在 WebGPU 中,缓冲区(GPUBuffer)是指 GPU 可操作的内存块(显存块)。
首先说一声抱歉,我在上一篇文章 “05 WebGPU基础之命令队列(GPUQueue)” 中简单介绍了一些 GPUBuffer,但是由于当时我对于 缓冲区 的理解不够深,导致那篇文章中关于 GPUBuffer 的一些观点可能是不太正确的。
请忘掉之前关于 GPUBuffer 的讲解,以本文为准。
当然,我也不能保证本文讲解的就一定正确,随着学习的深入,新写的文章推翻之前文章中某些观点的事情还会继续发生,因为我也是处于学习过程中。
在正式学习 GPUBuffer 之前,我们先了解一下在计算机中 “缓冲区(buffer)与缓存区(cache)” 的概念。
以下相关知识来源于网上,我进行了适当整理和补充。
什么是缓冲区(Buffer)?
在内存中预留一定的存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。
- 缓冲区所占用的存储空间是具有一定大小的,并不是无限的。
- 缓冲区根据对应的是输入设备还是输出设备,分为输入缓冲区和输入缓冲区。
缓冲区的作用是什么?
缓冲区的作用是解决高速设备与低速设备的不匹配。
- 解除高速设备与低速设备的制约关系:高速设备直接将数据发送到缓冲区,高速设备不用再等待低速设备,减少高速设备等待低速设备的时间。
- 尽管缓冲区是具有一定大小的(不是无限的),但是通常高速设备可以一次写入很多数据,可以减少数据的写入次数。假设高速设备需要写入的数据大小超出了缓冲区的最大值,那么这一次写入不完就等待缓冲区有新的空间后再写入。
高速设备?低速设备?不匹配?等待时间?
听着很迷糊,但是举一个 打印文档 的例子你就立马明白了。
- CPU 读取和发送整个文档内容(数据)的速度很快
- 假设打印机每次只能记住一页文档的内容,且打印一页需要 3 秒
- 很明显 CPU 就是那个高速设备、打印机就是那个低速设备
- 假设没有缓冲区,CPU 需要等待打印机每打印完一页后再发送新的一页内容给打印机,在这期间CPU只能等待,不能做别的事情。
- 但是有了缓冲区后,CPU 一次性把需要打印的全部文档内容都发送到缓冲区,然后 CPU 就可以去处理其他事情,而打印机则开始逐页打印,每打印完一张后再去缓冲区读取(并删除)下一页内容,直至缓冲区为空,打印结束。
再举缓冲区的另外一个使用场景:
假设每秒需要 100 次将数据写入硬盘,且连续写入 3 秒,那么就意味着在这期间一共需要 300 次硬盘写入操作。如果有缓冲区就可以先将要写入的数据发送到缓冲区,等 3 秒后需要写入的全部数据都已在缓冲区(当然前提条件是 缓冲区 能够承载这些全部的写入数据),最后将这些数据 一次性写入到硬盘中。
这样就会由之前的 300 次硬盘写入操作减少为 1 次操作。
300 次 与 1 次相比而言,很明显后者会对硬盘、系统的冲击力小,这样也会提高硬盘的使用寿命。
这个使用场景中 高速设备(CPU) 降低了对 低速设备(硬盘写入) 的频繁操作次数,提高写入效率(尽管看上去好像延长了一点整体的写入所需时间)。
注意:上面所说的 300 次、3秒、1次这些都仅仅是举例而已,实际上写入硬盘数据肯定不是这个频率。
什么是缓存区(cache)?
缓存区也被称为 缓存,中文名称是:高速缓冲存储器,其读写速度非常快,几乎和 CPU 相同。
由于 CPU 的运算速度极快,内存的数存取速度无法跟上 CPU 的速度,所以在 CPU 和 内存中间设置了数据快取区(也就是缓存区),当计算机执行程序时,数据和地址管理部件预测可能要用到的数据和指令,并将这些数据和指令预先从内存中读出来送到缓存区。CPU 一旦需要数据时会先检查 缓存区,若有则读取(速度快),若无则从内存中读取(速度慢)。
假设 CPU 在缓存区中找到了需要的数据被称为 命中,未找到需要的数据,则对应称为 未命中。
缓存还区分有 一级缓存、二级缓存。
对于较早的计算机硬件而言,一级缓存是指在 CPU 内核中集成的缓存、二级缓存是指位于 CPU 外部(除CPU以外的其他硬件)的缓存。
但是随着 CPU 生产工艺的提升,上述划分方式已经过时,现在的 CPU 中可以同时划分有 一级缓存和二级缓存。CPU 中二级缓存的容量越大也就意味着 CPU 中需要更多的晶体管。
一级缓存容量在 4KB ~ 64KB 之间。二级缓存容量有 128KB、256KB、512KB、1MB、2MB ...
