
Figure: Data Science Africa http://datascienceafrica.org is a ground up initiative for capacity building around data science, machine learning and artificial intelligence on the African continent.
+Figure: Data Science Africa http://datascienceafrica.org is a ground up initiative +for capacity building around data science, machine learning and +artificial intelligence on the African continent.
Data Science Africa is a bottom up initiative for capacity building in data science, machine learning and artificial intelligence on the African continent.
-As of 2019 there have been five workshops and five schools, located in Nyeri, Kenya (twice); Kampala, Uganda; Arusha, Tanzania; Abuja, Nigeria; Addis Ababa, Ethiopia and Accra, Ghana. The next event is scheduled for June 2020 in Kampala, Uganda.
-The main notion is end-to-end data science. For example, going from data collection in the farmer’s field to decision making in the Ministry of Agriculture. Or going from malaria disease counts in health centers to medicine distribution.
-The philosophy is laid out in (Lawrence 2015). The key idea is that the modern information infrastructure presents new solutions to old problems. Modes of development change because less capital investment is required to take advantage of this infrastructure. The philosophy is that local capacity building is the right way to leverage these challenges in addressing data science problems in the African context.
-Data Science Africa is now a non-govermental organization registered in Kenya. The organising board of the meeting is entirely made up of scientists and academics based on the African continent.
+
+Figure: Data Science Africa meetings held up to October 2021.
+Data Science Africa is a bottom up initiative for capacity building +in data science, machine learning and artificial intelligence on the +African continent.
+As of May 2023 there have been eleven workshops and schools, located +in seven different countries: Nyeri, Kenya (twice); Kampala, Uganda; +Arusha, Tanzania; Abuja, Nigeria; Addis Ababa, Ethiopia; Accra, Ghana; +Kampala, Uganda and Kimberley, South Africa (virtual), and in Kigali, +Rwanda.
+The main notion is end-to-end data science. For example, +going from data collection in the farmer’s field to decision making in +the Ministry of Agriculture. Or going from malaria disease counts in +health centers to medicine distribution.
+The philosophy is laid out in (Lawrence, 2015). The key idea is +that the modern information infrastructure presents new +solutions to old problems. Modes of development change because less +capital investment is required to take advantage of this infrastructure. +The philosophy is that local capacity building is the right way to +leverage these challenges in addressing data science problems in the +African context.
+Data Science Africa is now a non-govermental organization registered +in Kenya. The organising board of the meeting is entirely made up of +scientists and academics based on the African continent.
 +
+
Figure: The lack of existing physical infrastructure on the African continent makes it a particularly interesting environment for deploying solutions based on the information infrastructure. The idea is explored more in this Guardian op-ed on Guardian article on How African can benefit from the data revolution.
-Figure: The lack of existing physical infrastructure on the African +continent makes it a particularly interesting environment for deploying +solutions based on the information infrastructure. The idea is +explored more in this Guardian op-ed on Guardian article on How +African can benefit from the data revolution.
+Guardian article on Data +Science Africa
+Example: +Prediction of Malaria Incidence in Uganda
+ -Guardian article on Data Science Africa
-Example: Prediction of Malaria Incidence in Uganda
-[edit]
As an example of using Gaussian process models within the full pipeline from data to decsion, we’ll consider the prediction of Malaria incidence in Uganda. For the purposes of this study malaria reports come in two forms, HMIS reports from health centres and Sentinel data, which is curated by the WHO. There are limited sentinel sites and many HMIS sites.
-The work is from Ricardo Andrade Pacheco’s PhD thesis, completed in collaboration with John Quinn and Martin Mubangizi (Andrade-Pacheco et al. 2014; Mubangizi et al. 2014). John and Martin were initally from the AI-DEV group from the University of Makerere in Kampala and more latterly they were based at UN Global Pulse in Kampala.
-Malaria data is spatial data. Uganda is split into districts, and health reports can be found for each district. This suggests that models such as conditional random fields could be used for spatial modelling, but there are two complexities with this. First of all, occasionally districts split into two. Secondly, sentinel sites are a specific location within a district, such as Nagongera which is a sentinel site based in the Tororo district.
+As an example of using Gaussian process models within the full +pipeline from data to decsion, we’ll consider the prediction of Malaria +incidence in Uganda. For the purposes of this study malaria reports come +in two forms, HMIS reports from health centres and Sentinel data, which +is curated by the WHO. There are limited sentinel sites and many HMIS +sites.
+The work is from Ricardo Andrade Pacheco’s PhD thesis, completed in +collaboration with John Quinn and Martin Mubangizi (Andrade-Pacheco +et al., 2014; Mubangizi et al., 2014). John and Martin were +initally from the AI-DEV group from the University of Makerere in +Kampala and more latterly they were based at UN Global Pulse in Kampala. +You can see the work summarized on the UN Global Pulse disease +outbreaks project site here.
+ +Malaria data is spatial data. Uganda is split into districts, and +health reports can be found for each district. This suggests that models +such as conditional random fields could be used for spatial modelling, +but there are two complexities with this. First of all, occasionally +districts split into two. Secondly, sentinel sites are a specific +location within a district, such as Nagongera which is a sentinel site +based in the Tororo district.
 +
+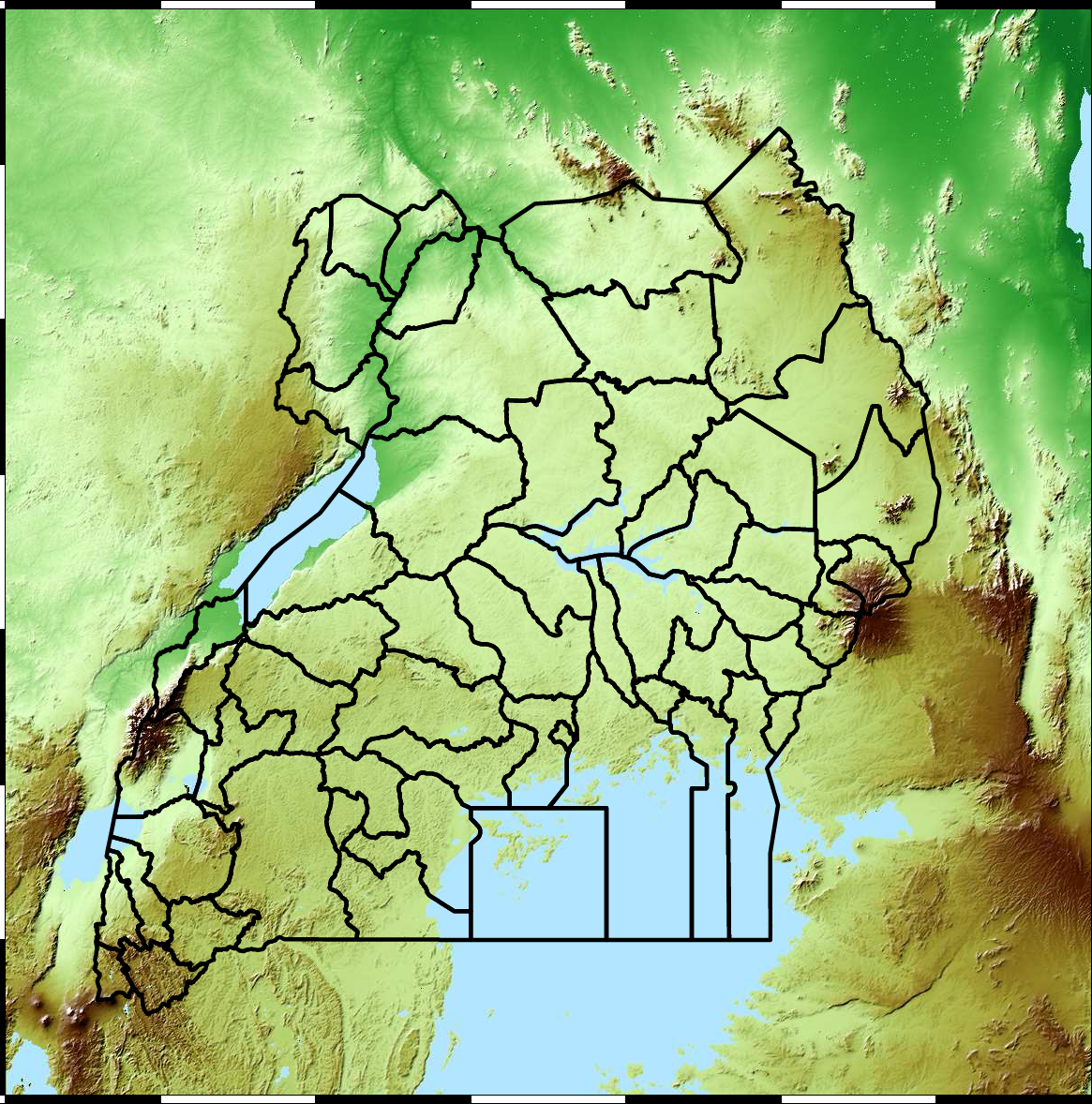
Figure: Ugandan districs. Data SRTM/NASA from https://dds.cr.usgs.gov/srtm/version2_1.
+Figure: Ugandan districts. Data SRTM/NASA from https://dds.cr.usgs.gov/srtm/version2_1.
(Andrade-Pacheco et al. 2014; Mubangizi et al. 2014)
-The common standard for collecting health data on the African continent is from the Health management information systems (HMIS). However, this data suffers from missing values (Gething et al. 2006) and diagnosis of diseases like typhoid and malaria may be confounded.
+The common standard for collecting health data on the African +continent is from the Health management information systems (HMIS). +However, this data suffers from missing values (Gething et al., 2006) and diagnosis +of diseases like typhoid and malaria may be confounded.
Figure: The Tororo district, where the sentinel site, Nagongera, is located.
+Figure: The Tororo district, where the sentinel site, Nagongera, is +located.
World Health Organization Sentinel Surveillance systems are set up “when high-quality data are needed about a particular disease that cannot be obtained through a passive system”. Several sentinel sites give accurate assessment of malaria disease levels in Uganda, including a site in Nagongera.
+World +Health Organization Sentinel Surveillance systems are set up “when +high-quality data are needed about a particular disease that cannot be +obtained through a passive system”. Several sentinel sites give accurate +assessment of malaria disease levels in Uganda, including a site in +Nagongera.
 +
+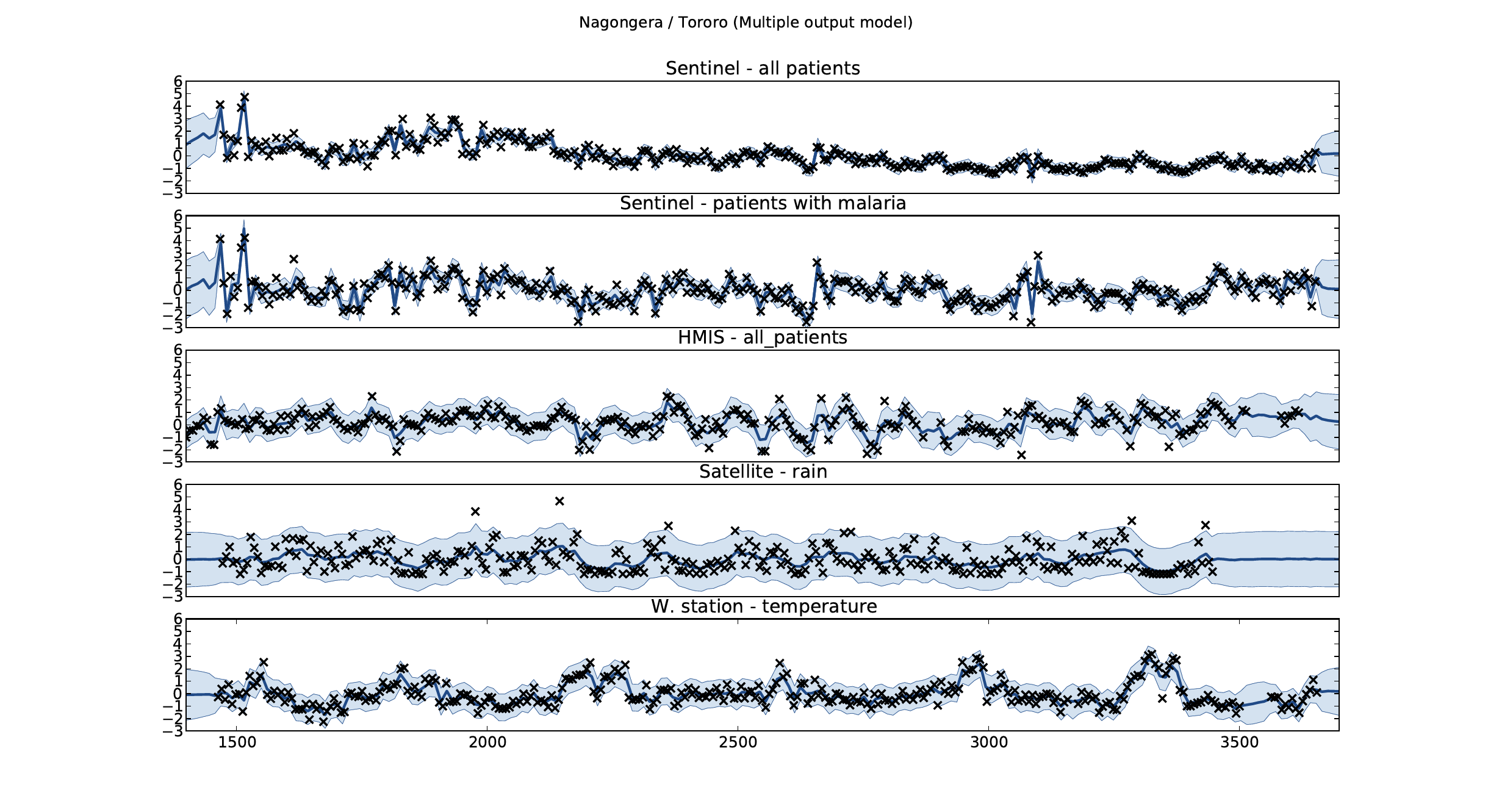
Figure: Sentinel and HMIS data along with rainfall and temperature for the Nagongera sentinel station in the Tororo district.
-In collaboration with the AI Research Group at Makerere we chose to investigate whether Gaussian process models could be used to assimilate information from these two different sources of disease informaton. Further, we were interested in whether local information on rainfall and temperature could be used to improve malaria estimates.
-The aim of the project was to use WHO Sentinel sites, alongside rainfall and temperature, to improve predictions from HMIS data of levels of malaria.
+Figure: Sentinel and HMIS data along with rainfall and temperature +for the Nagongera sentinel station in the Tororo district.
+In collaboration with the AI Research Group at Makerere we chose to +investigate whether Gaussian process models could be used to assimilate +information from these two different sources of disease informaton. +Further, we were interested in whether local information on rainfall and +temperature could be used to improve malaria estimates.
+The aim of the project was to use WHO Sentinel sites, alongside +rainfall and temperature, to improve predictions from HMIS data of +levels of malaria.
Example: Prediction o
- +
+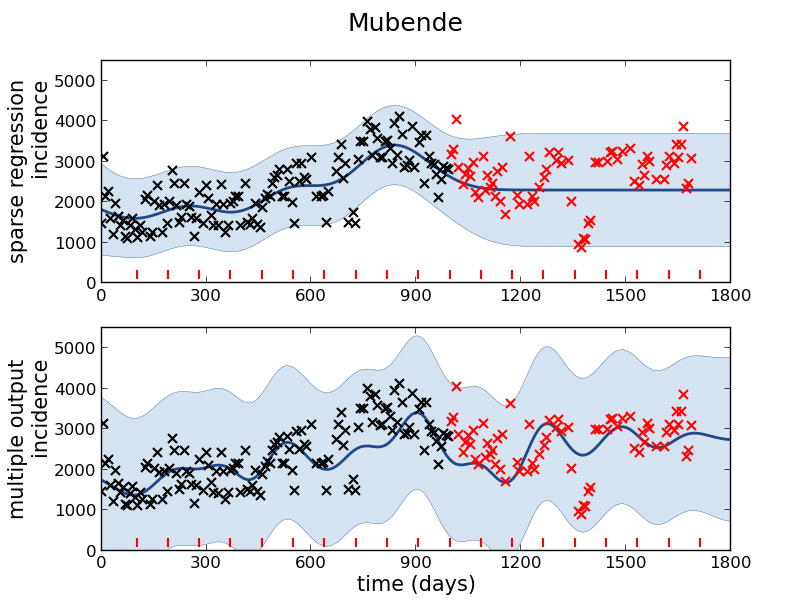 -
+
@@ -182,24 +294,27 @@
-
+
@@ -182,24 +294,27 @@ Example: Prediction o
-
- +
+
+
+ -
-Figure: The project arose out of the Gaussian process summer school held at Makerere in Kampala in 2013. The school led, in turn, to the Data Science Africa initiative.
+Figure: The project arose out of the Gaussian process summer school
+held at Makerere in Kampala in 2013. The school led, in turn, to the
+Data Science Africa initiative.
Early Warning Systems
-
-
+
@@ -209,347 +324,940 @@ Early Warning Systems
- +
+ -
+
-
-
+
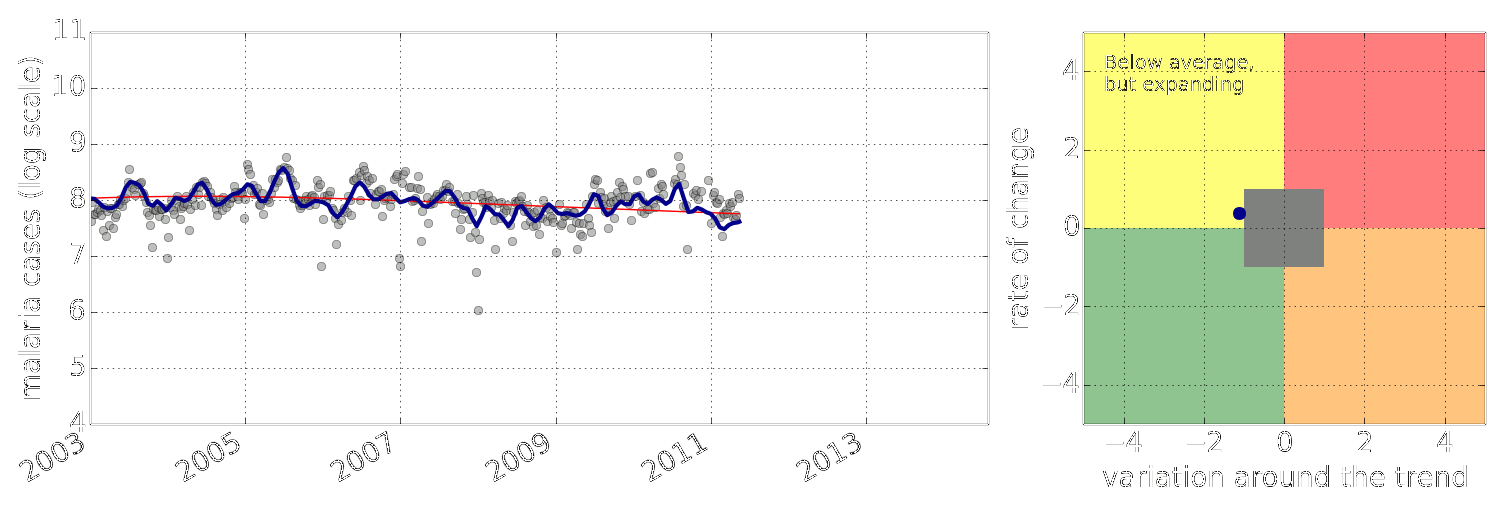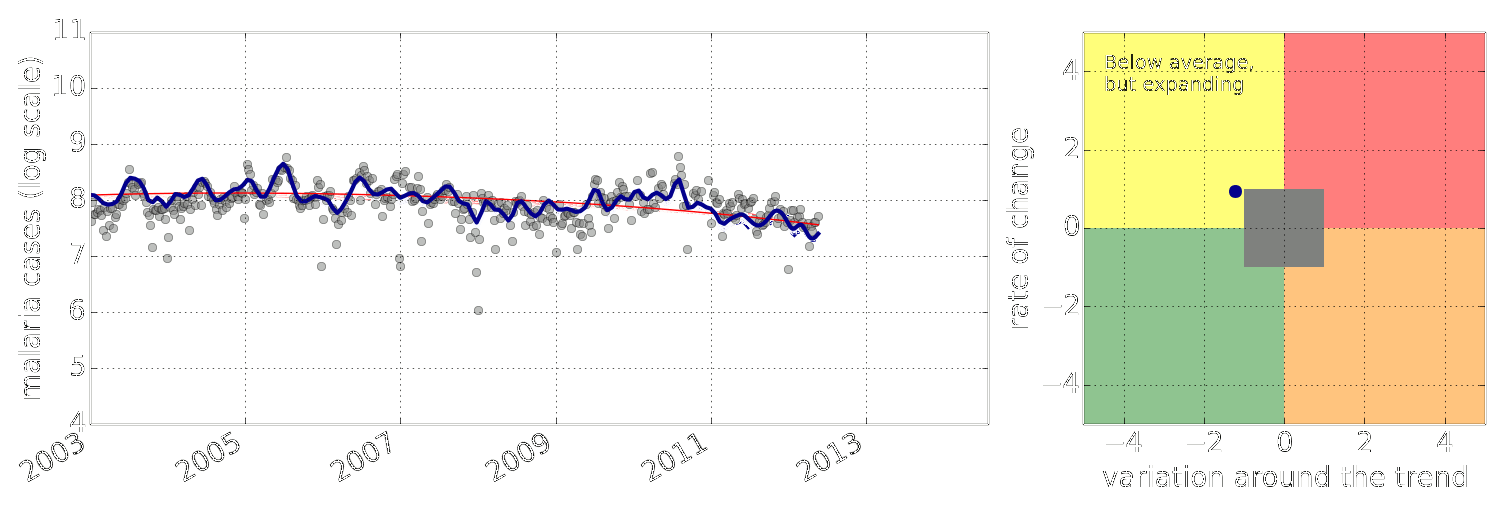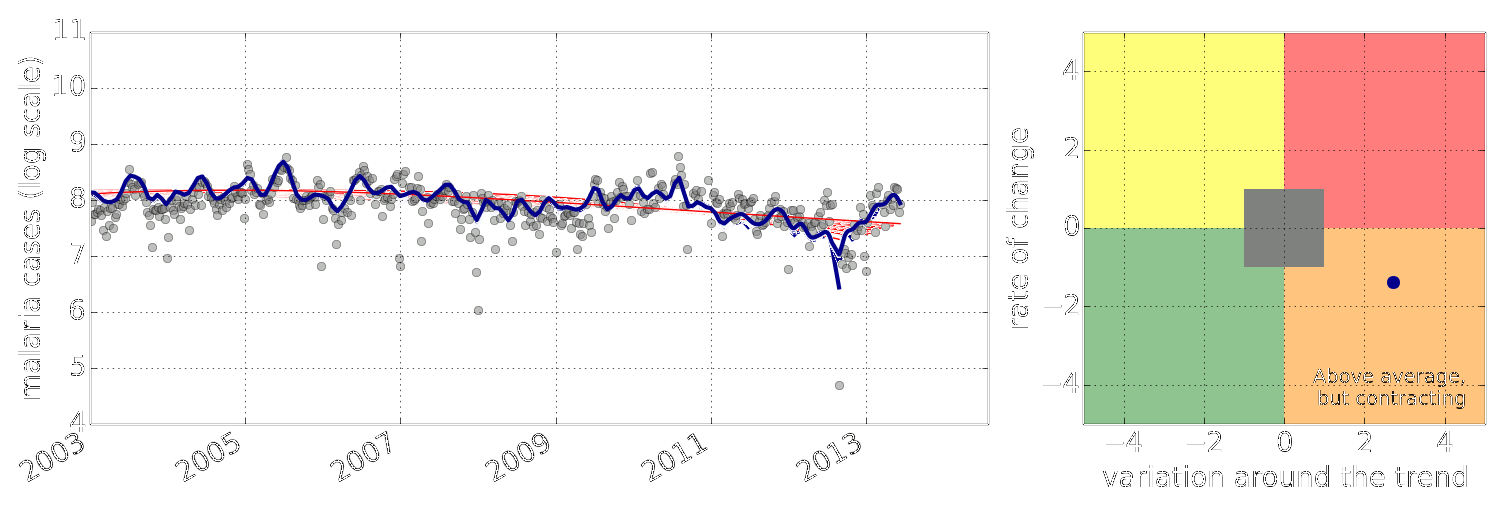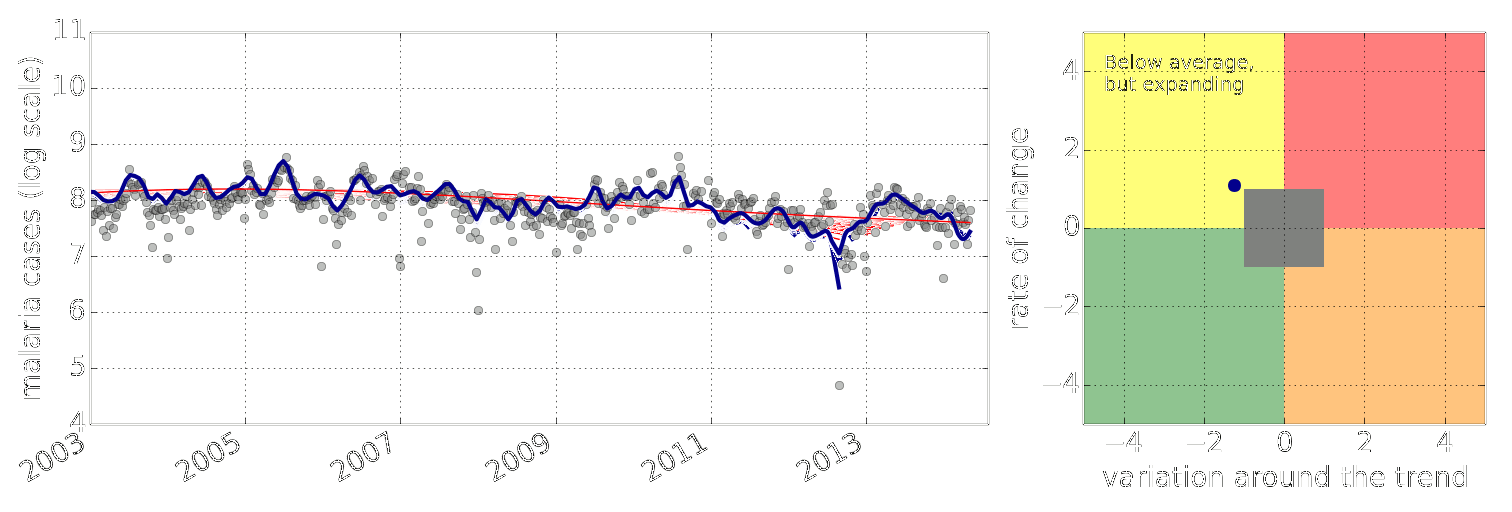
-Figure: Estimate of the current disease situation in the Kabarole district over time. Estimate is constructed with a Gaussian process with an additive covariance funciton.
