Our Elasticsearch example is installed in the basic configuration. In terms of high data availability, the following mechanisms are used:
- Multiple nodes for data.
- Multiple replicas for indexes.
- Indexes roll over according to the recommended schema:
- When the index reaches 50GB, a new index is created;
- A new index is created every thirty days.
- The data is sent to the alias linked to the active index, that is, the index rollover must not affect operability of the schema in the example.
Index rollover uses the following Elasticsearch entities:
- Indexes and index aliases.
- Index template.
- Index lifecycle policy.
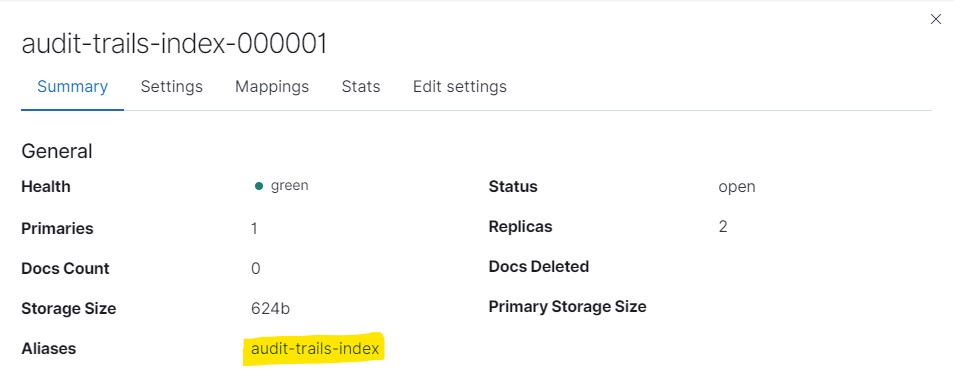
The first index in the example is created with a numeric suffix. This is to ensure that a new index with a modified suffix is created as a result of rollover.
An alias is assigned to the created index, and this alias is then assigned to the new index at rollover.
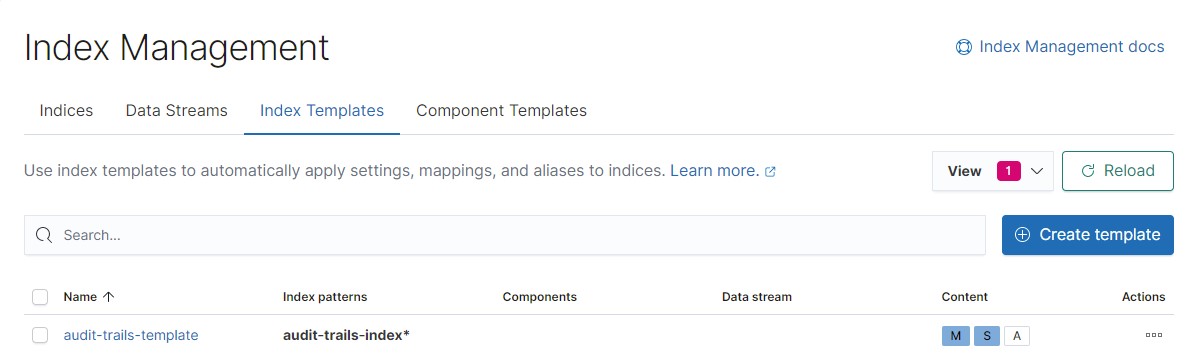
An index template contains all the necessary parameters to create a new index as a result of the rollover:
- Index pattern. Newly created indexes that meet the pattern are automatically created with the template parameters.
- Index settings. In our case, this is the name of the index rollover policy, the number of data replicas, and the
rollover_alias, that is, the alias that will be moved to the new index.
{
"index": {
"lifecycle": {
"name": "audit-trails-ilm",
"rollover_alias": "audit-trails-index"
},
"number_of_replicas": "2"
}
}
- Mapping parameters.
The index lifecycle policy tracks the lifecycle of our data. As the data becomes older, you can move it to lower-end servers or disks, and, finally, delete them, after a certain period.
