From 436d48818d0c2e48fcb2ceb1fcb1fc411e2e192c Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Haian=20Huang=28=E6=B7=B1=E5=BA=A6=E7=9C=B8=29?=
<1286304229@qq.com>
Date: Fri, 5 Jan 2024 14:04:08 +0800
Subject: [PATCH] Bump version to 3.3.0 (#11338)
---
README.md | 44 ++---------------
README_zh-CN.md | 45 +++--------------
configs/mm_grounding_dino/README.md | 12 ++++-
configs/mm_grounding_dino/dataset_prepare.md | 2 +-
.../dataset_prepare_zh-CN.md | 4 +-
configs/mm_grounding_dino/usage.md | 7 +--
configs/mm_grounding_dino/usage_zh-CN.md | 6 +--
docker/serve/Dockerfile | 2 +-
docker/serve_cn/Dockerfile | 2 +-
docs/en/notes/changelog.md | 30 +++++++++++-
docs/en/notes/faq.md | 1 +
docs/zh_cn/notes/faq.md | 1 +
mmdet/version.py | 2 +-
tools/dataset_converters/grit_processing.py | 49 ++++++-------------
14 files changed, 82 insertions(+), 125 deletions(-)
diff --git a/README.md b/README.md
index edeac51017e..15f71dad5fb 100644
--- a/README.md
+++ b/README.md
@@ -103,50 +103,16 @@ Apart from MMDetection, we also released [MMEngine](https://github.com/open-mmla
### Highlight
-**v3.2.0** was released in 12/10/2023:
+**v3.3.0** was released in 5/1/2024:
-**1. Detection Transformer SOTA Model Collection**
-(1) Supported four updated and stronger SOTA Transformer models: [DDQ](configs/ddq/README.md), [CO-DETR](projects/CO-DETR/README.md), [AlignDETR](projects/AlignDETR/README.md), and [H-DINO](projects/HDINO/README.md).
-(2) Based on CO-DETR, MMDet released a model with a COCO performance of 64.1 mAP.
-(3) Algorithms such as DINO support `AMP/Checkpoint/FrozenBN`, which can effectively reduce memory usage.
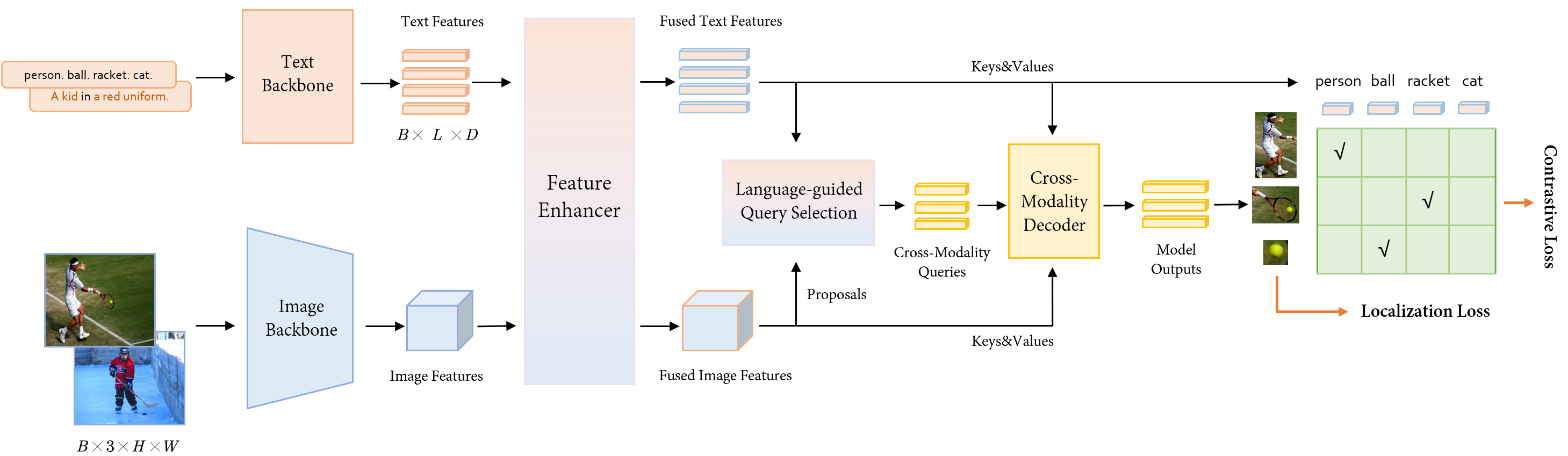
+**[MM-Grounding-DINO: An Open and Comprehensive Pipeline for Unified Object Grounding and Detection](https://arxiv.org/abs/2401.02361)**
-**2. [Comprehensive Performance Comparison between CNN and Transformer](projects/RF100-Benchmark/README.md)**
-RF100 consists of a dataset collection of 100 real-world datasets, including 7 domains. It can be used to assess the performance differences of Transformer models like DINO and CNN-based algorithms under different scenarios and data volumes. Users can utilize this benchmark to quickly evaluate the robustness of their algorithms in various scenarios.
+Grounding DINO is a grounding pre-training model that unifies 2d open vocabulary object detection and phrase grounding, with wide applications. However, its training part has not been open sourced. Therefore, we propose MM-Grounding-DINO, which not only serves as an open source replication version of Grounding DINO, but also achieves significant performance improvement based on reconstructed data types, exploring different dataset combinations and initialization strategies. Moreover, we conduct evaluations from multiple dimensions, including OOD, REC, Phrase Grounding, OVD, and Fine-tune, to fully excavate the advantages and disadvantages of Grounding pre-training, hoping to provide inspiration for future work.
-
-

-
-

+

-
-
-
+
+
+
+
+
-

+

-
+