这篇文章的目的是,教会初学者轻松掌握Git,理解Git的设计理念。
这篇文章的目的是,教会常用的、简单的、高频的Git命令。
这篇文章的目的是,不仅理解Git的操作,还能大概理解其背后的原理。
学习这篇文章最好的方法是,跟着做,一边做一边思考和理解。
本篇教程演绎自廖雪峰的 git教程,我在此基础上增加了一些细节的东西,并且会进一步深入的探究 git 的一些原理,这个系列教程会比廖雪峰的更加深入一些,可能会关于一些更有趣的内容,并且注重讲透某些命令的本质原理。
首先说明一下为什么需要使用版本管理工具。
如果只有一个文件,那么每次修改后保存一下就可以。
如果有不满足于单纯保存,想知道每次修改了哪些内容,可以每次修改都复制一份并做好命名,比如有一个文件初始名字叫 hello.txt, 第一次修改后就拷贝一份叫做 hello_v2.txt, 第二次修改就叫做 hello_v3.txt....
如果有两个文件,hello.txt 和 happy.txt, 不仅仅想知道每次修改了哪些内容,还需要知道每次修改后现在两个文件的内容,那么需要建立一个文件夹,把两个文件放进去,假设名字叫 my_file。第一次修改了 hello.txt, 那么把文件夹复制一份,改名为 my_file_v2, 第二次修改了 happy.txt, 又把文件夹复制一份,改名为 my_file_v3....
如果这两个文件夹几个协作的人都需要同时编辑,那么你还要给每个版本后面加上修改人的名字,再继续复制文件...
想象一下,在多人协作场景下,为了控制更加精细,你需要知道每一次谁修改了哪里,那么拷贝文件夹的方式可能无法胜任了!!
如果一个项目文件有成千个,那么每次拷贝文件就愈发不可能了,这个时候,版本管理工具就派上用场了!
而当下最经典最流行的版本工具就非 Git 莫属了。
Git可以在Linux、Unix、Mac和Windows这几大平台上跨平台运行。
要使用Git,第一步当然是安装Git了。可以访问 Git官网,选择自己的系统进行安装。
另外补充的是,MacOS 和 Linux 个人发行版应该是默认安装了 Git的,可以在终端使用 git --version 查看。
在这里说明一下,git 的命令风格和其他 shell 命令风格非常相似,使用 git 命令以 git SUB_COMMAND 开始,然后指定各种参数。
什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
所以,创建一个版本库非常简单,首先,选择一个合适的地方,创建一个空目录并且进入这个目录:
$ mkdir learngit && cd learngit
第二步,通过git init命令把这个目录变成Git可以管理的仓库:
$ git init
Initialized empty Git repository in /Users/liaoxuefeng/learngit/.git/
瞬间Git就把仓库建好了,而且告诉你是一个空的仓库(empty Git repository),细心的读者可以发现当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的。不要手动修改这个目录里面的文件,我也从来不曾修改过里面的文件。
如果你没有看到.git目录,那是因为这个目录默认是隐藏的,用ls -ah命令就可以看见。(MacOS用户可以使用 command + shift + . 在 finder 下查看隐藏文件)
虽然选择一个已经有文件的目录也是可以创建Git仓库的,但是在学习阶段还是先从空目录开始进行练习。
当然,也可以在别人的仓库上修改,使用到 git clone 命令,我们后续会讲到。
首先这里再明确一下,现在的版本控制系统,其实只能跟踪文本文件的改动,比如TXT文件,网页,所有的程序源代码等等,Git也不例外。
版本控制系统可以告诉你每次的改动,比如在第5行加了一个单词“Linux”,在第8行删了一个单词“Windows”。
而图片、视频这些二进制文件,虽然也能由版本控制系统管理,但没法跟踪文件的变化,只能把二进制文件每次改动串起来,也就是只知道图片从100KB改成了120KB,但到底改了啥,版本控制系统不知道,也没法知道。
原因是,文本文件的基本单位是行,Git可以清楚的看到一行的变化,而二进制文件的格式则是不同的,由产生这个文件的程序规定,所以管理起来非常的麻烦和复杂。
所以,如果要使用版本控制系统,就要以纯文本方式编写文件。比如记事本文件 *.txt,或者markdown文本,或者各种代码文件,比如 *.c, *.java, *.py, *.html 。
现在我们编写一个readme.txt文件,内容如下:
Git is a version control system.
Git is free software.
一定要放到 Git 管理的目录下(子目录也行),否则 Git 无法管理其内容。
和把大象放到冰箱需要3步相比,把一个文件放到Git仓库只需要两步。
第一步,用命令git add告诉Git,把文件添加到仓库:
$ git add readme.txt
执行上面的命令,没有任何显示,这就对了,Unix的哲学是“没有消息就是好消息”,说明添加成功。
“没有消息就是好消息”并不是一个放之四海而皆准的道理,有的时候需要消息。
因为有的时候人们渴望看到提示和反馈,比如你从自己的银行账户里存了一笔钱,你肯定希望银行给你发个消息确认一下的对吧。不要迷信什么Unix哲学。这个哲学的前提是,人们确信这是一个可靠的系统,所以不需要提示,提示了肯定是坏消息。
第二步,用命令 git commit 告诉Git,把文件提交到仓库:
$ git commit -m "wrote a readme file"
[master (root-commit) eaadf4e] wrote a readme file
1 file changed, 2 insertions(+)
create mode 100644 readme.txt
当你commit 的时候,Git 会给我们提示,因为它知道提示是必须的。可以让人确信自己的操作是对的。曾经有一个人总爱跟我强调没有消息就是好消息,一昧的不给提示和模仿Unix的行为,这是错误的!
简单解释一下git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。
git commit命令执行成功后会告诉你,1 file changed:1个文件被改动(我们新添加的readme.txt文件);2 insertions:插入了两行内容(readme.txt有两行内容)。
如何写一个好的消息呢?这个值得大书特书,现在先简单的提一下,这个消息应该是让人印象深刻,容易回忆起自己干了什么的。这个是最重要的原则,至于中文,英文,动宾结构,那都是次要的。
为什么Git添加文件需要add,commit一共两步呢?先这么记住,这确实有点烦,我们后面会解释。
因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:
$ git add file1.txt
$ git add file2.txt file3.txt
$ git commit -m "add 3 files."
我们已经成功地添加并提交了一个readme.txt文件,现在,是时候继续工作了,于是,我们继续修改readme.txt文件,改成如下内容:
Git is a distributed version control system.
Git is free software.
现在,运行git status命令看看结果:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
git status命令可以让我们时刻掌握仓库当前的状态,上面的命令输出告诉我们,readme.txt被修改过了,但还没有准备提交的修改。
虽然Git告诉我们readme.txt被修改了,但如果能看看具体修改了什么内容,自然是很好的。比如你玩了两天,再回来接着写代码,已经记不清上次怎么修改的readme.txt,所以,需要用git diff这个命令看看:
$ git diff readme.txt
diff --git a/readme.txt b/readme.txt
index 46d49bf..9247db6 100644
--- a/readme.txt
+++ b/readme.txt
@@ -1,2 +1,2 @@
-Git is a version control system.
+Git is a distributed version control system.
Git is free software.
git diff顾名思义就是查看difference,显示的格式正是Unix通用的diff格式,可以从上面的命令输出看到,我们在第一行添加了一个distributed单词。关于diff 命令的格式,我们简单介绍一下,它有一个漫长的发展史,有兴趣的可以查阅资料,但是我们现在直奔主题,来看看它到底是什么意思。
还记得我们上一次修改的文件是什么样子吗?
Git is a version control system.
Git is free software.
改成了
Git is a distributed version control system.
Git is free software.
所以, 我们来看看,Git diff怎么阅读。
@@ -1,2 +1,2 @@
- 表示第一个文件,+表示第二个文件,-1,2表示下面展示的是,第一个文件第1行开始,连续2行的内容。
-表示第一个文件的内容,+表示第二个文件的内容,没有+、-的表示没有变动的内容。
@@ -1,2 +1,2 @@
-Git is a version control system.