-
-
-Health monitoring system for the Kabarole district. Here we have fitted the reports with a Gaussian process with an additive covariance function. It has two components, one is a long time scale component (in red above) the other is a short time scale component (in blue).
-Monitoring proceeds by considering two aspects of the curve. Is the blue line (the short term report signal) above the red (which represents the long term trend? If so we have higher than expected reports. If this is the case and the gradient is still positive (i.e. reports are going up) we encode this with a red color. If it is the case and the gradient of the blue line is negative (i.e. reports are going down) we encode this with an amber color. Conversely, if the blue line is below the red and decreasing, we color green. On the other hand if it is below red but increasing, we color yellow.
-This gives us an early warning system for disease. Red is a bad situation getting worse, amber is bad, but improving. Green is good and getting better and yellow good but degrading.
-Finally, there is a gray region which represents when the scale of the effect is small.
+Figure: Estimate of the current disease situation in the Kabarole
+district over time. Estimate is constructed with a Gaussian process with
+an additive covariance funciton.
+
+
+Health monitoring system for the Kabarole district. Here we have
+fitted the reports with a Gaussian process with an additive covariance
+function. It has two components, one is a long time scale component (in
+red above) the other is a short time scale component (in blue).
+Monitoring proceeds by considering two aspects of the curve. Is the
+blue line (the short term report signal) above the red (which represents
+the long term trend? If so we have higher than expected reports. If this
+is the case and the gradient is still positive (i.e. reports
+are going up) we encode this with a red color. If it is the
+case and the gradient of the blue line is negative (i.e. reports are
+going down) we encode this with an amber color. Conversely, if
+the blue line is below the red and decreasing, we color
+green. On the other hand if it is below red but increasing, we
+color yellow.
+This gives us an early warning system for disease. Red is a bad
+situation getting worse, amber is bad, but improving. Green is good and
+getting better and yellow good but degrading.
+Finally, there is a gray region which represents when the scale of
+the effect is small.
- +
+ -
+
-
-
+
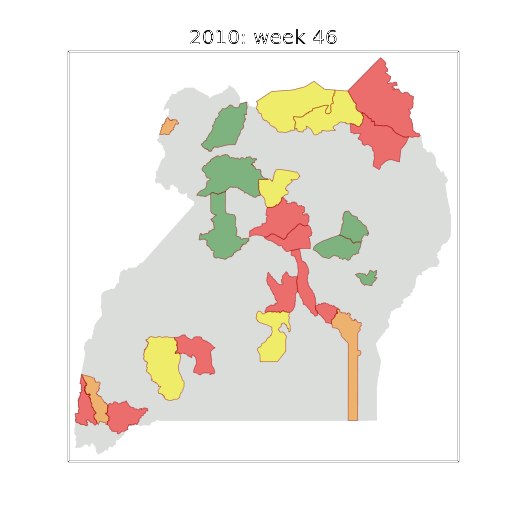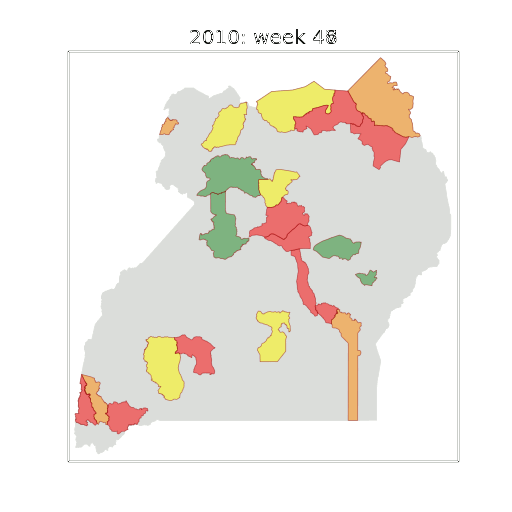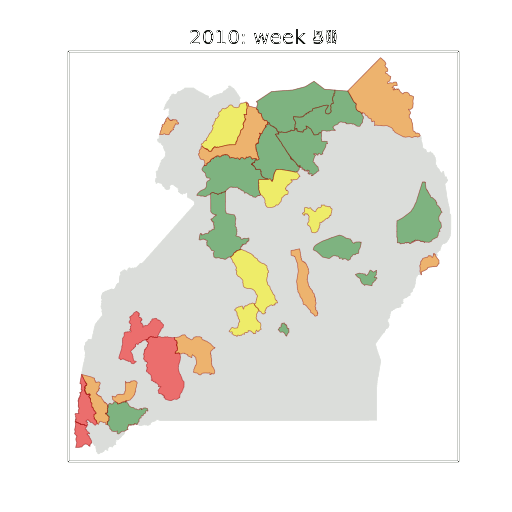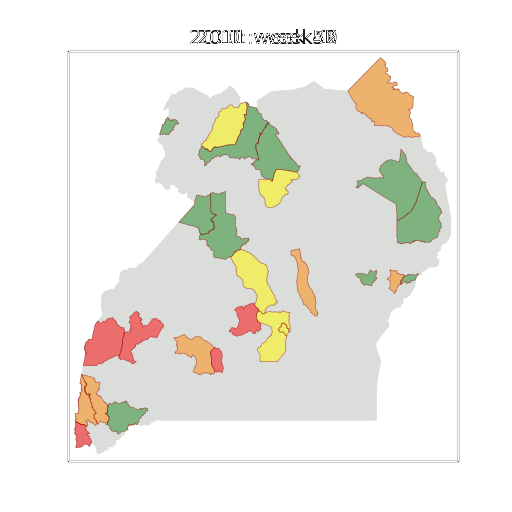
-Figure: The map of Ugandan districts with an overview of the Malaria situation in each district.
+Figure: The map of Ugandan districts with an overview of the Malaria
+situation in each district.
-These colors can now be observed directly on a spatial map of the districts to give an immediate impression of the current status of the disease across the country.
+These colors can now be observed directly on a spatial map of the
+districts to give an immediate impression of the current status of the
+disease across the country.
Machine Learning
-This talk is a general introduction to machine learning, we will highlight the technical challenges and the current solutions. We will give an overview of what is machine learning and why it is important.
+This talk is a general introduction to machine learning, we will
+highlight the technical challenges and the current solutions. We will
+give an overview of what is machine learning and why it is
+important.
Rise of Machine Learning
-Machine learning is the combination of data and models, through computation, to make predictions.
$$
-\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}
-$$
+Machine learning is the combination of data and models, through
+computation, to make predictions. \[
+\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow}
+\text{prediction}
+\]
Data Revolution
-Machine learning has risen in prominence due to the rise in data availability, and its interconnection with computers. The high bandwidth connection between data and computer leads to a new interaction between us and data via the computer. It is that channel that is being mediated by machine learning techniques.
+Machine learning has risen in prominence due to the rise in data
+availability, and its interconnection with computers. The high bandwidth
+connection between data and computer leads to a new interaction between
+us and data via the computer. It is that channel that is being mediated
+by machine learning techniques.
-
-
+
-Figure: Large amounts of data and high interconnection bandwidth mean that we receive much of our information about the world around us through computers.
+Figure: Large amounts of data and high interconnection bandwidth mean
+that we receive much of our information about the world around us
+through computers.
Supply Chain
-[edit]
+
-
- +
+
+
+ -
+
-
-
+
-Figure: Packhorse Bridge under Burbage Edge. This packhorse route climbs steeply out of Hathersage and heads towards Sheffield. Packhorses were the main route for transporting goods across the Peak District. The high cost of transport is one driver of the ‘smith’ model, where there is a local skilled person responsible for assembling or creating goods (e.g. a blacksmith).
-
-
-On Sunday mornings in Sheffield, I often used to run across Packhorse Bridge in Burbage valley. The bridge is part of an ancient network of trails crossing the Pennines that, before Turnpike roads arrived in the 18th century, was the main way in which goods were moved. Given that the moors around Sheffield were home to sand quarries, tin mines, lead mines and the villages in the Derwent valley were known for nail and pin manufacture, this wasn’t simply movement of agricultural goods, but it was the infrastructure for industrial transport.
-The profession of leading the horses was known as a Jagger and leading out of the village of Hathersage is Jagger’s Lane, a trail that headed underneath Stanage Edge and into Sheffield.
-The movement of goods from regions of supply to areas of demand is fundamental to our society. The physical infrastructure of supply chain has evolved a great deal over the last 300 years.
