p01f3Jn48c1dDwurXIOLgKUZ+vo2Il7tTbLHwbVQ8Df3cWLI9gR0n0vhsRDsKSiwkZ+Tz5opoOjXw4aOH2uJkbwvA090b3tg34iajxekqQFxcHAMGDGDv3r3WbZMnT8bNzY2XX36ZGTNm8O9//xsnJyfs7e159tlnefTRR+nevTuJiYk4OztTUFDA+PHjGTVqlLWPnTt30qZNG1auXEm/fv0qpO6NGzfy0EMPXfe+5eZUFT5PIiIiInJtiksszFwbw5nsAhZsO3HN/a14tgst6nheh8pEi9NVUZ988gk//fQTW7duxcPDg8zMTJYuXWrdP3/+fMLCwkhNTaVBgwaMHDkSBwcHAMLDw+nSpQvh4eEVFty/+eYbBXcRERERkQswTZNii0lhsQVbGwNHO5tKm9ZdWGzhRFoudbycrSPXf5SSXcBflu5l1b6ki/YzrH0Qbw9qQUJaHuHbjpOUkc/+xExOZRUwfUhL6vm4sP1YOoPa1MHBzqaiXo5cRPUO7isnQNKe69tnzduh/7SrPvzvf/87EREReHh4AODh4cGIESPOa5ednY2rqyu2tqUfQNM0+fbbb/npp5/o2rUr+fn5ODk5AfDWW2/x9ddf4+fnR926dQkNDeXll18mNjaWcePGcfr0aVxcXPj0009p2rQpI0eOxMPDg8jISJKSknjvvfcYMmQIEyZMYP/+/bRu3ZoRI0Ywfvz4q36dIiIiInLzKSqx8N/9yWw+ksrmIykMbF2H22p70LSmO4Zh4OPqQHpeEe5Odtjb/h7gcguLeWTuVu4PDeTB9kGV+AoqxordJ3nmmx3l7gvwcGRkp2DGdm+AxVI6/dzOtuLCbUZuEb/FnuHp+dvP2zc0rC4LI0/g5WKPo50NyZkFZfYPblOHKQNvw8PJvty+g3xceK1f03L3NfR3v/bi5apV7+BexeTm5pKVlUVISMgF2wwfPhxHR0diYmKYOXOmNbhv3LiR4OBgGjRoQPfu3fnxxx+577772LZtG9999x27du2iqKiItm3bEhoaCsCoUaP45JNPaNSoEVu2bOHpp59m3bp1ACQmJrJhwwYOHDjAvffey5AhQ5g2bRozZsxgxYoVFf9miIiIiEilMk2Tj9fHElTDhV7NAjiTXUCXd38u0+bAqgNX1GfUsTQmLCk7cPZCr0b8cug0A1vXwTBgaLu6ONrZYjm7wrhhUGbE+kx2AR+sjaGmpxNfbIxj0oDmDGhZC8MwWBudzJNfRuLj6sA7f76dED836vm4lPkS4X9ZLCbLdyXwbWQ8NT2d+Mf9rTAMg4y8IiwWE09ne2xsDI6eyeGDtYc4lprLnvgMii0m7ep7k5xZwPHU3Av2n5xZwLurDvDu2feqhqsDPz7XhVqezpd8v0zTPG+0Pr+ohINJWXg62/PFxji+2Bh3yX7OWRhZOg0+PbfIuq1xgBtLnu6Mm6Oi382sev/0rmFk/FpcaKrM5awncG6q/OnTp+nUqRP9+vWjXr16hIeH8+CDDwLw4IMP8uWXX3Lffffx22+/MXDgQJycnHBycuKee+4BSkfsN27cyP3332/tu6Dg92/cBg0ahI2NDc2bNyc5OflaXq6IiIiIXEcFxSWcyiygsMTC/M3H+ey30hW4W9X14u+DW3D3hxtwsLVh2n2306OpP14uDhftzzRN9iZk8vH6w7g62PFtVDyt6nqRW1BMzKnsco8ZEhpILU8n9idmsnb/KVrU8SAxPZ+UnMILnueuJn4cPp3NidS8Mttnro0BYPvxdAAmLd933rHuTnY42NqQnldEiaXs38zPhu/g2fCyo90pOYWM+irK+rxbYz/6NA/gzsZ+1K3hApTOHnjs821sOHymzLFLtidc8DX8r21xaQCE+LryWv+mhNXzxsfN0bq/uMRCTmEJo7+K5HhKLicz8knNKWTYnM188GAblu88SaC3M4Pb1MHLxR7ThPi0PLpN//0Lkhn3t2LS8r083KEeW4+msvNE+kVr8nS2p3+LmlhMk7/dcxuuZwP5hO92E5eSw78eDsPV0ZbU3EL83By1Ons1Ub2DeyXx8fEhLS2tzLbU1FRCQ0Nxc3PjyJEjFx11B/Dz86Nt27Zs2bKFwMBAvvvuO5YvX87UqVMxTZOUlBSysrIueLzFYsHLy4udO8+//QKAo+Pv/8O5mRcoFBEREflf5/62KS+wWCwmNjZVM8hYLCbPLtjBj7sTy92/60Q6d3+4AYDCEgsvLipd7Xvl811pVsujTNvIuFQiDp6mno8LC7adIOpY2nl9AdzTqjZ5hcWs3X8Ke1uDz0a2o2sjv8uqN7ewmJyCEvKLSgj0dra+3+m5hdYvE05nFTB3w1Ey8oqo7emEjY3B9NUHz+srK7/4vG0P3RFEXmEJZ7IL+DWmNHzb2hh8N7YTLg62DP/3Fmq4OHAwOYtfDp3ml0OnL1pv54Y+ZBeUWF97eTqG+PBsj4aE1vfmyOkc3lt1gH4tajK0XfnT/+1sbfB0tmHBqI5A6e/eb4dTGP1VJAP/+Zu13Zsroi94znOrts/55fcV233dHDmTXTrotv/Nfjja2Vzy93bafS3LPPd3d7poe7m5KLhXADc3N2rVqsW6devo0aMHqamprFq1iueff56JEycybtw4Fi5ciIeHB9nZ2SxZsoRHH320TB+5ubns2LGDV199lf/+97+0bNmS1atXW/ePGDGCpUuX0rlzZ0aPHs3EiRMpLi5mxYoVjBo1Cg8PD4KDg/n222+5//77MU2T3bt306pVqwvW7e7uftEvA0RERETyi0qwMYxrXqDqdFYBro62uDhc/Z+jpmmyKTaF+r6uFBRbWLD1OMt3niQpMx+AOl7OhNbzpkOID072Ntag62Bnw6Md6jGqWwj+HueHm6ISi/WxnY2BxYRzmWlPQgZD/7WZ1nW9+PKJ9tYp2ifT87C1MXB3suPRuVvZnZDBb6/1wM/dsUzfJ9Pz6P/Br3Rt5EubIG/eukigg9JR9g+GtsYw4Mc9iew6kU77YB/6NA9g1roYFkXG0/+DXxnRsR7zNh27YD9dG/mSmV/MZyPCWLDtBJ9ExDKmewPG3dXQ+l7ChWeOlsfFwa7cn98fZwD4uTsyoX/Za6aH3xFEWm4R9X1KR8bTc4soKrGQmV9MoLfzeYu9maZJWm4RJ9PzCPFztZ5z2196nT2+kPi0PL7cFMeiyPj/qcWe9x9oRZeGftbf2ZPpedRwdbAu5rbjeBpLdyQw+s4G1PH6fXp7s1oefP5Y+8t+P6D0/evSyJdFYzry9//sJ7ugpPTv8PiMMu1e6NWI5rU8KLGYjJ2/nXb1vXmpTxPWHTjFsPZBBPu6XtF5pfrT7eAqSHR0NOPGjbOOvL/yyisMHz4c0zSZPn06c+fOxd7eHnt7e1566SUefvjh824H98gjj/D666/z2GOPcccddzBmzBhr/99//z0ff/wxK1euZPLkyXzzzTcEBATg7+9Pv379eOqppzh69Chjx44lMTGRoqIiHnzwQSZNmsTIkSMZMGAAQ4YMAUq/aMjOzqaoqIi+ffuSkpLCyJEjtTidVJnPk4hIZdtyJIWVe5Po0zyAO0J8sDFKr+VtVsuDlOxC/D0cOZVZgJ+7I8UWC+4XWPjpSuQUFOPiYEuJxcTGMBi/aCdpuUU429sQdSydhv6u1PFyYVS3EJrUrLhFowqLLfzt+30s2R5PQXFpoHVxsKWhvxshvq4UWUx+2peMg50N2QXFuDvZsfL5rgR6u1BYbCGvqISPI2IZ1r4udb1dMAx4cdEulu4ona4cWs+b46m53F7HEy8Xe4aG1eW2Op64OthiMaHYYsHRzhbTNDmTXcjMtYeIOZXN8ZRca0C/Vutf6U5dbxc+3xjHqr2J1unR10PdGs6cSM0j2NeVo2dyLtn+4Q5BTOjf7LKvR/7t8BmG/3vLedsDPBwZ1j6IpTsSmPNIWIX+jlQluYXFHEjKollND5wdzl9lXaSqudzbwSm4VwPZ2dm4ubmRm5tLt27dmDNnDm3btq3ssqQauBU/TyJya0rLKWTcN9vZdSIdNyc77g+ty0c/H76mPj99NIywet4sjDyBm6MdiRl5pOYUMbpbCMdSc5n8/T4a+rvh5mjH0h0J+Lo5cCb7wtcPX0yf5gF88GCb6xpUcgqKmbn2EJ/+erTM9o4hPpzOLuDwBa6NrgzujnbY29kQVMOFDiE+jOhUj1qezhSVWNiTkMHzC3bQs2np9c93NfUH4OvNx3hj2V6Ai773LQM9y4yWtqjjwUu9m/D8gh1k/mF6t4uDLTU9nAis4ULrul7sTchg3YFT5fb53n0tyS4o5vONR5k5tA2maXIqq4AeTf3LvaXXpexPzOSdlQfILyxhVLcQ7mrqj20VvRxARMpScL+FPPTQQ0RHR5Ofn8+IESOYOHFiZZck1cSt+HkSkVtPflEJA2ZtuGQQHdUthB3H06yjsc1reXA8NZcQP1dqejixJrpiFnsN8HAkObOANkFe/OuRUIpKTD6OOEzcmVxuD/Tk44hYABztbPj11bvKnfp9zrlFyhoFuFkD4h9XtV65J5Gx87fTq1kAa/f//nqe6hrMxP7NyMwvwsvFgaISCz/uTqSwxMIPu04yuE0dWtTxxN/dkbd/3M/iqLLTlZvX8iA6MdP6vGlNd1Y82wUbw+DImRy2xaXSuq4XSZn5rNiVyHfbyx7/Rw/dEcQTXYIJ8XWl2GJedDXxy7H5SAqz1sXw2+EU7giuwaA2dfjT7bXwdL62WROmabInIYOmNT1wsLPBNE0Kzt73+1prFpHqQ8FdRK6ZPk8iUp2ZpsmBpCz6f/ArULpI16xhbVh/6DQrdp3klX5NyC+04O1qj6uD3RUtaHYyPY97P/qNM9kFjO4Wwup9STzeJZgjp3Ost3ZaNLojvx0+Qw1XB1rV9aJ1XS8AkjLycXawvaLgOH31Af75c2mAbxLgzohO9enexI/af7heNyOviPZT11qnu9/VxA+LCesvsqDXQ3cEMb5X4/Ou076UhPQ8PJ3tz5vufSa7gGMpuYTW876i/kREqisFdxG5Zvo8icjN6lRmPuFbT+DhXBocF0fFs+9k5gXbO9vbsm9K3yq72vjl+GbLcV5fWvb+2YHezsSnlYbojLyiCxxZ1mv9mlLfxwVPF3s6NfCtiFJFROSsyw3uWlVeREREqpXRX0Wyet/lT1t/qmswf7m7eQVWdGM8dEcQ/VvUJCkz3zqLID6t9H7a50L7x8Pb0r2JPy8s3MHqfcnc2diPfz0SipO9bZkp8yIiUrUouIuIiEi1kFtYzIBZGzhyunTl7pd6N8bJ3pYvNsYxuE0dujTyxc3RjhA/VwwM7G0N7KrZtcberg54uzoQN+1ucgqK+euyvXRu6Evbet6cysznjhAfAP71yPmDOwrtIiJVl4K7iIiIVHn5RSUYBjjalS6olltYTPNJq637f331Ll5fusca2ndO6m29l/RT3UJufMFVgKujHe8PbW19rvtCi4jcvBTcr7OUlBR69uwJQFJSEra2tvj5+REXF0ft2rWJjo6u5AqvjMVi4YUXXmDdunUYhoGTkxOLFi0iODi4ws5Zv359IiMj8fX1pVOnTmzcuPGa+hs0aBBJSUls3rz5OlVY1hdffEGfPn2oXbt2hfQvInIrSs8tpPuMCNJzz78uu6G/23krwHd972cA2gR58e9Hw6yhXUREpDpQcL/OfHx82LlzJwCTJ0/Gzc2Nl19+mbi4OAYMGFDJ1V25hQsXcvLkSXbv3o2NjQ3x8fG4ut64b+yvNbSnp6cTFRWFm5sbR44cISTk+o+6fPHFF7Ro0ULBXUTkGr26eBeLIi98G7BzDp/KplVdLzqG+PBi78asP3Sab7Yco0OID6O6hWjKt4iIVDvVOri/u/VdDqQeuK59Nq3RlNfav3ZVx5aUlPDUU0+xceNTQ9WCAAAgAElEQVRG6tSpw/Lly3F2dmbnzp2MGTOG3NxcGjRowGeffYa3tzfdu3enTZs2/Prrr+Tk5PDll1/yzjvvsGfPHoYOHcrbb79NXFwc/fr1IzQ0lO3bt3Pbbbfx5Zdf4uLiwoQJE/j++++xs7OjT58+zJgxg7i4OB5//HHOnDmDn58fn3/+OUFBQYwcORIPDw8iIyNJSkrivffeY8iQISQmJlKrVi1sbEqvAQwMDLS+nrFjx7Jt2zby8vIYMmQIU6ZMAUpHzIcNG8bKlSuxs7Njzpw5TJw4kcOHD/PKK68wZswYIiIimDRpEu7u7hw+fJi77rqL2bNnW89zjpubG9nZ2URERDB58mR8fX3Zu3cvoaGhfP311xiGwX/+8x9efPFFXF1d6dy5M0eOHGHFihUALFmyhHvuuYeAgAAWLFjA66+/DkBsbCzDhw8nJyeHgQMHMnPmTLKzS0dvpk+fzqJFiygoKGDw4MFMmTKFuLg4+vfvT5cuXcr8/H788UciIyMZPnw4zs7ObNq0CWdnZ0REpNSO42nM2xhH67peDGxdB29XB1JzClm47QRnsgvIyCvC0c4GE8qEdgc7G4aG1WXSPc3L3PP6p+hkfNwcaBv0++3EejcPoHfzgBv5skRERG6o6rUiSxUXExPDuHHj2LdvH15eXnz33XcAPProo7z77rvs3r2b22+/3RqAARwcHIiMjGTMmDEMHDiQf/7zn+zdu5cvvviClJQUAA4ePMjTTz/N/v378fDwYPbs2aSkpLB06VL27dvH7t27eeONNwB49tlnGTFiBLt372b48OE899xz1nMlJiayYcMGVqxYwYQJEwB44IEH+OGHH2jdujUvvfQSO3bssLafOnUqkZGR7N69m/Xr17N7927rvqCgIHbu3EnXrl0ZOXIkixcvZvPmzfztb3+zttm6dSuzZs0iOjqa2NhYlixZctH3b8eOHcycOZPo6GiOHDnCb7/9Rn5+PqNHj2blypVERUVx+nTZe9GGh4czbNgwhg0bRnh4uHX7888/z/PPP8+ePXvKfBmxZs0aYmJi2Lp1Kzt37iQqKopffvnlgj+/IUOGEBYWxvz589m5c6dCu4jcVLLyi/jHmoMs2R5Po7/8h6Z/XUmbN9eQX1QClN7nPLugmLScQs7dPjYjr4iiEot1P0BqTiFfborj15jTnEzPo6C4BNM0+Sk6mcGzN7Js50km/xBNm7d+ov6EH2n71k+8u+oAczccZXFUPPO3HOebLcep6eFE7N//RNy0uzn4Vj/eGtSiTGiH0pD+x9AuIiJyK6jwEXfDMGyBSCDBNM0BhmEEAwsAHyAKeMQ0zULDMByBL4FQIAUYappm3LWc+2pHxitKcHAwrVuXLhITGhpKXFwcGRkZpKenc+eddwIwYsQI7r//fusx9957LwC33347t912G7Vq1QIgJCSEEydO4OXlRd26dencuTMADz/8MB9++CEvvPACTk5OPPHEEwwYMMA6TX/Tpk3WgPzII4/w6quvWs81aNAgbGxsaN68OcnJpbfRCQwM5ODBg6xbt45169bRs2dPvv32W3r27MmiRYuYM2cOxcXFJCYmEh0dTcuWLc+rOzs7G3d3d9zd3XF0dCQ9PR2A9u3bW6euDxs2jA0bNjBkyJALvn/t27e3huzWrVsTFxeHm5sbISEh1mvuhw0bxpw5cwBITk4mJiaGLl26YBgG9vb27N27lxYtWrBp0yaWLVsGwEMPPcTLL78MlAb3NWvW0KZNGwCys7OJiYkhKCio3J+fiMjNYui/NrHlaCpNa7pzICmr3DZFJSb5RRaa/nXVdT332O4NqO/jwvs/HSI5swAHWxs6NfQhMT2f94a05Mc9iRxKzuLDYW2wPXsfdU13FxER+d2NmCr/PLAf8Dj7/F3g/0zTXGAYxifAE8DHZ/+bZppmQ8MwHjzbbugNqO+GcXR0tD62tbUlLy/vso+xsbEpc7yNjQ3FxcXA+X/cGIaBnZ0dW7du5b///S+LFy/mo48+Yt26dZdd37lRlHPb+/fvT//+/QkICGDZsmWEhIQwY8YMtm3bhre3NyNHjiQ/P/+a677c+mxtba39XMiiRYtIS0uzhvrMzEzCw8OZOnXqBY8xTZOJEycyevToMtvj4uKu6ucnIlJZIg6eYlNsCgXFFg4lZ7HlaCrAeaG9SYA7B5OzmNC/Ke2Da/Dn2Ve3tsh9bQNZuz/Zer/wc8b3aszzvRoBMLRdULnHtqrrdVXnFBERuVVUaHA3DCMQuBuYCrxolCazHsBDZ5vMAyZTGtwHnn0MsBj4yDAMw/xjgqyGPD098fb25tdff6Vr16589dVX1tH3y3X8+HE2bdpEx44d+eabb+jSpQvZ2dnk5ubypz/9ic6dO1tHtjt16sSCBQt45JFHmD9/Pl27dr1o39u3b6dmzZrUrl0bi8XC7t27admyJZmZmbi6uuLp6UlycjIrV66ke/fuV1T31q1bOXr0KPXq1WPhwoWMGjXqio4HaNKkCUeOHCEuLo769euzcOFC677w8HBWrVpFx44dATh69Ci9evVi6tSpdOjQge+++46hQ4eyYMEC6zF9+/blr3/9K8OHD8fNzY2EhATs7e0vWoO7uztZWeWPXolI9XA6q4D/7ElkyfZ4nOxtqePlzN6TGcx5JIz613CLrfyiEpzsba/6+Iy8IgqKSnBzsqPEYrLlSCpPfhlZbtsWdTyY9ueWxKfl0THEB3cnO2xszv/CNG7a3Rc8X3GJBTtbGzLyirCzMXCwsyG3oAQTs8wq7qZp8vPBU3g62xNar8ZVvz4REREpVdEj7jOBVwH3s899gHTTNM8NlcYDdc4+rgOcADBNs9gwjIyz7c/8sUPDMEYBo6D0OurqYN68edbF6UJCQvj888+v6PgmTZrwz3/+k8cff5zmzZszduxYMjIyGDhwIPn5+Zimyfvvvw/ArFmzeOyxx5g+fbp1cbqLOXXqFE899RQFBQVA6XT1Z555BicnJ9q0aUPTpk3LTNW/Eu3ateOZZ56xLk43ePDgK+7D2dmZ2bNn069fP1xdXWnXrh1QOkJ+7NgxOnToYG0bHByMp6cnW7ZsYebMmTz88MNMnTqVfv364enpCUCfPn3Yv3+/Ney7ubnx9ddfY2t74T+sR44cyZgxY7Q4nchN6mR6Hku2xzNjzSHrttf6NeXJrsHsjk/nzR+i2RWfUe6x3WdEnLetlqcTiRn55zc+K9jXlXta1qLYYjI7IhaA3yb0YHNsCv/Zk0iPZv7kFBSTW1jC6G4NsLM1sLMxMAyDzUdSeHDOld3a8rmejXisU328XUuDdYs6nld0/B/Znb3e3NP59y80PV3OXy7HMAx6NNVicSIiIteLUVED2oZhDAD+ZJrm04ZhdAdeBkYCm03TbHi2TV1gpWmaLQzD2Av0M00z/uy+WOAO0zTPlHsCICwszIyMLDuysH//fpo1a1YRL6lKOnebub1791Z2KVckIiKCGTNmWFd/vxbZ2dm4ublhmibjxo2jUaNGjB8//qLH5Obm4uzsjGEYLFiwgPDwcJYvX37NtVQ3t9rn6WZmmqauCb4Cx1NymfnfQyzZnnBZ7W1tDLo09OX+sEBiT+VQ28uJoBoujPk6irRy7jNeWYa1r8sjHeqTW1hM67pe1qAtIiIiVZNhGFGmaYZdql1Fjrh3Bu41DONPgBOl17h/AHgZhmF3dtQ9EDj3V1MCUBeINwzDDvCkdJE6kYv69NNPmTdvHoWFhbRp0+a869PLExUVxTPPPINpmnh5efHZZ5/dgEpFrozFYvLT/mT2JmQwolN9fN0cKSguwc7Ghq1HUxn26fkjr7OGtaFVoBdzNxwhp7CEYF9XDp/KxsPJjh7NAujcwAcbwyh3ivQ5xSUWCootuDraUVhs4UBSJgYGmflFbD2ayonUXCIOnaZ3swAaBbixOCqevKISXuzdmI4hPszdcJSujfywMaBNkDeOdjb8fPAUDf3dqOfz+7TycyuTJ6Tl8bfv92FrYxBW35v3Vh0Efr/2+skuwSyMPEFWfulkrQZ+rpxMz+eLx9oRceg0Tna2dG7oQ6u6XtaR6ZV7EsnKL6bPbQG4OdpZA2xuYTGHkrN55N9byCr4fZ2MGq4ORLzSHXsbG976MZpTmfnsTcikcU13Jg1oRkN/d8qz5fVe7ElIp0lND9wc7cgvKuGn6GQaBbjh6+aIu5MdDrY2LIo8QZsgbw4mZXEwKQsnexsWRp7gi8faszchg1e+3U0DfzfuauLHyfQ84lJy2Xkivdxz/vOhtnRr7IvFAk4ONjjaXf1UexEREbk5VNiIe5mTnB1xP7uq/LfAd39YnG63aZqzDcMYB9xumuaYs4vT/dk0zQcu1q9G3EUqlj5PlSc1p5BnvtnOxtjfv78cGlaXhZEnrts5Rnaqz9IdCWTlF+HqaEeHEB9yCorLnPN6a17Lg4LiEtoEebM4Kv7SB1xHDnY2FBZbrM97NPVnxv2tqOHqcJGjqo5jKTkEeDhd0zXxIiIiUrVUhRH3C3kNWGAYxtvADmDu2e1zga8MwzgMpAIPXu0JNGVU5NpV83Uhq6TM/CLyC0s4kZbLfR9vOm///4b2ZeM6U8PFgZqeTjjY2ZCaU8jg2b+RmlPIXwc0J6+whPCtx2le24PHOwczYNaGMsd/sTHO+jgrv5ifopMvWl+3xn40q+lOak4hz/ZoxL83HGHzkRQOJWfz70fDrIui3Vbbg2MpudTzcWHfyUy8XexpGejF+kOniU7MBCD2dA4Azva25BWV8ErfJjQJcCfi0CneuLs5mflFFBRZSM8t4nR2PodPZTOgZW1yC0sIquHCxtgzLN95kvWHTvPufS2JOpbGJ+tjrbU2q+XBg+3q8tXmY5xIzaWg2EJhsYWG/m4MbFWbAa1qE3wNi8pVhj/OVhAREZFbyw0Zca8o5Y24Hz16FHd3d3x8fBTeRa6SaZqkpKSQlZVlvZ2eVIxTmfnM33KcVXuTOJhc9u4EL/dpzDM9Sm+jdTwll5/2J9MmyIu2Qd7XdM4Si8n3uxJwtrcj2NeVJjXd2XE8jcOnsskrKqG2pzN3NvEjPbcIbxf763ad9PGUXNZEJ2Ga8EvMaf5ydzOa1vS49IHXgcViYhhQbDGx13XfIiIiUkVc7oh7tQvuRUVFxMfHl7mnuIhcOScnJwIDAy95Ozy5eiv3JDJ2/nbrc3tbg6KS0v8nP9ejIS/2aVJZpYmIiIjIDVCVp8pXKHt7e40QikiVFJ+Wy7hvdlBisbA3IdO6/bkeDenYwJcOITU0U0hEREREzlPtgruISFWyZHs8Ly7adcH9q17oesOmi4uIiIjIzUnBXUSkApimyX0fb2T78bK39HqtX1P63hbA1qOp9L2tJt43yYrmIiIiIlJ5FNxFRK6DrPwijqXksjchgyKLyV+X7bXue/+BVvRsGoCHs511KnyIn1tllSoiIiIiNxkFdxGRa/DlpjgmLd93wf2Hp/a/bquyi4iIiMitScFdROQy/PPnw0xfffCC+wM8HHmiSzCdG/pyJrsQXzcHGge4K7SLiIiIyDVTcBcRuYi9CRkMmLXhgvtDfF354rH2BPm43MCqRERERORWouAuIlKOg0lZvPTtzjK3bXtrUAua1XQnxM+N/KISPJ3tcXXU/0ZFREREpGLpL04Rkf/x7qoDfBwRa32+9OlOtAnyrsSKRERERORWpuAuIvIH87ccs4b2F3o14rkejbCxMSq5KhERERG5lSm4i8gt6/01B8kqKOaXQ6eJPZ1j3e7pbM/miT1xdrCtxOpEREREREopuIvILaWw2MJ9H28kK7+IuJTc8/b7ujmy6oWuCu0iIiIiUmUouItItZSZX0RkXCrhW0/w84FTDGhZi+TMAjYdSbG2aVXXiyFt61BiMRnYug7erg6VWLGIiIiISPkU3EWkWsjKL+Lej37j6Jmccvcv23nS+rhzQx++fuIODEPXrouIiIhI1afgLiI3tTPZBZxMz+OtFdHlhvZPHw2jgZ8r+xOzaBzgRt0aLjjZaxq8iIiIiNw8FNxF5KZksZjc9Y8Ijv3hOvXnejRkZOdgkjLyaVbLvcyIeoifW2WUKSIiIiJyzRTcRaRKSMkuYMPhM7Sp602Qj4t1+9roZCIOnaJjiC//2ZPI2O4N2JOQwbyNcWVC+8hO9XmxTxMAauhadRERERGpRhTcRaRSRR1L5Z3/HCDyWJp1m6+bI22CvDBNWLs/GYCvNx8H4Mc9iWWOPzy1P3a2NjeuYBERERGRG0zBXUQqlMViUmwxsTHAMAxScwr5YddJ+t9eE4D7Pt5kbfun22vynz1JnMku4Kfo0sA+rH0QLQM9OZaSS2Gxha82x1FUYvJU12BG39lAoV1EREREqj3DNM3KruGqhYWFmZGRkZVdhohcwKHkLAbM2kBhseWCbQwDFo/pSEM/dzxd7AHYn5jJ2K+j+ODBNrSq63WjyhURERERuaEMw4gyTTPsUu004i4iFeL9nw7x4X9jyt3XMcTHej/1OY+EEVqvRpn9zWp5EPHKXRVeo4iIiIjIzUDBXUSumWmaRBw8TXx6HoeSsvhq8zEAGvm78ebAFnRs4FPuMYDupS4iIiIicgkK7iJyTZbvTOD5BTvL3Rc+qgO+bo7l7lNgFxERERG5PAruInLVfjl02hra+91Wk1X7kmgb5MU/HmhNfR8XhXMRERERketAwV1ELtvJ9DzeW3UAZwc7Yk9lszUuFYD5T95B54a+lVydiIiIiEj1pOAuIhdUYjFZsj2e9YdOsz8xk9jTOWX2h/i68nyvRgrtIiIiIiIVSMFdRCgstrDh8GmSMwsI8XXlk/WxNK7pzvIdJ0nKzC/T9qXejQms4cztdbxo6O9WSRWLiIiIiNw6FNxFbmF5hSW8u+oAX2yMO2/fzwdPA/Cn22uy/uBpejUP4P8eaI2Nja5bFxERERG5kRTcRW4Bn204ypsrohnfqzHD7qjL5iOpbD+WViawh9bzxtYwOJicRYeQGtT1dsHD2Z7nejaqvMJFRERERATj3L2Ub0ZhYWFmZGRkZZchUuXkFZYwffVBPvvtKN4u9qTlFl2wbeMAN74d3QlPF/sbWKGIiIiIiBiGEWWaZtil2mnEXaSaeWflfv61/oj1eVpuEW6Odkwd3IL/7j+FnY3B6ewChoQG0jjAnWa1PCqxWhERERERuRQFd5FqIr+ohMGzN7I/MROAV/o2IaiGCyF+rjSv5YFhGAxsXaeSqxQRERERkSul4C5SDby+dA/fbDlufb7k6U60DfKuxIpEREREROR6UXAXuUmZpsnDc7fw2+EU67bX+jVlbPcGlViViIiIiIhcbwruIjcR0zT558+HmbHm0Hn7tv6lJ/7uTpVQlYiIiIiIVCQFd5EqbumOeF5fspe8opJy9++Z3Ad3J60ILyIiIiJSXSm4i1RR8Wm59P/gV7Lyi8tsr+nhxNdPtieohiv2tgaGYVRShSIiIiIiciMouItUQXsTMhgwawMA7ep789UTd5CSU0gdL+dKrkxERERERG40BXeRKsQ0TYbO2czWo6kAtA3yYv6THXCws1FoFxERERG5RSm4i1QB+UUlvLp4N9/vOmndtnliT2p6arE5EREREZFbnYK7SCXKLSzmo3WHmR0Ra93Wu3kAs4a1wcnethIrExERERGRqkLBXaQSpOUU0uatn8pss7c12DulL452CuwiIiIiIvI7BXeRGyy/qKRMaH+iSzAjO9Wnbg2XSqxKRERERESqKgV3kRsor7CEnv+IAKCGqwORf+mFjY1u5yYiIiIiIhdmU9kFiNwqSiwm9360gZMZ+bSo48HW13sqtIuIiIiIyCVpxF3kBvlqUxwxp7J5rkdDxvdujGEotIuIiIiIyKVpxF3kBsgvKmHyD9G4OtjyQi+FdhERERERuXwK7iIVbOWeRFq/uQaARzvV1/R4ERERERG5IpoqL1JBfo05zSNztwLgYGvDA2GBvNCrUSVXJSIiIiIiNxsFd5HrLDIulWGfbqaoxLRu2/DaXfh7OFViVSIiIiIicrNScBe5ThLS8xj9VSR7EzIBaOTvxhePt6eOl3MlVyYiIiIiIjczBXeR6+CP0+IB5j95B50b+lZiRSIiIiIiUl0ouItco10n0q2hffqQlgwJDdSq8SIiIiIict0ouItco49+PgzA0qc70SbIu5KrERERERGR6ka3gxO5Bqv2JvFTdDLP9Wio0C4iIiIiIhVCwV3kKi2KPMGYr6MAeLxLcCVXIyIiIiIi1ZWCu8hVWLojnlcX7wZg1rA2eLk4VHJFIiIiIiJSXekad5ErNG9jHJN/2AeU3p890NulkisSEREREZHqTMFd5AqM+jKSNdHJAHw7pqNCu4iIiIiIVDgFd5HLlJCeZw3tu/7WB09n+0quSEREREREbgW6xl3kMs3ffAyAdS/dqdAuIiIiIiI3jEbcRS7DWyuimbvhKPe2qk2In1tllyMiIiIiIrcQjbiLXMKm2BTmbjgKwN/uaV7J1YiIiIiIyK1GwV3kIjJyixj26WZcHWzZPLEnPm6OlV2SiIiIiIjcYhTcRS7inZX7Afi/oa2p6elUydWIiIiIiMitSMFd5ALScgpZuiOBQa1r0+e2mpVdjoiIiIiI3KIU3EUu4PtdJykotvBk15DKLkVERERERG5hCu4iF7BqbxK1PZ1oUcezsksREREREZFbmIK7SDl+3J3IpiMpdGroW9mliIiIiIjILU7BXeR/bD+exrhvtgMwsX/TSq5GRERERERudQruIn/wy6HT/Hn2RgC+G9tRt38TEREREZFKZ1fZBYhUBYXFFhq/sdL6fNHojoTWq1GJFYmIiIiIiJRScBcBxnwdBUADP1cm3XMb7YMV2kVEREREpGpQcJdb3s4T6aw7cAqAtS/eiWEYlVyRiIiIiIjI73SNu9zSikosDP90MzVcHdg1qY9Cu4iIiIiIVDkK7nLLMk2TMV9FkVNYwrM9GuLpYl/ZJYmIiIiIiJxHU+XllrRmXxKjviq9rj3E15WRnepXbkEiIiIiIiIXoOAut5ztx9Osob1VXS/mjgjTFHkREREREamyFNzllvLj7kTGfbMdRzsbFo/pxO2BnpVdkoiIiIiIyEUpuMstI7+ohKk/RgOw9OnONK/tUckViYiIiIiIXJoWp5Nbxmvf7eZkRj7fPHmHQruIiIiIiNw0NOIu1V5+UQkzVh9k+c6T9GjqT6eGvpVdkoiIiIiIyGWrsBF3wzCcDMPYahjGLsMw9hmGMeXs9mDDMLYYhnHYMIyFhmE4nN3uePb54bP761dUbXJreX3pHv694SgDW9dm9vC2lV2OiIiIiIjIFanIqfIFQA/TNFsBrYF+hmF0AN4F/s80zYZAGvDE2fZPAGlnt//f2XYi12TH8TSWbE+gbg1nPniwDU72tpVdkoiIiIiIyBWpsOBulso++9T+7D8T6AEsPrt9HjDo7OOBZ59zdn9PQ/fokmtQVGJh8OyNGAaEP9WhsssRERERERG5KhW6OJ1hGLaGYewETgE/AbFAummaxWebxAN1zj6uA5wAOLs/A/App89RhmFEGoYRefr06YosX25yX206BsC47g0J9Hap5GpERERERESuToUGd9M0S0zTbA0EAu2BptehzzmmaYaZphnm5+d3zTVK9WSaJouj4rG3NXi+V6PKLkdEREREROSq3ZDbwZmmmQ78DHQEvAzDOLeafSCQcPZxAlAX4Ox+TyDlRtQn1Ytpmvzf2hiiEzOZOvh27G1110MREREREbl5VeSq8n6GYXidfewM9Ab2Uxrgh5xtNgJYfvbx92efc3b/OtM0zYqqT6qn/+xJ5La/rebD/8ZQ38eFIW0DK7skERERERGRa1KR93GvBcwzDMOW0i8IFpmmucIwjGhggWEYbwM7gLln288FvjIM4zCQCjxYgbVJNbR6XxJPz99uff7vEe2wsdH6hiIiIiIicnOrsOBumuZuoE05249Qer37/27PB+6vqHqkent/zUE+XHcYgCe6BPNynyY4O+jWbyIiIiIi/8/efYdnVd//H3+eDEIIe+8pIAioDAdu3Ku2arVqXR12aW1rh+1X2/rV/mpr7bDa1lptrVr3F+veOFG2iIrsPQNhZa/z++MDhghIgCTnTvJ8XFeunPuM+37fGZDX+Sw1fHXZ4i7Vi/veXcJtr86nS+ss7r50DMN6tEm6JEmSJEmqNQZ3NWgT56/j+ic+oEvrLF695lhysvyRliRJktS4ON22GqzZqzZz4T8mAXDzOSMM7ZIkSZIaJZOOGqTisgpO/dObAPzn64cydkDHhCuSJEmSpLphi7sapH+8uRCAbx4zwNAuSZIkqVGzxV0NShzH3PDUR/xr4mKG92jDj04enHRJkiRJklSnDO5qMMorKvnGfdN45eO1nH1wD359znDSXaddkiRJUiNncFeD8bV/T+W1ObmcN7onN589gjRDuyRJkqQmwOCuBuGWFz7mtTm5NM9M4zfnjCCKDO2SJEmSmgYnp1PKu/XFOdwxYQH9OuYw8drjDe2SJEmSmhRb3JXSHpu2nD+/Op9zRvbkt+eOcEy7JEmSpCbHFnelrMLScn746EwAbvr8MEO7JEmSpCbJ4K6U9Z0HpgNw3elDyG6WnnA1kiRJkpQMg7tS0qJ1Bbw2N5dzR/Xka0f1T7ocSZIkSUqMwV0p6cHJS4mAH588OOlSJEmSJClRBnelnLWbi7l34mLG7d+Fzq2bJ12OJEmSJCXK4K6Uc/dbiyitqOS604ckXYokSZIkJc7grpSydnMx/5y4mC8c1IO+HXOSLkeSJEmSEmdwV0p5eMoySssr+fZxA5IuRZIkSZJSgsFdKaO0vJJ731nCcYM7sV/nVkmXI0mSJEkpweCulPHiR6tZl1/CJYf3TboUSZIkSUoZBneljPvfXULPdtkcPahT0qVIkiRJUsowuCslTF2cx7sL8zh3VE/S0/WMUdEAACAASURBVKKky5EkSZKklGFwV+LKKir57oMz6N6mOeeP6ZV0OZIkSZKUUjKSLkD61TOzWbmpmH9cMppubbKTLkeSJEmSUoot7krU8x+s4l8TFzO4SyuOH9I56XIkSZIkKeUY3JWYTUVlXPmfGQA8eMVhRJFj2yVJkiTp0wzuSsy/Jy6mvDLmqSuPpH1Os6TLkSRJkqSUZHBXItZuKeZvry/gxKFdGN6zTdLlSJIkSVLKMrgrEfe/s4TCsgp+eur+SZciSZIkSSnN4K56l19Szm2vzue4wZ3p36ll0uVIkiRJUkozuKvePTR5KQCXHN4n4UokSZIkKfUZ3FWv4jjmP5OWMrpPO44d7PJvkiRJkrQ7BnfVq4kL1rNwXQHnj+mVdCmSJEmS1CAY3FVvVmws4qJ/TALgzAO7J1yNJEmSJDUMBnfVi7KKSo64+VUALhvbl+aZ6QlXJEmSJEkNg8Fd9eK2V+YBcMEhvfnl5w5IuBpJkiRJajgM7qpzRaUV/GviYk4d1pVfnz086XIkSZIkqUExuKvOPTtrFVuKy7nk8L5JlyJJkiRJDY7BXXVq0boCrnl0Jt3aNOew/u2TLkeSJEmSGhyDu+rU/4yfBcCvvjCMKIoSrkaSJEmSGh6Du+rMCx+uZuKC9Xz/hEGM279L0uVIkiRJUoNkcFedyN1Swjfum0bv9i245PA+SZcjSZIkSQ2WwV11YvyM5QDcfPZw2uU0S7gaSZIkSWq4DO6qdXEc88jU5Yzs3Zax+3VMuhxJkiRJatAM7qp1T72/ivlr8zlvdK+kS5EkSZKkBs/grlpVVlHJrS/OAeCMA7snXI0kSZIkNXwGd9Wq1+bksmR9IX/78ihaZmUkXY4kSZIkNXgGd9WaOI65642FdG3dnOOHdE66HEmSJElqFAzuqjXjZ6xg8uI8vnXsADLT/dGSJEmSpNpgulKt2FJcxk3PzKZzqyy+dIiT0kmSJElSbXEQsmrF315fQF5BKf+4ZDRZGelJlyNJkiRJjYYt7tpn05du4J63FnPCkM6cMLRL0uVIkiRJUqNicNc+u/utRWSmR9xw1rCkS5EkSZKkRsfgrn1SVlHJG3NyOWVYV3q0zU66HEmSJElqdAzu2idPv7+SLSXlnDDELvKSJEmSVBcM7tprBSXl3Pzcx4zo2cbgLkmSJEl1xOCuvfbHl+eyZnMJvzjzANLSoqTLkSRJkqRGyeCuvfLG3FzuenMRXxzVk1F92iVdjiRJkiQ1WgZ37bGi0gouuWcyXVs356YvOJO8JEmSJNWlGgX3KIqursk+NQ1/emUeAN85bgBZGekJVyNJkiRJjVtNW9wv3cm+y2qxDjUQ05Zs4K43F3LUwI5cfHjfpMuRJEmSpEYv47MORlF0AXAh0C+Koie3O9QKyKvLwpSafv3sbDq1zOL2C0cmXYokSZIkNQmfGdyBicAqoCNw63b7twDv11VRSk3z1+YzdckGrjt9CG2yM5MuR5IkSZKahM8M7nEcLwGWAIdHUdQHGBjH8ctRFGUD2YQArybitq1j208Z1jXhSiRJkiSp6ajp5HRfBx4D7ty6qyfwRF0VpdQzfekGnpy5kosO7U3Pdi2SLkeSJEmSmoyaTk73HeAIYDNAHMfzgM51VZRSy8bCUs7+y0R6tsvmhycNTrocSZIkSWpSahrcS+I4Lt32IIqiDCCum5KUah6duhyAG88aRrucZglXI0mSJElNS02D++tRFP0MyI6i6ETgUeCpuitLqWT8jBUc2Kstx+1vJwtJkiRJqm81De7XArnALOAbwLPAdXVVlFLHsrxCPlq1mTOGd0u6FEmSJElqkna3HBxRFKUD/47j+CLgrrovSalkwpy1ALa2S5IkSVJCdtviHsdxBdAniiIHNzdBz85axX6dW7Jf55ZJlyJJkiRJTdJuW9y3Wgi8HUXRk0DBtp1xHP++TqpSSli+oZBJi/K4atzApEuRJEmSpCarpsF9wdaPNKBV3ZWjVPK31xeQmZbGF0f1TLoUSZIkSWqyahTc4zi+oa4LUWpZl1/CI1OXc+aB3enVvkXS5UiSJElSk1Wj4B5F0VPsuG77JmAqcGccx8W1XZiSNX76CkrLK7ni6P5JlyJJkiRJTVpNl4NbCOQTZpW/C9gMbAEG4UzzjU4cxzw0ZSmj+rRjcFdHRkiSJElSkmo6xn1sHMdjtnv8VBRFU+I4HhNF0Yd1UZiSM23JBhbkFvDbcwckXYokSZIkNXk1bXFvGUVR720Ptm5vWx+stNarUqIem7acnGbpnDGiW9KlSJIkSVKTV9MW92uAt6IoWgBEQD/g21EU5QD31lVxqn/lFZW8+NEaThjahRbNavrjIUmSJEmqKzWdVf7ZKIoGAvtv3TVnuwnp/lgnlSkRL320hryCUs4c0T3pUiRJkiRJ1LCrfBRFLYAfAVfGcTwT6BVF0Rl1WpkS8dCUZXRt3Zzj9u+cdCmSJEmSJGo+xv2fhLHsh299vAK4qU4qUmJWbizijXm5nDe6J+lpUdLlSJIkSZKoeXAfEMfxb4EygDiOCwlj3XcpiqJeURRNiKLooyiKPoyi6Oqt+9tHUfRSFEXztn5ut3V/FEXRbVEUzY+i6P0oikbuw/vSXnh06nIAvji6V8KVSJIkSZK2qWlwL42iKBuIAaIoGgCU7OaacuCaOI6HAocB34miaChwLfBKHMcDgVe2PgY4FRi49eMK4K978ka0b0rKK3hoylKOGNCRXu1bJF2OJEmSJGmr3Qb3KIoi4G/A84Sx7Q8QAvePP+u6OI5XxXE8fev2FmA20AM4i6qZ6O8FPr91+yzg33HwLtA2iiLXI6snj0xdzqpNxXz96P5JlyJJkiRJ2s5uZ5WP4ziOouhHwLGElvMIuDqO43U1fZEoivoCBwOTgC5xHK/aemg10GXrdg9g2XaXLd+6b9V2+4ii6ApCizy9e/dG+y6OY+57ZzEH9mzD0QM7Jl2OJEmSJGk7Ne0qPx3oH8fxM3EcP72Hob0l8DjwvTiON29/LI7jmK3d72sqjuO/x3E8Oo7j0Z06ddqTS7ULM5ZtZO6afL50SG9CBwtJkiRJUqqo0TruwKHARVEULQEKCK3ucRzHIz7roiiKMgmh/YE4jv9v6+41URR1i+N41dau8Gu37l8BbD8rWs+t+1THHpmyjOzMdM4Y4cgESZIkSUo1NQ3uJ+/pE28dG383MDuO499vd+hJ4FLg5q2f/7vd/iujKHqIcKNg03Zd6lVHCkrKeWrmSk4f0Y1WzTOTLkeSJEmS9Ck1Cu5xHC/Zi+c+ArgYmBVF0Xtb9/2MENgfiaLoq8AS4Lytx54FTgPmA4XA5XvxmtpDj09fTkFpBeePcQk4SZIkSUpFNW1x32NxHL/Frtd6P34n58fAd+qqHu2osjLmn28vZliP1ozu0y7pciRJkiRJO1HTyenUCL3y8VoWrSvgq0f2c1I6SZIkSUpRBvcmbPyM5XRqlcXpw7snXYokSZIkaRcM7k1UHMe8uzCPowd2olmGPwaSJEmSlKpMbE3UR6s2k1dQyuEDOiRdiiRJkiTpMxjcm6i35q0D4OiBHROuRJIkSZL0WQzuTdTbC9bTv1MOnVs3T7oUSZIkSdJnMLg3QevzS3h7/jpOGto16VIkSZIkSbthcG+Cnn5/FRWVMV84uEfSpUiSJEmSdsPg3gSNn7GC/bu2YnDXVkmXIkmSJEnaDYN7E7N4XQHvLdtoa7skSZIkNRAG9ybm1Y/XAnDa8G4JVyJJkiRJqgmDexMSxzGPTF1G3w4t6NW+RdLlSJIkSZJqwODehLy3bCMfr97C5Uf0S7oUSZIkSVINGdybkEemLic7M52zRzq+XZIkSZIaCoN7E1FUWsFTM1dy2vButGqemXQ5kiRJkqQaMrg3Ec99sIr8knLOG90z6VIkSZIkSXvA4N5EbJuU7pB+7ZMuRZIkSZK0BwzuTcCKjUW8uzCPc0f1JIqipMuRJEmSJO0Bg3sT8Na8XABOOqBrwpVIkiRJkvaUwb2Rq6yM+c+kpfRom83Azi2TLkeSJEmStIcM7o3cxAXrmbl8E987YaDd5CVJkiSpATK4N3K3vDgHgNNHdEu4EkmSJEnS3jC4N2IrNxYxc9lGjhrYkRbNMpIuR5IkSZK0FwzujdjtE+bTLD2NX589POlSJEmSJEl7yeDeSJVXVPLM+6s4fUQ3erZrkXQ5kiRJkqS9ZHBvpKYs3sCmojJOGtol6VIkSZIkSfvA4N5IPTRlKS2zMjh6UKekS5EkSZIk7QODeyM0f20+/31vJeeP6UVOlpPSSZIkSVJDZnBvhB6avBSAiw/rk3AlkiRJkqR9ZXBvZErKK3hp9hpG92lH3445SZcjSZIkSdpHBvdG5okZK1iyvpArju6fdCmSJEmSpFpgcG9E4jjmn28vZv+urTjR2eQlSZIkqVEwuDciH67czMert3DJ4X2JoijpciRJkiRJtcDg3oi8+vFaoghOOsDWdkmSJElqLAzujURlZcz4GSsY3acdHVtmJV2OJEmSJKmWGNwbiYkL1rNoXQEXHeoScJIkSZLUmBjcG4n/TF5CuxaZnDKsa9KlSJIkSZJqkcG9EVi7pZgXP1zDOSN70jwzPelyJEmSJEm1yODeCDw2bTnllTEXHWY3eUmSJElqbAzujcBrH+cyrEdr+nXMSboUSZIkSVItM7g3cFuKy5i+dANHD+yUdCmSJEmSpDpgcG/gJi5YT3llzNGDDO6SJEmS1BgZ3Bu4N+bmktMsnZG92yVdiiRJkiSpDhjcG7g3563j8AEdaZbht1KSJEmSGiPTXgO2ZH0BS/MKOWpgx6RLkSRJkiTVEYN7A/by7LUAHOP4dkmSJElqtAzuDdgLH6xm/66t6OsycJIkSZLUaBncG6i1W4qZsiSPU4Z1TboUSZIkSVIdMrg3UJMW5hHHcNzgzkmXIkmSJEmqQwb3Bmrakg1kZ6YztHvrpEuRJEmSJNUhg3sDNX3pBg7s1YbMdL+FkiRJktSYmfoaoMLScj5cuZnRfdonXYokSZIkqY4Z3Bug95ZtpKIyZlSfdkmXIkmSJEmqYwb3Bmja4g1EEYzsbXCXJEmSpMbO4N4ATVmygcFdWtGmRWbSpUiSJEmS6pjBvYGprIyZsWSD3eQlSZIkqYkwuDcwi9cXsKWknAN7tU26FEmSJElSPTC4NzAfrNwMwLDubRKuRJIkSZJUHwzuDcyHKzbRLD2NgV1aJl2KJEmSJKkeGNwbmOlLNzCke2sy0/3WSZIkSVJTYPprQErLK5m5fBOH9HViOkmSJElqKgzuDcjsVZspLa/kYNdvlyRJkqQmw+DegLy3bCMABzmjvCRJkiQ1GQb3BmTG0g10aZ1FtzbNky5FkiRJkupOZQXMfAheuRFK8rfuqwz7m6CMpAtQzb23bCMH9WpLFEVJlyJJkiRJu7ZsMky8DYhgzFehxyjIarX76965A174WfV9b/6u+uOLHoNeh0Lz1lBeAsWboGXnWis9FRncG4i8glIWry/k/DG9ky5FkiRJkqqUl0B6s/A5LQOeuhreu7/q+Ownq5/fZRjkLYSjfwRlhfDGLTt/3nZ94cgfwFPfrb7/gXPD5ygN4sqwfcpvIDMbpt8Llz0TthsRg3sDMXPr+PaDezu+XZIkSVLCKsrguZ/A1Lt3fjyjOZz2O5j7PHz8dPVjaz4In1+5YefXnncf9D0SWrQPj0ddCnEMUQRrP4a/HBr2bwvtAM//pGr7oyfhwPP3/D2lMIN7AzFj6QbSIhjeo03SpUiSJElqysqKYMKvdh3aT7oJRl4aurKPvLhq/5Y1MOtRaN8P2veHvxwGWW1g7FVw5PchLT2E853Ztr/z/vDLTWG7ohwqSmH9PJj3Ygj1g06BEV+svfeaIgzuDcR7yzcxqEsrcrL8lkmSpFoUxzDjfti4JIwt/coL0G1EMrVUlEGUDmnOnyyllOJN8NrWrugbFsEHj1cd+/ak0KU9swYTaLfqAmOvrHq8LYDvrfSM8NHtwPDRiJkCG4A4jvlgxSaO379xT7ggSZLqycZl8OSVkN0ePnqienfTO48Kn7Naw3cmQdFGqCiBbgftuiVsV0q2wJS7YdRlkP2p4X7Fm+DlX8Koy8ONgg8eh8e+Eo4dfmXoZpu3ANr0hAWvQVZLOPM26DRoL990CisvDS2NaelJV6Kmas1H0K5PuHk261EYMA4m/Q22rILZT+36uiteDy3gqnMG9wZg5aZi8gpKGdHTbvKSJGkPbVwKfxwettv3h03LQ9fS7Q39PBz3P7BmFrx4PWxeASWb4fdDqp938q/h8G9XPd6wGJq3gex21c9b81FoxZ98J1SWw8u/gK+9El73mR9CeXEI5QBT74GczlCwtur6d27f+Xu5Y0z1xxnZcNKNcMjXa/SlSExFOaycAemZ0GFAuHHSogMsfhMe/2o4JzMHzvxT6EL8xLfD96B9P/jcn6HTkDDxlz0RgspKWDEVWnWDtr2Sria1VZQBUZgIrmQzLJsEk+6E/DXhhl3nIbBqZs2e69BvQs8x4ed46Fl1WrZ2FMVxnHQNe2306NHx1KlTky6jzj3/wSq+ef90xn97LAf3brf7CyRJkt75C7zw050fa9U9TPbUrh8MPLFqAigIXefXzYM5z8LrvwkzPnc7CFa9F443awnN24axq2s/Cvv6Hwen/hZyOobQOfe57V6rW2i1q4mvvgytuoaxs8smhdb47LawZXUI+2/euvPrRn8FTvhluIkAISiX5le18pcVw0s/h+FfhF5jdv4cdaG0ILRavnErlBXs23Nlt4crXgtf/8oyePG60DJ64o1wxHd3d3XDVlYUvvfv/g1Kt1Q/lpkDB10Ix14bfv72VUV5eI3sduF3YeZDsG4ujLs+uRsnFWUw5zkghun3Qf7qMKSlWU64EVe0Mfy853QKN4a2XfP8T2HKXTV/nbTM8LO1zXH/E2729T8ufD28cVQnoiiaFsfx6N2eZ3BPff/v2dn86+3FzLrhJLIy7EIlSZI+ZeMymPhnWDIRivJCa+32Ln8e+hwORRvC40+3kNdEWTE8dAEseLVm5w/9fJigqm0vmP9KCF4F6+Cwb0Lfrd3xOw4M4aiyIoxT3ZNaCteHdZsfOBcWvhb2t+waQs02466DeS+FmwDbjDgfzvgjNGtRtW/h62G5qhNvrNpfUR5a/ovywiRbBevCDNgn3RRuRDx0YfWaRl4K+50ArbvDP08Lwwu217onbF5efV/HwXDBgyFs5c6Bf50RWtaP/F5YLqs0H57+Pmxa9tlfjw4DYdDJYZzxllUw8CTofdjuvoqpbcV0WPwWvHbzrm96tOkNm5ZWPT7zNug0GB68IHzfOg6G46+HtbOhIBcm/z2cd8HDYT3x+S+H7/eCCeF3KH/1jr1Rtuk8NIyh/ui/cP79sN/xVce25alPDyXZvArefzgE/+ZtoeN+oafFfifC/JegbW/ofnDV+YV54QbZ+4+E37P8NeF7u37enn3tdqb7weHno+twaNkF+oyF0sLwfnuM3Pfn114zuDci5/x1IgCPf2tswpVIktQEVFbAG7+D1/5feNyyC/Q+HLofBGOvTqbVKXdu9W7i+58RWsK3D9FROsQV1a+7Zk7ohl5bNVdWwvLJIQjlLYBDvhFa1Oe9CJP+CitnwqFXwLE/q7+vU3kpPH/trme33iYtI3Tb397Qz4dxvW//qe7qi9LgwkdDUNr+ZsGemvFAaEEt2TqZV8sucPlz8O5fd92q2qZXCP39j4Wz/xFC4558X8qKazbhWE29/afQ82GbK6eGmzcQwu+WVaFlecGrOy4fNupyOOSK0AK8fl7oNZLTAWY/DQ9/GajDTNOiIxSuq9m5vQ6D034LK9/bce3xXfn2u2Foya6GiGzTrBWc8utww2Hei+HfAIC2fWDM1+Cl66uf37IrXPZ01ddYKcng3kiUV1Qy9BcvcMlhfbjujKFJlyNJUs1tW3M3KRVlYSzmp2sp3gyv3hS61mZkhe6m25SXhhbcRa/v/DlP/n9w+HfCdmFeaLne2/dYWhBajdv23vnxki1hUqgnvlWz5/vGG1VBLat1GB/dlOTODTcVhn8xfF8L1ofx8+36wIjzqs77+JkdW8s77Afr5+/4nG37wIFfCkMGINww2RYoL34itGrPfzm0xjZvA49eFsatn3pLuIFRXzYsgTd/F1pyS7ZUD/if1mMUfOHO8DXa1c9eHMMNn5pMMKM5lJeE3gBjvxuGV6xfEL7GB5wNPUft+rlWTA/DNrbv+QBAFILogldDEP20E26AkZdUH8qxKyvfC9/bFu0h92MYciasmx++X+Oug1mPwWHfgswW8OH/heEgrXuE398R5+34taj2b8YmeO7acNOjbV+YcNPWr0k2lBd9dl0DxoXW7uJN4T2O+3lohc+dU723wPa6HQQHfxl6jg4/gzt7/5WV4Ubdtn/jtqkoD/NFtO6+2y+ZUoPBvZGYvzafE37/Ord+8UDOGdUz6XIkSdrRhiXhD9LNK+CtP4R9HQeHx6f/Hla/H8JUl2Hhj9znroX37q+6/ptvQ9dhe/faBetg88owK3lpQQgA6+aGicBmP1W96/SAcTt2887pFFpC05uF8cLbDDwZTr81hLGyojCB2KqZYXKn7fU/Ds77dxjvXVYMr94Yxn13Hhpad2c+FN53ZTkse3fra35qIrbsdvCFv4fWs56jQ0ti3kK4/VNB6DtTQhhPzwzdvx/4InxrYhgTXpNgoypxHL6vHz8duj6fdkv1oLNpRfi6NtRZ3uM43BRqlhOC/KzHdj3fAYThAwdeAPefvbXbdw3yQUbzMO/ANpk5MOYrodv5mg92fd3XJ4QW4Gd/BDMfrH4sLSPUMuiUMOxgX3ooJGX6fWHFhqFnhSEZu/vdnPsC/GfrjaXrciGjWd3XqJRicG8knnl/Fd/5z3SevupIhvVwVnlJUoqI47CM2KOX1c7znXRTCNnv3Q95i0LL3tdfhTY9djx3ycSwdNiaj2BpGE5GetaOY4p3p0WHEG6216xlaIkfe9WO5xdtDJOmTf57CNvbxou37gFn3wX/Om3PXr8mstvDOf+Afsfs2RhwaVcWvw2PXhrGfH+WLsNCyC7ZEm5MxZXhZ/7DJ+D5n+z56466LLQ253So2jf/lTAJ4qHfDL9HDTGoS/vI4N5I/P7FOdw+YT4f/e8pNM9soHd9JUkNV/EmKMkPf7y37h4mdJr1GPzf16qf94U7w4zORRuh0/5hQrK8hfDRk2FsaNHGMPkXQO+xcPH4MHZ2yt3wzA92/foDjg9dXtv0DEsYzX9pJydFoWW8eGOYJf3gi0Lreo9RoRW+sjyEjqd/AL0OhYMuqJp9vGDd1lbxA0Lr+560/McxvPK/8Nbvq++/4KFwc6HDAMhfGya0yl8Dw84NrbxxZWi9b98vhJUPx4ebDivfg2n/DOdvXglH/TBM5CbVlYqtvxtv/SHM6XDIN8KwgZEXQ2b2rq8ryQ8311q0D93JSwtCd/jK8jBMo0P/MBlbyeaq3zVJO2VwbyS+cd9U5q3N59Vrjk26FElSU1JZCc98H6b9a9fnDDw5tEx3HbZ3s5RvU7QBHroodBXve1QYQ/7qTTDjvp2fH6WFWZ17H169G2pZcRi3W9/j6ksLQ1f6tR/Bd99Ldly/JKlBqWlwt89VipuzegtDurVOugxJUlOycSn85fCwFBWEyaHef7RqEqYxX4exV4alhWpDdju4/Nnq+866HU66Ed76Y5jsC2D4eTDkjND6vjO1Ofv1nmjWIizpJUlSHTG4p7Ci0gqW5BXy+YN3Mr5PkqTaVF4aumuvmwd3HRf27X9GmHgtLR0+9+ewr7Ki/ibsym4HJ95QP68lSVIKM7insHlrtxDHsH/XVkmXIkl1I28htO7pLLr1acGEMCP5cT8N49XLS+GWATvOln7E1XDi/+54fUOdZVuSpAbM4J7CPl69BYBBXQzukhqZsmJ48X9gyj/C4xYdqpa1qi3Fm8NkZpP+Bp0Gh/WAe4xsmsEzd24YP/73Y6r2vXvHzs/tMBC++E/oOrx+apMkSbtVZ8E9iqJ7gDOAtXEcD9u6rz3wMNAXWAycF8fxhiiKIuBPwGlAIXBZHMfT66q2hmLu6i1kZaTRp0NO0qVIUs1VlME/T4XlU6DPETD086HL84RfwcYlYQbjTytcD7cOhnPvgYEnQUY2zH0uzPTdtg+8/Es44PNhlvDy0hA6l74Lh34jzHaetxBGXgrP/TiskT3kTHj4y2E2c4Al6+DuE6pe75Sb4aWfw5Hfh2N/2nAnEyvZAnefDGs/DEH70G+FGdVnPx2WLFv0+s6va9klzHK+zajLwnrDDfXrIElSI1dns8pHUXQ0kA/8e7vg/lsgL47jm6MouhZoF8fxT6IoOg24ihDcDwX+FMfxobt7jcY+q/zFd09iQ2EpT191VNKlSNLuVVbCP0+BZZNqdv6ZfwqBsXgTLH4LHrqw9mvqtH+4EdD7MHjpF7B+3q7PPfZncOyn1iaurIS0tNqva09VlMGyySFsv3EL9BwNzVrtutX807Lbw+BTw/JjR/+oav+iNyAzB3qOqpu6JUnSZ0qJ5eCiKOoLPL1dcJ8DHBvH8aooiroBr8VxPDiKoju3bj/46fM+6/kbe3Af86uXOXpgJ24978CkS5GkHVVWhlnHm7WEl38BE2+rfvyny2HG/aHlvX3/sHTXgHHh2M5adjcshom3w5S7wuNh58IHj1Udz2oDJZvCdvsBMOrS0Gp+/C/gvQdg/XzodhAcdBEsfgOO+F4IuJ828c9hveyjfgDjvwmr369+PLsd9BwTgu7T3w/7Rl0GY78b3kddtUoX5oUbGINPhfRMWL8AWnULy4zNeXbX1x1yBYy7Dt68FWY9DpuXh/1n3wX9jg69GToPtTVdkqQUlKrBfWMcx223bkfAhjiO20ZR9DRwcxzHb2099grwkziOd0jlURRdAVwB3z039QAAIABJREFU0Lt371FLliyps/qTlFdQysgbX+J/ThvC14/un3Q5klTdjAfgv98GImC7/0dadIQfzqu9VurCvNC9vvvB4XHRhjBeu/vBO05oF8d7H05L8uHOoyFvwe7PHXc9HHUNbFoOc56Dgy4Ik7ztiYpySM+A/FyoKIVp/wwt6bBjN/btNW8bblis+TDcMDnkCuh7xJ69tiRJShkpv457HMdxFEV7fNcgjuO/A3+H0OJe64WliDnbJqZzRnlJda14Ezx3LRSshXP+EVqctykvgbuOhzWzoHkbOPIHoXX9E1v/GW7ZBX4wu/YnfmvRPnxsk90Oeu9iJNW+tChntYTvbp1aJY5h+r/hqe/CpU+FseOPXh5C/cal8OqN4WOb57brev65P0N6VhhrX7yxquaiDfD1CWGSvAfOgyVv7bqWdn2rB/d2feGrL0HLznv//iRJUoNW38F9TRRF3bbrKr926/4VQK/tzuu5dV+TNWd1WJbHpeAk1ap182DC/4MPx0PHgWGiuPXzq47/pm9oUT7k62FM+LR/Vh0r3lQ9tF8zJ8wCX7QRstvW21uoc1EUWrVHXVq175InwueKcnj1f0N3+7gS2vSCTcuqznvyqh2fr13fENy3rY2+vR6jYMW0MCzgxP+FNj3C/rIiyMwOs+9nZNnNXZKkJq6+g/uTwKXAzVs//3e7/VdGUfQQYXK6Tbsb397YzVmTT5vsTDq3ykq6FEkN1eynwszqAD0PgeWTqx9fN7dqu03vMGv7xNt2bFE+4w8w/Ivw9m2Q3gxGXlx92bbGFNp3Jz0jBOzt1zfftDxM/lZRCi9eF5a2G/NVWPRmaGHvORqm/Queujqcf8gVcNKvIC1j10MKMrO3fm5ep29HkiQ1DHU5q/yDwLFAR2AN8AvgCeARoDewhLAcXN7W8e63A6cQloO7fGfj2z+tMU9Od96d71BRGfP4t8YmXYqkhmDzKnjjt2EM9Fu/D921K0p2fu6Yr8Hpt8KW1bB2NvQ/tqpFN28R3D4GKsvCOO6DLoIOA+rrXUiSJDUpiY9xj+P4gl0cOn4n58bAd+qqloZo0boCjh3UKekyJKWiN34HHz4Rxl5//EzVTOvb2xbaL3w0tKwX5MJxPwvdrrdp1bV6yzmE5cKuz4XSgjDuW5IkSYlLbHI67dqW4jJyt5TQv5N/NEuN3mfNhL7mI5h+L0z62y6Oz6r+OKsNlBfBabfAAWdD89Zh/6CT9qymKDK0S5IkpRCDewpamFsAQP9OOQlXIqnOlOSHNbsfuxyIwvjo4efCEVeH2dvf/UuYAG17zVpBaVhxgjP/BK17hqXA4hgK10Hb3vX+NiRJklT3DO4paOG6fAAGGNylhmXZFLj7BNjvRDj4Ihhy1s4nH8udC3eM2XH/zAfDxzZpmXDcT2HgydDlgM+eWbyZoV2SJKmxMrinoIW5BaRF0Lu9wV1qMJZNhrtPDNvzXwofXYaFcegzH4RO+0PXEbD0Xdi0NJyX0xm+8Tq07h6WBHvz9/Dx05DZIqyXftg3IcslISVJkpo6g3sKWriugF7tW9AsYxfLBEmqO5WVULwRSjbDggmwcAKM+zl03G8X51fA8z+FyXeGx0f/OIwPL8kPs7uv+SDsz/04fGzzuT/DwRdXtaL3GAVfeqDu3pckSZIaLIN7ClqYW0D/jra2S4l46rsw477q+1bOgFN+Ax/9N8zCfsTV0KwlvPNneGW79bwvfAQGnVz1+PBvw4rp0HkoZLeDWY9AWREcdKEt6ZIkSaoxg3uKqayMWbQun7EDOiRditS0zHoMHv9q1eOeY0KLOIQw/9B2K1y+/cfq17btDVdOg4xm1fdnt4P9tlsBc+QltVuzJEmSmgSDe4pZtbmY4rJKZ5SX6trqD+DBL4WW77WzgTjsb9Udvvkm5HSsOrdoA3z4f5C/FvodDbMehbgyBPsTbghd4z8d2iVJkqRaYnBPMQtzw4zy/Tu6hrJU6/LXwpznQgv6zvx0xc7XLz/ye+Fjm7P/DusXQLu+kJZeJ6VKkiRJ2xjcU8yida7hLtWq8pKwzvl9n4el71Q/dui3oKwQjroG2vXZs+ftMKD2apQkSZI+g8E9xcxfm0+rrAw6t8pKuhSpYZv1GCx4Fd771EztOZ3D2ugjvgTNWiRTmyRJkrQHDO4pZkFuPv07tyTatkSUVNvKS0KoLVwH7/wFOuwHp/0Wuhyw589VWQGT7woBePh5ofU6qxWkZ9Z+3Z8ld25Ydu3VmyBvwc7P6bAfXPH6zrvCS5IkSSnM4J5i5q/N58j9OiVdhhqqOA7rgpcWQEVZmHSt40D43SCIKyAtEyrLql+Tvxr+OjZsj7seRn8FmrcJ12Zmw6r3YPI/oMdIGHY2tOwCE/5fWBqtNL/qeZ68qmo7qzX8cC5kNIcnr4RlU6DvEXDa73Y+Jry8BJ74FnzweHjt4k3QaQic8QfodWhYUz13DvQ6JLy/uS/A/10R1lvflZGXwJE/CDO7N29TtV66JEmS1MBEcRwnXcNeGz16dDx16tSky6g1m4vLGPHLF/nxKYP59rH7JV2OUlkcw5R/wOwnYeVMKNkEnfaHzavC9u606wct2oe1yYs3wQPn7H0tPQ8J65I//T1o3RM2L//s86M0OP8B2O8EePcv8PpvQkt9TTVvu+vAfuZtMOrSmj+XJEmSlKAoiqbFcTx6d+fZ4p5CFuaGien262RXXu1EYR5M/nsYs52ZA7mzqx/P/bhqO6czZDaHjUvD47FXwXH/A1E6bFm140Rs1+VC/powedv/fb1qf9+jQqv7yEvDTYL3H4aWXUPL+1HXhC7xWa1Da/boy6uue+gi+PjpsN28DXz+r/DuX2H1rBC6t18THcJNhxHnwf5nhq72LbvAtHvgmWuqnzf4NJjzbNg+/udwxPchLW3Pvo6SJElSA2OLewp5bNpyfvjoTF655hgGGN61zYvXwcQ/7/zYlVNDMI5jeOnncNi3oPtB1c+pKKv/MefbFG8K9W1v7Wy45+RwDOCyZ6DvkfVfmyRJkpQwW9wboAW5+WSmR/Ru70zXTVIcQ9EGWDYZJt4GJVtg9fvVz+l1aOjm3v1gGH4u5HSsOnb2nTt/3qRCO+wY2gE6D4Frl9Z/LZIkSVIDZXBPIfPX5tOnQw6Z6Xb9bTIqK8JkbSumw/1nh+D+aWkZcPET0O+o+q9PkiRJUuIM7ilkwdp8BnVplXQZqi8zH4Lx39j5saumh9bq0nxo17dey5IkSZKUWgzuKaK