+Git is a distributed version control system.
Git is free software.
知道了对readme.txt作了什么修改后,再把它提交到仓库就放心多了,提交修改和提交新文件是一样的两步,第一步是git add:
$ git add readme.txt
同样没有任何输出。在执行第二步git commit之前,我们再运行git status看看当前仓库的状态:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: readme.txt
git status告诉我们,将要被提交的修改包括readme.txt,下一步,就可以放心地提交了:
$ git commit -m "add distributed"
[master e475afc] add distributed
1 file changed, 1 insertion(+), 1 deletion(-)
提交后,我们再用git status命令看看仓库的当前状态:
$ git status
On branch master
nothing to commit, working tree clean
Git告诉我们当前没有需要提交的修改,而且,工作目录是干净(working tree clean)的。
补充一下,
总结一下:
- 如果新创建了一个文件,使用
git add NEW_FILE_NAME把文件加入版本控制中。如果修改了一个已经存在于版本库中的文件,也需要使用git add UPDATED_FILE_NAME把修改加入版本控制中。 - 使用
git commit命令提交刚才的修改内容。
现在,你已经学会了修改文件,然后把修改提交到Git版本库,现在,再练习一次,修改readme.txt文件如下:
Git is a distributed version control system.
Git is free software distributed under the GPL.
然后尝试提交:
$ git add readme.txt
$ git commit -m "append GPL"
[master 1094adb] append GPL
1 file changed, 1 insertion(+), 1 deletion(-)
像这样,你不断对文件进行修改,然后不断提交修改到版本库里,就好比玩RPG游戏时,每通过一关就会自动把游戏状态存盘,如果某一关没过去,你还可以选择读取前一关的状态。有些时候,在打Boss之前,你会手动存盘,以便万一打Boss失败了,可以从最近的地方重新开始。Git也是一样,每当你觉得文件修改到一定程度的时候,就可以“保存一个快照”,这个快照在Git中被称为commit。一旦你把文件改乱了,或者误删了文件,还可以从最近的一个commit恢复,然后继续工作,而不是把几个月的工作成果全部丢失。
现在,我们回顾一下readme.txt文件一共有几个版本被提交到Git仓库里了:
版本1:wrote a readme file
Git is a version control system.
Git is free software.
版本2:add distributed
Git is a distributed version control system.
Git is free software.
版本3:append GPL
Git is a distributed version control system.
Git is free software distributed under the GPL.
当然了,在实际工作中,我们脑子里怎么可能记得一个几千行的文件每次都改了什么内容,不然要版本控制系统干什么。版本控制系统肯定有某个命令可以告诉我们历史记录,在Git中,我们用git log命令查看:
tip:git log 展示的提交历史默认顺序是从最新的到最早的,可以指定参数修改这一行为
$ git log
commit 1094adb7b9b3807259d8cb349e7df1d4d6477073 (HEAD -> master)
Author: Michael Liao <[email protected]>
Date: Fri May 18 21:06:15 2018 +0800
append GPL
commit e475afc93c209a690c39c13a46716e8fa000c366
Author: Michael Liao <[email protected]>
Date: Fri May 18 21:03:36 2018 +0800
add distributed
commit eaadf4e385e865d25c48e7ca9c8395c3f7dfaef0
Author: Michael Liao <[email protected]>
Date: Fri May 18 20:59:18 2018 +0800
wrote a readme file
git log命令显示从最近到最远的提交日志,我们可以看到3次提交,最近的一次是append GPL,上一次是add distributed,最早的一次是wrote a readme file。
如果嫌输出信息太多,看得眼花缭乱的,可以试试加上--pretty=oneline参数:
$ git log --pretty=oneline
1094adb7b9b3807259d8cb349e7df1d4d6477073 (HEAD -> master) append GPL
e475afc93c209a690c39c13a46716e8fa000c366 add distributed
eaadf4e385e865d25c48e7ca9c8395c3f7dfaef0 wrote a readme file
需要友情提示的是,你看到的一大串类似1094adb...的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示,而且你看到的commit id和我的肯定不一样,以你自己的为准。为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。
每提交一个新版本,实际上Git就会把它们自动串成一条时间线。如果使用可视化工具查看Git历史,就可以更清楚地看到提交历史的时间线:
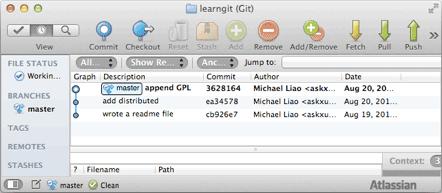
好了,现在我们启动时光穿梭机,准备把readme.txt回退到上一个版本,也就是add distributed的那个版本,怎么做呢?
首先,Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交1094adb...(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。也可以使用HEAD@{N}来表示当前指针的上N次历史记录(我更习惯的方式)。
现在,我们要把当前版本append GPL回退到上一个版本add distributed,就可以使用git reset命令:
$ git reset --hard HEAD^
HEAD is now at e475afc add distributed
--hard参数有啥意义?这个后面再讲,现在你先放心使用。
tip: --hard 中间不能有空格,否则命令无效
看看readme.txt的内容是不是版本add distributed:
$ cat readme.txt
Git is a distributed version control system.
Git is free software.
果然被还原了。
还可以继续回退到上一个版本wrote a readme file,不过且慢,然我们用git log再看看现在版本库的状态:
$ git log
commit e475afc93c209a690c39c13a46716e8fa000c366 (HEAD -> master)
Author: Michael Liao <[email protected]>
Date: Fri May 18 21:03:36 2018 +0800
add distributed
commit eaadf4e385e865d25c48e7ca9c8395c3f7dfaef0
Author: Michael Liao <[email protected]>
Date: Fri May 18 20:59:18 2018 +0800
wrote a readme file
最新的那个版本append GPL已经看不到了!好比你从21世纪坐时光穿梭机来到了19世纪,想再回去已经回不去了,肿么办?
办法其实还是有的,只要上面的命令行窗口还没有被关掉,你就可以顺着往上找啊找啊,找到那个append GPL的commit id是1094adb...,于是就可以指定回到未来的某个版本:
$ git reset --hard 1094a
HEAD is now at 83b0afe append GPL
版本号没必要写全,前几位就可以了(一般至少写前4位就够了,如果前4位不能唯一确定一个提交,多谢几位),Git会自动去找。当然也不能只写前一两位,因为Git可能会找到多个版本号,就无法确定是哪一个了。
再小心翼翼地看看readme.txt的内容:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
果然,readme 上次提交的内容又回来了。
Git的版本回退速度非常快,因为Git在内部有个指向当前版本的HEAD指针,当你回退版本的时候,Git仅仅是把HEAD从指向append GPL:
┌────┐
│HEAD│
└────┘
│
└──> ○ append GPL
│
○ add distributed
│
○ wrote a readme file
改为指向add distributed:
┌────┐
│HEAD│
└────┘
│
│ ○ append GPL
│ │
└──> ○ add distributed
│
○ wrote a readme file
然后顺便把工作区的文件更新了(--hard的缘故)。所以你让HEAD指向哪个版本号,你就把当前版本定位在哪。
现在,你回退到了某个版本,关掉了电脑,第二天早上就后悔了,想恢复到新版本怎么办?找不到新版本的commit id怎么办?
