+
+
+
+
+
+ Posts
+Tags:
+ +
+
+
+
+
+The benefits of LDBC membership are:
+Note: Apart from conformance to membership agreement, including the Byelaws and the Fair Use Policy, becoming an LDBC member does not involve any further obligations. Members are not required to attend meetings, travel to events, or be involved in any task forces/working groups.
+Note: For non-sponsor organizations, there is a 2,000 GBP auditing fee, to be paid for each audit to LDBC. Sponsors are exempt from this additional fee.
+For the latest information on becoming an LDBC member, see the LDBC Membership – Joining and Renewing 2023 document.
+Please fill out this form if you are an organization or individual applying to join LDBC:
+Fill out one of these forms if you are just contributing to a project in the LDBC GitHub organization
+ +In either case please email your completed form to info@ldbcouncil.org
See the constitutional documents page.
+ +The text of this page is based on our Byelaws.
+LDBC expects all its members to conscientiously observe the provisions of this Fair Use Policy for LDBC Benchmarks. LDBC-approved auditors must bring this Fair Use Policy for LDBC Benchmarks to the attention of any prospective or actual Test Sponsor. The Board of Directors of LDBC is responsible for enforcing this Policy and any alleged violations should be notified to info@ldbcouncil.org.
Once an auditor has approved a performance test result, including all required supporting documentation, as being successfully audited, then the Members Council and the Task Force responsible for the benchmark will be notified. The Board will have the results added to the LDBC web site as an LDBC Benchmark Results set according to the following procedure:
+Any party wishing to avoid infringement of the trademarked term “LDBC BENCHMARK” should follow the following guidelines relating to its fair use.
+LDBC encourages use, derived use, study, descriptions, critiques of and suggestions for improvement of LDBC Draft Benchmarks and LDBC Benchmarks. Our benchmark specifications are open-source, and we always welcome new contributors and members. These guidelines are only intended to prevent false or confusing claims relating to performance test results that are intended to be used for product comparisons.
+An example that illustrates these points: you might say something like this in a presentation:
+++“We used the LDBC SNB benchmark as a starting point. This isn’t the official LDBC standard: we added four queries because of X, and we don’t attempt to deal with the ACID requirement. The test results aren’t audited, so we want to be clear that this is not an LDBC Benchmark test run, and these numbers are not LDBC Benchmark Results. If you look at this link on the slide I’m showing you can see all the details of how our work is derived from, and varies from, the SNB 2.0 spec.”
+
Or you might say:
+++ +“For this example of a GQL graph type we used the LDBC SNB data model. This is nothing to do with the actual LDBC benchmark specification: we just used their data model as a use-case for illustrating what a graph schema might look like. We took this from the SNB 2.0 spec.”
+
The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as
+anti-fraud and risk control. It is maintained by the LDBC FinBench Task Force.
The benchmark has one workload, Transaction Workload, capturing OLTP scenario with complex read queries that access the neighbourhood of a given node in the graph and write queries that continuously insert or delete data in the graph. Its data sets are available in the Google Drive.
+For a brief overview, see the slides presented in the 16th TUC meeting. The Financial Benchmark’s specification can be found on arXiv.
+There are no audited results yet.
+For auditing requests, please reach out at info@ldbcouncil.org. Audits can only be commissioned by LDBC member companies by contracting any of the LDBC-certified auditors. Note that there is a 2,000 GBP auditing fee to be paid for the LDBC for non-sponsor company members. Sponsor companies are exempt from this.
The LDBC Social Network Benchmark is subject to the LDBC Fair Use Policies.
+ +The Graphalytics benchmark is an industrial-grade benchmark for graph analysis platforms such as Giraph, Spark GraphX, and GraphBLAS. It consists of six core algorithms, standard data sets, and reference outputs, enabling the objective comparison of graph analysis platforms.
+The benchmark harness consists of a core component, which is extendable by a driver for each different platform implementation. The benchmark includes the following algorithms:
+The choice of these algorithms was carefully motivated, using the LDBC TUC and extensive literature surveys to ensure good coverage of scenarios. The standard data sets include both real and synthetic data sets, which are classified into intuitive “T-shirt” sizes (S, M, L, etc.).
+Each experiment set in Graphalytics consists of multiple platform runs (a platform executes an algorithm on a data set), and diverse set of experiments are carried out to evaluate different performance characteristics of a system-under-test.
+All completed benchmarks must go through a strict validation process to ensure the integrity of the performance results.
+The development of Graphalytics is supported by many active vendors in the field of large-scale graph analytics. Currently, Graphalytics already facilitates benchmarks for a large number of graph analytics platforms, such as GraphBLAS, Giraph, GraphX, and PGX.D, allowing comparison of the state-of-the-art system performance of both community-driven and industrial-driven platforms. To get started, the details of the Graphalyics documentation and its software components are described below.
+ldbc_graphalytics_docs repositoryldbc_graphalytics: Generic driverldbc_graphalytics_platforms_umbra: Umbra implementationldbc_graphalytics_platforms_graphblas: GraphBLAS implementationIn 2023, we will hold a new round of the Graphalytics competition. See the LDBC Graphalytics Benchmark presentation for an introduction to the benchmark framework and the competition’s rules.
+Artifacts:
+The Graphalytics data sets are compressed using zstd. The total size of the compressed archives is approx. 350GB. When decompressed, the data sets require approximately 1.5TB of disk space.
For detailed information on the data sets, see the table with their statistics.
+The data sets are available in two locations:
+Note that some of the Graphalytics data sets were fixed in March 2023. Prior to this, they were incorrectly packaged or had missing/incorrect reference outputs for certain algorithms. If you are uncertain whether you have the correct versions, cross-check them against these MD5 checksums: datagen-9_4-fb, datagen-sf3k-fb, datagen-sf10k-fb, graph500-27, graph500-28, graph500-29, graph500-30.
| data set | +#nodes | +#edges | +scale | +link | +size | +
|---|---|---|---|---|---|
| cit-Patents | +3,774,768 | +16,518,947 | +XS | +cit-Patents.tar.zst |
+119.1 MB | +
| com-friendster | +65,608,366 | +1,806,067,135 | +XL | +com-friendster.tar.zst |
+6.7 GB | +
| datagen-7_5-fb | +633,432 | +34,185,747 | +S | +datagen-7_5-fb.tar.zst |
+162.3 MB | +
| datagen-7_6-fb | +754,147 | +42,162,988 | +S | +datagen-7_6-fb.tar.zst |
+200.0 MB | +
| datagen-7_7-zf | +13,180,508 | +32,791,267 | +S | +datagen-7_7-zf.tar.zst |
+434.5 MB | +
| datagen-7_8-zf | +16,521,886 | +41,025,255 | +S | +datagen-7_8-zf.tar.zst |
+544.3 MB | +
| datagen-7_9-fb | +1,387,587 | +85,670,523 | +S | +datagen-7_9-fb.tar.zst |
+401.2 MB | +
| datagen-8_0-fb | +1,706,561 | +107,507,376 | +M | +datagen-8_0-fb.tar.zst |
+502.5 MB | +
| datagen-8_1-fb | +2,072,117 | +134,267,822 | +M | +datagen-8_1-fb.tar.zst |
+625.4 MB | +
| datagen-8_2-zf | +43,734,497 | +106,440,188 | +M | +datagen-8_2-zf.tar.zst |
+1.4 GB | +
| datagen-8_3-zf | +53,525,014 | +130,579,909 | +M | +datagen-8_3-zf.tar.zst |
+1.7 GB | +
| datagen-8_4-fb | +3,809,084 | +269,479,177 | +M | +datagen-8_4-fb.tar.zst |
+1.2 GB | +
| datagen-8_5-fb | +4,599,739 | +332,026,902 | +L | +datagen-8_5-fb.tar.zst |
+1.5 GB | +
| datagen-8_6-fb | +5,667,674 | +421,988,619 | +L | +datagen-8_6-fb.tar.zst |
+1.9 GB | +
| datagen-8_7-zf | +145,050,709 | +340,157,363 | +L | +datagen-8_7-zf.tar.zst |
+4.6 GB | +
| datagen-8_8-zf | +168,308,893 | +413,354,288 | +L | +datagen-8_8-zf.tar.zst |
+5.3 GB | +
| datagen-8_9-fb | +10,572,901 | +848,681,908 | +L | +datagen-8_9-fb.tar.zst |
+3.7 GB | +
| datagen-9_0-fb | +12,857,671 | +1,049,527,225 | +XL | +datagen-9_0-fb.tar.zst |
+4.6 GB | +
| datagen-9_1-fb | +16,087,483 | +1,342,158,397 | +XL | +datagen-9_1-fb.tar.zst |
+5.8 GB | +
| datagen-9_2-zf | +434,943,376 | +1,042,340,732 | +XL | +datagen-9_2-zf.tar.zst |
+13.7 GB | +
| datagen-9_3-zf | +555,270,053 | +1,309,998,551 | +XL | +datagen-9_3-zf.tar.zst |
+17.4 GB | +
| datagen-9_4-fb | +29,310,565 | +2,588,948,669 | +XL | +datagen-9_4-fb.tar.zst |
+14.0 GB | +
| datagen-sf3k-fb | +33,484,375 | +2,912,009,743 | +XL | +datagen-sf3k-fb.tar.zst |
+12.7 GB | +
| datagen-sf10k-fb | +100,218,750 | +9,404,822,538 | +2XL | +datagen-sf10k-fb.tar.zst |
+40.5 GB | +
| dota-league | +61,170 | +50,870,313 | +S | +dota-league.tar.zst |
+114.3 MB | +
| graph500-22 | +2,396,657 | +64,155,735 | +S | +graph500-22.tar.zst |
+202.4 MB | +
| graph500-23 | +4,610,222 | +129,333,677 | +M | +graph500-23.tar.zst |
+410.6 MB | +
| graph500-24 | +8,870,942 | +260,379,520 | +M | +graph500-24.tar.zst |
+847.7 MB | +
| graph500-25 | +17,062,472 | +523,602,831 | +L | +graph500-25.tar.zst |
+1.7 GB | +
| graph500-26 | +32,804,978 | +1,051,922,853 | +XL | +graph500-26.tar.zst |
+3.4 GB | +
| graph500-27 | +63,081,040 | +2,111,642,032 | +XL | +graph500-27.tar.zst |
+7.1 GB | +
| graph500-28 | +121,242,388 | +4,236,163,958 | +2XL | +graph500-28.tar.zst |
+14.4 GB | +
| graph500-29 | +232,999,630 | +8,493,569,115 | +2XL | +graph500-29.tar.zst |
+29.6 GB | +
| graph500-30 | +447,797,986 | +17,022,117,362 | +3XL | +graph500-30.tar.zst |
+60.8 GB | +
| kgs | +832,247 | +17,891,698 | +XS | +kgs.tar.zst |
+65.7 MB | +
| twitter_mpi | +52,579,678 | +1,963,263,508 | +XL | +twitter_mpi.tar.zst |
+5.7 GB | +
| wiki-Talk | +2,394,385 | +5,021,410 | +2XS | +wiki-Talk.tar.zst |
+34.9 MB | +
| example-directed | +10 | +17 | +- | +example-directed.tar.zst |
+1.0 KB | +
| example-undirected | +9 | +12 | +- | +example-undirected.tar.zst |
+1.0 KB | +
| test-bfs-directed | +<100 | +<100 | +- | +test-bfs-directed.tar.zst |
+<2.0 KB | +
| test-bfs-undirected | +<100 | +<100 | +- | +test-bfs-undirected.tar.zst |
+<2.0 KB | +
| test-cdlp-directed | +<100 | +<100 | +- | +test-cdlp-directed.tar.zst |
+<2.0 KB | +
| test-cdlp-undirected | +<100 | +<100 | +- | +test-cdlp-undirected.tar.zst |
+<2.0 KB | +
| test-pr-directed | +<100 | +<100 | +- | +test-pr-directed.tar.zst |
+<2.0 KB | +
| test-pr-undirected | +<100 | +<100 | +- | +test-pr-undirected.tar.zst |
+<2.0 KB | +
| test-lcc-directed | +<100 | +<100 | +- | +test-lcc-directed.tar.zst |
+<2.0 KB | +
| test-lcc-undirected | +<100 | +<100 | +- | +test-lcc-undirected.tar.zst |
+<2.0 KB | +
| test-wcc-directed | +<100 | +<100 | +- | +test-wcc-directed.tar.zst |
+<2.0 KB | +
| test-wcc-undirected | +<100 | +<100 | +- | +test-wcc-undirected.tar.zst |
+<2.0 KB | +
| test-sssp-directed | +<100 | +<100 | +- | +test-sssp-directed.tar.zst |
+<2.0 KB | +
| test-sssp-undirected | +<100 | +<100 | +- | +test-sssp-undirected.tar.zst |
+<2.0 KB | +
We are happy to annonunce new audited results for the SNB Interactive workload, achieved by the open-source GraphScope Flex system.
+The current audit of the system has broken several records:
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and tests for the GQL language. See this announcement from Alastair Green, Vice-chair of LDBC.
+These tools are the work of the LDBC GQL Implementation Working Group, headed up by Michael Burbidge. Damian Wileński and Dominik Tomaszuk have worked …
+ +We are delighted to announce the official release of the initial version (v0.1.0) of Financial Benchmark (FinBench).
+The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as anti-fraud and risk control. It is maintained by the LDBC FinBench Task Force. The benchmark has one workload currently, Transaction Workload, capturing OLTP scenario with complex read queries that access the …
+ +2023 has been an eventful year for us so far. Here is a summary of our recent activities.
+Our paper The LDBC Social Network Benchmark: Business Intelligence Workload was published in PVLDB.
+David Püroja just completed his MSc thesis on creating a design towards SNB Interactive v2 at CWI’s Database Architectures group. David and I gave a deep-dive talk at the FOSDEM conference’s graph developer room titled The LDBC Social Network …
LDBC SNB provides a data generator, which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. More than two years have elapsed since my last technical update on LDBC SNB Datagen, in which I discussed the reasons for moving the code to Apache Spark from the MapReduce-based Apache Hadoop implementation and the …
+ +LDBC currently offers the following benchmarks:
+Uses of LDBC benchmarks are subject to the Fair Use Policy for LDBC Benchmarks.
+ +We are delighted to announce the set up of the Financial Benchmark (FinBench) task force.
+The Financial Benchmark (FinBench) project aims to define a graph database evaluating benchmark and develop a data generation process and a query driver to make the evaluation of the graph database representative, reliable and comparable, especially in financial scenarios, such as anti-fraud and risk control. The FinBench is scheduled to be released in the …
+ +LDBC’s Social Network Benchmark [4] (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data …
+ + +
+
+
+
+
+ LDBC is proud to announce the new LDBC Graphalytics Benchmark draft specification.
+LDBC Graphalytics is the first industry-grade graph data management benchmark …
+ +Apache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
+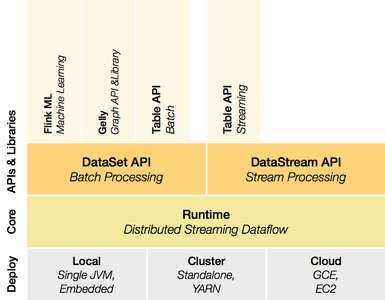
Flink offers multiple APIs to process data …
+ +The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of web resources through “same-as” links which specify that two URIs correspond to the same real world object. In the vast number of data sources participating in the Linked Data Cloud, this information is not …
+ +In this post we will look at running the LDBC SNB on Virtuoso.
+First, let’s recap what the benchmark is about:
+fairly frequent short updates, with no update contention worth mentioning
+short random lookups
+medium complex queries centered around a person’s social environment
+The updates exist so as to invalidate strategies that rely too heavily on precomputation. The short lookups exist for the sake of realism; after all, an …
+ +Next 31st of May the GRADES workshop will take place in Melbourne within the ACM/SIGMOD presentation. GRADES started as an initiative of the Linked Data Benchmark Council in the SIGMOD/PODS 2013 held in New York.
+Among the papers published in this edition we have “Graphalytics: A Big Data Benchmark for Graph-Processing Platforms”, which presents a new benchmark that uses the Social Network Benchmark data generator of LDBC (that can …
+ +SNB Interactive is the wild frontier, with very few rules. This is necessary, among other reasons, because there is no standard property graph data model, and because the contestants support a broad mix of programming models, ranging from in-process APIs to declarative query.
+In the case of Virtuoso, we have played with SQL and SPARQL implementations. For a fixed schema and well known workload, SQL will always win. The reason for this is that …
+ +LDBC is presenting two papers at the next edition of the ACM SIGMOD/PODS conference held in Melbourne from May 31st to June 4th, 2015. The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools and experiences.
+On the industry track, LDBC will be presenting the Social Network Benchmark Interactive …
+ +This post is the first in a series of blogs analyzing the LDBC Social Network Benchmark Interactive workload. This is written from the dual perspective of participating in the benchmark design and of building the OpenLink Virtuoso implementation of same.
+With two implementations of SNB interactive at four different scales, we can take a first look at what the benchmark is really about. The hallmark of a benchmark implementation is that its …
+ +In a previous 3-part blog series we touched upon the difficulties of executing the LDBC SNB Interactive (SNB) workload, while achieving good performance and scalability. What we didn’t discuss is why these difficulties were unique to SNB, and what aspects of the way we perform workload execution are scientific contributions - novel solutions to previously unsolved problems. This post will highlight the differences between SNB and more …
+ +As discussed in previous posts, one of the features that makes Datagen more realistic is the fact that the activity volume of the simulated Persons is not uniform, but forms spikes. In this blog entry I want to explain more in depth how this is actually implemented inside of the generator.
+First of all, I start with a few basics of how Datagen works internally. In Datagen, once the person graph has been created (persons and their relationships), …
+ +This blog entry is about one of the features of DATAGEN that makes it different from other synthetic graph generators that can be found in the literature: the community structure of the graph.
+When generating synthetic graphs, one must not only pay attention to quantitative measures such as the number of nodes and edges, but also to other more qualitative characteristics such as the degree distribution, clustering coefficient. Real graphs, and …
+ + +
+
+
+
+
+ I took this picture in June 2010 next to Union Square in San Francisco. I was smoking and …
+ +The Linked Data paradigm has become the prominent enabler for sharing huge volumes of data using Semantic Web technologies, and has created novel challenges for non-relational data management systems, such as RDF and graph engines. Efficient data access through queries is perhaps the most important data management task, and is enabled through query optimization techniques, which amount to the discovery of optimal or close to optimal execution …
+ +When talking about DATAGEN and other graph generators with social network characteristics, our attention is typically borrowed by the friendship subgraph and/or its structure. However, a social graph is more than a bunch of people being connected by friendship relations, but has a lot more of other things is worth to look at. With a quick view to commercial social networks like Facebook, Twitter or Google+, one can easily identify a lot of other …
+ +The SNB Driver part 1 post introduced, broadly, the challenges faced when developing a workload driver for the LDBC SNB benchmark. In this blog we’ll drill down deeper into the details of what it means to execute “dependent queries” during benchmark execution, and how this is handled in the driver. First of all, as many driver-specific terms will be used, below is a listing of their definitions. There is no need to read them in …
+ +Up until now we have introduced the challenges faced when executing the LDBC SNB benchmark, as well as explained how some of these are overcome. With the foundations laid, we can now explain precisely how operations are executed.
+Based on the dependencies certain operations have, and on the granularity of parallelism we wish to achieve while executing them, we assign a Dependency Mode and an Execution Mode to every operation type. Using these …
+ +Until now we have discussed several aspects of the Semantic Publishing Benchmark (SPB) such as the difference in performance between virtual and real servers configuration, how to choose an appropriate query mix for a benchmark run and our experience with using SPB in the development process of GraphDB for finding performance issues.
+In this post we provide a step-by-step guide on how to run SPB using the Sesame RDF data store on a fresh install …
+ +The Semantic Publishing Instance Matching Benchmark (SPIMBench) is a novel benchmark for the assessment of instance matching techniques for RDF data with an associated schema. SPIMBench extends the state-of-the art instance matching benchmarks for RDF data in three main aspects: it allows for systematic scalability testing, supports a wider range of test cases including semantics-aware ones, and provides an enriched gold standard.
+The SPIMBench …
+ +We are presently working on the SNB BI workload. Andrey Gubichev of TU Munchen and myself are going through the queries and are playing with two SQL based implementations, one on Virtuoso and the other on Hyper.
+As discussed before, the BI workload has the same choke points as TPC-H as a base but pushes further in terms of graphiness and query complexity.
+There are obvious marketing applications for a SNB-like dataset. There are also security …
+ +LDBC’s Semantic Publishing Benchmark (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the famous BBC Dynamic Semantic Publishing scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volume of read requests (SPARQL queries collecting recent content and data to generate web page on a specific subject, e.g. Frank …
+ +In previous posts (Getting started with snb, DATAGEN: data generation for the Social Network Benchmark), Arnau Prat discussed the main features and characteristics of DATAGEN: realism, scalability, determinism, usability. DATAGEN is the social network data generator used by the three LDBC-SNB workloads, which produces data simulating the activity in a social network site during a period of time. In this post, we conduct a series of experiments …
+ +In this multi-part blog we consider the challenge of running the LDBC Social Network Interactive Benchmark (LDBC SNB) workload in parallel, i.e. the design of the workload driver that will issue the queries against the System Under Test (SUT). We go through design principles that were implemented for the LDBC SNB workload generator/load tester (simply referred to as driver). Software and documentation for this driver is available here: …
+ +LDBC SPB (Semantic Publishing Benchmark) is based on the BBC linked data platform use case. Thus the data modelling and transaction mix reflects the BBC’s actual utilization of RDF. But a benchmark is not only a condensation of current best practices. The BBC linked data platform is an Ontotext Graph DB deployment. Graph DB was formerly known as Owlim.
+So, in SPB we wanted to address substantially more complex queries than the lookups that …
+ +The Semantic Publishing Benchmark (SPB), developed in the context of LDBC, aims at measuring the read and write operations that can be performed in the context of a media organisation. It simulates the management and consumption of RDF metadata describing media assets and creative works. The scenario is based around a media organisation that maintains RDF descriptions of its catalogue of creative works. These descriptions use a set of ontologies …
+ +The Linked Data Benchmark Council (LDBC) mission is to design and maintain benchmarks for graph data management systems, and establish and enforce standards in running these benchmarks, and publish and arbitrate around the official benchmark results. The council and its https://ldbcouncil.org website just launched, and in its first 1.5 year of existence, most effort at LDBC has gone into investigating the needs of the field through interaction …
+ +The Linked Data Benchmark Council (LDBC) is reaching a milestone today, June 23 2014, in announcing that two of the benchmarks that it has been developing since 1.5 years have now reached the status of Public Draft. This concerns the Semantic Publishing Benchmark (SPB) and the interactive workload of the Social Network Benchmark (SNB). In case of LDBC, the release is staged: now the benchmark software just runs read-only queries. This will be …
+ +Social Network interaction is amongst the most natural and widely spread activities in the internet society, and it has turned out to be a very useful way for people to socialise at different levels (friendship, professional, hobby, etc.). As such, Social Networks are well understood from the point of view of the data involved and the interaction required by their actors. Thus, the concepts of friends of friends, or retweet are well established …
+ +It is with great pleasure that we announce the new LDBC organisation site at www.ldbcouncil.org. The LDBC started as a European Community FP7 funded project with the objective to create, foster and become an industry reference for benchmarking RDF and Graph technologies. A period of more than one and a half years has led us to the creation of the first two workloads, the Semantic Publishing Benchmark and the Social Network Benchmark in its …
+ +Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate …
+ +As explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 [1].
+One of the most …
+ +In a previous blog post titled “Is SNB like Facebook’s LinkBench?”, Peter Boncz discusses the design philosophy that shapes SNB and how it compares to other existing benchmarks such as LinkBench. In this post, I will briefly introduce the essential parts forming SNB, which are DATAGEN, the LDBC execution driver and the workloads.
+DATAGEN is the data generator used by all the workloads of SNB. Here we introduced the …
+ +The LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.
+The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.
+This …
+ + +
+
+
+
+
+ In this post, I will discuss in some detail the rationale and goals of the design of the Social Network Benchmark (SNB) and explain how it relates to real …
+ +Synopsis: Now is the time to finalize the interactive part of the Social Network Benchmark (SNB). The benchmark must be both credible in a real social network setting and pose new challenges. There are many hard queries but not enough representation for what online systems in fact do. So, the workload mix must strike a balance between the practice and presenting new challenges.
+It is about to be showtime for LDBC. The initial installment of the …
+ +In previous posts (this and this) we briefly introduced the design goals and philosophy behind DATAGEN, the data generator used in LDBC-SNB. In this post, I will explain how to use DATAGEN to generate the necessary datatsets to run LDBC-SNB. Of course, as DATAGEN is continuously under development, the instructions given in this tutorial might change in the future.
+DATAGEN runs on top of hadoop 1.2.1 to be scale. …
+ +Note: consider this post as a continuation of the “Making it interactive” post by Orri Erling.
+I have now completed the Virtuoso TPC-H work, including scale out. Optimization possibilities extend to infinity but the present level is good enough. TPC-H is the classic of all analytics benchmarks and is difficult enough, I have extensive commentary on this on my blog (In Hoc Signo Vinces series), including experimental results. This is, …
+ +During the past six months we (the OWLIM Team at Ontotext) have integrated the LDBC Semantic Publishing Benchmark (LDBC-SPB) as a part of our development and release process.
+First thing we’ve started using the LDBC-SPB for is to monitor the performance of our RDF Store when a new release is about to come out.
+Initially we’ve decided to fix some of the benchmark parameters :
+The LDBC SNB Business Intelligence workload is focusing on aggregation- and join-heavy complex queries touching a large portion of the graph with microbatches of insert/delete operations. Its data sets are available in Cloudflare R2.
+For an overview of the workload, see the VLDB 2023 paper and its presentation by Gabor Szarnyas.
+The workload produces scoring metrics for performance (power and throughput scores) at the given scale and price/performance metrics. The full disclosure reports (FDR) further break down the composition of the metric into its constituent parts, e.g. single query execution times.
+Note that the system cost is the sum of the license, hardware, and maintenance costs, where maintenance means 24/7 support with a response time of less than 4 hours.
+| Benchmark setup | +SF | +Hardware | +Performance metrics and cost | +Documents | +
|---|---|---|---|---|
+
|
+
+ 30,000 | +72 Alibaba Cloud ecs.r7.16xlarge instances: 64×Intel Xeon Platinum 8369B vCPUs, 512 GiB RAM per instance |
+
+
|
+
+ + + | + +
+
|
+
+ 100 | +1 AWS r6a.4xlarge instance: 16×AMD EPYC 7R13 vCPUs, 128GiB RAM |
+
+
|
+
+ + + | + +
+
|
+
+ 1,000 | +4 AWS r6a.8xlarge instances: 32×AMD EPYC 7R13 vCPUs, 256GiB RAM per instance |
+
+
|
+
+ + + | + +
+
|
+
+ 10,000 | +48 AWS r6a.8xlarge instances: 32×AMD EPYC 7R13 vCPUs, 256GiB RAM per instance |
+
+
|
+
+ + + | + +
+
|
+
+ 1,000 | +Dell PowerEdge 6625 with 64×AMD EPYC 9354 CPU cores and 1.5TiB RAM |
+
+
|
+
+ + + | + +
The audited LDBC SNB BI results displayed above are available as a CSV file.
+SNB BI audits can be commissioned from the following LDBC-certified auditors:
+The LDBC SNB Interactive workload captures transactional graph processing scenario with complex read queries that access the neighbourhood of a given node in the graph and update operations that continuously insert new data in the graph. Its data sets are available in the CWI/SURF data repository.
+The workload produces the throughput metric to characterize the performance at the given scale. The full disclosure reports (FDR) further detail the performance of the system under test by listing the data loading time and single query execution times.
+Note that the system cost is the sum of the license, hardware, and maintenance costs, where maintenance means 24/7 support with a response time of less than 4 hours.
+| Benchmark setup | +SF | +Hardware | +Throughput | +Documents | +
|---|---|---|---|---|
+
|
+
+ 30 | +AWS r6id.8xlarge, 256GiB RAM, 32×Intel Xeon Platinum 8375C vCPUs, 1 read thread, 1 write thread |
+ 3.04 ops/s | + ++ + | + +
| 30 | +AWS r6id.8xlarge, 256GiB RAM, 32×Intel Xeon Platinum 8375C vCPUs, 2 read threads, 2 write threads |
+ 6.76 ops/s | + +||
| 30 | +AWS r6id.8xlarge, 256GiB RAM, 32×Intel Xeon Platinum 8375C vCPUs, 4 read threads, 4 write threads |
+ 12.16 ops/s | + +
| Benchmark setup | +SF | +Hardware | +Throughput | +Documents | +
|---|---|---|---|---|
+
|
+
+ 100 | +Alibaba Cloud ecs.r8a.16xlarge, 512GiB RAM, 64×AMD EPYC 9T24 @ 3.7GHz vCPUs |
+ 130,098.36 ops/s | + ++ + | + +
| 300 | +Alibaba Cloud ecs.r8a.16xlarge, 512GiB RAM, 64×AMD EPYC 9T24 @ 3.7GHz vCPUs |
+ 131,263.87 ops/s | + +||
| 1000 | +Alibaba Cloud ecs.r8a.16xlarge, 512GiB RAM, 64×AMD EPYC 9T24 @ 3.7GHz vCPUs |
+ 127,784.51 ops/s | + +||
+
|
+
+ 30 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 37,631.25 ops/s | + ++ + | + +
| 100 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 48,764.08 ops/s | + +||
| 300 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 48,311.63 ops/s | + +||
+
|
+
+ 30 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 33,180.87 ops/s | + ++ + | + +
| 100 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 33,625.36 ops/s | + +||
| 300 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 33,261.38 ops/s | + +||
+
|
+
+ 30 | +Alibaba Cloud ecs.g8y.16xlarge, 256GiB RAM, 64×Arm-based YiTian 710 vCPUs |
+ 16,133.08 ops/s | + ++ + | + +
| 100 | +Alibaba Cloud ecs.g8y.16xlarge, 256GiB RAM, 64×Arm-based YiTian 710 vCPUs |
+ 16,966.26 ops/s | + +||
| 300 | +Alibaba Cloud ecs.g8y.16xlarge, 256GiB RAM, 64×Arm-based YiTian 710 vCPUs |
+ 13,532.62 ops/s | + +||
+
|
+
+ 30 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 12,252.50 ops/s | + ++ + | + +
| 100 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 12,934.61 ops/s | + +||
| 300 | +AWS r5d.12xlarge, 384GiB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 12,721.24 ops/s | + +||
+
|
+
+ 30 | +AWS r5d.12xlarge, 372GB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 9,285.86 ops/s | + ++ + | + +
| 100 | +AWS r5d.12xlarge, 372GB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 8,501.21 ops/s | + +||
| 300 | +AWS r5d.12xlarge, 372GB RAM, 48×Intel Xeon Platinum 8259CL vCPUs |
+ 8,370.52 ops/s | + +||
+
|
+
+ 30 | +AWS r5d.12xlarge, 374GB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 5,436.47 ops/s | + ++ + | + +
| 100 | +AWS r5d.12xlarge, 374GB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 5,010.77 ops/s | + +||
| 300 | +AWS r5d.12xlarge, 374GB RAM, 48×Intel Xeon Platinum 8175M vCPUs |
+ 4,855.52 ops/s | + +
The audited LDBC SNB Interactive results displayed above are available as a CSV file.
+SNB Interactive audits can be commissioned from the following LDBC-certified auditors:
+Social Network Benchmark Interactive, version 0.2.2
+The LDBC SNB Interactive v2 workload is currently under development. See the TPCTC 2023 paper “The LDBC Social Network Benchmark Interactive Workload v2: A Transactional Graph Query Benchmark with Deep Delete Operations” and its slide deck for details.
+ +| SF | +Throughput | +Cost | +Software | +Hardware | +Test Sponsor | +Date | +Full Disclosure Report | +
|---|---|---|---|---|---|---|---|
10 |
+101.20 ops/s |
+30,427 EUR | +Sparksee 5.1.1 | +2×Xeon 2630v3 8-core 2.4GHz, 256GB RAM | +Sparsity Technologies SA | ++ | Full Disclosure Report | +
30 |
+1,287.17 ops/s |
+20,212 EUR | +Virtuoso 07.50.3213 v7fasttrack | +2×Xeon2630 6-core 2.4GHz, 192GB RAM | +OpenLink Software | ++ | Full Disclosure Report | +
30 |
+86.50 ops/s |
+30,427 EUR | +Sparksee 5.1.1 | +2×Xeon 2630v3 8-core 2.4GHz, 256GB RAM | +Sparsity Technologies SA | ++ | Full Disclosure Report | +
100 |
+1,200.00 ops/s |
+20,212 EUR | +Virtuoso 07.50.3213 v7fasttrack | +2×Xeon2630 6-core 2.4GHz, 192GB RAM | +OpenLink Software | ++ | Full Disclosure Report | +
100 |
+81.70 ops/s |
+37,927 EUR | +Sparksee 5.1.1 | +2×Xeon 2630v3 8-core 2.4GHz, 256GB RAM | +Sparsity Technologies SA | ++ | Full Disclosure Report | +
300 |
+635.00 ops/s |
+20,212 EUR | +Virtuoso 07.50.3213 v7fasttrack | +2×Xeon2630 6-core 2.4GHz, 192GB RAM | +OpenLink Software | ++ | Full Disclosure Report | +
The Social Network Benchmark (SNB) suite defines graph workloads targeting database management systems and is maintained by the LDBC SNB Task Force.
+The benchmark suite consists of two distinct workloads on a common dataset:
+For a brief overview, see our talk given at FOSDEM 2023’s graph developer room. The Social Network Benchmark’s specification can be found on arXiv.
+For auditing requests, please reach out at info@ldbcouncil.org. Audits can only be commissioned by LDBC member companies by contracting any of the LDBC-certified auditors. Note that there is a 2,000 GBP auditing fee to be paid for the LDBC for non-sponsor company members. Sponsor companies are exempt from this.
For a short summary of LDBC’s auditing process, including preparation steps, timelines, and pricing, see the Auditing process for the LDBC Social Network Benchmark document.
+The LDBC Social Network Benchmark is subject to the LDBC Fair Use Policies.
+The Semantic Publishing Benchmark (SPB) is an LDBC benchmark for testing the performance of RDF engines inspired by the Media/Publishing industry. In particular, LDBC worked with British Broadcasting Corporation BBC to define this benchmark, for which BBC donated workloads, ontologies and data. The publishing industry is an area where significant adoption of RDF is taking place.
+There have been many academic benchmarks for RDF but none of these are truly industrial-grade. The SPB combines a set of complex queries under inference with continuous updates and special failover tests for systems implementing replication.
+SPB performance is measured by producing a workload of CRUD (Create, Read, Update, Delete) operations which are executed simultaneously. The benchmark offers a data generator that uses real reference data to produce datasets of various sizes and tests the scalability aspect of RDF systems. The benchmark workload consists of (a) editorial operations that add new data, alter or delete existing (b) aggregation operations that retrieve content according to various criteria. The benchmark also tests conformance for various rules inside the OWL2-RL rule-set.
+The SPB specification contains the description of the benchmark and the data generator and all information about its software components can be found on the SPB developer page.
+| SF | +Triples | +RW Agents | +Interactive (Q/sec) | +Updates (ops/sec) | +Cost | +Software | +Hardware | +Test Sponsor | +Date | +FDR | +
|---|---|---|---|---|---|---|---|---|---|---|
3 |
+256M |
+16 / 4 |
+335.48 |
+25.66 |
+177,474 USD |
+GraphDB EE 10.0.1 | +AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
3 |
+256M |
+24 / 0 |
+413.16 |
+0.00 |
+207,474 USD |
+GraphDB EE 10.0.1 | +AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
3 |
+256M |
+64 / 4 |
+1121.76 |
+9.53 |
+652,422 USD |
+GraphDB EE 10.0.1 | +3×AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
3 |
+256M |
+64 / 0 |
+985.63 |
+0.00 |
+562,422 USD |
+GraphDB EE 10.0.1 | +3×AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
5 |
+1B |
+16 / 4 |
+105.76 |
+10.45 |
+177,474 USD |
+GraphDB EE 10.0.1 | +AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
5 |
+1B |
+24 / 0 |
+158.10 |
+0.00 |
+207,474 USD |
+GraphDB EE 10.0.1 | +AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
5 |
+1B |
+64 / 4 |
+372.56 |
+4.04 |
+652,422 USD |
+GraphDB EE 10.0.1 | +3×AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
5 |
+1B |
+64 / 0 |
+408.68 |
+0.00 |
+562,422 USD |
+GraphDB EE 10.0.1 | +3×AWS r6id.8xlarge | +Ontotext AD | ++ | FDR, summary | +
1 |
+64M |
+8 / 2 |
+100.85 |
+10.19 |
+37,504 EUR |
+GraphDB EE 6.2 | +Intel Xeon E5-1650v3 6×3.5Ghz, 96GB RAM | +Ontotext AD | ++ | FDR | +
1 |
+64M |
+8 / 2 |
+142.76 |
+10.67 |
+35,323 EUR |
+GraphDB SE 6.3 alpha | +Intel Xeon E5-1650v3 6×3.5GHz, 64GB RAM | +Ontotext AD | ++ | FDR | +
3 |
+256M |
+8 / 2 |
+29.90 |
+9.50 |
+37,504 EUR |
+GraphDB EE 6.2 | +Intel Xeon E5-1650v3 6×3.5Ghz, 96GB RAM | +Ontotext AD | ++ | FDR | +
3 |
+256M |
+8 / 2 |
+54.64 |
+9.50 |
+35,323 EUR |
+GraphDB SE 6.3 alpha | +Intel Xeon E5-1650v3 6×3.5GHz, 64GB RAM | +Ontotext AD | ++ | FDR | +
1 |
+64M |
+22 / 2 |
+149.04 |
+156.83 |
+20,213 USD |
+Virtuoso v7.50.3213 | +Intel Xeon E5-2630 6×2.30GHz, 192 GB RAM | +OpenLink Software | ++ | FDR | +
3 |
+256M |
+22 / 2 |
+80.62 |
+92.71 |
+20,213 USD |
+Virtuoso v7.50.3213 | +Intel Xeon E5-2630 6×2.30GHz, 192 GB RAM | +OpenLink Software | ++ | FDR | +
3 |
+256M |
+30 / 3 |
+115.38 |
+109.85 |
+24,528 USD |
+Virtuoso v7.50.3213 | +AWS r3.8xlarge | +OpenLink Software | ++ | FDR | +
5 |
+1B |
+22 / 2 |
+32.28 |
+72.72 |
+20,213 USD |
+Virtuoso v7.50.3213 | +Intel Xeon E5-2630 6×2.30GHz, 192 GB RAM | +OpenLink Software | ++ | FDR | +
5 |
+1B |
+30 / 3 |
+45.81 |
+55.45 |
+24,528 USD |
+Virtuoso v7.50.3213 | +AWS r3.8xlarge | +OpenLink Software | ++ | FDR | +
SPB audits can be commissioned from the following LDBC-certified auditors:
+This page contains LDBC’s constitutional documents: its Articles of Association and Byelaws.
+If you are interested in joining our benchmark task forces, please reach out at info@ldbcouncil.org.
Our benchmarks are licensed under the Apache Software License, Version 2.0 (license file, notice file).
+To contribute to the LDBC repositories, we ask you to sign a CLA or become an LDBC member. These options are available for both individuals and organizations.
+ +Organizers: Shipeng Qi (AntGroup), Wenyuan Yu (Alibaba Demo), Yan Zhou (CreateLink)
+LDBC is hosting a two-day hybrid workshop, co-located in Guangzhou with VLDB 2024 on August 30-31 (Friday-Saturday).
+The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. If you would like to participate please register using our form.
+All times are in PDT.
+Location: Langham Place, Guangzhou, room 1,
+co-located with VLDB (N0.630-638 Xingang Dong Road, Haizhu District, Guangzhou, China). See the map here.
Agenda: TBA
+Location: Alibaba Center, Guangzhou (N0.88 Dingxin Road, Haizhu District, Guangzhou, China), near to VLDB Langham Place. See the map here.
+Agenda: TBA
+A map of the LDBC TUC events we hosted so far.
+ +The LDBC consortium is pleased to announce its Eighth Technical User Community (TUC) meeting.
+This will be a two-day event/eighth-tuc-meeting/attachments at Oracle Conference Center in Redwood Shores facility on Wednesday and Thursday June 22-23, 2016.
+This will be the second TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event/eighth-tuc-meeting/attachments will basically set the following aspects:
+We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at damaris@ac.upc.edu; in order to notify Oracle security in advance, registration requests need to be in by June 12.
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is graph data management related. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also event/eighth-tuc-meeting/attachmentsually its membership base.
+In this page, you’ll find information about the following items:
+On Wednesday, lunch is provided for all attendees at 12 pm. The TUC Meeting will start at 1pm.
+(full morning: LDBC Board of Directors meeting)
+At the same venue: the fourth international workshop on Graph Data Management, Experience and Systems (GRADES16).
+18:30 social dinner for GRADES registrants (place to be announced)
+22nd and 23rd June 2016
+The TUC meeting will be held in the Oracle Conference Center
+The address is:
+Room 203 (Wed-Thu) & Room 105 (Fri)
+Oracle Conference Center
+350 Oracle Parkway
+Redwood City, CA 94065, USA
Maps and situation
+ +Oracle Campus map:
+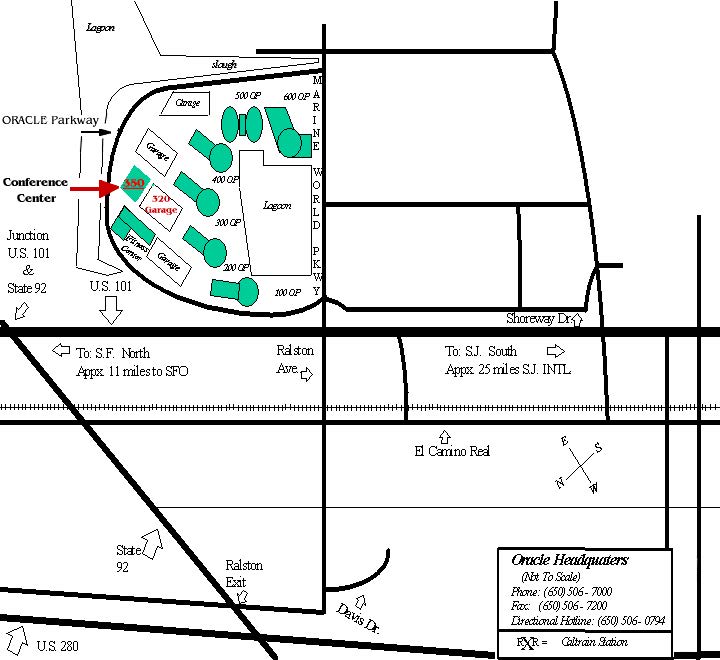
The Conference Center has a designated parking lot located directly across from the building. If the lot is filled there is also additional parking in any of the parking garages located near by. No parking permits are needed.
+Take the Caltrain to either San Carlos or Hillsdale and take the free Oracle shuttle from there. Get off the Oracle shuttle at 100 Oracle Parkway (second stop) and walk 5 minutes to get to the Conference Center.
+You can also take the Caltrain to Belmont and walk 23 min, instead of taking the Oracle shuttle.
+Alternatively, SamTrans (San Mateo County’s Transit Agency) provides public bus service between the Millbrae BART station and Palo Alto with three stops on Oracle Parkway - one of which is directly in front of the Oracle Conference Center.
+ +LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmark development, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j and Huawei among its members.
+This TUC meeting will be a one-day event preceding the SIGMOD/PODS 2018 conference in Houston, Texas (not too far away, the whole next week). Note also that at SIGMOD/PODS in Houston on Sunday 10, there is a research workshop on graph data management technology called GRADES-NDA 2018 as well, so you might combine travel.
+We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Damaris Coll (UPC) at damaris@ac.upc.edu to register.
+=> registration is free, but required <=
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals are handled by Peter Boncz (boncz@cwi.nl) and Larri (larri@ac.upc.edu). Local organizer is Juan Sequeda (juanfederico@gmail.com).
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.
+In the TUC meeting there will be:
+The meeting will start on Friday morning, with a program from 10:30-17:00:
+10:30-10:35 Peter Boncz (CWI) - introduction to the LDBC TUC meeting
+11:00-11:30 coffee break
+11:30-11:55 Gabor Szarnyas (BME) - LDBC benchmarks: three aspects of graph processing
+11:55-12:20 Peter Boncz (CWI) - G-CORE: a composable graph query language by LDBC
+12:20-12:45 Yinglong Xia (Huawei) - Graph Engine for Cloud AI
+12:45-14:00 lunch
+14:25-14:50 Oskar van Rest (Oracle) - Analyzing Stack Exchange data using Property Graph in Oracle
+14:50-15:15 Brad Bebee (Amazon) - Neptune: the AWS graph management service
+15:15-15:40 coffee break
+15:40-16:05 Bryon Jacob (data.world): Broadening the Semantic Web
+16:05-16:30 Jason Plurad (IBM) - Graph Computing with JanusGraph
+16:55-17:20 Molham Aref (relational.ai)) - Introducing.. relational.ai
+18:00 - 20:00 social dinner in Austin (sponsored by Intel Corp.), Coopers BBQ, 217 Congress Ave, Austin, TX 78701
+The TUC will be held at the University of Texas at Austin, Department of Computer Science in the Gates Dell Complex (GDC): 2317 Speedway, Austin TX, 78712 Room: GDC 6.302
+The GDC building has a North and a South building. GDC 6.302 is in the North building. When you enter the main entrance, the North building is on the left and it is served by a pair of elevators. You can take or the elevator to the 6th floor. Exit the elevator on the 6th floor. Turn left, right, left.
+Many of the attendees will be going to SIGMOD/PODS which will be held in Houston.
+One option is to take a MegaBus that departs from downtown Austin and arrives at downtown Houston.
+There is a bus that departs at 12:00PM and arrives at 3:00pm. Cost is $20 (as of April 23).
+If you want to spend the day in Austin, there is a bus that departs at 9:55PM and arrives at 12:50am. Cost is $5 (as of April 23).
+ +Organizers: Gábor Szárnyas, Jack Waudby, Peter Boncz, Alastair Green
+LDBC is hosting a two-day hybrid workshop, co-located with SIGMOD 2022 on June 17-18 (Friday-Saturday).
+The program consists of 10-15 minute talks followed by a Q&A session. The talks will be recorded and made available online.
+The tenative program is the following. All times are in EDT.
We will have a social event on Friday at 17:30 at El Vez (Google Maps).
+| start | +finish | +speaker | +title | +
|---|---|---|---|
| 09:20 | +09:30 | +Peter Boncz (LDBC/CWI) | +State of the union – slides, video | +
| 09:30 | +09:45 | +Alastair Green (LDBC/Birkbeck) | +LDBC’s fair use policies – slides, video | +
| 09:50 | +10:05 | +Gábor Szárnyas (LDBC/CWI), Jack Waudby (Newcastle University) | +LDBC Social Network Benchmark: Business Intelligence workload v1.0 – slides, video | +
| 10:10 | +10:25 | +Heng Lin (Ant Group) | +LDBC Financial Benchmark introduction – slides, video | +
| 10:30 | +11:00 | +coffee break | ++ |
| 11:00 | +11:15 | +Chen Zhang (CreateLink) | +New LDBC SNB benchmark record by Galaxybase: More than 6 times faster and 70% higher throughput – slides, video | +
| 11:20 | +11:35 | +James Clarkson (Neo4j) | +LDBC benchmarks: Promoting good science and industrial consumption – slides, video | +
| 11:40 | +11:55 | +Oskar van Rest (Oracle) | +Creating and querying property graphs in Oracle, on-premise and in the cloud – slides, video | +
| 12:00 | +12:15 | +Mingxi Wu (TigerGraph) | +Conquering LDBC SNB BI at SF-10k – slides, video | +
| 12:20 | +13:20 | +lunch (on your own) | ++ |
| 13:20 | +13:35 | +Altan Birler (Technische Universität München) | +Relational databases can handle graphs too! Experiences with optimizing the Umbra RDBMS for LDBC SNB BI – slides, video | +
| 13:40 | +13:55 | +David Püroja (CWI) | +LDBC Social Network Benchmark: Interactive workload v2.0 – slides | +
| 14:00 | +14:15 | +Angela Bonifati (Lyon 1 University) | +The quest for schemas in graph databases – slides, video | +
| 14:20 | +14:35 | +Matteo Lissandrini (Aalborg University) | +Understanding graph data representations in triplestores – slides, video | +
| 14:40 | +14:55 | +Wim Martens (University of Bayreuth) | +Path representations – slides, video | +
| 15:00 | +15:20 | +Audrey Cheng (UC Berkeley) | +TAOBench: An end-to-end benchmark for social network workloads – slides, video | +
| start | +finish | +speaker | +title | +
|---|---|---|---|
| 10:00 | +10:15 | +Keith Hare (WG3) | +An update on the GQL & SQL/PGQ standards efforts – slides, video | +
| 10:20 | +10:35 | +Leonid Libkin (ENS Paris) | +Pattern matching in GQL and SQL/PGQ – slides, video | +
| 10:40 | +10:55 | +Petra Selmer (Neo4j/WG3) | +An overview of GQL – slides, video | +
| 11:00 | +11:15 | +Alastair Green (LDBC/WG3) | +GQL 2.0: A technical manifesto – slides, video | +
| 11:20 | +11:35 | +George Fletcher (TU Eindhoven) | +PG-Keys (LDBC Property Graph Schema Working Group) – slides, video | +
| 11:40 | +11:55 | +Arvind Shyamsundar (Microsoft) | +Graph capabilities in Microsoft SQL Server and Azure SQL Database – slides, video | +
| 12:00 | +13:30 | +lunch (on your own) | ++ |
| 13:30 | +13:45 | +Daniël ten Wolde (CWI) | +Implementing SQL/PGQ in DuckDB – slides, video | +
| 13:50 | +14:05 | +Oszkár Semeráth, Kristóf Marussy (TU Budapest) | +Generation techniques for consistent, realistic, diverse, and scalable graphs – slides, video | +
| 14:10 | +14:25 | +Molham Aref (RelationalAI) | +Graph Normal Form – slides, video | +
| 14:30 | +14:45 | +Naomi Arnold (Queen Mary University of London) | +Temporal graph analysis of the far-right social network Gab – slides, video | +
| 14:50 | +15:05 | +Domagoj Vrgoč (PUC Chile) | +Evaluating path queries in MillenniumDB – slides, video | +
| 15:10 | +15:25 | +Pavel Klinov, Evren Sirin (Stardog) | +Stardog’s experience with LDBC – slides, video | +
The LDBC consortium are pleased to announce its fifth Technical User
+Community (TUC) meeting.
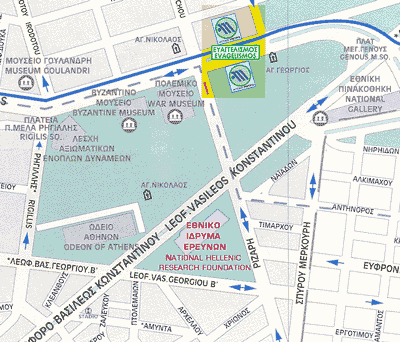
This will be a one-day event at the National Hellenic Research Institute
+in Athens, Greece on Friday November 14, 2014.
10:30 - 11:00 Coffee Break
+11:00 - 11:10 Peter Boncz (VUA) Welcome & LDBC project status update (Presentation)
+11:10 - 11:25 Venelin Kotsev (ONTO) Semantic Publishing Benchmark:Short Presentation of SPB and Status
+Feedback & Roadmap for SPB & OWLIM (Presentation)
+11:25 - 11:30 Orri Erling (OGL) Status, Feedback & Roadmap for SPB & Virtuoso (Presentation)
+11:30 - 11:45 Alex Averbuch (NEO) Social Network Benchmark: Short Presentation of SNB and Status, Feedback & Roadmap for SNB & Neo4J (Presentation)
+11:45 - 12:00 Orri Erling (OGL) Status, Feedback & Roadmap for SNB & Virtuoso (Presentation)
+12:00 - 12:20 Arnau Prat (UPC) & Andrey Gubichev Status, Feedback & Roadmap for SNB Interactive & Sparksee (Presentation ) and Business Intelligence (Presentation)
+12:20 - 12:40 Tomer Sagi, “Experience with SNB and TitanDB at HP” (Presentation )
+12:40 - 13:00 Jakob Nelson, “graphbench.org on the SNB datagen”
+13:00 - 14:30 Lunch Break@Byzantine & Christian Museum (link)
+14:30 - 14:50 Olaf Hartig, “Integrating the Property Graph and RDF data models” (Presentation)\
+Documents: arxiv/1409.3288, arxiv/1406.3399
+14:50 - 15:10 Maria-Esther Vidal and Maribel Acosta, “Challenges to be addressed during Benchmarking SPARQL Federated Engines” (Presentation)
+15:10 - 15:30 Evaggelia Pitoura, “Historical Queries on Graphs” (Presentation)
+15:30 - 16:00 Coffee Break
+16:00 - 16:20 Manolis Terrovitis, Giannis Liagos, George Papastefanatos, “Efficient Identification of Implicit Facts in Incomplete OWL2-EL Knowledge Bases” (Presentation)
+16:20 - 16:40 Gunes Aluc, “WatDiv: How to Tune-up your RDF Data Management System” (Presentation)
+16:40 - 17:00 Giorgos Kollias, Yannis Smaragdakis, “Benchmarking @LogicBlox” (Presentation)
+17:00 - 17:15 Hassan Chafi, “Oracle Labs Graph Strategy”
+17:15 - 17:25 Yinglong Xia, “Property Graphs for Industry Solution at IBM” (Presentation)
+17:25 - 17:30 Arthur Keen, “Short Introduction to SPARQLcity”
+20:30 Dinner @ Konservokouti (link)
+Get a Taxi, and go to Ippokratous 148, Athens, Neapoli Exarheion
+The meeting will be held at the National Hellenic Research Foundation located in downtown Athens.
+
Athens, Greece’s capital city, is easily accessible by air. Travelers on flights to Athens will land at Athens Eleftherios Venizelos International Airport.
+To arrive in the city center, you can take the metro from the airport (Line #3) and stop at either stop Evangelismos (ΕΥΑΓΓΕΛΙΣΜΟΣ) or at Syntagma (ΣΥΝΤΑΓΜΑ) stations. You can also take express Bus X95 and stop again at either Evangelismos (ΕΥΑΓΓΕΛΙΣΜΟΣ) or at Syntagma (ΣΥΝΤΑΓΜΑ) stations (the latter is the terminus for the bus).
+You can also take a taxi from the airport that runs on a fixed price for the city center (45 euros). More information on how to move around in Athens from the airport can be found here: http://www.aia.gr/traveler/
+ +The LDBC consortium are pleased to announce the first Technical User Community (TUC) meeting. This will be a two day event in Barcelona on the 19/20th November 2012.
+So far more than six commercial consumers of graph/RDF database technology have expressed an interest in attending the event and more are welcome. The proposed format of the event wil include:
+The exact agenda will be published here as things get finalised before the event.
+All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu
+ +We will start at 9:00 on Monday for a full day, followed by a half a day on Tuesday to allow attendees to travel home on the evening of the 20th.
+Day 1
+09:00 Welcome (Location: Aula Master)
+09:30 Project overview (Emphasis on task forces?) + Questionnaire results?
+10:30 Coffee break
+11:00 User talks (To gather information for use cases?)
13:00 Lunch
+14:00 User talks (cont.)
+15:00 Use case discussions (based on questionnaire results + consortium proposal + user talks).
+16:00 Task force proposals (consortium)
+17:00 Finish first day
20:00 Social dinner
+Day 2
+10:00 Task force discussion (consortium + TUC)
+11:00 Coffe break
+11:30 Task force discussion (consortium + TUC)
+12:30 Summaries (Task forces, use cases, …) and actions
13:00 Lunch and farewell
+15:00 LDBC Internal meeting
+Opening session:
+User stories:
+Benchmark proposals:
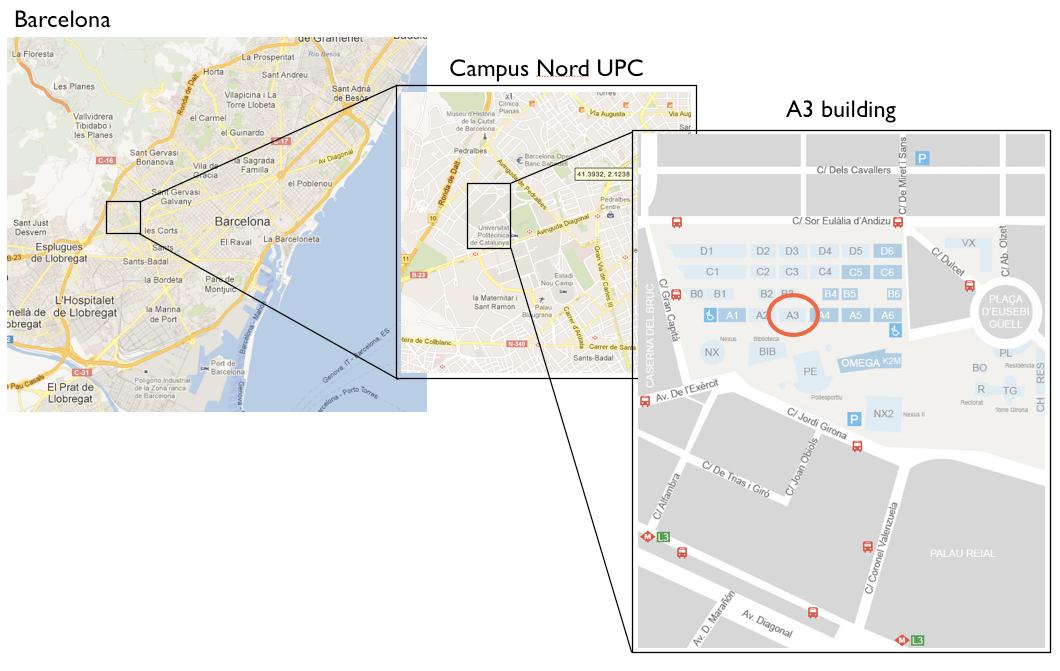
+19th and 20th November 2012
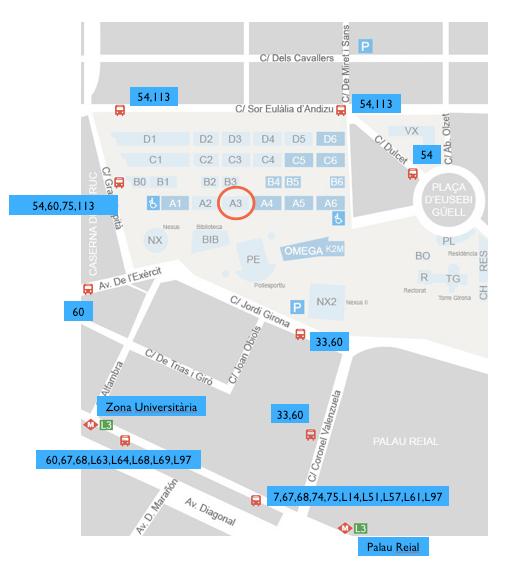
+The TUC meeting will be held at “Aula Master” at A3 building located inside the “Campus Nord de la UPC” in Barcelona. The address is:
+Aula Master
+Edifici A3, Campus Nord UPC
+C. Jordi Girona, 1-3
+08034 Barcelona, Spain
To reach the campus, there are several options, including Taxi, Metro and Bus.
+
Finding UPC
+
Finding the meeting room
+Flying: Barcelona airport is situated 12 km from the city. There are several ways of getting from the airport to the centre of Barcelona, the cheapest of which is to take the train located outside just a few minutes walking distance past the parking lots at terminal 2 (there is a free bus between terminal 1 and terminal 2, see this map of the airport). It is possible to buy 10 packs of train tickets which makes it cheaper. Taking the bus to the centre of town is more convenient as they leave directly from terminal 1 and 2, however it is more expensive than the train.
+Rail: The Renfe commuter train leaves the airport every 30 minutes from 6.13 a.m. to 11.40 p.m. Tickets cost around 3€ and the journey to the centre of Barcelona (Sants or Plaça Catalunya stations) takes 20 minutes.
+Bus: The Aerobus leaves the airport every 12 minutes, from 6.00 a.m. to 24.00, Monday to Friday, and from 6.30 a.m. to 24.00 on Saturdays, Sundays and public holidays. Tickets cost 6€ and the journey ends in Plaça Catalunya in the centre of Barcelona.
+Taxi: From the airport, you can take one of Barcelona’s typical black and yellow taxis. Taxis may not take more than four passengers. Unoccupied taxis display a green light and have a clearly visible sign showing LIBRE or LLIURE. The trip to Sants train station costs approximately €16 and trips to other destinations in the city cost approximately €18.
+Train and bus: Barcelona has two international train stations: Sants and França. Bus companies have different points of arrival in different parts of the city. You can find detailed information in the following link: http://www.barcelona-airport.com/eng/transport_eng.htm
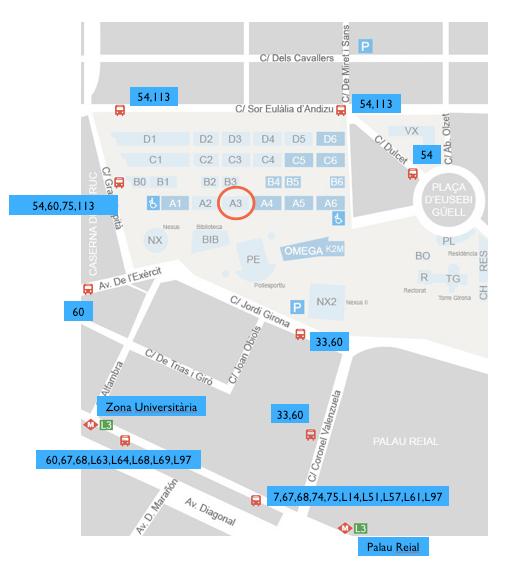
+
The locations of the airport and the city centre
+
Bus map
+ +LDBC was hosting a one-day hybrid workshop, co-located with VLDB 2021 on August 16 (Monday) between 16:00–20:00 CEST.
+The physical part of the workshop was held in room Akvariet 2 of the Tivoli Hotel (Copenhagen), while the virtual part was hosted on Zoom. Our programme consisted of talks that provide an overview of LDBC’s recent efforts. Moreover, we have invited industry practitioners and academic researchers to present their latest results.
+Talks were scheduled to be 10 minutes with a short Q&A session. We had three sessions. Their schedules are shown below.
+| start | +speaker | +title | +
|---|---|---|
| 16:00 | +Peter Boncz (CWI) | +State of the union – slides | +
| 16:05 | +Gábor Szárnyas (CWI) | +Overview of LDBC benchmarks – slides | +
| 16:12 | +Mingxi Wu (TigerGraph) | +LDBC Social Network Benchmark results with TigerGraph – slides | +
| 16:24 | +Xiaowei Zhu (Ant Group) | +Financial Benchmark proposal – slides | +
| 16:36 | +Petra Selmer (Neo4j) | +Status report from the Existing Languages Working Group (ELWG) – slides, video | +
| 16:48 | +Jan Hidders (Birkbeck) | +Status report from the Property Graph Schema Working Group (PGSWG) – slides, video | +
| 17:00 | +Keith Hare (JCC Consulting) | +Database Language Standards Structure and Process, SQL/PGQ – slides, video | +
| 17:12 | +Stefan Plantikow (GQL Editor) | +Report on the GQL standard – slides, video | +
coffee break (10 minutes)
+| start | +speaker | +title | +
|---|---|---|
| 17:35 | +Vasileios Trigonakis (Oracle Labs) | +PGX.D aDFS: An Almost Depth-First-Search Distributed Graph-Querying System – slides, video | +
| 17:47 | +Matthias Hauck (SAP) | +JSON, Spatial, Graph – Multi-model Workloads with SAP HANA Cloud – slides, video | +
| 17:59 | +Nikolay Yakovets (Eindhoven University of Technology) | +AvantGraph – slides, video | +
| 18:11 | +Semih Salihoglu (University of Waterloo) | +GRainDB: Making RDBMSs Efficient on Graph Workloads Through Predefined Joins – slides, video | +
| 18:23 | +Semyon Grigorev (Saint Petersburg University) | +Context-free path querying: Obstacles on the way to adoption – slides, video | +
| 18:35 | +Per Fuchs (Technical University of Munich) | +Sortledton: A universal, transactional graph data structure – slides, video | +
coffee break (10 minutes)
+| start | +speaker | +title | +
|---|---|---|
| 18:55 | +Angelos-Christos Anadiotis (Ecole Polytechnique and Institut Polytechnique de Paris) | +Empowering Investigative Journalism with Graph-based Heterogeneous Data Management – slides, video | +
| 19:07 | +Vasia Kalavri (Boston University) | +Learning to partition unbounded graph streams – slides, video | +
| 19:19 | +Muhammad Attahir Jibril (TU Ilmenau) | +Towards a Hybrid OLTP-OLAP Graph Benchmark – slides, video | +
| 19:31 | +Riccardo Tommasini (University of Tartu) | +An outlook on Benchmarks for Graph Stream Processing – slides, video | +
| 19:43 | +Mohamed Ragab (University of Tartu) | +Benchranking: Towards prescriptive analysis of big graph processing: the case of SparkSQL – slides, video | +
The LDBC consortium are pleased to announce the fourth Technical User Community (TUC) meeting.
+This will be a one-day event at CWI in Amsterdam on Thursday April 3, 2014.
+The event will include:
+All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu
+For presenters please limit your talks to just 15 minutes
+April 3rd
+10:00 Peter Boncz (VUA) – pptx, video: LDBC project status update
+10:20 Norbert Martinez (UPC) – pdf, video: Status update on the LDBC Social Network Benchmark (SNB) task force.
+10:50 Alexandru Iosup (TU Delft) – ppt, video: Towards Benchmarking Graph-Processing Platforms
+11:10 Mike Bryant (Kings College) – pptx, video: EHRI Project: Archival Integration with Neo4j
+11:30 coffee
+11:50 Thilo Muth (University of Magdeburg) – pptx, video: MetaProteomeAnalyzer: a graph database backed software for functional and taxonomic protein data analysis
+12:10 Davy Suvee (Janssen Pharmaceutica / Johnson & Johnson) – video: Euretos Brain - Experiences on using a graph database to analyse data stored as a scientific knowledge graph
+12:30 Yongming Luo (TU Eindhoven) – pdf, video: Regularities and dynamics in bisimulation reductions of big graphs
+12:50 Christopher Davis (TU Delft) – pdf, video: Enipedia - Enipedia is an active exploration into the applications of wikis and the semantic web for energy and industry issues
+13:10 - 14:30 lunch @ restaurant Polder
+14:30 SPB task force report
+15:00 Bastiaan Bijl (Sysunite) – pdf, video: Using a semantic approach for monitoring applications in large engineering projects
+15:20 Frans Knibbe (Geodan) – pptx, video: Benchmarks for geographical data
+15:40 Armando Stellato (University of Rome, Tor Vergata & UN Food and Agriculture Organization) – pptx, video: VocBench2.0, a Collaborative Environment for SKOS/SKOS-XL Management: scalability and (inter)operatibility challenges
+16:00 coffee
+16:20 Ralph Hodgson (TopQuadrant) – [pdf](https://pu b-3834 10a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachment s/5538064/5506367.pdf), video:Customer experiences in implementing SKOS-based vocabularymanagement systems
+16:40 Simon Jupp (European Bioinformatics Institute) – pdf, video: [Delivering RDF for the life science at the European Bioinformatics Institute: Six months in.]
+17:00 Jerven Bolleman (Swiss Institute of Bioinformatics) – pdf, video: Breakmarking UniProt RDF. SPARQL queries that make your database cry…
+17:20 Rein van ’t Veer (Digital Heritage Netherlands) – pptx, video Time and space for heritage
+17:40 end of meeting
+19:00 - 21:30 Social Dinner in restaurant Boom
+April 4th
+LDBC plenary meeting for project partners.
+The meeting will be held at the Dutch national research institute for computer science and mathematics (CWI - Centrum voor Wiskunde en Informatica). It is located at Amsterdam Science Park:
+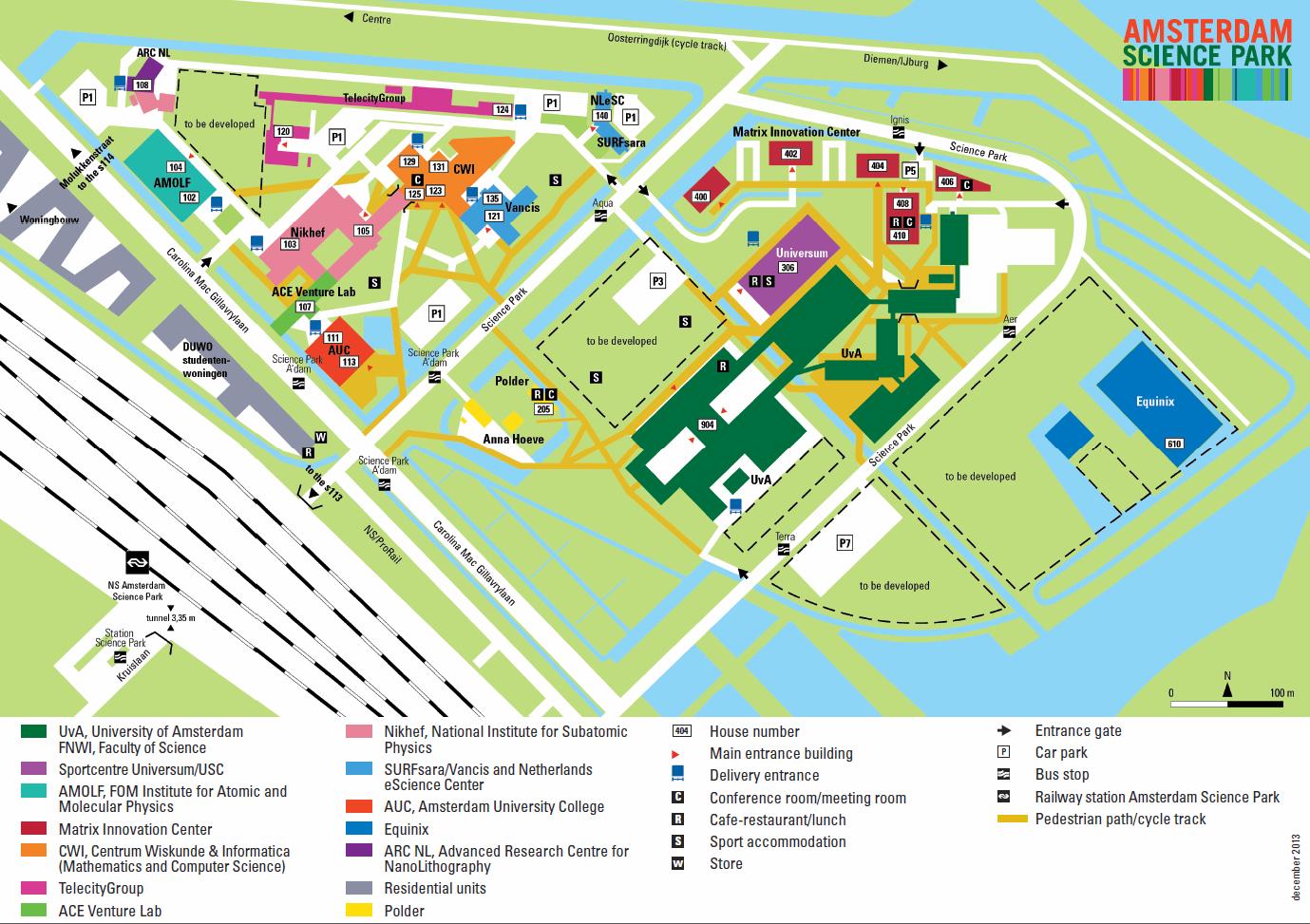
(A5 map)
+Arriving & departing:
+Amsterdam has a well-functioning and nearby airport called Schiphol (AMS, www.schiphol.nl) that serves all main European carriers and also very many low-fare carriers.
+ +Trains (~5 per hour) are the most convenient means of transport between Schiphol airport and Amsterdam city center, the Centraal Station (17 minutes, a train every 15 minutes) – which station you are also likely arriving at in case of an international train trip.
+From the Centraal Station in Amsterdam, there is a direct train (every half an hour, runs 11 minutes) to the Science Park station, which is walking distance of CWI. If you go from the Centraal Station to one of the hotels, you should take tram 9 – it starts at Centraal Station (exception: for Hotel Casa 400, you should take the metro to Amstel station - any of the metros will do).
+Taxi is an alternative, though expensive. The price from Schiphol will be around 45 EUR to the CWI or another point in the city center (depending on traffic, the ride is 20-30 minutes).
+Public transportation (tram, bus, metro) tickets for a single ride and 1-day (24 hour) passes can be purchased from the driver/conductor on trams and buses (cash only) and from vending machines in the metro stations.
+Only the “disposable” cards are interesting for you as visitor.
+Multi-day (up to 7-days/168 hours) passes can only be purchased from the vending machines or from the ticket office opposite of Centraal Station.
+Getting Around: the fastest way to move in the city of Amsterdam generally is by bicycle. Consider renting such a device at your hotel. For getting from your hotel to the CWI, you can either take a taxi (expensive), have a long walk (35min), use public transportation (for NH Tropen/The Manor take bus 40 from Muiderpoort Station, for Hotel Casa 400 same bus 40 but from Amstel station, and for the Rembrandt Hotel it is tram 9 until Middenweg/Kruislaan and then bus 40), or indeed bike for 12 minutes.
+Cars
+In case you plan to arrive by car, please be aware that parking space in Amsterdam is scarce and hence very expensive. But, you can park your car on the “WCW” terrain where CWI is located. To enter the terrain by car, you have to get a ticket from the machine at the gate. To leave the terrain, again, you can get an exit ticket from the CWI reception.
+Arriving at CWI: Once you arrive at CWI, you need to meet the reception, and tell them that you are attending the LDBC TUC meeting. Then, you’ll receive a visitor’s pass that allows you to enter our building.
+Social Dinner
+The social dinner will take place at 7pm on April 3 in Restaurant Boom (boometenendrinken.nl), Linneausstraat 63, Amsterdam.
+ +Organizers: Shipeng Qi (AntGroup), Wenyuan Yu (Alibaba Demo), Yan Zhou (CreateLink)
+LDBC is hosting a two-day hybrid workshop, co-located in Guangzhou with VLDB 2024 on August 30-31 (Friday-Saturday).
+The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. If you would like to participate please register using our form.
+All times are in PDT.
+Organizers: Renzo Angles, Sebastián Ferrada
+LDBC is hosting a one-day in-person workshop, co-located in Santiago de Chile with SIGMOD 2024 on June 9 (Sunday).
+The workshop will be held in the Hotel Plaza El Bosque Ebro (https://www.plazaelbosque.cl), which is two blocks away from SIGMOD’s venue. See the map here.
+If you would like to participate please register using this form.
+All times are in Chile time (GMT-4).
+Each speaker will …
+ +Organizers: Oskar van Rest, Alastair Green, Gábor Szárnyas
+LDBC is hosting a two-day hybrid workshop, co-located with SIGMOD 2023 on June 23-24 (Friday-Saturday).
+The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. If you would like to participate please register using our form.
+LDBC will host a social event on Friday at the Black Bottle gastrotavern in Belltown: …
+ +Organizers: Gábor Szárnyas, Jack Waudby, Peter Boncz, Alastair Green
+LDBC is hosting a two-day hybrid workshop, co-located with SIGMOD 2022 on June 17-18 (Friday-Saturday).
+The program consists of 10-15 minute talks followed by a Q&A session. The talks will be recorded and made available online.
+The tenative program is the following. All times are in EDT.
We will have a social event on Friday at 17:30 at El Vez (Google Maps).
+LDBC was hosting a one-day hybrid workshop, co-located with VLDB 2021 on August 16 (Monday) between 16:00–20:00 CEST.
+The physical part of the workshop was held in room Akvariet 2 of the Tivoli Hotel (Copenhagen), while the virtual part was hosted on Zoom. Our programme consisted of talks that provide an overview of LDBC’s recent efforts. Moreover, we have invited industry practitioners and academic researchers to present their latest …
+ +LDBC is pleased to announce its Thirteenth Technical User Community (TUC) meeting.
+LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, TigerGraph …
+ +LDBC is pleased to announce its Ninth Technical User Community (TUC) meeting.
+This will be a two-day event at SAP Headquarters in Walldorf, Germany on February 9+10, 2017.
+This will be the third TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:
+We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at damaris@ac.upc.edu;
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.
+In the TUC meeting there will be
+The meeting will start on Thursday morning, with a program from 09:00-18:00, interrupted by a lunch break.
+Thursday evening (19:00-21:00) there will be a social dinner in Heidelberg.
+Friday morning the event resumes from 9:00-12:00. In the afternoon, there is a (closed) LDBC Board of Directors meeting (13:00-16:30) at the same venue.
+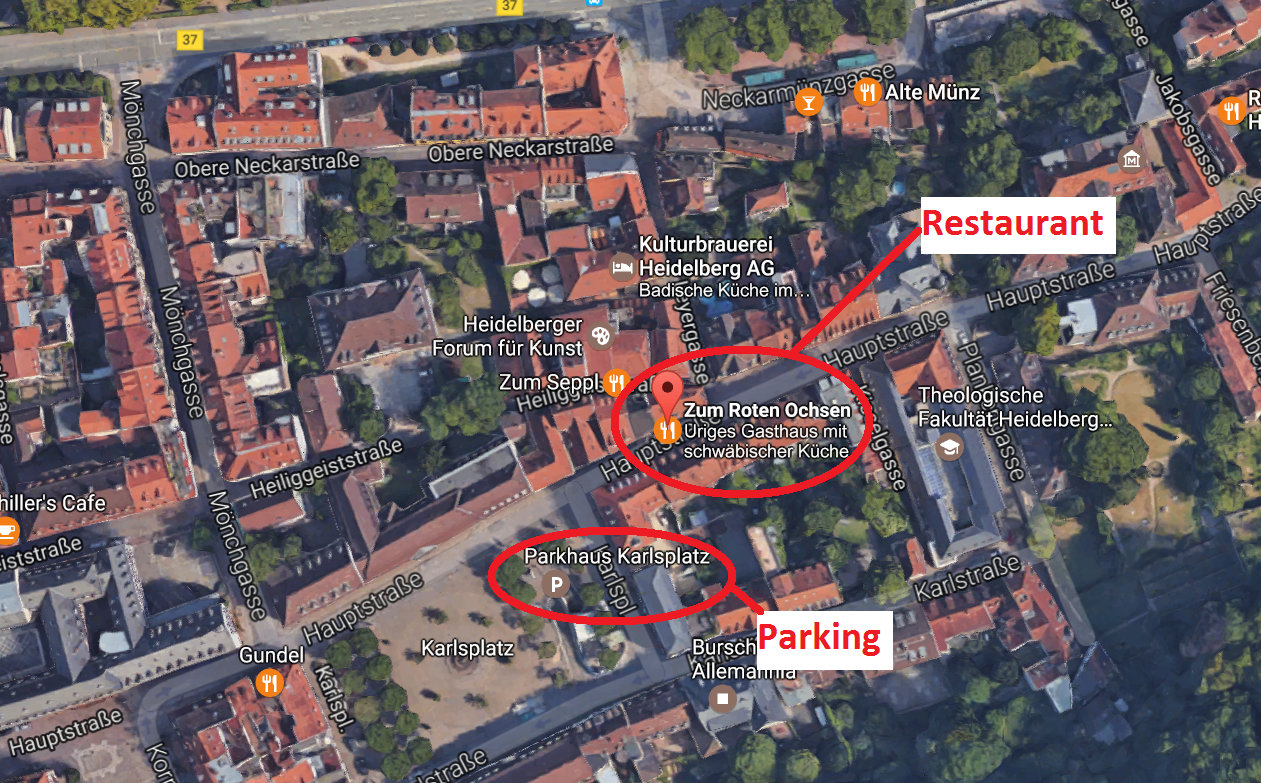
Address: Hauptstraße 217, 69117 Heidelberg
+Time: 19:00 / 7pm
(See attachments at the bottom of the page)
+| start time | +title – speaker | +
|---|---|
| 9:00 | +Welcome and logistics - Marcus Paradies (SAP) | +
| 9:10 | +Intro + state of the LDBC - Josep Lluis Larriba Pey (UPC) | +
| 9:20 | +LDBC Graph QL task force - Hannes Voigt (TU Dresden) | +
| 9:40 | +PGQL Status Update and Comparison to LDBC’s Graph QL proposals - Oskar van Rest (Oracle Labs) | +
| 10:00 | +Adding shortest-paths to MonetDB - Dean de Leo (CWI) | +
| 10:20 | +coffee | +
| 10:50 | +Evolving Cypher for processing multiple graphs - Stefan Plantikow (Neo Technology) | +
| 11:10 | +Standardizing Graph Database Functionality - An Invitation to Collaborate - Jan Michels (ISO/ANSI SQL, Oracle)" | +
| 11:30 | +Dgraph: Graph database for production environment - Tomasz Zdybal (Dgraph.io) | +
| 12:00 | +lunch | +
| 13:00 | +LDBC Graphalytics: Current Capabilities, Upcoming Features, and Long-Term Roadmap - Alexandru Iosup (TU Delft) | +
| 13:20 | +LDBC Graphalytics: Demo of the Live Archive and Competition Features - Tim Hegeman (TU Delft) | +
| 13:40 | +LDBC SNB Datagen Update - Arnau Prat (UPC) | +
| 14:00 | +LDBC SNB Business Intelligence Workload: Chokepoint Analysis - Arnau Prat (UPC) | +
| 14:20 | +LDBC Benchmark Cost Specification (+discussion) - Moritz Kaufmann (TU Munich) | +
| 14:40 | +coffee break | +
| 15:10 | +EYWA: the Distributed Graph Engine in Huawei MIND Platform (Yinglong Xia) | +
| 15:30 | +Graph Processing in SAP HANA - Marcus Paradies (SAP) | +
| 15:50 | +Distributed Graph Analytics with Gradoop - Martin Junghanns (Univ Leipzig) | +
| 16:10 | +Distributed graph flows: Cypher on Flink and Gradoop - Max Kießling (Neo Technology) | +
| 16:30 | +closing - Peter Boncz | +
| 17:30 | +end | +
| start time | +title – speaker | +
|---|---|
| 9:00 | +welcome - Peter Boncz | +
| 9:20 | +Graph processing in obi4wan - Frank Smit (OBI4WAN) | +
| 9:40 | +Graph problems in the space domain - Albrecht Schmidt (ESA) | +
| 10:00 | +Medical Ontologies for Healthcare - Michael Neumann (SAP) | +
| 10:20 | +coffee | +
| 10:50 | +The Train Benchmark: Cross-Technology Performance Evaluation of Continuous Model Queries - Gabor Szarnyas (BME) | +
| 11:10 | +Efficient sparse matrix computations and their generalization to graph computing applications - Albert-Jan Yzelman (Huawei) | +
| 11:30 | +Experiments on Semantic Publishing Benchmark with large scale real news and LOD data at FactForge - Atanas Kyriakov (Ontotext) | +
| 12:00 | +lunch | +
| 13:00 | +LDBC Board of Directors Meeting | +
| 17:00 | +end | +
The following PDF guide provides additional information, such as recommended restaurants as well as sightseeing spots: link
+The TUC meeting will be held in the SAP Headquarters at the SAP Guesthouse Kalipeh (https://www.kalipeh.com). The address is:
+WDF 44 / SAP Guesthouse Kalipeh
+Dietmar-Hopp-Allee 15
+69190 Walldorf
+Germany
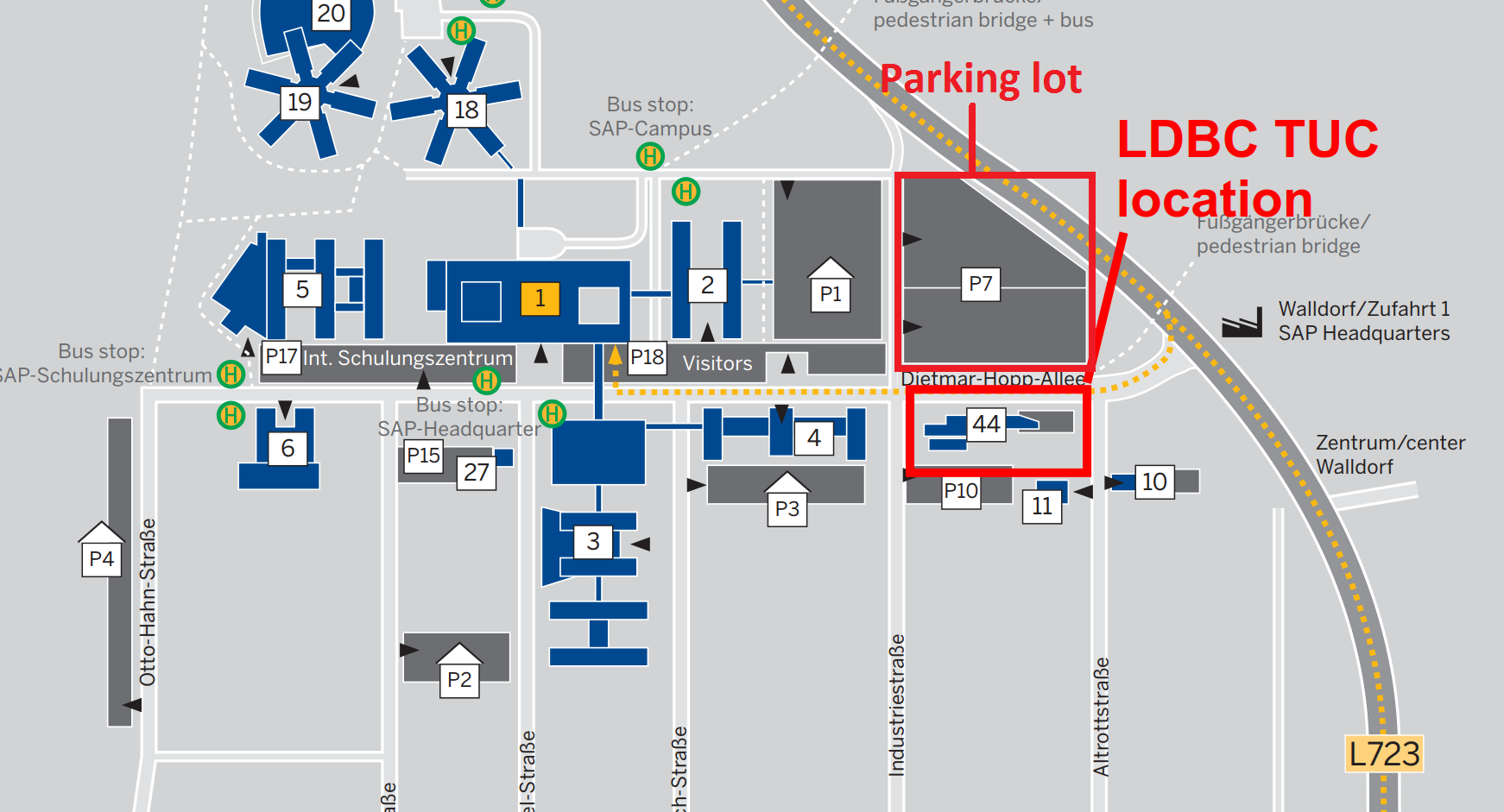
There are two airports close to SAP’s headquarter: Frankfurt Airport (FRA) and Stuttgart-Echterdingen Airport (STR). The journey from Frankfurt Airport to SAP headquarters takes about one hour by car, while it takes slightly longer from Stuttgart- Echterdingen Airport. Concerning airfare, flights to Frankfurt are usually somewhat more expensive than to Stuttgart.
+When booking flights to Frankfurt, you should be aware of Frankfurt-Hahn Airport (HHN), which serves low-cost carriers but is not connected to Frankfurt Airport. Frankfurt Hahn is approximately one hour from the Frankfurt main airport by car.
+The journey from Frankfurt Airport to SAP headquarters takes about one hour by car (95 kilometers, or 59 miles).
+Journey time from Stuttgart-Echterdingen Airport to SAP headquarters takes about 1 hour and 15 minutes by car (115 kilometers, or 71 miles).
+Traveling from Frankfurt Airport (FRA) to SAP Headquarters:
+Directions to SAP headquarters:
+(Should you use a navigational system which does not recognize the street name ‘Dietmar-Hopp-Allee’ please use ‘Neurottstrasse’ instead.)
+Traveling from Stuttgart-Echterdingen Airport (STR) to SAP Headquarters:
+To get to SAP headquarters by car, there are two possible routes to take. The first leads you via Heilbronn and the second via Karlsruhe. The route via Karlsruhe is a bit shorter yet may be more congested.
+Directions to SAP headquarters:
+The closest parking lot to the event location is P7 (see figure above).
+As the infrastructure is very well developed in Europe, and in Germany in particular, taking the train is a great and easy way of traveling. Furthermore, the trains usually run on time, so this mode of travel is very convenient, especially for a group of people on longer journeys to major cities.
+From Frankfurt Airport (FRA) to SAP Headquarters
+Directions to SAP headquarters:
+From Stuttgart-Echterdingen Airport (STR) to SAP Headquarters
+Directions to SAP headquarters:
+LDBC is pleased to announce its Twelfth Technical User Community (TUC) meeting.
+LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, …
+ +LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmark development, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j and Huawei among its members.
+This TUC meeting will be a one-day event preceding the SIGMOD/PODS …
+ +This will be a one-day event at the VLDB 2017 conference in Munich, Germany on September 1, 2017.
+Topics and activities of interest in these TUC meetings are:
+We welcome all users of RDF …
+ +LDBC is pleased to announce its Ninth Technical User Community (TUC) meeting.
+This will be a two-day event at SAP Headquarters in Walldorf, Germany on February 9+10, 2017.
+This will be the third TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:
+The LDBC consortium is pleased to announce its Eighth Technical User Community (TUC) meeting.
+This will be a two-day event/eighth-tuc-meeting/attachments at Oracle Conference Center in Redwood Shores facility on Wednesday and Thursday June 22-23, 2016.
+This will be the second TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event/eighth-tuc-meeting/attachments will basically set the following aspects:
+The LDBC consortium is pleased to announce its Seventh Technical User Community (TUC) meeting.
+This will be a two-day event at IBM’s TJ Watson facility on Monday and Tuesday November 9/10, 2015.
+This will be the first TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:
+The LDBC consortium are pleased to announce its Sixth Technical User Community (TUC) meeting.
+This will be a two-day event at Universitat Politècnica de Catalunya, Barcelona on Thursday and Friday March 19/20, 2015.
+The LDBC FP7 EC funded project is reaching its finalisation, and this will be the last event sponsored directly by the project. However, tasks within LDBC will continue based on the LDBC independent organisation. The event will …
+ +The LDBC consortium are pleased to announce its fifth Technical User
+Community (TUC) meeting.
This will be a one-day event at the National Hellenic Research Institute
+in Athens, Greece on Friday November 14, 2014.
10:30 - 11:00 Coffee Break
+11:00 - 11:10 Peter Boncz (VUA) Welcome & LDBC project status update (Presentation)
+11:10 - 11:25 Venelin Kotsev (ONTO) Semantic Publishing Benchmark:Short Presentation of SPB and Status
+Feedback …
+ +The LDBC consortium are pleased to announce the fourth Technical User Community (TUC) meeting.
+This will be a one-day event at CWI in Amsterdam on Thursday April 3, 2014.
+The event will include:
+The LDBC consortium is pleased to announce the third Technical User Community (TUC) meeting!
+This will be a one day event in London on the 19 November 2013 running in collaboration with the GraphConnect event (18/19 November). Registered TUC participants that would like a free pass to all of GraphConnect should register for GraphConnect using this following coupon code: LDBCTUC.
+The TUC event will include:
+The LDBC consortium are pleased to announce the second Technical User Community (TUC) meeting.
+This will be a two day event in Munich on the 22/23rd April 2013.
+The event will include:
+The LDBC consortium are pleased to announce the first Technical User Community (TUC) meeting. This will be a two day event in Barcelona on the 19/20th November 2012.
+So far more than six commercial consumers of graph/RDF database technology have expressed an interest in attending the event and more are welcome. The proposed format of the event wil include:
+The LDBC consortium are pleased to announce the second Technical User Community (TUC) meeting.
+This will be a two day event in Munich on the 22/23rd April 2013.
+The event will include:
+All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu
+ +April 22nd
+10:00 Registration.
+10:30 Josep Lluis Larriba Pey (UPC) - Welcome and Introduction.
+10:30 Peter Boncz (VUA): LDBC: goals and status
Social Network Use Cases (with discussion moderated by Josep Lluis Larriba Pey)
+11:00 Josep Lluis Larriba Pey (UPC): Social Network Benchmark Task Force
+11:30 Gustavo González (Mediapro): Graph-based User Modeling through Real-time Social Streams
+12:00 Klaus Großmann (Dshini): Neo4j at Dshini
12:30 Lunch
+Semantic Publishing Use Cases (with discussion moderated by Barry Bishop)
+13:30 Barry Bishop (Ontotext): Semantic Publishing Benchmark Task Force
+14:00 Dave Rogers (BBC): Linked Data Platform at the BBC
+14:30 Edward Thomas (Wolters Kluwer): Semantic Publishing at Wolters Kluwer
15:00 Coffee break
+Projects Related to LDBC
+15:30 Fabian Suchanek (MPI): “YAGO: A large knowledge base from Wikipedia and WordNet”
+16:00 Antonis Loziou (VUA): The OpenPHACTS approach to data integration
+16:30 Mirko Kämpf (Brox): “GeoKnow - Spatial Data Web project and Supply Chain Use Case”
17:00 End of first day
+19:00 Social dinner
+April 23rd
+Industry & Hardware Aspects
+10:00 Xavier Lopez (Oracle): Graph Database Performance an Oracle Perspective.pdf
+10:30 Pedro Trancoso (University of Cyprus): “Benchmarking and computer architecture: the research side”
11:00 Coffee break
+Future Steps and TUC feedback session
+11:30 Peter Boncz (VUA) moderates: next steps in the Social Networking Task Force
+12:00 Barry Bishop (Ontotext) moderates: next steps in the Semantic Publishing Task Force"
12:30 End of meeting
+22nd and 23th April 2013
+The TUC meeting will be held at LE009 room at LRZ (Leibniz-Rechenzentrum) located inside the TU Munich campus in Garching, Germany. The address is:
+LRZ (Leibniz-Rechenzentrum)
+Boltzmannstraße 1
+85748 Garching, Germany
To reach the campus, there are several options, including Taxi and Subway Ubahn
+Take the U-bahn line U6 in the direction of Garching-Forschungszentrum, exit at the end station. Take the south exit to MI-Building and LRZ on the Garching Campus. The time of the journey from the city center is approx. 25-30 minutes. In order to get here from the City Center, you need the Munich XXL ticket that costs around 7.50 euros and covers all types of transportation for one day. The ticket has to be validated before ride.
+(except weekends) S-Bahn S8 line in the direction of (Hauptbahnhof) Munich Central Station until the third stop, Ismaning (approx. 13 minutes). From here Bus Nr. 230 until stop MI-Building on the Garching Campus. Alternatively: S1 line until Neufahrn, then with the Bus 690, which stops at Boltzmannstraße.
+S-Bahn lines S8 or S1 towards City Center until Marienplatz stop. Then change to U-bahn U6 line towards Garching-Forschungszentrum, exit at the last station. Take the south exit to MI-Building and LRZ.
+Taxi: fare is ca. 30-40 euros.
+For cases 1 and 2, before the trip get the One-day Munich Airport ticket and validate it. It will cover all public transportation for that day.
+The city of Garching is located on the U6 line, one stop before the Garching-Forschungszentrum. In order to get from Garching to Garching-Forschungszentrum with the U-bahn, a special one-way ticket called Kurzstrecke (1.30 euros) can be purchased.