0vJIleYWcOrxr0qWoLhVvXdbs7hN2PPatd6DL0Or7tu8KL0mSJKlJMriniCXrC6iojJ2UrrFaPhX+cfyO+8++C4Z/0TXGJUmSJO2SwT1FLMjNB2C/zgb3RmfNhzuG9kufCkutGdglSZIk7YbBPUXMXxuCuy3ujUzxJnjowrDu+vn3hbCe0SzpqiRJkiQ1IAb3FLEgt4DubZqTk+W3pNGY+TCMvyJsX/oU9Ds62XokSZIkNUimxBQxf20+A+wm3zisnAEPfRk2Lw+PB59maJckSZK01wzuKaCyMmZBbj7nje6VdCnaV7Meg8e/GrYHHA+f/yu07JxsTZIkSZIaNIN7Cli9uZjC0gonpmvI5r4AL14H6+aGx195EXofmmxNkiRJkhoFg3sKmLfWGeUbnPISePK7UJALI86D8d+oOnbZs4Z2SZIkSbXG4J4C5q7eAsCgLq0SrkS7tfA1ePIq2Li0at+CV8Lnix6D/sdBur9WkiRJkmqPCSMFzFu7hY4tm9E+x2XCUkoch6CeOweGngXL3oVHL6s63v1gGHgSbFwGfcbCwBOTqlSSJElSI2ZwTwHz1+bbTT4phXmQ3Q7KiyGjOURR1bFXb4Q3bw3bz/+kav/pt8Kwc6B52+rnS5IkSVIdMLgnLI5jFuQWcMaIbkmX0nBUVsIbt8Daj+DsuyCjGRRthOy2Nbu+ohzevQPmPA9LJ1btb90Thp8DXUdUzQwPMPYqmPjnsH3Yt2HM12rvvUiSJEnSbhjcE7a+oJRNRWUM6GSL+yfyFsID58H6efCjhZDTofrxm3tDaZgXgI+eCC3l5cXQc0wYZ74twJcVhe7u6+fDO7fD+w9/9uuWFcLbf6p63KIjXPgI9BwFJ91Ue+9PkiRJkvaAwT1hC3MLAOjfKSfhSupIHO+8O/mWNXDnUZC/BnofHj7y14SP+S9XnXdL//D5C3fCpuWhpb28OOzrfTgsfafq8fIp8Js+MOgUWDcP8hbsuq7OQ+G030HfI6rX+vIvw+uffiv0Pmyf3rokSZIk1QaDe8IW5oal4BpVi3tFeQjQpflV+zofEMaSL3lrx/OXvhM+tnf+A7BiGrz1+/B4++XWMnPgR/OgWU64AVBeFMabT/83vHQ9zH2++nO17gn9joYW7eG4n0Fmi53fTIgiOPGG8CFJkiRJKcLgnrCF6wpolpFG97bZSZdSO179Fbzx2x33r/1wx339joaBJ0O3A0NX9vb9YfCp0GM0NGsBQ86Ao38Iy6fCA+eGGdxP/S206VH1HK26VG0f8d1wzcLX4YAv1HzMuyRJkiSlMIN7whbm5tOvQw7paQ18dvJ18+H2UVWPs9vDd6eHVvaSLZCRDYvfhHZ9oX2/Ha/vd9TOn7dZDvQ/Bq7PrVkd7fuHD0mSJElqJAzuCVuYW8Dgrq2SLmPf5C2qHtoP/SYc+9OqFu+sre9vwHH1X5skSZIkNXAG9wSVVVSyNK+QU4d3TbqUvffghTDnmbB94v/CEVcnW48kSZIkNTIG9wQtWV9IeWXMfp0b0MR0RRvh+Wth49LQgr4ttA8719AuSZIkSXXA4J6g+WtTbEb5Je/Acz+Gs24PE8bNegzmvQSVZXDUNTDtXph853bnvx2WZDv7LmjbK7m6JUmSJKkRM7gnaMHWpeD6Jx3cKytg/Ddh1iPh8Z1H73jOB49XbR/xPShcBwXr4dx7wgzwkiRJkqQ6YXBP0ILcfLq1aU7LrAS+DWXFkJEF7z8C468I+7oMgwM+D2/cGtZGP+jLMOhk2LIaCnKh0+CwJFvz1vVfryRJkiQ1UQb3BC1Ym1+/3eRXfwCPXAJ5C8LjnE4hkAP0OQIuewaiCI68BuJKSPfHQ5IkSZKSlpZ0AU1VHMcsyC1gQKecunuR0kIoCd3xmfIP+NsRVaEdqkL7Kb+By58NoR0gLc3QLkmSJEkpwnSWkDWbS8gvKWdAXc0ov2wy3H3ijvvPvC10ee91KMx5Flp1hR6jdjxPkiRJkpQSDO4J2TYx3X613VV+5Qz4+7E7P/aVF6D3YVWP9z+9dl9bkiRJklTrDO4JWbg1uNd6i/sjl1Ztn3gjjL0KCtZBdltIz6zd15IkSZIk1TmDe0IW5BbQolk6nVtl1c4TxjHMeQ42LoGjfwzj/qfqWMtOtfMakiRJkqR6Z3BPyKJ1BfTrmEO0bUK4fVG8Ce46HtbPC4+P/uG+P6ckSZIkKSUY3BOyeH0Bw3u02bcnKcyDvx4BW1ZW7Tvtd2F9dkmSJElSo2BwT0BZRSXLNxRxxohue/cEJVvg3s/ByulV+y54CAaeBGnptVOkJEmSJCklGNwTsHJjERWVMX3a7+Ua7u/+rXpov3YZNG9dO8VJkiRJklJKWtIFNEVL1hcC0LtDiz2/uLQQJtwUtsddBz9ZYmiXJEmSpEbMFvcELMkLwb3P3gT3F68Lnz93O4y8uBarkiRJkiSlIoN7ApauL6BZRhpdWjWv+UX5a+F3A8N2m95w8JfrpjhJkiRJUkqxq3wClqwvpHf7FqSl7cFScI9/tWr7woegNpaRkyRJkiSlPFvcE7A0r5A+7fegm/zbf4JFb8CgU+GL/4TM7LorTpIkSZKUUmxxr2dxHLM0r7DmE9OVl8A7fwnbX/yXoV2SJEmSmhiDez3LzS+hsLSi5i3ur94E+avhy49D5h6MiZckSZIkNQoG93q2dP22GeVrsIb7ojdg4m3QcRAMOL6OK5MkSZIkpSKDez2r8RruK9+De88M25c86WR0kiRJktREGdzr2ZK8QqIIerbbzVj1V24In7/2KrTuVveFSZIkSZJSksG9ni1dX0D3NtlkZaTv/ITcOfDQRbDgVTjpV9BzVP0WKEmSJElKKS4HV8+W5IU13Hdq9lPw8JfDduseMOZr9VeYJEmS1Ai9n/s+Fz17EQBH9jiSQe0G8dqy1xjSYQjPLHwGgC4tulBUXkTbrLbccfwddM3pSnpaOplpmUmWLn3C4F7Plq4v5MShXXY8EMfw3LVhe+DJ8Lk/O4u8JCkxcRwTRdEnnz8trziPjLQMWjdrXa91VcaVvLzkZQa0HUC/Nv1Ii+w8KGlHj8x5hBvfvXGH/W+teIu3VrwFwMJNCz/Zv6ZwDQCbSzdz5hNhnqn0KJ2Lh15Mt5xuHNPrGHq07FEPle9cHMdUxpVEUfTJv3slFSWsLlhNn9Z9dnv943MfZ9LqSWwu3czxvY/nnIHnfPI8y7csZ3n+cv4z+z/0btWbgvICNhRvoG1WW4rKi3hh8QtUxBUA7Nd2P/q16cetx9y6w/8N64vW0zyjOeuL1jNx5UTOH3x+tXMKywqZu2EuB3Y6cKf/r2xv9vrZ3DbjNq477LpEv+6pJIrjOOka9tro0aPjqVOnJl1GjeWXlDPsFy/w41MG8+1j96t+cNGbcO8ZcMYfYfTlyRQoSWqS4jhm/sb5DGg7gK+88BWmrZm2wzmXHXAZp/c/nQnLJjBl9RSmrJ7yybGjehzFrcfeSkVlBZNWTWJc73G7/KOsoKyAZxc9yxn9zyA7YzfzvWxn8qrJfPXFr+6wv11WOw7qfBATlk1gZOeRTF87nSHth3DB/hdw5oAzyUizjWJXdnVT5oN1HzA7bzZf2O8LZKRlsLl0M9kZ2dVaHnd17a72S/WhvLKcdUXruO+j+/j3R/+uduymI26ia05Xpq2ZxjG9jmFO3hx+MfEX/OuUfzGqyyjWF63n5SUv0yKzBePnj6/2b9z2xvUaxyUHXMLwjsNplt6s2rE4jpm4ciJrCtfQr00/2mW1o2+bvvv8virjSg7894G7PJ6TmcP1h13Pod0O5aZ3b+LYXsdyUp+TeGL+E/x68q93eV1mWiZllWX7VNuYrmMY02UMd826a6fP1apZK87e72w+3vAxk1ZN+mT/fafex0GdD6IyrmTG2hm8vORl7p99/05fo1erXnTL6cZVB1/FQZ0P2uF4aUUp09dOZ8LSCfzn4/8wsvNIbhh7Q6187etDFEXT4jgevdvzDO7158OVmzj9tre448KRnD7iUxPOPfU9eP8R+PECyKz5HzKSklNUXkRmWqbBQIm6c+ad3P7e7Z88bpnZkt8e/VsGtx9MVnoWbbLaAKGr6LqidQxqN4g73ruDE/ucyJTVU3b5h9K+6t+mP78c+0t6tepFWUUZxRXF3PjujSzZtIS1RWs/OefC/S/kpkk30TKzJVeMuILLDrjsk+B396y7+eP0P9KjZQ9W5K/YqzouHXop14y+pl7D5PbhtbCskBaZu1lJph4s27yMjSUbmZk7k8WbF/PwnIerHT9n4Dkc3/t4rn3zWjaXbt7pc1x+wOUc2eNIbnjnBpZuWQrABftfwEVDLqIiruDs/55NRVzBOQPP4brDrmP5luU8POdh7p99P0PaD+H6w65n2pppzFo3ixeXvEirZq346wl/5cBOuw4kUk3MWDuDS567ZIf9dxx/B0PaDyEnM2evfg9fX/Y6izYtYkX+Ch6a89AOx/u07sOSzUt2+zytm7X+5Pfq+sOup1WzVrRu1pqlW5YyoM0ARncdvUPvodKKUlbkr+CpBU9x16y79rj2nXntvNcoLC/kng/u4bG5jzGqy6hPbtQe2/NYjuxxJDExXXO6sn/7/ZmwbAKTVk3i10f9ms0lm8lKzyInM4d7P7qXFxa/wMd5H9dKXbtybM9j2ViykYLyAhZuXPhJq3/3nO6c0u8U7vngnl1e+8fj/sjxvRvGctoG9xT0/Aer+Ob903nqyiMZ3rNN1YGlk+Cek2DE+XD235MrMEH3fngvv5v6O47peQwtMlowrs84xvUax/L85fRv0z90DSLyLr5SxuqC1Zz02EnExBzU6SBuPvrmGnfliuOYDSUbaN+8PasLVgPQNacrlXHlbrv9bizeSFllGZ1adNrn96CG743lb/CdV77zmedkRBmUx+U1fs6O2R357+f/S+tmramMKymvLGfRpkVcPeFqMtMyWZG/gntOvueTlpJlW5bxrw//xRPzn6C8MrxO15yun/xs78whXQ9h8urJOz3WLK0Z6Wnp9GjZg/kb53+yb0DbAfzkkJ8wqkv1SVvHzxtPaUUpZ+13FgVlBWwu3cySzUt4YPYDvLvq3U/O29aydEb/M7hh7A07tJTtqaLyIt5d+S5vrniT5xc/z5bSLTW6bmz3sdww9gY6ZXciPW3nE9UWlxeTkZZBepTO6oLVRFFE62atWbZlGZ1bdKZd83Z7VOu0NdO47PnLanx+p+xO5BblfuY5o7uMZuqaff8bLDsjm/+c9h+6t+xOi8wWbCndQnZG9g43RCsqK/h4w8dMXT2V8waft0NvjUfmPMJTC57ixD4ncs6gc1iRv4JerXrtUa8ONUwfrPuAC565oNq+iIgHz3iQAzocUKuvVV5Zzo9e/xFvrniTkoqSXZ5Xk9+hnbl65NWMnzeeirhih5uVR/U4ijuOvwOAl5a8RLecbgzvNByAOXlzuOCZC8hIy2Bk55E0S2/GOyvfoX/b/tww9gYGtRtUJ8OK1hWto6CsgDl5cziu93FkpmVWG2a1aPMiyivLeXL+k7TIbMGZA86kV6te3PPBPfxh2h+qPdeQ9kM4uPPBXHnwlZRUlNCheYdqf/evKVjDCY+dsMtaMtMy+eNxf6R3q960z25f78O49oXBPQXd9cZCfvXsbGb+/CTatNja3ay8BG7qHLavngnt+iZWX30rKCvgkTmP8Ptpv6/R+c3TmzP+rPF0b9ndMY2qd4s3LeZ7E75Hx+yOzNs4j7zivB3OOarHUfzlhL9QGVdy+4zbaZPVhkuGXkIURcxeP5s/TPsD76x6h5aZLckvy9/p67TJasOmkk2c2f9MDup8EMf1Oo7WWa15e8XbXD3h6mrnntH/DH591K67wDUEFZUVuwwvTd2PX/8xH67/kDZZbejcojPjeo/j5L4nk5Wexfh54/n5xJ9/cu6fjvsT43qPozKuZPLqyXz9xa/v9DmzM7I5a8BZ9GvTj9tn3M4RPY7g+sOv/+QPnNUFq+nQvAOZ6fs+GdOH6z/kS09/qdq+b4z4Bl8d/lWyM7KpjCv59aRfs3TLUm455hbyivI458lzyEjLoLC88JNrrj3kWs4bdN5e1RTHMV9+7su8n/v+DscuH3Y5awvX8oNRP6Bzi86feV3Plj0/aSF7f937FJUX7XEtO3Nav9MY3H4wERFPLniSxZsXA3xyA2RXhrQfwsqClXTL6cZp/U5jRKcRDGk/hKz0LMrjcm6ZcguvLH2FgrICmqc3Z0PJBgAO6HAAA9sNZFSXURzZ40g6NO8AQBRFrMpfxdMLn+aIHkcwtMPQT14rvzSfnMwc8svy/3979x0fVZX/f/x10qtAEgKk0BEENNKJCEgTKav8vpaVZZUvin5t64JfsK1t7bqiroruqoir7pcVXVYUUQRERUSQXqQlgdBJSIckk8nM+f0xw5hAKEJIJuT9fDx4ZObec2/ODWfO3M9pl2eXP0tseCy3p9xOeFA4+aX5DP/PcIrKihjSYgjNo5tzW8ptPLb0MT7P+Jyu8V3pm9SXmzrfxI97f+STtE9oFNaIyOBIhrQYQoAJYPTno487VPeOi+/g9pTbySjI4KpPrqq0b2jLoYzuMJpuTboxb8c8Jn87GUvV97QNQxtS7i4nOTqZty5/yzcKpaY5Xc5q+WxVpyNxQF2Z9nCo7BDGGL7f872v8fvB7x8E4IPhH9To6I3CskI+S/+MDjEduCDmAiKCI475m5WWl2KxrNi/gvYx7XG5Xfx19V/ZVbSLddnr+EOXP5BXmsdHWz+qsiHg/p73s+/QPn7T5je0j2l/wvw4XU6Ky4trrXz/Wml5abisi/CgcJqf1/yUjjlSNzpcDl5c8SL9kvrRP7k/5e7yOj36UYG7H3pk9gb+s3oP6x8b+svG90ZBxiLoOwkGPVx7mTtLjteDmJGfwVWzf/kSTopK4qlLn6JxeGOaRjXlnfXvVBr6ebS+iX3pFNeJv639GwDDWg1jRKsR9E/uf9p5dbldTNswjQWZC5jYbSKpCamA54trS94WIoIiaBbV7KSri7qtm3xHPuuy17Hh4Ab6JPahS3yX086X1Dy3dfNV5lcs2rmImLAYQgNDmb5xOm7rrpTuvh73cV3763h9zetM2zANgOjgaIqcp9bzVhWDOe7NZ0WNQhuR58gjMSqRkMAQUpulMrD5QM4LOY8GoQ1IiEqgwFFAmauMnNIcZm2bxV1d7qrUAp1RkEFUcBRx4XFnpTGs2FnMYedh3+gAh8tBXmkezy5/lr2H9rIpd5Mv7Z0X38ltKbdVex7qiqKyIm796lYahDVgyZ4lv+rYr67+imZRladfHal7HS4HBY4CIoIiiAqJqs4sn1VlrjL+uuqvJEYl8rsLfnfG5/vHxn+QV5rHXV3u4oHFD/Dlji+Pm3Zy98lkFGTw723/Bn5pTKvKDR1vYEDyADblbKJVg1b0SeyD27oJCghiffZ6QgJDOL/R+Rhj2F20m+CAYLblb+O55c/5gvSqxIXHcbDk4Bld89FeG/jaGX1Hni2rs1YzYdGEKhtDqxITFlMpbWhgKA6Xg86xnXm237PMyZjDvB3z2FO0hx5Ne7Aqa1WVDS3J0cnc2+NeUhqnUOAo4H/m/w9u3PRs2pMHez1IZHDkKeWnYuNjubvc9/9fsU5dkLmAid9MBDw9qmM7jSU4IJjc0lxWHViFwYCB9za+R89mPbn1wltPO8AdCy4nAAAYiklEQVTPLc1ld9Fu/rb2b2zJ20JWcRa/af0bHuj1AOn56XyW/hmz02cz/sLx7D+831fOwVP2R7YZyY6CHYz9ciwhASE80/cZUhqnEB0STZmrjH9v+zcvr3oZgIigCCZ0m0DfxL4s3bcUp8vJxpyNhAaGYrFM7j75Vw1PP1hykMKyQorKiugc27lSo+7Owp2M+M+I4x77aOqjXHP+NafxF/Mfh8oOMTt9NgZDr2a9aBLRpE7V23L6FLj7oXHTl3Og0MHcP/b1bNg0Bz4cAwld4NZvajNrxyh3l2OxlYLUqWumMm/HPLYXbPdt+0u/vzC05VC25m0lPT+doS2Hkl2STb4jn9sX3H7SG4++iX15sNeDJEYlVtmqW+YqY8bmGVx7/rVszNnItPXTWLL35De1g5sPpqS8hKX7ljJz5Ezax7RnY85GZmyaQXBgMBsPbmRT7iauaHkFLc5rwaxts6oc0hQfHk++I58yd9kx+1Iap3BXl7uIj4hnxqYZrMlew6WJl/L2+rerzNPA5IGEBYWxu2g36w6uI7VZKlMHTfW71vf6pLS8lGkbphEZFEnjiMYUOAqYt2Meq7JWVZl+UvdJuK2bn3N+rtRLCZ4RJE8ve5rPMz7HZV0EBQQd02v2WOpjdI7rfEyrudu6ycjPoE3DNoBnddfCskI+2voRa7LWkF6QTmJUIo+kPsIlCZcAnpvFl1e9zLsb3/3V190vqR/f7f7O9z40MJTHL3mcHk17UO4up2lk01PqZTnsPIzBMHPLTF5d/SpBAUF8MPwDMgoy+HDLh5UW9jlyc3206JDoSkOML4q7iF1FuxjZZiSTuk+qk6NrHC6H76b8vY3vcaD4AEVlRWzM2UjzaE+vwprsNTzc+2G6NenmG2ZelamDpvLiihd5OPVhnlj6BOkF6b59V7e7mondJtaZ3hV/UuAoYF32Ov6T9h/mZ86vMk1ceBwLrllAYECgrxfN6XJSWFZIbHjsGefBWsucjDn8tP8nGoU1IrMwk9+2/y0AqQmpOF1OggKCfJ/FI5+f0MBQPkv/jOCAYAY2H8gLK15gxuYZvvP2atqL9jHtuS3lNqJDoikpL6HAUUDTyKZnnOezbf/h/b58lpaX8vu5v2dL3hYAhrUcxvP9nwc8f7ufc3/mgcUPEB4UzmHnYd4b9h4xYTHHnNPldpHvyCcyOJJvd3/LpG8nnVJeBjUfxMO9Hz7m/3rx7sWeEQBtrmLU7FHklObQLLIZLw14yTfCJMgE0SSyCQOSB5zWGhLhQeH8c/g/iY+IZ8meJfRs1pO48Djffmstq7JWsfLASubtmEdoYCh7Du055caPmtStSTdanNeCZpHNSM9PZ0DyADrGdmTxnsWsy15HWn4a6fnpJEcn+9ZNAAgwATyW+hg/7P2hyoa2mzvfTFRIFNnF2dzQ8QaSopNq8rJEqpUCdz80aMo3tI2P4u83dIfc7fCKd1XE+3dCWM3feB25EVmXvY57v7uXUW1Hse/wPmZtm1Wtv+fo1vEjXr7sZQa1+PWLRpS7y3lz3Ztkl2RzdburCQ0MZdGuRczPnH/Gi2SEBITwdN+neerHp8hz5BEeFE5JeQnJ0cnklORUGr55Io1CG5ESn0K/pH48vvTx46YLDwrnmvOvYULXCb75loVlhcxJn0NqQiofbvmQqOAo5mTMqTTX6byQ85g6aCpFZUVMWDSBlg1a8nDvh8l35HNZ8mVA7Qxx21GwgyeXPcnhssNsyNlAn4Q+jGo3ivaN2tOqQasazUtFR/4WTy97mrnb51LgKKDleS1P2OMVExbD7Sm3061JN4rKioiPiD+lGwNrLQeKD/huPq21zM+cz0WNLzorN86bcjYxYdEERrQeQamrlAJHAZ+mfwp4ppeUukpp3aA1Q1oM4YvtX1S6MTqRo+dFhwWG8edL/kxafppvRMKuol2ndK6jpwbc0+0exnX+5ekZh8oOkTojtcpjZ4yYQUhgCF9s/4Lr219Pk0jPc3bDAsNYf3A9C3YuYEyHMTSJ9Dxm86WVL+FwObin2z1nPIf5ZN5a9xavrH4F8AwB7960OyXOEu5edPdpn3P2qNlk5GeQ58ijf1L/Y4ZwF5YVUuIs8V2vVI9DZYeIComi2FnsW4n61oturZMNR+cap9tJkAmq1u+zorIiNudu5pO0T/hqx1eUukoZ12kcm3M3E2ACquwgGN5qOPmOfH7Y+8Np/c73h71Ph5gOPPfTc3y89WPf9s6xnSlyFhEbFstTlz7FZxmf8fqa16s8R9f4rgxIHsCUlVNO+Lsubnwxw1sP5/r211PuLuehJQ8xd/tcOsd25r/O/y86xnYksyATh8vBpYmX0jiiMU63kz99/ye+2P4F/ZP6c1+P+4gIjuCbXd8wd/tc35oUvZv15ok+T9AkognF5cW8tvo1ckpyOFh6kJ/2/8RNnW8iJiyGpXuXnlJHyxGxYbHklOacMM0jqY9w7fnXnvI5ReoKBe5+xlpLh4e/5IbeLXhoZEd4ayDsWQk9xsOIE1fA1aHAUcCcjDk8u/xZwDM/ruIw1apEBEUcE6j+MPoHggOCKS4v5lDZIV5Y8QKLdi0C4Mo2V/oCBoA3Br9Bn4Q+GGMoKitifuZ8EqISuDDuwlMegnY6dhbu5I6FdzCs1TA6xXbi8aWP+3rTu8Z3JS0/jWGthjGp+yScbicLdy6kXaN2VS5gYq2lsKywUo+W0+1kV+EuskqyuOWrW+jZtCcXxFxA20ZteX3N6zzf7/kqH1XxxfYv2FW0i8zCTO7tcS9rs9fyf5v/zzcs9up2V1caslYd3rr8LXo3631G53BbN1nFWazNXsukbyfRJb4LaflpXNnmSjrFduLCuAu597t72ZS76YRzt18d+KqvUWFB5gJWZ63mkoRLaH5ec0ICQqo9EHG6nDyz/Bk+2vrRCdMNazmM/sn9mb5hOlvytvD3wX8nNSHV7+b1VZfDzsPM2DyDdg3b+YbNHiw5yJCPh5x0Xu3RgkwQKfEpJEUlMbnHZKZvmM68HfPYfWg3z/R9hsHNBxMWFAZ4hm+63K6TLqpX7CwmpySHF1e+yIKdC07vIr2mD51O96Yn/R781ay1fLf7O+76+q6Tph1zwRiub3898RHxZJdkkxiV6BsKOmXFFKJDolmXvY43h7x5zHB3Eakd5e5yluxZctzP+LCWw3C4HHRv2p3fX/B7MgszWbpvKb2a9qJ1w9Y4XA62F2zn213f0j+5Px1iOlQ6Pj0/nfCgcBKiEqo8/4HDB1iwc4Hvnu14U6gGNx9McnQySdFJhAeFkxSd5FdT80rKS3CUO/h+7/c0DG1I04im3PzVzeSW5tI1viuXJFzCLRfdgrX2mLVOCssKeX758+Q78okLjyMuPI47Lr5DjWlyTlLg7meyCkvp+fRCHr+qEzfGb4f3R0Gv22HYs5XSlZSXMHPLTDblbiItL40pl00hOTr5tCoqt3VTWl7KnQvvPOnKr+M6jyM2LJYmEU3oHNeZhKgErLW+33u8IMZaS6mrVKu2niZrLdfNue64IwVu7HgjQ1sOpbS8lJ7NevqOOVB8gOX7l1PuLqdfUj+yirO4f/H9laYxVDTt8mk88P0DJEQm8ESfJ6p8rqXD5WDJniUs3LmQpOgk3t3w7imPMDiib2JfJnabSHBAMPmOfIrLi/nj13+k1FXqS3O84D7ABDCo+SCSo5MZ3WH0KfdOu62btPw037DsIzc6x/Ptb7/F6XJy07ybeL7/874GG2stJeUlfvHYptp2ZPGcy5Iuo2uTruSX5vP93u95d8O7RIdEc9h5uEYWeKq4uNnxRkj0bta70srh4PncHP38XvAMfV24cyGPpj7K8FbDT/h/XewsZk7GHNo1audZMyAyocphtjNHziQ6JJopK6b4GhoqNlKJSN23Oms1b69/m7Edx/q+i2vappxNTN84nfT8dCZ1n+Rbh0dE6j4F7n5mZWYuV7+xlOljuzPgu+ugOBf+sAKCQn1pXln1ygmf0zggeQATuk2gdYPWrMteR1RwlK9l1+V28Wn6p2zO3cznGZ9XCpSOGNR8ENedfx3nx3geCRESEEJkcOQ527NYV1hr+Xrn12wv3M6g5oPOeEi5tZYCRwG5pbmVFgA82mXJl/Fo6qOMnze+0rzZ47myzZXcefGdHCg+4AuSP9z8IVklWdzd5W7GXDDmuIHQvkP7GP/V+ErDtBuHN6ZH0x6Ulpfy9a6vqzxucvfJhAaGsvLASuIi4hhzwRhCA0PJLMwkKjiKorIixs0bV+WxR3ww/AM6xnZkc85mOsd1Vnk/R1ScCrL/8H7iI+IpLS/1lcFiZzH9Pux3wsf1VDSu0zgGtRjE+Hnjq6w/qzJ10FT6JfU7vQsQERERQYG73/lk9R4mfLiG726Mo/nMy2HEFF4PLmN22mz2Ht5bKe2YC8ZwY8cbWbx7MU8ue5LQwFCcbucxK1qfqqvbXc2fev/ppKuhy7lpc+5mJiyawOgOowkNDOWNtW8cdwGbxuGNuS3lNsKCwli2bxl3d7m72oawu9wuSl2lx50msSZrDbPTZ9OjSQ/uW3zfrz7/kBZDyC3NZfyF47k08dIzza6cI47Um4echzhYfJCdRTt5dfWrbM3besLjkqOTCQ30NKw2CG1ARFAEi/csZvrQ6XSJ76JH2ImIiEi1UODuZ15duI0p87ey7fL17P3hBUYmHzuXMTEqkdcHvU7rhq2rPMeOgh3MSpvFiv0rWH9wfZVpRrUdRduGbRnRegSxYbHqXZQqudwuJn4zkUW7FjGy9Uiua38dF8Vd5DfByP7D+1l1YBUNwxryc87PON1Ovtz+JRkFGb40V7a5krYN25LSOIWuTbrWYm6lLnK6nSzft5xOsZ1oENqAORlzWJO1hrT8NN4Y/AahgaF+83kQERGRc5cCdz8z+aO1/LBlF1MDx3FDwi9zd98f9j4/5/zM6A6jTyvIzinJITQwlMjgSJxu51lfRVlERERERESqx6kG7kE1kRmBXXnF9G74d26I9gTt4zqNY2K3iRhjqlyB/FRVfL6ognYREREREZFzjwL3GpKdk8OhxmlAECmNU7in+z21nSURERERERGpA/QwxBrgdLnpy2tkBgfxePIIPhj+QW1nSUREREREROoI9bjXgH35pRRE7ibSDSP7/bm2syMiIiIiIiJ1iF/1uBtjrjDGbDHGpBlj7q/t/FSX3Xv3sjHCxUUhiQRXeG67iIiIiIiIyMn4TeBujAkEpgLDgI7AaGNMx9rNVfXYu20W+4KD6JXQt7azIiIiIiIiInWM3wTuQE8gzVqbYa0tA/4FXFXLeaoWm/KWAjAk5Xe1nBMRERERERGpa/wpcE8EdlV4v9u7rRJjzK3GmBXGmBXZ2dk1lrkzYWJa084dQ/OY1rWdFREREREREalj6tzidNbaN4E3Abp3725rOTun5KH/N6W2syAiIiIiIiJ1lD/1uO8Bkiu8T/JuExEREREREam3/Clw/wloZ4xpZYwJAa4HPq3lPImIiIiIiIjUKr8ZKm+tLTfG3AXMAwKBd6y1G2s5WyIiIiIiIiK1ym8CdwBr7Vxgbm3nQ0RERERERMRf+NNQeRERERERERE5igJ3ERERERERET+mwF1ERERERETEjylwFxEREREREfFjCtxFRERERERE/JgCdxERERERERE/psBdRERERERExI8pcBcRERERERHxYwrcRURERERERPyYAncRERERERERP6bAXURERERERMSPKXAXERERERER8WMK3EVERERERET8mAJ3ERERERERET9mrLW1nYfTZozJBjJrOx+nKA44WNuZEPkVVGalLlF5lbpGZVbqEpVXqWvqUpltYa1tfLJEdTpwr0uMMSustd1rOx8ip0plVuoSlVepa1RmpS5ReZW65lwssxoqLyIiIiIiIuLHFLiLiIiIiIiI+DEF7jXnzdrOgMivpDIrdYnKq9Q1KrNSl6i8Sl1zzpVZzXEXERERERER8WPqcRcRERERERHxYwrcRURERERERPyYAvcaYIy5whizxRiTZoy5v7bzI/WTMSbZGLPIGPOzMWajMeaP3u0xxpj5xpht3p+NvNuNMeYVb7ldZ4zpWuFcY73ptxljxtbWNcm5zxgTaIxZbYyZ433fyhizzFsuPzTGhHi3h3rfp3n3t6xwjge827cYY4bWzpVIfWCMaWiM+dgYs9kYs8kYk6o6VvyVMWai935ggzFmhjEmTHWs+BNjzDvGmCxjzIYK26qtTjXGdDPGrPce84oxxtTsFf46CtzPMmNMIDAVGAZ0BEYbYzrWbq6knioH/tda2xHoDdzpLYv3Awutte2Ahd734Cmz7bz/bgXeAE+FCTwK9AJ6Ao8eqTRFzoI/ApsqvH8OeMla2xbIA272br8ZyPNuf8mbDm8Zvx7oBFwBvO6tl0XOhr8CX1prOwApeMqu6ljxO8aYROBuoLu1tjMQiKeuVB0r/uRdPOWqouqsU98Abqlw3NG/y68ocD/7egJp1toMa20Z8C/gqlrOk9RD1tp91tpV3tdFeG4oE/GUx394k/0DGOV9fRXwnvX4EWhojGkGDAXmW2tzrbV5wHz8vKKTuskYkwSMAN72vjfAQOBjb5Kjy+uRcvwxMMib/irgX9Zah7V2O5CGp14WqVbGmAZAP2AagLW2zFqbj+pY8V9BQLgxJgiIAPahOlb8iLX2OyD3qM3VUqd6951nrf3RelZrf6/CufySAvezLxHYVeH9bu82kVrjHeLWBVgGNLHW7vPu2g808b4+XtlVmZaa8jJwL+D2vo8F8q215d73Fcuer1x69xd406u8Sk1pBWQD073TO942xkSiOlb8kLV2D/ACsBNPwF4ArER1rPi/6qpTE72vj97utxS4i9Qzxpgo4N/ABGttYcV93hZHPSNSap0xZiSQZa1dWdt5ETlFQUBX4A1rbRfgML8M4QRUx4r/8A4VvgpPg1MCEIlGdkgdU9/qVAXuZ98eILnC+yTvNpEaZ4wJxhO0/9NaO8u7+YB3uBDen1ne7ccruyrTUhP6AFcaY3bgmWI0EM/84YbeYZ1Quez5yqV3fwMgB5VXqTm7gd3W2mXe9x/jCeRVx4o/Ggxst9ZmW2udwCw89a7qWPF31VWn7vG+Pnq731Lgfvb9BLTzrtIZgmcBj09rOU9SD3nnok0DNllrX6yw61PgyAqbY4HZFbbf6F2lszdQ4B2aNA+43BjTyNtif7l3m0i1sdY+YK1Nsta2xFNvfm2tHQMsAq7xJju6vB4px9d401vv9uu9KyK3wrP4zPIaugypR6y1+4Fdxpj23k2DgJ9RHSv+aSfQ2xgT4b0/OFJeVceKv6uWOtW7r9AY09v7Gbixwrn8UtDJk8iZsNaWG2PuwlNoAoF3rLUbazlbUj/1AW4A1htj1ni3PQg8C8w0xtwMZALXeffNBYbjWWimGBgHYK3NNcY8gadRCuBxa+3RC4eInC33Af8yxjwJrMa7EJj35/vGmDQ8C9lcD2Ct3WiMmYnnhrQcuNNa66r5bEs98Qfgn96G+gw89WYAqmPFz1hrlxljPgZW4akbVwNvAp+jOlb8hDFmBnAZEGeM2Y1ndfjqvG+9A8/K9eHAF95/fst4GstERERERERExB9pqLyIiIiIiIiIH1PgLiIiIiIiIuLHFLiLiIiIiIiI+DEF7iIiIiIiIiJ+TIG7iIiIiIiIiB9T4C4iIlKPGWMmGGMiajsfIiIicnx6HJyIiEg9ZozZAXS31h6s7byIiIhI1dTjLiIiUk8YYyKNMZ8bY9YaYzYYYx4FEoBFxphF3jSXG2OWGmNWGWM+MsZEebfvMMY8b4xZb4xZboxp691+rfdca40x39Xe1YmIiJy7FLiLiIjUH1cAe621KdbazsDLwF5ggLV2gDEmDngIGGyt7QqsAO6pcHyBtfZC4DXvsQCPAEOttSnAlTV1ISIiIvWJAncREZH6Yz0wxBjznDGmr7W24Kj9vYGOwBJjzBpgLNCiwv4ZFX6mel8vAd41xtwCBJ69rIuIiNRfQbWdAREREakZ1tqtxpiuwHDgSWPMwqOSGGC+tXb08U5x9Gtr7W3GmF7ACGClMaabtTanuvMuIiJSn6nHXUREpJ4wxiQAxdbaD4C/AF2BIiDam+RHoE+F+euRxpjzK5zitxV+LvWmaWOtXWatfQTIBpLP/pWIiIjUL+pxFxERqT8uBP5ijHEDTuB2PEPevzTG7PXOc/9vYIYxJtR7zEPAVu/rRsaYdYADONIr/xdjTDs8vfULgbU1cykiIiL1hx4HJyIiIielx8aJiIjUHg2VFxEREREREfFj6nEXERERERER8WPqcRcRERERERHxYwrcRURERERERPyYAncRERERERERP6bAXURERERERMSPKXAXERERERER8WP/H26slP2kNJxQAAAAAElFTkSuQmCC\n","text/plain":[""]},"metadata":{"tags":[]}}]},{"cell_type":"markdown","metadata":{"id":"-6zWwScp9ia-"},"source":["### Submit to coursera"]},{"cell_type":"code","metadata":{"id":"69GBxWkC9ia_"},"source":["from submit import submit_bandits\n","\n","submit_bandits(agents, regret, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from abc import ABCMeta, abstractmethod, abstractproperty\n",
+ "import enum\n",
+ "\n",
+ "import numpy as np\n",
+ "np.set_printoptions(precision=3)\n",
+ "np.set_printoptions(suppress=True)\n",
+ "\n",
+ "import pandas\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Bernoulli Bandit\n",
+ "\n",
+ "We are going to implement several exploration strategies for simplest problem - bernoulli bandit.\n",
+ "\n",
+ "The bandit has $K$ actions. Action produce 1.0 reward $r$ with probability $0 \\le \\theta_k \\le 1$, which is unknown to the agent, but fixed over time. Agent's objective is to minimize the regret over fixed number $T$ of action selections:\n",
+ "\n",
+ "$$\\rho = T\\theta^* - \\sum_{t=1}^T r_t$$\n",
+ "\n",
+ "Where $\\theta^* = \\max_k\\{\\theta_k\\}$\n",
+ "\n",
+ "**Real-world analogy:**\n",
+ "\n",
+ "Clinical trials - we have $K$ pills and ill patient $T$. After taking the pill, a patient is cured with the probability $\\theta_k$. Task is to find the most efficient pill.\n",
+ "\n",
+ "A research on clinical trials - https://arxiv.org/pdf/1507.08025.pdf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class BernoulliBandit:\n",
+ " def __init__(self, n_actions=5):\n",
+ " self._probs = np.random.random(n_actions)\n",
+ "\n",
+ " @property\n",
+ " def action_count(self):\n",
+ " return len(self._probs)\n",
+ "\n",
+ " def pull(self, action):\n",
+ " if np.any(np.random.random() > self._probs[action]):\n",
+ " return 0.0\n",
+ " return 1.0\n",
+ "\n",
+ " def optimal_reward(self):\n",
+ " \"\"\" Used for regret calculation\n",
+ " \"\"\"\n",
+ " return np.max(self._probs)\n",
+ "\n",
+ " def step(self):\n",
+ " \"\"\" Used in nonstationary version\n",
+ " \"\"\"\n",
+ " pass\n",
+ "\n",
+ " def reset(self):\n",
+ " \"\"\" Used in nonstationary version\n",
+ " \"\"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class AbstractAgent(metaclass=ABCMeta):\n",
+ " def init_actions(self, n_actions):\n",
+ " self._successes = np.zeros(n_actions)\n",
+ " self._failures = np.zeros(n_actions)\n",
+ " self._total_pulls = 0\n",
+ "\n",
+ " @abstractmethod\n",
+ " def get_action(self):\n",
+ " \"\"\"\n",
+ " Get current best action\n",
+ " :rtype: int\n",
+ " \"\"\"\n",
+ " pass\n",
+ "\n",
+ " def update(self, action, reward):\n",
+ " \"\"\"\n",
+ " Observe reward from action and update agent's internal parameters\n",
+ " :type action: int\n",
+ " :type reward: int\n",
+ " \"\"\"\n",
+ " self._total_pulls += 1\n",
+ " if reward == 1:\n",
+ " self._successes[action] += 1\n",
+ " else:\n",
+ " self._failures[action] += 1\n",
+ "\n",
+ " @property\n",
+ " def name(self):\n",
+ " return self.__class__.__name__\n",
+ "\n",
+ "\n",
+ "class RandomAgent(AbstractAgent):\n",
+ " def get_action(self):\n",
+ " return np.random.randint(0, len(self._successes))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Epsilon-greedy agent\n",
+ "\n",
+ "**for** $t = 1,2,...$ **do**\n",
+ "\n",
+ " **for** $k = 1,...,K$ **do**\n",
+ "\n",
+ " $\\hat\\theta_k \\leftarrow \\alpha_k / (\\alpha_k + \\beta_k)$\n",
+ "\n",
+ " **end for** \n",
+ "\n",
+ " $x_t \\leftarrow argmax_{k}\\hat\\theta$ with the probability $1 - \\epsilon$ or random action with the probability $\\epsilon$\n",
+ "\n",
+ " Apply $x_t$ and observe $r_t$\n",
+ "\n",
+ " $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n",
+ "\n",
+ "**end for**\n",
+ "\n",
+ "Implement the algorithm above in the cell below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class EpsilonGreedyAgent(AbstractAgent):\n",
+ " def __init__(self, epsilon=0.01):\n",
+ " self._epsilon = epsilon\n",
+ "\n",
+ " def get_action(self):\n",
+ " \n",
+ "\n",
+ " @property\n",
+ " def name(self):\n",
+ " return self.__class__.__name__ + \"(epsilon={})\".format(self._epsilon)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### UCB Agent\n",
+ "Epsilon-greedy strategy heve no preference for actions. It would be better to select among actions, that are uncertain or have potential to be optimal. One can come up with an idea of index for each action, that represents optimality and uncertainty at the same time. One efficient way to do it is to use UCB1 algorithm:\n",
+ "\n",
+ "**for** $t = 1,2,...$ **do**\n",
+ "\n",
+ " **for** $k = 1,...,K$ **do**\n",
+ "\n",
+ " $w_k \\leftarrow \\alpha_k / (\\alpha_k + \\beta_k) + \\sqrt{2log\\ t \\ / \\ (\\alpha_k + \\beta_k)}$\n",
+ "\n",
+ " **end for** \n",
+ "\n",
+ " **end for** \n",
+ " $x_t \\leftarrow argmax_{k}w$\n",
+ "\n",
+ " Apply $x_t$ and observe $r_t$\n",
+ "\n",
+ " $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n",
+ "\n",
+ "**end for**\n",
+ "\n",
+ "__Note:__ in practice, one can multiply $\\sqrt{2log\\ t \\ / \\ (\\alpha_k + \\beta_k)}$ by some tunable parameter to regulate the agent's optimism and wilingness to abandon non-promising actions.\n",
+ "\n",
+ "More versions and optimality analysis - https://homes.di.unimi.it/~cesabian/Pubblicazioni/ml-02.pdf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class UCBAgent(AbstractAgent):\n",
+ " def get_action(self):\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Thompson sampling\n",
+ "\n",
+ "UCB1 algorithm does not take into account the actual distribution of rewards. If we know the distribution - we can do much better by using Thompson sampling:\n",
+ "\n",
+ "**for** $t = 1,2,...$ **do**\n",
+ "\n",
+ " **for** $k = 1,...,K$ **do**\n",
+ "\n",
+ " Sample $\\hat\\theta_k \\sim beta(\\alpha_k, \\beta_k)$\n",
+ "\n",
+ " **end for** \n",
+ "\n",
+ " $x_t \\leftarrow argmax_{k}\\hat\\theta$\n",
+ "\n",
+ " Apply $x_t$ and observe $r_t$\n",
+ "\n",
+ " $(\\alpha_{x_t}, \\beta_{x_t}) \\leftarrow (\\alpha_{x_t}, \\beta_{x_t}) + (r_t, 1-r_t)$\n",
+ "\n",
+ "**end for**\n",
+ " \n",
+ "\n",
+ "More on Thompson Sampling:\n",
+ "https://web.stanford.edu/~bvr/pubs/TS_Tutorial.pdf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class ThompsonSamplingAgent(AbstractAgent):\n",
+ " def get_action(self):\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from collections import OrderedDict\n",
+ "\n",
+ "def get_regret(env, agents, n_steps=5000, n_trials=50):\n",
+ " scores = OrderedDict({\n",
+ " agent.name: [0.0 for step in range(n_steps)] for agent in agents\n",
+ " })\n",
+ "\n",
+ " for trial in range(n_trials):\n",
+ " env.reset()\n",
+ "\n",
+ " for a in agents:\n",
+ " a.init_actions(env.action_count)\n",
+ "\n",
+ " for i in range(n_steps):\n",
+ " optimal_reward = env.optimal_reward()\n",
+ "\n",
+ " for agent in agents:\n",
+ " action = agent.get_action()\n",
+ " reward = env.pull(action)\n",
+ " agent.update(action, reward)\n",
+ " scores[agent.name][i] += optimal_reward - reward\n",
+ "\n",
+ " env.step() # change bandit's state if it is unstationary\n",
+ "\n",
+ " for agent in agents:\n",
+ " scores[agent.name] = np.cumsum(scores[agent.name]) / n_trials\n",
+ "\n",
+ " return scores\n",
+ "\n",
+ "def plot_regret(agents, scores):\n",
+ " for agent in agents:\n",
+ " plt.plot(scores[agent.name])\n",
+ "\n",
+ " plt.legend([agent.name for agent in agents])\n",
+ "\n",
+ " plt.ylabel(\"regret\")\n",
+ " plt.xlabel(\"steps\")\n",
+ "\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAA+4AAAHjCAYAAAC95UVJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAALEgAACxIB0t1+/AAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAIABJREFUeJzs3Xd0VVXexvHvSe+FNEoIJHREWgLSRTojCowoIirYKGLDCo7DgMqIwviiOOjgoKJiAJGiOBQZDIrUhE4oIRAgIQmQ3ts97x+BqxlCJySE57MWy3vP2Wef373JdeW5e599DNM0EREREREREZGqyaayCxARERERERGRC1NwFxEREREREanCFNxFREREREREqjAFdxEREREREZEqTMFdREREREREpApTcBcRERERERGpwhTcRURERERERKowBXcRERERERGRKkzBXURERERERKQKs6vsAq6Fr6+vWb9+/couQ0REREREROSKRUVFnTFN0+9S7W7q4F6/fn0iIyMruwwRERERERGRK2YYxrHLaaep8iIiIiIiIiJVmIK7iIiIiIiISBWm4C4iIiIiIiJShd3U17iXp6ioiPj4ePLz8yu7FJGbmpOTE4GBgdjb21d2KSIiIiIit7RqF9zj4+Nxd3enfv36GIZR2eWI3JRM0yQlJYX4+HiCg4MruxwRERERkVtatZsqn5+fj4+Pj0K7yDUwDAMfHx/NXBERERERqQKqXXAHFNpFrgN9jkREREREqoZqGdxFREREREREqgsF9wpga2tL69atrf+mTZt2xX1ERkby3HPPAfDFF1/wzDPPXHU9MTExDBgwgAYNGhAaGspdd93FL7/8ctX9XczkyZOZMWPGJdudOXMGe3t7PvnkkwqpIz09ndmzZ5fZlpiYyIABA67reSZNmsTatWsB6N69O5GRkde1/z+aN28ejRo1olGjRsybN6/cNqmpqfTu3ZtGjRrRu3dv0tLSADhw4AAdO3bE0dGxzM+nsLCQbt26UVxcXGF1i4iIiIjItVFwrwDOzs7s3LnT+m/ChAlX3EdYWBgffvjhNdeSn5/P3XffzahRo4iNjSUqKopZs2Zx5MiR89reyPD27bff0qFDB8LDwyuk//KC+/vvv89TTz11Xc/z5ptv0qtXr+vaZ3lSU1OZMmUKW7ZsYevWrUyZMsUayv9o2rRp9OzZk5iYGHr27Gn90qhGjRp8+OGHvPzyy2XaOzg40LNnTxYuXFjhr0FERERERK5OtVtV/o+m/LCP6JOZ17XP5rU9+Ns9t13VsfXr1+eBBx5g5cqVODs7880339CwYUO+/fZbpkyZgq2tLZ6envzyyy9EREQwY8YMVqxYUaaPuLg4Hn/8cc6cOYOfnx+ff/45QUFBjBw5Eg8PDyIjI0lKSuK9995jyJAhzJ8/n44dO3Lvvfda+2jRogUtWrQASkfIY2NjOXLkCEFBQXz99ddMmDCBiIgICgoKGDduHKNHjwZg+vTpLFq0iIKCAgYPHsyUKVMAmDp1KvPmzcPf35+6desSGhpKbGws999/P9u3bwdKR/2HDh1qfR4eHs4//vEPHnroIeLj4wkMDARg7ty5vPvuu3h5edGqVSscHR356KOPOH36NGPGjOH48eMAzJw5k86dOzN58mSOHz/OkSNHOH78OC+88ALPPfccEyZMIDY2ltatW9O7d2+mT5/Od999x9tvvw1ASUlJua8zIiKCSZMm4e7uzuHDh7nrrruYPXs2pmnyxBNPEBkZiWEYPP7444wfP56RI0cyYMAAhgwZUubnFB4ezt///ndM0+Tuu+/m3XffBcDNzY3nn3+eFStW4OzszPLlywkICLjk787q1avp3bs3NWrUAKB3796sWrWKYcOGlWm3fPlyIiIiABgxYgTdu3fn3Xffxd/fH39/f3788cfz+h40aBATJ05k+PDhl6xDRERERERuvGod3CtLXl4erVu3tj6fOHEiQ4cOBcDT05M9e/bw5Zdf8sILL7BixQrefPNNVq9eTZ06dUhPT79o388++ywjRoxgxIgRfPbZZzz33HMsW7YMKJ0KvmHDBg4cOMC9997LkCFD2LdvH23btr1on9HR0WzYsAFnZ2fmzJmDp6cn27Zto6CggM6dO9OnTx9iYmKIiYlh69atmKbJvffeyy+//IKrqysLFixg586dFBcX07ZtW0JDQ2nQoAGenp7s3LmT1q1b8/nnn/PYY48BcOLECRITE2nfvj0PPPAACxcu5KWXXuLkyZO89dZbbN++HXd3d3r06EGrVq0AeP755xk/fjxdunTh+PHj9O3bl/379wOl08B//vlnsrKyaNKkCWPHjmXatGns3buXnTt3AnD06FG8vb1xdHQESr8gKO91AmzdupXo6Gjq1atHv379WLJkCcHBwSQkJLB3716Ai/6cTp48yWuvvUZUVBTe3t706dOHZcuWMWjQIHJycujQoQNTp07l1Vdf5dNPP+WNN95g/vz5TJ8+/by+GjZsyOLFi0lISKBu3brW7YGBgSQkJJzXPjk5mVq1agFQs2ZNkpOTL/qzh9IvcrZt23bJdiIiIiIiUjmqdXC/2pHxa3Vuqnx5zo2QDhs2jPHjxwPQuXNnRo4cyQMPPMCf//zni/a9adMmlixZAsAjjzzCq6++at03aNAgbGxsaN68+QUD2+DBg4mJiaFx48bWfu69916cnZ0BWLNmDbt372bx4sUAZGRkEBMTw5o1a1izZg1t2rQBIDs7m5iYGLKyshg8eDAuLi7Wvs558skn+fzzz3n//fdZuHAhW7duBWDhwoU88MADADz44IM8/vjjvPTSS2zdupU777zTOqp8//33c+jQIQDWrl1LdHS0te/MzEyys7MBuPvuu3F0dMTR0RF/f/9yX3tiYiJ+fn7W5xd6nQ4ODrRv356QkBCg9Oe0YcMGevbsyZEjR3j22We5++67rSG/PNu2baN79+7W8w0fPpxffvmFQYMG4eDgYL3OPjQ0lJ9++sna5nqPeBuGcVkrw9va2uLg4EBWVhbu7u7XtQYREREREbl21Tq4V0V/DFLnHn/yySds2bKFH3/8kdDQUKKioq6q73OjyQCmaQJw2223lVmIbunSpURGRpa51tnV1bXMcbNmzaJv375l+l69ejUTJ060Tps/Z+bMmRes57777mPKlCn06NGD0NBQfHx8gNJp5ElJScyfPx8oHaGOiYm56GuzWCxs3rwZJyeni75uW1vbcq/Vd3Z2LnNP8gu9zoiIiPPCrmEYeHt7s2vXLlavXs0nn3zCokWL+Oyzzy5ac3ns7e2t/f+x1kuNuNepU8c6BR4gPj6e7t27n9c+ICCAxMREatWqRWJiIv7+/pdVV0FBQbnvrYiIiIiIVD4tTneDnVsEbOHChXTs2BGA2NhY7rjjDt588038/Pw4ceLEBY/v1KkTCxYsAErDXteuXS96voceeojffvuN77//3rotNzf3gu379u3Lxx9/TFFREQCHDh0iJyeHvn378tlnn1lHuRMSEjh16hTdunVj2bJl5OXlkZWVxQ8//GDty8nJib59+zJ27FjrNPlDhw6RnZ1NQkICcXFxxMXFMXHiRMLDw2nXrh3r168nLS2N4uJivvvuO2tfffr0YdasWdbnF5rRcI67uztZWVnW540bNyYuLu6SrxNKp8ofPXoUi8XCwoUL6dKlC2fOnMFisXDffffx9ttvW6/VL0/79u1Zv349Z86coaSkhPDwcO68886L1jt8+PAyCxqe+3duRkDfvn1Zs2YNaWlppKWlsWbNmvO+dIDSGQ/nVpyfN28eAwcOvOh5AVJSUvD19cXe3v6SbUVERERE5MbTiHsF+N9r3Pv162dd3TstLY2WLVvi6OhoXVH9lVdeISYmBtM06dmzJ61atWL9+vXl9j1r1iwee+wxpk+fbl2c7mKcnZ1ZsWIFL774Ii+88AIBAQG4u7vzxhtvlNv+ySefJC4ujrZt22KaJn5+fixbtow+ffqwf/9+65cNbm5ufP3117Rt25ahQ4fSqlUr/P39adeuXZn+hg8fztKlS61Ty8PDwxk8eHCZNvfddx9Dhw5l0qRJvP7667Rv354aNWrQtGlTPD09Afjwww8ZN24cLVu2pLi4mG7dul30VnI+Pj507tyZFi1a0L9/f6ZPn06DBg04fPgwDRs2vODrBGjXrh3PPPOMdXG6wYMHs2fPHh577DEsFgsA77zzzgXPXatWLaZNm8Zdd91lXZzucgL0xdSoUYO//vWv1vd30qRJ1ksKnnzyScaMGUNYWBgTJkzggQceYO7cudSrV49FixYBkJSURFhYGJmZmdjY2DBz5kyio6Px8PDg559/5u67776m+kREREREpOIY56ZU34zCwsLM/71v9v79+2nWrFklVXRx9evXJzIyEl9f38ou5YaZMWMGGRkZvPXWW5fVPjs7Gzc3N4qLixk8eDCPP/74eUH/ai1dupSoqCjryvLludBq/tXZn//8Z6ZNm0bjxo3P21eVP08iIiIicusxTRPDMLBYTGxsLr2eU1VnGEaUaZphl2qnEXepMIMHDyY2NpZ169Zd9jGTJ09m7dq15Ofn06dPHwYNGnRd60lJSblu/VUHhYWFDBo0qNzQLiIiIiJSVeQWFvPgnM0cPpVNbmGJdXvPpv5sOpJC05ruNK3lwfhejfFzd7xITzcnjbiLyAXp8yQiIiIiN1JiRh49ZqxnzqOhNKnpzq4TGXyyPpaoY2mX3cfHw9vS//ZaFVjl9aMRdxEREREREamyEjPyeGPpXup4OzOxfzP2nszg/k82AfDI3K3ntW8V6MmycZ0pKjExDCgqsbDzRDpO9rYs25FAUYmF7cfSuSPE50a/lAqn4C4iIiIiIiKXLTO/iPjUPJIy89gWl8bHEbE0CXAnr6iE4hILJzPy6dXMn9NZBTzWOZiiEgsTl+yh2FI62/uprsHkFJbwzZbj1j6/3HTM+riGqwPt6ntz9EwO7k72BHo783CHeoTV88YwDBzsSq9tt7e1oVOD0vXD2gZ538B34MZTcBcREREREZHLsnRHPOMX7iqzzcvFnoPJWWW2rd1/CoAXFp5/G+dPfz1qfdyrmT9t63nzwdoYCootPNU1mNf/1AzDuPkXnrueFNxFRERERERuEefWOCsqMbGYJoeSs3jnPwc4k11AZn4Rf24biLeLPT2bBbDjeDovf1sa0kffGcK/1h8p01f3Jn48c1dDwurXIOLgKUZ+vo2Il7tTbLHwbVQ8Df3cWLI9gR0n0vhsRDsKSiwkZ+Tz5opoOjXw4aOH2uJkbwvA090b3tg34iajxekqQFxcHAMGDGDv3r3WbZMnT8bNzY2XX36ZGTNm8O9//xsnJyfs7e159tlnefTRR+nevTuJiYk4OztTUFDA+PHjGTVqlLWPnTt30qZNG1auXEm/fv0qpO6NGzfy0EMPXfe+5eZUFT5PIiIiInJtiksszFwbw5nsAhZsO3HN/a14tgst6nheh8pEi9NVUZ988gk//fQTW7duxcPDg8zMTJYuXWrdP3/+fMLCwkhNTaVBgwaMHDkSBwcHAMLDw+nSpQvh4eEVFty/+eYbBXcRERERkQswTZNii0lhsQVbGwNHO5tKm9ZdWGzhRFoudbycrSPXf5SSXcBflu5l1b6ki/YzrH0Qbw9qQUJaHuHbjpOUkc/+xExOZRUwfUhL6vm4sP1YOoPa1MHBzqaiXo5cRPUO7isnQNKe69tnzduh/7SrPvzvf/87EREReHh4AODh4cGIESPOa5ednY2rqyu2tqUfQNM0+fbbb/npp5/o2rUr+fn5ODk5AfDWW2/x9ddf4+fnR926dQkNDeXll18mNjaWcePGcfr0aVxcXPj0009p2rQpI0eOxMPDg8jISJKSknjvvfcYMmQIEyZMYP/+/bRu3ZoRI0Ywfvz4q36dIiIiInLzKSqx8N/9yWw+ksrmIykMbF2H22p70LSmO4Zh4OPqQHpeEe5Odtjb/h7gcguLeWTuVu4PDeTB9kGV+AoqxordJ3nmmx3l7gvwcGRkp2DGdm+AxVI6/dzOtuLCbUZuEb/FnuHp+dvP2zc0rC4LI0/g5WKPo50NyZkFZfYPblOHKQNvw8PJvty+g3xceK1f03L3NfR3v/bi5apV7+BexeTm5pKVlUVISMgF2wwfPhxHR0diYmKYOXOmNbhv3LiR4OBgGjRoQPfu3fnxxx+577772LZtG9999x27du2iqKiItm3bEhoaCsCoUaP45JNPaNSoEVu2bOHpp59m3bp1ACQmJrJhwwYOHDjAvffey5AhQ5g2bRozZsxgxYoVFf9miIiIiEilMk2Tj9fHElTDhV7NAjiTXUCXd38u0+bAqgNX1GfUsTQmLCk7cPZCr0b8cug0A1vXwTBgaLu6ONrZYjm7wrhhUGbE+kx2AR+sjaGmpxNfbIxj0oDmDGhZC8MwWBudzJNfRuLj6sA7f76dED836vm4lPkS4X9ZLCbLdyXwbWQ8NT2d+Mf9rTAMg4y8IiwWE09ne2xsDI6eyeGDtYc4lprLnvgMii0m7ep7k5xZwPHU3Av2n5xZwLurDvDu2feqhqsDPz7XhVqezpd8v0zTPG+0Pr+ohINJWXg62/PFxji+2Bh3yX7OWRhZOg0+PbfIuq1xgBtLnu6Mm6Oi382sev/0rmFk/FpcaKrM5awncG6q/OnTp+nUqRP9+vWjXr16hIeH8+CDDwLw4IMP8uWXX3Lffffx22+/MXDgQJycnHBycuKee+4BSkfsN27cyP3332/tu6Dg92/cBg0ahI2NDc2bNyc5OflaXq6IiIiIXEcFxSWcyiygsMTC/M3H+ey30hW4W9X14u+DW3D3hxtwsLVh2n2306OpP14uDhftzzRN9iZk8vH6w7g62PFtVDyt6nqRW1BMzKnsco8ZEhpILU8n9idmsnb/KVrU8SAxPZ+UnMILnueuJn4cPp3NidS8Mttnro0BYPvxdAAmLd933rHuTnY42NqQnldEiaXs38zPhu/g2fCyo90pOYWM+irK+rxbYz/6NA/gzsZ+1K3hApTOHnjs821sOHymzLFLtidc8DX8r21xaQCE+LryWv+mhNXzxsfN0bq/uMRCTmEJo7+K5HhKLicz8knNKWTYnM188GAblu88SaC3M4Pb1MHLxR7ThPi0PLpN//0Lkhn3t2LS8r083KEeW4+msvNE+kVr8nS2p3+LmlhMk7/dcxuuZwP5hO92E5eSw78eDsPV0ZbU3EL83By1Ons1Ub2DeyXx8fEhLS2tzLbU1FRCQ0Nxc3PjyJEjFx11B/Dz86Nt27Zs2bKFwMBAvvvuO5YvX87UqVMxTZOUlBSysrIueLzFYsHLy4udO8+//QKAo+Pv/8O5mRcoFBEREflf5/62KS+wWCwmNjZVM8hYLCbPLtjBj7sTy92/60Q6d3+4AYDCEgsvLipd7Xvl811pVsujTNvIuFQiDp6mno8LC7adIOpY2nl9AdzTqjZ5hcWs3X8Ke1uDz0a2o2sjv8uqN7ewmJyCEvKLSgj0dra+3+m5hdYvE05nFTB3w1Ey8oqo7emEjY3B9NUHz+srK7/4vG0P3RFEXmEJZ7IL+DWmNHzb2hh8N7YTLg62DP/3Fmq4OHAwOYtfDp3ml0OnL1pv54Y+ZBeUWF97eTqG+PBsj4aE1vfmyOkc3lt1gH4tajK0XfnT/+1sbfB0tmHBqI5A6e/eb4dTGP1VJAP/+Zu13Zsroi94znOrts/55fcV233dHDmTXTrotv/Nfjja2Vzy93bafS3LPPd3d7poe7m5KLhXADc3N2rVqsW6devo0aMHqamprFq1iueff56JEycybtw4Fi5ciIeHB9nZ2SxZsoRHH320TB+5ubns2LGDV199lf/+97+0bNmS1atXW/ePGDGCpUuX0rlzZ0aPHs3EiRMpLi5mxYoVjBo1Cg8PD4KDg/n222+5//77MU2T3bt306pVqwvW7e7uftEvA0RERETyi0qwMYxrXqDqdFYBro62uDhc/Z+jpmmyKTaF+r6uFBRbWLD1OMt3niQpMx+AOl7OhNbzpkOID072Ntag62Bnw6Md6jGqWwj+HueHm6ISi/WxnY2BxYRzmWlPQgZD/7WZ1nW9+PKJ9tYp2ifT87C1MXB3suPRuVvZnZDBb6/1wM/dsUzfJ9Pz6P/Br3Rt5EubIG/eukigg9JR9g+GtsYw4Mc9iew6kU77YB/6NA9g1roYFkXG0/+DXxnRsR7zNh27YD9dG/mSmV/MZyPCWLDtBJ9ExDKmewPG3dXQ+l7ChWeOlsfFwa7cn98fZwD4uTsyoX/Za6aH3xFEWm4R9X1KR8bTc4soKrGQmV9MoLfzeYu9maZJWm4RJ9PzCPFztZ5z2196nT2+kPi0PL7cFMeiyPj/qcWe9x9oRZeGftbf2ZPpedRwdbAu5rbjeBpLdyQw+s4G1PH6fXp7s1oefP5Y+8t+P6D0/evSyJdFYzry9//sJ7ugpPTv8PiMMu1e6NWI5rU8KLGYjJ2/nXb1vXmpTxPWHTjFsPZBBPu6XtF5pfrT7eAqSHR0NOPGjbOOvL/yyisMHz4c0zSZPn06c+fOxd7eHnt7e1566SUefvjh824H98gjj/D666/z2GOPcccddzBmzBhr/99//z0ff/wxK1euZPLkyXzzzTcEBATg7+9Pv379eOqppzh69Chjx44lMTGRoqIiHnzwQSZNmsTIkSMZMGAAQ4YMAUq/aMjOzqaoqIi+ffuSkpLCyJEjtTidVJnPk4hIZdtyJIWVe5Po0zyAO0J8sDFKr+VtVsuDlOxC/D0cOZVZgJ+7I8UWC+4XWPjpSuQUFOPiYEuJxcTGMBi/aCdpuUU429sQdSydhv6u1PFyYVS3EJrUrLhFowqLLfzt+30s2R5PQXFpoHVxsKWhvxshvq4UWUx+2peMg50N2QXFuDvZsfL5rgR6u1BYbCGvqISPI2IZ1r4udb1dMAx4cdEulu4ona4cWs+b46m53F7HEy8Xe4aG1eW2Op64OthiMaHYYsHRzhbTNDmTXcjMtYeIOZXN8ZRca0C/Vutf6U5dbxc+3xjHqr2J1unR10PdGs6cSM0j2NeVo2dyLtn+4Q5BTOjf7LKvR/7t8BmG/3vLedsDPBwZ1j6IpTsSmPNIWIX+jlQluYXFHEjKollND5wdzl9lXaSqudzbwSm4VwPZ2dm4ubmRm5tLt27dmDNnDm3btq3ssqQauBU/TyJya0rLKWTcN9vZdSIdNyc77g+ty0c/H76mPj99NIywet4sjDyBm6MdiRl5pOYUMbpbCMdSc5n8/T4a+rvh5mjH0h0J+Lo5cCb7wtcPX0yf5gF88GCb6xpUcgqKmbn2EJ/+erTM9o4hPpzOLuDwBa6NrgzujnbY29kQVMOFDiE+jOhUj1qezhSVWNiTkMHzC3bQs2np9c93NfUH4OvNx3hj2V6Ai773LQM9y4yWtqjjwUu9m/D8gh1k/mF6t4uDLTU9nAis4ULrul7sTchg3YFT5fb53n0tyS4o5vONR5k5tA2maXIqq4AeTf3LvaXXpexPzOSdlQfILyxhVLcQ7mrqj20VvRxARMpScL+FPPTQQ0RHR5Ofn8+IESOYOHFiZZck1cSt+HkSkVtPflEJA2ZtuGQQHdUthB3H06yjsc1reXA8NZcQP1dqejixJrpiFnsN8HAkObOANkFe/OuRUIpKTD6OOEzcmVxuD/Tk44hYABztbPj11bvKnfp9zrlFyhoFuFkD4h9XtV65J5Gx87fTq1kAa/f//nqe6hrMxP7NyMwvwsvFgaISCz/uTqSwxMIPu04yuE0dWtTxxN/dkbd/3M/iqLLTlZvX8iA6MdP6vGlNd1Y82wUbw+DImRy2xaXSuq4XSZn5rNiVyHfbyx7/Rw/dEcQTXYIJ8XWl2GJedDXxy7H5SAqz1sXw2+EU7giuwaA2dfjT7bXwdL62WROmabInIYOmNT1wsLPBNE0Kzt73+1prFpHqQ8FdRK6ZPk8iUp2ZpsmBpCz6f/ArULpI16xhbVh/6DQrdp3klX5NyC+04O1qj6uD3RUtaHYyPY97P/qNM9kFjO4Wwup9STzeJZgjp3Ost3ZaNLojvx0+Qw1XB1rV9aJ1XS8AkjLycXawvaLgOH31Af75c2mAbxLgzohO9enexI/af7heNyOviPZT11qnu9/VxA+LCesvsqDXQ3cEMb5X4/Ou076UhPQ8PJ3tz5vufSa7gGMpuYTW876i/kREqisFdxG5Zvo8icjN6lRmPuFbT+DhXBocF0fFs+9k5gXbO9vbsm9K3yq72vjl+GbLcV5fWvb+2YHezsSnlYbojLyiCxxZ1mv9mlLfxwVPF3s6NfCtiFJFROSsyw3uWlVeREREqpXRX0Wyet/lT1t/qmswf7m7eQVWdGM8dEcQ/VvUJCkz3zqLID6t9H7a50L7x8Pb0r2JPy8s3MHqfcnc2diPfz0SipO9bZkp8yIiUrUouIuIiEi1kFtYzIBZGzhyunTl7pd6N8bJ3pYvNsYxuE0dujTyxc3RjhA/VwwM7G0N7KrZtcberg54uzoQN+1ucgqK+euyvXRu6Evbet6cysznjhAfAP71yPmDOwrtIiJVl4K7iIiIVHn5RSUYBjjalS6olltYTPNJq637f331Ll5fusca2ndO6m29l/RT3UJufMFVgKujHe8PbW19rvtCi4jcvBTcr7OUlBR69uwJQFJSEra2tvj5+REXF0ft2rWJjo6u5AqvjMVi4YUXXmDdunUYhoGTkxOLFi0iODi4ws5Zv359IiMj8fX1pVOnTmzcuPGa+hs0aBBJSUls3rz5OlVY1hdffEGfPn2oXbt2hfQvInIrSs8tpPuMCNJzz78uu6G/23krwHd972cA2gR58e9Hw6yhXUREpDpQcL/OfHx82LlzJwCTJ0/Gzc2Nl19+mbi4OAYMGFDJ1V25hQsXcvLkSXbv3o2NjQ3x8fG4ut64b+yvNbSnp6cTFRWFm5sbR44cISTk+o+6fPHFF7Ro0ULBXUTkGr26eBeLIi98G7BzDp/KplVdLzqG+PBi78asP3Sab7Yco0OID6O6hWjKt4iIVDvVOri/u/VdDqQeuK59Nq3RlNfav3ZVx5aUlPDUU0+xceNTQ9WCAAAgAElEQVRG6tSpw/Lly3F2dmbnzp2MGTOG3NxcGjRowGeffYa3tzfdu3enTZs2/Prrr+Tk5PDll1/yzjvvsGfPHoYOHcrbb79NXFwc/fr1IzQ0lO3bt3Pbbbfx5Zdf4uLiwoQJE/j++++xs7OjT58+zJgxg7i4OB5//HHOnDmDn58fn3/+OUFBQYwcORIPDw8iIyNJSkrivffeY8iQISQmJlKrVi1sbEqvAQwMDLS+nrFjx7Jt2zby8vIYMmQIU6ZMAUpHzIcNG8bKlSuxs7Njzpw5TJw4kcOHD/PKK68wZswYIiIimDRpEu7u7hw+fJi77rqL2bNnW89zjpubG9nZ2URERDB58mR8fX3Zu3cvoaGhfP311xiGwX/+8x9efPFFXF1d6dy5M0eOHGHFihUALFmyhHvuuYeAgAAWLFjA66+/DkBsbCzDhw8nJyeHgQMHMnPmTLKzS0dvpk+fzqJFiygoKGDw4MFMmTKFuLg4+vfvT5cuXcr8/H788UciIyMZPnw4zs7ObNq0CWdnZ0REpNSO42nM2xhH67peDGxdB29XB1JzClm47QRnsgvIyCvC0c4GE8qEdgc7G4aG1WXSPc3L3PP6p+hkfNwcaBv0++3EejcPoHfzgBv5skRERG6o6rUiSxUXExPDuHHj2LdvH15eXnz33XcAPProo7z77rvs3r2b22+/3RqAARwcHIiMjGTMmDEMHDiQf/7zn+zdu5cvvviClJQUAA4ePMjTTz/N/v378fDwYPbs2aSkpLB06VL27dvH7t27eeONNwB49tlnGTFiBLt372b48OE899xz1nMlJiayYcMGVqxYwYQJEwB44IEH+OGHH2jdujUvvfQSO3bssLafOnUqkZGR7N69m/Xr17N7927rvqCgIHbu3EnXrl0ZOXIkixcvZvPmzfztb3+zttm6dSuzZs0iOjqa2NhYlixZctH3b8eOHcycOZPo6GiOHDnCb7/9Rn5+PqNHj2blypVERUVx+nTZe9GGh4czbNgwhg0bRnh4uHX7888/z/PPP8+ePXvKfBmxZs0aYmJi2Lp1Kzt37iQqKopffvnlgj+/IUOGEBYWxvz589m5c6dCu4jcVLLyi/jHmoMs2R5Po7/8h6Z/XUmbN9eQX1QClN7nPLugmLScQs7dPjYjr4iiEot1P0BqTiFfborj15jTnEzPo6C4BNM0+Sk6mcGzN7Js50km/xBNm7d+ov6EH2n71k+8u+oAczccZXFUPPO3HOebLcep6eFE7N//RNy0uzn4Vj/eGtSiTGiH0pD+x9AuIiJyK6jwEXfDMGyBSCDBNM0BhmEEAwsAHyAKeMQ0zULDMByBL4FQIAUYappm3LWc+2pHxitKcHAwrVuXLhITGhpKXFwcGRkZpKenc+eddwIwYsQI7r//fusx9957LwC33347t912G7Vq1QIgJCSEEydO4OXlRd26dencuTMADz/8MB9++CEvvPACTk5OPPHEEwwYMMA6TX/Tpk3WgPzII4/w6quvWs81aNAgbGxsaN68OcnJpbfRCQwM5ODBg6xbt45169bRs2dPvv32W3r27MmiRYuYM2cOxcXFJCYmEh0dTcuWLc+rOzs7G3d3d9zd3XF0dCQ9PR2A9u3bW6euDxs2jA0bNjBkyJALvn/t27e3huzWrVsTFxeHm5sbISEh1mvuhw0bxpw5cwBITk4mJiaGLl26YBgG9vb27N27lxYtWrBp0yaWLVsGwEMPPcTLL78MlAb3NWvW0KZNGwCys7OJiYkhKCio3J+fiMjNYui/NrHlaCpNa7pzICmr3DZFJSb5RRaa/nXVdT332O4NqO/jwvs/HSI5swAHWxs6NfQhMT2f94a05Mc9iRxKzuLDYW2wPXsfdU13FxER+d2NmCr/PLAf8Dj7/F3g/0zTXGAYxifAE8DHZ/+bZppmQ8MwHjzbbugNqO+GcXR0tD62tbUlLy/vso+xsbEpc7yNjQ3FxcXA+X/cGIaBnZ0dW7du5b///S+LFy/mo48+Yt26dZdd37lRlHPb+/fvT//+/QkICGDZsmWEhIQwY8YMtm3bhre3NyNHjiQ/P/+a677c+mxtba39XMiiRYtIS0uzhvrMzEzCw8OZOnXqBY8xTZOJEycyevToMtvj4uKu6ucnIlJZIg6eYlNsCgXFFg4lZ7HlaCrAeaG9SYA7B5OzmNC/Ke2Da/Dn2Ve3tsh9bQNZuz/Zer/wc8b3aszzvRoBMLRdULnHtqrrdVXnFBERuVVUaHA3DCMQuBuYCrxolCazHsBDZ5vMAyZTGtwHnn0MsBj4yDAMw/xjgqyGPD098fb25tdff6Vr16589dVX1tH3y3X8+HE2bdpEx44d+eabb+jSpQvZ2dnk5ubypz/9ic6dO1tHtjt16sSCBQt45JFHmD9/Pl27dr1o39u3b6dmzZrUrl0bi8XC7t27admyJZmZmbi6uuLp6UlycjIrV66ke/fuV1T31q1bOXr0KPXq1WPhwoWMGjXqio4HaNKkCUeOHCEuLo769euzcOFC677w8HBWrVpFx44dATh69Ci9evVi6tSpdOjQge+++46hQ4eyYMEC6zF9+/blr3/9K8OHD8fNzY2EhATs7e0vWoO7uztZWeWPXolI9XA6q4D/7ElkyfZ4nOxtqePlzN6TGcx5JIz613CLrfyiEpzsba/6+Iy8IgqKSnBzsqPEYrLlSCpPfhlZbtsWdTyY9ueWxKfl0THEB3cnO2xszv/CNG7a3Rc8X3GJBTtbGzLyirCzMXCwsyG3oAQTs8wq7qZp8vPBU3g62xNar8ZVvz4REREpVdEj7jOBVwH3s899gHTTNM8NlcYDdc4+rgOcADBNs9gwjIyz7c/8sUPDMEYBo6D0OurqYN68edbF6UJCQvj888+v6PgmTZrwz3/+k8cff5zmzZszduxYMjIyGDhwIPn5+Zimyfvvvw/ArFmzeOyxx5g+fbp1cbqLOXXqFE899RQFBQVA6XT1Z555BicnJ9q0aUPTpk3LTNW/Eu3ateOZZ56xLk43ePDgK+7D2dmZ2bNn069fP1xdXWnXrh1QOkJ+7NgxOnToYG0bHByMp6cnW7ZsYebMmTz88MNMnTqVfv364enpCUCfPn3Yv3+/Ney7ubnx9ddfY2t74T+sR44cyZgxY7Q4nchN6mR6Hku2xzNjzSHrttf6NeXJrsHsjk/nzR+i2RWfUe6x3WdEnLetlqcTiRn55zc+K9jXlXta1qLYYjI7IhaA3yb0YHNsCv/Zk0iPZv7kFBSTW1jC6G4NsLM1sLMxMAyDzUdSeHDOld3a8rmejXisU328XUuDdYs6nld0/B/Znb3e3NP59y80PV3OXy7HMAx6NNVicSIiIteLUVED2oZhDAD+ZJrm04ZhdAdeBkYCm03TbHi2TV1gpWmaLQzD2Av0M00z/uy+WOAO0zTPlHsCICwszIyMLDuysH//fpo1a1YRL6lKOnebub1791Z2KVckIiKCGTNmWFd/vxbZ2dm4ublhmibjxo2jUaNGjB8//qLH5Obm4uzsjGEYLFiwgPDwcJYvX37NtVQ3t9rn6WZmmqauCb4Cx1NymfnfQyzZnnBZ7W1tDLo09OX+sEBiT+VQ28uJoBoujPk6irRy7jNeWYa1r8sjHeqTW1hM67pe1qAtIiIiVZNhGFGmaYZdql1Fjrh3Bu41DONPgBOl17h/AHgZhmF3dtQ9EDj3V1MCUBeINwzDDvCkdJE6kYv69NNPmTdvHoWFhbRp0+a869PLExUVxTPPPINpmnh5efHZZ5/dgEpFrozFYvLT/mT2JmQwolN9fN0cKSguwc7Ghq1HUxn26fkjr7OGtaFVoBdzNxwhp7CEYF9XDp/KxsPJjh7NAujcwAcbwyh3ivQ5xSUWCootuDraUVhs4UBSJgYGmflFbD2ayonUXCIOnaZ3swAaBbixOCqevKISXuzdmI4hPszdcJSujfywMaBNkDeOdjb8fPAUDf3dqOfz+7TycyuTJ6Tl8bfv92FrYxBW35v3Vh0Efr/2+skuwSyMPEFWfulkrQZ+rpxMz+eLx9oRceg0Tna2dG7oQ6u6XtaR6ZV7EsnKL6bPbQG4OdpZA2xuYTGHkrN55N9byCr4fZ2MGq4ORLzSHXsbG976MZpTmfnsTcikcU13Jg1oRkN/d8qz5fVe7ElIp0lND9wc7cgvKuGn6GQaBbjh6+aIu5MdDrY2LIo8QZsgbw4mZXEwKQsnexsWRp7gi8faszchg1e+3U0DfzfuauLHyfQ84lJy2Xkivdxz/vOhtnRr7IvFAk4ONjjaXf1UexEREbk5VNiIe5mTnB1xP7uq/LfAd39YnG63aZqzDcMYB9xumuaYs4vT/dk0zQcu1q9G3EUqlj5PlSc1p5BnvtnOxtjfv78cGlaXhZEnrts5Rnaqz9IdCWTlF+HqaEeHEB9yCorLnPN6a17Lg4LiEtoEebM4Kv7SB1xHDnY2FBZbrM97NPVnxv2tqOHqcJGjqo5jKTkEeDhd0zXxIiIiUrVUhRH3C3kNWGAYxtvADmDu2e1zga8MwzgMpAIPXu0JNGVU5NpV83Uhq6TM/CLyC0s4kZbLfR9vOm///4b2ZeM6U8PFgZqeTjjY2ZCaU8jg2b+RmlPIXwc0J6+whPCtx2le24PHOwczYNaGMsd/sTHO+jgrv5ifopMvWl+3xn40q+lOak4hz/ZoxL83HGHzkRQOJWfz70fDrIui3Vbbg2MpudTzcWHfyUy8XexpGejF+kOniU7MBCD2dA4Azva25BWV8ErfJjQJcCfi0CneuLs5mflFFBRZSM8t4nR2PodPZTOgZW1yC0sIquHCxtgzLN95kvWHTvPufS2JOpbGJ+tjrbU2q+XBg+3q8tXmY5xIzaWg2EJhsYWG/m4MbFWbAa1qE3wNi8pVhj/OVhAREZFbyw0Zca8o5Y24Hz16FHd3d3x8fBTeRa6SaZqkpKSQlZVlvZ2eVIxTmfnM33KcVXuTOJhc9u4EL/dpzDM9Sm+jdTwll5/2J9MmyIu2Qd7XdM4Si8n3uxJwtrcj2NeVJjXd2XE8jcOnsskrKqG2pzN3NvEjPbcIbxf763ad9PGUXNZEJ2Ga8EvMaf5ydzOa1vS49IHXgcViYhhQbDGx13XfIiIiUkVc7oh7tQvuRUVFxMfHl7mnuIhcOScnJwIDAy95Ozy5eiv3JDJ2/nbrc3tbg6KS0v8nP9ejIS/2aVJZpYmIiIjIDVCVp8pXKHt7e40QikiVFJ+Wy7hvdlBisbA3IdO6/bkeDenYwJcOITU0U0hEREREzlPtgruISFWyZHs8Ly7adcH9q17oesOmi4uIiIjIzUnBXUSkApimyX0fb2T78bK39HqtX1P63hbA1qOp9L2tJt43yYrmIiIiIlJ5FNxFRK6DrPwijqXksjchgyKLyV+X7bXue/+BVvRsGoCHs511KnyIn1tllSoiIiIiNxkFdxGRa/DlpjgmLd93wf2Hp/a/bquyi4iIiMitScFdROQy/PPnw0xfffCC+wM8HHmiSzCdG/pyJrsQXzcHGge4K7SLiIiIyDVTcBcRuYi9CRkMmLXhgvtDfF354rH2BPm43MCqRERERORWouAuIlKOg0lZvPTtzjK3bXtrUAua1XQnxM+N/KISPJ3tcXXU/0ZFREREpGLpL04Rkf/x7qoDfBwRa32+9OlOtAnyrsSKRERERORWpuAuIvIH87ccs4b2F3o14rkejbCxMSq5KhERERG5lSm4i8gt6/01B8kqKOaXQ6eJPZ1j3e7pbM/miT1xdrCtxOpEREREREopuIvILaWw2MJ9H28kK7+IuJTc8/b7ujmy6oWuCu0iIiIiUmUouItItZSZX0RkXCrhW0/w84FTDGhZi+TMAjYdSbG2aVXXiyFt61BiMRnYug7erg6VWLGIiIiISPkU3EWkWsjKL+Lej37j6Jmccvcv23nS+rhzQx++fuIODEPXrouIiIhI1afgLiI3tTPZBZxMz+OtFdHlhvZPHw2jgZ8r+xOzaBzgRt0aLjjZaxq8iIiIiNw8FNxF5KZksZjc9Y8Ijv3hOvXnejRkZOdgkjLyaVbLvcyIeoifW2WUKSIiIiJyzRTcRaRKSMkuYMPhM7Sp602Qj4t1+9roZCIOnaJjiC//2ZPI2O4N2JOQwbyNcWVC+8hO9XmxTxMAauhadRERERGpRhTcRaRSRR1L5Z3/HCDyWJp1m6+bI22CvDBNWLs/GYCvNx8H4Mc9iWWOPzy1P3a2NjeuYBERERGRG0zBXUQqlMViUmwxsTHAMAxScwr5YddJ+t9eE4D7Pt5kbfun22vynz1JnMku4Kfo0sA+rH0QLQM9OZaSS2Gxha82x1FUYvJU12BG39lAoV1EREREqj3DNM3KruGqhYWFmZGRkZVdhohcwKHkLAbM2kBhseWCbQwDFo/pSEM/dzxd7AHYn5jJ2K+j+ODBNrSq63WjyhURERERuaEMw4gyTTPsUu004i4iFeL9nw7x4X9jyt3XMcTHej/1OY+EEVqvRpn9zWp5EPHKXRVeo4iIiIjIzUDBXUSumWmaRBw8TXx6HoeSsvhq8zEAGvm78ebAFnRs4FPuMYDupS4iIiIicgkK7iJyTZbvTOD5BTvL3Rc+qgO+bo7l7lNgFxERERG5PAruInLVfjl02hra+91Wk1X7kmgb5MU/HmhNfR8XhXMRERERketAwV1ELtvJ9DzeW3UAZwc7Yk9lszUuFYD5T95B54a+lVydiIiIiEj1pOAuIhdUYjFZsj2e9YdOsz8xk9jTOWX2h/i68nyvRgrtIiIiIiIVSMFdRCgstrDh8GmSMwsI8XXlk/WxNK7pzvIdJ0nKzC/T9qXejQms4cztdbxo6O9WSRWLiIiIiNw6FNxFbmF5hSW8u+oAX2yMO2/fzwdPA/Cn22uy/uBpejUP4P8eaI2Nja5bFxERERG5kRTcRW4Bn204ypsrohnfqzHD7qjL5iOpbD+WViawh9bzxtYwOJicRYeQGtT1dsHD2Z7nejaqvMJFRERERATj3L2Ub0ZhYWFmZGRkZZchUuXkFZYwffVBPvvtKN4u9qTlFl2wbeMAN74d3QlPF/sbWKGIiIiIiBiGEWWaZtil2mnEXaSaeWflfv61/oj1eVpuEW6Odkwd3IL/7j+FnY3B6ewChoQG0jjAnWa1PCqxWhERERERuRQFd5FqIr+ohMGzN7I/MROAV/o2IaiGCyF+rjSv5YFhGAxsXaeSqxQRERERkSul4C5SDby+dA/fbDlufb7k6U60DfKuxIpEREREROR6UXAXuUmZpsnDc7fw2+EU67bX+jVlbPcGlViViIiIiIhcbwruIjcR0zT558+HmbHm0Hn7tv6lJ/7uTpVQlYiIiIiIVCQFd5EqbumOeF5fspe8opJy9++Z3Ad3J60ILyIiIiJSXSm4i1RR8Wm59P/gV7Lyi8tsr+nhxNdPtieohiv2tgaGYVRShSIiIiIiciMouItUQXsTMhgwawMA7ep789UTd5CSU0gdL+dKrkxERERERG40BXeRKsQ0TYbO2czWo6kAtA3yYv6THXCws1FoFxERERG5RSm4i1QB+UUlvLp4N9/vOmndtnliT2p6arE5EREREZFbnYK7SCXKLSzmo3WHmR0Ra93Wu3kAs4a1wcnethIrExERERGRqkLBXaQSpOUU0uatn8pss7c12DulL452CuwiIiIiIvI7BXeRGyy/qKRMaH+iSzAjO9Wnbg2XSqxKRERERESqKgV3kRsor7CEnv+IAKCGqwORf+mFjY1u5yYiIiIiIhdmU9kFiNwqSiwm9360gZMZ+bSo48HW13sqtIuIiIiIyCVpxF3kBvlqUxwxp7J5rkdDxvdujGEotIuIiIiIyKVpxF3kBsgvKmHyD9G4OtjyQi+FdhERERERuXwK7iIVbOWeRFq/uQaARzvV1/R4ERERERG5IpoqL1JBfo05zSNztwLgYGvDA2GBvNCrUSVXJSIiIiIiNxsFd5HrLDIulWGfbqaoxLRu2/DaXfh7OFViVSIiIiIicrNScBe5ThLS8xj9VSR7EzIBaOTvxhePt6eOl3MlVyYiIiIiIjczBXeR6+CP0+IB5j95B50b+lZiRSIiIiIiUl0ouItco10n0q2hffqQlgwJDdSq8SIiIiIict0ouItco49+PgzA0qc70SbIu5KrERERERGR6ka3gxO5Bqv2JvFTdDLP9Wio0C4iIiIiIhVCwV3kKi2KPMGYr6MAeLxLcCVXIyIiIiIi1ZWCu8hVWLojnlcX7wZg1rA2eLk4VHJFIiIiIiJSXekad5ErNG9jHJN/2AeU3p890NulkisSEREREZHqTMFd5AqM+jKSNdHJAHw7pqNCu4iIiIiIVDgFd5HLlJCeZw3tu/7WB09n+0quSEREREREbgW6xl3kMs3ffAyAdS/dqdAuIiIiIiI3jEbcRS7DWyuimbvhKPe2qk2In1tllyMiIiIiIrcQjbiLXMKm2BTmbjgKwN/uaV7J1YiIiIiIyK1GwV3kIjJyixj26WZcHWzZPLEnPm6OlV2SiIiIiIjcYhTcRS7inZX7Afi/oa2p6elUydWIiIiIiMitSMFd5ALScgpZuiOBQa1r0+e2mpVdjoiIiIiI3KIU3EUu4PtdJykotvBk15DKLkVERERERG5hCu4iF7BqbxK1PZ1oUcezsksREREREZFbmIK7SDl+3J3IpiMpdGroW9mliIiIiIjILU7BXeR/bD+exrhvtgMwsX/TSq5GRERERERudQruIn/wy6HT/Hn2RgC+G9tRt38TEREREZFKZ1fZBYhUBYXFFhq/sdL6fNHojoTWq1GJFYmIiIiIiJRScBcBxnwdBUADP1cm3XMb7YMV2kVEREREpGpQcJdb3s4T6aw7cAqAtS/eiWEYlVyRiIiIiIjI73SNu9zSikosDP90MzVcHdg1qY9Cu4iIiIiIVDkK7nLLMk2TMV9FkVNYwrM9GuLpYl/ZJYmIiIiIiJxHU+XllrRmXxKjviq9rj3E15WRnepXbkEiIiIiIiIXoOAut5ztx9Osob1VXS/mjgjTFHkREREREamyFNzllvLj7kTGfbMdRzsbFo/pxO2BnpVdkoiIiIiIyEUpuMstI7+ohKk/RgOw9OnONK/tUckViYiIiIiIXJoWp5Nbxmvf7eZkRj7fPHmHQruIiIiIiNw0NOIu1V5+UQkzVh9k+c6T9GjqT6eGvpVdkoiIiIiIyGWrsBF3wzCcDMPYahjGLsMw9hmGMeXs9mDDMLYYhnHYMIyFhmE4nN3uePb54bP761dUbXJreX3pHv694SgDW9dm9vC2lV2OiIiIiIjIFanIqfIFQA/TNFsBrYF+hmF0AN4F/s80zYZAGvDE2fZPAGlnt//f2XYi12TH8TSWbE+gbg1nPniwDU72tpVdkoiIiIiIyBWpsOBulso++9T+7D8T6AEsPrt9HjDo7OOBZ59zdn9PQ/fokmtQVGJh8OyNGAaEP9WhsssRERERERG5KhW6OJ1hGLaGYewETgE/AbFAummaxWebxAN1zj6uA5wAOLs/A/App89RhmFEGoYRefr06YosX25yX206BsC47g0J9Hap5GpERERERESuToUGd9M0S0zTbA0EAu2BptehzzmmaYaZphnm5+d3zTVK9WSaJouj4rG3NXi+V6PKLkdEREREROSq3ZDbwZmmmQ78DHQEvAzDOLeafSCQcPZxAlAX4Ox+TyDlRtQn1Ytpmvzf2hiiEzOZOvh27G1110MREREREbl5VeSq8n6GYXidfewM9Ab2Uxrgh5xtNgJYfvbx92efc3b/OtM0zYqqT6qn/+xJ5La/rebD/8ZQ38eFIW0DK7skERERERGRa1KR93GvBcwzDMOW0i8IFpmmucIwjGhggWEYbwM7gLln288FvjIM4zCQCjxYgbVJNbR6XxJPz99uff7vEe2wsdH6hiIiIiIicnOrsOBumuZuoE05249Qer37/27PB+6vqHqkent/zUE+XHcYgCe6BPNynyY4O+jWbyIiIiIi/8/efYdnVd//H3+eDEIIe+8pIAioDAdu3Ku2arVqXR12aW1rh+1X2/rV/mpr7bDa1lptrVr3F+veOFG2iIrsPQNhZa/z++MDhghIgCTnTvJ8XFeunPuM+37fGZDX+Sw1fHXZ4i7Vi/veXcJtr86nS+ss7r50DMN6tEm6JEmSJEmqNQZ3NWgT56/j+ic+oEvrLF695lhysvyRliRJktS4ON22GqzZqzZz4T8mAXDzOSMM7ZIkSZIaJZOOGqTisgpO/dObAPzn64cydkDHhCuSJEmSpLphi7sapH+8uRCAbx4zwNAuSZIkqVGzxV0NShzH3PDUR/xr4mKG92jDj04enHRJkiRJklSnDO5qMMorKvnGfdN45eO1nH1wD359znDSXaddkiRJUiNncFeD8bV/T+W1ObmcN7onN589gjRDuyRJkqQmwOCuBuGWFz7mtTm5NM9M4zfnjCCKDO2SJEmSmgYnp1PKu/XFOdwxYQH9OuYw8drjDe2SJEmSmhRb3JXSHpu2nD+/Op9zRvbkt+eOcEy7JEmSpCbHFnelrMLScn746EwAbvr8MEO7JEmSpCbJ4K6U9Z0HpgNw3elDyG6WnnA1kiRJkpQMg7tS0qJ1Bbw2N5dzR/Xka0f1T7ocSZIkSUqMwV0p6cHJS4mAH588OOlSJEmSJClRBnelnLWbi7l34mLG7d+Fzq2bJ12OJEmSJCXK4K6Uc/dbiyitqOS604ckXYokSZIkJc7grpSydnMx/5y4mC8c1IO+HXOSLkeSJEmSEmdwV0p5eMoySssr+fZxA5IuRZIkSZJSgsFdKaO0vJJ731nCcYM7sV/nVkmXI0mSJEkpweCulPHiR6tZl1/CJYf3TboUSZIkSUoZBneljPvfXULPdtkcPahT0qVIkiRJUsowuCslTF2cx7sL8zh3VE/S0/WMUdEAACAASURBVKKky5EkSZKklGFwV+LKKir57oMz6N6mOeeP6ZV0OZIkSZKUUjKSLkD61TOzWbmpmH9cMppubbKTLkeSJEmSUoot7krU8x+s4l8TFzO4SyuOH9I56XIkSZIkKeUY3JWYTUVlXPmfGQA8eMVhRJFj2yVJkiTp0wzuSsy/Jy6mvDLmqSuPpH1Os6TLkSRJkqSUZHBXItZuKeZvry/gxKFdGN6zTdLlSJIkSVLKMrgrEfe/s4TCsgp+eur+SZciSZIkSSnN4K56l19Szm2vzue4wZ3p36ll0uVIkiRJUkozuKvePTR5KQCXHN4n4UokSZIkKfUZ3FWv4jjmP5OWMrpPO44d7PJvkiRJkrQ7BnfVq4kL1rNwXQHnj+mVdCmSJEmS1CAY3FVvVmws4qJ/TALgzAO7J1yNJEmSJDUMBnfVi7KKSo64+VUALhvbl+aZ6QlXJEmSJEkNg8Fd9eK2V+YBcMEhvfnl5w5IuBpJkiRJajgM7qpzRaUV/GviYk4d1pVfnz086XIkSZIkqUExuKvOPTtrFVuKy7nk8L5JlyJJkiRJDY7BXXVq0boCrnl0Jt3aNOew/u2TLkeSJEmSGhyDu+rU/4yfBcCvvjCMKIoSrkaSJEmSGh6Du+rMCx+uZuKC9Xz/hEGM279L0uVIkiRJUoNkcFedyN1Swjfum0bv9i245PA+SZcjSZIkSQ2WwV11YvyM5QDcfPZw2uU0S7gaSZIkSWq4DO6qdXEc88jU5Yzs3Zax+3VMuhxJkiRJatAM7qp1T72/ivlr8zlvdK+kS5EkSZKkBs/grlpVVlHJrS/OAeCMA7snXI0kSZIkNXwGd9Wq1+bksmR9IX/78ihaZmUkXY4kSZIkNXgGd9WaOI65642FdG3dnOOHdE66HEmSJElqFAzuqjXjZ6xg8uI8vnXsADLT/dGSJEmSpNpgulKt2FJcxk3PzKZzqyy+dIiT0kmSJElSbXEQsmrF315fQF5BKf+4ZDRZGelJlyNJkiRJjYYt7tpn05du4J63FnPCkM6cMLRL0uVIkiRJUqNicNc+u/utRWSmR9xw1rCkS5EkSZKkRsfgrn1SVlHJG3NyOWVYV3q0zU66HEmSJElqdAzu2idPv7+SLSXlnDDELvKSJEmSVBcM7tprBSXl3Pzcx4zo2cbgLkmSJEl1xOCuvfbHl+eyZnMJvzjzANLSoqTLkSRJkqRGyeCuvfLG3FzuenMRXxzVk1F92iVdjiRJkiQ1WgZ37bGi0gouuWcyXVs356YvOJO8JEmSJNWlGgX3KIqursk+NQ1/emUeAN85bgBZGekJVyNJkiRJjVtNW9wv3cm+y2qxDjUQ05Zs4K43F3LUwI5cfHjfpMuRJEmSpEYv47MORlF0AXAh0C+Koie3O9QKyKvLwpSafv3sbDq1zOL2C0cmXYokSZIkNQmfGdyBicAqoCNw63b7twDv11VRSk3z1+YzdckGrjt9CG2yM5MuR5IkSZKahM8M7nEcLwGWAIdHUdQHGBjH8ctRFGUD2YQArybitq1j208Z1jXhSiRJkiSp6ajp5HRfBx4D7ty6qyfwRF0VpdQzfekGnpy5kosO7U3Pdi2SLkeSJEmSmoyaTk73HeAIYDNAHMfzgM51VZRSy8bCUs7+y0R6tsvmhycNTrocSZIkSWpSahrcS+I4Lt32IIqiDCCum5KUah6duhyAG88aRrucZglXI0mSJElNS02D++tRFP0MyI6i6ETgUeCpuitLqWT8jBUc2Kstx+1vJwtJkiRJqm81De7XArnALOAbwLPAdXVVlFLHsrxCPlq1mTOGd0u6FEmSJElqkna3HBxRFKUD/47j+CLgrrovSalkwpy1ALa2S5IkSVJCdtviHsdxBdAniiIHNzdBz85axX6dW7Jf55ZJlyJJkiRJTdJuW9y3Wgi8HUXRk0DBtp1xHP++TqpSSli+oZBJi/K4atzApEuRJEmSpCarpsF9wdaPNKBV3ZWjVPK31xeQmZbGF0f1TLoUSZIkSWqyahTc4zi+oa4LUWpZl1/CI1OXc+aB3enVvkXS5UiSJElSk1Wj4B5F0VPsuG77JmAqcGccx8W1XZiSNX76CkrLK7ni6P5JlyJJkiRJTVpNl4NbCOQTZpW/C9gMbAEG4UzzjU4cxzw0ZSmj+rRjcFdHRkiSJElSkmo6xn1sHMdjtnv8VBRFU+I4HhNF0Yd1UZiSM23JBhbkFvDbcwckXYokSZIkNXk1bXFvGUVR720Ptm5vWx+stNarUqIem7acnGbpnDGiW9KlSJIkSVKTV9MW92uAt6IoWgBEQD/g21EU5QD31lVxqn/lFZW8+NEaThjahRbNavrjIUmSJEmqKzWdVf7ZKIoGAvtv3TVnuwnp/lgnlSkRL320hryCUs4c0T3pUiRJkiRJ1LCrfBRFLYAfAVfGcTwT6BVF0Rl1WpkS8dCUZXRt3Zzj9u+cdCmSJEmSJGo+xv2fhLHsh299vAK4qU4qUmJWbizijXm5nDe6J+lpUdLlSJIkSZKoeXAfEMfxb4EygDiOCwlj3XcpiqJeURRNiKLooyiKPoyi6Oqt+9tHUfRSFEXztn5ut3V/FEXRbVEUzY+i6P0oikbuw/vSXnh06nIAvji6V8KVSJIkSZK2qWlwL42iKBuIAaIoGgCU7OaacuCaOI6HAocB34miaChwLfBKHMcDgVe2PgY4FRi49eMK4K978ka0b0rKK3hoylKOGNCRXu1bJF2OJEmSJGmr3Qb3KIoi4G/A84Sx7Q8QAvePP+u6OI5XxXE8fev2FmA20AM4i6qZ6O8FPr91+yzg33HwLtA2iiLXI6snj0xdzqpNxXz96P5JlyJJkiRJ2s5uZ5WP4ziOouhHwLGElvMIuDqO43U1fZEoivoCBwOTgC5xHK/aemg10GXrdg9g2XaXLd+6b9V2+4ii6ApCizy9e/dG+y6OY+57ZzEH9mzD0QM7Jl2OJEmSJGk7Ne0qPx3oH8fxM3EcP72Hob0l8DjwvTiON29/LI7jmK3d72sqjuO/x3E8Oo7j0Z06ddqTS7ULM5ZtZO6afL50SG9CBwtJkiRJUqqo0TruwKHARVEULQEKCK3ucRzHIz7roiiKMgmh/YE4jv9v6+41URR1i+N41dau8Gu37l8BbD8rWs+t+1THHpmyjOzMdM4Y4cgESZIkSUo1NQ3uJ+/pE28dG383MDuO499vd+hJ4FLg5q2f/7vd/iujKHqIcKNg03Zd6lVHCkrKeWrmSk4f0Y1WzTOTLkeSJEmS9Ck1Cu5xHC/Zi+c+ArgYmBVF0Xtb9/2MENgfiaLoq8AS4Lytx54FTgPmA4XA5XvxmtpDj09fTkFpBeePcQk4SZIkSUpFNW1x32NxHL/Frtd6P34n58fAd+qqHu2osjLmn28vZliP1ozu0y7pciRJkiRJO1HTyenUCL3y8VoWrSvgq0f2c1I6SZIkSUpRBvcmbPyM5XRqlcXpw7snXYokSZIkaRcM7k1UHMe8uzCPowd2olmGPwaSJEmSlKpMbE3UR6s2k1dQyuEDOiRdiiRJkiTpMxjcm6i35q0D4OiBHROuRJIkSZL0WQzuTdTbC9bTv1MOnVs3T7oUSZIkSdJnMLg3QevzS3h7/jpOGto16VIkSZIkSbthcG+Cnn5/FRWVMV84uEfSpUiSJEmSdsPg3gSNn7GC/bu2YnDXVkmXIkmSJEnaDYN7E7N4XQHvLdtoa7skSZIkNRAG9ybm1Y/XAnDa8G4JVyJJkiRJqgmDexMSxzGPTF1G3w4t6NW+RdLlSJIkSZJqwODehLy3bCMfr97C5Uf0S7oUSZIkSVINGdybkEemLic7M52zRzq+XZIkSZIaCoN7E1FUWsFTM1dy2vButGqemXQ5kiRJkqQaMrg3Ec99sIr8knLOG90z6VIkSZIkSXvA4N5EbJuU7pB+7ZMuRZIkSZK0BwzuTcCKjUW8uzCPc0f1JIqipMuRJEmSJO0Bg3sT8Na8XABOOqBrwpVIkiRJkvaUwb2Rq6yM+c+kpfRom83Azi2TLkeSJEmStIcM7o3cxAXrmbl8E987YaDd5CVJkiSpATK4N3K3vDgHgNNHdEu4EkmSJEnS3jC4N2IrNxYxc9lGjhrYkRbNMpIuR5IkSZK0FwzujdjtE+bTLD2NX589POlSJEmSJEl7yeDeSJVXVPLM+6s4fUQ3erZrkXQ5kiRJkqS9ZHBvpKYs3sCmojJOGtol6VIkSZIkSfvA4N5IPTRlKS2zMjh6UKekS5EkSZIk7QODeyM0f20+/31vJeeP6UVOlpPSSZIkSVJDZnBvhB6avBSAiw/rk3AlkiRJkqR9ZXBvZErKK3hp9hpG92lH3445SZcjSZIkSdpHBvdG5okZK1iyvpArju6fdCmSJEmSpFpgcG9E4jjmn28vZv+urTjR2eQlSZIkqVEwuDciH67czMert3DJ4X2JoijpciRJkiRJtcDg3oi8+vFaoghOOsDWdkmSJElqLAzujURlZcz4GSsY3acdHVtmJV2OJEmSJKmWGNwbiYkL1rNoXQEXHeoScJIkSZLUmBjcG4n/TF5CuxaZnDKsa9KlSJIkSZJqkcG9EVi7pZgXP1zDOSN70jwzPelyJEmSJEm1yODeCDw2bTnllTEXHWY3eUmSJElqbAzujcBrH+cyrEdr+nXMSboUSZIkSVItM7g3cFuKy5i+dANHD+yUdCmSJEmSpDpgcG/gJi5YT3llzNGDDO6SJEmS1BgZ3Bu4N+bmktMsnZG92yVdiiRJkiSpDhjcG7g3563j8AEdaZbht1KSJEmSGiPTXgO2ZH0BS/MKOWpgx6RLkSRJkiTVEYN7A/by7LUAHOP4dkmSJElqtAzuDdgLH6xm/66t6OsycJIkSZLUaBncG6i1W4qZsiSPU4Z1TboUSZIkSVIdMrg3UJMW5hHHcNzgzkmXIkmSJEmqQwb3Bmrakg1kZ6YztHvrpEuRJEmSJNUhg3sDNX3pBg7s1YbMdL+FkiRJktSYmfoaoMLScj5cuZnRfdonXYokSZIkqY4Z3Bug95ZtpKIyZlSfdkmXIkmSJEmqYwb3Bmja4g1EEYzsbXCXJEmSpMbO4N4ATVmygcFdWtGmRWbSpUiSJEmS6pjBvYGprIyZsWSD3eQlSZIkqYkwuDcwi9cXsKWknAN7tU26FEmSJElSPTC4NzAfrNwMwLDubRKuRJIkSZJUHwzuDcyHKzbRLD2NgV1aJl2KJEmSJKkeGNwbmOlLNzCke2sy0/3WSZIkSVJTYPprQErLK5m5fBOH9HViOkmSJElqKgzuDcjsVZspLa/kYNdvlyRJkqQmw+DegLy3bCMABzmjvCRJkiQ1GQb3BmTG0g10aZ1FtzbNky5FkiRJkupOZQXMfAheuRFK8rfuqwz7m6CMpAtQzb23bCMH9WpLFEVJlyJJkiRJu7ZsMky8DYhgzFehxyjIarX76965A174WfV9b/6u+uOLHoNeh0Lz1lBeAsWboGXnWis9FRncG4i8glIWry/k/DG9ky5FkiRJkqqUl0B6s/A5LQOeuhreu7/q+Ownq5/fZRjkLYSjfwRlhfDGLTt/3nZ94cgfwFPfrb7/gXPD5ygN4sqwfcpvIDMbpt8Llz0TthsRg3sDMXPr+PaDezu+XZIkSVLCKsrguZ/A1Lt3fjyjOZz2O5j7PHz8dPVjaz4In1+5YefXnncf9D0SWrQPj0ddCnEMUQRrP4a/HBr2bwvtAM//pGr7oyfhwPP3/D2lMIN7AzFj6QbSIhjeo03SpUiSJElqysqKYMKvdh3aT7oJRl4aurKPvLhq/5Y1MOtRaN8P2veHvxwGWW1g7FVw5PchLT2E853Ztr/z/vDLTWG7ohwqSmH9PJj3Ygj1g06BEV+svfeaIgzuDcR7yzcxqEsrcrL8lkmSpFoUxzDjfti4JIwt/coL0G1EMrVUlEGUDmnOnyyllOJN8NrWrugbFsEHj1cd+/ak0KU9swYTaLfqAmOvrHq8LYDvrfSM8NHtwPDRiJkCG4A4jvlgxSaO379xT7ggSZLqycZl8OSVkN0ePnqienfTO48Kn7Naw3cmQdFGqCiBbgftuiVsV0q2wJS7YdRlkP2p4X7Fm+DlX8Koy8ONgg8eh8e+Eo4dfmXoZpu3ANr0hAWvQVZLOPM26DRoL990CisvDS2NaelJV6Kmas1H0K5PuHk261EYMA4m/Q22rILZT+36uiteDy3gqnMG9wZg5aZi8gpKGdHTbvKSJGkPbVwKfxwettv3h03LQ9fS7Q39PBz3P7BmFrx4PWxeASWb4fdDqp938q/h8G9XPd6wGJq3gex21c9b81FoxZ98J1SWw8u/gK+9El73mR9CeXEI5QBT74GczlCwtur6d27f+Xu5Y0z1xxnZcNKNcMjXa/SlSExFOaycAemZ0GFAuHHSogMsfhMe/2o4JzMHzvxT6EL8xLfD96B9P/jcn6HTkDDxlz0RgspKWDEVWnWDtr2Sria1VZQBUZgIrmQzLJsEk+6E/DXhhl3nIbBqZs2e69BvQs8x4ed46Fl1WrZ2FMVxnHQNe2306NHx1KlTky6jzj3/wSq+ef90xn97LAf3brf7CyRJkt75C7zw050fa9U9TPbUrh8MPLFqAigIXefXzYM5z8LrvwkzPnc7CFa9F443awnN24axq2s/Cvv6Hwen/hZyOobQOfe57V6rW2i1q4mvvgytuoaxs8smhdb47LawZXUI+2/euvPrRn8FTvhluIkAISiX5le18pcVw0s/h+FfhF5jdv4cdaG0ILRavnErlBXs23Nlt4crXgtf/8oyePG60DJ64o1wxHd3d3XDVlYUvvfv/g1Kt1Q/lpkDB10Ix14bfv72VUV5eI3sduF3YeZDsG4ujLs+uRsnFWUw5zkghun3Qf7qMKSlWU64EVe0Mfy853QKN4a2XfP8T2HKXTV/nbTM8LO1zXH/E2729T8ufD28cVQnoiiaFsfx6N2eZ3BPff/v2dn86+3FzLrhJLIy7EIlSZI+ZeMymPhnWDIRivJCa+32Ln8e+hwORRvC40+3kNdEWTE8dAEseLVm5w/9fJigqm0vmP9KCF4F6+Cwb0Lfrd3xOw4M4aiyIoxT3ZNaCteHdZsfOBcWvhb2t+waQs02466DeS+FmwDbjDgfzvgjNGtRtW/h62G5qhNvrNpfUR5a/ovywiRbBevCDNgn3RRuRDx0YfWaRl4K+50ArbvDP08Lwwu217onbF5efV/HwXDBgyFs5c6Bf50RWtaP/F5YLqs0H57+Pmxa9tlfjw4DYdDJYZzxllUw8CTofdjuvoqpbcV0WPwWvHbzrm96tOkNm5ZWPT7zNug0GB68IHzfOg6G46+HtbOhIBcm/z2cd8HDYT3x+S+H7/eCCeF3KH/1jr1Rtuk8NIyh/ui/cP79sN/xVce25alPDyXZvArefzgE/+ZtoeN+oafFfifC/JegbW/ofnDV+YV54QbZ+4+E37P8NeF7u37enn3tdqb7weHno+twaNkF+oyF0sLwfnuM3Pfn114zuDci5/x1IgCPf2tswpVIktQEVFbAG7+D1/5feNyyC/Q+HLofBGOvTqbVKXdu9W7i+58RWsK3D9FROsQV1a+7Zk7ohl5bNVdWwvLJIQjlLYBDvhFa1Oe9CJP+CitnwqFXwLE/q7+vU3kpPH/trme33iYtI3Tb397Qz4dxvW//qe7qi9LgwkdDUNr+ZsGemvFAaEEt2TqZV8sucPlz8O5fd92q2qZXCP39j4Wz/xFC4558X8qKazbhWE29/afQ82GbK6eGmzcQwu+WVaFlecGrOy4fNupyOOSK0AK8fl7oNZLTAWY/DQ9/GajDTNOiIxSuq9m5vQ6D034LK9/bce3xXfn2u2Foya6GiGzTrBWc8utww2Hei+HfAIC2fWDM1+Cl66uf37IrXPZ01ddYKcng3kiUV1Qy9BcvcMlhfbjujKFJlyNJUs1tW3M3KRVlYSzmp2sp3gyv3hS61mZkhe6m25SXhhbcRa/v/DlP/n9w+HfCdmFeaLne2/dYWhBajdv23vnxki1hUqgnvlWz5/vGG1VBLat1GB/dlOTODTcVhn8xfF8L1ofx8+36wIjzqs77+JkdW8s77Afr5+/4nG37wIFfCkMGINww2RYoL34itGrPfzm0xjZvA49eFsatn3pLuIFRXzYsgTd/F1pyS7ZUD/if1mMUfOHO8DXa1c9eHMMNn5pMMKM5lJeE3gBjvxuGV6xfEL7GB5wNPUft+rlWTA/DNrbv+QBAFILogldDEP20E26AkZdUH8qxKyvfC9/bFu0h92MYciasmx++X+Oug1mPwWHfgswW8OH/heEgrXuE398R5+34taj2b8YmeO7acNOjbV+YcNPWr0k2lBd9dl0DxoXW7uJN4T2O+3lohc+dU723wPa6HQQHfxl6jg4/gzt7/5WV4Ubdtn/jtqkoD/NFtO6+2y+ZUoPBvZGYvzafE37/Ord+8UDOGdUz6XIkSdrRhiXhD9LNK+CtP4R9HQeHx6f/Hla/H8JUl2Hhj9znroX37q+6/ptvQ9dhe/faBetg88owK3lpQQgA6+aGicBmP1W96/SAcTt2887pFFpC05uF8cLbDDwZTr81hLGyojCB2KqZYXKn7fU/Ds77dxjvXVYMr94Yxn13Hhpad2c+FN53ZTkse3fra35qIrbsdvCFv4fWs56jQ0ti3kK4/VNB6DtTQhhPzwzdvx/4InxrYhgTXpNgoypxHL6vHz8duj6fdkv1oLNpRfi6NtRZ3uM43BRqlhOC/KzHdj3fAYThAwdeAPefvbXbdw3yQUbzMO/ANpk5MOYrodv5mg92fd3XJ4QW4Gd/BDMfrH4sLSPUMuiUMOxgX3ooJGX6fWHFhqFnhSEZu/vdnPsC/GfrjaXrciGjWd3XqJRicG8knnl/Fd/5z3SevupIhvVwVnlJUoqI47CM2KOX1c7znXRTCNnv3Q95i0LL3tdfhTY9djx3ycSwdNiaj2BpGE5GetaOY4p3p0WHEG6216xlaIkfe9WO5xdtDJOmTf57CNvbxou37gFn3wX/Om3PXr8mstvDOf+Afsfs2RhwaVcWvw2PXhrGfH+WLsNCyC7ZEm5MxZXhZ/7DJ+D5n+z56466LLQ253So2jf/lTAJ4qHfDL9HDTGoS/vI4N5I/P7FOdw+YT4f/e8pNM9soHd9JUkNV/EmKMkPf7y37h4mdJr1GPzf16qf94U7w4zORRuh0/5hQrK8hfDRk2FsaNHGMPkXQO+xcPH4MHZ2yt3wzA92/foDjg9dXtv0DEsYzX9pJydFoWW8eGOYJf3gi0Lreo9RoRW+sjyEjqd/AL0OhYMuqJp9vGDd1lbxA0Lr+560/McxvPK/8Nbvq++/4KFwc6HDAMhfGya0yl8Dw84NrbxxZWi9b98vhJUPx4ebDivfg2n/DOdvXglH/TBM5CbVlYqtvxtv/SHM6XDIN8KwgZEXQ2b2rq8ryQ8311q0D93JSwtCd/jK8jBMo0P/MBlbyeaq3zVJO2VwbyS+cd9U5q3N59Vrjk26FElSU1JZCc98H6b9a9fnDDw5tEx3HbZ3s5RvU7QBHroodBXve1QYQ/7qTTDjvp2fH6WFWZ17H169G2pZcRi3W9/j6ksLQ1f6tR/Bd99Ldly/JKlBqWlwt89VipuzegtDurVOugxJUlOycSn85fCwFBWEyaHef7RqEqYxX4exV4alhWpDdju4/Nnq+866HU66Ed76Y5jsC2D4eTDkjND6vjO1Ofv1nmjWIizpJUlSHTG4p7Ci0gqW5BXy+YN3Mr5PkqTaVF4aumuvmwd3HRf27X9GmHgtLR0+9+ewr7Ki/ibsym4HJ95QP68lSVIKM7insHlrtxDHsH/XVkmXIkl1I28htO7pLLr1acGEMCP5cT8N49XLS+GWATvOln7E1XDi/+54fUOdZVuSpAbM4J7CPl69BYBBXQzukhqZsmJ48X9gyj/C4xYdqpa1qi3Fm8NkZpP+Bp0Gh/WAe4xsmsEzd24YP/73Y6r2vXvHzs/tMBC++E/oOrx+apMkSbtVZ8E9iqJ7gDOAtXEcD9u6rz3wMNAXWAycF8fxhiiKIuBPwGlAIXBZHMfT66q2hmLu6i1kZaTRp0NO0qVIUs1VlME/T4XlU6DPETD086HL84RfwcYlYQbjTytcD7cOhnPvgYEnQUY2zH0uzPTdtg+8/Es44PNhlvDy0hA6l74Lh34jzHaetxBGXgrP/TiskT3kTHj4y2E2c4Al6+DuE6pe75Sb4aWfw5Hfh2N/2nAnEyvZAnefDGs/DEH70G+FGdVnPx2WLFv0+s6va9klzHK+zajLwnrDDfXrIElSI1dns8pHUXQ0kA/8e7vg/lsgL47jm6MouhZoF8fxT6IoOg24ihDcDwX+FMfxobt7jcY+q/zFd09iQ2EpT191VNKlSNLuVVbCP0+BZZNqdv6ZfwqBsXgTLH4LHrqw9mvqtH+4EdD7MHjpF7B+3q7PPfZncOyn1iaurIS0tNqva09VlMGyySFsv3EL9BwNzVrtutX807Lbw+BTw/JjR/+oav+iNyAzB3qOqpu6JUnSZ0qJ5eCiKOoLPL1dcJ8DHBvH8aooiroBr8VxPDiKoju3bj/46fM+6/kbe3Af86uXOXpgJ24978CkS5GkHVVWhlnHm7WEl38BE2+rfvyny2HG/aHlvX3/sHTXgHHh2M5adjcshom3w5S7wuNh58IHj1Udz2oDJZvCdvsBMOrS0Gp+/C/gvQdg/XzodhAcdBEsfgOO+F4IuJ828c9hveyjfgDjvwmr369+PLsd9BwTgu7T3w/7Rl0GY78b3kddtUoX5oUbGINPhfRMWL8AWnULy4zNeXbX1x1yBYy7Dt68FWY9DpuXh/1n3wX9jg69GToPtTVdkqQUlKrBfWMcx223bkfAhjiO20ZR9DRwcxzHb2099grwkziOd0jlURRdAVwB3z039QAAIABJREFU0Lt371FLliyps/qTlFdQysgbX+J/ThvC14/un3Q5klTdjAfgv98GImC7/0dadIQfzqu9VurCvNC9vvvB4XHRhjBeu/vBO05oF8d7H05L8uHOoyFvwe7PHXc9HHUNbFoOc56Dgy4Ik7ztiYpySM+A/FyoKIVp/wwt6bBjN/btNW8bblis+TDcMDnkCuh7xJ69tiRJShkpv457HMdxFEV7fNcgjuO/A3+H0OJe64WliDnbJqZzRnlJda14Ezx3LRSshXP+EVqctykvgbuOhzWzoHkbOPIHoXX9E1v/GW7ZBX4wu/YnfmvRPnxsk90Oeu9iJNW+tChntYTvbp1aJY5h+r/hqe/CpU+FseOPXh5C/cal8OqN4WOb57brev65P0N6VhhrX7yxquaiDfD1CWGSvAfOgyVv7bqWdn2rB/d2feGrL0HLznv//iRJUoNW38F9TRRF3bbrKr926/4VQK/tzuu5dV+TNWd1WJbHpeAk1ap182DC/4MPx0PHgWGiuPXzq47/pm9oUT7k62FM+LR/Vh0r3lQ9tF8zJ8wCX7QRstvW21uoc1EUWrVHXVq175InwueKcnj1f0N3+7gS2vSCTcuqznvyqh2fr13fENy3rY2+vR6jYMW0MCzgxP+FNj3C/rIiyMwOs+9nZNnNXZKkJq6+g/uTwKXAzVs//3e7/VdGUfQQYXK6Tbsb397YzVmTT5vsTDq3ykq6FEkN1eynwszqAD0PgeWTqx9fN7dqu03vMGv7xNt2bFE+4w8w/Ivw9m2Q3gxGXlx92bbGFNp3Jz0jBOzt1zfftDxM/lZRCi9eF5a2G/NVWPRmaGHvORqm/Queujqcf8gVcNKvIC1j10MKMrO3fm5ep29HkiQ1DHU5q/yDwLFAR2AN8AvgCeARoDewhLAcXN7W8e63A6cQloO7fGfj2z+tMU9Od96d71BRGfP4t8YmXYqkhmDzKnjjt2EM9Fu/D921K0p2fu6Yr8Hpt8KW1bB2NvQ/tqpFN28R3D4GKsvCOO6DLoIOA+rrXUiSJDUpiY9xj+P4gl0cOn4n58bAd+qqloZo0boCjh3UKekyJKWiN34HHz4Rxl5//EzVTOvb2xbaL3w0tKwX5MJxPwvdrrdp1bV6yzmE5cKuz4XSgjDuW5IkSYlLbHI67dqW4jJyt5TQv5N/NEuN3mfNhL7mI5h+L0z62y6Oz6r+OKsNlBfBabfAAWdD89Zh/6CT9qymKDK0S5IkpRCDewpamFsAQP9OOQlXIqnOlOSHNbsfuxyIwvjo4efCEVeH2dvf/UuYAG17zVpBaVhxgjP/BK17hqXA4hgK10Hb3vX+NiRJklT3DO4paOG6fAAGGNylhmXZFLj7BNjvRDj4Ihhy1s4nH8udC3eM2XH/zAfDxzZpmXDcT2HgydDlgM+eWbyZoV2SJKmxMrinoIW5BaRF0Lu9wV1qMJZNhrtPDNvzXwofXYaFcegzH4RO+0PXEbD0Xdi0NJyX0xm+8Tq07h6WBHvz9/Dx05DZIqyXftg3IcslISVJkpo6g3sKWriugF7tW9AsYxfLBEmqO5WVULwRSjbDggmwcAKM+zl03G8X51fA8z+FyXeGx0f/OIwPL8kPs7uv+SDsz/04fGzzuT/DwRdXtaL3GAVfeqDu3pckSZIaLIN7ClqYW0D/jra2S4l46rsw477q+1bOgFN+Ax/9N8zCfsTV0KwlvPNneGW79bwvfAQGnVz1+PBvw4rp0HkoZLeDWY9AWREcdKEt6ZIkSaoxg3uKqayMWbQun7EDOiRditS0zHoMHv9q1eOeY0KLOIQw/9B2K1y+/cfq17btDVdOg4xm1fdnt4P9tlsBc+QltVuzJEmSmgSDe4pZtbmY4rJKZ5SX6trqD+DBL4WW77WzgTjsb9Udvvkm5HSsOrdoA3z4f5C/FvodDbMehbgyBPsTbghd4z8d2iVJkqRaYnBPMQtzw4zy/Tu6hrJU6/LXwpznQgv6zvx0xc7XLz/ye+Fjm7P/DusXQLu+kJZeJ6VKkiRJ2xjcU8yida7hLtWq8pKwzvl9n4el71Q/dui3oKwQjroG2vXZs+ftMKD2apQkSZI+g8E9xcxfm0+rrAw6t8pKuhSpYZv1GCx4Fd771EztOZ3D2ugjvgTNWiRTmyRJkrQHDO4pZkFuPv07tyTatkSUVNvKS0KoLVwH7/wFOuwHp/0Wuhyw589VWQGT7woBePh5ofU6qxWkZ9Z+3Z8ld25Ydu3VmyBvwc7P6bAfXPH6zrvCS5IkSSnM4J5i5q/N58j9OiVdhhqqOA7rgpcWQEVZmHSt40D43SCIKyAtEyrLql+Tvxr+OjZsj7seRn8FmrcJ12Zmw6r3YPI/oMdIGHY2tOwCE/5fWBqtNL/qeZ68qmo7qzX8cC5kNIcnr4RlU6DvEXDa73Y+Jry8BJ74FnzweHjt4k3QaQic8QfodWhYUz13DvQ6JLy/uS/A/10R1lvflZGXwJE/CDO7N29TtV66JEmS1MBEcRwnXcNeGz16dDx16tSky6g1m4vLGPHLF/nxKYP59rH7JV2OUlkcw5R/wOwnYeVMKNkEnfaHzavC9u606wct2oe1yYs3wQPn7H0tPQ8J65I//T1o3RM2L//s86M0OP8B2O8EePcv8PpvQkt9TTVvu+vAfuZtMOrSmj+XJEmSlKAoiqbFcTx6d+fZ4p5CFuaGien262RXXu1EYR5M/nsYs52ZA7mzqx/P/bhqO6czZDaHjUvD47FXwXH/A1E6bFm140Rs1+VC/powedv/fb1qf9+jQqv7yEvDTYL3H4aWXUPL+1HXhC7xWa1Da/boy6uue+gi+PjpsN28DXz+r/DuX2H1rBC6t18THcJNhxHnwf5nhq72LbvAtHvgmWuqnzf4NJjzbNg+/udwxPchLW3Pvo6SJElSA2OLewp5bNpyfvjoTF655hgGGN61zYvXwcQ/7/zYlVNDMI5jeOnncNi3oPtB1c+pKKv/MefbFG8K9W1v7Wy45+RwDOCyZ6DvkfVfmyRJkpQwW9wboAW5+WSmR/Ru70zXTVIcQ9EGWDYZJt4GJVtg9fvVz+l1aOjm3v1gGH4u5HSsOnb2nTt/3qRCO+wY2gE6D4Frl9Z/LZIkSVIDZXBPIfPX5tOnQw6Z6Xb9bTIqK8JkbSumw/1nh+D+aWkZcPET0O+o+q9PkiRJUuIM7ilkwdp8BnVplXQZqi8zH4Lx39j5saumh9bq0nxo17dey5IkSZKUWgzuKaK0vJIleYWcOrxr0qWoLhVvXdbs7hN2PPatd6DL0Or7tu8KL0mSJKlJMriniCXrC6iojJ2UrrFaPhX+cfyO+8++C4Z/0TXGJUmSJO2SwT1FLMjNB2C/zgb3RmfNhzuG9kufCkutGdglSZIk7YbBPUXMXxuCuy3ujUzxJnjowrDu+vn3hbCe0SzpqiRJkiQ1IAb3FLEgt4DubZqTk+W3pNGY+TCMvyJsX/oU9Ds62XokSZIkNUimxBQxf20+A+wm3zisnAEPfRk2Lw+PB59maJckSZK01wzuKaCyMmZBbj7nje6VdCnaV7Meg8e/GrYHHA+f/yu07JxsTZIkSZIaNIN7Cli9uZjC0gonpmvI5r4AL14H6+aGx195EXofmmxNkiRJkhoFg3sKmLfWGeUbnPISePK7UJALI86D8d+oOnbZs4Z2SZIkSbXG4J4C5q7eAsCgLq0SrkS7tfA1ePIq2Li0at+CV8Lnix6D/sdBur9WkiRJkmqPCSMFzFu7hY4tm9E+x2XCUkoch6CeOweGngXL3oVHL6s63v1gGHgSbFwGfcbCwBOTqlSSJElSI2ZwTwHz1+bbTT4phXmQ3Q7KiyGjOURR1bFXb4Q3bw3bz/+kav/pt8Kwc6B52+rnS5IkSVIdMLgnLI5jFuQWcMaIbkmX0nBUVsIbt8Daj+DsuyCjGRRthOy2Nbu+ohzevQPmPA9LJ1btb90Thp8DXUdUzQwPMPYqmPjnsH3Yt2HM12rvvUiSJEnSbhjcE7a+oJRNRWUM6GSL+yfyFsID58H6efCjhZDTofrxm3tDaZgXgI+eCC3l5cXQc0wYZ74twJcVhe7u6+fDO7fD+w9/9uuWFcLbf6p63KIjXPgI9BwFJ91Ue+9PkiRJkvaAwT1hC3MLAOjfKSfhSupIHO+8O/mWNXDnUZC/BnofHj7y14SP+S9XnXdL//D5C3fCpuWhpb28OOzrfTgsfafq8fIp8Js+MOgUWDcP8hbsuq7OQ+G030HfI6rX+vIvw+uffiv0Pmyf3rokSZIk1QaDe8IW5oal4BpVi3tFeQjQpflV+zofEMaSL3lrx/OXvhM+tnf+A7BiGrz1+/B4++XWMnPgR/OgWU64AVBeFMabT/83vHQ9zH2++nO17gn9joYW7eG4n0Fmi53fTIgiOPGG8CFJkiRJKcLgnrCF6wpolpFG97bZSZdSO179Fbzx2x33r/1wx339joaBJ0O3A0NX9vb9YfCp0GM0NGsBQ86Ao38Iy6fCA+eGGdxP/S206VH1HK26VG0f8d1wzcLX4YAv1HzMuyRJkiSlMIN7whbm5tOvQw7paQ18dvJ18+H2UVWPs9vDd6eHVvaSLZCRDYvfhHZ9oX2/Ha/vd9TOn7dZDvQ/Bq7PrVkd7fuHD0mSJElqJAzuCVuYW8Dgrq2SLmPf5C2qHtoP/SYc+9OqFu+sre9vwHH1X5skSZIkNXAG9wSVVVSyNK+QU4d3TbqUvffghTDnmbB94v/CEVcnW48kSZIkNTIG9wQtWV9IeWXMfp0b0MR0RRvh+Wth49LQgr4ttA8719AuSZIkSXXA4J6g+WtTbEb5Je/Acz+Gs24PE8bNegzmvQSVZXDUNTDtXph853bnvx2WZDv7LmjbK7m6JUmSJKkRM7gnaMHWpeD6Jx3cKytg/Ddh1iPh8Z1H73jOB49XbR/xPShcBwXr4dx7wgzwkiRJkqQ6YXBP0ILcfLq1aU7LrAS+DWXFkJEF7z8C468I+7oMgwM+D2/cGtZGP+jLMOhk2LIaCnKh0+CwJFvz1vVfryRJkiQ1UQb3BC1Ym1+/3eRXfwCPXAJ5C8LjnE4hkAP0OQIuewaiCI68BuJKSPfHQ5IkSZKSlpZ0AU1VHMcsyC1gQKecunuR0kIoCd3xmfIP+NsRVaEdqkL7Kb+By58NoR0gLc3QLkmSJEkpwnSWkDWbS8gvKWdAXc0ov2wy3H3ijvvPvC10ee91KMx5Flp1hR6jdjxPkiRJkpQSDO4J2TYx3X613VV+5Qz4+7E7P/aVF6D3YVWP9z+9dl9bkiRJklTrDO4JWbg1uNd6i/sjl1Ztn3gjjL0KCtZBdltIz6zd15IkSZIk1TmDe0IW5BbQolk6nVtl1c4TxjHMeQ42LoGjfwzj/qfqWMtOtfMakiRJkqR6Z3BPyKJ1BfTrmEO0bUK4fVG8Ce46HtbPC4+P/uG+P6ckSZIkKSUY3BOyeH0Bw3u02bcnKcyDvx4BW1ZW7Tvtd