缓存区是用来解决 CPU 与 内存之间速度不匹配的问题,避免内存和辅助内存频繁存取数据,提高系统的执行效率。
缓存区与内存的差别:
-
缓存区主要用于 暂存 那些 CPU 可能马上就需要用到的数据
缓存区也会包含上一次某些复杂计算的结果,如果再遇到相同的运算则直接将上次运算结果提供给 CPU,从而提高运算性能。
-
内存 则 暂存 所有的数据。
假设内存中的一些数据再也不可能被 CPU 读取,但是却因为某些原因无法被释放,这种情况被称为 内存泄漏。
-
缓存是一种特殊的内存。
当然,对于前端开发者而言,平时所说的 “缓存” 更多是指浏览器缓存。浏览器中的缓存文件有 "过期时间" 这个概念,浏览器缓存的作用和 CPU 缓存几乎是相似的:都是为了快速获取数据。
缓冲区(buffer)与缓存区(cache)的主要区别:
-
缓冲区的核心作用:缓和数据的频繁写入
例如打印文档时 CPU 将文档内容一次推送到缓冲区,而无需每打印一页推送一页。
例如硬盘写入时 CPU 逐次将内容推送到缓冲区,而缓冲区一次性将所有数据写入到硬盘中。
-
缓存区的核心作用:加快数据的读取速度
这个加快是相对于 CPU 读取内存的速度而言的。
请注意:
- 上述关于 缓冲区(buffer) 的解释是指针对
CPU 内存而言的 缓冲区。 - 而 我们本文要学习的 GPUBuffer 中的 buffer(缓冲区) 是指针对
GPU 显存而言的缓冲区。 - 尽管一个是CPU内存,一个是GPU显存,但是 “缓冲区/缓存区” 的概念和作用是相同的。
在理解完 CPU、GPU、内存、显存、缓冲区、缓存 这些计算机底层知识后,终于要开始学习 GPUBuffer 了。
-
GPUBuffer 表示可用于 GPU 操作的内存块。
请注意:更加严谨的说法,不是内存块,而是显存块。
CPU操作的是内存,GPU操作的是显存。官方文档中的上面那句话,暗含以下几个意思:
-
每一个 GPUBuffer 实例都是从 显存 中划分出来的一块特殊的内存块
注:实际上那只是我们希望的结果,还存在创建 GPUBuffer 失败的情况
-
这个内存块可以快速被 GPU 读取
-
所谓 “内存块”,“块” 的意思就是:大小(容量)是有限且固定的
-
-
数据以线性布局存储:GPUBuffer 实例内部保存的每一个字节都可以通过偏移量(索引值)获取到。
所谓线性布局 简单理解就是:在内部每一个字节都紧挨着下一个字节。
-
一些 GPUBuffer 可以被映射,这使得内存块可以通过 ArrayBuffer 访问并调动它的映射。
在 MDN 上关于 ArrayBuffer 的定义为:ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。你不能直接操作 ArrayBuffer 的内容,而是要通过类型数组对象或 DataView 对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer -
GPUBuffer 实例只能通过 GPUDevice.createBuffer(descriptor) 创建。
参数 descriptor 为申请创建该缓冲区的一些配置,例如该申请该缓冲区的长度(字节)、声明该缓冲区有哪些可操作的行为,以及映射相关的,等等,具体稍后我们会详细讲解。
-
GPUBuffer.createBuffer() 返回一个处于
mapped或unmapped状态的缓冲区。mapped 翻译就是:映射
unmapped 自然就是:未映射若存在映射则意味着可以被 CPU 操作。
请注意一旦被映射,CPU 是可以操作它了,但也意味着 GPU 无法再操作它了,直至该 GPUBuffer 实例调用 unmap() 解除映射。
综上所述,关于 GPU 和 GPUBuffer,我制作了下面这张示意图。
这只是我目前的理解,不敢保证一定正确。
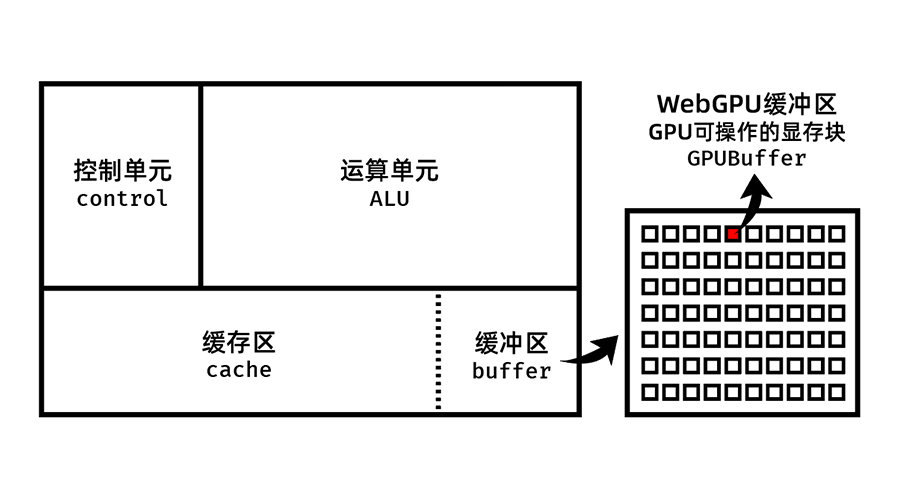
特别提醒:下面的内容仅为个人理解,仅供参考。
-
本文中提到的 “显存” 实际上是一个笼统的概念,按照显卡硬件、功能还会细分为其他多个模块。
我认为对于现阶段的我们(前端开发人员)而言无需过多深入去研究这些,我们只需要对 GPU 有一些基础的知识了解即可。
关于内存(显存)有很多种形式和专有名词,例如:VRAM(随机存取存储器)、DRAM(动态随机存取存储器)、SRAM(静态随机存取存储器)
-
WebGPU 会暴露当前设备(电脑或手机)的 全局内存堆中的分配错误,允许探测系统剩余可用内存(显存)的大小,并尝试分配和监控分配失败。
再重复一遍:不一定保证每次创建 GPUBuffer 都可以成功。
-
GPU 内部有一个或多个 内存堆,所有正在运行的应用程序共享这些内存堆。当内存堆耗尽时 WebGPU 将无法创建新的资源。
通常程序内存按照功能可划分为 3 类:
- 栈(stack)区:在执行函数时,函数参数、局部变量、函数调用后返回的对象,这些都临时储存在栈区。当函数执行结束后这些内容会被自动释放。
- 堆(heap)区:动态内存分配,程序在运行时通过 new 来申请任意大小的内存,由开发者控制在适当的时机释放掉(销毁)。若程序员一直没有释放掉(销毁)则会在程序结束时被释放。
- 静态(static)(全局)存储区:这块内存在程序整个运行期间都存在,主要存放静态、全局数据和常量,程序结束后由操作系统释放。
请注意:
- 上述言论中的 栈和堆 并不是数据结构中的 栈和堆。
- 上述言论中是按照 “常见程序(例如C++)” 内存划分的,并不是操作系统。
既然此处说的 “内存堆” 并不是操作系统的内容堆,你讲它有何用?