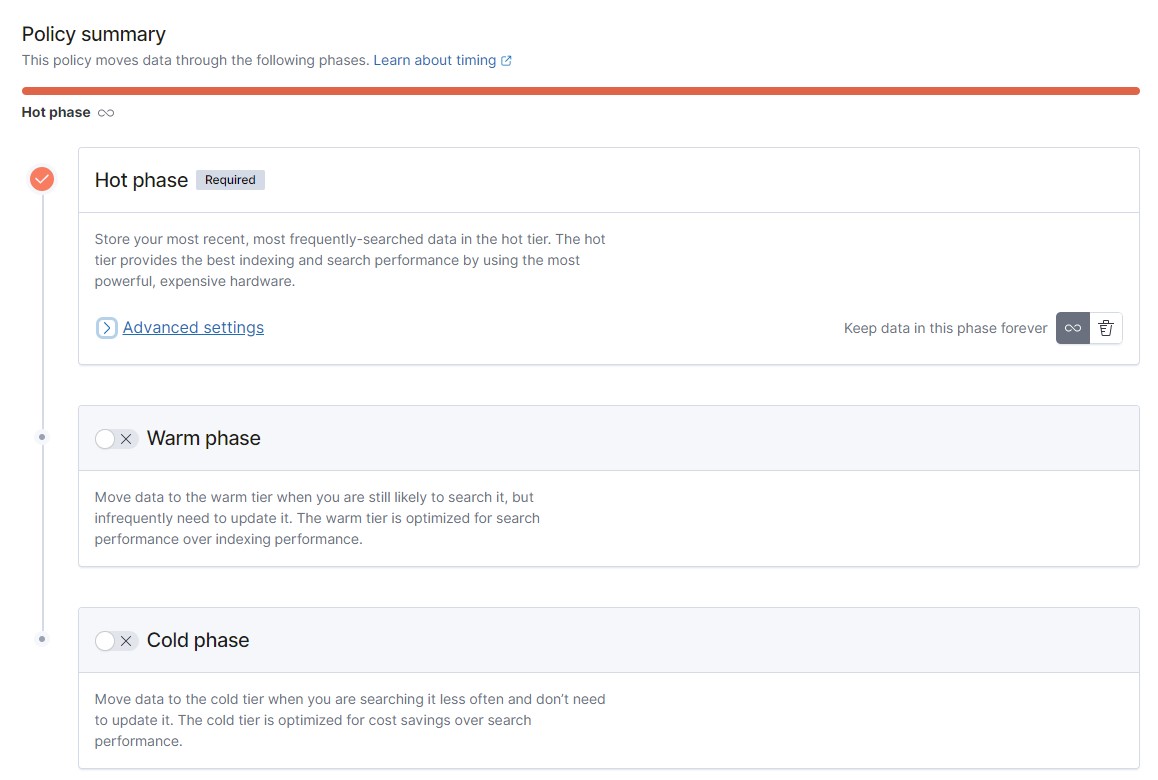
In our example, we configured only the hot phase, with only default metrics for the rollover procedure enabled.

But for production deployment, we recommended to plan for the process of data obsolescence (that is, moving it to "slow" nodes), and deletion.
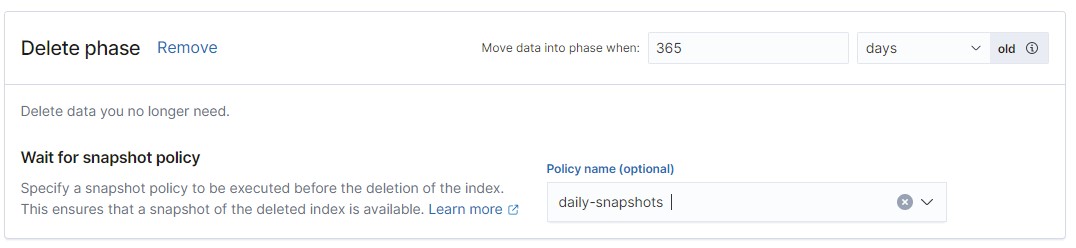
It is recommended to enable data deletion when you have no other phase but the hot one.
After a certain period, indexes with obsolete data will be deleted. If you have set up data snapshots, you can enable the delete option only if a snapshot is present. In this case, specify the name of the snapshot policy.