在Git中,总是有后悔药可以吃的。当你用$ git reset --hard HEAD^回退到add distributed版本时,再想恢复到append GPL,就必须找到append GPL的commit id。Git提供了一个命令git reflog用来记录你的每一次命令:
$ git reflog
e475afc HEAD@{1}: reset: moving to HEAD^
1094adb (HEAD -> master) HEAD@{2}: commit: append GPL
e475afc HEAD@{3}: commit: add distributed
eaadf4e HEAD@{4}: commit (initial): wrote a readme file
终于舒了口气,从输出可知,append GPL的commit id是1094adb,现在,你又可以乘坐时光机回到未来了。
tip: 正如你看到的那样,如果我们想版本回退,那么每一次提交说明都必须尽可能的写清楚,否则就会在代码审查的时候遇到麻烦。
总结一下:
HEAD指向的版本就是当前版本,因此,Git允许我们在版本的历史之间穿梭,使用命令git reset --hard commit_id。- 穿梭前,用
git log可以查看提交历史,以便确定要回退到哪个版本。 - 要重返未来,用
git reflog查看命令历史,以便确定要回到未来的哪个版本。
Git和其他版本控制系统如SVN的一个不同之处就是有暂存区的概念。
先来看名词解释。
就是你在电脑里能看到的目录,比如我的learngit文件夹就是一个工作区:
工作区有一个隐藏目录.git,这个不算工作区,而是Git的版本库。
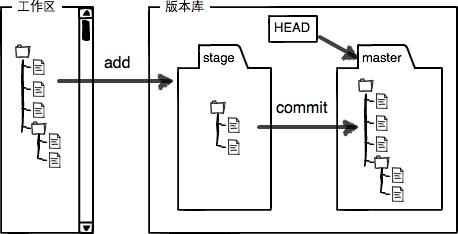
Git的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。需要说明的是,如果仓库里一次提交都没有的话,是没有 master 分支的。
分支和HEAD的概念我们以后再讲。
前面讲了我们把文件往Git版本库里添加的时候,是分两步执行的:
第一步是用git add把文件添加进去,实际上就是把文件修改添加到暂存区;
第二步是用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支。
因为我们创建Git版本库时,Git自动为我们创建了唯一一个master分支,所以,现在,git commit就是往master分支上提交更改。
你可以简单理解为,需要提交的文件修改通通放到暂存区,然后,一次性提交暂存区的所有修改。
俗话说,实践出真知。现在,我们再练习一遍,先对readme.txt做个修改,比如加上一行内容:
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
然后,在工作区新增一个LICENSE文本文件(内容随便写)。
先用git status查看一下状态:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
Untracked files:
(use "git add <file>..." to include in what will be committed)
LICENSE
no changes added to commit (use "git add" and/or "git commit -a")
Git非常清楚地告诉我们,readme.txt被修改了,而LICENSE还从来没有被添加过,所以它的状态是Untracked。
现在,使用两次命令git add,把readme.txt和LICENSE都添加后,用git status再查看一下:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: LICENSE
modified: readme.txt
现在,暂存区的状态就变成这样了:
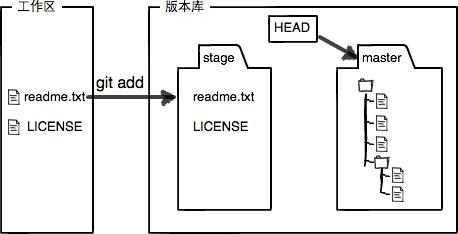
所以,git add命令实际上就是把要提交的所有修改放到暂存区(Stage),然后,执行git commit就可以一次性把暂存区的所有修改提交到分支。
$ git commit -m "understand how stage works"
[master e43a48b] understand how stage works
2 files changed, 2 insertions(+)
create mode 100644 LICENSE
一旦提交后,如果你又没有对工作区做任何修改,那么工作区就是“干净”的:
$ git status
On branch master
nothing to commit, working tree clean
现在版本库变成了这样,暂存区就没有任何内容了:
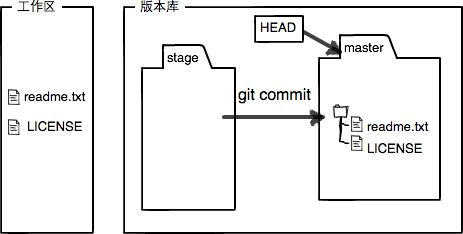
总结一下:
- 想要修改需要两步,先把修改放到暂存区,然后再从暂存区提交到版本库。
- 暂存区的好处是,修改的文件不一定需要立即提交,可以选择自己想提交的内容进行提交。
现在,假定你已经完全掌握了暂存区的概念。下面,我们要讨论的就是,为什么Git比其他版本控制系统设计得优秀,因为Git跟踪并管理的是修改,而非文件。
你会问,什么是修改?比如你新增了一行,这就是一个修改,删除了一行,也是一个修改,更改了某些字符,也是一个修改,删了一些又加了一些,也是一个修改,甚至创建一个新文件,也算一个修改。
为什么说Git管理的是修改,而不是文件呢?我们还是做实验。第一步,对readme.txt做一个修改,比如加一行内容:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes.
然后,添加:
$ git add readme.txt
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: readme.txt
#
然后,再修改readme.txt:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes of files.
提交:
$ git commit -m "git tracks changes"
[master 519219b] git tracks changes
1 file changed, 1 insertion(+)
提交后,再看看状态:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
咦,怎么第二次的修改没有被提交?
别激动,我们回顾一下操作过程:
第一次修改 -> git add -> 第二次修改 -> git commit
你看,我们前面讲了,Git管理的是修改,当你用git add命令后,在工作区的第一次修改被放入暂存区,准备提交,但是,在工作区的第二次修改并没有放入暂存区,所以,git commit只负责把暂存区的修改提交了,也就是第一次的修改被提交了,第二次的修改不会被提交。
提交后,用git diff HEAD -- readme.txt命令可以查看工作区和版本库里面最新版本的区别( --表示后面是一个可选参数,和Linux的shell风格一致, HEAD表示最后一次提交的指针):
$ git diff HEAD -- readme.txt
diff --git a/readme.txt b/readme.txt
index 76d770f..a9c5755 100644
--- a/readme.txt
+++ b/readme.txt
@@ -1,4 +1,4 @@
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
-Git tracks changes.
+Git tracks changes of files.
可见,第二次修改确实没有被提交。
那怎么提交第二次修改呢?你可以继续git add再git commit,也可以别着急提交第一次修改,先git add第二次修改,再git commit,就相当于把两次修改合并后一块提交了:
第一次修改 -> git add -> 第二次修改 -> git add -> git commit
总结一下:
- 如上一节所说,修改的步骤是,先加入暂存区,再提交暂存区的内容。如果修改了没有加入暂存区,那么修改的内容就不会被提交。
Git也有很高的容错率,比如,你不小心在readme.txt中添加了一行字:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes of files.
adfafadfadfaadadfadfadadfadfadfadadfafds
在你准备提交前,你发现最后一行字是错误的,这行字是你不小心手压倒键盘了,一串毫无意义的文字。
既然错误发现得很及时,就可以很容易地纠正它。你可以删掉最后一行,手动把文件恢复到上一个版本的状态。如果用git status查看一下:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
你可以发现,Git会告诉你,git checkout -- file可以丢弃工作区的修改:
$ git checkout -- readme.txt
命令git checkout -- readme.txt意思就是,把readme.txt文件在工作区的修改全部撤销,这里有两种情况:
一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;
一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。
总之,就是让这个文件回到最近一次git commit或git add时的状态。
现在,看看readme.txt的文件内容:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes of files.
文件内容果然复原了。
git checkout -- file命令中的--很重要,没有--,就变成了“切换到另一个分支”的命令,我们在后面的分支管理中会再次遇到git checkout命令。
现在假定是凌晨3点,你不但写了一些胡话,还git add到暂存区了:
$ cat readme.txt
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes of files.
adfafadfadfaadadfadfadadfadfadfadadfafds.
$ git add readme.txt
庆幸的是,在commit之前,你发现了这个问题。用git status查看一下,修改只是添加到了暂存区,还没有提交:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: readme.txt
Git同样告诉我们,用命令git reset HEAD <file>可以把暂存区的修改撤销掉(unstage),重新放回工作区:
$ git reset HEAD readme.txt
Unstaged changes after reset:
M readme.txt
git reset命令既可以回退版本,也可以把暂存区的修改回退到工作区。当我们用HEAD时,表示最新的版本。
再用git status查看一下,现在暂存区是干净的,工作区有修改:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
还记得如何丢弃工作区的修改吗?
$ git checkout -- readme.txt
$ git status
On branch master
nothing to commit, working tree clean
整个世界终于清静了!
tip: 再复习一下,这个命令
git checkout -- FILE_NAME的解释是:使用暂存区的内容覆盖工作区的内容,而暂存区的内容在使用 git add 命令之前是和版本区最新的内容保持一致的。如何恢复暂存区的内容呢?使用 git reset HEAD 即可取消所有暂存动作,恢复暂存区到最后一次提交内容。
现在,假设你不但改错了东西,还从暂存区提交到了版本库,怎么办呢?还记得版本回退一节吗?可以回退到上一个版本。不过,这是有条件的,就是你还没有把自己的本地版本库推送到远程。还记得Git是分布式版本控制系统吗?我们后面会讲到远程版本库,一旦你把提交推送到远程版本库,你就真的惨了……
小结一下:
场景1:当你改乱了工作区某个文件的内容,想直接丢弃工作区的修改时,用命令git checkout -- file。
场景2:当你不但改乱了工作区某个文件的内容,还添加到了暂存区时,想丢弃修改,分两步,第一步用命令git reset HEAD <file>,就回到了场景1,第二步按场景1操作。
场景3:已经提交了不合适的修改到版本库时,想要撤销本次提交,参考版本回退一节,不过前提是没有推送到远程库。
在Git中,删除也是一个修改操作,我们实战一下,先添加一个新文件test.txt到Git并且提交:
$ git add test.txt
$ git commit -m "add test.txt"
[master b84166e] add test.txt
1 file changed, 1 insertion(+)
create mode 100644 test.txt
一般情况下,你通常直接在文件管理器中把没用的文件删了,或者用rm命令删了:
$ rm test.txt
这个时候,Git知道你删除了文件,因此,工作区和版本库就不一致了,git status命令会立刻告诉你哪些文件被删除了:
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: test.txt
no changes added to commit (use "git add" and/or "git commit -a")
现在你有两个选择,一是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit:
$ git rm test.txt
rm 'test.txt'
$ git commit -m "remove test.txt"
[master d46f35e] remove test.txt
1 file changed, 1 deletion(-)
delete mode 100644 test.txt
现在,文件就从版本库中被删除了。
小提示:先手动删除文件,然后使用git rm 和git add效果是一样的。
另一种情况是删错了,因为版本库里还有呢,所以可以很轻松地把误删的文件恢复到最新版本:
$ git checkout -- test.txt
git checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。
注意:从来没有被添加到版本库就被删除的文件,是无法恢复的!
小结一下:
命令git rm用于删除一个文件。
如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最后提交的版本,你会丢失最近一次提交后你修改的内容。
到目前为止,我们已经掌握了如何在Git仓库里对一个文件进行时光穿梭,你再也不用担心文件备份或者丢失的问题了。
可是有用过集中式版本控制系统SVN的同学会站出来说,这些功能在SVN里早就有了,没看出Git有什么特别的地方。
没错,如果只是在一个仓库里管理文件历史,Git和SVN真没啥区别。为了保证你现在所学的Git物超所值,将来绝对不会后悔,同时为了打击已经不幸学了SVN的同学,本章开始介绍Git的杀手级功能之一:远程仓库。
Git是分布式版本控制系统,同一个Git仓库,可以分布到不同的机器上。怎么分布呢?最早,肯定只有一台机器有一个原始版本库,此后,别的机器可以“克隆”这个原始版本库,而且每台机器的版本库其实都是一样的,并没有主次之分。
你肯定会想,至少需要两台机器才能玩远程库不是?但是我只有一台电脑,怎么玩?
其实一台电脑上也是可以克隆多个版本库的,只要不在同一个目录下。不过,现实生活中是不会有人这么傻的在一台电脑上搞几个远程库玩,因为一台电脑上搞几个远程库完全没有意义,而且硬盘挂了会导致所有库都挂掉,所以我也不告诉你在一台电脑上怎么克隆多个仓库。
实际情况往往是这样,找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个“服务器”仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。
完全可以自己搭建一台运行Git的服务器,不过现阶段,为了学Git先搭个服务器绝对是小题大作。好在这个世界上有个叫GitHub的神奇的网站,从名字就可以看出,这个网站就是提供Git仓库托管服务的,所以,只要注册一个GitHub账号,就可以免费获得Git远程仓库。
在继续阅读后续内容前,请自行注册GitHub账号。由于你的本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,所以,需要一点设置:
第1步:创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,打开Shell(Windows下打开Git Bash),创建SSH Key:
$ ssh-keygen -t rsa -C "[email protected]"
你需要把邮件地址换成你自己的邮件地址,然后一路回车,使用默认值即可,由于这个Key也不是用于军事目的,所以也无需设置密码。
如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去,id_rsa.pub是公钥,可以放心地告诉任何人。
第2步:登陆GitHub,打开“Account settings”,“SSH Keys”页面:
然后,点“Add SSH Key”,填上任意Title,在Key文本框里粘贴id_rsa.pub文件的内容:
点“Add Key”,你就应该看到已经添加的Key:
为什么GitHub需要SSH Key呢?因为GitHub需要识别出你推送的提交确实是你推送的,而不是别人冒充的,而Git支持SSH协议,所以,GitHub只要知道了你的公钥,就可以确认只有你自己才能推送。
当然,GitHub允许你添加多个Key。假定你有若干电脑,你一会儿在公司提交,一会儿在家里提交,只要把每台电脑的Key都添加到GitHub,就可以在每台电脑上往GitHub推送了。
最后友情提示,在GitHub上免费托管的Git仓库,任何人都可以看到喔(但只有你自己才能改)。所以,不要把敏感信息放进去。
如果你不想让别人看到Git库,有两个办法,一个是把GitHub公开的仓库变成私有的,这样别人就看不见了。另一个办法是自己动手,搭一个Git服务器,因为是你自己的Git服务器,所以别人也是看不见的。这个方法我们后面会讲到的,相当简单,公司内部开发必备。
确保你拥有一个GitHub账号后,我们就即将开始远程仓库的学习。
现在的情景是,你已经在本地创建了一个Git仓库后,又想在GitHub创建一个Git仓库,并且让这两个仓库进行远程同步,这样,GitHub上的仓库既可以作为备份,又可以让其他人通过该仓库来协作,真是一举多得。
首先,登陆GitHub,然后,在右上角找到“Create a new repo”按钮,创建一个新的仓库:
在Repository name填入learngit,其他保持默认设置,点击“Create repository”按钮,就成功地创建了一个新的Git仓库:
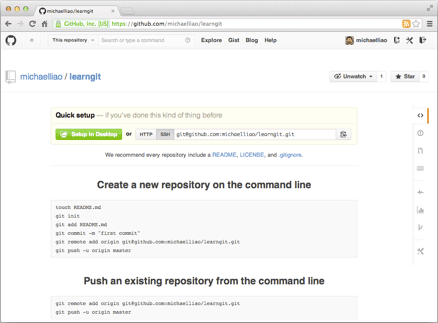
目前,在GitHub上的这个learngit仓库还是空的,GitHub告诉我们,可以从这个仓库克隆出新的仓库,也可以把一个已有的本地仓库与之关联,然后,把本地仓库的内容推送到GitHub仓库。
现在,我们根据GitHub的提示,在本地的learngit仓库下运行命令:
$ git remote add origin [email protected]:michaelliao/learngit.git
请千万注意,把上面的michaelliao替换成你自己的GitHub账户名,否则,你在本地关联的就是我的远程库,关联没有问题,但是你以后推送是推不上去的,因为你的SSH Key公钥不在我的账户列表中。
添加后,远程库的名字就是origin,这是Git默认的叫法,也可以改成别的,但是origin这个名字一看就知道是远程库。
下一步,就可以把本地库的所有内容推送到远程库上:
$ git push -u origin master
Counting objects: 20, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (15/15), done.
Writing objects: 100% (20/20), 1.64 KiB | 560.00 KiB/s, done.
Total 20 (delta 5), reused 0 (delta 0)
remote: Resolving deltas: 100% (5/5), done.
To github.com:michaelliao/learngit.git
* [new branch] master -> master
Branch 'master' set up to track remote branch 'master' from 'origin'.
把本地库的内容推送到远程,用git push命令,实际上是把当前分支master推送到远程。
由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
推送成功后,可以立刻在GitHub页面中看到远程库的内容已经和本地一模一样:
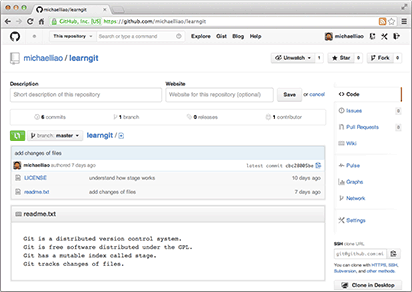
从现在起,只要本地作了提交,就可以通过命令:
$ git push origin master
把本地master分支的最新修改推送至GitHub,现在,你就拥有了真正的分布式版本库!
当你第一次使用Git的clone或者push命令连接GitHub时,会得到一个警告:
The authenticity of host 'github.com (xx.xx.xx.xx)' can't be established.
RSA key fingerprint is xx.xx.xx.xx.xx.
Are you sure you want to continue connecting (yes/no)?
这是因为Git使用SSH连接,而SSH连接在第一次验证GitHub服务器的Key时,需要你确认GitHub的Key的指纹信息是否真的来自GitHub的服务器,输入yes回车即可。
Git会输出一个警告,告诉你已经把GitHub的Key添加到本机的一个信任列表里了:
Warning: Permanently added 'github.com' (RSA) to the list of known hosts.
这个警告只会出现一次,后面的操作就不会有任何警告了。
如果你实在担心有人冒充GitHub服务器,输入yes前可以对照GitHub的RSA Key的指纹信息是否与SSH连接给出的一致。
小结
要关联一个远程库,使用命令git remote add origin git@server-name:path/repo-name.git;
关联后,使用命令git push -u origin master第一次推送master分支的所有内容;
此后,每次本地提交后,只要有必要,就可以使用命令git push origin master推送最新修改;
分布式版本系统的最大好处之一是在本地工作完全不需要考虑远程库的存在,也就是有没有联网都可以正常工作,而SVN在没有联网的时候是拒绝干活的!当有网络的时候,再把本地提交推送一下就完成了同步,真是太方便了!
上次我们讲了先有本地库,后有远程库的时候,如何关联远程库。
现在,假设我们从零开发,那么最好的方式是先创建远程库,然后,从远程库克隆。
首先,登陆GitHub,创建一个新的仓库,名字叫gitskills:
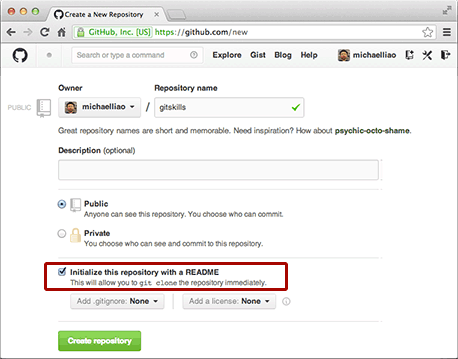
我们勾选Initialize this repository with a README,这样GitHub会自动为我们创建一个README.md文件。创建完毕后,可以看到README.md文件:
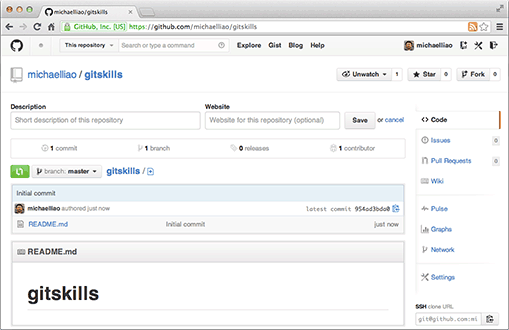
现在,远程库已经准备好了,下一步是用命令git clone克隆一个本地库:
$ git clone [email protected]:michaelliao/gitskills.git
Cloning into 'gitskills'...
remote: Counting objects: 3, done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 3
Receiving objects: 100% (3/3), done.
注意把Git库的地址换成你自己的,然后进入gitskills目录看看,已经有README.md文件了:
$ cd gitskills
$ ls
README.md
如果有多个人协作开发,那么每个人各自从远程克隆一份就可以了。
你也许还注意到,GitHub给出的地址不止一个,还可以用https://github.com/michaelliao/gitskills.git这样的地址。实际上,Git支持多种协议,默认的git://使用ssh,但也可以使用https等其他协议。
使用https除了速度慢以外,还有个最大的麻烦是每次推送都必须输入口令,但是在某些只开放http端口的公司内部就无法使用ssh协议而只能用https。
tip: 在下载Git项目上,很多时候都是直接使用https url克隆到本地,当然也可以使用SSH url克隆到本地。
这两种方式的主要区别在于:使用https url 克隆对初学者来说会比较方便,但是每次fetch和push代码都需要输入账号和密码,而使用SSH url克隆仓库后,每次push代码都不需要输入账号和密码(push的前提是你拥有推送的权限),如果你想要每次都输入账号密码才能进行fetch和push也可以另外进行设置。
使用ssh 协议的url全称,以上面的地址为例是 ssh://[email protected]/michaelliao/gitskills.git
小结一下:
要克隆一个仓库,首先必须知道仓库的地址,然后使用git clone命令克隆。
Git支持多种协议,包括https,但ssh协议速度最快。
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN。
如果两个平行宇宙互不干扰,那对现在的你也没啥影响。不过,在某个时间点,两个平行宇宙合并了,结果,你既学会了Git又学会了SVN!
分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。
现在有了分支,就不用怕了。你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样,既安全,又不影响别人工作。
其他版本控制系统如SVN等都有分支管理,但是用过之后你会发现,这些版本控制系统创建和切换分支比蜗牛还慢,简直让人无法忍受,结果分支功能成了摆设,大家都不去用。
但Git的分支是与众不同的,无论创建、切换和删除分支,Git在1秒钟之内就能完成!无论你的版本库是1个文件还是1万个文件。
在版本回退里,你已经知道,每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支。截止到目前,只有一条时间线,在Git里,这个分支叫主分支,即master分支。HEAD严格来说不是指向提交,而是指向master,master才是指向提交的,所以,HEAD指向的就是当前分支。
一开始的时候,master分支是一条线,Git用master指向最新的提交,再用HEAD指向master,就能确定当前分支,以及当前分支的提交点:
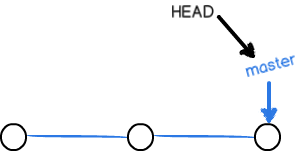
每次提交,master分支都会向前移动一步,这样,随着你不断提交,master分支的线也越来越长。
当我们创建新的分支,例如dev时,Git新建了一个指针叫dev,指向master相同的提交,再把HEAD指向dev,就表示当前分支在dev上:
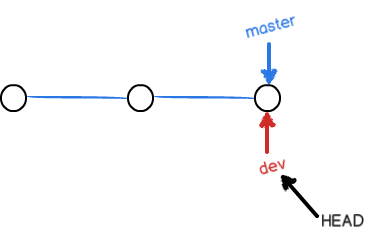
你看,Git创建一个分支很快,因为除了增加一个dev指针,改改HEAD的指向,工作区的文件都没有任何变化!
不过,从现在开始,对工作区的修改和提交就是针对dev分支了,比如新提交一次后,dev指针往前移动一步,而master指针不变:
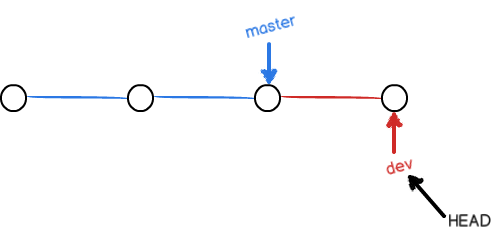
假如我们在dev上的工作完成了,就可以把dev合并到master上。Git怎么合并呢?最简单的方法,就是直接把master指向dev的当前提交,就完成了合并:
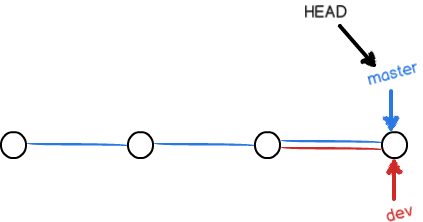
所以Git合并分支也很快!就改改指针,工作区内容也不变!