- 首先我觉得这部分知识点挺有用的。
- 通过对 程序中的 内存堆 的介绍,可以扩大、反推、脑补出 “GPU内存堆” 究竟大致是个什么样子。
-
由于是所有程序应用共享 内存堆,那么就有可能存在一些恶意程序应用去猜测哪些堆是被其他应用程序使用,以及这些堆所占的大小。
关于 WebGPU 安全方面,我们把基础的知识学完后,会单独用一篇来讲解。
-
对于计算单元,假设有 2 个站点同时使用 WebGPU,那么其中一个站点不断提交相关计算要求,那么另外一个站点是能感受到的。
简单来说就是其中一个站点计算时占用了更多的GPU计算资源,导致另外一个站点的计算力下降了,自然能猜到是其他站点正在占用 WebGPU 资源。
在 @webgpu/types 中我们可以看到,createBuffer() 需要传递的参数类型为 GPUBufferDescriptor。
//注意:该方法为同步,而非异步
createBuffer(descriptor: GPUBufferDescriptor): GPUBuffer
descriptor 单词的翻译为:描述。
我们可以想象到 GPUBufferDescriptor 中的各项配置将决定我们得到的 GPUBuffer 实例的特征。
补充:目前
@webgpu/types最新版为 0.1.11再次强调一遍:本教程中关于类、属性和方法中的介绍都是指
在 TypeScript 中开发 WebGPU ,由 @webgpu/types 定义的,而不是指原生的 WebGPU。为什么要这样?因为 TypeScript 很好用,并且
@webgpu/types帮我们额外做了一些提高我们编程效率、正确性的事情。如果你不使用 TypeScript,那么对于 值类型 相关介绍可以忽略。
GPUBufferDescriptor的属性
| 属性名 | 值类型 | 是否必填 | 对应含义 |
|---|---|---|---|
| size | GPUSize64(number) | 必填 | 该缓冲区的容量(字节)大小 |
| usage | GPUBufferUsageFlags(number) 在原生中对应的是 GPUBufferUsage |
必填 | 该缓冲区的使用标记 |
| mappedAtCreation | boolean | 可选 | 是否在创建之初就建立映射 |
| label | string | 可选 | 该GPUBuffer实例的标记名称 |
针对上述 4 个属性的详细说明:
-
size:明确(希望)得到缓冲区的容量(字节)大小,且应该是 4 的倍数。
还记得本文上面讲述 CPU 对应的 缓冲区吗?当时使用的文字是 “缓冲区所占用的存储空间是具有一定大小的”,够用即可,不要试图去 “贪心” 申请过大的容量。
-
usage:明确缓冲区的使用标记。什么叫 使用标记?其实就是定义:你打算对该 GPUBuffer 都有哪些操作。
可选常量 值 对应含义 MAP_READ 0x0001 映射和读取 MAP_WRITE 0x0002 映射和写入 COPY_SRC 0x0004 可以作为拷贝源 COPY_DST 0x0008 可以作为拷贝目标 INDEX 0x0010 索引 VERTEX 0x0020 顶点 UNIFORM 0x0040 Uniform(通用变量) STORAGE 0x0080 仅存储 INDIRECT 0x0100 间接使用 QUERY_RESOLVE 0x0200 用于查询 本文是基础篇,只是简单介绍一下 GPUBuffer,不打算写具体的使用示例代码。我计划是等我们把所有的基础类都学完后才开始写示例代码。
先简单对使用标记做几点补充:
-
通常情况下 映射读搭配的是拷贝目标、映射写搭配的是拷贝源
const mapReadBuffer = device.createBuffer({ size: 128, usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST }) const mapWriteBuffer = device.createBuffer({ size: 128, usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC }) -
Uniform:用于存储着色器需要的各种数据,例如:转换矩阵、光照参数、颜色等。这些数据可以同时被 顶点着色器、片元着色器访问使用。
Uniform 这个单词本意为 “统一的”,在图形学的文章中通常不会把 uniform 进行翻译,但是结合它的含义是可以把它翻译为 "通用变量"。
-
-
mappedAtCreation:是否在创建之初(还未真正创建成功)即可映射,默认值为 false。
如果将该项设置为 true,也就是说无论最终创建 GPUBuffer 成功或失败,始终让这个 实例 看上去好像是可以 写入/读取 映射的范围,直到它被取消映射。
-
label:标记名称,便于开发者容易区分出该实例与其他 GPUBuffer 实例,默认值为 null。
关于 label 属性的补充:
在前面几篇文章中,在创建 GPUAdapter、GPUDevice、GPUQueue 时,我们遗漏了一个知识点:这些类都是继承于 GPUObjectBase,因此他们都有一个名为 label 的只读属性。可以通过这个属性我们来对不同的实例进行简单的区分。
- 在创建这些不同类型的实例时,通过添加参数来设置 label 值。
- 不同的实例 label 值是可以相同的,label 值并不需要必须是唯一的,因此只能达到 “简单的区分”。
- 对于我们还有很多未曾讲到的类,他们绝大多数也都继承于 GPUObjectBase,他们也有 label 属性。
