diff --git a/README.md b/README.md
index 34277595..f5024799 100644
--- a/README.md
+++ b/README.md
@@ -23,7 +23,7 @@
- +
+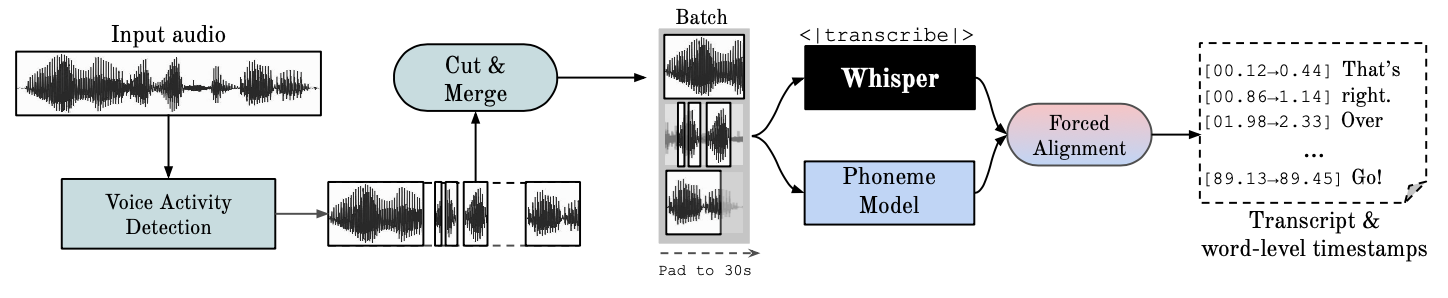 @@ -80,21 +80,40 @@ GPU execution requires the NVIDIA libraries cuBLAS 11.x and cuDNN 8.x to be inst
See other methods [here.](https://pytorch.org/get-started/previous-versions/#v200)
-### 3. Install this repo
+### 3. Install WhisperX
-`pip install git+https://github.com/m-bain/whisperx.git`
+You have several installation options:
-If already installed, update package to most recent commit
+#### Option A: Stable Release (recommended)
+Install the latest stable version from PyPI:
-`pip install git+https://github.com/m-bain/whisperx.git --upgrade`
+```bash
+pip install whisperx
+```
+
+#### Option B: Development Version
+Install the latest development version directly from GitHub (may be unstable):
-If wishing to modify this package, clone and install in editable mode:
+```bash
+pip install git+https://github.com/m-bain/whisperx.git
```
-$ git clone https://github.com/m-bain/whisperX.git
-$ cd whisperX
-$ pip install -e .
+
+If already installed, update to the most recent commit:
+
+```bash
+pip install git+https://github.com/m-bain/whisperx.git --upgrade
```
+#### Option C: Development Mode
+If you wish to modify the package, clone and install in editable mode:
+```bash
+git clone https://github.com/m-bain/whisperX.git
+cd whisperX
+pip install -e .
+```
+
+> **Note**: The development version may contain experimental features and bugs. Use the stable PyPI release for production environments.
+
You may also need to install ffmpeg, rust etc. Follow openAI instructions here https://github.com/openai/whisper#setup.
### Speaker Diarization
diff --git a/requirements.txt b/requirements.txt
index 8f1aabd6..e3bdecfe 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,7 +1,7 @@
torch>=2
torchaudio>=2
faster-whisper==1.1.0
-ctranslate2==4.4.0
+ctranslate2<4.5.0
transformers
pandas
setuptools>=65
diff --git a/setup.py b/setup.py
index 203a0790..ef7ed34b 100644
--- a/setup.py
+++ b/setup.py
@@ -1,19 +1,22 @@
import os
-import platform
import pkg_resources
from setuptools import find_packages, setup
+with open("README.md", "r", encoding="utf-8") as f:
+ long_description = f.read()
+
setup(
name="whisperx",
py_modules=["whisperx"],
- version="3.2.0",
+ version="3.3.0",
description="Time-Accurate Automatic Speech Recognition using Whisper.",
- readme="README.md",
+ long_description=long_description,
+ long_description_content_type="text/markdown",
python_requires=">=3.9, <3.13",
author="Max Bain",
url="https://github.com/m-bain/whisperx",
- license="MIT",
+ license="BSD-2-Clause",
packages=find_packages(exclude=["tests*"]),
install_requires=[
str(r)
diff --git a/whisperx/SubtitlesProcessor.py b/whisperx/SubtitlesProcessor.py
index 5ffd1afa..351b8830 100644
--- a/whisperx/SubtitlesProcessor.py
+++ b/whisperx/SubtitlesProcessor.py
@@ -1,5 +1,5 @@
import math
-from conjunctions import get_conjunctions, get_comma
+from .conjunctions import get_conjunctions, get_comma
from typing import TextIO
def normal_round(n):
diff --git a/whisperx/alignment.py b/whisperx/alignment.py
index 42d9b176..d6241bbc 100644
--- a/whisperx/alignment.py
+++ b/whisperx/alignment.py
@@ -3,7 +3,7 @@
C. Max Bain
"""
from dataclasses import dataclass
-from typing import Iterable, Union, List
+from typing import Iterable, Optional, Union, List
import numpy as np
import pandas as pd
@@ -65,7 +65,7 @@
}
-def load_align_model(language_code, device, model_name=None, model_dir=None):
+def load_align_model(language_code: str, device: str, model_name: Optional[str] = None, model_dir=None):
if model_name is None:
# use default model
if language_code in DEFAULT_ALIGN_MODELS_TORCH:
diff --git a/whisperx/asr.py b/whisperx/asr.py
index 0ea03b6c..43575c29 100644
--- a/whisperx/asr.py
+++ b/whisperx/asr.py
@@ -1,17 +1,20 @@
import os
import warnings
-from typing import List, Union, Optional, NamedTuple
+from typing import List, NamedTuple, Optional, Union
import ctranslate2
import faster_whisper
import numpy as np
import torch
+from faster_whisper.tokenizer import Tokenizer
+from faster_whisper.transcribe import TranscriptionOptions, get_ctranslate2_storage
from transformers import Pipeline
from transformers.pipelines.pt_utils import PipelineIterator