2F9dkmSJElSo2BwT0BZRSXLNxRxxohue/cEJVvg3s/ByulV+y54CAaeBGnptVOkJEmSJCklGNwTsHJjERWVMX3a7+Ua7u/+rXpov3YZNG9dO8VJkiRJklJKWtIFNEVL1hcC0LtDiz2/uLQQJtwUtsddBz9ZYmiXJEmSpEbMFvcELMkLwb3P3gT3F68Lnz93O4y8uBarkiRJkiSlIoN7ApauL6BZRhpdWjWv+UX5a+F3A8N2m95w8JfrpjhJkiRJUkqxq3wClqwvpHf7FqSl7cFScI9/tWr7woegNpaRkyRJkiSlPFvcE7A0r5A+7fegm/zbf4JFb8CgU+GL/4TM7LorTpIkSZKUUmxxr2dxHLM0r7DmE9OVl8A7fwnbX/yXoV2SJEmSmhiDez3LzS+hsLSi5i3ur94E+avhy49D5h6MiZckSZIkNQoG93q2dP22GeVrsIb7ojdg4m3QcRAMOL6OK5MkSZIkpSKDez2r8RruK9+De88M25c86WR0kiRJktREGdzr2ZK8QqIIerbbzVj1V24In7/2KrTuVveFSZIkSZJSksG9ni1dX0D3NtlkZaTv/ITcOfDQRbDgVTjpV9BzVP0WKEmSJElKKS4HV8+W5IU13Hdq9lPw8JfDduseMOZr9VeYJEmS1Ai9n/s+Fz17EQBH9jiSQe0G8dqy1xjSYQjPLHwGgC4tulBUXkTbrLbccfwddM3pSnpaOplpmUmWLn3C4F7Plq4v5MShXXY8EMfw3LVhe+DJ8Lk/O4u8JCkxcRwTRdEnnz8trziPjLQMWjdrXa91VcaVvLzkZQa0HUC/Nv1Ii+w8KGlHj8x5hBvfvXGH/W+teIu3VrwFwMJNCz/Zv6ZwDQCbSzdz5hNhnqn0KJ2Lh15Mt5xuHNPrGHq07FEPle9cHMdUxpVEUfTJv3slFSWsLlhNn9Z9dnv943MfZ9LqSWwu3czxvY/nnIHnfPI8y7csZ3n+cv4z+z/0btWbgvICNhRvoG1WW4rKi3hh8QtUxBUA7Nd2P/q16cetx9y6w/8N64vW0zyjOeuL1jNx5UTOH3x+tXMKywqZu2EuB3Y6cKf/r2xv9vrZ3DbjNq477LpEv+6pJIrjOOka9tro0aPjqVOnJl1GjeWXlDPsFy/w41MG8+1j96t+cNGbcO8ZcMYfYfTlyRQoSWqS4jhm/sb5DGg7gK+88BWmrZm2wzmXHXAZp/c/nQnLJjBl9RSmrJ7yybGjehzFrcfeSkVlBZNWTWJc73G7/KOsoKyAZxc9yxn9zyA7YzfzvWxn8qrJfPXFr+6wv11WOw7qfBATlk1gZOeRTF87nSHth3DB/hdw5oAzyUizjWJXdnVT5oN1HzA7bzZf2O8LZKRlsLl0M9kZ2dVaHnd17a72S/WhvLKcdUXruO+j+/j3R/+uduymI26ia05Xpq2ZxjG9jmFO3hx+MfEX/OuUfzGqyyjWF63n5SUv0yKzBePnj6/2b9z2xvUaxyUHXMLwjsNplt6s2rE4jpm4ciJrCtfQr00/2mW1o2+bvvv8virjSg7894G7PJ6TmcP1h13Pod0O5aZ3b+LYXsdyUp+TeGL+E/x68q93eV1mWiZllWX7VNuYrmMY02UMd826a6fP1apZK87e72w+3vAxk1ZN+mT/fafex0GdD6IyrmTG2hm8vORl7p99/05fo1erXnTL6cZVB1/FQZ0P2uF4aUUp09dOZ8LSCfzn4/8wsvNIbhh7Q6187etDFEXT4jgevdvzDO7158OVmzj9tre448KRnD7iUxPOPfU9eP8R+PECyKz5HzKSklNUXkRmWqbBQIm6c+ad3P7e7Z88bpnZkt8e/VsGtx9MVnoWbbLaAKGr6LqidQxqN4g73ruDE/ucyJTVU3b5h9K+6t+mP78c+0t6tepFWUUZxRXF3PjujSzZtIS1RWs/OefC/S/kpkk30TKzJVeMuILLDrjsk+B396y7+eP0P9KjZQ9W5K/YqzouHXop14y+pl7D5PbhtbCskBaZu1lJph4s27yMjSUbmZk7k8WbF/PwnIerHT9n4Dkc3/t4rn3zWjaXbt7pc1x+wOUc2eNIbnjnBpZuWQrABftfwEVDLqIiruDs/55NRVzBOQPP4brDrmP5luU8POdh7p99P0PaD+H6w65n2pppzFo3ixeXvEirZq346wl/5cBOuw4kUk3MWDuDS567ZIf9dxx/B0PaDyEnM2evfg9fX/Y6izYtYkX+Ch6a89AOx/u07sOSzUt2+zytm7X+5Pfq+sOup1WzVrRu1pqlW5YyoM0ARncdvUPvodKKUlbkr+CpBU9x16y79rj2nXntvNcoLC/kng/u4bG5jzGqy6hPbtQe2/NYjuxxJDExXXO6sn/7/ZmwbAKTVk3i10f9ms0lm8lKzyInM4d7P7qXFxa/wMd5H9dKXbtybM9j2ViykYLyAhZuXPhJq3/3nO6c0u8U7vngnl1e+8fj/sjxvRvGctoG9xT0/Aer+Ob903nqyiMZ3rNN1YGlk+Cek2DE+XD235MrMEH3fngvv5v6O47peQwtMlowrs84xvUax/L85fRv0z90DSLyLr5SxuqC1Zz02EnExBzU6SBuPvrmGnfliuOYDSUbaN+8PasLVgPQNacrlXHlbrv9bizeSFllGZ1adNrn96CG743lb/CdV77zmedkRBmUx+U1fs6O2R357+f/S+tmramMKymvLGfRpkVcPeFqMtMyWZG/gntOvueTlpJlW5bxrw//xRPzn6C8MrxO15yun/xs78whXQ9h8urJOz3WLK0Z6Wnp9GjZg/kb53+yb0DbAfzkkJ8wqkv1SVvHzxtPaUUpZ+13FgVlBWwu3cySzUt4YPYDvLvq3U/O29aydEb/M7hh7A07tJTtqaLyIt5d+S5vrniT5xc/z5bSLTW6bmz3sdww9gY6ZXciPW3nE9UWlxeTkZZBepTO6oLVRFFE62atWbZlGZ1bdKZd83Z7VOu0NdO47PnLanx+p+xO5BblfuY5o7uMZuqaff8bLDsjm/+c9h+6t+xOi8wWbCndQnZG9g43RCsqK/h4w8dMXT2V8waft0NvjUfmPMJTC57ixD4ncs6gc1iRv4JerXrtUa8ONUwfrPuAC565oNq+iIgHz3iQAzocUKuvVV5Zzo9e/xFvrniTkoqSXZ5Xk9+hnbl65NWMnzeeirhih5uVR/U4ijuOvwOAl5a8RLecbgzvNByAOXlzuOCZC8hIy2Bk55E0S2/GOyvfoX/b/tww9gYGtRtUJ8OK1hWto6CsgDl5cziu93FkpmVWG2a1aPMiyivLeXL+k7TIbMGZA86kV6te3PPBPfxh2h+qPdeQ9kM4uPPBXHnwlZRUlNCheYdqf/evKVjDCY+dsMtaMtMy+eNxf6R3q960z25f78O49oXBPQXd9cZCfvXsbGb+/CTatNja3ay8BG7qHLavngnt+iZWX30rKCvgkTmP8Ptpv6/R+c3TmzP+rPF0b9ndMY2qd4s3LeZ7E75Hx+yOzNs4j7zivB3OOarHUfzlhL9QGVdy+4zbaZPVhkuGXkIURcxeP5s/TPsD76x6h5aZLckvy9/p67TJasOmkk2c2f9MDup8EMf1Oo7WWa15e8XbXD3h6mrnntH/DH591K67wDUEFZUVuwwvTd2PX/8xH67/kDZZbejcojPjeo/j5L4nk5Wexfh54/n5xJ9/cu6fjvsT43qPozKuZPLqyXz9xa/v9DmzM7I5a8BZ9GvTj9tn3M4RPY7g+sOv/+QPnNUFq+nQvAOZ6fs+GdOH6z/kS09/qdq+b4z4Bl8d/lWyM7KpjCv59aRfs3TLUm455hbyivI458lzyEjLoLC88JNrrj3kWs4bdN5e1RTHMV9+7su8n/v+DscuH3Y5awvX8oNRP6Bzi86feV3Plj0/aSF7f937FJUX7XEtO3Nav9MY3H4wERFPLniSxZsXA3xyA2RXhrQfwsqClXTL6cZp/U5jRKcRDGk/hKz0LMrjcm6ZcguvLH2FgrICmqc3Z0PJBgAO6HAAA9sNZFSXURzZ40g6NO8AQBRFrMpfxdMLn+aIHkcwtMPQT14rvzSfnMwc8svy/3979x0fVZX/f/x10qtAEgKk0BEENNKJCEgTKav8vpaVZZUvin5t64JfsK1t7bqiroruqoir7pcVXVYUUQRERUSQXqQlgdBJSIckk8nM+f0xw5hAKEJIJuT9fDx4ZObec2/ODWfO3M9pl2eXP0tseCy3p9xOeFA4+aX5DP/PcIrKihjSYgjNo5tzW8ptPLb0MT7P+Jyu8V3pm9SXmzrfxI97f+STtE9oFNaIyOBIhrQYQoAJYPTno487VPeOi+/g9pTbySjI4KpPrqq0b2jLoYzuMJpuTboxb8c8Jn87GUvV97QNQxtS7i4nOTqZty5/yzcKpaY5Xc5q+WxVpyNxQF2Z9nCo7BDGGL7f872v8fvB7x8E4IPhH9To6I3CskI+S/+MDjEduCDmAiKCI475m5WWl2KxrNi/gvYx7XG5Xfx19V/ZVbSLddnr+EOXP5BXmsdHWz+qsiHg/p73s+/QPn7T5je0j2l/wvw4XU6Ky4trrXz/Wml5abisi/CgcJqf1/yUjjlSNzpcDl5c8SL9kvrRP7k/5e7yOj36UYG7H3pk9gb+s3oP6x8b+svG90ZBxiLoOwkGPVx7mTtLjteDmJGfwVWzf/kSTopK4qlLn6JxeGOaRjXlnfXvVBr6ebS+iX3pFNeJv639GwDDWg1jRKsR9E/uf9p5dbldTNswjQWZC5jYbSKpCamA54trS94WIoIiaBbV7KSri7qtm3xHPuuy17Hh4Ab6JPahS3yX086X1Dy3dfNV5lcs2rmImLAYQgNDmb5xOm7rrpTuvh73cV3763h9zetM2zANgOjgaIqcp9bzVhWDOe7NZ0WNQhuR58gjMSqRkMAQUpulMrD5QM4LOY8GoQ1IiEqgwFFAmauMnNIcZm2bxV1d7qrUAp1RkEFUcBRx4XFnpTGs2FnMYedh3+gAh8tBXmkezy5/lr2H9rIpd5Mv7Z0X38ltKbdVex7qiqKyIm796lYahDVgyZ4lv+rYr67+imZRladfHal7HS4HBY4CIoIiiAqJqs4sn1VlrjL+uuqvJEYl8rsLfnfG5/vHxn+QV5rHXV3u4oHFD/Dlji+Pm3Zy98lkFGTw723/Bn5pTKvKDR1vYEDyADblbKJVg1b0SeyD27oJCghiffZ6QgJDOL/R+Rhj2F20m+CAYLblb+O55c/5gvSqxIXHcbDk4Bld89FeG/jaGX1Hni2rs1YzYdGEKhtDqxITFlMpbWhgKA6Xg86xnXm237PMyZjDvB3z2FO0hx5Ne7Aqa1WVDS3J0cnc2+NeUhqnUOAo4H/m/w9u3PRs2pMHez1IZHDkKeWnYuNjubvc9/9fsU5dkLmAid9MBDw9qmM7jSU4IJjc0lxWHViFwYCB9za+R89mPbn1wltPO8AdCy4nAAAYiklEQVTPLc1ld9Fu/rb2b2zJ20JWcRa/af0bHuj1AOn56XyW/hmz02cz/sLx7D+831fOwVP2R7YZyY6CHYz9ciwhASE80/cZUhqnEB0STZmrjH9v+zcvr3oZgIigCCZ0m0DfxL4s3bcUp8vJxpyNhAaGYrFM7j75Vw1PP1hykMKyQorKiugc27lSo+7Owp2M+M+I4x77aOqjXHP+NafxF/Mfh8oOMTt9NgZDr2a9aBLRpE7V23L6FLj7oXHTl3Og0MHcP/b1bNg0Bz4cAwld4NZvajNrxyh3l2OxlYLUqWumMm/HPLYXbPdt+0u/vzC05VC25m0lPT+doS2Hkl2STb4jn9sX3H7SG4++iX15sNeDJEYlVtmqW+YqY8bmGVx7/rVszNnItPXTWLL35De1g5sPpqS8hKX7ljJz5Ezax7RnY85GZmyaQXBgMBsPbmRT7iauaHkFLc5rwaxts6oc0hQfHk++I58yd9kx+1Iap3BXl7uIj4hnxqYZrMlew6WJl/L2+rerzNPA5IGEBYWxu2g36w6uI7VZKlMHTfW71vf6pLS8lGkbphEZFEnjiMYUOAqYt2Meq7JWVZl+UvdJuK2bn3N+rtRLCZ4RJE8ve5rPMz7HZV0EBQQd02v2WOpjdI7rfEyrudu6ycjPoE3DNoBnddfCskI+2voRa7LWkF6QTmJUIo+kPsIlCZcAnpvFl1e9zLsb3/3V190vqR/f7f7O9z40MJTHL3mcHk17UO4up2lk01PqZTnsPIzBMHPLTF5d/SpBAUF8MPwDMgoy+HDLh5UW9jlyc3206JDoSkOML4q7iF1FuxjZZiSTuk+qk6NrHC6H76b8vY3vcaD4AEVlRWzM2UjzaE+vwprsNTzc+2G6NenmG2ZelamDpvLiihd5OPVhnlj6BOkF6b59V7e7mondJtaZ3hV/UuAoYF32Ov6T9h/mZ86vMk1ceBwLrllAYECgrxfN6XJSWFZIbHjsGefBWsucjDn8tP8nGoU1IrMwk9+2/y0AqQmpOF1OggKCfJ/FI5+f0MBQPkv/jOCAYAY2H8gLK15gxuYZvvP2atqL9jHtuS3lNqJDoikpL6HAUUDTyKZnnOezbf/h/b58lpaX8vu5v2dL3hYAhrUcxvP9nwc8f7ufc3/mgcUPEB4UzmHnYd4b9h4xYTHHnNPldpHvyCcyOJJvd3/LpG8nnVJeBjUfxMO9Hz7m/3rx7sWeEQBtrmLU7FHklObQLLIZLw14yTfCJMgE0SSyCQOSB5zWGhLhQeH8c/g/iY+IZ8meJfRs1pO48Djffmstq7JWsfLASubtmEdoYCh7Du055caPmtStSTdanNeCZpHNSM9PZ0DyADrGdmTxnsWsy15HWn4a6fnpJEcn+9ZNAAgwATyW+hg/7P2hyoa2mzvfTFRIFNnF2dzQ8QaSopNq8rJEqpUCdz80aMo3tI2P4u83dIfc7fCKd1XE+3dCWM3feB25EVmXvY57v7uXUW1Hse/wPmZtm1Wtv+fo1vEjXr7sZQa1+PWLRpS7y3lz3Ztkl2RzdburCQ0MZdGuRczPnH/Gi2SEBITwdN+neerHp8hz5BEeFE5JeQnJ0cnklORUGr55Io1CG5ESn0K/pH48vvTx46YLDwrnmvOvYULXCb75loVlhcxJn0NqQiofbvmQqOAo5mTMqTTX6byQ85g6aCpFZUVMWDSBlg1a8nDvh8l35HNZ8mVA7Qxx21GwgyeXPcnhssNsyNlAn4Q+jGo3ivaN2tOqQasazUtFR/4WTy97mrnb51LgKKDleS1P2OMVExbD7Sm3061JN4rKioiPiD+lGwNrLQeKD/huPq21zM+cz0WNLzorN86bcjYxYdEERrQeQamrlAJHAZ+mfwp4ppeUukpp3aA1Q1oM4YvtX1S6MTqRo+dFhwWG8edL/kxafppvRMKuol2ndK6jpwbc0+0exnX+5ekZh8oOkTojtcpjZ4yYQUhgCF9s/4Lr219Pk0jPc3bDAsNYf3A9C3YuYEyHMTSJ9Dxm86WVL+FwObin2z1nPIf5ZN5a9xavrH4F8AwB7960OyXOEu5edPdpn3P2qNlk5GeQ58ijf1L/Y4ZwF5YVUuIs8V2vVI9DZYeIComi2FnsW4n61oturZMNR+cap9tJkAmq1u+zorIiNudu5pO0T/hqx1eUukoZ12kcm3M3E2ACquwgGN5qOPmOfH7Y+8Np/c73h71Ph5gOPPfTc3y89WPf9s6xnSlyFhEbFstTlz7FZxmf8fqa16s8R9f4rgxIHsCUlVNO+Lsubnwxw1sP5/r211PuLuehJQ8xd/tcOsd25r/O/y86xnYksyATh8vBpYmX0jiiMU63kz99/ye+2P4F/ZP6c1+P+4gIjuCbXd8wd/tc35oUvZv15ok+T9AkognF5cW8tvo1ckpyOFh6kJ/2/8RNnW8iJiyGpXuXnlJHyxGxYbHklOacMM0jqY9w7fnXnvI5ReoKBe5+xlpLh4e/5IbeLXhoZEd4ayDsWQk9xsOIE1fA1aHAUcCcjDk8u/xZwDM/ruIw1apEBEUcE6j+MPoHggOCKS4v5lDZIV5Y8QKLdi0C4Mo2V/oCBoA3Br9Bn4Q+GGMoKitifuZ8EqISuDDuwlMegnY6dhbu5I6FdzCs1TA6xXbi8aWP+3rTu8Z3JS0/jWGthjGp+yScbicLdy6kXaN2VS5gYq2lsKywUo+W0+1kV+EuskqyuOWrW+jZtCcXxFxA20ZteX3N6zzf7/kqH1XxxfYv2FW0i8zCTO7tcS9rs9fyf5v/zzcs9up2V1caslYd3rr8LXo3631G53BbN1nFWazNXsukbyfRJb4LaflpXNnmSjrFduLCuAu597t72ZS76YRzt18d+KqvUWFB5gJWZ63mkoRLaH5ec0ICQqo9EHG6nDyz/Bk+2vrRCdMNazmM/sn9mb5hOlvytvD3wX8nNSHV7+b1VZfDzsPM2DyDdg3b+YbNHiw5yJCPh5x0Xu3RgkwQKfEpJEUlMbnHZKZvmM68HfPYfWg3z/R9hsHNBxMWFAZ4hm+63K6TLqpX7CwmpySHF1e+yIKdC07vIr2mD51O96Yn/R781ay1fLf7O+76+q6Tph1zwRiub3898RHxZJdkkxiV6BsKOmXFFKJDolmXvY43h7x5zHB3Eakd5e5yluxZctzP+LCWw3C4HHRv2p3fX/B7MgszWbpvKb2a9qJ1w9Y4XA62F2zn213f0j+5Px1iOlQ6Pj0/nfCgcBKiEqo8/4HDB1iwc4Hvnu14U6gGNx9McnQySdFJhAeFkxSd5FdT80rKS3CUO/h+7/c0DG1I04im3PzVzeSW5tI1viuXJFzCLRfdgrX2mLVOCssKeX758+Q78okLjyMuPI47Lr5DjWlyTlLg7meyCkvp+fRCHr+qEzfGb4f3R0Gv22HYs5XSlZSXMHPLTDblbiItL40pl00hOTr5tCoqt3VTWl7KnQvvPOnKr+M6jyM2LJYmEU3oHNeZhKgErLW+33u8IMZaS6mrVKu2niZrLdfNue64IwVu7HgjQ1sOpbS8lJ7NevqOOVB8gOX7l1PuLqdfUj+yirO4f/H9laYxVDTt8mk88P0DJEQm8ESfJ6p8rqXD5WDJniUs3LmQpOgk3t3w7imPMDiib2JfJnabSHBAMPmOfIrLi/nj13+k1FXqS3O84D7ABDCo+SCSo5MZ3WH0KfdOu62btPw037DsIzc6x/Ptb7/F6XJy07ybeL7/874GG2stJeUlfvHYptp2ZPGcy5Iuo2uTruSX5vP93u95d8O7RIdEc9h5uEYWeKq4uNnxRkj0bta70srh4PncHP38XvAMfV24cyGPpj7K8FbDT/h/XewsZk7GHNo1audZMyAyocphtjNHziQ6JJopK6b4GhoqNlKJSN23Oms1b69/m7Edx/q+i2vappxNTN84nfT8dCZ1n+Rbh0dE6j4F7n5mZWYuV7+xlOljuzPgu+ugOBf+sAKCQn1pXln1ygmf0zggeQATuk2gdYPWrMteR1RwlK9l1+V28Wn6p2zO3cznGZ9XCpSOGNR8ENedfx3nx3geCRESEEJkcOQ527NYV1hr+Xrn12wv3M6g5oPOeEi5tZYCRwG5pbmVFgA82mXJl/Fo6qOMnze+0rzZ47myzZXcefGdHCg+4AuSP9z8IVklWdzd5W7GXDDmuIHQvkP7GP/V+ErDtBuHN6ZH0x6Ulpfy9a6vqzxucvfJhAaGsvLASuIi4hhzwRhCA0PJLMwkKjiKorIixs0bV+WxR3ww/AM6xnZkc85mOsd1Vnk/R1ScCrL/8H7iI+IpLS/1lcFiZzH9Pux3wsf1VDSu0zgGtRjE+Hnjq6w/qzJ10FT6JfU7vQsQERERQYG73/lk9R4mfLiG726Mo/nMy2HEFF4PLmN22mz2Ht5bKe2YC8ZwY8cbWbx7MU8ue5LQwFCcbucxK1qfqqvbXc2fev/ppKuhy7lpc+5mJiyawOgOowkNDOWNtW8cdwGbxuGNuS3lNsKCwli2bxl3d7m72oawu9wuSl2lx50msSZrDbPTZ9OjSQ/uW3zfrz7/kBZDyC3NZfyF47k08dIzza6cI47Um4echzhYfJCdRTt5dfWrbM3besLjkqOTCQ30NKw2CG1ARFAEi/csZvrQ6XSJ76JH2ImIiEi1UODuZ15duI0p87ey7fL17P3hBUYmHzuXMTEqkdcHvU7rhq2rPMeOgh3MSpvFiv0rWH9wfZVpRrUdRduGbRnRegSxYbHqXZQqudwuJn4zkUW7FjGy9Uiua38dF8Vd5DfByP7D+1l1YBUNwxryc87PON1Ovtz+JRkFGb40V7a5krYN25LSOIWuTbrWYm6lLnK6nSzft5xOsZ1oENqAORlzWJO1hrT8NN4Y/AahgaF+83kQERGRc5cCdz8z+aO1/LBlF1MDx3FDwi9zd98f9j4/5/zM6A6jTyvIzinJITQwlMjgSJxu51lfRVlERERERESqx6kG7kE1kRmBXXnF9G74d26I9gTt4zqNY2K3iRhjqlyB/FRVfL6ognYREREREZFzjwL3GpKdk8OhxmlAECmNU7in+z21nSURERERERGpA/QwxBrgdLnpy2tkBgfxePIIPhj+QW1nSUREREREROoI9bjXgH35pRRE7ibSDSP7/bm2syMiIiIiIiJ1iF/1uBtjrjDGbDHGpBlj7q/t/FSX3Xv3sjHCxUUhiQRXeG67iIiIiIiIyMn4TeBujAkEpgLDgI7AaGNMx9rNVfXYu20W+4KD6JXQt7azIiIiIiIiInWM3wTuQE8gzVqbYa0tA/4FXFXLeaoWm/KWAjAk5Xe1nBMRERERERGpa/wpcE8EdlV4v9u7rRJjzK3GmBXGmBXZ2dk1lrkzYWJa084dQ/OY1rWdFREREREREalj6tzidNbaN4E3Abp3725rOTun5KH/N6W2syAiIiIiIiJ1lD/1uO8Bkiu8T/JuExEREREREam3/Clw/wloZ4xpZYwJAa4HPq3lPImIiIiIiIjUKr8ZKm+tLTfG3AXMAwKBd6y1G2s5WyIiIiIiIiK1ym8CdwBr7Vxgbm3nQ0RERERERMRf+NNQeRERERERERE5igJ3ERERERERET+mwF1ERERERETEjylwFxEREREREfFjCtxFRERERERE/JgCdxERERERERE/psBdRERERERExI8pcBcRERERERHxYwrcRURERERERPyYAncRERERERERP6bAXURERERERMSPKXAXERERERER8WMK3EVERERERET8mAJ3ERERERERET9mrLW1nYfTZozJBjJrOx+nKA44WNuZEPkVVGalLlF5lbpGZVbqEpVXqWvqUpltYa1tfLJEdTpwr0uMMSustd1rOx8ip0plVuoSlVepa1RmpS5ReZW65lwssxoqLyIiIiIiIuLHFLiLiIiIiIiI+DEF7jXnzdrOgMivpDIrdYnKq9Q1KrNSl6i8Sl1zzpVZzXEXERERERER8WPqcRcRERERERHxYwrcRURERERERPyYAvcaYIy5whizxRiTZoy5v7bzI/WTMSbZGLPIGPOzMWajMeaP3u0xxpj5xpht3p+NvNuNMeYVb7ldZ4zpWuFcY73ptxljxtbWNcm5zxgTaIxZbYyZ433fyhizzFsuPzTGhHi3h3rfp3n3t6xwjge827cYY4bWzpVIfWCMaWiM+dgYs9kYs8kYk6o6VvyVMWai935ggzFmhjEmTHWs+BNjzDvGmCxjzIYK26qtTjXGdDPGrPce84oxxtTsFf46CtzPMmNMIDAVGAZ0BEYbYzrWbq6knioH/tda2xHoDdzpLYv3Awutte2Ahd734Cmz7bz/bgXeAE+FCTwK9AJ6Ao8eqTRFzoI/ApsqvH8OeMla2xbIA272br8ZyPNuf8mbDm8Zvx7oBFwBvO6tl0XOhr8CX1prOwApeMqu6ljxO8aYROBuoLu1tjMQiKeuVB0r/uRdPOWqouqsU98Abqlw3NG/y68ocD/7egJp1toMa20Z8C/gqlrOk9RD1tp91tpV3tdFeG4oE/GUx394k/0DGOV9fRXwnvX4EWhojGkGDAXmW2tzrbV5wHz8vKKTuskYkwSMAN72vjfAQOBjb5Kjy+uRcvwxMMib/irgX9Zah7V2O5CGp14WqVbGmAZAP2AagLW2zFqbj+pY8V9BQLgxJgiIAPahOlb8iLX2OyD3qM3VUqd6951nrf3RelZrf6/CufySAvezLxHYVeH9bu82kVrjHeLWBVgGNLHW7vPu2g808b4+XtlVmZaa8jJwL+D2vo8F8q215d73Fcuer1x69xd406u8Sk1pBWQD073TO942xkSiOlb8kLV2D/ACsBNPwF4ArER1rPi/6qpTE72vj97utxS4i9Qzxpgo4N/ABGttYcV93hZHPSNSap0xZiSQZa1dWdt5ETlFQUBX4A1rbRfgML8M4QRUx4r/8A4VvgpPg1MCEIlGdkgdU9/qVAXuZ98eILnC+yTvNpEaZ4wJxhO0/9NaO8u7+YB3uBDen1ne7ccruyrTUhP6AFcaY3bgmWI0EM/84YbeYZ1Quez5yqV3fwMgB5VXqTm7gd3W2mXe9x/jCeRVx4o/Ggxst9ZmW2udwCw89a7qWPF31VWn7vG+Pnq731Lgfvb9BLTzrtIZgmcBj09rOU9SD3nnok0DNllrX6yw61PgyAqbY4HZFbbf6F2lszdQ4B2aNA+43BjTyNtif7l3m0i1sdY+YK1Nsta2xFNvfm2tHQMsAq7xJju6vB4px9d401vv9uu9KyK3wrP4zPIaugypR6y1+4Fdxpj23k2DgJ9RHSv+aSfQ2xgT4b0/OFJeVceKv6uWOtW7r9AY09v7Gbixwrn8UtDJk8iZsNaWG2PuwlNoAoF3rLUbazlbUj/1AW4A1htj1ni3PQg8C8w0xtwMZALXeffNBYbjWWimGBgHYK3NNcY8gadRCuBxa+3RC4eInC33Af8yxjwJrMa7EJj35/vGmDQ8C9lcD2Ct3WiMmYnnhrQcuNNa66r5bEs98Qfgn96G+gw89WYAqmPFz1hrlxljPgZW4akbVwNvAp+jOlb8hDFmBnAZEGeM2Y1ndfjqvG+9A8/K9eHAF95/fst4GstERERERERExB9pqLyIiIiIiIiIH1PgLiIiIiIiIuLHFLiLiIiIiIiI+DEF7iIiIiIiIiJ+TIG7iIiIiIiIiB9T4C4iIlKPGWMmGGMiajsfIiIicnx6HJyIiEg9ZozZAXS31h6s7byIiIhI1dTjLiIiUk8YYyKNMZ8bY9YaYzYYYx4FEoBFxphF3jSXG2OWGmNWGWM+MsZEebfvMMY8b4xZb4xZboxp691+rfdca40x39Xe1YmIiJy7FLiLiIjUH1cAe621KdbazsDLwF5ggLV2gDEmDngIGGyt7QqsAO6pcHyBtfZC4DXvsQCPAEOttSnAlTV1ISIiIvWJAncREZH6Yz0wxBjznDGmr7W24Kj9vYGOwBJjzBpgLNCiwv4ZFX6mel8vAd41xtwCBJ69rIuIiNRfQbWdAREREakZ1tqtxpiuwHDgSWPMwqOSGGC+tXb08U5x9Gtr7W3GmF7ACGClMaabtTanuvMuIiJSn6nHXUREpJ4wxiQAxdbaD4C/AF2BIiDam+RHoE+F+euRxpjzK5zitxV+LvWmaWOtXWatfQTIBpLP/pWIiIjUL+pxFxERqT8uBP5ijHEDTuB2PEPevzTG7PXOc/9vYIYxJtR7zEPAVu/rRsaYdYADONIr/xdjTDs8vfULgbU1cykiIiL1hx4HJyIiIielx8aJiIjUHg2VFxEREREREfFj6nEXERERERER8WPqcRcRERERERHxYwrcRURERERERPyYAncRERERERERP6bAXURERERERMSPKXAXERERERER8WP/H26slP2kNJxQAAAAAElFTkSuQmCC\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "tags": []
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "# Uncomment agents\n",
+ "agents = [\n",
+ " # EpsilonGreedyAgent(),\n",
+ " # UCBAgent(),\n",
+ " # ThompsonSamplingAgent()\n",
+ "]\n",
+ "\n",
+ "regret = get_regret(BernoulliBandit(), agents, n_steps=10000, n_trials=10)\n",
+ "plot_regret(agents, regret)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Submit to coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_bandits\n",
+ "\n",
+ "submit_bandits(agents, regret, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week6_outro/practice_mcts.ipynb b/week6_outro/practice_mcts.ipynb
index f550ef465..275e39a3f 100644
--- a/week6_outro/practice_mcts.ipynb
+++ b/week6_outro/practice_mcts.ipynb
@@ -1 +1,743 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_mcts.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"gui142r7LbyG"},"source":["## Seminar: Monte-carlo tree search (5 pts)\n","\n","Monte Carlo tree search (MCTS) is a heuristic search algorithm, which shows cool results in such challenging domains as Go and chess. The algorithm builds a search tree, iteratively traverses it, and evaluates its nodes using a Monte-Carlo simulation.\n","\n","In this seminar, we'll implement a MCTS([[1]](#1), [[2]](#2)) planning and use it to solve in some Gym envs.\n","\n",""]},{"cell_type":"markdown","metadata":{"id":"VmUiuI_ELbzH"},"source":["__How it works?__\n","We just start with an empty tree and expand it. There are several common procedures.\n","\n","__1) Selection__\n","Starting from the root, recursively select the node, that corresponds to the tree policy. \n","\n","There are several options for tree policies, which we saw earlier as exploration strategies: epsilon-greedy, Thomson sampling, UCB-1. It was shown, that in MCTS, UCB-1 achieves a good result. Further, we will consider this one, but you can try to use others.\n","\n","Following the UCB-1 tree policy, we will choose an action, that, on the one hand, is expected to have the highest return, and on the other hand, we haven't explored much.\n","\n","$$\n","\\DeclareMathOperator*{\\argmax}{arg\\,max}\n","$$\n","\n","$$\n","\\dot{a} = \\argmax_{a} \\dot{Q}(s, a)\n","$$\n","\n","$$\n","\\dot{Q}(s, a) = Q(s, a) + C_p \\sqrt{\\frac{2 \\log {N}}{n_a}}\n","$$\n","\n","where: \n","- $N$ - number of times we have visited the state $s$,\n","- $n_a$ - number of times we have taken the action $a$,\n","- $C_p$ - exploration balance parameter, which is performed between exploration and exploitation. \n","\n","Using Hoeffding inequality for rewards $R \\in [0,1]$ it can be shown [[3]](#3), that optimal $C_p = 1/\\sqrt{2}$. For rewards outside this range, the parameter should be tuned. We'll be using 10, but you can experiment with other values.\n","\n","__2) Expansion__\n","After the selection procedure, we can achieve a leaf node or node, in which we don't complete actions. In this case, we expand the tree by feasible actions and get new state nodes. \n","\n","__3) Simulation__\n","How we can estimate node Q-values? The idea is to estimate action values for a given _rollout policy_ by averaging the return of many simulated trajectories from the current node. Simply, we can play with random or some special policy or use a model, that can estimate it.\n","\n","__4) Backpropagation__\n","The reward of the last simulation is backed up through the traversed nodes and propagates Q-value estimations, upwards to the root.\n","\n","$$\n","Q({\\text{parent}}, a) = r + \\gamma \\cdot Q({\\text{child}}, a)\n","$$\n","\n","There are a lot of modifications of MCTS, more details about it you can find in this paper [[4]](#4)"]},{"cell_type":"code","metadata":{"id":"KekgrHT8LbzO"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/submit.py\n","\n"," !touch .setup_complete\n","\n","# This code creates a virtual display to draw game images on.\n","# It won't have any effect, if your machine has a monitor.\n","if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n"," !bash ../xvfb start\n"," os.environ['DISPLAY'] = ':1'"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"aalBBGLzLbzP"},"source":["import numpy as np\n","import matplotlib.pyplot as plt\n","%matplotlib inline"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"gSHGN9TlLbzP"},"source":["---\n","\n","But before we do that, we first need to make a wrapper for Gym environments to allow us to save and load the game states to facilitate backtracking."]},{"cell_type":"code","metadata":{"id":"Nuo0vFYzLbzQ"},"source":["import gym\n","from gym.core import Wrapper\n","from pickle import dumps, loads\n","from collections import namedtuple\n","\n","# a container for get_result function below. Works just like tuple, but prettier\n","ActionResult = namedtuple(\n"," \"action_result\", (\"snapshot\", \"observation\", \"reward\", \"is_done\", \"info\"))\n","\n","\n","class WithSnapshots(Wrapper):\n"," \"\"\"\n"," Creates a wrapper, that supports saving and loading environemnt states.\n"," Required for planning algorithms.\n","\n"," This class will have access to the core environment as self.env, e.g.:\n"," - self.env.reset() #reset original env\n"," - self.env.ale.cloneState() #make snapshot for atari. load with .restoreState()\n"," - ...\n","\n"," You can also use reset() and step() directly for convenience.\n"," - s = self.reset() # same as self.env.reset()\n"," - s, r, done, _ = self.step(action) # same as self.env.step(action)\n"," \n"," Note, that while you may use self.render(), it will spawn a window, that cannot be pickled.\n"," Thus, you will need to call self.close() before the pickling will work again.\n"," \"\"\"\n","\n"," def get_snapshot(self, render=False):\n"," \"\"\"\n"," :returns: environment state, that can be loaded with load_snapshot \n"," Snapshots guarantee same env behaviour each time they are loaded.\n","\n"," Warning! Snapshots can be arbitrary things (strings, integers, json, tuples)\n"," Don't count on them being pickle strings, when implementing MCTS.\n","\n"," Developer Note: Make sure the object you return will not be affected by \n"," anything, that happens to the environment after it's saved.\n"," You shouldn't, for example, return self.env. \n"," In case of doubt, use pickle.dumps or deepcopy.\n","\n"," \"\"\"\n"," if render:\n"," self.render() # close popup windows since we can't pickle them\n"," self.close()\n"," \n"," if self.unwrapped.viewer is not None:\n"," self.unwrapped.viewer.close()\n"," self.unwrapped.viewer = None\n"," return dumps(self.env)\n","\n"," def load_snapshot(self, snapshot, render=False):\n"," \"\"\"\n"," Loads snapshot as current env state.\n"," Should not change snapshot inplace (in case of doubt, deepcopy).\n"," \"\"\"\n","\n"," assert not hasattr(self, \"_monitor\") or hasattr(\n"," self.env, \"_monitor\"), \"can't backtrack while recording\"\n","\n"," if render:\n"," self.render() # close popup windows since we can't load into them\n"," self.close()\n"," self.env = loads(snapshot)\n","\n"," def get_result(self, snapshot, action):\n"," \"\"\"\n"," A convenience function that: \n"," - loads snapshot, \n"," - commits action via self.step,\n"," - and takes snapshot again :)\n","\n"," :returns: next snapshot, next_observation, reward, is_done, info\n","\n"," Basically it returns the next snapshot and everything, that env.step has returned.\n"," \"\"\"\n","\n"," \n","\n"," return ActionResult(\n"," , # fill in the variables\n"," ,\n"," ,\n"," ,\n"," ,\n"," )"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"-9RCWqaGLbzR"},"source":["### Try out snapshots:\n","Let`s check our wrapper. At first, reset environment and save it, then randomly play some actions and restore our environment from the snapshot. It should be the same as our previous initial state."]},{"cell_type":"code","metadata":{"id":"FKTpH-ExLbzS"},"source":["# make env\n","env = WithSnapshots(gym.make(\"CartPole-v0\"))\n","env.reset()\n","\n","n_actions = env.action_space.n"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"EBXXokycLbzS"},"source":["print(\"initial_state:\")\n","plt.imshow(env.render('rgb_array'))\n","env.close()\n","\n","# create first snapshot\n","snap0 = env.get_snapshot()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"4PNefwYXLbzT"},"source":["# play without making snapshots (faster)\n","while True:\n"," is_done = env.step(env.action_space.sample())[2]\n"," if is_done:\n"," print(\"Whoops! We died!\")\n"," break\n","\n","print(\"final state:\")\n","plt.imshow(env.render('rgb_array'))\n","env.close()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"aW6HrCywLbzT"},"source":["# reload initial state\n","env.load_snapshot(snap0)\n","\n","print(\"\\n\\nAfter loading snapshot\")\n","plt.imshow(env.render('rgb_array'))\n","env.close()"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"J8QpKoFdLbzT"},"source":["# get outcome (snapshot, observation, reward, is_done, info)\n","res = env.get_result(snap0, env.action_space.sample())\n","\n","snap1, observation, reward = res[:3]\n","\n","# second step\n","res2 = env.get_result(snap1, env.action_space.sample())"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"YznSlflLLbzU"},"source":["# MCTS: Monte-Carlo tree search\n","\n","\n","We will start by implementing the `Node` class - a simple class, that acts like MCTS node and supports some of the MCTS algorithm steps.\n","\n","This MCTS implementation makes some assumptions about the environment, you can find those _in the notes section at the end of the notebook_."]},{"cell_type":"code","metadata":{"id":"iWJt1cvhLbzU"},"source":["assert isinstance(env, WithSnapshots)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"xTCWvfq5LbzV"},"source":["class Node:\n"," \"\"\"A tree node for MCTS.\n"," \n"," Each Node corresponds to the result of performing a particular action (self.action)\n"," in a particular state (self.parent), and is essentially one arm in the multi-armed bandit, that\n"," we model in that state.\"\"\"\n","\n"," # metadata:\n"," parent = None # parent Node\n"," qvalue_sum = 0. # sum of Q-values from all visits (numerator)\n"," times_visited = 0 # counter of visits (denominator)\n","\n"," def __init__(self, parent, action):\n"," \"\"\"\n"," Creates and empty node with no children.\n"," Does so by commiting an action and recording outcome.\n","\n"," :param parent: parent Node\n"," :param action: action to commit from parent Node\n"," \"\"\"\n","\n"," self.parent = parent\n"," self.action = action\n"," self.children = set() # set of child nodes\n","\n"," # get action outcome and save it\n"," res = env.get_result(parent.snapshot, action)\n"," self.snapshot, self.observation, self.immediate_reward, self.is_done, _ = res\n","\n"," def is_leaf(self):\n"," return len(self.children) == 0\n","\n"," def is_root(self):\n"," return self.parent is None\n","\n"," def get_qvalue_estimate(self):\n"," return self.qvalue_sum / self.times_visited if self.times_visited != 0 else 0\n","\n"," def ucb_score(self, scale=10, max_value=1e100):\n"," \"\"\"\n"," Computes ucb1 upper bound using the current value and visit counts for node and its parent.\n","\n"," :param scale: Multiplies upper bound by that. From Hoeffding inequality,\n"," assumes reward range to be [0, scale].\n"," :param max_value: a value that represents infinity (for unvisited nodes).\n","\n"," \"\"\"\n","\n"," if self.times_visited == 0:\n"," return max_value\n","\n"," # compute ucb-1 additive component (to be added to mean value)\n"," # hint: you can use self.parent.times_visited for N times node was considered,\n"," # and self.times_visited for n times it was visited\n","\n"," U = \n","\n"," return self.get_qvalue_estimate() + scale * U\n","\n"," # MCTS steps\n","\n"," def select_best_leaf(self):\n"," \"\"\"\n"," Picks the leaf with the highest priority to expand.\n"," Does so by recursively picking nodes with the best UCB-1 score until it reaches the leaf.\n"," \"\"\"\n"," if self.is_leaf():\n"," return self\n","\n"," children = self.children\n","\n"," # Select the child node with the highest UCB score. You might want to implement some heuristics\n"," # to break ties in a smart way, although CartPole should work just fine without them.\n"," best_child = \n","\n"," return best_child.select_best_leaf()\n","\n"," def expand(self):\n"," \"\"\"\n"," Expands the current node by creating all possible child nodes.\n"," Then returns one of those children.\n"," \"\"\"\n","\n"," assert not self.is_done, \"can't expand from terminal state\"\n","\n"," for action in range(n_actions):\n"," self.children.add(Node(self, action))\n","\n"," # If you have implemented any heuristics in select_best_leaf(), they will be used here.\n"," # Otherwise, this is equivalent to picking some undefined newly created child node.\n"," return self.select_best_leaf()\n","\n"," def rollout(self, t_max=10**4):\n"," \"\"\"\n"," Play the game from this state to the end (done) or for t_max steps.\n","\n"," On each step, pick the action at random (hint: env.action_space.sample()).\n","\n"," Compute the sum of rewards from the current state until the end of the episode.\n"," Note 1: use env.action_space.sample() for picking a random action.\n"," Note 2: if the node is terminal (self.is_done is True), just return self.immediate_reward.\n","\n"," \"\"\"\n","\n"," # set env into the appropriate state\n"," env.load_snapshot(self.snapshot)\n"," obs = self.observation\n"," is_done = self.is_done\n","\n"," \n","\n"," return rollout_reward\n","\n"," def propagate(self, child_qvalue):\n"," \"\"\"\n"," Uses child Q-value (sum of rewards) to update parents recursively.\n"," \"\"\"\n"," # compute node Q-value\n"," my_qvalue = self.immediate_reward + child_qvalue\n","\n"," # update qvalue_sum and times_visited\n"," self.qvalue_sum += my_qvalue\n"," self.times_visited += 1\n","\n"," # propagate upwards\n"," if not self.is_root():\n"," self.parent.propagate(my_qvalue)\n","\n"," def safe_delete(self):\n"," \"\"\"safe delete to prevent memory leak in some python versions\"\"\"\n"," del self.parent\n"," for child in self.children:\n"," child.safe_delete()\n"," del child"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"qVcLTTDWLbzm"},"source":["class Root(Node):\n"," def __init__(self, snapshot, observation):\n"," \"\"\"\n"," creates special node, that acts like tree root\n"," :snapshot: snapshot (from env.get_snapshot) to start planning from\n"," :observation: last environment observation\n"," \"\"\"\n","\n"," self.parent = self.action = None\n"," self.children = set() # set of child nodes\n","\n"," # root: load snapshot and observation\n"," self.snapshot = snapshot\n"," self.observation = observation\n"," self.immediate_reward = 0\n"," self.is_done = False\n","\n"," @staticmethod\n"," def from_node(node):\n"," \"\"\"initializes node as root\"\"\"\n"," root = Root(node.snapshot, node.observation)\n"," # copy data\n"," copied_fields = [\"qvalue_sum\", \"times_visited\", \"children\", \"is_done\"]\n"," for field in copied_fields:\n"," setattr(root, field, getattr(node, field))\n"," return root"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"wqor9EwlLbzz"},"source":["## Main MCTS loop\n","\n","With all we implemented, MCTS boils down to a trivial piece of code."]},{"cell_type":"code","metadata":{"id":"Px41kDS4Lbzz"},"source":["def plan_mcts(root, n_iters=10):\n"," \"\"\"\n"," builds tree with monte-carlo tree search for n_iters iterations\n"," :param root: tree node to plan from\n"," :param n_iters: how many select-expand-simulate-propagete loops to make\n"," \"\"\"\n"," for _ in range(n_iters):\n"," node = \n","\n"," if node.is_done:\n"," # All rollouts from a terminal node are empty, and, thus, have 0 reward.\n"," node.propagate(0)\n"," else:\n"," # Expand the best leaf. Perform a rollout from it. Propagate the results upwards.\n"," # Note, that here you have some leeway in choosing, where to propagate from.\n"," # Any reasonable choice should work.\n"," \n"," "],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Bc9FwxI0Lbzz"},"source":["## Plan and execute\n","\n","Let's use our MCTS implementation to find the optimal policy."]},{"cell_type":"code","metadata":{"id":"zRSR2D3mLbzz"},"source":["env = WithSnapshots(gym.make(\"CartPole-v0\"))\n","root_observation = env.reset()\n","root_snapshot = env.get_snapshot()\n","root = Root(root_snapshot, root_observation)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"SIjGUETQLbz0"},"source":["# plan from root:\n","plan_mcts(root, n_iters=1000)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Mx8vj-_JLbz0"},"source":["# import copy\n","# saved_root = copy.deepcopy(root)\n","# root = saved_root"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"i2X4ZQgHLbz0"},"source":["from IPython.display import clear_output\n","from itertools import count\n","from gym.wrappers import Monitor\n","\n","total_reward = 0 # sum of rewards\n","test_env = loads(root_snapshot) # env used to show progress\n","\n","for i in count():\n","\n"," # get best child\n"," best_child = \n","\n"," # take action\n"," s, r, done, _ = test_env.step(best_child.action)\n","\n"," # show image\n"," clear_output(True)\n"," plt.title(\"step %i\" % i)\n"," plt.imshow(test_env.render('rgb_array'))\n"," plt.show()\n","\n"," total_reward += r\n"," if done:\n"," print(\"Finished with reward = \", total_reward)\n"," break\n","\n"," # discard unrealized part of the tree [because not every child matters :(]\n"," for child in root.children:\n"," if child != best_child:\n"," child.safe_delete()\n","\n"," # declare best child in a new root\n"," root = Root.from_node(best_child)\n","\n"," assert not root.is_leaf(), \\\n"," \"We ran out of tree! Need more planning! Try growing the tree right inside the loop.