+Finding LRZ@TUM
+ + +
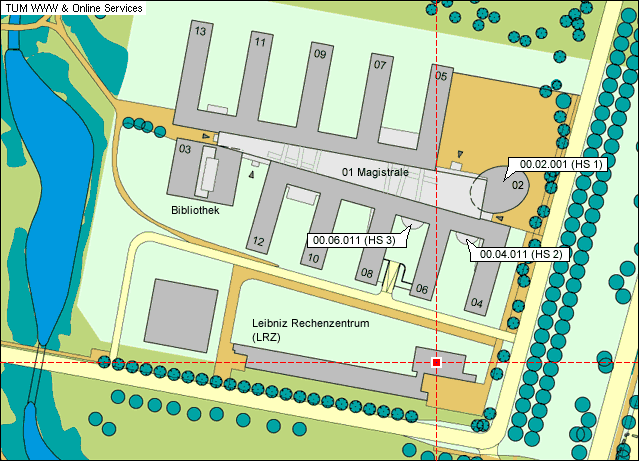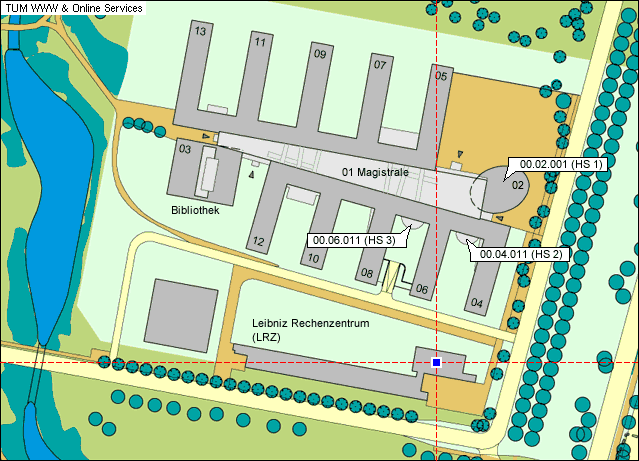
Flying: Munich airport is located 28.5 km northeast of Munich. There are two ways to get from the airport to the city center: suburban train (S-bahn) and Taxi.
+S-Bahn: S-bahn lines S1 and S8 will get you from the Munich airport to the city center, stopping at both Munich Central Station (Hauptbahnhof) and Marienplatz. One-day Airport-City ticket costs 11.20 euros and is valid for the entire Munich area public transportation during the day of purchase (the tickets needs to be validated before the journey). S-bahn leaves every 5-20 minutes and reaches the city center in approx. 40 minutes.
+Taxi: taxi from the airport to the city center costs approximately 50 euros
+The social dinner will take place at 7 pm on April 22 in Hofbräuhaus (second floor)
+Address: Hofbräuhaus, Platzl 9, Munich
+ +Organizers: Renzo Angles, Sebastián Ferrada
+LDBC is hosting a one-day in-person workshop, co-located in Santiago de Chile with SIGMOD 2024 on June 9 (Sunday).
+The workshop will be held in the Hotel Plaza El Bosque Ebro (https://www.plazaelbosque.cl), which is two blocks away from SIGMOD’s venue. See the map here.
+If you would like to participate please register using this form.
+All times are in Chile time (GMT-4).
+Each speaker will have 20 minutes for exposition plus 5 minutes for questions.
+| Time | +Speaker | +Title | +
|---|---|---|
| 09:00 | +Welcome | +“Canelo” saloon | +
| 09:30 | +Alastair Green (LDBC Vice-chair) | +Status of the LDBC Extended GQL Schema Working Group | +
| 10:00 | +Hannes Voigt (Neo4j) | +Inside the Standardization Machine Room: How ISO/IEC 39075:2024 – GQL was produced | +
| 10:30 | +Calin Iorgulescu (Oracle) | +PGX.D: Distributed graph processing engine | +
| 11:00 | +Coffee break | ++ |
| 11:30 | +Ricky Sun (Ultipa, Inc.) | +A Unified Graph Framework with SCC (Storage-Compute Coupled) and HDC (High-Density Computing) Clustering | +
| 12:00 | +Daan de Graaf (TU Eindhoven) | +Algorithm Support in a Graph Database, Done Right | +
| 12:30 | +Angela Bonifati (Lyon 1 University and IUF, France) | +Transforming Property Graphs | +
| 13:00 | +Brunch | ++ |
| 14:00 | +Juan Sequeda (data.world) | +A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases | +
| 14:30 | +Olaf Hartig (Linköping University) | +FedShop: A Benchmark for Testing the Scalability of SPARQL Federation Engines | +
| 15:00 | +Olaf Hartig (Amazon) | +Datatypes for Lists and Maps in RDF Literals | +
| 15:30 | +Peter Boncz (CWI and MotherDuck) | +The state of DuckPGQ | +
| 16:00 | +Coffee break | ++ |
| 16:30 | +Juan Reutter (IMFD and PUC Chile) | +MillenniumDB: A Persistent, Open-Source, Graph Database | +
| 17:00 | +Carlos Rojas (IMFD) | +WDBench: A Wikidata Graph Query Benchmark | +
| 17:30 | +Sebastián Ferrada (IMFD and Univ. de Chile) | +An algebra for evaluating path queries | +
| 19:30 | +Dinner | ++ |
The LDBC consortium is pleased to announce its Seventh Technical User Community (TUC) meeting.
+This will be a two-day event at IBM’s TJ Watson facility on Monday and Tuesday November 9/10, 2015.
+This will be the first TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:
+We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at damaris@ac.upc.edu; in order to notify IBM security in advance, registration requests need to be in by Nov 1.
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is graph data management related. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.
+In this page, you’ll find information about the following items:
+Monday, 9th of November 2015
+8:45 - 9:15 Registration and welcome (Yinglong Xia and Josep L. Larriba Pey)
+9:15 - 9:30 LDBC introduction and status update (Josep L. Larriba-Pey)
+9:30 - 10:30 Details on the progress of LDBC Task Forces 1 (chair Josep L. Larriba-Pey)
+9:30 Arnau Prat (DAMA-UPC). Social Network Benchmark, Interactive workload
+10:00 Orri Erling (OpenLink Software). Social Network Benchmark, Business Intelligence workload
+10:30-11:00 Coffee break
+11:00 - 12:30 Details on the progress of LDBC Task Forces 2 (chair Yinglong Xia)
+11:00 Alexandru Iosup (TU Delft). Social Network Benchmark, Analytics workload.
+11:30 Claudio Gutierrez (U Chile). Query Language Task Force status.
+12:00 Atanas Kiryakov (Ontotext). Semantic Publishing Benchmark status
+12:30 - 14:00 Lunch break
+14:00 - 16:00 Technologies and benchmarking (chair Hassan Chafi)
+14:00 Molham Aref (LogicBlox). Graph Data Management with LogicBlox
+14:30 Peter Kogge (Notre Dame). BFS as in Graph500 on today’s architectures
+15:00 Ching-Yung Lin (IBM). Status and Demo of IBM System G
+15:30-16:00 Coffee break
+16:00 - 17:00 Technologies (chair Irini Fundulaki)
+16:00 Kavitha Srinivas (IBM). SQLGraph: An efficient relational based property graph store
+16:30 David Ediger (GeorgiaTech). STINGER
+17:00 Gary King (Franz Inc.). AllegroGraph’s SPARQL implementation with Social Network Analytics abilities using Magic Properties
+17:30 Manoj Kumar (IBM). Linear Algebra Formulation for Large Graph Analytics
+18:00 Reihaneh Amini (Wright State University) Linked Data in the GeoLink Usecase
+19:00 Social dinner
+Tuesday 10th November 2015
+9:00 - 10:30 Technology, Applications and Benchmarking (chair Alexandru Iosup)
+9:00 Philip Rathle (Neo). On openCypher
+9:20 Morteza Shahriari (University of Florida). Multi-modal Probabilistic Knowledge Base for Remote Sensing Species Identification
+9:50 Peter Kogge (Notre Dame). Challenging problems with Lexis Nexis Risk Solutions
+10:10 Arnau Prat (DAMA-UPC). DATAGEN, status and perspectives for synthetic data generation
+10:30 - 11:00 Coffee break
+11:00 - 12:45 Applications and use of Graph Technologies (chair Atanas Kiryakov)
+11:00 Hassan Chafi (Oracle). Status and characteristics of PGQL
+11:20 David Guedalia (TAGIIO). Multi-tier distributed mobile applications and how they split their workload,
+11:40 Guojing Cong (IBM). Algorithmic technique and architectural support for fast graph analysis
+12:00 Josep Lluis Larriba-Pey. Conclusions for the TUC meeting and future perspectives
+12:30 - 14:00 Lunch break
+14:00 LDBC Board of Directors
+9th and 10th November 2015
+The TUC meeting will be held in the IBM Thomas J Watson Research Center.
+The address is:
IBM Thomas J Watson Research Center
+1101 Kitchawan Rd,
+Yorktown Heights, NY 10598, USA
If you are using a GPS system, please enter “200 Aqueduct Road, Ossining NY, 10562” for accurate directions to the lab entrance. You may also want to check the routing online.
+The meeting will take place in the Auditorium on November 9th, and in Meeting Room 20-043 on November 10th.
+You are highly suggested to rent a car for your convenience, since the public transportation system does not cover this area very well. Besides, there is no hotel within walkable distance to the IBM T.J. Watson Research Center. Feel free to find carpool with other attendees. You may find car rental and hotels through www.orbitz.com, or www.expedia.com Feel free to email yxia@us.ibm.com for any questions.
+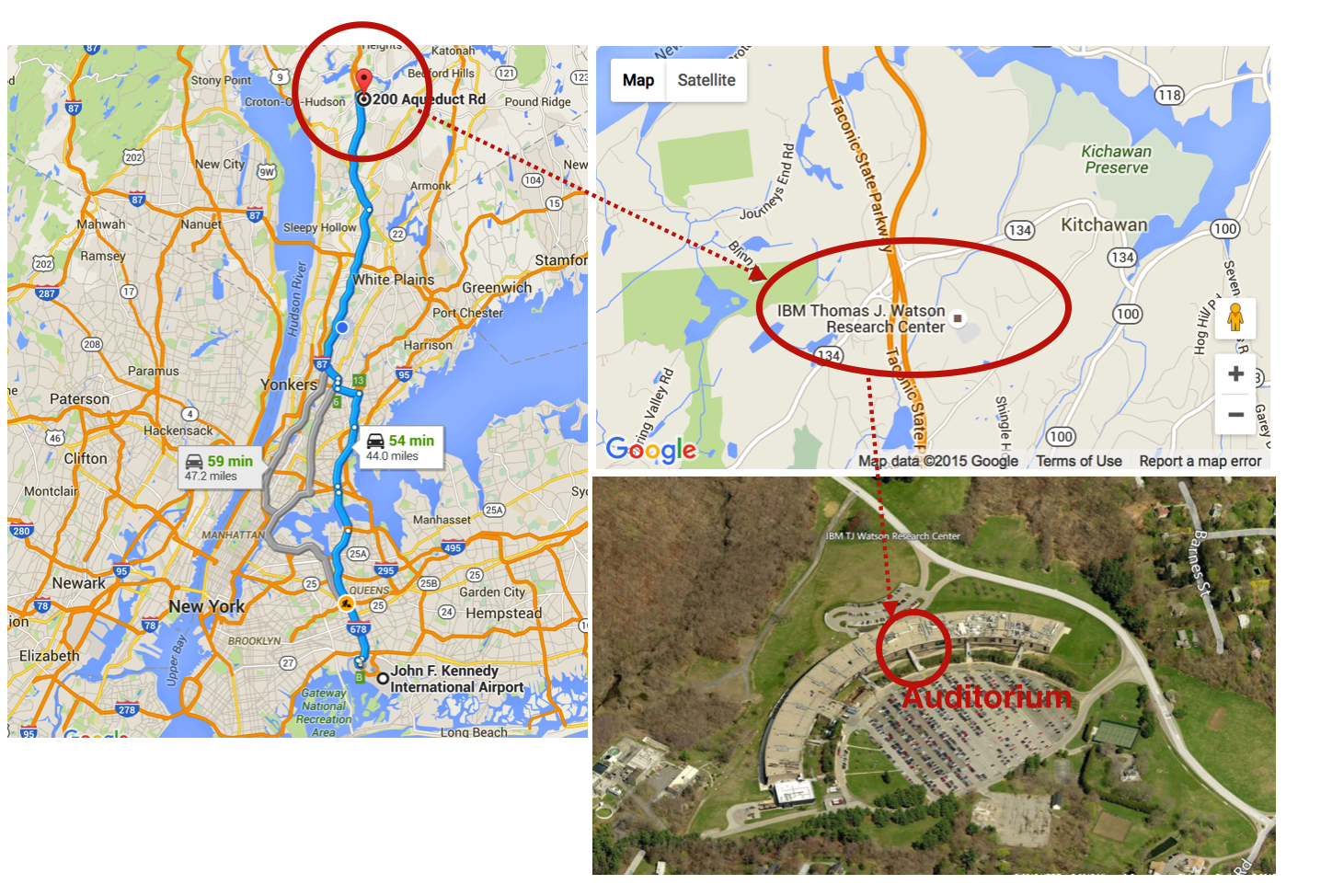
Upper and Eastern New England
+Route I-84 west to Route I-684, south to Exit 6, west on Route 35 to Route 100, south to Route 134, west 2.5 miles. IBM is on the left.
+New Haven and Connecticut Shores
+Merritt Parkway or New England Thruway (Route I-95) west to Route I-287, west to Exit 3, north on Sprain Brook Parkway, which merges into Taconic State Parkway, north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.
+New Jersey
+Take New York State Thruway (Route I-87) east across the Tappan Zee Bridge and follow signs to the Saw Mill Parkway north. Proceed north on Saw Mill River Parkway to Taconic State Parkway exit, north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.
+Upstate New York
+Route I-84 east across Newburgh-Beacon Bridge to Exit 16-S. Taconic State Parkway south to Route 134 East exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.
+New York City (Manhattan)
+Henry Hudson Parkway north, which becomes Saw Mill River Parkway, north to Taconic State Parkway exit. North on Taconic State Parkway to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.
+John F. Kennedy International Airport
+North on Van Wyck Expressway to the Whitestone Expressway and continue north across the Bronx-Whitestone Bridge to the Hutchinson River Parkway north to the Cross County Parkway exit and proceed west to the Bronx River Parkway. North on the Bronx River Parkway to the Sprain Brook Parkway, which merges into the Taconic State Parkway. Continue north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.
+LaGuardia Airport
+East on the Grand Central Parkway, north on the Whitestone Expressway, and continue north across the Bronx-Whitestone Bridge. Continue with instructions from John F. Kennedy International Airport, above.
+Newark International Airport
+North on the New Jersey Turnpike (Route I-95). Stay in local lanes and take Exit 72 for Palisades Interstate Parkway. North on the Palisades Interstate Parkway to the New York State Thruway, Route I-87, and east across the Tappan Zee Bridge. Continue with instructions from New Jersey, above.
+Stewart International Airport
+Route 207 east to Route I-84, east across Newburgh-Beacon Bridge to Taconic State Parkway, south. Continue with instructions from Upstate New York, above.
+Westchester County Airport
+Right on Route 120, north. Turn left where Route 120 merges with Route 133. Continue on Route 120. Cross Route 100 and continue straight on Shingle House Road to Pines Bridge Road. Turn right and proceed several hundred yards. IBM is on the left.
+Public Transportation
+Metropolitan Transportation Authority (MTA) train stations nearest to the Yorktown Heights location are the Croton-Harmon and White Plains stations. Taxi service is available at both locations.
+ +Organizers: Oskar van Rest, Alastair Green, Gábor Szárnyas
+LDBC is hosting a two-day hybrid workshop, co-located with SIGMOD 2023 on June 23-24 (Friday-Saturday).
+The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. If you would like to participate please register using our form.
+LDBC will host a social event on Friday at the Black Bottle gastrotavern in Belltown: 2600 1st Ave (on the corner of Vine), Seattle, WA 98121.
+In addition, AWS will host a Happy Hour (rooftop grill with beverages) on Saturday on the Amazon Nitro South building’s 8th floor deck: 2205 8th Ave, Seattle, WA 98121.
+All times are in PDT.
+Location: Hyatt Regency Bellevue on Seattle’s Eastside, room Grand K, co-located with SIGMOD (900 Bellevue Way NE, Bellevue, WA 98004-4272)
+| start | +finish | +speaker | +title | +
|---|---|---|---|
| 08:30 | +08:45 | +Oskar van Rest (Oracle) | +LDBC – State of the union – slides, video | +
| 08:50 | +09:05 | +Keith Hare (JCC / WG3) | +An update on the GQL & SQL/PGQ standards efforts – slides, video | +
| 09:10 | +09:25 | +Stefan Plantikow (Neo4j / WG3) | +GQL - Introduction to a new query language standard – slides | +
| 09:30 | +09:45 | +Leonid Libkin (University of Edinburgh & RelationalAI) | +Formalizing GQL – slides, video | +
| 09:50 | +10:05 | +Semen Panenkov (JetBrains Research) | +Mechanizing the GQL semantics in Coq – slides, videos | +
| 10:10 | +10:25 | +Oskar van Rest (Oracle) | +SQL Property Graphs in Oracle Database and Oracle Graph Server (PGX) – slides, video | +
| 10:30 | +11:00 | +coffee break | ++ |
| 11:00 | +11:15 | +Alastair Green (JCC) | +LDBC’s organizational changes and fair use policies – slides | +
| 11:20 | +11:35 | +Ioana Manolescu (INRIA) | +Integrating Connection Search in Graph Queries – slides, video | +
| 11:40 | +11:55 | +Maciej Besta (ETH Zurich) | +Neural Graph Databases with Graph Neural Networks – video | +
| 12:00 | +12:10 | +Longbin Lai (Alibaba Damo Academy) | +To Revisit Benchmarking Graph Analytics – slides, video | +
| 12:15 | +13:30 | +lunch | ++ |
| 13:30 | +13:45 | +Yuanyuan Tian (Gray Systems Lab, Microsoft) | +The World of Graph Databases from An Industry Perspective – slides, video | +
| 13:50 | +14:05 | +Alin Deutsch (UC San Diego & TigerGraph) | +TigerGraph’s Parallel Computation Model – slides, video | +
| 14:10 | +14:25 | +Chen Zhang (CreateLink) | +Applications of a Native Distributed Graph Database in the Financial Industry – video | +
| 14:30 | +14:45 | +Ricky Sun (Ultipa) | +Design of highly scalable graph database systems – slides, video | +
| 14:50 | +15:30 | +coffee break | ++ |
| 15:30 | +15:45 | +Heng Lin (Ant Group) | +The LDBC SNB implementation in TuGraph – slides, video | +
| 15:50 | +16:05 | +Shipeng Qi (Ant Group) | +FinBench: The new LDBC benchmark targeting financial scenario – slides, video | +
| 16:10 | +17:00 | +host: Heng Lin (Ant Group), panelists: Longbin Lai (Alibaba Damo Academy), Ricky Sun (Ultipa), Gabor Szarnyas (CWI), Yuanyuan Tian (Gray Systems Lab, Microsoft) | +FinBench panel – slides | +
| 19:00 | +22:00 | +dinner | +Black Bottle gastrotavern in Belltown: 2600 1st Ave (on the corner of Vine), Seattle, WA 98121 | +
Location: Amazon Nitro South building, room 03.204 (2205 8th Ave, Seattle, WA 98121)
+| start | +finish | +speaker | +title | +
|---|---|---|---|
| 09:00 | +09:45 | +Brad Bebee (AWS) | +Customers don’t want a graph database, so why are we still here? – slides, video | +
| 10:00 | +10:15 | +Muhammad Attahir Jibril (TU Ilmenau) | +Fast and Efficient Update Handling for Graph H2TAP – slides, video | +
| 10:20 | +11:00 | +coffee break | ++ |
| 11:00 | +11:15 | +Gabor Szarnyas (CWI) | +LDBC Social Network Benchmark and Graphalytics – slides | +
| 11:20 | +11:30 | +Atanas Kiryakov and Tomas Kovachev (Ontotext) | +GraphDB – Benchmarking against LDBC SNB & SPB – slides, video | +
| 11:35 | +11:50 | +Roi Lipman (Redis Labs) | +Delta sparse matrices within RedisGraph – slides, video | +
| 11:55 | +12:05 | +Rathijit Sen (Microsoft) | +Microarchitectural Analysis of Graph BI Queries on RDBMS – slides, video | +
| 12:10 | +13:30 | +lunch | +on your own | +
| 13:30 | +13:45 | +Alastair Green (JCC) | +LEX – LDBC Extended GQL Schema – slides, video | +
| 13:50 | +14:05 | +Ora Lassila (AWS) | +Why limit yourself to {RDF, LPG} when you can do {RDF, LPG}, too – slides, video | +
| 14:10 | +14:25 | +Jan Hidders (Birkbeck, University of London) | +PG-Schema: a proposal for a schema language for property graphs – slides, video | +
| 14:30 | +14:45 | +Max de Marzi (RageDB and RelationalAI) | +RageDB: Building a Graph Database in Anger – slides, video | +
| 14:50 | +15:30 | +coffee break | ++ |
| 15:30 | +15:45 | +Umit Catalyurek (AWS) | +HPC Graph Analytics on the OneGraph Model – slides, video | +
| 15:50 | +16:05 | +David J. Haglin (Trovares) | +How LDBC impacts Trovares – slides, video | +
| 16:10 | +16:25 | +Wenyuan Yu (Alibaba Damo Academy) | +GraphScope Flex: A Graph Computing Stack with LEGO-Like Modularity – slides, video | +
| 16:30 | +16:40 | +Scott McMillan (Carnegie Mellon University) | +Graph processing using GraphBLAS – slides, video | +
| 16:45 | +16:55 | +Tim Mattson (Intel) | +Graphs (GraphBLAS) and storage (TileDB) as Sparse Linear algebra – slides | +
| 17:00 | +20:00 | +happy hour (rooftop grill with beverages) | +on the Nitro South building’s 8th floor deck | +
A map of the LDBC TUC events we hosted so far.
+ +The LDBC consortium are pleased to announce its Sixth Technical User Community (TUC) meeting.
+This will be a two-day event at Universitat Politècnica de Catalunya, Barcelona on Thursday and Friday March 19/20, 2015.
+The LDBC FP7 EC funded project is reaching its finalisation, and this will be the last event sponsored directly by the project. However, tasks within LDBC will continue based on the LDBC independent organisation. The event will basically set the following aspects:
+We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact damaris@ac.upc.edu.
+Thursday 19th March
+11:00 - 11:30 Registration, coffee break and welcome (Josep Larriba Pey)
+11:30 - 12:00 LDBC introduction and status update (Peter Boncz) – slides
+12:00 - 13:30 Technology and benchmarking (chair: Peter Boncz)
+12:00 Venelin Kotsev (Ontotext). Semantic Publishing Benchmark v2.0. – slides
+12:30 Nina Saveta (FORTH). SPIMBENCH: A Scalable, Schema-Aware, Instance Matching Benchmark for the Semantic Publishing Domain
+12:50 Tomer Sagi (HP). Titan DB on LDBC SNB Interactive
+13:10 Claudio Martella (VUA): Giraph and Lighthouse
+13:30 - 14:30 Lunch break
+14:30 - 16:00 Applications and use of Graph Technologies (chair: Hassan Chafi)
+14:30 Jerven Bolleman (Swiss Institute of Bioinformatics): 20 billion triples in production slides
+14:50 Mark Wilkinson (Universidad Politécnica de Madrid): Design principles for Linked-Data-native Semantic Web Services slides
+15:10 Peter Haase (Metaphacts, Systap LLC): Querying the Wikidata Knowledge Graph slides
+15:30 Esteban Sota (GNOSS): Human Interaction with Faceted Searching Systems for big or complex graphs
+18:30 - 20:00 Cultural visit Barcelona city center. Meet at Plaça Catalunya.
+20:00 Social dinner at Bastaix Restaurant.
+Friday 20th March
+9:30 - 11:00 Technology and Benchmarking (chair: Josep L. Larriba-Pey)
+9:30 Yinglong Xia (IBM): Towards Temporal Graph Management and Analytics
+9:50 Alexandru Iosup (TU Delft). Graphalytics: A big data benchmark for graph-processing platforms
+10:10 John Snelson (MarkLogic): Introduction to MarkLogic
+10:30 Arnau Prat (UPC-Sparsity Technologies) and Alex Averbuch (Neo): Social Network Benchmark, Interactive Workload
+10:50 Moritz Kaufmann. The auditing experience
+11:15 - 11:45 Coffee break
+11:45 - 12:45 Applications and use of Graph Technologies (chair: Atanas Kiryakov)
+11:45 Boris Motik (Oxford University): Parallel and Incremental Materialisation of RDF/Datalog in RDFox
+12:05 Andreas Both (Unister): E-Commerce and Graph-driven Applications: Experiences and Optimizations while moving to Linked Data
+12:25 Smrati Gupta (CA Technologies). Modaclouds Decision Support System in multicloud environments
+12:45 Peter Boncz. Conclusions for the LDBC project and future perspectives. slides
+13:30 - 14:30 Lunch break
+15:00 LDBC Board of Directors
+19th and 20th March 2015
+The TUC meeting will be held at “Aula Master” at A3 building located inside the “Campus Nord UPC” in Barcelona. The address is:
+Aula Master
+Edifici A3, Campus Nord UPC
+C. Jordi Girona, 1-3
+08034 Barcelona, Spain
To reach the campus, there are several options, including Taxi, Metro and Bus.
+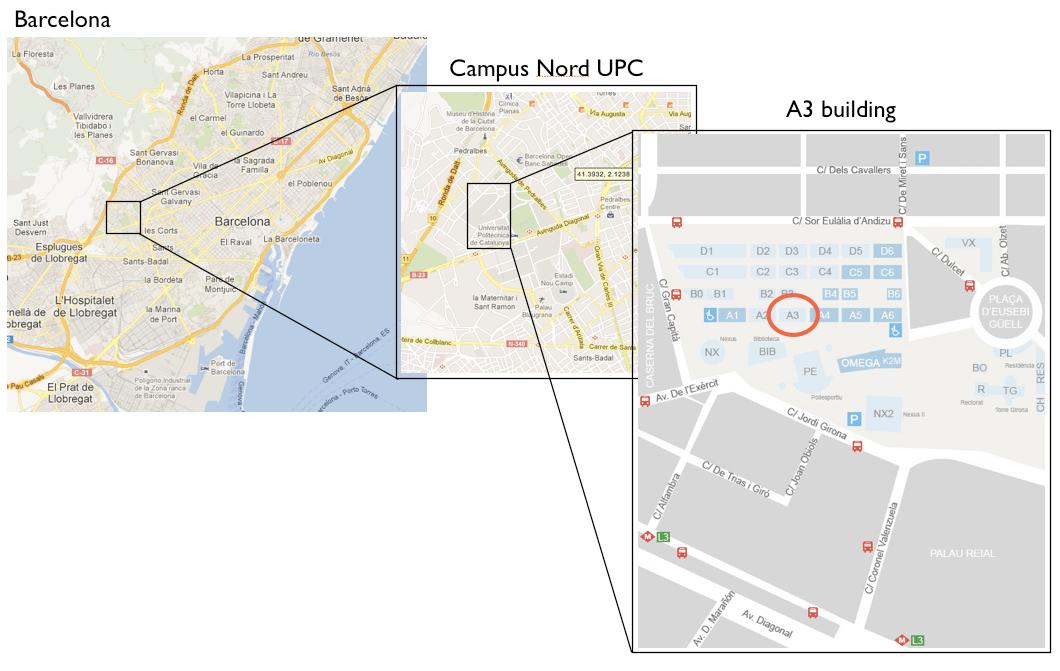
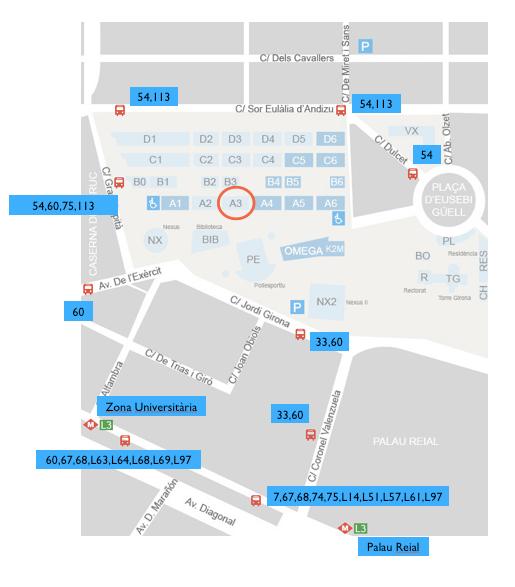
Flying: Barcelona airport is situated 12 km from the city. There are several ways of getting from the airport to the centre of Barcelona, the cheapest of which is to take the train located outside just a few minutes walking distance past the parking lots at terminal 2 (there is a free bus between terminal 1 and terminal 2, see this map of the airport). It is possible to buy 10 packs of train tickets which makes it cheaper. Taking the bus to the centre of town is more convenient as they leave directly from terminal 1 and 2, however it is more expensive than the train.
+Rail: The Renfe commuter train leaves the airport every 30 minutes from 6.13 a.m. to 11.40 p.m. Tickets cost around 3€ and the journey to
+the centre of Barcelona (Sants or Plaça Catalunya stations) takes 20 minutes.
Bus: The Aerobus leaves the airport every 12 minutes, from 6.00 a.m. to 24.00, Monday to Friday, and from 6.30 a.m. to 24.00 on Saturdays, Sundays and public holidays. Tickets cost 6€ and the journey ends in Plaça Catalunya in the centre of Barcelona.
+Taxi: From the airport, you can take one of Barcelona’s typical black and yellow taxis. Taxis may not take more than four passengers. Unoccupied taxis display a green light and have a clearly visible sign showing LIBRE or LLIURE. The trip to Sants train station costs approximately €20 and trips to other destinations in the city cost approximately €25-30.
+Train and bus: Barcelona has two international train stations: Sants and França. Bus companies have different points of arrival in different parts of the city. You can find detailed information in the following link: http://www.barcelona-airport.com/eng/transport_eng.htm
+
This will be a one-day event at the VLDB 2017 conference in Munich, Germany on September 1, 2017.
+Topics and activities of interest in these TUC meetings are:
+We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Adrian Diaz (UPC) at adiaz@ac.upc.edu to register; registration is free, but required.
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals are handled by Peter Boncz and Larri.
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.
+In the TUC meeting there will be:
+The meeting will start on Friday morning, with a program from 10:30-17:00
+10:30-12:00: TUC session (public)
+12:00-13:30: lunch break
+13:30-15:00: TUC session (public)
+15:00-15:30: break
+15:30-17:00: TUC session (public)
+Speakers should aim for a 20-minute talk.
+Further:
+The Technical University of Munich (TUM) is hosting that week the VLDB conference; on the day of the TUC meeting the main conference will have finished, but there will be a number of co-located workshops ongoing, and the TUC participants will blend in with that crowd for the breaks and lunch.
+The TUC meeting will be held in in Room 2607 alongside the VLDB workshops that day (MATES, ADMS, DMAH, DBPL and BOSS).
+address: Technische Universität München (TUM), Arcisstraße 21, 80333 München
+ +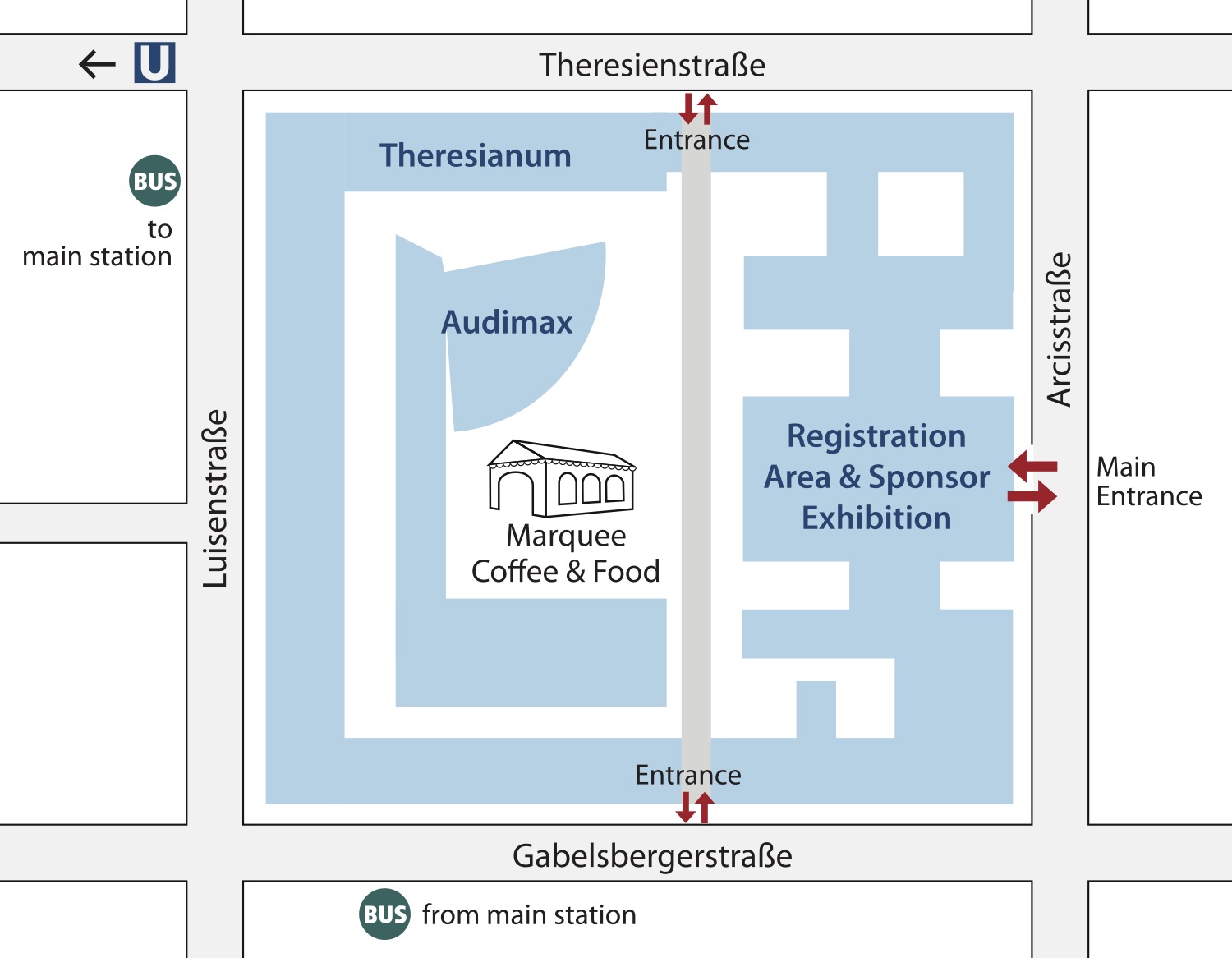
+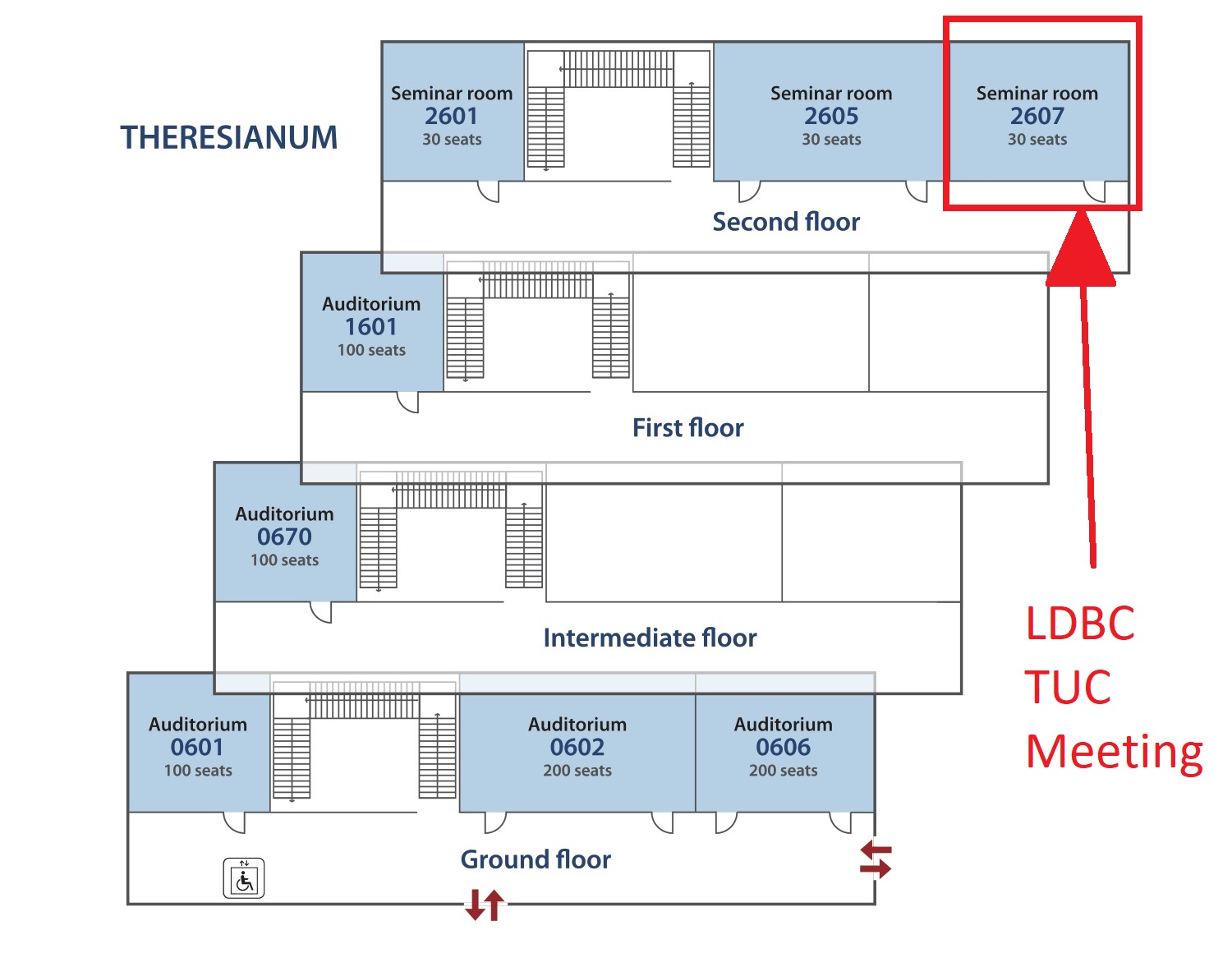
The LDBC consortium is pleased to announce the third Technical User Community (TUC) meeting!
+This will be a one day event in London on the 19 November 2013 running in collaboration with the GraphConnect event (18/19 November). Registered TUC participants that would like a free pass to all of GraphConnect should register for GraphConnect using this following coupon code: LDBCTUC.
+The TUC event will include:
+We will also be launching the LDBC non-profit organization, so anyone outside the EU project will be able to join as a member.
+We will kick off new benchmark development task forces in the coming year, and talks at this coming TUC will play an important role in deciding the use case scenarios that will drive those benchmarks.
+All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu
+November 19th - Public TUC Meeting
+8:00 Breakfast and registration will open for Graph Connect/TUC at 8:00 am (Dexter House)
+short LDBC presentation (Peter Boncz) during GraphConnect keynote by Emil Eifrem (09:00-09:30 Dexter House)
+NOTE: the TUC meeting is at the Tower Hotel, nearby Dexter House.
+10:00 TUC Meeting Opening (Peter Boncz)
+10:10 TUC Presentations (RDF Application Descriptions)
+11:30 Semantic Publishing Benchmark (SPB)
+12:00-13:00 Lunch at the Graph Connect venue
+Talks During Lunch:
+13:00 TUC Presentations (Graph Application Descriptions)
+14:00 Social Network Benchmark (SNB)
+14:30 Break
+14:45 TUC Presentations (Graph Analytics)
+15:45 Break
+16:00 TUC Presentations* (Possible Future RDF Benchmarking Topics)*
+17:20 Meeting Conclusion (Josep Larriba Pey)
+17:30 End of TUC meeting
+19:00 Social dinner
+November 20th - Internal LDBC Meeting
+10:00 Start
+12:30 End of meeting
+Date
+19th November 2013
+Location
+The TUC meeting will be held in The Tower hotel (Google Maps link) approximately 4 minutes walk from the GraphConnect conference in London.
+Getting there
+Looking back, we have been working on two benchmarks for the past year: a Social Network Benchmark (SNB) and a Semantic Publishing Benchmark (SPB). While below we provide a short summary, all the details of the work on these benchmark development efforts can be found in the first yearly progress reports:
+ +A summary of these efforts can be read below or, for a more detailed account, please refer to: The Linked Data Benchmark Council: a Graph and RDF industry benchmarking effort. Annual reports about the progress, results, and future work of these two efforts will soon be available for download here, and will be discussed in depth at the TUC.
+The Social Network Benchmark (SNB) is designed for evaluating a broad range of technologies for tackling graph data management workloads. The systems targeted are quite broad: from graph, RDF, and relational database systems to Pregel-like graph compute frameworks. The social network scenario was chosen with the following goals in mind:
+SNB includes a data generator for creation of synthetic social network data with the following characteristics:
+SNB is intended to cover a broad range of aspects of social network data management, and therefore includes three distinct workloads:
+The Semantic Publishing Benchmark (SPB) simulates the management and consumption of RDF metadata that describes media assets, or creative works.
+The scenario is a media organization that maintains RDF descriptions of its catalogue of creative works – input was provided by actual media organizations which make heavy use of RDF, including the BBC. The benchmark is designed to reflect a scenario where a large number of aggregation agents provide the heavy query workload, while at the same time a steady stream of creative work description management operations are in progress. This benchmark only targets RDF databases, which support at least basic forms of semantic inference. A tagging ontology is used to connect individual creative work descriptions to instances from reference datasets, e.g. sports, geographical, or political information. The data used will fall under the following categories: reference data, which is a combination of several Linked Open Data datasets, e.g. GeoNames and DBpedia; domain ontologies, that are specialist ontologies used to describe certain areas of expertise of the publishing, e.g., sport and education; publication asset ontologies, that describe the structure and form of the assets that are published, e.g., news stories, photos, video, audio, etc.; and tagging ontologies and the metadata, that links assets with reference/domain ontologies.
+The data generator is initialized by using several ontologies and datasets. The instance data collected from these datasets are then used at several points during the execution of the benchmark. Data generation is performed by generating SPARQL fragments for create operations on creative works and executing them against the RDF database system.
+Two separate workloads are modeled in SPB:
+LDBC is pleased to announce its Thirteenth Technical User Community (TUC) meeting.
+LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, TigerGraph and Huawei among its members.
+This TUC meeting will be a two-day event hosted online. We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Gabor Szarnyas (BME) to register.
+Zoom links will be sent through email.
+ +LDBC is pleased to announce its Twelfth Technical User Community (TUC) meeting.
+LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, TigerGraph and Huawei among its members.
+This TUC meeting will be a one-day event on the last Friday of SIGMOD/PODS 2019 in Amsterdam, The Netherlands, in the conference venue of Beurs van Berlage. The room is the Mendes da Silva kamer. Please check its tips for accommodation in Amsterdam.
+Note also that at SIGMOD/PODS in Amsterdam on Sunday, June 30, there is a research workshop on graph data management technology called GRADES-NDA 2019, that may be of interest to our audience (this generally holds for the whole SIGMOD/PODS program, of course).
+We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Damaris Coll (UPC) at damaris@ac.upc.edu to register.
+=> registration is free, but required <=
+You need to be registered in order to get into the SIGMOD/PODS venue. Friday, July 5, is the final, workshop, day of SIGMOD/PODS, and the LDBC TUC meeting joins the other workshops for coffee and lunch.
+In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management.
+Talk proposals can be sent to Peter Boncz, who is also the local organizer. Please also send your slides to this email for archiving on this site.
+Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.
+In the TUC meeting, there will be:
+The morning slot (08:30-10:30) is reserved for an LDBC Board Meeting, to which in principle only LDBC directors are invited (that meeting will be held in the same room).
+The TUC meeting will start on Friday morning after the morning coffee break of SIGMOD/PODS 2019 (room: Mendes da Silva kamer):
+08:30-10:30 LDBC Board Meeting (non-public)
+10:30-11:00 Coffee
+11:00-12:45 Session 1: Graph Benchmarks
+11:00-11:05 Welcome & introduction
+11:45-12:00 Frank McSherry (Materialize): Experiences implementing LDBC queries in a dataflow system
+12:25-12:45 Ahmed Musaafir (VU Amsterdam): LDBC Graphalytics
+12:45-14:00 Lunch
+14:00-16:05 Session 2: Graph Query Languages
+14:00-14:25 Juan Sequeda (Capsenta): Property Graph Schema Working Group: A progress report
+14:25-14:50 Stefan Plantikow (Neo4j): GQL: Scope and features, report
+14:50-15:15 Vasileios Trigonakis (Oracle): Property graph extensions for the SQL standard
+15:40-16:05 Jan Posiadała (Nodes and Edges, Poland): Executable semantics of graph query language
+16:05-16:30 Coffee
+16:30-17:50 Session 3: Graph System Performance
+16:30-16:50 Per Fuchs (CWI): Fast, scalable WCOJ graph-pattern matching on in-memory graphs in Spark
+16:50-17:10 Semih Salihoglu (University of Waterloo): Optimizing subgraph queries with a mix of tradition and modernity pptx
+17:30-17:50 Alexandru Uta (VU Amsterdam): Low-latency Spark queries on updatable data
+If there is interest, we will organize a social dinner on Friday evening for LDBC attendees.
+ +Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and …
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and …
+We are happy to annonunce new audited results for the SNB Interactive workload, achieved by the open-source GraphScope Flex system.
+The current audit of the system has broken several records:
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and tests for the GQL language. See this announcement from Alastair Green, Vice-chair of LDBC.
+These tools are the work of the LDBC GQL Implementation Working Group, headed up by Michael Burbidge. Damian Wileński and Dominik Tomaszuk have worked …
+ +We are delighted to announce the official release of the initial version (v0.1.0) of Financial Benchmark (FinBench).
+The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as anti-fraud and risk control. It is maintained by the LDBC FinBench Task Force. The benchmark has one workload currently, Transaction Workload, capturing OLTP scenario with complex read queries that access the …
+ +2023 has been an eventful year for us so far. Here is a summary of our recent activities.
+Our paper The LDBC Social Network Benchmark: Business Intelligence Workload was published in PVLDB.
+David Püroja just completed his MSc thesis on creating a design towards SNB Interactive v2 at CWI’s Database Architectures group. David and I gave a deep-dive talk at the FOSDEM conference’s graph developer room titled The LDBC Social Network …
LDBC SNB provides a data generator, which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. More than two years have elapsed since my last technical update on LDBC SNB Datagen, in which I discussed the reasons for moving the code to Apache Spark from the MapReduce-based Apache Hadoop implementation and the …
+ +Group leader: Alastair Green (JCC)
+Active members:
+See the LEX work charter which details the group’s mission, motivation, and scope of work.
+ +LDBC’s working groups investigate research questions on graph query languages and language extensions for graphs.
+Their work targeted the ISO/IEC SQL/PGQ language extension (released in June 2023) and the ISO/IEC GQL language (released in April 2024).
+LDBC has released open GQL language tools in May 2024.
We are delighted to announce the set up of the Financial Benchmark (FinBench) task force.
+The Financial Benchmark (FinBench) project aims to define a graph database evaluating benchmark and develop a data generation process and a query driver to make the evaluation of the graph database representative, reliable and comparable, especially in financial scenarios, such as anti-fraud and risk control. The FinBench is scheduled to be released in the …
+ +LDBC’s Social Network Benchmark [4] (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data …
+ +
+
+
+ LDBC is proud to announce the new LDBC Graphalytics Benchmark draft specification.
+LDBC Graphalytics is the first industry-grade graph data management benchmark …
+ +Apache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
+
Flink offers multiple APIs to process data …
+ +The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of web resources through “same-as” links which specify that two URIs correspond to the same real world object. In the vast number of data sources participating in the Linked Data Cloud, this information is not …
+ +In this post we will look at running the LDBC SNB on Virtuoso.
+First, let’s recap what the benchmark is about:
+fairly frequent short updates, with no update contention worth mentioning
+short random lookups
+medium complex queries centered around a person’s social environment
+The updates exist so as to invalidate strategies that rely too heavily on precomputation. The short lookups exist for the sake of realism; after all, an …
+ +Next 31st of May the GRADES workshop will take place in Melbourne within the ACM/SIGMOD presentation. GRADES started as an initiative of the Linked Data Benchmark Council in the SIGMOD/PODS 2013 held in New York.
+Among the papers published in this edition we have “Graphalytics: A Big Data Benchmark for Graph-Processing Platforms”, which presents a new benchmark that uses the Social Network Benchmark data generator of LDBC (that can …
+ +SNB Interactive is the wild frontier, with very few rules. This is necessary, among other reasons, because there is no standard property graph data model, and because the contestants support a broad mix of programming models, ranging from in-process APIs to declarative query.
+In the case of Virtuoso, we have played with SQL and SPARQL implementations. For a fixed schema and well known workload, SQL will always win. The reason for this is that …
+ +LDBC is presenting two papers at the next edition of the ACM SIGMOD/PODS conference held in Melbourne from May 31st to June 4th, 2015. The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools and experiences.
+On the industry track, LDBC will be presenting the Social Network Benchmark Interactive …
+ +This post is the first in a series of blogs analyzing the LDBC Social Network Benchmark Interactive workload. This is written from the dual perspective of participating in the benchmark design and of building the OpenLink Virtuoso implementation of same.
+With two implementations of SNB interactive at four different scales, we can take a first look at what the benchmark is really about. The hallmark of a benchmark implementation is that its …
+ +In a previous 3-part blog series we touched upon the difficulties of executing the LDBC SNB Interactive (SNB) workload, while achieving good performance and scalability. What we didn’t discuss is why these difficulties were unique to SNB, and what aspects of the way we perform workload execution are scientific contributions - novel solutions to previously unsolved problems. This post will highlight the differences between SNB and more …
+ +As discussed in previous posts, one of the features that makes Datagen more realistic is the fact that the activity volume of the simulated Persons is not uniform, but forms spikes. In this blog entry I want to explain more in depth how this is actually implemented inside of the generator.
+First of all, I start with a few basics of how Datagen works internally. In Datagen, once the person graph has been created (persons and their relationships), …
+ +This blog entry is about one of the features of DATAGEN that makes it different from other synthetic graph generators that can be found in the literature: the community structure of the graph.
+When generating synthetic graphs, one must not only pay attention to quantitative measures such as the number of nodes and edges, but also to other more qualitative characteristics such as the degree distribution, clustering coefficient. Real graphs, and …
+ +
+
+
+ I took this picture in June 2010 next to Union Square in San Francisco. I was smoking and …
+ +The Linked Data paradigm has become the prominent enabler for sharing huge volumes of data using Semantic Web technologies, and has created novel challenges for non-relational data management systems, such as RDF and graph engines. Efficient data access through queries is perhaps the most important data management task, and is enabled through query optimization techniques, which amount to the discovery of optimal or close to optimal execution …
+ +When talking about DATAGEN and other graph generators with social network characteristics, our attention is typically borrowed by the friendship subgraph and/or its structure. However, a social graph is more than a bunch of people being connected by friendship relations, but has a lot more of other things is worth to look at. With a quick view to commercial social networks like Facebook, Twitter or Google+, one can easily identify a lot of other …
+ +The SNB Driver part 1 post introduced, broadly, the challenges faced when developing a workload driver for the LDBC SNB benchmark. In this blog we’ll drill down deeper into the details of what it means to execute “dependent queries” during benchmark execution, and how this is handled in the driver. First of all, as many driver-specific terms will be used, below is a listing of their definitions. There is no need to read them in …
+ +Up until now we have introduced the challenges faced when executing the LDBC SNB benchmark, as well as explained how some of these are overcome. With the foundations laid, we can now explain precisely how operations are executed.
+Based on the dependencies certain operations have, and on the granularity of parallelism we wish to achieve while executing them, we assign a Dependency Mode and an Execution Mode to every operation type. Using these …
+ +Until now we have discussed several aspects of the Semantic Publishing Benchmark (SPB) such as the difference in performance between virtual and real servers configuration, how to choose an appropriate query mix for a benchmark run and our experience with using SPB in the development process of GraphDB for finding performance issues.
+In this post we provide a step-by-step guide on how to run SPB using the Sesame RDF data store on a fresh install …
+ +The Semantic Publishing Instance Matching Benchmark (SPIMBench) is a novel benchmark for the assessment of instance matching techniques for RDF data with an associated schema. SPIMBench extends the state-of-the art instance matching benchmarks for RDF data in three main aspects: it allows for systematic scalability testing, supports a wider range of test cases including semantics-aware ones, and provides an enriched gold standard.
+The SPIMBench …
+ +We are presently working on the SNB BI workload. Andrey Gubichev of TU Munchen and myself are going through the queries and are playing with two SQL based implementations, one on Virtuoso and the other on Hyper.
+As discussed before, the BI workload has the same choke points as TPC-H as a base but pushes further in terms of graphiness and query complexity.
+There are obvious marketing applications for a SNB-like dataset. There are also security …
+ +LDBC’s Semantic Publishing Benchmark (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the famous BBC Dynamic Semantic Publishing scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volume of read requests (SPARQL queries collecting recent content and data to generate web page on a specific subject, e.g. Frank …
+ +In previous posts (Getting started with snb, DATAGEN: data generation for the Social Network Benchmark), Arnau Prat discussed the main features and characteristics of DATAGEN: realism, scalability, determinism, usability. DATAGEN is the social network data generator used by the three LDBC-SNB workloads, which produces data simulating the activity in a social network site during a period of time. In this post, we conduct a series of experiments …
+ +In this multi-part blog we consider the challenge of running the LDBC Social Network Interactive Benchmark (LDBC SNB) workload in parallel, i.e. the design of the workload driver that will issue the queries against the System Under Test (SUT). We go through design principles that were implemented for the LDBC SNB workload generator/load tester (simply referred to as driver). Software and documentation for this driver is available here: …
+ +LDBC SPB (Semantic Publishing Benchmark) is based on the BBC linked data platform use case. Thus the data modelling and transaction mix reflects the BBC’s actual utilization of RDF. But a benchmark is not only a condensation of current best practices. The BBC linked data platform is an Ontotext Graph DB deployment. Graph DB was formerly known as Owlim.
+So, in SPB we wanted to address substantially more complex queries than the lookups that …
+ +The Semantic Publishing Benchmark (SPB), developed in the context of LDBC, aims at measuring the read and write operations that can be performed in the context of a media organisation. It simulates the management and consumption of RDF metadata describing media assets and creative works. The scenario is based around a media organisation that maintains RDF descriptions of its catalogue of creative works. These descriptions use a set of ontologies …
+ +The Linked Data Benchmark Council (LDBC) mission is to design and maintain benchmarks for graph data management systems, and establish and enforce standards in running these benchmarks, and publish and arbitrate around the official benchmark results. The council and its https://ldbcouncil.org website just launched, and in its first 1.5 year of existence, most effort at LDBC has gone into investigating the needs of the field through interaction …
+ +The Linked Data Benchmark Council (LDBC) is reaching a milestone today, June 23 2014, in announcing that two of the benchmarks that it has been developing since 1.5 years have now reached the status of Public Draft. This concerns the Semantic Publishing Benchmark (SPB) and the interactive workload of the Social Network Benchmark (SNB). In case of LDBC, the release is staged: now the benchmark software just runs read-only queries. This will be …
+ +Social Network interaction is amongst the most natural and widely spread activities in the internet society, and it has turned out to be a very useful way for people to socialise at different levels (friendship, professional, hobby, etc.). As such, Social Networks are well understood from the point of view of the data involved and the interaction required by their actors. Thus, the concepts of friends of friends, or retweet are well established …
+ +It is with great pleasure that we announce the new LDBC organisation site at www.ldbcouncil.org. The LDBC started as a European Community FP7 funded project with the objective to create, foster and become an industry reference for benchmarking RDF and Graph technologies. A period of more than one and a half years has led us to the creation of the first two workloads, the Semantic Publishing Benchmark and the Social Network Benchmark in its …
+ +Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate …
+ +As explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 [1].
+One of the most …
+ +In a previous blog post titled “Is SNB like Facebook’s LinkBench?”, Peter Boncz discusses the design philosophy that shapes SNB and how it compares to other existing benchmarks such as LinkBench. In this post, I will briefly introduce the essential parts forming SNB, which are DATAGEN, the LDBC execution driver and the workloads.
+DATAGEN is the data generator used by all the workloads of SNB. Here we introduced the …
+ +The LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.
+The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.
+This …
+ +
+
+
+ In this post, I will discuss in some detail the rationale and goals of the design of the Social Network Benchmark (SNB) and explain how it relates to real …
+ +Synopsis: Now is the time to finalize the interactive part of the Social Network Benchmark (SNB). The benchmark must be both credible in a real social network setting and pose new challenges. There are many hard queries but not enough representation for what online systems in fact do. So, the workload mix must strike a balance between the practice and presenting new challenges.
+It is about to be showtime for LDBC. The initial installment of the …
+ +In previous posts (this and this) we briefly introduced the design goals and philosophy behind DATAGEN, the data generator used in LDBC-SNB. In this post, I will explain how to use DATAGEN to generate the necessary datatsets to run LDBC-SNB. Of course, as DATAGEN is continuously under development, the instructions given in this tutorial might change in the future.
+DATAGEN runs on top of hadoop 1.2.1 to be scale. …
+ +Note: consider this post as a continuation of the “Making it interactive” post by Orri Erling.
+I have now completed the Virtuoso TPC-H work, including scale out. Optimization possibilities extend to infinity but the present level is good enough. TPC-H is the classic of all analytics benchmarks and is difficult enough, I have extensive commentary on this on my blog (In Hoc Signo Vinces series), including experimental results. This is, …
+ +During the past six months we (the OWLIM Team at Ontotext) have integrated the LDBC Semantic Publishing Benchmark (LDBC-SPB) as a part of our development and release process.
+First thing we’ve started using the LDBC-SPB for is to monitor the performance of our RDF Store when a new release is about to come out.
+Initially we’ve decided to fix some of the benchmark parameters :
+Group leaders: Jan Hidders (Birkbeck College, University of London), Juan Sequeda (data.world)
+The PGSWG has 4 sub-groups: PG-Basic, PG-Constraints, PG-Properties, PG-Nulls
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and …
+Organizers: Shipeng Qi (AntGroup), Wenyuan Yu (Alibaba Demo), Yan Zhou (CreateLink)
+LDBC is hosting a two-day hybrid workshop, co-located in Guangzhou with VLDB 2024 on August 30-31 (Friday-Saturday).
+The …
+Organizers: Renzo Angles, Sebastián Ferrada
+LDBC is hosting a one-day in-person workshop, co-located in Santiago de Chile with SIGMOD 2024 on June 9 (Sunday).
+The workshop will be held in the Hotel Plaza El …
+We are happy to annonunce new audited results for the SNB Interactive workload, achieved by the open-source GraphScope Flex system.
+The current audit of the system has broken several records:
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and …
+We are delighted to announce the official release of the initial version (v0.1.0) of Financial Benchmark (FinBench).
+The Financial Benchmark (FinBench) project defines a graph database benchmark targeting …
+The Linked Data Benchmark Council (LDBC) is a non-profit organization aiming to define standard graph benchmarks to foster a community around graph processing technologies. LDBC consists of members from both industry and academia, including organizations and individuals.
+An overview of our activites is summarized in a lightning talk at FOSDEM 2023’s HPC room (9 minutes):
+ +See also our TPCTC 2023 paper and its slide deck.
+To learn more about LDBC, reach out at info@ldbcouncil.org.
First Floor, Two Chamberlain Square
+Birmingham
+B3 3AX
+United Kingdom
We are happy to annonunce new audited results for the SNB Interactive workload, achieved by the open-source GraphScope Flex system.
+The current audit of the system has broken several records:
+Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and tests for the GQL language. See this announcement from Alastair Green, Vice-chair of LDBC.
+These tools are the work of the LDBC GQL Implementation Working Group, headed up by Michael Burbidge. Damian Wileński and Dominik Tomaszuk have worked …
+ +We are delighted to announce the official release of the initial version (v0.1.0) of Financial Benchmark (FinBench).
+The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as anti-fraud and risk control. It is maintained by the LDBC FinBench Task Force. The benchmark has one workload currently, Transaction Workload, capturing OLTP scenario with complex read queries that access the …
+ +2023 has been an eventful year for us so far. Here is a summary of our recent activities.
+Our paper The LDBC Social Network Benchmark: Business Intelligence Workload was published in PVLDB.
+David Püroja just completed his MSc thesis on creating a design towards SNB Interactive v2 at CWI’s Database Architectures group. David and I gave a deep-dive talk at the FOSDEM conference’s graph developer room titled The LDBC Social Network …
LDBC SNB provides a data generator, which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. More than two years have elapsed since my last technical update on LDBC SNB Datagen, in which I discussed the reasons for moving the code to Apache Spark from the MapReduce-based Apache Hadoop implementation and the …
+ +We are delighted to announce the set up of the Financial Benchmark (FinBench) task force.
+The Financial Benchmark (FinBench) project aims to define a graph database evaluating benchmark and develop a data generation process and a query driver to make the evaluation of the graph database representative, reliable and comparable, especially in financial scenarios, such as anti-fraud and risk control. The FinBench is scheduled to be released in the …
+ +LDBC’s Social Network Benchmark [4] (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data …
+ +
+
+
+ LDBC is proud to announce the new LDBC Graphalytics Benchmark draft specification.
+LDBC Graphalytics is the first industry-grade graph data management benchmark …
+ +Apache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
+
Flink offers multiple APIs to process data …
+ +The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of web resources through “same-as” links which specify that two URIs correspond to the same real world object. In the vast number of data sources participating in the Linked Data Cloud, this information is not …
+ +In this post we will look at running the LDBC SNB on Virtuoso.
+First, let’s recap what the benchmark is about:
+fairly frequent short updates, with no update contention worth mentioning
+short random lookups
+medium complex queries centered around a person’s social environment
+The updates exist so as to invalidate strategies that rely too heavily on precomputation. The short lookups exist for the sake of realism; after all, an …
+ +Next 31st of May the GRADES workshop will take place in Melbourne within the ACM/SIGMOD presentation. GRADES started as an initiative of the Linked Data Benchmark Council in the SIGMOD/PODS 2013 held in New York.
+Among the papers published in this edition we have “Graphalytics: A Big Data Benchmark for Graph-Processing Platforms”, which presents a new benchmark that uses the Social Network Benchmark data generator of LDBC (that can …
+ +SNB Interactive is the wild frontier, with very few rules. This is necessary, among other reasons, because there is no standard property graph data model, and because the contestants support a broad mix of programming models, ranging from in-process APIs to declarative query.
+In the case of Virtuoso, we have played with SQL and SPARQL implementations. For a fixed schema and well known workload, SQL will always win. The reason for this is that …
+ +LDBC is presenting two papers at the next edition of the ACM SIGMOD/PODS conference held in Melbourne from May 31st to June 4th, 2015. The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools and experiences.
+On the industry track, LDBC will be presenting the Social Network Benchmark Interactive …
+ +This post is the first in a series of blogs analyzing the LDBC Social Network Benchmark Interactive workload. This is written from the dual perspective of participating in the benchmark design and of building the OpenLink Virtuoso implementation of same.
+With two implementations of SNB interactive at four different scales, we can take a first look at what the benchmark is really about. The hallmark of a benchmark implementation is that its …
+ +In a previous 3-part blog series we touched upon the difficulties of executing the LDBC SNB Interactive (SNB) workload, while achieving good performance and scalability. What we didn’t discuss is why these difficulties were unique to SNB, and what aspects of the way we perform workload execution are scientific contributions - novel solutions to previously unsolved problems. This post will highlight the differences between SNB and more …
+ +As discussed in previous posts, one of the features that makes Datagen more realistic is the fact that the activity volume of the simulated Persons is not uniform, but forms spikes. In this blog entry I want to explain more in depth how this is actually implemented inside of the generator.
+First of all, I start with a few basics of how Datagen works internally. In Datagen, once the person graph has been created (persons and their relationships), …
+ +This blog entry is about one of the features of DATAGEN that makes it different from other synthetic graph generators that can be found in the literature: the community structure of the graph.
+When generating synthetic graphs, one must not only pay attention to quantitative measures such as the number of nodes and edges, but also to other more qualitative characteristics such as the degree distribution, clustering coefficient. Real graphs, and …
+ +
+
+
+ I took this picture in June 2010 next to Union Square in San Francisco. I was smoking and …
+ +The Linked Data paradigm has become the prominent enabler for sharing huge volumes of data using Semantic Web technologies, and has created novel challenges for non-relational data management systems, such as RDF and graph engines. Efficient data access through queries is perhaps the most important data management task, and is enabled through query optimization techniques, which amount to the discovery of optimal or close to optimal execution …
+ +When talking about DATAGEN and other graph generators with social network characteristics, our attention is typically borrowed by the friendship subgraph and/or its structure. However, a social graph is more than a bunch of people being connected by friendship relations, but has a lot more of other things is worth to look at. With a quick view to commercial social networks like Facebook, Twitter or Google+, one can easily identify a lot of other …
+ +The SNB Driver part 1 post introduced, broadly, the challenges faced when developing a workload driver for the LDBC SNB benchmark. In this blog we’ll drill down deeper into the details of what it means to execute “dependent queries” during benchmark execution, and how this is handled in the driver. First of all, as many driver-specific terms will be used, below is a listing of their definitions. There is no need to read them in …
+ +Up until now we have introduced the challenges faced when executing the LDBC SNB benchmark, as well as explained how some of these are overcome. With the foundations laid, we can now explain precisely how operations are executed.
+Based on the dependencies certain operations have, and on the granularity of parallelism we wish to achieve while executing them, we assign a Dependency Mode and an Execution Mode to every operation type. Using these …
+ +Until now we have discussed several aspects of the Semantic Publishing Benchmark (SPB) such as the difference in performance between virtual and real servers configuration, how to choose an appropriate query mix for a benchmark run and our experience with using SPB in the development process of GraphDB for finding performance issues.
+In this post we provide a step-by-step guide on how to run SPB using the Sesame RDF data store on a fresh install …
+ +The Semantic Publishing Instance Matching Benchmark (SPIMBench) is a novel benchmark for the assessment of instance matching techniques for RDF data with an associated schema. SPIMBench extends the state-of-the art instance matching benchmarks for RDF data in three main aspects: it allows for systematic scalability testing, supports a wider range of test cases including semantics-aware ones, and provides an enriched gold standard.
+The SPIMBench …
+ +We are presently working on the SNB BI workload. Andrey Gubichev of TU Munchen and myself are going through the queries and are playing with two SQL based implementations, one on Virtuoso and the other on Hyper.
+As discussed before, the BI workload has the same choke points as TPC-H as a base but pushes further in terms of graphiness and query complexity.
+There are obvious marketing applications for a SNB-like dataset. There are also security …
+ +LDBC’s Semantic Publishing Benchmark (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the famous BBC Dynamic Semantic Publishing scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volume of read requests (SPARQL queries collecting recent content and data to generate web page on a specific subject, e.g. Frank …
+ +In previous posts (Getting started with snb, DATAGEN: data generation for the Social Network Benchmark), Arnau Prat discussed the main features and characteristics of DATAGEN: realism, scalability, determinism, usability. DATAGEN is the social network data generator used by the three LDBC-SNB workloads, which produces data simulating the activity in a social network site during a period of time. In this post, we conduct a series of experiments …
+ +In this multi-part blog we consider the challenge of running the LDBC Social Network Interactive Benchmark (LDBC SNB) workload in parallel, i.e. the design of the workload driver that will issue the queries against the System Under Test (SUT). We go through design principles that were implemented for the LDBC SNB workload generator/load tester (simply referred to as driver). Software and documentation for this driver is available here: …
+ +LDBC SPB (Semantic Publishing Benchmark) is based on the BBC linked data platform use case. Thus the data modelling and transaction mix reflects the BBC’s actual utilization of RDF. But a benchmark is not only a condensation of current best practices. The BBC linked data platform is an Ontotext Graph DB deployment. Graph DB was formerly known as Owlim.
+So, in SPB we wanted to address substantially more complex queries than the lookups that …
+ +The Semantic Publishing Benchmark (SPB), developed in the context of LDBC, aims at measuring the read and write operations that can be performed in the context of a media organisation. It simulates the management and consumption of RDF metadata describing media assets and creative works. The scenario is based around a media organisation that maintains RDF descriptions of its catalogue of creative works. These descriptions use a set of ontologies …
+ +The Linked Data Benchmark Council (LDBC) mission is to design and maintain benchmarks for graph data management systems, and establish and enforce standards in running these benchmarks, and publish and arbitrate around the official benchmark results. The council and its https://ldbcouncil.org website just launched, and in its first 1.5 year of existence, most effort at LDBC has gone into investigating the needs of the field through interaction …
+ +The Linked Data Benchmark Council (LDBC) is reaching a milestone today, June 23 2014, in announcing that two of the benchmarks that it has been developing since 1.5 years have now reached the status of Public Draft. This concerns the Semantic Publishing Benchmark (SPB) and the interactive workload of the Social Network Benchmark (SNB). In case of LDBC, the release is staged: now the benchmark software just runs read-only queries. This will be …
+ +Social Network interaction is amongst the most natural and widely spread activities in the internet society, and it has turned out to be a very useful way for people to socialise at different levels (friendship, professional, hobby, etc.). As such, Social Networks are well understood from the point of view of the data involved and the interaction required by their actors. Thus, the concepts of friends of friends, or retweet are well established …
+ +It is with great pleasure that we announce the new LDBC organisation site at www.ldbcouncil.org. The LDBC started as a European Community FP7 funded project with the objective to create, foster and become an industry reference for benchmarking RDF and Graph technologies. A period of more than one and a half years has led us to the creation of the first two workloads, the Semantic Publishing Benchmark and the Social Network Benchmark in its …
+ +Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate …
+ +As explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 [1].
+One of the most …
+ +In a previous blog post titled “Is SNB like Facebook’s LinkBench?”, Peter Boncz discusses the design philosophy that shapes SNB and how it compares to other existing benchmarks such as LinkBench. In this post, I will briefly introduce the essential parts forming SNB, which are DATAGEN, the LDBC execution driver and the workloads.
+DATAGEN is the data generator used by all the workloads of SNB. Here we introduced the …
+ +The LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.
+The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.
+This …
+ +
+
+
+ In this post, I will discuss in some detail the rationale and goals of the design of the Social Network Benchmark (SNB) and explain how it relates to real …
+ +Synopsis: Now is the time to finalize the interactive part of the Social Network Benchmark (SNB). The benchmark must be both credible in a real social network setting and pose new challenges. There are many hard queries but not enough representation for what online systems in fact do. So, the workload mix must strike a balance between the practice and presenting new challenges.
+It is about to be showtime for LDBC. The initial installment of the …
+ +In previous posts (this and this) we briefly introduced the design goals and philosophy behind DATAGEN, the data generator used in LDBC-SNB. In this post, I will explain how to use DATAGEN to generate the necessary datatsets to run LDBC-SNB. Of course, as DATAGEN is continuously under development, the instructions given in this tutorial might change in the future.
+DATAGEN runs on top of hadoop 1.2.1 to be scale. …
+ +Note: consider this post as a continuation of the “Making it interactive” post by Orri Erling.
+I have now completed the Virtuoso TPC-H work, including scale out. Optimization possibilities extend to infinity but the present level is good enough. TPC-H is the classic of all analytics benchmarks and is difficult enough, I have extensive commentary on this on my blog (In Hoc Signo Vinces series), including experimental results. This is, …
+ +During the past six months we (the OWLIM Team at Ontotext) have integrated the LDBC Semantic Publishing Benchmark (LDBC-SPB) as a part of our development and release process.
+First thing we’ve started using the LDBC-SPB for is to monitor the performance of our RDF Store when a new release is about to come out.
+Initially we’ve decided to fix some of the benchmark parameters :
+ block within , so we wish to replace parent node.
+ [].push.apply(mermaids, document.getElementsByClassName('language-mermaid'));
+ for (let i = 0; i < mermaids.length; i++) {
+ // Convert
block to and add `mermaid` class so that Mermaid will parse it.
+ let mermaidCodeElement = mermaids[i];
+ let newElement = document.createElement('div');
+ newElement.innerHTML = mermaidCodeElement.innerHTML;
+ newElement.classList.add('mermaid');
+ if (render) {
+ window.mermaid.mermaidAPI.render(`mermaid-${i}`, newElement.textContent, function (svgCode) {
+ newElement.innerHTML = svgCode;
+ });
+ }
+ mermaidCodeElement.parentNode.replaceWith(newElement);
+ }
+ console.debug(`Processed ${mermaids.length} Mermaid code blocks`);
+}
+
+/**
+ * @param {Element} parent
+ * @param {Element} child
+ */
+function scrollParentToChild(parent, child) {
+ // Where is the parent on the page?
+ const parentRect = parent.getBoundingClientRect();
+
+ // What can the client see?
+ const parentViewableArea = {
+ height: parent.clientHeight,
+ width: parent.clientWidth,
+ };
+
+ // Where is the child?
+ const childRect = child.getBoundingClientRect();
+
+ // Is the child in view?
+ const isChildInView =
+ childRect.top >= parentRect.top && childRect.bottom <= parentRect.top + parentViewableArea.height;
+
+ // If the child isn't in view, attempt to scroll the parent to it.
+ if (!isChildInView) {
+ // Scroll by offset relative to parent.
+ parent.scrollTop = childRect.top + parent.scrollTop - parentRect.top;
+ }
+}
+
+export {fixMermaid, scrollParentToChild};
diff --git a/js/wowchemy.js b/js/wowchemy.js
new file mode 100644
index 00000000..2a4bb3a7
--- /dev/null
+++ b/js/wowchemy.js
@@ -0,0 +1,345 @@
+
+/*************************************************
+ * Wowchemy
+ * https://github.com/wowchemy/wowchemy-hugo-modules
+ *
+ * Core JS functions and initialization.
+ **************************************************/
+
+// Stripped-down version, only kept filtering
+
+/* ---------------------------------------------------------------------------
+ * Filter publications.
+ * --------------------------------------------------------------------------- */
+
+// Active publication filters.
+let pubFilters = {};
+
+// Search term.
+let searchRegex;
+
+// Filter values (concatenated).
+let filterValues;
+
+// Publication container.
+let $grid_pubs = $('#container-publications');
+
+// Initialise Isotope publication layout if required.
+if ($grid_pubs.length) {
+ $grid_pubs.isotope({
+ itemSelector: '.isotope-item',
+ percentPosition: true,
+ masonry: {
+ // Use Bootstrap compatible grid layout.
+ columnWidth: '.grid-sizer',
+ },
+ filter: function () {
+ let $this = $(this);
+ let searchResults = searchRegex ? $this.text().match(searchRegex) : true;
+ let filterResults = filterValues ? $this.is(filterValues) : true;
+ return searchResults && filterResults;
+ },
+ });
+
+ // Filter by search term.
+ let $quickSearch = $('.filter-search').keyup(
+ debounce(function () {
+ searchRegex = new RegExp($quickSearch.val(), 'gi');
+ $grid_pubs.isotope();
+ }),
+ );
+
+ $('.pub-filters').on('change', function () {
+ let $this = $(this);
+
+ // Get group key.
+ let filterGroup = $this[0].getAttribute('data-filter-group');
+
+ // Set filter for group.
+ pubFilters[filterGroup] = this.value;
+
+ // Combine filters.
+ filterValues = concatValues(pubFilters);
+
+ // Activate filters.
+ $grid_pubs.isotope();
+
+ // If filtering by publication type, update the URL hash to enable direct linking to results.
+ if (filterGroup === 'pubtype') {
+ // Set hash URL to current filter.
+ let url = $(this).val();
+ if (url.substr(0, 9) === '.pubtype-') {
+ window.location.hash = url.substr(9);
+ } else {
+ window.location.hash = '';
+ }
+ }
+ });
+}
+
+// Debounce input to prevent spamming filter requests.
+function debounce(fn, threshold) {
+ let timeout;
+ threshold = threshold || 100;
+ return function debounced() {
+ clearTimeout(timeout);
+ let args = arguments;
+ let _this = this;
+
+ function delayed() {
+ fn.apply(_this, args);
+ }
+
+ timeout = setTimeout(delayed, threshold);
+ };
+}
+
+// Flatten object by concatenating values.
+function concatValues(obj) {
+ let value = '';
+ for (let prop in obj) {
+ value += obj[prop];
+ }
+ return value;
+}
+
+// Filter publications according to hash in URL.
+function filter_publications() {
+ // Check for Isotope publication layout.
+ if (!$grid_pubs.length) return;
+
+ let urlHash = window.location.hash.replace('#', '');
+ let filterValue = '*';
+
+ // Check if hash is numeric.
+ if (urlHash != '' && !isNaN(urlHash)) {
+ filterValue = '.pubtype-' + urlHash;
+ }
+
+ // Set filter.
+ let filterGroup = 'pubtype';
+ pubFilters[filterGroup] = filterValue;
+ filterValues = concatValues(pubFilters);
+
+ // Activate filters.
+ $grid_pubs.isotope();
+
+ // Set selected option.
+ $('.pubtype-select').val(filterValue);
+}
+
+/* ---------------------------------------------------------------------------
+ * On window loaded.
+ * --------------------------------------------------------------------------- */
+
+$(window).on('load', function () {
+ // Re-initialize Scrollspy with dynamic navbar height offset.
+ fixScrollspy();
+
+ // Detect instances of the Portfolio widget.
+ let isotopeInstances = document.querySelectorAll('.projects-container');
+ let isotopeInstancesCount = isotopeInstances.length;
+
+ // Fix ScrollSpy highlighting previous Book page ToC link for some anchors.
+ // Check if isotopeInstancesCount>0 as that case performs its own scrollToAnchor.
+ if (window.location.hash && isotopeInstancesCount === 0) {
+ scrollToAnchor(decodeURIComponent(window.location.hash), 0);
+ }
+
+ // Scroll Book page's active ToC sidebar link into view.
+ // Action after calling scrollToAnchor to fix Scrollspy highlighting otherwise wrong link may have active class.
+ let child = document.querySelector('.docs-toc .nav-link.active');
+ let parent = document.querySelector('.docs-toc');
+ if (child && parent) {
+ scrollParentToChild(parent, child);
+ }
+
+ // Enable images to be zoomed.
+ let zoomOptions = {};
+ if (document.body.classList.contains('dark')) {
+ zoomOptions.background = 'rgba(0,0,0,0.9)';
+ } else {
+ zoomOptions.background = 'rgba(255,255,255,0.9)';
+ }
+ // mediumZoom('[data-zoomable]', zoomOptions);
+
+ // Init Isotope Layout Engine for instances of the Portfolio widget.
+ let isotopeCounter = 0;
+ isotopeInstances.forEach(function (isotopeInstance, index) {
+ console.debug(`Loading Isotope instance ${index}`);
+
+ // Isotope instance
+ let iso;
+
+ // Get the layout for this Isotope instance
+ let isoSection = isotopeInstance.closest('section');
+ let layout = '';
+ if (isoSection.querySelector('.isotope').classList.contains('js-layout-row')) {
+ layout = 'fitRows';
+ } else {
+ layout = 'masonry';
+ }
+
+ // Get default filter (if any) for this instance
+ let defaultFilter = isoSection.querySelector('.default-project-filter');
+ let filterText = '*';
+ if (defaultFilter !== null) {
+ filterText = defaultFilter.textContent;
+ }
+ console.debug(`Default Isotope filter: ${filterText}`);
+
+ // Init Isotope instance once its images have loaded.
+ imagesLoaded(isotopeInstance, function () {
+ iso = new Isotope(isotopeInstance, {
+ itemSelector: '.isotope-item',
+ layoutMode: layout,
+ masonry: {
+ gutter: 20,
+ },
+ filter: filterText,
+ });
+
+ // Filter Isotope items when a toolbar filter button is clicked.
+ let isoFilterButtons = isoSection.querySelectorAll('.project-filters a');
+ isoFilterButtons.forEach((button) =>
+ button.addEventListener('click', (e) => {
+ e.preventDefault();
+ let selector = button.getAttribute('data-filter');
+
+ // Apply filter
+ console.debug(`Updating Isotope filter to ${selector}`);
+ iso.arrange({filter: selector});
+
+ // Update active toolbar filter button
+ button.classList.remove('active');
+ button.classList.add('active');
+ let buttonSiblings = getSiblings(button);
+ buttonSiblings.forEach((buttonSibling) => {
+ buttonSibling.classList.remove('active');
+ buttonSibling.classList.remove('all');
+ });
+ }),
+ );
+
+ // Check if all Isotope instances have loaded.
+ incrementIsotopeCounter();
+ });
+ });
+
+ // Hook to perform actions once all Isotope instances have loaded.
+ function incrementIsotopeCounter() {
+ isotopeCounter++;
+ if (isotopeCounter === isotopeInstancesCount) {
+ console.debug(`All Portfolio Isotope instances loaded.`);
+ // Once all Isotope instances and their images have loaded, scroll to hash (if set).
+ // Prevents scrolling to the wrong location due to the dynamic height of Isotope instances.
+ // Each Isotope instance height is affected by applying filters and loading images.
+ // Without this logic, the scroll location can appear correct, but actually a few pixels out and hence Scrollspy
+ // can highlight the wrong nav link.
+ if (window.location.hash) {
+ scrollToAnchor(decodeURIComponent(window.location.hash), 0);
+ }
+ }
+ }
+
+ // Enable publication filter for publication index page.
+ if ($('.pub-filters-select')) {
+ filter_publications();
+ // Useful for changing hash manually (e.g. in development):
+ // window.addEventListener('hashchange', filter_publications, false);
+ }
+
+ // Load citation modal on 'Cite' click.
+ $('.js-cite-modal').click(function (e) {
+ e.preventDefault();
+ let filename = $(this).attr('data-filename');
+ let modal = $('#modal');
+ modal.find('.modal-body code').load(filename, function (response, status, xhr) {
+ if (status == 'error') {
+ let msg = 'Error: ';
+ $('#modal-error').html(msg + xhr.status + ' ' + xhr.statusText);
+ } else {
+ $('.js-download-cite').attr('href', filename);
+ }
+ });
+ modal.modal('show');
+ });
+
+ // Copy citation text on 'Copy' click.
+ $('.js-copy-cite').click(function (e) {
+ e.preventDefault();
+ // Get selection.
+ let range = document.createRange();
+ let code_node = document.querySelector('#modal .modal-body');
+ range.selectNode(code_node);
+ window.getSelection().addRange(range);
+ try {
+ // Execute the copy command.
+ document.execCommand('copy');
+ } catch (e) {
+ console.log('Error: citation copy failed.');
+ }
+ // Remove selection.
+ window.getSelection().removeRange(range);
+ });
+
+ // Initialise Google Maps if necessary.
+ // initMap();
+
+ // Print latest version of GitHub projects.
+ // // let githubReleaseSelector = '.js-github-release';
+ // // if ($(githubReleaseSelector).length > 0) {
+ // // printLatestRelease(githubReleaseSelector, $(githubReleaseSelector).data('repo'));
+ // // }
+
+ // // Parse Wowchemy keyboard shortcuts.
+ // document.addEventListener('keyup', (event) => {
+ // if (event.code === 'Escape') {
+ // const body = document.body;
+ // if (body.classList.contains('searching')) {
+ // // Close search dialog.
+ // toggleSearchDialog();
+ // }
+ // }
+ // // Use `key` to check for slash. Otherwise, with `code` we need to check for modifiers.
+ // if (event.key === '/') {
+ // let focusedElement =
+ // (document.hasFocus() &&
+ // document.activeElement !== document.body &&
+ // document.activeElement !== document.documentElement &&
+ // document.activeElement) ||
+ // null;
+ // let isInputFocused = focusedElement instanceof HTMLInputElement || focusedElement instanceof HTMLTextAreaElement;
+ // if (searchEnabled && !isInputFocused) {
+ // // Open search dialog.
+ // event.preventDefault();
+ // toggleSearchDialog();
+ // }
+ // }
+ // });
+
+ // // Search event handler
+ // // Check that built-in search or Algolia enabled.
+ // if (searchEnabled) {
+ // // On search icon click toggle search dialog.
+ // $('.js-search').click(function (e) {
+ // e.preventDefault();
+ // toggleSearchDialog();
+ // });
+ // }
+
+ // Init. author notes (tooltips).
+ $('[data-toggle="tooltip"]').tooltip();
+});
+
+
+// Make Scrollspy responsive.
+function fixScrollspy() {
+ let $body = $('body');
+ let data = $body.data('bs.scrollspy');
+ if (data) {
+ data._config.offset = getNavBarHeight();
+ $body.data('bs.scrollspy', data);
+ $body.scrollspy('refresh');
+ }
+}
diff --git a/ldbc-graphalytics-0/index.html b/ldbc-graphalytics-0/index.html
new file mode 100644
index 00000000..66b5ac71
--- /dev/null
+++ b/ldbc-graphalytics-0/index.html
@@ -0,0 +1,10 @@
+
+
+
+ https://ldbcouncil.org/benchmarks/graphalytics/
+
+
+
+
+
+
diff --git a/leadership/index.html b/leadership/index.html
new file mode 100644
index 00000000..e8ef8318
--- /dev/null
+++ b/leadership/index.html
@@ -0,0 +1,397 @@
+
+
+
+
+ Leadership
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Board of Directors
+ Contact: info AT ldbcouncil DOT org
+
+
+
+ Administation and Task Forces
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/licensing/LICENSE.txt b/licensing/LICENSE.txt
new file mode 100644
index 00000000..75b52484
--- /dev/null
+++ b/licensing/LICENSE.txt
@@ -0,0 +1,202 @@
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/licensing/NOTICE.txt b/licensing/NOTICE.txt
new file mode 100644
index 00000000..d2fbb4a6
--- /dev/null
+++ b/licensing/NOTICE.txt
@@ -0,0 +1,13 @@
+ Copyright [2020-]2022 Linked Data Benchmark Council
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
\ No newline at end of file
diff --git a/licensing/ldbc-data-set-license.txt b/licensing/ldbc-data-set-license.txt
new file mode 100644
index 00000000..6da393e7
--- /dev/null
+++ b/licensing/ldbc-data-set-license.txt
@@ -0,0 +1,5 @@
+# LDBC Data set license (2022/03/15)
+
+LDBC BENCHMARK is a registered trademark of Linked Data Benchmark Council (LDBC). LDBC wishes to avoid mistaken or false claims that performance test results are LDBC benchmark test results. We are working on developing a policy on fair use of the term "LDBC benchmark" when reporting performance test results, backed up by the grant of trademark licences, or a commitment not to pursue those who follow our fair use policies for trademark infringement.
+
+In the interim, you are not licensed to refer to any presentation of the results of running benchmark tests using these data sets using the words "LDBC benchmark" or anything that is likely to be reasonably construed as being equivalent in meaning to the words "LDBC benchmark". However, if you contact LDBC at info@ldbcouncil.org then we will discuss with you a form of words to describe or characterize any test results you produce in a way that accurately states the relationship of any report, presentation or other publication of those results to LBDC benchmark results, and which will avoid the possibility of you infringing our trademark inadvertently.
diff --git a/organizational-members/index.html b/organizational-members/index.html
new file mode 100644
index 00000000..b4671dc9
--- /dev/null
+++ b/organizational-members/index.html
@@ -0,0 +1,560 @@
+
+
+
+
+ Organizational Members
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Sponsor companies
+
+
+
+
+
+
+  +
+
+ Oracle Labs
+
+
+
+
+
+
+
+
+
+ Oracle Labs
+
+
+
+
+
+
+ Companies
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Non-commercial institutes
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/index.html b/pages/index.html
new file mode 100644
index 00000000..0c9d8ae0
--- /dev/null
+++ b/pages/index.html
@@ -0,0 +1,777 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Posts
+ Tags:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Record-Breaking SNB Interactive Results for GraphScope
+ Tags:
+ BENCHMARK
+ , SNB
+
+
+
+
+ We are happy to annonunce new audited results for the SNB Interactive workload, achieved by the open-source GraphScope Flex system.
+The current audit of the system has broken several records:
+
+- It achieved 130.1k ops/s on scale factor 100, compared to the previous record of 48.8k ops/s.
+- It achieved 131.3k ops/s on scale factor 300, compared to the previous record of 48.3k ops/s.
+- It is the first system to successfully complete the benchmark on …
+
+
+
+
+
+
+
+
+
+
+
+ Launching open-source language tools for ISO/IEC GQL
+ Tags:
+ GQL
+
+
+
+
+ Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and tests for the GQL language. See this announcement from Alastair Green, Vice-chair of LDBC.
+These tools are the work of the LDBC GQL Implementation Working Group, headed up by Michael Burbidge. Damian Wileński and Dominik Tomaszuk have worked …
+
+
+
+
+
+
+
+
+
+
+
+ Announcing the Official Release of LDBC Financial Benchmark v0.1.0
+ Tags:
+ FINBENCH
+
+
+
+
+ We are delighted to announce the official release of the initial version (v0.1.0) of Financial Benchmark (FinBench).
+The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as anti-fraud and risk control. It is maintained by the LDBC FinBench Task Force. The benchmark has one workload currently, Transaction Workload, capturing OLTP scenario with complex read queries that access the …
+
+
+
+
+
+
+
+
+
+
+
+ LDBC SNB – Early 2023 updates
+ Tags:
+ DATAGEN
+ , SNB
+
+
+
+
+ 2023 has been an eventful year for us so far. Here is a summary of our recent activities.
+
+-
+
Our paper The LDBC Social Network Benchmark: Business Intelligence Workload was published in PVLDB.
+
+-
+
David Püroja just completed his MSc thesis on creating a design towards SNB Interactive v2 at CWI’s Database Architectures group. David and I gave a deep-dive talk at the FOSDEM conference’s graph developer room titled The LDBC Social Network …
+
+
+
+
+
+
+
+
+
+
+
+ LDBC SNB Datagen – The winding path to SF100K
+ Tags:
+ DATAGEN
+ , SNB
+
+
+
+
+ LDBC SNB provides a data generator, which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. More than two years have elapsed since my last technical update on LDBC SNB Datagen, in which I discussed the reasons for moving the code to Apache Spark from the MapReduce-based Apache Hadoop implementation and the …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/index.xml b/pages/index.xml
new file mode 100644
index 00000000..bc7b14ac
--- /dev/null
+++ b/pages/index.xml
@@ -0,0 +1,5468 @@
+
+
+
+ Pages on Linked Data Benchmark Council
+ https://ldbcouncil.org/pages/
+ Recent content in Pages on Linked Data Benchmark Council
+ Hugo -- gohugo.io
+ en-us
+ © Copyright LDBC 2024
+ Fri, 03 May 2024 00:00:00 +0000 -
+
Eighteenth TUC Meeting
+ https://ldbcouncil.org/event/eighteenth-tuc-meeting/
+ Fri, 30 Aug 2024 09:00:00 -0800
+
+ https://ldbcouncil.org/event/eighteenth-tuc-meeting/
+ <p><strong>Organizers:</strong> Shipeng Qi (AntGroup), Wenyuan Yu (Alibaba Demo), Yan Zhou (CreateLink)</p>
+<p>LDBC is hosting a <strong>two-day</strong> hybrid workshop, co-located in <strong>Guangzhou</strong> with <a href="https://vldb.org/2024/">VLDB 2024</a> on <strong>August 30-31 (Friday-Saturday)</strong>.</p>
+<p>The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. <strong>If you would like to participate please register using <a href="https://forms.gle/aVPrrcxXpSwrWPnh6">our form</a>.</strong></p>
+<h3 id="program">Program</h3>
+<p><strong>All times are in PDT.</strong></p>
+<h4 id="august-30-friday">August 30, Friday</h4>
+<p><strong>Location:</strong> <a href="https://www.langhamhotels.com/en/the-langham/guangzhou/">Langham Place</a>, Guangzhou, <strong>room 1</strong>,<br>
+co-located with VLDB (N0.630-638 Xingang Dong Road, Haizhu District, Guangzhou, China). See the map <a href="https://maps.app.goo.gl/86jD3Dy9Aa7bwLs36">here</a>.</p>
+<p><strong>Agenda:</strong> TBA</p>
+<h4 id="august-31-saturday">August 31, Saturday</h4>
+<p><strong>Location:</strong> Alibaba Center, Guangzhou (N0.88 Dingxin Road, Haizhu District, Guangzhou, China), near to VLDB Langham Place. See the map <a href="https://maps.app.goo.gl/HgEVafZMRmrzUsgW8">here</a>.</p>
+<p><strong>Agenda:</strong> TBA</p>
+<h4 id="tuc-event-locations">TUC event locations</h4>
+<p>A <a href="https://www.google.com/maps/d/u/0/edit?mid=19_fi4fV-3-PZkNWCCcmhU86ct2EZXbgo">map of the LDBC TUC events</a> we hosted so far.</p>
+
+
+
+ -
+
Seventeenth TUC Meeting
+ https://ldbcouncil.org/event/seventeenth-tuc-meeting/
+ Sun, 09 Jun 2024 09:00:00 -0400
+
+ https://ldbcouncil.org/event/seventeenth-tuc-meeting/
+ <p><strong>Organizers:</strong> Renzo Angles, Sebastián Ferrada</p>
+<p>LDBC is hosting a one-day in-person workshop, co-located in <strong>Santiago de Chile</strong> with <a href="https://2024.sigmod.org/venue.shtml">SIGMOD 2024</a> on <strong>June 9 (Sunday)</strong>.</p>
+<p>The workshop will be held in the <strong>Hotel Plaza El Bosque Ebro</strong> (<a href="https://www.plazaelbosque.cl">https://www.plazaelbosque.cl</a>), which is two blocks away from SIGMOD’s venue. See the map <a href="https://maps.app.goo.gl/78oiw3zo2pH3gy5R6">here</a>.</p>
+<p><strong>If you would like to participate please register using <a href="https://forms.gle/XXgaQfwBZAMMZJb78">this form</a>.</strong></p>
+<h3 id="program">Program</h3>
+<p><strong>All times are in Chile time (GMT-4).</strong></p>
+<p><strong>Each speaker will have 20 minutes for exposition plus 5 minutes for questions.</strong></p>
+<table>
+<thead>
+<tr>
+<th>Time</th>
+<th>Speaker</th>
+<th>Title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>09:00</td>
+<td>Welcome</td>
+<td>“Canelo” saloon</td>
+</tr>
+<tr>
+<td>09:30</td>
+<td>Alastair Green (LDBC Vice-chair)</td>
+<td>Status of the LDBC Extended GQL Schema Working Group</td>
+</tr>
+<tr>
+<td>10:00</td>
+<td>Hannes Voigt (Neo4j)</td>
+<td>Inside the Standardization Machine Room: How ISO/IEC 39075:2024 – GQL was produced</td>
+</tr>
+<tr>
+<td>10:30</td>
+<td>Calin Iorgulescu (Oracle)</td>
+<td>PGX.D: Distributed graph processing engine</td>
+</tr>
+<tr>
+<td>11:00</td>
+<td>Coffee break</td>
+<td></td>
+</tr>
+<tr>
+<td>11:30</td>
+<td>Ricky Sun (Ultipa, Inc.)</td>
+<td>A Unified Graph Framework with SCC (Storage-Compute Coupled) and HDC (High-Density Computing) Clustering</td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>Daan de Graaf (TU Eindhoven)</td>
+<td>Algorithm Support in a Graph Database, Done Right</td>
+</tr>
+<tr>
+<td>12:30</td>
+<td>Angela Bonifati (Lyon 1 University and IUF, France)</td>
+<td>Transforming Property Graphs</td>
+</tr>
+<tr>
+<td>13:00</td>
+<td>Brunch</td>
+<td></td>
+</tr>
+<tr>
+<td>14:00</td>
+<td>Juan Sequeda (data.world)</td>
+<td>A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases</td>
+</tr>
+<tr>
+<td>14:30</td>
+<td>Olaf Hartig (Linköping University)</td>
+<td>FedShop: A Benchmark for Testing the Scalability of SPARQL Federation Engines</td>
+</tr>
+<tr>
+<td>15:00</td>
+<td>Olaf Hartig (Amazon)</td>
+<td>Datatypes for Lists and Maps in RDF Literals</td>
+</tr>
+<tr>
+<td>15:30</td>
+<td>Peter Boncz (CWI and MotherDuck)</td>
+<td>The state of DuckPGQ</td>
+</tr>
+<tr>
+<td>16:00</td>
+<td>Coffee break</td>
+<td></td>
+</tr>
+<tr>
+<td>16:30</td>
+<td>Juan Reutter (IMFD and PUC Chile)</td>
+<td>MillenniumDB: A Persistent, Open-Source, Graph Database</td>
+</tr>
+<tr>
+<td>17:00</td>
+<td>Carlos Rojas (IMFD)</td>
+<td>WDBench: A Wikidata Graph Query Benchmark</td>
+</tr>
+<tr>
+<td>17:30</td>
+<td>Sebastián Ferrada (IMFD and Univ. de Chile)</td>
+<td>An algebra for evaluating path queries</td>
+</tr>
+<tr>
+<td>19:30</td>
+<td>Dinner</td>
+<td></td>
+</tr>
+</tbody>
+</table>
+
+
+
+ -
+
Record-Breaking SNB Interactive Results for GraphScope
+ https://ldbcouncil.org/post/record-breaking-snb-interactive-results-for-graphscope/
+ Sun, 26 May 2024 00:00:00 +0000
+
+ https://ldbcouncil.org/post/record-breaking-snb-interactive-results-for-graphscope/
+ <p>We are happy to annonunce new <a href="https://ldbcouncil.org/benchmarks/snb-interactive/">audited results for the SNB Interactive workload</a>, achieved by the open-source <a href="https://github.com/alibaba/GraphScope">GraphScope Flex</a> system.</p>
+<p>The current audit of the system has broken several records:</p>
+<ul>
+<li>It achieved 130.1k ops/s on scale factor 100, compared to the previous record of 48.8k ops/s.</li>
+<li>It achieved 131.3k ops/s on scale factor 300, compared to the previous record of 48.3k ops/s.</li>
+<li>It is the first system to successfully complete the benchmark on scale factor 1000. It achieved a throughput of 127.8k ops/s</li>
+</ul>
+<p>The audit was commissioned by the <a href="https://www.alibabacloud.com/">Alibaba Cloud</a> and was conducted by <a href="https://www.linkedin.com/in/arnau-prat-a70283bb/">Dr. Arnau Prat-Pérez</a>, one of the original authors of the SNB Interactive benchmark. The queries were implemented as C++ stored procedures and the benchmark was executed on the Alibaba Cloud’s infrastructure. The <a href="https://ldbcouncil.org/benchmarks/snb/LDBC_SNB_I_20240514_SF100-300-1000_graphscope-executive_summary.pdf">executive summary</a>, <a href="https://ldbcouncil.org/benchmarks/snb/LDBC_SNB_I_20240514_SF100-300-1000_graphscope.pdf">full disclosure report</a>, and <a href="%5B/benchmarks/snb/%5D(https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/audits/LDBC_SNB_I_20240514_SF100-300-1000_graphscope-attachments.tar.gz)">supplementary package</a> describe the benchmark’s steps and include instructions for reproduction.</p>
+<p>LDBC would like to congratulate the GraphScope Flex team on their record-breaking results.</p>
+<div align="center"><img src="https://ldbcouncil.org/images/graphscope.svg" width="200"></div>
+
+
+
+ -
+
Launching open-source language tools for ISO/IEC GQL
+ https://ldbcouncil.org/post/ldbc-announces-open-source-gql-tools/
+ Thu, 09 May 2024 00:00:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-announces-open-source-gql-tools/
+ <p>Following the publication of ISO/IEC GQL (graph query language) in April 2024, LDBC today launches open-source language engineering tools to help implementers, and assist in generation of code examples and tests for the GQL language. See this <a href="https://ldbcouncil.org/pages/opengql-announce">announcement from Alastair Green, Vice-chair of LDBC</a>.</p>
+<p>These tools are the work of the <strong>LDBC GQL Implementation Working Group</strong>, headed up by Michael Burbidge. Damian Wileński and Dominik Tomaszuk have worked with Michael to create these artefacts based on his ANTLR grammar for GQL.</p>
+
+
+
+ -
+
Announcing the Official Release of LDBC Financial Benchmark v0.1.0
+ https://ldbcouncil.org/post/announcing-the-official-release-of-ldbc-financial-benchmark/
+ Tue, 27 Jun 2023 00:00:00 +0000
+
+ https://ldbcouncil.org/post/announcing-the-official-release-of-ldbc-financial-benchmark/
+ <p>We are delighted to announce the official release of the initial version (v0.1.0) of <a href="https://ldbcouncil.org/benchmarks/finbench/">Financial Benchmark (FinBench)</a>.</p>
+<p>The Financial Benchmark (FinBench) project defines a graph database benchmark targeting financial scenarios such as anti-fraud and risk control. It is maintained by the <a href="https://ldbcouncil.org/benchmarks/finbench/ldbc-finbench-work-charter.pdf">LDBC FinBench Task Force</a>. The benchmark has one workload currently, <strong>Transaction Workload</strong>, capturing OLTP scenario with complex read queries that access the neighbourhood of a given node in the graph and write queries that continuously insert or delete data in the graph.</p>
+<p>Compared to LDBC SNB, the FinBench differs in application scenarios, data patterns, and workloads, resulting in different schema characteristics, latency bounds, path filters, etc. For a brief overview, see the <a href="https://ldbcouncil.org/benchmarks/finbench/finbench-talk-16th-tuc.pdf">slides</a> in the 16th TUC. The <a href="https://arxiv.org/pdf/2306.15975.pdf">Financial Benchmark’s specification</a> can be found on arXiv.</p>
+<p>The release of FinBench initial version (v0.1.0) was approved by LDBC on June 23, 2023. It is the good beginning of FinBench. In the future, the FinBench Task Force will polish the benchmark continuously.</p>
+<p>If you are interested in joining FinBench Task Force, please reach out at info at ldbcouncil.org or qishipeng.qsp at antgroup.com.</p>
+
+
+
+ -
+
Sixteenth TUC Meeting
+ https://ldbcouncil.org/event/sixteenth-tuc-meeting/
+ Fri, 23 Jun 2023 09:00:00 -0800
+
+ https://ldbcouncil.org/event/sixteenth-tuc-meeting/
+ <p><strong>Organizers:</strong> Oskar van Rest, Alastair Green, Gábor Szárnyas</p>
+<p>LDBC is hosting a <strong>two-day</strong> hybrid workshop, co-located with <a href="https://2023.sigmod.org/venue.shtml">SIGMOD 2023</a> on <strong>June 23-24 (Friday-Saturday)</strong>.</p>
+<p>The program consists of 10- and 15-minute talks followed by a Q&A session. The talks will be recorded and made available online. <strong>If you would like to participate please register using <a href="https://forms.gle/T6bwVHzK9V5FaKyR9">our form</a>.</strong></p>
+<p>LDBC will host a <strong>social event</strong> on Friday at the <a href="https://www.blackbottleseattle.com/">Black Bottle gastrotavern</a> in Belltown: <a href="https://goo.gl/maps/hQzBRR2nerZEQExw7">2600 1st Ave (on the corner of Vine), Seattle, WA 98121</a>.</p>
+<p>In addition, AWS will host a <strong>Happy Hour</strong> (rooftop grill with beverages) on Saturday on the Amazon Nitro South building’s 8th floor deck: <a href="https://goo.gl/maps/md5kWUHaNUGhR9JB7">2205 8th Ave, Seattle, WA 98121</a>.</p>
+<h3 id="program">Program</h3>
+<p><strong>All times are in PDT.</strong></p>
+<h4 id="friday">Friday</h4>
+<p><strong>Location:</strong> Hyatt Regency Bellevue on Seattle’s Eastside, <strong>room Grand K</strong>, co-located with SIGMOD (<a href="https://www.hyatt.com/en-US/hotel/washington/hyatt-regency-bellevue-on-seattles-eastside/belle">900 Bellevue Way NE, Bellevue, WA 98004-4272</a>)</p>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>finish</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>08:30</td>
+<td>08:45</td>
+<td>Oskar van Rest (Oracle)</td>
+<td>LDBC – State of the union – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/oskar-van-rest-ldbc-state-of-the-union.pdf">slides</a>, <a href="https://youtu.be/Frk7ITssaSY">video</a></td>
+</tr>
+<tr>
+<td>08:50</td>
+<td>09:05</td>
+<td>Keith Hare (JCC / WG3)</td>
+<td>An update on the GQL & SQL/PGQ standards efforts – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/keith-hare-an-update-on-the-gql-and-sql-pgq-standards-efforts.pdf">slides</a>, <a href="https://youtu.be/LQYkal_0j6E">video</a></td>
+</tr>
+<tr>
+<td>09:10</td>
+<td>09:25</td>
+<td>Stefan Plantikow (Neo4j / WG3)</td>
+<td>GQL - Introduction to a new query language standard – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/stefan-plantikow-gql-v1.pdf">slides</a></td>
+</tr>
+<tr>
+<td>09:30</td>
+<td>09:45</td>
+<td>Leonid Libkin (University of Edinburgh & RelationalAI)</td>
+<td>Formalizing GQL – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/leonid-libkin-formalizing-gql.pdf">slides</a>, <a href="https://youtu.be/YZE1a00h1I4">video</a></td>
+</tr>
+<tr>
+<td>09:50</td>
+<td>10:05</td>
+<td>Semen Panenkov (JetBrains Research)</td>
+<td>Mechanizing the GQL semantics in Coq – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/semyon-panenkov-gql-in-coq.pdf">slides</a>, <a href="https://youtu.be/5xBGohqWCzo">videos</a></td>
+</tr>
+<tr>
+<td>10:10</td>
+<td>10:25</td>
+<td>Oskar van Rest (Oracle)</td>
+<td>SQL Property Graphs in Oracle Database and Oracle Graph Server (PGX) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/oskar-van-rest-sql-property-graphs-in-oracle-database-and-oracle-graph-server-pgx.pdf">slides</a>, <a href="https://youtu.be/owM9WiQubpg">video</a></td>
+</tr>
+<tr>
+<td>10:30</td>
+<td>11:00</td>
+<td><em>coffee break</em></td>
+<td></td>
+</tr>
+<tr>
+<td>11:00</td>
+<td>11:15</td>
+<td>Alastair Green (JCC)</td>
+<td>LDBC’s organizational changes and fair use policies – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/alastair-green-ldbc-corporate-restructuring-and-fair-use-policies.pdf">slides</a></td>
+</tr>
+<tr>
+<td>11:20</td>
+<td>11:35</td>
+<td>Ioana Manolescu (INRIA)</td>
+<td>Integrating Connection Search in Graph Queries – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/ioana-manolescu-integrating-connection-search-in-graph-queries.pdf">slides</a>, <a href="https://youtu.be/LQPnmcrkUpY">video</a></td>
+</tr>
+<tr>
+<td>11:40</td>
+<td>11:55</td>
+<td>Maciej Besta (ETH Zurich)</td>
+<td>Neural Graph Databases with Graph Neural Networks – <a href="https://youtu.be/ce5qNievRNs">video</a></td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>12:10</td>
+<td>Longbin Lai (Alibaba Damo Academy)</td>
+<td>To Revisit Benchmarking Graph Analytics – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/longbin-lai-benchmark-ldbc.pdf">slides</a>, <a href="https://youtu.be/s9Vtt-6t_FI">video</a></td>
+</tr>
+<tr>
+<td>12:15</td>
+<td>13:30</td>
+<td><em>lunch</em></td>
+<td></td>
+</tr>
+<tr>
+<td>13:30</td>
+<td>13:45</td>
+<td>Yuanyuan Tian (Gray Systems Lab, Microsoft)</td>
+<td>The World of Graph Databases from An Industry Perspective – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/yuanyuan-tian-world-of-graph-databases.pdf">slides</a>, <a href="https://youtu.be/AZuP_b95GPM">video</a></td>
+</tr>
+<tr>
+<td>13:50</td>
+<td>14:05</td>
+<td>Alin Deutsch (UC San Diego & TigerGraph)</td>
+<td>TigerGraph’s Parallel Computation Model – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/alin-deutsch-tigergraphs-computation-model.pdf">slides</a>, <a href="https://youtu.be/vcxdieJB80Y">video</a></td>
+</tr>
+<tr>
+<td>14:10</td>
+<td>14:25</td>
+<td>Chen Zhang (CreateLink)</td>
+<td>Applications of a Native Distributed Graph Database in the Financial Industry – <a href="https://youtu.be/GCCT79Sps9I">video</a></td>
+</tr>
+<tr>
+<td>14:30</td>
+<td>14:45</td>
+<td>Ricky Sun (Ultipa)</td>
+<td>Design of highly scalable graph database systems – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/ricky-sun-ultipa.pdf">slides</a>, <a href="https://youtu.be/Sg1F64O4vGM">video</a></td>
+</tr>
+<tr>
+<td>14:50</td>
+<td>15:30</td>
+<td><em>coffee break</em></td>
+<td></td>
+</tr>
+<tr>
+<td>15:30</td>
+<td>15:45</td>
+<td>Heng Lin (Ant Group)</td>
+<td>The LDBC SNB implementation in TuGraph – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/heng-lin-the-ldbc-snb-implementation-in-tugraph.pdf">slides</a>, <a href="https://youtu.be/fy8AuVerwnY">video</a></td>
+</tr>
+<tr>
+<td>15:50</td>
+<td>16:05</td>
+<td>Shipeng Qi (Ant Group)</td>
+<td>FinBench: The new LDBC benchmark targeting financial scenario – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/shipeng-qi-finbench.pdf">slides</a>, <a href="https://youtu.be/0xLZadDOfZk">video</a></td>
+</tr>
+<tr>
+<td>16:10</td>
+<td>17:00</td>
+<td>host: Heng Lin (Ant Group), panelists: Longbin Lai (Alibaba Damo Academy), Ricky Sun (Ultipa), Gabor Szarnyas (CWI), Yuanyuan Tian (Gray Systems Lab, Microsoft)</td>
+<td>FinBench panel – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/heng-lin-finbench-panel.pdf">slides</a></td>
+</tr>
+<tr>
+<td>19:00</td>
+<td>22:00</td>
+<td><em>dinner</em></td>
+<td><em><a href="https://www.blackbottleseattle.com/">Black Bottle gastrotavern</a> in Belltown: <a href="https://goo.gl/maps/hQzBRR2nerZEQExw7">2600 1st Ave (on the corner of Vine), Seattle, WA 98121</a></em></td>
+</tr>
+</tbody>
+</table>
+<h4 id="saturday">Saturday</h4>
+<p><strong>Location:</strong> Amazon Nitro South building, <strong>room 03.204</strong> (<a href="https://goo.gl/maps/md5kWUHaNUGhR9JB7">2205 8th Ave, Seattle, WA 98121</a>)</p>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>finish</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>09:00</td>
+<td>09:45</td>
+<td>Brad Bebee (AWS)</td>
+<td>Customers don’t want a graph database, so why are we still here? – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/brad-bebee-tuc-keynote.pdf">slides</a>, <a href="https://youtu.be/bJlkpDC--fM">video</a></td>
+</tr>
+<tr>
+<td>10:00</td>
+<td>10:15</td>
+<td>Muhammad Attahir Jibril (TU Ilmenau)</td>
+<td>Fast and Efficient Update Handling for Graph H2TAP – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/muhammad-attahir-jibril-fast-and-efficient-update-handling-for-graph-h2tap.pdf">slides</a>, <a href="https://youtu.be/e8ZAszBsXV0">video</a></td>
+</tr>
+<tr>
+<td>10:20</td>
+<td>11:00</td>
+<td><em>coffee break</em></td>
+<td></td>
+</tr>
+<tr>
+<td>11:00</td>
+<td>11:15</td>
+<td>Gabor Szarnyas (CWI)</td>
+<td>LDBC Social Network Benchmark and Graphalytics – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/gabor-szarnyas-ldbc-social-network-benchmark-and-graphalytics.pdf">slides</a></td>
+</tr>
+<tr>
+<td>11:20</td>
+<td>11:30</td>
+<td>Atanas Kiryakov and Tomas Kovachev (Ontotext)</td>
+<td>GraphDB – Benchmarking against LDBC SNB & SPB – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/tomas-kovatchev-atanas-kiryakov-benchmarking-graphdb-with-snb-and-spb.pdf">slides</a>, <a href="https://youtu.be/U6OPpNFOWqg">video</a></td>
+</tr>
+<tr>
+<td>11:35</td>
+<td>11:50</td>
+<td>Roi Lipman (Redis Labs)</td>
+<td>Delta sparse matrices within RedisGraph – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/roi-lipman-delta-matrix.pdf">slides</a>, <a href="https://youtu.be/qfKsplV4Ihk">video</a></td>
+</tr>
+<tr>
+<td>11:55</td>
+<td>12:05</td>
+<td>Rathijit Sen (Microsoft)</td>
+<td>Microarchitectural Analysis of Graph BI Queries on RDBMS – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/rathijit-sen-microarchitectural-analysis.pdf">slides</a>, <a href="https://youtu.be/55B8CkH09js">video</a></td>
+</tr>
+<tr>
+<td>12:10</td>
+<td>13:30</td>
+<td><em>lunch</em></td>
+<td><em>on your own</em></td>
+</tr>
+<tr>
+<td>13:30</td>
+<td>13:45</td>
+<td>Alastair Green (JCC)</td>
+<td>LEX – LDBC Extended GQL Schema – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/alastair-green-lex.pdf">slides</a>, <a href="https://youtu.be/DVpeb4Ce9Uw">video</a></td>
+</tr>
+<tr>
+<td>13:50</td>
+<td>14:05</td>
+<td>Ora Lassila (AWS)</td>
+<td>Why limit yourself to {RDF, LPG} when you can do {RDF, LPG}, too – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/ora-lassila-why-limit-yourself-to-lpg-when-you-can-do-rdf-too.pdf">slides</a>, <a href="https://youtu.be/7uAInoUwdds">video</a></td>
+</tr>
+<tr>
+<td>14:10</td>
+<td>14:25</td>
+<td>Jan Hidders (Birkbeck, University of London)</td>
+<td>PG-Schema: a proposal for a schema language for property graphs – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/jan-hidders-pg-schema.pdf">slides</a>, <a href="https://youtu.be/yQNL8hBTE4M">video</a></td>
+</tr>
+<tr>
+<td>14:30</td>
+<td>14:45</td>
+<td>Max de Marzi (RageDB and RelationalAI)</td>
+<td>RageDB: Building a Graph Database in Anger – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/max-de-marzi-ragedb-building-a-graph-database-in-anger.pdf">slides</a>, <a href="https://youtu.be/LBbF8aslYFE">video</a></td>
+</tr>
+<tr>
+<td>14:50</td>
+<td>15:30</td>
+<td><em>coffee break</em></td>
+<td></td>
+</tr>
+<tr>
+<td>15:30</td>
+<td>15:45</td>
+<td>Umit Catalyurek (AWS)</td>
+<td>HPC Graph Analytics on the OneGraph Model – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/umit-catalyurek-onegraph-hpc.pdf">slides</a>, <a href="https://youtu.be/64tv5LA6Wr8">video</a></td>
+</tr>
+<tr>
+<td>15:50</td>
+<td>16:05</td>
+<td>David J. Haglin (Trovares)</td>
+<td>How LDBC impacts Trovares – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/david-haglin-trovares.pdf">slides</a>, <a href="">video</a></td>
+</tr>
+<tr>
+<td>16:10</td>
+<td>16:25</td>
+<td>Wenyuan Yu (Alibaba Damo Academy)</td>
+<td>GraphScope Flex: A Graph Computing Stack with LEGO-Like Modularity – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/wenyuan-yu-graphscope-flex.pdf">slides</a>, <a href="https://youtu.be/cRikoyDmMks">video</a></td>
+</tr>
+<tr>
+<td>16:30</td>
+<td>16:40</td>
+<td>Scott McMillan (Carnegie Mellon University)</td>
+<td>Graph processing using GraphBLAS – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/scott-mcmillan-graph-processing-using-graphblas.pdf">slides</a>, <a href="https://youtu.be/yb4hGBhUzQQ">video</a></td>
+</tr>
+<tr>
+<td>16:45</td>
+<td>16:55</td>
+<td>Tim Mattson (Intel)</td>
+<td>Graphs (GraphBLAS) and storage (TileDB) as Sparse Linear algebra – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixteenth-tuc-meeting/attachments/tim-mattson-graphblas-and-tiledb.pdf">slides</a></td>
+</tr>
+<tr>
+<td>17:00</td>
+<td>20:00</td>
+<td><em>happy hour (rooftop grill with beverages)</em></td>
+<td><em>on the Nitro South building’s 8th floor deck</em></td>
+</tr>
+</tbody>
+</table>
+<h4 id="tuc-event-locations">TUC event locations</h4>
+<p>A <a href="https://www.google.com/maps/d/u/0/edit?mid=19_fi4fV-3-PZkNWCCcmhU86ct2EZXbgo">map of the LDBC TUC events</a> we hosted so far.</p>
+
+
+
+ -
+
LDBC SNB – Early 2023 updates
+ https://ldbcouncil.org/post/ldbc-snb-early-2023-updates/
+ Wed, 15 Feb 2023 00:00:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-snb-early-2023-updates/
+ <p>2023 has been an eventful year for us so far. Here is a summary of our recent activities.</p>
+<ol>
+<li>
+<p>Our paper <a href="https://ldbcouncil.org/docs/papers/ldbc-snb-bi-vldb-2022.pdf">The LDBC Social Network Benchmark: Business Intelligence Workload</a> was published in PVLDB.</p>
+</li>
+<li>
+<p>David Püroja just completed his MSc thesis on creating a design towards <a href="https://ldbcouncil.org/docs/papers/msc-thesis-david-puroja-snb-interactive-v2-2023.pdf">SNB Interactive v2</a> at CWI’s Database Architectures group. David and I gave a deep-dive talk at the FOSDEM conference’s graph developer room titled <a href="https://fosdem.org/2023/schedule/event/graph_ldbc/">The LDBC Social Network Benchmark</a> (<a href="https://www.youtube.com/watch?v=YNF6z6gtXY4">YouTube mirror</a>).</p>
+</li>
+<li>
+<p>I gave a lightning talk at FOSDEM’s HPC developer room titled <a href="https://www.youtube.com/watch?v=q26DHnQFw54">The LDBC Benchmark Suite</a> (<a href="https://www.youtube.com/watch?v=q26DHnQFw54">YouTube mirror</a>).</p>
+</li>
+<li>
+<p>Our auditors have successfully benchmark a number of systems:</p>
+<ul>
+<li>SPB with the Ontotext GraphDB systems for the SF3 and SF5 data sets (auditor: Pjotr Scholtze)</li>
+<li>SNB Interactive with the Ontotext GraphDB system for the SF30 data set (auditor: David Püroja)</li>
+<li>SNB Interactive with the TuGraph system running in the Aliyun cloud for the SF30, SF100, and SF300 data sets (auditor: Márton Búr)</li>
+</ul>
+</li>
+</ol>
+<p>The results and the full disclosure reports are available under the <a href="https://ldbcouncil.org/benchmarks/spb/">SPB</a> and <a href="https://ldbcouncil.org/benchmarks/snb/">SNB benchmark pages</a>.</p>
+
+
+
+ -
+
LDBC SNB Datagen – The winding path to SF100K
+ https://ldbcouncil.org/post/ldbc-snb-datagen-the-winding-path-to-sf100k/
+ Tue, 13 Sep 2022 00:00:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-snb-datagen-the-winding-path-to-sf100k/
+ <p>LDBC SNB provides a data generator, which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. More than two years have elapsed since my <a href="https://ldbcouncil.org/post/speeding-up-ldbc-snb-datagen/">last technical update</a> on LDBC SNB Datagen, in which I discussed the reasons for moving the code to Apache Spark from the MapReduce-based Apache Hadoop implementation and the challenges I faced during the migration. Since then, we reached several goals such as we refactored the serializers to use Spark’s high-level writers to support the popular Parquet data format and to enable running on spot nodes; brought back factor generation; implemented support for the novel BI benchmark; and optimized the runtime to generate SF30K on 20 i3.4xlarge machines on AWS.</p>
+<h1 id="moving-to-sparksql">Moving to SparkSQL</h1>
+<p>We planned to move parts of the code to SparkSQL, an optimized runtime framework for tabular data. We hypothesized that this would benefit us on multiple fronts: SparkSQL offers an efficient batch analytics runtime, with higher level abstractions that are simpler to understand and work with, and we could easily add support for serializing to Parquet based on SparkSQL’s capabilites.</p>
+<blockquote>
+<p>Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine. Spark SQL includes a cost-based optimizer, columnar storage, and code generation to make queries fast.</p>
+</blockquote>
+<p>Dealing with the dataset generator proved quite tricky, because it samples from various hand-written distributions and dictionaries, and contains complex domain logic, for which SparkSQL unsuitable. We assessed that the best thing we could do is wrap entire entity generation procedures in UDFs (user defined SQL functions). However, several of these generators return entity trees<sup id="fnref:1"><a href="#fn:1" class="footnote-ref" role="doc-noteref">1</a></sup>, which are spread across multiple tables by the serializer, and these would have needed to be split up. Further complicating matters, we would have also had to find a way to coordinate the inner random generators’ state between the UDFs to ensure deterministic execution. Weighing these and that we could not find much benefit in SparkSQL, we ultimately decided to leave entity generation as it is. We limited the SparkSQL refactor to the following areas:</p>
+<ol>
+<li>table manipulations related to shaping the output into the supported layouts and data types as set forth in the specification;</li>
+<li>deriving the Interactive and BI datasets;</li>
+<li>and generating the factor tables, which contain analytic information, such as population per country, number of friendships between city pairs, number of messages per day, etc., used by the substitution parameter generator to ensure predictable query runtimes.</li>
+</ol>
+<p>We refer to points (1.) and (2.) collectively as dataset transformation, while (3.) as factor generation. Initially, these had been part of the generator, extracted as part of this refactor, which resulted in cleaner, more maintainable design.</p>
+<p><img src="datagen_df_0.png" alt="Datagen stages"></p>
+<p>The diagram above shows the components on a high level. The generator outputs a dataset called IR (intermediate representation), which is immediately written to disk. Then, the IR is input to the dataset transformation and factor generation stages, which respectively generate the final dataset and the factor tables. We are aware that spitting out the IR adds considerable runtime overhead and doubles the disk requirements in the worst-case scenario, however, we found that there’s no simple way to avoid<br>
+it, as the generator produces entity trees, which are incompatible with the flat, tabular, column oriented layout of SparkSQL. On the positive side, this design enables us to reuse the generator output for multiple transformations and add new factor tables without regenerating the data.</p>
+<p>I’ll skip describing the social network graph dataset generator (i.e. stage 1) in any more detail, apart from its serializer, as that was the only part involved in the current refactor. If you are interested in more details, you may look up the <a href="https://ldbcouncil.org/post/speeding-up-ldbc-snb-datagen/">previous blogpost in the series</a> or the <a href="https://arxiv.org/abs/2001.02299">Interactive benchmark specification</a>.</p>
+<h1 id="transformation-pipeline">Transformation pipeline</h1>
+<p>The dataset transformation stage sets off where generation finished, and applies an array of pluggable transformations:</p>
+<ul>
+<li>explodes edges and / or attributes into separate tables,</li>
+<li>subsets the snapshot part and creates insert / delete batches for the BI workload,</li>
+<li>subsets the snapshot part for the Interactive workload,</li>
+<li>applies formatting related options such as date time representation,</li>
+<li>serializes the data to a Spark supported format (CSV, Parquet),</li>
+</ul>
+<p>We utilize a flexible data pipeline that operates on the graph.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">trait</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M1</span> <span style="color:#66d9ef"><:</span> <span style="color:#66d9ef">Mode</span>, <span style="color:#66d9ef">M2</span> <span style="color:#66d9ef"><:</span> <span style="color:#66d9ef">Mode</span><span style="color:#f92672">]</span> <span style="color:#a6e22e">extends</span> <span style="color:#f92672">(</span><span style="color:#a6e22e">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M1</span><span style="color:#f92672">]</span> <span style="color:#66d9ef">=></span> <span style="color:#a6e22e">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M2</span><span style="color:#f92672">])</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">In</span> <span style="color:#f92672">=</span> <span style="color:#a6e22e">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M1</span><span style="color:#f92672">]</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#a6e22e">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M2</span><span style="color:#f92672">]</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> apply<span style="color:#f92672">(</span>v<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M1</span><span style="color:#f92672">])</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M2</span><span style="color:#f92672">]</span> <span style="color:#66d9ef">=</span> transform<span style="color:#f92672">(</span>v<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span></code></pre></div><p>The <code>Transform</code> trait encodes a pure (side effect-free) function polymorphic over graphs, so that transformation pipelines can be expressed with ordinary function composition in a type safe manner. Let’s see some of the transformations we have.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">RawToBiTransform</span><span style="color:#f92672">(</span>mode<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">BI</span><span style="color:#f92672">,</span> simulationStart<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Long</span><span style="color:#f92672">,</span> simulationEnd<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Long</span><span style="color:#f92672">,</span> keepImplicitDeletes<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Boolean</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span>, <span style="color:#66d9ef">Mode.BI</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#f92672">???</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">RawToInteractiveTransform</span><span style="color:#f92672">(</span>mode<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Mode.Interactive</span><span style="color:#f92672">,</span> simulationStart<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Long</span><span style="color:#f92672">,</span> simulationEnd<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Long</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span>, <span style="color:#66d9ef">Mode.Interactive</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#f92672">???</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">object</span> <span style="color:#a6e22e">ExplodeEdges</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span>, <span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#f92672">???</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">object</span> <span style="color:#a6e22e">ExplodeAttrs</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span>, <span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#f92672">???</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span></code></pre></div><p>Therefore, a transformation pipeline may look like this:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">val</span> transform <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">ExplodeAttrs</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>andThen<span style="color:#f92672">(</span><span style="color:#a6e22e">ExplodeEdges</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>andThen<span style="color:#f92672">(</span><span style="color:#a6e22e">RawToInteractiveTransform</span><span style="color:#f92672">(</span>params<span style="color:#f92672">,</span> start<span style="color:#f92672">,</span> end<span style="color:#f92672">))</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> outputGraph <span style="color:#66d9ef">=</span> transform<span style="color:#f92672">(</span>inputGraph<span style="color:#f92672">)</span>
+</span></span></code></pre></div><p>The <code>Graph</code> record has a <code>definition</code> field containing graph-global metadata, whereas <code>entities</code> holds the datasets keyed by their entity type. There are 3 graph <em>modes</em> currently: <code>Raw</code>, <code>Interactive</code> and <code>BI</code>. The BI dataset has different layout than the rest, as it contains incremental inserts and deletes for the entities additionally to the bulk snapshot. This is captured in the <code>Layout</code> dependent type, over which the entities are polymorphic.</p>
+<p>It’s important to understand that <code>Graph</code> holds <code>DataFrame</code>s, and these are lazily computed by Spark. So, <code>Graph</code> is merely a description of transformations used to derive the comprising datasets, which makes them subject to all the SparkSQL fanciness such as query optimization, whole stage code generation, and so on. Processing is delayed until an action (such as a disk write) forces it.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">GraphDef</span><span style="color:#f92672">[</span><span style="color:#66d9ef">+M</span> <span style="color:#66d9ef"><:</span> <span style="color:#66d9ef">Mode</span><span style="color:#f92672">](</span>
+</span></span><span style="display:flex;"><span> isAttrExploded<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Boolean</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> isEdgesExploded<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Boolean</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> useTimestamp<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Boolean</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> mode<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">M</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> entities<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Map</span><span style="color:#f92672">[</span><span style="color:#66d9ef">EntityType</span>, <span style="color:#66d9ef">Option</span><span style="color:#f92672">[</span><span style="color:#66d9ef">String</span><span style="color:#f92672">]]</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">+M</span> <span style="color:#66d9ef"><:</span> <span style="color:#66d9ef">Mode</span><span style="color:#f92672">](</span>
+</span></span><span style="display:flex;"><span> definition<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">GraphDef</span><span style="color:#f92672">[</span><span style="color:#66d9ef">M</span><span style="color:#f92672">],</span>
+</span></span><span style="display:flex;"><span> entities<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Map</span><span style="color:#f92672">[</span><span style="color:#66d9ef">EntityType</span>, <span style="color:#66d9ef">M</span><span style="color:#66d9ef">#</span><span style="color:#66d9ef">Layout</span><span style="color:#f92672">]</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">sealed</span> <span style="color:#66d9ef">trait</span> <span style="color:#a6e22e">Mode</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Layout</span>
+</span></span><span style="display:flex;"><span> <span style="color:#75715e">/* ... */</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">object</span> <span style="color:#a6e22e">Mode</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">final</span> <span style="color:#66d9ef">case</span> <span style="color:#66d9ef">object</span> <span style="color:#a6e22e">Raw</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Mode</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Layout</span> <span style="color:#f92672">=</span> <span style="color:#a6e22e">DataFrame</span>
+</span></span><span style="display:flex;"><span> <span style="color:#75715e">/* ... */</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">final</span> <span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">Interactive</span><span style="color:#f92672">(</span>bulkLoadPortion<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Double</span><span style="color:#f92672">)</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Mode</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Layout</span> <span style="color:#f92672">=</span> <span style="color:#a6e22e">DataFrame</span>
+</span></span><span style="display:flex;"><span> <span style="color:#75715e">/* ... */</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">final</span> <span style="color:#66d9ef">case</span> <span style="color:#66d9ef">class</span> <span style="color:#a6e22e">BI</span><span style="color:#f92672">(</span>bulkloadPortion<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Double</span><span style="color:#f92672">,</span> batchPeriod<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">String</span><span style="color:#f92672">)</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Mode</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Layout</span> <span style="color:#f92672">=</span> <span style="color:#a6e22e">BatchedEntity</span>
+</span></span><span style="display:flex;"><span> <span style="color:#75715e">/* ... */</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span></code></pre></div><p>You may notice that <code>Transform</code> is statically typed w.r.t. <code>Mode</code>, however other properties, like <code>isAttrExploded</code>, or <code>isEdgesExploded</code> are not captured in the type, and remain merely dynamic. This makes some nonsensical transformation pipelines (i.e. that explodes edges twice in a row) syntactically valid. This trade-off in compile-time safety was made to prevent overcomplicating the types.</p>
+<p>As we already mentioned, <code>Graph</code> is essentially a persistent container of <code>EntityType -> DataFrame</code> mappings. <code>EntityType</code> can be <code>Node</code>, <code>Edge</code> and <code>Attr</code>, and is used to identify the entity and embellish with static metadata, such a descriptive name and primary key, whether it is static or dynamic (as per the specification), and in case of edges, the source and destination type and cardinality. This makes it very simple to create transformation rules on static entity properties with pattern matching.</p>
+<p>Usually, a graph transformation involves matching entities based on their <code>EntityType</code>, and modifying the mapping (and if required, other metadata). Take, for example, the <code>ExplodeAttrs</code> transformation, which explodes into separate tables the values of two columns of <code>Person</code> stored as arrays:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">object</span> <span style="color:#a6e22e">ExplodeAttrs</span> <span style="color:#66d9ef">extends</span> <span style="color:#a6e22e">Transform</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span>, <span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">override</span> <span style="color:#66d9ef">def</span> transform<span style="color:#f92672">(</span>input<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">In</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Out</span> <span style="color:#f92672">=</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">if</span> <span style="color:#f92672">(</span>input<span style="color:#f92672">.</span>definition<span style="color:#f92672">.</span>isAttrExploded<span style="color:#f92672">)</span> <span style="color:#f92672">{</span> <span style="color:#75715e">// assert at runtime that the transformation hasn't been applied yet
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> <span style="color:#66d9ef">throw</span> <span style="color:#66d9ef">new</span> <span style="color:#a6e22e">AssertionError</span><span style="color:#f92672">(</span><span style="color:#e6db74">"Attributes already exploded in the input graph"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">def</span> explodedAttr<span style="color:#f92672">(</span>attr<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Attr</span><span style="color:#f92672">,</span> node<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">DataFrame</span><span style="color:#f92672">,</span> column<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Column</span><span style="color:#f92672">)</span> <span style="color:#66d9ef">=</span>
+</span></span><span style="display:flex;"><span> attr <span style="color:#f92672">-></span> node<span style="color:#f92672">.</span>select<span style="color:#f92672">(</span>withRawColumns<span style="color:#f92672">(</span>attr<span style="color:#f92672">,</span> $<span style="color:#e6db74">"id"</span><span style="color:#f92672">.</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">s"</span><span style="color:#e6db74">${</span>attr<span style="color:#f92672">.</span>parent<span style="color:#e6db74">}</span><span style="color:#e6db74">Id"</span><span style="color:#f92672">),</span> explode<span style="color:#f92672">(</span>split<span style="color:#f92672">(</span>column<span style="color:#f92672">,</span> <span style="color:#e6db74">";"</span><span style="color:#f92672">)).</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">s"</span><span style="color:#e6db74">${</span>attr<span style="color:#f92672">.</span>attribute<span style="color:#e6db74">}</span><span style="color:#e6db74">Id"</span><span style="color:#f92672">)))</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> modifiedEntities <span style="color:#66d9ef">=</span> input<span style="color:#f92672">.</span>entities
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>collect <span style="color:#f92672">{</span> <span style="color:#66d9ef">case</span> <span style="color:#f92672">(</span>k <span style="color:#66d9ef">@</span> <span style="color:#a6e22e">Node</span><span style="color:#f92672">(</span><span style="color:#e6db74">"Person"</span><span style="color:#f92672">,</span> <span style="color:#66d9ef">false</span><span style="color:#f92672">),</span> df<span style="color:#f92672">)</span> <span style="color:#66d9ef">=></span> <span style="color:#75715e">// match the Person node. This is the only one ExplodeAttrs should modify
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> <span style="color:#a6e22e">Map</span><span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> explodedAttr<span style="color:#f92672">(</span><span style="color:#a6e22e">Attr</span><span style="color:#f92672">(</span><span style="color:#e6db74">"Email"</span><span style="color:#f92672">,</span> k<span style="color:#f92672">,</span> <span style="color:#e6db74">"EmailAddress"</span><span style="color:#f92672">),</span> df<span style="color:#f92672">,</span> $<span style="color:#e6db74">"email"</span><span style="color:#f92672">),</span> <span style="color:#75715e">// add a new "PersonEmailEmailAddress" entity derived by exploding the email column of Person
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> explodedAttr<span style="color:#f92672">(</span><span style="color:#a6e22e">Attr</span><span style="color:#f92672">(</span><span style="color:#e6db74">"Speaks"</span><span style="color:#f92672">,</span> k<span style="color:#f92672">,</span> <span style="color:#e6db74">"Language"</span><span style="color:#f92672">),</span> df<span style="color:#f92672">,</span> $<span style="color:#e6db74">"language"</span><span style="color:#f92672">),</span> <span style="color:#75715e">// add a new "PersonSpeaksLanguage" entity derived by exploding the language column of Person
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> k <span style="color:#f92672">-></span> df<span style="color:#f92672">.</span>drop<span style="color:#f92672">(</span><span style="color:#e6db74">"email"</span><span style="color:#f92672">,</span> <span style="color:#e6db74">"language"</span><span style="color:#f92672">)</span> <span style="color:#75715e">// drop the exploded columns from person
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> <span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> updatedEntities <span style="color:#66d9ef">=</span> modifiedEntities
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>foldLeft<span style="color:#f92672">(</span>input<span style="color:#f92672">.</span>entities<span style="color:#f92672">)(</span><span style="color:#66d9ef">_</span> <span style="color:#f92672">++</span> <span style="color:#66d9ef">_</span><span style="color:#f92672">)</span> <span style="color:#75715e">// merge-replace the modified entities in the graph
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> updatedEntityDefinitions <span style="color:#66d9ef">=</span> modifiedEntities
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>foldLeft<span style="color:#f92672">(</span>input<span style="color:#f92672">.</span>definition<span style="color:#f92672">.</span>entities<span style="color:#f92672">)</span> <span style="color:#f92672">{</span> <span style="color:#f92672">(</span>e<span style="color:#f92672">,</span> v<span style="color:#f92672">)</span> <span style="color:#66d9ef">=></span>
+</span></span><span style="display:flex;"><span> e <span style="color:#f92672">++</span> v<span style="color:#f92672">.</span>map<span style="color:#f92672">{</span> <span style="color:#66d9ef">case</span> <span style="color:#f92672">(</span>k<span style="color:#f92672">,</span> v<span style="color:#f92672">)</span> <span style="color:#66d9ef">=></span> k <span style="color:#f92672">-></span> <span style="color:#a6e22e">Some</span><span style="color:#f92672">(</span>v<span style="color:#f92672">.</span>schema<span style="color:#f92672">.</span>toDDL<span style="color:#f92672">)</span> <span style="color:#f92672">}</span> <span style="color:#75715e">// update the entity definition schema to reflect the modifications
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> <span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> l <span style="color:#66d9ef">=</span> lens<span style="color:#f92672">[</span><span style="color:#66d9ef">In</span><span style="color:#f92672">]</span> <span style="color:#75715e">// lenses provide a terse syntax for modifying nested fields
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">(</span>l<span style="color:#f92672">.</span>definition<span style="color:#f92672">.</span>isAttrExploded <span style="color:#f92672">~</span> l<span style="color:#f92672">.</span>definition<span style="color:#f92672">.</span>entities <span style="color:#f92672">~</span> l<span style="color:#f92672">.</span>entities<span style="color:#f92672">).</span>set<span style="color:#f92672">(</span>input<span style="color:#f92672">)((</span><span style="color:#66d9ef">true</span><span style="color:#f92672">,</span> updatedEntityDefinitions<span style="color:#f92672">,</span> updatedEntities<span style="color:#f92672">))</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">}</span>
+</span></span></code></pre></div><p>Note that <code>EntityType</code> does not hold the dataset’s full SQL schema currently, as it’s not useful for pattern matching, but can be accessed directly from <code>DataFrame</code> if needed.</p>
+<h1 id="inputoutput">Input/output</h1>
+<p>The <code>Reader</code> and <code>Writer</code> typeclasses are used to read from a <code>Source</code> and write to a <code>Sink</code> respectively, terminating a graph transformation pipeline<br>
+on both ends.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">trait</span> <span style="color:#a6e22e">Reader</span><span style="color:#f92672">[</span><span style="color:#66d9ef">T</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Ret</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">def</span> read<span style="color:#f92672">(</span>self<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">T</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Ret</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">def</span> exists<span style="color:#f92672">(</span>self<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">T</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Boolean</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">trait</span> <span style="color:#a6e22e">Writer</span><span style="color:#f92672">[</span><span style="color:#66d9ef">S</span><span style="color:#f92672">]</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">type</span> <span style="color:#66d9ef">Data</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">def</span> write<span style="color:#f92672">(</span>self<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Data</span><span style="color:#f92672">,</span> sink<span style="color:#66d9ef">:</span> <span style="color:#66d9ef">S</span><span style="color:#f92672">)</span><span style="color:#66d9ef">:</span> <span style="color:#66d9ef">Unit</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">}</span>
+</span></span></code></pre></div><p>There are implementations under <code>ldbc.datagen.io.instances</code> that read a graph from a <code>GraphSource</code> and write to a <code>GraphSink</code>.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.model
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.model.Mode
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.graphs.<span style="color:#f92672">{</span><span style="color:#a6e22e">GraphSource</span><span style="color:#f92672">,</span> <span style="color:#a6e22e">GraphSink</span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.instances._
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// read
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> inputPath <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"path/to/input/graph"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> inputFormat <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"parquet"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> source <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">GraphSource</span><span style="color:#f92672">(</span>model<span style="color:#f92672">.</span>graphs<span style="color:#f92672">.</span><span style="color:#a6e22e">Raw</span><span style="color:#f92672">.</span>graphDef<span style="color:#f92672">,</span> inputPath<span style="color:#f92672">,</span> inputFormat<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> graph <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">Reader</span><span style="color:#f92672">[</span><span style="color:#66d9ef">GraphSource</span>, <span style="color:#66d9ef">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span><span style="color:#f92672">]].</span>read<span style="color:#f92672">(</span>source<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// transform
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> transform <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">ExplodeAttrs</span><span style="color:#f92672">.</span>andThen<span style="color:#f92672">(</span><span style="color:#a6e22e">ExplodeEdges</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> transformedGraph <span style="color:#66d9ef">=</span> transform<span style="color:#f92672">(</span>graph<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// write
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> outputPath <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"path/to/output/graph"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> outputFormat <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"csv"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> sink <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">GraphSink</span><span style="color:#f92672">(</span>outputPath<span style="color:#f92672">,</span> outputFormat<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">Writer</span><span style="color:#f92672">[</span><span style="color:#66d9ef">GraphSink</span>, <span style="color:#66d9ef">Graph</span><span style="color:#f92672">[</span><span style="color:#66d9ef">Mode.Raw.</span><span style="color:#66d9ef">type</span><span style="color:#f92672">]].</span>write<span style="color:#f92672">(</span>transformedGraph<span style="color:#f92672">,</span> sink<span style="color:#f92672">)</span>
+</span></span></code></pre></div><p>We provide <a href="https://github.com/typelevel/simulacrum">Ops syntax</a> to make it shorter:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.model
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.model.Mode
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.graphs.<span style="color:#f92672">{</span><span style="color:#a6e22e">GraphSource</span><span style="color:#f92672">,</span> <span style="color:#a6e22e">GraphSink</span><span style="color:#f92672">}</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.instances._
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.Reader.ops._
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">import</span> ldbc.snb.datagen.io.Writer.ops._
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// read
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> inputPath <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"path/to/input/graph"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> inputFormat <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"parquet"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> graph <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">GraphSource</span><span style="color:#f92672">(</span>model<span style="color:#f92672">.</span>graphs<span style="color:#f92672">.</span><span style="color:#a6e22e">Raw</span><span style="color:#f92672">.</span>graphDef<span style="color:#f92672">,</span> inputPath<span style="color:#f92672">,</span> inputFormat<span style="color:#f92672">).</span>read
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// transform
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> transformedGraph <span style="color:#66d9ef">=</span> <span style="color:#f92672">???</span> <span style="color:#75715e">/* ... */</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// write
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span><span style="color:#66d9ef">val</span> outputPath <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"path/to/output/graph"</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">val</span> outputFormat <span style="color:#66d9ef">=</span> <span style="color:#e6db74">"csv"</span>
+</span></span><span style="display:flex;"><span>transformedGraph<span style="color:#f92672">.</span>write<span style="color:#f92672">(</span><span style="color:#a6e22e">GraphSink</span><span style="color:#f92672">(</span>outputPath<span style="color:#f92672">,</span> outputFormat<span style="color:#f92672">))</span>
+</span></span></code></pre></div><p>The reader/writer architecture is layered, the graph reader/writer uses dataframe readers/writers for each of its entities. One interesting aspect of implementing the reader was dealing with the input schema. Parquet is self-describing, however as we also support the CSV format, we had to provide a way for correct schema detection and column parsing.</p>
+<p>Spark has a facility to derive SparkSQL schema from case classes automatically<sup id="fnref:2"><a href="#fn:2" class="footnote-ref" role="doc-noteref">2</a></sup>. We created case classes for each entity in the <code>Raw</code> dataset. We also created a typeclass <code>EntityTraits</code> associating these classes with their <code>EntityType</code>, so we can summon them (and consequently their SparkSQL schema) in the reader.</p>
+<p>The case classes are used during the serialization of the generated dataset too, but more about that later.</p>
+<h1 id="factor-generation">Factor generation</h1>
+<p>As we already mentioned, factor generation was originally part of the data generator, i.e. factor tables were calculated on the fly and emitted as side outputs. This design had some problems. Auxiliary data structures had to be maintained and interleaved with generation, which violated separation of concerns, consequently hurting readability and maintainability. Also, anything more complicated than entity local aggregates where impossible to express in the original MapReduce framework. To keep the preceding Spark rewrite at a managable scope, the original factor generation code had been removed.</p>
+<p>We decided it’s best to reintroduce factor generation as a post-processing step that operates on the generated data. This makes it possible to express more complex analytical queries, requires no prior knowledge about the generator, can be done in SparkSQL (making it much simpler), and removes the impact on the generator’s performance, so that we can optimize them separately. Since this refactor, we almost tripled the number factor tables (up to 31 to cover both SNB workloads, BI and Interactive). The queries computing of certain factor tables even use <a href="https://spark.apache.org/graphx/">GraphX</a>, which was unimaginable with the previous design.</p>
+<p>Factor tables are added by extending a map with a <code>name -> Factor</code> pair. <code>Factor</code> declares is input entities, and accepts a function that receives input <code>DataFrames</code>, and returns a single <code>DataFrame</code> as output.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-scala" data-lang="scala"><span style="display:flex;"><span><span style="color:#66d9ef">val</span> factors <span style="color:#66d9ef">=</span> <span style="color:#a6e22e">Map</span> <span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"personDisjointEmployerPairs"</span> <span style="color:#f92672">-></span> <span style="color:#a6e22e">Factor</span><span style="color:#f92672">(</span><span style="color:#a6e22e">PersonType</span><span style="color:#f92672">,</span> <span style="color:#a6e22e">PersonKnowsPersonType</span><span style="color:#f92672">,</span> <span style="color:#a6e22e">OrganisationType</span><span style="color:#f92672">,</span> <span style="color:#a6e22e">PersonWorkAtCompanyType</span><span style="color:#f92672">)</span> <span style="color:#f92672">{</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">case</span> <span style="color:#a6e22e">Seq</span><span style="color:#f92672">(</span>person<span style="color:#f92672">,</span> personKnowsPerson<span style="color:#f92672">,</span> organisation<span style="color:#f92672">,</span> workAt<span style="color:#f92672">)</span> <span style="color:#66d9ef">=></span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> knows <span style="color:#66d9ef">=</span> undirectedKnows<span style="color:#f92672">(</span>personKnowsPerson<span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> company <span style="color:#66d9ef">=</span> organisation<span style="color:#f92672">.</span>where<span style="color:#f92672">(</span>$<span style="color:#e6db74">"Type"</span> <span style="color:#f92672">===</span> <span style="color:#e6db74">"Company"</span><span style="color:#f92672">).</span>cache<span style="color:#f92672">()</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">val</span> personSample <span style="color:#66d9ef">=</span> person
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>orderBy<span style="color:#f92672">(</span>$<span style="color:#e6db74">"id"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>limit<span style="color:#f92672">(</span><span style="color:#ae81ff">20</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> personSample
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">"Person2"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>join<span style="color:#f92672">(</span>knows<span style="color:#f92672">.</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">"knows"</span><span style="color:#f92672">),</span> $<span style="color:#e6db74">"knows.person2Id"</span> <span style="color:#f92672">===</span> $<span style="color:#e6db74">"Person2.id"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>join<span style="color:#f92672">(</span>workAt<span style="color:#f92672">.</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">"workAt"</span><span style="color:#f92672">),</span> $<span style="color:#e6db74">"workAt.PersonId"</span> <span style="color:#f92672">===</span> $<span style="color:#e6db74">"knows.Person1id"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>join<span style="color:#f92672">(</span>company<span style="color:#f92672">.</span>as<span style="color:#f92672">(</span><span style="color:#e6db74">"Company"</span><span style="color:#f92672">),</span> $<span style="color:#e6db74">"Company.id"</span> <span style="color:#f92672">===</span> $<span style="color:#e6db74">"workAt.CompanyId"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>select<span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> $<span style="color:#e6db74">"Person2.id"</span><span style="color:#f92672">.</span>alias<span style="color:#f92672">(</span><span style="color:#e6db74">"person2id"</span><span style="color:#f92672">),</span>
+</span></span><span style="display:flex;"><span> $<span style="color:#e6db74">"Company.name"</span><span style="color:#f92672">.</span>alias<span style="color:#f92672">(</span><span style="color:#e6db74">"companyName"</span><span style="color:#f92672">),</span>
+</span></span><span style="display:flex;"><span> $<span style="color:#e6db74">"Company.id"</span><span style="color:#f92672">.</span>alias<span style="color:#f92672">(</span><span style="color:#e6db74">"companyId"</span><span style="color:#f92672">),</span>
+</span></span><span style="display:flex;"><span> $<span style="color:#e6db74">"Person2.creationDate"</span><span style="color:#f92672">.</span>alias<span style="color:#f92672">(</span><span style="color:#e6db74">"person2creationDate"</span><span style="color:#f92672">),</span>
+</span></span><span style="display:flex;"><span> $<span style="color:#e6db74">"Person2.deletionDate"</span><span style="color:#f92672">.</span>alias<span style="color:#f92672">(</span><span style="color:#e6db74">"person2deletionDate"</span><span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">)</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span>distinct<span style="color:#f92672">()</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">},</span>
+</span></span><span style="display:flex;"><span> <span style="color:#75715e">/* more factors */</span>
+</span></span><span style="display:flex;"><span><span style="color:#f92672">)</span>
+</span></span></code></pre></div><p>As you can see, it’s not much complicated than using plain SQL, with the added benefit of being able to extract recurring subqueries to functions (e.g. <code>undirectedKnows</code>). Currently, there’s no parallelization between different factor tables (although each of them is parallelized internally by Spark). The Factor table writer uses the same componentized architecture as the graph writer, i.e. it uses the dataframe writer under the hood.</p>
+<h1 id="revamping-the-data-generators-serializer">Revamping the data generator’s serializer</h1>
+<p>At this point, both the transformation pipeline and factor generator was ready, however the data generator was still chugging with the old serializer, emitting the IR in CSV. We wanted to move this to Parquet to improve performance and reduce its size, but there was a problem: due to the generator’s custom data representation, SparkSQL (and its DataSource API) was off-limits. So we’ve bitten the bullet, and rewritten the existing serializer to emit Parquet.</p>
+<blockquote>
+<p><a href="https://parquet.apache.org/">Parquet</a> is an open source data format that evolved to be the de facto standard for Big Data batch pipelines. It offers a column-oriented, compressed, schemaful representation that is space-efficient and suited for analytic queries. The file format leverages a record shredding and assembly model, which originated at Google. This results in a file that is optimized for query performance and minimizing I/O.</p>
+</blockquote>
+<p>The new serialization framework is heavily influenced by the design of Java <code>OutputStreams</code>, in the sense that stateful objects are composed to form a pipeline. For example, in case of <em>activities</em>, the input is an activity tree, and the output is a set of rows in multiple files (eg. forum, forumHasTag, post, postHasTag, etc.). The components that take part in activity serialization are shown on the diagram below. The activity tree is iterated (1st component) and the corresponding entity serializer is called (2nd component), which is fed into a component that splits the records (3rd one) among several output streams writing individual files (last).</p>
+<p><img src="activity.png" alt="Activity serialization pipeline"></p>
+<p>The benefit of this architecture is that only the last component needs to change when we add support for a new output format.</p>
+<p>To support Parquet, we made use of row-level serializers available in Hadoop’s Parquet library (bundled with SparkSQL), and internal classes in SparkSQL to derive Parquet schema for our entities. Remember how we used case classes for the <code>Raw</code> entities to derive the input schema in the graph reader during dataset transformation? Here we use the same classes (e.g. <code>Forum</code>) and Spark’s <code>Encoder</code> framework to encode the entities in Parquet, which means that the generated output remains consistent with <code>DataFrame</code>-based reader, and we spare a lot of code duplication.</p>
+<h1 id="optimizations">Optimizations</h1>
+<p>After these refactors, we were able to generate the BI dataset with scale factor 10K on 300 i3.4xlarge machines in one hour. Decreasing the number of machines resulted in out of memory errors in the generator. We realized partition sizes (and thus the number of partitions) should be determined based on available memory. Our experiments showed that a machine with 128GB of memory is capable of generating SF3K (scale factor 3000) reliably with 3 blocks<sup id="fnref:3"><a href="#fn:3" class="footnote-ref" role="doc-noteref">3</a></sup> per partition given ample disk size to allow for spills (tested with 3.8TB); while less partitions (subsequently, larger block/partition ratio) would introduce OOM errors. Furthermore, we split the data generator output after a certain number of rows written, to fend against the skew between different kinds of entities possibly causing problems during transformation<sup id="fnref:4"><a href="#fn:4" class="footnote-ref" role="doc-noteref">4</a></sup>. These optimizations enabled us to run SF10K reliably on 4 i3.4xlarge machines in 11 hours (which is still more than 6x reduction in cost). We weren’t able to run SF30K run on 10 machines (1 machine / SF3K), even 15 ran out of disk. This non-linear disk use should be investigated further as it complicates calculating cluster sizes for larger scale factors.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>./tools/emr/submit_datagen_job.py sf3k_bi <span style="color:#ae81ff">3000</span> parquet bi <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --sf-per-executor <span style="color:#ae81ff">3000</span> <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --partitions <span style="color:#ae81ff">330</span> <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --jar $JAR_NAME <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --instance-type i3.4xlarge <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --bucket $BUCKET_NAME <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> -- --explode-edges --explode-attrs
+</span></span></code></pre></div><div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>./tools/emr/submit_datagen_job.py sf10k_bi <span style="color:#ae81ff">10000</span> parquet bi <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --sf-per-executor <span style="color:#ae81ff">3000</span> <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --partitions <span style="color:#ae81ff">1000</span> <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --jar $JAR_NAME <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --instance-type i3.4xlarge <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> --bucket $BUCKET_NAME <span style="color:#ae81ff">\
+</span></span></span><span style="display:flex;"><span><span style="color:#ae81ff"></span> -- --explode-edges --explode-attrs
+</span></span></code></pre></div><p>The above examples working configurations for generating the 3K and 10K BI datasets. The <code>--sf-per-executor</code> option controls the number of worker nodes allocated, in this case 1 node per every 3000 SF, i.e. 1 and 4 nodes correspondingly. The <code>--partitions</code> option controls the total number of partitions, and was calculated based on the number of persons using the formula <code>partitions = ceil(number_of_persons / block_size / 3)</code> to get a maximum of 3 blocks per partition.</p>
+<h1 id="conclusion">Conclusion</h1>
+<p>These improvements made LDBC SNB datagen more modular, maintainable and efficient, costing under a cent per scale factor to generate the BI dataset, which enables us to generate datasets beyond SF 100K.</p>
+<h1 id="footnotes">Footnotes</h1>
+<div class="footnotes" role="doc-endnotes">
+<hr>
+<ol>
+<li id="fn:1">
+<p>The generator produces hierarchies, such as forum wall with a random number of posts, that have comments, etc. This tree is iterated, and different entities are written to separate files. <a href="#fnref:1" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:2">
+<p>Shameless plug: You can learn more on this from <a href="https://www.dataversity.net/case-study-deriving-spark-encoders-and-schemas-using-implicits/">another blogpost of mine</a>. <a href="#fnref:2" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:3">
+<p>The datagenerator produces blocks of 10,000 persons and their related entities. Entities from different blocks are unrelated (isolated). <a href="#fnref:3" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:4">
+<p>The maximum row count per file is currently 10M, however, this can be modified with a command line option. We also had an alternative design in mind where this number would have been determined based on the average row size of each entity, however, we stayed with the first version for simplicity. <a href="#fnref:4" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+</ol>
+</div>
+
+
+
+ -
+
Fifteenth TUC Meeting
+ https://ldbcouncil.org/event/fifteenth-tuc-meeting/
+ Fri, 17 Jun 2022 09:20:00 -0500
+
+ https://ldbcouncil.org/event/fifteenth-tuc-meeting/
+ <p><strong>Organizers:</strong> Gábor Szárnyas, Jack Waudby, Peter Boncz, Alastair Green</p>
+<p>LDBC is hosting a <strong>two-day</strong> hybrid workshop, co-located with <a href="https://2022.sigmod.org/venue.shtml">SIGMOD 2022</a> on <strong>June 17-18 (Friday-Saturday)</strong>.</p>
+<p>The program consists of 10-15 minute talks followed by a Q&A session. The talks will be recorded and made available online.<br>
+The tenative program is the following. <strong>All times are in EDT.</strong></p>
+<p>We will have a social event on Friday at 17:30 at <a href="https://elvezrestaurant.com/">El Vez</a> (<a href="https://g.page/ElVezPhilly">Google Maps</a>).</p>
+<h4 id="friday-pennsylvania-convention-centerhttpswwwpaconventioncom-room-204bhttps2022sigmodorgprogramshtml">Friday (<a href="https://www.paconvention.com/">Pennsylvania Convention Center</a>, <a href="https://2022.sigmod.org/program.shtml">room 204B</a>)</h4>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>finish</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>09:20</td>
+<td>09:30</td>
+<td>Peter Boncz (LDBC/CWI)</td>
+<td>State of the union – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/peter-boncz-state-of-the-union.pdf">slides</a>, <a href="https://youtu.be/39BoOIGk9Is">video</a></td>
+</tr>
+<tr>
+<td>09:30</td>
+<td>09:45</td>
+<td>Alastair Green (LDBC/Birkbeck)</td>
+<td>LDBC’s fair use policies – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/alastair-green-fair-use-of-the-ldbc-trademark.pdf">slides</a>, <a href="https://youtu.be/7zmCysN4Rpg">video</a></td>
+</tr>
+<tr>
+<td>09:50</td>
+<td>10:05</td>
+<td>Gábor Szárnyas (LDBC/CWI), Jack Waudby (Newcastle University)</td>
+<td>LDBC Social Network Benchmark: Business Intelligence workload v1.0 – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/gabor-szarnyas-the-ldbc-social-network-benchmark-business-intelligence-workload.pdf">slides</a>, <a href="https://youtu.be/AJ96M8_njxE">video</a></td>
+</tr>
+<tr>
+<td>10:10</td>
+<td>10:25</td>
+<td>Heng Lin (Ant Group)</td>
+<td>LDBC Financial Benchmark introduction – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/heng-lin-ldbc-financial-benchmark-introduction.pdf">slides</a>, <a href="https://youtu.be/iBhud_YjafY">video</a></td>
+</tr>
+<tr>
+<td>10:30</td>
+<td>11:00</td>
+<td><em>coffee break</em></td>
+<td></td>
+</tr>
+<tr>
+<td>11:00</td>
+<td>11:15</td>
+<td>Chen Zhang (CreateLink)</td>
+<td>New LDBC SNB benchmark record by Galaxybase: More than 6 times faster and 70% higher throughput – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/chen-zhang-new-ldbc-snb-benchmark-record-by-galaxybase-more-than-6-times-faster-and-70-percent-higher-throughput.pdf">slides</a>, <a href="https://youtu.be/sMzTsb8iw_Y">video</a></td>
+</tr>
+<tr>
+<td>11:20</td>
+<td>11:35</td>
+<td>James Clarkson (Neo4j)</td>
+<td>LDBC benchmarks: Promoting good science and industrial consumption – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/james-clarkson-ldbc-benchmarks-promoting-good-science-and-industrial-consumption.pdf">slides</a>, <a href="https://youtu.be/VYG1mzcl9qQ">video</a></td>
+</tr>
+<tr>
+<td>11:40</td>
+<td>11:55</td>
+<td>Oskar van Rest (Oracle)</td>
+<td>Creating and querying property graphs in Oracle, on-premise and in the cloud – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/oskar-van-rest-creating-and-querying-property-graphs-in-oracle-on-premise-and-in-the-cloud.pdf">slides</a>, <a href="https://youtu.be/2HX2Vixf2gs">video</a></td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>12:15</td>
+<td>Mingxi Wu (TigerGraph)</td>
+<td>Conquering LDBC SNB BI at SF-10k – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/mingxi-wu-conquering-ldbc-snb-bi-at-sf10k.pdf">slides</a>, <a href="https://youtu.be/oJbqzQ_t3G8">video</a></td>
+</tr>
+<tr>
+<td>12:20</td>
+<td>13:20</td>
+<td><em>lunch (on your own)</em></td>
+<td></td>
+</tr>
+<tr>
+<td>13:20</td>
+<td>13:35</td>
+<td>Altan Birler (Technische Universität München)</td>
+<td>Relational databases can handle graphs too! Experiences with optimizing the Umbra RDBMS for LDBC SNB BI – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/altan-birler-relational-databases-can-handle-graphs-too.pdf">slides</a>, <a href="https://youtu.be/cRgbdY3I2i4">video</a></td>
+</tr>
+<tr>
+<td>13:40</td>
+<td>13:55</td>
+<td>David Püroja (CWI)</td>
+<td>LDBC Social Network Benchmark: Interactive workload v2.0 – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/david-puroja-ldbc-snb-interactive-workload-v2.0.pdf">slides</a></td>
+</tr>
+<tr>
+<td>14:00</td>
+<td>14:15</td>
+<td>Angela Bonifati (Lyon 1 University)</td>
+<td>The quest for schemas in graph databases – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/angela-bonifati-the-quest-for-schemas-in-graph-databases.pdf">slides</a>, <a href="https://youtu.be/VT7cx3Jp7V8">video</a></td>
+</tr>
+<tr>
+<td>14:20</td>
+<td>14:35</td>
+<td>Matteo Lissandrini (Aalborg University)</td>
+<td>Understanding graph data representations in triplestores – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/matteo-lissandrini-understanding-graph-data-representations-in-triplestores.pdf">slides</a>, <a href="https://youtu.be/xqVMJZfh_JU">video</a></td>
+</tr>
+<tr>
+<td>14:40</td>
+<td>14:55</td>
+<td>Wim Martens (University of Bayreuth)</td>
+<td>Path representations – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/wim-martens-path-representations.pdf">slides</a>, <a href="https://youtu.be/Ma-E5dwgf-E">video</a></td>
+</tr>
+<tr>
+<td>15:00</td>
+<td>15:20</td>
+<td>Audrey Cheng (UC Berkeley)</td>
+<td>TAOBench: An end-to-end benchmark for social network workloads – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/audrey-cheng-taobench.pdf">slides</a>, <a href="https://youtu.be/1p8AStxS3es">video</a></td>
+</tr>
+</tbody>
+</table>
+<h4 id="saturday-philadelphia-marriott-downtownhttpswwwmarriottcomen-ushotelsphldt-philadelphia-marriott-downtown-room-401-402-4th-floor">Saturday (<a href="https://www.marriott.com/en-us/hotels/phldt-philadelphia-marriott-downtown/">Philadelphia Marriott Downtown</a>, room 401-402, 4th floor)</h4>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>finish</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>10:00</td>
+<td>10:15</td>
+<td>Keith Hare (WG3)</td>
+<td>An update on the GQL & SQL/PGQ standards efforts – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/keith-hare-property-graph-standards-process-and-timing.pdf">slides</a>, <a href="https://youtu.be/xFVD3LWnKlc">video</a></td>
+</tr>
+<tr>
+<td>10:20</td>
+<td>10:35</td>
+<td>Leonid Libkin (ENS Paris)</td>
+<td>Pattern matching in GQL and SQL/PGQ – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/leonid-libkin-pattern-matching-in-gql-and-sql-pgq.pdf">slides</a>, <a href="https://youtu.be/OvGsa0qLANE">video</a></td>
+</tr>
+<tr>
+<td>10:40</td>
+<td>10:55</td>
+<td>Petra Selmer (Neo4j/WG3)</td>
+<td>An overview of GQL – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/petra-selmer-towards-gql-v1-a-property-graph-query-language-standard.pdf">slides</a>, <a href="https://youtu.be/tncf2FgyIyo">video</a></td>
+</tr>
+<tr>
+<td>11:00</td>
+<td>11:15</td>
+<td>Alastair Green (LDBC/WG3)</td>
+<td>GQL 2.0: A technical manifesto – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/alastair-green-gql-2.0-a-technical-manifesto.pdf">slides</a>, <a href="https://youtu.be/upIvpYy8C2g">video</a></td>
+</tr>
+<tr>
+<td>11:20</td>
+<td>11:35</td>
+<td>George Fletcher (TU Eindhoven)</td>
+<td>PG-Keys (LDBC Property Graph Schema Working Group) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/george-fletcher-pg-keys-keys-for-property-graphs.pdf">slides</a>, <a href="https://youtu.be/_W8-jOtcObc">video</a></td>
+</tr>
+<tr>
+<td>11:40</td>
+<td>11:55</td>
+<td>Arvind Shyamsundar (Microsoft)</td>
+<td>Graph capabilities in Microsoft SQL Server and Azure SQL Database – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/arvind-shyamsundar-graph-capabilities-in-microsoft-sql-server-and-azure-database.pdf">slides</a>, <a href="https://youtu.be/xxV2BfZupGw">video</a></td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>13:30</td>
+<td><em>lunch (on your own)</em></td>
+<td></td>
+</tr>
+<tr>
+<td>13:30</td>
+<td>13:45</td>
+<td>Daniël ten Wolde (CWI)</td>
+<td>Implementing SQL/PGQ in DuckDB – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/daniel-ten-wolde-implementing-sql-pgq-in-duckdb.pdf">slides</a>, <a href="https://youtu.be/JmSfU0BTH5w">video</a></td>
+</tr>
+<tr>
+<td>13:50</td>
+<td>14:05</td>
+<td>Oszkár Semeráth, Kristóf Marussy (TU Budapest)</td>
+<td>Generation techniques for consistent, realistic, diverse, and scalable graphs – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/oszkar-semerath-generation-techniques-for-consistent-realistic-diverse-and-scalable-graphs.pdf">slides</a>, <a href="https://youtu.be/hB6j6mvh-vA">video</a></td>
+</tr>
+<tr>
+<td>14:10</td>
+<td>14:25</td>
+<td>Molham Aref (RelationalAI)</td>
+<td>Graph Normal Form – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/molham-aref-graph-normal-form.pdf">slides</a>, <a href="https://youtu.be/-kP4Raqr5KA">video</a></td>
+</tr>
+<tr>
+<td>14:30</td>
+<td>14:45</td>
+<td>Naomi Arnold (Queen Mary University of London)</td>
+<td>Temporal graph analysis of the far-right social network Gab – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/naomi-arnold-temporal-graph-analysis-of-the-far-right-social-network-gab.pdf">slides</a>, <a href="https://youtu.be/ugSkFlif4PE">video</a></td>
+</tr>
+<tr>
+<td>14:50</td>
+<td>15:05</td>
+<td>Domagoj Vrgoč (PUC Chile)</td>
+<td>Evaluating path queries in MillenniumDB – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/domagoj-vrgoc-regular-path-queries-in-millenniumdb.pdf">slides</a>, <a href="https://youtu.be/_OzJ6vI7GNU">video</a></td>
+</tr>
+<tr>
+<td>15:10</td>
+<td>15:25</td>
+<td>Pavel Klinov, Evren Sirin (Stardog)</td>
+<td>Stardog’s experience with LDBC – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifteenth-tuc-meeting/attachments/evren-sirin-stardog-experience-with-ldbc.pdf">slides</a>, <a href="https://youtu.be/CBrEeOTqGKM">video</a></td>
+</tr>
+</tbody>
+</table>
+
+
+
+ -
+
Announcing the LDBC Financial Benchmark Task Force
+ https://ldbcouncil.org/post/announcing-the-ldbc-financial-benchmark-task-force/
+ Thu, 26 May 2022 00:00:00 +0000
+
+ https://ldbcouncil.org/post/announcing-the-ldbc-financial-benchmark-task-force/
+ <p>We are delighted to announce the set up of the <a href="https://ldbcouncil.org/benchmarks/finbench/">Financial Benchmark (FinBench) task force</a>.</p>
+<p>The Financial Benchmark (FinBench) project aims to define a graph database evaluating benchmark and develop a data generation process and a query driver to make the evaluation of the graph database representative, reliable and comparable, especially in financial scenarios, such as anti-fraud and risk control. The FinBench is scheduled to be released in the end of 2022.</p>
+<p>Compared to LDBC SNB, the FinBench will differ in application scenarios, data patterns, and workloads, resulting in different schema characteristics, latency bounds, path filters, etc. FinBench is going to redesign the data pattern and workloads, including the data generation, the query driver, and also some other facilities referred to LDBC SNB.</p>
+<p>The FinBench Task Force was approved by LDBC on May 16, 2022. The FinBench Task Force is led by Ant Group, and the initial members also include Pometry, Create Link, StarGraph, Ultipa, Katana, Intel, Memgraph (observer) and Koji Annoura (individual member). See the <a href="https://ldbcouncil.org/benchmarks/finbench/ldbc-finbench-work-charter.pdf">Work Charter for FinBench</a></p>
+<p>If you are interested in joining FinBench Task Force, please reach out at info at ldbcouncil.org or guozhihui.gzh at antgroup.com.</p>
+
+
+
+ -
+
Fourteenth TUC Meeting
+ https://ldbcouncil.org/event/fourteenth-tuc-meeting/
+ Mon, 16 Aug 2021 16:00:00 +0200
+
+ https://ldbcouncil.org/event/fourteenth-tuc-meeting/
+ <p>LDBC was hosting a one-day hybrid workshop, co-located with <a href="https://vldb.org/2021/">VLDB 2021</a> on <strong>August 16 (Monday) between 16:00–20:00 CEST</strong>.</p>
+<p>The physical part of the workshop was held in room Akvariet 2 of the <a href="https://www.tivolihotel.com/">Tivoli Hotel</a> (Copenhagen), while the virtual part was hosted on Zoom. Our programme consisted of talks that provide an overview of LDBC’s recent efforts. Moreover, we have invited industry practitioners and academic researchers to present their latest results.</p>
+<p>Talks were scheduled to be 10 minutes with a short Q&A session. We had three sessions. Their schedules are shown below.</p>
+<h4 id="16001725-cest-ldbc-updates-benchmarks-query-languages">[16:00–17:25 CEST] LDBC updates, benchmarks, query languages</h4>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>16:00</td>
+<td>Peter Boncz (CWI)</td>
+<td>State of the union – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/peter-boncz-state-of-the-union.pdf">slides</a></td>
+</tr>
+<tr>
+<td>16:05</td>
+<td>Gábor Szárnyas (CWI)</td>
+<td>Overview of LDBC benchmarks – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/gabor-szarnyas-ldbc-benchmarks.pdf">slides</a></td>
+</tr>
+<tr>
+<td>16:12</td>
+<td>Mingxi Wu (TigerGraph)</td>
+<td>LDBC Social Network Benchmark results with TigerGraph – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/mingxi-wu-tigergraph-snb-preliminary-results.pdf">slides</a></td>
+</tr>
+<tr>
+<td>16:24</td>
+<td>Xiaowei Zhu (Ant Group)</td>
+<td>Financial Benchmark proposal – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/xiaowei-zhu-financial-benchmark.pdf">slides</a></td>
+</tr>
+<tr>
+<td>16:36</td>
+<td>Petra Selmer (Neo4j)</td>
+<td>Status report from the Existing Languages Working Group (ELWG) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/petra-selmer-elwg.pdf">slides</a>, <a href="https://youtu.be/I5A8VuFDhsA">video</a></td>
+</tr>
+<tr>
+<td>16:48</td>
+<td>Jan Hidders (Birkbeck)</td>
+<td>Status report from the Property Graph Schema Working Group (PGSWG) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/jan-hidders-pgswg.pdf">slides</a>, <a href="https://youtu.be/iEbVi9T-HVk">video</a></td>
+</tr>
+<tr>
+<td>17:00</td>
+<td>Keith Hare (JCC Consulting)</td>
+<td>Database Language Standards Structure and Process, SQL/PGQ – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/keith-hare-database-language-standards-structure-and-process-sql-pgq.pdf">slides</a>, <a href="https://youtu.be/ZgFCuzods4g">video</a></td>
+</tr>
+<tr>
+<td>17:12</td>
+<td>Stefan Plantikow (GQL Editor)</td>
+<td>Report on the GQL standard – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/stefan-plantikow-gql.pdf">slides</a>, <a href="https://youtu.be/z0pN5NwKsgc">video</a></td>
+</tr>
+</tbody>
+</table>
+<p><em>coffee break (10 minutes)</em></p>
+<h4 id="17351845-cest-systems-and-data-structures">[17:35–18:45 CEST] Systems and data structures</h4>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>17:35</td>
+<td>Vasileios Trigonakis (Oracle Labs)</td>
+<td>PGX.D aDFS: An Almost Depth-First-Search Distributed Graph-Querying System – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/vasileios-trigonakis-pgxd-adfs.pdf">slides</a>, <a href="https://youtu.be/cv2ZfWRBOek">video</a></td>
+</tr>
+<tr>
+<td>17:47</td>
+<td>Matthias Hauck (SAP)</td>
+<td>JSON, Spatial, Graph – Multi-model Workloads with SAP HANA Cloud – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/matthias-hauck-json-spatial-graph-sap-hana-cloud.pdf">slides</a>, <a href="https://youtu.be/dgpMJFho6Q8">video</a></td>
+</tr>
+<tr>
+<td>17:59</td>
+<td>Nikolay Yakovets (Eindhoven University of Technology)</td>
+<td>AvantGraph – <a href="https://youtu.be/z0pN5NwKsgcttachments/nikolay-yakovets-avantgraph.pdf">slides</a>, <a href="https://youtu.be/9M9FOycovTw">video</a></td>
+</tr>
+<tr>
+<td>18:11</td>
+<td>Semih Salihoglu (University of Waterloo)</td>
+<td>GRainDB: Making RDBMSs Efficient on Graph Workloads Through Predefined Joins – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/semih-salihoglu-graindb.pdf">slides</a>, <a href="https://youtu.be/FFK3y6vPHJs">video</a></td>
+</tr>
+<tr>
+<td>18:23</td>
+<td>Semyon Grigorev (Saint Petersburg University)</td>
+<td>Context-free path querying: Obstacles on the way to adoption – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/semyon-grigorev-cfpq.pdf">slides</a>, <a href="https://youtu.be/pha1xIpEL3I">video</a></td>
+</tr>
+<tr>
+<td>18:35</td>
+<td>Per Fuchs (Technical University of Munich)</td>
+<td>Sortledton: A universal, transactional graph data structure – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/per-fuchs-sortledton.pdf">slides</a>, <a href="https://youtu.be/33ZjsNN0hhU">video</a></td>
+</tr>
+</tbody>
+</table>
+<p><em>coffee break (10 minutes)</em></p>
+<h4 id="1855-2000-cest-high-level-approaches-and-benchmarks">[18:55-20:00 CEST] High-level approaches and benchmarks</h4>
+<table>
+<thead>
+<tr>
+<th>start</th>
+<th>speaker</th>
+<th>title</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>18:55</td>
+<td>Angelos-Christos Anadiotis (Ecole Polytechnique and Institut Polytechnique de Paris)</td>
+<td>Empowering Investigative Journalism with Graph-based Heterogeneous Data Management – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/angelos-christos-anadiotis-investigative-journalism-graph-data-management.pdf">slides</a>, <a href="https://youtu.be/a1VYjyec8dg">video</a></td>
+</tr>
+<tr>
+<td>19:07</td>
+<td>Vasia Kalavri (Boston University)</td>
+<td>Learning to partition unbounded graph streams – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/vasia-kalavri-learning-to-partition-unbounded-graph-streams.pdf">slides</a>, <a href="https://youtu.be/PTlUABKWniA">video</a></td>
+</tr>
+<tr>
+<td>19:19</td>
+<td>Muhammad Attahir Jibril (TU Ilmenau)</td>
+<td>Towards a Hybrid OLTP-OLAP Graph Benchmark – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/muhammad-attahir-jibril-hybrid-oltp-olap-benchmark.pdf">slides</a>, <a href="https://youtu.be/tMBVszTSJXc">video</a></td>
+</tr>
+<tr>
+<td>19:31</td>
+<td>Riccardo Tommasini (University of Tartu)</td>
+<td>An outlook on Benchmarks for Graph Stream Processing – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/riccardo-tommasini-graph-stream-processing-benchmarks.pdf">slides</a>, <a href="https://youtu.be/HabvJvPXsLc">video</a></td>
+</tr>
+<tr>
+<td>19:43</td>
+<td>Mohamed Ragab (University of Tartu)</td>
+<td>Benchranking: Towards prescriptive analysis of big graph processing: the case of SparkSQL – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourteenth-tuc-meeting/attachments/mohamed-ragab-benchranking.pdf">slides</a>, <a href="https://youtu.be/mZ8LhGUq7Wg">video</a></td>
+</tr>
+</tbody>
+</table>
+
+
+
+ -
+
Thirteenth TUC Meeting
+ https://ldbcouncil.org/event/thirteenth-tuc-meeting/
+ Tue, 30 Jun 2020 14:00:00 +0000
+
+ https://ldbcouncil.org/event/thirteenth-tuc-meeting/
+ <p>LDBC is pleased to announce its Thirteenth Technical User Community (TUC) meeting.</p>
+<p>LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, TigerGraph and Huawei among its members.</p>
+<p>This TUC meeting will be a two-day event hosted online. We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Gabor Szarnyas (BME) to register.</p>
+<h3 id="snb-task-force">SNB Task Force</h3>
+<ul>
+<li>Progress report
+<ul>
+<li>ACID compliance test suite</li>
+<li>Integrating deletions to Datagen</li>
+<li>Migrating Datagen to Spark</li>
+<li>Redesign of BI read queries</li>
+<li>Extensions to the driver</li>
+</ul>
+</li>
+<li>Ongoing work
+<ul>
+<li>Datagen: tuning the distribution of deletes</li>
+<li>Interactive 2.0 workload</li>
+<li>BI 1.0 workload</li>
+</ul>
+</li>
+</ul>
+<p>Zoom links will be sent through email.</p>
+
+
+
+ -
+
Speeding Up LDBC SNB Datagen
+ https://ldbcouncil.org/post/speeding-up-ldbc-snb-datagen/
+ Fri, 12 Jun 2020 00:00:00 +0000
+
+ https://ldbcouncil.org/post/speeding-up-ldbc-snb-datagen/
+ <p>LDBC’s <a href="#references">Social Network Benchmark [4]</a> (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data management.</p>
+<p>LDBC SNB provides <a href="https://github.com/ldbc/ldbc_snb_datagen">Datagen</a> (Data Generator), which produces synthetic datasets, mimicking a social network’s activity during a period of time. Datagen is defined by the charasteristics of realism, scalability, determinism and usability. To address scalability in particular, Datagen has been implemented on the MapReduce computation model to enable scaling out across a distributed cluster. However, since its inception in the early 2010s there has been a tremendous amount of development in the big data landscape, both in the sophistication of distributed processing platforms, as well as public cloud IaaS offerings. In the light of this, we should reevaluate this implementation, and in particular, investigate if Apache Spark would be a more cost-effective solution for generating datasets on the scale of tens of terabytes, on public clouds such as Amazon Web Services (AWS).</p>
+<h2 id="overview">Overview</h2>
+<p>The benchmark’s specification describes a social network <a href="https://github.com/ldbc/ldbc_snb_docs/blob/9253abbde94ec7eaccd366c5d4c15cca30752e36/figures/schema-comfortable.pdf">data model</a> which divides its components into two broad categories: static and dynamic. The dynamic element consists of an evolving network where people make friends, post in forums, comment or like each others posts, etc. In contrast, the static component contains related attributes such as countries, universities and organizations and are fixed values. For the detailed specifications of the benchmark and the Datagen component, see <a href="#references">References</a>.</p>
+<p>Datasets are generated in a multi-stage process captured as a sequence of MapReduce steps (shown in the diagram below).</p>
+<p><img src="datagen_flow.png" alt=""> \ <em>Figure 1. LDBC SNB Datagen Process on Hadoop</em></p>
+<p>In the initialization phase dictionaries are populated and distributions are initialized. In the first generation phase persons are synthesized, then relationships are wired between them along 3 dimensions (university, interest and random). After merging the graph of person relationships, the resulting dataset is output. Following this, activities such as forum posts, comments, likes and photos are generated and output. Finally, the static components are output.</p>
+<p><em>Note: The diagram shows the call sequence as implemented. All steps are sequential – including the relationship generation –, even in cases when the data dependencies would allow for parallelization.</em></p>
+<p>Entities are generated by procedural Java code and are represented as POJOs in memory and as sequence files on disk. Most entities follow a shallow representation, i.e foreign keys (in relational terms) are mapped to integer ids, which makes serialization straightforward.<sup id="fnref:1"><a href="#fn:1" class="footnote-ref" role="doc-noteref">1</a></sup> A notable exception is the Knows edge which contains only the target vertex, and is used as a navigation property on the source Person. The target Person is replaced with only the foreign key augmented with some additional information in order to keep the structure free of cycles. Needless to say, this <em>edge as property</em> representation makes the data harder to handle in SQL than it would be with a flat join table.</p>
+<p>Entity generation amounts to roughly one fifth of the main codebase. It generates properties drawn from several random distributions using mutable pRNGs. Determinism is achieved by initializing the pRNGs to seeds that are fully defined by the configuration with constants, and otherwise having no external state in the logic.<sup id="fnref:2"><a href="#fn:2" class="footnote-ref" role="doc-noteref">2</a></sup></p>
+<p>Serialization is done by hand-written serializers for the supported output formats (e.g. CSV) and comprises just a bit less than one third of the main codebase. Most of the output is created by directly interacting with low-level HDFS file streams. Ideally, this code should be migrated to higher-level writers that handle faults and give consistent results when the task has to be restarted.</p>
+<h2 id="motivations-for-the-migration">Motivations for the migration</h2>
+<p>The application is written using Hadoop MapReduce, which is now largely superseded by more modern distributed batch processing platforms, notably Apache Spark. For this reason, it was proposed to migrate Datagen to Spark. The migration provides the following benefits:</p>
+<ul>
+<li>
+<p><strong>Better memory utilization:</strong> MapReduce is disk-oriented, i.e. it writes the output to disk after each reduce stage which is then read by the next MapReduce job. As public clouds provide virtual machines with sufficient RAM to encapsulate any generated dataset, time and money are wasted by the overhead this unnecessary disk I/O incurs. Instead, the intermediate results should be cached in memory where possible. The lack of support for this is a well-known limitation of MapReduce.</p>
+</li>
+<li>
+<p><strong>Smaller codebase:</strong> The Hadoop MapReduce library is fairly ceremonial and boilerplatey. Spark provides a higher-level abstraction that is simpler to work with, while still providing enough control on the lower-level details required for this workload.</p>
+</li>
+<li>
+<p><strong>Small entry cost:</strong> Spark and MapReduce are very close conceptually, they both utilise HDFS under the hood, and run on the JVM. This means that a large chunk of the existing code can be reused, and migration to Spark can, therefore, be completed with relatively small effort. Additionally, MapReduce and Spark jobs can be run on AWS EMR using basically the same HW/SW configuration, which facilitates straightforward performance comparisons.</p>
+</li>
+<li>
+<p><strong>Incremental improvements:</strong> Spark exposes multiple APIs for different workloads and operating on different levels of abstraction. Datagen may initially utilise the lower-level, Java-oriented RDDs (which offer the clearest 1 to 1 mapping when coming from MapReduce) and gradually move towards DataFrames to support Parquet output in the serializers and maybe unlock some SQL optimization capabilities in the generators later down the road.</p>
+</li>
+<li>
+<p><strong>OSS, commodity:</strong> Spark is one of the most widely used open-source big data platforms. Every major public cloud provides a managed offering for Spark. Together these mean that the migration increases the approachability and portability of the code.</p>
+</li>
+</ul>
+<h2 id="first-steps">First steps</h2>
+<p>The first milestone is a successful run of LDBC Datagen on Spark while making the minimum necessary amount of code alterations. This entails the migration of the Hadoop wrappers around the generators and serializers. The following bullet-points summarize the key notions that cropped up during the process.</p>
+<ul>
+<li>
+<p><strong>Use your memory:</strong> A strong focus was placed on keeping the call sequence intact, so that the migrated code evaluates the same steps in the same order, but with data passed as RDDs. It was hypothesised that the required data could be either cached in memory entirely at all times, or if not, regenerating them would still be faster than involving the disk I/O loop (e.g. by using <code>MEMORY_AND_DISK</code>). In short, the default caching strategy was used everywhere.</p>
+</li>
+<li>
+<p><strong>Regression tests:</strong> Lacking tests apart from an id uniqueness check, meant there were no means to detect bugs introduced by the migration. Designing and implementing a comprehensive test suite was out of scope, so instead, regression testing was utilised, with the MapReduce output as the baseline. The original output mostly consists of Hadoop sequence files which can be read into Spark, allowing comparisons to be drawn with the output from the RDD produced by the migrated code.</p>
+</li>
+<li>
+<p><strong>Thread-safety concerns:</strong> Soon after migrating the first generator and running the regression tests, there were clear discrepancies in the output. These only surfaced when the parallelization level was set greater than 1. This indicated the presence of potential race conditions. Thread-safety wasn’t a concern in the original implementation due to the fact that MapReduce doesn’t use thread-based parallelization for mappers and reducers.<sup id="fnref:3"><a href="#fn:3" class="footnote-ref" role="doc-noteref">3</a></sup> In Spark however, tasks are executed by parallel threads in the same JVM application, so the code is required to be thread-safe. After some debugging, a bug was discovered originating from the shared use of java.text.SimpleDateFormat (notoriously known to be not thread-safe) in the serializers. This was resolved simply by changing to java.time.format.DateTimeFormatter. There were multiple instances of some static field on an object being mutated concurrently. In some cases this was a temporary buffer and was easily resolved by making it an instance variable. In another case a shared context variable was used, which was resolved by passing dedicated instances as function arguments. Sadly, the Java language has the same syntax for accessing locals, fields and statics, <sup id="fnref:4"><a href="#fn:4" class="footnote-ref" role="doc-noteref">4</a></sup> which makes it somewhat harder to find potential unguarded shared variables.</p>
+</li>
+</ul>
+<h2 id="case-study-person-ranking">Case study: Person ranking</h2>
+<p>Migrating was rather straightforward, however, the so-called person ranking step required some thought. The goal of this step is to organize persons so that similar ones appear close to each other in a deterministic order. This provides a scalable way to cluster persons according to a similarity metric, as introduced in the <a href="#references">S3G2 paper [3]</a>.</p>
+<h3 id="the-original-mapreduce-version">The original MapReduce version</h3>
+<p><img src="person_ranking.svg" alt=""> \ <em>Figure 2. Diagram of the MapReduce code for ranking persons</em></p>
+<p>The implementation, shown in pseudocode above, works as follows:</p>
+<ol>
+<li>The equivalence keys are mapped to each person and fed into TotalOrderPartitioner which maintains an order sensitive partitioning while trying to emit more or less equal sized groups to keep the data skew low.</li>
+<li>The reducer keys the partitions with its own task id and a counter variable which has been initialized to zero and incremented on each person, establishing a local ranking inside the group. The final state of the counter (which is the total number of persons in that group) is saved to a separate “side-channel” file upon the completion of a reduce task.</li>
+<li>In a consecutive reduce-only stage, the global order is established by reading all of these previously emitted count files in the order of their partition number in each reducer, then creating an ordered map from each partition number to the corresponding cumulative count of persons found in all preceding ones. This is done in the setup phase. In the reduce function, the respective count is incremented and assigned to each person.</li>
+</ol>
+<p>Once this ranking is done, the whole range is sliced up into equally sized blocks, which are processed independently. For example, when wiring relationships between persons, only those appearing in the same block are considered.</p>
+<h3 id="the-migrated-version">The migrated version</h3>
+<p>Spark provides a sortBy function which takes care of the first step above in a single line. The gist of the problem remains collecting the partition sizes and making them available in a later step. While the MapReduce version uses a side output, in Spark the partition sizes are collected in a separate job and passed into the next phase using a broadcast variable. The resulting code size is a fraction of the original one.</p>
+<h2 id="benchmarks">Benchmarks</h2>
+<p>Benchmarks were carried out on AWS <a href="https://aws.amazon.com/emr/">EMR</a>, originally utilising <a href="https://aws.amazon.com/ec2/instance-types/i3/">i3.xlarge</a> instances because of their fast NVMe SSD storage and ample amount of RAM.</p>
+<p>The application parameter hadoop.numThreads controls the number of reduce threads in each Hadoop job for the MapReduce version and the number of partitions in the serialization jobs in the Spark one. For MapReduce, this was set to n_nodes, i.e. the number of machines; experimentation yield slowdowns for higher values. The Spark version on the other hand, performed better with this parameter set to n_nodes * v_cpu. The scale factor (SF) parameter determines the output size. It is defined so that one SF unit generates around 1 GB of data. That is, SF10 generates around 10 GB, SF30 around 30 GB, etc. It should be noted however, that incidentally the output was only 60% of this in these experiments, stemming from two reasons. One, update stream serialization was not migrated to Spark, due to problems in the original implementation. Of course, for the purpose of faithful comparison the corresponding code was removed from the MapReduce version as well before executing the benchmarks. This explains a 10% reduction from the expected size. The rest can be attributed to incorrectly tuned parameters.<sup id="fnref:5"><a href="#fn:5" class="footnote-ref" role="doc-noteref">5</a></sup> The MapReduce results were as follows:</p>
+<table>
+<thead>
+<tr>
+<th>SF</th>
+<th>workers</th>
+<th>Platform</th>
+<th>Instance Type</th>
+<th>runtime (min)</th>
+<th>runtime * worker/SF (min)</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>10</td>
+<td>1</td>
+<td>MapReduce</td>
+<td>i3.xlarge</td>
+<td>16</td>
+<td>1.60</td>
+</tr>
+<tr>
+<td>30</td>
+<td>1</td>
+<td>MapReduce</td>
+<td>i3.xlarge</td>
+<td>34</td>
+<td>1.13</td>
+</tr>
+<tr>
+<td>100</td>
+<td>3</td>
+<td>MapReduce</td>
+<td>i3.xlarge</td>
+<td>40</td>
+<td>1.20</td>
+</tr>
+<tr>
+<td>300</td>
+<td>9</td>
+<td>MapReduce</td>
+<td>i3.xlarge</td>
+<td>44</td>
+<td>1.32</td>
+</tr>
+</tbody>
+</table>
+<p>It can be observed that the runtime per scale factor only increases slowly, which is good. The metric charts show an underutilized, bursty CPU. The bursts are supposedly interrupted by the disk I/O parts when the node is writing the results of a completed job. It can also be seen that the memory only starts to get consumed after 10 minutes of the run have assed.</p>
+<p><img src="mr_sf100_cpu_load.png" alt=""> <br>
+<em>Figure 3. CPU Load for the Map Reduce cluster is bursty and less than<br>
+50% on average (SF100, 2nd graph shows master)</em></p>
+<p><img src="mr_sf100_mem_free.png" alt=""> <br>
+<em>Figure 4. The job only starts to consume memory when already 10 minutes<br>
+into the run (SF100, 2nd graph shows master)</em></p>
+<p>Let’s see how Spark fares.</p>
+<table>
+<thead>
+<tr>
+<th>SF</th>
+<th>workers</th>
+<th>Platform</th>
+<th>Instance Type</th>
+<th>runtime (min)</th>
+<th>runtime * worker/SF (min)</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>10</td>
+<td>1</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>10</td>
+<td>1.00</td>
+</tr>
+<tr>
+<td>30</td>
+<td>1</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>21</td>
+<td>0.70</td>
+</tr>
+<tr>
+<td>100</td>
+<td>3</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>27</td>
+<td>0.81</td>
+</tr>
+<tr>
+<td>300</td>
+<td>9</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>36</td>
+<td>1.08</td>
+</tr>
+<tr>
+<td>1000</td>
+<td>30</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>47</td>
+<td>1.41</td>
+</tr>
+<tr>
+<td>3000</td>
+<td>90</td>
+<td>Spark</td>
+<td>i3.xlarge</td>
+<td>47</td>
+<td>1.41</td>
+</tr>
+</tbody>
+</table>
+<p>A similar trend here, however the run times are around 70% of the MapReduce version. It can be seen that the larger scale factors (SF1000 and SF3000) yielded a long runtime than expected. On the metric charts of SF100 the CPU shows full utilization, except at the end, when the results are serialized in one go and the CPU is basically idle (the snapshot of the diagram doesn’t include this part unfortunately). Spark can be seen to have used up all memory pretty fast even in case of SF100. In case of SF1000 and SF3000, the nodes are running so low on memory that most probably some of the RDDs have to be calculated multiple times (no disk level serialization was used here), which seem to be the most plausible explanation for the slowdowns experienced. In fact, the OOM errors encountered when running SF3000 supports this hypothesis even further. It was thus proposed to scale up the RAM in the instances. The CPU utilization hints that adding some extra vCPUs as well can further yield speedup.</p>
+<p><img src="spark_sf100_cpu_load.png" alt=""> <br>
+<em>Figure 5. Full CPU utilization for Spark (SF100, last graph shows<br>
+master)</em></p>
+<p><img src="spark_sf100_mem_free.png" alt=""> <br>
+<em>Figure 6. Spark eats up memory fast (SF100, 2nd graph shows master)</em></p>
+<p>i3.2xlarge would have been the most straightforward option for scaling up the instances, however the humongous 1.9 TB disk of this image is completely unnecessary for the job. Instead the cheaper r5d.2xlarge instance was utilised, largely identical to i3.2xlarge, except it <em>only</em> has a 300 GB SSD.</p>
+<table>
+<thead>
+<tr>
+<th>SF</th>
+<th>workers</th>
+<th>Platform</th>
+<th>Instance Type</th>
+<th>runtime (min)</th>
+<th>runtime * worker/SF (min)</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>100</td>
+<td>3</td>
+<td>Spark</td>
+<td>r5d.2xlarge</td>
+<td>16</td>
+<td>0.48</td>
+</tr>
+<tr>
+<td>300</td>
+<td>9</td>
+<td>Spark</td>
+<td>r5d.2xlarge</td>
+<td>21</td>
+<td>0.63</td>
+</tr>
+<tr>
+<td>1000</td>
+<td>30</td>
+<td>Spark</td>
+<td>r5d.2xlarge</td>
+<td>26</td>
+<td>0.78</td>
+</tr>
+<tr>
+<td>3000</td>
+<td>90</td>
+<td>Spark</td>
+<td>r5d.2xlarge</td>
+<td>25</td>
+<td>0.75</td>
+</tr>
+<tr>
+<td>10000</td>
+<td>303</td>
+<td>Spark</td>
+<td>r5d.2xlarge</td>
+<td>25</td>
+<td>0.75</td>
+</tr>
+</tbody>
+</table>
+<p>The last column clearly demonstrates our ability to keep the cost per scale factor unit constant.</p>
+<h2 id="next-steps">Next steps</h2>
+<p>The next improvement is refactoring the serializers so they use Spark’s high-level writer facilities. The most compelling benefit is that it will make the jobs fault-tolerant, as Spark maintains the integrity of the output files in case the task that writes it fails. This makes Datagen more resilient and opens up the possibility to run on less reliable hardware configuration (e.g. EC2 spot nodes on AWS) for additional cost savings. They will supposedly also yield some speedup on the same cluster configuration.</p>
+<p>As already mentioned, the migration of the update stream serialization was ignored due to problems with the original code. Ideally, they should be implemented with the new serializers.</p>
+<p>The Spark migration also serves as an important building block for the next generation of LDBC benchmarks. As part of extending the SNB benchmark suite, the SNB task force has recently extended Datagen with support for <a href="#references">generating delete operations [1]</a>. The next step for the task force is to fine-tune the temporal distributions of these deletion operations to ensure that the emerging sequence of events is realistic, i.e. the emerging distribution resembles what a database system would experience when serving a real social network.</p>
+<h2 id="acknowledgements">Acknowledgements</h2>
+<p>This work is based upon the work of Arnau Prat, Gábor Szárnyas, Ben Steer, Jack Waudby and other LDBC contributors. Thanks for your help and feedback!</p>
+<h2 id="references">References</h2>
+<p>[1] <a href="https://ldbcouncil.org/docs/papers/datagen-deletes-grades-nda-2020.pdf">Supporting Dynamic Graphs and Temporal Entity Deletions in the LDBC Social Network Benchmark’s Data Generator</a></p>
+<p>[2] <a href="https://www.youtube.com/watch?v=ZQOLuCOOpSI">9th TUC Meeting – LDBC SNB Datagen Update – Arnau Prat (UPC)</a> - <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431942.pdf">slides</a></p>
+<p>[3] <a href="https://research.vu.nl/en/publications/s3g2-a-scalable-structure-correlated-social-graph-generator">S3G2: a Scalable Structure-correlated Social Graph Generator</a></p>
+<p>[4] <a href="https://arxiv.org/abs/2001.02299">The LDBC Social Network Benchmark</a></p>
+<p>[5] <a href="https://ldbcouncil.org/">LDBC</a> - <a href="https://github.com/ldbc">LDBC GitHub organization</a></p>
+<div class="footnotes" role="doc-endnotes">
+<hr>
+<ol>
+<li id="fn:1">
+<p>Also makes it easier to map to a tabular format thus it is a SQL friendly representation. <a href="#fnref:1" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:2">
+<p>It’s hard to imagine this done declaratively in SQL. <a href="#fnref:2" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:3">
+<p>Instead, multiple YARN containers have to be used if you want to parallelize on the same machine. <a href="#fnref:3" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:4">
+<p>Although editors usually render these using different font styles. <a href="#fnref:4" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+<li id="fn:5">
+<p>With the addition of deletes, entities often get inserted and deleted during the simulation (which is normal in a social network). During serialization, we check for such entities and omit them. However, we forgot to calculate this when determining the output size, which we will amend when tuning the distributions. <a href="#fnref:5" class="footnote-backref" role="doc-backlink">↩︎</a></p>
+</li>
+</ol>
+</div>
+
+
+
+ -
+
Twelfth TUC Meeting
+ https://ldbcouncil.org/event/twelfth-tuc-meeting/
+ Fri, 05 Jul 2019 08:30:00 +0100
+
+ https://ldbcouncil.org/event/twelfth-tuc-meeting/
+ <p>LDBC is pleased to announce its Twelfth Technical User Community (TUC) meeting.</p>
+<p>LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmarks and graph standards, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j, TigerGraph and Huawei among its members.</p>
+<p>This TUC meeting will be a one-day event on the last Friday of <strong><a href="https://sigmod2019.org/">SIGMOD/PODS 2019</a></strong> in Amsterdam, The Netherlands, in the conference venue of <strong><a href="http://sigmod2019.org/conf_venue">Beurs van Berlage</a></strong>. The room is the Mendes da Silva kamer. Please check its tips for <strong><a href="http://sigmod2019.org/accommodation">accommodation in Amsterdam</a></strong>.</p>
+<p>Note also that at SIGMOD/PODS in Amsterdam on Sunday, June 30, there is a research workshop on graph data management technology called <a href="https://sites.google.com/site/gradesnda2019">GRADES-NDA 2019</a>, that may be of interest to our audience (this generally holds for the whole SIGMOD/PODS program, of course).</p>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Damaris Coll (UPC) at <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a> to register.</p>
+<p><strong>=> registration is free, but required <=</strong></p>
+<p>You need to be registered in order to get into the SIGMOD/PODS venue. Friday, July 5, is the final, workshop, day of SIGMOD/PODS, and the LDBC TUC meeting joins the other workshops for coffee and lunch.</p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management.</p>
+<p><strong>Talk proposals can be sent to Peter Boncz</strong>, who is also the local organizer. <strong>Please also send your slides to this email for archiving on this site.</strong></p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.</p>
+<h3 id="agenda">Agenda</h3>
+<p>In the TUC meeting, there will be:</p>
+<ul>
+<li>updates on progress with LDBC benchmarks, specifically the Social Network Benchmark (SNB) and its Interactive, Business Intelligence and Graphalytics workloads.</li>
+<li>talks by data management practitioners highlighting graph data management challenges and products</li>
+</ul>
+<p>The morning slot (08:30-10:30) is reserved for an LDBC Board Meeting, to which in principle only LDBC directors are invited (that meeting will be held in the same room).</p>
+<p>The TUC meeting will start on Friday morning after the morning coffee break of SIGMOD/PODS 2019 (<strong>room: Mendes da Silva kamer</strong>):</p>
+<p>08:30-10:30 LDBC Board Meeting (non-public)</p>
+<p>10:30-11:00 Coffee</p>
+<p>11:00-12:45 Session 1: Graph Benchmarks</p>
+<ul>
+<li>
+<p>11:00-11:05 Welcome & introduction</p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/112230404.pdf">11:05-11:45 Gabor Szarnyas (BME), Benjamin Steer (QMUL), Jack Waudby (Newcastle University): Business Intelligence workload: Progress report and roadmap</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706117.pdf">11:45-12:00 Frank McSherry (Materialize): Experiences implementing LDBC queries in a dataflow system</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706118.pdf">12:00-12:25 Vasileios Trigonakis (Oracle): Evaluating a new distributed graph query engine with LDBC: Experiences and limitations</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706130.pdf">12:25-12:45 Ahmed Musaafir (VU Amsterdam): LDBC Graphalytics</a></p>
+</li>
+</ul>
+<p>12:45-14:00 Lunch</p>
+<p>14:00-16:05 Session 2: Graph Query Languages</p>
+<ul>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706120.pdf">14:00-14:25 Juan Sequeda (Capsenta): Property Graph Schema Working Group: A progress report</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706121.pdf">14:25-14:50 Stefan Plantikow (Neo4j): GQL: Scope and features</a>, <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706122.pdf">report</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706119.pdf">14:50-15:15 Vasileios Trigonakis (Oracle): Property graph extensions for the SQL standard</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706129.pdf">15:15-15:40 Alin Deutsch (TigerGraph): Modern graph analytics support in GSQL, TigerGraph’s query language</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/112230401.pdf">15:40-16:05 Jan Posiadała (Nodes and Edges, Poland): Executable semantics of graph query language</a></p>
+</li>
+</ul>
+<p>16:05-16:30 Coffee</p>
+<p>16:30-17:50 Session 3: Graph System Performance</p>
+<ul>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111968258.pdf">16:30-16:50 Per Fuchs (CWI): Fast, scalable WCOJ graph-pattern matching on in-memory graphs in Spark</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706124.pdf">16:50-17:10 Semih Salihoglu (University of Waterloo): Optimizing subgraph queries with a mix of tradition and modernity</a> <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706116.pptx">pptx</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706128.pdf">17:10-17:30 Roi Lipman (RedisGraph): Evaluating Cypher queries and procedures as algebraic operations within RedisGraph</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/twelfth-tuc-meeting/attachments/106233859/111706133.pdf">17:30-17:50 Alexandru Uta (VU Amsterdam): Low-latency Spark queries on updatable data</a></p>
+</li>
+</ul>
+<p>If there is interest, we will organize a social dinner on Friday evening for LDBC attendees.</p>
+
+
+
+ -
+
Eleventh TUC Meeting
+ https://ldbcouncil.org/event/eleventh-tuc-meeting/
+ Fri, 08 Jun 2018 08:30:00 -0500
+
+ https://ldbcouncil.org/event/eleventh-tuc-meeting/
+ <p>LDBC Technical User Community meetings serve to (1) learn about progress in the LDBC task forces on graph benchmark development, (2) to give feedback on these, and (3) hear about user experiences with graph data management technologies or (4) learn about new graph technologies from researchers or industry – LDBC counts Oracle, IBM, Intel, Neo4j and Huawei among its members.</p>
+<p>This TUC meeting will be a one-day event preceding the <a href="https://sigmod2018.org/">SIGMOD/PODS 2018</a> conference in Houston, Texas (not too far away, the whole next week). Note also that at SIGMOD/PODS in Houston on Sunday 10, there is a research workshop on graph data management technology called <a href="https://sites.google.com/site/gradesnda2018/">GRADES-NDA 2018</a> as well, so you might combine travel.</p>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Damaris Coll (UPC) at <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a> to register.</p>
+<p><strong>=> registration is free, but required <=</strong></p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals are handled by Peter Boncz (<a href="mailto:boncz@cwi.nl">boncz@cwi.nl</a>) and Larri (<a href="mailto:larri@ac.upc.ed">larri@ac.upc.edu</a>). Local organizer is Juan Sequeda (<a href="mailto:juanfederico@gmail.com">juanfederico@gmail.com</a>).</p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.</p>
+<h3 id="agenda">Agenda</h3>
+<p>In the TUC meeting there will be:</p>
+<ul>
+<li>updates on progress with LDBC benchmarks, specifically the Social Network Benchmark (SNB) and its interactive, business analytics and graphalytics workloads.</li>
+<li>talks by data management practitioners highlighting graph data management challenges and products</li>
+</ul>
+<p>The meeting will start on Friday morning, with a program from 10:30-17:00:</p>
+<ul>
+<li>
+<p>10:30-10:35 Peter Boncz (CWI) - introduction to the LDBC TUC meeting</p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090478.pdf">10:35-11:00 Juan Sequeda (Capsenta) - Announcing: gra.fo</a></p>
+</li>
+<li>
+<p>11:00-11:30 coffee break</p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090466.pdf">11:30-11:55 Gabor Szarnyas (BME) - LDBC benchmarks: three aspects of graph processing</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090463.pdf">11:55-12:20 Peter Boncz (CWI) - G-CORE: a composable graph query language by LDBC</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090472.pdf">12:20-12:45 Yinglong Xia (Huawei) - Graph Engine for Cloud AI</a></p>
+</li>
+<li>
+<p>12:45-14:00 lunch</p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090474.pdf">14:00-14:25 Stefan Plantikow (Neo4j) - Composable Graph Queries and Multiple Named Graphs in Cypher for Apache Spark</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090481.pdf">14:25-14:50 Oskar van Rest (Oracle) - Analyzing Stack Exchange data using Property Graph in Oracle</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99090485.pdf">14:50-15:15 Brad Bebee (Amazon) - Neptune: the AWS graph management service</a></p>
+</li>
+<li>
+<p>15:15-15:40 coffee break</p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99811329.pdf">15:40-16:05 Bryon Jacob (data.world): Broadening the Semantic Web</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99287041.pdf">16:05-16:30 Jason Plurad (IBM) - Graph Computing with JanusGraph</a></p>
+</li>
+<li>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99745793.pdf">16:30-16:55 Arthur Keen (Cambridge Semantics): AnzoGraph</a></p>
+</li>
+<li>
+<p><a href="http://relational.ai/">16:55-17:20 Molham Aref (relational.ai)</a>) - Introducing.. <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eleventh-tuc-meeting/attachments/91422722/99418113.pdf">relational.ai</a></p>
+</li>
+<li>
+<p>18:00 - 20:00 social dinner in Austin (sponsored by Intel Corp.), Coopers BBQ, 217 Congress Ave, Austin, TX 78701</p>
+</li>
+</ul>
+<h3 id="location">Location</h3>
+<p>The TUC will be held at the <a href="https://www.cs.utexas.edu/">University of Texas at Austin, Department of Computer Science</a> in the <a href="https://www.google.com/maps/place/The+University+of+Texas:+Department+of+Computer+Science/@30.2860955,-97.737582,18z/data=!4m5!3m4!1s0x0:0x12edecc8226b3241!8m2!3d30.2862279!4d-97.7365348">Gates Dell Complex (GDC): 2317 Speedway, Austin TX, 78712</a> Room: GDC 6.302</p>
+<p>The GDC building has a North and a South building. GDC 6.302 is in the North building. When you enter the main entrance, the North building is on the left and it is served by a pair of elevators. You can take or the elevator to the 6th floor. Exit the elevator on the 6th floor. Turn left, right, left.</p>
+<h3 id="from-austin-to-sigmodpods-houston-on-saturday-june-9">From Austin to SIGMOD/PODS (Houston) on Saturday June 9</h3>
+<p>Many of the attendees will be going to SIGMOD/PODS which will be held in Houston.</p>
+<h4 id="bus">Bus</h4>
+<p>One option is to take a <a href="https://us.megabus.com/journey-planner/journeys?days=1&concessionCount=0&departureDate=2018-06-09&destinationId=318&inboundOtherDisabilityCount=0&inboundPcaCount=0&inboundWheelchairSeated=0&nusCount=0&originId=320&otherDisabilityCount=0&pcaCount=0&totalPassengers=1&wheelchairSeated=0">MegaBus that departs from downtown Austin and arrives at downtown Houston</a>.</p>
+<p>There is a bus that departs at 12:00PM and arrives at 3:00pm. Cost is $20 (as of April 23).</p>
+<p>If you want to spend the day in Austin, there is a bus that departs at 9:55PM and arrives at 12:50am. Cost is $5 (as of April 23).</p>
+
+
+
+ -
+
Tenth TUC Meeting
+ https://ldbcouncil.org/event/tenth-tuc-meeting/
+ Fri, 01 Sep 2017 10:30:00 +0100
+
+ https://ldbcouncil.org/event/tenth-tuc-meeting/
+ <p>This will be a one-day event at the <a href="http://www.vldb.org/2017">VLDB 2017</a> conference in Munich, Germany on September 1, 2017.</p>
+<p>Topics and activities of interest in these TUC meetings are:</p>
+<ul>
+<li>Presentation on graph data management usage scenarios.</li>
+<li>Presentation of the benchmarking results for the different benchmarks, as well as the graph query language task force.</li>
+<li>Interaction with the new LDBC Board of Directors and the LDBC organisation officials.</li>
+</ul>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested to attend the event, please, contact Adrian Diaz (UPC) at <a href="mailto:adiaz@ac.upc.edu">adiaz@ac.upc.edu</a> to register; registration is free, but required.</p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals are handled by Peter Boncz and Larri.</p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.</p>
+<h3 id="agenda">Agenda</h3>
+<p>In the TUC meeting there will be:</p>
+<ul>
+<li>updates on progress with LDBC benchmarks, specifically the Social Network Benchmark (SNB) and its Interactive, Business Intelligence and Graphalytics workloads.</li>
+<li>talks by data management practitioners highlighting graph data management challenges</li>
+<li>selected scientific talks on graph data management technology</li>
+</ul>
+<p>The meeting will start on Friday morning, with a program from 10:30-17:00</p>
+<p>10:30-12:00: TUC session (public)</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/87588865.pdf">Peter Boncz (CWI): GraphQL task force update - the G-CORE proposal</a> (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868018.pptx">pptx</a>)</li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868008.pdf">Gabor Szarnyas (Budapest University of Technology and Economics Hungarian Academy of Sciences): Updates on the Social Network Benchmark BI Workload</a></li>
+<li>Alexandru Iosup, Wing Lung Ngai (VU/TU Delft): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868014.pdf">LDBC Graphalytics v0.9</a>, <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868013.pdf">Graphalytics Global Competition and Graphalytics Custom Benchmark</a></li>
+</ul>
+<p>12:00-13:30: lunch break</p>
+<p>13:30-15:00: TUC session (public)</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868024.pdf">Arnau Prat (UPC): Datasynth: Democratizing property graph generation</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/86868026.pdf">Marcus Paradies (SAP): SAP HANA GraphScript</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/87031809.pdf">Yinglong Xia (Huawei): The EYWA Graph Engine in a Cloud AI Platform</a></li>
+<li>Gaétan Hains (Huawei): Cost semantics for graph queries</li>
+</ul>
+<p>15:00-15:30: break</p>
+<p>15:30-17:00: TUC session (public)</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/87031812.pdf">Petra Selmer and Stefan Plantikow (Neo4j): openCypher Developments in 2017</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/87195650.pdf">Markus Kaindl (Springer): SN SciGraph – Building a Linked Data Knowledge Graph for the Scholarly Publishing Domain</a></li>
+<li>Irini Fundulaki (FORTH): The HOBBIT Link Discovery and Versioning Benchmarks</li>
+<li>Ghislain Atemezing (Mondeca): Benchmarking Enterprise RDF stores with Publications Office Dataset</li>
+</ul>
+<p>Speakers should aim for a <strong>20-minute talk</strong>.</p>
+<p>Further:</p>
+<ul>
+<li>on Friday evening (19:00-21:00) there will be a <strong>social dinner</strong> at <a href="https://www.loewenbraeukeller.com/en/pub-and-beer-garden/">Löwenbräukeller</a>, sponsored and arranged by LDBC member Huawei (who have their European Research Center in Munich).</li>
+<li>on Friday morning (8:30-10:30) there will be a meeting of the LDBC board of directors, but this meeting is not public.</li>
+</ul>
+<h3 id="venue">Venue</h3>
+<p>The Technical University of Munich (TUM) is hosting that week the <a href="http://www.vldb.org/2017">VLDB conference</a>; on the day of the TUC meeting the main conference will have finished, but there will be a number of co-located workshops ongoing, and the TUC participants will blend in with that crowd for the breaks and lunch.</p>
+<p>The TUC meeting will be held in in <strong>Room 2607</strong> alongside the VLDB workshops that day (MATES, ADMS, DMAH, DBPL and BOSS).</p>
+<p><strong>address: Technische Universität München (TUM), Arcisstraße 21, 80333 München</strong></p>
+<p><a href="https://www.google.nl/maps/place/Technische+Universit%C3%A4t+M%C3%BCnchen/@48.14966,11.5656715,17z/data=!3m1!4b1!4m5!3m4!1s0x479e7261336d8c11:0x79a04d44dc5bf19d!8m2!3d48.14966!4d11.5678602?hl=en">Google Maps</a></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/81920002.jpg" alt=""><br>
+<img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/tenth-tuc-meeting/attachments/81920005/81920003.jpg" alt=""></p>
+
+
+
+ -
+
Ninth TUC Meeting
+ https://ldbcouncil.org/event/ninth-tuc-meeting/
+ Thu, 09 Feb 2017 15:07:18 -0400
+
+ https://ldbcouncil.org/event/ninth-tuc-meeting/
+ <p>LDBC is pleased to announce its Ninth Technical User Community (TUC) meeting.</p>
+<p>This will be a two-day event at <a href="https://websmp201.sap-ag.de/~sapidp/011000358700001204882013E.pdf">SAP Headquarters</a> in Walldorf, Germany on February 9+10, 2017.</p>
+<p>This will be the third TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:</p>
+<ul>
+<li>Two day event with one day devoted to User’s experiences and one day devoted to benchmarking experiences.</li>
+<li>Presentation of the benchmarking results for the different benchmarks.</li>
+<li>Interaction with the new LDBC Board of Directors and the LDBC organisation officials.</li>
+</ul>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a>;</p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is related to graph data management. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.</p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.</p>
+<h3 id="agenda">Agenda</h3>
+<p>In the TUC meeting there will be</p>
+<ul>
+<li>updates on progress with LDBC benchmarks, specifically the Social Network Benchmark (SNB) and its Interactive, Business Inalytics and Graphalytics workloads.</li>
+<li>talks by data management practitioners highlighting graph data management challenges</li>
+<li>selected scientific talks on graph data management technology</li>
+</ul>
+<p>The meeting will start on Thursday morning, with a program from 09:00-18:00, interrupted by a lunch break.</p>
+<p>Thursday evening (19:00-21:00) there will be a <strong>social dinner</strong> in Heidelberg.</p>
+<p>Friday morning the event resumes from 9:00-12:00. In the afternoon, there is a (closed) LDBC Board of Directors meeting (13:00-16:30) at the same venue.</p>
+<h4 id="social-dinner">Social Dinner</h4>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235334.png" alt=""></p>
+<p><strong>Address: Hauptstraße 217, 69117 Heidelberg</strong><br>
+<strong>Time: 19:00 / 7pm</strong></p>
+<p>(See attachments at the bottom of the page)</p>
+<h5 id="thursday">Thursday</h5>
+<table>
+<thead>
+<tr>
+<th>start time</th>
+<th>title – speaker</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>9:00</td>
+<td>Welcome and logistics - Marcus Paradies (SAP)</td>
+</tr>
+<tr>
+<td>9:10</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235329.pdf">Intro + state of the LDBC - Josep Lluis Larriba Pey</a> (UPC)</td>
+</tr>
+<tr>
+<td>9:20</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235338.pdf">LDBC Graph QL task force</a> - Hannes Voigt (TU Dresden)</td>
+</tr>
+<tr>
+<td>9:40</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235335.pdf">PGQL Status Update and Comparison to LDBC’s Graph QL proposals</a> - Oskar van Rest (Oracle Labs)</td>
+</tr>
+<tr>
+<td>10:00</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75628546.pdf">Adding shortest-paths to MonetDB</a> - Dean de Leo (CWI)</td>
+</tr>
+<tr>
+<td>10:20</td>
+<td>coffee</td>
+</tr>
+<tr>
+<td>10:50</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431939.pdf">Evolving Cypher for processing multiple graphs</a> - Stefan Plantikow (Neo Technology)</td>
+</tr>
+<tr>
+<td>11:10</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235346.pdf">Standardizing Graph Database Functionality - An Invitation to Collaborate</a> - Jan Michels (ISO/ANSI SQL, Oracle)"</td>
+</tr>
+<tr>
+<td>11:30</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75235343.pdf">Dgraph: Graph database for production environment</a> - Tomasz Zdybal (Dgraph.io)</td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>lunch</td>
+</tr>
+<tr>
+<td>13:00</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431945.pdf">LDBC Graphalytics: Current Capabilities, Upcoming Features, and Long-Term Roadmap</a> - Alexandru Iosup (TU Delft)</td>
+</tr>
+<tr>
+<td>13:20</td>
+<td>LDBC Graphalytics: Demo of the Live Archive and Competition Features - Tim Hegeman (TU Delft)</td>
+</tr>
+<tr>
+<td>13:40</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431942.pdf">LDBC SNB Datagen Update</a> - Arnau Prat (UPC)</td>
+</tr>
+<tr>
+<td>14:00</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431943.pdf">LDBC SNB Business Intelligence Workload: Chokepoint Analysis</a> - Arnau Prat (UPC)</td>
+</tr>
+<tr>
+<td>14:20</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431947.pdf">LDBC Benchmark Cost Specification</a> (+discussion) - Moritz Kaufmann (TU Munich)</td>
+</tr>
+<tr>
+<td>14:40</td>
+<td>coffee break</td>
+</tr>
+<tr>
+<td>15:10</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76316673.pdf">EYWA: the Distributed Graph Engine in Huawei MIND Platform</a> (Yinglong Xia)</td>
+</tr>
+<tr>
+<td>15:30</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75431949.pdf">Graph Processing in SAP HANA</a> - Marcus Paradies (SAP)</td>
+</tr>
+<tr>
+<td>15:50</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75628563.pdf">Distributed Graph Analytics with Gradoop</a> - Martin Junghanns (Univ Leipzig)</td>
+</tr>
+<tr>
+<td>16:10</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76152834.pdf">Distributed graph flows: Cypher on Flink and Gradoop</a> - Max Kießling (Neo Technology)</td>
+</tr>
+<tr>
+<td>16:30</td>
+<td>closing - Peter Boncz</td>
+</tr>
+<tr>
+<td>17:30</td>
+<td>end</td>
+</tr>
+</tbody>
+</table>
+<h5 id="friday">Friday</h5>
+<table>
+<thead>
+<tr>
+<th>start time</th>
+<th>title – speaker</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>9:00</td>
+<td>welcome - Peter Boncz</td>
+</tr>
+<tr>
+<td>9:20</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76152833.pdf">Graph processing in obi4wan</a> - Frank Smit (OBI4WAN)</td>
+</tr>
+<tr>
+<td>9:40</td>
+<td>Graph problems in the space domain - Albrecht Schmidt (ESA)</td>
+</tr>
+<tr>
+<td>10:00</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/75792387.pdf">Medical Ontologies for Healthcare</a> - Michael Neumann (SAP)</td>
+</tr>
+<tr>
+<td>10:20</td>
+<td>coffee</td>
+</tr>
+<tr>
+<td>10:50</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76447745.pdf">The Train Benchmark: Cross-Technology Performance Evaluation of Continuous Model Queries</a> - Gabor Szarnyas (BME)</td>
+</tr>
+<tr>
+<td>11:10</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76021761.pdf">Efficient sparse matrix computations and their generalization to graph computing applications</a> - Albert-Jan Yzelman (Huawei)</td>
+</tr>
+<tr>
+<td>11:30</td>
+<td><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/76152837.pdf">Experiments on Semantic Publishing Benchmark with large scale real news and LOD data at FactForge</a> - Atanas Kyriakov (Ontotext)</td>
+</tr>
+<tr>
+<td>12:00</td>
+<td>lunch</td>
+</tr>
+<tr>
+<td>13:00</td>
+<td>LDBC Board of Directors Meeting</td>
+</tr>
+<tr>
+<td>17:00</td>
+<td>end</td>
+</tr>
+</tbody>
+</table>
+<h3 id="logistics">Logistics</h3>
+<h5 id="important-things-to-know"><strong>Important things to know</strong></h5>
+<p>The following PDF guide provides additional information, such as recommended restaurants as well as sightseeing spots: <a href="https://websmp201.sap-ag.de/~sapidp/011000358700001204882013E.pdf">link</a></p>
+<h5 id="venue"><strong>Venue</strong></h5>
+<p>The TUC meeting will be held in the <a href="https://websmp201.sap-ag.de/~sapidp/011000358700001204882013E.pdf">SAP Headquarters</a> at the SAP Guesthouse Kalipeh (<a href="https://www.kalipeh.com">https://www.kalipeh.com</a>). The address is:</p>
+<p><strong>WDF 44 / SAP Guesthouse Kalipeh<br>
+Dietmar-Hopp-Allee 15<br>
+69190 Walldorf<br>
+Germany</strong></p>
+<h6 id="maps-and-situation"><strong>Maps and situation</strong></h6>
+<p><a href="https://www.google.com/maps/place/SAP+Guesthouse+Kalipeh/@49.2951903,8.6436224,17z/data=!3m1!4b1!4m5!3m4!1s0x4797bea343a566af:0xd70698f3503ab74b!8m2!3d49.2951868!4d8.6458111">Google Maps link</a></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/ninth-tuc-meeting/attachments/59277315/69042180.png" alt=""></p>
+<h4 id="getting-there"><strong>Getting there</strong></h4>
+<h5 id="by-plane"><strong>By plane</strong></h5>
+<p>There are two airports close to SAP’s headquarter: Frankfurt Airport (FRA) and Stuttgart-Echterdingen Airport (STR). The journey from Frankfurt Airport to SAP headquarters takes about one hour by car, while it takes slightly longer from Stuttgart- Echterdingen Airport. Concerning airfare, flights to Frankfurt are usually somewhat more expensive than to Stuttgart.</p>
+<p>When booking flights to Frankfurt, you should be aware of Frankfurt-Hahn Airport (HHN), which serves low-cost carriers but is not connected to Frankfurt Airport. Frankfurt Hahn is approximately one hour from the Frankfurt main airport by car.</p>
+<p>The journey from Frankfurt Airport to SAP headquarters takes about one hour by car (95 kilometers, or 59 miles).</p>
+<p>Journey time from Stuttgart-Echterdingen Airport to SAP headquarters takes about 1 hour and 15 minutes by car (115 kilometers, or 71 miles).</p>
+<h6 id="driving-directions"><strong>Driving directions</strong></h6>
+<p><strong>Traveling from Frankfurt Airport (FRA) to SAP Headquarters:</strong></p>
+<p>Directions to SAP headquarters:</p>
+<ul>
+<li>When leaving the airport, follow the highway symbol onto “A3/Würzburg/A5/Kassel/Basel/Frankfurt.”</li>
+<li>Follow the A5 to “Basel/Karlsruhe/Heidelberg.”</li>
+<li>Take exit 39 – “Walldorf/Wiesloch.”</li>
+<li>Turn left onto B291.</li>
+<li>Turn right onto Dietmar-Hopp-Allee.</li>
+</ul>
+<p>(Should you use a navigational system which does not recognize the street name ‘Dietmar-Hopp-Allee’ please use ‘Neurottstrasse’ instead.)</p>
+<p><strong>Traveling from Stuttgart-Echterdingen Airport (STR) to SAP Headquarters:</strong></p>
+<p>To get to SAP headquarters by car, there are two possible routes to take. The first leads you via Heilbronn and the second via Karlsruhe. The route via Karlsruhe is a bit shorter yet may be more congested.</p>
+<p>Directions to SAP headquarters:</p>
+<ul>
+<li>When leaving the airport, follow the highway symbol onto “A8/Stuttgart/B27.”</li>
+<li>Stay on A8 and follow the sign for “Karlsruhe/Heilbronn/Singen/A8.”</li>
+<li>Follow A8 to Karlsruhe.</li>
+<li>Take exit 41 – “Dreieck Karlsruhe” to merge onto A5 toward “Frankfurt/Mannheim/Karlsruhe/Landau (Pfalz).”</li>
+<li>Take exit 39 – “Walldorf/Wiesloch.”</li>
+<li>Turn left onto B291.</li>
+<li>Turn right onto Dietmar-Hopp-Allee.</li>
+</ul>
+<h6 id="parking"><strong>Parking</strong></h6>
+<p>The closest parking lot to the event location is P7 (see figure above).</p>
+<h5 id="by-train"><strong>By Train</strong></h5>
+<p>As the infrastructure is very well developed in Europe, and in Germany in particular, taking the train is a great and easy way of traveling. Furthermore, the trains usually run on time, so this mode of travel is very convenient, especially for a group of people on longer journeys to major cities.</p>
+<p><strong>From Frankfurt Airport (FRA) to SAP Headquarters</strong></p>
+<p>Directions to SAP headquarters:</p>
+<ul>
+<li>Go to Terminal 1, level T (see overview in Appendix).</li>
+<li>Go to the AIRail Terminal – “Fernbahnhof” (long-distance trains).</li>
+<li>Choose a connection with the destination train station “Wiesloch–Walldorf”.</li>
+<li>From station “Wiesloch–Walldorf,” take bus number 707 or 721 toward “Industriegebiet Walldorf, SAP.” It is a 10-minute ride to reach bus stop ‘SAP headquarters’.</li>
+</ul>
+<p><strong>From Stuttgart-Echterdingen Airport (STR) to SAP Headquarters</strong></p>
+<p>Directions to SAP headquarters:</p>
+<ul>
+<li>Go to the S-Bahn station in the airport, following the sign (station is called “Stuttgart Flughafen/Messe”).</li>
+<li>Take train number S2 or S3 to “Stuttgart Hauptbahnhof” (main station).</li>
+<li>From Stuttgart Hauptbahnhof choose a connection with the destination train station “Wiesloch–Walldorf”.</li>
+<li>From station “Wiesloch–Walldorf,” take bus number 707 or 721 toward “Industriegebiet Walldorf, SAP”. It is a 10-minute ride to reach bus stop ‘SAP headquarters’.</li>
+</ul>
+
+
+
+ -
+
LDBC Is Proud to Announce the New LDBC Graphalytics Benchmark Draft Specification
+ https://ldbcouncil.org/post/ldbc-is-proud-to-announce-the-new-ldbc-graphalytics-benchmark-draft-specification/
+ Tue, 06 Sep 2016 00:00:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-is-proud-to-announce-the-new-ldbc-graphalytics-benchmark-draft-specification/
+ <p>LDBC is proud to announce the new LDBC Graphalytics Benchmark draft specification.</p>
+<p>LDBC Graphalytics is the first industry-grade graph data management benchmark for graph analysis platforms such as Giraph. It consists of six core algorithms, standard datasets, synthetic dataset generators, and reference outputs, enabling the objective comparison of graph analysis platforms. It has strong industry support from Oracle, Intel, Huawei and IBM, and was tested and optimized on the best industrial and open-source systems.</p>
+<p>Tim Hegeman of <a href="https://www.tudelft.nl">TU Delft</a> is today presenting the technical paper describing LDBC Graphalytics at the important <a href="https://www.vldb.org/conference.html">VLDB</a> (Very Large DataBases) conference in New Delhi, where his talk also marks the release by LDBC of Graphalytics as a benchmark draft. Practitioners are invited to read the PVLDB paper, download the software and try running it.</p>
+<p>LDBC is eager to use any feedback for its future adoption of LDBC Graphalytics.</p>
+<p>Learn more: [/ldbc-graphalytics](LDBC Graphalytics)</p>
+<p>GitHub: <a href="https://github.com/tudelft-atlarge/graphalytics">https://github.com/tudelft-atlarge/graphalytics</a></p>
+
+
+
+ -
+
Eighth TUC Meeting
+ https://ldbcouncil.org/event/eighth-tuc-meeting/
+ Wed, 22 Jun 2016 14:45:20 -0400
+
+ https://ldbcouncil.org/event/eighth-tuc-meeting/
+ <p>The LDBC consortium is pleased to announce its Eighth Technical User Community (TUC) meeting.</p>
+<p>This will be a two-day event/eighth-tuc-meeting/attachments at <a href="http://www.oracle.com/technetwork/database/rdb/hqcc-dir-134199.pdf">Oracle Conference Center</a> in Redwood Shores facility on <strong>Wednesday and Thursday June 22-23, 2016</strong>.</p>
+<p>This will be the second TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event/eighth-tuc-meeting/attachments will basically set the following aspects:</p>
+<ul>
+<li>Two day event/eighth-tuc-meeting/attachments with one day devoted to User’s experiences and one day devoted to benchmarking experiences.</li>
+<li>Presentation of the benchmarking results for the different benchmarks.</li>
+<li>Interaction with the new LDBC Board of Directors and the LDBC organisation officials.</li>
+</ul>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a>; in order to notify Oracle security in advance, registration requests need to be in by <strong>June 12</strong>.</p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is graph data management related. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.</p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also event/eighth-tuc-meeting/attachmentsually its membership base.</p>
+<p>In this page, you’ll find information about the following items:</p>
+<ul>
+<li><a href="#agenda">Agenda</a></li>
+<li><a href="#logistics">Logistics</a>
+<ul>
+<li><a href="#date">Date</a></li>
+<li><a href="#venue">Venue</a></li>
+<li><a href="#getting-there">Getting there</a></li>
+</ul>
+</li>
+<li><a href="#accommodation">Accommodation</a></li>
+</ul>
+<h3 id="agenda">Agenda</h3>
+<p>On Wednesday, lunch is provided for all attendees at 12 pm. The TUC Meeting will start at 1pm.</p>
+<h6 id="wednesday-22th-of-june-2016-room-203"><strong>Wednesday, 22th of June 2016 (<strong>Room 203)</strong></strong></h6>
+<p>(full morning: LDBC Board of Directors meeting)</p>
+<ul>
+<li>12:00 - 13:00 Lunch (provided)</li>
+<li>13:00 - 13:30 Hassan Chafi (Oracle) and Josep L. Larriba-Pey (Sparsity) Registration and welcome.</li>
+<li>13:30 - 14:00 Peter Boncz (CWI) <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133891.pdf">LDBC introduction and status update</a>.</li>
+<li>14:00 - 15:00 Details on the progress of LDBC Task Forces 1 (chair Josep L. Larriba-Pey)</li>
+<li>14:00 Arnau Prat (DAMA-UPC). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133902.pdf">Social Network Benchmark, Interactive workload</a>.</li>
+<li>14:30 Tim Hegeman (TU Delft). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133893.pdf">Social Network Benchmark, Analytics workload</a>.</li>
+<li>15:00 - 15:30 Coffee break</li>
+<li>15:30 - 17:00 Applications and use of Graph Technologies (chair Hassan Chafi)
+<ul>
+<li>15:30 Martin Zand (University of Rochester Clinical and Translational Science Institute). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133897.pdf">Graphing Healthcare Networks: Data, Analytics, and Use Cases.</a></li>
+<li>16:00 David Meibusch, Nathan Hawes (Oracle Labs Australia). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133901.pdf">Frappé: Querying and managing evolving code dependency graphs</a>.</li>
+<li>16:30 Jerven Bolleman (SIB Swiss Institute of Bioinformatics/UniProt consortium). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133895.pdf">UniProt: challenges of a public SPARQL endpoint.</a></li>
+</ul>
+</li>
+<li>17:00 - 18:30 Graph Technologies (chair Peter Boncz)
+<ul>
+<li>17:00 Eugene I. Chong (Oracle USA). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133904.pdf">Balancing Act to improve RDF Query Performance in Oracle Database</a>.</li>
+<li>17:30 Lijun Chang (University of New South Wales). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133906.pdf">Efficient Subgraph Matching by Postponing Cartesian Products</a>.</li>
+<li>18:00 Weining Qian (East China Normal University). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133908.pdf">On Statistical Characteristics of Real-Life Knowledge Graphs</a>.</li>
+</ul>
+</li>
+</ul>
+<h6 id="thursday-23th-of-june-2016-room-203"><strong>Thursday, 23th of June 2016 (Room 203)</strong></h6>
+<ul>
+<li>08:00 - 09:00 Breakfast (provided)</li>
+<li>09:00 - 10:00 Details on the progress of LDBC Task Forces 2 (chair Josep L. Larriba-Pey)
+<ul>
+<li>09:00 Peter Boncz (CWI). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52133896.pdf">Query Language Task Force status</a></li>
+<li>09:45 Marcus Paradies (SAP). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297729.pdf">Social Network Benchmark, Business Intelligence workload</a></li>
+</ul>
+</li>
+<li>10:00 - 12:00 Graph Technologies and Benchmarking (chair Oskar van Rest)
+<ul>
+<li>10:00 Sergey Edunov (Facebook). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297731.pdf">Generating realistic trillion-edge graphs</a></li>
+<li>10:30 George Fletcher (TU Eindhoven). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297733.pdf">An open source framework for schema-driven graph instance and graph query workload generation</a>.</li>
+<li>11:00 Yinglong Xia (Huawei Research America): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297735.pdf">An Efficient Big Graph Analytics Platform</a>.</li>
+<li>11:30 Zhe Wu (Oracle USA). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297737.pdf">Bridging RDF Graph and Property Graph Data Models</a></li>
+</ul>
+</li>
+<li>12:00 - 13:30 Lunch (provided)</li>
+<li>13:30 - 15:30 Graph Technologies (chair Arnau Prat)
+<ul>
+<li>13:30 Tobias Lindaaker (Neo Technology). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297740.pdf">An open standard for graph queries: the Cypher contribution</a></li>
+<li>14:00 Arash Termehchy (Oregon State University). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297742.pdf">Toward Representation Independent Graph Querying & Analytics</a></li>
+<li>14:30 Jerven Bolleman (SIB Swiss Institute of Bioinformatics/UniProt consortium). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297745.pdf">In the service of the federation</a></li>
+<li>15:00 Nandish Jayaram (Pivotal). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52297747.pdf">Orion: Enabling Suggestions in a Visual Query Builder for Ultra-Heterogeneous Graphs</a>.</li>
+</ul>
+</li>
+<li>15:30 - 16:00 Coffee break</li>
+<li>16:00 - 17:15 Applications and use of Graph Technologies (chair Hassan Chafi)
+<ul>
+<li>16:00 Jans Aasman (Franz Inc.). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52428806.pdf">Semantic Data Lake for Healthcare</a></li>
+<li>16:15 Kevin Madden (Tom Sawyer Software). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52428812.pdf">Dismantling Criminal Networks with Graph and Spatial Visualization and Analysis</a></li>
+<li>16:45 Juan Sequeda (Capsenta). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52428810.pdf">Using graph representation and semantic technology to virtually integrate and search multiple diverse data sources</a></li>
+<li>17:15 Kevin Wilkinson (Hewlett Packard Labs). <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/52428808.pdf">LDBC SNB extensions</a></li>
+</ul>
+</li>
+<li>17:45 - 18:15 Closing discussion</li>
+</ul>
+<h6 id="friday-24th-of-june-2016-room-105"><strong>Friday, 24th of June 2016 (Room 105)</strong></h6>
+<p>At the same venue: the fourth international workshop on Graph Data Management, Experience and Systems (<strong>GRADES16</strong>).</p>
+<p>18:30 social dinner for GRADES registrants (place to be announced)</p>
+<h3 id="logistics">Logistics</h3>
+<h6 id="date"><strong>Date</strong></h6>
+<p>22nd and 23rd June 2016</p>
+<h6 id="venue"><strong>Venue</strong></h6>
+<p>The TUC meeting will be held in the <a href="http://www.oracle.com/technetwork/database/rdb/hqcc-dir-134199.pdf">Oracle Conference Center</a></p>
+<p>The address is:</p>
+<p><strong>Room 203 (Wed-Thu) & Room 105 (Fri)</strong><br>
+<strong>Oracle Conference Center</strong><br>
+<strong>350 Oracle Parkway</strong><br>
+<strong>Redwood City, CA 94065, USA</strong></p>
+<p><strong>Maps and situation</strong></p>
+<p><a href="https://www.google.com/maps/place/Oracle+Conference+Center/@37.5322827,-122.2667034,17z/data=!3m1!4b1!4m2!3m1!1s0x808f98b5450e8ca3:0xdc75e8b1c02bbb91">Google Maps link</a></p>
+<p>Oracle Campus map:</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/eighth-tuc-meeting/attachments/40927235/40927234.jpg" alt=""></p>
+<h5 id="getting-there"><strong>Getting there</strong></h5>
+<h6 id="driving-directions"><strong>Driving directions</strong></h6>
+<ul>
+<li>[Southbound] <strong>-</strong> Take Highway 101 South (toward San Jose) to the Ralston Ave./Marine World Parkway exit. Take Marine World Parkway east which will loop you back over the freeway. Make a left at the first light onto Oracle Parkway. 350 Oracle Parkway will be on the right.</li>
+<li>[Northbound] <strong>-</strong> Take Highway 101 North (toward San Francisco) to the Ralston Ave./Marine World Parkway exit. Take the first exit ramp onto Marine World Parkway. Make a left at the first light onto Oracle Parkway. 350 Oracle Parkway will be on the right.</li>
+</ul>
+<h5 id="parking"><strong>Parking</strong></h5>
+<p>The Conference Center has a designated parking lot located directly across from the building. If the lot is filled there is also additional parking in any of the parking garages located near by. No parking permits are needed.</p>
+<h5 id="public-transport"><strong>Public transport</strong></h5>
+<p>Take the Caltrain to either San Carlos or Hillsdale and take the free Oracle shuttle from there. Get off the Oracle shuttle at 100 Oracle Parkway (second stop) and walk 5 minutes to get to the Conference Center.</p>
+<ul>
+<li>Caltrain timetables: <a href="http://www.caltrain.com/schedules/weekdaytimetable.html">http://www.caltrain.com/schedules/weekdaytimetable.html</a></li>
+<li>Oracle Shuttle timetables: <a href="http://www.caltrain.com/schedules/weekdaytimetable.html">http://www.caltrain.com/schedules/Shuttles/Oracle_Shuttle.html</a></li>
+</ul>
+<p>You can also take the Caltrain to Belmont and walk 23 min, instead of taking the Oracle shuttle.</p>
+<p>Alternatively, SamTrans (San Mateo County’s Transit Agency) provides public bus service between the Millbrae BART station and Palo Alto with three stops on Oracle Parkway - one of which is directly in front of the Oracle Conference Center.</p>
+
+
+
+ -
+
LDBC and Apache Flink
+ https://ldbcouncil.org/post/ldbc-and-apache-flink/
+ Mon, 16 Nov 2015 14:47:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-and-apache-flink/
+ <p>Apache Flink <a href="#references">[1]</a> is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.</p>
+<p><img src="https://flink.apache.org/img/flink-stack-small.png" alt=""></p>
+<p>Flink offers multiple APIs to process data from various data sources (e.g. HDFS, HBase, Kafka and JDBC). The DataStream and DataSet APIs allow the user to apply general-purpose data operations, like map, reduce, groupBy and join, on streams and static data respectively. In addition, Flink provides libraries for machine learning (Flink ML), graph processing (Gelly) and SQL-like operations (Table). All APIs can be used together in a single Flink program which enables the definition of powerful analytical workflows and the implementation of distributed algorithms.</p>
+<p>The following snippet shows how a wordcount program can be expressed in Flink using the DataSet API:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-java" data-lang="java"><span style="display:flex;"><span>DataSet<span style="color:#f92672"><</span>String<span style="color:#f92672">></span> text <span style="color:#f92672">=</span> env<span style="color:#f92672">.</span><span style="color:#a6e22e">fromElements</span><span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"He who controls the past controls the future."</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"He who controls the present controls the past."</span><span style="color:#f92672">);</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span>DataSet<span style="color:#f92672"><</span>Tuple2<span style="color:#f92672"><</span>String<span style="color:#f92672">,</span> Integer<span style="color:#f92672">>></span> wordCounts <span style="color:#f92672">=</span> text
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span><span style="color:#a6e22e">flatMap</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> LineSplitter<span style="color:#f92672">())</span> <span style="color:#75715e">// splits the line and outputs (word,1)
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>
+</span></span><span style="display:flex;"><span>tuples<span style="color:#f92672">.</span><span style="color:#a6e22e">groupBy</span><span style="color:#f92672">(</span><span style="color:#ae81ff">0</span><span style="color:#f92672">)</span> <span style="color:#75715e">// group by word
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> <span style="color:#f92672">.</span><span style="color:#a6e22e">sum</span><span style="color:#f92672">(</span><span style="color:#ae81ff">1</span><span style="color:#f92672">);</span> <span style="color:#75715e">// sum the 1's
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>
+</span></span><span style="display:flex;"><span>wordCounts<span style="color:#f92672">.</span><span style="color:#a6e22e">print</span><span style="color:#f92672">();</span>
+</span></span></code></pre></div><p>At the Leipzig University, we use Apache Flink as execution layer for our graph analytics platform Gradoop <a href="#references">[2]</a>. The LDBC datagen helps us to evaluate the scalability of our algorithms and operators in a distributed execution environment. To use the generated graph data in Flink, we wrote a tool that transforms the LDBC output files into Flink data sets for further processing <a href="#references">[3]</a>. Using the class <code>LDBCToFlink</code>, LDBC output files can be read directly from HDFS or from the local file system:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-java" data-lang="java"><span style="display:flex;"><span><span style="color:#66d9ef">final</span> ExecutionEnvironment env <span style="color:#f92672">=</span>
+</span></span><span style="display:flex;"><span> ExecutionEnvironment<span style="color:#f92672">.</span><span style="color:#a6e22e">getExecutionEnvironment</span><span style="color:#f92672">();</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">final</span> LDBCToFlink ldbcToFlink <span style="color:#f92672">=</span> <span style="color:#66d9ef">new</span> LDBCToFlink<span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"hdfs:///ldbc_snb_datagen/social_network"</span><span style="color:#f92672">,</span> <span style="color:#75715e">// or "/path/to/social_network"
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span> env<span style="color:#f92672">);</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span>DataSet<span style="color:#f92672"><</span>LDBCVertex<span style="color:#f92672">></span> vertices <span style="color:#f92672">=</span> ldbcToFlink<span style="color:#f92672">.</span><span style="color:#a6e22e">getVertices</span><span style="color:#f92672">();</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span>DataSet<span style="color:#f92672"><</span>LDBCEdge<span style="color:#f92672">></span> edges <span style="color:#f92672">=</span> ldbcToFlink<span style="color:#f92672">.</span><span style="color:#a6e22e">getEdges</span><span style="color:#f92672">();</span>
+</span></span></code></pre></div><p>The tuple classes <code>LDBCVertex</code> and <code>LDBCEdge</code> hold the information generated by the LDBC datagen and are created directly from its output files. During the transformation process, globally unique vertex identifiers are created based on the LDBC identifier and the vertex class. When reading edge files, source and target vertex identifiers are computed in the same way to ensure consistent linking between vertices.</p>
+<p>Each <code>LDBCVertex</code> instance contains:</p>
+<ul>
+<li>an identifier, which is unique among all vertices * a vertex label (e.g. <code>Person</code>, <code>Comment</code>) * a key-value map of properties including also multivalued properties<br>
+(e.g. <code>Person.email</code>)</li>
+</ul>
+<p>Each <code>LDBCEdge</code> instance contains:</p>
+<ul>
+<li>an identifier, which is unique among all edges</li>
+<li>an edge label (e.g. <code>knows</code>, <code>likes</code>)</li>
+<li>a source vertex identifier</li>
+<li>a target vertex identifier</li>
+<li>a key-value map of properties</li>
+</ul>
+<p>The resulting datasets can be used by the DataSet API and all libraries that are built on top of it (i.e. Flink ML, Gelly and Table). In the following example, we load the LDBC graph from HDFS, filter vertices with the label <code>Person</code> and edges with the label <code>knows</code> and use Gelly to compute the connected components of that subgraph. The full source code is available on GitHub <a href="#references">[4]</a>.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-java" data-lang="java"><span style="display:flex;"><span><span style="color:#66d9ef">final</span> ExecutionEnvironment env <span style="color:#f92672">=</span>
+</span></span><span style="display:flex;"><span> ExecutionEnvironment<span style="color:#f92672">.</span><span style="color:#a6e22e">getExecutionEnvironment</span><span style="color:#f92672">();</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">final</span> LDBCToFlink ldbcToFlink <span style="color:#f92672">=</span> <span style="color:#66d9ef">new</span> LDBCToFlink<span style="color:#f92672">(</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"/home/s1ck/Devel/Java/ldbc_snb_datagen/social_network"</span><span style="color:#f92672">,</span>
+</span></span><span style="display:flex;"><span> env<span style="color:#f92672">);</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// filter vertices with label “Person”
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>DataSet<span style="color:#f92672"><</span>LDBCVertex<span style="color:#f92672">></span> ldbcVertices <span style="color:#f92672">=</span> ldbcToFlink<span style="color:#f92672">.</span><span style="color:#a6e22e">getVertices</span><span style="color:#f92672">()</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span><span style="color:#a6e22e">filter</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> VertexLabelFilter<span style="color:#f92672">(</span>LDBCConstants<span style="color:#f92672">.</span><span style="color:#a6e22e">VERTEX_CLASS_PERSON</span><span style="color:#f92672">));</span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// filter edges with label “knows”
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>DataSet<span style="color:#f92672"><</span>LDBCEdge<span style="color:#f92672">></span> ldbcEdges <span style="color:#f92672">=</span> ldbcToFlink<span style="color:#f92672">.</span><span style="color:#a6e22e">getEdges</span><span style="color:#f92672">()</span>
+</span></span><span style="display:flex;"><span> <span style="color:#f92672">.</span><span style="color:#a6e22e">filter</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> EdgeLabelFilter<span style="color:#f92672">(</span>LDBCConstants<span style="color:#f92672">.</span><span style="color:#a6e22e">EDGE_CLASS_KNOWS</span><span style="color:#f92672">));</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// create Gelly vertices suitable for connected components
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>DataSet<span style="color:#f92672"><</span>Vertex<span style="color:#f92672"><</span>Long<span style="color:#f92672">,</span> Long<span style="color:#f92672">>></span> vertices <span style="color:#f92672">=</span> ldbcVertices<span style="color:#f92672">.</span><span style="color:#a6e22e">map</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> VertexInitializer<span style="color:#f92672">());</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// create Gelly edges suitable for connected components
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>DataSet<span style="color:#f92672"><</span>Edge<span style="color:#f92672"><</span>Long<span style="color:#f92672">,</span> NullValue<span style="color:#f92672">>></span> edges <span style="color:#f92672">=</span> ldbcEdges<span style="color:#f92672">.</span><span style="color:#a6e22e">map</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> EdgeInitializer<span style="color:#f92672">());</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// create Gelly graph
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>Graph<span style="color:#f92672"><</span>Long<span style="color:#f92672">,</span> Long<span style="color:#f92672">,</span> NullValue<span style="color:#f92672">></span> g <span style="color:#f92672">=</span> Graph<span style="color:#f92672">.</span><span style="color:#a6e22e">fromDataSet</span><span style="color:#f92672">(</span>vertices<span style="color:#f92672">,</span> edges<span style="color:#f92672">,</span> env<span style="color:#f92672">);</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// run connected components on the subgraph for 10 iterations
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>DataSet<span style="color:#f92672"><</span>Vertex<span style="color:#f92672"><</span>Long<span style="color:#f92672">,</span> Long<span style="color:#f92672">>></span> components <span style="color:#f92672">=</span>
+</span></span><span style="display:flex;"><span> g<span style="color:#f92672">.</span><span style="color:#a6e22e">run</span><span style="color:#f92672">(</span><span style="color:#66d9ef">new</span> ConnectedComponents<span style="color:#f92672"><</span>Long<span style="color:#f92672">,</span> NullValue<span style="color:#f92672">>(</span><span style="color:#ae81ff">10</span><span style="color:#f92672">));</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">// print the component id of the first 10 vertices
+</span></span></span><span style="display:flex;"><span><span style="color:#75715e"></span>components<span style="color:#f92672">.</span><span style="color:#a6e22e">first</span><span style="color:#f92672">(</span><span style="color:#ae81ff">10</span><span style="color:#f92672">).</span><span style="color:#a6e22e">print</span><span style="color:#f92672">();</span>
+</span></span></code></pre></div><p>The ldbc-flink-import tool is available on Github <a href="#references">[3]</a> and licensed under the GNU GPLv3. If you have any questions regarding the tool please feel free to contact me on GitHub. If you find bugs or have any ideas for improvements, please create an issue or a pull request.</p>
+<p>If you want to learn more about Apache Flink, a good starting point is the main documentation <a href="#references">[5]</a> and if you have any question feel free to ask the official mailing lists.<br>
+There is also a nice set of videos <a href="#references">[6]</a> available from the latest Flink Forward conference.</p>
+<h4 id="references">References</h4>
+<p>[1] <a href="http://flink.apache.org/">http://flink.apache.org/</a></p>
+<p>[2] <a href="https://github.com/dbs-leipzig/gradoop">https://github.com/dbs-leipzig/gradoop</a></p>
+<p>[3] <a href="https://github.com/s1ck/ldbc-flink-import">https://github.com/s1ck/ldbc-flink-import</a></p>
+<p>[4] <a href="https://gist.github.com/s1ck/b33e6a4874c15c35cd16">https://gist.github.com/s1ck/b33e6a4874c15c35cd16</a></p>
+<p>[5] <a href="https://ci.apache.org/projects/flink/flink-docs-release-0.10/">https://ci.apache.org/projects/flink/flink-docs-release-0.10/</a></p>
+<p>[6] <a href="https://www.youtube.com/channel/UCY8_lgiZLZErZPF47a2hXMA">https://www.youtube.com/channel/UCY8_lgiZLZErZPF47a2hXMA</a></p>
+
+
+
+ -
+
Seventh TUC Meeting
+ https://ldbcouncil.org/event/seventh-tuc-meeting/
+ Mon, 09 Nov 2015 14:17:30 -0400
+
+ https://ldbcouncil.org/event/seventh-tuc-meeting/
+ <p>The LDBC consortium is pleased to announce its Seventh Technical User Community (TUC) meeting.</p>
+<p>This will be a two-day event at <a href="http://www.research.ibm.com/labs/watson">IBM’s TJ Watson</a> facility on <strong>Monday and Tuesday November 9/10, 2015.</strong></p>
+<p>This will be the first TUC meeting after the finalisation of the LDBC FP7 EC funded project. The event will basically set the following aspects:</p>
+<ul>
+<li>Two day event with one day devoted to User’s experiences and one day devoted to benchmarking experiences.</li>
+<li>Presentation of the benchmarking results for the different benchmarks.</li>
+<li>Interaction with the new LDBC Board of Directors and the LDBC organisation officials.</li>
+</ul>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact Damaris Coll (UPC) at <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a>; in order to notify IBM security in advance, registration requests need to be in by Nov 1.</p>
+<p>In the agenda, there will be talks given by LDBC members and LDBC activities, but there will also be room for a number of short 20-minute talks by other participants. We are specifically interested in learning about new challenges in graph data management (where benchmarking would become useful) and on hearing about actual user stories and scenarios that could inspire benchmarks. Further, talks that provide feedback on existing benchmark (proposals) are very relevant. But nothing is excluded a priori if it is graph data management related. Talk proposals can be forwarded to Damaris as well and will be handled by Peter Boncz and Larri.</p>
+<p>Further, we call on you if you or your colleagues would happen to have contacts with companies that deal with graph data management scenarios to also attend and possibly present. LDBC is always looking to expand its circle of participants in TUCs meeting, its graph technology users contacts but also eventually its membership base.</p>
+<p>In this page, you’ll find information about the following items:</p>
+<ul>
+<li><a href="#agenda">Agenda</a></li>
+<li><a href="#logistics">Logistics</a><br>
+- <a href="#date"><strong>Date</strong></a><br>
+- <a href="#venue"><strong>Venue</strong></a><br>
+- <a href="#maps-and-situation"><strong>Maps and situation</strong></a><br>
+- <a href="#getting-there"><strong>Getting there</strong></a></li>
+</ul>
+<h3 id="agenda">Agenda</h3>
+<p><strong>Monday, 9th of November 2015</strong></p>
+<p>8:45 - 9:15 Registration and welcome (Yinglong Xia and Josep L. Larriba Pey)</p>
+<p>9:15 - 9:30 LDBC introduction and status update (Josep L. Larriba-Pey)</p>
+<p>9:30 - 10:30 Details on the progress of LDBC Task Forces 1 (chair Josep L. Larriba-Pey)</p>
+<p>9:30 Arnau Prat (DAMA-UPC). Social Network Benchmark, Interactive workload</p>
+<p>10:00 Orri Erling (OpenLink Software). Social Network Benchmark, Business Intelligence workload</p>
+<p>10:30-11:00 Coffee break</p>
+<p>11:00 - 12:30 Details on the progress of LDBC Task Forces 2 (chair Yinglong Xia)</p>
+<p>11:00 Alexandru Iosup (TU Delft). Social Network Benchmark, Analytics workload.</p>
+<p>11:30 Claudio Gutierrez (U Chile). Query Language Task Force status.</p>
+<p>12:00 Atanas Kiryakov (Ontotext). Semantic Publishing Benchmark status</p>
+<p>12:30 - 14:00 Lunch break</p>
+<p>14:00 - 16:00 Technologies and benchmarking (chair Hassan Chafi)</p>
+<p>14:00 Molham Aref (LogicBlox). Graph Data Management with LogicBlox</p>
+<p>14:30 Peter Kogge (Notre Dame). BFS as in Graph500 on today’s architectures</p>
+<p>15:00 Ching-Yung Lin (IBM). Status and Demo of IBM System G</p>
+<p>15:30-16:00 Coffee break</p>
+<p>16:00 - 17:00 Technologies (chair Irini Fundulaki)</p>
+<p>16:00 Kavitha Srinivas (IBM). SQLGraph: An efficient relational based property graph store</p>
+<p>16:30 David Ediger (GeorgiaTech). STINGER</p>
+<p>17:00 Gary King (Franz Inc.). AllegroGraph’s SPARQL implementation with Social Network Analytics abilities using Magic Properties</p>
+<p>17:30 Manoj Kumar (IBM). Linear Algebra Formulation for Large Graph Analytics</p>
+<p>18:00 Reihaneh Amini (Wright State University) Linked Data in the GeoLink Usecase</p>
+<p>19:00 Social dinner</p>
+<p><strong>Tuesday 10th November 2015</strong></p>
+<p>9:00 - 10:30 Technology, Applications and Benchmarking (chair Alexandru Iosup)</p>
+<p>9:00 Philip Rathle (Neo). On openCypher</p>
+<p>9:20 Morteza Shahriari (University of Florida). Multi-modal Probabilistic Knowledge Base for Remote Sensing Species Identification</p>
+<p>9:50 Peter Kogge (Notre Dame). Challenging problems with Lexis Nexis Risk Solutions</p>
+<p>10:10 Arnau Prat (DAMA-UPC). DATAGEN, status and perspectives for synthetic data generation</p>
+<p>10:30 - 11:00 Coffee break</p>
+<p>11:00 - 12:45 Applications and use of Graph Technologies (chair Atanas Kiryakov)</p>
+<p>11:00 Hassan Chafi (Oracle). Status and characteristics of PGQL</p>
+<p>11:20 David Guedalia (TAGIIO). Multi-tier distributed mobile applications and how they split their workload,</p>
+<p>11:40 Guojing Cong (IBM). Algorithmic technique and architectural support for fast graph analysis</p>
+<p>12:00 Josep Lluis Larriba-Pey. Conclusions for the TUC meeting and future perspectives</p>
+<p>12:30 - 14:00 Lunch break</p>
+<p>14:00 LDBC Board of Directors</p>
+<h3 id="logistics">Logistics</h3>
+<h6 id="date"><strong>Date</strong></h6>
+<p>9th and 10th November 2015</p>
+<h6 id="venue"><strong>Venue</strong></h6>
+<p>The TUC meeting will be held in the IBM Thomas J Watson Research Center.<br>
+The address is:</p>
+<p><strong>IBM Thomas J Watson Research Center</strong><br>
+<strong>1101 Kitchawan Rd,</strong><br>
+<strong>Yorktown Heights, NY 10598, USA</strong></p>
+<p>If you are using a <em>GPS system</em>, please enter <strong>“200 Aqueduct Road, Ossining NY, 10562”</strong> for accurate directions to the lab entrance. You may also want to check the routing online.</p>
+<p>The meeting will take place in the <em>Auditorium</em> on November 9th, and in Meeting Room <em>20-043</em> on November 10th.</p>
+<h6 id="maps-and-situation"><strong>Maps and situation</strong></h6>
+<p>You are highly suggested to <strong>rent a car</strong> for your convenience, since the public transportation system does not cover this area very well. Besides, there is no hotel within walkable distance to the IBM T.J. Watson Research Center. Feel free to find carpool with other attendees. You may find car rental and hotels through <a href="http://www.orbitz.com">www.orbitz.com</a>, or <a href="http://www.expedia.com">www.expedia.com</a> Feel free to email <a href="mailto:yxia@us.ibm.com">yxia@us.ibm.com</a> for any questions.</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/seventh-tuc-meeting/attachments/6882333/15926330.png" alt=""></p>
+<h6 id="getting-there"><strong>Getting there</strong></h6>
+<p><strong>Upper and Eastern New England</strong></p>
+<p>Route I-84 west to Route I-684, south to Exit 6, west on Route 35 to Route 100, south to Route 134, west 2.5 miles. IBM is on the left.</p>
+<p><strong>New Haven and Connecticut Shores</strong></p>
+<p>Merritt Parkway or New England Thruway (Route I-95) west to Route I-287, west to Exit 3, north on Sprain Brook Parkway, which merges into Taconic State Parkway, north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.</p>
+<p><strong>New Jersey</strong></p>
+<p>Take New York State Thruway (Route I-87) east across the Tappan Zee Bridge and follow signs to the Saw Mill Parkway north. Proceed north on Saw Mill River Parkway to Taconic State Parkway exit, north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.</p>
+<p><strong>Upstate New York</strong></p>
+<p>Route I-84 east across Newburgh-Beacon Bridge to Exit 16-S. Taconic State Parkway south to Route 134 East exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.</p>
+<p><strong>New York City (Manhattan)</strong></p>
+<p>Henry Hudson Parkway north, which becomes Saw Mill River Parkway, north to Taconic State Parkway exit. North on Taconic State Parkway to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.</p>
+<p><strong>John F. Kennedy International Airport</strong></p>
+<p>North on Van Wyck Expressway to the Whitestone Expressway and continue north across the Bronx-Whitestone Bridge to the Hutchinson River Parkway north to the Cross County Parkway exit and proceed west to the Bronx River Parkway. North on the Bronx River Parkway to the Sprain Brook Parkway, which merges into the Taconic State Parkway. Continue north to Ossining/Route 134 exit. Turn right and proceed east on Route 134 several hundred yards. IBM is on the right.</p>
+<p><strong>LaGuardia Airport</strong></p>
+<p>East on the Grand Central Parkway, north on the Whitestone Expressway, and continue north across the Bronx-Whitestone Bridge. Continue with instructions from John F. Kennedy International Airport, above.</p>
+<p><strong>Newark International Airport</strong></p>
+<p>North on the New Jersey Turnpike (Route I-95). Stay in local lanes and take Exit 72 for Palisades Interstate Parkway. North on the Palisades Interstate Parkway to the New York State Thruway, Route I-87, and east across the Tappan Zee Bridge. Continue with instructions from New Jersey, above.</p>
+<p><strong>Stewart International Airport</strong></p>
+<p>Route 207 east to Route I-84, east across Newburgh-Beacon Bridge to Taconic State Parkway, south. Continue with instructions from Upstate New York, above.</p>
+<p><strong>Westchester County Airport</strong></p>
+<p>Right on Route 120, north. Turn left where Route 120 merges with Route 133. Continue on Route 120. Cross Route 100 and continue straight on Shingle House Road to Pines Bridge Road. Turn right and proceed several hundred yards. IBM is on the left.</p>
+<p><strong>Public Transportation</strong></p>
+<p>Metropolitan Transportation Authority (MTA) train stations nearest to the Yorktown Heights location are the Croton-Harmon and White Plains stations. Taxi service is available at both locations.</p>
+
+
+
+ -
+
Elements of Instance Matching Benchmarks: a Short Overview
+ https://ldbcouncil.org/post/elements-of-instance-matching-benchmarks-a-short-overview/
+ Tue, 16 Jun 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/elements-of-instance-matching-benchmarks-a-short-overview/
+ <p>The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of web resources through “same-as” links which specify that two URIs correspond to the same real world object. In the vast number of data sources participating in the Linked Data Cloud, this information is not explicitly stated but is discovered using <strong>instance matching</strong> techniques and tools. Instance matching is also known as <strong>record linkage</strong> <a href="#references">[1]</a>, <strong>duplicate detection</strong> <a href="#references">[2]</a>, <strong>entity resolution</strong> <a href="#references">[3]</a> and <strong>object identification</strong> <a href="#references">[4]</a>.</p>
+<p>For instance, a search in Geonames (<a href="http://www.geonames.org/">http://www.geonames.org/</a>) for “Athens” would return a resource (i.e., URI) accompanied with a map of the area and information about the place; additional information for the city of Athens can be found in other datasets such as for instance DBpedia (<a href="http://dbpedia.org/">http://dbpedia.org/</a>) or Open Government Datasets (<a href="http://data.gov.gr/">http://data.gov.gr/</a>). To exploit all obtain all necessary information about the city of Athens we need to establish that the retrieved resources refer to the same real world object.</p>
+<p>Web resources are published by “autonomous agents” who choose their preferred information representation or the one that best fits the application of interest. Furthermore, different representations of the same real world entity are due to data acquisition errors or different acquisition techniques used to process scientific data. Moreover, real world entities evolve and change over time, and sources need to keep track of these developments, a task that is very hard and often not possible. Finally, when integrating data from multiple sources, the process itself may add new erroneous data. Clearly, these reasons are not limited to problems that did arise in the era of Web Data, it is thus not surprising that instance matching systems have been around for several years <a href="#references">[2]</a><a href="#references">[5]</a>.</p>
+<p>It is though essential at this point to develop, along with instance and entity matching systems, <em>instance matching benchmarks to determine the weak and strong points of those systems, as well as their overall quality in order to support users in deciding the system to use for their needs</em>. Hence, well defined, and good quality benchmarks are important for comparing the performance of the available or under development instance matching systems. Benchmarks are used not only to inform users of the strengths and weaknesses of systems, but also to motivate developers, researchers and technology vendors to deal with the weak points of their systems and to ameliorate their performance and functionality. They are also useful for identifying the settings in which each of the systems has optimal performance. Benchmarking aims at providing an objective basis for such assessments.</p>
+<p>An instance matching benchmark for Linked Data consists of a <em>source</em> and <em>target dataset</em> implementing a set of <em>test-cases</em>, where each test case addresses a different kind of requirement regarding instance matching, a <em>ground truth</em> or <em>gold standard</em> and finally the <em>evaluation metrics</em> used to <em>assess the benchmark.</em></p>
+<p>Datasets are the raw material of a benchmark. A benchmark comprises of a <em>source</em> and <em>target</em> dataset and the objective of an instance matching system is to discover the matches of the two. Datasets are characterized by (a) their <em>nature</em> (<em>real</em> or <em>synthetic</em>), (b) the <em>schemas/ontologies</em> they use, (c) their <em>domains</em>, (d) the <em>languages</em> they are written in, and (e) the <em>variations/heterogeneities</em> of the datasets. Real datasets are widely used in benchmarks since they offer realistic conditions for heterogeneity problems and they have realistic distributions. <em>Synthetic datasets</em> are generated using automated data generators and are useful because they offer fully controlled test conditions, have accurate gold standards and allow setting the focus on specific types of heterogeneity problems in a systematic manner</p>
+<p>Datasets (and benchmarks) may contain different <em>kinds of variations</em> that correspond to <em>different test cases</em>. According to Ferrara et.al. <a href="#references">[6]</a><a href="#references">[7]</a>, three kinds of variations exist for Linked Data, namely <em>data variations</em>, <em>structural variations</em> and <em>logical variations</em>. The first refers mainly to differences due to typographical errors, differences in the employed data formats, language etc. The second refers to the differences in the structure of the employed Linked Data schemas. Finally, the third type derives from the use of semantically rich RDF and OWL constructs that enable one to define hierarchies and equivalence of classes and properties, (in)equality of instances, complex class definitions through union and intersection among others.</p>
+<p>The common case in real benchmarks is that the datasets to be matched contain different kinds (combinations) of variations. On the other hand, synthetic datasets may be purposefully designed to contain specific types (or combinations) of variations (e.g., only structural), or may be more general in an effort to illustrate all the common cases of discrepancies that appear in reality between individual descriptions.</p>
+<p>The <em>gold standard</em> is considered as the “correct answer sheet” of the benchmark, and is used to judge the completeness and soundness of the result sets of the benchmarked systems. For instance matching benchmarks employing synthetic datasets, the gold standard is always automatically generated, as the errors (variations) that are added into the datasets are known and systematically created. When it comes to real datasets, the gold standard can be either manually curated or (semi-) automatically generated. In the first case, domain experts manually mark the matches between the datasets, whereas in the second, supervised and crowdsourcing techniques aid the process of finding the matches, a process that is often time consuming and error prone.</p>
+<p>Last, an instance matching benchmark uses <em>evaluation metrics</em> to determine and assess the systems’ output quality and performance. For instance matching tools, performance is not a critical aspect. On the other hand, an instance matching tool should return all and only the correct answers. So, what matters most is returning the relevant matches, rather than returning them quickly. For this reason, the evaluation metrics that are dominantly employed for instance matching benchmarks are the standard <em>precision</em>, <em>recall</em> and <em>f-measure</em> metrics.</p>
+<h4 id="references">References</h4>
+<p>[1] Li, C., Jin, L., and Mehrotra, S. (2006) Supporting efficient record linkage for large data sets using mapping techniques. WWW 2006.</p>
+<p>[2] Dragisic, Z., Eckert, K., Euzenat, J., Faria, D., Ferrara, A., Granada, R., Ivanova, V., Jimenez-Ruiz, E., Oskar Kempf, A., Lambrix, P., Montanelli, S., Paulheim, H., Ritze, D., Shvaiko, P., Solimando, A., Trojahn, C., Zamaza, O., and Cuenca Grau, B. (2014) Results of the Ontology Alignment Evaluation Initiative 2014. Proc. 9th ISWC workshop on ontology matching (OM 2014).</p>
+<p>[3] Bhattacharya, I. and Getoor, L. (2006) Entity resolution in graphs. Mining Graph Data. Wiley and Sons 2006.</p>
+<p>[4] Noessner, J., Niepert, M., Meilicke, C., and Stuckenschmidt, H. (2010) Leveraging Terminological Structure for Object Reconciliation. In ESWC 2010.</p>
+<p>[5] Flouris, G., Manakanatas, D., Kondylakis, H., Plexousakis, D., Antoniou, G. Ontology Change: Classification and Survey (2008) Knowledge Engineering Review (KER 2008), pages 117-152.</p>
+<p>[6] Ferrara, A., Lorusso, D., Montanelli, S., and Varese, G. (2008) Towards a Benchmark for Instance Matching. Proc. 3th ISWC workshop on ontology matching (OM 2008).</p>
+<p>[7] Ferrara, A., Montanelli, S., Noessner, J., and Stuckenschmidt, H. (2011) Benchmarking Matching Applications on the Semantic Web. In ESWC, 2011.</p>
+
+
+
+ -
+
SNB Interactive Part 3: Choke Points and Initial Run on Virtuoso
+ https://ldbcouncil.org/post/snb-interactive-part-3-choke-points-and-initial-run-on-virtuoso/
+ Wed, 10 Jun 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-interactive-part-3-choke-points-and-initial-run-on-virtuoso/
+ <p>In this post we will look at running the <a href="https://ldbcouncil.org/developer/snb">LDBC SNB</a> on <a href="https://virtuoso.openlinksw.com/">Virtuoso</a>.</p>
+<p>First, let’s recap what the benchmark is about:</p>
+<ol>
+<li>
+<p>fairly frequent short updates, with no update contention worth mentioning</p>
+</li>
+<li>
+<p>short random lookups</p>
+</li>
+<li>
+<p>medium complex queries centered around a person’s social environment</p>
+</li>
+</ol>
+<p>The updates exist so as to invalidate strategies that rely too heavily on precomputation. The short lookups exist for the sake of realism; after all, an online social application does lookups for the most part. The medium complex queries are to challenge the DBMS.</p>
+<p>The DBMS challenges have to do firstly with query optimization, and secondly with execution with a lot of non-local random access patterns. Query optimization is not a requirement, <em>per se,</em> since imperative implementations are allowed, but we will see that these are no more free of the laws of nature than the declarative ones.</p>
+<p>The workload is arbitrarily parallel, so intra-query parallelization is not particularly useful, if also not harmful. There are latency constraints on operations which strongly encourage implementations to stay within a predictable time envelope regardless of specific query parameters. The parameters are a combination of person and date range, and sometimes tags or countries. The hardest queries have the potential to access all content created by people within 2 steps of a central person, so possibly thousands of people, times 2000 posts per person, times up to 4 tags per post. We are talking in the millions of key lookups, aiming for sub-second single-threaded execution.</p>
+<p>The test system is the same as used in the <a href="http://www.openlinksw.com/weblog/oerling/?id=1739">TPC-H series</a>: dual Xeon E5-2630, 2x6 cores x 2 threads, 2.3GHz, 192 GB RAM. The software is the <a href="https://github.com/v7fasttrack/virtuoso-opensource/tree/feature/analytics">feature/analytics branch</a> of <a href="https://github.com/v7fasttrack/virtuoso-opensource/">v7fasttrack, available from www.github.com</a>.</p>
+<p>The dataset is the SNB 300G set, with:</p>
+<table>
+<thead>
+<tr>
+<th>1,136,127</th>
+<th>persons</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>125,249,604</td>
+<td>knows edges</td>
+</tr>
+<tr>
+<td>847,886,644</td>
+<td>posts, including replies</td>
+</tr>
+<tr>
+<td>1,145,893,841</td>
+<td>tags of posts or replies</td>
+</tr>
+<tr>
+<td>1,140,226,235</td>
+<td>likes of posts or replies</td>
+</tr>
+</tbody>
+</table>
+<p>As an initial step, we run the benchmark as fast as it will go. We use 32 threads on the driver side for 24 hardware threads.</p>
+<p>Below are the numerical quantities for a 400K operation run after 150K operations worth of warmup.</p>
+<p><strong>Duration:</strong> 10:41.251<br>
+<strong>Throughput:</strong> 623.71 (op/s)</p>
+<p>The statistics that matter are detailed below, with operations ranked in order of descending client-side wait-time. All times are in milliseconds.</p>
+<table>
+<thead>
+<tr>
+<th>% of total</th>
+<th>total_wait</th>
+<th>name</th>
+<th>count</th>
+<th>mean</th>
+<th>min</th>
+<th>max</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>20%</td>
+<td>4,231,130</td>
+<td>LdbcQuery5</td>
+<td>656</td>
+<td>6,449.89</td>
+<td>245</td>
+<td>10,311</td>
+</tr>
+<tr>
+<td>11%</td>
+<td>2,272,954</td>
+<td>LdbcQuery8</td>
+<td>18,354</td>
+<td>123.84</td>
+<td>14</td>
+<td>2,240</td>
+</tr>
+<tr>
+<td>10%</td>
+<td>2,200,718</td>
+<td>LdbcQuery3</td>
+<td>388</td>
+<td>5,671.95</td>
+<td>468</td>
+<td>17,368</td>
+</tr>
+<tr>
+<td>7.3%</td>
+<td>1,561,382</td>
+<td>LdbcQuery14</td>
+<td>1,124</td>
+<td>1,389.13</td>
+<td>4</td>
+<td>5,724</td>
+</tr>
+<tr>
+<td>6.7%</td>
+<td>1,441,575</td>
+<td>LdbcQuery12</td>
+<td>1,252</td>
+<td>1,151.42</td>
+<td>15</td>
+<td>3,273</td>
+</tr>
+<tr>
+<td>6.5%</td>
+<td>1,396,932</td>
+<td>LdbcQuery10</td>
+<td>1,252</td>
+<td>1,115.76</td>
+<td>13</td>
+<td>4,743</td>
+</tr>
+<tr>
+<td>5%</td>
+<td>1,064,457</td>
+<td>LdbcShortQuery3PersonFriends</td>
+<td>46,285</td>
+<td>22.9979</td>
+<td>0</td>
+<td>2,287</td>
+</tr>
+<tr>
+<td>4.9%</td>
+<td>1,047,536</td>
+<td>LdbcShortQuery2PersonPosts</td>
+<td>46,285</td>
+<td>22.6323</td>
+<td>0</td>
+<td>2,156</td>
+</tr>
+<tr>
+<td>4.1%</td>
+<td>885,102</td>
+<td>LdbcQuery6</td>
+<td>1,721</td>
+<td>514.295</td>
+<td>8</td>
+<td>5,227</td>
+</tr>
+<tr>
+<td>3.3%</td>
+<td>707,901</td>
+<td>LdbcQuery1</td>
+<td>2,117</td>
+<td>334.389</td>
+<td>28</td>
+<td>3,467</td>
+</tr>
+<tr>
+<td>2.4%</td>
+<td>521,738</td>
+<td>LdbcQuery4</td>
+<td>1,530</td>
+<td>341.005</td>
+<td>49</td>
+<td>2,774</td>
+</tr>
+<tr>
+<td>2.1%</td>
+<td>440,197</td>
+<td>LdbcShortQuery4MessageContent</td>
+<td>46,302</td>
+<td>9.50708</td>
+<td>0</td>
+<td>2,015</td>
+</tr>
+<tr>
+<td>1.9%</td>
+<td>407,450</td>
+<td>LdbcUpdate5AddForumMembership</td>
+<td>14,338</td>
+<td>28.4175</td>
+<td>0</td>
+<td>2,008</td>
+</tr>
+<tr>
+<td>1.9%</td>
+<td>405,243</td>
+<td>LdbcShortQuery7MessageReplies</td>
+<td>46,302</td>
+<td>8.75217</td>
+<td>0</td>
+<td>2,112</td>
+</tr>
+<tr>
+<td>1.9%</td>
+<td>404,002</td>
+<td>LdbcShortQuery6MessageForum</td>
+<td>46,302</td>
+<td>8.72537</td>
+<td>0</td>
+<td>1,968</td>
+</tr>
+<tr>
+<td>1.8%</td>
+<td>387,044</td>
+<td>LdbcUpdate3AddCommentLike</td>
+<td>12,659</td>
+<td>30.5746</td>
+<td>0</td>
+<td>2,060</td>
+</tr>
+<tr>
+<td>1.7%</td>
+<td>361,290</td>
+<td>LdbcShortQuery1PersonProfile</td>
+<td>46,285</td>
+<td>7.80577</td>
+<td>0</td>
+<td>2,015</td>
+</tr>
+<tr>
+<td>1.6%</td>
+<td>334,409</td>
+<td>LdbcShortQuery5MessageCreator</td>
+<td>46,302</td>
+<td>7.22234</td>
+<td>0</td>
+<td>2,055</td>
+</tr>
+<tr>
+<td>1%</td>
+<td>220,740</td>
+<td>LdbcQuery2</td>
+<td>1,488</td>
+<td>148.347</td>
+<td>2</td>
+<td>2,504</td>
+</tr>
+<tr>
+<td>0.96%</td>
+<td>205,910</td>
+<td>LdbcQuery7</td>
+<td>1,721</td>
+<td>119.646</td>
+<td>11</td>
+<td>2,295</td>
+</tr>
+<tr>
+<td>0.93%</td>
+<td>198,971</td>
+<td>LdbcUpdate2AddPostLike</td>
+<td>5,974</td>
+<td>33.3062</td>
+<td>0</td>
+<td>1,987</td>
+</tr>
+<tr>
+<td>0.88%</td>
+<td>189,871</td>
+<td>LdbcQuery11</td>
+<td>2,294</td>
+<td>82.7685</td>
+<td>4</td>
+<td>2,219</td>
+</tr>
+<tr>
+<td>0.85%</td>
+<td>182,964</td>
+<td>LdbcQuery13</td>
+<td>2,898</td>
+<td>63.1346</td>
+<td>1</td>
+<td>2,201</td>
+</tr>
+<tr>
+<td>0.74%</td>
+<td>158,188</td>
+<td>LdbcQuery9</td>
+<td>78</td>
+<td>2,028.05</td>
+<td>1,108</td>
+<td>4,183</td>
+</tr>
+<tr>
+<td>0.67%</td>
+<td>143,457</td>
+<td>LdbcUpdate7AddComment</td>
+<td>3,986</td>
+<td>35.9902</td>
+<td>1</td>
+<td>1,912</td>
+</tr>
+<tr>
+<td>0.26%</td>
+<td>54,947</td>
+<td>LdbcUpdate8AddFriendship</td>
+<td>571</td>
+<td>96.2294</td>
+<td>1</td>
+<td>988</td>
+</tr>
+<tr>
+<td>0.2%</td>
+<td>43,451</td>
+<td>LdbcUpdate6AddPost</td>
+<td>1,386</td>
+<td>31.3499</td>
+<td>1</td>
+<td>2,060</td>
+</tr>
+<tr>
+<td>0.01%</td>
+<td>1,848</td>
+<td>LdbcUpdate4AddForum</td>
+<td>103</td>
+<td>17.9417</td>
+<td>1</td>
+<td>65</td>
+</tr>
+<tr>
+<td>0.00%</td>
+<td>44</td>
+<td>LdbcUpdate1AddPerson</td>
+<td>2</td>
+<td>22</td>
+<td>10</td>
+<td>34</td>
+</tr>
+</tbody>
+</table>
+<p>At this point we have in-depth knowledge of the choke points the benchmark stresses, and we can give a first assessment of whether the design meets its objectives for setting an agenda for the coming years of graph database development.</p>
+<p>The implementation is well optimized in general but still has maybe 30% room for improvement. We note that this is based on a compressed column store. One could think that alternative data representations, like in-memory graphs of structs and pointers between them, are better for the task. This is not necessarily so; at the least, a compressed column store is much more space efficient. Space efficiency is the root of cost efficiency, since as soon as the working set is not in memory, a random access workload is badly hit.</p>
+<p>The set of choke points (technical challenges) actually revealed by the benchmark is so far as follows:</p>
+<ul>
+<li>
+<p><em>Cardinality estimation under heavy data skew —</em> Many queries take a tag or a country as a parameter. The cardinalities associated with tags vary from 29M posts for the most common to 1 for the least common. Q6 has a common tag (in top few hundred) half the time and a random, most often very infrequent, one the rest of the time. A declarative implementation must recognize the cardinality implications from the literal and plan accordingly. An imperative one would have to count. Missing this makes Q6 take about 40% of the time instead of 4.1% when adapting.</p>
+</li>
+<li>
+<p><em>Covering indices —</em> Being able to make multi-column indices that duplicate some columns from the table often saves an entire table lookup. For example, an index onpost by author can also contain the post’s creation date.</p>
+</li>
+<li>
+<p><em>Multi-hop graph traversal —</em> Most queries access a two-hop environment starting at a person. Two queries look for shortest paths of unbounded length. For the two-hop case, it makes almost no difference whether this is done as a union or a special graph traversal operator. For shortest paths, this simply must be built into the engine; doing this client-side incurs prohibitive overheads. A bidirectional shortest path operation is a requirement for the benchmark.</p>
+</li>
+<li>
+<p><em>Top <em>K</em> —</em> Most queries returning posts order results by descending date. Once there are at least <em>k</em> results, anything older than the __k__th can be dropped, adding a dateselection as early as possible in the query. This interacts with vectored execution, so that starting with a short vector size more rapidly produces an initial top <em>k</em>.</p>
+</li>
+<li>
+<p><em>Late projection —</em> Many queries access several columns and touch millions of rows but only return a few. The columns that are not used in sorting or selection can be retrieved only for the rows that are actually returned. This is especially useful with a column store, as this removes many large columns (e.g., text of a post) from the working set.</p>
+</li>
+<li>
+<p><em>Materialization —</em> Q14 accesses an expensive-to-compute edge weight, the number of post-reply pairs between two people. Keeping this precomputed drops Q14 from the top place. Other materialization would be possible, for example Q2 (top 20 posts by friends), but since Q2 is just 1% of the load, there is no need. One could of course argue that this should be 20x more frequent, in which case there could be a point to this.</p>
+</li>
+<li>
+<p><em>Concurrency control —</em> Read-write contention is rare, as updates are randomly spread over the database. However, some pages get read very frequently, e.g., some middle level index pages in the post table. Keeping a count of reading threads requires a mutex, and there is significant contention on this. Since the hot set can be one page, adding more mutexes does not always help. However, hash partitioning the index into many independent trees (as in the case of a cluster) helps for this. There is also contention on a mutex for assigning threads to client requests, as there are large numbers of short operations.</p>
+</li>
+</ul>
+<p>In subsequent posts, we will look at specific queries, what they in fact do, and what their theoretical performance limits would be. In this way we will have a precise understanding of which way SNB can steer the graph DB community.</p>
+<h3 id="snb-interactive-series">SNB Interactive Series</h3>
+<ul>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-1-what-is-snb-interactive-really-about">SNB Interactive, Part 1: What is SNB Interactive Really About?</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-2-modeling-choices">SNB Interactive, Part 2: Modeling Choices</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-3-choke-points-and-initial-run-on-virtuoso/">SNB Interactive, Part 3: Choke Points and Initial Run on Virtuoso</a></li>
+</ul>
+
+
+
+ -
+
SNB and Graphs Related Presentations at GRADES '15
+ https://ldbcouncil.org/post/snb-and-graphs-related-presentations-at-grades-15/
+ Fri, 29 May 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-and-graphs-related-presentations-at-grades-15/
+ <p>Next 31st of May the GRADES workshop will take place in Melbourne within the ACM/SIGMOD presentation. GRADES started as an initiative of the Linked Data Benchmark Council in the SIGMOD/PODS 2013 held in New York.</p>
+<p>Among the papers published in this edition we have “Graphalytics: A Big Data Benchmark for Graph-Processing Platforms”, which presents a new benchmark that uses the Social Network Benchmark data generator of LDBC (that can be found in <a href="https://github.com/ldbc">https://github.com/ldbc</a>) as the base to execute the algorithms used for the benchmark, among which we have BFS, community detection and connected components. We also have “Microblogging Queries on Graph Databases: an Introspection” which benchmarks two of the most significant Graph Databases in the market, i.e. Neo4j and Sparksee using microblogging queries on top of twitter data. We can finally mention “Frappé: Querying the Linux Kernel Dependency Graph” which presents a framework for querying and visualising the dependencies of large C/C++ software systems.</p>
+<p><a href="http://event.cwi.nl/grades2015/program.shtml">Check the complete agenda.</a></p>
+<p>Meet you in Melbourne!</p>
+
+
+
+ -
+
SNB Interactive Part 2: Modeling Choices
+ https://ldbcouncil.org/post/snb-interactive-part-2-modeling-choices/
+ Tue, 26 May 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-interactive-part-2-modeling-choices/
+ <p><a href="https://ldbcouncil.org/benchmarks/snb">SNB Interactive</a> is the wild frontier, with very few rules. This is necessary, among other reasons, because there is no standard property graph data model, and because the contestants support a broad mix of programming models, ranging from in-process APIs to declarative query.</p>
+<p>In the case of <a href="http://dbpedia.org/resource/Virtuoso_Universal_Server">Virtuoso</a>, we have played with <a href="http://dbpedia.org/resource/SQL">SQL</a> and <a href="http://dbpedia.org/resource/SPARQL">SPARQL</a> implementations. For a fixed schema and well known workload, SQL will always win. The reason for this is that this allows to materialize multi-part indices and data orderings that make sense for the application. In other words, there is transparency into physical design. An RDF application may also have physical design by means ofstructure-aware storage but this is more complex and here we are just concerned with speed and having things work precisely as we intend.</p>
+<h3 id="schema-design">Schema Design</h3>
+<p>SNB has a regular schema described by a <a href="https://en.wikipedia.org/wiki/Unified_Modeling_Language">UML</a> diagram. This has a number of relationships of which some have attributes. There are no heterogenous sets, e.g. no need for run-time typed attributes or graph edges with the same label but heterogeneous end points. Translation into SQL or RDF is straightforward. Edges with attributes, e.g. the knows relation between people would end up represented as a subject with the end points and the date since as properties. The relational implementation has a two-part primary key and the date since as a dependent column. A native property graph database would use an edge with an extra property for this, as such are typically supported.</p>
+<p>The only table-level choice has to do with whether <code>posts</code> and <code>comments</code> are kept in the same or different data structures. The Virtuoso schema has a single table for both, with nullable columns for the properties that occur only in one. This makes the queries more concise. There are cases where only non-reply posts of a given author are accessed. This is supported by having two author foreign key columns each with its own index. There is a single nullable foreign key from the reply to the post/comment being replied to.</p>
+<p>The workload has some frequent access paths that need to be supported by index. Some queries reward placing extra columns in indices. For example, a common pattern is accessing the most recent posts of an author or group of authors. There, having a composite key <code>of ps_creatorid</code>, <code>ps_creationdate</code>, <code>ps_postid</code> pays off since the top-k on <code>creationdate</code> can be pushed down into the index without needing a reference to the table.</p>
+<p>The implementation is free to choose data types for attributes, specifically datetimes. The Virtuoso implementation adopts the practice of the <a href="http://dbpedia.org/resource/DEX_(Graph_database)">Sparksee</a> and <a href="http://dbpedia.org/resource/Neo4j">Neo4J</a> implementations and represents this is a count of milliseconds since epoch. This is less confusing, faster to compare and more compact than a native datetime datatype that may or may not have timezones etc. Using a built-in datetime seems to be nearly always a bad idea. A dimension table or a number for a time dimension avoids the ambiguities of a calendar or at least makes these explicit.</p>
+<p>The benchmark allows procedurally maintaining materializations of intermediate results for use by queries as long as these are maintained transaction by transaction. For example, each person could have the 20 newest posts by immediate contacts precomputed. This would reduce Q2 “top of the wall” to a single lookup. This dows not however appear to be worthwhile. The Virtuoso implementation does do one such materialization for Q14: A connection weight is calculated for every pair of persons that know each other. This is related to the count of replies by one or the other to content generated by the other. If there does not exist a single reply in either direction, the weight is taken to be 0. This weight is precomputed after bulk load and subsequently maintained each time a reply is added. The table for this is the only row-wise structure in the schema and represents a half matrix of connected people, i.e. <code>person1</code>, <code>person2</code> -> <code>weight</code>. <code>Person1</code> is by convention the one with the smaller <code>p_personid</code>. Note that comparing id’s in this way is useful but not normally supported by RDF systems. RDF would end up comparing strings of URI’s with disastrous performance implications unless an implementation specific trick were used.</p>
+<p>In the next installment we will analyze an actual run.</p>
+<h3 id="snb-interactive-series">SNB Interactive Series</h3>
+<ul>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-1-what-is-snb-interactive-really-about">SNB Interactive, Part 1: What is SNB Interactive Really About?</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-2-modeling-choices">SNB Interactive, Part 2: Modeling Choices</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-3-choke-points-and-initial-run-on-virtuoso/">SNB Interactive, Part 3: Choke Points and Initial Run on Virtuoso</a></li>
+</ul>
+
+
+
+ -
+
LDBC Participates in the 36th Edition of the ACM SIGMOD/PODS Conference
+ https://ldbcouncil.org/post/ldbc-participates-in-the-36th-edition-of-the-acm-sigmod-pods-conference/
+ Mon, 25 May 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/ldbc-participates-in-the-36th-edition-of-the-acm-sigmod-pods-conference/
+ <p>LDBC is presenting two papers at the next edition of the ACM SIGMOD/PODS conference held in Melbourne from May 31st to June 4th, 2015. The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools and experiences.</p>
+<p>On the industry track, LDBC will be presenting the <em>Social Network Benchmark Interactive Workload</em> by Orri Erling (OpenLink Software), Alex Averbuch (Neo Technology), Josep Larriba-Pey (Sparsity Technologies), Hassan Chafi (Oracle Labs), Andrey Gubichev (TU Munich), Arnau Prat (Universitat Politècnica de Catalunya), Minh-Duc Pham (VU University Amsterdam) and Peter Boncz (CWI).</p>
+<p>You can read more about the <a href="https://ldbcouncil.org/benchmarks/snb">Social Network Benchmark here</a> and collaborate if you’re interested!</p>
+<p>The other presentation will be at the GRADES workshop within the SIGMOD program regarding <em>Graphalytics: A Big Data Benchmark for Graph-Processing platforms</em> by Mihai Capotă, Tim Hegeman, Alexandru Iosup (Delft University of Technology), Arnau Prat (Universitat Politècnica de Catalunya), Orri Erling (OpenLink Sotware) and Peter Boncz (CWI). We will provide more information about GRADES and this specific presentation in a following post as GRADES is part of the events organized by LDBC.</p>
+<p>Don’t forget to check our presentations if you’re attending the SIGMOD!</p>
+
+
+
+ -
+
SNB Interactive Part 1: What Is SNB Interactive Really About?
+ https://ldbcouncil.org/post/snb-interactive-part-1-what-is-snb-interactive-really-about/
+ Thu, 14 May 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-interactive-part-1-what-is-snb-interactive-really-about/
+ <p>This post is the first in a series of blogs analyzing the LDBC Social Network Benchmark Interactive workload. This is written from the dual perspective of participating in the benchmark design and of building the OpenLink Virtuoso implementation of same.</p>
+<p>With two implementations of SNB interactive at four different scales, we can take a first look at what the benchmark is really about. The hallmark of a benchmark implementation is that its performance characteristics are understood and even if these do not represent the maximum of the attainable, there are no glaring mistakes and the implementation represents a reasonable best effort by those who ought to know, namely the system vendors.</p>
+<p>The essence of a benchmark is a set of trick questions or choke points, as LDBC calls them. A number of these were planned from the start. It is then the role of experience to tell whether addressing these is really the key to winning the race. Unforeseen ones will also surface.</p>
+<p>So far, we see that SNB confronts the implementor with choices in the following areas:</p>
+<ul>
+<li>Data model: Relational, RF, property graph?</li>
+<li>Physical model, e.g. row-wise vs. column wise storage</li>
+<li>Materialized data ordering: Sorted projections, composite keys, replicating columns in auxxiliary data structures</li>
+<li>Maintaining precomputed, materialized intermediate results, e.g. use of materialized views, triggers</li>
+<li>Query optimization: join order/type, interesting physical data orderings, late projection, top k, etc.</li>
+<li>Parameters vs. literals: Sometimes different parameter values result in different optimal query plans</li>
+<li>Predictable, uniform latency: The measurement rules stipulate the SUT must not fall behind the simulated workload</li>
+<li>Durability - how to make data durable while maintaining steady throughput? Logging vs. checkpointing.</li>
+</ul>
+<p>In the process of making a benchmark implementation, one naturally encounters questions about the validity, reasonability and rationale of the benchmark definition itself. Additionally, even though the benchmark might not directly measure certain aspects of a system, making an implementation will take a system past its usual envelope and highlight some operational aspects.</p>
+<ul>
+<li>Data generation - Generating a mid-size dataset takes time, e.g. 8 hours for 300G. In a cloud situation, keeping the dataset in S3 or similar is necessary, re-generating every time is not an option.</li>
+<li>Query mix - Are the relative frequencies of the operations reasonable? What bias does this introduce?</li>
+<li>Uniformity of parameters: Due to non-uniform data distributions in the dataset, there is easily a 100x difference between a ‘fast’ and ‘slow’ case of a single query template. How long does one need to run to balance these fluctuations?</li>
+<li>Working set: Experience shows that there is a large difference between almost warm and steady state of working set. This can be a factor of 1.5 in throughput.</li>
+<li>Are the latency constraints reasonable? In the present case, a qualifying run must have under 5% of all query executions starting over 1 second late. Each execution is scheduled beforehand and done at the intended time. If the SUT does not keep up, it will have all available threads busy and must finish some work before accepting new work, so some queries will start late. Is this a good criterion for measuring consistency of response time? There are some obvious possibilities of abuse.</li>
+<li>Is the benchmark easy to implement/run? Perfection is open-ended and optimization possibilities infinite, albeit with diminishing returns. Still, getting startyed should not be too hard. Since systems will be highly diverse, testing that these in fact do the same thing is important. The SNB validation suite is good for this and given publicly available reference implementations, the effort of getting started is not unreasonable.</li>
+<li>Since a Qualifying run must meet latency constraints while going as fast as possible, setting the performance target involves trial and error. Does the tooling make this easy?</li>
+<li>Is the durability rule reasonable? Right now, one is not required to do checkpoints but must report the time to roll forward from the last checkpoint or initial state. Incenting vendors to build faster recovery is certainly good, but we are not through with all the implications. What about redundant clusters?</li>
+</ul>
+<p>The following posts will look at the above in light of actual experience.</p>
+<h3 id="snb-interactive-series">SNB Interactive Series</h3>
+<ul>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-1-what-is-snb-interactive-really-about">SNB Interactive, Part 1: What is SNB Interactive Really About?</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-2-modeling-choices">SNB Interactive, Part 2: Modeling Choices</a></li>
+<li><a href="https://ldbcouncil.org/post/snb-interactive-part-3-choke-points-and-initial-run-on-virtuoso/">SNB Interactive, Part 3: Choke Points and Initial Run on Virtuoso</a></li>
+</ul>
+
+
+
+ -
+
Why Do We Need an LDBC SNB-Specific Workload Driver?
+ https://ldbcouncil.org/post/why-do-we-need-an-ldbc-snb-specific-workload-driver/
+ Tue, 21 Apr 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/why-do-we-need-an-ldbc-snb-specific-workload-driver/
+ <p>In a previous <a href="https://ldbcouncil.org/tags/driver">3-part blog series</a> we touched upon the difficulties of executing the LDBC SNB Interactive (SNB) workload, while achieving good performance and scalability. What we didn’t discuss is why these difficulties were unique to SNB, and what aspects of the way we perform workload execution are scientific contributions - novel solutions to previously unsolved problems. This post will highlight the differences between SNB and more traditional database benchmark workloads. Additionally, it will motivate why we chose to develop a new workload driver as part of this work, rather than using existing tooling that was developed in other database benchmarking efforts. To briefly recap, the task of the driver is to run a transactional database benchmark against large synthetic graph datasets - “graph” is the word that best captures the novelty and difficulty of this work.</p>
+<p><strong>Workload Execution - Traditional vs Graph</strong></p>
+<p>Transactional graph workloads differ from traditional relational workloads in several fundamental ways, one of them being the complex dependencies that exist between queries of a graph workload.</p>
+<p>To understand what is meant by “traditional relational workloads”, take the classical TPC-C benchmark as an example. In TPC-C Remote Terminal Emulators (emulators) are used to issue update transactions in parallel, where the transactions issued by these emulators do not depend on one another. Note, “dependency” is used here in the context of scheduling, i.e., one query is dependent on another if it can not start until the other completes. For example, a New-Order transaction does not depend on other orders from this or other users. Naturally, the results of Stock-Level transactions depend on the items that were previously sold, but in TPC-C it is not an emulator’s responsibility to enforce any such ordering. The scheduling strategy employed by TPC-C is tailored to the scenario where transactional updates do not depend on one another. In reality, one would expect to also have scheduling dependencies between transactions, e.g., checking the status of the order should only be done after the order is registered in the system. TPC-C, however, does not do this and instead only asks for the status of the last order <em>for a given user</em>. Furthermore, adding such dependencies to TPC-C would make scheduling only slightly more elaborate. Indeed, the Load Tester (LT) would need to make sure a New-Order transaction always precedes the read requests that check its status, but because users (and their orders) are partitioned across LTs, and orders belong to a particular user, this scheduling does not require inter-LT communication.</p>
+<p>A significantly more difficult scheduling problem arises when we consider the SNB benchmark that models a real-world social network. Its domain includes users that form a social friendship graph and which leave posts/comments/likes on each others walls (forums). The update transactions are generated (exported as a log) by the data generator, with assigned timestamps, e.g. user 123 added post 456 to forum 789 at time T. Suppose we partition this workload by user, such that each driver gets all the updates (friendship requests, posts, comments and likes on other user’s posts etc) initiated by a given user. Now, if the benchmark is to resemble a real-world social network, the update operations represent a highly connected (and dependent) network: a user should not create comments before she joins the network, a friendship request can not be sent to a non-existent user, a comment can only be added to a post that already exists, etc. Given a user partitioning scheme, most such dependencies would cross the boundaries between driver threads/processes, because the correct execution of update operations requires that the social network is in a particular state, and that state depends on the progress of other threads/processes.</p>
+<p>Such scheduling dependencies in the SNB workload essentially replicate the underlying graph-like shape of its dataset. That is, every time a user comments on a friend’s wall, for example, there is a dependency between two operations that is captured by an edge of the social graph. <em>Partitioning the workload among the LTs therefore becomes equivalent to graph partitioning, a known hard problem.</em></p>
+<p><strong>Because it’s a graph</strong></p>
+<p>In short, unlike previous database benchmarking efforts, the SNB workload has necessitated a redefining of the state-of-the-art in workload execution. It is no longer sufficient to rely solely on workload partitioning to safely capture inter-query dependencies in complex database benchmark workloads. The graph-centric nature of SNB introduces new challenges, and novel mechanisms had to be developed to overcome these challenges. To the best of our knowledge, the LDBC SNB Interactive benchmark is the first benchmark that requires a non-trivial partitioning of the workload, among the benchmark drivers. In the context of workload execution, our contribution is therefore the principled design of a driver that executes dependent update operations in a performant and scalable way, across parallel/distributed LTs, while providing repeatable, vendor-independent execution of the benchmark.</p>
+
+
+
+ -
+
Event Driven Post Generation in Datagen
+ https://ldbcouncil.org/post/event-driven-post-generation-in-datagen/
+ Fri, 10 Apr 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/event-driven-post-generation-in-datagen/
+ <p>As discussed in previous posts, one of the features that makes Datagen more realistic is the fact that the activity volume of the simulated Persons is not uniform, but forms spikes. In this blog entry I want to explain more in depth how this is actually implemented inside of the generator.</p>
+<p>First of all, I start with a few basics of how Datagen works internally. In Datagen, once the person graph has been created (persons and their relationships), the activity generation starts. Persons are divided into blocks of 10k, in the same way they are during friendship edges generation process. Then, for each person of the block, three types of forums are created:</p>
+<ul>
+<li>
+<p>The wall of the person</p>
+</li>
+<li>
+<p>The albums of the person</p>
+</li>
+<li>
+<p>The groups where the person is a moderator</p>
+</li>
+</ul>
+<p>We will put our attention to group generation, but the same concepts apply to the other types of forums. Once a group is created, the members of the group are selected. These are selected from either the friends of the moderator, or random persons within the same block.</p>
+<p>After assigning the members to the group, the post generation starts. We have two types of post generators, the uniform post generator and the event based post generator. Each post generator is responsible of, given a forum, generate a set of posts for the forum, whose authors are taken from the set of members of the forum. The uniform post generator distributes the dates of the generated posts uniformly in the time line (from the date of the membership until the end of the simulation time). On the other hand, the event based post generator assigns dates to posts, based on what we call “flashmob events”.</p>
+<p>Flashmob events are generated at the beginning of the execution. Their number is predefined by a configuration parameter which is set to 30 events per month of simulation, and the time of the event is distributed uniformly along all the time line. Also, each event has a volume level assigned (between 1 and 20) following a power law distribution, which determines how relevant or important the event is, and a tag representing the concept or topic of the event. Two different events can have the same tag. For example, one of the flashmob events created for SF1 is one related to “Enrique Iglesias” tag, whose level is 11 and occurs on 29th of May of 2012 at 09:33:47.</p>
+<p>Once the event based post generation starts for a given group, a subset of the generated flashmob events is extracted. These events must be correlated with the tag/topic of the group, and the set of selected events is restricted by the creation date of the group (in a group one cannot talk about an event previous to the creation of the group). Given this subset of events and their volume level, a cumulative probability distribution (using the events sorted by event date and their level) is computed, which is later used to determine to which event a given post is associated. Therefore, those events with a larger lavel will have a larger probability to receive posts, making their volume larger. Then, post generation starts, which can be summarized as follows:</p>
+<ul>
+<li>
+<p>Determine the number of posts to generate</p>
+</li>
+<li>
+<p>Select a random member of the group that will generate the post</p>
+</li>
+<li>
+<p>Determine the event the post will be related to given the aforementioned cumulative distribution</p>
+</li>
+<li>
+<p>Assign the date of the post based on the event date</p>
+</li>
+</ul>
+<p>In order to assign the date to the post, based on the date of the event the post is assigned to, we follow the following probability density, which has been extracted from <a href="#references">[1]</a>. The shape of the probability density consists of a combination of an exponential function in the 8 hour interval around the peak, while the volume outside this interval follows a logarithmic function. The following figure shows the actual shape of the volume, centered at the date of the event.</p>
+<p><img src="index.png" alt=""></p>
+<p>Following the example of “Enrique Iglesias”, the following figure shows the activity volume of posts around the event as generated by Datagen.</p>
+<p><img src="index2.png" alt=""></p>
+<p>In this blog entry we have seen how datagen creates event driven user activity. This allows us to reproduce the heterogenous post creation density found in a real social network, where post creation is driven by real world events.</p>
+<h4 id="references">References</h4>
+<p>[1] Jure Leskovec, Lars Backstrom, Jon M. Kleinberg: Meme-tracking and the dynamics of the news cycle. KDD 2009: 497-506</p>
+
+
+
+ -
+
Sixth TUC Meeting
+ https://ldbcouncil.org/event/sixth-tuc-meeting/
+ Thu, 19 Mar 2015 13:53:33 -0400
+
+ https://ldbcouncil.org/event/sixth-tuc-meeting/
+ <p>The LDBC consortium are pleased to announce its Sixth Technical User Community (TUC) meeting.</p>
+<p>This will be a two-day event at Universitat Politècnica de Catalunya, Barcelona on <strong>Thursday and Friday March 19/20, 2015.</strong></p>
+<p>The LDBC FP7 EC funded project is reaching its finalisation, and this will be the last event sponsored directly by the project. However, tasks within LDBC will continue based on the LDBC independent organisation. The event will basically set the following aspects:</p>
+<ul>
+<li>Two day event with one day devoted to User’s experiences and one day devoted to benchmarking experiences.</li>
+<li>Presentation of the first benchmarking results for the different benchmarks.</li>
+<li>Interaction with the new LDBC Board of Directors and the whole new LDBC organisation officials.</li>
+<li>Pre-event with the 3rd Graph-TA workshop organised on March 18th at the same premises, with a lot of interaction and interesting research presentations.</li>
+</ul>
+<p>We welcome all users of RDF and Graph technologies to attend. If you are interested, please, contact <a href="mailto:damaris@ac.upc.edu">damaris@ac.upc.edu</a>.</p>
+<h3 id="agenda">Agenda</h3>
+<p><strong>Thursday 19th March</strong></p>
+<p>11:00 - 11:30 Registration, coffee break and welcome (Josep Larriba Pey)</p>
+<p>11:30 - 12:00 LDBC introduction and status update (Peter Boncz) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981131.pdf">slides</a></p>
+<p>12:00 - 13:30 Technology and benchmarking (chair: Peter Boncz)</p>
+<p>12:00 Venelin Kotsev (Ontotext). Semantic Publishing Benchmark v2.0. – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981137.pdf">slides</a></p>
+<p>12:30 Nina Saveta (FORTH). SPIMBENCH: A Scalable, Schema-Aware, Instance Matching Benchmark for the Semantic Publishing Domain</p>
+<p>12:50 Tomer Sagi (HP). Titan DB on LDBC SNB Interactive</p>
+<p>13:10 Claudio Martella (VUA): Giraph and Lighthouse</p>
+<p>13:30 - 14:30 Lunch break</p>
+<p>14:30 - 16:00 Applications and use of Graph Technologies (chair: Hassan Chafi)</p>
+<p>14:30 Jerven Bolleman (Swiss Institute of Bioinformatics): 20 billion triples in production <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981132.pdf">slides</a></p>
+<p>14:50 Mark Wilkinson (Universidad Politécnica de Madrid): Design principles for Linked-Data-native Semantic Web Services <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981133.pdf">slides</a></p>
+<p>15:10 Peter Haase (Metaphacts, Systap LLC): Querying the Wikidata Knowledge Graph <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981139.pdf">slides</a></p>
+<p>15:30 Esteban Sota (GNOSS): Human Interaction with Faceted Searching Systems for big or complex graphs</p>
+<p>18:30 - 20:00 Cultural visit Barcelona city center. Meet at Plaça Catalunya.</p>
+<p>20:00 Social dinner at <a href="http://www.bastaix.com">Bastaix Restaurant</a>.</p>
+<p><strong>Friday 20th March</strong></p>
+<p>9:30 - 11:00 Technology and Benchmarking (chair: Josep L. Larriba-Pey)</p>
+<p>9:30 Yinglong Xia (IBM): Towards Temporal Graph Management and Analytics</p>
+<p>9:50 Alexandru Iosup (TU Delft). Graphalytics: A big data benchmark for graph-processing platforms</p>
+<p>10:10 John Snelson (MarkLogic): Introduction to MarkLogic</p>
+<p>10:30 Arnau Prat (UPC-Sparsity Technologies) and Alex Averbuch (Neo): Social Network Benchmark, Interactive Workload</p>
+<p>10:50 Moritz Kaufmann. <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/moritz-kaufmann-ldbc-snb-benchmark-auditing-6th-ldbc-tuc.pdf">The auditing experience</a></p>
+<p>11:15 - 11:45 Coffee break</p>
+<p>11:45 - 12:45 Applications and use of Graph Technologies (chair: Atanas Kiryakov)</p>
+<p>11:45 Boris Motik (Oxford University): Parallel and Incremental Materialisation of RDF/Datalog in RDFox</p>
+<p>12:05 Andreas Both (Unister): E-Commerce and Graph-driven Applications: Experiences and Optimizations while moving to Linked Data</p>
+<p>12:25 Smrati Gupta (CA Technologies). Modaclouds Decision Support System in multicloud environments</p>
+<p>12:45 Peter Boncz. Conclusions for the LDBC project and future perspectives. <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/6881717/6981138.pdf">slides</a></p>
+<p>13:30 - 14:30 Lunch break</p>
+<p>15:00 LDBC Board of Directors</p>
+<h3 id="logistics">Logistics</h3>
+<h6 id="date"><strong>Date</strong></h6>
+<p>19th and 20th March 2015</p>
+<h6 id="venue"><strong>Venue</strong></h6>
+<p>The TUC meeting will be held at “Aula Master” at A3 building located inside the “Campus Nord UPC” in Barcelona. The address is:</p>
+<p>Aula Master<br>
+Edifici A3, Campus Nord UPC<br>
+C. Jordi Girona, 1-3<br>
+08034 Barcelona, Spain</p>
+<h5 id="maps-and-situation"><strong>Maps and situation</strong></h5>
+<p>To reach the campus, there are several options, including Taxi, <a href="http://www.tmb.cat/ca/c/document_library/get_file?uuid=c8996f6c-8ad5-4d21-b59b-faf9fceebd80&groupId=10168">Metro</a> and <a href="http://www.tmb.cat/ca/c/document_library/get_file?uuid=5e6af5e2-7677-4ce8-85bb-8e63f2b086f1&groupId=10168">Bus</a>.</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/1671180/1933315.jpg" alt=""></p>
+<h5 id="finding-upc"><strong>Finding UPC</strong></h5>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/1671180/1933318.jpg" alt=""></p>
+<h5 id="finding-the-meeting-room"><strong>Finding the meeting room</strong></h5>
+<h5 id="getting-there">Getting there</h5>
+<p><strong>Flying:</strong> Barcelona airport is situated 12 km from the city. There are several ways of getting from the airport to the centre of Barcelona, the cheapest of which is to take the train located outside just a few minutes walking distance past the parking lots at terminal 2 (there is a free bus between terminal 1 and terminal 2, see this <a href="http://goo.gl/maps/iJqlj">map of the airport</a>). It is possible to buy 10 packs of train tickets which makes it cheaper. Taking the bus to the centre of town is more convenient as they leave directly from terminal 1 and 2, however it is more expensive than the train.</p>
+<p><strong>Rail:</strong> The Renfe commuter train leaves the airport every 30 minutes from 6.13 a.m. to 11.40 p.m. Tickets cost around 3€ and the journey to<br>
+the centre of Barcelona (Sants or Plaça Catalunya stations) takes 20 minutes.</p>
+<p><strong>Bus:</strong> The Aerobus leaves the airport every 12 minutes, from 6.00 a.m. to 24.00, Monday to Friday, and from 6.30 a.m. to 24.00 on Saturdays, Sundays and public holidays. Tickets cost 6€ and the journey ends in Plaça Catalunya in the centre of Barcelona.</p>
+<p><strong>Taxi:</strong> From the airport, you can take one of Barcelona’s typical black and yellow taxis. Taxis may not take more than four passengers. Unoccupied taxis display a green light and have a clearly visible sign showing LIBRE or LLIURE. The trip to Sants train station costs approximately €20 and trips to other destinations in the city cost approximately €25-30.</p>
+<p><strong>Train and bus:</strong> Barcelona has two international train stations: Sants and França. Bus companies have different points of arrival in different parts of the city. You can find detailed information in the following link: <a href="http://www.barcelona-airport.com/eng/transport_eng.htm">http://www.barcelona-airport.com/eng/transport_eng.htm</a></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/sixth-tuc-meeting/attachments/1671180/1933316.jpg" alt=""></p>
+<h5 id="the-locations-of-the-airport-and-the-city-centre"><strong>The locations of the airport and the city centre</strong></h5>
+
+
+
+ -
+
The LDBC Datagen Community Structure
+ https://ldbcouncil.org/post/the-ldbc-datagen-community-structure/
+ Sun, 15 Mar 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/the-ldbc-datagen-community-structure/
+ <p>This blog entry is about one of the features of DATAGEN that makes it different from other synthetic graph generators that can be found in the literature: the community structure of the graph.</p>
+<p>When generating synthetic graphs, one must not only pay attention to quantitative measures such as the number of nodes and edges, but also to other more qualitative characteristics such as the degree distribution, clustering coefficient. Real graphs, and specially social networks, have typically highly skewed degree distributions with a long tail, a moderatelly large clustering coefficient and an appreciable community structure.</p>
+<p>The first two characteristics are deliberately modeled in DATAGEN. DATAGEN generates persons with a degree distribution that matches that observed in Facebook, and thanks to the attribute correlated edge generation process, we obtain graphs with a moderately large clustering coefficient. But what about the community structure of graphs generated with DATAGEN? The answer can be found in the paper titled “How community-like is the structure of synthetically generated graphs”, which was published in GRADES 2014 <a href="#references">[1]</a>. Here we summarize the paper and its contributions and findings.</p>
+<p>Existing synthetic graph generators such as Rmat <a href="#references">[1]</a> and Mag <a href="#references">[2]</a>, are graphs generators designed to produce graphs with long tailed distributions and large clustering coefficient, but completely ignore the fact that real graphs are structured into communities. For this reason, Lancichinetti et al. proposed LFR <a href="#references">[3]</a>, a graph generator that did not only produced graphs with realistic high level characteristics, but enforced an appreciable community structure. This generator, has become the de facto standard for benchmarking community detection algorithms, as it does not only outputs a graph but also the communities present in that graph, hence it can be used to test the quality of a community detection algorithm.</p>
+<p>However, no one studied if the community structure produced by LFR, was in fact realistic compared to real graphs. Even though the community structure in LFR exhibit interesting properties, such as the expected larger internal density than external, or a longtailed distribution of community sizes, they lack the noise and inhomogeneities present in a real graph. And more importantly, how does the community structure of DATAGEN compares to that exhibited in LFR and reap graphs? Is it more or less realistic? The authors of <a href="#references">[1]</a> set up an experiment where they analized the characteristics of the communities output by LFR, and the groups (groups of people interested in a given topic) output by DATAGEN, and compared them to a set of real graphs with metadata. These real graphs, which can be downloaded from the Snap project website, are graphs that have recently become very popular in the field of community detection, as they contain ground truth communities extracted from their metadata. The ground truth graphs used in this experiment are shown in the following table. For more details about how this ground truth is generated, please refer to <a href="#references">[4]</a>.</p>
+<table>
+<thead>
+<tr>
+<th></th>
+<th><em>Nodes</em></th>
+<th><em>Edges</em></th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td><em>Amazon</em></td>
+<td>334863</td>
+<td>925872</td>
+</tr>
+<tr>
+<td><em>Dblp</em></td>
+<td>317080</td>
+<td>1049866</td>
+</tr>
+<tr>
+<td><em>Youtube</em></td>
+<td>1134890</td>
+<td>2987624</td>
+</tr>
+<tr>
+<td><em>Livejournal</em></td>
+<td>3997962</td>
+<td>34681189</td>
+</tr>
+</tbody>
+</table>
+<p>The authors of <a href="#references">[1]</a> selected a set of statistical indicators to<br>
+characterize the communities:</p>
+<ul>
+<li>The clustering coefficient</li>
+<li>The triangle participation ration (TPR), which is the ratio of nodes that close at least one triangle in the community.</li>
+<li>The bridge ratio, which is the ratio of edges whose removal disconnects the community.</li>
+<li>The diameter</li>
+<li>The conductance</li>
+<li>The size</li>
+</ul>
+<p>The authors start by analyzing each community of the ground truth graphs using the above statistical indicators and ploting the distributions of each of them. The following are the plots of the Livejournal graph. We summarize the findings of the authors regarding real graphs: + Several indicators (Clustering Coefficient, TPR and Bridge ratio) exihibit a multimodal distribution, with two peaks aht their extremes.</p>
+<ul>
+<li>Many of the communities (44%) have a small clustering coefficient between 0 and 0.01. Out of them, 56% have just three vertices. On the other hand, 11% of the communities have a clustering coefficient between 0.99 and 1.0. In between, communities exhibit different values of clustering coefficients. This trend is also observed for TPR and Bridgeratio. This suggests that communities cannot be modeled using a single model. * 84% of the communities have a diameter smaller than five, suggesting that ground truth communities are small and compact * Ground truth communities are not very isolated, they have a lot of connections pointing outside of the community.</li>
+<li>Most of the communities are small (10 or less nodes).</li>
+<li>In general, ground truth communities are, small with a low diameter, not isolated and with different ranges of internal connectivity.</li>
+</ul>
+<table>
+<thead>
+<tr>
+<th style="text-align:center"></th>
+<th style="text-align:center"></th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td style="text-align:center"><img src="index.png" alt=""></td>
+<td style="text-align:center"><img src="index2.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Clustering Coefficient</td>
+<td style="text-align:center">TPR</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index3.png" alt=""></td>
+<td style="text-align:center"><img src="index4.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Bridge Ratio</td>
+<td style="text-align:center">Diameter</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index5.png" alt=""></td>
+<td style="text-align:center"><img src="index6.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Conductance</td>
+<td style="text-align:center">Size</td>
+</tr>
+</tbody>
+</table>
+<p>The authors performed the same experiment but for DATAGEN and LFR graphs. They generated a graph of 150k nodes, using their default parameters. In the case of LFR, they tested five different values of the mixing factor, which specifies the ratio of edges of the community pointing outside of the community, They ranged this value from 0 to 0.5. The following are the distributions for DATAGEN.</p>
+<table>
+<thead>
+<tr>
+<th style="text-align:center"></th>
+<th style="text-align:center"></th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td style="text-align:center"><img src="index8.png" alt=""></td>
+<td style="text-align:center"><img src="index9.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Clustering Coefficient</td>
+<td style="text-align:center">TPR</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index10.png" alt=""></td>
+<td style="text-align:center"><img src="index11.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Bridge Ratio</td>
+<td style="text-align:center">TPRDiameter</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index11.png" alt=""></td>
+<td style="text-align:center"><img src="index12.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Conductance</td>
+<td style="text-align:center">Size</td>
+</tr>
+</tbody>
+</table>
+<p>The main conclusions that can be extracted from DATAGEN can be summarized asfollows:</p>
+<ul>
+<li>DATAGEN is able to reproduce the multimodal distribution observed for clustering coefficient, TPR and bridge ratio.</li>
+<li>The central part of the clustering coefficient is biased towards the left, in a similar way as observed for the youtube and livejournal graphs.</li>
+<li>Communities of DATAGEN graphs are not, as in real graphs, isolated, but in this case their level of isolation if significantly larger.</li>
+<li>The diameter is small like in the real graphs.</li>
+<li>It is significant that communities in DATAGEN graphs are closer to those observed in Youtube and Livejournal, as these are social networks like the graphs produced by DATAGEN. We see that DATAGEN is able to reproduce many of their characteristics.</li>
+</ul>
+<p>Finally, the authors repeat the same experiment for LFR graphs. The following are the plots for the LFR graph with mixing ratio 0.3. From them, the authors extract the following conclusions:</p>
+<ul>
+<li>LFR graphs donot show the multimodal distribution observed in real graphs</li>
+<li>Only the diameter shows a similar shape as in the ground truth.</li>
+</ul>
+<table>
+<thead>
+<tr>
+<th style="text-align:center"></th>
+<th style="text-align:center"></th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td style="text-align:center"><img src="index13.png" alt=""></td>
+<td style="text-align:center"><img src="index14.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Clustering Coefficient</td>
+<td style="text-align:center">TPR</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index15.png" alt=""></td>
+<td style="text-align:center"><img src="index16.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Bridge Ratio</td>
+<td style="text-align:center">TPRDiameter</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index17.png" alt=""></td>
+<td style="text-align:center"><img src="index18.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Conductance</td>
+<td style="text-align:center">Size</td>
+</tr>
+</tbody>
+</table>
+<p>To better quanify how similar are the distribuions between the different graphs, the authors also show the correlograms for each of the statisticsl indicators. These correlograms, contain the Spearman’s correlation coefficient between each pair of graphs for a given statistical indicator. The more blue the color, the better the correlation is. We see that DATAGEN distributions correlate very well with those observed in real graphs, specially as we commented above, with Youtube and Livejournal. On the other hand, LFR only succeds significantly in the case of the Diameter.</p>
+<table>
+<thead>
+<tr>
+<th style="text-align:center"></th>
+<th style="text-align:center"></th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td style="text-align:center"><img src="index19.png" alt=""></td>
+<td style="text-align:center"><img src="index20.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Clustering Coefficient</td>
+<td style="text-align:center">TPR</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index21.png" alt=""></td>
+<td style="text-align:center"><img src="index22.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Bridge Ratio</td>
+<td style="text-align:center">TPRDiameter</td>
+</tr>
+<tr>
+<td style="text-align:center"><img src="index23.png" alt=""></td>
+<td style="text-align:center"><img src="index24.png" alt=""></td>
+</tr>
+<tr>
+<td style="text-align:center">Conductance</td>
+<td style="text-align:center">Size</td>
+</tr>
+</tbody>
+</table>
+<p>We see that DATAGEN is able to reproduce a realistics community structure, compared to existing graph generators. This feature, could be potentially exploited to define new benchmakrs to measure the quality of novel community detection algorithms. Stay tuned for future blog posts about his topic!</p>
+<h4 id="references">References</h4>
+<p>[1] Arnau Prat-Pérez, <a href="http://dblp.uni-trier.de/pers/hd/d/Dom=iacute=nguez=Sal:David">David Domínguez-Sal</a>: How community-like is the structure of synthetically generated graphs? <a href="http://dblp.uni-trier.de/db/conf/sigmod/grades2014.html#PratD14">GRADES 2014</a></p>
+<p>[2] Deepayan Chakrabarti, Yiping Zhan, and ChristosFaloutsos. R-mat: A recursive model for graph mining. SIAM 2014</p>
+<p>[3] Myunghwan Kim and Jure Leskovec. Multiplicative attribute graph model of real-world networks. Internet Mathematics</p>
+<p>[4] Andrea Lancichinetti, Santo Fortunato, and Filippo Radicchi. Benchmark graphs for testing community detection algorithms. Physical Review E 2008.</p>
+
+
+
+ -
+
Industry Relevance of the Semantic Publishing Benchmark
+ https://ldbcouncil.org/post/industry-relevance-of-the-semantic-publishing-benchmark/
+ Tue, 03 Mar 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/industry-relevance-of-the-semantic-publishing-benchmark/
+ <h3 id="publishing-and-media-businesses-are-going-through-transformation">Publishing and media businesses are going through transformation</h3>
+<p>I took this picture in June 2010 next to Union Square in San Francisco. I was smoking and wrestling my jetlag in front of Hilton. In the lobby inside the SemTech 2010 conference attendants were watching a game from the FIFA World Cup in South Africa. In the picture, the self-service newspaper stand is empty, except for one free paper. It was not long ago, in the year 2000, this stand was full. Back than the people in the Bay area were willing to pay for printed newspapers. But this is no longer true.</p>
+<p>What’s driving this change in publishing and media?</p>
+<ul>
+<li>
+<p>Widespread and instantaneous distribution of information over the Internet has turned news into somewhat of a “commodity” and few people are willing to pay for it</p>
+</li>
+<li>
+<p>The wealth of free content on YouTube and similar services spoiled the comfort of many mainstream broadcasters;</p>
+</li>
+<li>
+<p>Open access publishing has limited academic publishers to sell journals and books at prices that were considered fair ten years ago.</p>
+</li>
+</ul>
+<p><em>Alongside other changes in the industry, publishers figured out that it is critical to add value through better authoring, promotion, discoverability, delivery and presentation of precious content.</em></p>
+<h3 id="imagine-instant-news-in-context-imagine-personal-channels-imagine--triplestores">Imagine instant news in context, Imagine personal channels, Imagine … triplestores</h3>
+<p>While plain news can be created repeatedly, premium content and services are not as easy to create. Think of an article that not only tells the new facts, but refers back to previous events and is complemented by an info-box of relevant facts. It allows one to interpret and comprehend news more effectively. This is the well-known journalistic aim to put news in context. It is also well-known that producing such news in “near real time” is difficult and expensive using legacy processes and content management technology.</p>
+<p>Another example would be a news feed that delivers good coverage of information relevant to a narrow subject – for example a company, a story line or a region. Judging by the demand for intelligent press clipping services like <a href="http://new.dowjones.com/products/factiva/">Factiva</a>, such channels are in demand but are not straightforward to produce with today’s technology. Despite the common perception that automated recommendations for related content and personalized news are technology no-brainers, suggesting truly relevant content is far from trivial.</p>
+<p>Finally, if we use an example in life sciences, the ability to quickly find scientific articles discussing asthma and x-rays, while searching for respiration disorders and radiation, requires a search service that is not easy to deliver.</p>
+<p>Many publishers have been pressed to advance their business. This, in turn, had led to quest to innovate. And semantic technology can help publishers in two fundamental ways:</p>
+<ol>
+<li>Generation of rich and “meaningful” (trying not to use “semantic” :-) metadata descriptions; 1. Dynamic retrieval of content, based on this rich metadata, enabling better delivery.</li>
+</ol>
+<p>In this post I write about “semantic annotation” and how it enables application scenarios like BBC’s Dynamic Semantic Publishing (DSP). I will also present the business case behind DSP. The final part of the post is about triplestores – semantic graph database engines, used in DSP. To be more concrete I write about the Semantic Publishing Benchmark (SPB), which evaluates the performance of triplestores in DSP scenarios.</p>
+<h3 id="semantic-annotation-produces-rich-metadata-descriptions--the-fuel-for-semantic-publishing">Semantic Annotation produces Rich Metadata Descriptions – the fuel for semantic publishing</h3>
+<p>The most popular meaning of “semantic annotation” is the process of enrichment of text with links to (descriptions of) concepts and entities mentioned in the text. This usually means tagging either the entire document or specific parts of it with identifiers of entities. These identifiers allow one to retrieve descriptions of the entities and relations to other entities – additional structured information that fuels better search and presentation.</p>
+<p><img src="02_semantic_repository.png" alt=""></p>
+<p>The concept of using <a href="http://infosys3.elfak.ni.ac.rs/nastava/attach/SemantickiWebKurs/sdarticle.pdf">text-mining for automatic semantic annotation</a> of text with respect to very large datasets, such as <a href="http://dbpedia.org/">DBPedia</a>, emerged in early 2000. In practical terms it means using such large datasets as a sort of gigantic gazetteer (name lookup tool) and the ability to disambiguate. Figuring out whether “Paris” in the text refers to the capital of France or to Paris, Texas, or to Paris Hilton is crucial in such context. Sometimes this is massively difficult – try to instruct a computer how to guess whether “Hilton” in the second sentence of this post refers to a hotel from the chain founded by her grandfather or that I had the chance to meet Paris Hilton in person on the street in San Francisco.</p>
+<p>Today there are plenty of tools (such as the <a href="https://www.ontotext.com/semantic-solutions/media-publishing/">Ontotext Media and Publishing</a> platform and <a href="https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki">DBPedia Spotlight</a>) and services (such as Thomson Reuter’s <a href="http://www.opencalais.com/">OpenCalais</a> and Ontotext’s <a href="http://s4.ontotext.com">S4</a>) that offer automatic semantic annotation. Although text-mining cannot deliver 100% correct annotations, there are plenty of scenarios, where technology like this would revoluntionize a business. This is the case with the Dynamic Semantic Publishing scenario described below.</p>
+<h3 id="the-bbcs-dynamic-semantic-publishing-dsp">The BBC’s Dynamic Semantic Publishing (DSP)</h3>
+<p>Dynamic Semantic Publishing is a model for using semantic technology in media developed by a group led by John O’Donovan and Jem Rayfield at the BBC. The implementation of DSP behind BBC’s FIFA World Cup 2010 website was the first high-profile success story for usage of semantic technology in media. It is also the basis for the SPB benchmark – sufficient reasons to introduce this use case at length below.</p>
+<p>BBC Future Media & Technology department have transformed the BBC relational content management model and static publishing framework to a fully dynamic semantic publishing architecture. With minimal journalistic management, media assets are being enriched with links to concepts, semantically described in a triplestore. This novel semantic approach provides improved navigation, content re-use and re-purposing through automatic aggregation and rendering of links to relevant stories. At the end of the day DSP improves the user experience on BBC’s web site.</p>
+<p><em>“A high-performance dynamic semantic publishing framework facilitates the publication of automated metadata-driven web pages that are light-touch, requiring minimal journalistic management, as they automatically aggregate and render links to relevant stories”.</em> – <a href="http://www.bbc.co.uk/blogs/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html">Jem Rayfield, Senior Technical Architect</a>, BBC News and Knowledge</p>
+<p>The Dynamic Semantic Publishing (DSP) architecture of the BBC curates and publishes content (e.g. articles or images) based on embedded Linked Data identifiers, ontologies and associated inference. It allows for journalists to determine levels of automation (“edited by exception”) and support semantic advertisement placement for audiences outside of the UK. The following quote explains the workflow when a new article gets into BBC’s content management system.</p>
+<p><em>“In addition to the manual selective tagging process, journalist-authored content is automatically analysed against the World Cup ontology. A <a href="http://www.bbc.co.uk/blogs/legacy/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html#language">natural language and ontological determiner process</a> automatically extracts World Cup concepts embedded within a textual representation of a story. The concepts are moderated and, again, selectively applied before publication. Moderated, automated concept analysis improves the depth, breadth and quality of metadata publishing.</em></p>
+<p><img src="03_bbc_sport.png" alt=""></p>
+<p><em>Journalist-published metadata is captured and made persistent for querying using the resource description framework (<a href="http://www.bbc.co.uk/blogs/legacy/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html#RDF"><em>RDF</em></a>) metadata representation and triple store technology. <a href="http://www.bbc.co.uk/blogs/legacy/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html#BigOWLIM">A RDF triplestore</a> and <a href="http://www.bbc.co.uk/blogs/legacy/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html#SPARQL">SPARQL</a> approach was chosen over and above traditional relational database technologies due to the requirements for interpretation of metadata with respect to an ontological domain model. The high level goal is that the domain ontology allows for intelligent mapping of journalist assets to concepts and queries. The chosen triplestore provides reasoning following the forward-chaining model and thus implied inferred statements are automatically derived from the explicitly applied journalist metadata concepts. For example, if a journalist selects and applies the single concept “Frank Lampard”, then the framework infers and applies concepts such as “England Squad”, “Group C” and “FIFA World Cup 2010” …”</em> – Jem Rayfield</p>
+<p>One can consider each of the “aggregation pages” of BBC as a sort of feed or channel serving content related to a specific topic. If you take this perspective, with its World Cup 2010 website BBC was able to provide more than 700 thematic channels.</p>
+<p><em>“The World Cup site is a large site with over 700 aggregation pages (called index pages) designed to lead you on to the thousands of story pages and content</em></p>
+<p><strong>…</strong><strong><em>we are not publishing pages, but publishing content</em></strong> <em>as assets which are then organized by the metadata dynamically into pages, but could be re-organized into any format we want much more easily than we could before.</em></p>
+<p><img src="04_content_tagging.png" alt=""></p>
+<p><em>… The index pages are published automatically. This process is what assures us of the highest quality output, but still <strong>save large amounts of time</strong> in managing the site and <strong>makes it possible for us to efficiently run so many pages</strong> for the World Cup.”</em> – <a href="http://www.bbc.co.uk/blogs/bbcinternet/2010/07/the_world_cup_and_a_call_to_ac.html">John O’Donovan, Chief Technical Architect, BBC Future Media & Technology</a></p>
+<p>To get a real feeling about the load of the triplestore behind BBC’s World Cup web site, here are some statistics:</p>
+<ul>
+<li>
+<p>800+ aggregation pages (Player, Team, Group, etc.), generated through SPARQL queries;</p>
+</li>
+<li>
+<p>Average unique page requests/day: 2 million;</p>
+</li>
+<li>
+<p>Average <strong>SPARQL queries/day: 1 million;</strong></p>
+</li>
+<li>
+<p><strong>100s repository updates/inserts per minute</strong> with OWL 2 RL reasoning;</p>
+</li>
+<li>
+<p>Multi data center that is fully resilient, clustered 6 node triplestore.</p>
+</li>
+</ul>
+<h3 id="the-semantic-publishing-benchmark">The Semantic Publishing Benchmark</h3>
+<p>LDBC’s <a href="https://ldbcouncil.org/developer/spb">Semantic Publishing Benchmark</a> (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the BBC Dynamic Semantic Publishing scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volumes of read requests (SPARQL queries collecting recent content and data to generate web pages on a specific subject, e.g. Frank Lampard).</p>
+<p>SPB simulates a setup for media that deals with large volumes of streaming content, e.g. articles, pictures, videos. This content is being enriched with metadata that describes it through links to reference knowledge:</p>
+<ul>
+<li>
+<p><em>Reference knowledge:</em> taxonomies and databases that include relevant concepts, entities and factual information (e.g. sport statistics);</p>
+</li>
+<li>
+<p><em>Metadata</em> for each individual piece of content allows publishers to efficiently produce live streams of content relevant to specific subjects.</p>
+</li>
+</ul>
+<p>In this scenario the triplestore holds both reference knowledge and metadata. The main interactions with the repository are of two types:</p>
+<ul>
+<li>
+<p><em>Aggregation queries</em> retrieve content according to various criteria. There are two sets (mixes) of aggregation queries. The basic one includes interactive queries that involve retrieval of concrete pieces of content, as well as aggregation functions, geo-spatial and full-text search constraints. The analytical query mix includes analytical queries, faceted search and drill-down queries;</p>
+</li>
+<li>
+<p><em>Updates</em>, adding new metadata or updating the reference knowledge. It is important that such updates should immediately impact the results of the aggregation queries. Imagine a fan checking the page for Frank Lampard right after he scored a goal – she will be very disappointed to see out of date statistics there.</p>
+</li>
+</ul>
+<p>SPB v.1.0 directly reproduces the DSP setup at the BBC. The reference dataset consists of BBC Ontologies (Core, Sport, News), BBC datasets (list of F1 teams, MPs, etc.) and an excerpt from <a href="http://www.geonames.org/">Geonames</a> for the UK. The benchmark is packed with metadata generator that allows one to set up experiments at different scales. The metadata generator produces 19 statements per Creative Work (BBC’s slang for all sorts of media assets). The standard scale factor is 50 million statements.</p>
+<p>A more technical introduction to SPB can be found in this <a href="https://ldbcouncil.org/post/getting-started-with-the-semantic-publishing-benchmark">post</a>. Results from experiments with SPB on different hardware configurations, including AWS instances, are available in this <a href="https://ldbcouncil.org/post/sizing-aws-instances-for-the-semantic-publishing-benchmark">post</a>. An interesting discovery is that given the current state of the technology (particularly the GraphDB v.6.1 engine) and today’s cloud infrastructure, the load of BBC’s World Cup 2010 website can be handled at AWS by a cluster that costs only $81/day.</p>
+<p>Despite the fact that SPB v.1.0 follows closely the usage scenario for triplestores in BBC’s DSP incarnations, it is relevant to a wide range of media and publishing scenarios, where large volumes of “fast flowing” content need to be “dispatched” to serve various information needs of a huge number of consumers. The main challenges can be summarized as follows:</p>
+<ul>
+<li>
+<p>The Triplestore is used as operational database serving a massive number of read queries (hundreds of queries per second) in parallel with tens of update transactions per second. Transactions need to be handled instantly and in a reliable and consistent manner;</p>
+</li>
+<li>
+<p>Reasoning is needed to map content descriptions to queries in a flexible manner;</p>
+</li>
+<li>
+<p>There are specific requirements, such as efficient handling of full-text search, geo-spatial and temporal constraints.</p>
+</li>
+</ul>
+<h3 id="spb-v20--steeper-for-the-engines-closer-to-the-publishers">SPB v.2.0 – steeper for the engines, closer to the publishers</h3>
+<p>We are in the final testing of the new version 2.0 of SPB. The benchmark has evolved to allow for retrieval of semantically relevant content in a more advanced manner and at the same time to demonstrate how triplestores can offer simplified and more efficient querying.</p>
+<p>The major changes in SPB v.2.0 can be summarized as follows:</p>
+<ul>
+<li>
+<p>Much bigger reference dataset: from 170 thousand to 22 million statements. Now it includes GeoNames data about all of Europe (around 7 million statements) and DBPedia data about companies, people and events (14 million statements). This way we can simulate media archives described against datasets with good global coverage for specific types of objects. Such large reference sets also provide a better testing ground for experiments with very large content archives – think of 50 million documents (1 billion statements) or more;</p>
+</li>
+<li>
+<p>Better interconnected reference data: more than 5 million links between entities, including 500,000 owl:sameAs links between DBPedia and Geonames descriptions. The latter evaluates the capabilities of the engine to deal with data coming from multiple sources, which use different identifiers for one and the same entity;</p>
+</li>
+<li>
+<p>Retrieval of relevant content through links in the reference data, including inferred ones. To this end it is important than SPB v.2.0 involves much more comprehensive inference, particularly with respect to transitive closure of parent-company and geographic nesting chains.</p>
+</li>
+</ul>
+
+
+
+ -
+
OWL-Empowered SPARQL Query Optimization
+ https://ldbcouncil.org/post/owl-empowered-sparql-query-optimization/
+ Wed, 18 Feb 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/owl-empowered-sparql-query-optimization/
+ <p>The Linked Data paradigm has become the prominent enabler for sharing huge volumes of data using Semantic Web technologies, and has created novel challenges for non-relational data management systems, such as RDF and graph engines. Efficient data access through queries is perhaps the most important data management task, and is enabled through query optimization techniques, which amount to the discovery of optimal or close to optimal execution plans for a given query.</p>
+<p>In this post, we propose a different approach to query optimization, which is meant to complement (rather than replace) the standard optimization methodologies for SPARQL queries. Our approach is based on the use of schema information, encoded using OWL constructs, which often accompany Linked Data.</p>
+<p>OWL adopts the Open World Assumption and hence OWL axioms are perceived primarily to infer new knowledge. Nevertheless, ontology designers consider OWL as an expressive schema language used to express constraints for validating the datasets, hence following the Closed World Assumption when interpreting OWL ontologies. Such constraints include disjointness/equivalence of classes/properties, cardinality constraints, domain and range restrictions for properties and others.</p>
+<p>This richness of information carried over by OWL axioms can be the basis for the development of schema-aware techniques that will allow significant improvements in the performance of existing RDF query engines when used in tandem with data statistics or even other heuristics based on patterns found in SPARQL queries. As a simple example, a cardinality constraint at the schema level can provide a hint on the proper join ordering, even if data statistics are missing or incomplete.</p>
+<p>The aim of this post is to show that the richness of information carried over by OWL axioms under the Close World Assumption can be the basis for the development of schema-aware optimization techniques that will allow considerable improvement for query processing. To attain this objective, we discuss a small set of interesting cases of OWL axioms; a full list can be found <a href="LDBC_D4.4.2_final.pdf">here</a>.</p>
+<h3 id="schema-based-optimization-techniques">Schema-Based Optimization Techniques</h3>
+<p>Here we provide some examples of queries, which, when combined with specific schema constraints expressed in OWL, can help the optimizer in formulating the (near to) optimal query plans.</p>
+<p>A simple first case is the case of constraint violation. Consider the query below, which returns all instances of class <code><A></code> which are fillers of a specific property <code><P></code>. If the underlying schema contains the information that the range of <code><P></code> is class <code><B></code>, and that class <code><B></code> is disjoint from class <code><A></code>, then this query should return the empty result, with no further evaluation (assuming that the constraints associated with the schema are satisfied by the data). An optimizer that takes into account schema information should return an empty result in constant time instead of trying to optimize or evaluate the large star join.</p>
+<pre tabindex="0"><code>SELECT ?v
+WHERE { ?v rdf : type <A> .
+ ?u <P> ?v . ?u <P> ?v1 .
+ ?u <P1 > ?v2 . ?u <P2 > ?v3 .
+ ?u <P3 > ?v4 . ?u <P4 > ?v5}
+</code></pre><p>Schema-aware optimizers could also prune the search space by eliminating results that are known a priori not to be in the answer set of a query. The query above is an extreme such example (where all potential results are pruned), but other cases are possible, such as the case of the query below, where all subclasses of class <code><A1></code> can immediately be identified as not being in the answer set.</p>
+<pre tabindex="0"><code>SELECT ?c
+WHERE { ?x rdf: type ?c . ?x <P> ?y .
+ FILTER NOT EXISTS \{ ?x rdf: type <A1 > }}
+</code></pre><p>Another category of schema-empowered optimizations has to do with improved selectivity estimation. In this respect, knowledge about the cardinality (minimum cardinality, maximum cardinality, exact cardinality, functionality) of a property can be exploited to formulate better query plans, even if data statistics are incomplete, missing or erroneous.</p>
+<p>Similarly, taking into account class hierarchies, or the definition of classes/properties via set theoretic constructs (union, intersection) at the schema level, can provide valuable information on the selectivity of certain triple patterns, thus facilitating the process of query optimization. Similar effects can be achieved using information about properties (functionality, transitivity, symmetry etc).</p>
+<p>As an example of these patterns, consider the query below, where class <code><C></code> is defined as the intersection of classes <code><C1></code>,<code> <C2></code>. Thus, the triple pattern <code>(?x rdf:type <C>)</code> is more selective than <code>(?y rdf:type <C1>)</code> and <code>(?z rdf:type <C2>)</code> and this should be immediately recognizable by the optimizer, without having to resort to cost estimations. This example shows also how unnecessary triple patterns can be pruned from a query to reduce the number of necessary joins. Figure 1 illustrates the query plan obtained when the OWL intersectionOf construct is used.</p>
+<pre tabindex="0"><code>SELECT ?x
+WHERE { ?x rdf: type <C> . ?x <P1 > ?y .
+ ?y rdf : type <C1 > . ?y <P2 > ?z . ?z rdf : type <C2 > }
+</code></pre><p><img src="owl_constraints.png" alt="image"></p>
+<p>Schema information can also be used by the query optimizer to rewrite SPARQL queries to equivalent ones that are found in a form for which already known optimization techniques are easily applicable. For example, the query below could easily be transformed into a classical star-join query if we know (from the schema) that property <code>P4</code> is a symmetric property.</p>
+<pre tabindex="0"><code>SELECT ?y ?y1 ?y2 ?y3
+WHERE { ?x <P1 > ?y . ?x <P2 > ?y1 .
+ ?x <P3 > ?y2 . ?y3 <P4 > ?x }
+</code></pre><h3 id="conclusion">Conclusion</h3>
+<p>In this post we argued that OWL-empowered optimization techniques can be beneficial for SPARQL query optimization when used in tandem with standard heuristics based on statistics. We provided some examples which showed the power of such optimizations in various cases, namely:</p>
+<ul>
+<li>Cases where the search space can be pruned due to the schema and the associated constraints; an extreme special sub-case is the identification of queries that violate schema constraints and thus produce no results.</li>
+<li>Cases where the schema can help in the estimation of triple pattern selectivity, even if statistics are incomplete or missing.</li>
+<li>Cases where the schema can identify redundant triple patterns that do not affect the result and can be safely eliminated from the query.</li>
+<li>Cases where the schema can be used for rewriting a query in an equivalent form that would facilitate optimization using well-known optimization techniques.</li>
+</ul>
+<p>This list is by no means complete, as further cases can be identified by optimizers. Our aim in this post was not to provide a complete listing, but to demonstrate the potential of the idea in various directions.</p>
+
+
+
+ -
+
Person Activity Subgraph Features in LDBC DATAGEN
+ https://ldbcouncil.org/post/person-activity-subgraph-features-in-ldbc-datagen/
+ Wed, 04 Feb 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/person-activity-subgraph-features-in-ldbc-datagen/
+ <p>When talking about DATAGEN and other graph generators with social network characteristics, our attention is typically borrowed by the friendship subgraph and/or its structure. However, a social graph is more than a bunch of people being connected by friendship relations, but has a lot more of other things is worth to look at. With a quick view to commercial social networks like Facebook, Twitter or Google+, one can easily identify a lot of other elements such as text images or even video assets. More importantly, all these elements form other subgraphs within the social network! For example, the person activity subgraph is composed by posts and their replies in the different forums/groups in a social network, and has a tree-like structure connecting people through their message interactions.</p>
+<p>When looking at the LDBC Social Network Benchmark (SNB) and its interactive workload, one realizes that these other subgraphs, and especially the person activity subgraph, play a role even more important than that played by the friendship subgraph. Just two numbers that illustrate this importance: 11 out of the 14 interactive workload queries needs traversing parts of the person activity subgraph, and about 80% of all the generated data by DATAGEN belongs to this subgraph. As a consequence, a lot of effort has been devoted to make sure that the person activity subgraph is realistic enough to fulfill the needs of the benchmark. In the rest of this post, I will discuss some of the features implemented in DATAGEN that make the person activity subgraph interesting.</p>
+<h3 id="reaslistic-message-content">Reaslistic Message Content</h3>
+<p>Messages’ content in DATAGEN is not random, but contains snippets of text extracted from Dbpedia talking about the tags the message has. Furthermore, not all messages are the same size, depending on whether they are posts or replies to them. For example, the size of a post is selected uniformly between a minimum and a maximum, but also, there is a small probability that the content is very large (about 2000 characters). In the case of commets (replies to posts), there is a probability of 0.66 to be very short (“ok”, “good”, “cool”, “thanks”, etc.). Moreover, in real forum conversations, it is tipical to see conversations evolving from one topic to another. For this reason, there is a probability that the tags of comments replying posts to change during the flow of the conversation, moving from post’s tags to other related or randomly selected tags.</p>
+<h3 id="non-uniform-activity-levels">Non uniform activity levels</h3>
+<p>In a real social network, not all the members show the same level of activity. Some people post messages more sporadically than others, whose activity is significantly higher. DATAGEN reproduces this phenomena by correlating the activity level with the amount of friends the person has. That is, the larger the amount of friends a person has, the larger the number of posts it creates, and also, the larger the number of groups it belongs to.</p>
+<h3 id="time-correlated-post-and-comment-generation">Time correlated post and comment generation</h3>
+<p>In a real social network, user activity is driven by real world events such as sport events, elections or natural disasters, just to cite a few of them. For this reason, we observe spikes of activity around these events, where the amount of messages created increases significantly during a short period of time, reaching a maximum and then decreasing. DATAGEN emulates this behavior by generating a set of real world events about specific tags. Then, when dates of posts and comments are generated, these events are taken into account in such a way that posts and comments are clustered around them. Also not all the events are equally relevant, thus having spikes larger than others. The shape of the activity is modeled following the model described in <a href="#references">[1]</a>. Furthermore, in order to represent the more normal and uniform person activity levels, we also generate uniformly distributed messages along the time line. The following figure shows the user activity volume along the time line.</p>
+<p><img src="1.png" alt="image"></p>
+<p>As we see, the timeline contains spikes of activity, instead of being uniform. Note that the generally increasing volume activity is due to the fact that more people is added to the social network as time advances.</p>
+<p>In this post we have reviewed several interesting characteristics of the person activity generation process in DATAGEN. Stay tuned for future blog posts about this topic.</p>
+<h4 id="references">References</h4>
+<p>[1] Leskovec, J., Backstrom, L., & Kleinberg, J. (2009, June). Meme-tracking and the dynamics of the news cycle. In <em>Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining</em> (pp. 497-506). ACM.</p>
+
+
+
+ -
+
SNB Driver - Part 2: Tracking Dependencies Between Queries
+ https://ldbcouncil.org/post/snb-driver-part-2-tracking-dependencies-between-queries/
+ Fri, 23 Jan 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-driver-part-2-tracking-dependencies-between-queries/
+ <p>The <a href="https://ldbcouncil.org/post/snb-driver-part-1">SNB Driver part 1</a> post introduced, broadly, the challenges faced when developing a workload driver for the LDBC SNB benchmark. In this blog we’ll drill down deeper into the details of what it means to execute “dependent queries” during benchmark execution, and how this is handled in the driver. First of all, as many driver-specific terms will be used, below is a listing of their definitions. There is no need to read them in detail, it is just there to serve as a point of reference.</p>
+<h3 id="definitions">Definitions</h3>
+<ul>
+<li>
+<p><em>Simulation Time (ST)</em>: notion of time created by data generator. All time stamps in the generated data set are in simulation time</p>
+</li>
+<li>
+<p><em>Real Time (RT)</em>: wall clock time</p>
+</li>
+<li>
+<p><em>Time Compression Ratio</em>: function that maps simulation time to real time, e.g., an offset in combination with a compression ratio. It is a static value, set in driver configuration. Real Time Ratio is reported along with benchmark results, allowing others to recreate the same benchmark</p>
+</li>
+<li>
+<p><em>Operation</em>: read and/or write</p>
+</li>
+<li>
+<p><em>Dependencies</em>: operations in this set introduce dependencies in the workload. That is, for every operation in this set there exists at least one other operation (in Dependents) that can not be executed until this operation has been processed</p>
+</li>
+<li>
+<p><em>Dependents</em>: operations in this set are dependent on at least one other operation (in Dependencies) in the workload</p>
+</li>
+<li>
+<p><em>Due Time (DueT)</em>: point in simulation time at which the execution of an operation should be initiated.</p>
+</li>
+<li>
+<p><em>Dependent Time (DepT)</em>: in addition to Due Time, every operation in Dependents also has a Dependent Time, which corresponds to the Due Time of the operation that it depends on. Dependent Time is always before Due Time. For operations with multiple dependencies Dependent Time is the maximum Due Time of all the operations it depends on.</p>
+</li>
+<li>
+<p><em>Safe Time (SafeT)</em>: time duration.</p>
+<ul>
+<li>
+<p>when two operations have a necessary order in time (i.e., dependency) there is at least a SafeT interval between them</p>
+</li>
+<li>
+<p>SafeT is the minimum duration between the Dependency Time and Due Time of any operations in Dependents</p>
+</li>
+</ul>
+</li>
+<li>
+<p><em>Operation Stream</em>: sequence of operations ordered by Due Time (dependent operations must separated by at least SafeT)</p>
+</li>
+<li>
+<p><em>Initiated Operations</em>: operations that have started executing but not yet finished</p>
+</li>
+<li>
+<p><em>Local Completion Time (per driver)</em>: point in simulation time behind which there are no uncompleted operationsLocal Completion Time = min(min(Initiated Operations), max(Completed Operations))</p>
+</li>
+<li>
+<p><em>Global Completion Time (GCT)</em>: minimum completion time of all drivers. Once GCT has advanced to the Dependent Time of some operation that operation is safe to execute, i.e., the operations it depends on have all completed executing. Global Completion Time = min(Local Completion Time)</p>
+</li>
+<li>
+<p><em>Execution Window (Window)</em>: a timespan within which all operations can be safely executed</p>
+<ul>
+<li>
+<p>All operations satisfying window.startTime <= operation.DueT < window.endTime may be executed</p>
+</li>
+<li>
+<p>Within a window no restrictions on operation ordering or operation execution time are enforced, driver has a freedom of choosing an arbitrary scheduling strategy inside the window</p>
+</li>
+<li>
+<p>To ensure that execution order respects dependencies between operations, window size is bounded by SafeT, such that: 0 < window.duration <= SafeT</p>
+</li>
+<li>
+<p>Window duration is fixed, per operation stream; this is to simplify scheduling and make benchmark runs repeatable</p>
+</li>
+<li>
+<p>Before any operations within a window can start executing it is required that: GCT >= window.startTime - (SafeT - window.duration)</p>
+</li>
+<li>
+<p>All operations within a window must initiate and complete between window start and end times: window.startTime <= operation.initiate < window.endTime and window.startTime <= operation.complete < window.endTime</p>
+</li>
+</ul>
+</li>
+<li>
+<p><em>Dependency Mode</em>: defines dependencies, constraints on operation execution order</p>
+</li>
+<li>
+<p><em>Execution Mode</em>: defines how the runtime should execute operations of a given type</p>
+</li>
+</ul>
+<h3 id="tracking-dependencies">Tracking Dependencies</h3>
+<p>Now, the fun part, making sure dependent operations are executed in the correct order.</p>
+<p>Consider that every operation in a workload belongs to none, one, or both of the following sets: Dependencies and Dependents. As mentioned, the driver uses operation time stamps (Due Times) to ensure that dependencies are maintained. It keeps track of the latest point in time behind which every operation has completed. That is, every operation (i.e., dependency) with a Due Time lower or equal to this time is guaranteed to have completed execution. It does this by maintaining a monotonically increasing variable called Global Completion Time (GCT).</p>
+<p>Logically, every time the driver (via a database connector) begins execution of an operation from Dependencies that operation is added to Initiated Operations:</p>
+<ul>
+<li>the set of operations that have started executing but not yet finished.</li>
+</ul>
+<p>Then, upon completion, the operation is removed from Initiated Operations and added to Completed Operations:</p>
+<ul>
+<li>the set of operations that have started and finished executing.</li>
+</ul>
+<p>Using these sets, each driver process maintains its own view of GCT in the following way. Local progress is monitored and managed using a variable called Local Completion Time (LCT):</p>
+<ul>
+<li>the point in time behind which there are no uncompleted operations. No operation in Initiated Operations has a lower or equal Due Time and no operation in Completed Operations has an equal or higher Due Time.</li>
+</ul>
+<p>LCT is periodically sent to all other driver processes, which all then (locally) set their view of GCT to the minimum LCT of all driver processes. At this point the driver has two, of the necessary three (third covered shortly), pieces of information required for knowing when to execute an operation:</p>
+<ul>
+<li>
+<p><em>Due Time</em>: point in time at which an operation should be executed, assuming all preconditions (e.g., dependencies) have been fulfilled</p>
+</li>
+<li>
+<p><em>GCT</em>: every operation (from Dependencies) with a Due Time before this point in time has completed execution</p>
+</li>
+</ul>
+<p>However, with only GCT to track dependencies the driver has no way of knowing when it is safe to execute any particular dependent operation. What GCT communicates is that all dependencies up to some point in time have completed, but whether or not the dependencies for any particular operation are within these completed operations is unknown. The driver would have to wait until GCT has passed the Due Time (because Dependency Time is always lower) of an operation before that operation could be safely executed, which would result in the undesirable outcome of every operation missing its Due Time. The required information is which particular operation in Dependencies does any operation in Dependents depend on. More specifically, the Due Time of this operation. This is referred to as Dependent Time:</p>
+<ul>
+<li>in addition to Due Time, every operation in Dependents also has (read: must have) a Dependent Time, which corresponds to the latest Due Time of all the operations it depends on. Once GCT has advanced beyond the Dependent Time of an operation that operation is safe to execute.</li>
+</ul>
+<p>Using these three mechanisms (Due Time, GCT, and Dependent Time) the driver is able to execute operations, while ensuring their dependencies are satisfied beforehand.</p>
+<h3 id="scalable-execution-in-the-presence-of-dependencies">Scalable execution in the Presence of Dependencies</h3>
+<p>The mechanisms introduced in part 1 guarantee that dependency constraints are not violated, but in doing so they unavoidably introduce overhead of communication/synchronization between driver threads/processes. To minimize the negative effects that synchronization has on scalability an additional Execution Mode was introduced (more about Execution Modes will be discussed shortly): Windowed Execution. Windowed Execution has two design goals:</p>
+<p>a) make the generated load less ‘bursty’</p>
+<p>b) allow the driver to ‘scale’, so when the driver is given more resources (CPUs, servers, etc.) it is able to generate more load.</p>
+<p>In the context of Windowed Execution, operations are executed in groups (Windows), where operations are grouped according to their Due Time. Every Window has a Start Time, a Duration, and an End Time, and Windows contain only those operations that have a Due Time between Window.startTime and Window.endTime. Logically, all operations within a Window are executed at the same time, some time within the Window. No guaranty is made regarding exactly when, or in what order, an operation will execute within its Window.</p>
+<p>The reasons this approach is correct are as follows:</p>
+<ul>
+<li>
+<p>Operations belonging to the Dependencies set are never executed in this manner - the Due Times of Dependencies operations are never modified as this would affect how dependencies are tracked</p>
+</li>
+<li>
+<p>The minimum duration between the Dependency Time and Due Time of any operation in Dependents is known (can be calculated by scanning through workload once), this duration is referred to as Safe Time (SafeT)</p>
+</li>
+<li>
+<p>A window does not start executing until the dependencies of all its operations have been fulfilled. This is ensured by enforcing that window execution does not start until</p>
+<p>GCT >= window.startTime - (SafeT - window.duration) = window.endTime - SafeT; that is, the duration between GCT and the end of the window is no longer than SafeT</p>
+</li>
+</ul>
+<p>The advantages of such an execution mode are as follows:</p>
+<ul>
+<li>
+<p>As no guarantees are made regarding time or order of operation execution within a Window, GCT no longer needs to be read before the execution of every operation, only before the execution of every window</p>
+</li>
+<li>
+<p>Then, as GCT is read less frequently, it follows that it does not need to be communicated between driver processes as frequently. There is no need or benefit to communicating GCT protocol message more frequently than approximately Window.duration, the side effect of which is reduced network traffic</p>
+</li>
+<li>
+<p>Further, by making no guarantees regarding the order of execution the driver is free to reschedule operations (within Window bounds). The advantage being that operations can be rearranged in such a way as to reduce unwanted bursts of load during execution, which could otherwise occur while synchronizing GCT during demanding workloads. For example, a uniform scheduler may modify operation Due Times to be uniformly distributed across the Window timespan, to ‘smoothen’ the load within a Window.</p>
+</li>
+</ul>
+<p>As with any system, there are trade-offs to this design, particularly regarding Window.duration. The main trade-off is that between ‘workload resolution’ and scalability. Increasing Window.duration reduces synchronization but also reduces the resolution at which the workload definition is followed. That is, the generated workload becomes less like the workload definition. However, as this is both bounded and configurable, it is not a major concern. This issue is illustrated in Figure 1, where the same stream of events is split into two different workloads based on different size of the Window. The workload with Window size 5 (on the right) has better resolution, especially for the ‘bursty’ part of the event stream.</p>
+<p><img src="window-scheduling.png" alt="image"><br>
+Figure 1. Window scheduling</p>
+<p>This design also trades a small amount of repeatability for scalability: as there are no timing or ordering guarantees within a window, two executions of the same window are not guaranteed to be equivalent - ‘what happens in the window stays in the window’. Despite sacrificing this repeatability, the results of operations do not change. No dependency-altering operations occur during the execution of a Window, therefore results for all queries should be equivalent between two executions of the same workload, there is no effect on the expected result for any given operation.</p>
+
+
+
+ -
+
SNB Driver - Part 3: Workload Execution Putting It All Together
+ https://ldbcouncil.org/post/snb-driver-part-3-workload-execution-putting-it-all-together/
+ Tue, 20 Jan 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-driver-part-3-workload-execution-putting-it-all-together/
+ <p>Up until now we have introduced the <a href="https://ldbcouncil.org/post/snb-driver-part-1">challenges faced when executing the LDBC SNB benchmark</a>, as well as explained <a href="https://ldbcouncil.org/post/snb-driver-part-2-tracking-dependencies-between-queries">how some of these are overcome</a>. With the foundations laid, we can now explain precisely how operations are executed.</p>
+<p>Based on the dependencies certain operations have, and on the granularity of parallelism we wish to achieve while executing them, we assign a Dependency Mode and an Execution Mode to every operation type. Using these classifications the driver runtime then knows how each operation should be executed. These modes, as well as what they mean to the driver runtime, are described below.</p>
+<h3 id="dependency-modes">Dependency Modes</h3>
+<p>While executing a workload the driver treats operations differently, depending on their Dependency Mode. In the previous section operations were categorized by whether or not they are in the sets Dependencies and/or Dependents.</p>
+<p>Another way of communicating the same categorization is by assigning a Dependency Mode to operations - every operation type generated by a workload definition must be assigned to exactly one Dependency Mode. Dependency modes define dependencies, constraints on operation execution order. The driver supports a number of different Dependency Modes: None, Read Only, Write Only, Read Write. During workload execution, operations of each type are treated as follows:</p>
+<p><strong>• None</strong></p>
+<p>Depended On (NO): operations do not introduce dependencies with other operations (i.e., the correct execution of no other operation depends on these operations to have completed executing)</p>
+<p>– Prior Execution: do nothing – After Execution: do nothing</p>
+<p><strong>• Read Only</strong></p>
+<p>Depended On (NO): operations do not introduce dependencies with other operations (i.e., the correct execution of no other operation depends on these operations to have completed executing)</p>
+<p>Dependent On (YES): operation execution does depend on GCT to have advanced sufficiently (i.e., correct execution of these operations requires that certain operations have completed execution)</p>
+<p>– Prior Execution: wait for GCT >= operation.DepTime – After Execution: do nothing</p>
+<p><strong>• Write Only</strong></p>
+<p>Depended On (YES): operations do introduce dependencies with other operations (i.e., the correct execution of certain other operations requires that these operations to have completed executing, i.e., to advance GCT)</p>
+<p>Dependent On (NO): operation execution does not depend on GCT to have advanced sufficiently (i.e., correct execution of these operations does not depend on any other operations to have completed execution)</p>
+<p>– Prior Execution: add operation to Initiated Operations</p>
+<p>– After Execution: remove operation from Initiated Operations, add operation to Completed Operations</p>
+<p><strong>• Read Write</strong></p>
+<p>Depended On (YES): operations do introduce dependencies with other operations (i.e., the correct execution of certain other operations requires that these operations to have completed executing, i.e., to advance GCT)</p>
+<p>Dependent On (YES): operation execution does depend on GCT to have advanced sufficiently (i.e., correct execution of these operations requires that certain operations have completed execution)</p>
+<p>– Prior Execution: add operation to Initiated Operations, wait for GCT < operation.DepT</p>
+<p>– After Execution: remove operation from Initiated Operations, add operation to Completed Operations</p>
+<h3 id="execution-modes">Execution Modes</h3>
+<p>Execution Modes relate to how operations are scheduled, when they are executed, and what their failure conditions are. Each operation type in a workload definition must be assigned to exactly one Execution Mode. The driver supports a number of different Execution Modes: Asynchronous, Synchronous, Partially Synchronous. It splits a single workload operation stream into multiple streams, zero or more steams per Execution Mode. During workload execution, operations from each of these streams are treated as follows.</p>
+<p><strong>• Asynchronous</strong>: operations are executed individually, when their Due Time arrives.</p>
+<p>Motivation: This is the default execution mode, it executes operations as true to the workload definition as possible.</p>
+<p>– Re-scheduling Before Execution: None: operation.DueT not modified by scheduler – Execute When time >= operation.DueT (and GCT >= operation.DepT)</p>
+<p>– Max Concurrent Executions: unbounded</p>
+<p>– Max Execution Time: unbounded</p>
+<p>– Failure: operation execution starts later than: operation.DueT Tolerated Delay</p>
+<p><strong>• Synchronous</strong>: operations are executed individually, sequentially, in blocking manner.</p>
+<p>Motivation: Some dependencies are difficult to capture efficiently with SafeT and GCT alone. For example, social applications often support conversations via posts and likes, where likes depend on the existence of posts. Furthermore, posts and likes also depend on the existence of the users that make them. However, users are created at a lower frequency than posts and likes, and it can be assumed they do not immediately start creating content. As such, a reasonably long SafeT can be used between the creation of a user and the first time that user creates posts or likes. Conversely, posts are often replied to and/or liked soon after their creation, meaning a short SafeT would be necessary to maintain the ordering dependency. Consequently, maintaining the dependencies related to conversations would require a short SafeT, and hence a small window. This results in windows containing fewer operations, leading to less potential for parallelism within windows, less freedom in scheduling, more synchronization, and greater likelihood of bursty behavior - all negative things.</p>
+<p>The alternative offered by Synchronous Execution is that, when practical, operations of certain types can be partitioned (e.g. posts and likes could be partitioned by the forum in which they appear), and partitions assigned to driver processes. Using the social application example from above, if all posts and likes were partitioned by forum the driver process that executes the operations from any partition could simply execute them sequentially. Then the only dependency to maintain would be on user operations, reducing synchronization dramatically, and parallelism could still be achieved as each partition would be executed independently, in parallel, by a different driver process.</p>
+<p>– Re-scheduling Before Execution: None: operation.DueT not modified by scheduler</p>
+<p>– Execute When time >= operation.DueT and previousOperation.completed == true (and GCT >= operation.DepT)</p>
+<p>– Max Concurrent Executions: 1</p>
+<p>– Max Execution Time: nextOperation.DueT - operation.DueT</p>
+<p>– Failure: operation execution starts later than: operation.DueT Tolerated Delay E.g., if previousOperation did not complete in time, forcing current operation to wait for longer than the tolerated-delay</p>
+<p><strong>• Partially Synchronous</strong> (Windowed Execution, described in Section 3.4 in more details), groups of operations from the same time window are executed together</p>
+<p>– Re-scheduling Before Execution: Yes, as long as the following still holds:</p>
+<p>window.startTime <= operation.DueT < window.startTime + window.duration</p>
+<p>Operations within a window may be scheduled in any way, as long as they remain in the window from which they originated: their Due Times, and therefore ordering, may be modified</p>
+<p>– Execute When time >= operation.DueT (and GCT >= operation.DepT)</p>
+<p>– Max Concurrent Executions: number of operations within window</p>
+<p>– Max Execution Time: (window.startTime + window.duration) - operation.DueT</p>
+<p>– Failure: operation execution starts later than: window.startTime window.duration operation execution does not finish by: window.startTime + window.duration</p>
+<h3 id="tying-it-back-to-ldbc-snb">Tying it back to LDBC SNB</h3>
+<p>The driver was designed to execute the workload of LDBC SNB. As discussed, the main challenge of running queries in parallel on graph-shaped data stem from dependencies introduced by the graph structure. In other words, workload partitioning becomes as hard as graph partitioning.</p>
+<p>The LDBC SNB data can in fact be seen as a union of two parts:</p>
+<ol>
+<li>
+<p>Core Data: relatively small and dense friendship graph (not more than 10% of the data). Updates on this part are very hard to partition among driver threads, since the graph is essentially a single dense strongly connected component.</p>
+</li>
+<li>
+<p>User Activity Data: posts, replies, likes; this is by far the biggest part of the data. Updates on this part are easily partitioned as long as the dependencies with the “core” part are satisfied (i.e., users don’t post things before the profiles are created, etc.).</p>
+</li>
+</ol>
+<p>In order to avoid friendship graph partitioning, the driver introduces the concept SafeT, the minimal simulation time that should pass between two dependent events.</p>
+<p>This property is enforced by the data generator, i.e. the driver does not need to change or delay some operations in order to guarantee dependency safety. Respecting dependencies now means globally communicating the advances of the Global Completion Time, and making sure the operations do not start earlier than SafeT from their dependents.</p>
+<p>On the other hand, the driver exploits the fact that some of the dependencies in fact do not hinder partitioning: although replies to the post can only be sent after the post is created, these kinds of dependencies are satisfied if we partition workload by forums. This way, all (update) operations on posts and comments from one forum are assigned to one driver thread. Since there is typically a lot of forums, each driver thread gets multiple ones. Updates from one forum are then run in Synchronous Execution Mode, and parallelism is achieved by running many distinct forums in parallel. By doing so, we can add posts and replies to forums at very high frequency without the need to communicate the GCT across driver instances (i.e. we efficiently create the so-called flash-mob effects in the posting/replying workload).</p>
+
+
+
+ -
+
Running the Semantic Publishing Benchmark on Sesame, a Step by Step Guide
+ https://ldbcouncil.org/post/running-the-semantic-publishing-benchmark-on-sesame-a-step-by-step-guide/
+ Tue, 13 Jan 2015 00:00:00 +0000
+
+ https://ldbcouncil.org/post/running-the-semantic-publishing-benchmark-on-sesame-a-step-by-step-guide/
+ <p>Until now we have discussed several aspects of the <a href="https://ldbcouncil.org/benchmarks/spb">Semantic Publishing Benchmark (SPB)</a> such as the <a href="https://ldbcouncil.org/post/sizing-aws-instances-for-the-semantic-publishing-benchmark">difference in performance between virtual and real servers configuration</a>, how to choose an <a href="https://ldbcouncil.org/post/making-semantic-publishing-execution-rules">appropriate query mix</a> for a benchmark run and our experience with using SPB in the development process of GraphDB for <a href="https://ldbcouncil.org/post/using-ldbc-spb-to-find-owlim-performance-issues">finding performance issues</a>.</p>
+<p>In this post we provide a step-by-step guide on how to run SPB using the <a href="http://rdf4j.org/">Sesame</a> RDF data store on a fresh install of <a href="http://releases.ubuntu.com/14.04.1/">Ubuntu Server 14.04.1</a>. The scenario is easy to adapt to other RDF triple stores which support the Sesame Framework used for querying and analyzing RDF data.</p>
+<h3 id="prerequisites">Prerequisites</h3>
+<p>We start with a fresh server installation, but before proceeding with setup of the Sesame Data Store and SPB benchmark we need the following pieces of software up and running:</p>
+<ul>
+<li>Git</li>
+<li>Apache Ant 1.8 or higher</li>
+<li>OpenJDK 6 or Oracle JDK 6 or higher</li>
+<li>Apache Tomcat 7 or higher</li>
+</ul>
+<p>If you already have these components installed on your machine you can directly proceed to the next section: <em>Installing Sesame</em></p>
+<p>Following are sample commands which can be used to install the required software components:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>sudo apt-get install git
+</span></span><span style="display:flex;"><span>sudo apt-get install ant
+</span></span><span style="display:flex;"><span>sudo apt-get install default-jdk
+</span></span><span style="display:flex;"><span>sudo apt-get install tomcat7
+</span></span></code></pre></div><p>Optionally Apache Tomcat Server can be downloaded as a zipped file and extracted in a location of choice.</p>
+<p>After a successful installation of Apache Tomcat you should be able to get the default splash page <em>“It works”</em> when you open your web browser and enter the following address: http://<your_ip_address>:8080</p>
+<h3 id="installing-sesame">Installing Sesame</h3>
+<p>We will use current Sesame version 2.7.14. You can download it <a href="http://sourceforge.net/projects/sesame/files/Sesame%202/">here</a> or run following command:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>wget <span style="color:#ae81ff">\\</span>
+</span></span><span style="display:flex;"><span> <span style="color:#e6db74">"http://sourceforge.net/projects/sesame/files/Sesame%202/2.7.14/openrdf-sesame-2.7.14-sdk.tar.gz/download"</span> <span style="color:#ae81ff">\\</span>
+</span></span><span style="display:flex;"><span> -O openrdf-sesame-2.7.14-sdk.tar.gz
+</span></span></code></pre></div><p>Then extract the Sesame tarball:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>tar -xvzf openrdf-sesame-2.7.14-sdk.tar.gz
+</span></span></code></pre></div><p>To deploy sesame you have to copy the two war files that are in <em>openrdf-sesame-2.7.14/war</em> to <em>/var/lib/tomcat7/webapps</em></p>
+<p>From <em>openrdf-sesame-2.7.14/war</em> you can do it with command:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>cp openrdf-*.war <tomcat_install>/webapps
+</span></span></code></pre></div><p>Sesame applications write and store configuration files in a single directory and the tomcat server needs permissions for it.</p>
+<p>By default the configuration directory is: <em>/usr/share/tomcat7/.aduna</em></p>
+<p>Create the directory:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>sudo mkdir /usr/share/tomcat7/.aduna
+</span></span></code></pre></div><p>Then change the ownership:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>sudo chown tomcat7 /usr/share/tomcat7/.aduna
+</span></span></code></pre></div><p>And finally you should give the necessary permissions:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>sudo chmod o+rwx /usr/share/tomcat7/.aduna
+</span></span></code></pre></div><p>Now when you go to: http://<your_ip_address>:8080/openrdf-workbench/repositories</p>
+<p>You should get a screen like this:</p>
+<p><img src="01-Sesame-repo-list.png" alt="image"></p>
+<h3 id="setup-spb">Setup SPB</h3>
+<p>You can download the SPB code and find brief documentation on GitHub:</p>
+<p><a href="https://github.com/ldbc/ldbc_spb_bm">https://github.com/ldbc/ldbc_spb_bm</a></p>
+<p>A detailed documentation is located here:</p>
+<p><a href="https://github.com/ldbc/ldbc_spb_bm/blob/master/doc/LDBC_SPB_v0.3.pdf">https://github.com/ldbc/ldbc_spb_bm/blob/master/doc/LDBC_SPB_v0.3.pdf</a></p>
+<p>SPB offers many configuration options which control various features of the benchmark e.g.:</p>
+<ul>
+<li>query mixes</li>
+<li>dataset size</li>
+<li>loading datasets</li>
+<li>number of agents</li>
+<li>validating results</li>
+<li>test conformance to OWL2-RL ruleset</li>
+<li>update rate of agents</li>
+</ul>
+<p>Here we demonstrate how to generate a dataset and execute a simple test<br>
+run with it.</p>
+<p>First download the SPB source code from the repository:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>git clone https://github.com/ldbc/ldbc_spb_bm.git
+</span></span></code></pre></div><p>Then in the ldbc_spb_bm directory build the project:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>ant build-basic-querymix
+</span></span></code></pre></div><p>If you simply execute the command:</p>
+<pre tabindex="0"><code>ant
+</code></pre><p>you’ll get a list of all available build configurations for the SPB test driver, but for the purpose of this step-by-step guide, configuration shown above is sufficient.</p>
+<p>Depending on generated dataset size a bigger java heap size may be required for the Sesame Store. You can change it by adding following arguments to Tomcat’s startup files e.g. in <em>catalina.sh</em>:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>export JAVA_OPTS<span style="color:#f92672">=</span><span style="color:#e6db74">"-d64 -Xmx4G"</span>
+</span></span></code></pre></div><p>To run the Benchmark you need to create a repository in the Sesame Data Store, similar to the following screenshot:</p>
+<p><img src="02-Sesame-create-repo.png" alt="image"></p>
+<p>Then we need to point the benchmark test driver to the SPARQL endpoint of that repository. This is done in <em>ldbc_spb_bm/dist/test.properties</em> file.</p>
+<p>The default value of <em>datasetSize</em> in the properties is set to be 10M, but for the purpose of this guide we will decrease it to 1M.</p>
+<p>You need to change</p>
+<pre tabindex="0"><code>datasetSize=1000000
+</code></pre><p>Also the URLs of the SPARQL endpoint for the repository</p>
+<pre tabindex="0"><code>endpointURL=http://localhost:8080/openrdf-sesame/repositories/ldbc1
+endpointUpdateURL=http://localhost:8080/openrdf-sesame/repositories/ldbc1/statements
+</code></pre><p>First step, before measuring the performance of a triple store, is to load the reference-knowledge data, generate a 1M dataset, load it into the repository and finally generate query substitution parameters.</p>
+<p>These are the settings to do that, following parameters will ‘instruct’ the SPB test driver to perform all the actions described above:</p>
+<pre tabindex="0"><code>#Benchmark Operational Phases
+loadOntologies=true
+loadReferenceDatasets=true
+generateCreativeWorks=true
+loadCreativeWorks=true
+generateQuerySubstitutionParameters=true
+validateQueryResults=false
+warmUp=false
+runBenchmark=false
+runBenchmarkOnlineReplicationAndBackup=false
+checkConformance=false
+</code></pre><p>To run the benchmark execute the following:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>java -jar semantic_publishing_benchmark-basic-standard.jar
+</span></span><span style="display:flex;"><span>test.properties
+</span></span></code></pre></div><p>When the initial run has finished, we should have a 1M dataset loaded into the repository and a set of files with query substitution parameters.</p>
+<p>Next we will measure the performance of Sesame Data Store by changing some configuration properties:</p>
+<pre tabindex="0"><code>#Benchmark Configuration Parameters
+warmupPeriodSeconds=60
+benchmarkRunPeriodSeconds=300
+...
+#Benchmark Operational Phases
+loadOntologies=false
+loadReferenceDatasets=false
+generateCreativeWorks=false
+loadCreativeWorks=false
+generateQuerySubstitutionParameters=false
+validateQueryResults=false
+warmUp=true
+runBenchmark=true
+runBenchmarkOnlineReplicationAndBackup=false
+checkConformance=false
+</code></pre><p>After the benchmark test run has finished result files are saved in folder: <em>dist/logs</em></p>
+<p>There you will find three types of results: the result summary of the benchmark run (<em>semantic_publishing_benchmark_results.log),</em> brief results and detailed results.</p>
+<p>In <em>semantic_publishing_benchmark_results.log</em> you will find the results distributed per seconds. They should be similar to the listing bellow:</p>
+<p>Benchmark Results for the 300-th second</p>
+<pre tabindex="0"><code>Seconds : 300 (completed query mixes : 0)
+ Editorial:
+ 2 agents
+
+ 9 inserts (avg : 22484 ms, min : 115 ms, max : 81389 ms)
+ 0 updates (avg : 0 ms, min : 0 ms, max : 0 ms)
+ 0 deletes (avg : 0 ms, min : 0 ms, max : 0 ms)
+
+ 9 operations (9 CW Inserts (0 errors), 0 CW Updates (1 errors), 0 CW Deletions (2 errors))
+ 0.0300 average operations per second
+
+ Aggregation:
+ 8 agents
+
+ 2 Q1 queries (avg : 319 ms, min : 188 ms, max : 451 ms, 0 errors)
+ 3 Q2 queries (avg : 550 ms, min : 256 ms, max : 937 ms, 0 errors)
+ 1 Q3 queries (avg : 58380 ms, min : 58380 ms, max : 58380 ms, 0 errors)
+ 2 Q4 queries (avg : 65250 ms, min : 40024 ms, max : 90476 ms, 0 errors)
+ 1 Q5 queries (avg : 84220 ms, min : 84220 ms, max : 84220 ms, 0 errors)
+ 2 Q6 queries (avg : 34620 ms, min : 24499 ms, max : 44741 ms, 0 errors)
+ 3 Q7 queries (avg : 5892 ms, min : 4410 ms, max : 8528 ms, 0 errors)
+ 2 Q8 queries (avg : 3537 ms, min : 546 ms, max : 6528 ms, 0 errors)
+ 4 Q9 queries (avg : 148573 ms, min : 139078 ms, max : 169559 ms, 0 errors)
+</code></pre><p>This step-by-step guide gave an introduction on how to setup and run the SPB on a Sesame Data Store. Further details can be found in the reference documentation listed above.</p>
+<p>If you have any troubles running the benchmark, don’t hesitate to comment or use our social media channels.</p>
+<p>In a future post we will go through some of the parameters of SPB and check their performance implications.</p>
+
+
+
+ -
+
Semantic Publishing Instance Matching Benchmark
+ https://ldbcouncil.org/post/semantic-publishing-instance-matching-benchmark/
+ Tue, 30 Dec 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/semantic-publishing-instance-matching-benchmark/
+ <p>The Semantic Publishing Instance Matching Benchmark (SPIMBench) is a novel benchmark for the assessment of instance matching techniques for RDF data with an associated schema. SPIMBench extends the state-of-the art instance matching benchmarks for RDF data in three main aspects: it allows for systematic scalability testing, supports a wider range of test cases including semantics-aware ones, and provides an enriched gold standard.</p>
+<p>The SPIMBench test cases provide a systematic way for testing the performance of instance matching systems in different settings. SPIMBench supports the types of test cases already adopted by existing instance matching benchmarks:</p>
+<ul>
+<li>value-based test cases based on applying value transformations (e.g., blank character addition and deletion, change of date format, abbreviations, synonyms) on triples relating to given input entity</li>
+<li>structure-based test cases characterized by a structural transformation (e.g., different nesting levels for properties, property splitting, aggregation)</li>
+</ul>
+<p>The novelty of SPIMBench lies in the support for the following semantics-aware test cases defined on the basis of OWL constructs:</p>
+<ul>
+<li>instance (in)equality (owl:sameAs, owl:differentFrom)</li>
+<li>class and property equivalence (owl:equivalentClass, owl:equivalentProperty)</li>
+<li>class and property disjointness (owl:disjointWith, owl:AllDisjointClasses, owl:propertyDisjointWith, owl:AllDisjointProperties)</li>
+<li>class and property hierarchies (rdfs:subClassOf, rdfs:subPropertyOf)</li>
+<li>property constraints (owl:FunctionalProperty, owl:InverseFunctionalProperty)</li>
+<li>complex class definitions (owl:unionOf, owl:intersectionOf)</li>
+</ul>
+<p>SPIMBench uses and extends the ontologies of LDBC’s Semantic Publishing Benchmark (SPB) to tackle the more complex schema constructs expressed in terms of OWL. It also extends SPB’s data generator to first generate a synthetic source dataset that does not contain any matches, and then to generate matches and non-matches to entities of the source dataset to address the supported transformations and OWL constructs. The data generation process allows the creation of arbitrary large datasets, thus supporting the evaluation of both the scalability and the matching quality of an instance matching system.</p>
+<p>Value and structure-based test cases are implemented using the SWING framework <a href="#references">[1]</a> on data and object type properties respectively. These are produced by applying the appropriate transformation(s) on a source instance to obtain a target instance. Semantics-based test cases are produced in the same way as with the value and structure-based test cases with the difference that appropriate triples are constructed and added in the target dataset to consider the respective OWL constructs.</p>
+<p>SPIMBench, in addition to the semantics-based test cases that differentiate it from existing instance matching benchmarks, also offers a weighted gold standard used to judge the quality of answers of instance matching systems. It contains generated matches (a pair consisting of an entity of the source dataset and an entity of the target dataset) the type of test case it represents, the property on which a transformation was applied (in the case of value-based and structure-based test cases), and a weight that quantifies how easy it is to detect this match automatically. SPIMBench adopts an information-theoretical approach by applying multi-relational learning to compute the weight of the pair of matched instances by measuring the information loss that results from applying transformations to the source data to generate the target data. This detailed information, which is not provided by state of the art benchmarks, allows users of SPIMBench (e.g., developers of IM systems) to more easily identify the reasons underlying the performance results obtained using SPIMBench and thereby supports the debugging of instance matching systems.</p>
+<p>SPIMBench can be downloaded from <a href="https://github.com/jsaveta/SPIMBench">our repository</a> and a more thorough description thereof can be found on <a href="http://www.ics.forth.gr/isl/spimbench/">http://www.ics.forth.gr/isl/spimbench/</a>.</p>
+<h4 id="references">References</h4>
+<p>[1] A. Ferrara, S. Montanelli, J. Noessner, and H. Stuckenschmidt. Benchmarking Matching Applications on the Semantic Web. In ESWC, 2011.</p>
+
+
+
+ -
+
Further Developments in SNB BI Workload
+ https://ldbcouncil.org/post/further-developments-in-snb-bi-workload/
+ Thu, 18 Dec 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/further-developments-in-snb-bi-workload/
+ <p>We are presently working on the SNB BI workload. Andrey Gubichev of TU Munchen and myself are going through the queries and are playing with two SQL based implementations, one on Virtuoso and the other on Hyper.</p>
+<p>As discussed before, the BI workload has the same choke points as TPC-H as a base but pushes further in terms of graphiness and query complexity.</p>
+<p>There are obvious marketing applications for a SNB-like dataset. There are also security related applications, ranging from fraud detection to intelligence analysis. The latter category is significant but harder to approach, as much of the detail of best practice is itself not in the open. In this post, I will outline some ideas discussed over time that might cristallize into a security related section in the SNB BI workload. We invite comments from practitioners for making the business questions more relevant while protecting sensitive details.</p>
+<p>Let’s look at what scenarios would fit with the dataset. We have people, different kinds of connections between people, organizations, places and messages. Messages (posts/replies), people and organizations are geo-tagged. Making a finer level of geo-tagging, with actual GPS coordinates, travel itineraries etc, all referring to real places would make the data even more interesting. The geo dimension will be explored separately in a forthcoming post.</p>
+<p>One of the first things to appear when approaching the question isthat the analysis of behavior patterns over time is not easily captured in purely declarative queries. For example, temporal sequence of events and the quantity and quality of interactions between players leads to intractably long queries which are hard to understand and debug. Therefore, views and intermediate materializations become increasingly necessary.</p>
+<p>Another feature of the scene is that information is never complete. Even if logs are complete for any particular system, there are always possible interactions outside of the system. Therefore we tend to get match scores more then strictly Boolean conditions. Since everybody is related to everybody else via a relative short path, the nature and stremgth of the relationship is key to interpreting its significance.</p>
+<p>Since a query consisting of scores and outer joins only is difficult to interpret and optimize, and since the information is seldom complete, some blanks may have to be filled in by guesses. The database must therefore contain metadata about this.</p>
+<p>An orthogonal aspect to security applications is the access control of the database itself. One might assume that if a data warehouse of analyzable information is put together, the analyst would have access to the entirety of it. This is however not necessarily the case since the information itself and its provenance may fall under different compartments.</p>
+<p>So, let’s see how some of these aspects could be captured in the SNB context.</p>
+<p>Geography - We materialize a table of travel events, so that an unbroken sequence of posts from the same location (e.g. country) other than the residence of the poster forms a travel event. The posts may have a fine grained position (IP, GPS coordinates of photos) that marks an itinerary. This is already beyond basicSQL, needing a procedure or window functions.</p>
+<p>The communication between people is implicit in reply threads and forum memberships. A reply is the closest that one comes to a person to person message in the dataset. Otherwise all content is posted to forumns with more or less participants. Membership in a high traffic forum with few participants would indicate a strong connection. Calculating these time varying connection strengths is a lot of work and a lot of text in queries. Keeping things simple requires materializing a sparse “adjacency cube,” i.e. a relation of person1, person2, time bucket -> connection strength. In the SNB case the connection strength may be derived from reciprocal replies, likes, being in the same forums, knowing each other etc. Selectivity is important, i.e. being in many small forumns together counts for more than being in ones where everybody else also participates.</p>
+<p>The behaviors of people in SNB is not identical from person to person but for the same person follows a preset pattern. Suppose a question like “ which person with access to secrets has a marked change of online behavior?” The change would be starting or stopping communication with a given set of people, for example. Think that the spy meets the future spymaster in a public occasion, has a series of exchanges, travels to an atypical destination, then stops all open contact with the spymaster or related individuals. Patterns like this do not occur in the data but can be introduced easily enough.</p>
+<p>In John Le Carre’s A Perfect Spy the main character is caught because it comes to light that his travel routes near always corresponded to his controller’s. This would make a query. This could be cast in marketing terms as a “(un)common shopping basket.”</p>
+<p>Analytics becomes prediction when one part of a pattern exists without the expected next stage. Thus the same query template can serve for detecting full or partial instances of a pattern, depending on how the scores are interpreted.</p>
+<p>From a database angle, these questions group on an item with internal structure. For the shopping basket this is a set. For the travel routes this is an ordered sequence of space/time points, with a match tolerance on the spatial and temporal elements. Another characteristic is that there is a baseline of expectations and the actual behavior. Both have structure, e.g. the occupation/location/interest/age of one’s social circle. These need to be condensed into a sort of metric space and then changes and rates of change can be observed. Again, this calls for a multidimensional cube to be created as a summary, then algorithms to be applied to this. The declarative BI query a la TPC-H does not easily capture this all.</p>
+<p>This leads us to graph analytics in a broader sense. Some of the questions addressed here will still fit in the materialized summaries+declarative queries pattern but the more complex summarization and clustering moves towards iterative algorithms.</p>
+<p>There is at present a strong interest in developing graph analytics benchmarks in LDBC. This is an activity that extends beyond the FP7 project duration and beyond the initial partners. To this effect I have implemented some SQL extensions for BSP style processing, as hinted at on my blog. These will be covered in more detail in January, when there are actual experiments.</p>
+
+
+
+ -
+
Sizing AWS Instances for the Semantic Publishing Benchmark
+ https://ldbcouncil.org/post/sizing-aws-instances-for-the-semantic-publishing-benchmark/
+ Wed, 17 Dec 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/sizing-aws-instances-for-the-semantic-publishing-benchmark/
+ <p>LDBC’s <a href="https://ldbcouncil.org/developer/spb">Semantic Publishing Benchmark</a> (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the famous <a href="http://www.bbc.co.uk/blogs/legacy/bbcinternet/2010/07/bbc_world_cup_2010_dynamic_sem.html">BBC Dynamic Semantic Publishing</a> scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volume of read requests (SPARQL queries collecting recent content and data to generate web page on a specific subject, e.g. Frank Lampard). As we <a href="https://ldbcouncil.org/post/using-ldbc-spb-to-find-owlim-performance-issues">wrote earlier</a>, SPB was already successfully used to help developers to identify performance issues and to introduce optimizations in SPARQL engines such as GraphDB and Virtuoso. Now we are at the point to experiment with different sizes of the benchmark and different hardware configurations.</p>
+<p>Lately we tested different Amazon Web Services (<a href="https://aws.amazon.com/">AWS</a>) instance types for running SPB basic interactive query mix in parallel with the standard editorial updates – precisely the type of workload that <a href="https://www.ontotext.com/products/ontotext-graphdb/">GraphDB</a> experiences in the backend of BBC Sport website. We discovered and report below a number of practical guidelines about the optimal instance types and configurations. We have proven that SPB 50M workloads can be executed efficiently on a mid-sized AWS instance – c3.2xlarge machine executes 16 read queries and 15 update operations per second. For $1 paid to Amazon for such instance GraphDB executes 140 000 queries and 120 000 updates. The most interesting discovery in this experiment is that if BBC were hosting the triplestore behind their Dynamic Semantic Publishing architecture at AWS, the total cost of the server infrastructure behind their Worldcup 2010 website would have been about $80/day.</p>
+<h3 id="the-experiment">The Experiment</h3>
+<p>For our tests we use:</p>
+<ul>
+<li>GraphDB Standard v6.1</li>
+<li>LDBC-SPB test driver (version 0.1.dc9a626 from 10.Nov.2014) configured as follows:
+<ul>
+<li>8 aggregation agents (read threads) and 2 editorial agents (write threads); for some configurations we experimented with different numbers of agents also</li>
+<li>50M dataset (SF1)</li>
+<li>40 minutes of benchmark run time (60 seconds of warm up)</li>
+</ul>
+</li>
+<li>5 different Amazon EC2 instances and one local server</li>
+</ul>
+<p>Each test run is cold, i.e. data is newly loaded for each run. We set a 5 GByte cache configuration, which is sufficient for the size of the generated dataset. We use the same query substitution parameters (the same randomization seed) for every run, so that we are sure that all test runs are identical.</p>
+<p>We use two types of instances – M3 and C3 instances. They both provide SSD storage for fast I/O performance. The M3 instances are with E5-2670v2, 2.50GHz CPU and provide good all-round performance, while the C3 instances are compute optimized with stronger CPU – E5-2680v2, 2.80GHz, but have half as much memory as the M3.</p>
+<p>We also use a local physical server with dual-CPU – E5-2650v2, 2.60Ghz; 256GB of RAM and RAID-0 array of SSD in order to provide ground for interpretation of the performance for the virtualized AWS instances. The CPU capacity of the AWS instances is measured in vCPUs (virtual CPU). A vCPU is a logical core – one hyper-thread of one physical core of the corresponding Intel Xeon processor used by Amazon. This means that a vCPU represents roughly half a physical core, even though the performance of a hyper-threaded core is not directly comparable with two non-hyper-threaded cores. We should keep this in mind comparing AWS instances to physical machines, i.e. our local server with two CPUs with 8 physical cores each has 32 logical cores, which is more than c3.4xlarge instance with 16 vCPUs.</p>
+<h3 id="the-results">The Results</h3>
+<p>For the tests we measured:</p>
+<ul>
+<li><em>queries/s</em> for the read threads, where queries include SELECT and CONSTRUCT</li>
+<li><em>updates/s</em> for the write threads, where an update operation is INSERT or DELETE</li>
+<li><em>queries/$</em> and <em>updates/$</em> – respectively queries or updates per dollar is calculated for each AWS instance type based on price and update throughput</li>
+<li><em>update/vCPU</em> – modification operations per vCPU per second</li>
+</ul>
+<p>Results (Table 1.) provide strong evidence that performance depends mostly on processor power. This applies to both queries and updates - which in the current AWS setup go on par with one another. Comparing M3 and C3 instances with equal vCPUs we can see that performance is only slightly higher for the M3 machines and even lower for selects with 8 vCPUs. Taking into account the lower price of C3 because of their lower memory, it is clear that C3 machines are better suited for this type of workload and the sweet spot between price and performance is c3.2xlarge machine.</p>
+<p>The improvement in performance between the c3.xlarge and c3.2xlarge is more than twofold where the improvement between c3.2xlarge and c3.4xlarge is considerably lower. We also observe slower growth between c3.4xlarge and the local server machine. This is an indication that for SPB at this scale the difference between 7.5GB and 15GB of RAM is substantial, but RAM above this amount cannot be utilized efficiently by GraphDB.</p>
+<p>Table 1. SPB Measurement Results on AWS and Local Servers</p>
+<table>
+<thead>
+<tr>
+<th>Server Type</th>
+<th>vCPUs</th>
+<th>R/W Agents</th>
+<th>RAM (GB)</th>
+<th>“Storage (GB, SSD)”</th>
+<th>Price USD/h</th>
+<th>Queries/ sec.</th>
+<th>Updates/ sec.</th>
+<th>Queries/ USD</th>
+<th>Updates/ USD</th>
+<th>Updates/ vCPU</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>m3.xlarge</td>
+<td>4</td>
+<td>8/2</td>
+<td>15</td>
+<td>2x 40</td>
+<td>0.28</td>
+<td>8.39</td>
+<td>8.23</td>
+<td>107 882</td>
+<td>105 873</td>
+<td>2.06</td>
+</tr>
+<tr>
+<td>m3.2xlarge</td>
+<td>8</td>
+<td>8/2</td>
+<td>30</td>
+<td>2x 80</td>
+<td>0.56</td>
+<td>15.44</td>
+<td>15.67</td>
+<td>99 282</td>
+<td>100 752</td>
+<td>1.96</td>
+</tr>
+<tr>
+<td>c3.xlarge</td>
+<td>4</td>
+<td>8/2</td>
+<td>7.5</td>
+<td>2x 40</td>
+<td>0.21</td>
+<td>7.17</td>
+<td>6.78</td>
+<td>122 890</td>
+<td>116 292</td>
+<td>1.7</td>
+</tr>
+<tr>
+<td><strong>c3.2xlarge</strong></td>
+<td><strong>8</strong></td>
+<td><strong>8/2</strong></td>
+<td><strong>15</strong></td>
+<td><strong>2x 80</strong></td>
+<td><strong>0.42</strong></td>
+<td><strong>16.46</strong></td>
+<td><strong>14.56</strong></td>
+<td><strong>141 107</strong></td>
+<td><strong>124 839</strong></td>
+<td><strong>1.82</strong></td>
+</tr>
+<tr>
+<td><strong>c3.4xlarge</strong></td>
+<td><strong>16</strong></td>
+<td><strong>8/2</strong></td>
+<td><strong>30</strong></td>
+<td><strong>2x 160</strong></td>
+<td><strong>0.84</strong></td>
+<td><strong>23.23</strong></td>
+<td><strong>21.17</strong></td>
+<td><strong>99 578</strong></td>
+<td><strong>90 736</strong></td>
+<td><strong>1.32</strong></td>
+</tr>
+<tr>
+<td>c3.4xlarge</td>
+<td>16</td>
+<td>8/3</td>
+<td>30</td>
+<td>2x 160</td>
+<td>0.84</td>
+<td>22.89</td>
+<td>20.39</td>
+<td>98 100</td>
+<td>87 386</td>
+<td>1.27</td>
+</tr>
+<tr>
+<td>c3.4xlarge</td>
+<td>16</td>
+<td>10/2</td>
+<td>30</td>
+<td>2x 160</td>
+<td>0.84</td>
+<td>26.6</td>
+<td>19.11</td>
+<td>114 000</td>
+<td>81 900</td>
+<td>1.19</td>
+</tr>
+<tr>
+<td>c3.4xlarge</td>
+<td>16</td>
+<td>10/3</td>
+<td>30</td>
+<td>2x 160</td>
+<td>0.84</td>
+<td>26.19</td>
+<td>19.18</td>
+<td>112 243</td>
+<td>82 200</td>
+<td>1.2</td>
+</tr>
+<tr>
+<td><strong>c3.4xlarge</strong></td>
+<td><strong>16</strong></td>
+<td><strong>14/2</strong></td>
+<td><strong>30</strong></td>
+<td><strong>2x 160</strong></td>
+<td><strong>0.84</strong></td>
+<td><strong>30.84</strong></td>
+<td><strong>16.88</strong></td>
+<td><strong>132 171</strong></td>
+<td><strong>72 343</strong></td>
+<td><strong>1.06</strong></td>
+</tr>
+<tr>
+<td>c3.4xlarge</td>
+<td>16</td>
+<td>14/3</td>
+<td>30</td>
+<td>2x 160</td>
+<td>0.84</td>
+<td>29.67</td>
+<td>17.8</td>
+<td>127 157</td>
+<td>76 286</td>
+<td>1.11</td>
+</tr>
+<tr>
+<td>Local</td>
+<td>32</td>
+<td>8/2</td>
+<td>256</td>
+<td>8x 256</td>
+<td>0.85</td>
+<td>37.11</td>
+<td>32.04</td>
+<td>156 712</td>
+<td>135 302</td>
+<td>1</td>
+</tr>
+<tr>
+<td>Local</td>
+<td>32</td>
+<td>8/3</td>
+<td>256</td>
+<td>8x 256</td>
+<td>0.85</td>
+<td>37.31</td>
+<td>32.07</td>
+<td>157 557</td>
+<td>135 429</td>
+<td>1</td>
+</tr>
+<tr>
+<td><strong>Local</strong></td>
+<td><strong>32</strong></td>
+<td><strong>10/2</strong></td>
+<td><strong>256</strong></td>
+<td><strong>8x 256</strong></td>
+<td><strong>0.85</strong></td>
+<td><strong>40</strong></td>
+<td><strong>31.01</strong></td>
+<td><strong>168 916</strong></td>
+<td><strong>130 952</strong></td>
+<td><strong>0.97</strong></td>
+</tr>
+<tr>
+<td>Local</td>
+<td>32</td>
+<td>14/2</td>
+<td>256</td>
+<td>8x 256</td>
+<td>0.85</td>
+<td>36.39</td>
+<td>26.42</td>
+<td>153 672</td>
+<td>111 569</td>
+<td>0.83</td>
+</tr>
+<tr>
+<td>Local</td>
+<td>32</td>
+<td>14/3</td>
+<td>256</td>
+<td>8x 256</td>
+<td>0.85</td>
+<td>36.22</td>
+<td>26.39</td>
+<td>152 954</td>
+<td>111 443</td>
+<td>0.82</td>
+</tr>
+<tr>
+<td>Local</td>
+<td>32</td>
+<td>20/2</td>
+<td>256</td>
+<td>8x 256</td>
+<td>0.85</td>
+<td>34.59</td>
+<td>23.86</td>
+<td>146 070</td>
+<td>100 759</td>
+<td>0.75</td>
+</tr>
+</tbody>
+</table>
+<h3 id="the-optimal-number-of-test-agents">The Optimal Number of Test Agents</h3>
+<p>Experimenting with different number of aggregation (read) and editorial (write) agents at c3.4xlarge and the local server, we made some interesting observations:</p>
+<ul>
+<li>There is almost no benefit to use more than 2 write agents. This can be explained by the fact that certain aspects of handling writes in GraphDB are serialized, i.e. they cannot be executed in parallel across multiple write threads;</li>
+<li>Using more read agents can have negative impact on update performance. This is proven by the c3.4xlarge results with 8/2 and with 14/2 agents - while in the later case GraphDB handles a bit higher amount of queries (31 vs. 23) we see a drop in the updates rates (from 21 to 17);</li>
+<li>Overall, the configuration with 8 read agents and 2 write agents delivers good balanced results across various hardware configurations;</li>
+<li>For machines with more than 16 cores, a configuration like 10/2 or 14/2, would maximize the number of selects, still with good update rates. This way one can get 30 queries/sec. on c3.4xlarge and 40 queries/sec. on a local server;</li>
+<li>Launching more than 14 read agents does not help even on local server with 32 logical cores. This indicates that at this point we are reaching some constraints such as memory bandwidth or IO throughput and degree of parallelization.</li>
+<li>There is some overhead when handling bigger number of agents as the results for the local server tests with 14/3 and 20/2 show the worst results for both queries and updates.</li>
+</ul>
+<h3 id="efficiency-and-cost">Efficiency and Cost</h3>
+<p>AWS instance type c3.2xlarge provides the best price/performance ratio for applications where 15 updates/sec. are sufficient even at peak times. More intensive applications should use type c3.4xlarge, which guarantees more than 20 updates/sec.</p>
+<p>Cloud infrastructure providers like Amazon, allow one to have a very clear account of the full cost for the server infrastructure, including hardware, hosting, electricity, network, etc.</p>
+<p>$1 spent on c3.2xlarge ($0.41/hour) allows for handling 140 000 queries, along with more than 120 000 update operations!</p>
+<p>The full cost of the server infrastructure is harder to compute in the case of purchasing a server and hosting it in a proprietary data center. Still, one can estimate the upper limits - for machine, like the local server used in this benchmark, this price is way lower than $1/hour. One should consider that this machine is with 256GB of RAM, which is an overkill for Semantic Publishing Benchmark ran at 50M scale. Under all these assumptions we see that using local server is cheaper than the most cost-efficient AWS instance. This is expected - owning a car is always cheaper than renting it for 3 years in a row. Actually, the fact that the difference of the prices/query in this case are low indicates that using AWS services comes at very low extra cost.</p>
+<p>To put these figures in the context of a known real world application, let us model the case of a GraphDB Enterprise replication cluster with 2 master nodes and 6 worker nodes - the size of cluster that BBC used for their FIFA Worldcup 2010 project. Given c3.2xlarge instance type, the math works as follows:</p>
+<ul>
+<li><strong>100 queries/sec.</strong> handled by the cluster. This means about 360 000 queries per hour or more than 4 million queries per day. This is at least 2 times more than the actual loads of GraphDB at BBC during the peak times of big sports events.</li>
+<li><strong>10 updates/sec.</strong> - the speed of updates in GraphDB Enterprise cluster is lower than the speed of each worker node in separation. There are relatively few content management applications that need more than 36 000 updates per hour.</li>
+<li><strong>$81/day</strong> is the full cost for the server infrastructure. This indicates an annual operational cost for cluster of this type in the range of $30 000, even without any effort to release some of the worker nodes in non-peak times.</li>
+</ul>
+
+
+
+ -
+
DATAGEN: a Realistic Social Network Data Generator
+ https://ldbcouncil.org/post/datagen-a-realistic-social-network-data-generator/
+ Sat, 06 Dec 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/datagen-a-realistic-social-network-data-generator/
+ <p>In previous posts (<a href="https://ldbcouncil.org/post/getting-started-with-snb">Getting started with snb</a>, <a href="https://ldbcouncil.org/post/datagen-data-generation-for-the-social-network-benchmark">DATAGEN: data generation for the Social Network Benchmark</a>), Arnau Prat discussed the main features and characteristics of DATAGEN: <em>realism</em>, <em>scalability</em>, <em>determinism</em>, <em>usability</em>. DATAGEN is the social network data generator used by the three LDBC-SNB workloads, which produces data simulating the activity in a social network site during a period of time. In this post, we conduct a series of experiments that will shed some light on how realistic data produced by DATAGEN looks. For our testing, we generated a dataset of scale factor 10 (i.e., social network of 73K users during 3 years) and loaded it into Virtuoso by following the <a href="https://github.com/ldbc/ldbc_snb_datagen">instructions for generating a SNB dataset</a> and <a href="https://github.com/ldbc/ldbc_snb_implementations/tree/master/interactive/virtuoso">for loading the dataset into Virtuoso</a>. In the following sections, we analyze several aspects of the generated dataset.</p>
+<h3 id="a-realistic-social-graph">A Realistic social graph</h3>
+<p>One of the most complexly structured graphs that can be found in the data produced by DATAGEN is the friends graph, formed by people and their <em><knows></em> relationships. We used the R script after Figure 1 to draw the social degree distribution in the SNB friends graph. As shown in Figure 1, the cumulative social degree distribution of the friends graph is similar to that from Facebook (See the note about <a href="https://www.facebook.com/notes/facebook-data-team/anatomy-of-facebook/10150388519243859">Facebook Anatomy</a>). This is not by chance, as DATAGEN has been designed to deliberately reproduce the Facebook’s graph distribution.</p>
+<p><img src="Cumulative-distribution.png" alt="image"> <br>
+Figure 1: Cumulative distribution #friends per user</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-r" data-lang="r"><span style="display:flex;"><span><span style="color:#75715e">#R script for generating the social degree distribution </span>
+</span></span><span style="display:flex;"><span><span style="color:#75715e">#Input files: person_knows_person_*.csv</span>
+</span></span><span style="display:flex;"><span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">library</span>(data.table)
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">library</span>(igraph)
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">library</span>(plotrix)
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">require</span>(bit64)
+</span></span><span style="display:flex;"><span>dflist <span style="color:#f92672"><-</span> <span style="color:#a6e22e">lapply</span>(<span style="color:#a6e22e">commandArgs</span>(trailingOnly <span style="color:#f92672">=</span> <span style="color:#66d9ef">TRUE</span>), fread, sep<span style="color:#f92672">=</span><span style="color:#e6db74">"|"</span>,
+</span></span><span style="display:flex;"><span> header<span style="color:#f92672">=</span>T, select<span style="color:#f92672">=</span><span style="color:#ae81ff">1</span><span style="color:#f92672">:</span><span style="color:#ae81ff">2</span>, colClasses<span style="color:#f92672">=</span><span style="color:#e6db74">"integer64"</span>)
+</span></span><span style="display:flex;"><span> df <span style="color:#f92672"><-</span> <span style="color:#a6e22e">rbindlist</span>(dflist) <span style="color:#a6e22e">setNames</span>(df, <span style="color:#a6e22e">c</span>(<span style="color:#e6db74">"P1"</span>, <span style="color:#e6db74">"P2"</span>))
+</span></span><span style="display:flex;"><span>d2 <span style="color:#f92672"><-</span> df[,<span style="color:#a6e22e">length</span>(P2),by<span style="color:#f92672">=</span>P1]
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">pdf</span>(<span style="color:#e6db74">"socialdegreedist.pdf"</span>)
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">plot</span>(<span style="color:#a6e22e">ecdf</span>(d2<span style="color:#f92672">$</span>V1),main<span style="color:#f92672">=</span><span style="color:#e6db74">"Cummulative distribution #friends per user"</span>,
+</span></span><span style="display:flex;"><span> xlab<span style="color:#f92672">=</span><span style="color:#e6db74">"Number of friends"</span>, ylab<span style="color:#f92672">=</span><span style="color:#e6db74">"Percentage number of users"</span>, log<span style="color:#f92672">=</span><span style="color:#e6db74">"x"</span>,
+</span></span><span style="display:flex;"><span> xlim<span style="color:#f92672">=</span><span style="color:#a6e22e">c</span>(<span style="color:#ae81ff">0.8</span>, <span style="color:#a6e22e">max</span>(d2<span style="color:#f92672">$</span>V1) <span style="color:#f92672">+</span> <span style="color:#ae81ff">20</span>))
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">dev.off</span>()
+</span></span></code></pre></div><h3 id="data-correlations">Data Correlations</h3>
+<p>Data in real life as well as in a real social network is correlated; e.g. names of people living in Germany have a different distribution than those living in Netherlands, people who went to the same university in the same period have a much higher probability to be friends and so on and so forth. In this experiment we will analyze if data produced by DATAGEN also reproduces these phenomena.</p>
+<p><em>Which are the most popular names of a country?</em></p>
+<p>We run the following query on the database built in Virtuoso, which computes the distribution of the names of the people for a given country. In this query, <em>‘A_country_name’</em> is the name of a particular country such as <em>‘Germany’, ‘Netherlands’, or ‘Vietnam’</em>.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-sql" data-lang="sql"><span style="display:flex;"><span><span style="color:#66d9ef">SELECT</span> p_lastname, <span style="color:#66d9ef">count</span> (p_lastname) <span style="color:#66d9ef">as</span> namecnt
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">FROM</span> person, country
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">WHERE</span> p_placeid <span style="color:#f92672">=</span> ctry_city
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> ctry_name <span style="color:#f92672">=</span> <span style="color:#e6db74">'A_country_name'</span>
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">GROUP</span> <span style="color:#66d9ef">BY</span> p_lastname <span style="color:#66d9ef">order</span> <span style="color:#66d9ef">by</span> namecnt <span style="color:#66d9ef">desc</span>;
+</span></span></code></pre></div><p>As we can see from Figures 2, 3, and 4, the distributions of names in Germany, Netherlands and Vietnam are different. A name that is popular in Germany such as <em>Muller</em> is not popular in the Netherlands, and it even does not appear in the names of people in Vietnam. We note that the names’ distribution may not be exactly the same as the contemporary names’ distribution in these countries, since the names resource files used in DATAGEN are extracted from Dbpedia, which may contain names from different periods of time.</p>
+<p><img src="distribution-germany.png" alt="image"> <br>
+Figure 2. Distribution of names in Germany</p>
+<p><img src="distribution-netherlands.png" alt=""> <br>
+Figure 3. Distribution of names in Netherlands</p>
+<p><img src="distribution-vietnam.png" alt=""> <br>
+Figure 4. Distribution of names in Vietnam</p>
+<p><em>Where my friends are living?</em></p>
+<p>We run the following query, which computes the locations of the friends of people living in China.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-sql" data-lang="sql"><span style="display:flex;"><span><span style="color:#66d9ef">SELECT</span> top <span style="color:#ae81ff">10</span> fctry.ctry_name, <span style="color:#66d9ef">count</span> (<span style="color:#f92672">*</span>) <span style="color:#66d9ef">from</span> person <span style="color:#66d9ef">self</span>, person
+</span></span><span style="display:flex;"><span>friend, country pctry, knows, country fctry
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">WHERE</span> pctry.ctry_name <span style="color:#f92672">=</span> <span style="color:#e6db74">'China'</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> <span style="color:#66d9ef">self</span>.p_placeid <span style="color:#f92672">=</span> pctry.ctry_city
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> k_person1id <span style="color:#f92672">=</span> <span style="color:#66d9ef">self</span>.p_personid <span style="color:#66d9ef">and</span> friend.p_personid <span style="color:#f92672">=</span> k_person2id
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> fctry.ctry_city <span style="color:#f92672">=</span> friend.p_placeid
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">GROUP</span> <span style="color:#66d9ef">BY</span> fctry.ctry_name <span style="color:#66d9ef">ORDER</span> <span style="color:#66d9ef">BY</span> <span style="color:#ae81ff">2</span> <span style="color:#66d9ef">desc</span>;
+</span></span></code></pre></div><p>As shown in the graph, most of the friends of people living in China are also living in China. The rest comes predominantly from near-by countries such as India, Vietnam.</p>
+<p><img src="chinese-friends.png" alt=""> <br>
+Figure 5. Locations of friends of people in China</p>
+<p><em>Where my friends are studying?</em></p>
+<p>Finally, we run the following query to find where the friends of people studying at a specific university (e.g., “Hangzhou_International_School”) are studying at.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-sql" data-lang="sql"><span style="display:flex;"><span><span style="color:#66d9ef">SELECT</span> top <span style="color:#ae81ff">10</span> o2.o_name, <span style="color:#66d9ef">count</span>(o2.o_name) <span style="color:#66d9ef">from</span> knows, person_university
+</span></span><span style="display:flex;"><span>p1, person_university p2, organisation o1, organisation o2
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">WHERE</span>
+</span></span><span style="display:flex;"><span> p1.pu_organisationid <span style="color:#f92672">=</span> o1.o_organisationid
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> o1.o_name<span style="color:#f92672">=</span><span style="color:#e6db74">'Hangzhou_International_School'</span>
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> k_person1id <span style="color:#f92672">=</span> p1.pu_personid <span style="color:#66d9ef">and</span> p2.pu_personid <span style="color:#f92672">=</span> k_person2id
+</span></span><span style="display:flex;"><span> <span style="color:#66d9ef">and</span> p2.pu_organisationid <span style="color:#f92672">=</span> o2.o_organisationid
+</span></span><span style="display:flex;"><span><span style="color:#66d9ef">GROUP</span> <span style="color:#66d9ef">BY</span> o2.o_name <span style="color:#66d9ef">ORDER</span> <span style="color:#66d9ef">BY</span> <span style="color:#ae81ff">2</span> <span style="color:#66d9ef">desc</span>;
+</span></span></code></pre></div><p>As we see from Figure 6, most of the friends of the Hangzhou International School students also study at that university. This is a realistic correlation, as people studying at the same university have a much higher probability to be friends. Furthermore, top-10 universities for the friends of the Hangzhou School students’ are from China, while people from foreign universities have small number of friends that study in Hangzhou School (See Table 1).</p>
+<p><img src="friends-international-school.png" alt=""> <br>
+Figure 6. Top-10 universities where the friends of Hangzhou International School students are studying at.</p>
+<table>
+<thead>
+<tr>
+<th>Name</th>
+<th># of friends</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>Hangzhou_International_School</td>
+<td>12696</td>
+</tr>
+<tr>
+<td>Anhui_University_of_Science_and_Technology</td>
+<td>4071</td>
+</tr>
+<tr>
+<td>China_Jiliang_University</td>
+<td>3519</td>
+</tr>
+<tr>
+<td>…</td>
+<td></td>
+</tr>
+<tr>
+<td>Darmstadt_University_of_Applied_Sciences</td>
+<td>1</td>
+</tr>
+<tr>
+<td>Calcutta_School_of_Tropical_Medicine</td>
+<td>1</td>
+</tr>
+<tr>
+<td>Chettinad_Vidyashram</td>
+<td>1</td>
+</tr>
+<tr>
+<td>Women’s_College_Shillong</td>
+<td>1</td>
+</tr>
+<tr>
+<td>Universitas_Nasional</td>
+<td>1</td>
+</tr>
+</tbody>
+</table>
+<p>Table 1. Universities where friends of Hangzhou International School students are studying at.</p>
+<p>In a real social network, data is riddled with many more correlations; it is a true data mining task to extract these. Even though DATAGEN may not be able to model all the real life data correlations, it can generate a dataset that reproduce many of those important characteristics found in a real social network, and additionally introduce a series of plausible correlations in it. More and more interesting data correlations may also be found from playing with the SNB generated data.</p>
+
+
+
+ -
+
SNB Driver - Part 1
+ https://ldbcouncil.org/post/snb-driver-part-1/
+ Thu, 27 Nov 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-driver-part-1/
+ <p>In this multi-part blog we consider the challenge of running the LDBC Social Network Interactive Benchmark (LDBC SNB) workload in parallel, i.e. the design of the workload driver that will issue the queries against the System Under Test (SUT). We go through design principles that were implemented for the LDBC SNB workload generator/load tester (simply referred to as driver). Software and documentation for this driver is available here: <a href="https://github.com/ldbc/ldbc_driver/">https://github.com/ldbc/ldbc_driver/</a>. Multiple reference implementations by two vendors are available here: <a href="https://github.com/ldbc/ldbc_snb_implementations">https://github.com/ldbc/ldbc_snb_implementations</a>, and discussion of the schema, data properties, and related content is available here: <a href="https://github.com/ldbc/ldbc_snb_docs">https://github.com/ldbc/ldbc_snb_docs</a>.</p>
+<p>The following will concentrate on key decisions and techniques that were developed to support scalable, repeatable, distributed workload execution.</p>
+<h3 id="problem-description">Problem Description</h3>
+<p>The driver generates a stream of operations (e.g. create user, create post, create comment, retrieve person’s posts etc.) and then executes them using the provided database connector. To be capable of generating heavier loads, it executes the operations from this stream in parallel. If there were no dependencies between operations (e.g., reads that depend on the completion of writes) this would be trivial. This is the case, for example, for the classical TPC-C benchmark, where splitting transaction stream into parallel clients (terminals) is trivial. However, for LDBC SNB Interactive Workload this is not the case: some operations within the stream do depend on others, others are depended on, some both depend on others and are depended on, and some neither depend on others nor are they depended on.</p>
+<p>Consider, for example, a Social Network Benchmark scenario, where the data generator outputs a sequence of events such as User A posted a picture, User B left a comment to the picture of User A, etc. The second event depends on the first one in a sense that there is a causal ordering between them: User B can only leave a comment on the picture once it has been posted. The generated events are already ordered by their time stamp, so in case of the single-threaded execution this ordering is observed by default: the driver issues a request to the SUT with the first event (i.e., User A posts a picture), after its completion it issues the second event (create a comment). However, if events are executed in parallel, these two events may end up in different parallel sequences of events. Therefore, a driver needs a mechanism to ensure the dependency is observed even when the dependent events are in different parallel update streams.</p>
+<p>The next blog entries in this series will discuss the approaches used in the driver to deal with these challenges.</p>
+
+
+
+ -
+
Making Semantic Publishing Execution Rules
+ https://ldbcouncil.org/post/making-semantic-publishing-execution-rules/
+ Tue, 18 Nov 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/making-semantic-publishing-execution-rules/
+ <p><a href="https://ldbcouncil.org/">LDBC</a> <a href="https://ldbcouncil.org/benchmarks/spb">SPB (Semantic Publishing Benchmark)</a> is based on the BBC linked data platform use case. Thus the data modelling and transaction mix reflects the BBC’s actual utilization of RDF. But a benchmark is not only a condensation of current best practices. The BBC linked data platform is an <a href="https://www.ontotext.com/products/ontotext-graphdb-owlim/">Ontotext Graph DB</a> deployment. Graph DB was formerly known as Owlim.</p>
+<p>So, in SPB we wanted to address substantially more complex queries than the lookups that the BBC linked data platform primarily serves. Diverse dataset summaries, timelines and faceted search qualified by keywords and/or geography are examples of online user experience that SPB needs to cover.</p>
+<p>SPB is not per se an analytical workload but we still find that the queries fall broadly in two categories:</p>
+<ul>
+<li>
+<p>Some queries are centred on a particular search or entity. The data touched by the query size does not grow at the same rate as the dataset.</p>
+</li>
+<li>
+<p>Some queries cover whole cross sections of the dataset, e.g. find the most popular tags across the whole database.</p>
+</li>
+</ul>
+<p>These different classes of questions need to be separated in a metric, otherwise the short lookup dominates at small scales and the large query at large scales.</p>
+<p>Another guiding factor of SPB was the BBC’s and others’ express wish to cover operational aspects such as online backups, replication and fail-over in a benchmark. True, most online installations have to deal with these things, which are yet as good as absent from present benchmark practice. We will look at these aspects in a different article, for now, I will just discuss the matter of workload mix and metric.</p>
+<p>Normally the lookup and analytics workloads are divided into different benchmarks. Here we will try something different. There are three things the benchmark does:</p>
+<ul>
+<li>
+<p>Updates - These sometimes insert a graph, sometimes delete and re-insert the same graph, sometimes just delete a graph. These are logarithmic to data size.</p>
+</li>
+<li>
+<p>Short queries - These are lookups that most often touch on recent data and can drive page impressions. These are roughly logarithmic to data scale.</p>
+</li>
+<li>
+<p>Analytics - These cover a large fraction of the dataset and are roughly linear to data size.</p>
+</li>
+</ul>
+<p>A test sponsor can decide on the query mix within certain bounds. A qualifying run must sustain a minimum, scale-dependent update throughput and must execute a scale-dependent number of analytical query mixes or run for a scale-dependent duration. The minimum update rate, the minimum number of analytics mixes and the minimum duration all grow logarithmically to data size. Within these limits, the test sponsor can decide how to mix the workloads. Publishing several results, emphasizing different aspects is also possible. A given system may be specially good at one aspect, leading the test sponsor to accentuate this.</p>
+<p>The benchmark has been developed and tested at small scales, between 50 and 150M triples. Next we need to see how it actually scales. There we expect to see how the two query sets behave differently. One effect that we see right away when loading data is that creating the full text index on the literals is in fact the longest running part. For a SF 32 ( 1.6 billion triples) SPB database we have the following space consumption figures:</p>
+<ul>
+<li>
+<p>46886 MB of RDF literal text</p>
+</li>
+<li>
+<p>23924 MB of full text index for RDF literals</p>
+</li>
+<li>
+<p>23598 MB of URI strings</p>
+</li>
+<li>
+<p>21981 MB of quads, stored column-wise with default index scheme</p>
+</li>
+</ul>
+<p>Clearly, applying column-wise compression to the strings is the best move for increasing scalability. The literals are individually short, so literal per literal compression will do little or nothing but applying this by the column is known to get a 2x size reduction with Google Snappy. The full text index does not get much from column store techniques, as it already consists of words followed by space efficient lists of word positions. The above numbers are measured with Virtuoso column store, with quads column wise and the rest row-wise. Each number includes the table(s) and any extra indices associated to them.</p>
+<p>Let’s now look at a full run at unit scale, i.e. 50M triples.</p>
+<p>The run rules stipulate a minimum of 7 updates per second. The updates are comparatively fast, so we set the update rate to 70 updates per second. This is seen not to take too much CPU. We run 2 threads of updates, 20 of short queries and 2 of long queries. The minimum run time for the unit scale is 10 minutes, so we do 10 analytical mixes, as this is expected to take 10 a little over 10 minutes. The run stops by itself when the last of the analytical mixes finishes.</p>
+<p>The interactive driver reports:</p>
+<pre tabindex="0"><code>Seconds run : 2144
+ Editorial:
+ 2 agents
+
+ 68164 inserts (avg : 46 ms, min : 5 ms, max : 3002 ms)
+ 8440 updates (avg : 72 ms, min : 15 ms, max : 2471 ms)
+ 8539 deletes (avg : 37 ms, min : 4 ms, max : 2531 ms)
+
+ 85143 operations (68164 CW Inserts (98 errors), 8440 CW Updates (0 errors), 8539 CW Deletions (0 errors))
+ 39.7122 average operations per second
+
+ Aggregation:
+ 20 agents
+
+ 4120 Q1 queries (avg : 789 ms, min : 197 ms, max : 6767 ms, 0 errors)
+ 4121 Q2 queries (avg : 85 ms, min : 26 ms, max : 3058 ms, 0 errors)
+ 4124 Q3 queries (avg : 67 ms, min : 5 ms, max : 3031 ms, 0 errors)
+ 4118 Q5 queries (avg : 354 ms, min : 3 ms, max : 8172 ms, 0 errors)
+ 4117 Q8 queries (avg : 975 ms, min : 25 ms, max : 7368 ms, 0 errors)
+ 4119 Q11 queries (avg : 221 ms, min : 75 ms, max : 3129 ms, 0 errors)
+ 4122 Q12 queries (avg : 131 ms, min : 45 ms, max : 1130 ms, 0 errors)
+ 4115 Q17 queries (avg : 5321 ms, min : 35 ms, max : 13144 ms, 0 errors)
+ 4119 Q18 queries (avg : 987 ms, min : 138 ms, max : 6738 ms, 0 errors)
+ 4121 Q24 queries (avg : 917 ms, min : 33 ms, max : 3653 ms, 0 errors)
+ 4122 Q25 queries (avg : 451 ms, min : 70 ms, max : 3695 ms, 0 errors)
+
+ 22.5239 average queries per second. Pool 0, queries [ Q1 Q2 Q3 Q5 Q8 Q11 Q12 Q17 Q18 Q24 Q25 ]
+
+ 45318 total retrieval queries (0 timed-out)
+ 22.5239 average queries per second
+</code></pre><p>The analytical driver reports:</p>
+<pre tabindex="0"><code>Aggregation:
+ 2 agents
+
+ 14 Q4 queries (avg : 9984 ms, min : 4832 ms, max : 17957 ms, 0 errors)
+ 12 Q6 queries (avg : 4173 ms, min : 46 ms, max : 7843 ms, 0 errors)
+ 13 Q7 queries (avg : 1855 ms, min : 1295 ms, max : 2415 ms, 0 errors)
+ 13 Q9 queries (avg : 561 ms, min : 446 ms, max : 662 ms, 0 errors)
+ 14 Q10 queries (avg : 2641 ms, min : 1652 ms, max : 4238 ms, 0 errors)
+ 12 Q13 queries (avg : 595 ms, min : 373 ms, max : 1167 ms, 0 errors)
+ 12 Q14 queries (avg : 65362 ms, min : 6127 ms, max : 136346 ms, 2 errors)
+ 13 Q15 queries (avg : 45737 ms, min : 12698 ms, max : 59935 ms, 0 errors)
+ 13 Q16 queries (avg : 30939 ms, min : 10224 ms, max : 38161 ms, 0 errors)
+ 13 Q19 queries (avg : 310 ms, min : 26 ms, max : 1733 ms, 0 errors)
+ 12 Q20 queries (avg : 13821 ms, min : 11092 ms, max : 15435 ms, 0 errors)
+ 13 Q21 queries (avg : 36611 ms, min : 14164 ms, max : 70954 ms, 0 errors)
+ 13 Q22 queries (avg : 42048 ms, min : 7106 ms, max : 74296 ms, 0 errors)
+ 13 Q23 queries (avg : 48474 ms, min : 18574 ms, max : 93656 ms, 0 errors)
+ 0.0862 average queries per second. Pool 0, queries [ Q4 Q6 Q7 Q9 Q10 Q13 Q14 Q15 Q16 Q19 Q20 Q21 Q22 Q23 ]
+
+ 180 total retrieval queries (2 timed-out)
+ 0.0862 average queries per second
+</code></pre><p>The metric would be 22.52 qi/s, 310 qa/h, 39.7 u/s @ 50Mt (SF 1)</p>
+<p>The SUT is dual Xeon E5-2630, all in memory. The platform utilization is steadily above 2000% CPU (over 20/24 hardware threads busy on the DBMS). The DBMS is Virtuoso open source, (<a href="https://github.com/v7fasttrack/virtuoso-opensource/">v7fasttrack at github.com</a>, <a href="https://github.com/v7fasttrack/virtuoso-opensource/tree/feature/analytics">feature/analytics</a>).</p>
+<p>The minimum update rate of 7/s was sustained but fell short of the target of 70./s. In this run, most demand was put on the interactive queries. Different thread allocations would give different ratios of the metric components. The analytics mix is for example about 3x faster without other concurrent activity.</p>
+<p>Is this good or bad? I would say that this is possible but better can certainly be accomplished.</p>
+<p>The initial observation is that Q17 is the worst of the interactive lot. 3x better is easily accomplished by avoiding a basic stupidity. The query does the evil deed of checking for a substring in a URI. This is done in the wrong place and accounts for most of the time. The query is meant to test geo retrieval but ends up doing something quite different. Optimizing this right would almost double the interactive score. There are some timeouts in the analytical run, which as such disqualifies the run. This is not a fully compliant result but is close enough to give an idea of the dynamics. So we see that the experiment is definitely feasible, is reasonably defined and that the dynamics seen make sense.</p>
+<p>As an initial comment of the workload mix, I’d say that interactive should have a few more very short point lookups to stress compilation times and give a higher absolute score of queries per second.</p>
+<p>Adjustments to the mix will depend on what we find out about scaling. As with SNB, it is likely that the workload will shift a little, so this result might not be comparable with future ones.</p>
+<p>In the next SPB article, we will look closer at performance dynamics and choke points and will have an initial impression on scaling the workload.</p>
+
+
+
+ -
+
Fifth TUC Meeting
+ https://ldbcouncil.org/event/fifth-tuc-meeting/
+ Fri, 14 Nov 2014 12:32:22 -0400
+
+ https://ldbcouncil.org/event/fifth-tuc-meeting/
+ <p>The LDBC consortium are pleased to announce its fifth Technical User<br>
+Community (TUC) meeting.</p>
+<p>This will be a one-day event at the National Hellenic Research Institute<br>
+in Athens, Greece on <strong>Friday November 14, 2014</strong>.</p>
+<h3 id="agenda">Agenda</h3>
+<p>10:30 - 11:00 Coffee Break</p>
+<p>11:00 - 11:10 Peter Boncz (VUA) Welcome & LDBC project status update (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979841.pptx">Presentation</a>)</p>
+<p>11:10 - 11:25 Venelin Kotsev (ONTO) Semantic Publishing Benchmark:Short Presentation of SPB and Status</p>
+<p>Feedback & Roadmap for SPB & OWLIM (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979839.pdf">Presentation</a>)</p>
+<p>11:25 - 11:30 Orri Erling (OGL) Status, Feedback & Roadmap for SPB & Virtuoso (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979828.pdf">Presentation</a>)</p>
+<p>11:30 - 11:45 Alex Averbuch (NEO) Social Network Benchmark: Short Presentation of SNB and Status, Feedback & Roadmap for SNB & Neo4J (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979830.pdf">Presentation</a>)</p>
+<p>11:45 - 12:00 Orri Erling (OGL) Status, Feedback & Roadmap for SNB & Virtuoso (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979829.pdf">Presentation</a>)</p>
+<p>12:00 - 12:20 Arnau Prat (UPC) & Andrey Gubichev Status, Feedback & Roadmap for SNB Interactive & Sparksee (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979836.pdf">Presentation</a> ) and Business Intelligence (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979837.pdf">Presentation</a>)</p>
+<p>12:20 - 12:40 Tomer Sagi, “Experience with SNB and TitanDB at HP” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979838.pptx">Presentation</a> )</p>
+<p>12:40 - 13:00 Jakob Nelson, “graphbench.org on the SNB datagen”</p>
+<p>13:00 - 14:30 Lunch Break@Byzantine & Christian Museum (<a href="http://www.byzantinemuseum.gr/en/">link</a>)</p>
+<p>14:30 - 14:50 Olaf Hartig, “Integrating the Property Graph and RDF data models” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979831.pdf">Presentation</a>)\</p>
+<p>Documents: <a href="http://arxiv.org/abs/1409.3288">arxiv/1409.3288</a>, <a href="http://arxiv.org/abs/1406.3399">arxiv/1406.3399</a></p>
+<p>14:50 - 15:10 Maria-Esther Vidal and Maribel Acosta, “Challenges to be addressed during Benchmarking SPARQL Federated Engines” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979842.pdf">Presentation</a>)</p>
+<p>15:10 - 15:30 Evaggelia Pitoura, “Historical Queries on Graphs” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979835.pdf">Presentation</a>)</p>
+<p>15:30 - 16:00 Coffee Break</p>
+<p>16:00 - 16:20 Manolis Terrovitis, Giannis Liagos, George Papastefanatos, “Efficient Identification of Implicit Facts in Incomplete OWL2-EL Knowledge Bases” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979843.pdf">Presentation</a>)</p>
+<p>16:20 - 16:40 Gunes Aluc, “WatDiv: How to Tune-up your RDF Data Management System” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979832.pdf">Presentation</a>)</p>
+<p>16:40 - 17:00 Giorgos Kollias, Yannis Smaragdakis, “Benchmarking @LogicBlox” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979840.pdf">Presentation</a>)</p>
+<p>17:00 - 17:15 Hassan Chafi, “Oracle Labs Graph Strategy”</p>
+<p>17:15 - 17:25 Yinglong Xia, “Property Graphs for Industry Solution at IBM” (<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/6979834.pdf">Presentation</a>)</p>
+<p>17:25 - 17:30 Arthur Keen, “Short Introduction to SPARQLcity”</p>
+<p><em><strong>20:30 Dinner @ Konservokouti <a href="https://plus.google.com/114240752029716758955/about?gl=gr&hl=en">(link)</a></strong></em></p>
+<p><em><strong>Get a Taxi, and go to Ippokratous 148, Athens, Neapoli Exarheion</strong></em></p>
+<h4 id="logistics">Logistics</h4>
+<p>The meeting will be held at the <a href="http://www.eie.gr/index-en.html">National Hellenic Research Foundation</a> located in <a href="http://www.eie.gr/location-en.html">downtown Athens</a>.</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fifth-tuc-meeting/attachments/5996808/5964344.gif" alt=""></p>
+<h4 id="travel">Travel</h4>
+<p>Athens, Greece’s capital city, is easily accessible by air. Travelers on flights to Athens will land at Athens Eleftherios Venizelos International Airport.</p>
+<p>To arrive in the city center, you can take the metro from the airport (Line #3) and stop at either stop Evangelismos (ΕΥΑΓΓΕΛΙΣΜΟΣ) or at Syntagma (ΣΥΝΤΑΓΜΑ) stations. You can also take express Bus X95 and stop again at either Evangelismos (ΕΥΑΓΓΕΛΙΣΜΟΣ) or at Syntagma (ΣΥΝΤΑΓΜΑ) stations (the latter is the terminus for the bus).</p>
+<p>You can also take a taxi from the airport that runs on a fixed price for the city center (45 euros). More information on how to move around in Athens from the airport can be found here: <a href="http://www.aia.gr/traveler/">http://www.aia.gr/traveler/</a></p>
+
+
+
+ -
+
Getting Started With the Semantic Publishing Benchmark
+ https://ldbcouncil.org/post/getting-started-with-the-semantic-publishing-benchmark/
+ Sun, 09 Nov 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/getting-started-with-the-semantic-publishing-benchmark/
+ <p>The Semantic Publishing Benchmark (SPB), developed in the context of LDBC, aims at measuring the read and write operations that can be performed in the context of a media organisation. It simulates the management and consumption of RDF metadata describing media assets and creative works. The scenario is based around a media organisation that maintains RDF descriptions of its catalogue of creative works. These descriptions use a set of ontologies proposed by BBC that define numerous properties for content; they contain asll RDFS schema constructs and certain OWL ones.</p>
+<p>The benchmark proposes a data generator that uses the ontologies provided by BBC and reference datasets (again provided by BBC) to produce a set of valid instances; it works with a predefined set of distributions derived from the reference datasets. In addition to these distributions, the data generator also models:</p>
+<ul>
+<li>clustering of creative works around certain entities from the reference datasets (e.g. the association of an entity with creative works would decay exponentially in time)</li>
+<li>correlations between entities - there will be creative works about two entities for a certain period in time, that way a history of interactions is also modelled (e.g. J. Biden and B. Obama are tagged in creative works for a continuous period in time)</li>
+</ul>
+<p>The driver proposed by the benchmark measures the performance of CRUD operations of a SPARQL endpoint by starting a number of concurrently running editorial and aggregation agents. The former executes a series of insert, update and delete operations, whereas the latter a set of construct, describe, and select queries on a SPARQL endpoint. The benchmark can access all SPARQL endpoints that support the SPARQL 1.1 protocol. Tests have been run on OWLIM and Virtuoso. Attempts were also made for Stardog.</p>
+<p>Currently, the benchmark offers two workloads: a base version that consists of a mix of nine queries of different complexity that consider nearly all the features of SPARQL 1.1 query language including sorting, subqueries, limit, regular expressions and grouping. The queries aim at checking different choke points relevant to query optimisation such as:</p>
+<ul>
+<li>join ordering based on cardinality constraints - expressed by the different kinds of properties defined in the schema</li>
+<li>subselects that aggregate the query results that the optimiser should recognise and evaluate first</li>
+<li>optional and nested optional clauses where the optimiser is called to produce a plan where the execution of the optional triple patterns is performed last</li>
+<li>reasoning along the RDFS constructs (subclass, subproperty hierarchies, functional, object and transitive properties etc.)</li>
+<li>unions to be executed in parallel</li>
+<li>optionals that contain filter expressions that should be executed as early as possible in order to eliminate intermediate results</li>
+<li>ordering where the optimiser could consider the possibility to choose query plan(s) that facilitate the ordering of results</li>
+<li>handling of geo-spatial predicates</li>
+<li>full-text search optimisation</li>
+<li>asynchronous execution of the aggregate sub-queries</li>
+<li>use of distinct to choose the optimal query plan</li>
+</ul>
+<p>We give below Query 1 of the Semantic Publishing Benchmark.</p>
+<pre tabindex="0"><code>PREFIX bbcevent:<http://www.bbc.co.uk/ontologies/event/>
+PREFIX geo-pos:<http://www.w3.org/2003/01/geo/wgs84_pos#>
+PREFIX bbc:<http://www.bbc.co.uk/ontologies/bbc/>
+PREFIX time:<http://www.w3.org/2006/time#>
+PREFIX event:<http://purl.org/NET/c4dm/event.owl#>
+PREFIX music-ont:<http://purl.org/ontology/mo/>
+PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
+PREFIX foaf:<http://xmlns.com/foaf/0.1/>
+PREFIX provenance:<http://www.bbc.co.uk/ontologies/provenance/>
+PREFIX owl:<http://www.w3.org/2002/07/owl#>
+PREFIX cms:<http://www.bbc.co.uk/ontologies/cms/>
+PREFIX news:<http://www.bbc.co.uk/ontologies/news/>
+PREFIX cnews:<http://www.bbc.co.uk/ontologies/news/cnews/>
+PREFIX cconcepts:<http://www.bbc.co.uk/ontologies/coreconcepts/>
+PREFIX dbp-prop:<http://dbpedia.org/property/>
+PREFIX geonames:<http://sws.geonames.org/>
+PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
+PREFIX domain:<http://www.bbc.co.uk/ontologies/domain/>
+PREFIX dbpedia:<http://dbpedia.org/resource/>
+PREFIX geo-ont:<http://www.geonames.org/ontology#>
+PREFIX bbc-pont:<http://purl.org/ontology/po/>
+PREFIX tagging:<http://www.bbc.co.uk/ontologies/tagging/>
+PREFIX sport:<http://www.bbc.co.uk/ontologies/sport/>
+PREFIX skosCore:<http://www.w3.org/2004/02/skos/core#>
+PREFIX dbp-ont:<http://dbpedia.org/ontology/>
+PREFIX xsd:<http://www.w3.org/2001/XMLSchema#>
+PREFIX core:<http://www.bbc.co.uk/ontologies/coreconcepts/>
+PREFIX curric:<http://www.bbc.co.uk/ontologies/curriculum/>
+PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
+PREFIX cwork:<http://www.bbc.co.uk/ontologies/creativework/>
+PREFIX fb:<http://rdf.freebase.com/ns/>
+
+# Query Name : query1
+# Query Description :
+# Retrieve creative works about thing t (or that mention t)
+# reasoning: rdfs:subClassOf, rdf:type
+# join ordering: cwork:dateModified rdf:type owl:FunctionalProperty
+# join ordering: cwork:dateCreated rdf:type owl:FunctionalProperty
+# Choke Points :
+# - join ordering based on cardinality of functional proerties cwork:dateCreated, cwork:dateModified
+# Optimizer should use an efficient cost evaluation method for choosing the optimal join tree
+# - A sub-select which aggregates results. Optimizer should recognize it and execute it first
+# - OPTIONAL and nested OPTIONAL clauses (treated by query optimizer as nested sub-queries)
+# Optimizer should decide to put optional triples on top of the join tree
+# (i.e. delay their execution to the last possible moment) because OPTIONALs are treated as a left join
+# - qiery optimizer has the chance to recognize the triple pattern : ?cWork a ?type . ?type rdfs:subClassOf cwork:CreativeWork
+# and eliminate first triple (?cwork a ?type .) since ?cwork is a cwork:CreativeWork
+
+CONSTRUCT {
+ ?creativeWork a cwork:CreativeWork ;
+ a ?type ;
+ cwork:title ?title ;
+ cwork:shortTitle ?shortTitle ;
+ cwork:about ?about ;
+ cwork:mentions ?mentions ;
+ cwork:dateCreated ?created ;
+ cwork:dateModified ?modified ;
+ cwork:description ?description ;
+ cwork:primaryFormat ?primaryFormat ;
+ bbc:primaryContentOf ?webDocument .
+ ?webDocument bbc:webDocumentType ?webDocType .
+ ?about rdfs:label ?aboutLabel ;
+ bbc:shortLabel ?aboutShortLabel ;
+ bbc:preferredLabel ?aboutPreferredLabel .
+ ?mentions rdfs:label ?mentionsLabel ;
+ bbc:shortLabel ?mentionsShortLabel ;
+ bbc:preferredLabel ?mentionsPreferredLabel .
+ ?creativeWork cwork:thumbnail ?thumbnail .
+ ?thumbnail a cwork:Thumbnail ;
+ cwork:altText ?thumbnailAltText ;
+ cwork:thumbnailType ?thumbnailType .
+}
+WHERE {
+ {
+ SELECT ?creativeWork
+ WHERE {
+ ?creativeWork {{{cwAboutOrMentions}}} {{{cwAboutOrMentionsUri}}} .
+ ?creativeWork a cwork:CreativeWork ;
+ cwork:dateModified ?modified .
+ }
+ ORDER BY DESC(?modified)
+ LIMIT 10
+ }
+ ?creativeWork a cwork:CreativeWork ;
+ a ?type ;
+ cwork:title ?title ;
+ cwork:dateModified ?modified .
+ OPTIONAL { ?creativeWork cwork:shortTitle ?shortTitle . }
+ OPTIONAL { ?creativeWork cwork:description ?description . }
+ OPTIONAL { ?creativeWork cwork:about ?about .
+ OPTIONAL { ?about rdfs:label ?aboutLabel . }
+ OPTIONAL { ?about bbc:shortLabel ?aboutShortLabel . }
+ OPTIONAL { ?about bbc:preferredLabel ?aboutPreferredLabel . }
+ }
+ OPTIONAL {
+ ?creativeWork cwork:mentions ?mentions .
+ OPTIONAL { ?mentions rdfs:label ?mentionsLabel . }
+ OPTIONAL { ?mentions bbc:shortLabel ?mentionsShortLabel . }
+ OPTIONAL { ?mentions bbc:preferredLabel ?mentionsPreferredLabel . }
+ }
+ OPTIONAL { ?creativeWork cwork:dateCreated ?created . }
+ OPTIONAL { ?creativeWork cwork:primaryFormat ?primaryFormat . }
+ OPTIONAL { ?webDocument bbc:primaryContent ?creativeWork .
+ OPTIONAL { ?webDocument bbc:webDocumentType ?webDocType . }
+ }
+ OPTIONAL { ?creativeWork bbc:primaryContentOf ?webDocument .
+ OPTIONAL { ?webDocument bbc:webDocumentType ?webDocType . }
+ }
+ OPTIONAL { ?creativeWork cwork:thumbnail ?thumbnail .
+ OPTIONAL { ?thumbnail cwork:altText ?thumbnailAltText . }
+ OPTIONAL { ?thumbnail cwork:thumbnailType ?thumbnailType . }
+ }
+}
+</code></pre><p>Listing 1. Semantic Publishing Benchmark: Query 1</p>
+<p>The benchmark test driver is distributed as a jar file, but can also be built using an ant script. It is distributed with the BBC ontologies and reference datasets, the queries and update workloads discussed earlier and the configuration parameters for running the benchmark and for generating the data. It is organised in the following different phases: ontology loading and reference dataset loading, dataset generation and loading, warm up (where a series of aggregation queries are run for a predefined amount of time), benchmark where all queries (aggregation and editorial) are run, conformance checking (that allows one to check whether the employed RDF engine implements OWL reasoning) and finally cleanup that removes all the data from the repository. The benchmark provides a certain degree of freedom where each phase can run independently of the others.</p>
+<p>The data generator uses an RDF repository to load ontologies and reference datasets; actually, any system that will be benchmarked should have those ontologies loaded. Any repository that will be used for the data generation should be set up with context indexing, and finally geo-spatial indexing, if available, to serve the spatial queries. The current version of the benchmark has been tested with Virtuoso and OWLIM.</p>
+<p>The generator uses configuration files that must be configured appropriately to set the values regarding the dataset size to produce, the number of aggregation and editorial agents, the query time out etc. The distributions used by the data generator could also be edited. The benchmark is very simple to run (once the RDF repository used to store the ontologies and the reference datasets is set up, and the configuration files updated appropriately) using the command: java -jar semantic_publishing_benchmark-*.jar test.properties. The benchmark produces three kinds of files that contain (a) brief information about each executed query, the size of the returned result, and the execution time (semantic_publishing_benchmark_queries_brief.log), (b) the detailed log of each executed query and its result (semantic_publishing_benchmark_queries_detailed.log) (c) the benchmark results (semantic_publishing_benchmark_results.log ).</p>
+<p>Below we give an example of a run of the benchmark for OWLIM-SE. The benchmark reports the number of edit operations (inserts, updates, and writes) and queries executed at the Nth second of a benchmark run. It also reports that total number of retrieval queries as well as the average number of queries executed per second.</p>
+<pre tabindex="0"><code>Seconds run : 600
+ Editorial:
+ 0 agents
+
+ 0 operations (0 CW Inserts, 0 CW Updates, 0 CW Deletions)
+ 0.0000 average operations per second
+
+ Aggregation:
+ 8 agents
+
+ 298 Q1 queries
+ 267 Q2 queries
+ 243 Q3 queries
+ 291 Q4 queries
+ 320 Q5 queries
+ 286 Q6 queries
+ 255 Q7 queries
+ 274 Q8 queries
+ 271 Q9 queries
+
+ 2505 total retrieval queries
+ 4.1750 average queries per second
+</code></pre><p>Listing 2. A snippet of semantic_publishing_benchmark_results.log</p>
+<p>We run the benchmark under the following configuration: we used 8 aggregation agents for query execution and 4 data generator workers all running in parallel. The warm up period is 120 seconds during which a number of aggregation agents is executed to prepare the tested systems for query execution. Aggregation agents run for a period of 600 seconds, and queries timeout after 90 seconds. We used 10 sets of substitution parameters for each query. For data generation, ontologies and reference datasets are loaded in the OWLIM-SE repository. We used OWLIM-SE, Version 5.4.6287 with Sesame Version 2.6 and Tomcat Version 6. The results we obtained for the 10M, 100M and 1B triple datasets are given in the table below:</p>
+<table>
+<thead>
+<tr>
+<th>#triples</th>
+<th>Q1</th>
+<th>Q2</th>
+<th>Q3</th>
+<th>Q4</th>
+<th>Q5</th>
+<th>Q6</th>
+<th>Q7</th>
+<th>Q8</th>
+<th>Q9</th>
+<th>#queries</th>
+<th>avg. #q. per sec.</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>10M</td>
+<td>298</td>
+<td>267</td>
+<td>243</td>
+<td>291</td>
+<td>320</td>
+<td>286</td>
+<td>255</td>
+<td>274</td>
+<td>271</td>
+<td>2505</td>
+<td>41,750</td>
+</tr>
+<tr>
+<td>100M</td>
+<td>53</td>
+<td>62</td>
+<td>51</td>
+<td>52</td>
+<td>44</td>
+<td>62</td>
+<td>25</td>
+<td>55</td>
+<td>45</td>
+<td>449</td>
+<td>7,483</td>
+</tr>
+<tr>
+<td>1B</td>
+<td>34</td>
+<td>29</td>
+<td>22</td>
+<td>24</td>
+<td>25</td>
+<td>29</td>
+<td>0</td>
+<td>29</td>
+<td>28</td>
+<td>220</td>
+<td>3,667</td>
+</tr>
+</tbody>
+</table>
+
+
+
+ -
+
Choke Point Based Benchmark Design
+ https://ldbcouncil.org/post/choke-point-based-benchmark-design/
+ Tue, 14 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/choke-point-based-benchmark-design/
+ <p>The <em>Linked Data Benchmark Council</em> (LDBC) mission is to design and maintain benchmarks for graph data management systems, and establish and enforce standards in running these benchmarks, and publish and arbitrate around the official benchmark results. The council and its <a href="https://ldbcouncil.org">https://ldbcouncil.org</a> website just launched, and in its first 1.5 year of existence, most effort at LDBC has gone into investigating the needs of the field through interaction with the LDBC Technical User Community (<a href="https://ldbcouncil.org/event/fifth-tuc-meeting">next TUC meeting</a> will be on October 5 in Athens) and indeed in <em>designing benchmarks</em>.</p>
+<p>So, what makes a good benchmark design? Many talented people have paved our way in addressing this question and for relational database systems specifically the benchmarks produced by <a href="http://www.tpc.org/">TPC</a> have been very helpful in maturing relational database technology, and making it successful. Good benchmarks are <em>relevant</em> and <em>representative</em> (address important challenges encountered in practice), <em>understandable</em> , <em>economical</em> (implementable on simple hardware), <em>fair</em> (such as not to favor a particular product or approach), <em>scalable</em>, <em>accepted</em> by the community and <em>public</em> (e.g. all of its software is available in open source). This list stems from Jim Gray’s <a href="http://research.microsoft.com/en-us/um/people/gray/BenchmarkHandbook/TOC.htm">Benchmark Handbook</a>. In this blogpost, I will share some thoughts on each of these aspects of good benchmark design.</p>
+<p>A very important aspect of benchmark development is making sure that the community <em>accepts</em> a certain benchmark, and starts using it. A benchmark without published results and therefore opportunity to compare results, remains irrelevant. A European FP7 project is a good place to start gathering a critical mass of support (and consensus, in the process) for a new benchmark from the core group of benchmark designers in the joint work performed by the consortium. Since in LDBC multiple commercial graph and RDF vendors are on the table (Neo Technologies, Openlink, Ontotext and Sparsity) a minimal consensus on <strong>fairness</strong> had to be established immediately. The Linked Data Benchmark Council itself is a noncommercial, neutral, entity which releases all its benchmark specifications, software, as well as many materials created during the design. LDBC has spent a lot of time engaging interested parties (mainly through its <a href="https://ldbcouncil.org/tags/tuc-meeting/">Technical User Community gatherings</a>) as well as lining up additional organizations as members of the Linked Data Benchmark Council. There is, in other words, a strong non-technical, human factor in getting benchmarks accepted.</p>
+<p>The need for <em>understandability</em> for me means that a database benchmark should consist of a limited number of queries and result metrics. Hence I find TPC-H with its 22 queries more understandable than TPC-DS with its 99, because after (quite some) study and experience it is possible to understand the underlying challnges of all queries in TPC-H. It may also be possible for TPC-DS but the amount of effort is just much larger. Understandable also means for me that a particular query should behave similarly, regardless of the query parameters. Often, a particular query needs to be executed many times, and in order not to play into the hands of simple query caching and also enlarge the access footprint of the workload, different query parameters should be used. However, parameters can strongly change the nature of a query but this is not desirable for the understandability of the workload. For instance, we know that TPC-H Q01 tests raw computation power, as its selection predicate eliminates almost nothing from the main fact table (LINEITEM), that it scans and aggregates into a small 4-tuple result. Using a selection parameter that would select only 0.1% of the data instead, would seriously change the nature of Q01, e.g. making it amendable to indexing. This stability of parameter bindings is an interesting challenge for the <a href="https://ldbcouncil.org/benchmarks/snb">Social Network Benchmark</a> (SNB) of LDBC which is not as uniform and uncorrelated as TPC-H. Addressing the challenge of obtaining parameter bindings that have similar execution characteristics will be the topic of a future blog post.</p>
+<p>The <em>economical</em> aspect of benchmarking means that while rewarding high-end benchmark runs with higher scores, it is valuable if a meaningful run can also be done with small hardware. For this reason, it is good practice to use a performance-per-EURO (or $) metric, so small installations despite a lower absolute score can still do well on that metric. The economical aspect is right now hurting the (still) leading relational OLTP benchmark TPC-C. Its implementation rules are such that for higher reported rates of throughput, a higher number of warehouses (i.e. larger data size) is needed. In the current day and age of JIT-compiled machinecode SQL procedures and CPU-cache optimized main memory databases, the OLTP throughput numbers now obtainable on modern transactional systems like Hyper on even a single server (it reaches more than 100.000 transactions per second) are so high that they lead to petabyte storage requirements. Not only does this make TPC-C very expensive to run, just by the sheer amount of hardware needed according to the rules, but it also undermines it representativity, since OLTP data sizes encountered in the field are much smaller than OLAP data sizes and do not run in the petabytes.</p>
+<p><em>Representative</em> benchmarks can be designed by studying or even directly using real workload information, e.g. query logs. A rigorous example of this is the <a href="http://aksw.org/Projects/DBPSB.html">DBpedia benchmark</a> whose workload is based on the query logs of dbpedia.org. However, this SPARQL endpoint is a single public Virtuoso instance that has been configured to interrupt all long running queries, such as to ensure the service remains responsive to as many users as possible. As a result, it is only practical to run small lookup queries on this database service, so the query log only contained solely such light queries. As a consequence, the DBpedia benchmark only tests small SPARQL queries that stress simple B-tree lookups only (and not joins, aggregations, path expressions or inference) and poses almost no technical challenges for either query optimization or execution. The lesson, thus, is to balance representativity with relevance (see later).</p>
+<p>The fact that a benchmark can be <em>scaled</em> in size favors the use of synthetic data (i.e. created by a data generator) because data generators can produce any desired quantity of data. I hereby note that in this day and age, data generators should be parallel. Single-threaded single-machine data generation just becomes unbearable even at terabyte scales. A criticism of synthetic data is that it may not be representative of real data, which e.g. tends to contain highly correlated data with skewed distributions. This may be addressed to a certain extent by injecting specific skew and correlations into synthetic data as well (but: which skew and which correlations?). An alternative is to use real data and somehow blow up or contract the data. This is the approach in the mentioned DBpedia benchmark, though such scaling will distort the original distributions and correlations. Scaling a benchmark is very useful to investigate the effect of data size on the metric, on individual queries, or even in micro-benchmark tests that are not part of the official query set. Typically OLTP database benchmarks have queries whose complexity is O(log(N)) of the data size N, whereas OLAP benchmarks have queries which are linear, O(N) or at most O(N.log(N)) – otherwise executing the benchmark on large instances is infeasible. OLTP queries thus typically touch little data, in the order of log(N) tuples. In order not to measure fully cold query performance, OLTP benchmarks for that reason need a warmup phase with O(N/log(N)) queries in order to get the system into a representative state.</p>
+<p>Now, what makes a benchmark <em>relevant</em>? In LDBC we think that benchmarks should be designed such that crucial areas of functionality are highlighted, and in turn system architects are stimulated to innovate. Either to catch up with competitors and bring the performance and functionality in line with the state-of-the-art but even to innovate and address technical challenges for which until now no good solutions exist, but which can give a decisive performance advantage in the benchmark. Inversely stated, benchmark design can thus be a powerful tool to influence the industry, as a benchmark design may set the agendas for multiple commercial design teams and database architects around the globe. To structure this design process, LDBC introduces the notion of <em>“choke points”</em>: by which we mean problems that challenge current technology. These choke points are collected and described early in the LDBC design process, and the workloads developed later are scored in terms of their coverage of relevant choke points. In case of graph data querying, one of the choke points that is unique to the area is recursive Top-N query handling (e.g. shortest path queries). Another choke point that arises is the impact of correlations between attribute value of graph nodes (e.g. both employed by TUM) and the connectivity degree between nodes (the probability to be friends). The notion observed in practice is that people who are direct colleagues, often are in each others friend network. A query that selects people in a social graph that work for the same company, and then does a friendship traversal, may get a bad intermediate result size estimates and therefore suboptimal query plan, if optimizers remain unaware of value/structure correlations. So this is an area of functionality that the Social Network Benchmark (SNB) by LDBC will test.</p>
+<p>To illustrate what choke points are in more depth, we wrote a <a href="https://ldbcouncil.org/docs/papers/tpc-h-analyzed-choke-points-tpctc2013.pdf">paper in the TPCTC 2013</a> conference that performs a post-mortem analysis of TPC-H and identified 28 such choke points. <em><a href="chokepoints.png">This table</a></em> lists them all, grouped into six Choke Point (CP) areas (CP1 Agregation, CP2 Join, CP3 Locality, CP4 Calculations, CP5 Subqueries and CP6 Parallelism). The classification also shows CP coverage over each of the 22 TPC-H queries (black is high impact, white is no impact):</p>
+<p>I would recommend reading this paper to anyone who is interested in improving the TPC-H score of a relational database system, since this paper contains the collected experience of three database architects who have worked with TPC-H at length: Orri Erling (of Virtuoso), Thomas Neumann (Hyper,RDF-3X), and me (MonetDB,Vectorwise). Recently Orri Erling showed that this paper is not complete as he discovered one more choke-point area for TPC-H: Top-N pushdown. In a detailed blog entry, Orri shows how this technique can <a href="http://www.openlinksw.com/weblog/oerling/?id=1779">trivialize Q18</a>; and this optimization can single handedly improve the overall TPC-score by 10-15%. This is also a lesson for LDBC: even though we design benchmarks with choke points in mind, the queries themselves may bring to light unforeseen opportunities and choke-points that may give rise to yet unknown innovations.</p>
+<p>LDBC has just published two benchmarks as Public Drafts, which essentially means that you are cordially invited to download and try out the RDF-focused Semantic Publishing Benchmark <a href="https://ldbcouncil.org/developer/spb">(SPB)</a> and the more graph-focused Social Network Benchmark (<a href="https://ldbcouncil.org/developer/snb">SNB</a>), and <a href="https://groups.google.com/forum/#!forum/ldbcouncil">tell us what you think</a>. Stay tuned for the coming detailed blog posts about these benchmarks, which will explain the graph and RDF processing choke-points that they test.</p>
+<p><em>(for more posts from Peter Boncz, see also <a href="https://databasearchitects.blogspot.com">Database Architects</a>, a blog about data management challenges and techniques written by people who design and implement database systems)</em></p>
+
+
+
+ -
+
New Website Online LDBC Benchmarks Reach Public Draft
+ https://ldbcouncil.org/post/new-website-online-ldbc-benchmarks-reach-public-draft/
+ Tue, 14 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/new-website-online-ldbc-benchmarks-reach-public-draft/
+ <p>The Linked Data Benchmark Council (LDBC) is reaching a milestone today, June 23 2014, in announcing that two of the benchmarks that it has been developing since 1.5 years have now reached the status of Public Draft. This concerns the Semantic Publishing Benchmark (SPB) and the interactive workload of the Social Network Benchmark (SNB). In case of LDBC, the release is staged: now the benchmark software just runs read-only queries. This will be expanded in a few weeks with a mix of read- and insert-queries. Also, query validation will be added later. Watch this blog for the announcements to come, as this will be a matter of weeks to add.</p>
+<p>The Public Draft stage means that the initial software (data generator, query driver) work and an initial technical specification and documentation has been written. In other words, there is a testable version of the benchmark available for anyone who is interested. Public Draft status does not mean that the benchmark has been adopted yet, it rather means that LDBC has come closer to adopting them, but is now soliciting feedback from the users. The benchmarks will remain in this stage at least until October 6. On that date, LDBC is organizing its fifth <a href="https://ldbcouncil.org/event/fifth-tuc-meeting">Technical User Community meeting</a>. One of the themes for that meeting is collecting user feedback on the Public Drafts; which input will be used to either further evolve the benchmarks, or adopt them.</p>
+<p>You can also see that we created a this new website and a new logo. This website is different from <code>http://ldbc.eu</code> that describes the EU project which kick-starts LDBC. The ldbcouncil.org is a website maintained by the Linked Data Benchmark Council legal entity, which will live on after the EU project stops (in less than a year). The Linked Data Benchmark Council is an independent, impartial, member-sustained organization dedicated to the creation of RDF and graph data management benchmarks and benchmark practices.</p>
+<p>In the next weeks, you will see many contributors in LDBC post items on this blog. Some of these blog entries will be very technical, others not, but all aim to explain what LDBC is doing for RDF and graph benchmarking, and why.</p>
+
+
+
+ -
+
Social Network Benchmark Goals
+ https://ldbcouncil.org/post/social-network-benchmark-goals/
+ Tue, 14 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/social-network-benchmark-goals/
+ <p>Social Network interaction is amongst the most natural and widely spread activities in the internet society, and it has turned out to be a very useful way for people to socialise at different levels (friendship, professional, hobby, etc.). As such, Social Networks are well understood from the point of view of the data involved and the interaction required by their actors. Thus, the concepts of friends of friends, or retweet are well established for the data attributes they represent, and queries such as “find the friend of a specified person who has long worked in a company in a specified country” are natural for the users and easy to understand from a functional point of view.</p>
+<p>From a totally different perspective, Social Networks are challenging technologically, being part of the Big Data arena, and require the execution of queries that involve complex relationship search and data traversal computations that turn out to be choke points for the data management solutions in the market.</p>
+<p>With the objective of shaping a benchmark which is up to date as a use case, well understood by everybody and poses significant technological challenges, the LDBC consortium decided to create the Social Network Benchmark, <a href="https://ldbcouncil.org/benchmarks/snb">SNB</a>, which is eventually going to include three workloads: the Interactive, the Business Intelligence and the Analytical. Those workloads are going to share a unique synthetic data generation tool that will mimic the data managed by real Social Networks.</p>
+<p>The SNB data generator created by LDBC is an evolution of the S3G2 data generator and can be found at the <a href="https://github.com/ldbc/ldbc_socialnet_bm/tree/master/ldbc_socialnet_dbgen">LDBC Github repository</a>. The data generator is unique because it generates data that contains realistic distributions and correlations among variables that were not taken into consideration before. It also allows generating large datasets because it uses a Hadoop based implementation to compute the complex data generated. The SNB data generator has already been used in different situations like the <a href="https://arxiv.org/pdf/2010.12243.pdf">ACM SIGMOD programming contest 2014</a>.</p>
+<p>The SNB presents the Interactive workload as first of a breed with the objective to resemble the queries that users may place to a Social Network portal. Those are a combination of read and write small queries that express the needs of a user who is interacting with her friends and connections through the Social Network. Queries like that explained above (Q12 in the workload) are examples that set up choke points like pattern recognition or full traversals.</p>
+<p>More details will be given in blogs to follow both for the data generator as well as for the specific characteristics of the workloads allowing the users to obtain a first contact with the benchmarks.</p>
+
+
+
+ -
+
Welcome to the New Industry Oriented LDBC Organisation for Benchmarking RDF and Graph Technologies
+ https://ldbcouncil.org/post/welcome-to-the-new-industry-oriented-ldbc-organisation-for-benchmarking-rdf-and-graph-technologies/
+ Tue, 14 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/welcome-to-the-new-industry-oriented-ldbc-organisation-for-benchmarking-rdf-and-graph-technologies/
+ <p>It is with great pleasure that we announce the new LDBC organisation site at <a href="https://www.ldbcouncil.org">www.ldbcouncil.org</a>. The LDBC started as a European Community FP7 funded project with the objective to create, foster and become an industry reference for benchmarking RDF and Graph technologies. A period of more than one and a half years has led us to the creation of the first two workloads, the Semantic Publishing Benchmark and the Social Network Benchmark in its interactive workload, which you will find in the <em>benchmarks</em> menu on this site.</p>
+<p>Those benchmarks will allow all the actors in the RDF and Graph industry to know who is who and how the different technology players are reacting to the results of their competing industry companies. Thus, the users will have results to compare the technologies and vendors will have a clear idea of how their products evolve compared to other vendors, all with the objective to foster the technological growth of the RDF and Graph arena.</p>
+<p>While the main objective of LDBC is to create benchmarks, we know that we need a strong community to grow and evolve those benchmarks taking into consideration all the market and technology needs. With this objective, we have created a special section to engage all the interested community through a blog, forums to discuss interesting issues and a lot of information on benchmarking, including links to other benchmarks, pointers to interesting conferences and venues and all the publications on benchmarking RDF and Graph technologies.</p>
+<p>We want to make sure that we all know what benchmarking and the LDBC effort means, both historically, and from the global needs perspective. To make sure that this is accomplished, we set up a section open to the public with in depth explanations of the history of industry benchmarking, LDBC and why our society needs such efforts globally.</p>
+<p>Finally, we want to invite you to our Fifth Technical Users Community (TUC) meeting to be held in Athens next Monday Oct. 6th 2014. This event will have as its main objective to allow for presentations on experiences with the two already released benchmarks, SNB and SPB. You’ll find updated information here.</p>
+<p>In all, we expect that the LDBC organisation site engages all of you and that the growth of RDF and Graph technologies in the future is secured by the benchmarks fostered by us.</p>
+
+
+
+ -
+
2nd International Workshop on Benchmarking RDF Systems
+ https://ldbcouncil.org/post/2nd-international-workshop-on-benchmarking-rdf-systems/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/2nd-international-workshop-on-benchmarking-rdf-systems/
+ <p>Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate discussions on best practices, different application needs and scenarios related to different aspects of RDF data management.</p>
+<p>More at: <a href="http://events.sti2.at/bersys2014/">http://events.sti2.at/bersys2014/</a></p>
+
+
+
+ -
+
DATAGEN: Data Generation for the Social Network Benchmark
+ https://ldbcouncil.org/post/datagen-data-generation-for-the-social-network-benchmark/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/datagen-data-generation-for-the-social-network-benchmark/
+ <p>As explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 <a href="#references">[1]</a>.</p>
+<p>One of the most important components of a benchmark is the dataset. However, directly using real data in a benchmark is not always possible. On the one hand, it is difficult to find data with all the scaling characteristics the benchmark requires. On the other hand, collecting real data can be expensive or simply not possible due to privacy concerns.</p>
+<p>For these reasons, LDBC-SNB provides DATAGEN which is the synthetic data generator responsible for generating the datasets for the three LDBC-SNB workloads: the Interactive, the Business Intelligence and the Analytical. DATAGEN has been carefully designed with the following goals in mind:</p>
+<ul>
+<li><strong>Realism.</strong> The data generated by DATAGEN has to mimic the features of those found in a real social network. In DATAGEN, output attributes, cardinalities, correlations and distributions have been finely tuned to reproduce a real social network in each of its aspects. DATAGEN is aware of the data and link distributions found in a real social network such as Facebook <a href="#references">[2]</a>. Also, it uses real data from DBPedia, such as property dictionaries, which ensure that the content is realistic and correlated.</li>
+<li><strong>Scalability.</strong> Since LDBC-SNB is targeting systems of different scales and budgets, DBGEN must be capable of generating datasets of different sizes, from a few Gigabytes to Terabytes. DATAGEN is implemented following the MapReduce paradigm, allowing for the generation of large datasets on commodity clusters.</li>
+<li><strong>Determinism.</strong> DATAGEN is deterministic regardless of the number of cores/machines used to produce the data. This important feature guarantees that all Test Sponsors will face the same dataset, thus, making the comparisons between different systems fair and the benchmarks’ results reproducible.</li>
+<li><strong>Usability.</strong> LDBC-SNB has been designed to have an affordable entry point. As such, DATAGEN has been severely influenced by this philosophy, and therefore it has been designed to be as easy to use as possible.</li>
+</ul>
+<p>Finally, the area of action of DATAGEN is not only limited to the scope of LDBC-SNB. Several researchers and practitioners are already using DATAGEN in a wide variety of situations. If you are interested on the internals and possibilities of DATAGEN, please visit its official repository (<a href="https://github.com/ldbc/ldbc_snb_datagen)">https://github.com/ldbc/ldbc_snb_datagen)</a>.</p>
+<h4 id="references">References</h4>
+<p>[1] Pham, Minh-Duc, Peter Boncz, and Orri Erling. “S3g2: A scalable structure-correlated social graph generator.” Selected Topics in Performance Evaluation and Benchmarking. Springer Berlin Heidelberg, 2013. 156-172.</p>
+<p>[2] Prat-Pérez, Arnau, and David Dominguez-Sal. “How community-like is the structure of synthetically generated graphs?.” Proceedings of Workshop on GRAph Data management Experiences and Systems. ACM, 2014.</p>
+
+
+
+ -
+
Getting Started With SNB
+ https://ldbcouncil.org/post/getting-started-with-snb/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/getting-started-with-snb/
+ <p>In a previous blog post titled “<a href="https://ldbcouncil.org/post/is-snb-like-facebooks-linkbench/">Is SNB like Facebook’s LinkBench?</a>”, Peter Boncz discusses the design philosophy that shapes SNB and how it compares to other existing benchmarks such as LinkBench. In this post, I will briefly introduce the essential parts forming SNB, which are DATAGEN, the LDBC execution driver and the workloads.</p>
+<h3 id="datagen">DATAGEN</h3>
+<p>DATAGEN is the data generator used by all the workloads of SNB. <a href="https://ldbcouncil.org/post/datagen-data-generation-for-the-social-network-benchmark/">Here</a> we introduced the design goals that drive the development of DATAGEN, which can be summarized as: <em>Realism, Scalability, Determinism and Usability.</em></p>
+<p>DATAGEN produces datasets with the following schema, in terms of entities and their relations. Data generated represents a snapshot of the activity of a social network similar to real social networks such as Facebook, during a period of time. Data includes entities such as Persons, Organizations, and Places. The schema also models the way persons interact, by means of the friendship relations established with other persons, and the sharing of content such as messages (both textual and images), replies to messages and likes to messages. People form groups to talk about specific topics, which are represented as tags.</p>
+<p><img src="schema.png" alt="image"></p>
+<p>For the sake of credibility, data produced by DATAGEN has to be realistic. In this sense, data produced by DATAGEN not only has a realistic schema, but also pays attention to the following items:</p>
+<ul>
+<li>
+<p>Realistic distributions. The degree distribution of friendship relationships has been modeled to reproduce that found in the Facebook graph. Also, other distributions such as the number of replies to a post, the number of persons per country or the popularity of a tag has been realistically modeled either using known distributions or data extracted from real sources such as Dbpedia.</p>
+</li>
+<li>
+<p>Correlated attributes and relations. Attribute values are not chosen at random, but follow correlations. For instance, people from a specific country have a larger probability to have names typical from that country, to work on companies from that country or to study at universities of that country. Also, we DATAGEN implements a relationship creation process that tries to reproduce the homophily principle, that is, people with similar characteristics tend to be connected.</p>
+</li>
+</ul>
+<p>DATAGEN is built on top of Hadoop, to generate datasets of different sizes. It works either on single node SMP machines or a cluster environment. DATAGEN supports different output formats targeting different systems. On the one hand, we have the CSV format, where each entity and relation is output into a different comma separated value file. On the other hand, it also supports the Turtle format for RDF systems.</p>
+<p>Finally, DATAGEN outputs two other things:</p>
+<ul>
+<li>
+<p>Update Streams, which will be used in the future to implement updates in the workloads.</p>
+</li>
+<li>
+<p>Substitution parameters, which are the parameters of the query instances the LDBC driver will issue. These are select so the query plans of the resulting query executions do not differ significantly.</p>
+</li>
+</ul>
+<p>Configuring and using DATAGEN is easy. Please visit <a href="https://github.com/ldbc/ldbc_snb_datagen">this page</a> for more information.</p>
+<h3 id="ldbc-driver">LDBC driver</h3>
+<p>SNB is designed to be as easier to adopt as possible. Therefore, SNB provides the LDBC execution driver, which is designed to automatically generated the benchmark workload and gather the benchmark results. It then generates a stream of operations in conformance with a workload definition, and executes those operations against some system using the provided database connector, and with the substitution parameters produced by DATAGEN. During execution, the driver continuously measures performance metrics, then upon completion it generates a report of those metrics.</p>
+<p>It is capable of generating parallel workloads (e.g. concurrent reads and writes), while respecting the configured operation mix and ensuring that ordering between dependent operations is maintained. For further details on how the driver achieves that, please visit the Documentation <a href="https://github.com/ldbc/ldbc_driver/wiki">page</a>.</p>
+<p>The test sponsor (aka the implementer of the benchmark), has to provide a set of implemented interfaces, that form a benchmark implementation to plug into the driver, and then the benchmark is automatically executed.</p>
+<p>Given a workload consisting of a series of <em>Operations</em>, the test sponsor implements <em>OperationHandlers</em> __ for them. <em>OperationHandlers</em> are responsible of executing instances of an specific operation (query) type. This is done by overriding the method <em>executeOperation</em>(), which receives as input parameter an <em>Operation</em> instance and returns the result. From <em>Operation</em> __ instance, the operation’s input parameters can be retrieved, as well as the database connection state.</p>
+<p>The database connector is used to initialize, cleanup and get the database connection state. The database connector must implement the <em>Db</em> interface, which consists of three methods: <em>onInit</em>(), <em>onCleanup</em>() and <em>getConnectionState</em>(). <em>onInit</em>() is called before the benchmark is executed, and is responsible of initializing the database and registering the different <em>OperationHandlers</em>. <em>onCleanup</em>() is called after the benchmark has completed. Any resources that need to be released should be released here.</p>
+<p>Finally, <em>getConnectionState</em>() returns an instance of <em>DbConnectionState</em>, which encapsulates any state that needs to be shared between <em>OperationHandler</em> instances. For instance, this state could contain the necessary classes used to execute a given query for the implementing system.</p>
+<p>A good example on how to implement the benchmark can be found <a href="https://github.com/ldbc/ldbc_driver/wiki/Implementing%20a%20Database%20Connector">here</a>.</p>
+<h3 id="workloads">Workloads</h3>
+<p>Currently, LDBC has only released the first draft of the Interactive workload, but the business intelligence and analytical workloads are on the works. Workloads are designed to mimic the different usage scenarios found in operating a real social network site, and each of them targets one or more types of systems. Each workload defines a set of queries and query mixes, designed to stress the systems under test in different choke-point areas, while being credible and realistic.</p>
+<p>Interactive workload reproduces the interaction between the users of the social network by including lookups and transactions that update small portions of the data base. These queries are designed to be interactive and target systems capable of responding such queries with low latency for multiple concurrent users. Examples of Interactive queries are, given a user, retrieve those friends with a specific name, or finding the most recent post and comments created by your friends.</p>
+<p>Business Intelligence workload, will represent those business intelligence analytics a social network company would like to perform in the social network, in order to take advantage of the data to discover new business opportunities. This workload will explore moderate portions of data from different entities, and will perform more complex and data intensive operations compared to the Interactive ones.</p>
+<p>Examples of possible Business Intelligence queries could be finding trending topics in country in a given moment, or looking for fraudulent “likers”.</p>
+<p>Finally, the Analytical workload will aim at exploring the characteristics of the underlying structure of the network. Shortest paths, community detection or centrality, are representative queries of this workload, and will imply touching a vast amount of the dataset.</p>
+<h3 id="final-remarks">Final remarks</h3>
+<p>This is just a quick overview of the SNB benchmark. For a more detailed description, do not hesitate to read the official SNB specification <a href="https://github.com/ldbc/ldbc_snb_docs">draft</a>, and stay tunned to the LDBC blog for future blog posts detailing all of the SNB parts in depth.</p>
+
+
+
+ -
+
Introducing SNB Interactive, the LDBC Social Network Benchmark Online Workload
+ https://ldbcouncil.org/post/introducing-snb-interactive-the-ldbc-social-network-benchmark-online-workload/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/introducing-snb-interactive-the-ldbc-social-network-benchmark-online-workload/
+ <p>The LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.</p>
+<p>The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.</p>
+<p>This is representative of an operational application. This goes beyond OLTP (On Line Transaction Processing) by having substantially more complex queries touching much more data than the point lookups and short reports in TPC-C or E. The emphasis is presenting a rich and timely view of a constantly changing environment.</p>
+<p>SNB Interactive gives end users and application developers a reference workload for comparing the relative merits of different technologies for graph data management. These range from dedicated graph databases to RDF stores and relational databases. There are graph serving benchmarks such as the Facebook Linkbench but SMB Interactive goes well beyond this in richness of schema and queries.</p>
+<p>The challenge to implementors is handling the user facing logic of a social network in a single system as the scale increases. The present practice in large social networks is massive sharding and use of different SQL and key value stores for different aspects of the service. The SNB workload is not intended to replicate this situation but to look for ways forward, so that one system can keep up with transactions and offer user rich and varied insight into their environment. The present practice relies on massive precomputation but SNB interactive seeks more agility and adhoc capability also on the operational side.</p>
+<p>The dataset is scaled in buckets, with distinct scales for 10, 30, 100, 300GB and so forth. A 100GB dataset has approximately 500,000 simulated users with their connections and online history. This is a convenient low-end single server size while 500 million users is 100TB, which is a data center scale requiring significant scale-out.</p>
+<p>The metric is operations per minute at scale. Online benchmarks typically have a fixed ratio between throughput and dataset size. Here we depart from this, thus one can report arbitrarily high throughputs at any scale. This makes main memory approaches feasible, which corresponds to present online practices. The benchmark makes transactions and queries on a simulated timeline of social interactions. The challenge for the systm is to run this as fast as possible at the selected scale while providing fast and predictable response times. Throughput can be increased at the cost of latency but here the system must satisfy response time criteria while running at the reported throughput.</p>
+<p>Different technologies can be used for implementing SNB interactive. The workload is defined in natural language with sample implementations in SPARQL and Cypher. Other possibilities include SQL and graph database API’s.</p>
+<p>SNB Interactive is an example of LDBC’s choke point driven design methodology, where we draw on the combined knowledge and experience of several database system architects for defining realistic, yet ambitious challenges whose solution will advance the state of the art</p>
+<p>The benchmark specification and associated tools are now offered for public feedback. The LDBC partners working on SNB nteractive will provide sample implementations of the workload on their systems, including Virtuoso, Neo4J and Sparsity. Specifics of availability and coverage may vary.</p>
+<p>Subsequent posts will address the workload in more detail.</p>
+
+
+
+ -
+
Is SNB Like Facebooks LinkBench
+ https://ldbcouncil.org/post/is-snb-like-facebooks-linkbench/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/is-snb-like-facebooks-linkbench/
+ <p>In this post, I will discuss in some detail the rationale and goals of the design of the <a href="https://ldbcouncil.org/benchmarks/snb">Social Network Benchmark</a> (SNB) and explain how it relates to real social network data as in Facebook, and in particular FaceBook’s own graph benchmark called <a href="https://www.facebook.com/notes/facebook-engineering/linkbench-a-database-benchmark-for-the-social-graph/10151391496443920">LinkBench</a>. We think SNB is the most intricate graph database benchmark to date (it’s also available in RDF!), that already has made some waves. SNB recently received praise at the most important database systems conference <a href="http://www.sigmod2014.org/">SIGMOD in Snowbird</a> after being used for this year’s <a href="https://arxiv.org/pdf/2010.12243.pdf">ACM SIGMOD Programming Contest</a>, which was about graph analytics.</p>
+<p>SNB is intended to provide the following <strong>value</strong> to different stakeholders:</p>
+<ul>
+<li>
+<p>For end users facing graph processing tasks, SNB provides a recognizable scenario against which it is possible to <em>compare merits of different products</em> and technologies. By covering a wide variety of scales and price points, SNB can serve as an aid to technology selection.</p>
+</li>
+<li>
+<p>For vendors of graph database technology, SNB provides a <em>checklist of features</em> and performance characteristics that helps in product positioning and can serve to guide new development.</p>
+</li>
+<li>
+<p>For researchers, both industrial and academic, the SNB dataset and workload provide <em>interesting challenges</em> in multiple technical areas, such as query optimization, (distributed) graph analysis, transactional throughput, and provides a way to objectively compare the effectiveness and efficiency of new and existing technology in these areas.</p>
+</li>
+</ul>
+<p>I should clarify that even though the data model of SNB resembles Facebook (and we’re extending it to also look more like Twitter), the goal of SNB is not to advise Facebook or Twitter what systems to use, they don’t need LDBC for that. Rather, we take social network data as a model for the much more broader graph data management problems that IT practitioners face. The particular characteristic of a graph data management problem is that the queries and analysis is not just about finding data by value, but about learning about the <em>connection patterns</em> between data. The scenario of the SNB, a social network, was chosen with the following goals in mind:</p>
+<ul>
+<li>
+<p>the benchmark scenario should be <strong>understandable</strong> to a large audience, and this audience should also understand the relevance of managing such data.</p>
+</li>
+<li>
+<p>the scenario in the benchmark should cover the complete range of challenges <strong>relevant</strong> for graph data management, according to the benchmark scope.</p>
+</li>
+<li>
+<p>the query challenges in it should be <strong>realistic</strong> in the sense that, though synthetic, similar data and workloads are encountered in practice.</p>
+</li>
+</ul>
+<p>The SNB is in fact three distinct benchmarks with a common dataset, since there are <em>three different workloads</em>. Each workload produces a single metric for performance at the given scale and a price/performance metric at the scale. The full disclosure further breaks down the composition of the metric into its constituent parts, e.g. single query execution times.</p>
+<ul>
+<li>
+<p><strong>Interactive Workload.</strong> The Interactive SNB workload is the first one we are releasing. It is defined in plain text, yet we have example implementations in Neo4j’s Cypher, SPARQL and SQL. The interactive workloads tests a system’s throughput with relatively simple queries with concurrent updates. The system under test (SUT) is expected to run in a steady state, providing durable storage with smooth response times. Inserts are typically small, affecting a few nodes at a time, e.g. uploading of a post and its tags. Transactions may require serializability, e.g. verifying that something does not exist before committing the transaction. Reads do not typically require more than read committed isolation. One could call the Interactive Workload an OLTP workload, but while queries typically touch a small fraction of the database, this can still be up to hundreds of thousands of values (the two-step neighborhood of a person in the social graph, often). Note that in order to support the read-queries, there is a lot of liberty to create indexing structures or materialized views, however such structures need to be maintained with regards to the continues inserts that also part of the workload. This workload is now in draft stage, which means that the <a href="https://github.com/ldbc/ldbc_socialnet_bm/tree/master/ldbc_socialnet_dbgen">data generator</a> and <a href="https://github.com/ldbc/ldbc_driver">driver software stack</a> are ready and the purpose is to obtain user feedback, as well as develop good system implementations. The first implementations of this workload are now running on Openlink Virtuoso, Neo4j and Sparsity Sparksee, and we are eager to see people try these, and optimize and involve these.</p>
+</li>
+<li>
+<p><strong>Business Intelligence Workload.</strong> There is a first stab at this workload formulated in SPARQL, tested against Openlink Virtuoso. The BI workload consists of complex structured queries for analyzing online behavior of users for marketing purposes. The workload stresses query execution and optimization. Queries typically touch a large fraction of the data and do not require repeatable read. The queries will be concurrent with trickle load (not out yet). Unlike the interactive workload, the queries touch more data as the database grows.</p>
+</li>
+<li>
+<p><strong>Graph Analytics Workload.</strong> This workload is not yet available. It will test the functionality and scalability of the SUT for graph analytics that typically cannot be expressed in a query language. As such it is the natural domain for graph programming frameworks like Giraph. The workload is still under development, but will consist of algorithms like PageRank, Clustering and Breadth First Search. The analytics is done on most of the data in the graph as a single operation. The analysis itself produces large intermediate results. The analysis is not expected to be transactional or to have isolation from possible concurrent updates.</p>
+</li>
+</ul>
+<p>All the SNB scenarios share a common scalable synthetic data set, generated by a state-of-the art <a href="https://github.com/ldbc/ldbc_socialnet_bm/tree/master/ldbc_socialnet_dbgen">data generator</a>. We strongly believe in a single dataset that makes sense for all workloads, that is, the interactive and BI workloads will traverse data that has sensible PageRank outcomes, and graph clustering structure, etc. This is in contrast to <a href="http://people.cs.uchicago.edu/~tga/pubs/sigmod-linkbench-2013.pdf">LinkBench</a>, released by the team of Facebook that manages the OLTP workload on the Facebook Graph, which closely tunes to the <strong>low-level</strong> MySQL query patterns Facebook sees, but whose graph structure does not attempt to be realistic beyond average out degree of the nodes (so, it makes no attempts to create realistic community patterns or correlations) . The authors of LinkBench may be right that the graph structure does not make a difference for simple insert/update/delete/lookup actions which LinkBench itself tests, but for the SNB queries in the Interactive and BI workloads this is not true. Note that <a href="http://borthakur.com/ftp/sigmod2013.pdf">Facebook’s IT infrastructure</a> does not store all user data in MySQL and its modified memcached ("<a href="http://www.cs.cmu.edu/~pavlo/courses/fall2013/static/papers/11730-atc13-bronson.pdf">TAO</a>"), some of it ends up in separate subsystems (using HDFS and HBase), which is outside of the scope of LinkBench. However, for queries like in the SNB Interactive and BI workloads it <strong>does</strong> matter how people are connected, and how the attribute values of connected people correlate. In fact, the SNB data generator is unique in that it generates a huge graph with <em>correlations</em>, where people who live together, have the same interests or work for the same company have greater chance to be connected, and people from Germany have mostly German names, etc. Correlations frequently occur in practice and can strongly influence the quality of query optimization and execution, therefore LDBC wants to test their effects on graph data management systems (the impact of correlation among values and structure on query optimization and execution are a “choke point” for graph data management system where LDBC wants to stimulate innovation).</p>
+
+
+
+ -
+
Making It Interactive
+ https://ldbcouncil.org/post/making-it-interactive/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/making-it-interactive/
+ <p><em>Synopsis:</em> Now is the time to finalize the interactive part of the Social Network Benchmark (SNB). The benchmark must be both credible in a real social network setting and pose new challenges. There are many hard queries but not enough representation for what online systems in fact do. So, the workload mix must strike a balance between the practice and presenting new challenges.</p>
+<p>It is about to be showtime for LDBC. The initial installment of the LDBC Social Network Benchmark (SNB) is the full data generator, test driver, workload and reference implementation for the interactive workload. SNB will further acquire business intelligence and graph analytics workloads but this post is about the interactive workload.</p>
+<p>As part of finalizing the interactive workload, we need to determine precise mixes of the component queries and updates. We note that the interactive mix so far consists of very heavy queries. These touch, depending on the scale upwards of a million entities in the database.</p>
+<p>Now, rendering a page view in a social network site does not touch millions of entities. The query that needs to be correct and up to date touches tens or hundreds of entities, e.g. posts or social connections for a single page impression. There are also statistical views like the count of people within so many steps or contact recommendations but these are not real time and not recalculated each time they are shown.</p>
+<p>So, LDBC SNB has a twofold task:</p>
+<ol>
+<li>In order to be a credible interactive workload, it must in fact have characteristics of one</li>
+<li>In order to stimulate progress it must have queries that are harder than those that go in routine page views but are still not database-wide analytics.</li>
+</ol>
+<p>Designing a workload presents specific challenges:</p>
+<ol>
+<li>The workload must be realistic enough for users to identify with it.</li>
+<li>The workload must pose challenges and drive innovation in a useful direction.</li>
+<li>The component operations must all play a noticeable role in it. If the operation’s relative performance doe does not affect the score, why is it in the workload?</li>
+</ol>
+<p>The interactive mix now has 14 queries that are interesting from a query optimization and execution viewpoint but touch millions of entities. This is not what drives page inpressions in online sites. Many users of GDB and RDF are about online sites, so this aspect must not be ignored.</p>
+<p>Very roughly, the choke points (technical challenges) of SNB interactive are as follows:</p>
+<ul>
+<li>Random access - Traversing between people, content makes large numbers of random lookups. These can be variously parallelized and/or vectored.</li>
+<li>Query optmization must produce right plans - The primary point isjoin order and join type. Index vs. hash based joins have very different performance properties and the right choice depends on corectly guessing the number of rows and of distinct keys on either side of the join.</li>
+<li>When doing updates and lookups, the execution plan is obvious but there the choke point is the scheduling of large numbers of short operations.</li>
+<li>Many queries have aggregation, many have distinct, all have result ordering and a limit on result count. The diverse interactions of these operators produce optimization opportunities.</li>
+</ul>
+<p>Dreaming up a scenario and workload is not enough for a benchmark. There must also be a strong indication that the job is do-able and plausible in the scenario.</p>
+<p>In online benchmarks different operations have different frequencies and the operations are repeated large numbers of times. There is a notion of steady state, so that the reported result represents a level of performance a system can sustain indefinitely.</p>
+<p>A key part of the workload definition is the workload mix, i.e. the relative frequencies of the operations. This decides in fact what the benchmark measures.</p>
+<p>The other aspect is the metric, typically some variation on operations per unit of time.</p>
+<p>All these are interrelated. Here we can take clicks per second as a metric, which is easy to understand. We wish to avoid the pitfall of TPC-C which ties the metric to a data size, so that for a high metric one must have a correspondingly larger database. This rule makes memory-only implementations in practice unworkable, while in reality many online systems in fact run from memory. So, here we scale in buckets, like in TPC-H but we still have an online workload. The scenario of the benchmark has its own timeline, here called simulation time. A benchmark run produces events in the simulation time but takes place in real time. This defines an accelration ratio. For example we could say that a system does 1000 operations per second at 300G scale, with an acceleration of 7x, i.e. 7 hours worth of simulation time are done in one hour of real time. A metric of this form is directly understandable for sizing a system, as long as the workload mix is realistic. We note that online sites usually are provisioned so that servers do not run anywhere near their peak throughput at a busy time.</p>
+<p>So how to define the actual mix? By measuring. But measuring requires a reference implementation that is generally up to date for the database science of the time and where the individual workload pieces are implemented in a reasonable manner, so no bad query plans or bad schema design. For the reference implementation, we use Virtuoso column store in SQL.</p>
+<p>But SQL is not graphy! Why not SPARQL? Because SPARQL has diverse fixed overheads and this is not a RDF-only workload. We do not want SPARQL overheads to bias the metric, we just want an implementation where we know exactly what goes on and how it works, with control of physical data placement so we know there are no obvious stupidities in any of this. SPARQL will come. Anyway, as said elsewhere, we believe that SPARQL will outgrow its overheads, at which point SQL or SPARQL is a matter of esthetic preference. For now, it is SQL and all we want is transparency into the metal.</p>
+<p>Having this, we peg the operation mix to the update stream generated by the data generator. At the 30G scale, there are 3.5M new posts/replies per month of simulation time. For each such, a query mix will be run, so as to establish a realistic read/write ratio. The query mix will have fractional queries, for example 0.2 friends recommendations per new post, but that is not a problem, since we run large numbers of these and at the end of the run can check that the ratios of counts are as expected. Next, we run this as fast as it will go on the test system. Then we adjust the ratio of short and long queries to get two objectives:</p>
+<ul>
+<li>Short queries should collectively be about 45% of the CPU load.</li>
+<li>Updates will be under 5%</li>
+<li>Long queries will take up the rest. For long queries, we further tune the relative frequencies so that each represents a roughly equal slice of the time. Having a query that does not influence the metric is useless, so each gets enough showtime to have an impact but by their nature some are longer than others.</li>
+</ul>
+<p>The reason why short queries should have a large slice is the fact that this is so in real interactive systems. The reason why long queries are important is driving innovation. Like this we get both scheduling (short lookup/update) and optimization choke points covered. As a bonus be make the mix so that we get a high metric, so many clicks per second, since this is what the operator of an online site wants.</p>
+<p>There is a further catch: Different scales have different degrees of the friends graph and this will have a different influence on different queries. To see whether this twists the metric out of shape we must experiment. For example, one must not have ogarithmic and linear complexity queries in the same mix, as BSBM for example has. So this is to be kept in mind as we proceed.</p>
+<p>In the next post we will look at the actual mix and execution times on the test system.</p>
+
+
+
+ -
+
SNB Data Generator - Getting Started
+ https://ldbcouncil.org/post/snb-data-generator-getting-started/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/snb-data-generator-getting-started/
+ <p>In previous posts (<a href="https://ldbcouncil.org/post/datagen-data-generation-for-the-social-network-benchmark">this</a> and <a href="https://ldbcouncil.org/post/getting-started-with-snb">this</a>) we briefly introduced the design goals and philosophy behind DATAGEN, the data generator used in LDBC-SNB. In this post, I will explain how to use DATAGEN to generate the necessary datatsets to run LDBC-SNB. Of course, as DATAGEN is continuously under development, the instructions given in this tutorial might change in the future.</p>
+<h3 id="getting-and-configuring-hadoop">Getting and Configuring Hadoop</h3>
+<p>DATAGEN runs on top of hadoop 1.2.1 to be scale. You can download it from here. Open a console and type the following commands to decompress hadoop into /home/user folder:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>$ cd /home/user
+</span></span><span style="display:flex;"><span>$ tar xvfz hadoop-1.2.1.tar.gz
+</span></span></code></pre></div><p>For simplicity, in this tutorial we will run DATAGEN in standalone mode, that is, only one machine will be used, using only one thread at a time to run the mappers and reducers. This is the default configuration, and therefore anything else needs to be done for configuring it. For other configurations, such as Pseudo-Distributed (multiple threads on a single node) or Distributed (a cluster machine), visit the <a href="https://github.com/ldbc/ldbc_snb_datagen_hadoop/wiki/Configuration">LDBC DATAGEN wiki</a>.</p>
+<h3 id="getting-and-configuring-datagen">Getting and configuring DATAGEN</h3>
+<p>Before downloading DATAGEN, be sure to fulfill the following requirements:</p>
+<ul>
+<li>Linux based machine</li>
+<li>java 1.6 or greater</li>
+<li>python 2.7.X</li>
+<li>maven 3</li>
+</ul>
+<p>After configuring hadoop, now is the time to get DATAGEN from the LDBC-SNB official repositories. Always download the latest release, which at this time is v0.1.2. Releases page is be found <a href="https://github.com/ldbc/ldbc_snb_datagen_hadoop/releases">here</a>. Again, decompress the downloaded file with the following commands:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>$ cd /home/user
+</span></span><span style="display:flex;"><span>$ tar xvfz ldbc_snb_datagen-0.1.2.tar.gz
+</span></span></code></pre></div><p>This will create a folder called “ldbc_snb_datagen-0.1.2”.</p>
+<p>DATAGEN provides a <em>run.sh</em> is a script to automate the compilation and execution of DATAGEN. It needs to be configured for your environment, so open it and set the two variables at the top of the script to the corresponding paths.</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>HADOOP_HOME<span style="color:#f92672">=</span>/home/user/hadoop-1.2.1
+</span></span><span style="display:flex;"><span>LDBC_SNB_DATAGEN_HOME<span style="color:#f92672">=</span>/home/user/ldbc_snb_datagen
+</span></span></code></pre></div><p>HADOOP_HOME points to the path where hadoop-1.2.1 is installed, while LDBC_SNB_DATAGEN_HOME points to where DATAGEN is installed. Change these variables to the appropriate values. Now, we can execute <em>run.sh</em> script to compile and execute DATAGEN using default parameters. Type the following commands:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-bash" data-lang="bash"><span style="display:flex;"><span>$ cd /home/user/ldbc_snb_datagen-0.1.2
+</span></span><span style="display:flex;"><span>$ ./run.sh
+</span></span></code></pre></div><p>This will run DATAGEN, and two folders will be created at the same directory: <em>social_network</em> containing the scale factor 1 dataset with csv uncompressed files, and <em>substitution_parameters</em> containing the substituion parameters needed by the driver to execute the benchmark.</p>
+<h3 id="changing-the-generated-dataset">Changing the generated dataset</h3>
+<p>The characteristics of the dataset to be generated are specified in the <em>params.ini</em> file. By default, this file has the following content:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-ini" data-lang="ini"><span style="display:flex;"><span><span style="color:#a6e22e">scaleFactor:1</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">compressed:false</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">serializer:csv</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">numThreads:1</span>
+</span></span></code></pre></div><p>The following is the list of options and their default values supported by DATAGEN:</p>
+<table>
+<thead>
+<tr>
+<th>Option</th>
+<th>Default value</th>
+<th>Description</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>scaleFactor</td>
+<td>1</td>
+<td>“The scale factor of the data to generate. Possible values are: 1, 3, 10, 30, 100, 300 and 1000”</td>
+</tr>
+<tr>
+<td>serializer</td>
+<td>csv</td>
+<td>“The format of the output data. Options are: csv, csv_merge_foreign, ttl”</td>
+</tr>
+<tr>
+<td>compressed</td>
+<td>FALSE</td>
+<td>Specifies to compress the output data in gzip.</td>
+</tr>
+<tr>
+<td>outputDir</td>
+<td>./</td>
+<td>Specifies the folder to output the data.</td>
+</tr>
+<tr>
+<td>updateStreams</td>
+<td>FALSE</td>
+<td>“Specifies to generate the update streams of the network. If set to false, then the update portion of the network is output as static”</td>
+</tr>
+<tr>
+<td>numThreads</td>
+<td>1</td>
+<td>Sets the number of threads to use. Only works for pseudo-distributed mode</td>
+</tr>
+</tbody>
+</table>
+<p>For instance, a possible <em>params.ini</em> file could be the following:</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-ini" data-lang="ini"><span style="display:flex;"><span><span style="color:#a6e22e">scaleFactor:30</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">serializer:ttl</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">compressed:true</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">updateStreams:false</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">outputDir:/home/user/output</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">numThreads:4</span>
+</span></span></code></pre></div><p>For those not interested on generating a dataset for a given predefined scale factor, but for other applications, the following parameters can be specified (they need to be specified all together):</p>
+<table>
+<thead>
+<tr>
+<th>Option</th>
+<th>Default value</th>
+<th>Description</th>
+</tr>
+</thead>
+<tbody>
+<tr>
+<td>numPersons</td>
+<td>-</td>
+<td>The number of persons to generate</td>
+</tr>
+<tr>
+<td>numYears</td>
+<td>-</td>
+<td>The amount of years of activity</td>
+</tr>
+<tr>
+<td>startYear</td>
+<td>-</td>
+<td>The start year of simulation.</td>
+</tr>
+</tbody>
+</table>
+<p>The following is an example of another possible <em>params.ini</em> file</p>
+<div class="highlight"><pre tabindex="0" style="color:#f8f8f2;background-color:#272822;-moz-tab-size:4;-o-tab-size:4;tab-size:4;"><code class="language-ini" data-lang="ini"><span style="display:flex;"><span><span style="color:#a6e22e">numPersons:100000</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">numYears:3</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">startYear:2010</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">serializer:csv_merge_foreign</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">compressed:false</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">updateStreams:true</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">outputDir:/home/user/output</span>
+</span></span><span style="display:flex;"><span><span style="color:#a6e22e">numThreads:4</span>
+</span></span></code></pre></div><p>For more information about the schema of the generated data, the different scale factors and serializers, please visit the wiki page of DATAGEN at <a href="https://github.com/ldbc/ldbc_snb_datagen_hadoop/">GitHub</a>!</p>
+
+
+
+ -
+
The Day of Graph Analytics
+ https://ldbcouncil.org/post/the-day-of-graph-analytics/
+ Thu, 09 Oct 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/the-day-of-graph-analytics/
+ <p><em>Note: consider this post as a continuation of the “<a href="https://ldbcouncil.org/post/making-it-interactive">Making it interactive</a>” post by Orri Erling.</em></p>
+<p>I have now completed the <a href="https://github.com/openlink/virtuoso-opensource">Virtuoso</a> TPC-H work, including scale out. Optimization possibilities extend to infinity but the present level is good enough. <a href="http://www.tpc.org/tpch/">TPC-H</a> is the classic of all analytics benchmarks and is difficult enough, I have extensive commentary on this on my blog (In Hoc Signo Vinces series), including experimental results. This is, as it were, the cornerstone of the true science. This is however not the totality of it. From the LDBC angle, we might liken this to the last camp before attempting a mountain peak.</p>
+<p>So, we may now seriously turn to graph analytics. The project has enough left to run in order to get a good BI and graph analytics workload. In LDBC in general, as in the following, BI or business intelligence means complex analytical queries. Graph analytics means graph algorithms that are typically done in graph programming frameworks or libraries.</p>
+<p>The BI part is like TPC-H, except for adding the following challenges:</p>
+<ul>
+<li>
+<p>Joins of derived tables with group by, e.g. comparing popularity of items on consecutive time periods.</p>
+</li>
+<li>
+<p>Transitive dimensions - A geographical or tag hierarchy can be seen as a dimension table. To get the star schema plan with the selective hash join, the count of the transitive traversal of the hierarchy (hash build side) must be correctly guessed.</p>
+</li>
+<li>
+<p>Transitivity in fact table, i.e. average length of reply thread. There the cost model must figure that the reply link is much too high cardinality for hash build side, besides a transitive operation is not a good candidate for a build in multiple passes, hence the plan will have to be by index.</p>
+</li>
+<li>
+<p>Graph traversal with condition on end point and navigation step. The hierarchical dimensions and reply threads are in fact trees, the social graph is not. Again the system must know some properties of connectedness (in/out degree, count of vertices) to guess a traversal fanout. This dictates the join type in the step (hash or index). An example is a transitive closure with steps satisfying a condition, e.g. all connected persons have a specific clearance.</p>
+</li>
+<li>
+<p>Running one query with parameters from different buckets, implying different best plan.</p>
+</li>
+<li>
+<p>Data correlations, e.g. high selectivity arising from two interests seldom occurring together, in places where the correct estimation makes the difference between a good and a bad plan.</p>
+</li>
+<li>
+<p>Large intermediate results stored in tables, as in materializing complex summaries of data for use in follow up queries.</p>
+</li>
+<li>
+<p>More unions and outer joins.</p>
+</li>
+</ul>
+<p>The idea is to cover the base competences the world has come to expect and to build in challenges to last another 10-15 years.</p>
+<p>For rules and metric, we can use the TPC-H or <a href="http://www.tpc.org/tpcds/default.asp">TPC-DS</a> ones as a template. The schema may differ from an implementation of the interactive workload, as these things would normally run on different systems anyway. As another activity that is not directly LDBC, I will do a merge of SNB and <a href="http://www.openstreetmap.org/">Open Street Map</a>. The geolocated things (persons, posts) will get real coordinates from their vicinity and diverse geo analytics will become possible. This is of some significant interest to Geoknow, another FP7 where OpenLink is participating.</p>
+<p>Doing the BI mix and even optimizing the interactive part involves some redoing of the present support for transitivity in Virtuoso. The partitioned group by with some custom aggregates is the right tool for the job, with all parallelization, scale-out, etc ready. You see, TPC-H is very useful also in places one does not immediately associate with it.</p>
+<p>As a matter of fact, this becomes a BSP (bulk synchronous processing) control structure. Run any number of steps, each item produces results/effects scattered across partitions. The output of the previous is the input of the next. We might say BSP is an attractor or “Platonic” control structure to which certain paths inevitably lead. Last year I did a BSP implementation in SQL, reading and writing tables and using transactions for serializable update of the border. This is possible but will not compete with a memory based framework and not enough of the optimization potential, e.g. message combining, is visible to the engine in this formulation. So, now we will get this right, as suggested.</p>
+<p>So, the transitive derived table construct can have pluggable aggregations, e.g. remembering a path, a minimum length or such), reduction like a scalar-valued aggregate (min/max), different grouping sets like in a group by with cube or grouping sets, some group-by like reduction for message combining and so forth. If there is a gather phase that is not just the result of the scatter of the previous step, this can be expressed as an arbitrary database query, also cross partition in a scale-out setting.</p>
+<p>The distributed/partitioned group by hash table will be a first class citizen, like a procedure scoped temporary table to facilitate returning multiple results and passing large data between multiple steps with different vertex operations, e.g. forward and backward in betweenness centrality.</p>
+<p>This brings us to the graph analytics proper, which is often done in BSP style, e.g. <a href="http://es.slideshare.net/shatteredNirvana/pregel-a-system-for-largescale-graph-processing">Pregel</a>, <a href="http://giraph.apache.org">Giraph</a>, <a href="http://uzh.github.io/signal-collect/">Signal-Collect</a>, some but not all <a href="http://ppl.stanford.edu/main/green_marl.html">Green-Marl</a> applications. In fact, a Green-Marl back end for Virtuoso is conceivable, whether one will be made is a different matter.</p>
+<p>With BSP in the database engine, a reference implementation of many standard algorithms is readily feasible and performant enough to do reasonable sizing for the workload and to have a metric. This could be edges or vertices per unit of time, across a mix of algorithms, for example. Some experimentation will be needed. The algorithms themselves may be had from the Green-Marl sample programs or other implementations. Among others, Oracle would presumably agree that this sort of functionality will in time migrate into core database. We will here have a go at this and along the way formulate some benchmark tasks for a graph analytics workload. Whenever feasible, this will derive from existing work such as <a href="http://graphbench.org/">graphbench.org</a> but will be adapted to the SNB dataset.</p>
+<p>The analytics part will be done with more community outreach than the interactive one. I will blog about the business questions, queries and choke points as we go through them. The interested may pitch in as the matter comes up.</p>
+
+
+
+ -
+
Using LDBC SPB to Find OWLIM Performance Issues
+ https://ldbcouncil.org/post/using-ldbc-spb-to-find-owlim-performance-issues/
+ Wed, 20 Aug 2014 00:00:00 +0000
+
+ https://ldbcouncil.org/post/using-ldbc-spb-to-find-owlim-performance-issues/
+ <p>During the past six months we (the OWLIM Team at Ontotext) have integrated the LDBC <a href="https://ldbcouncil.org/developer/spb">Semantic Publishing Benchmark</a> (LDBC-SPB) as a part of our development and release process.</p>
+<p>First thing we’ve started using the LDBC-SPB for is to monitor the performance of our RDF Store when a new release is about to come out.</p>
+<p>Initially we’ve decided to fix some of the benchmark parameters :</p>
+<ul>
+<li>the dataset size - 50 million triples (LDBC-SPB50) * benchmark warmup and benchmark run times - 60s and 600s respectively. * maximum number of Editorail Agents (E) : 2 (threads that will execute INSERT/UPDATE operations) * maximum number of Aggregation Agents (A) : 16 (threads that will execute SELECT operations) * generated data by the benchmark driver to be “freshly” deployed before each benchmark run - benchmark driver can be configured to generate the data and stop. We’re using that option and have a fresh copy of it put aside ready for each run.</li>
+</ul>
+<p>Having those parameters fixed, running LDBC-SPB is a straight-forward task. The hardware we’re using for benchmarking is a machine with 2 Intel Xeon CPUs, 8 cores each, 256 GB of memory and SSD storage, running Linux. Another piece of hardware we’ve tested with is a regular desktop machine with Intel i7, 32 GB of memory and HDD storage. During our experiments we have allowed a deviation in results of 5% to 10% because of the multi-threaded nature of the benchmark driver.</p>
+<p>We’ve also decided to produce some benchmark results on Amazon’s EC2 Instances and compare with the results we’ve had so far. Starting with m3.2xlarge instance (8 vCPUs, 30GB of memory and 2x80GB SSD storage) on a 50M dataset we’ve achieved more than 50% lower results than ones on our own hardware. On a largrer Amazon Instance c3.4xlarge (16 vCPUs, 30GB of memory and doubled SSD storage) we’ve achieved the same performance in terms of aggregation operations and even worse performance in terms for editorial operations, which we give to the fact that Amazon instances are not providing consistent performance all the time.</p>
+<p>Following two charts are showing how OWLIM performs on different hardware and with different configurations. They also give an indication of Amazon’s capabilities compared to the results achieved on a bare-metal hardware.</p>
+<p><img src="16-2-Performance.png" alt="image"></p>
+<p>Figure 1 : OWLIM Performance : 2 amazon instances and 2 local machines. 16 aggregation and 2 editorial agents running simultaneously. Aggregation and editorial operations displayed here should be considered independently, i.e. even though editorial opeartions graph shows higher results on Amazon m3.2xlarge instance, values are normalized and are referring to corresponding type of operation.</p>
+<p><img src="8-0-Performance.png" alt="image"></p>
+<p>Figure 2 : OWLIM Performance : 2 amazon instances and 2 local machines. 8 aggregation running simultaneously. Read-only mode.</p>
+<p>Another thing that we’re using LDBC-SPB for is to monitor load performance speeds. Loading of generated data can be done either manually by creating some sort of a script (CURL), or by the benchmark driver itself which will execute a standard POST request against a provided SPARQL endpoint. Benchmark’s data generator can be configured to produce chunks of generated data in various sizes, which can be used for exeperiments on load performance. Of course load times of forward-chaining reasoners can not be compared to backward-chaining ones which is not the goal of the benchmark. Loading performances is not measured “officially“ by LDBC-SPB (although time for loading the data is reported), but its good thing to have when comparing RDF Stores.</p>
+<p>An additional and interesting feature of the SPB is the test for conformance to OWL2-RL rule-set. It is a part of the LDBC-SPB benchmark and that phase is called <em>checkConformance</em>. The phase is run independently of the benchmark phase itself. It requires no data generation or loading except the initial set of ontologies. It tests RDF store’s capabilities for conformance to the rules in OWL2-RL rule-set by executing a number of INSERT/ASK queries specific for each rule. The result of that phase is a list of all rules that have been passed or failed which is very useful for regression testing.</p>
+
+
+
+ -
+
Fourth TUC meeting
+ https://ldbcouncil.org/event/fourth-tuc-meeting/
+ Thu, 03 Apr 2014 12:32:22 -0400
+
+ https://ldbcouncil.org/event/fourth-tuc-meeting/
+ <p>The LDBC consortium are pleased to announce the fourth Technical User Community (TUC) meeting.</p>
+<p>This will be a one-day event at CWI in Amsterdam on <em>Thursday April 3, 2014</em>.</p>
+<p>The event will include:</p>
+<ul>
+<li>Introduction to the objectives and progress of the LDBC project.</li>
+<li>Description of the progress of the benchmarks being evolved through Task Forces.</li>
+<li>Users explaining their use-cases and describing the limitations they have found in current technology.</li>
+<li>Industry discussions on the contents of the benchmarks.</li>
+</ul>
+<p>All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu</p>
+<p><strong>For presenters please limit your talks to just 15 minutes</strong></p>
+<h3 id="agenda">Agenda</h3>
+<p><strong>April 3rd</strong></p>
+<ul>
+<li>
+<p>10:00 Peter Boncz (VUA) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506371.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=JYWVgrP1kVY">video</a>: <em>LDBC project status update</em></p>
+</li>
+<li>
+<p>10:20 Norbert Martinez (UPC) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506375.pdf">pdf</a>, <a href="https://www.youtube.com/watch?v=4yREJQ3yDr0">video</a>: <em>Status update on the LDBC Social Network Benchmark (SNB) task force</em>.</p>
+</li>
+<li>
+<p>10:50 Alexandru Iosup (TU Delft) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506363.ppt">ppt</a>, <a href="https://www.youtube.com/watch?v=ulT-RFwKpOE">video</a>: <em>Towards Benchmarking Graph-Processing Platforms</em></p>
+</li>
+<li>
+<p>11:10 Mike Bryant (Kings College) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506364.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=KiHRTu9xx0A">video</a>: <em>EHRI Project: Archival Integration with Neo4j</em></p>
+</li>
+</ul>
+<p><strong>11:30 coffee</strong></p>
+<ul>
+<li>
+<p>11:50 Thilo Muth (University of Magdeburg) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506369.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=5xH3UDLP6Oc">video</a>: <em>MetaProteomeAnalyzer: a graph database backed software for functional and taxonomic protein data analysis</em></p>
+</li>
+<li>
+<p>12:10 Davy Suvee (Janssen Pharmaceutica / Johnson & Johnson) – <a href="https://www.youtube.com/watch?v=XN3LRJUfJIU">video</a>: <em>Euretos Brain - Experiences on using a graph database to analyse data stored as a scientific knowledge graph</em></p>
+</li>
+<li>
+<p>12:30 Yongming Luo (TU Eindhoven) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506366.pdf">pdf</a>, <a href="https://www.youtube.com/watch?v=g_my3tBB2_s">video</a>: <em>Regularities and dynamics in bisimulation reductions of big graphs</em></p>
+</li>
+<li>
+<p>12:50 Christopher Davis (TU Delft) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506370.pdf">pdf</a>, <a href="https://www.youtube.com/channel/UC6HbzfJ4016Vez-2HKNeDag">video</a>: <em>Enipedia - Enipedia is an active exploration into the applications of wikis and the semantic web for energy and industry issues</em></p>
+</li>
+</ul>
+<p><strong>13:10 - 14:30 lunch @ restaurant Polder</strong></p>
+<ul>
+<li>
+<p>14:30 <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506365.pptx">SPB task force report</a></p>
+</li>
+<li>
+<p>15:00 Bastiaan Bijl (Sysunite) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506373.pdf">pdf</a>, <a href="https://www.youtube.com/watch?v=TsCeKDHShMY">video</a>: <em>Using a semantic approach for monitoring applications in large engineering projects</em></p>
+</li>
+<li>
+<p>15:20 Frans Knibbe (Geodan) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506372.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=uAX-m4OewPM">video</a>: <em>Benchmarks for geographical data</em></p>
+</li>
+<li>
+<p>15:40 Armando Stellato (University of Rome, Tor Vergata & UN Food and Agriculture Organization) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506374.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=mfA4csAs72Y">video</a>: <em>VocBench2.0, a Collaborative Environment for SKOS/SKOS-XL Management: scalability and (inter)operatibility challenges</em></p>
+</li>
+</ul>
+<p><strong>16:00 coffee</strong></p>
+<ul>
+<li>
+<p>16:20 Ralph Hodgson (TopQuadrant) – [pdf](https://pu b-3834 10a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachment s/5538064/5506367.pdf), <a href="https://www.youtube.com/watch?v=ZUDnVw9P_Rc">video</a>:<em>Customer experiences in implementing SKOS-based vocabularymanagement systems</em></p>
+</li>
+<li>
+<p>16:40 Simon Jupp (European Bioinformatics Institute) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506368.pdf">pdf</a>, <a href="https://www.youtube.com/watch?v=CgTuOGK92W8">video</a>: <em>[Delivering RDF for the life science at the European Bioinformatics Institute: Six months in.]</em></p>
+</li>
+<li>
+<p>17:00 Jerven Bolleman (Swiss Institute of Bioinformatics) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506381.pdf">pdf</a>, <a href="https://www.youtube.com/watch?v=QTc3yOgoEsg">video</a>: <em>Breakmarking UniProt RDF. SPARQL queries that make your database cry…</em></p>
+</li>
+<li>
+<p>17:20 Rein van ’t Veer (Digital Heritage Netherlands) – <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506380.pptx">pptx</a>, <a href="https://www.youtube.com/watch?v=2vDrZoskGyQ">video</a> <em>Time and space for heritage</em></p>
+</li>
+<li>
+<p>17:40 <strong>end of meeting</strong></p>
+</li>
+<li>
+<p>19:00 - 21:30 Social Dinner in restaurant Boom</p>
+</li>
+</ul>
+<p><strong>April 4th</strong></p>
+<p>LDBC plenary meeting for project partners.</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5506362.ppt">Benchmarking Graph-Processing Platforms: A Vision</a> – Alexandru Iosup</li>
+</ul>
+<h3 id="logistics">Logistics</h3>
+<p>The meeting will be held at the Dutch national research institute for computer science and mathematics (<a href="http://www.cwi.nl">CWI</a> - Centrum voor Wiskunde en Informatica). It is located at <a href="http://www.amsterdamsciencepark.nl/">Amsterdam Science Park</a>:</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5505821.jpg" alt=""></p>
+<p>(<a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/fourth-tuc-meeting/attachments/5538064/5505820.pdf">A5 map</a>)</p>
+<h6 id="travel">Travel</h6>
+<p><strong>Arriving & departing:</strong></p>
+<p>Amsterdam has a well-functioning and nearby airport called Schiphol (AMS, <a href="http://www.schiphol.com/">www.schiphol.nl</a>) that serves all main European carriers and also very many low-fare carriers.</p>
+<p><a href="http://www.iamsterdam.com/en/visiting/touristinformation/gettingaround/arrival-and-departure/arrival-by-plane">http://www.iamsterdam.com/en/visiting/touristinformation/gettingaround/arrival-and-departure/arrival-by-plane</a></p>
+<p><strong>Trains</strong> (~5 per hour) are the most convenient means of transport between Schiphol airport and Amsterdam city center, the Centraal Station (17 minutes, a train every 15 minutes) – which station you are also likely arriving at in case of an international train trip.</p>
+<p>From the Centraal Station in Amsterdam, there is a direct train (every half an hour, runs 11 minutes) to the Science Park station, which is walking distance of CWI. If you go from the Centraal Station to one of the hotels, you should take tram 9 – it starts at Centraal Station (exception: for Hotel Casa 400, you should take the metro to Amstel station - any of the metros will do).</p>
+<p><strong>Taxi</strong> is an alternative, though expensive. The price from Schiphol will be around 45 EUR to the CWI or another point in the city center (depending on traffic, the ride is 20-30 minutes).</p>
+<p><strong>Public transportation</strong> (tram, bus, metro) tickets for a single ride and 1-day (24 hour) passes can be purchased from the driver/conductor on trams and buses (cash only) and from vending machines in the metro stations.</p>
+<p><strong>Only the “disposable” cards are interesting for you as visitor.</strong></p>
+<p>Multi-day (up to 7-days/168 hours) passes can only be purchased from the vending machines or from the ticket office opposite of Centraal Station.</p>
+<p><strong>Getting Around:</strong> the fastest way to move in the city of Amsterdam generally is by bicycle. Consider renting such a device at your hotel. For getting from your hotel to the CWI, you can either take a taxi (expensive), have a long walk (35min), use public transportation (for NH Tropen/The Manor take bus 40 from Muiderpoort Station, for Hotel Casa 400 same bus 40 but from Amstel station, and for the Rembrandt Hotel it is tram 9 until Middenweg/Kruislaan and then bus 40), or indeed bike for 12 minutes.</p>
+<p><strong>Cars</strong></p>
+<p>In case you plan to arrive by car, please be aware that parking space in Amsterdam is scarce and hence very expensive. But, you can park your car on the “WCW” terrain where CWI is located. To enter the terrain by car, you have to get a ticket from the machine at the gate. To leave the terrain, again, you can get an exit ticket from the CWI reception.</p>
+<p><strong>Arriving at CWI:</strong> Once you arrive at CWI, you need to meet the reception, and tell them that you are attending the LDBC TUC meeting. Then, you’ll receive a visitor’s pass that allows you to enter our building.</p>
+<p><strong>Social Dinner</strong></p>
+<p>The social dinner will take place at 7pm on April 3 in Restaurant Boom (<a href="http://www.boometenendrinken.nl/">boometenendrinken.nl</a>), Linneausstraat 63, Amsterdam.</p>
+
+
+
+ -
+
Third TUC Meeting
+ https://ldbcouncil.org/event/third-tuc-meeting/
+ Tue, 19 Nov 2013 08:00:00 +0000
+
+ https://ldbcouncil.org/event/third-tuc-meeting/
+ <p>The LDBC consortium is pleased to announce the third Technical User Community (TUC) meeting!</p>
+<p>This will be a one day event in London on the <strong>19 November 2013</strong> running in collaboration with the <a href="http://www.graphconnect.com/london/">GraphConnect</a> event (18/19 November). Registered TUC participants that would like a free pass to all of GraphConnect should register for GraphConnect using this following coupon code: <strong>LDBCTUC</strong>.</p>
+<p>The TUC event will include:</p>
+<ul>
+<li>Introduction to the objectives and progress of the LDBC project</li>
+<li>Description of the progress of the benchmarks being evolved through Task Forces</li>
+<li>Users explaining their use-cases and describing the limitations they have found in current technology</li>
+<li>Industry discussions on the contents of the benchmarks</li>
+</ul>
+<p>We will also be launching the LDBC non-profit organization, so anyone outside the EU project will be able to join as a member.</p>
+<p>We will kick off new benchmark development task forces in the coming year, and talks at this coming TUC will play an important role in deciding the use case scenarios that will drive those benchmarks.</p>
+<p>All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu</p>
+<ul>
+<li><a href="#agenda">Agenda</a></li>
+<li><a href="#logistics">Logistics</a></li>
+<li><a href="#ldbctuc-background">LDBC/TUC Background</a>
+<ul>
+<li><a href="#social-network-benchmark">Social Network Benchmark</a></li>
+<li><a href="#semantic-publishing-benchmark">Semantic Publishing Benchmark</a></li>
+</ul>
+</li>
+</ul>
+<h3 id="agenda">Agenda</h3>
+<p><strong>November 19th - Public TUC Meeting</strong></p>
+<p>8:00 Breakfast and registration will open for Graph Connect/TUC at 8:00 am (Dexter House)</p>
+<p>short LDBC presentation (Peter Boncz) during GraphConnect keynote by Emil Eifrem (09:00-09:30 Dexter House)</p>
+<p>NOTE: the TUC meeting is at the Tower Hotel, nearby Dexter House.</p>
+<p>10:00 TUC Meeting Opening (Peter Boncz)</p>
+<p>10:10 TUC Presentations (RDF Application Descriptions)</p>
+<ul>
+<li>Johan Hjerling (BBC): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275669.pdf">BBC Linked Data and the Semantic Publishing Benchmark</a></strong></em></li>
+<li>Andreas Both (Unister): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5505027.pdf">Ontology-driven applications in an e-commerce context</a></strong></em></li>
+<li>Nuno Carvalho (Fujitsu Laboratories Europe): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275666.pdf"><em><strong>Fujitsu RDF use cases and benchmarking requirements</strong></em></a></li>
+<li>Robina Clayphan (Europeana): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816977.ppt">Europeana and Open Data</a></strong></em></li>
+</ul>
+<p>11:30 Semantic Publishing Benchmark (SPB)</p>
+<ul>
+<li>Venelin Kotsev (Ontotext - LDBC): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816974.pdf">Semantic Publishing Benchmark Task Force Update</a></strong></em> and <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816974.pdf">report</a></strong></em></li>
+</ul>
+<p>12:00-13:00 Lunch at the Graph Connect venue</p>
+<p><em>Talks During Lunch:</em></p>
+<ul>
+<li>Pedro Furtado, Jorge Bernardino (Univ. Coimbra): <strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275671.pdf">KEYSTONE Cost Action</a></strong></li>
+</ul>
+<p>13:00 TUC Presentations (Graph Application Descriptions)</p>
+<ul>
+<li>Minqi Zhou / Weining Qian (East China Normal University): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275670.pdf">Elastic and realistic social media data generation</a></strong></em></li>
+<li>Andrew Sherlock (Shapespace): <em><strong>Shapespace Use Case</strong></em></li>
+<li>Sebastian Verheughe (Telenor): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275667.pdf">Real-time Resource Authorization</a></strong></em></li>
+</ul>
+<p>14:00 Social Network Benchmark (SNB)</p>
+<ul>
+<li>Norbert Martinez (UPC - LDBC): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5505025.pdf">Social Network Benchmark Task Force Update</a></strong></em> and <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816975.pdf">Report</a></li>
+</ul>
+<p><em>14:30 Break</em></p>
+<p>14:45 TUC Presentations (Graph Analytics)</p>
+<ul>
+<li>Keith Houck (IBM): <em><strong>Benchmarking experiences with [System G Native Store (tentative title)]</strong></em></li>
+<li>Abraham Bernstein (University of Zurich): <em><strong>Streams and Advanced Processing: Benchmarking RDF querying beyond the Standard SPARQL Triple Store</strong></em></li>
+<li>Luis Ceze (University of Washington): <em><strong>Grappa and GraphBench Status Update</strong></em></li>
+</ul>
+<p><em>15:45 Break</em></p>
+<p>16:00 TUC Presentations* (Possible Future RDF Benchmarking Topics)*</p>
+<ul>
+<li>Christian-Emil Ore (Unit for Digital Documentation, University of Oslo, Norway): <em><strong>CIDOC-CRM</strong></em></li>
+<li>Atanas Kiryakov (Ontotext): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275672.pdf">Large-scale Reasoning with a Complex Cultural Heritage Ontology (CIDOC CRM)</a></strong></em></li>
+<li>Kostis Kyzirakos (National and Kapodistrian University of Athens / CWI): <em><strong><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5275668.pdf">Geographica: A Benchmark for Geospatial RDF Stores</a></strong></em></li>
+<li>Xavier Lopez (Oracle): <em><strong>W3C Property Graph progress</strong></em></li>
+<li>Thomas Scharrenbach (University Zurich) <em><strong>PCKS: Benchmarking Semantic Flow Processing Systems</strong></em></li>
+</ul>
+<p>17:20 Meeting Conclusion (Josep Larriba Pey)</p>
+<p>17:30 End of TUC meeting</p>
+<p>19:00 Social dinner</p>
+<p><strong>November 20th - Internal LDBC Meeting</strong></p>
+<p>10:00 Start</p>
+<p>12:30 <em>End of meeting</em></p>
+<ul>
+<li>coffee and lunch provided</li>
+</ul>
+<h3 id="logistics">Logistics</h3>
+<p><strong>Date</strong></p>
+<p>19th November 2013</p>
+<p><strong>Location</strong></p>
+<p>The TUC meeting will be held in <strong>The Tower</strong> hotel (<a href="http://goo.gl/qZt8Fz">Google Maps link</a>) approximately 4 minutes walk from the <a href="http://www.graphconnect.com/london/">GraphConnect</a> conference in London.</p>
+<p>Getting there</p>
+<ul>
+<li>From City Airport is the easiest: short ride on the DLR to Tower Gateway. Easy.</li>
+<li>From London Heathrow: first need to take the Heathrow Express to Paddington. Then take the Circle line to Tower Hill. <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4554995.pdf">See attached</a>.</li>
+</ul>
+<h3 id="ldbctuc-background">LDBC/TUC Background</h3>
+<p>Looking back, we have been working on two benchmarks for the past year: a Social Network Benchmark (SNB) and a Semantic Publishing Benchmark (SPB). While below we provide a short summary, all the details of the work on these benchmark development efforts can be found in the first yearly progress reports:</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816974.pdf">LDBC_SNB_Report_Nov2013.pdf</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4816974.pdf">LDBC_SPB_Report_Nov2013.pdf</a></li>
+</ul>
+<p>A summary of these efforts can be read below or, for a more detailed account, please refer to: <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/4554967.pdf">The Linked Data Benchmark Council: a Graph and RDF industry benchmarking effort</a>. Annual reports about the progress, results, and future work of these two efforts will soon be available for download here, and will be discussed in depth at the TUC.</p>
+<h4 id="social-network-benchmark">Social Network Benchmark</h4>
+<p>The Social Network Benchmark (SNB) is designed for evaluating a broad range of technologies for tackling graph data management workloads. The systems targeted are quite broad: from graph, RDF, and relational database systems to Pregel-like graph compute frameworks. The social network scenario was chosen with the following goals in mind:</p>
+<ul>
+<li>it should be understandable, and the relevance of managing such data should be understandable</li>
+<li>it should cover the complete range of interesting challenges, according to the benchmark scope</li>
+<li>the queries should be realistic, i.e., similar data and workloads are encountered in practice</li>
+</ul>
+<p>SNB includes a data generator for creation of synthetic social network data with the following characteristics:</p>
+<ul>
+<li>data schema is representative of real social networks</li>
+<li>data generated includes properties occurring in real data, e.g. irregular structure, structure/value correlations, power-law distributions</li>
+<li>the software generator is easy-to-use, configurable and scalable</li>
+</ul>
+<p>SNB is intended to cover a broad range of aspects of social network data management, and therefore includes three distinct workloads:</p>
+<ul>
+<li><strong>Interactive</strong>
+<ul>
+<li>Tests system throughput with relatively simple queries and concurrent updates, it is designed to test ACID features and scalability in an online operational setting.</li>
+<li>The targeted systems are expected to be those that offer transactional functionality.</li>
+</ul>
+</li>
+<li><strong>Business Intelligence</strong>
+<ul>
+<li>Consists of complex structured queries for analyzing online behavior of users for marketing purposes, it is designed to stress query execution and optimization.</li>
+<li>The targeted systems are expected to be those that offer an abstract query language.</li>
+</ul>
+</li>
+<li><strong>Graph Analytics</strong>
+<ul>
+<li>Tests the functionality and scalability of systems for graph analytics, which typically cannot be expressed in a query language.</li>
+<li>Analytics is performed on most/all of the data in the graph as a single operation and produces large intermediate results, and it is not not expected to be transactional or need isolation.</li>
+<li>The targeted systems are graph compute frameworks though database systems may compete, for example by using iterative implementations that repeatedly execute queries and keep intermediate results in temporary data structures.</li>
+</ul>
+</li>
+</ul>
+<h4 id="semantic-publishing-benchmark">Semantic Publishing Benchmark</h4>
+<p>The Semantic Publishing Benchmark (SPB) simulates the management and consumption of RDF metadata that describes media assets, or creative works.</p>
+<p>The scenario is a media organization that maintains RDF descriptions of its catalogue of creative works – input was provided by actual media organizations which make heavy use of RDF, including the BBC. The benchmark is designed to reflect a scenario where a large number of aggregation agents provide the heavy query workload, while at the same time a steady stream of creative work description management operations are in progress. This benchmark only targets RDF databases, which support at least basic forms of semantic inference. A tagging ontology is used to connect individual creative work descriptions to instances from reference datasets, e.g. sports, geographical, or political information. The data used will fall under the following categories: reference data, which is a combination of several Linked Open Data datasets, e.g. GeoNames and DBpedia; domain ontologies, that are specialist ontologies used to describe certain areas of expertise of the publishing, e.g., sport and education; publication asset ontologies, that describe the structure and form of the assets that are published, e.g., news stories, photos, video, audio, etc.; and tagging ontologies and the metadata, that links assets with reference/domain ontologies.</p>
+<p>The data generator is initialized by using several ontologies and datasets. The instance data collected from these datasets are then used at several points during the execution of the benchmark. Data generation is performed by generating SPARQL fragments for create operations on creative works and executing them against the RDF database system.</p>
+<p>Two separate workloads are modeled in SPB:</p>
+<ul>
+<li><strong>Editorial:</strong> Simulates creating, updating and deleting creative work metadata descriptions. Media companies use both manual and semi-automated processes for efficiently and correctly managing asset descriptions, as well as annotating them with relevant instances from reference ontologies.</li>
+<li><strong>Aggregation:</strong> Simulates the dynamic aggregation of content for consumption by the distribution pipelines (e.g. a web-site). The publishing activity is described as “dynamic”, because the content is not manually selected and arranged on, say, a web page. Instead, templates for pages are defined and the content is selected when a consumer accesses the page.</li>
+</ul>
+<p><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/third-tuc-meeting/attachments/4325436/5505026.pdf">Status of the Semantic Publishing Benchmark</a></p>
+
+
+
+ -
+
Second TUC Meeting
+ https://ldbcouncil.org/event/second-tuc-meeting/
+ Mon, 22 Apr 2013 10:00:00 +0000
+
+ https://ldbcouncil.org/event/second-tuc-meeting/
+ <p>The LDBC consortium are pleased to announce the second Technical User Community (TUC) meeting.</p>
+<p>This will be a two day event in Munich on the <strong>22/23rd April 2013</strong>.</p>
+<p>The event will include:</p>
+<ul>
+<li>Introduction to the objectives and progress of the LDBC project.</li>
+<li>Description of the progress of the benchmarks being evolved through Task Forces.</li>
+<li>Users explaining their use-cases and describing the limitations they have found in current technology.</li>
+<li>Industry discussions on the contents of the benchmarks.</li>
+</ul>
+<p>All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu</p>
+<ul>
+<li><a href="#agenda">Agenda</a></li>
+<li><a href="#logistics">Logistics</a>
+<ul>
+<li><a href="#date">Date</a></li>
+<li><a href="#location">Location</a></li>
+<li><a href="#venue">Venue</a>
+<ul>
+<li><a href="#getting-to-the-tum-campus-from-the-munich-city-center-subway-u-bahn">Getting to the TUM Campus from the Munich city center: Subway (U-Bahn)</a></li>
+<li><a href="#getting-to-the-tum-campus-from-the-munich-airport">Getting to the TUM Campus from the Munich Airport</a></li>
+<li><a href="#getting-to-the-tum-campus-from-garching-u-bahn">Getting to the TUM Campus from Garching: U-Bahn</a></li>
+</ul>
+</li>
+<li><a href="#getting-there">Getting there</a></li>
+<li><a href="#social-dinner">Social Dinner</a></li>
+</ul>
+</li>
+</ul>
+<h3 id="agenda">Agenda</h3>
+<p><strong>April 22nd</strong></p>
+<p>10:00 <em>Registration.</em><br>
+10:30 Josep Lluis Larriba Pey (UPC) - <em>Welcome and Introduction.</em><br>
+10:30 Peter Boncz (VUA): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687373.pptx">LDBC: goals and status</a></p>
+<p><em>Social Network Use Cases (with discussion moderated by Josep Lluis Larriba Pey)</em></p>
+<p>11:00 Josep Lluis Larriba Pey (UPC): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687372.pdf">Social Network Benchmark Task Force</a><br>
+11:30 Gustavo González (Mediapro): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687367.pdf">Graph-based User Modeling through Real-time Social Streams</a><br>
+12:00 Klaus Großmann (Dshini): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687365.pdf">Neo4j at Dshini</a></p>
+<p>12:30 Lunch</p>
+<p><em>Semantic Publishing Use Cases (with discussion moderated by Barry Bishop)</em></p>
+<p>13:30 Barry Bishop (Ontotext): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687366.pptx">Semantic Publishing Benchmark Task Force</a><br>
+14:00 Dave Rogers (BBC): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687364.pptx">Linked Data Platform at the BBC</a><br>
+14:30 Edward Thomas (Wolters Kluwer): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687374.pdf">Semantic Publishing at Wolters Kluwer</a></p>
+<p>15:00 Coffee break</p>
+<p><em>Projects Related to LDBC</em></p>
+<p>15:30 Fabian Suchanek (MPI): “YAGO: A large knowledge base from Wikipedia and WordNet”<br>
+16:00 Antonis Loziou (VUA): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687375.pptx">The OpenPHACTS approach to data integration</a><br>
+16:30 Mirko Kämpf (Brox): “GeoKnow - Spatial Data Web project and Supply Chain Use Case”</p>
+<p>17:00 <em>End of first day</em></p>
+<p>19:00 Social dinner</p>
+<p><strong>April 23rd</strong></p>
+<p><em>Industry & Hardware Aspects</em></p>
+<p>10:00 Xavier Lopez (Oracle): <a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687384.pdf">Graph Database Performance an Oracle Perspective.pdf</a><br>
+10:30 Pedro Trancoso (University of Cyprus): “Benchmarking and computer architecture: the research side”</p>
+<p>11:00 Coffee break</p>
+<p><em>Future Steps and TUC feedback session</em></p>
+<p>11:30 Peter Boncz (VUA) moderates: next steps in the Social Networking Task Force<br>
+12:00 Barry Bishop (Ontotext) moderates: next steps in the Semantic Publishing Task Force"</p>
+<p>12:30 <em>End of meeting</em></p>
+<h3 id="logistics">Logistics</h3>
+<h4 id="date">Date</h4>
+<p>22nd and 23th April 2013</p>
+<h4 id="location">Location</h4>
+<p>The TUC meeting will be held at LE009 room at LRZ (Leibniz-Rechenzentrum) located inside the TU Munich campus in Garching, Germany. The address is:</p>
+<p>LRZ (Leibniz-Rechenzentrum)<br>
+Boltzmannstraße 1<br>
+85748 Garching, Germany</p>
+<h4 id="venue">Venue</h4>
+<p>To reach the campus, there are several options, including Taxi and Subway <a href="http://www.in.tum.de/fileadmin/user_upload/Sonstiges/anfahrt_garching.pdf">Ubahn</a></p>
+<h5 id="getting-to-the-tum-campus-from-the-munich-city-center-subway-u-bahn">Getting to the TUM Campus from the Munich city center: Subway (U-Bahn)</h5>
+<p>Take the U-bahn line U6 in the direction of Garching-Forschungszentrum, exit at the end station. Take the south exit to MI-Building and LRZ on the Garching Campus. The time of the journey from the city center is approx. 25-30 minutes. In order to get here from the City Center, you need the Munich XXL ticket that costs around 7.50 euros and covers all types of transportation for one day. The ticket has to be validated before ride.</p>
+<h5 id="getting-to-the-tum-campus-from-the-munich-airport">Getting to the TUM Campus from the Munich Airport</h5>
+<ol>
+<li>
+<p>(except weekends) S-Bahn S8 line in the direction of (Hauptbahnhof) Munich Central Station until the third stop, Ismaning (approx. 13 minutes). From here Bus Nr. 230 until stop MI-Building on the Garching Campus. Alternatively: S1 line until Neufahrn, then with the Bus 690, which stops at Boltzmannstraße.</p>
+</li>
+<li>
+<p>S-Bahn lines S8 or S1 towards City Center until Marienplatz stop. Then change to U-bahn U6 line towards Garching-Forschungszentrum, exit at the last station. Take the south exit to MI-Building and LRZ.</p>
+</li>
+<li>
+<p>Taxi: fare is ca. 30-40 euros.</p>
+</li>
+</ol>
+<p>For cases 1 and 2, before the trip get the One-day Munich Airport ticket and validate it. It will cover all public transportation for that day.</p>
+<h5 id="getting-to-the-tum-campus-from-garching-u-bahn">Getting to the TUM Campus from Garching: U-Bahn</h5>
+<p>The city of Garching is located on the U6 line, one stop before the Garching-Forschungszentrum. In order to get from Garching to Garching-Forschungszentrum with the U-bahn, a special one-way ticket called Kurzstrecke (1.30 euros) can be purchased.</p>
+<p><strong>Finding LRZ@TUM</strong></p>
+<p><a href="http://www.openstreetmap.org/?mlat=48.2615702464&mlon=11.6686558264&zoom=32">OpenStreetMap link</a></p>
+<p><a href="https://maps.google.com/maps?q=48.2615702464,11.6686558264&spn=0.005,0.005&t=k">Google Maps link</a></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687268.gif" alt=""></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/second-tuc-meeting/attachments/2523698/2687269.gif" alt=""></p>
+<h4 id="getting-there">Getting there</h4>
+<p><strong>Flying: Munich</strong> airport is located 28.5 km northeast of Munich. There are two ways to get from the airport to the city center: suburban train (S-bahn) and Taxi.</p>
+<p><strong>S-Bahn:</strong> S-bahn lines S1 and S8 will get you from the Munich airport to the city center, stopping at both Munich Central Station (Hauptbahnhof) and Marienplatz. One-day Airport-City ticket costs 11.20 euros and is valid for the entire Munich area public transportation during the day of purchase (the tickets needs to be validated before the journey). S-bahn leaves every 5-20 minutes and reaches the city center in approx. 40 minutes.</p>
+<p><strong>Taxi:</strong> taxi from the airport to the city center costs approximately 50 euros</p>
+<h4 id="social-dinner">Social Dinner</h4>
+<p>The social dinner will take place at 7 pm on April 22 in Hofbräuhaus (second floor)</p>
+<p>Address: Hofbräuhaus, Platzl 9, Munich</p>
+
+
+
+ -
+
First TUC Meeting
+ https://ldbcouncil.org/event/first-tuc-meeting/
+ Mon, 19 Nov 2012 09:00:00 +0100
+
+ https://ldbcouncil.org/event/first-tuc-meeting/
+ <p>The LDBC consortium are pleased to announce the first Technical User Community (TUC) meeting. This will be a two day event in Barcelona on the <strong>19/20th November 2012</strong>.</p>
+<p>So far more than six commercial consumers of graph/RDF database technology have expressed an interest in attending the event and more are welcome. The proposed format of the event wil include:</p>
+<ul>
+<li>Introduction by the coordinator and technical director explaining the objectives of the LDBC project</li>
+<li>Invitation to users to explain their use-cases and describe the limitations they have found in current technology</li>
+<li>Brain-storming session for identifying trends and mapping out strategies to tackle existing choke-points</li>
+</ul>
+<p>The exact agenda will be published here as things get finalised before the event.</p>
+<p>All users of RDF and graph databases are welcome to attend. If you are interested, please contact: ldbc AT ac DOT upc DOT edu</p>
+<ul>
+<li><a href="#agenda">Agenda</a></li>
+<li><a href="#slide">Slide</a>
+<ul>
+<li><a href="#logistics">Logistics</a>
+<ul>
+<li><a href="#date">Date</a></li>
+<li><a href="#location">Location</a></li>
+</ul>
+</li>
+<li><a href="#venue">Venue</a></li>
+<li><a href="#getting-there">Getting there</a></li>
+</ul>
+</li>
+</ul>
+<h3 id="agenda">Agenda</h3>
+<p>We will start at 9:00 on Monday for a full day, followed by a half a day on Tuesday to allow attendees to travel home on the evening of the 20th.</p>
+<p><strong>Day 1</strong></p>
+<p>09:00 Welcome (Location: Aula Master)<br>
+09:30 Project overview (Emphasis on task forces?) + Questionnaire results?<br>
+10:30 Coffee break<br>
+11:00 User talks (To gather information for use cases?)</p>
+<p>13:00 Lunch</p>
+<p>14:00 User talks (cont.)<br>
+15:00 Use case discussions (based on questionnaire results + consortium proposal + user talks).<br>
+16:00 Task force proposals (consortium)<br>
+17:00 Finish first day</p>
+<p>20:00 Social dinner</p>
+<p><strong>Day 2</strong></p>
+<p>10:00 Task force discussion (consortium + TUC)<br>
+11:00 Coffe break<br>
+11:30 Task force discussion (consortium + TUC)<br>
+12:30 Summaries (Task forces, use cases, …) and actions</p>
+<p>13:00 Lunch and farewell</p>
+<p>15:00 LDBC Internal meeting</p>
+<h3 id="slide">Slide</h3>
+<p>Opening session:</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2686995.pptx">CWI – Peter Boncz</a> – Objectives</li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687001.pdf">UPC – Larri</a> – Questionnaire</li>
+</ul>
+<p>User stories:</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2686998.pdf">BBC – Jem Rayfield</a></li>
+<li>CA Technologies – Victor Muntés</li>
+<li>Connected Discovery (Open Phacts) – Bryn Williams-Jones</li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687003.pptx">Elsevier – Alan Yagoda</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687000.pptx">ERA7 Bioinformatics – Eduardo Pareja</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687005.pptx">Press Association – Jarred McGinnis</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687004.pptx">RJLee – David Neuer</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2686994.pdf">Yale – Lec Maj</a></li>
+</ul>
+<p>Benchmark proposals:</p>
+<ul>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2686991.pdf">Publishing benchmark proposal – Ontotext – Barry Bishop</a></li>
+<li><a href="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/2687002.pdf">Social Network Benchmark Proposal – UPC – Larri</a></li>
+</ul>
+<h4 id="logistics">Logistics</h4>
+<h5 id="date">Date</h5>
+<p>19th and 20th November 2012</p>
+<h5 id="location">Location</h5>
+<p>The TUC meeting will be held at “Aula Master” at A3 building located inside the “Campus Nord de la UPC” in Barcelona. The address is:</p>
+<p>Aula Master<br>
+Edifici A3, Campus Nord UPC<br>
+C. Jordi Girona, 1-3<br>
+08034 Barcelona, Spain</p>
+<h4 id="venue">Venue</h4>
+<p>To reach the campus, there are several options, including Taxi, <a href="http://www.tmb.cat/ca/c/document_library/get_file?uuid=c8996f6c-8ad5-4d21-b59b-faf9fceebd80&groupId=10168">Metro</a> and <a href="http://www.tmb.cat/ca/c/document_library/get_file?uuid=5e6af5e2-7677-4ce8-85bb-8e63f2b086f1&groupId=10168">Bus</a>.</p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/1933315.jpg" alt=""></p>
+<p><strong>Finding UPC</strong></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/1933318.jpg" alt=""></p>
+<p><strong>Finding the meeting room</strong></p>
+<h4 id="getting-there">Getting there</h4>
+<p><strong>Flying:</strong> Barcelona airport is situated 12 km from the city. There are several ways of getting from the airport to the centre of Barcelona, the cheapest of which is to take the train located outside just a few minutes walking distance past the parking lots at terminal 2 (there is a free bus between terminal 1 and terminal 2, see this <a href="http://goo.gl/maps/iJqlj">map of the airport</a>). It is possible to buy 10 packs of train tickets which makes it cheaper. Taking the bus to the centre of town is more convenient as they leave directly from terminal 1 and 2, however it is more expensive than the train.</p>
+<p><strong>Rail:</strong> The Renfe commuter train leaves the airport every 30 minutes from 6.13 a.m. to 11.40 p.m. Tickets cost around 3€ and the journey to the centre of Barcelona (Sants or Plaça Catalunya stations) takes 20 minutes.</p>
+<p><strong>Bus:</strong> The Aerobus leaves the airport every 12 minutes, from 6.00 a.m. to 24.00, Monday to Friday, and from 6.30 a.m. to 24.00 on Saturdays, Sundays and public holidays. Tickets cost 6€ and the journey ends in Plaça Catalunya in the centre of Barcelona.</p>
+<p><strong>Taxi:</strong> From the airport, you can take one of Barcelona’s typical black and yellow taxis. Taxis may not take more than four passengers. Unoccupied taxis display a green light and have a clearly visible sign showing LIBRE or LLIURE. The trip to Sants train station costs approximately €16 and trips to other destinations in the city cost approximately €18.</p>
+<p><strong>Train and bus:</strong> Barcelona has two international train stations: Sants and França. Bus companies have different points of arrival in different parts of the city. You can find detailed information in the following link: <a href="http://www.barcelona-airport.com/eng/transport_eng.htm">http://www.barcelona-airport.com/eng/transport_eng.htm</a></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/1933316.jpg" alt=""></p>
+<p><strong>The locations of the airport and the city centre</strong></p>
+<p><img src="https://pub-383410a98aef4cb686f0c7601eddd25f.r2.dev/event/first-tuc-meeting/attachments/1671180/1933317.jpg" alt=""></p>
+<p><strong>Bus map</strong></p>
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/opengql-announce/index.html b/pages/opengql-announce/index.html
new file mode 100644
index 00000000..f3fbc4de
--- /dev/null
+++ b/pages/opengql-announce/index.html
@@ -0,0 +1,382 @@
+
+
+
+
+ LDBC open source GQL tools
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ By Alastair Green, Vice-chair LDBC, and author of the GQL Manifesto.
+9 May 2024
+The GQL standard was published in mid-April by ISO. See WG3 Convenor Keith Hare’s summary: ISO/IEC JTC 1 GQL Database Language
+Linked Data Benchmark Council (LDBC) is releasing early-version open-source GQL grammar tools.
+Open GQL Language Tools
+There are three interlinked projects:
+
+- ANTLR grammar repository
+- GQL Code Editor Web UI (and repository)
+- Railroad Diagrams Web Page (and repository)
+
+A commit of a new version of the grammar automatically rebuilds and deploys the Code Editor and the Railroad Diagrams.
+Michael Burbidge (who leads our GQL Implementation Working Group), Damian Wileński, and Dominik Tomaszuk are responsible for making all this happen, so soon after the release of GQL. Wonderful work!
+The tools are a work in progress, so expect evolution. Feel free to raise issues on Github.
+The mission of the GQL Implementation Working Group is to create tooling and documentation to assist in and accelerate the implementation and adoption of GQL. See the working group charter for more information.
+Code examples for Technical Reports
+The Code Editor lets you create syntactically correct GQL examples. It is not connected to an implementation of the GQL spec, so type checking, variable scoping rules, etc., that are typically done by semantic analysis of the parse tree, are not enforced by the Code Editor.
+I used Code Editor to create/check the code examples in my last post on LinkedIn, GQL in code, which links through to
+GQL on one page: DDL, DML and GPML
+It is also being used to help create a forthcoming LDBC Technical Report on GQL, which (unlike the spec) will be freely available to all, and will contain numerous examples.
+Towards a GQL TCK
+More is in the works: we have begun work on a Test Compatibility Kit, modelled on the the openCypher TCK, but that’s a big job.
+We need and welcome active contributions to all these community efforts.
+If you are interested, please ping Michael at michael.burbidge@ldbcouncil.org.
+The Linked Data Benchmark Council
+LDBC is a non-profit consortium of vendors, researchers and independent practitioners interested in graph data management.
+LDBC defines benchmark standards for graph data workloads (using RDF, SQL, and property graph languages). It is a meeting point and working space for community efforts supportive of the GQL and SQL/PGQ property graph standards.
+It supervises the audited execution of comparable benchmark runs which are reported with cost metrics, following the lead of TPC. Only audited results published by LDBC can be described as LDBC Benchmark(R) results.
+LDBC is run by its 20+ organizational members including Oracle, Ant Group, Intel, Neo4j, TigerGraph, Fabarta, thatDot, Ontotext, ArangoDB, Relational AI, Stargraph, Nebula Graph, Sparksee, FORTH, Memgraph, Createlink, Alibaba DAMO Academy (Graphscope), Birkbeck University of London and AWS.
+There are 70+ individual associate members (who join for free and support its working groups and task forces).
+Recent and current initiatives include the Finance Benchmark, LDBC Extended GQL Schema (LEX), and GQL Implementation.
+The G-CORE, PG-Keys, Graph Pattern Matching in GQL and SQL/PGQ and PG-Schema papers (all published at SIGMOD) directly reflect the work of LDBC participants on graph data languages, over the years.
+LDBC is a Category C Liaison of ISO/IEC JTC1 SC32/WG3 (the SQL and GQL standards committee). Jan Hidders, Michael Burbidge and Alastair Green are LDBC’s representatives in WG3.
+For all enquiries, including membership enquiries, please email info@ldbcouncil.org.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page-name/index.html b/pages/page-name/index.html
new file mode 100644
index 00000000..76749792
--- /dev/null
+++ b/pages/page-name/index.html
@@ -0,0 +1,342 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/1/index.html b/pages/page/1/index.html
new file mode 100644
index 00000000..cb682eb1
--- /dev/null
+++ b/pages/page/1/index.html
@@ -0,0 +1,10 @@
+
+
+
+ https://ldbcouncil.org/pages/
+
+
+
+
+
+
diff --git a/pages/page/2/index.html b/pages/page/2/index.html
new file mode 100644
index 00000000..4f29620e
--- /dev/null
+++ b/pages/page/2/index.html
@@ -0,0 +1,804 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Announcing the LDBC Financial Benchmark Task Force
+ Tags:
+ FINBENCH
+
+
+
+
+ We are delighted to announce the set up of the Financial Benchmark (FinBench) task force.
+The Financial Benchmark (FinBench) project aims to define a graph database evaluating benchmark and develop a data generation process and a query driver to make the evaluation of the graph database representative, reliable and comparable, especially in financial scenarios, such as anti-fraud and risk control. The FinBench is scheduled to be released in the …
+
+
+
+
+
+
+
+
+
+
+
+ Speeding Up LDBC SNB Datagen
+ Tags:
+ DATAGEN
+ , SNB
+
+
+
+
+ LDBC’s Social Network Benchmark [4] (LDBC SNB) is an industrial and academic initiative, formed by principal actors in the field of graph-like data management. Its goal is to define a framework where different graph-based technologies can be fairly tested and compared, that can drive the identification of systems’ bottlenecks and required functionalities, and can help researchers open new frontiers in high-performance graph data …
+
+
+
+
+
+
+
+
+
+
+
+ LDBC Is Proud to Announce the New LDBC Graphalytics Benchmark Draft Specification
+ Tags:
+ BENCHMARK
+ , TU DELFT
+ , GRAPHALYTICS
+
+
+
+
+
+
+
+
+ LDBC is proud to announce the new LDBC Graphalytics Benchmark draft specification.
+LDBC Graphalytics is the first industry-grade graph data management benchmark …
+
+
+
+
+
+
+
+
+
+
+
+ LDBC and Apache Flink
+ Tags:
+ FLINK
+ , DATAGEN
+ , SNB
+
+
+
+
+ Apache Flink [1] is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
+
+Flink offers multiple APIs to process data …
+
+
+
+
+
+
+
+
+
+
+
+ Elements of Instance Matching Benchmarks: a Short Overview
+ Tags:
+ INSTANCE MATCHING
+ , SPB
+
+
+
+
+ The number of datasets published in the Web of Data as part of the Linked Data Cloud is constantly increasing. The Linked Data paradigm is based on the unconstrained publication of information by different publishers, and the interlinking of web resources through “same-as” links which specify that two URIs correspond to the same real world object. In the vast number of data sources participating in the Linked Data Cloud, this information is not …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Interactive Part 3: Choke Points and Initial Run on Virtuoso
+ Tags:
+ SNB
+ , INTERACTIVE
+
+
+
+
+ In this post we will look at running the LDBC SNB on Virtuoso.
+First, let’s recap what the benchmark is about:
+
+-
+
fairly frequent short updates, with no update contention worth mentioning
+
+-
+
short random lookups
+
+-
+
medium complex queries centered around a person’s social environment
+
+
+The updates exist so as to invalidate strategies that rely too heavily on precomputation. The short lookups exist for the sake of realism; after all, an …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/3/index.html b/pages/page/3/index.html
new file mode 100644
index 00000000..c41c3366
--- /dev/null
+++ b/pages/page/3/index.html
@@ -0,0 +1,796 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ SNB and Graphs Related Presentations at GRADES '15
+ Tags:
+ SIGMOD
+ , GRAPHALYTICS
+ , GRADES
+ , SNB
+ , DATAGEN
+ , WORKSHOP
+
+
+
+
+ Next 31st of May the GRADES workshop will take place in Melbourne within the ACM/SIGMOD presentation. GRADES started as an initiative of the Linked Data Benchmark Council in the SIGMOD/PODS 2013 held in New York.
+Among the papers published in this edition we have “Graphalytics: A Big Data Benchmark for Graph-Processing Platforms”, which presents a new benchmark that uses the Social Network Benchmark data generator of LDBC (that can …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Interactive Part 2: Modeling Choices
+ Tags:
+ SNB
+ , VIRTUOSO
+ , INTERACTIVE
+
+
+
+
+ SNB Interactive is the wild frontier, with very few rules. This is necessary, among other reasons, because there is no standard property graph data model, and because the contestants support a broad mix of programming models, ranging from in-process APIs to declarative query.
+In the case of Virtuoso, we have played with SQL and SPARQL implementations. For a fixed schema and well known workload, SQL will always win. The reason for this is that …
+
+
+
+
+
+
+
+
+
+
+
+ LDBC Participates in the 36th Edition of the ACM SIGMOD/PODS Conference
+ Tags:
+ SIGMOD
+ , GRADES
+ , SNB
+ , GRAPHALYTICS
+ , WORKSHOP
+
+
+
+
+ LDBC is presenting two papers at the next edition of the ACM SIGMOD/PODS conference held in Melbourne from May 31st to June 4th, 2015. The annual ACM SIGMOD/PODS conference is a leading international forum for database researchers, practitioners, developers, and users to explore cutting-edge ideas and results, and to exchange techniques, tools and experiences.
+On the industry track, LDBC will be presenting the Social Network Benchmark Interactive …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Interactive Part 1: What Is SNB Interactive Really About?
+ Tags:
+ SNB
+ , VIRTUOSO
+ , INTERACTIVE
+
+
+
+
+ This post is the first in a series of blogs analyzing the LDBC Social Network Benchmark Interactive workload. This is written from the dual perspective of participating in the benchmark design and of building the OpenLink Virtuoso implementation of same.
+With two implementations of SNB interactive at four different scales, we can take a first look at what the benchmark is really about. The hallmark of a benchmark implementation is that its …
+
+
+
+
+
+
+
+
+
+
+
+ Why Do We Need an LDBC SNB-Specific Workload Driver?
+ Tags:
+ SNB
+ , DRIVER
+ , INTERACTIVE
+
+
+
+
+ In a previous 3-part blog series we touched upon the difficulties of executing the LDBC SNB Interactive (SNB) workload, while achieving good performance and scalability. What we didn’t discuss is why these difficulties were unique to SNB, and what aspects of the way we perform workload execution are scientific contributions - novel solutions to previously unsolved problems. This post will highlight the differences between SNB and more …
+
+
+
+
+
+
+
+
+
+
+
+ Event Driven Post Generation in Datagen
+ Tags:
+ DATAGEN
+ , SOCIAL NETWORK
+ , SNB
+
+
+
+
+ As discussed in previous posts, one of the features that makes Datagen more realistic is the fact that the activity volume of the simulated Persons is not uniform, but forms spikes. In this blog entry I want to explain more in depth how this is actually implemented inside of the generator.
+First of all, I start with a few basics of how Datagen works internally. In Datagen, once the person graph has been created (persons and their relationships), …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/4/index.html b/pages/page/4/index.html
new file mode 100644
index 00000000..e19c20e7
--- /dev/null
+++ b/pages/page/4/index.html
@@ -0,0 +1,768 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ The LDBC Datagen Community Structure
+ Tags:
+ DATAGEN
+ , SOCIAL NETWORK
+ , SNB
+
+
+
+
+ This blog entry is about one of the features of DATAGEN that makes it different from other synthetic graph generators that can be found in the literature: the community structure of the graph.
+When generating synthetic graphs, one must not only pay attention to quantitative measures such as the number of nodes and edges, but also to other more qualitative characteristics such as the degree distribution, clustering coefficient. Real graphs, and …
+
+
+
+
+
+
+
+
+
+
+
+ Industry Relevance of the Semantic Publishing Benchmark
+ Tags:
+ INDUSTRY
+ , SPB
+
+
+
+
+
+
+
+
+ Publishing and media businesses are going through transformation
+I took this picture in June 2010 next to Union Square in San Francisco. I was smoking and …
+
+
+
+
+
+
+
+
+
+
+
+ OWL-Empowered SPARQL Query Optimization
+ Tags:
+ DEVELOPER
+ , INDUSTRY
+
+
+
+
+ The Linked Data paradigm has become the prominent enabler for sharing huge volumes of data using Semantic Web technologies, and has created novel challenges for non-relational data management systems, such as RDF and graph engines. Efficient data access through queries is perhaps the most important data management task, and is enabled through query optimization techniques, which amount to the discovery of optimal or close to optimal execution …
+
+
+
+
+
+
+
+
+
+
+
+ Person Activity Subgraph Features in LDBC DATAGEN
+ Tags:
+ SNB
+ , DATAGEN
+
+
+
+
+ When talking about DATAGEN and other graph generators with social network characteristics, our attention is typically borrowed by the friendship subgraph and/or its structure. However, a social graph is more than a bunch of people being connected by friendship relations, but has a lot more of other things is worth to look at. With a quick view to commercial social networks like Facebook, Twitter or Google+, one can easily identify a lot of other …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Driver - Part 2: Tracking Dependencies Between Queries
+ Tags:
+ SNB
+ , DRIVER
+ , INTERACTIVE
+
+
+
+
+ The SNB Driver part 1 post introduced, broadly, the challenges faced when developing a workload driver for the LDBC SNB benchmark. In this blog we’ll drill down deeper into the details of what it means to execute “dependent queries” during benchmark execution, and how this is handled in the driver. First of all, as many driver-specific terms will be used, below is a listing of their definitions. There is no need to read them in …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Driver - Part 3: Workload Execution Putting It All Together
+ Tags:
+ SNB
+ , DRIVER
+ , INTERACTIVE
+
+
+
+
+ Up until now we have introduced the challenges faced when executing the LDBC SNB benchmark, as well as explained how some of these are overcome. With the foundations laid, we can now explain precisely how operations are executed.
+Based on the dependencies certain operations have, and on the granularity of parallelism we wish to achieve while executing them, we assign a Dependency Mode and an Execution Mode to every operation type. Using these …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/5/index.html b/pages/page/5/index.html
new file mode 100644
index 00000000..1d6b0a9e
--- /dev/null
+++ b/pages/page/5/index.html
@@ -0,0 +1,768 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Running the Semantic Publishing Benchmark on Sesame, a Step by Step Guide
+ Tags:
+ SPB
+ , SESAME
+ , RDF
+ , TUTORIAL
+ , GUIDE
+
+
+
+
+ Until now we have discussed several aspects of the Semantic Publishing Benchmark (SPB) such as the difference in performance between virtual and real servers configuration, how to choose an appropriate query mix for a benchmark run and our experience with using SPB in the development process of GraphDB for finding performance issues.
+In this post we provide a step-by-step guide on how to run SPB using the Sesame RDF data store on a fresh install …
+
+
+
+
+
+
+
+
+
+
+
+ Semantic Publishing Instance Matching Benchmark
+ Tags:
+ INSTANCE MATCHING
+ , BENCHMARK
+
+
+
+
+ The Semantic Publishing Instance Matching Benchmark (SPIMBench) is a novel benchmark for the assessment of instance matching techniques for RDF data with an associated schema. SPIMBench extends the state-of-the art instance matching benchmarks for RDF data in three main aspects: it allows for systematic scalability testing, supports a wider range of test cases including semantics-aware ones, and provides an enriched gold standard.
+The SPIMBench …
+
+
+
+
+
+
+
+
+
+
+
+ Further Developments in SNB BI Workload
+ Tags:
+ SNB
+ , BI
+
+
+
+
+ We are presently working on the SNB BI workload. Andrey Gubichev of TU Munchen and myself are going through the queries and are playing with two SQL based implementations, one on Virtuoso and the other on Hyper.
+As discussed before, the BI workload has the same choke points as TPC-H as a base but pushes further in terms of graphiness and query complexity.
+There are obvious marketing applications for a SNB-like dataset. There are also security …
+
+
+
+
+
+
+
+
+
+
+
+ Sizing AWS Instances for the Semantic Publishing Benchmark
+ Tags:
+ SPB
+ , AMAZON
+ , EC2
+ , AWS
+ , RDF
+
+
+
+
+ LDBC’s Semantic Publishing Benchmark (SPB) measures the performance of an RDF database in a load typical for metadata-based content publishing, such as the famous BBC Dynamic Semantic Publishing scenario. Such load combines tens of updates per second (e.g. adding metadata about new articles) with even higher volume of read requests (SPARQL queries collecting recent content and data to generate web page on a specific subject, e.g. Frank …
+
+
+
+
+
+
+
+
+
+
+
+ DATAGEN: a Realistic Social Network Data Generator
+ Tags:
+ DEVELOPER
+ , INDUSTRY
+
+
+
+
+ In previous posts (Getting started with snb, DATAGEN: data generation for the Social Network Benchmark), Arnau Prat discussed the main features and characteristics of DATAGEN: realism, scalability, determinism, usability. DATAGEN is the social network data generator used by the three LDBC-SNB workloads, which produces data simulating the activity in a social network site during a period of time. In this post, we conduct a series of experiments …
+
+
+
+
+
+
+
+
+
+
+
+ SNB Driver - Part 1
+ Tags:
+ SNB
+ , DRIVER
+ , TPC-C
+ , INTERACTIVE
+
+
+
+
+ In this multi-part blog we consider the challenge of running the LDBC Social Network Interactive Benchmark (LDBC SNB) workload in parallel, i.e. the design of the workload driver that will issue the queries against the System Under Test (SUT). We go through design principles that were implemented for the LDBC SNB workload generator/load tester (simply referred to as driver). Software and documentation for this driver is available here: …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/6/index.html b/pages/page/6/index.html
new file mode 100644
index 00000000..1cc4a65a
--- /dev/null
+++ b/pages/page/6/index.html
@@ -0,0 +1,776 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Making Semantic Publishing Execution Rules
+ Tags:
+ SPB
+ , TEST RUN
+
+
+
+
+ LDBC SPB (Semantic Publishing Benchmark) is based on the BBC linked data platform use case. Thus the data modelling and transaction mix reflects the BBC’s actual utilization of RDF. But a benchmark is not only a condensation of current best practices. The BBC linked data platform is an Ontotext Graph DB deployment. Graph DB was formerly known as Owlim.
+So, in SPB we wanted to address substantially more complex queries than the lookups that …
+
+
+
+
+
+
+
+
+
+
+
+ Getting Started With the Semantic Publishing Benchmark
+ Tags:
+ SPB
+ , SPARQL
+
+
+
+
+ The Semantic Publishing Benchmark (SPB), developed in the context of LDBC, aims at measuring the read and write operations that can be performed in the context of a media organisation. It simulates the management and consumption of RDF metadata describing media assets and creative works. The scenario is based around a media organisation that maintains RDF descriptions of its catalogue of creative works. These descriptions use a set of ontologies …
+
+
+
+
+
+
+
+
+
+
+
+ Choke Point Based Benchmark Design
+ Tags:
+ DATABASE
+ , BENCHMARK
+ , DESIGN
+
+
+
+
+ The Linked Data Benchmark Council (LDBC) mission is to design and maintain benchmarks for graph data management systems, and establish and enforce standards in running these benchmarks, and publish and arbitrate around the official benchmark results. The council and its https://ldbcouncil.org website just launched, and in its first 1.5 year of existence, most effort at LDBC has gone into investigating the needs of the field through interaction …
+
+
+
+
+
+
+
+
+
+
+
+ New Website Online LDBC Benchmarks Reach Public Draft
+ Tags:
+ DEVELOPER
+ , INDUSTRY
+
+
+
+
+ The Linked Data Benchmark Council (LDBC) is reaching a milestone today, June 23 2014, in announcing that two of the benchmarks that it has been developing since 1.5 years have now reached the status of Public Draft. This concerns the Semantic Publishing Benchmark (SPB) and the interactive workload of the Social Network Benchmark (SNB). In case of LDBC, the release is staged: now the benchmark software just runs read-only queries. This will be …
+
+
+
+
+
+
+
+
+
+
+
+ Social Network Benchmark Goals
+ Tags:
+ SNB
+ , DATAGEN
+ , INTERACTIVE
+ , BI
+ , GRAPHALYTICS
+
+
+
+
+ Social Network interaction is amongst the most natural and widely spread activities in the internet society, and it has turned out to be a very useful way for people to socialise at different levels (friendship, professional, hobby, etc.). As such, Social Networks are well understood from the point of view of the data involved and the interaction required by their actors. Thus, the concepts of friends of friends, or retweet are well established …
+
+
+
+
+
+
+
+
+
+
+
+ Welcome to the New Industry Oriented LDBC Organisation for Benchmarking RDF and Graph Technologies
+ Tags:
+ LDBC
+
+
+
+
+ It is with great pleasure that we announce the new LDBC organisation site at www.ldbcouncil.org. The LDBC started as a European Community FP7 funded project with the objective to create, foster and become an industry reference for benchmarking RDF and Graph technologies. A period of more than one and a half years has led us to the creation of the first two workloads, the Semantic Publishing Benchmark and the Social Network Benchmark in its …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/7/index.html b/pages/page/7/index.html
new file mode 100644
index 00000000..a17ef87b
--- /dev/null
+++ b/pages/page/7/index.html
@@ -0,0 +1,794 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 2nd International Workshop on Benchmarking RDF Systems
+ Tags:
+ WORKSHOP
+ , CFP
+ , BENCHMARK
+ , BERSYS
+
+
+
+
+ Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate …
+
+
+
+
+
+
+
+
+
+
+
+ DATAGEN: Data Generation for the Social Network Benchmark
+ Tags:
+ DATAGEN
+ , SOCIAL NETWORK
+ , SNB
+
+
+
+
+ As explained in a previous post, the LDBC Social Network Benchmark (LDBC-SNB) has the objective to provide a realistic yet challenging workload, consisting of a social network and a set of queries. Both have to be realistic, easy to understand and easy to generate. This post has the objective to discuss the main features of DATAGEN, the social network data generator provided by LDBC-SNB, which is an evolution of S3G2 [1].
+One of the most …
+
+
+
+
+
+
+
+
+
+
+
+ Getting Started With SNB
+ Tags:
+ SNB
+ , INTERACTIVE
+ , DATAGEN
+
+
+
+
+ In a previous blog post titled “Is SNB like Facebook’s LinkBench?”, Peter Boncz discusses the design philosophy that shapes SNB and how it compares to other existing benchmarks such as LinkBench. In this post, I will briefly introduce the essential parts forming SNB, which are DATAGEN, the LDBC execution driver and the workloads.
+DATAGEN
+DATAGEN is the data generator used by all the workloads of SNB. Here we introduced the …
+
+
+
+
+
+
+
+
+
+
+
+ Introducing SNB Interactive, the LDBC Social Network Benchmark Online Workload
+ Tags:
+ SNB
+ , INTERACTIVE
+
+
+
+
+ The LDBC Social Network Benchmark (SNB) is composed of three distinct workloads, interactive, business intelligence and graph analytics. This post introduces the interactive workload.
+The benchmark measures the speed of queries of medium complexity against a social network being constantly updated. The queries are scoped to a user’s social environment and potentially access data associated with the friends or a user and their friends.
+This …
+
+
+
+
+
+
+
+
+
+
+
+ Is SNB Like Facebooks LinkBench
+ Tags:
+ DEVELOPER
+ , SNB
+ , INTERACTIVE
+ , BI
+ , GRAPHALYTICS
+
+
+
+
+
+
+
+
+ In this post, I will discuss in some detail the rationale and goals of the design of the Social Network Benchmark (SNB) and explain how it relates to real …
+
+
+
+
+
+
+
+
+
+
+
+ Making It Interactive
+ Tags:
+ SNB
+ , BENCHMARKING
+ , TPC
+ , SPARQL
+ , INTERACTIVE
+
+
+
+
+ Synopsis: Now is the time to finalize the interactive part of the Social Network Benchmark (SNB). The benchmark must be both credible in a real social network setting and pose new challenges. There are many hard queries but not enough representation for what online systems in fact do. So, the workload mix must strike a balance between the practice and presenting new challenges.
+It is about to be showtime for LDBC. The initial installment of the …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/pages/page/8/index.html b/pages/page/8/index.html
new file mode 100644
index 00000000..4213869e
--- /dev/null
+++ b/pages/page/8/index.html
@@ -0,0 +1,709 @@
+
+
+
+
+ Pages
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ SNB Data Generator - Getting Started
+ Tags:
+ DATAGEN
+ , SNB
+ , SOCIAL NETWORK
+
+
+
+
+ In previous posts (this and this) we briefly introduced the design goals and philosophy behind DATAGEN, the data generator used in LDBC-SNB. In this post, I will explain how to use DATAGEN to generate the necessary datatsets to run LDBC-SNB. Of course, as DATAGEN is continuously under development, the instructions given in this tutorial might change in the future.
+Getting and Configuring Hadoop
+DATAGEN runs on top of hadoop 1.2.1 to be scale. …
+
+
+
+
+
+
+
+
+
+
+
+ The Day of Graph Analytics
+ Tags:
+ ANALYTICS
+ , SNB
+
+
+
+
+ Note: consider this post as a continuation of the “Making it interactive” post by Orri Erling.
+I have now completed the Virtuoso TPC-H work, including scale out. Optimization possibilities extend to infinity but the present level is good enough. TPC-H is the classic of all analytics benchmarks and is difficult enough, I have extensive commentary on this on my blog (In Hoc Signo Vinces series), including experimental results. This is, …
+
+
+
+
+
+
+
+
+
+
+
+ Using LDBC SPB to Find OWLIM Performance Issues
+ Tags:
+ LDBC
+ , SPB
+ , RDF
+
+
+
+
+ During the past six months we (the OWLIM Team at Ontotext) have integrated the LDBC Semantic Publishing Benchmark (LDBC-SPB) as a part of our development and release process.
+First thing we’ve started using the LDBC-SPB for is to monitor the performance of our RDF Store when a new release is about to come out.
+Initially we’ve decided to fix some of the benchmark parameters :
+
+- the dataset size - 50 million triples (LDBC-SPB50) * benchmark warmup …
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/plugins/animate/animate.css b/plugins/animate/animate.css
new file mode 100644
index 00000000..943f8454
--- /dev/null
+++ b/plugins/animate/animate.css
@@ -0,0 +1,3623 @@
+@charset "UTF-8";
+
+/*!