from .audio import N_SAMPLES, SAMPLE_RATE, load_audio, log_mel_spectrogram
-from .vad import load_vad_model, merge_chunks
-from .types import TranscriptionResult, SingleSegment
+from .types import SingleSegment, TranscriptionResult
+from .vad import VoiceActivitySegmentation, load_vad_model, merge_chunks
+
def find_numeral_symbol_tokens(tokenizer):
numeral_symbol_tokens = []
@@ -28,7 +31,13 @@ class WhisperModel(faster_whisper.WhisperModel):
Currently only works in non-timestamp mode and fixed prompt for all samples in batch.
'''
- def generate_segment_batched(self, features: np.ndarray, tokenizer: faster_whisper.tokenizer.Tokenizer, options: faster_whisper.transcribe.TranscriptionOptions, encoder_output = None):
+ def generate_segment_batched(
+ self,
+ features: np.ndarray,
+ tokenizer: Tokenizer,
+ options: TranscriptionOptions,
+ encoder_output=None,
+ ):
batch_size = features.shape[0]
all_tokens = []
prompt_reset_since = 0
@@ -81,7 +90,7 @@ def encode(self, features: np.ndarray) -> ctranslate2.StorageView:
# unsqueeze if batch size = 1
if len(features.shape) == 2:
features = np.expand_dims(features, 0)
- features = faster_whisper.transcribe.get_ctranslate2_storage(features)
+ features = get_ctranslate2_storage(features)
return self.model.encode(features, to_cpu=to_cpu)
@@ -94,17 +103,17 @@ class FasterWhisperPipeline(Pipeline):
# - add support for custom inference kwargs
def __init__(
- self,
- model,
- vad,
- vad_params: dict,
- options : NamedTuple,
- tokenizer=None,
- device: Union[int, str, "torch.device"] = -1,
- framework = "pt",
- language : Optional[str] = None,
- suppress_numerals: bool = False,
- **kwargs
+ self,
+ model: WhisperModel,
+ vad: VoiceActivitySegmentation,
+ vad_params: dict,
+ options: TranscriptionOptions,
+ tokenizer: Optional[Tokenizer] = None,
+ device: Union[int, str, "torch.device"] = -1,
+ framework="pt",
+ language: Optional[str] = None,
+ suppress_numerals: bool = False,
+ **kwargs,
):
self.model = model
self.tokenizer = tokenizer
@@ -156,7 +165,13 @@ def postprocess(self, model_outputs):
return model_outputs
def get_iterator(
- self, inputs, num_workers: int, batch_size: int, preprocess_params, forward_params, postprocess_params
+ self,
+ inputs,
+ num_workers: int,
+ batch_size: int,
+ preprocess_params: dict,
+ forward_params: dict,
+ postprocess_params: dict,
):
dataset = PipelineIterator(inputs, self.preprocess, preprocess_params)
if "TOKENIZERS_PARALLELISM" not in os.environ:
@@ -171,7 +186,16 @@ def stack(items):
return final_iterator
def transcribe(
- self, audio: Union[str, np.ndarray], batch_size=None, num_workers=0, language=None, task=None, chunk_size=30, print_progress = False, combined_progress=False, verbose=False
+ self,
+ audio: Union[str, np.ndarray],
+ batch_size: Optional[int] = None,
+ num_workers=0,
+ language: Optional[str] = None,
+ task: Optional[str] = None,
+ chunk_size=30,
+ print_progress=False,
+ combined_progress=False,
+ verbose=False,
) -> TranscriptionResult:
if isinstance(audio, str):
audio = load_audio(audio)
@@ -193,17 +217,23 @@ def data(audio, segments):
if self.tokenizer is None:
language = language or self.detect_language(audio)
task = task or "transcribe"
- self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
- self.model.model.is_multilingual, task=task,
- language=language)
+ self.tokenizer = Tokenizer(
+ self.model.hf_tokenizer,
+ self.model.model.is_multilingual,
+ task=task,
+ language=language,
+ )
else:
language = language or self.tokenizer.language_code
task = task or self.tokenizer.task
if task != self.tokenizer.task or language != self.tokenizer.language_code:
- self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
- self.model.model.is_multilingual, task=task,
- language=language)
-
+ self.tokenizer = Tokenizer(
+ self.model.hf_tokenizer,
+ self.model.model.is_multilingual,
+ task=task,
+ language=language,
+ )
+
if self.suppress_numerals:
previous_suppress_tokens = self.options.suppress_tokens
numeral_symbol_tokens = find_numeral_symbol_tokens(self.tokenizer)
@@ -243,8 +273,7 @@ def data(audio, segments):
return {"segments": segments, "language": language}
-
- def detect_language(self, audio: np.ndarray):
+ def detect_language(self, audio: np.ndarray) -> str:
if audio.shape[0] < N_SAMPLES:
print("Warning: audio is shorter than 30s, language detection may be inaccurate.")