\"\n","\n"," # You may want to run more planning here\n"," # "],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"QbNM3PZFLbz0"},"source":["from submit import submit_mcts\n","\n","submit_mcts(total_reward, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Kh5nmxwdLbz1"},"source":["## Bonus assignments (10+pts each)\n","\n","There are a few things you might want to try if you want to dig deeper:\n","\n","### Node selection and expansion\n","\n","\"Analyze this\" assignment\n","\n","UCB-1 is a weak bound as it relies on a very general bounds (Hoeffding Inequality, to be exact). \n","* Try playing with the exploration parameter $C_p$. The theoretically optimal $C_p$ you can get from a max reward of the environment (max reward for CartPole is 200).\n","* Try using a different exploration strategy (bayesian UCB, for example)\n","* Expand not all, but several random actions per `expand` call. See __the notes below__ for details.\n","\n","The goal is to define, what gives the optimal performance for `CartPole-v0` for different time budgets (i.e. different n_iter in plan_mcts.)\n","\n","Evaluate your results on `Acrobot-v1` - do the results change and if so, how can you explain it?\n","\n","\n","### Atari-RAM\n","\n","\"Build this\" assignment\n","\n","Apply MCTS to play Atari games. In particular, let's start with ```gym.make(\"MsPacman-ramDeterministic-v0\")```.\n","\n","This requires two things:\n","* Slightly modify WithSnapshots wrapper to work with atari.\n","\n"," * Atari has a special interface for snapshots:\n"," ``` \n"," snapshot = self.env.ale.cloneState()\n"," ...\n"," self.env.ale.restoreState(snapshot)\n"," ```\n"," * Try it on the env above to make sure it does what you told it to.\n"," \n","* Run MCTS on the game above. \n"," * Start with small tree size to speed-up computations\n"," * You will probably want to rollout for 10-100 steps (t_max) for starters\n"," * Consider using discounted rewards (see __notes at the end__)\n"," * Try a better rollout policy\n"," \n"," \n","### Integrate learning into planning\n","\n","Planning on each iteration is a costly thing to do. You can speed things up drastically if you train a classifier to predict, which action will turn out to be best according to MCTS.\n","\n","To do so, just record, which action did the MCTS agent take on each step and fit something to [state, mcts_optimal_action]\n","* You can also use optimal actions from discarded states to get more (dirty) samples. Just don't forget to fine-tune without them.\n","* It's also worth a try to use P(best_action|state) from your model to select best nodes in addition to UCB\n","* If your model is lightweight enough, try using it as a rollout policy.\n","\n","While CartPole is glorious enough, try expanding this to ```gym.make(\"MsPacmanDeterministic-v0\")```\n","* See previous section on how to wrap atari\n","\n","* Also consider what [AlphaGo Zero](https://deepmind.com/blog/alphago-zero-learning-scratch/) did in this area.\n","\n","### Integrate planning into learning \n","_(this will likely take long time, better consider this as side project, when all other deadlines are met)_\n","\n","Incorporate planning into the agent's architecture. The goal is to implement [Value Iteration Networks](https://arxiv.org/abs/1602.02867).\n","\n","Do you remember [week5 assignment](https://github.com/yandexdataschool/Practical_RL/blob/coursera/week5_policy_based/practice_a3c.ipynb)? You will need to switch it into a maze-like game, like MsPacman, and implement a special layer, that performs value iteration-like update to a recurrent memory. This can be implemented the same way you did in the POMDP assignment."]},{"cell_type":"markdown","metadata":{"id":"ToN7WICpLbz1"},"source":["## Notes\n","\n","\n","#### Assumptions\n","\n"," Here is the full list of assumptions:\n","\n","* __Finite number of actions__: we enumerate all actions in `expand`.\n","* __Episodic (finite) MDP__: while technically it works for infinite MDPs, we perform a rollout for $10^4$ steps. If you are knowingly infinite, please adjust `t_max` to something more reasonable.\n","* __Deterministic MDP__: `Node` represents the single outcome of taking `self.action` in `self.parent`, and does not support the situation, where taking an action in a state may lead to different rewards and next states.\n","* __No discounted rewards__: we assume $\\gamma=1$. If that isn't the case, you only need to change two lines in `rollout()` and use `my_qvalue = self.immediate_reward + gamma * child_qvalue` for `propagate()`.\n","* __pickleable env__: won't work if e.g. your env is connected to a web-browser surfing the internet. For custom envs, you may need to modify get_snapshot/load_snapshot from `WithSnapshots`.\n","\n","#### On `get_best_leaf` and `expand` functions\n","\n","This MCTS implementation only selects leaf nodes for expansion.\n","This doesn't break things down because `expand` adds all possible actions. Hence, all non-leaf nodes are by design fully expanded and shouldn't be selected.\n","\n","If you want to add only a few random actions on each expand, you will also have to modify `get_best_leaf` to consider returning non-leafs.\n","\n","#### Rollout policy\n","\n","We use a simple uniform policy for rollouts. This introduces a negative bias to good situations, that can be messed up completely with random bad action. As a simple example, if you tend to rollout with uniform policy, you better don't use sharp knives and walk near cliffs.\n","\n","You can improve that by integrating a reinforcement _learning_ algorithm with a computationally light agent. You can even train this agent on the optimal policy found by the tree search.\n","\n","#### Contributions\n","* Reusing some code from 5vision [solution for deephack.RL](https://github.com/5vision/uct_atari), code by Mikhail Pavlov\n","* Using some code from [this gist](https://gist.github.com/blole/dfebbec182e6b72ec16b66cc7e331110)\n","\n","#### References\n","* [1] _Coulom R. (2007) Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. In: van den Herik H.J., Ciancarini P., Donkers H.H.L.M.. (eds) Computers and Games. CG 2006. Lecture Notes in Computer Science, vol 4630. Springer, Berlin, Heidelberg_\n","\n","* [2] _Kocsis L., Szepesvári C. (2006) Bandit Based Monte-Carlo Planning. In: Fürnkranz J., Scheffer T., Spiliopoulou M. (eds) Machine Learning: ECML 2006. ECML 2006. Lecture Notes in Computer Science, vol 4212. Springer, Berlin, Heidelberg_\n","\n","* [3] _Kocsis, Levente, Csaba Szepesvári, and Jan Willemson. \"Improved monte-carlo search.\" Univ. Tartu, Estonia, Tech. Rep 1 (2006)._\n","\n","* [4] _C. B. Browne et al., \"A Survey of Monte Carlo Tree Search Methods,\" in IEEE Transactions on Computational Intelligence and AI in Games, vol. 4, no. 1, pp. 1-43, March 2012, doi: 10.1109/TCIAIG.2012.2186810._"]},{"cell_type":"code","metadata":{"id":"NPdSknxdLbz7"},"source":[""],"execution_count":null,"outputs":[]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Seminar: Monte-carlo tree search (5 pts)\n",
+ "\n",
+ "Monte Carlo tree search (MCTS) is a heuristic search algorithm, which shows cool results in such challenging domains as Go and chess. The algorithm builds a search tree, iteratively traverses it, and evaluates its nodes using a Monte-Carlo simulation.\n",
+ "\n",
+ "In this seminar, we'll implement a MCTS([[1]](#1), [[2]](#2)) planning and use it to solve in some Gym envs.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__How it works?__\n",
+ "We just start with an empty tree and expand it. There are several common procedures.\n",
+ "\n",
+ "__1) Selection__\n",
+ "Starting from the root, recursively select the node, that corresponds to the tree policy. \n",
+ "\n",
+ "There are several options for tree policies, which we saw earlier as exploration strategies: epsilon-greedy, Thomson sampling, UCB-1. It was shown, that in MCTS, UCB-1 achieves a good result. Further, we will consider this one, but you can try to use others.\n",
+ "\n",
+ "Following the UCB-1 tree policy, we will choose an action, that, on the one hand, is expected to have the highest return, and on the other hand, we haven't explored much.\n",
+ "\n",
+ "$$\n",
+ "\\DeclareMathOperator*{\\argmax}{arg\\,max}\n",
+ "$$\n",
+ "\n",
+ "$$\n",
+ "\\dot{a} = \\argmax_{a} \\dot{Q}(s, a)\n",
+ "$$\n",
+ "\n",
+ "$$\n",
+ "\\dot{Q}(s, a) = Q(s, a) + C_p \\sqrt{\\frac{2 \\log {N}}{n_a}}\n",
+ "$$\n",
+ "\n",
+ "where: \n",
+ "- $N$ - number of times we have visited the state $s$,\n",
+ "- $n_a$ - number of times we have taken the action $a$,\n",
+ "- $C_p$ - exploration balance parameter, which is performed between exploration and exploitation. \n",
+ "\n",
+ "Using Hoeffding inequality for rewards $R \\in [0,1]$ it can be shown [[3]](#3), that optimal $C_p = 1/\\sqrt{2}$. For rewards outside this range, the parameter should be tuned. We'll be using 10, but you can experiment with other values.\n",
+ "\n",
+ "__2) Expansion__\n",
+ "After the selection procedure, we can achieve a leaf node or node, in which we don't complete actions. In this case, we expand the tree by feasible actions and get new state nodes. \n",
+ "\n",
+ "__3) Simulation__\n",
+ "How we can estimate node Q-values? The idea is to estimate action values for a given _rollout policy_ by averaging the return of many simulated trajectories from the current node. Simply, we can play with random or some special policy or use a model, that can estimate it.\n",
+ "\n",
+ "__4) Backpropagation__\n",
+ "The reward of the last simulation is backed up through the traversed nodes and propagates Q-value estimations, upwards to the root.\n",
+ "\n",
+ "$$\n",
+ "Q({\\text{parent}}, a) = r + \\gamma \\cdot Q({\\text{child}}, a)\n",
+ "$$\n",
+ "\n",
+ "There are a lot of modifications of MCTS, more details about it you can find in this paper [[4]](#4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/submit.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect, if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "---\n",
+ "\n",
+ "But before we do that, we first need to make a wrapper for Gym environments to allow us to save and load the game states to facilitate backtracking."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import gym\n",
+ "from gym.core import Wrapper\n",
+ "from pickle import dumps, loads\n",
+ "from collections import namedtuple\n",
+ "\n",
+ "# a container for get_result function below. Works just like tuple, but prettier\n",
+ "ActionResult = namedtuple(\n",
+ " \"action_result\", (\"snapshot\", \"observation\", \"reward\", \"is_done\", \"info\"))\n",
+ "\n",
+ "\n",
+ "class WithSnapshots(Wrapper):\n",
+ " \"\"\"\n",
+ " Creates a wrapper, that supports saving and loading environemnt states.\n",
+ " Required for planning algorithms.\n",
+ "\n",
+ " This class will have access to the core environment as self.env, e.g.:\n",
+ " - self.env.reset() #reset original env\n",
+ " - self.env.ale.cloneState() #make snapshot for atari. load with .restoreState()\n",
+ " - ...\n",
+ "\n",
+ " You can also use reset() and step() directly for convenience.\n",
+ " - s = self.reset() # same as self.env.reset()\n",
+ " - s, r, done, _ = self.step(action) # same as self.env.step(action)\n",
+ " \n",
+ " Note, that while you may use self.render(), it will spawn a window, that cannot be pickled.\n",
+ " Thus, you will need to call self.close() before the pickling will work again.\n",
+ " \"\"\"\n",
+ "\n",
+ " def get_snapshot(self, render=False):\n",
+ " \"\"\"\n",
+ " :returns: environment state, that can be loaded with load_snapshot \n",
+ " Snapshots guarantee same env behaviour each time they are loaded.\n",
+ "\n",
+ " Warning! Snapshots can be arbitrary things (strings, integers, json, tuples)\n",
+ " Don't count on them being pickle strings, when implementing MCTS.\n",
+ "\n",
+ " Developer Note: Make sure the object you return will not be affected by \n",
+ " anything, that happens to the environment after it's saved.\n",
+ " You shouldn't, for example, return self.env. \n",
+ " In case of doubt, use pickle.dumps or deepcopy.\n",
+ "\n",
+ " \"\"\"\n",
+ " if render:\n",
+ " self.render() # close popup windows since we can't pickle them\n",
+ " self.close()\n",
+ " \n",
+ " if self.unwrapped.viewer is not None:\n",
+ " self.unwrapped.viewer.close()\n",
+ " self.unwrapped.viewer = None\n",
+ " return dumps(self.env)\n",
+ "\n",
+ " def load_snapshot(self, snapshot, render=False):\n",
+ " \"\"\"\n",
+ " Loads snapshot as current env state.\n",
+ " Should not change snapshot inplace (in case of doubt, deepcopy).\n",
+ " \"\"\"\n",
+ "\n",
+ " assert not hasattr(self, \"_monitor\") or hasattr(\n",
+ " self.env, \"_monitor\"), \"can't backtrack while recording\"\n",
+ "\n",
+ " if render:\n",
+ " self.render() # close popup windows since we can't load into them\n",
+ " self.close()\n",
+ " self.env = loads(snapshot)\n",
+ "\n",
+ " def get_result(self, snapshot, action):\n",
+ " \"\"\"\n",
+ " A convenience function that: \n",
+ " - loads snapshot, \n",
+ " - commits action via self.step,\n",
+ " - and takes snapshot again :)\n",
+ "\n",
+ " :returns: next snapshot, next_observation, reward, is_done, info\n",
+ "\n",
+ " Basically it returns the next snapshot and everything, that env.step has returned.\n",
+ " \"\"\"\n",
+ "\n",
+ " \n",
+ "\n",
+ " return ActionResult(\n",
+ " , # fill in the variables\n",
+ " ,\n",
+ " ,\n",
+ " ,\n",
+ " ,\n",
+ " )"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Try out snapshots:\n",
+ "Let`s check our wrapper. At first, reset environment and save it, then randomly play some actions and restore our environment from the snapshot. It should be the same as our previous initial state."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# make env\n",
+ "env = WithSnapshots(gym.make(\"CartPole-v0\"))\n",
+ "env.reset()\n",
+ "\n",
+ "n_actions = env.action_space.n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"initial_state:\")\n",
+ "plt.imshow(env.render('rgb_array'))\n",
+ "env.close()\n",
+ "\n",
+ "# create first snapshot\n",
+ "snap0 = env.get_snapshot()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# play without making snapshots (faster)\n",
+ "while True:\n",
+ " is_done = env.step(env.action_space.sample())[2]\n",
+ " if is_done:\n",
+ " print(\"Whoops! We died!\")\n",
+ " break\n",
+ "\n",
+ "print(\"final state:\")\n",
+ "plt.imshow(env.render('rgb_array'))\n",
+ "env.close()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# reload initial state\n",
+ "env.load_snapshot(snap0)\n",
+ "\n",
+ "print(\"\\n\\nAfter loading snapshot\")\n",
+ "plt.imshow(env.render('rgb_array'))\n",
+ "env.close()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# get outcome (snapshot, observation, reward, is_done, info)\n",
+ "res = env.get_result(snap0, env.action_space.sample())\n",
+ "\n",
+ "snap1, observation, reward = res[:3]\n",
+ "\n",
+ "# second step\n",
+ "res2 = env.get_result(snap1, env.action_space.sample())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# MCTS: Monte-Carlo tree search\n",
+ "\n",
+ "\n",
+ "We will start by implementing the `Node` class - a simple class, that acts like MCTS node and supports some of the MCTS algorithm steps.\n",
+ "\n",
+ "This MCTS implementation makes some assumptions about the environment, you can find those _in the notes section at the end of the notebook_."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "assert isinstance(env, WithSnapshots)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Node:\n",
+ " \"\"\"A tree node for MCTS.\n",
+ " \n",
+ " Each Node corresponds to the result of performing a particular action (self.action)\n",
+ " in a particular state (self.parent), and is essentially one arm in the multi-armed bandit, that\n",
+ " we model in that state.\"\"\"\n",
+ "\n",
+ " # metadata:\n",
+ " parent = None # parent Node\n",
+ " qvalue_sum = 0. # sum of Q-values from all visits (numerator)\n",
+ " times_visited = 0 # counter of visits (denominator)\n",
+ "\n",
+ " def __init__(self, parent, action):\n",
+ " \"\"\"\n",
+ " Creates and empty node with no children.\n",
+ " Does so by commiting an action and recording outcome.\n",
+ "\n",
+ " :param parent: parent Node\n",
+ " :param action: action to commit from parent Node\n",
+ " \"\"\"\n",
+ "\n",
+ " self.parent = parent\n",
+ " self.action = action\n",
+ " self.children = set() # set of child nodes\n",
+ "\n",
+ " # get action outcome and save it\n",
+ " res = env.get_result(parent.snapshot, action)\n",
+ " self.snapshot, self.observation, self.immediate_reward, self.is_done, _ = res\n",
+ "\n",
+ " def is_leaf(self):\n",
+ " return len(self.children) == 0\n",
+ "\n",
+ " def is_root(self):\n",
+ " return self.parent is None\n",
+ "\n",
+ " def get_qvalue_estimate(self):\n",
+ " return self.qvalue_sum / self.times_visited if self.times_visited != 0 else 0\n",
+ "\n",
+ " def ucb_score(self, scale=10, max_value=1e100):\n",
+ " \"\"\"\n",
+ " Computes ucb1 upper bound using the current value and visit counts for node and its parent.\n",
+ "\n",
+ " :param scale: Multiplies upper bound by that. From Hoeffding inequality,\n",
+ " assumes reward range to be [0, scale].\n",
+ " :param max_value: a value that represents infinity (for unvisited nodes).\n",
+ "\n",
+ " \"\"\"\n",
+ "\n",
+ " if self.times_visited == 0:\n",
+ " return max_value\n",
+ "\n",
+ " # compute ucb-1 additive component (to be added to mean value)\n",
+ " # hint: you can use self.parent.times_visited for N times node was considered,\n",
+ " # and self.times_visited for n times it was visited\n",
+ "\n",
+ " U = \n",
+ "\n",
+ " return self.get_qvalue_estimate() + scale * U\n",
+ "\n",
+ " # MCTS steps\n",
+ "\n",
+ " def select_best_leaf(self):\n",
+ " \"\"\"\n",
+ " Picks the leaf with the highest priority to expand.\n",
+ " Does so by recursively picking nodes with the best UCB-1 score until it reaches the leaf.\n",
+ " \"\"\"\n",
+ " if self.is_leaf():\n",
+ " return self\n",
+ "\n",
+ " children = self.children\n",
+ "\n",
+ " # Select the child node with the highest UCB score. You might want to implement some heuristics\n",
+ " # to break ties in a smart way, although CartPole should work just fine without them.\n",
+ " best_child = \n",
+ "\n",
+ " return best_child.select_best_leaf()\n",
+ "\n",
+ " def expand(self):\n",
+ " \"\"\"\n",
+ " Expands the current node by creating all possible child nodes.\n",
+ " Then returns one of those children.\n",
+ " \"\"\"\n",
+ "\n",
+ " assert not self.is_done, \"can't expand from terminal state\"\n",
+ "\n",
+ " for action in range(n_actions):\n",
+ " self.children.add(Node(self, action))\n",
+ "\n",
+ " # If you have implemented any heuristics in select_best_leaf(), they will be used here.\n",
+ " # Otherwise, this is equivalent to picking some undefined newly created child node.\n",
+ " return self.select_best_leaf()\n",
+ "\n",
+ " def rollout(self, t_max=10**4):\n",
+ " \"\"\"\n",
+ " Play the game from this state to the end (done) or for t_max steps.\n",
+ "\n",
+ " On each step, pick the action at random (hint: env.action_space.sample()).\n",
+ "\n",
+ " Compute the sum of rewards from the current state until the end of the episode.\n",
+ " Note 1: use env.action_space.sample() for picking a random action.\n",
+ " Note 2: if the node is terminal (self.is_done is True), just return self.immediate_reward.\n",
+ "\n",
+ " \"\"\"\n",
+ "\n",
+ " # set env into the appropriate state\n",
+ " env.load_snapshot(self.snapshot)\n",
+ " obs = self.observation\n",
+ " is_done = self.is_done\n",
+ "\n",
+ " \n",
+ "\n",
+ " return rollout_reward\n",
+ "\n",
+ " def propagate(self, child_qvalue):\n",
+ " \"\"\"\n",
+ " Uses child Q-value (sum of rewards) to update parents recursively.\n",
+ " \"\"\"\n",
+ " # compute node Q-value\n",
+ " my_qvalue = self.immediate_reward + child_qvalue\n",
+ "\n",
+ " # update qvalue_sum and times_visited\n",
+ " self.qvalue_sum += my_qvalue\n",
+ " self.times_visited += 1\n",
+ "\n",
+ " # propagate upwards\n",
+ " if not self.is_root():\n",
+ " self.parent.propagate(my_qvalue)\n",
+ "\n",
+ " def safe_delete(self):\n",
+ " \"\"\"safe delete to prevent memory leak in some python versions\"\"\"\n",
+ " del self.parent\n",
+ " for child in self.children:\n",
+ " child.safe_delete()\n",
+ " del child"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Root(Node):\n",
+ " def __init__(self, snapshot, observation):\n",
+ " \"\"\"\n",
+ " creates special node, that acts like tree root\n",
+ " :snapshot: snapshot (from env.get_snapshot) to start planning from\n",
+ " :observation: last environment observation\n",
+ " \"\"\"\n",
+ "\n",
+ " self.parent = self.action = None\n",
+ " self.children = set() # set of child nodes\n",
+ "\n",
+ " # root: load snapshot and observation\n",
+ " self.snapshot = snapshot\n",
+ " self.observation = observation\n",
+ " self.immediate_reward = 0\n",
+ " self.is_done = False\n",
+ "\n",
+ " @staticmethod\n",
+ " def from_node(node):\n",
+ " \"\"\"initializes node as root\"\"\"\n",
+ " root = Root(node.snapshot, node.observation)\n",
+ " # copy data\n",
+ " copied_fields = [\"qvalue_sum\", \"times_visited\", \"children\", \"is_done\"]\n",
+ " for field in copied_fields:\n",
+ " setattr(root, field, getattr(node, field))\n",
+ " return root"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Main MCTS loop\n",
+ "\n",
+ "With all we implemented, MCTS boils down to a trivial piece of code."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def plan_mcts(root, n_iters=10):\n",
+ " \"\"\"\n",
+ " builds tree with monte-carlo tree search for n_iters iterations\n",
+ " :param root: tree node to plan from\n",
+ " :param n_iters: how many select-expand-simulate-propagete loops to make\n",
+ " \"\"\"\n",
+ " for _ in range(n_iters):\n",
+ " node = \n",
+ "\n",
+ " if node.is_done:\n",
+ " # All rollouts from a terminal node are empty, and, thus, have 0 reward.\n",
+ " node.propagate(0)\n",
+ " else:\n",
+ " # Expand the best leaf. Perform a rollout from it. Propagate the results upwards.\n",
+ " # Note, that here you have some leeway in choosing, where to propagate from.\n",
+ " # Any reasonable choice should work.\n",
+ " \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Plan and execute\n",
+ "\n",
+ "Let's use our MCTS implementation to find the optimal policy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "env = WithSnapshots(gym.make(\"CartPole-v0\"))\n",
+ "root_observation = env.reset()\n",
+ "root_snapshot = env.get_snapshot()\n",
+ "root = Root(root_snapshot, root_observation)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# plan from root:\n",
+ "plan_mcts(root, n_iters=1000)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# import copy\n",
+ "# saved_root = copy.deepcopy(root)\n",
+ "# root = saved_root"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "from itertools import count\n",
+ "from gym.wrappers import Monitor\n",
+ "\n",
+ "total_reward = 0 # sum of rewards\n",
+ "test_env = loads(root_snapshot) # env used to show progress\n",
+ "\n",
+ "for i in count():\n",
+ "\n",
+ " # get best child\n",
+ " best_child = \n",
+ "\n",
+ " # take action\n",
+ " s, r, done, _ = test_env.step(best_child.action)\n",
+ "\n",
+ " # show image\n",
+ " clear_output(True)\n",
+ " plt.title(\"step %i\" % i)\n",
+ " plt.imshow(test_env.render('rgb_array'))\n",
+ " plt.show()\n",
+ "\n",
+ " total_reward += r\n",
+ " if done:\n",
+ " print(\"Finished with reward = \", total_reward)\n",
+ " break\n",
+ "\n",
+ " # discard unrealized part of the tree [because not every child matters :(]\n",
+ " for child in root.children:\n",
+ " if child != best_child:\n",
+ " child.safe_delete()\n",
+ "\n",
+ " # declare best child in a new root\n",
+ " root = Root.from_node(best_child)\n",
+ "\n",
+ " assert not root.is_leaf(), \\\n",
+ " \"We ran out of tree! Need more planning! Try growing the tree right inside the loop.\"\n",
+ "\n",
+ " # You may want to run more planning here\n",
+ " # "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_mcts\n",
+ "\n",
+ "submit_mcts(total_reward, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Bonus assignments (10+pts each)\n",
+ "\n",
+ "There are a few things you might want to try if you want to dig deeper:\n",
+ "\n",
+ "### Node selection and expansion\n",
+ "\n",
+ "\"Analyze this\" assignment\n",
+ "\n",
+ "UCB-1 is a weak bound as it relies on a very general bounds (Hoeffding Inequality, to be exact). \n",
+ "* Try playing with the exploration parameter $C_p$. The theoretically optimal $C_p$ you can get from a max reward of the environment (max reward for CartPole is 200).\n",
+ "* Try using a different exploration strategy (bayesian UCB, for example)\n",
+ "* Expand not all, but several random actions per `expand` call. See __the notes below__ for details.\n",
+ "\n",
+ "The goal is to define, what gives the optimal performance for `CartPole-v0` for different time budgets (i.e. different n_iter in plan_mcts.)\n",
+ "\n",
+ "Evaluate your results on `Acrobot-v1` - do the results change and if so, how can you explain it?\n",
+ "\n",
+ "\n",
+ "### Atari-RAM\n",
+ "\n",
+ "\"Build this\" assignment\n",
+ "\n",
+ "Apply MCTS to play Atari games. In particular, let's start with ```gym.make(\"MsPacman-ramDeterministic-v0\")```.\n",
+ "\n",
+ "This requires two things:\n",
+ "* Slightly modify WithSnapshots wrapper to work with atari.\n",
+ "\n",
+ " * Atari has a special interface for snapshots:\n",
+ " ``` \n",
+ " snapshot = self.env.ale.cloneState()\n",
+ " ...\n",
+ " self.env.ale.restoreState(snapshot)\n",
+ " ```\n",
+ " * Try it on the env above to make sure it does what you told it to.\n",
+ " \n",
+ "* Run MCTS on the game above. \n",
+ " * Start with small tree size to speed-up computations\n",
+ " * You will probably want to rollout for 10-100 steps (t_max) for starters\n",
+ " * Consider using discounted rewards (see __notes at the end__)\n",
+ " * Try a better rollout policy\n",
+ " \n",
+ " \n",
+ "### Integrate learning into planning\n",
+ "\n",
+ "Planning on each iteration is a costly thing to do. You can speed things up drastically if you train a classifier to predict, which action will turn out to be best according to MCTS.\n",
+ "\n",
+ "To do so, just record, which action did the MCTS agent take on each step and fit something to [state, mcts_optimal_action]\n",
+ "* You can also use optimal actions from discarded states to get more (dirty) samples. Just don't forget to fine-tune without them.\n",
+ "* It's also worth a try to use P(best_action|state) from your model to select best nodes in addition to UCB\n",
+ "* If your model is lightweight enough, try using it as a rollout policy.\n",
+ "\n",
+ "While CartPole is glorious enough, try expanding this to ```gym.make(\"MsPacmanDeterministic-v0\")```\n",
+ "* See previous section on how to wrap atari\n",
+ "\n",
+ "* Also consider what [AlphaGo Zero](https://deepmind.com/blog/alphago-zero-learning-scratch/) did in this area.\n",
+ "\n",
+ "### Integrate planning into learning \n",
+ "_(this will likely take long time, better consider this as side project, when all other deadlines are met)_\n",
+ "\n",
+ "Incorporate planning into the agent's architecture. The goal is to implement [Value Iteration Networks](https://arxiv.org/abs/1602.02867).\n",
+ "\n",
+ "Do you remember [week5 assignment](https://github.com/yandexdataschool/Practical_RL/blob/coursera/week5_policy_based/practice_a3c.ipynb)? You will need to switch it into a maze-like game, like MsPacman, and implement a special layer, that performs value iteration-like update to a recurrent memory. This can be implemented the same way you did in the POMDP assignment."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Notes\n",
+ "\n",
+ "\n",
+ "#### Assumptions\n",
+ "\n",
+ " Here is the full list of assumptions:\n",
+ "\n",
+ "* __Finite number of actions__: we enumerate all actions in `expand`.\n",
+ "* __Episodic (finite) MDP__: while technically it works for infinite MDPs, we perform a rollout for $10^4$ steps. If you are knowingly infinite, please adjust `t_max` to something more reasonable.\n",
+ "* __Deterministic MDP__: `Node` represents the single outcome of taking `self.action` in `self.parent`, and does not support the situation, where taking an action in a state may lead to different rewards and next states.\n",
+ "* __No discounted rewards__: we assume $\\gamma=1$. If that isn't the case, you only need to change two lines in `rollout()` and use `my_qvalue = self.immediate_reward + gamma * child_qvalue` for `propagate()`.\n",
+ "* __pickleable env__: won't work if e.g. your env is connected to a web-browser surfing the internet. For custom envs, you may need to modify get_snapshot/load_snapshot from `WithSnapshots`.\n",
+ "\n",
+ "#### On `get_best_leaf` and `expand` functions\n",
+ "\n",
+ "This MCTS implementation only selects leaf nodes for expansion.\n",
+ "This doesn't break things down because `expand` adds all possible actions. Hence, all non-leaf nodes are by design fully expanded and shouldn't be selected.\n",
+ "\n",
+ "If you want to add only a few random actions on each expand, you will also have to modify `get_best_leaf` to consider returning non-leafs.\n",
+ "\n",
+ "#### Rollout policy\n",
+ "\n",
+ "We use a simple uniform policy for rollouts. This introduces a negative bias to good situations, that can be messed up completely with random bad action. As a simple example, if you tend to rollout with uniform policy, you better don't use sharp knives and walk near cliffs.\n",
+ "\n",
+ "You can improve that by integrating a reinforcement _learning_ algorithm with a computationally light agent. You can even train this agent on the optimal policy found by the tree search.\n",
+ "\n",
+ "#### Contributions\n",
+ "* Reusing some code from 5vision [solution for deephack.RL](https://github.com/5vision/uct_atari), code by Mikhail Pavlov\n",
+ "* Using some code from [this gist](https://gist.github.com/blole/dfebbec182e6b72ec16b66cc7e331110)\n",
+ "\n",
+ "#### References\n",
+ "* [1] _Coulom R. (2007) Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search. In: van den Herik H.J., Ciancarini P., Donkers H.H.L.M.. (eds) Computers and Games. CG 2006. Lecture Notes in Computer Science, vol 4630. Springer, Berlin, Heidelberg_\n",
+ "\n",