合并完分支后,甚至可以删除dev分支。删除dev分支就是把dev指针给删掉,删掉后,我们就剩下了一条master分支:
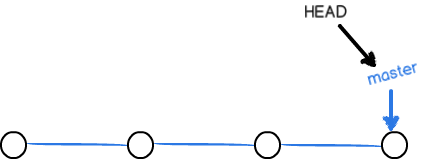
真是太神奇了,你看得出来有些提交是通过分支完成的吗?
下面开始实战。
首先,我们创建dev分支,然后切换到dev分支:
$ git checkout -b dev
Switched to a new branch 'dev'
git checkout命令加上-b参数表示创建并切换,相当于以下两条命令:
$ git branch dev
$ git checkout dev
Switched to branch 'dev'
然后,用git branch命令查看当前分支:
$ git branch
* dev
master
git branch命令会列出所有分支,当前分支前面会标一个*号。
然后,我们就可以在dev分支上正常提交,比如对readme.txt做个修改,加上一行:
Creating a new branch is quick.
然后提交:
$ git add readme.txt
$ git commit -m "branch test"
[dev b17d20e] branch test
1 file changed, 1 insertion(+)
现在,dev分支的工作完成,我们就可以切换回master分支:
$ git checkout master
Switched to branch 'master'
切换回master分支后,再查看一个readme.txt文件,刚才添加的内容不见了!因为那个提交是在dev分支上,而master分支此刻的提交点并没有变:
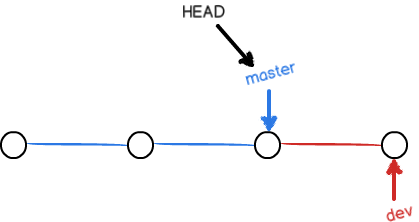
现在,我们把dev分支的工作成果合并到master分支上:
$ git merge dev
Updating d46f35e..b17d20e
Fast-forward
readme.txt | 1 +
1 file changed, 1 insertion(+)
git merge命令用于合并指定分支到当前分支。合并后,再查看readme.txt的内容,就可以看到,和dev分支的最新提交是完全一样的。也就是说,被合并的分支中含有当前分支不具有的提交,合并的结果是,让当前分支拥有了被合并分支的内容,而被合并分支本身并没有发生变化,而且一直存在。
注意到上面的Fast-forward信息,Git告诉我们,这次合并是“快进模式”,也就是直接把master指向dev的当前提交,所以合并速度非常快。
当然,也不是每次合并都能Fast-forward,我们后面会讲其他方式的合并。
合并完成后,就可以放心地删除dev分支了:
$ git branch -d dev
Deleted branch dev (was b17d20e).
删除后,查看branch,就只剩下master分支了:
$ git branch
* master
因为创建、合并和删除分支非常快,所以Git鼓励你使用分支完成某个任务,合并后再删掉分支,这和直接在master分支上工作效果是一样的,但过程更安全。
小结一下:
Git鼓励大量使用分支:
查看分支:git branch
创建分支:git branch <name>
切换分支:git checkout <name>或者git switch <name>
创建+切换分支:git checkout -b <name>或者git switch -c <name>
合并某分支到当前分支:git merge <name>
删除分支:git branch -d <name>
人生不如意之事十之八九,合并分支往往也不是一帆风顺的。
准备新的feature1分支,继续我们的新分支开发:
$ git checkout -b feature1
Switched to a new branch 'feature1'
修改readme.txt最后一行,改为:
Creating a new branch is quick AND simple.
在feature1分支上提交:
$ git add readme.txt
$ git commit -m "AND simple"
[feature1 14096d0] AND simple
1 file changed, 1 insertion(+), 1 deletion(-)
切换到master分支:
$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
Git还会自动提示我们当前master分支比远程的master分支要超前1个提交。
在master分支上把readme.txt文件的最后一行改为:
Creating a new branch is quick & simple.
提交:
$ git add readme.txt
$ git commit -m "& simple"
[master 5dc6824] & simple
1 file changed, 1 insertion(+), 1 deletion(-)
现在,master分支和feature1分支各自都分别有新的提交,变成了这样:
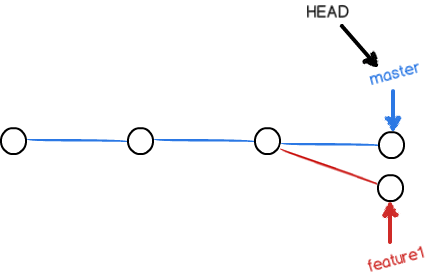
这种情况下,Git无法执行“快速合并”,只能试图把各自的修改合并起来,但这种合并就可能会有冲突,我们试试看:
$ git merge feature1
Auto-merging readme.txt
CONFLICT (content): Merge conflict in readme.txt
Automatic merge failed; fix conflicts and then commit the result.
果然冲突了!Git告诉我们,readme.txt文件存在冲突,必须手动解决冲突后再提交。git status也可以告诉我们冲突的文件:
$ git status
On branch master
Your branch is ahead of 'origin/master' by 2 commits.
(use "git push" to publish your local commits)
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
我们可以直接查看readme.txt的内容:
Git is a distributed version control system.
Git is free software distributed under the GPL.
Git has a mutable index called stage.
Git tracks changes of files.
<<<<<<< HEAD
Creating a new branch is quick & simple.
=======
Creating a new branch is quick AND simple.
>>>>>>> feature1
Git用<<<<<<<,=======,>>>>>>>标记出不同分支的内容,我们修改如下后保存:
Creating a new branch is quick and simple.
再提交:
$ git add readme.txt
$ git commit -m "conflict fixed"
[master cf810e4] conflict fixed
现在,master分支和feature1分支变成了下图所示:
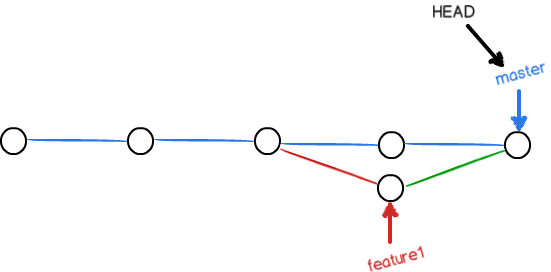
用带参数的git log也可以看到分支的合并情况:
$ git log --graph --pretty=oneline --abbrev-commit
* cf810e4 (HEAD -> master) conflict fixed
|\
| * 14096d0 (feature1) AND simple
* | 5dc6824 & simple
|/
* b17d20e branch test
* d46f35e (origin/master) remove test.txt
* b84166e add test.txt
* 519219b git tracks changes
* e43a48b understand how stage works
* 1094adb append GPL
* e475afc add distributed
* eaadf4e wrote a readme file
最后,删除feature1分支:
$ git branch -d feature1
Deleted branch feature1 (was 14096d0).
工作完成。
小结一下:
当Git无法自动合并分支时,就必须首先解决冲突。解决冲突后,再提交,合并完成。
解决冲突就是把Git合并失败的文件手动编辑为我们希望的内容,再提交。
用git log --graph命令可以看到分支合并图。
通常,合并分支时,如果可能,Git会用Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息。
如果要强制禁用Fast forward模式,Git就会在merge时生成一个新的commit,这样,从分支历史上就可以看出分支信息。
下面我们实战一下--no-ff方式的git merge:
首先,仍然创建并切换dev分支:
$ git checkout -b dev
Switched to a new branch 'dev'
修改readme.txt文件,并提交一个新的commit:
$ git add readme.txt
$ git commit -m "add merge"
[dev f52c633] add merge
1 file changed, 1 insertion(+)
现在,我们切换回master:
$ git switch master
Switched to branch 'master'
准备合并dev分支,请注意--no-ff参数,表示禁用Fast forward:
$ git merge --no-ff -m "merge with no-ff" dev
Merge made by the 'recursive' strategy.
readme.txt | 1 +
1 file changed, 1 insertion(+)
因为本次合并要创建一个新的commit,所以加上-m参数,把commit描述写进去。
合并后,我们用git log看看分支历史:
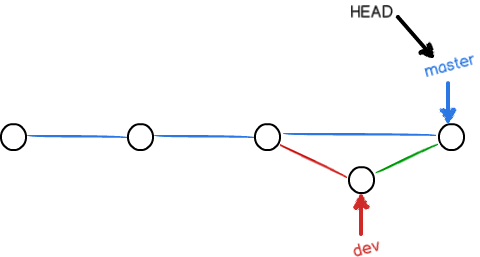
$ git log --graph --pretty=oneline --abbrev-commit
* e1e9c68 (HEAD -> master) merge with no-ff
|\
| * f52c633 (dev) add merge
|/
* cf810e4 conflict fixed
...
可以看到,不使用Fast forward模式,merge后就像这样:
在实际开发中,我们应该按照几个基本原则进行分支管理:
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
那在哪干活呢?干活都在dev分支上,也就是说,dev分支是不稳定的,到某个时候,比如1.0版本发布时,再把dev分支合并到master上,在master分支发布1.0版本;
你和你的小伙伴们每个人都在dev分支上干活,每个人都有自己的分支,时不时地往dev分支上合并就可以了。
所以,团队合作的分支看起来就像这样:
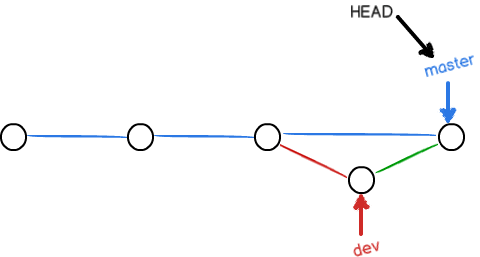
小结一下:
Git分支十分强大,在团队开发中应该充分应用。
合并分支时,加上--no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并,而fast forward合并就看不出来曾经做过合并。
软件开发中,bug就像家常便饭一样。有了bug就需要修复,在Git中,由于分支是如此的强大,所以,每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。
当你接到一个修复一个代号101的bug的任务时,很自然地,你想创建一个分支issue-101来修复它,但是,等等,当前正在dev上进行的工作还没有提交:
$ git status
On branch dev
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: hello.py
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
并不是你不想提交,而是工作只进行到一半,还没法提交,预计完成还需1天时间。但是,必须在两个小时内修复该bug,怎么办?
幸好,Git还提供了一个stash功能,可以把当前工作现场“储藏”起来,等以后恢复现场后继续工作:
$ git stash
Saved working directory and index state WIP on dev: f52c633 add merge
现在,用git status查看工作区,就是干净的(除非有没有被Git管理的文件),因此可以放心地创建分支来修复bug。
首先确定要在哪个分支上修复bug,假定需要在master分支上修复,就从master创建临时分支:
$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 6 commits.
(use "git push" to publish your local commits)
$ git checkout -b issue-101
Switched to a new branch 'issue-101'
现在修复bug,需要把“Git is free software ...”改为“Git is a free software ...”,然后提交:
$ git add readme.txt
$ git commit -m "fix bug 101"
[issue-101 4c805e2] fix bug 101
1 file changed, 1 insertion(+), 1 deletion(-)
修复完成后,切换到master分支,并完成合并,最后删除issue-101分支:
$ git checkout master
Switched to branch 'master'
Your branch is ahead of 'origin/master' by 6 commits.
(use "git push" to publish your local commits)
$ git merge --no-ff -m "merged bug fix 101" issue-101
Merge made by the 'recursive' strategy.
readme.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
太棒了,原计划两个小时的bug修复只花了5分钟!现在,是时候接着回到dev分支干活了!
$ git switch dev
Switched to branch 'dev'
$ git status
On branch dev
nothing to commit, working tree clean
工作区是干净的,刚才的工作现场存到哪去了?用git stash list命令看看:
$ git stash list
stash@{0}: WIP on dev: f52c633 add merge
工作现场还在,Git把stash内容存在某个地方了,但是需要恢复一下,有两个办法:
一是用git stash apply恢复,但是恢复后,stash内容并不删除,你需要用git stash drop来删除;
另一种方式是用git stash pop,恢复的同时把stash内容也删了:
$ git stash pop
On branch dev
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: hello.py
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: readme.txt
Dropped refs/stash@{0} (5d677e2ee266f39ea296182fb2354265b91b3b2a)
再用git stash list查看,就看不到任何stash内容了:
$ git stash list
你可以多次stash,恢复的时候,先用git stash list查看,然后恢复指定的stash,用命令:
$ git stash apply stash@{0}
在master分支上修复了bug后,我们要想一想,dev分支是早期从master分支分出来的,所以,这个bug其实在当前dev分支上也存在。
那怎么在dev分支上修复同样的bug?重复操作一次,提交不就行了?
有木有更简单的方法?
有!
同样的bug,要在dev上修复,我们只需要把4c805e2 fix bug 101这个提交所做的修改“复制”到dev分支。注意:我们只想复制4c805e2 fix bug 101这个提交所做的修改,并不是把整个master分支merge过来。
为了方便操作,Git专门提供了一个cherry-pick命令,让我们能复制一个特定的提交到当前分支:
$ git branch
* dev
master
$ git cherry-pick 4c805e2
[master 1d4b803] fix bug 101
1 file changed, 1 insertion(+), 1 deletion(-)
Git自动给dev分支做了一次提交,注意这次提交的commit是1d4b803,它并不同于master的4c805e2,因为这两个commit只是改动相同,但确实是两个不同的commit。用git cherry-pick,我们就不需要在dev分支上手动再把修bug的过程重复一遍。
有些聪明的同学会想了,既然可以在master分支上修复bug后,在dev分支上可以“重放”这个修复过程,那么直接在dev分支上修复bug,然后在master分支上“重放”行不行?当然可以,不过你仍然需要git stash命令保存现场,才能从dev分支切换到master分支。
小结一下:
修复bug时,我们会通过创建新的bug分支进行修复,然后合并,最后删除;
当手头工作没有完成时,先把工作现场git stash一下,然后去修复bug,修复后,再git stash pop,回到工作现场;
在master分支上修复的bug,想要合并到当前dev分支,可以用git cherry-pick <commit>命令,把bug提交的修改“复制”到当前分支,避免重复劳动。
软件开发中,总有无穷无尽的新的功能要不断添加进来。
添加一个新功能时,你肯定不希望因为一些实验性质的代码,把主分支搞乱了,所以,每添加一个新功能,最好新建一个feature分支,在上面开发,完成后,合并,最后,删除该feature分支。
现在,你终于接到了一个新任务:开发代号为Vulcan的新功能,该功能计划用于下一代星际飞船。
于是准备开发:
$ git checkout -b feature-vulcan
Switched to a new branch 'feature-vulcan'
5分钟后,开发完毕:
$ git add vulcan.py
$ git status
On branch feature-vulcan
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: vulcan.py
$ git commit -m "add feature vulcan"
[feature-vulcan 287773e] add feature vulcan
1 file changed, 2 insertions(+)
create mode 100644 vulcan.py
切回dev,准备合并:
$ git checkout dev
一切顺利的话,feature分支和bug分支是类似的,合并,然后删除。
但是!
就在此时,接到上级命令,因经费不足,新功能必须取消!
虽然白干了,但是这个包含机密资料的分支还是必须就地销毁:
$ git branch -d feature-vulcan
error: The branch 'feature-vulcan' is not fully merged.
If you are sure you want to delete it, run 'git branch -D feature-vulcan'.
销毁失败。Git友情提醒,feature-vulcan分支还没有被合并,如果删除,将丢失掉修改,如果要强行删除,需要使用大写的-D参数。。
现在我们强行删除:
$ git branch -D feature-vulcan
Deleted branch feature-vulcan (was 287773e).
终于删除成功!
小结一下:
开发一个新feature,最好新建一个分支;
如果要丢弃一个没有被合并过的分支,可以通过git branch -D <name>强行删除。
当你从远程仓库克隆时,实际上Git自动把本地的master分支和远程的master分支对应起来了,并且,远程仓库的默认名称是origin。
要查看远程库的信息,用git remote:
$ git remote
origin
或者,用git remote -v显示更详细的信息:
$ git remote -v
origin [email protected]:michaelliao/learngit.git (fetch)
origin [email protected]:michaelliao/learngit.git (push)
上面显示了可以抓取和推送的origin的地址。如果没有推送权限,就看不到push的地址。
推送分支,就是把该分支上的所有本地提交推送到远程库。推送时,要指定本地分支,这样,Git就会把该分支推送到远程库对应的远程分支上:
$ git push origin master
如果要推送其他分支,比如dev,就改成:
$ git push origin dev
但是,并不是一定要把本地分支往远程推送,那么,哪些分支需要推送,哪些不需要呢?
master分支是主分支,因此要时刻与远程同步;dev分支是开发分支,团队所有成员都需要在上面工作,所以也需要与远程同步;- bug分支只用于在本地修复bug,就没必要推到远程了,除非老板要看看你每周到底修复了几个bug;
- feature分支是否推到远程,取决于你是否和你的小伙伴合作在上面开发。
总之,就是在Git中,分支完全可以在本地自己藏着玩,是否推送,视你的心情而定!
多人协作时,大家都会往master和dev分支上推送各自的修改。
现在,模拟一个你的小伙伴,可以在另一台电脑(注意要把SSH Key添加到GitHub)或者同一台电脑的另一个目录下克隆:
$ git clone [email protected]:michaelliao/learngit.git
Cloning into 'learngit'...
remote: Counting objects: 40, done.
remote: Compressing objects: 100% (21/21), done.
remote: Total 40 (delta 14), reused 40 (delta 14), pack-reused 0
Receiving objects: 100% (40/40), done.
Resolving deltas: 100% (14/14), done.
当你的小伙伴从远程库clone时,默认情况下,你的小伙伴只能看到本地的master分支。不信可以用git branch命令看看:
$ git branch
* master
现在,你的小伙伴要在dev分支上开发,就必须创建远程origin的dev分支到本地,于是他用这个命令创建本地dev分支:
$ git checkout -b dev origin/dev
现在,他就可以在dev上继续修改,然后,时不时地把dev分支push到远程:
$ git add env.txt
$ git commit -m "add env"
[dev 7a5e5dd] add env
1 file changed, 1 insertion(+)
create mode 100644 env.txt
$ git push origin dev
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 308 bytes | 308.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To github.com:michaelliao/learngit.git
f52c633..7a5e5dd dev -> dev
你的小伙伴已经向origin/dev分支推送了他的提交,而碰巧你也对同样的文件作了修改,并试图推送:
$ cat env.txt
env
$ git add env.txt
$ git commit -m "add new env"
[dev 7bd91f1] add new env
1 file changed, 1 insertion(+)
create mode 100644 env.txt
$ git push origin dev
To github.com:michaelliao/learngit.git
! [rejected] dev -> dev (non-fast-forward)
error: failed to push some refs to '[email protected]:michaelliao/learngit.git'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Integrate the remote changes (e.g.
hint: 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
推送失败,因为你的小伙伴的最新提交和你试图推送的提交有冲突,解决办法也很简单,Git已经提示我们,先用git pull把最新的提交从origin/dev抓下来,然后,在本地合并,解决冲突,再推送:
$ git pull
There is no tracking information for the current branch.
Please specify which branch you want to merge with.
See git-pull(1) for details.
git pull <remote> <branch>
If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=origin/<branch> dev
git pull也失败了,原因是没有指定本地dev分支与远程origin/dev分支的链接,根据提示,设置dev和origin/dev的链接:
$ git branch --set-upstream-to=origin/dev dev
Branch 'dev' set up to track remote branch 'dev' from 'origin'.
再pull:
$ git pull
Auto-merging env.txt
CONFLICT (add/add): Merge conflict in env.txt
Automatic merge failed; fix conflicts and then commit the result.
这回git pull成功,但是合并有冲突,需要手动解决,解决的方法和分支管理中的解决冲突完全一样。解决后,提交,再push:
$ git commit -m "fix env conflict"
[dev 57c53ab] fix env conflict
$ git push origin dev
Counting objects: 6, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (6/6), 621 bytes | 621.00 KiB/s, done.
Total 6 (delta 0), reused 0 (delta 0)
To github.com:michaelliao/learngit.git
7a5e5dd..57c53ab dev -> dev
因此,多人协作的工作模式通常是这样:
- 首先,可以试图用
git push origin <branch-name>推送自己的修改; - 如果推送失败,则因为远程分支比你的本地更新,需要先用
git pull试图合并; - 如果合并有冲突,则解决冲突,并在本地提交;
- 没有冲突或者解决掉冲突后,再用
git push origin <branch-name>推送就能成功!
如果git pull提示no tracking information,则说明本地分支和远程分支的链接关系没有创建,用命令git branch --set-upstream-to <branch-name> origin/<branch-name>。
这就是多人协作的工作模式,一旦熟悉了,就非常简单。
小结一下
- 查看远程库信息,使用
git remote -v; - 本地新建的分支如果不推送到远程,对其他人就是不可见的;
- 从本地推送分支,使用
git push origin branch-name,如果推送失败,先用git pull抓取远程的新提交; - 在本地创建和远程分支对应的分支,使用
git checkout -b branch-name origin/branch-name,本地和远程分支的名称最好一致; - 建立本地分支和远程分支的关联,使用
git branch --set-upstream branch-name origin/branch-name; - 从远程抓取分支,使用
git pull,如果有冲突,要先处理冲突。
集中式和分布式版本控制系统有什么区别呢?
先说集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
集中式版本控制系统最大的毛病就是必须联网才能工作,每次修改的内容都要推送到中央仓库。如果在局域网内还好,可如果在互联网上,遇到网速慢的话,就会阻塞在向服务器提交的过程中,因为提交期间,你是不能对文件做其他的修改的。
那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
当然,分布式也有坏处。必须一次下载所有的文件,因为要保证一个完整的版本库。而集中式的好处则恰恰是分布式的坏处,集中式的版本控制可以只下载一部分文件,并且随时与系统保持同步。
集中式工具包括CVS、SVN。
而分布式的经典代表则是Git。最快、最简单也最流行!其优势包括单机运行,高效分支管理。
值得说明的是,现在有很多传统软件公司内部开发可能因为遗留因素还在使用集中式代码管理工具,并不能说不好,只能说向后兼容。另外,在一个大家都熟悉SVN的团队里强行推行Git也是一个隐患,应该考虑使用习惯、熟练度和学习成本。没有必要为了用Git而用Git,说到底,工具没有优劣之分,只有合适与否。
Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了。
Linus虽然创建了Linux,但Linux的壮大是靠社区志愿者协作努力的,代码管理相当的麻烦。在2002年以前,世界各地的志愿者把源代码文件通过diff的方式(Unix下的文件对比格式)发给Linus,然后由Linus本人通过手工方式合并。
为什么Linus不把Linux代码放到版本控制系统里呢?
因为Linus坚定地反对CVS和SVN等等类似的集中式版本控制工具,这些集中式的版本控制系统面对全世界各地的开发者,速度相当的慢,而且必须联网才能使用。
不过,到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区开发者也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。
在2005年,由于一些不愉快的事情,BitMover公司收回了Linux社区的对于其BitKeeper免费使用权。然后Linus自己用C写了一个分布式版本控制系统,这就是Git的初始版本,并且很快就可以正式使用了。
后来,Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
现在,各大互联网公司应该都在使用Git作为其代码版本管理工具。git 非常的流行,作为开发人员和计算机专业人员,绝对值得学习。
这个教程大概说了一下 git 的入门使用手段,下个文章我们会详细讨论一下比较高级的主题,比如 rebase, cherry-pick 等等,如果你对此感兴趣,可以关注一下下次的更新。