model_n_mels = self.model.feat_kwargs.get("feature_size")
@@ -258,33 +287,36 @@ def detect_language(self, audio: np.ndarray):
print(f"Detected language: {language} ({language_probability:.2f}) in first 30s of audio...")
return language
-def load_model(whisper_arch,
- device,
- device_index=0,
- compute_type="float16",
- asr_options=None,
- language : Optional[str] = None,
- vad_model=None,
- vad_options=None,
- model : Optional[WhisperModel] = None,
- task="transcribe",
- download_root=None,
- local_files_only=False,
- threads=4):
- '''Load a Whisper model for inference.
+
+def load_model(
+ whisper_arch: str,
+ device: str,
+ device_index=0,
+ compute_type="float16",
+ asr_options: Optional[dict] = None,
+ language: Optional[str] = None,
+ vad_model: Optional[VoiceActivitySegmentation] = None,
+ vad_options: Optional[dict] = None,
+ model: Optional[WhisperModel] = None,
+ task="transcribe",
+ download_root: Optional[str] = None,
+ local_files_only=False,
+ threads=4,
+) -> FasterWhisperPipeline:
+ """Load a Whisper model for inference.
Args:
- whisper_arch: str - The name of the Whisper model to load.
- device: str - The device to load the model on.
- compute_type: str - The compute type to use for the model.
- options: dict - A dictionary of options to use for the model.
- language: str - The language of the model. (use English for now)
- model: Optional[WhisperModel] - The WhisperModel instance to use.
- download_root: Optional[str] - The root directory to download the model to.
- local_files_only: bool - If `True`, avoid downloading the file and return the path to the local cached file if it exists.
- threads: int - The number of cpu threads to use per worker, e.g. will be multiplied by num workers.
+ whisper_arch - The name of the Whisper model to load.
+ device - The device to load the model on.
+ compute_type - The compute type to use for the model.
+ options - A dictionary of options to use for the model.
+ language - The language of the model. (use English for now)
+ model - The WhisperModel instance to use.
+ download_root - The root directory to download the model to.
+ local_files_only - If `True`, avoid downloading the file and return the path to the local cached file if it exists.
+ threads - The number of cpu threads to use per worker, e.g. will be multiplied by num workers.
Returns:
A Whisper pipeline.
- '''
+ """
if whisper_arch.endswith(".en"):
language = "en"
@@ -297,7 +329,7 @@ def load_model(whisper_arch,
local_files_only=local_files_only,
cpu_threads=threads)
if language is not None:
- tokenizer = faster_whisper.tokenizer.Tokenizer(model.hf_tokenizer, model.model.is_multilingual, task=task, language=language)
+ tokenizer = Tokenizer(model.hf_tokenizer, model.model.is_multilingual, task=task, language=language)
else:
print("No language specified, language will be first be detected for each audio file (increases inference time).")