+Figure: Packhorse Bridge under Burbage Edge. This packhorse route
+climbs steeply out of Hathersage and heads towards Sheffield. Packhorses
+were the main route for transporting goods across the Peak District. The
+high cost of transport is one driver of the ‘smith’ model, where there
+is a local skilled person responsible for assembling or creating goods
+(e.g. a blacksmith).
+
+
+On Sunday mornings in Sheffield, I often used to run across Packhorse
+Bridge in Burbage valley. The bridge is part of an ancient network of
+trails crossing the Pennines that, before Turnpike roads arrived in the
+18th century, was the main way in which goods were moved. Given that the
+moors around Sheffield were home to sand quarries, tin mines, lead mines
+and the villages in the Derwent valley were known for nail and pin
+manufacture, this wasn’t simply movement of agricultural goods, but it
+was the infrastructure for industrial transport.
+The profession of leading the horses was known as a Jagger and
+leading out of the village of Hathersage is Jagger’s Lane, a trail that
+headed underneath Stanage Edge and into Sheffield.
+The movement of goods from regions of supply to areas of demand is
+fundamental to our society. The physical infrastructure of supply chain
+has evolved a great deal over the last 300 years.
Cromford
-[edit]
+
-
- +
+
+
+ -
+
-
-
+
-Figure: Richard Arkwright is regarded of the founder of the modern factory system. Factories exploit distribution networks to centralize production of goods. Arkwright located his factory in Cromford due to proximity to Nottingham Weavers (his market) and availability of water power from the tributaries of the Derwent river. When he first arrived there was almost no transportation network. Over the following 200 years The Cromford Canal (1790s), a Turnpike (now the A6, 1816-18) and the High Peak Railway (now closed, 1820s) were all constructed to improve transportation access as the factory blossomed.
-
-
-Richard Arkwright is known as the father of the modern factory system. In 1771 he set up a Mill for spinning cotton yarn in the village of Cromford, in the Derwent Valley. The Derwent valley is relatively inaccessible. Raw cotton arrived in Liverpool from the US and India. It needed to be transported on packhorse across the bridleways of the Pennines. But Cromford was a good location due to proximity to Nottingham, where weavers where consuming the finished thread, and the availability of water power from small tributaries of the Derwent river for Arkwright’s water frames which automated the production of yarn from raw cotton.
-By 1794 the Cromford Canal was opened to bring coal in to Cromford and give better transport to Nottingham. The construction of the canals was driven by the need to improve the transport infrastructure, facilitating the movement of goods across the UK. Canals, roads and railways were initially constructed by the economic need for moving goods. To improve supply chain.
-The A6 now does pass through Cromford, but at the time he moved there there was merely a track. The High Peak Railway was opened in 1832, it is now converted to the High Peak Trail, but it remains the highest railway built in Britain.
-Cooper (1991)
+Figure: Richard Arkwright is regarded of the founder of the modern
+factory system. Factories exploit distribution networks to centralize
+production of goods. Arkwright located his factory in Cromford due to
+proximity to Nottingham Weavers (his market) and availability of water
+power from the tributaries of the Derwent river. When he first arrived
+there was almost no transportation network. Over the following 200 years
+The Cromford Canal (1790s), a Turnpike (now the A6, 1816-18) and the
+High Peak Railway (now closed, 1820s) were all constructed to improve
+transportation access as the factory blossomed.
+
+
+Richard Arkwright is known as the father of the modern factory
+system. In 1771 he set up a Mill for spinning
+cotton yarn in the village of Cromford, in the Derwent Valley. The
+Derwent valley is relatively inaccessible. Raw cotton arrived in
+Liverpool from the US and India. It needed to be transported on
+packhorse across the bridleways of the Pennines. But Cromford was a good
+location due to proximity to Nottingham, where weavers where consuming
+the finished thread, and the availability of water power from small
+tributaries of the Derwent river for Arkwright’s water frames
+which automated the production of yarn from raw cotton.
+By 1794 the Cromford Canal
+was opened to bring coal in to Cromford and give better transport to
+Nottingham. The construction of the canals was driven by the need to
+improve the transport infrastructure, facilitating the movement of goods
+across the UK. Canals, roads and railways were initially constructed by
+the economic need for moving goods. To improve supply chain.
+The A6 now does pass through Cromford, but at the time he moved there
+there was merely a track. The High Peak Railway was opened in 1832, it
+is now converted to the High Peak Trail, but it remains the highest
+railway built in Britain.
+Cooper
+(1991)
Containerization
-[edit]
+
-
- +
+
+
+ -
+
-
-
+
-Figure: The container is one of the major drivers of globalization, and arguably the largest agent of social change in the last 100 years. It reduces the cost of transportation, significantly changing the appropriate topology of distribution networks. The container makes it possible to ship goods halfway around the world for cheaper than it costs to process those goods, leading to an extended distribution topology.
-
-
-Containerization has had a dramatic effect on global economics, placing many people in the developing world at the end of the supply chain.
+Figure: The container is one of the major drivers of globalization,
+and arguably the largest agent of social change in the last 100 years.
+It reduces the cost of transportation, significantly changing the
+appropriate topology of distribution networks. The container makes it
+possible to ship goods halfway around the world for cheaper than it
+costs to process those goods, leading to an extended distribution
+topology.
+
+
+Containerization has had a dramatic effect on global economics,
+placing many people in the developing world at the end of the supply
+chain.
-
- +
+
+
+
-
- +
+
+
+
-
+
-Figure: Wild Alaskan Cod, being solid in the Pacific Northwest, that is a product of China. It is cheaper to ship the deep frozen fish thousands of kilometers for processing than to process locally.
+Figure: Wild Alaskan Cod, being solid in the Pacific Northwest, that
+is a product of China. It is cheaper to ship the deep frozen fish
+thousands of kilometers for processing than to process locally.
+
+
+For example, you can buy Wild Alaskan Cod fished from Alaska,
+processed in China, sold in North America. This is driven by the low
+cost of transport for frozen cod vs the higher relative cost of cod
+processing in the US versus China. Similarly,
+Scottish
+prawns are also processed in China for sale in the UK.
+
+
+
+ +
+
+
-
+
+
+
-For example, you can buy Wild Alaskan Cod fished from Alaska, processed in China, sold in North America. This is driven by the low cost of transport for frozen cod vs the higher relative cost of cod processing in the US versus China. Similarly, Scottish prawns are also processed in China for sale in the UK.
-This effect on cost of transport vs cost of processing is the main driver of the topology of the modern supply chain and the associated effect of globalization. If transport is much cheaper than processing, then processing will tend to agglomerate in places where processing costs can be minimized.
-Large scale global economic change has principally been driven by changes in the technology that drives supply chain.
-Supply chain is a large-scale automated decision making network. Our aim is to make decisions not only based on our models of customer behavior (as observed through data), but also by accounting for the structure of our fulfilment center, and delivery network.
-Many of the most important questions in supply chain take the form of counterfactuals. E.g. “What would happen if we opened a manufacturing facility in Cambridge?” A counter factual is a question that implies a mechanistic understanding of a system. It goes beyond simple smoothness assumptions or translation invariants. It requires a physical, or mechanistic understanding of the supply chain network. For this reason, the type of models we deploy in supply chain often involve simulations or more mechanistic understanding of the network.
-In supply chain Machine Learning alone is not enough, we need to bridge between models that contain real mechanisms and models that are entirely data driven.
-This is challenging, because as we introduce more mechanism to the models we use, it becomes harder to develop efficient algorithms to match those models to data.
+
+Figure: The transport cost of most foods is a very small portion of
+the total cost. The exception is if foods are air freighted. Source: https://ourworldindata.org/food-choice-vs-eating-local
+by Hannah Ritche CC-BY
+
+
+This effect on cost of transport vs cost of processing is the main
+driver of the topology of the modern supply chain and the associated
+effect of globalization. If transport is much cheaper than processing,
+then processing will tend to agglomerate in places where processing
+costs can be minimized.
+Large scale global economic change has principally been driven by
+changes in the technology that drives supply chain.
+Supply chain is a large-scale automated decision making network. Our
+aim is to make decisions not only based on our models of customer
+behavior (as observed through data), but also by accounting for the
+structure of our fulfilment center, and delivery network.
+Many of the most important questions in supply chain take the form of
+counterfactuals. E.g. “What would happen if we opened a manufacturing
+facility in Cambridge?” A counter factual is a question that implies a
+mechanistic understanding of a system. It goes beyond simple smoothness
+assumptions or translation invariants. It requires a physical, or
+mechanistic understanding of the supply chain network. For this
+reason, the type of models we deploy in supply chain often involve
+simulations or more mechanistic understanding of the network.
+In supply chain Machine Learning alone is not enough, we need to
+bridge between models that contain real mechanisms and models that are
+entirely data driven.
+This is challenging, because as we introduce more mechanism to the
+models we use, it becomes harder to develop efficient algorithms to
+match those models to data.
