diff --git a/projects/NeRF-Det/README.md b/projects/NeRF-Det/README.md
new file mode 100644
index 0000000000..93119895e9
--- /dev/null
+++ b/projects/NeRF-Det/README.md
@@ -0,0 +1,115 @@
+# NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection
+
+> [NeRF-Det: Learning Geometry-Aware Volumetric Representation for Multi-View 3D Object Detection](https://arxiv.org/abs/2307.14620)
+
+
+
+## Abstract
+
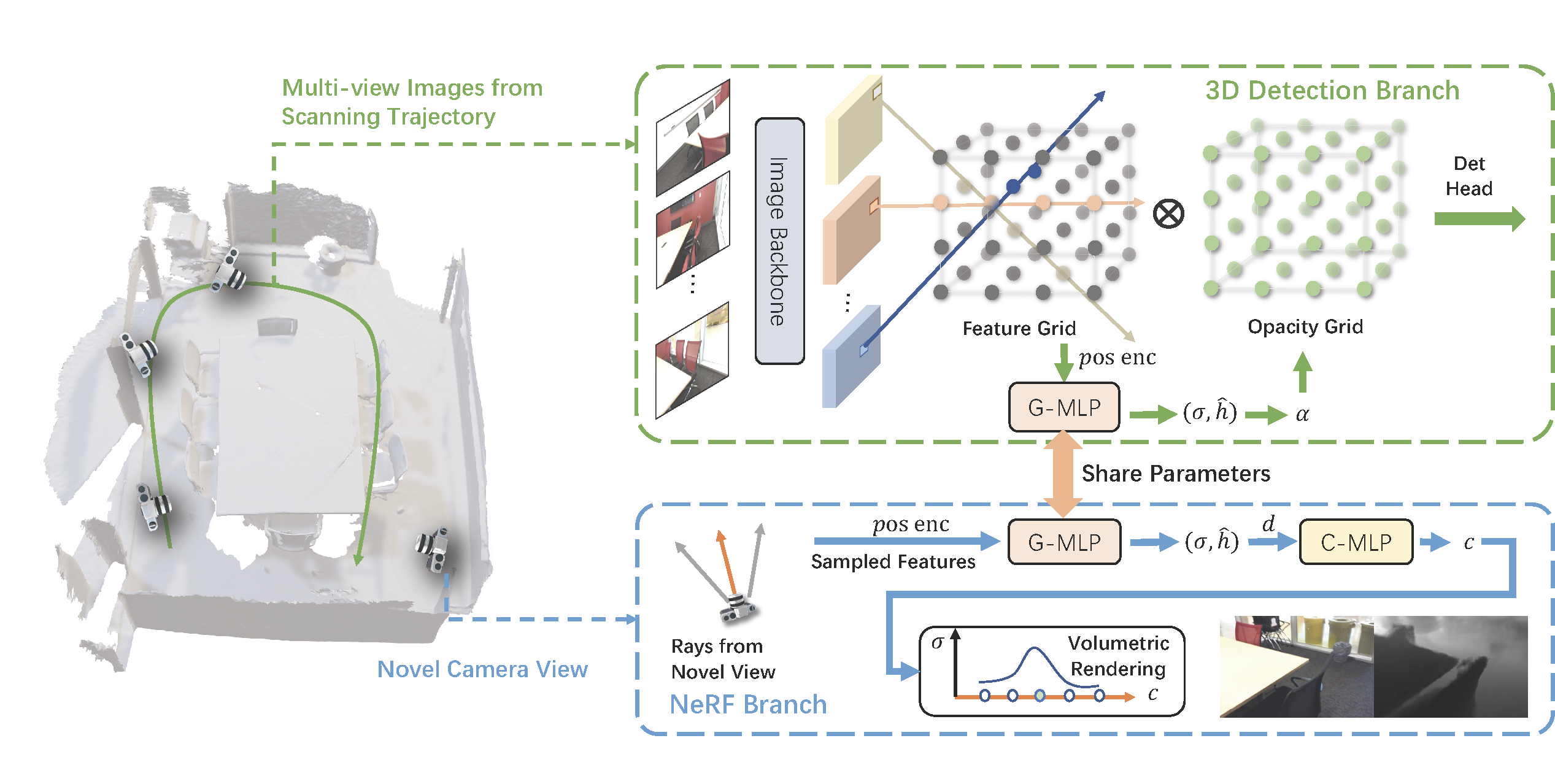
+NeRF-Det is a novel method for indoor 3D detection with posed RGB images as input. Unlike existing indoor 3D detection methods that struggle to model scene geometry, NeRF-Det makes novel use of NeRF in an end-to-end manner to explicitly estimate 3D geometry, thereby improving 3D detection performance. Specifically, to avoid the significant extra latency associated with per-scene optimization of NeRF, NeRF-Det introduce sufficient geometry priors to enhance the generalizability of NeRF-MLP. Furthermore, it subtly connect the detection and NeRF branches through a shared MLP, enabling an efficient adaptation of NeRF to detection and yielding geometry-aware volumetric representations for 3D detection. NeRF-Det outperforms state-of-the-arts by 3.9 mAP and 3.1 mAP on the ScanNet and ARKITScenes benchmarks, respectively. The author provide extensive analysis to shed light on how NeRF-Det works. As a result of joint-training design, NeRF-Det is able to generalize well to unseen scenes for object detection, view synthesis, and depth estimation tasks without requiring per-scene optimization. Code will be available at https://github.com/facebookresearch/NeRF-Det
+
+
+
+