tokenizer = None
@@ -338,7 +370,7 @@ def load_model(whisper_arch,
suppress_numerals = default_asr_options["suppress_numerals"]
del default_asr_options["suppress_numerals"]
- default_asr_options = faster_whisper.transcribe.TranscriptionOptions(**default_asr_options)
+ default_asr_options = TranscriptionOptions(**default_asr_options)
default_vad_options = {
"vad_onset": 0.500,
diff --git a/whisperx/audio.py b/whisperx/audio.py
index db210fb9..42f97b88 100644
--- a/whisperx/audio.py
+++ b/whisperx/audio.py
@@ -22,7 +22,7 @@
TOKENS_PER_SECOND = exact_div(SAMPLE_RATE, N_SAMPLES_PER_TOKEN) # 20ms per audio token
-def load_audio(file: str, sr: int = SAMPLE_RATE):
+def load_audio(file: str, sr: int = SAMPLE_RATE) -> np.ndarray:
"""
Open an audio file and read as mono waveform, resampling as necessary
diff --git a/whisperx/conjunctions.py b/whisperx/conjunctions.py
index a3d35ea6..24d63fc1 100644
--- a/whisperx/conjunctions.py
+++ b/whisperx/conjunctions.py
@@ -1,5 +1,8 @@
# conjunctions.py
+from typing import Set
+
+
conjunctions_by_language = {
'en': {'and', 'whether', 'or', 'as', 'but', 'so', 'for', 'nor', 'which', 'yet', 'although', 'since', 'unless', 'when', 'while', 'because', 'if', 'how', 'that', 'than', 'who', 'where', 'what', 'near', 'before', 'after', 'across', 'through', 'until', 'once', 'whereas', 'even', 'both', 'either', 'neither', 'though'},
'fr': {'et', 'ou', 'mais', 'parce', 'bien', 'pendant', 'quand', 'où', 'comme', 'si', 'que', 'avant', 'après', 'aussitôt', 'jusqu’à', 'à', 'malgré', 'donc', 'tant', 'puisque', 'ni', 'soit', 'bien', 'encore', 'dès', 'lorsque'},
@@ -36,8 +39,9 @@
'ur': '،'
}
-def get_conjunctions(lang_code):
+def get_conjunctions(lang_code: str) -> Set[str]:
return conjunctions_by_language.get(lang_code, set())
-def get_comma(lang_code):
- return commas_by_language.get(lang_code, ',')
\ No newline at end of file
+
+def get_comma(lang_code: str) -> str:
+ return commas_by_language.get(lang_code, ",")
diff --git a/whisperx/diarize.py b/whisperx/diarize.py
index c327c932..2a636e6e 100644
--- a/whisperx/diarize.py
+++ b/whisperx/diarize.py
@@ -5,6 +5,7 @@
import torch
from .audio import load_audio, SAMPLE_RATE
+from .types import TranscriptionResult, AlignedTranscriptionResult
class DiarizationPipeline:
@@ -18,7 +19,13 @@ def __init__(
device = torch.device(device)
self.model = Pipeline.from_pretrained(model_name, use_auth_token=use_auth_token).to(device)
- def __call__(self, audio: Union[str, np.ndarray], num_speakers=None, min_speakers=None, max_speakers=None):
+ def __call__(
+ self,
+ audio: Union[str, np.ndarray],
+ num_speakers: Optional[int] = None,
+ min_speakers: Optional[int] = None,
+ max_speakers: Optional[int] = None,
+ ):
if isinstance(audio, str):
audio = load_audio(audio)
audio_data = {
@@ -32,7 +39,11 @@ def __call__(self, audio: Union[str, np.ndarray], num_speakers=None, min_speaker
return diarize_df
-def assign_word_speakers(diarize_df, transcript_result, fill_nearest=False):
+def assign_word_speakers(
+ diarize_df: pd.DataFrame,
+ transcript_result: Union[AlignedTranscriptionResult, TranscriptionResult],
+ fill_nearest=False,
+) -> dict:
transcript_segments = transcript_result["segments"]
for seg in transcript_segments:
# assign speaker to segment (if any)
diff --git a/whisperx/transcribe.py b/whisperx/transcribe.py
index 7f10f5e3..6cbbbe55 100644
--- a/whisperx/transcribe.py
+++ b/whisperx/transcribe.py
@@ -10,8 +10,15 @@
from .asr import load_model
from .audio import load_audio
from .diarize import DiarizationPipeline, assign_word_speakers
-from .utils import (LANGUAGES, TO_LANGUAGE_CODE, get_writer, optional_float,
- optional_int, str2bool)
+from .types import AlignedTranscriptionResult, TranscriptionResult
+from .utils import (
+ LANGUAGES,
+ TO_LANGUAGE_CODE,
+ get_writer,
+ optional_float,
+ optional_int,
+ str2bool,
+)
def cli():
@@ -95,7 +102,7 @@ def cli():
align_model: str = args.pop("align_model")
interpolate_method: str = args.pop("interpolate_method")
no_align: bool = args.pop("no_align")
- task : str = args.pop("task")
+ task: str = args.pop("task")
if task == "translate":
# translation cannot be aligned
no_align = True
@@ -174,7 +181,13 @@ def cli():
audio = load_audio(audio_path)
# >> VAD & ASR
print(">>Performing transcription...")
- result = model.transcribe(audio, batch_size=batch_size, chunk_size=chunk_size, print_progress=print_progress, verbose=verbose)
+ result: TranscriptionResult = model.transcribe(
+ audio,
+ batch_size=batch_size,
+ chunk_size=chunk_size,
+ print_progress=print_progress,
+ verbose=verbose,
+ )
results.append((result, audio_path))
# Unload Whisper and VAD
@@ -201,7 +214,16 @@ def cli():
print(f"New language found ({result['language']})! Previous was ({align_metadata['language']}), loading new alignment model for new language...")
align_model, align_metadata = load_align_model(result["language"], device)
print(">>Performing alignment...")