+ "* [2] _Kocsis L., Szepesvári C. (2006) Bandit Based Monte-Carlo Planning. In: Fürnkranz J., Scheffer T., Spiliopoulou M. (eds) Machine Learning: ECML 2006. ECML 2006. Lecture Notes in Computer Science, vol 4212. Springer, Berlin, Heidelberg_\n",
+ "\n",
+ "* [3] _Kocsis, Levente, Csaba Szepesvári, and Jan Willemson. \"Improved monte-carlo search.\" Univ. Tartu, Estonia, Tech. Rep 1 (2006)._\n",
+ "\n",
+ "* [4] _C. B. Browne et al., \"A Survey of Monte Carlo Tree Search Methods,\" in IEEE Transactions on Computational Intelligence and AI in Games, vol. 4, no. 1, pp. 1-43, March 2012, doi: 10.1109/TCIAIG.2012.2186810._"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
diff --git a/week6_outro/seq2seq/practice_pytorch.ipynb b/week6_outro/seq2seq/practice_pytorch.ipynb
index fadcd441e..c1d0acd25 100644
--- a/week6_outro/seq2seq/practice_pytorch.ipynb
+++ b/week6_outro/seq2seq/practice_pytorch.ipynb
@@ -1 +1,882 @@
-{"nbformat":4,"nbformat_minor":0,"metadata":{"language_info":{"name":"python","pygments_lexer":"ipython3"},"colab":{"name":"practice_pytorch.ipynb","provenance":[],"collapsed_sections":[]}},"cells":[{"cell_type":"markdown","metadata":{"id":"RpGAC-5rz9i8"},"source":["# Reinforcement Learning for seq2seq\n","\n","This time we'll solve a problem of transribing hebrew words in english, also known as g2p (grapheme2phoneme)\n","\n"," * word (sequence of letters in source language) -> translation (sequence of letters in target language)\n","\n","Unlike what most deep learning practicioners do, we won't only train it to maximize likelihood of the correct translation, but also employ reinforcement learning to actually teach it to translate with as few errors as possible.\n","\n","\n","### About the task\n","\n","One notable property of Hebrew is that it's consonant language. That is, there are no vowels in the written language. One could represent vowels with diacritics above consonants, but you don't expect people to do that in everyday life.\n","\n","Therefore, some hebrew characters will correspond to several english letters and others --- to none, so we should use encoder-decoder architecture to figure that out.\n","\n","\n","_(img: esciencegroup.files.wordpress.com)_\n","\n","Encoder-decoder architectures are about converting anything to anything, including\n"," * Machine translation and spoken dialogue systems\n"," * [Image captioning](http://mscoco.org/dataset/#captions-challenge2015) and [image2latex](https://htmlpreview.github.io/?https://github.com/openai/requests-for-research/blob/master/_requests_for_research/im2latex.html) (convolutional encoder, recurrent decoder)\n"," * Generating [images by captions](https://arxiv.org/abs/1511.02793) (recurrent encoder, convolutional decoder)\n"," * Grapheme2phoneme - convert words to transcripts\n"," \n","We chose simplified __Hebrew->English__ machine translation for words and short phrases (character-level), as it is relatively quick to train even without a gpu cluster."]},{"cell_type":"code","metadata":{"id":"Arm0FLQjz9jD"},"source":["import sys, os\n","if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n","\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/submit.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/basic_model_torch.py\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/he-pron-wiktionary.txt\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/main_dataset.txt\n"," !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/voc.py\n","\n"," !touch .setup_complete"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"fo56EDccz9jE"},"source":["# If True, only translates phrases shorter than 20 characters (way easier).\n","EASY_MODE = True\n","# Useful for initial coding.\n","# If false, works with all phrases (please switch to this mode for homework assignment)\n","\n","# way we translate. Either \"he-to-en\" or \"en-to-he\"\n","MODE = \"he-to-en\"\n","# maximal length of _generated_ output, does not affect training\n","MAX_OUTPUT_LENGTH = 50 if not EASY_MODE else 20\n","REPORT_FREQ = 100 # how often to evaluate the validation score"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"5p1ob6o8z9jF"},"source":["## Preprocessing\n","\n","We shall store our dataset as a dictionary\n","`{ word1:[translation1,translation2,...], word2:[...],...}`.\n","\n","This is mostly due to the fact that many words have several correct translations.\n","\n","We have implemented this thing for you so that you can focus on more interesting parts."]},{"cell_type":"code","metadata":{"id":"MSm8fcQPz9jF"},"source":["import numpy as np\n","from collections import defaultdict\n","word_to_translation = defaultdict(list) # our dictionary\n","\n","bos = '_'\n","eos = ';'\n","\n","with open(\"main_dataset.txt\", encoding=\"utf-8\") as fin:\n"," for line in fin:\n","\n"," en, he = line[:-1].lower().replace(bos, ' ').replace(eos,\n"," ' ').split('\\t')\n"," word, trans = (he, en) if MODE == 'he-to-en' else (en, he)\n","\n"," if len(word) < 3:\n"," continue\n"," if EASY_MODE:\n"," if max(len(word), len(trans)) > 20:\n"," continue\n","\n"," word_to_translation[word].append(trans)\n","\n","print(\"size =\", len(word_to_translation))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"OKKOjDhUz9jF"},"source":["# get all unique lines in source language\n","all_words = np.array(list(word_to_translation.keys()))\n","# get all unique lines in translation language\n","all_translations = np.array([ts for all_ts in word_to_translation.values() for ts in all_ts])"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"nl9cEzNOz9jG"},"source":["### Split the dataset\n","\n","We hold out 10% of all words to be used for validation."]},{"cell_type":"code","metadata":{"id":"KPkMwnfdz9jG"},"source":["from sklearn.model_selection import train_test_split\n","train_words, test_words = train_test_split(\n"," all_words, test_size=0.1, random_state=42)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"18Kaogxiz9jG"},"source":["## Building vocabularies\n","\n","We now need to build vocabularies, that map strings to token ids and vice versa. We're gonna need these fellas, when we feed training data into model or convert output matrices into english words."]},{"cell_type":"code","metadata":{"id":"scBO_QIUz9jH"},"source":["from voc import Vocab\n","inp_voc = Vocab.from_lines(''.join(all_words), bos=bos, eos=eos, sep='')\n","out_voc = Vocab.from_lines(''.join(all_translations), bos=bos, eos=eos, sep='')"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"63BLwwraz9jH"},"source":["# Here's how you cast lines into ids and backwards.\n","batch_lines = all_words[:5]\n","batch_ids = inp_voc.to_matrix(batch_lines)\n","batch_lines_restored = inp_voc.to_lines(batch_ids)\n","\n","print(\"lines\")\n","print(batch_lines)\n","print(\"\\nwords to ids (0 = bos, 1 = eos):\")\n","print(batch_ids)\n","print(\"\\nback to words\")\n","print(batch_lines_restored)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Z9OzLOqnz9jH"},"source":["Draw word/translation length distributions to estimate the scope of the task."]},{"cell_type":"code","metadata":{"id":"LTRdWmWsz9jH"},"source":["import matplotlib.pyplot as plt\n","%matplotlib inline\n","plt.figure(figsize=[8, 4])\n","plt.subplot(1, 2, 1)\n","plt.title(\"words\")\n","plt.hist(list(map(len, all_words)), bins=20)\n","\n","plt.subplot(1, 2, 2)\n","plt.title('translations')\n","plt.hist(list(map(len, all_translations)), bins=20)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"cofbq62bz9jI"},"source":["## Deploy encoder-decoder\n","\n","__The assignment starts here:__\n","\n","Our architecture consists of two main blocks:\n","* Encoder reads words character by character and outputs code vector (usually a function of last RNN state)\n","* Decoder takes that code vector and produces translations character by character\n","\n","Than it gets fed into a model, that follows this simple interface:\n","* __`model(inp, out, **flags) -> logp`__ - takes symbolic int32 matrices of hebrew words and their english translations. Computes the log-probabilities of all possible english characters given english prefices and hebrew word.\n","* __`model.translate(inp, **flags) -> out, logp`__ - takes symbolic int32 matrix of hebrew words, produces output tokens sampled from the model and output log-probabilities for all possible tokens at each tick.\n"," * if given flag __`greedy=True`__, takes most likely next token at each iteration. Otherwise samples with next token probabilities predicted by model.\n","\n","That's all! It's as hard as it gets. With those two methods alone you can implement all kinds of prediction and training."]},{"cell_type":"code","metadata":{"id":"Vgu67u_Dz9jI"},"source":["import torch\n","import torch.nn as nn\n","import torch.nn.functional as F"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"UXV-0BpKz9jJ"},"source":["from basic_model_torch import BasicTranslationModel\n","model = BasicTranslationModel(inp_voc, out_voc,\n"," emb_size=64, hid_size=256)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"FqMQAoJUz9jJ"},"source":["# Play around with symbolic_translate and symbolic_score\n","inp = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n","out = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n","\n","# translate inp (with untrained model)\n","sampled_out, logp = model.translate(inp, greedy=False)\n","\n","print(\"Sample translations:\\n\", sampled_out)\n","print(\"Log-probabilities at each step:\\n\", logp)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"L0MM57lKz9jJ"},"source":["# score logp(out | inp) with untrained input\n","logp = model(inp, out)\n","print(\"Symbolic_score output:\\n\", logp)\n","\n","print(\"Log-probabilities of output tokens:\\n\",\n"," torch.gather(logp, dim=2, index=out[:, :, None]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"AyAs7kKPz9jJ"},"source":["def translate(lines, max_len=MAX_OUTPUT_LENGTH):\n"," \"\"\"\n"," You are given a list of input lines. \n"," Make your neural network translate them.\n"," :return: a list of output lines\n"," \"\"\"\n"," # Convert lines to a matrix of indices\n"," lines_ix = inp_voc.to_matrix(lines)\n"," lines_ix = torch.tensor(lines_ix, dtype=torch.int64)\n","\n"," # Compute translations in form of indices\n"," trans_ix = \n","\n"," # Convert translations back into strings\n"," return out_voc.to_lines(trans_ix.data.numpy())"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"s3dpunt4z9jK"},"source":["print(\"Sample inputs:\", all_words[:3])\n","print(\"Dummy translations:\", translate(all_words[:3]))\n","trans = translate(all_words[:3])\n","\n","assert translate(all_words[:3]) == translate(\n"," all_words[:3]), \"make sure translation is deterministic (use greedy=True and disable any noise layers)\"\n","assert type(translate(all_words[:3])) is list and (type(translate(all_words[:1])[0]) is str or type(\n"," translate(all_words[:1])[0]) is unicode), \"translate(lines) must return a sequence of strings!\"\n","# note: if translation freezes, make sure you used max_len parameter\n","print(\"Tests passed!\")"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"xzTYDisgz9jK"},"source":["### Scoring function\n","\n","LogLikelihood is a poor estimator of the model performance.\n","* If we predict zero probability once, it shouldn't ruin the entire model.\n","* It is enough to learn just one translation if there are several correct ones.\n","* What matters, is how many mistakes model's gonna make when it translates!\n","\n","Therefore, we will use minimal Levenshtein distance. It measures, how many characters do we need to add/remove/replace from model translation to make it perfect. Alternatively, one could use character-level BLEU/RougeL or other similar metrics.\n","\n","The catch here is that Levenshtein distance is not differentiable: it isn't even continuous. We can't train our neural network to maximize it by gradient descent."]},{"cell_type":"code","metadata":{"id":"-gpCq7nDz9jK"},"source":["import editdistance # !pip install editdistance\n","\n","\n","def get_distance(word, trans):\n"," \"\"\"\n"," A function, that takes a word and predicted translation\n"," and evaluates (Levenshtein's) edit distance to the closest correct translation\n"," \"\"\"\n"," references = word_to_translation[word]\n"," assert len(references) != 0, \"wrong/unknown word\"\n"," return min(editdistance.eval(trans, ref) for ref in references)\n","\n","\n","def score(words, bsize=100):\n"," \"\"\"a function, that computes levenshtein distance for bsize random samples\"\"\"\n"," assert isinstance(words, np.ndarray)\n","\n"," batch_words = np.random.choice(words, size=bsize, replace=False)\n"," batch_trans = translate(batch_words)\n","\n"," distances = list(map(get_distance, batch_words, batch_trans))\n","\n"," return np.array(distances, dtype='float32')"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ynf0eBjBz9jL"},"source":["# should be around 5-50 and decrease rapidly after training :)\n","[score(test_words, 10).mean() for _ in range(5)]"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Asg6V0nOz9jL"},"source":["## Supervised pre-training\n","\n","Here we define a function, that trains our model through maximizing log-likelihood a.k.a. minimizing crossentropy."]},{"cell_type":"code","metadata":{"id":"tXpcCtROz9jL"},"source":["import random\n","\n","\n","def sample_batch(words, word_to_translation, batch_size):\n"," \"\"\"\n"," sample random batch of words and random correct translation for each word\n"," example usage:\n"," batch_x,batch_y = sample_batch(train_words, word_to_translations,10)\n"," \"\"\"\n"," # choose words\n"," batch_words = np.random.choice(words, size=batch_size)\n","\n"," # choose translations\n"," batch_trans_candidates = list(map(word_to_translation.get, batch_words))\n"," batch_trans = list(map(random.choice, batch_trans_candidates))\n"," return batch_words, batch_trans"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"fnIfIV--z9jL"},"source":["bx, by = sample_batch(train_words, word_to_translation, batch_size=3)\n","print(\"Source:\")\n","print(bx)\n","print(\"Target:\")\n","print(by)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"nvcwYRsiz9jM"},"source":["from basic_model_torch import infer_length, infer_mask, to_one_hot\n","\n","\n","def compute_loss_on_batch(input_sequence, reference_answers):\n"," \"\"\" Compute crossentropy loss given a batch of sources and translations \"\"\"\n"," input_sequence = torch.tensor(inp_voc.to_matrix(input_sequence), dtype=torch.int64)\n"," reference_answers = torch.tensor(out_voc.to_matrix(reference_answers), dtype=torch.int64)\n","\n"," # Compute log-probabilities of all possible tokens at each step. Use model interface.\n"," logprobs_seq = \n","\n"," # compute elementwise crossentropy as negative log-probabilities of reference_answers.\n"," crossentropy = - \\\n"," torch.sum(logprobs_seq *\n"," to_one_hot(reference_answers, len(out_voc)), dim=-1)\n"," assert crossentropy.dim(\n"," ) == 2, \"please, return elementwise crossentropy, don't compute the mean just yet\"\n","\n"," # average with mask\n"," mask = infer_mask(reference_answers, out_voc.eos_ix)\n"," loss = torch.sum(crossentropy * mask) / torch.sum(mask)\n","\n"," return loss"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"Qe3Qx2DHz9jM"},"source":["# test it\n","loss = compute_loss_on_batch(*sample_batch(train_words, word_to_translation, 3))\n","print('loss = ', loss)\n","\n","assert loss.item() > 0.0\n","loss.backward()\n","for w in model.parameters():\n"," assert w.grad is not None and torch.max(torch.abs(w.grad)).item() != 0, \\\n"," \"Loss is not differentiable w.r.t. a weight with shape %s. Check comput_loss_on_batch.\" % (\n"," w.size(),)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"J5tjYuN9z9jM"},"source":["### Actually train the model\n","\n","Minibatches and stuff..."]},{"cell_type":"code","metadata":{"id":"GbYT-pyvz9jM"},"source":["from IPython.display import clear_output\n","from tqdm.notebook import tqdm, trange\n","loss_history = []\n","editdist_history = []\n","entropy_history = []\n","opt = torch.optim.Adam(model.parameters())"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"1xrmamiXz9jN"},"source":["for i in trange(25000):\n"," loss = compute_loss_on_batch(*sample_batch(train_words, word_to_translation, 32))\n","\n"," # train with backprop\n"," loss.backward()\n"," opt.step()\n"," opt.zero_grad()\n","\n"," loss_history.append(loss.item())\n","\n"," if (i+1) % REPORT_FREQ == 0:\n"," clear_output(True)\n"," current_scores = score(test_words)\n"," editdist_history.append(current_scores.mean())\n"," print(\"llh=%.3f, mean score=%.3f\" %\n"," (np.mean(loss_history[-10:]), np.mean(editdist_history[-10:])))\n"," plt.figure(figsize=(12, 4))\n"," plt.subplot(131)\n"," plt.title('train loss / traning time')\n"," plt.plot(loss_history)\n"," plt.grid()\n"," plt.subplot(132)\n"," plt.title('val score distribution')\n"," plt.hist(current_scores, bins=20)\n"," plt.subplot(133)\n"," plt.title('val score / traning time (lower is better)')\n"," plt.plot(editdist_history)\n"," plt.grid()\n"," plt.show()"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"vGYFDsv9z9jN"},"source":["__How to interpret the plots:__\n","\n","* __Train loss__ - that's your model's crossentropy over minibatches. It should go down steadily. Most importantly, it shouldn't be NaN :)\n","* __Val score distribution__ - distribution of translation edit distance (score) within the batch. It should move to the left over time.\n","* __Val score / training time__ - it's your current mean edit distance. This plot is much whimsier, than loss, but make sure it goes below 8 by 2500 steps. \n","\n","If it doesn't, first, try to re-create both model and opt. You may have changed it's weight too much while debugging. If that doesn't help, it's time for debugging."]},{"cell_type":"code","metadata":{"id":"pzk-EsrMz9jN"},"source":["for word in train_words[:10]:\n"," print(\"%s -> %s\" % (word, translate([word])[0]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"5vwCkkGmz9jN"},"source":["test_scores = []\n","for start_i in trange(0, len(test_words), 32):\n"," batch_words = test_words[start_i:start_i+32]\n"," batch_trans = translate(batch_words)\n"," distances = list(map(get_distance, batch_words, batch_trans))\n"," test_scores.extend(distances)\n","\n","print(\"Supervised test score:\", np.mean(test_scores))"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"bUDIcp5jz9jN"},"source":["## Self-critical policy gradient\n","\n","In this section you'll implement algorithm called self-critical sequence training (here's an [article](https://arxiv.org/abs/1612.00563)).\n","\n","The algorithm is a vanilla policy gradient with a special baseline. \n","\n","$$ \\nabla J = E_{x \\sim p(s)} E_{y \\sim \\pi(y|x)} \\nabla log \\pi(y|x) \\cdot (R(x,y) - b(x)) $$\n","\n","Here reward R(x,y) is a __negative levenshtein distance__ (since we minimize it). The baseline __b(x)__ represents, how well model fares on word __x__.\n","\n","In practice, this means, that we compute the baseline as a score of greedy translation, $b(x) = R(x,y_{greedy}(x)) $.\n","\n","\n","\n","\n","Luckily, we've already obtained the required outputs: `model.greedy_translations, model.greedy_mask` and we only need to compute levenshtein using `compute_levenshtein` function."]},{"cell_type":"code","metadata":{"id":"ipMjg1lAz9jO"},"source":["def compute_reward(input_sequence, translations):\n"," \"\"\" computes sample-wise reward given token ids for inputs and translations \"\"\"\n"," distances = list(map(get_distance,\n"," inp_voc.to_lines(input_sequence.data.numpy()),\n"," out_voc.to_lines(translations.data.numpy())))\n"," # use negative levenshtein distance so that larger reward means better policy\n"," return - torch.tensor(distances, dtype=torch.int64)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"U8uVdNmAz9jO"},"source":["def scst_objective_on_batch(input_sequence, max_len=MAX_OUTPUT_LENGTH):\n"," \"\"\" Compute pseudo-loss for policy gradient given a batch of sources \"\"\"\n"," input_sequence = torch.tensor(inp_voc.to_matrix(input_sequence), dtype=torch.int64)\n","\n"," # use model to __sample__ symbolic translations given input_sequence\n"," sample_translations, sample_logp = \n"," # use model to __greedy__ symbolic translations given input_sequence\n"," greedy_translations, greedy_logp = \n","\n"," # compute rewards and advantage\n"," rewards = compute_reward(input_sequence, sample_translations)\n"," baseline = \n","\n"," # compute advantage using rewards and baseline\n"," advantage = \n","\n"," # compute log_pi(a_t|s_t), shape = [batch, seq_length]\n"," logp_sample = \n"," \n"," # ^-- hint: look at how crossentropy is implemented in supervised learning loss above\n"," # mind the sign - this one should not be multiplied by -1 :)\n","\n"," # policy gradient pseudo-loss. Gradient of J is exactly policy gradient.\n"," J = logp_sample * advantage[:, None]\n","\n"," assert J.dim() == 2, \"please return elementwise objective, don't compute the mean just yet\"\n","\n"," # average with mask\n"," mask = infer_mask(sample_translations, out_voc.eos_ix)\n"," loss = - torch.sum(J * mask) / torch.sum(mask)\n","\n"," # regularize with negative entropy. Don't forget the sign!\n"," # note: for entropy you need probabilities for all tokens (sample_logp), not just logp_sample\n"," entropy = \n"," # hint: you can get sample probabilities from sample_logp using math :)\n","\n"," assert entropy.dim(\n"," ) == 2, \"please make sure elementwise entropy is of shape [batch,time]\"\n","\n"," reg = - 0.01 * torch.sum(entropy * mask) / torch.sum(mask)\n","\n"," return loss + reg, torch.sum(entropy * mask) / torch.sum(mask)"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"ffH9JKfRz9jO"},"source":["## Policy gradient training"]},{"cell_type":"code","metadata":{"id":"36Hbnglsz9jP"},"source":["entropy_history = [np.nan] * len(loss_history)\n","opt = torch.optim.Adam(model.parameters(), lr=1e-5)"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"hOaXJSOKz9jP"},"source":["for i in trange(100000):\n"," loss, ent = scst_objective_on_batch(\n"," sample_batch(train_words, word_to_translation, 32)[0]) # [0] = only source sentence\n","\n"," # train with backprop\n"," loss.backward()\n"," opt.step()\n"," opt.zero_grad()\n","\n"," loss_history.append(loss.item())\n"," entropy_history.append(ent.item())\n","\n"," if (i+1) % REPORT_FREQ == 0:\n"," clear_output(True)\n"," current_scores = score(test_words)\n"," editdist_history.append(current_scores.mean())\n"," plt.figure(figsize=(12, 4))\n"," plt.subplot(131)\n"," plt.title('val score distribution')\n"," plt.hist(current_scores, bins=20)\n"," plt.subplot(132)\n"," plt.title('val score / traning time')\n"," plt.plot(editdist_history)\n"," plt.grid()\n"," plt.subplot(133)\n"," plt.title('policy entropy / traning time')\n"," plt.plot(entropy_history)\n"," plt.grid()\n"," plt.show()\n"," print(\"J=%.3f, mean score=%.3f\" %\n"," (np.mean(loss_history[-10:]), np.mean(editdist_history[-10:])))"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"5UBl-v0Cz9jP"},"source":["__Debugging tips:__\n","\n","\n"," * As usual, don't expect the improvements right away, but in general the model should be able to show some positive changes by 5k steps.\n"," * Entropy is a good indicator of many problems: \n"," * If it reaches zero, you may need greater entropy regularizer.\n"," * If it has rapid changes time to time, you may need gradient clipping.\n"," * If it oscillates up and down in an erratic manner... it's perfectly okay for entropy to do so. But it should decrease at the end.\n"," \n"," * We don't show loss_history because it's uninformative for pseudo-losses in policy gradient. However, if something goes wrong you can check it to see if everything isn't a constant zero."]},{"cell_type":"markdown","metadata":{"id":"61F0RqbXz9jP"},"source":["## Results"]},{"cell_type":"code","metadata":{"id":"g2Ow2yl5z9jP"},"source":["for word in train_words[:10]:\n"," print(\"%s -> %s\" % (word, translate([word])[0]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ar_F4lBez9jQ"},"source":["test_scores = []\n","for start_i in trange(0, len(test_words), 32):\n"," batch_words = test_words[start_i:start_i+32]\n"," batch_trans = translate(batch_words)\n"," distances = list(map(get_distance, batch_words, batch_trans))\n"," test_scores.extend(distances)\n","print(\"Policy gradient test score:\", np.mean(test_scores))\n","\n","# ^^ If you get Out Of MemoryError, please replace this with batched computation"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"O6WCWlQ1z9jQ"},"source":["## Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"jFbQb0i9z9jQ"},"source":["from submit import submit_seq2seq\n","\n","submit_seq2seq(test_scores, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Azl_OUhXz9jQ"},"source":["## Optional: Make it actually work\n","\n","In this section we want you to finally __restart with EASY_MODE=False__ and experiment to find a good model/curriculum for that task.\n","\n","We recommend you to start with the following architecture\n","\n","```\n","encoder---decoder\n","\n"," P(y|h)\n"," ^\n"," LSTM -> LSTM\n"," ^ ^\n"," biLSTM -> LSTM\n"," ^ ^\n","input y_prev\n","```\n","\n","__Note:__ you can fit all 4 state tensors of both LSTMs into a in a single state - just assume that it contains, for example, [h0, c0, h1, c1] - pack it in encode and update in decode.\n","\n","\n","Here are some cool ideas on what you can do then.\n","\n","__General tips & tricks:__\n","* You will likely need to adjust pre-training time for such a network.\n","* Supervised pre-training may benefit from clipping gradients somehow.\n","* SCST may indulge a higher learning rate in some cases and changing entropy regularizer over time.\n","* It's often useful to save pre-trained model parameters to not re-train it every time you want new policy gradient parameters. \n","* When leaving training for nighttime, try setting REPORT_FREQ to a larger value (e.g. 500) not to waste time on it.\n","\n","### Attention\n","There's more than one way to connect decoder to encoder:\n"," * __Vanilla:__ layer_i of encoder last state goes to layer_i of decoder initial state.\n"," * __Every tick:__ feed encoder last state _on every iteration_ of decoder.\n"," * __Attention:__ allow decoder to \"peek\" at one (or several) positions of encoded sequence on every tick.\n"," \n","The most effective (and cool) of those is, of course, attention.\n","You can read more about attention [in this nice blog post](https://distill.pub/2016/augmented-rnns/). The easiest way to begin is to use \"soft\" attention with \"additive\" or \"dot-product\" intermediate layers.\n","\n","__Tips__\n","* Model usually generalizes better if you no longer allow decoder to see the final encoder state.\n","* Once your model made it through several epochs, it is a good idea to visualize attention maps to understand what your model has actually learned.\n","\n","* There's more stuff [here](https://github.com/yandexdataschool/Practical_RL/blob/master/week8_scst/bonus.ipynb)\n","* If you opted for hard attention, we recommend [gumbel-softmax](https://blog.evjang.com/2016/11/tutorial-categorical-variational.html) instead of sampling. Also please make sure soft attention works fine before you switch to hard one.\n","\n","### UREX\n","* This is a way to improve exploration in policy-based settings. The main idea is that you find and upweight under-appreciated actions.\n","* Here's [video](https://www.youtube.com/watch?v=fZNyHoXgV7M&feature=youtu.be&t=3444)\n"," and an [article](https://arxiv.org/abs/1611.09321).\n","* You may want to reduce batch size 'cuz UREX requires you to sample multiple times per source sentence.\n","* Once you got it working, try using experience replay with importance sampling instead of (in addition to) basic UREX.\n","\n","### Some additional ideas:\n","* (advanced deep learning) It may be a good idea to first train on small phrases and then adapt to larger ones (a.k.a. training curriculum).\n","* (advanced nlp) You may want to switch from raw utf8 to something like unicode or even syllables to make task easier.\n","* (advanced nlp) Since hebrew words are written __with vowels omitted__, you may want to use a small Hebrew vowel markup dataset at `he-pron-wiktionary.txt`.\n","\n"]},{"cell_type":"code","metadata":{"id":"Ew9EQRwVz9jQ"},"source":["assert not EASY_MODE, \"make sure you set EASY_MODE = False at the top of the notebook.\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"XRQvGtpyz9jQ"},"source":["__Contributions:__ This notebook is brought to you by\n","* Yandex [MT team](https://tech.yandex.com/translate/)\n","* Denis Mazur ([DeniskaMazur](https://github.com/DeniskaMazur)), Oleg Vasilev ([Omrigan](https://github.com/Omrigan/)), Dmitry Emelyanenko ([TixFeniks](https://github.com/tixfeniks)) and Fedor Ratnikov ([justheuristic](https://github.com/justheuristic/))\n","* Dataset is parsed from [Wiktionary](https://en.wiktionary.org), which is under CC-BY-SA and GFDL licenses.\n"]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Reinforcement Learning for seq2seq\n",
+ "\n",
+ "This time we'll solve a problem of transribing hebrew words in english, also known as g2p (grapheme2phoneme)\n",
+ "\n",
+ " * word (sequence of letters in source language) -> translation (sequence of letters in target language)\n",
+ "\n",
+ "Unlike what most deep learning practicioners do, we won't only train it to maximize likelihood of the correct translation, but also employ reinforcement learning to actually teach it to translate with as few errors as possible.\n",
+ "\n",
+ "\n",
+ "### About the task\n",
+ "\n",
+ "One notable property of Hebrew is that it's consonant language. That is, there are no vowels in the written language. One could represent vowels with diacritics above consonants, but you don't expect people to do that in everyday life.\n",
+ "\n",
+ "Therefore, some hebrew characters will correspond to several english letters and others --- to none, so we should use encoder-decoder architecture to figure that out.\n",
+ "\n",
+ "\n",
+ "_(img: esciencegroup.files.wordpress.com)_\n",
+ "\n",
+ "Encoder-decoder architectures are about converting anything to anything, including\n",
+ " * Machine translation and spoken dialogue systems\n",
+ " * [Image captioning](http://mscoco.org/dataset/#captions-challenge2015) and [image2latex](https://htmlpreview.github.io/?https://github.com/openai/requests-for-research/blob/master/_requests_for_research/im2latex.html) (convolutional encoder, recurrent decoder)\n",
+ " * Generating [images by captions](https://arxiv.org/abs/1511.02793) (recurrent encoder, convolutional decoder)\n",
+ " * Grapheme2phoneme - convert words to transcripts\n",
+ " \n",