GPUBuffer只有一个只读属性:.label。
以下为 GPUBuffer 的方法。
destroy():销毁
当不再需要 GPUBuffer 实例时,可以通过调用它的 .destroy() 方法对其销毁以及取消映射。
mapAsync(mode,offset,size):异步设置映射范围
-
mode:number,映射类型标记(读或写),该值由 GPUMapMode 所定义的常量。
常量 实际值 含义 GPUMapMode.READ 0x0001 读 GPUMapMode.WRITE 0x0002 写 -
offset:number,映射起始索引的偏移量,需要是 8 的倍数
-
size:number,映射范围长度大小,需要是 4 的倍数
getMappedRange(offset, size):获取带有给定范围内 GPUBuffer 内容的 ArrayBuffer
- offset:以字节为单位的缓冲区偏移量,需要是 8 的倍数
- size:可选参数,要返回的 ArrayBuffer 长度大小,需要是 4 的倍数。默认长度为从 offset 开始一直到结束。
一个简单示例:
const handleEffect = async () => {
const adapter = await navigator.gpu.requestAdapter()
const device = await adapter?.requestDevice()
const mapReadBuffer = device?.createBuffer({
size: 128,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST,
label: 'mapReadBuffer'
})
await mapReadBuffer?.mapAsync(GPUMapMode.READ) //注意这是一个异步操作,所以前面需要加上 await
const arrayBuffer = mapReadBuffer?.getMappedRange()
console.log(arrayBuffer)
}
关于 ArrayBuffer 的介绍:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer
unmap():取消映射
对已映射的 GPUBuffer 范围取消映射,取消映射后 GPU 可操作该 GPUBuffer 对应的内存(显存)块。
当被取消映射后,此时再针对 ArrayBuffer 做的任何修改都将被丢弃(忽略)。
本文小结:
本文花费了大量的文字用来讲述 “缓冲区(Buffer)” 的概念,我认为对于普通前端开发者而言平时是很少会接触计算机底层知识的,所以我认为这部分是很有必要的。
受限于我本身的水平,讲得不对的地方还请担待。
对于本文的主角 GPUBuffer 而言,你只需明白以下几点即可:
-
GPUBuffer 是 GPU 可操作的内存块。
你也可以把这句话记成:GPUBuffer 是 GPU 可操作的显存块。
因为无论是英文直译,还是一些其他讲解 WebGPU 的文章,都使用的是 “内存块”。但实际上更加精准的还是应该翻译成 “显存块”。
-
GPUBuffer 在创建的时候需要添加一些配置参数,包括该 GPUBuffer 的大小(size)、使用标记(usage)、是否创建之初就设置为已映射(mappedAtCreation)、标记名(label)
-
GPUBuffer 通过 .mapAsync() 设置映射范围,此时 GPU 无法操作该 GPUBuffer
-
通过 .getMappedRange() 获取映射范围对应的 ArrayBuffer 供 CPU 操作
-
当 CPU 操作完成后可执行 .unmap() 取消映射,重新供 GPU 操作
-
当不再需要这个 GPUBuffer 实例时可通过 .destroy() 销毁该实例
GPUBuffer 基础知识搞明白之后,后期我们再进行大量实际例子练习,目前可以先不要着急写代码。
我认为 GPUBuffer 是学习 WebGPU 第一个遇到的比较难的小山坡,翻越过去后就是一片新天地。
接下来,我们将学习新的类:纹理(GPUTexture)和纹理视图(GPUTextureView)
尽管本文篇幅已经很长了,但是还要插播一个其他事情:
有一家公司名叫 北京鸥睿零世科技有限公司,他们公司成立的目的就是为了打造一款基于 WebGPU 的免费开源引擎。类似 Three.js/Babylon.js,该引擎目前还处于开发阶段,暂未对外公布。
对我们而言有用的事情是,他们基于 W3C 网站翻译了一些文档:
- WebGPU 简体中文 文档:https://www.orillusion.com/zh/webgpu.html
- WGSL 简体中文 文档:https://www.orillusion.com/zh/wgsl.html
这些文档个别地方有些不太通顺,但还是能够帮助绝大多数英文不好的人来学习 WebGPU。
如果你觉得某些地方翻译的不太好,可以给他们提交 PR:
https://github.com/Orillusion/orillusion-web/tree/master/webgpu/zh
此外,他们还创建了一个号称 “WebGPU第一中文社区”:
论坛地址:https://forum.orillusion.com/
实话实话,目前该论坛基本没有什么人发帖,毕竟大家有问题更习惯在微信/QQ交流群里沟通。
但是,你可以加他们这个论坛的管理员,然后管理员会拉你进微信交流群,这个还是沟通比较方便的。
他们管理员的微信二维码:
