Structure Aware Single-stage 3D Object Detection from Point Cloud
3D object detection from point cloud data plays an essential role in autonomous driving. Current single-stage detectors are efficient by progressively downscaling the 3D point clouds in a fully convolutional manner. However, the downscaled features inevitably lose spatial information and cannot make full use of the structure information of 3D point cloud, degrading their localization precision. In this work, we propose to improve the localization precision of single-stage detectors by explicitly leveraging the structure information of 3D point cloud. Specifically, we design an auxiliary network which converts the convolutional features in the backbone network back to point-level representations. The auxiliary network is jointly optimized, by two point-level supervisions, to guide the convolutional features in the backbone network to be aware of the object structure. The auxiliary network can be detached after training and therefore introduces no extra computation in the inference stage. Besides, considering that single-stage detectors suffer from the discordance between the predicted bounding boxes and corresponding classification confidences, we develop an efficient part-sensitive warping operation to align the confidences to the predicted bounding boxes. Our proposed detector ranks at the top of KITTI 3D/BEV detection leaderboards and runs at 25 FPS for inference.
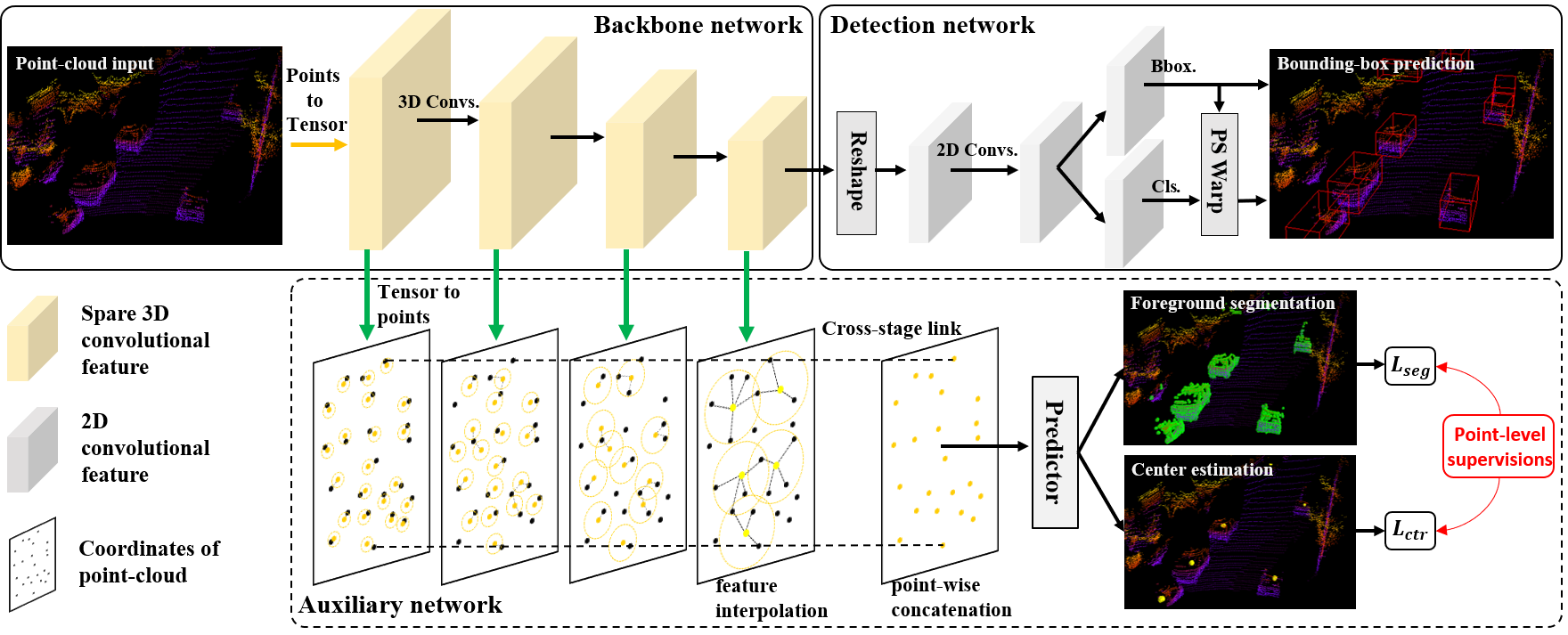
We implement SA-SSD and provide the results and checkpoints on KITTI dataset.
@InProceedings{he2020sassd,
title={Structure Aware Single-stage 3D Object Detection from Point Cloud},
author={He, Chenhang and Zeng, Hui and Huang, Jianqiang and Hua, Xian-Sheng and Zhang, Lei},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}