- result = align(result["segments"], align_model, align_metadata, input_audio, device, interpolate_method=interpolate_method, return_char_alignments=return_char_alignments, print_progress=print_progress)
+ result: AlignedTranscriptionResult = align(
+ result["segments"],
+ align_model,
+ align_metadata,
+ input_audio,
+ device,
+ interpolate_method=interpolate_method,
+ return_char_alignments=return_char_alignments,
+ print_progress=print_progress,
+ )
results.append((result, audio_path))
diff --git a/whisperx/utils.py b/whisperx/utils.py
index 16ce116e..0b440b79 100644
--- a/whisperx/utils.py
+++ b/whisperx/utils.py
@@ -214,7 +214,12 @@ class WriteTXT(ResultWriter):
def write_result(self, result: dict, file: TextIO, options: dict):
for segment in result["segments"]:
- print(segment["text"].strip(), file=file, flush=True)
+ speaker = segment.get("speaker")
+ text = segment["text"].strip()
+ if speaker is not None:
+ print(f"[{speaker}]: {text}", file=file, flush=True)
+ else:
+ print(text, file=file, flush=True)
class SubtitlesWriter(ResultWriter):
@@ -80,21 +80,40 @@ GPU execution requires the NVIDIA libraries cuBLAS 11.x and cuDNN 8.x to be inst
See other methods [here.](https://pytorch.org/get-started/previous-versions/#v200)
-### 3. Install this repo
+### 3. Install WhisperX
-`pip install git+https://github.com/m-bain/whisperx.git`
+You have several installation options:
-If already installed, update package to most recent commit
+#### Option A: Stable Release (recommended)
+Install the latest stable version from PyPI:
-`pip install git+https://github.com/m-bain/whisperx.git --upgrade`
+```bash
+pip install whisperx
+```
+
+#### Option B: Development Version
+Install the latest development version directly from GitHub (may be unstable):
-If wishing to modify this package, clone and install in editable mode:
+```bash
+pip install git+https://github.com/m-bain/whisperx.git
```
-$ git clone https://github.com/m-bain/whisperX.git
-$ cd whisperX
-$ pip install -e .
+
+If already installed, update to the most recent commit:
+
+```bash
+pip install git+https://github.com/m-bain/whisperx.git --upgrade
```
+#### Option C: Development Mode
+If you wish to modify the package, clone and install in editable mode:
+```bash
+git clone https://github.com/m-bain/whisperX.git
+cd whisperX
+pip install -e .
+```
+
+> **Note**: The development version may contain experimental features and bugs. Use the stable PyPI release for production environments.
+
You may also need to install ffmpeg, rust etc. Follow openAI instructions here https://github.com/openai/whisper#setup.
### Speaker Diarization
diff --git a/requirements.txt b/requirements.txt
index 8f1aabd6..e3bdecfe 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,7 +1,7 @@
torch>=2
torchaudio>=2
faster-whisper==1.1.0
-ctranslate2==4.4.0
+ctranslate2<4.5.0
transformers
pandas
setuptools>=65
diff --git a/setup.py b/setup.py
index 203a0790..ef7ed34b 100644
--- a/setup.py
+++ b/setup.py
@@ -1,19 +1,22 @@
import os
-import platform
import pkg_resources
from setuptools import find_packages, setup
+with open("README.md", "r", encoding="utf-8") as f:
+ long_description = f.read()
+
setup(
name="whisperx",
py_modules=["whisperx"],
- version="3.2.0",
+ version="3.3.0",
description="Time-Accurate Automatic Speech Recognition using Whisper.",
- readme="README.md",
+ long_description=long_description,
+ long_description_content_type="text/markdown",
python_requires=">=3.9, <3.13",
author="Max Bain",
url="https://github.com/m-bain/whisperx",
- license="MIT",
+ license="BSD-2-Clause",
packages=find_packages(exclude=["tests*"]),
install_requires=[
str(r)
diff --git a/whisperx/SubtitlesProcessor.py b/whisperx/SubtitlesProcessor.py
index 5ffd1afa..351b8830 100644
--- a/whisperx/SubtitlesProcessor.py
+++ b/whisperx/SubtitlesProcessor.py
@@ -1,5 +1,5 @@
import math
-from conjunctions import get_conjunctions, get_comma
+from .conjunctions import get_conjunctions, get_comma
from typing import TextIO
def normal_round(n):
diff --git a/whisperx/alignment.py b/whisperx/alignment.py
index 42d9b176..d6241bbc 100644
--- a/whisperx/alignment.py
+++ b/whisperx/alignment.py
@@ -3,7 +3,7 @@
C. Max Bain
"""
from dataclasses import dataclass
-from typing import Iterable, Union, List
+from typing import Iterable, Optional, Union, List
import numpy as np
import pandas as pd
@@ -65,7 +65,7 @@
}
-def load_align_model(language_code, device, model_name=None, model_dir=None):
+def load_align_model(language_code: str, device: str, model_name: Optional[str] = None, model_dir=None):
if model_name is None:
# use default model
if language_code in DEFAULT_ALIGN_MODELS_TORCH:
diff --git a/whisperx/asr.py b/whisperx/asr.py
index 0ea03b6c..43575c29 100644
--- a/whisperx/asr.py
+++ b/whisperx/asr.py
@@ -1,17 +1,20 @@
import os
import warnings
-from typing import List, Union, Optional, NamedTuple
+from typing import List, NamedTuple, Optional, Union
import ctranslate2
import faster_whisper
import numpy as np
import torch
+from faster_whisper.tokenizer import Tokenizer
+from faster_whisper.transcribe import TranscriptionOptions, get_ctranslate2_storage
from transformers import Pipeline
from transformers.pipelines.pt_utils import PipelineIterator
from .audio import N_SAMPLES, SAMPLE_RATE, load_audio, log_mel_spectrogram
-from .vad import load_vad_model, merge_chunks
-from .types import TranscriptionResult, SingleSegment
+from .types import SingleSegment, TranscriptionResult
+from .vad import VoiceActivitySegmentation, load_vad_model, merge_chunks
+
def find_numeral_symbol_tokens(tokenizer):
numeral_symbol_tokens = []
@@ -28,7 +31,13 @@ class WhisperModel(faster_whisper.WhisperModel):
Currently only works in non-timestamp mode and fixed prompt for all samples in batch.