For Africa
-[edit]
-There is a large opportunity because infrastructures around automation are moving from physical infrastructure towards information infrastructures. How can African countries benefit from a modern information infrastructure? The aim of Data Science Africa is to answer this question, with the answers coming from the attendees.
-Machine learning aims to replicate processes through the direct use of data. When deployed in the domain of ‘artificial intelligence’, the processes that it is replicating, or emulating, are cognitive processes.
-The first trick in machine learning is to convert the process itself into a mathematical function. That function has a set of parameters which control its behaviour. What we call learning is the adaption of these parameters to change the behavior of the function. The choice of mathematical function we use is a vital component of the model.
+
+There is a large opportunity because infrastructures around
+automation are moving from physical infrastructure towards information
+infrastructures. How can African countries benefit from a modern
+information infrastructure? The aim of Data Science Africa is to answer
+this question, with the answers coming from the attendees.
+Machine learning aims to replicate processes through the direct use
+of data. When deployed in the domain of ‘artificial intelligence’, the
+processes that it is replicating, or emulating, are cognitive
+processes.
+The first trick in machine learning is to convert the process itself
+into a mathematical function. That function has a set of
+parameters which control its behaviour. What we call learning is the
+adaption of these parameters to change the behavior of the function. The
+choice of mathematical function we use is a vital component of the
+model.
-
-
+
-Figure: The Kapchorwa District, home district of Stephen Kiprotich.
+Figure: The Kapchorwa District, home district of Stephen
+Kiprotich.
-Stephen Kiprotich, the 2012 gold medal winner from the London Olympics, comes from Kapchorwa district, in eastern Uganda, near the border with Kenya.
+Stephen Kiprotich, the 2012 gold medal winner from the London
+Olympics, comes from Kapchorwa district, in eastern Uganda, near the
+border with Kenya.
Olympic Marathon Data
-[edit]
+
- Gold medal times for Olympic Marathon since 1896.
-- Marathons before 1924 didn’t have a standardised distance.
+- Marathons before 1924 didn’t have a standardized distance.
- Present results using pace per km.
-- In 1904 Marathon was badly organised leading to very slow times.
+- In 1904 Marathon was badly organized leading to very slow
+times.
-
- +
+
+
+ -Image from Wikimedia Commons http://bit.ly/16kMKHQ
+Image from Wikimedia Commons http://bit.ly/16kMKHQ
-Image from Wikimedia Commons http://bit.ly/16kMKHQ
+Image from Wikimedia Commons http://bit.ly/16kMKHQ
-The first thing we will do is load a standard data set for regression modelling. The data consists of the pace of Olympic Gold Medal Marathon winners for the Olympics from 1896 to present. First we load in the data and plot.
-
-
-data = pods.datasets.olympic_marathon_men()
-x = data['X']
-y = data['Y']
-
-offset = y.mean()
-scale = np.sqrt(y.var())
+The first thing we will do is load a standard data set for regression
+modelling. The data consists of the pace of Olympic Gold Medal Marathon
+winners for the Olympics from 1896 to present. Let’s load in the data
+and plot.
+%pip install pods
+import numpy as np
+import pods
+data = pods.datasets.olympic_marathon_men()
+x = data['X']
+y = data['Y']
+
+offset = y.mean()
+scale = np.sqrt(y.var())
+yhat = (y - offset)/scale
-
-
+
-Figure: Olympic marathon pace times since 1892.
-
-
-Things to notice about the data include the outlier in 1904, in this year, the olympics was in St Louis, USA. Organizational problems and challenges with dust kicked up by the cars following the race meant that participants got lost, and only very few participants completed.
-More recent years see more consistently quick marathons.
-Polynomial Fits to Olympic Data
-[edit]
-
-basis = mlai.polynomial
-
-data = pods.datasets.olympic_marathon_men()
-
-x = data['X']
-y = data['Y']
-
-xlim = [1892, 2020]
-
-basis=mlai.Basis(mlai.polynomial, number=1, data_limits=xlim)
-import numpy as np
-from matplotlib import pyplot as plt
-import teaching_plots as plot
-import mlai
-import pods
-basis = mlai.polynomial
-
-data = pods.datasets.olympic_marathon_men()
-
-x = data['X']
-y = data['Y']
-
-xlim = [1892, 2020]
-max_basis = 27
-
-ll = np.array([np.nan]*(max_basis))
-sum_squares = np.array([np.nan]*(max_basis))
-basis=mlai.Basis(mlai.polynomial, number=1, data_limits=xlim)
-plot.rmse_fit(x, y, param_name='number', param_range=(1, 28),
- model=mlai.LM, basis=basis,
- xlim=xlim, objective_ylim=[0, 0.8],
- diagrams='../slides/diagrams/ml')
+Figure: Olympic marathon pace times since 1896.
+
+
+Things to notice about the data include the outlier in 1904, in that
+year the Olympics was in St Louis, USA. Organizational problems and
+challenges with dust kicked up by the cars following the race meant that
+participants got lost, and only very few participants completed. More
+recent years see more consistently quick marathons.
+Polynomial Fits to
+Olympic Marthon Data
+
+import numpy as np
+Define the polynomial basis function.
+import mlai
+
+from mlai import polynomial
+def polynomial(x, num_basis=4, data_limits=[-1., 1.]):
+ "Polynomial basis"
+ centre = data_limits[0]/2. + data_limits[1]/2.
+ span = data_limits[1] - data_limits[0]
+ z = np.asarray(x, dtype=float) - centre
+ z = 2*z/span # scale the inputs to be within -1, 1 where polynomials are well behaved
+ Phi = np.zeros((x.shape[0], num_basis))
+ for i in range(num_basis):
+ Phi[:, i:i+1] = z**i
+ return Phi
+Now we include the solution for the linear regression through
+QR-decomposition.
+def basis_fit(Phi, y):
+ "Use QR decomposition to fit the basis."""
+ Q, R = np.linalg.qr(Phi)
+ return sp.linalg.solve_triangular(R, Q.T@y)
+Linear Fit
+poly_args = {'num_basis':2, # two basis functions (1 and x)
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)
+Now we make some predictions for the fit.
+x_pred = np.linspace(xlim[0], xlim[1], 400)[:, np.newaxis]
+Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@w
+
+
+
+
+
+
+
+
+Figure: Fit of a 1-degree polynomial (a linear model) to the Olympic
+marathon data.
+
+
+Cubic Fit
+poly_args = {'num_basis':4, # four basis: 1, x, x^2, x^3
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)
+Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@w
+
+
+
+
+
+
+
+
+Figure: Fit of a 3-degree polynomial (a cubic model) to the Olympic
+marathon data.
+
+
+9th Degree Polynomial Fit
+Now we’ll try a 9th degree polynomial fit to the data.
+poly_args = {'num_basis':10, # basis up to x^9
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)
+Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@w
+
+
+
+
+
+
+
+
+Figure: Fit of a 9-degree polynomial to the Olympic marathon
+data.
+
+
+16th Degree Polynomial Fit
+Now we’ll try a 16th degree polynomial fit to the data.
+poly_args = {'num_basis':17, # basis up to x^16
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)
+Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@w
-
-
+
Example: Prediction o
+
Figure: The project arose out of the Gaussian process summer school held at Makerere in Kampala in 2013. The school led, in turn, to the Data Science Africa initiative.
+Figure: The project arose out of the Gaussian process summer school +held at Makerere in Kampala in 2013. The school led, in turn, to the +Data Science Africa initiative.
Early Warning Systems
Early Warning Systems
+
Figure: Estimate of the current disease situation in the Kabarole district over time. Estimate is constructed with a Gaussian process with an additive covariance funciton.
-Health monitoring system for the Kabarole district. Here we have fitted the reports with a Gaussian process with an additive covariance function. It has two components, one is a long time scale component (in red above) the other is a short time scale component (in blue).
-Monitoring proceeds by considering two aspects of the curve. Is the blue line (the short term report signal) above the red (which represents the long term trend? If so we have higher than expected reports. If this is the case and the gradient is still positive (i.e. reports are going up) we encode this with a red color. If it is the case and the gradient of the blue line is negative (i.e. reports are going down) we encode this with an amber color. Conversely, if the blue line is below the red and decreasing, we color green. On the other hand if it is below red but increasing, we color yellow.
-This gives us an early warning system for disease. Red is a bad situation getting worse, amber is bad, but improving. Green is good and getting better and yellow good but degrading.
-Finally, there is a gray region which represents when the scale of the effect is small.
+Figure: Estimate of the current disease situation in the Kabarole +district over time. Estimate is constructed with a Gaussian process with +an additive covariance funciton.
+Health monitoring system for the Kabarole district. Here we have +fitted the reports with a Gaussian process with an additive covariance +function. It has two components, one is a long time scale component (in +red above) the other is a short time scale component (in blue).
+Monitoring proceeds by considering two aspects of the curve. Is the +blue line (the short term report signal) above the red (which represents +the long term trend? If so we have higher than expected reports. If this +is the case and the gradient is still positive (i.e. reports +are going up) we encode this with a red color. If it is the +case and the gradient of the blue line is negative (i.e. reports are +going down) we encode this with an amber color. Conversely, if +the blue line is below the red and decreasing, we color +green. On the other hand if it is below red but increasing, we +color yellow.