+ "We chose simplified __Hebrew->English__ machine translation for words and short phrases (character-level), as it is relatively quick to train even without a gpu cluster."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/basic_model_torch.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/he-pron-wiktionary.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/main_dataset.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/voc.py\n",
+ "\n",
+ " !touch .setup_complete"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# If True, only translates phrases shorter than 20 characters (way easier).\n",
+ "EASY_MODE = True\n",
+ "# Useful for initial coding.\n",
+ "# If false, works with all phrases (please switch to this mode for homework assignment)\n",
+ "\n",
+ "# way we translate. Either \"he-to-en\" or \"en-to-he\"\n",
+ "MODE = \"he-to-en\"\n",
+ "# maximal length of _generated_ output, does not affect training\n",
+ "MAX_OUTPUT_LENGTH = 50 if not EASY_MODE else 20\n",
+ "REPORT_FREQ = 100 # how often to evaluate the validation score"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Preprocessing\n",
+ "\n",
+ "We shall store our dataset as a dictionary\n",
+ "`{ word1:[translation1,translation2,...], word2:[...],...}`.\n",
+ "\n",
+ "This is mostly due to the fact that many words have several correct translations.\n",
+ "\n",
+ "We have implemented this thing for you so that you can focus on more interesting parts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from collections import defaultdict\n",
+ "word_to_translation = defaultdict(list) # our dictionary\n",
+ "\n",
+ "bos = '_'\n",
+ "eos = ';'\n",
+ "\n",
+ "with open(\"main_dataset.txt\", encoding=\"utf-8\") as fin:\n",
+ " for line in fin:\n",
+ "\n",
+ " en, he = line[:-1].lower().replace(bos, ' ').replace(eos,\n",
+ " ' ').split('\\t')\n",
+ " word, trans = (he, en) if MODE == 'he-to-en' else (en, he)\n",
+ "\n",
+ " if len(word) < 3:\n",
+ " continue\n",
+ " if EASY_MODE:\n",
+ " if max(len(word), len(trans)) > 20:\n",
+ " continue\n",
+ "\n",
+ " word_to_translation[word].append(trans)\n",
+ "\n",
+ "print(\"size =\", len(word_to_translation))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# get all unique lines in source language\n",
+ "all_words = np.array(list(word_to_translation.keys()))\n",
+ "# get all unique lines in translation language\n",
+ "all_translations = np.array([ts for all_ts in word_to_translation.values() for ts in all_ts])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Split the dataset\n",
+ "\n",
+ "We hold out 10% of all words to be used for validation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.model_selection import train_test_split\n",
+ "train_words, test_words = train_test_split(\n",
+ " all_words, test_size=0.1, random_state=42)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Building vocabularies\n",
+ "\n",
+ "We now need to build vocabularies, that map strings to token ids and vice versa. We're gonna need these fellas, when we feed training data into model or convert output matrices into english words."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from voc import Vocab\n",
+ "inp_voc = Vocab.from_lines(''.join(all_words), bos=bos, eos=eos, sep='')\n",
+ "out_voc = Vocab.from_lines(''.join(all_translations), bos=bos, eos=eos, sep='')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here's how you cast lines into ids and backwards.\n",
+ "batch_lines = all_words[:5]\n",
+ "batch_ids = inp_voc.to_matrix(batch_lines)\n",
+ "batch_lines_restored = inp_voc.to_lines(batch_ids)\n",
+ "\n",
+ "print(\"lines\")\n",
+ "print(batch_lines)\n",
+ "print(\"\\nwords to ids (0 = bos, 1 = eos):\")\n",
+ "print(batch_ids)\n",
+ "print(\"\\nback to words\")\n",
+ "print(batch_lines_restored)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Draw word/translation length distributions to estimate the scope of the task."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "plt.figure(figsize=[8, 4])\n",
+ "plt.subplot(1, 2, 1)\n",
+ "plt.title(\"words\")\n",
+ "plt.hist(list(map(len, all_words)), bins=20)\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "plt.title('translations')\n",
+ "plt.hist(list(map(len, all_translations)), bins=20)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Deploy encoder-decoder\n",
+ "\n",
+ "__The assignment starts here:__\n",
+ "\n",
+ "Our architecture consists of two main blocks:\n",
+ "* Encoder reads words character by character and outputs code vector (usually a function of last RNN state)\n",
+ "* Decoder takes that code vector and produces translations character by character\n",
+ "\n",
+ "Than it gets fed into a model, that follows this simple interface:\n",
+ "* __`model(inp, out, **flags) -> logp`__ - takes symbolic int32 matrices of hebrew words and their english translations. Computes the log-probabilities of all possible english characters given english prefices and hebrew word.\n",
+ "* __`model.translate(inp, **flags) -> out, logp`__ - takes symbolic int32 matrix of hebrew words, produces output tokens sampled from the model and output log-probabilities for all possible tokens at each tick.\n",
+ " * if given flag __`greedy=True`__, takes most likely next token at each iteration. Otherwise samples with next token probabilities predicted by model.\n",
+ "\n",
+ "That's all! It's as hard as it gets. With those two methods alone you can implement all kinds of prediction and training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from basic_model_torch import BasicTranslationModel\n",
+ "model = BasicTranslationModel(inp_voc, out_voc,\n",
+ " emb_size=64, hid_size=256)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Play around with symbolic_translate and symbolic_score\n",
+ "inp = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "out = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "\n",
+ "# translate inp (with untrained model)\n",
+ "sampled_out, logp = model.translate(inp, greedy=False)\n",
+ "\n",
+ "print(\"Sample translations:\\n\", sampled_out)\n",
+ "print(\"Log-probabilities at each step:\\n\", logp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# score logp(out | inp) with untrained input\n",
+ "logp = model(inp, out)\n",
+ "print(\"Symbolic_score output:\\n\", logp)\n",
+ "\n",
+ "print(\"Log-probabilities of output tokens:\\n\",\n",
+ " torch.gather(logp, dim=2, index=out[:, :, None]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def translate(lines, max_len=MAX_OUTPUT_LENGTH):\n",
+ " \"\"\"\n",
+ " You are given a list of input lines. \n",
+ " Make your neural network translate them.\n",
+ " :return: a list of output lines\n",
+ " \"\"\"\n",
+ " # Convert lines to a matrix of indices\n",
+ " lines_ix = inp_voc.to_matrix(lines)\n",
+ " lines_ix = torch.tensor(lines_ix, dtype=torch.int64)\n",
+ "\n",
+ " # Compute translations in form of indices\n",
+ " trans_ix = \n",
+ "\n",
+ " # Convert translations back into strings\n",
+ " return out_voc.to_lines(trans_ix.data.numpy())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Sample inputs:\", all_words[:3])\n",
+ "print(\"Dummy translations:\", translate(all_words[:3]))\n",
+ "trans = translate(all_words[:3])\n",
+ "\n",
+ "assert translate(all_words[:3]) == translate(\n",
+ " all_words[:3]), \"make sure translation is deterministic (use greedy=True and disable any noise layers)\"\n",
+ "assert type(translate(all_words[:3])) is list and (type(translate(all_words[:1])[0]) is str or type(\n",
+ " translate(all_words[:1])[0]) is unicode), \"translate(lines) must return a sequence of strings!\"\n",
+ "# note: if translation freezes, make sure you used max_len parameter\n",
+ "print(\"Tests passed!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Scoring function\n",
+ "\n",
+ "LogLikelihood is a poor estimator of the model performance.\n",
+ "* If we predict zero probability once, it shouldn't ruin the entire model.\n",
+ "* It is enough to learn just one translation if there are several correct ones.\n",
+ "* What matters, is how many mistakes model's gonna make when it translates!\n",
+ "\n",
+ "Therefore, we will use minimal Levenshtein distance. It measures, how many characters do we need to add/remove/replace from model translation to make it perfect. Alternatively, one could use character-level BLEU/RougeL or other similar metrics.\n",
+ "\n",
+ "The catch here is that Levenshtein distance is not differentiable: it isn't even continuous. We can't train our neural network to maximize it by gradient descent."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import editdistance # !pip install editdistance\n",
+ "\n",
+ "\n",
+ "def get_distance(word, trans):\n",
+ " \"\"\"\n",
+ " A function, that takes a word and predicted translation\n",
+ " and evaluates (Levenshtein's) edit distance to the closest correct translation\n",
+ " \"\"\"\n",
+ " references = word_to_translation[word]\n",
+ " assert len(references) != 0, \"wrong/unknown word\"\n",
+ " return min(editdistance.eval(trans, ref) for ref in references)\n",
+ "\n",
+ "\n",
+ "def score(words, bsize=100):\n",
+ " \"\"\"a function, that computes levenshtein distance for bsize random samples\"\"\"\n",
+ " assert isinstance(words, np.ndarray)\n",
+ "\n",
+ " batch_words = np.random.choice(words, size=bsize, replace=False)\n",
+ " batch_trans = translate(batch_words)\n",
+ "\n",
+ " distances = list(map(get_distance, batch_words, batch_trans))\n",
+ "\n",
+ " return np.array(distances, dtype='float32')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# should be around 5-50 and decrease rapidly after training :)\n",
+ "[score(test_words, 10).mean() for _ in range(5)]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Supervised pre-training\n",
+ "\n",
+ "Here we define a function, that trains our model through maximizing log-likelihood a.k.a. minimizing crossentropy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import random\n",
+ "\n",
+ "\n",
+ "def sample_batch(words, word_to_translation, batch_size):\n",
+ " \"\"\"\n",
+ " sample random batch of words and random correct translation for each word\n",
+ " example usage:\n",
+ " batch_x,batch_y = sample_batch(train_words, word_to_translations,10)\n",
+ " \"\"\"\n",
+ " # choose words\n",
+ " batch_words = np.random.choice(words, size=batch_size)\n",
+ "\n",
+ " # choose translations\n",
+ " batch_trans_candidates = list(map(word_to_translation.get, batch_words))\n",
+ " batch_trans = list(map(random.choice, batch_trans_candidates))\n",
+ " return batch_words, batch_trans"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "bx, by = sample_batch(train_words, word_to_translation, batch_size=3)\n",
+ "print(\"Source:\")\n",
+ "print(bx)\n",
+ "print(\"Target:\")\n",
+ "print(by)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from basic_model_torch import infer_length, infer_mask, to_one_hot\n",
+ "\n",
+ "\n",
+ "def compute_loss_on_batch(input_sequence, reference_answers):\n",
+ " \"\"\" Compute crossentropy loss given a batch of sources and translations \"\"\"\n",
+ " input_sequence = torch.tensor(inp_voc.to_matrix(input_sequence), dtype=torch.int64)\n",
+ " reference_answers = torch.tensor(out_voc.to_matrix(reference_answers), dtype=torch.int64)\n",
+ "\n",
+ " # Compute log-probabilities of all possible tokens at each step. Use model interface.\n",
+ " logprobs_seq = \n",
+ "\n",
+ " # compute elementwise crossentropy as negative log-probabilities of reference_answers.\n",
+ " crossentropy = - \\\n",
+ " torch.sum(logprobs_seq *\n",
+ " to_one_hot(reference_answers, len(out_voc)), dim=-1)\n",
+ " assert crossentropy.dim(\n",
+ " ) == 2, \"please, return elementwise crossentropy, don't compute the mean just yet\"\n",
+ "\n",
+ " # average with mask\n",
+ " mask = infer_mask(reference_answers, out_voc.eos_ix)\n",
+ " loss = torch.sum(crossentropy * mask) / torch.sum(mask)\n",
+ "\n",
+ " return loss"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# test it\n",
+ "loss = compute_loss_on_batch(*sample_batch(train_words, word_to_translation, 3))\n",
+ "print('loss = ', loss)\n",
+ "\n",
+ "assert loss.item() > 0.0\n",
+ "loss.backward()\n",
+ "for w in model.parameters():\n",
+ " assert w.grad is not None and torch.max(torch.abs(w.grad)).item() != 0, \\\n",
+ " \"Loss is not differentiable w.r.t. a weight with shape %s. Check comput_loss_on_batch.\" % (\n",
+ " w.size(),)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Actually train the model\n",
+ "\n",
+ "Minibatches and stuff..."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import clear_output\n",
+ "from tqdm.notebook import tqdm, trange\n",
+ "loss_history = []\n",
+ "editdist_history = []\n",
+ "entropy_history = []\n",
+ "opt = torch.optim.Adam(model.parameters())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in trange(25000):\n",
+ " loss = compute_loss_on_batch(*sample_batch(train_words, word_to_translation, 32))\n",
+ "\n",
+ " # train with backprop\n",
+ " loss.backward()\n",
+ " opt.step()\n",
+ " opt.zero_grad()\n",
+ "\n",
+ " loss_history.append(loss.item())\n",
+ "\n",
+ " if (i+1) % REPORT_FREQ == 0:\n",
+ " clear_output(True)\n",
+ " current_scores = score(test_words)\n",
+ " editdist_history.append(current_scores.mean())\n",
+ " print(\"llh=%.3f, mean score=%.3f\" %\n",
+ " (np.mean(loss_history[-10:]), np.mean(editdist_history[-10:])))\n",
+ " plt.figure(figsize=(12, 4))\n",
+ " plt.subplot(131)\n",
+ " plt.title('train loss / traning time')\n",
+ " plt.plot(loss_history)\n",
+ " plt.grid()\n",
+ " plt.subplot(132)\n",
+ " plt.title('val score distribution')\n",
+ " plt.hist(current_scores, bins=20)\n",
+ " plt.subplot(133)\n",
+ " plt.title('val score / traning time (lower is better)')\n",
+ " plt.plot(editdist_history)\n",
+ " plt.grid()\n",
+ " plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__How to interpret the plots:__\n",
+ "\n",
+ "* __Train loss__ - that's your model's crossentropy over minibatches. It should go down steadily. Most importantly, it shouldn't be NaN :)\n",
+ "* __Val score distribution__ - distribution of translation edit distance (score) within the batch. It should move to the left over time.\n",
+ "* __Val score / training time__ - it's your current mean edit distance. This plot is much whimsier, than loss, but make sure it goes below 8 by 2500 steps. \n",
+ "\n",
+ "If it doesn't, first, try to re-create both model and opt. You may have changed it's weight too much while debugging. If that doesn't help, it's time for debugging."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for word in train_words[:10]:\n",
+ " print(\"%s -> %s\" % (word, translate([word])[0]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_scores = []\n",
+ "for start_i in trange(0, len(test_words), 32):\n",
+ " batch_words = test_words[start_i:start_i+32]\n",
+ " batch_trans = translate(batch_words)\n",
+ " distances = list(map(get_distance, batch_words, batch_trans))\n",
+ " test_scores.extend(distances)\n",
+ "\n",
+ "print(\"Supervised test score:\", np.mean(test_scores))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Self-critical policy gradient\n",
+ "\n",
+ "In this section you'll implement algorithm called self-critical sequence training (here's an [article](https://arxiv.org/abs/1612.00563)).\n",
+ "\n",
+ "The algorithm is a vanilla policy gradient with a special baseline. \n",
+ "\n",
+ "$$ \\nabla J = E_{x \\sim p(s)} E_{y \\sim \\pi(y|x)} \\nabla log \\pi(y|x) \\cdot (R(x,y) - b(x)) $$\n",
+ "\n",
+ "Here reward R(x,y) is a __negative levenshtein distance__ (since we minimize it). The baseline __b(x)__ represents, how well model fares on word __x__.\n",
+ "\n",
+ "In practice, this means, that we compute the baseline as a score of greedy translation, $b(x) = R(x,y_{greedy}(x)) $.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "Luckily, we've already obtained the required outputs: `model.greedy_translations, model.greedy_mask` and we only need to compute levenshtein using `compute_levenshtein` function."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def compute_reward(input_sequence, translations):\n",
+ " \"\"\" computes sample-wise reward given token ids for inputs and translations \"\"\"\n",
+ " distances = list(map(get_distance,\n",
+ " inp_voc.to_lines(input_sequence.data.numpy()),\n",
+ " out_voc.to_lines(translations.data.numpy())))\n",
+ " # use negative levenshtein distance so that larger reward means better policy\n",
+ " return - torch.tensor(distances, dtype=torch.int64)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def scst_objective_on_batch(input_sequence, max_len=MAX_OUTPUT_LENGTH):\n",
+ " \"\"\" Compute pseudo-loss for policy gradient given a batch of sources \"\"\"\n",
+ " input_sequence = torch.tensor(inp_voc.to_matrix(input_sequence), dtype=torch.int64)\n",
+ "\n",
+ " # use model to __sample__ symbolic translations given input_sequence\n",
+ " sample_translations, sample_logp = \n",
+ " # use model to __greedy__ symbolic translations given input_sequence\n",
+ " greedy_translations, greedy_logp = \n",
+ "\n",
+ " # compute rewards and advantage\n",
+ " rewards = compute_reward(input_sequence, sample_translations)\n",
+ " baseline = \n",
+ "\n",
+ " # compute advantage using rewards and baseline\n",
+ " advantage = \n",
+ "\n",
+ " # compute log_pi(a_t|s_t), shape = [batch, seq_length]\n",
+ " logp_sample = \n",
+ " \n",
+ " # ^-- hint: look at how crossentropy is implemented in supervised learning loss above\n",
+ " # mind the sign - this one should not be multiplied by -1 :)\n",
+ "\n",
+ " # policy gradient pseudo-loss. Gradient of J is exactly policy gradient.\n",
+ " J = logp_sample * advantage[:, None]\n",
+ "\n",
+ " assert J.dim() == 2, \"please return elementwise objective, don't compute the mean just yet\"\n",
+ "\n",
+ " # average with mask\n",
+ " mask = infer_mask(sample_translations, out_voc.eos_ix)\n",
+ " loss = - torch.sum(J * mask) / torch.sum(mask)\n",
+ "\n",
+ " # regularize with negative entropy. Don't forget the sign!\n",
+ " # note: for entropy you need probabilities for all tokens (sample_logp), not just logp_sample\n",
+ " entropy = \n",
+ " # hint: you can get sample probabilities from sample_logp using math :)\n",
+ "\n",
+ " assert entropy.dim(\n",
+ " ) == 2, \"please make sure elementwise entropy is of shape [batch,time]\"\n",
+ "\n",
+ " reg = - 0.01 * torch.sum(entropy * mask) / torch.sum(mask)\n",
+ "\n",
+ " return loss + reg, torch.sum(entropy * mask) / torch.sum(mask)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Policy gradient training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "entropy_history = [np.nan] * len(loss_history)\n",
+ "opt = torch.optim.Adam(model.parameters(), lr=1e-5)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in trange(100000):\n",
+ " loss, ent = scst_objective_on_batch(\n",
+ " sample_batch(train_words, word_to_translation, 32)[0]) # [0] = only source sentence\n",
+ "\n",
+ " # train with backprop\n",
+ " loss.backward()\n",
+ " opt.step()\n",
+ " opt.zero_grad()\n",
+ "\n",
+ " loss_history.append(loss.item())\n",
+ " entropy_history.append(ent.item())\n",
+ "\n",
+ " if (i+1) % REPORT_FREQ == 0:\n",
+ " clear_output(True)\n",
+ " current_scores = score(test_words)\n",
+ " editdist_history.append(current_scores.mean())\n",
+ " plt.figure(figsize=(12, 4))\n",
+ " plt.subplot(131)\n",
+ " plt.title('val score distribution')\n",
+ " plt.hist(current_scores, bins=20)\n",
+ " plt.subplot(132)\n",
+ " plt.title('val score / traning time')\n",
+ " plt.plot(editdist_history)\n",
+ " plt.grid()\n",
+ " plt.subplot(133)\n",
+ " plt.title('policy entropy / traning time')\n",
+ " plt.plot(entropy_history)\n",
+ " plt.grid()\n",
+ " plt.show()\n",
+ " print(\"J=%.3f, mean score=%.3f\" %\n",
+ " (np.mean(loss_history[-10:]), np.mean(editdist_history[-10:])))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Debugging tips:__\n",
+ "\n",
+ "\n",
+ " * As usual, don't expect the improvements right away, but in general the model should be able to show some positive changes by 5k steps.\n",
+ " * Entropy is a good indicator of many problems: \n",
+ " * If it reaches zero, you may need greater entropy regularizer.\n",
+ " * If it has rapid changes time to time, you may need gradient clipping.\n",
+ " * If it oscillates up and down in an erratic manner... it's perfectly okay for entropy to do so. But it should decrease at the end.\n",
+ " \n",
+ " * We don't show loss_history because it's uninformative for pseudo-losses in policy gradient. However, if something goes wrong you can check it to see if everything isn't a constant zero."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Results"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for word in train_words[:10]:\n",
+ " print(\"%s -> %s\" % (word, translate([word])[0]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "test_scores = []\n",
+ "for start_i in trange(0, len(test_words), 32):\n",
+ " batch_words = test_words[start_i:start_i+32]\n",
+ " batch_trans = translate(batch_words)\n",
+ " distances = list(map(get_distance, batch_words, batch_trans))\n",
+ " test_scores.extend(distances)\n",
+ "print(\"Policy gradient test score:\", np.mean(test_scores))\n",
+ "\n",
+ "# ^^ If you get Out Of MemoryError, please replace this with batched computation"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Submit to Coursera"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from submit import submit_seq2seq\n",
+ "\n",
+ "submit_seq2seq(test_scores, 'your.email@example.com', 'YourAssignmentToken')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Optional: Make it actually work\n",
+ "\n",
+ "In this section we want you to finally __restart with EASY_MODE=False__ and experiment to find a good model/curriculum for that task.\n",
+ "\n",
+ "We recommend you to start with the following architecture\n",
+ "\n",
+ "```\n",
+ "encoder---decoder\n",
+ "\n",
+ " P(y|h)\n",
+ " ^\n",
+ " LSTM -> LSTM\n",
+ " ^ ^\n",
+ " biLSTM -> LSTM\n",
+ " ^ ^\n",
+ "input y_prev\n",
+ "```\n",
+ "\n",
+ "__Note:__ you can fit all 4 state tensors of both LSTMs into a in a single state - just assume that it contains, for example, [h0, c0, h1, c1] - pack it in encode and update in decode.\n",
+ "\n",
+ "\n",
+ "Here are some cool ideas on what you can do then.\n",
+ "\n",
+ "__General tips & tricks:__\n",
+ "* You will likely need to adjust pre-training time for such a network.\n",
+ "* Supervised pre-training may benefit from clipping gradients somehow.\n",
+ "* SCST may indulge a higher learning rate in some cases and changing entropy regularizer over time.\n",
+ "* It's often useful to save pre-trained model parameters to not re-train it every time you want new policy gradient parameters. \n",
+ "* When leaving training for nighttime, try setting REPORT_FREQ to a larger value (e.g. 500) not to waste time on it.\n",
+ "\n",
+ "### Attention\n",
+ "There's more than one way to connect decoder to encoder:\n",
+ " * __Vanilla:__ layer_i of encoder last state goes to layer_i of decoder initial state.\n",
+ " * __Every tick:__ feed encoder last state _on every iteration_ of decoder.\n",
+ " * __Attention:__ allow decoder to \"peek\" at one (or several) positions of encoded sequence on every tick.\n",
+ " \n",
+ "The most effective (and cool) of those is, of course, attention.\n",
+ "You can read more about attention [in this nice blog post](https://distill.pub/2016/augmented-rnns/). The easiest way to begin is to use \"soft\" attention with \"additive\" or \"dot-product\" intermediate layers.\n",
+ "\n",
+ "__Tips__\n",
+ "* Model usually generalizes better if you no longer allow decoder to see the final encoder state.\n",
+ "* Once your model made it through several epochs, it is a good idea to visualize attention maps to understand what your model has actually learned.\n",
+ "\n",
+ "* There's more stuff [here](https://github.com/yandexdataschool/Practical_RL/blob/master/week8_scst/bonus.ipynb)\n",
+ "* If you opted for hard attention, we recommend [gumbel-softmax](https://blog.evjang.com/2016/11/tutorial-categorical-variational.html) instead of sampling. Also please make sure soft attention works fine before you switch to hard one.\n",
+ "\n",
+ "### UREX\n",
+ "* This is a way to improve exploration in policy-based settings. The main idea is that you find and upweight under-appreciated actions.\n",
+ "* Here's [video](https://www.youtube.com/watch?v=fZNyHoXgV7M&feature=youtu.be&t=3444)\n",
+ " and an [article](https://arxiv.org/abs/1611.09321).\n",
+ "* You may want to reduce batch size 'cuz UREX requires you to sample multiple times per source sentence.\n",
+ "* Once you got it working, try using experience replay with importance sampling instead of (in addition to) basic UREX.\n",
+ "\n",
+ "### Some additional ideas:\n",
+ "* (advanced deep learning) It may be a good idea to first train on small phrases and then adapt to larger ones (a.k.a. training curriculum).\n",
+ "* (advanced nlp) You may want to switch from raw utf8 to something like unicode or even syllables to make task easier.\n",
+ "* (advanced nlp) Since hebrew words are written __with vowels omitted__, you may want to use a small Hebrew vowel markup dataset at `he-pron-wiktionary.txt`.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "assert not EASY_MODE, \"make sure you set EASY_MODE = False at the top of the notebook.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "__Contributions:__ This notebook is brought to you by\n",
+ "* Yandex [MT team](https://tech.yandex.com/translate/)\n",
+ "* Denis Mazur ([DeniskaMazur](https://github.com/DeniskaMazur)), Oleg Vasilev ([Omrigan](https://github.com/Omrigan/)), Dmitry Emelyanenko ([TixFeniks](https://github.com/tixfeniks)) and Fedor Ratnikov ([justheuristic](https://github.com/justheuristic/))\n",
+ "* Dataset is parsed from [Wiktionary](https://en.wiktionary.org), which is under CC-BY-SA and GFDL licenses.\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
 "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/mdp.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transition_probs = {\n",
+ " 's0': {\n",
+ " 'a0': {'s0': 0.5, 's2': 0.5},\n",
+ " 'a1': {'s2': 1}\n",
+ " },\n",
+ " 's1': {\n",
+ " 'a0': {'s0': 0.7, 's1': 0.1, 's2': 0.2},\n",
+ " 'a1': {'s1': 0.95, 's2': 0.05}\n",
+ " },\n",
+ " 's2': {\n",
+ " 'a0': {'s0': 0.4, 's2': 0.6},\n",
+ " 'a1': {'s0': 0.3, 's1': 0.3, 's2': 0.4}\n",
+ " }\n",
+ "}\n",
+ "rewards = {\n",
+ " 's1': {'a0': {'s0': +5}},\n",
+ " 's2': {'a1': {'s0': -1}}\n",
+ "}\n",
+ "\n",
+ "from mdp import MDP\n",
+ "mdp = MDP(transition_probs, rewards, initial_state='s0')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now use the MDP just as any other gym environment:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "initial state = s0\n",
+ "next_state = s2, reward = 0.0, done = False\n"
+ ]
+ }
+ ],
+ "source": [
+ "print('initial state =', mdp.reset())\n",
+ "next_state, reward, done, info = mdp.step('a1')\n",
+ "print('next_state = %s, reward = %s, done = %s' % (next_state, reward, done))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "but it also has other methods that you'll need for Value Iteration:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "mdp.get_all_states = ('s0', 's1', 's2')\n",
+ "mdp.get_possible_actions('s1') = ('a0', 'a1')\n",
+ "mdp.get_next_states('s1', 'a0') = {'s0': 0.7, 's1': 0.1, 's2': 0.2}\n",
+ "mdp.get_reward('s1', 'a0', 's0') = 5\n",
+ "mdp.get_transition_prob('s1', 'a0', 's0') = 0.7\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(\"mdp.get_all_states =\", mdp.get_all_states())\n",
+ "print(\"mdp.get_possible_actions('s1') = \", mdp.get_possible_actions('s1'))\n",
+ "print(\"mdp.get_next_states('s1', 'a0') = \", mdp.get_next_states('s1', 'a0'))\n",
+ "print(\"mdp.get_reward('s1', 'a0', 's0') = \", mdp.get_reward('s1', 'a0', 's0'))\n",
+ "print(\"mdp.get_transition_prob('s1', 'a0', 's0') = \", mdp.get_transition_prob('s1', 'a0', 's0'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Optional: Visualizing MDPs\n",
+ "\n",
+ "You can also visualize any MDP with the drawing fuction donated by [neer201](https://github.com/neer201).\n",
+ "\n",
+ "You have to install graphviz for system and for python. \n",
+ "\n",
+ "1. * For ubuntu just run: `sudo apt-get install graphviz` \n",
+ " * For OSX: `brew install graphviz`\n",
+ "2. `pip install graphviz`\n",
+ "3. restart the notebook\n",
+ "\n",
+ "__Note:__ Installing graphviz on some OS (esp. Windows) may be tricky. However, you can ignore this part alltogether and use the standart vizualization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Graphviz available: True\n"
+ ]
+ }
+ ],
+ "source": [
+ "from mdp import has_graphviz\n",
+ "from IPython.display import display\n",
+ "print(\"Graphviz available:\", has_graphviz)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/svg+xml": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ],
+ "text/plain": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week2_model_based/mdp.py\n",
+ "\n",
+ " !touch .setup_complete\n",
+ "\n",
+ "# This code creates a virtual display to draw game images on.\n",
+ "# It won't have any effect if your machine has a monitor.\n",
+ "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n",
+ " !bash ../xvfb start\n",
+ " os.environ['DISPLAY'] = ':1'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "transition_probs = {\n",
+ " 's0': {\n",
+ " 'a0': {'s0': 0.5, 's2': 0.5},\n",
+ " 'a1': {'s2': 1}\n",
+ " },\n",
+ " 's1': {\n",
+ " 'a0': {'s0': 0.7, 's1': 0.1, 's2': 0.2},\n",
+ " 'a1': {'s1': 0.95, 's2': 0.05}\n",
+ " },\n",
+ " 's2': {\n",
+ " 'a0': {'s0': 0.4, 's2': 0.6},\n",
+ " 'a1': {'s0': 0.3, 's1': 0.3, 's2': 0.4}\n",
+ " }\n",
+ "}\n",
+ "rewards = {\n",
+ " 's1': {'a0': {'s0': +5}},\n",
+ " 's2': {'a1': {'s0': -1}}\n",
+ "}\n",
+ "\n",
+ "from mdp import MDP\n",
+ "mdp = MDP(transition_probs, rewards, initial_state='s0')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We can now use the MDP just as any other gym environment:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "initial state = s0\n",
+ "next_state = s2, reward = 0.0, done = False\n"
+ ]
+ }
+ ],
+ "source": [
+ "print('initial state =', mdp.reset())\n",
+ "next_state, reward, done, info = mdp.step('a1')\n",
+ "print('next_state = %s, reward = %s, done = %s' % (next_state, reward, done))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "but it also has other methods that you'll need for Value Iteration:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "mdp.get_all_states = ('s0', 's1', 's2')\n",
+ "mdp.get_possible_actions('s1') = ('a0', 'a1')\n",
+ "mdp.get_next_states('s1', 'a0') = {'s0': 0.7, 's1': 0.1, 's2': 0.2}\n",
+ "mdp.get_reward('s1', 'a0', 's0') = 5\n",
+ "mdp.get_transition_prob('s1', 'a0', 's0') = 0.7\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(\"mdp.get_all_states =\", mdp.get_all_states())\n",
+ "print(\"mdp.get_possible_actions('s1') = \", mdp.get_possible_actions('s1'))\n",
+ "print(\"mdp.get_next_states('s1', 'a0') = \", mdp.get_next_states('s1', 'a0'))\n",
+ "print(\"mdp.get_reward('s1', 'a0', 's0') = \", mdp.get_reward('s1', 'a0', 's0'))\n",