'''
- def generate_segment_batched(self, features: np.ndarray, tokenizer: faster_whisper.tokenizer.Tokenizer, options: faster_whisper.transcribe.TranscriptionOptions, encoder_output = None):
+ def generate_segment_batched(
+ self,
+ features: np.ndarray,
+ tokenizer: Tokenizer,
+ options: TranscriptionOptions,
+ encoder_output=None,
+ ):
batch_size = features.shape[0]
all_tokens = []
prompt_reset_since = 0
@@ -81,7 +90,7 @@ def encode(self, features: np.ndarray) -> ctranslate2.StorageView:
# unsqueeze if batch size = 1
if len(features.shape) == 2:
features = np.expand_dims(features, 0)
- features = faster_whisper.transcribe.get_ctranslate2_storage(features)
+ features = get_ctranslate2_storage(features)
return self.model.encode(features, to_cpu=to_cpu)
@@ -94,17 +103,17 @@ class FasterWhisperPipeline(Pipeline):
# - add support for custom inference kwargs
def __init__(
- self,
- model,
- vad,
- vad_params: dict,
- options : NamedTuple,
- tokenizer=None,
- device: Union[int, str, "torch.device"] = -1,
- framework = "pt",
- language : Optional[str] = None,
- suppress_numerals: bool = False,
- **kwargs
+ self,
+ model: WhisperModel,
+ vad: VoiceActivitySegmentation,
+ vad_params: dict,
+ options: TranscriptionOptions,
+ tokenizer: Optional[Tokenizer] = None,
+ device: Union[int, str, "torch.device"] = -1,
+ framework="pt",
+ language: Optional[str] = None,
+ suppress_numerals: bool = False,
+ **kwargs,
):
self.model = model
self.tokenizer = tokenizer
@@ -156,7 +165,13 @@ def postprocess(self, model_outputs):
return model_outputs
def get_iterator(
- self, inputs, num_workers: int, batch_size: int, preprocess_params, forward_params, postprocess_params
+ self,
+ inputs,
+ num_workers: int,
+ batch_size: int,
+ preprocess_params: dict,
+ forward_params: dict,
+ postprocess_params: dict,
):
dataset = PipelineIterator(inputs, self.preprocess, preprocess_params)
if "TOKENIZERS_PARALLELISM" not in os.environ:
@@ -171,7 +186,16 @@ def stack(items):
return final_iterator
def transcribe(
- self, audio: Union[str, np.ndarray], batch_size=None, num_workers=0, language=None, task=None, chunk_size=30, print_progress = False, combined_progress=False, verbose=False
+ self,
+ audio: Union[str, np.ndarray],
+ batch_size: Optional[int] = None,
+ num_workers=0,
+ language: Optional[str] = None,
+ task: Optional[str] = None,
+ chunk_size=30,
+ print_progress=False,
+ combined_progress=False,
+ verbose=False,
) -> TranscriptionResult:
if isinstance(audio, str):
audio = load_audio(audio)
@@ -193,17 +217,23 @@ def data(audio, segments):
if self.tokenizer is None:
language = language or self.detect_language(audio)
task = task or "transcribe"
- self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
- self.model.model.is_multilingual, task=task,
- language=language)
+ self.tokenizer = Tokenizer(
+ self.model.hf_tokenizer,
+ self.model.model.is_multilingual,
+ task=task,
+ language=language,
+ )
else:
language = language or self.tokenizer.language_code
task = task or self.tokenizer.task
if task != self.tokenizer.task or language != self.tokenizer.language_code:
- self.tokenizer = faster_whisper.tokenizer.Tokenizer(self.model.hf_tokenizer,
- self.model.model.is_multilingual, task=task,
- language=language)
-
+ self.tokenizer = Tokenizer(
+ self.model.hf_tokenizer,
+ self.model.model.is_multilingual,
+ task=task,
+ language=language,
+ )
+
if self.suppress_numerals:
previous_suppress_tokens = self.options.suppress_tokens
numeral_symbol_tokens = find_numeral_symbol_tokens(self.tokenizer)
@@ -243,8 +273,7 @@ def data(audio, segments):
return {"segments": segments, "language": language}
-
- def detect_language(self, audio: np.ndarray):
+ def detect_language(self, audio: np.ndarray) -> str:
if audio.shape[0] < N_SAMPLES:
print("Warning: audio is shorter than 30s, language detection may be inaccurate.")