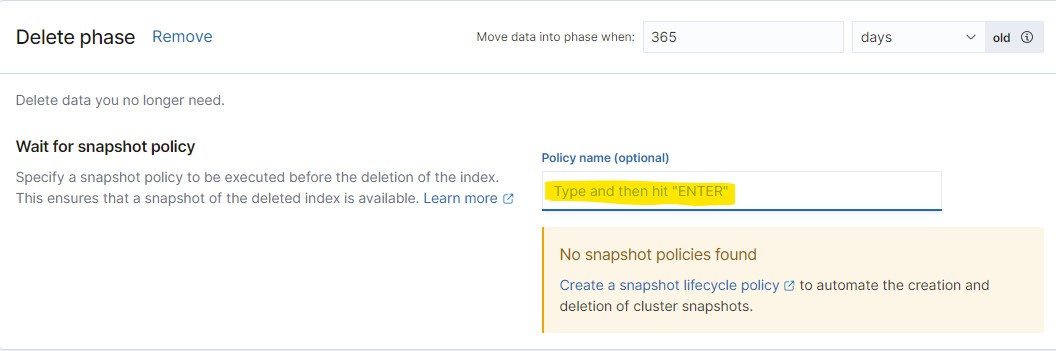
Setting up the snapshot creation policy is described below.
Data snapshots are used for backing up data at certain time points. We recommend setting up a snapshot creation policy for your production environment. The snapshots created can be stored in Yandex.Cloud S3 storage. The procedure for setting up the policy with an S3 storage is described below. Snapshots are created incrementally and consume a minimum space in the long run, because only changes are added.
To store snapshots in an S3 storage, you need:
- Set up a service account to work with S3 and connect it to the Elasticsearch cluster.
- Configure access rights.
- Connect the repository to Elasticsearch.
These steps are described in the documentation for Managed Service for Elasticsearch.
Example of a created snapshot repository:
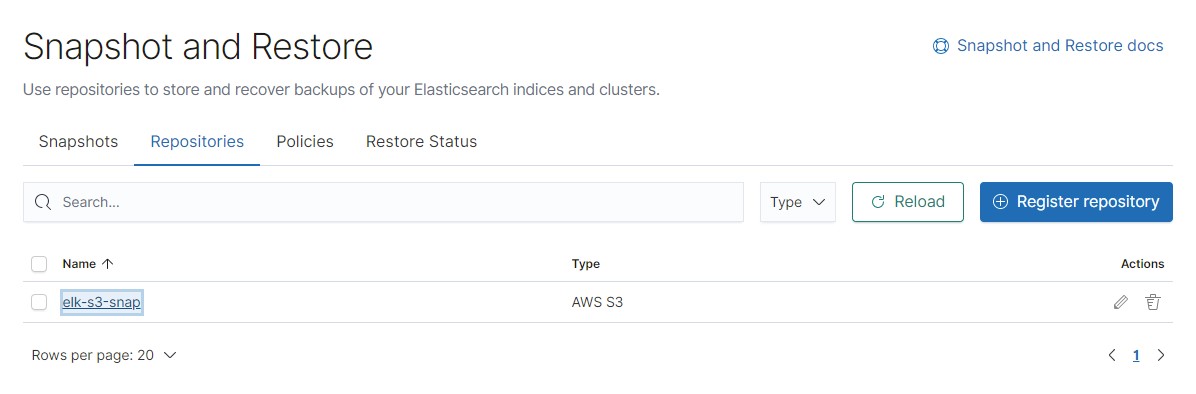
After the repository has been connected to Elasticsearch, you can configure your first snapshot creation policy.
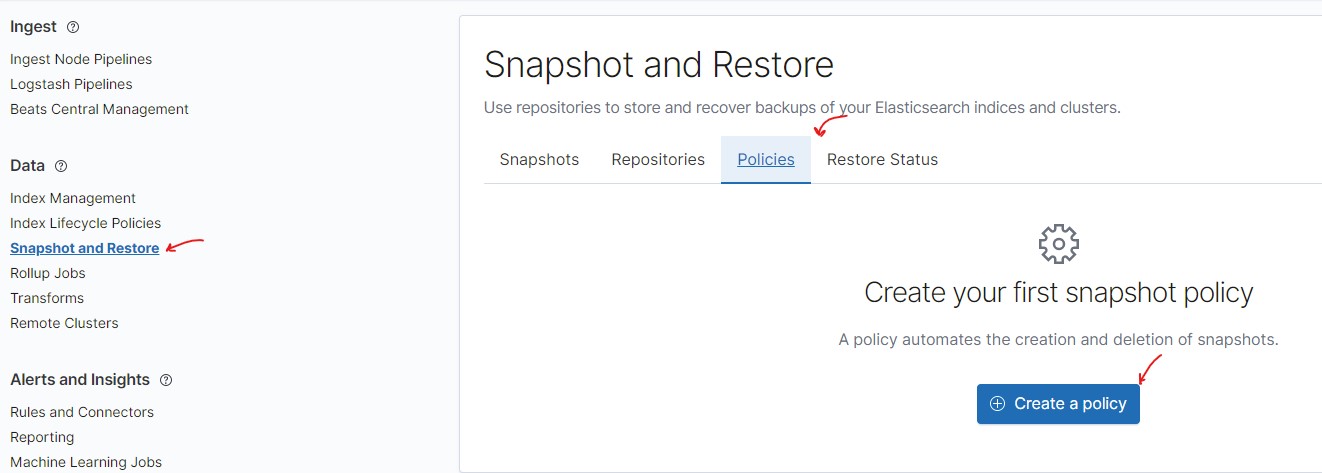
Then use a simple setup wizard to specify:
- The name of the snapshot policy.
- Pattern for the snapshot names.
- A repository for snapshots that your created previously.
- A schedule for creating snapshots (for example, every hour).
- Snapshot parameters: take snapshots for all or specific indexes, retain cluster state in the snapshot, and others.
- Snapshot retention parameters.
The created snapshot policy may look as follows:
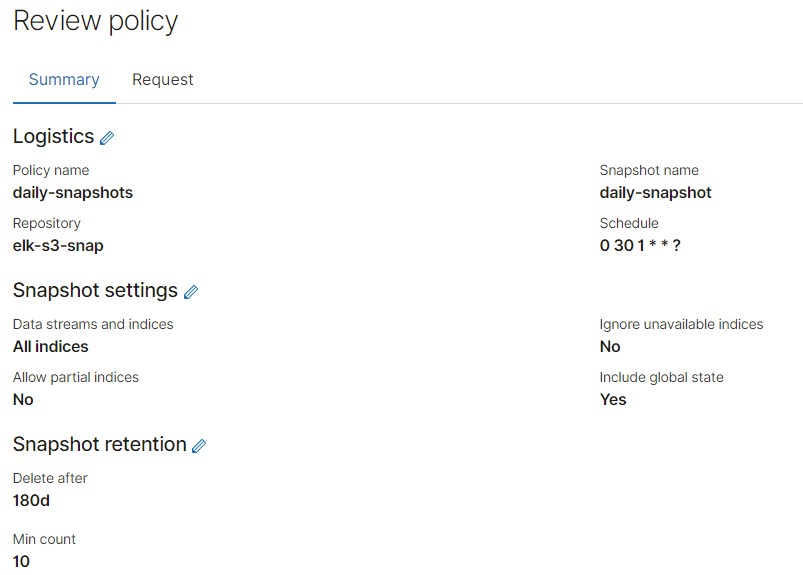
After the policy is created, you can see it in the list of all policies wherefrom you can run it and check straight away.