+ "print(\"mdp.get_transition_prob('s1', 'a0', 's0') = \", mdp.get_transition_prob('s1', 'a0', 's0'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Optional: Visualizing MDPs\n",
+ "\n",
+ "You can also visualize any MDP with the drawing fuction donated by [neer201](https://github.com/neer201).\n",
+ "\n",
+ "You have to install graphviz for system and for python. \n",
+ "\n",
+ "1. * For ubuntu just run: `sudo apt-get install graphviz` \n",
+ " * For OSX: `brew install graphviz`\n",
+ "2. `pip install graphviz`\n",
+ "3. restart the notebook\n",
+ "\n",
+ "__Note:__ Installing graphviz on some OS (esp. Windows) may be tricky. However, you can ignore this part alltogether and use the standart vizualization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Graphviz available: True\n"
+ ]
+ }
+ ],
+ "source": [
+ "from mdp import has_graphviz\n",
+ "from IPython.display import display\n",
+ "print(\"Graphviz available:\", has_graphviz)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "image/svg+xml": [
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ],
+ "text/plain": [
+ " \n","\n","#### Training with experience replay\n","1. Play game, sample `
\n","\n","#### Training with experience replay\n","1. Play game, sample ` \n","
\n"," \n","\n"," * As usual, don't expect the improvements right away, but in general the model should be able to show some positive changes by 5k steps.\n"," * Entropy is a good indicator of many problems: \n"," * If it reaches zero, you may need greater entropy regularizer.\n"," * If it has rapid changes time to time, you may need gradient clipping.\n"," * If it oscillates up and down in an erratic manner... it's perfectly okay for entropy to do so. But it should decrease at the end.\n"," \n"," * We don't show loss_history because it's uninformative for pseudo-losses in policy gradient. However, if something goes wrong you can check it to see if everything isn't a constant zero."]},{"cell_type":"markdown","metadata":{"id":"61F0RqbXz9jP"},"source":["## Results"]},{"cell_type":"code","metadata":{"id":"g2Ow2yl5z9jP"},"source":["for word in train_words[:10]:\n"," print(\"%s -> %s\" % (word, translate([word])[0]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ar_F4lBez9jQ"},"source":["test_scores = []\n","for start_i in trange(0, len(test_words), 32):\n"," batch_words = test_words[start_i:start_i+32]\n"," batch_trans = translate(batch_words)\n"," distances = list(map(get_distance, batch_words, batch_trans))\n"," test_scores.extend(distances)\n","print(\"Policy gradient test score:\", np.mean(test_scores))\n","\n","# ^^ If you get Out Of MemoryError, please replace this with batched computation"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"O6WCWlQ1z9jQ"},"source":["## Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"jFbQb0i9z9jQ"},"source":["from submit import submit_seq2seq\n","\n","submit_seq2seq(test_scores, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Azl_OUhXz9jQ"},"source":["## Optional: Make it actually work\n","\n","In this section we want you to finally __restart with EASY_MODE=False__ and experiment to find a good model/curriculum for that task.\n","\n","We recommend you to start with the following architecture\n","\n","```\n","encoder---decoder\n","\n"," P(y|h)\n"," ^\n"," LSTM -> LSTM\n"," ^ ^\n"," biLSTM -> LSTM\n"," ^ ^\n","input y_prev\n","```\n","\n","__Note:__ you can fit all 4 state tensors of both LSTMs into a in a single state - just assume that it contains, for example, [h0, c0, h1, c1] - pack it in encode and update in decode.\n","\n","\n","Here are some cool ideas on what you can do then.\n","\n","__General tips & tricks:__\n","* You will likely need to adjust pre-training time for such a network.\n","* Supervised pre-training may benefit from clipping gradients somehow.\n","* SCST may indulge a higher learning rate in some cases and changing entropy regularizer over time.\n","* It's often useful to save pre-trained model parameters to not re-train it every time you want new policy gradient parameters. \n","* When leaving training for nighttime, try setting REPORT_FREQ to a larger value (e.g. 500) not to waste time on it.\n","\n","### Attention\n","There's more than one way to connect decoder to encoder:\n"," * __Vanilla:__ layer_i of encoder last state goes to layer_i of decoder initial state.\n"," * __Every tick:__ feed encoder last state _on every iteration_ of decoder.\n"," * __Attention:__ allow decoder to \"peek\" at one (or several) positions of encoded sequence on every tick.\n"," \n","The most effective (and cool) of those is, of course, attention.\n","You can read more about attention [in this nice blog post](https://distill.pub/2016/augmented-rnns/). The easiest way to begin is to use \"soft\" attention with \"additive\" or \"dot-product\" intermediate layers.\n","\n","__Tips__\n","* Model usually generalizes better if you no longer allow decoder to see the final encoder state.\n","* Once your model made it through several epochs, it is a good idea to visualize attention maps to understand what your model has actually learned.\n","\n","* There's more stuff [here](https://github.com/yandexdataschool/Practical_RL/blob/master/week8_scst/bonus.ipynb)\n","* If you opted for hard attention, we recommend [gumbel-softmax](https://blog.evjang.com/2016/11/tutorial-categorical-variational.html) instead of sampling. Also please make sure soft attention works fine before you switch to hard one.\n","\n","### UREX\n","* This is a way to improve exploration in policy-based settings. The main idea is that you find and upweight under-appreciated actions.\n","* Here's [video](https://www.youtube.com/watch?v=fZNyHoXgV7M&feature=youtu.be&t=3444)\n"," and an [article](https://arxiv.org/abs/1611.09321).\n","* You may want to reduce batch size 'cuz UREX requires you to sample multiple times per source sentence.\n","* Once you got it working, try using experience replay with importance sampling instead of (in addition to) basic UREX.\n","\n","### Some additional ideas:\n","* (advanced deep learning) It may be a good idea to first train on small phrases and then adapt to larger ones (a.k.a. training curriculum).\n","* (advanced nlp) You may want to switch from raw utf8 to something like unicode or even syllables to make task easier.\n","* (advanced nlp) Since hebrew words are written __with vowels omitted__, you may want to use a small Hebrew vowel markup dataset at `he-pron-wiktionary.txt`.\n","\n"]},{"cell_type":"code","metadata":{"id":"Ew9EQRwVz9jQ"},"source":["assert not EASY_MODE, \"make sure you set EASY_MODE = False at the top of the notebook.\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"XRQvGtpyz9jQ"},"source":["__Contributions:__ This notebook is brought to you by\n","* Yandex [MT team](https://tech.yandex.com/translate/)\n","* Denis Mazur ([DeniskaMazur](https://github.com/DeniskaMazur)), Oleg Vasilev ([Omrigan](https://github.com/Omrigan/)), Dmitry Emelyanenko ([TixFeniks](https://github.com/tixfeniks)) and Fedor Ratnikov ([justheuristic](https://github.com/justheuristic/))\n","* Dataset is parsed from [Wiktionary](https://en.wiktionary.org), which is under CC-BY-SA and GFDL licenses.\n"]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Reinforcement Learning for seq2seq\n",
+ "\n",
+ "This time we'll solve a problem of transribing hebrew words in english, also known as g2p (grapheme2phoneme)\n",
+ "\n",
+ " * word (sequence of letters in source language) -> translation (sequence of letters in target language)\n",
+ "\n",
+ "Unlike what most deep learning practicioners do, we won't only train it to maximize likelihood of the correct translation, but also employ reinforcement learning to actually teach it to translate with as few errors as possible.\n",
+ "\n",
+ "\n",
+ "### About the task\n",
+ "\n",
+ "One notable property of Hebrew is that it's consonant language. That is, there are no vowels in the written language. One could represent vowels with diacritics above consonants, but you don't expect people to do that in everyday life.\n",
+ "\n",
+ "Therefore, some hebrew characters will correspond to several english letters and others --- to none, so we should use encoder-decoder architecture to figure that out.\n",
+ "\n",
+ "\n",
+ "_(img: esciencegroup.files.wordpress.com)_\n",
+ "\n",
+ "Encoder-decoder architectures are about converting anything to anything, including\n",
+ " * Machine translation and spoken dialogue systems\n",
+ " * [Image captioning](http://mscoco.org/dataset/#captions-challenge2015) and [image2latex](https://htmlpreview.github.io/?https://github.com/openai/requests-for-research/blob/master/_requests_for_research/im2latex.html) (convolutional encoder, recurrent decoder)\n",
+ " * Generating [images by captions](https://arxiv.org/abs/1511.02793) (recurrent encoder, convolutional decoder)\n",
+ " * Grapheme2phoneme - convert words to transcripts\n",
+ " \n",
+ "We chose simplified __Hebrew->English__ machine translation for words and short phrases (character-level), as it is relatively quick to train even without a gpu cluster."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/basic_model_torch.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/he-pron-wiktionary.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/main_dataset.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/voc.py\n",
+ "\n",
+ " !touch .setup_complete"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# If True, only translates phrases shorter than 20 characters (way easier).\n",
+ "EASY_MODE = True\n",
+ "# Useful for initial coding.\n",
+ "# If false, works with all phrases (please switch to this mode for homework assignment)\n",
+ "\n",
+ "# way we translate. Either \"he-to-en\" or \"en-to-he\"\n",
+ "MODE = \"he-to-en\"\n",
+ "# maximal length of _generated_ output, does not affect training\n",
+ "MAX_OUTPUT_LENGTH = 50 if not EASY_MODE else 20\n",
+ "REPORT_FREQ = 100 # how often to evaluate the validation score"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Preprocessing\n",
+ "\n",
+ "We shall store our dataset as a dictionary\n",
+ "`{ word1:[translation1,translation2,...], word2:[...],...}`.\n",
+ "\n",
+ "This is mostly due to the fact that many words have several correct translations.\n",
+ "\n",
+ "We have implemented this thing for you so that you can focus on more interesting parts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from collections import defaultdict\n",
+ "word_to_translation = defaultdict(list) # our dictionary\n",
+ "\n",
+ "bos = '_'\n",
+ "eos = ';'\n",
+ "\n",
+ "with open(\"main_dataset.txt\", encoding=\"utf-8\") as fin:\n",
+ " for line in fin:\n",
+ "\n",
+ " en, he = line[:-1].lower().replace(bos, ' ').replace(eos,\n",
+ " ' ').split('\\t')\n",
+ " word, trans = (he, en) if MODE == 'he-to-en' else (en, he)\n",
+ "\n",
+ " if len(word) < 3:\n",
+ " continue\n",
+ " if EASY_MODE:\n",
+ " if max(len(word), len(trans)) > 20:\n",
+ " continue\n",
+ "\n",
+ " word_to_translation[word].append(trans)\n",
+ "\n",
+ "print(\"size =\", len(word_to_translation))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# get all unique lines in source language\n",
+ "all_words = np.array(list(word_to_translation.keys()))\n",
+ "# get all unique lines in translation language\n",
+ "all_translations = np.array([ts for all_ts in word_to_translation.values() for ts in all_ts])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Split the dataset\n",
+ "\n",
+ "We hold out 10% of all words to be used for validation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.model_selection import train_test_split\n",
+ "train_words, test_words = train_test_split(\n",
+ " all_words, test_size=0.1, random_state=42)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Building vocabularies\n",
+ "\n",
+ "We now need to build vocabularies, that map strings to token ids and vice versa. We're gonna need these fellas, when we feed training data into model or convert output matrices into english words."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from voc import Vocab\n",
+ "inp_voc = Vocab.from_lines(''.join(all_words), bos=bos, eos=eos, sep='')\n",
+ "out_voc = Vocab.from_lines(''.join(all_translations), bos=bos, eos=eos, sep='')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here's how you cast lines into ids and backwards.\n",
+ "batch_lines = all_words[:5]\n",
+ "batch_ids = inp_voc.to_matrix(batch_lines)\n",
+ "batch_lines_restored = inp_voc.to_lines(batch_ids)\n",
+ "\n",
+ "print(\"lines\")\n",
+ "print(batch_lines)\n",
+ "print(\"\\nwords to ids (0 = bos, 1 = eos):\")\n",
+ "print(batch_ids)\n",
+ "print(\"\\nback to words\")\n",
+ "print(batch_lines_restored)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Draw word/translation length distributions to estimate the scope of the task."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "plt.figure(figsize=[8, 4])\n",
+ "plt.subplot(1, 2, 1)\n",
+ "plt.title(\"words\")\n",
+ "plt.hist(list(map(len, all_words)), bins=20)\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "plt.title('translations')\n",
+ "plt.hist(list(map(len, all_translations)), bins=20)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Deploy encoder-decoder\n",
+ "\n",
+ "__The assignment starts here:__\n",
+ "\n",
+ "Our architecture consists of two main blocks:\n",
+ "* Encoder reads words character by character and outputs code vector (usually a function of last RNN state)\n",
+ "* Decoder takes that code vector and produces translations character by character\n",
+ "\n",
+ "Than it gets fed into a model, that follows this simple interface:\n",
+ "* __`model(inp, out, **flags) -> logp`__ - takes symbolic int32 matrices of hebrew words and their english translations. Computes the log-probabilities of all possible english characters given english prefices and hebrew word.\n",
+ "* __`model.translate(inp, **flags) -> out, logp`__ - takes symbolic int32 matrix of hebrew words, produces output tokens sampled from the model and output log-probabilities for all possible tokens at each tick.\n",
+ " * if given flag __`greedy=True`__, takes most likely next token at each iteration. Otherwise samples with next token probabilities predicted by model.\n",
+ "\n",
+ "That's all! It's as hard as it gets. With those two methods alone you can implement all kinds of prediction and training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from basic_model_torch import BasicTranslationModel\n",
+ "model = BasicTranslationModel(inp_voc, out_voc,\n",
+ " emb_size=64, hid_size=256)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Play around with symbolic_translate and symbolic_score\n",
+ "inp = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "out = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "\n",
+ "# translate inp (with untrained model)\n",
+ "sampled_out, logp = model.translate(inp, greedy=False)\n",
+ "\n",
+ "print(\"Sample translations:\\n\", sampled_out)\n",
+ "print(\"Log-probabilities at each step:\\n\", logp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# score logp(out | inp) with untrained input\n",
+ "logp = model(inp, out)\n",
+ "print(\"Symbolic_score output:\\n\", logp)\n",
+ "\n",
+ "print(\"Log-probabilities of output tokens:\\n\",\n",
+ " torch.gather(logp, dim=2, index=out[:, :, None]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def translate(lines, max_len=MAX_OUTPUT_LENGTH):\n",
+ " \"\"\"\n",
+ " You are given a list of input lines. \n",
+ " Make your neural network translate them.\n",
+ " :return: a list of output lines\n",
+ " \"\"\"\n",
+ " # Convert lines to a matrix of indices\n",
+ " lines_ix = inp_voc.to_matrix(lines)\n",
+ " lines_ix = torch.tensor(lines_ix, dtype=torch.int64)\n",
+ "\n",
+ " # Compute translations in form of indices\n",
+ " trans_ix =
\n","\n"," * As usual, don't expect the improvements right away, but in general the model should be able to show some positive changes by 5k steps.\n"," * Entropy is a good indicator of many problems: \n"," * If it reaches zero, you may need greater entropy regularizer.\n"," * If it has rapid changes time to time, you may need gradient clipping.\n"," * If it oscillates up and down in an erratic manner... it's perfectly okay for entropy to do so. But it should decrease at the end.\n"," \n"," * We don't show loss_history because it's uninformative for pseudo-losses in policy gradient. However, if something goes wrong you can check it to see if everything isn't a constant zero."]},{"cell_type":"markdown","metadata":{"id":"61F0RqbXz9jP"},"source":["## Results"]},{"cell_type":"code","metadata":{"id":"g2Ow2yl5z9jP"},"source":["for word in train_words[:10]:\n"," print(\"%s -> %s\" % (word, translate([word])[0]))"],"execution_count":null,"outputs":[]},{"cell_type":"code","metadata":{"id":"ar_F4lBez9jQ"},"source":["test_scores = []\n","for start_i in trange(0, len(test_words), 32):\n"," batch_words = test_words[start_i:start_i+32]\n"," batch_trans = translate(batch_words)\n"," distances = list(map(get_distance, batch_words, batch_trans))\n"," test_scores.extend(distances)\n","print(\"Policy gradient test score:\", np.mean(test_scores))\n","\n","# ^^ If you get Out Of MemoryError, please replace this with batched computation"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"O6WCWlQ1z9jQ"},"source":["## Submit to Coursera"]},{"cell_type":"code","metadata":{"id":"jFbQb0i9z9jQ"},"source":["from submit import submit_seq2seq\n","\n","submit_seq2seq(test_scores, 'your.email@example.com', 'YourAssignmentToken')"],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"Azl_OUhXz9jQ"},"source":["## Optional: Make it actually work\n","\n","In this section we want you to finally __restart with EASY_MODE=False__ and experiment to find a good model/curriculum for that task.\n","\n","We recommend you to start with the following architecture\n","\n","```\n","encoder---decoder\n","\n"," P(y|h)\n"," ^\n"," LSTM -> LSTM\n"," ^ ^\n"," biLSTM -> LSTM\n"," ^ ^\n","input y_prev\n","```\n","\n","__Note:__ you can fit all 4 state tensors of both LSTMs into a in a single state - just assume that it contains, for example, [h0, c0, h1, c1] - pack it in encode and update in decode.\n","\n","\n","Here are some cool ideas on what you can do then.\n","\n","__General tips & tricks:__\n","* You will likely need to adjust pre-training time for such a network.\n","* Supervised pre-training may benefit from clipping gradients somehow.\n","* SCST may indulge a higher learning rate in some cases and changing entropy regularizer over time.\n","* It's often useful to save pre-trained model parameters to not re-train it every time you want new policy gradient parameters. \n","* When leaving training for nighttime, try setting REPORT_FREQ to a larger value (e.g. 500) not to waste time on it.\n","\n","### Attention\n","There's more than one way to connect decoder to encoder:\n"," * __Vanilla:__ layer_i of encoder last state goes to layer_i of decoder initial state.\n"," * __Every tick:__ feed encoder last state _on every iteration_ of decoder.\n"," * __Attention:__ allow decoder to \"peek\" at one (or several) positions of encoded sequence on every tick.\n"," \n","The most effective (and cool) of those is, of course, attention.\n","You can read more about attention [in this nice blog post](https://distill.pub/2016/augmented-rnns/). The easiest way to begin is to use \"soft\" attention with \"additive\" or \"dot-product\" intermediate layers.\n","\n","__Tips__\n","* Model usually generalizes better if you no longer allow decoder to see the final encoder state.\n","* Once your model made it through several epochs, it is a good idea to visualize attention maps to understand what your model has actually learned.\n","\n","* There's more stuff [here](https://github.com/yandexdataschool/Practical_RL/blob/master/week8_scst/bonus.ipynb)\n","* If you opted for hard attention, we recommend [gumbel-softmax](https://blog.evjang.com/2016/11/tutorial-categorical-variational.html) instead of sampling. Also please make sure soft attention works fine before you switch to hard one.\n","\n","### UREX\n","* This is a way to improve exploration in policy-based settings. The main idea is that you find and upweight under-appreciated actions.\n","* Here's [video](https://www.youtube.com/watch?v=fZNyHoXgV7M&feature=youtu.be&t=3444)\n"," and an [article](https://arxiv.org/abs/1611.09321).\n","* You may want to reduce batch size 'cuz UREX requires you to sample multiple times per source sentence.\n","* Once you got it working, try using experience replay with importance sampling instead of (in addition to) basic UREX.\n","\n","### Some additional ideas:\n","* (advanced deep learning) It may be a good idea to first train on small phrases and then adapt to larger ones (a.k.a. training curriculum).\n","* (advanced nlp) You may want to switch from raw utf8 to something like unicode or even syllables to make task easier.\n","* (advanced nlp) Since hebrew words are written __with vowels omitted__, you may want to use a small Hebrew vowel markup dataset at `he-pron-wiktionary.txt`.\n","\n"]},{"cell_type":"code","metadata":{"id":"Ew9EQRwVz9jQ"},"source":["assert not EASY_MODE, \"make sure you set EASY_MODE = False at the top of the notebook.\""],"execution_count":null,"outputs":[]},{"cell_type":"markdown","metadata":{"id":"XRQvGtpyz9jQ"},"source":["__Contributions:__ This notebook is brought to you by\n","* Yandex [MT team](https://tech.yandex.com/translate/)\n","* Denis Mazur ([DeniskaMazur](https://github.com/DeniskaMazur)), Oleg Vasilev ([Omrigan](https://github.com/Omrigan/)), Dmitry Emelyanenko ([TixFeniks](https://github.com/tixfeniks)) and Fedor Ratnikov ([justheuristic](https://github.com/justheuristic/))\n","* Dataset is parsed from [Wiktionary](https://en.wiktionary.org), which is under CC-BY-SA and GFDL licenses.\n"]}]}
\ No newline at end of file
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Reinforcement Learning for seq2seq\n",
+ "\n",
+ "This time we'll solve a problem of transribing hebrew words in english, also known as g2p (grapheme2phoneme)\n",
+ "\n",
+ " * word (sequence of letters in source language) -> translation (sequence of letters in target language)\n",
+ "\n",
+ "Unlike what most deep learning practicioners do, we won't only train it to maximize likelihood of the correct translation, but also employ reinforcement learning to actually teach it to translate with as few errors as possible.\n",
+ "\n",
+ "\n",
+ "### About the task\n",
+ "\n",
+ "One notable property of Hebrew is that it's consonant language. That is, there are no vowels in the written language. One could represent vowels with diacritics above consonants, but you don't expect people to do that in everyday life.\n",
+ "\n",
+ "Therefore, some hebrew characters will correspond to several english letters and others --- to none, so we should use encoder-decoder architecture to figure that out.\n",
+ "\n",
+ "\n",
+ "_(img: esciencegroup.files.wordpress.com)_\n",
+ "\n",
+ "Encoder-decoder architectures are about converting anything to anything, including\n",
+ " * Machine translation and spoken dialogue systems\n",
+ " * [Image captioning](http://mscoco.org/dataset/#captions-challenge2015) and [image2latex](https://htmlpreview.github.io/?https://github.com/openai/requests-for-research/blob/master/_requests_for_research/im2latex.html) (convolutional encoder, recurrent decoder)\n",
+ " * Generating [images by captions](https://arxiv.org/abs/1511.02793) (recurrent encoder, convolutional decoder)\n",
+ " * Grapheme2phoneme - convert words to transcripts\n",
+ " \n",
+ "We chose simplified __Hebrew->English__ machine translation for words and short phrases (character-level), as it is relatively quick to train even without a gpu cluster."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import sys, os\n",
+ "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n",
+ "\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/grading.py -O ../grading.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/submit.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/basic_model_torch.py\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/he-pron-wiktionary.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/main_dataset.txt\n",
+ " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/coursera/week6_outro/seq2seq/voc.py\n",
+ "\n",
+ " !touch .setup_complete"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# If True, only translates phrases shorter than 20 characters (way easier).\n",
+ "EASY_MODE = True\n",
+ "# Useful for initial coding.\n",
+ "# If false, works with all phrases (please switch to this mode for homework assignment)\n",
+ "\n",
+ "# way we translate. Either \"he-to-en\" or \"en-to-he\"\n",
+ "MODE = \"he-to-en\"\n",
+ "# maximal length of _generated_ output, does not affect training\n",
+ "MAX_OUTPUT_LENGTH = 50 if not EASY_MODE else 20\n",
+ "REPORT_FREQ = 100 # how often to evaluate the validation score"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Preprocessing\n",
+ "\n",
+ "We shall store our dataset as a dictionary\n",
+ "`{ word1:[translation1,translation2,...], word2:[...],...}`.\n",
+ "\n",
+ "This is mostly due to the fact that many words have several correct translations.\n",
+ "\n",
+ "We have implemented this thing for you so that you can focus on more interesting parts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from collections import defaultdict\n",
+ "word_to_translation = defaultdict(list) # our dictionary\n",
+ "\n",
+ "bos = '_'\n",
+ "eos = ';'\n",
+ "\n",
+ "with open(\"main_dataset.txt\", encoding=\"utf-8\") as fin:\n",
+ " for line in fin:\n",
+ "\n",
+ " en, he = line[:-1].lower().replace(bos, ' ').replace(eos,\n",
+ " ' ').split('\\t')\n",
+ " word, trans = (he, en) if MODE == 'he-to-en' else (en, he)\n",
+ "\n",
+ " if len(word) < 3:\n",
+ " continue\n",
+ " if EASY_MODE:\n",
+ " if max(len(word), len(trans)) > 20:\n",
+ " continue\n",
+ "\n",
+ " word_to_translation[word].append(trans)\n",
+ "\n",
+ "print(\"size =\", len(word_to_translation))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# get all unique lines in source language\n",
+ "all_words = np.array(list(word_to_translation.keys()))\n",
+ "# get all unique lines in translation language\n",
+ "all_translations = np.array([ts for all_ts in word_to_translation.values() for ts in all_ts])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Split the dataset\n",
+ "\n",
+ "We hold out 10% of all words to be used for validation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.model_selection import train_test_split\n",
+ "train_words, test_words = train_test_split(\n",
+ " all_words, test_size=0.1, random_state=42)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Building vocabularies\n",
+ "\n",
+ "We now need to build vocabularies, that map strings to token ids and vice versa. We're gonna need these fellas, when we feed training data into model or convert output matrices into english words."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from voc import Vocab\n",
+ "inp_voc = Vocab.from_lines(''.join(all_words), bos=bos, eos=eos, sep='')\n",
+ "out_voc = Vocab.from_lines(''.join(all_translations), bos=bos, eos=eos, sep='')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Here's how you cast lines into ids and backwards.\n",
+ "batch_lines = all_words[:5]\n",
+ "batch_ids = inp_voc.to_matrix(batch_lines)\n",
+ "batch_lines_restored = inp_voc.to_lines(batch_ids)\n",
+ "\n",
+ "print(\"lines\")\n",
+ "print(batch_lines)\n",
+ "print(\"\\nwords to ids (0 = bos, 1 = eos):\")\n",
+ "print(batch_ids)\n",
+ "print(\"\\nback to words\")\n",
+ "print(batch_lines_restored)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Draw word/translation length distributions to estimate the scope of the task."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "%matplotlib inline\n",
+ "plt.figure(figsize=[8, 4])\n",
+ "plt.subplot(1, 2, 1)\n",
+ "plt.title(\"words\")\n",
+ "plt.hist(list(map(len, all_words)), bins=20)\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "plt.title('translations')\n",
+ "plt.hist(list(map(len, all_translations)), bins=20)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Deploy encoder-decoder\n",
+ "\n",
+ "__The assignment starts here:__\n",
+ "\n",
+ "Our architecture consists of two main blocks:\n",
+ "* Encoder reads words character by character and outputs code vector (usually a function of last RNN state)\n",
+ "* Decoder takes that code vector and produces translations character by character\n",
+ "\n",
+ "Than it gets fed into a model, that follows this simple interface:\n",
+ "* __`model(inp, out, **flags) -> logp`__ - takes symbolic int32 matrices of hebrew words and their english translations. Computes the log-probabilities of all possible english characters given english prefices and hebrew word.\n",
+ "* __`model.translate(inp, **flags) -> out, logp`__ - takes symbolic int32 matrix of hebrew words, produces output tokens sampled from the model and output log-probabilities for all possible tokens at each tick.\n",
+ " * if given flag __`greedy=True`__, takes most likely next token at each iteration. Otherwise samples with next token probabilities predicted by model.\n",
+ "\n",
+ "That's all! It's as hard as it gets. With those two methods alone you can implement all kinds of prediction and training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "import torch.nn.functional as F"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from basic_model_torch import BasicTranslationModel\n",
+ "model = BasicTranslationModel(inp_voc, out_voc,\n",
+ " emb_size=64, hid_size=256)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Play around with symbolic_translate and symbolic_score\n",
+ "inp = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "out = torch.tensor(np.random.randint(0, 10, [3, 5]), dtype=torch.int64)\n",
+ "\n",
+ "# translate inp (with untrained model)\n",
+ "sampled_out, logp = model.translate(inp, greedy=False)\n",
+ "\n",
+ "print(\"Sample translations:\\n\", sampled_out)\n",
+ "print(\"Log-probabilities at each step:\\n\", logp)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# score logp(out | inp) with untrained input\n",
+ "logp = model(inp, out)\n",
+ "print(\"Symbolic_score output:\\n\", logp)\n",
+ "\n",
+ "print(\"Log-probabilities of output tokens:\\n\",\n",
+ " torch.gather(logp, dim=2, index=out[:, :, None]))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def translate(lines, max_len=MAX_OUTPUT_LENGTH):\n",
+ " \"\"\"\n",
+ " You are given a list of input lines. \n",
+ " Make your neural network translate them.\n",
+ " :return: a list of output lines\n",
+ " \"\"\"\n",
+ " # Convert lines to a matrix of indices\n",
+ " lines_ix = inp_voc.to_matrix(lines)\n",
+ " lines_ix = torch.tensor(lines_ix, dtype=torch.int64)\n",
+ "\n",
+ " # Compute translations in form of indices\n",
+ " trans_ix =