model_n_mels = self.model.feat_kwargs.get("feature_size")
@@ -258,33 +287,36 @@ def detect_language(self, audio: np.ndarray):
print(f"Detected language: {language} ({language_probability:.2f}) in first 30s of audio...")
return language
-def load_model(whisper_arch,
- device,
- device_index=0,
- compute_type="float16",
- asr_options=None,
- language : Optional[str] = None,
- vad_model=None,
- vad_options=None,
- model : Optional[WhisperModel] = None,
- task="transcribe",
- download_root=None,
- local_files_only=False,
- threads=4):
- '''Load a Whisper model for inference.
+
+def load_model(
+ whisper_arch: str,
+ device: str,
+ device_index=0,
+ compute_type="float16",
+ asr_options: Optional[dict] = None,
+ language: Optional[str] = None,
+ vad_model: Optional[VoiceActivitySegmentation] = None,
+ vad_options: Optional[dict] = None,
+ model: Optional[WhisperModel] = None,
+ task="transcribe",
+ download_root: Optional[str] = None,
+ local_files_only=False,
+ threads=4,
+) -> FasterWhisperPipeline:
+ """Load a Whisper model for inference.
Args:
- whisper_arch: str - The name of the Whisper model to load.
- device: str - The device to load the model on.
- compute_type: str - The compute type to use for the model.
- options: dict - A dictionary of options to use for the model.
- language: str - The language of the model. (use English for now)
- model: Optional[WhisperModel] - The WhisperModel instance to use.
- download_root: Optional[str] - The root directory to download the model to.
- local_files_only: bool - If `True`, avoid downloading the file and return the path to the local cached file if it exists.
- threads: int - The number of cpu threads to use per worker, e.g. will be multiplied by num workers.
+ whisper_arch - The name of the Whisper model to load.
+ device - The device to load the model on.
+ compute_type - The compute type to use for the model.
+ options - A dictionary of options to use for the model.
+ language - The language of the model. (use English for now)
+ model - The WhisperModel instance to use.
+ download_root - The root directory to download the model to.
+ local_files_only - If `True`, avoid downloading the file and return the path to the local cached file if it exists.
+ threads - The number of cpu threads to use per worker, e.g. will be multiplied by num workers.
Returns:
A Whisper pipeline.
- '''
+ """
if whisper_arch.endswith(".en"):
language = "en"
@@ -297,7 +329,7 @@ def load_model(whisper_arch,
local_files_only=local_files_only,
cpu_threads=threads)
if language is not None:
- tokenizer = faster_whisper.tokenizer.Tokenizer(model.hf_tokenizer, model.model.is_multilingual, task=task, language=language)
+ tokenizer = Tokenizer(model.hf_tokenizer, model.model.is_multilingual, task=task, language=language)
else:
print("No language specified, language will be first be detected for each audio file (increases inference time).")
tokenizer = None
@@ -338,7 +370,7 @@ def load_model(whisper_arch,
suppress_numerals = default_asr_options["suppress_numerals"]
del default_asr_options["suppress_numerals"]
- default_asr_options = faster_whisper.transcribe.TranscriptionOptions(**default_asr_options)
+ default_asr_options = TranscriptionOptions(**default_asr_options)
default_vad_options = {
"vad_onset": 0.500,
diff --git a/whisperx/audio.py b/whisperx/audio.py
index db210fb9..42f97b88 100644
--- a/whisperx/audio.py
+++ b/whisperx/audio.py
@@ -22,7 +22,7 @@
TOKENS_PER_SECOND = exact_div(SAMPLE_RATE, N_SAMPLES_PER_TOKEN) # 20ms per audio token
-def load_audio(file: str, sr: int = SAMPLE_RATE):
+def load_audio(file: str, sr: int = SAMPLE_RATE) -> np.ndarray:
"""
Open an audio file and read as mono waveform, resampling as necessary
diff --git a/whisperx/conjunctions.py b/whisperx/conjunctions.py
index a3d35ea6..24d63fc1 100644
--- a/whisperx/conjunctions.py
+++ b/whisperx/conjunctions.py
@@ -1,5 +1,8 @@
# conjunctions.py
+from typing import Set
+
+
conjunctions_by_language = {
'en': {'and', 'whether', 'or', 'as', 'but', 'so', 'for', 'nor', 'which', 'yet', 'although', 'since', 'unless', 'when', 'while', 'because', 'if', 'how', 'that', 'than', 'who', 'where', 'what', 'near', 'before', 'after', 'across', 'through', 'until', 'once', 'whereas', 'even', 'both', 'either', 'neither', 'though'},
'fr': {'et', 'ou', 'mais', 'parce', 'bien', 'pendant', 'quand', 'où', 'comme', 'si', 'que', 'avant', 'après', 'aussitôt', 'jusqu’à', 'à', 'malgré', 'donc', 'tant', 'puisque', 'ni', 'soit', 'bien', 'encore', 'dès', 'lorsque'},