+This gives us an early warning system for disease. Red is a bad +situation getting worse, amber is bad, but improving. Green is good and +getting better and yellow good but degrading.
+Finally, there is a gray region which represents when the scale of +the effect is small.
+
Figure: The map of Ugandan districts with an overview of the Malaria situation in each district.
+Figure: The map of Ugandan districts with an overview of the Malaria +situation in each district.
These colors can now be observed directly on a spatial map of the districts to give an immediate impression of the current status of the disease across the country.
+These colors can now be observed directly on a spatial map of the +districts to give an immediate impression of the current status of the +disease across the country.
Machine Learning
-This talk is a general introduction to machine learning, we will highlight the technical challenges and the current solutions. We will give an overview of what is machine learning and why it is important.
+This talk is a general introduction to machine learning, we will +highlight the technical challenges and the current solutions. We will +give an overview of what is machine learning and why it is +important.
Rise of Machine Learning
-Machine learning is the combination of data and models, through computation, to make predictions.
$$
-\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} \text{prediction}
-$$
Machine learning is the combination of data and models, through +computation, to make predictions. \[ +\text{data} + \text{model} \stackrel{\text{compute}}{\rightarrow} +\text{prediction} +\]
Data Revolution
-Machine learning has risen in prominence due to the rise in data availability, and its interconnection with computers. The high bandwidth connection between data and computer leads to a new interaction between us and data via the computer. It is that channel that is being mediated by machine learning techniques. +Machine learning has risen in prominence due to the rise in data +availability, and its interconnection with computers. The high bandwidth +connection between data and computer leads to a new interaction between +us and data via the computer. It is that channel that is being mediated +by machine learning techniques.
Figure: Large amounts of data and high interconnection bandwidth mean that we receive much of our information about the world around us through computers.
+Figure: Large amounts of data and high interconnection bandwidth mean +that we receive much of our information about the world around us +through computers.
Supply Chain
-[edit]
+
+
Figure: Packhorse Bridge under Burbage Edge. This packhorse route climbs steeply out of Hathersage and heads towards Sheffield. Packhorses were the main route for transporting goods across the Peak District. The high cost of transport is one driver of the ‘smith’ model, where there is a local skilled person responsible for assembling or creating goods (e.g. a blacksmith).
-On Sunday mornings in Sheffield, I often used to run across Packhorse Bridge in Burbage valley. The bridge is part of an ancient network of trails crossing the Pennines that, before Turnpike roads arrived in the 18th century, was the main way in which goods were moved. Given that the moors around Sheffield were home to sand quarries, tin mines, lead mines and the villages in the Derwent valley were known for nail and pin manufacture, this wasn’t simply movement of agricultural goods, but it was the infrastructure for industrial transport.
-The profession of leading the horses was known as a Jagger and leading out of the village of Hathersage is Jagger’s Lane, a trail that headed underneath Stanage Edge and into Sheffield.
-The movement of goods from regions of supply to areas of demand is fundamental to our society. The physical infrastructure of supply chain has evolved a great deal over the last 300 years.
+Figure: Packhorse Bridge under Burbage Edge. This packhorse route +climbs steeply out of Hathersage and heads towards Sheffield. Packhorses +were the main route for transporting goods across the Peak District. The +high cost of transport is one driver of the ‘smith’ model, where there +is a local skilled person responsible for assembling or creating goods +(e.g. a blacksmith).
+On Sunday mornings in Sheffield, I often used to run across Packhorse +Bridge in Burbage valley. The bridge is part of an ancient network of +trails crossing the Pennines that, before Turnpike roads arrived in the +18th century, was the main way in which goods were moved. Given that the +moors around Sheffield were home to sand quarries, tin mines, lead mines +and the villages in the Derwent valley were known for nail and pin +manufacture, this wasn’t simply movement of agricultural goods, but it +was the infrastructure for industrial transport.
+The profession of leading the horses was known as a Jagger and +leading out of the village of Hathersage is Jagger’s Lane, a trail that +headed underneath Stanage Edge and into Sheffield.
+The movement of goods from regions of supply to areas of demand is +fundamental to our society. The physical infrastructure of supply chain +has evolved a great deal over the last 300 years.
Cromford
-[edit]
+
+
Figure: Richard Arkwright is regarded of the founder of the modern factory system. Factories exploit distribution networks to centralize production of goods. Arkwright located his factory in Cromford due to proximity to Nottingham Weavers (his market) and availability of water power from the tributaries of the Derwent river. When he first arrived there was almost no transportation network. Over the following 200 years The Cromford Canal (1790s), a Turnpike (now the A6, 1816-18) and the High Peak Railway (now closed, 1820s) were all constructed to improve transportation access as the factory blossomed.
-Richard Arkwright is known as the father of the modern factory system. In 1771 he set up a Mill for spinning cotton yarn in the village of Cromford, in the Derwent Valley. The Derwent valley is relatively inaccessible. Raw cotton arrived in Liverpool from the US and India. It needed to be transported on packhorse across the bridleways of the Pennines. But Cromford was a good location due to proximity to Nottingham, where weavers where consuming the finished thread, and the availability of water power from small tributaries of the Derwent river for Arkwright’s water frames which automated the production of yarn from raw cotton.
-By 1794 the Cromford Canal was opened to bring coal in to Cromford and give better transport to Nottingham. The construction of the canals was driven by the need to improve the transport infrastructure, facilitating the movement of goods across the UK. Canals, roads and railways were initially constructed by the economic need for moving goods. To improve supply chain.
-The A6 now does pass through Cromford, but at the time he moved there there was merely a track. The High Peak Railway was opened in 1832, it is now converted to the High Peak Trail, but it remains the highest railway built in Britain.
-Cooper (1991)
+Figure: Richard Arkwright is regarded of the founder of the modern +factory system. Factories exploit distribution networks to centralize +production of goods. Arkwright located his factory in Cromford due to +proximity to Nottingham Weavers (his market) and availability of water +power from the tributaries of the Derwent river. When he first arrived +there was almost no transportation network. Over the following 200 years +The Cromford Canal (1790s), a Turnpike (now the A6, 1816-18) and the +High Peak Railway (now closed, 1820s) were all constructed to improve +transportation access as the factory blossomed.
+Richard Arkwright is known as the father of the modern factory +system. In 1771 he set up a Mill for spinning +cotton yarn in the village of Cromford, in the Derwent Valley. The +Derwent valley is relatively inaccessible. Raw cotton arrived in +Liverpool from the US and India. It needed to be transported on +packhorse across the bridleways of the Pennines. But Cromford was a good +location due to proximity to Nottingham, where weavers where consuming +the finished thread, and the availability of water power from small +tributaries of the Derwent river for Arkwright’s water frames +which automated the production of yarn from raw cotton.
+By 1794 the Cromford Canal +was opened to bring coal in to Cromford and give better transport to +Nottingham. The construction of the canals was driven by the need to +improve the transport infrastructure, facilitating the movement of goods +across the UK. Canals, roads and railways were initially constructed by +the economic need for moving goods. To improve supply chain.
+The A6 now does pass through Cromford, but at the time he moved there +there was merely a track. The High Peak Railway was opened in 1832, it +is now converted to the High Peak Trail, but it remains the highest +railway built in Britain.
+Cooper +(1991)
Containerization
-[edit]
+
+
Figure: The container is one of the major drivers of globalization, and arguably the largest agent of social change in the last 100 years. It reduces the cost of transportation, significantly changing the appropriate topology of distribution networks. The container makes it possible to ship goods halfway around the world for cheaper than it costs to process those goods, leading to an extended distribution topology.
-Containerization has had a dramatic effect on global economics, placing many people in the developing world at the end of the supply chain.
+Figure: The container is one of the major drivers of globalization, +and arguably the largest agent of social change in the last 100 years. +It reduces the cost of transportation, significantly changing the +appropriate topology of distribution networks. The container makes it +possible to ship goods halfway around the world for cheaper than it +costs to process those goods, leading to an extended distribution +topology.
+Containerization has had a dramatic effect on global economics, +placing many people in the developing world at the end of the supply +chain.
|
-
-
+
+
|
-
-
+
+
|
Figure: Wild Alaskan Cod, being solid in the Pacific Northwest, that is a product of China. It is cheaper to ship the deep frozen fish thousands of kilometers for processing than to process locally.
+Figure: Wild Alaskan Cod, being solid in the Pacific Northwest, that +is a product of China. It is cheaper to ship the deep frozen fish +thousands of kilometers for processing than to process locally.
+For example, you can buy Wild Alaskan Cod fished from Alaska, +processed in China, sold in North America. This is driven by the low +cost of transport for frozen cod vs the higher relative cost of cod +processing in the US versus China. Similarly, +Scottish +prawns are also processed in China for sale in the UK.
+
+
For example, you can buy Wild Alaskan Cod fished from Alaska, processed in China, sold in North America. This is driven by the low cost of transport for frozen cod vs the higher relative cost of cod processing in the US versus China. Similarly, Scottish prawns are also processed in China for sale in the UK.
