
Up until now there has been a lot of work using Google's Deepdream algorithm to visualize the internal representations of artificial neural networks. But to the best of our knowledge, there has not been any work with neural networks trained on sound data instead of image data. In this project we trained a convolutional neural network on sound data in order to apply the Deepdream algorithm to it.
This project has been DISCONTINUED. As of its latest state, training accuracies reach about 70 %. The Deepdream algorithm is not yet applied.
We used the UrbanSound8K dataset compiled by NYU researchers Justin Salamon, Christopher Jacoby and Juan Pablo Bello that we slightly modified ourselves. In order to use the network, please download the modified version manually from Google Drive storage (link provided in the reference section) and save it in your local copy of this repository. After extraction (it's a .zip), you should see the folder UrbanSound8K_modified in the main directory, which contains the README.txt and FREESOUNDCREDITS.txt files as well as the audio directory, in which all the .wav-files reside in their respective class. All of our modifications are explained in the README.txt.
To get an overview over the files in this repository, here is a short description:
- datatools includes several python and shell scripts we wrote for the modification of the dataset. Since the compiling of the dataset is finished these are not necessary for the training/Deepdream procedure and have been included for completeness only.
- images includes images used in this readme and some infographics about our current progress.
- train.py is the main file for training the network. It imports utilities.py which is responsible for creating appropriate training, testing and validation batches from the dataset as well as the Tensorflow implementation of a CNN that we wrote in model.py. The batches then will be fed into the model in order to train it on the data.
- cnn_architectures.py contains a simple helper class that returns python dicitonaries describing the shapes of the different neural network layers to ease playing around with different architectures.
- eval.py is the script for evaluating the performance of the network after training. It needs a valid protobuf file in order to obtain the network's graph def, which can be generated using the freeze_graph.py script.
More on that under Usage.
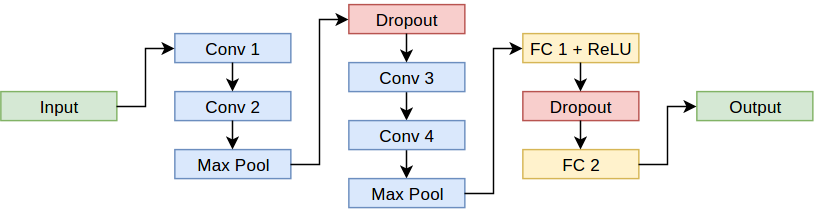
We used a convolutional neural network with four convolutional, two pooling, two dropout and two feed-forward/fully-connected layers. The graph looks as follows:
The following additional python libraries are needed:
- tensorflow
- scipy
- numpy
- matplotlib
- pickle
- urllib
- random
In order to train the network, navigate to the directory you cloned the repository in. From there, you need to run train.py using an installation of Python 3. In order to work, train.py needs the dataset described above which you should download and save as described. Furthermore, you can specify the number of iterations, batch size and path to the dataset with sys arguments.
python3 train.py 'number_of_iterations' 'batch_size' 'path'Appropriate usages are to either give only the first sys argument, the first two, all three or none at all. The defaults for arguments not given are:
number_of_iterations = 5000
batch_size = 100
path = "./UrbanSound8K_modified/urbansound.pkl"The meta graph, called graph.pb, will be saved in /logs/model/, as will be the model.ckpt checkpoint files for the weights after every 500 training iterations (don't worry about your local storage though - Tensorflow only ever keeps the last five checkpoint instances). Summary files that can be used for visualizations using tensorboard will be saved in /logs/tensorboard/. Don't worry if you do not see the logs directory yet, it will be created upon the first call of train.py, since git does not allow the syncing of empty directories.
If you want to obtain the weights and meta graph from our last training, simply head to the Reference section, where a download link to Google Drive storage is provided under [3].
We provided a script called eval.py which, after successfull training, can be used to further test the trained network on some samples. It needs a valid protobuf file that contains both the network structure (the meta graph) and the saved weights to work. To obtain such a file, use the freeze_graph.py script made by the Google developers. From this directory, an appropriate call from the shell inside of your tensorflow environment looks like this:
python freeze_graph.py --input_graph logs/model/graph.pb --input_checkpoint logs/model/model.ckpt --input_binary True --output_graph logs/model/output.pb --output_node_names fc2/fully_connected/fc_outThe freeze_graph.py script takes the graph.pb meta graph protobuf file and the model.ckpt checkpoint files that were generated during the training process as input and outputs the output.pb protobuf file that contains both the meta graph and the variable values from the checkpoints in one file. In addition to that, the output_node_name needs to be specified; our graph's output is simply the second feed-forward layer without an activation function, which is called fc2/fully_connected/fc_out due to the nature of Tensorflow's variable scopes .
eval.py imports the model from the generated output.pb file. Its usage is pretty simple, just make sure you have the appropriate file present in the /logs/model/ directory. On your local machine's console, type:
python3 eval.py and it will print the results.
As mentioned above, the deep dreaming process is not yet applied.
-
Thanks to the creators of the original UrbanSound8K dataset: J. Salamon, C. Jacoby and J. P. Bello, "A Dataset and Taxonomy for Urban Sound Research", 22nd ACM International Conference on Multimedia, Orlando USA, Nov. 2014.
-
The weights, metagraph, and complete graph of our last training session (8800 iterations, batch size: 100)
-
Further thanks to Arthur Juliani and his sound-cnn for providing us ideas on how to read wav files into a convolutional neural network.