Home
If you use AWS Opsworks, and want a command line interface that allows you to:
- manage stack json
- manage cookbooks
- generate ssh configurations
gem install opzworks
edit your ~/.aws/config and add a section similar to the following:
[opzworks]
ssh-user-name = grant
berks-github-org = mapzen
berks-s3-bucket = mapzen.opsworks
berks-repository-path = /Users/grant/repos/mapzen/projects-opsworks
ssh-user-name is your opsworks user name
berks-github-org is the Github org under which you'll have all the repos we'll be working with to manage your OpsWorks stacks
berks-s3-bucket is the S3 directory to which we'll push all cookbooks
berks-repository-path is the local directory under which we'll place all the repositories used to manage your stacks
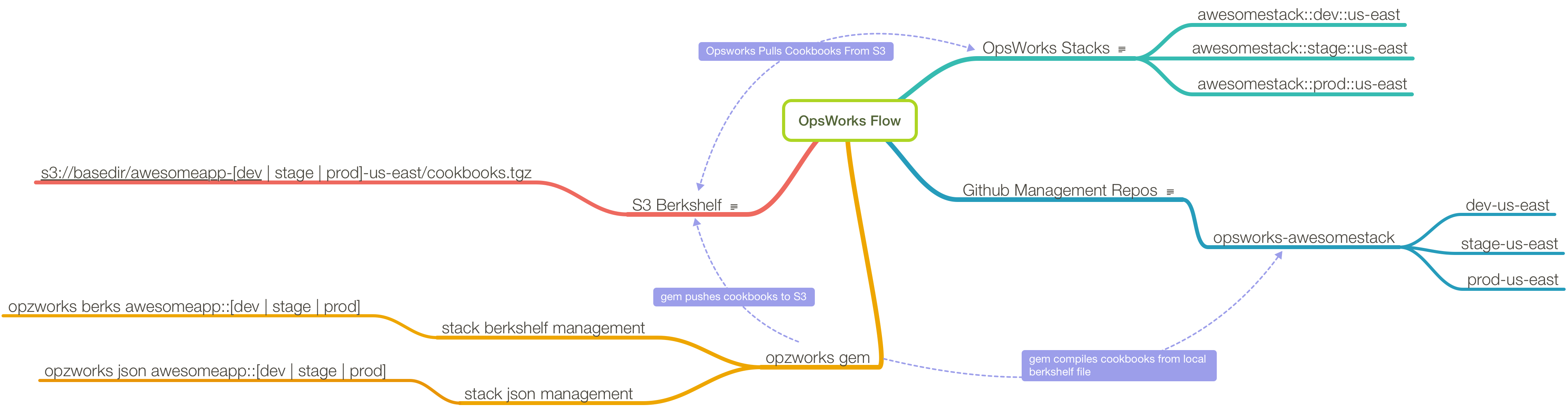
This gem makes a number of assumptions in order to enforce a specific workflow. First among them is the Opsworks stack naming convection. This will need to adhere to the following format:
PROJECT::ENV::REGION
If PROJECT will be comprised of multiple words, they should be joined with underscores, e.g.
my_awesome_rails_app::prod::us-east
So for example, if you have an Elastic cluster in dev and prod in us-east, and dev in us-west:
elastic::dev::us-east
elastic::dev::us-west
elastic::prod::us-east
The next workflow that must be conformed to is berkshelf management. In this context, that means a git repository that conforms to the following setup:
opsworks-project
Inside that repository, you will have branches that match each of your environments and regions.
So in our Elastic example, you would have the following setup:
- a git repository called opsworks-elastic
- branches in that repository called dev-us-east, dev-us-west and prod-us-east
In each of those branches, you should have the following:
- Berksfile
- stack.json (if you want to maintain the stack json using the
opzworks jsonutility)
The Berksfile will look similar to the following. If you're familiar with Berkshelf, there's nothing new here:
source 'https://api.berkshelf.com'
# opsworks
cookbook 'apache2' , github: 'aws/opsworks-cookbooks' , branch: 'release-chef-11.10' , rel: 'apache2'
# external
#
cookbook 'lvm', '= 1.0.8'
cookbook 'sensu', '= 2.10.0'
cookbook 'runit', '= 1.5.10'
cookbook 'java', '= 1.29.0'
cookbook 'nodejs', '= 2.1.0'
cookbook 'elasticsearch', '= 0.3.13'
cookbook 'chef_handler', '= 1.1.6'
# mapzen wrappers
#
cookbook 'mapzen_sensu_clients', git: '[email protected]:mapzen/chef-mapzen_sensu_clients', tag: '0.12.0'
cookbook 'mapzen_elasticsearch', git: '[email protected]:mapzen/chef-mapzen_elasticsearch', tag: '0.16.3'
cookbook 'mapzen_logstash', git: '[email protected]:mapzen/chef-mapzen_logstash', tag: '0.13.1'
cookbook 'mapzen_graphite', git: '[email protected]:mapzen/chef-mapzen_graphite', tag: '0.6.0'
cookbook 'mapzen_pelias', git: '[email protected]:mapzen/chef-mapzen_pelias', tag: '0.34.2'If we placed that Berkshelf file in opsworks-elastic, in the prod-us-east branch, we would run opzworks berks elastic::prod::us-east, which would do the following:
- build the berkshelf locally
- push the resultant cookbook tarball to: s3://opzworks/elastic-prod-us-east/cookbooks.tgz
- run
update_custom_cookbookon the stack (unless you pass the--no-updateflag)
Your stack should be configured to use a berkshelf from an S3 archive. The url will look as below:
https://s3.amazonaws.com/opzworks/elastic-prod-us-east/cookbooks.tgz
You'll need to set up an IAM user or users with permission to access the location.
Create an OpsWorks stack: myapp::dev::us-east. Note that the naming convention here is important. To use this workflow, you need to adhere to the naming convention of app::env::region. If your app name will have multiple words, use underscores, e.g. my_app.
To go along with this new stack, we need a github repo called opsworks-myapp. Create a new branch in the repo called dev-us-east. This corresponds directly to the env::region portion of the stack name, so if we add another stack in the future called myapp::prod::us-west, we would create a new branch called prod-us-east. Clone the repo locally to <berks-repository-path>/opsworks-myapp. Create a new Berksfile in the repo with whatever contents you need to run your stack. I'm going to assume a working knowledge of Berkshelf.
Edit the stack settings for myapp::dev::us-east. Set Use Custom Chef Cookbooks to Yes. Set the repository URL to https://s3.amazonaws.com/<berks-s3-bucket>/myapp-dev-us-east/cookbooks.tgz. Replace <berks-s3-bucket> with the name of the S3 bucket you specified when we got started. Note that you'll need to create the bucket manually: aws s3 mb s3://<my_bucket>. You'll want to create an IAM user as well, the credentials for which you can specify in the fields provided. The user only needs s3:Get and s3:List permissions.
Now we're ready to create a new cookbook repository for our stack. The default opzworks behavior for the berks command is to build the berkshelf, bundle it as cookbooks.tgz, and upload it to <berks-s3-bucket>/project-env-region/cookbooks.tgz. It will then execute update_custom_cookbooks on the stack so that the stack instances retrieve our updated cookbooks.
opzworks berks myapp will work in our case if the only stack we have created is myapp. If you have any other stacks that match myapp, the code will exit with a message that it detected more than one matching stack, in which case you need to be more explicit: opzworks berks myapp::dev::us-east, for example.
If you want to skip the execution of update_custom_cookbooks on the remote stack, pass the --no-update flag.
TODO
Generate and update SSH configuration files, or alternatively return a list of IPs for matching stacks.
Host names are based off the stack naming convention, project_name::env::region. The default
is to use public instance IPs (or elastic ip if one is assigned). Passing the --private option
will instead use instance private IPs.
For example, if we have a host 'api1' in the stack apiaxle::prod::us-east, the
resultant hostname will be api1-apiaxle-prod-us-east
By default, opsworks ssh will iterate over all stacks. If you wish to restrict the stacks
it searches, simply pass the stack name (or a partial match) as an argument:
opzworks ssh myproject::prod
If you wanted to automatically scrape all your stacks to populate your ssh config, and
you don't want to use the --update flag (which will overwrite the entire file contents),
you could do something like:
- add a crontab entry similar to:
0 * * * * /bin/bash -l -c /path/to/opzworks-ssh.sh - create
/path/to/opzworks-ssh.sh:
# this script reads .ssh/config, drops anything after the matched line,
# then generates a list of opsworks hosts and appends them to the file.
gsed -i '/OPSWORKS_CRON_LINE_MATCH/q' ~/.ssh/config
opzworks ssh >>~/.ssh/configNote this example assumes the use of a gnu sed-like utility, which on OSX means
installing gnu sed (brew install gsed if you're using homebrew). On Linux, simply
change gsed to sed.
Add the following line to the bottom of your existing ~/.ssh/config:
# OPSWORKS_CRON_LINE_MATCH
To return only a list of IPs, pass the --raw flag:
opzworks ssh -r mystack1 mystack2 or opzworks ssh -r -p mystack, etc.