-This effect on cost of transport vs cost of processing is the main driver of the topology of the modern supply chain and the associated effect of globalization. If transport is much cheaper than processing, then processing will tend to agglomerate in places where processing costs can be minimized.
-Large scale global economic change has principally been driven by changes in the technology that drives supply chain.
-Supply chain is a large-scale automated decision making network. Our aim is to make decisions not only based on our models of customer behavior (as observed through data), but also by accounting for the structure of our fulfilment center, and delivery network.
-Many of the most important questions in supply chain take the form of counterfactuals. E.g. “What would happen if we opened a manufacturing facility in Cambridge?” A counter factual is a question that implies a mechanistic understanding of a system. It goes beyond simple smoothness assumptions or translation invariants. It requires a physical, or mechanistic understanding of the supply chain network. For this reason, the type of models we deploy in supply chain often involve simulations or more mechanistic understanding of the network.
-In supply chain Machine Learning alone is not enough, we need to bridge between models that contain real mechanisms and models that are entirely data driven.
-This is challenging, because as we introduce more mechanism to the models we use, it becomes harder to develop efficient algorithms to match those models to data.
+Figure: The transport cost of most foods is a very small portion of +the total cost. The exception is if foods are air freighted. Source: https://ourworldindata.org/food-choice-vs-eating-local +by Hannah Ritche CC-BY
+This effect on cost of transport vs cost of processing is the main +driver of the topology of the modern supply chain and the associated +effect of globalization. If transport is much cheaper than processing, +then processing will tend to agglomerate in places where processing +costs can be minimized.
+Large scale global economic change has principally been driven by +changes in the technology that drives supply chain.
+Supply chain is a large-scale automated decision making network. Our +aim is to make decisions not only based on our models of customer +behavior (as observed through data), but also by accounting for the +structure of our fulfilment center, and delivery network.
+Many of the most important questions in supply chain take the form of +counterfactuals. E.g. “What would happen if we opened a manufacturing +facility in Cambridge?” A counter factual is a question that implies a +mechanistic understanding of a system. It goes beyond simple smoothness +assumptions or translation invariants. It requires a physical, or +mechanistic understanding of the supply chain network. For this +reason, the type of models we deploy in supply chain often involve +simulations or more mechanistic understanding of the network.
+In supply chain Machine Learning alone is not enough, we need to +bridge between models that contain real mechanisms and models that are +entirely data driven.
+This is challenging, because as we introduce more mechanism to the +models we use, it becomes harder to develop efficient algorithms to +match those models to data.
For Africa
-[edit]
-There is a large opportunity because infrastructures around automation are moving from physical infrastructure towards information infrastructures. How can African countries benefit from a modern information infrastructure? The aim of Data Science Africa is to answer this question, with the answers coming from the attendees.
-Machine learning aims to replicate processes through the direct use of data. When deployed in the domain of ‘artificial intelligence’, the processes that it is replicating, or emulating, are cognitive processes.
-The first trick in machine learning is to convert the process itself into a mathematical function. That function has a set of parameters which control its behaviour. What we call learning is the adaption of these parameters to change the behavior of the function. The choice of mathematical function we use is a vital component of the model.
+ +There is a large opportunity because infrastructures around +automation are moving from physical infrastructure towards information +infrastructures. How can African countries benefit from a modern +information infrastructure? The aim of Data Science Africa is to answer +this question, with the answers coming from the attendees.
+Machine learning aims to replicate processes through the direct use +of data. When deployed in the domain of ‘artificial intelligence’, the +processes that it is replicating, or emulating, are cognitive +processes.
+The first trick in machine learning is to convert the process itself +into a mathematical function. That function has a set of +parameters which control its behaviour. What we call learning is the +adaption of these parameters to change the behavior of the function. The +choice of mathematical function we use is a vital component of the +model.
Figure: The Kapchorwa District, home district of Stephen Kiprotich.
+Figure: The Kapchorwa District, home district of Stephen +Kiprotich.
Stephen Kiprotich, the 2012 gold medal winner from the London Olympics, comes from Kapchorwa district, in eastern Uganda, near the border with Kenya.
+Stephen Kiprotich, the 2012 gold medal winner from the London +Olympics, comes from Kapchorwa district, in eastern Uganda, near the +border with Kenya.
Olympic Marathon Data
-[edit]
+
|
-
-
+
+
-Image from Wikimedia Commons http://bit.ly/16kMKHQ
+Image from Wikimedia Commons http://bit.ly/16kMKHQ
|
The first thing we will do is load a standard data set for regression modelling. The data consists of the pace of Olympic Gold Medal Marathon winners for the Olympics from 1896 to present. First we load in the data and plot.
- - -data = pods.datasets.olympic_marathon_men()
-x = data['X']
-y = data['Y']
-
-offset = y.mean()
-scale = np.sqrt(y.var())The first thing we will do is load a standard data set for regression +modelling. The data consists of the pace of Olympic Gold Medal Marathon +winners for the Olympics from 1896 to present. Let’s load in the data +and plot.
+%pip install podsimport numpy as np
+import podsdata = pods.datasets.olympic_marathon_men()
+x = data['X']
+y = data['Y']
+
+offset = y.mean()
+scale = np.sqrt(y.var())
+yhat = (y - offset)/scaleFigure: Olympic marathon pace times since 1892.
-Things to notice about the data include the outlier in 1904, in this year, the olympics was in St Louis, USA. Organizational problems and challenges with dust kicked up by the cars following the race meant that participants got lost, and only very few participants completed.
-More recent years see more consistently quick marathons.
-Polynomial Fits to Olympic Data
-[edit]
- -basis = mlai.polynomial
-
-data = pods.datasets.olympic_marathon_men()
-
-x = data['X']
-y = data['Y']
-
-xlim = [1892, 2020]
-
-basis=mlai.Basis(mlai.polynomial, number=1, data_limits=xlim)import numpy as np
-from matplotlib import pyplot as plt
-import teaching_plots as plot
-import mlai
-import podsbasis = mlai.polynomial
-
-data = pods.datasets.olympic_marathon_men()
-
-x = data['X']
-y = data['Y']
-
-xlim = [1892, 2020]
-max_basis = 27
-
-ll = np.array([np.nan]*(max_basis))
-sum_squares = np.array([np.nan]*(max_basis))
-basis=mlai.Basis(mlai.polynomial, number=1, data_limits=xlim)plot.rmse_fit(x, y, param_name='number', param_range=(1, 28),
- model=mlai.LM, basis=basis,
- xlim=xlim, objective_ylim=[0, 0.8],
- diagrams='../slides/diagrams/ml')Figure: Olympic marathon pace times since 1896.
+Things to notice about the data include the outlier in 1904, in that +year the Olympics was in St Louis, USA. Organizational problems and +challenges with dust kicked up by the cars following the race meant that +participants got lost, and only very few participants completed. More +recent years see more consistently quick marathons.
+Polynomial Fits to +Olympic Marthon Data
+ +import numpy as npDefine the polynomial basis function.
+import mlai
+from mlai import polynomialdef polynomial(x, num_basis=4, data_limits=[-1., 1.]):
+ "Polynomial basis"
+ centre = data_limits[0]/2. + data_limits[1]/2.
+ span = data_limits[1] - data_limits[0]
+ z = np.asarray(x, dtype=float) - centre
+ z = 2*z/span # scale the inputs to be within -1, 1 where polynomials are well behaved
+ Phi = np.zeros((x.shape[0], num_basis))
+ for i in range(num_basis):
+ Phi[:, i:i+1] = z**i
+ return PhiNow we include the solution for the linear regression through +QR-decomposition.
+def basis_fit(Phi, y):
+ "Use QR decomposition to fit the basis."""
+ Q, R = np.linalg.qr(Phi)
+ return sp.linalg.solve_triangular(R, Q.T@y) Linear Fit
+poly_args = {'num_basis':2, # two basis functions (1 and x)
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)Now we make some predictions for the fit.
+x_pred = np.linspace(xlim[0], xlim[1], 400)[:, np.newaxis]
+Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@wFigure: Fit of a 1-degree polynomial (a linear model) to the Olympic +marathon data.
+Cubic Fit
+poly_args = {'num_basis':4, # four basis: 1, x, x^2, x^3
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@wFigure: Fit of a 3-degree polynomial (a cubic model) to the Olympic +marathon data.
+9th Degree Polynomial Fit
+Now we’ll try a 9th degree polynomial fit to the data.
+poly_args = {'num_basis':10, # basis up to x^9
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@wFigure: Fit of a 9-degree polynomial to the Olympic marathon +data.
+16th Degree Polynomial Fit
+Now we’ll try a 16th degree polynomial fit to the data.
+poly_args = {'num_basis':17, # basis up to x^16
+ 'data_limits':xlim}
+Phi = polynomial(x, **poly_args)
+w = basis_fit(Phi, y)Phi_pred = polynomial(x_pred, **poly_args)
+f_pred = Phi_pred@w