@@ -36,8 +39,9 @@
'ur': '،'
}
-def get_conjunctions(lang_code):
+def get_conjunctions(lang_code: str) -> Set[str]:
return conjunctions_by_language.get(lang_code, set())
-def get_comma(lang_code):
- return commas_by_language.get(lang_code, ',')
\ No newline at end of file
+
+def get_comma(lang_code: str) -> str:
+ return commas_by_language.get(lang_code, ",")
diff --git a/whisperx/diarize.py b/whisperx/diarize.py
index c327c932..2a636e6e 100644
--- a/whisperx/diarize.py
+++ b/whisperx/diarize.py
@@ -5,6 +5,7 @@
import torch
from .audio import load_audio, SAMPLE_RATE
+from .types import TranscriptionResult, AlignedTranscriptionResult
class DiarizationPipeline:
@@ -18,7 +19,13 @@ def __init__(
device = torch.device(device)
self.model = Pipeline.from_pretrained(model_name, use_auth_token=use_auth_token).to(device)
- def __call__(self, audio: Union[str, np.ndarray], num_speakers=None, min_speakers=None, max_speakers=None):
+ def __call__(
+ self,
+ audio: Union[str, np.ndarray],
+ num_speakers: Optional[int] = None,
+ min_speakers: Optional[int] = None,
+ max_speakers: Optional[int] = None,
+ ):
if isinstance(audio, str):
audio = load_audio(audio)
audio_data = {
@@ -32,7 +39,11 @@ def __call__(self, audio: Union[str, np.ndarray], num_speakers=None, min_speaker
return diarize_df
-def assign_word_speakers(diarize_df, transcript_result, fill_nearest=False):
+def assign_word_speakers(
+ diarize_df: pd.DataFrame,
+ transcript_result: Union[AlignedTranscriptionResult, TranscriptionResult],
+ fill_nearest=False,
+) -> dict:
transcript_segments = transcript_result["segments"]
for seg in transcript_segments:
# assign speaker to segment (if any)
diff --git a/whisperx/transcribe.py b/whisperx/transcribe.py
index 7f10f5e3..6cbbbe55 100644
--- a/whisperx/transcribe.py
+++ b/whisperx/transcribe.py
@@ -10,8 +10,15 @@
from .asr import load_model
from .audio import load_audio
from .diarize import DiarizationPipeline, assign_word_speakers
-from .utils import (LANGUAGES, TO_LANGUAGE_CODE, get_writer, optional_float,
- optional_int, str2bool)
+from .types import AlignedTranscriptionResult, TranscriptionResult
+from .utils import (
+ LANGUAGES,
+ TO_LANGUAGE_CODE,
+ get_writer,
+ optional_float,
+ optional_int,
+ str2bool,
+)
def cli():
@@ -95,7 +102,7 @@ def cli():
align_model: str = args.pop("align_model")
interpolate_method: str = args.pop("interpolate_method")
no_align: bool = args.pop("no_align")
- task : str = args.pop("task")
+ task: str = args.pop("task")
if task == "translate":
# translation cannot be aligned
no_align = True
@@ -174,7 +181,13 @@ def cli():
audio = load_audio(audio_path)
# >> VAD & ASR
print(">>Performing transcription...")
- result = model.transcribe(audio, batch_size=batch_size, chunk_size=chunk_size, print_progress=print_progress, verbose=verbose)
+ result: TranscriptionResult = model.transcribe(
+ audio,
+ batch_size=batch_size,
+ chunk_size=chunk_size,
+ print_progress=print_progress,
+ verbose=verbose,
+ )
results.append((result, audio_path))
# Unload Whisper and VAD
@@ -201,7 +214,16 @@ def cli():
print(f"New language found ({result['language']})! Previous was ({align_metadata['language']}), loading new alignment model for new language...")
align_model, align_metadata = load_align_model(result["language"], device)
print(">>Performing alignment...")
- result = align(result["segments"], align_model, align_metadata, input_audio, device, interpolate_method=interpolate_method, return_char_alignments=return_char_alignments, print_progress=print_progress)
+ result: AlignedTranscriptionResult = align(
+ result["segments"],
+ align_model,
+ align_metadata,
+ input_audio,
+ device,
+ interpolate_method=interpolate_method,
+ return_char_alignments=return_char_alignments,
+ print_progress=print_progress,
+ )
results.append((result, audio_path))
diff --git a/whisperx/utils.py b/whisperx/utils.py
index 16ce116e..0b440b79 100644
--- a/whisperx/utils.py
+++ b/whisperx/utils.py
@@ -214,7 +214,12 @@ class WriteTXT(ResultWriter):
def write_result(self, result: dict, file: TextIO, options: dict):
for segment in result["segments"]:
- print(segment["text"].strip(), file=file, flush=True)
+ speaker = segment.get("speaker")
+ text = segment["text"].strip()
+ if speaker is not None:
+ print(f"[{speaker}]: {text}", file=file, flush=True)
+ else:
+ print(text, file=file, flush=True)
class SubtitlesWriter(ResultWriter):