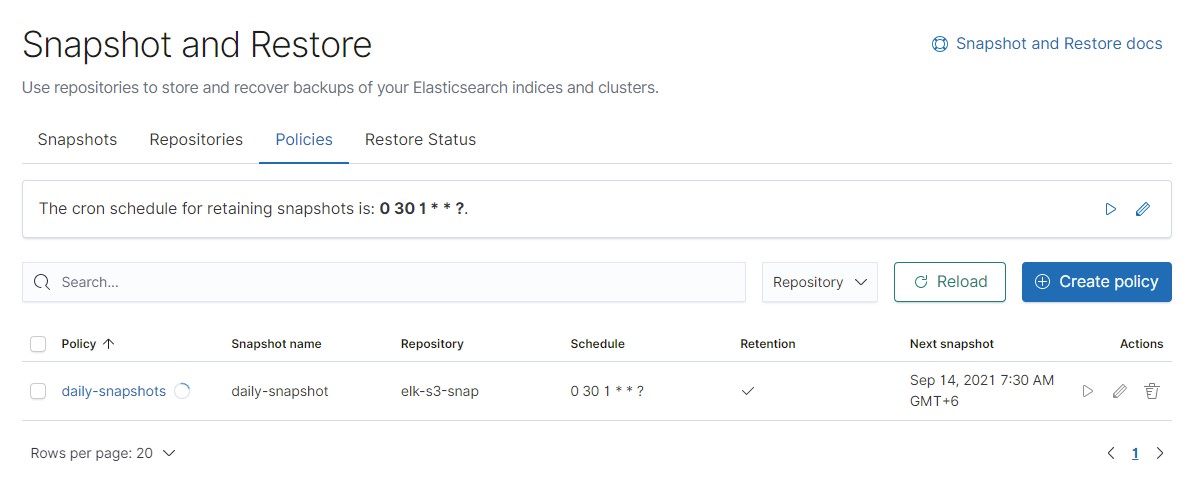
When you run the policy, a new snapshot is created and shown in the list.
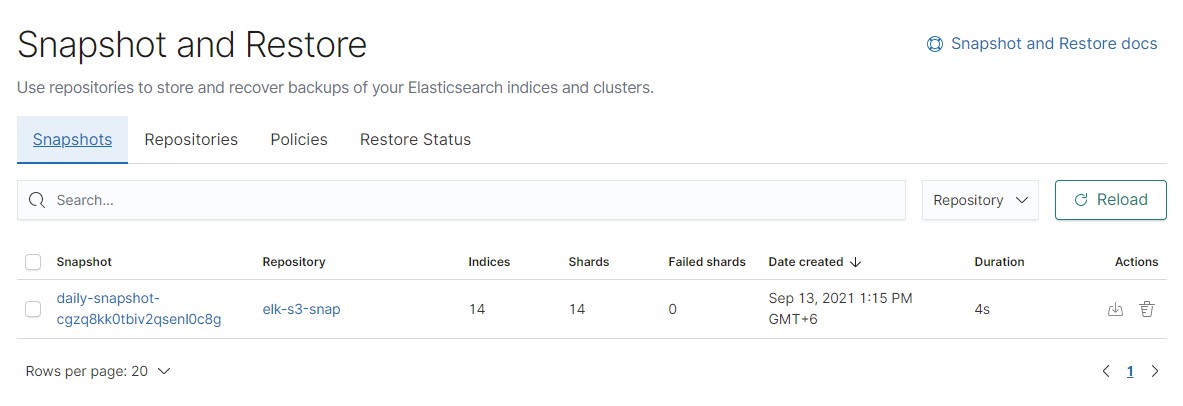
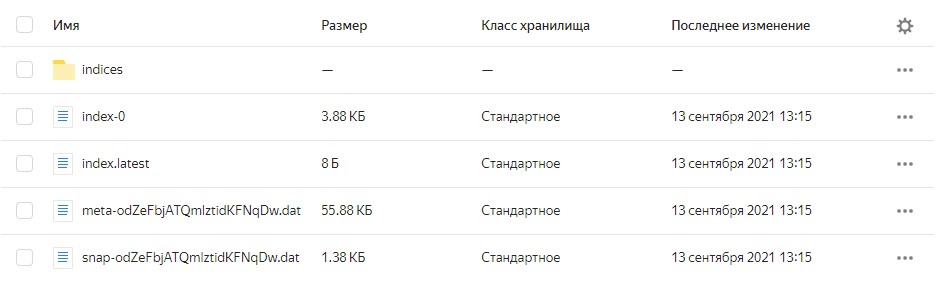
The data also appears in the object storage:
The snapshot policy can be used in the index lifecycle policy created previously.