+ * animate.css -http://daneden.me/animate
+ * Version - 3.7.0
+ * Licensed under the MIT license - http://opensource.org/licenses/MIT
+ *
+ * Copyright (c) 2018 Daniel Eden
+ */
+
+@-webkit-keyframes bounce {
+ from,
+ 20%,
+ 53%,
+ 80%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 40%,
+ 43% {
+ -webkit-animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ -webkit-transform: translate3d(0, -30px, 0);
+ transform: translate3d(0, -30px, 0);
+ }
+
+ 70% {
+ -webkit-animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ -webkit-transform: translate3d(0, -15px, 0);
+ transform: translate3d(0, -15px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, -4px, 0);
+ transform: translate3d(0, -4px, 0);
+ }
+}
+
+@keyframes bounce {
+ from,
+ 20%,
+ 53%,
+ 80%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 40%,
+ 43% {
+ -webkit-animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ -webkit-transform: translate3d(0, -30px, 0);
+ transform: translate3d(0, -30px, 0);
+ }
+
+ 70% {
+ -webkit-animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ animation-timing-function: cubic-bezier(0.755, 0.05, 0.855, 0.06);
+ -webkit-transform: translate3d(0, -15px, 0);
+ transform: translate3d(0, -15px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, -4px, 0);
+ transform: translate3d(0, -4px, 0);
+ }
+}
+
+.bounce {
+ -webkit-animation-name: bounce;
+ animation-name: bounce;
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+}
+
+@-webkit-keyframes flash {
+ from,
+ 50%,
+ to {
+ opacity: 1;
+ }
+
+ 25%,
+ 75% {
+ opacity: 0;
+ }
+}
+
+@keyframes flash {
+ from,
+ 50%,
+ to {
+ opacity: 1;
+ }
+
+ 25%,
+ 75% {
+ opacity: 0;
+ }
+}
+
+.flash {
+ -webkit-animation-name: flash;
+ animation-name: flash;
+}
+
+/* originally authored by Nick Pettit - https://github.com/nickpettit/glide */
+
+@-webkit-keyframes pulse {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 50% {
+ -webkit-transform: scale3d(1.05, 1.05, 1.05);
+ transform: scale3d(1.05, 1.05, 1.05);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+@keyframes pulse {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 50% {
+ -webkit-transform: scale3d(1.05, 1.05, 1.05);
+ transform: scale3d(1.05, 1.05, 1.05);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+.pulse {
+ -webkit-animation-name: pulse;
+ animation-name: pulse;
+}
+
+@-webkit-keyframes rubberBand {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 30% {
+ -webkit-transform: scale3d(1.25, 0.75, 1);
+ transform: scale3d(1.25, 0.75, 1);
+ }
+
+ 40% {
+ -webkit-transform: scale3d(0.75, 1.25, 1);
+ transform: scale3d(0.75, 1.25, 1);
+ }
+
+ 50% {
+ -webkit-transform: scale3d(1.15, 0.85, 1);
+ transform: scale3d(1.15, 0.85, 1);
+ }
+
+ 65% {
+ -webkit-transform: scale3d(0.95, 1.05, 1);
+ transform: scale3d(0.95, 1.05, 1);
+ }
+
+ 75% {
+ -webkit-transform: scale3d(1.05, 0.95, 1);
+ transform: scale3d(1.05, 0.95, 1);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+@keyframes rubberBand {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 30% {
+ -webkit-transform: scale3d(1.25, 0.75, 1);
+ transform: scale3d(1.25, 0.75, 1);
+ }
+
+ 40% {
+ -webkit-transform: scale3d(0.75, 1.25, 1);
+ transform: scale3d(0.75, 1.25, 1);
+ }
+
+ 50% {
+ -webkit-transform: scale3d(1.15, 0.85, 1);
+ transform: scale3d(1.15, 0.85, 1);
+ }
+
+ 65% {
+ -webkit-transform: scale3d(0.95, 1.05, 1);
+ transform: scale3d(0.95, 1.05, 1);
+ }
+
+ 75% {
+ -webkit-transform: scale3d(1.05, 0.95, 1);
+ transform: scale3d(1.05, 0.95, 1);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+.rubberBand {
+ -webkit-animation-name: rubberBand;
+ animation-name: rubberBand;
+}
+
+@-webkit-keyframes shake {
+ from,
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 10%,
+ 30%,
+ 50%,
+ 70%,
+ 90% {
+ -webkit-transform: translate3d(-10px, 0, 0);
+ transform: translate3d(-10px, 0, 0);
+ }
+
+ 20%,
+ 40%,
+ 60%,
+ 80% {
+ -webkit-transform: translate3d(10px, 0, 0);
+ transform: translate3d(10px, 0, 0);
+ }
+}
+
+@keyframes shake {
+ from,
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 10%,
+ 30%,
+ 50%,
+ 70%,
+ 90% {
+ -webkit-transform: translate3d(-10px, 0, 0);
+ transform: translate3d(-10px, 0, 0);
+ }
+
+ 20%,
+ 40%,
+ 60%,
+ 80% {
+ -webkit-transform: translate3d(10px, 0, 0);
+ transform: translate3d(10px, 0, 0);
+ }
+}
+
+.shake {
+ -webkit-animation-name: shake;
+ animation-name: shake;
+}
+
+@-webkit-keyframes headShake {
+ 0% {
+ -webkit-transform: translateX(0);
+ transform: translateX(0);
+ }
+
+ 6.5% {
+ -webkit-transform: translateX(-6px) rotateY(-9deg);
+ transform: translateX(-6px) rotateY(-9deg);
+ }
+
+ 18.5% {
+ -webkit-transform: translateX(5px) rotateY(7deg);
+ transform: translateX(5px) rotateY(7deg);
+ }
+
+ 31.5% {
+ -webkit-transform: translateX(-3px) rotateY(-5deg);
+ transform: translateX(-3px) rotateY(-5deg);
+ }
+
+ 43.5% {
+ -webkit-transform: translateX(2px) rotateY(3deg);
+ transform: translateX(2px) rotateY(3deg);
+ }
+
+ 50% {
+ -webkit-transform: translateX(0);
+ transform: translateX(0);
+ }
+}
+
+@keyframes headShake {
+ 0% {
+ -webkit-transform: translateX(0);
+ transform: translateX(0);
+ }
+
+ 6.5% {
+ -webkit-transform: translateX(-6px) rotateY(-9deg);
+ transform: translateX(-6px) rotateY(-9deg);
+ }
+
+ 18.5% {
+ -webkit-transform: translateX(5px) rotateY(7deg);
+ transform: translateX(5px) rotateY(7deg);
+ }
+
+ 31.5% {
+ -webkit-transform: translateX(-3px) rotateY(-5deg);
+ transform: translateX(-3px) rotateY(-5deg);
+ }
+
+ 43.5% {
+ -webkit-transform: translateX(2px) rotateY(3deg);
+ transform: translateX(2px) rotateY(3deg);
+ }
+
+ 50% {
+ -webkit-transform: translateX(0);
+ transform: translateX(0);
+ }
+}
+
+.headShake {
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ -webkit-animation-name: headShake;
+ animation-name: headShake;
+}
+
+@-webkit-keyframes swing {
+ 20% {
+ -webkit-transform: rotate3d(0, 0, 1, 15deg);
+ transform: rotate3d(0, 0, 1, 15deg);
+ }
+
+ 40% {
+ -webkit-transform: rotate3d(0, 0, 1, -10deg);
+ transform: rotate3d(0, 0, 1, -10deg);
+ }
+
+ 60% {
+ -webkit-transform: rotate3d(0, 0, 1, 5deg);
+ transform: rotate3d(0, 0, 1, 5deg);
+ }
+
+ 80% {
+ -webkit-transform: rotate3d(0, 0, 1, -5deg);
+ transform: rotate3d(0, 0, 1, -5deg);
+ }
+
+ to {
+ -webkit-transform: rotate3d(0, 0, 1, 0deg);
+ transform: rotate3d(0, 0, 1, 0deg);
+ }
+}
+
+@keyframes swing {
+ 20% {
+ -webkit-transform: rotate3d(0, 0, 1, 15deg);
+ transform: rotate3d(0, 0, 1, 15deg);
+ }
+
+ 40% {
+ -webkit-transform: rotate3d(0, 0, 1, -10deg);
+ transform: rotate3d(0, 0, 1, -10deg);
+ }
+
+ 60% {
+ -webkit-transform: rotate3d(0, 0, 1, 5deg);
+ transform: rotate3d(0, 0, 1, 5deg);
+ }
+
+ 80% {
+ -webkit-transform: rotate3d(0, 0, 1, -5deg);
+ transform: rotate3d(0, 0, 1, -5deg);
+ }
+
+ to {
+ -webkit-transform: rotate3d(0, 0, 1, 0deg);
+ transform: rotate3d(0, 0, 1, 0deg);
+ }
+}
+
+.swing {
+ -webkit-transform-origin: top center;
+ transform-origin: top center;
+ -webkit-animation-name: swing;
+ animation-name: swing;
+}
+
+@-webkit-keyframes tada {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 10%,
+ 20% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9) rotate3d(0, 0, 1, -3deg);
+ transform: scale3d(0.9, 0.9, 0.9) rotate3d(0, 0, 1, -3deg);
+ }
+
+ 30%,
+ 50%,
+ 70%,
+ 90% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, 3deg);
+ transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, 3deg);
+ }
+
+ 40%,
+ 60%,
+ 80% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, -3deg);
+ transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, -3deg);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+@keyframes tada {
+ from {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+
+ 10%,
+ 20% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9) rotate3d(0, 0, 1, -3deg);
+ transform: scale3d(0.9, 0.9, 0.9) rotate3d(0, 0, 1, -3deg);
+ }
+
+ 30%,
+ 50%,
+ 70%,
+ 90% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, 3deg);
+ transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, 3deg);
+ }
+
+ 40%,
+ 60%,
+ 80% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, -3deg);
+ transform: scale3d(1.1, 1.1, 1.1) rotate3d(0, 0, 1, -3deg);
+ }
+
+ to {
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+.tada {
+ -webkit-animation-name: tada;
+ animation-name: tada;
+}
+
+/* originally authored by Nick Pettit - https://github.com/nickpettit/glide */
+
+@-webkit-keyframes wobble {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 15% {
+ -webkit-transform: translate3d(-25%, 0, 0) rotate3d(0, 0, 1, -5deg);
+ transform: translate3d(-25%, 0, 0) rotate3d(0, 0, 1, -5deg);
+ }
+
+ 30% {
+ -webkit-transform: translate3d(20%, 0, 0) rotate3d(0, 0, 1, 3deg);
+ transform: translate3d(20%, 0, 0) rotate3d(0, 0, 1, 3deg);
+ }
+
+ 45% {
+ -webkit-transform: translate3d(-15%, 0, 0) rotate3d(0, 0, 1, -3deg);
+ transform: translate3d(-15%, 0, 0) rotate3d(0, 0, 1, -3deg);
+ }
+
+ 60% {
+ -webkit-transform: translate3d(10%, 0, 0) rotate3d(0, 0, 1, 2deg);
+ transform: translate3d(10%, 0, 0) rotate3d(0, 0, 1, 2deg);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(-5%, 0, 0) rotate3d(0, 0, 1, -1deg);
+ transform: translate3d(-5%, 0, 0) rotate3d(0, 0, 1, -1deg);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes wobble {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 15% {
+ -webkit-transform: translate3d(-25%, 0, 0) rotate3d(0, 0, 1, -5deg);
+ transform: translate3d(-25%, 0, 0) rotate3d(0, 0, 1, -5deg);
+ }
+
+ 30% {
+ -webkit-transform: translate3d(20%, 0, 0) rotate3d(0, 0, 1, 3deg);
+ transform: translate3d(20%, 0, 0) rotate3d(0, 0, 1, 3deg);
+ }
+
+ 45% {
+ -webkit-transform: translate3d(-15%, 0, 0) rotate3d(0, 0, 1, -3deg);
+ transform: translate3d(-15%, 0, 0) rotate3d(0, 0, 1, -3deg);
+ }
+
+ 60% {
+ -webkit-transform: translate3d(10%, 0, 0) rotate3d(0, 0, 1, 2deg);
+ transform: translate3d(10%, 0, 0) rotate3d(0, 0, 1, 2deg);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(-5%, 0, 0) rotate3d(0, 0, 1, -1deg);
+ transform: translate3d(-5%, 0, 0) rotate3d(0, 0, 1, -1deg);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.wobble {
+ -webkit-animation-name: wobble;
+ animation-name: wobble;
+}
+
+@-webkit-keyframes jello {
+ from,
+ 11.1%,
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 22.2% {
+ -webkit-transform: skewX(-12.5deg) skewY(-12.5deg);
+ transform: skewX(-12.5deg) skewY(-12.5deg);
+ }
+
+ 33.3% {
+ -webkit-transform: skewX(6.25deg) skewY(6.25deg);
+ transform: skewX(6.25deg) skewY(6.25deg);
+ }
+
+ 44.4% {
+ -webkit-transform: skewX(-3.125deg) skewY(-3.125deg);
+ transform: skewX(-3.125deg) skewY(-3.125deg);
+ }
+
+ 55.5% {
+ -webkit-transform: skewX(1.5625deg) skewY(1.5625deg);
+ transform: skewX(1.5625deg) skewY(1.5625deg);
+ }
+
+ 66.6% {
+ -webkit-transform: skewX(-0.78125deg) skewY(-0.78125deg);
+ transform: skewX(-0.78125deg) skewY(-0.78125deg);
+ }
+
+ 77.7% {
+ -webkit-transform: skewX(0.390625deg) skewY(0.390625deg);
+ transform: skewX(0.390625deg) skewY(0.390625deg);
+ }
+
+ 88.8% {
+ -webkit-transform: skewX(-0.1953125deg) skewY(-0.1953125deg);
+ transform: skewX(-0.1953125deg) skewY(-0.1953125deg);
+ }
+}
+
+@keyframes jello {
+ from,
+ 11.1%,
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ 22.2% {
+ -webkit-transform: skewX(-12.5deg) skewY(-12.5deg);
+ transform: skewX(-12.5deg) skewY(-12.5deg);
+ }
+
+ 33.3% {
+ -webkit-transform: skewX(6.25deg) skewY(6.25deg);
+ transform: skewX(6.25deg) skewY(6.25deg);
+ }
+
+ 44.4% {
+ -webkit-transform: skewX(-3.125deg) skewY(-3.125deg);
+ transform: skewX(-3.125deg) skewY(-3.125deg);
+ }
+
+ 55.5% {
+ -webkit-transform: skewX(1.5625deg) skewY(1.5625deg);
+ transform: skewX(1.5625deg) skewY(1.5625deg);
+ }
+
+ 66.6% {
+ -webkit-transform: skewX(-0.78125deg) skewY(-0.78125deg);
+ transform: skewX(-0.78125deg) skewY(-0.78125deg);
+ }
+
+ 77.7% {
+ -webkit-transform: skewX(0.390625deg) skewY(0.390625deg);
+ transform: skewX(0.390625deg) skewY(0.390625deg);
+ }
+
+ 88.8% {
+ -webkit-transform: skewX(-0.1953125deg) skewY(-0.1953125deg);
+ transform: skewX(-0.1953125deg) skewY(-0.1953125deg);
+ }
+}
+
+.jello {
+ -webkit-animation-name: jello;
+ animation-name: jello;
+ -webkit-transform-origin: center;
+ transform-origin: center;
+}
+
+@-webkit-keyframes heartBeat {
+ 0% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+
+ 14% {
+ -webkit-transform: scale(1.3);
+ transform: scale(1.3);
+ }
+
+ 28% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+
+ 42% {
+ -webkit-transform: scale(1.3);
+ transform: scale(1.3);
+ }
+
+ 70% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+}
+
+@keyframes heartBeat {
+ 0% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+
+ 14% {
+ -webkit-transform: scale(1.3);
+ transform: scale(1.3);
+ }
+
+ 28% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+
+ 42% {
+ -webkit-transform: scale(1.3);
+ transform: scale(1.3);
+ }
+
+ 70% {
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+}
+
+.heartBeat {
+ -webkit-animation-name: heartBeat;
+ animation-name: heartBeat;
+ -webkit-animation-duration: 1.3s;
+ animation-duration: 1.3s;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+}
+
+@-webkit-keyframes bounceIn {
+ from,
+ 20%,
+ 40%,
+ 60%,
+ 80%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ 20% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1);
+ transform: scale3d(1.1, 1.1, 1.1);
+ }
+
+ 40% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9);
+ transform: scale3d(0.9, 0.9, 0.9);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(1.03, 1.03, 1.03);
+ transform: scale3d(1.03, 1.03, 1.03);
+ }
+
+ 80% {
+ -webkit-transform: scale3d(0.97, 0.97, 0.97);
+ transform: scale3d(0.97, 0.97, 0.97);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+@keyframes bounceIn {
+ from,
+ 20%,
+ 40%,
+ 60%,
+ 80%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ 20% {
+ -webkit-transform: scale3d(1.1, 1.1, 1.1);
+ transform: scale3d(1.1, 1.1, 1.1);
+ }
+
+ 40% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9);
+ transform: scale3d(0.9, 0.9, 0.9);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(1.03, 1.03, 1.03);
+ transform: scale3d(1.03, 1.03, 1.03);
+ }
+
+ 80% {
+ -webkit-transform: scale3d(0.97, 0.97, 0.97);
+ transform: scale3d(0.97, 0.97, 0.97);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: scale3d(1, 1, 1);
+ transform: scale3d(1, 1, 1);
+ }
+}
+
+.bounceIn {
+ -webkit-animation-duration: 0.75s;
+ animation-duration: 0.75s;
+ -webkit-animation-name: bounceIn;
+ animation-name: bounceIn;
+}
+
+@-webkit-keyframes bounceInDown {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -3000px, 0);
+ transform: translate3d(0, -3000px, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 25px, 0);
+ transform: translate3d(0, 25px, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(0, -10px, 0);
+ transform: translate3d(0, -10px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, 5px, 0);
+ transform: translate3d(0, 5px, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes bounceInDown {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -3000px, 0);
+ transform: translate3d(0, -3000px, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 25px, 0);
+ transform: translate3d(0, 25px, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(0, -10px, 0);
+ transform: translate3d(0, -10px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, 5px, 0);
+ transform: translate3d(0, 5px, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.bounceInDown {
+ -webkit-animation-name: bounceInDown;
+ animation-name: bounceInDown;
+}
+
+@-webkit-keyframes bounceInLeft {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: translate3d(-3000px, 0, 0);
+ transform: translate3d(-3000px, 0, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(25px, 0, 0);
+ transform: translate3d(25px, 0, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(-10px, 0, 0);
+ transform: translate3d(-10px, 0, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(5px, 0, 0);
+ transform: translate3d(5px, 0, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes bounceInLeft {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ 0% {
+ opacity: 0;
+ -webkit-transform: translate3d(-3000px, 0, 0);
+ transform: translate3d(-3000px, 0, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(25px, 0, 0);
+ transform: translate3d(25px, 0, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(-10px, 0, 0);
+ transform: translate3d(-10px, 0, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(5px, 0, 0);
+ transform: translate3d(5px, 0, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.bounceInLeft {
+ -webkit-animation-name: bounceInLeft;
+ animation-name: bounceInLeft;
+}
+
+@-webkit-keyframes bounceInRight {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(3000px, 0, 0);
+ transform: translate3d(3000px, 0, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(-25px, 0, 0);
+ transform: translate3d(-25px, 0, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(10px, 0, 0);
+ transform: translate3d(10px, 0, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(-5px, 0, 0);
+ transform: translate3d(-5px, 0, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes bounceInRight {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(3000px, 0, 0);
+ transform: translate3d(3000px, 0, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(-25px, 0, 0);
+ transform: translate3d(-25px, 0, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(10px, 0, 0);
+ transform: translate3d(10px, 0, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(-5px, 0, 0);
+ transform: translate3d(-5px, 0, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.bounceInRight {
+ -webkit-animation-name: bounceInRight;
+ animation-name: bounceInRight;
+}
+
+@-webkit-keyframes bounceInUp {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 3000px, 0);
+ transform: translate3d(0, 3000px, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, -20px, 0);
+ transform: translate3d(0, -20px, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(0, 10px, 0);
+ transform: translate3d(0, 10px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, -5px, 0);
+ transform: translate3d(0, -5px, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes bounceInUp {
+ from,
+ 60%,
+ 75%,
+ 90%,
+ to {
+ -webkit-animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ animation-timing-function: cubic-bezier(0.215, 0.61, 0.355, 1);
+ }
+
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 3000px, 0);
+ transform: translate3d(0, 3000px, 0);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, -20px, 0);
+ transform: translate3d(0, -20px, 0);
+ }
+
+ 75% {
+ -webkit-transform: translate3d(0, 10px, 0);
+ transform: translate3d(0, 10px, 0);
+ }
+
+ 90% {
+ -webkit-transform: translate3d(0, -5px, 0);
+ transform: translate3d(0, -5px, 0);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.bounceInUp {
+ -webkit-animation-name: bounceInUp;
+ animation-name: bounceInUp;
+}
+
+@-webkit-keyframes bounceOut {
+ 20% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9);
+ transform: scale3d(0.9, 0.9, 0.9);
+ }
+
+ 50%,
+ 55% {
+ opacity: 1;
+ -webkit-transform: scale3d(1.1, 1.1, 1.1);
+ transform: scale3d(1.1, 1.1, 1.1);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+}
+
+@keyframes bounceOut {
+ 20% {
+ -webkit-transform: scale3d(0.9, 0.9, 0.9);
+ transform: scale3d(0.9, 0.9, 0.9);
+ }
+
+ 50%,
+ 55% {
+ opacity: 1;
+ -webkit-transform: scale3d(1.1, 1.1, 1.1);
+ transform: scale3d(1.1, 1.1, 1.1);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+}
+
+.bounceOut {
+ -webkit-animation-duration: 0.75s;
+ animation-duration: 0.75s;
+ -webkit-animation-name: bounceOut;
+ animation-name: bounceOut;
+}
+
+@-webkit-keyframes bounceOutDown {
+ 20% {
+ -webkit-transform: translate3d(0, 10px, 0);
+ transform: translate3d(0, 10px, 0);
+ }
+
+ 40%,
+ 45% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, -20px, 0);
+ transform: translate3d(0, -20px, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+}
+
+@keyframes bounceOutDown {
+ 20% {
+ -webkit-transform: translate3d(0, 10px, 0);
+ transform: translate3d(0, 10px, 0);
+ }
+
+ 40%,
+ 45% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, -20px, 0);
+ transform: translate3d(0, -20px, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+}
+
+.bounceOutDown {
+ -webkit-animation-name: bounceOutDown;
+ animation-name: bounceOutDown;
+}
+
+@-webkit-keyframes bounceOutLeft {
+ 20% {
+ opacity: 1;
+ -webkit-transform: translate3d(20px, 0, 0);
+ transform: translate3d(20px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+}
+
+@keyframes bounceOutLeft {
+ 20% {
+ opacity: 1;
+ -webkit-transform: translate3d(20px, 0, 0);
+ transform: translate3d(20px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+}
+
+.bounceOutLeft {
+ -webkit-animation-name: bounceOutLeft;
+ animation-name: bounceOutLeft;
+}
+
+@-webkit-keyframes bounceOutRight {
+ 20% {
+ opacity: 1;
+ -webkit-transform: translate3d(-20px, 0, 0);
+ transform: translate3d(-20px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+}
+
+@keyframes bounceOutRight {
+ 20% {
+ opacity: 1;
+ -webkit-transform: translate3d(-20px, 0, 0);
+ transform: translate3d(-20px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+}
+
+.bounceOutRight {
+ -webkit-animation-name: bounceOutRight;
+ animation-name: bounceOutRight;
+}
+
+@-webkit-keyframes bounceOutUp {
+ 20% {
+ -webkit-transform: translate3d(0, -10px, 0);
+ transform: translate3d(0, -10px, 0);
+ }
+
+ 40%,
+ 45% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 20px, 0);
+ transform: translate3d(0, 20px, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+}
+
+@keyframes bounceOutUp {
+ 20% {
+ -webkit-transform: translate3d(0, -10px, 0);
+ transform: translate3d(0, -10px, 0);
+ }
+
+ 40%,
+ 45% {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 20px, 0);
+ transform: translate3d(0, 20px, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+}
+
+.bounceOutUp {
+ -webkit-animation-name: bounceOutUp;
+ animation-name: bounceOutUp;
+}
+
+@-webkit-keyframes fadeIn {
+ from {
+ opacity: 0;
+ }
+
+ to {
+ opacity: 1;
+ }
+}
+
+@keyframes fadeIn {
+ from {
+ opacity: 0;
+ }
+
+ to {
+ opacity: 1;
+ }
+}
+
+.fadeIn {
+ -webkit-animation-name: fadeIn;
+ animation-name: fadeIn;
+}
+
+@-webkit-keyframes fadeInDown {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInDown {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInDown {
+ -webkit-animation-name: fadeInDown;
+ animation-name: fadeInDown;
+}
+
+@-webkit-keyframes fadeInDownBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInDownBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInDownBig {
+ -webkit-animation-name: fadeInDownBig;
+ animation-name: fadeInDownBig;
+}
+
+@-webkit-keyframes fadeInLeft {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInLeft {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInLeft {
+ -webkit-animation-name: fadeInLeft;
+ animation-name: fadeInLeft;
+}
+
+@-webkit-keyframes fadeInLeftBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInLeftBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInLeftBig {
+ -webkit-animation-name: fadeInLeftBig;
+ animation-name: fadeInLeftBig;
+}
+
+@-webkit-keyframes fadeInRight {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInRight {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInRight {
+ -webkit-animation-name: fadeInRight;
+ animation-name: fadeInRight;
+}
+
+@-webkit-keyframes fadeInRightBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInRightBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInRightBig {
+ -webkit-animation-name: fadeInRightBig;
+ animation-name: fadeInRightBig;
+}
+
+@-webkit-keyframes fadeInUp {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInUp {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInUp {
+ -webkit-animation-name: fadeInUp;
+ animation-name: fadeInUp;
+}
+
+@-webkit-keyframes fadeInUpBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes fadeInUpBig {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.fadeInUpBig {
+ -webkit-animation-name: fadeInUpBig;
+ animation-name: fadeInUpBig;
+}
+
+@-webkit-keyframes fadeOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ }
+}
+
+@keyframes fadeOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ }
+}
+
+.fadeOut {
+ -webkit-animation-name: fadeOut;
+ animation-name: fadeOut;
+}
+
+@-webkit-keyframes fadeOutDown {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+}
+
+@keyframes fadeOutDown {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+}
+
+.fadeOutDown {
+ -webkit-animation-name: fadeOutDown;
+ animation-name: fadeOutDown;
+}
+
+@-webkit-keyframes fadeOutDownBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+}
+
+@keyframes fadeOutDownBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, 2000px, 0);
+ transform: translate3d(0, 2000px, 0);
+ }
+}
+
+.fadeOutDownBig {
+ -webkit-animation-name: fadeOutDownBig;
+ animation-name: fadeOutDownBig;
+}
+
+@-webkit-keyframes fadeOutLeft {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+}
+
+@keyframes fadeOutLeft {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+}
+
+.fadeOutLeft {
+ -webkit-animation-name: fadeOutLeft;
+ animation-name: fadeOutLeft;
+}
+
+@-webkit-keyframes fadeOutLeftBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+}
+
+@keyframes fadeOutLeftBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(-2000px, 0, 0);
+ transform: translate3d(-2000px, 0, 0);
+ }
+}
+
+.fadeOutLeftBig {
+ -webkit-animation-name: fadeOutLeftBig;
+ animation-name: fadeOutLeftBig;
+}
+
+@-webkit-keyframes fadeOutRight {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+}
+
+@keyframes fadeOutRight {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+}
+
+.fadeOutRight {
+ -webkit-animation-name: fadeOutRight;
+ animation-name: fadeOutRight;
+}
+
+@-webkit-keyframes fadeOutRightBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+}
+
+@keyframes fadeOutRightBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(2000px, 0, 0);
+ transform: translate3d(2000px, 0, 0);
+ }
+}
+
+.fadeOutRightBig {
+ -webkit-animation-name: fadeOutRightBig;
+ animation-name: fadeOutRightBig;
+}
+
+@-webkit-keyframes fadeOutUp {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+}
+
+@keyframes fadeOutUp {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+}
+
+.fadeOutUp {
+ -webkit-animation-name: fadeOutUp;
+ animation-name: fadeOutUp;
+}
+
+@-webkit-keyframes fadeOutUpBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+}
+
+@keyframes fadeOutUpBig {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(0, -2000px, 0);
+ transform: translate3d(0, -2000px, 0);
+ }
+}
+
+.fadeOutUpBig {
+ -webkit-animation-name: fadeOutUpBig;
+ animation-name: fadeOutUpBig;
+}
+
+@-webkit-keyframes flip {
+ from {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, -360deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0) rotate3d(0, 1, 0, -360deg);
+ -webkit-animation-timing-function: ease-out;
+ animation-timing-function: ease-out;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -190deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -190deg);
+ -webkit-animation-timing-function: ease-out;
+ animation-timing-function: ease-out;
+ }
+
+ 50% {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -170deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -170deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) scale3d(0.95, 0.95, 0.95) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ transform: perspective(400px) scale3d(0.95, 0.95, 0.95) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0) rotate3d(0, 1, 0, 0deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+}
+
+@keyframes flip {
+ from {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, -360deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0) rotate3d(0, 1, 0, -360deg);
+ -webkit-animation-timing-function: ease-out;
+ animation-timing-function: ease-out;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -190deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -190deg);
+ -webkit-animation-timing-function: ease-out;
+ animation-timing-function: ease-out;
+ }
+
+ 50% {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -170deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 150px)
+ rotate3d(0, 1, 0, -170deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) scale3d(0.95, 0.95, 0.95) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ transform: perspective(400px) scale3d(0.95, 0.95, 0.95) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0)
+ rotate3d(0, 1, 0, 0deg);
+ transform: perspective(400px) scale3d(1, 1, 1) translate3d(0, 0, 0) rotate3d(0, 1, 0, 0deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+}
+
+.animated.flip {
+ -webkit-backface-visibility: visible;
+ backface-visibility: visible;
+ -webkit-animation-name: flip;
+ animation-name: flip;
+}
+
+@-webkit-keyframes flipInX {
+ from {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ opacity: 0;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 60% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 10deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 10deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -5deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -5deg);
+ }
+
+ to {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+}
+
+@keyframes flipInX {
+ from {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ opacity: 0;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 60% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 10deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 10deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -5deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -5deg);
+ }
+
+ to {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+}
+
+.flipInX {
+ -webkit-backface-visibility: visible !important;
+ backface-visibility: visible !important;
+ -webkit-animation-name: flipInX;
+ animation-name: flipInX;
+}
+
+@-webkit-keyframes flipInY {
+ from {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ opacity: 0;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -20deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -20deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 60% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 10deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 10deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -5deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -5deg);
+ }
+
+ to {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+}
+
+@keyframes flipInY {
+ from {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ opacity: 0;
+ }
+
+ 40% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -20deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -20deg);
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+ }
+
+ 60% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 10deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 10deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -5deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -5deg);
+ }
+
+ to {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+}
+
+.flipInY {
+ -webkit-backface-visibility: visible !important;
+ backface-visibility: visible !important;
+ -webkit-animation-name: flipInY;
+ animation-name: flipInY;
+}
+
+@-webkit-keyframes flipOutX {
+ from {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+
+ 30% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ opacity: 0;
+ }
+}
+
+@keyframes flipOutX {
+ from {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+
+ 30% {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, -20deg);
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ transform: perspective(400px) rotate3d(1, 0, 0, 90deg);
+ opacity: 0;
+ }
+}
+
+.flipOutX {
+ -webkit-animation-duration: 0.75s;
+ animation-duration: 0.75s;
+ -webkit-animation-name: flipOutX;
+ animation-name: flipOutX;
+ -webkit-backface-visibility: visible !important;
+ backface-visibility: visible !important;
+}
+
+@-webkit-keyframes flipOutY {
+ from {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+
+ 30% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -15deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -15deg);
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ opacity: 0;
+ }
+}
+
+@keyframes flipOutY {
+ from {
+ -webkit-transform: perspective(400px);
+ transform: perspective(400px);
+ }
+
+ 30% {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, -15deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, -15deg);
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ transform: perspective(400px) rotate3d(0, 1, 0, 90deg);
+ opacity: 0;
+ }
+}
+
+.flipOutY {
+ -webkit-animation-duration: 0.75s;
+ animation-duration: 0.75s;
+ -webkit-backface-visibility: visible !important;
+ backface-visibility: visible !important;
+ -webkit-animation-name: flipOutY;
+ animation-name: flipOutY;
+}
+
+@-webkit-keyframes lightSpeedIn {
+ from {
+ -webkit-transform: translate3d(100%, 0, 0) skewX(-30deg);
+ transform: translate3d(100%, 0, 0) skewX(-30deg);
+ opacity: 0;
+ }
+
+ 60% {
+ -webkit-transform: skewX(20deg);
+ transform: skewX(20deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: skewX(-5deg);
+ transform: skewX(-5deg);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes lightSpeedIn {
+ from {
+ -webkit-transform: translate3d(100%, 0, 0) skewX(-30deg);
+ transform: translate3d(100%, 0, 0) skewX(-30deg);
+ opacity: 0;
+ }
+
+ 60% {
+ -webkit-transform: skewX(20deg);
+ transform: skewX(20deg);
+ opacity: 1;
+ }
+
+ 80% {
+ -webkit-transform: skewX(-5deg);
+ transform: skewX(-5deg);
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.lightSpeedIn {
+ -webkit-animation-name: lightSpeedIn;
+ animation-name: lightSpeedIn;
+ -webkit-animation-timing-function: ease-out;
+ animation-timing-function: ease-out;
+}
+
+@-webkit-keyframes lightSpeedOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: translate3d(100%, 0, 0) skewX(30deg);
+ transform: translate3d(100%, 0, 0) skewX(30deg);
+ opacity: 0;
+ }
+}
+
+@keyframes lightSpeedOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: translate3d(100%, 0, 0) skewX(30deg);
+ transform: translate3d(100%, 0, 0) skewX(30deg);
+ opacity: 0;
+ }
+}
+
+.lightSpeedOut {
+ -webkit-animation-name: lightSpeedOut;
+ animation-name: lightSpeedOut;
+ -webkit-animation-timing-function: ease-in;
+ animation-timing-function: ease-in;
+}
+
+@-webkit-keyframes rotateIn {
+ from {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: rotate3d(0, 0, 1, -200deg);
+ transform: rotate3d(0, 0, 1, -200deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+@keyframes rotateIn {
+ from {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: rotate3d(0, 0, 1, -200deg);
+ transform: rotate3d(0, 0, 1, -200deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+.rotateIn {
+ -webkit-animation-name: rotateIn;
+ animation-name: rotateIn;
+}
+
+@-webkit-keyframes rotateInDownLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+@keyframes rotateInDownLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+.rotateInDownLeft {
+ -webkit-animation-name: rotateInDownLeft;
+ animation-name: rotateInDownLeft;
+}
+
+@-webkit-keyframes rotateInDownRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+@keyframes rotateInDownRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+.rotateInDownRight {
+ -webkit-animation-name: rotateInDownRight;
+ animation-name: rotateInDownRight;
+}
+
+@-webkit-keyframes rotateInUpLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+@keyframes rotateInUpLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+.rotateInUpLeft {
+ -webkit-animation-name: rotateInUpLeft;
+ animation-name: rotateInUpLeft;
+}
+
+@-webkit-keyframes rotateInUpRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -90deg);
+ transform: rotate3d(0, 0, 1, -90deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+@keyframes rotateInUpRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -90deg);
+ transform: rotate3d(0, 0, 1, -90deg);
+ opacity: 0;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ opacity: 1;
+ }
+}
+
+.rotateInUpRight {
+ -webkit-animation-name: rotateInUpRight;
+ animation-name: rotateInUpRight;
+}
+
+@-webkit-keyframes rotateOut {
+ from {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: rotate3d(0, 0, 1, 200deg);
+ transform: rotate3d(0, 0, 1, 200deg);
+ opacity: 0;
+ }
+}
+
+@keyframes rotateOut {
+ from {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: center;
+ transform-origin: center;
+ -webkit-transform: rotate3d(0, 0, 1, 200deg);
+ transform: rotate3d(0, 0, 1, 200deg);
+ opacity: 0;
+ }
+}
+
+.rotateOut {
+ -webkit-animation-name: rotateOut;
+ animation-name: rotateOut;
+}
+
+@-webkit-keyframes rotateOutDownLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+}
+
+@keyframes rotateOutDownLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 45deg);
+ transform: rotate3d(0, 0, 1, 45deg);
+ opacity: 0;
+ }
+}
+
+.rotateOutDownLeft {
+ -webkit-animation-name: rotateOutDownLeft;
+ animation-name: rotateOutDownLeft;
+}
+
+@-webkit-keyframes rotateOutDownRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+}
+
+@keyframes rotateOutDownRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+}
+
+.rotateOutDownRight {
+ -webkit-animation-name: rotateOutDownRight;
+ animation-name: rotateOutDownRight;
+}
+
+@-webkit-keyframes rotateOutUpLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+}
+
+@keyframes rotateOutUpLeft {
+ from {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: left bottom;
+ transform-origin: left bottom;
+ -webkit-transform: rotate3d(0, 0, 1, -45deg);
+ transform: rotate3d(0, 0, 1, -45deg);
+ opacity: 0;
+ }
+}
+
+.rotateOutUpLeft {
+ -webkit-animation-name: rotateOutUpLeft;
+ animation-name: rotateOutUpLeft;
+}
+
+@-webkit-keyframes rotateOutUpRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 90deg);
+ transform: rotate3d(0, 0, 1, 90deg);
+ opacity: 0;
+ }
+}
+
+@keyframes rotateOutUpRight {
+ from {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform-origin: right bottom;
+ transform-origin: right bottom;
+ -webkit-transform: rotate3d(0, 0, 1, 90deg);
+ transform: rotate3d(0, 0, 1, 90deg);
+ opacity: 0;
+ }
+}
+
+.rotateOutUpRight {
+ -webkit-animation-name: rotateOutUpRight;
+ animation-name: rotateOutUpRight;
+}
+
+@-webkit-keyframes hinge {
+ 0% {
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ }
+
+ 20%,
+ 60% {
+ -webkit-transform: rotate3d(0, 0, 1, 80deg);
+ transform: rotate3d(0, 0, 1, 80deg);
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ }
+
+ 40%,
+ 80% {
+ -webkit-transform: rotate3d(0, 0, 1, 60deg);
+ transform: rotate3d(0, 0, 1, 60deg);
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 700px, 0);
+ transform: translate3d(0, 700px, 0);
+ opacity: 0;
+ }
+}
+
+@keyframes hinge {
+ 0% {
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ }
+
+ 20%,
+ 60% {
+ -webkit-transform: rotate3d(0, 0, 1, 80deg);
+ transform: rotate3d(0, 0, 1, 80deg);
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ }
+
+ 40%,
+ 80% {
+ -webkit-transform: rotate3d(0, 0, 1, 60deg);
+ transform: rotate3d(0, 0, 1, 60deg);
+ -webkit-transform-origin: top left;
+ transform-origin: top left;
+ -webkit-animation-timing-function: ease-in-out;
+ animation-timing-function: ease-in-out;
+ opacity: 1;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 700px, 0);
+ transform: translate3d(0, 700px, 0);
+ opacity: 0;
+ }
+}
+
+.hinge {
+ -webkit-animation-duration: 2s;
+ animation-duration: 2s;
+ -webkit-animation-name: hinge;
+ animation-name: hinge;
+}
+
+@-webkit-keyframes jackInTheBox {
+ from {
+ opacity: 0;
+ -webkit-transform: scale(0.1) rotate(30deg);
+ transform: scale(0.1) rotate(30deg);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ }
+
+ 50% {
+ -webkit-transform: rotate(-10deg);
+ transform: rotate(-10deg);
+ }
+
+ 70% {
+ -webkit-transform: rotate(3deg);
+ transform: rotate(3deg);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+}
+
+@keyframes jackInTheBox {
+ from {
+ opacity: 0;
+ -webkit-transform: scale(0.1) rotate(30deg);
+ transform: scale(0.1) rotate(30deg);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ }
+
+ 50% {
+ -webkit-transform: rotate(-10deg);
+ transform: rotate(-10deg);
+ }
+
+ 70% {
+ -webkit-transform: rotate(3deg);
+ transform: rotate(3deg);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: scale(1);
+ transform: scale(1);
+ }
+}
+
+.jackInTheBox {
+ -webkit-animation-name: jackInTheBox;
+ animation-name: jackInTheBox;
+}
+
+/* originally authored by Nick Pettit - https://github.com/nickpettit/glide */
+
+@-webkit-keyframes rollIn {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0) rotate3d(0, 0, 1, -120deg);
+ transform: translate3d(-100%, 0, 0) rotate3d(0, 0, 1, -120deg);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes rollIn {
+ from {
+ opacity: 0;
+ -webkit-transform: translate3d(-100%, 0, 0) rotate3d(0, 0, 1, -120deg);
+ transform: translate3d(-100%, 0, 0) rotate3d(0, 0, 1, -120deg);
+ }
+
+ to {
+ opacity: 1;
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.rollIn {
+ -webkit-animation-name: rollIn;
+ animation-name: rollIn;
+}
+
+/* originally authored by Nick Pettit - https://github.com/nickpettit/glide */
+
+@-webkit-keyframes rollOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0) rotate3d(0, 0, 1, 120deg);
+ transform: translate3d(100%, 0, 0) rotate3d(0, 0, 1, 120deg);
+ }
+}
+
+@keyframes rollOut {
+ from {
+ opacity: 1;
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: translate3d(100%, 0, 0) rotate3d(0, 0, 1, 120deg);
+ transform: translate3d(100%, 0, 0) rotate3d(0, 0, 1, 120deg);
+ }
+}
+
+.rollOut {
+ -webkit-animation-name: rollOut;
+ animation-name: rollOut;
+}
+
+@-webkit-keyframes zoomIn {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ 50% {
+ opacity: 1;
+ }
+}
+
+@keyframes zoomIn {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ 50% {
+ opacity: 1;
+ }
+}
+
+.zoomIn {
+ -webkit-animation-name: zoomIn;
+ animation-name: zoomIn;
+}
+
+@-webkit-keyframes zoomInDown {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -1000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -1000px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomInDown {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -1000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -1000px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomInDown {
+ -webkit-animation-name: zoomInDown;
+ animation-name: zoomInDown;
+}
+
+@-webkit-keyframes zoomInLeft {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(-1000px, 0, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(-1000px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(10px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(10px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomInLeft {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(-1000px, 0, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(-1000px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(10px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(10px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomInLeft {
+ -webkit-animation-name: zoomInLeft;
+ animation-name: zoomInLeft;
+}
+
+@-webkit-keyframes zoomInRight {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(1000px, 0, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(1000px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(-10px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(-10px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomInRight {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(1000px, 0, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(1000px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(-10px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(-10px, 0, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomInRight {
+ -webkit-animation-name: zoomInRight;
+ animation-name: zoomInRight;
+}
+
+@-webkit-keyframes zoomInUp {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 1000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 1000px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomInUp {
+ from {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 1000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 1000px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ 60% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomInUp {
+ -webkit-animation-name: zoomInUp;
+ animation-name: zoomInUp;
+}
+
+@-webkit-keyframes zoomOut {
+ from {
+ opacity: 1;
+ }
+
+ 50% {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ to {
+ opacity: 0;
+ }
+}
+
+@keyframes zoomOut {
+ from {
+ opacity: 1;
+ }
+
+ 50% {
+ opacity: 0;
+ -webkit-transform: scale3d(0.3, 0.3, 0.3);
+ transform: scale3d(0.3, 0.3, 0.3);
+ }
+
+ to {
+ opacity: 0;
+ }
+}
+
+.zoomOut {
+ -webkit-animation-name: zoomOut;
+ animation-name: zoomOut;
+}
+
+@-webkit-keyframes zoomOutDown {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 2000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 2000px, 0);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomOutDown {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, -60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 2000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, 2000px, 0);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomOutDown {
+ -webkit-animation-name: zoomOutDown;
+ animation-name: zoomOutDown;
+}
+
+@-webkit-keyframes zoomOutLeft {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(42px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(42px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale(0.1) translate3d(-2000px, 0, 0);
+ transform: scale(0.1) translate3d(-2000px, 0, 0);
+ -webkit-transform-origin: left center;
+ transform-origin: left center;
+ }
+}
+
+@keyframes zoomOutLeft {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(42px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(42px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale(0.1) translate3d(-2000px, 0, 0);
+ transform: scale(0.1) translate3d(-2000px, 0, 0);
+ -webkit-transform-origin: left center;
+ transform-origin: left center;
+ }
+}
+
+.zoomOutLeft {
+ -webkit-animation-name: zoomOutLeft;
+ animation-name: zoomOutLeft;
+}
+
+@-webkit-keyframes zoomOutRight {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(-42px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(-42px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale(0.1) translate3d(2000px, 0, 0);
+ transform: scale(0.1) translate3d(2000px, 0, 0);
+ -webkit-transform-origin: right center;
+ transform-origin: right center;
+ }
+}
+
+@keyframes zoomOutRight {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(-42px, 0, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(-42px, 0, 0);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale(0.1) translate3d(2000px, 0, 0);
+ transform: scale(0.1) translate3d(2000px, 0, 0);
+ -webkit-transform-origin: right center;
+ transform-origin: right center;
+ }
+}
+
+.zoomOutRight {
+ -webkit-animation-name: zoomOutRight;
+ animation-name: zoomOutRight;
+}
+
+@-webkit-keyframes zoomOutUp {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -2000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -2000px, 0);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+@keyframes zoomOutUp {
+ 40% {
+ opacity: 1;
+ -webkit-transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ transform: scale3d(0.475, 0.475, 0.475) translate3d(0, 60px, 0);
+ -webkit-animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ animation-timing-function: cubic-bezier(0.55, 0.055, 0.675, 0.19);
+ }
+
+ to {
+ opacity: 0;
+ -webkit-transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -2000px, 0);
+ transform: scale3d(0.1, 0.1, 0.1) translate3d(0, -2000px, 0);
+ -webkit-transform-origin: center bottom;
+ transform-origin: center bottom;
+ -webkit-animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1);
+ }
+}
+
+.zoomOutUp {
+ -webkit-animation-name: zoomOutUp;
+ animation-name: zoomOutUp;
+}
+
+@-webkit-keyframes slideInDown {
+ from {
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes slideInDown {
+ from {
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.slideInDown {
+ -webkit-animation-name: slideInDown;
+ animation-name: slideInDown;
+}
+
+@-webkit-keyframes slideInLeft {
+ from {
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes slideInLeft {
+ from {
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.slideInLeft {
+ -webkit-animation-name: slideInLeft;
+ animation-name: slideInLeft;
+}
+
+@-webkit-keyframes slideInRight {
+ from {
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes slideInRight {
+ from {
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.slideInRight {
+ -webkit-animation-name: slideInRight;
+ animation-name: slideInRight;
+}
+
+@-webkit-keyframes slideInUp {
+ from {
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+@keyframes slideInUp {
+ from {
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ visibility: visible;
+ }
+
+ to {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+}
+
+.slideInUp {
+ -webkit-animation-name: slideInUp;
+ animation-name: slideInUp;
+}
+
+@-webkit-keyframes slideOutDown {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+}
+
+@keyframes slideOutDown {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(0, 100%, 0);
+ transform: translate3d(0, 100%, 0);
+ }
+}
+
+.slideOutDown {
+ -webkit-animation-name: slideOutDown;
+ animation-name: slideOutDown;
+}
+
+@-webkit-keyframes slideOutLeft {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+}
+
+@keyframes slideOutLeft {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(-100%, 0, 0);
+ transform: translate3d(-100%, 0, 0);
+ }
+}
+
+.slideOutLeft {
+ -webkit-animation-name: slideOutLeft;
+ animation-name: slideOutLeft;
+}
+
+@-webkit-keyframes slideOutRight {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+}
+
+@keyframes slideOutRight {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(100%, 0, 0);
+ transform: translate3d(100%, 0, 0);
+ }
+}
+
+.slideOutRight {
+ -webkit-animation-name: slideOutRight;
+ animation-name: slideOutRight;
+}
+
+@-webkit-keyframes slideOutUp {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+}
+
+@keyframes slideOutUp {
+ from {
+ -webkit-transform: translate3d(0, 0, 0);
+ transform: translate3d(0, 0, 0);
+ }
+
+ to {
+ visibility: hidden;
+ -webkit-transform: translate3d(0, -100%, 0);
+ transform: translate3d(0, -100%, 0);
+ }
+}
+
+.slideOutUp {
+ -webkit-animation-name: slideOutUp;
+ animation-name: slideOutUp;
+}
+
+.animated {
+ -webkit-animation-duration: 1s;
+ animation-duration: 1s;
+ -webkit-animation-fill-mode: both;
+ animation-fill-mode: both;
+}
+
+.animated.infinite {
+ -webkit-animation-iteration-count: infinite;
+ animation-iteration-count: infinite;
+}
+
+.animated.delay-1s {
+ -webkit-animation-delay: 1s;
+ animation-delay: 1s;
+}
+
+.animated.delay-2s {
+ -webkit-animation-delay: 2s;
+ animation-delay: 2s;
+}
+
+.animated.delay-3s {
+ -webkit-animation-delay: 3s;
+ animation-delay: 3s;
+}
+
+.animated.delay-4s {
+ -webkit-animation-delay: 4s;
+ animation-delay: 4s;
+}
+
+.animated.delay-5s {
+ -webkit-animation-delay: 5s;
+ animation-delay: 5s;
+}
+
+.animated.fast {
+ -webkit-animation-duration: 800ms;
+ animation-duration: 800ms;
+}
+
+.animated.faster {
+ -webkit-animation-duration: 500ms;
+ animation-duration: 500ms;
+}
+
+.animated.slow {
+ -webkit-animation-duration: 2s;
+ animation-duration: 2s;
+}
+
+.animated.slower {
+ -webkit-animation-duration: 3s;
+ animation-duration: 3s;
+}
+
+@media (prefers-reduced-motion) {
+ .animated {
+ -webkit-animation: unset !important;
+ animation: unset !important;
+ -webkit-transition: none !important;
+ transition: none !important;
+ }
+}
diff --git a/plugins/bootstrap/bootstrap.min.css b/plugins/bootstrap/bootstrap.min.css
new file mode 100644
index 00000000..7aebd0ff
--- /dev/null
+++ b/plugins/bootstrap/bootstrap.min.css
@@ -0,0 +1,7 @@
+/*!
+ * Bootstrap v4.1.1 (https://getbootstrap.com/)
+ * Copyright 2011-2018 The Bootstrap Authors
+ * Copyright 2011-2018 Twitter, Inc.
+ * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE)
+ */:root{--blue:#007bff;--indigo:#6610f2;--purple:#6f42c1;--pink:#e83e8c;--red:#dc3545;--orange:#fd7e14;--yellow:#ffc107;--green:#28a745;--teal:#20c997;--cyan:#17a2b8;--white:#fff;--gray:#6c757d;--gray-dark:#343a40;--primary:#007bff;--secondary:#6c757d;--success:#28a745;--info:#17a2b8;--warning:#ffc107;--danger:#dc3545;--light:#f8f9fa;--dark:#343a40;--breakpoint-xs:0;--breakpoint-sm:576px;--breakpoint-md:768px;--breakpoint-lg:992px;--breakpoint-xl:1200px;--font-family-sans-serif:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,sans-serif,"Apple Color Emoji","Segoe UI Emoji","Segoe UI Symbol";--font-family-monospace:SFMono-Regular,Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace}*,::after,::before{box-sizing:border-box}html{font-family:sans-serif;line-height:1.15;-webkit-text-size-adjust:100%;-ms-text-size-adjust:100%;-ms-overflow-style:scrollbar;-webkit-tap-highlight-color:transparent}@-ms-viewport{width:device-width}article,aside,figcaption,figure,footer,header,hgroup,main,nav,section{display:block}body{margin:0;font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,sans-serif,"Apple Color Emoji","Segoe UI Emoji","Segoe UI Symbol";font-size:1rem;font-weight:400;line-height:1.5;color:#212529;text-align:left;background-color:#fff}[tabindex="-1"]:focus{outline:0!important}hr{box-sizing:content-box;height:0;overflow:visible}h1,h2,h3,h4,h5,h6{margin-top:0;margin-bottom:.5rem}p{margin-top:0;margin-bottom:1rem}abbr[data-original-title],abbr[title]{text-decoration:underline;-webkit-text-decoration:underline dotted;text-decoration:underline dotted;cursor:help;border-bottom:0}address{margin-bottom:1rem;font-style:normal;line-height:inherit}dl,ol,ul{margin-top:0;margin-bottom:1rem}ol ol,ol ul,ul ol,ul ul{margin-bottom:0}dt{font-weight:700}dd{margin-bottom:.5rem;margin-left:0}blockquote{margin:0 0 1rem}dfn{font-style:italic}b,strong{font-weight:bolder}small{font-size:80%}sub,sup{position:relative;font-size:75%;line-height:0;vertical-align:baseline}sub{bottom:-.25em}sup{top:-.5em}a{color:#007bff;text-decoration:none;background-color:transparent;-webkit-text-decoration-skip:objects}a:hover{color:#0056b3;text-decoration:underline}a:not([href]):not([tabindex]){color:inherit;text-decoration:none}a:not([href]):not([tabindex]):focus,a:not([href]):not([tabindex]):hover{color:inherit;text-decoration:none}a:not([href]):not([tabindex]):focus{outline:0}code,kbd,pre,samp{font-family:SFMono-Regular,Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;font-size:1em}pre{margin-top:0;margin-bottom:1rem;overflow:auto;-ms-overflow-style:scrollbar}figure{margin:0 0 1rem}img{vertical-align:middle;border-style:none}svg:not(:root){overflow:hidden}table{border-collapse:collapse}caption{padding-top:.75rem;padding-bottom:.75rem;color:#6c757d;text-align:left;caption-side:bottom}th{text-align:inherit}label{display:inline-block;margin-bottom:.5rem}button{border-radius:0}button:focus{outline:1px dotted;outline:5px auto -webkit-focus-ring-color}button,input,optgroup,select,textarea{margin:0;font-family:inherit;font-size:inherit;line-height:inherit}button,input{overflow:visible}button,select{text-transform:none}[type=reset],[type=submit],button,html [type=button]{-webkit-appearance:button}[type=button]::-moz-focus-inner,[type=reset]::-moz-focus-inner,[type=submit]::-moz-focus-inner,button::-moz-focus-inner{padding:0;border-style:none}input[type=checkbox],input[type=radio]{box-sizing:border-box;padding:0}input[type=date],input[type=datetime-local],input[type=month],input[type=time]{-webkit-appearance:listbox}textarea{overflow:auto;resize:vertical}fieldset{min-width:0;padding:0;margin:0;border:0}legend{display:block;width:100%;max-width:100%;padding:0;margin-bottom:.5rem;font-size:1.5rem;line-height:inherit;color:inherit;white-space:normal}progress{vertical-align:baseline}[type=number]::-webkit-inner-spin-button,[type=number]::-webkit-outer-spin-button{height:auto}[type=search]{outline-offset:-2px;-webkit-appearance:none}[type=search]::-webkit-search-cancel-button,[type=search]::-webkit-search-decoration{-webkit-appearance:none}::-webkit-file-upload-button{font:inherit;-webkit-appearance:button}output{display:inline-block}summary{display:list-item;cursor:pointer}template{display:none}[hidden]{display:none!important}.h1,.h2,.h3,.h4,.h5,.h6,h1,h2,h3,h4,h5,h6{margin-bottom:.5rem;font-family:inherit;font-weight:500;line-height:1.2;color:inherit}.h1,h1{font-size:2.5rem}.h2,h2{font-size:2rem}.h3,h3{font-size:1.75rem}.h4,h4{font-size:1.5rem}.h5,h5{font-size:1.25rem}.h6,h6{font-size:1rem}.lead{font-size:1.25rem;font-weight:300}.display-1{font-size:6rem;font-weight:300;line-height:1.2}.display-2{font-size:5.5rem;font-weight:300;line-height:1.2}.display-3{font-size:4.5rem;font-weight:300;line-height:1.2}.display-4{font-size:3.5rem;font-weight:300;line-height:1.2}hr{margin-top:1rem;margin-bottom:1rem;border:0;border-top:1px solid rgba(0,0,0,.1)}.small,small{font-size:80%;font-weight:400}.mark,mark{padding:.2em;background-color:#fcf8e3}.list-unstyled{padding-left:0;list-style:none}.list-inline{padding-left:0;list-style:none}.list-inline-item{display:inline-block}.list-inline-item:not(:last-child){margin-right:.5rem}.initialism{font-size:90%;text-transform:uppercase}.blockquote{margin-bottom:1rem;font-size:1.25rem}.blockquote-footer{display:block;font-size:80%;color:#6c757d}.blockquote-footer::before{content:"\2014 \00A0"}.img-fluid{max-width:100%;height:auto}.img-thumbnail{padding:.25rem;background-color:#fff;border:1px solid #dee2e6;border-radius:.25rem;max-width:100%;height:auto}.figure{display:inline-block}.figure-img{margin-bottom:.5rem;line-height:1}.figure-caption{font-size:90%;color:#6c757d}code{font-size:87.5%;color:#e83e8c;word-break:break-word}a>code{color:inherit}kbd{padding:.2rem .4rem;font-size:87.5%;color:#fff;background-color:#212529;border-radius:.2rem}kbd kbd{padding:0;font-size:100%;font-weight:700}pre{display:block;font-size:87.5%;color:#212529}pre code{font-size:inherit;color:inherit;word-break:normal}.pre-scrollable{max-height:340px;overflow-y:scroll}.container{width:100%;padding-right:15px;padding-left:15px;margin-right:auto;margin-left:auto}@media (min-width:576px){.container{max-width:540px}}@media (min-width:768px){.container{max-width:720px}}@media (min-width:992px){.container{max-width:960px}}@media (min-width:1200px){.container{max-width:1140px}}.container-fluid{width:100%;padding-right:15px;padding-left:15px;margin-right:auto;margin-left:auto}.row{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;margin-right:-15px;margin-left:-15px}.no-gutters{margin-right:0;margin-left:0}.no-gutters>.col,.no-gutters>[class*=col-]{padding-right:0;padding-left:0}.col,.col-1,.col-10,.col-11,.col-12,.col-2,.col-3,.col-4,.col-5,.col-6,.col-7,.col-8,.col-9,.col-auto,.col-lg,.col-lg-1,.col-lg-10,.col-lg-11,.col-lg-12,.col-lg-2,.col-lg-3,.col-lg-4,.col-lg-5,.col-lg-6,.col-lg-7,.col-lg-8,.col-lg-9,.col-lg-auto,.col-md,.col-md-1,.col-md-10,.col-md-11,.col-md-12,.col-md-2,.col-md-3,.col-md-4,.col-md-5,.col-md-6,.col-md-7,.col-md-8,.col-md-9,.col-md-auto,.col-sm,.col-sm-1,.col-sm-10,.col-sm-11,.col-sm-12,.col-sm-2,.col-sm-3,.col-sm-4,.col-sm-5,.col-sm-6,.col-sm-7,.col-sm-8,.col-sm-9,.col-sm-auto,.col-xl,.col-xl-1,.col-xl-10,.col-xl-11,.col-xl-12,.col-xl-2,.col-xl-3,.col-xl-4,.col-xl-5,.col-xl-6,.col-xl-7,.col-xl-8,.col-xl-9,.col-xl-auto{position:relative;width:100%;min-height:1px;padding-right:15px;padding-left:15px}.col{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;max-width:100%}.col-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto;max-width:none}.col-1{-ms-flex:0 0 8.333333%;flex:0 0 8.333333%;max-width:8.333333%}.col-2{-ms-flex:0 0 16.666667%;flex:0 0 16.666667%;max-width:16.666667%}.col-3{-ms-flex:0 0 25%;flex:0 0 25%;max-width:25%}.col-4{-ms-flex:0 0 33.333333%;flex:0 0 33.333333%;max-width:33.333333%}.col-5{-ms-flex:0 0 41.666667%;flex:0 0 41.666667%;max-width:41.666667%}.col-6{-ms-flex:0 0 50%;flex:0 0 50%;max-width:50%}.col-7{-ms-flex:0 0 58.333333%;flex:0 0 58.333333%;max-width:58.333333%}.col-8{-ms-flex:0 0 66.666667%;flex:0 0 66.666667%;max-width:66.666667%}.col-9{-ms-flex:0 0 75%;flex:0 0 75%;max-width:75%}.col-10{-ms-flex:0 0 83.333333%;flex:0 0 83.333333%;max-width:83.333333%}.col-11{-ms-flex:0 0 91.666667%;flex:0 0 91.666667%;max-width:91.666667%}.col-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}.order-first{-ms-flex-order:-1;order:-1}.order-last{-ms-flex-order:13;order:13}.order-0{-ms-flex-order:0;order:0}.order-1{-ms-flex-order:1;order:1}.order-2{-ms-flex-order:2;order:2}.order-3{-ms-flex-order:3;order:3}.order-4{-ms-flex-order:4;order:4}.order-5{-ms-flex-order:5;order:5}.order-6{-ms-flex-order:6;order:6}.order-7{-ms-flex-order:7;order:7}.order-8{-ms-flex-order:8;order:8}.order-9{-ms-flex-order:9;order:9}.order-10{-ms-flex-order:10;order:10}.order-11{-ms-flex-order:11;order:11}.order-12{-ms-flex-order:12;order:12}.offset-1{margin-left:8.333333%}.offset-2{margin-left:16.666667%}.offset-3{margin-left:25%}.offset-4{margin-left:33.333333%}.offset-5{margin-left:41.666667%}.offset-6{margin-left:50%}.offset-7{margin-left:58.333333%}.offset-8{margin-left:66.666667%}.offset-9{margin-left:75%}.offset-10{margin-left:83.333333%}.offset-11{margin-left:91.666667%}@media (min-width:576px){.col-sm{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;max-width:100%}.col-sm-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto;max-width:none}.col-sm-1{-ms-flex:0 0 8.333333%;flex:0 0 8.333333%;max-width:8.333333%}.col-sm-2{-ms-flex:0 0 16.666667%;flex:0 0 16.666667%;max-width:16.666667%}.col-sm-3{-ms-flex:0 0 25%;flex:0 0 25%;max-width:25%}.col-sm-4{-ms-flex:0 0 33.333333%;flex:0 0 33.333333%;max-width:33.333333%}.col-sm-5{-ms-flex:0 0 41.666667%;flex:0 0 41.666667%;max-width:41.666667%}.col-sm-6{-ms-flex:0 0 50%;flex:0 0 50%;max-width:50%}.col-sm-7{-ms-flex:0 0 58.333333%;flex:0 0 58.333333%;max-width:58.333333%}.col-sm-8{-ms-flex:0 0 66.666667%;flex:0 0 66.666667%;max-width:66.666667%}.col-sm-9{-ms-flex:0 0 75%;flex:0 0 75%;max-width:75%}.col-sm-10{-ms-flex:0 0 83.333333%;flex:0 0 83.333333%;max-width:83.333333%}.col-sm-11{-ms-flex:0 0 91.666667%;flex:0 0 91.666667%;max-width:91.666667%}.col-sm-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}.order-sm-first{-ms-flex-order:-1;order:-1}.order-sm-last{-ms-flex-order:13;order:13}.order-sm-0{-ms-flex-order:0;order:0}.order-sm-1{-ms-flex-order:1;order:1}.order-sm-2{-ms-flex-order:2;order:2}.order-sm-3{-ms-flex-order:3;order:3}.order-sm-4{-ms-flex-order:4;order:4}.order-sm-5{-ms-flex-order:5;order:5}.order-sm-6{-ms-flex-order:6;order:6}.order-sm-7{-ms-flex-order:7;order:7}.order-sm-8{-ms-flex-order:8;order:8}.order-sm-9{-ms-flex-order:9;order:9}.order-sm-10{-ms-flex-order:10;order:10}.order-sm-11{-ms-flex-order:11;order:11}.order-sm-12{-ms-flex-order:12;order:12}.offset-sm-0{margin-left:0}.offset-sm-1{margin-left:8.333333%}.offset-sm-2{margin-left:16.666667%}.offset-sm-3{margin-left:25%}.offset-sm-4{margin-left:33.333333%}.offset-sm-5{margin-left:41.666667%}.offset-sm-6{margin-left:50%}.offset-sm-7{margin-left:58.333333%}.offset-sm-8{margin-left:66.666667%}.offset-sm-9{margin-left:75%}.offset-sm-10{margin-left:83.333333%}.offset-sm-11{margin-left:91.666667%}}@media (min-width:768px){.col-md{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;max-width:100%}.col-md-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto;max-width:none}.col-md-1{-ms-flex:0 0 8.333333%;flex:0 0 8.333333%;max-width:8.333333%}.col-md-2{-ms-flex:0 0 16.666667%;flex:0 0 16.666667%;max-width:16.666667%}.col-md-3{-ms-flex:0 0 25%;flex:0 0 25%;max-width:25%}.col-md-4{-ms-flex:0 0 33.333333%;flex:0 0 33.333333%;max-width:33.333333%}.col-md-5{-ms-flex:0 0 41.666667%;flex:0 0 41.666667%;max-width:41.666667%}.col-md-6{-ms-flex:0 0 50%;flex:0 0 50%;max-width:50%}.col-md-7{-ms-flex:0 0 58.333333%;flex:0 0 58.333333%;max-width:58.333333%}.col-md-8{-ms-flex:0 0 66.666667%;flex:0 0 66.666667%;max-width:66.666667%}.col-md-9{-ms-flex:0 0 75%;flex:0 0 75%;max-width:75%}.col-md-10{-ms-flex:0 0 83.333333%;flex:0 0 83.333333%;max-width:83.333333%}.col-md-11{-ms-flex:0 0 91.666667%;flex:0 0 91.666667%;max-width:91.666667%}.col-md-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}.order-md-first{-ms-flex-order:-1;order:-1}.order-md-last{-ms-flex-order:13;order:13}.order-md-0{-ms-flex-order:0;order:0}.order-md-1{-ms-flex-order:1;order:1}.order-md-2{-ms-flex-order:2;order:2}.order-md-3{-ms-flex-order:3;order:3}.order-md-4{-ms-flex-order:4;order:4}.order-md-5{-ms-flex-order:5;order:5}.order-md-6{-ms-flex-order:6;order:6}.order-md-7{-ms-flex-order:7;order:7}.order-md-8{-ms-flex-order:8;order:8}.order-md-9{-ms-flex-order:9;order:9}.order-md-10{-ms-flex-order:10;order:10}.order-md-11{-ms-flex-order:11;order:11}.order-md-12{-ms-flex-order:12;order:12}.offset-md-0{margin-left:0}.offset-md-1{margin-left:8.333333%}.offset-md-2{margin-left:16.666667%}.offset-md-3{margin-left:25%}.offset-md-4{margin-left:33.333333%}.offset-md-5{margin-left:41.666667%}.offset-md-6{margin-left:50%}.offset-md-7{margin-left:58.333333%}.offset-md-8{margin-left:66.666667%}.offset-md-9{margin-left:75%}.offset-md-10{margin-left:83.333333%}.offset-md-11{margin-left:91.666667%}}@media (min-width:992px){.col-lg{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;max-width:100%}.col-lg-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto;max-width:none}.col-lg-1{-ms-flex:0 0 8.333333%;flex:0 0 8.333333%;max-width:8.333333%}.col-lg-2{-ms-flex:0 0 16.666667%;flex:0 0 16.666667%;max-width:16.666667%}.col-lg-3{-ms-flex:0 0 25%;flex:0 0 25%;max-width:25%}.col-lg-4{-ms-flex:0 0 33.333333%;flex:0 0 33.333333%;max-width:33.333333%}.col-lg-5{-ms-flex:0 0 41.666667%;flex:0 0 41.666667%;max-width:41.666667%}.col-lg-6{-ms-flex:0 0 50%;flex:0 0 50%;max-width:50%}.col-lg-7{-ms-flex:0 0 58.333333%;flex:0 0 58.333333%;max-width:58.333333%}.col-lg-8{-ms-flex:0 0 66.666667%;flex:0 0 66.666667%;max-width:66.666667%}.col-lg-9{-ms-flex:0 0 75%;flex:0 0 75%;max-width:75%}.col-lg-10{-ms-flex:0 0 83.333333%;flex:0 0 83.333333%;max-width:83.333333%}.col-lg-11{-ms-flex:0 0 91.666667%;flex:0 0 91.666667%;max-width:91.666667%}.col-lg-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}.order-lg-first{-ms-flex-order:-1;order:-1}.order-lg-last{-ms-flex-order:13;order:13}.order-lg-0{-ms-flex-order:0;order:0}.order-lg-1{-ms-flex-order:1;order:1}.order-lg-2{-ms-flex-order:2;order:2}.order-lg-3{-ms-flex-order:3;order:3}.order-lg-4{-ms-flex-order:4;order:4}.order-lg-5{-ms-flex-order:5;order:5}.order-lg-6{-ms-flex-order:6;order:6}.order-lg-7{-ms-flex-order:7;order:7}.order-lg-8{-ms-flex-order:8;order:8}.order-lg-9{-ms-flex-order:9;order:9}.order-lg-10{-ms-flex-order:10;order:10}.order-lg-11{-ms-flex-order:11;order:11}.order-lg-12{-ms-flex-order:12;order:12}.offset-lg-0{margin-left:0}.offset-lg-1{margin-left:8.333333%}.offset-lg-2{margin-left:16.666667%}.offset-lg-3{margin-left:25%}.offset-lg-4{margin-left:33.333333%}.offset-lg-5{margin-left:41.666667%}.offset-lg-6{margin-left:50%}.offset-lg-7{margin-left:58.333333%}.offset-lg-8{margin-left:66.666667%}.offset-lg-9{margin-left:75%}.offset-lg-10{margin-left:83.333333%}.offset-lg-11{margin-left:91.666667%}}@media (min-width:1200px){.col-xl{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;max-width:100%}.col-xl-auto{-ms-flex:0 0 auto;flex:0 0 auto;width:auto;max-width:none}.col-xl-1{-ms-flex:0 0 8.333333%;flex:0 0 8.333333%;max-width:8.333333%}.col-xl-2{-ms-flex:0 0 16.666667%;flex:0 0 16.666667%;max-width:16.666667%}.col-xl-3{-ms-flex:0 0 25%;flex:0 0 25%;max-width:25%}.col-xl-4{-ms-flex:0 0 33.333333%;flex:0 0 33.333333%;max-width:33.333333%}.col-xl-5{-ms-flex:0 0 41.666667%;flex:0 0 41.666667%;max-width:41.666667%}.col-xl-6{-ms-flex:0 0 50%;flex:0 0 50%;max-width:50%}.col-xl-7{-ms-flex:0 0 58.333333%;flex:0 0 58.333333%;max-width:58.333333%}.col-xl-8{-ms-flex:0 0 66.666667%;flex:0 0 66.666667%;max-width:66.666667%}.col-xl-9{-ms-flex:0 0 75%;flex:0 0 75%;max-width:75%}.col-xl-10{-ms-flex:0 0 83.333333%;flex:0 0 83.333333%;max-width:83.333333%}.col-xl-11{-ms-flex:0 0 91.666667%;flex:0 0 91.666667%;max-width:91.666667%}.col-xl-12{-ms-flex:0 0 100%;flex:0 0 100%;max-width:100%}.order-xl-first{-ms-flex-order:-1;order:-1}.order-xl-last{-ms-flex-order:13;order:13}.order-xl-0{-ms-flex-order:0;order:0}.order-xl-1{-ms-flex-order:1;order:1}.order-xl-2{-ms-flex-order:2;order:2}.order-xl-3{-ms-flex-order:3;order:3}.order-xl-4{-ms-flex-order:4;order:4}.order-xl-5{-ms-flex-order:5;order:5}.order-xl-6{-ms-flex-order:6;order:6}.order-xl-7{-ms-flex-order:7;order:7}.order-xl-8{-ms-flex-order:8;order:8}.order-xl-9{-ms-flex-order:9;order:9}.order-xl-10{-ms-flex-order:10;order:10}.order-xl-11{-ms-flex-order:11;order:11}.order-xl-12{-ms-flex-order:12;order:12}.offset-xl-0{margin-left:0}.offset-xl-1{margin-left:8.333333%}.offset-xl-2{margin-left:16.666667%}.offset-xl-3{margin-left:25%}.offset-xl-4{margin-left:33.333333%}.offset-xl-5{margin-left:41.666667%}.offset-xl-6{margin-left:50%}.offset-xl-7{margin-left:58.333333%}.offset-xl-8{margin-left:66.666667%}.offset-xl-9{margin-left:75%}.offset-xl-10{margin-left:83.333333%}.offset-xl-11{margin-left:91.666667%}}.table{width:100%;max-width:100%;margin-bottom:1rem;background-color:transparent}.table td,.table th{padding:.75rem;vertical-align:top;border-top:1px solid #dee2e6}.table thead th{vertical-align:bottom;border-bottom:2px solid #dee2e6}.table tbody+tbody{border-top:2px solid #dee2e6}.table .table{background-color:#fff}.table-sm td,.table-sm th{padding:.3rem}.table-bordered{border:1px solid #dee2e6}.table-bordered td,.table-bordered th{border:1px solid #dee2e6}.table-bordered thead td,.table-bordered thead th{border-bottom-width:2px}.table-borderless tbody+tbody,.table-borderless td,.table-borderless th,.table-borderless thead th{border:0}.table-striped tbody tr:nth-of-type(odd){background-color:rgba(0,0,0,.05)}.table-hover tbody tr:hover{background-color:rgba(0,0,0,.075)}.table-primary,.table-primary>td,.table-primary>th{background-color:#b8daff}.table-hover .table-primary:hover{background-color:#9fcdff}.table-hover .table-primary:hover>td,.table-hover .table-primary:hover>th{background-color:#9fcdff}.table-secondary,.table-secondary>td,.table-secondary>th{background-color:#d6d8db}.table-hover .table-secondary:hover{background-color:#c8cbcf}.table-hover .table-secondary:hover>td,.table-hover .table-secondary:hover>th{background-color:#c8cbcf}.table-success,.table-success>td,.table-success>th{background-color:#c3e6cb}.table-hover .table-success:hover{background-color:#b1dfbb}.table-hover .table-success:hover>td,.table-hover .table-success:hover>th{background-color:#b1dfbb}.table-info,.table-info>td,.table-info>th{background-color:#bee5eb}.table-hover .table-info:hover{background-color:#abdde5}.table-hover .table-info:hover>td,.table-hover .table-info:hover>th{background-color:#abdde5}.table-warning,.table-warning>td,.table-warning>th{background-color:#ffeeba}.table-hover .table-warning:hover{background-color:#ffe8a1}.table-hover .table-warning:hover>td,.table-hover .table-warning:hover>th{background-color:#ffe8a1}.table-danger,.table-danger>td,.table-danger>th{background-color:#f5c6cb}.table-hover .table-danger:hover{background-color:#f1b0b7}.table-hover .table-danger:hover>td,.table-hover .table-danger:hover>th{background-color:#f1b0b7}.table-light,.table-light>td,.table-light>th{background-color:#fdfdfe}.table-hover .table-light:hover{background-color:#ececf6}.table-hover .table-light:hover>td,.table-hover .table-light:hover>th{background-color:#ececf6}.table-dark,.table-dark>td,.table-dark>th{background-color:#c6c8ca}.table-hover .table-dark:hover{background-color:#b9bbbe}.table-hover .table-dark:hover>td,.table-hover .table-dark:hover>th{background-color:#b9bbbe}.table-active,.table-active>td,.table-active>th{background-color:rgba(0,0,0,.075)}.table-hover .table-active:hover{background-color:rgba(0,0,0,.075)}.table-hover .table-active:hover>td,.table-hover .table-active:hover>th{background-color:rgba(0,0,0,.075)}.table .thead-dark th{color:#fff;background-color:#212529;border-color:#32383e}.table .thead-light th{color:#495057;background-color:#e9ecef;border-color:#dee2e6}.table-dark{color:#fff;background-color:#212529}.table-dark td,.table-dark th,.table-dark thead th{border-color:#32383e}.table-dark.table-bordered{border:0}.table-dark.table-striped tbody tr:nth-of-type(odd){background-color:rgba(255,255,255,.05)}.table-dark.table-hover tbody tr:hover{background-color:rgba(255,255,255,.075)}@media (max-width:575.98px){.table-responsive-sm{display:block;width:100%;overflow-x:auto;-webkit-overflow-scrolling:touch;-ms-overflow-style:-ms-autohiding-scrollbar}.table-responsive-sm>.table-bordered{border:0}}@media (max-width:767.98px){.table-responsive-md{display:block;width:100%;overflow-x:auto;-webkit-overflow-scrolling:touch;-ms-overflow-style:-ms-autohiding-scrollbar}.table-responsive-md>.table-bordered{border:0}}@media (max-width:991.98px){.table-responsive-lg{display:block;width:100%;overflow-x:auto;-webkit-overflow-scrolling:touch;-ms-overflow-style:-ms-autohiding-scrollbar}.table-responsive-lg>.table-bordered{border:0}}@media (max-width:1199.98px){.table-responsive-xl{display:block;width:100%;overflow-x:auto;-webkit-overflow-scrolling:touch;-ms-overflow-style:-ms-autohiding-scrollbar}.table-responsive-xl>.table-bordered{border:0}}.table-responsive{display:block;width:100%;overflow-x:auto;-webkit-overflow-scrolling:touch;-ms-overflow-style:-ms-autohiding-scrollbar}.table-responsive>.table-bordered{border:0}.form-control{display:block;width:100%;padding:.375rem .75rem;font-size:1rem;line-height:1.5;color:#495057;background-color:#fff;background-clip:padding-box;border:1px solid #ced4da;border-radius:.25rem;transition:border-color .15s ease-in-out,box-shadow .15s ease-in-out}@media screen and (prefers-reduced-motion:reduce){.form-control{transition:none}}.form-control::-ms-expand{background-color:transparent;border:0}.form-control:focus{color:#495057;background-color:#fff;border-color:#80bdff;outline:0;box-shadow:0 0 0 .2rem rgba(0,123,255,.25)}.form-control::-webkit-input-placeholder{color:#6c757d;opacity:1}.form-control::-moz-placeholder{color:#6c757d;opacity:1}.form-control:-ms-input-placeholder{color:#6c757d;opacity:1}.form-control::-ms-input-placeholder{color:#6c757d;opacity:1}.form-control::placeholder{color:#6c757d;opacity:1}.form-control:disabled,.form-control[readonly]{background-color:#e9ecef;opacity:1}select.form-control:not([size]):not([multiple]){height:calc(2.25rem + 2px)}select.form-control:focus::-ms-value{color:#495057;background-color:#fff}.form-control-file,.form-control-range{display:block;width:100%}.col-form-label{padding-top:calc(.375rem + 1px);padding-bottom:calc(.375rem + 1px);margin-bottom:0;font-size:inherit;line-height:1.5}.col-form-label-lg{padding-top:calc(.5rem + 1px);padding-bottom:calc(.5rem + 1px);font-size:1.25rem;line-height:1.5}.col-form-label-sm{padding-top:calc(.25rem + 1px);padding-bottom:calc(.25rem + 1px);font-size:.875rem;line-height:1.5}.form-control-plaintext{display:block;width:100%;padding-top:.375rem;padding-bottom:.375rem;margin-bottom:0;line-height:1.5;color:#212529;background-color:transparent;border:solid transparent;border-width:1px 0}.form-control-plaintext.form-control-lg,.form-control-plaintext.form-control-sm,.input-group-lg>.form-control-plaintext.form-control,.input-group-lg>.input-group-append>.form-control-plaintext.btn,.input-group-lg>.input-group-append>.form-control-plaintext.input-group-text,.input-group-lg>.input-group-prepend>.form-control-plaintext.btn,.input-group-lg>.input-group-prepend>.form-control-plaintext.input-group-text,.input-group-sm>.form-control-plaintext.form-control,.input-group-sm>.input-group-append>.form-control-plaintext.btn,.input-group-sm>.input-group-append>.form-control-plaintext.input-group-text,.input-group-sm>.input-group-prepend>.form-control-plaintext.btn,.input-group-sm>.input-group-prepend>.form-control-plaintext.input-group-text{padding-right:0;padding-left:0}.form-control-sm,.input-group-sm>.form-control,.input-group-sm>.input-group-append>.btn,.input-group-sm>.input-group-append>.input-group-text,.input-group-sm>.input-group-prepend>.btn,.input-group-sm>.input-group-prepend>.input-group-text{padding:.25rem .5rem;font-size:.875rem;line-height:1.5;border-radius:.2rem}.input-group-sm>.input-group-append>select.btn:not([size]):not([multiple]),.input-group-sm>.input-group-append>select.input-group-text:not([size]):not([multiple]),.input-group-sm>.input-group-prepend>select.btn:not([size]):not([multiple]),.input-group-sm>.input-group-prepend>select.input-group-text:not([size]):not([multiple]),.input-group-sm>select.form-control:not([size]):not([multiple]),select.form-control-sm:not([size]):not([multiple]){height:calc(1.8125rem + 2px)}.form-control-lg,.input-group-lg>.form-control,.input-group-lg>.input-group-append>.btn,.input-group-lg>.input-group-append>.input-group-text,.input-group-lg>.input-group-prepend>.btn,.input-group-lg>.input-group-prepend>.input-group-text{padding:.5rem 1rem;font-size:1.25rem;line-height:1.5;border-radius:.3rem}.input-group-lg>.input-group-append>select.btn:not([size]):not([multiple]),.input-group-lg>.input-group-append>select.input-group-text:not([size]):not([multiple]),.input-group-lg>.input-group-prepend>select.btn:not([size]):not([multiple]),.input-group-lg>.input-group-prepend>select.input-group-text:not([size]):not([multiple]),.input-group-lg>select.form-control:not([size]):not([multiple]),select.form-control-lg:not([size]):not([multiple]){height:calc(2.875rem + 2px)}.form-group{margin-bottom:1rem}.form-text{display:block;margin-top:.25rem}.form-row{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;margin-right:-5px;margin-left:-5px}.form-row>.col,.form-row>[class*=col-]{padding-right:5px;padding-left:5px}.form-check{position:relative;display:block;padding-left:1.25rem}.form-check-input{position:absolute;margin-top:.3rem;margin-left:-1.25rem}.form-check-input:disabled~.form-check-label{color:#6c757d}.form-check-label{margin-bottom:0}.form-check-inline{display:-ms-inline-flexbox;display:inline-flex;-ms-flex-align:center;align-items:center;padding-left:0;margin-right:.75rem}.form-check-inline .form-check-input{position:static;margin-top:0;margin-right:.3125rem;margin-left:0}.valid-feedback{display:none;width:100%;margin-top:.25rem;font-size:80%;color:#28a745}.valid-tooltip{position:absolute;top:100%;z-index:5;display:none;max-width:100%;padding:.5rem;margin-top:.1rem;font-size:.875rem;line-height:1;color:#fff;background-color:rgba(40,167,69,.8);border-radius:.2rem}.custom-select.is-valid,.form-control.is-valid,.was-validated .custom-select:valid,.was-validated .form-control:valid{border-color:#28a745}.custom-select.is-valid:focus,.form-control.is-valid:focus,.was-validated .custom-select:valid:focus,.was-validated .form-control:valid:focus{border-color:#28a745;box-shadow:0 0 0 .2rem rgba(40,167,69,.25)}.custom-select.is-valid~.valid-feedback,.custom-select.is-valid~.valid-tooltip,.form-control.is-valid~.valid-feedback,.form-control.is-valid~.valid-tooltip,.was-validated .custom-select:valid~.valid-feedback,.was-validated .custom-select:valid~.valid-tooltip,.was-validated .form-control:valid~.valid-feedback,.was-validated .form-control:valid~.valid-tooltip{display:block}.form-control-file.is-valid~.valid-feedback,.form-control-file.is-valid~.valid-tooltip,.was-validated .form-control-file:valid~.valid-feedback,.was-validated .form-control-file:valid~.valid-tooltip{display:block}.form-check-input.is-valid~.form-check-label,.was-validated .form-check-input:valid~.form-check-label{color:#28a745}.form-check-input.is-valid~.valid-feedback,.form-check-input.is-valid~.valid-tooltip,.was-validated .form-check-input:valid~.valid-feedback,.was-validated .form-check-input:valid~.valid-tooltip{display:block}.custom-control-input.is-valid~.custom-control-label,.was-validated .custom-control-input:valid~.custom-control-label{color:#28a745}.custom-control-input.is-valid~.custom-control-label::before,.was-validated .custom-control-input:valid~.custom-control-label::before{background-color:#71dd8a}.custom-control-input.is-valid~.valid-feedback,.custom-control-input.is-valid~.valid-tooltip,.was-validated .custom-control-input:valid~.valid-feedback,.was-validated .custom-control-input:valid~.valid-tooltip{display:block}.custom-control-input.is-valid:checked~.custom-control-label::before,.was-validated .custom-control-input:valid:checked~.custom-control-label::before{background-color:#34ce57}.custom-control-input.is-valid:focus~.custom-control-label::before,.was-validated .custom-control-input:valid:focus~.custom-control-label::before{box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(40,167,69,.25)}.custom-file-input.is-valid~.custom-file-label,.was-validated .custom-file-input:valid~.custom-file-label{border-color:#28a745}.custom-file-input.is-valid~.custom-file-label::before,.was-validated .custom-file-input:valid~.custom-file-label::before{border-color:inherit}.custom-file-input.is-valid~.valid-feedback,.custom-file-input.is-valid~.valid-tooltip,.was-validated .custom-file-input:valid~.valid-feedback,.was-validated .custom-file-input:valid~.valid-tooltip{display:block}.custom-file-input.is-valid:focus~.custom-file-label,.was-validated .custom-file-input:valid:focus~.custom-file-label{box-shadow:0 0 0 .2rem rgba(40,167,69,.25)}.invalid-feedback{display:none;width:100%;margin-top:.25rem;font-size:80%;color:#dc3545}.invalid-tooltip{position:absolute;top:100%;z-index:5;display:none;max-width:100%;padding:.5rem;margin-top:.1rem;font-size:.875rem;line-height:1;color:#fff;background-color:rgba(220,53,69,.8);border-radius:.2rem}.custom-select.is-invalid,.form-control.is-invalid,.was-validated .custom-select:invalid,.was-validated .form-control:invalid{border-color:#dc3545}.custom-select.is-invalid:focus,.form-control.is-invalid:focus,.was-validated .custom-select:invalid:focus,.was-validated .form-control:invalid:focus{border-color:#dc3545;box-shadow:0 0 0 .2rem rgba(220,53,69,.25)}.custom-select.is-invalid~.invalid-feedback,.custom-select.is-invalid~.invalid-tooltip,.form-control.is-invalid~.invalid-feedback,.form-control.is-invalid~.invalid-tooltip,.was-validated .custom-select:invalid~.invalid-feedback,.was-validated .custom-select:invalid~.invalid-tooltip,.was-validated .form-control:invalid~.invalid-feedback,.was-validated .form-control:invalid~.invalid-tooltip{display:block}.form-control-file.is-invalid~.invalid-feedback,.form-control-file.is-invalid~.invalid-tooltip,.was-validated .form-control-file:invalid~.invalid-feedback,.was-validated .form-control-file:invalid~.invalid-tooltip{display:block}.form-check-input.is-invalid~.form-check-label,.was-validated .form-check-input:invalid~.form-check-label{color:#dc3545}.form-check-input.is-invalid~.invalid-feedback,.form-check-input.is-invalid~.invalid-tooltip,.was-validated .form-check-input:invalid~.invalid-feedback,.was-validated .form-check-input:invalid~.invalid-tooltip{display:block}.custom-control-input.is-invalid~.custom-control-label,.was-validated .custom-control-input:invalid~.custom-control-label{color:#dc3545}.custom-control-input.is-invalid~.custom-control-label::before,.was-validated .custom-control-input:invalid~.custom-control-label::before{background-color:#efa2a9}.custom-control-input.is-invalid~.invalid-feedback,.custom-control-input.is-invalid~.invalid-tooltip,.was-validated .custom-control-input:invalid~.invalid-feedback,.was-validated .custom-control-input:invalid~.invalid-tooltip{display:block}.custom-control-input.is-invalid:checked~.custom-control-label::before,.was-validated .custom-control-input:invalid:checked~.custom-control-label::before{background-color:#e4606d}.custom-control-input.is-invalid:focus~.custom-control-label::before,.was-validated .custom-control-input:invalid:focus~.custom-control-label::before{box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(220,53,69,.25)}.custom-file-input.is-invalid~.custom-file-label,.was-validated .custom-file-input:invalid~.custom-file-label{border-color:#dc3545}.custom-file-input.is-invalid~.custom-file-label::before,.was-validated .custom-file-input:invalid~.custom-file-label::before{border-color:inherit}.custom-file-input.is-invalid~.invalid-feedback,.custom-file-input.is-invalid~.invalid-tooltip,.was-validated .custom-file-input:invalid~.invalid-feedback,.was-validated .custom-file-input:invalid~.invalid-tooltip{display:block}.custom-file-input.is-invalid:focus~.custom-file-label,.was-validated .custom-file-input:invalid:focus~.custom-file-label{box-shadow:0 0 0 .2rem rgba(220,53,69,.25)}.form-inline{display:-ms-flexbox;display:flex;-ms-flex-flow:row wrap;flex-flow:row wrap;-ms-flex-align:center;align-items:center}.form-inline .form-check{width:100%}@media (min-width:576px){.form-inline label{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;-ms-flex-pack:center;justify-content:center;margin-bottom:0}.form-inline .form-group{display:-ms-flexbox;display:flex;-ms-flex:0 0 auto;flex:0 0 auto;-ms-flex-flow:row wrap;flex-flow:row wrap;-ms-flex-align:center;align-items:center;margin-bottom:0}.form-inline .form-control{display:inline-block;width:auto;vertical-align:middle}.form-inline .form-control-plaintext{display:inline-block}.form-inline .custom-select,.form-inline .input-group{width:auto}.form-inline .form-check{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;-ms-flex-pack:center;justify-content:center;width:auto;padding-left:0}.form-inline .form-check-input{position:relative;margin-top:0;margin-right:.25rem;margin-left:0}.form-inline .custom-control{-ms-flex-align:center;align-items:center;-ms-flex-pack:center;justify-content:center}.form-inline .custom-control-label{margin-bottom:0}}.btn{display:inline-block;font-weight:400;text-align:center;white-space:nowrap;vertical-align:middle;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none;border:1px solid transparent;padding:.375rem .75rem;font-size:1rem;line-height:1.5;border-radius:.25rem;transition:color .15s ease-in-out,background-color .15s ease-in-out,border-color .15s ease-in-out,box-shadow .15s ease-in-out}@media screen and (prefers-reduced-motion:reduce){.btn{transition:none}}.btn:focus,.btn:hover{text-decoration:none}.btn.focus,.btn:focus{outline:0;box-shadow:0 0 0 .2rem rgba(0,123,255,.25)}.btn.disabled,.btn:disabled{opacity:.65}.btn:not(:disabled):not(.disabled){cursor:pointer}.btn:not(:disabled):not(.disabled).active,.btn:not(:disabled):not(.disabled):active{background-image:none}a.btn.disabled,fieldset:disabled a.btn{pointer-events:none}.btn-primary{color:#fff;background-color:#007bff;border-color:#007bff}.btn-primary:hover{color:#fff;background-color:#0069d9;border-color:#0062cc}.btn-primary.focus,.btn-primary:focus{box-shadow:0 0 0 .2rem rgba(0,123,255,.5)}.btn-primary.disabled,.btn-primary:disabled{color:#fff;background-color:#007bff;border-color:#007bff}.btn-primary:not(:disabled):not(.disabled).active,.btn-primary:not(:disabled):not(.disabled):active,.show>.btn-primary.dropdown-toggle{color:#fff;background-color:#0062cc;border-color:#005cbf}.btn-primary:not(:disabled):not(.disabled).active:focus,.btn-primary:not(:disabled):not(.disabled):active:focus,.show>.btn-primary.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(0,123,255,.5)}.btn-secondary{color:#fff;background-color:#6c757d;border-color:#6c757d}.btn-secondary:hover{color:#fff;background-color:#5a6268;border-color:#545b62}.btn-secondary.focus,.btn-secondary:focus{box-shadow:0 0 0 .2rem rgba(108,117,125,.5)}.btn-secondary.disabled,.btn-secondary:disabled{color:#fff;background-color:#6c757d;border-color:#6c757d}.btn-secondary:not(:disabled):not(.disabled).active,.btn-secondary:not(:disabled):not(.disabled):active,.show>.btn-secondary.dropdown-toggle{color:#fff;background-color:#545b62;border-color:#4e555b}.btn-secondary:not(:disabled):not(.disabled).active:focus,.btn-secondary:not(:disabled):not(.disabled):active:focus,.show>.btn-secondary.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(108,117,125,.5)}.btn-success{color:#fff;background-color:#28a745;border-color:#28a745}.btn-success:hover{color:#fff;background-color:#218838;border-color:#1e7e34}.btn-success.focus,.btn-success:focus{box-shadow:0 0 0 .2rem rgba(40,167,69,.5)}.btn-success.disabled,.btn-success:disabled{color:#fff;background-color:#28a745;border-color:#28a745}.btn-success:not(:disabled):not(.disabled).active,.btn-success:not(:disabled):not(.disabled):active,.show>.btn-success.dropdown-toggle{color:#fff;background-color:#1e7e34;border-color:#1c7430}.btn-success:not(:disabled):not(.disabled).active:focus,.btn-success:not(:disabled):not(.disabled):active:focus,.show>.btn-success.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(40,167,69,.5)}.btn-info{color:#fff;background-color:#17a2b8;border-color:#17a2b8}.btn-info:hover{color:#fff;background-color:#138496;border-color:#117a8b}.btn-info.focus,.btn-info:focus{box-shadow:0 0 0 .2rem rgba(23,162,184,.5)}.btn-info.disabled,.btn-info:disabled{color:#fff;background-color:#17a2b8;border-color:#17a2b8}.btn-info:not(:disabled):not(.disabled).active,.btn-info:not(:disabled):not(.disabled):active,.show>.btn-info.dropdown-toggle{color:#fff;background-color:#117a8b;border-color:#10707f}.btn-info:not(:disabled):not(.disabled).active:focus,.btn-info:not(:disabled):not(.disabled):active:focus,.show>.btn-info.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(23,162,184,.5)}.btn-warning{color:#212529;background-color:#ffc107;border-color:#ffc107}.btn-warning:hover{color:#212529;background-color:#e0a800;border-color:#d39e00}.btn-warning.focus,.btn-warning:focus{box-shadow:0 0 0 .2rem rgba(255,193,7,.5)}.btn-warning.disabled,.btn-warning:disabled{color:#212529;background-color:#ffc107;border-color:#ffc107}.btn-warning:not(:disabled):not(.disabled).active,.btn-warning:not(:disabled):not(.disabled):active,.show>.btn-warning.dropdown-toggle{color:#212529;background-color:#d39e00;border-color:#c69500}.btn-warning:not(:disabled):not(.disabled).active:focus,.btn-warning:not(:disabled):not(.disabled):active:focus,.show>.btn-warning.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(255,193,7,.5)}.btn-danger{color:#fff;background-color:#dc3545;border-color:#dc3545}.btn-danger:hover{color:#fff;background-color:#c82333;border-color:#bd2130}.btn-danger.focus,.btn-danger:focus{box-shadow:0 0 0 .2rem rgba(220,53,69,.5)}.btn-danger.disabled,.btn-danger:disabled{color:#fff;background-color:#dc3545;border-color:#dc3545}.btn-danger:not(:disabled):not(.disabled).active,.btn-danger:not(:disabled):not(.disabled):active,.show>.btn-danger.dropdown-toggle{color:#fff;background-color:#bd2130;border-color:#b21f2d}.btn-danger:not(:disabled):not(.disabled).active:focus,.btn-danger:not(:disabled):not(.disabled):active:focus,.show>.btn-danger.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(220,53,69,.5)}.btn-light{color:#212529;background-color:#f8f9fa;border-color:#f8f9fa}.btn-light:hover{color:#212529;background-color:#e2e6ea;border-color:#dae0e5}.btn-light.focus,.btn-light:focus{box-shadow:0 0 0 .2rem rgba(248,249,250,.5)}.btn-light.disabled,.btn-light:disabled{color:#212529;background-color:#f8f9fa;border-color:#f8f9fa}.btn-light:not(:disabled):not(.disabled).active,.btn-light:not(:disabled):not(.disabled):active,.show>.btn-light.dropdown-toggle{color:#212529;background-color:#dae0e5;border-color:#d3d9df}.btn-light:not(:disabled):not(.disabled).active:focus,.btn-light:not(:disabled):not(.disabled):active:focus,.show>.btn-light.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(248,249,250,.5)}.btn-dark{color:#fff;background-color:#343a40;border-color:#343a40}.btn-dark:hover{color:#fff;background-color:#23272b;border-color:#1d2124}.btn-dark.focus,.btn-dark:focus{box-shadow:0 0 0 .2rem rgba(52,58,64,.5)}.btn-dark.disabled,.btn-dark:disabled{color:#fff;background-color:#343a40;border-color:#343a40}.btn-dark:not(:disabled):not(.disabled).active,.btn-dark:not(:disabled):not(.disabled):active,.show>.btn-dark.dropdown-toggle{color:#fff;background-color:#1d2124;border-color:#171a1d}.btn-dark:not(:disabled):not(.disabled).active:focus,.btn-dark:not(:disabled):not(.disabled):active:focus,.show>.btn-dark.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(52,58,64,.5)}.btn-outline-primary{color:#007bff;background-color:transparent;background-image:none;border-color:#007bff}.btn-outline-primary:hover{color:#fff;background-color:#007bff;border-color:#007bff}.btn-outline-primary.focus,.btn-outline-primary:focus{box-shadow:0 0 0 .2rem rgba(0,123,255,.5)}.btn-outline-primary.disabled,.btn-outline-primary:disabled{color:#007bff;background-color:transparent}.btn-outline-primary:not(:disabled):not(.disabled).active,.btn-outline-primary:not(:disabled):not(.disabled):active,.show>.btn-outline-primary.dropdown-toggle{color:#fff;background-color:#007bff;border-color:#007bff}.btn-outline-primary:not(:disabled):not(.disabled).active:focus,.btn-outline-primary:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-primary.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(0,123,255,.5)}.btn-outline-secondary{color:#6c757d;background-color:transparent;background-image:none;border-color:#6c757d}.btn-outline-secondary:hover{color:#fff;background-color:#6c757d;border-color:#6c757d}.btn-outline-secondary.focus,.btn-outline-secondary:focus{box-shadow:0 0 0 .2rem rgba(108,117,125,.5)}.btn-outline-secondary.disabled,.btn-outline-secondary:disabled{color:#6c757d;background-color:transparent}.btn-outline-secondary:not(:disabled):not(.disabled).active,.btn-outline-secondary:not(:disabled):not(.disabled):active,.show>.btn-outline-secondary.dropdown-toggle{color:#fff;background-color:#6c757d;border-color:#6c757d}.btn-outline-secondary:not(:disabled):not(.disabled).active:focus,.btn-outline-secondary:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-secondary.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(108,117,125,.5)}.btn-outline-success{color:#28a745;background-color:transparent;background-image:none;border-color:#28a745}.btn-outline-success:hover{color:#fff;background-color:#28a745;border-color:#28a745}.btn-outline-success.focus,.btn-outline-success:focus{box-shadow:0 0 0 .2rem rgba(40,167,69,.5)}.btn-outline-success.disabled,.btn-outline-success:disabled{color:#28a745;background-color:transparent}.btn-outline-success:not(:disabled):not(.disabled).active,.btn-outline-success:not(:disabled):not(.disabled):active,.show>.btn-outline-success.dropdown-toggle{color:#fff;background-color:#28a745;border-color:#28a745}.btn-outline-success:not(:disabled):not(.disabled).active:focus,.btn-outline-success:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-success.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(40,167,69,.5)}.btn-outline-info{color:#17a2b8;background-color:transparent;background-image:none;border-color:#17a2b8}.btn-outline-info:hover{color:#fff;background-color:#17a2b8;border-color:#17a2b8}.btn-outline-info.focus,.btn-outline-info:focus{box-shadow:0 0 0 .2rem rgba(23,162,184,.5)}.btn-outline-info.disabled,.btn-outline-info:disabled{color:#17a2b8;background-color:transparent}.btn-outline-info:not(:disabled):not(.disabled).active,.btn-outline-info:not(:disabled):not(.disabled):active,.show>.btn-outline-info.dropdown-toggle{color:#fff;background-color:#17a2b8;border-color:#17a2b8}.btn-outline-info:not(:disabled):not(.disabled).active:focus,.btn-outline-info:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-info.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(23,162,184,.5)}.btn-outline-warning{color:#ffc107;background-color:transparent;background-image:none;border-color:#ffc107}.btn-outline-warning:hover{color:#212529;background-color:#ffc107;border-color:#ffc107}.btn-outline-warning.focus,.btn-outline-warning:focus{box-shadow:0 0 0 .2rem rgba(255,193,7,.5)}.btn-outline-warning.disabled,.btn-outline-warning:disabled{color:#ffc107;background-color:transparent}.btn-outline-warning:not(:disabled):not(.disabled).active,.btn-outline-warning:not(:disabled):not(.disabled):active,.show>.btn-outline-warning.dropdown-toggle{color:#212529;background-color:#ffc107;border-color:#ffc107}.btn-outline-warning:not(:disabled):not(.disabled).active:focus,.btn-outline-warning:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-warning.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(255,193,7,.5)}.btn-outline-danger{color:#dc3545;background-color:transparent;background-image:none;border-color:#dc3545}.btn-outline-danger:hover{color:#fff;background-color:#dc3545;border-color:#dc3545}.btn-outline-danger.focus,.btn-outline-danger:focus{box-shadow:0 0 0 .2rem rgba(220,53,69,.5)}.btn-outline-danger.disabled,.btn-outline-danger:disabled{color:#dc3545;background-color:transparent}.btn-outline-danger:not(:disabled):not(.disabled).active,.btn-outline-danger:not(:disabled):not(.disabled):active,.show>.btn-outline-danger.dropdown-toggle{color:#fff;background-color:#dc3545;border-color:#dc3545}.btn-outline-danger:not(:disabled):not(.disabled).active:focus,.btn-outline-danger:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-danger.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(220,53,69,.5)}.btn-outline-light{color:#f8f9fa;background-color:transparent;background-image:none;border-color:#f8f9fa}.btn-outline-light:hover{color:#212529;background-color:#f8f9fa;border-color:#f8f9fa}.btn-outline-light.focus,.btn-outline-light:focus{box-shadow:0 0 0 .2rem rgba(248,249,250,.5)}.btn-outline-light.disabled,.btn-outline-light:disabled{color:#f8f9fa;background-color:transparent}.btn-outline-light:not(:disabled):not(.disabled).active,.btn-outline-light:not(:disabled):not(.disabled):active,.show>.btn-outline-light.dropdown-toggle{color:#212529;background-color:#f8f9fa;border-color:#f8f9fa}.btn-outline-light:not(:disabled):not(.disabled).active:focus,.btn-outline-light:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-light.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(248,249,250,.5)}.btn-outline-dark{color:#343a40;background-color:transparent;background-image:none;border-color:#343a40}.btn-outline-dark:hover{color:#fff;background-color:#343a40;border-color:#343a40}.btn-outline-dark.focus,.btn-outline-dark:focus{box-shadow:0 0 0 .2rem rgba(52,58,64,.5)}.btn-outline-dark.disabled,.btn-outline-dark:disabled{color:#343a40;background-color:transparent}.btn-outline-dark:not(:disabled):not(.disabled).active,.btn-outline-dark:not(:disabled):not(.disabled):active,.show>.btn-outline-dark.dropdown-toggle{color:#fff;background-color:#343a40;border-color:#343a40}.btn-outline-dark:not(:disabled):not(.disabled).active:focus,.btn-outline-dark:not(:disabled):not(.disabled):active:focus,.show>.btn-outline-dark.dropdown-toggle:focus{box-shadow:0 0 0 .2rem rgba(52,58,64,.5)}.btn-link{font-weight:400;color:#007bff;background-color:transparent}.btn-link:hover{color:#0056b3;text-decoration:underline;background-color:transparent;border-color:transparent}.btn-link.focus,.btn-link:focus{text-decoration:underline;border-color:transparent;box-shadow:none}.btn-link.disabled,.btn-link:disabled{color:#6c757d;pointer-events:none}.btn-group-lg>.btn,.btn-lg{padding:.5rem 1rem;font-size:1.25rem;line-height:1.5;border-radius:.3rem}.btn-group-sm>.btn,.btn-sm{padding:.25rem .5rem;font-size:.875rem;line-height:1.5;border-radius:.2rem}.btn-block{display:block;width:100%}.btn-block+.btn-block{margin-top:.5rem}input[type=button].btn-block,input[type=reset].btn-block,input[type=submit].btn-block{width:100%}.fade{transition:opacity .15s linear}@media screen and (prefers-reduced-motion:reduce){.fade{transition:none}}.fade:not(.show){opacity:0}.collapse:not(.show){display:none}.collapsing{position:relative;height:0;overflow:hidden;transition:height .35s ease}@media screen and (prefers-reduced-motion:reduce){.collapsing{transition:none}}.dropdown,.dropleft,.dropright,.dropup{position:relative}.dropdown-toggle::after{display:inline-block;width:0;height:0;margin-left:.255em;vertical-align:.255em;content:"";border-top:.3em solid;border-right:.3em solid transparent;border-bottom:0;border-left:.3em solid transparent}.dropdown-toggle:empty::after{margin-left:0}.dropdown-menu{position:absolute;top:100%;left:0;z-index:1000;display:none;float:left;min-width:10rem;padding:.5rem 0;margin:.125rem 0 0;font-size:1rem;color:#212529;text-align:left;list-style:none;background-color:#fff;background-clip:padding-box;border:1px solid rgba(0,0,0,.15);border-radius:.25rem}.dropdown-menu-right{right:0;left:auto}.dropup .dropdown-menu{top:auto;bottom:100%;margin-top:0;margin-bottom:.125rem}.dropup .dropdown-toggle::after{display:inline-block;width:0;height:0;margin-left:.255em;vertical-align:.255em;content:"";border-top:0;border-right:.3em solid transparent;border-bottom:.3em solid;border-left:.3em solid transparent}.dropup .dropdown-toggle:empty::after{margin-left:0}.dropright .dropdown-menu{top:0;right:auto;left:100%;margin-top:0;margin-left:.125rem}.dropright .dropdown-toggle::after{display:inline-block;width:0;height:0;margin-left:.255em;vertical-align:.255em;content:"";border-top:.3em solid transparent;border-right:0;border-bottom:.3em solid transparent;border-left:.3em solid}.dropright .dropdown-toggle:empty::after{margin-left:0}.dropright .dropdown-toggle::after{vertical-align:0}.dropleft .dropdown-menu{top:0;right:100%;left:auto;margin-top:0;margin-right:.125rem}.dropleft .dropdown-toggle::after{display:inline-block;width:0;height:0;margin-left:.255em;vertical-align:.255em;content:""}.dropleft .dropdown-toggle::after{display:none}.dropleft .dropdown-toggle::before{display:inline-block;width:0;height:0;margin-right:.255em;vertical-align:.255em;content:"";border-top:.3em solid transparent;border-right:.3em solid;border-bottom:.3em solid transparent}.dropleft .dropdown-toggle:empty::after{margin-left:0}.dropleft .dropdown-toggle::before{vertical-align:0}.dropdown-menu[x-placement^=bottom],.dropdown-menu[x-placement^=left],.dropdown-menu[x-placement^=right],.dropdown-menu[x-placement^=top]{right:auto;bottom:auto}.dropdown-divider{height:0;margin:.5rem 0;overflow:hidden;border-top:1px solid #e9ecef}.dropdown-item{display:block;width:100%;padding:.25rem 1.5rem;clear:both;font-weight:400;color:#212529;text-align:inherit;white-space:nowrap;background-color:transparent;border:0}.dropdown-item:focus,.dropdown-item:hover{color:#16181b;text-decoration:none;background-color:#f8f9fa}.dropdown-item.active,.dropdown-item:active{color:#fff;text-decoration:none;background-color:#007bff}.dropdown-item.disabled,.dropdown-item:disabled{color:#6c757d;background-color:transparent}.dropdown-menu.show{display:block}.dropdown-header{display:block;padding:.5rem 1.5rem;margin-bottom:0;font-size:.875rem;color:#6c757d;white-space:nowrap}.dropdown-item-text{display:block;padding:.25rem 1.5rem;color:#212529}.btn-group,.btn-group-vertical{position:relative;display:-ms-inline-flexbox;display:inline-flex;vertical-align:middle}.btn-group-vertical>.btn,.btn-group>.btn{position:relative;-ms-flex:0 1 auto;flex:0 1 auto}.btn-group-vertical>.btn:hover,.btn-group>.btn:hover{z-index:1}.btn-group-vertical>.btn.active,.btn-group-vertical>.btn:active,.btn-group-vertical>.btn:focus,.btn-group>.btn.active,.btn-group>.btn:active,.btn-group>.btn:focus{z-index:1}.btn-group .btn+.btn,.btn-group .btn+.btn-group,.btn-group .btn-group+.btn,.btn-group .btn-group+.btn-group,.btn-group-vertical .btn+.btn,.btn-group-vertical .btn+.btn-group,.btn-group-vertical .btn-group+.btn,.btn-group-vertical .btn-group+.btn-group{margin-left:-1px}.btn-toolbar{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;-ms-flex-pack:start;justify-content:flex-start}.btn-toolbar .input-group{width:auto}.btn-group>.btn:first-child{margin-left:0}.btn-group>.btn-group:not(:last-child)>.btn,.btn-group>.btn:not(:last-child):not(.dropdown-toggle){border-top-right-radius:0;border-bottom-right-radius:0}.btn-group>.btn-group:not(:first-child)>.btn,.btn-group>.btn:not(:first-child){border-top-left-radius:0;border-bottom-left-radius:0}.dropdown-toggle-split{padding-right:.5625rem;padding-left:.5625rem}.dropdown-toggle-split::after,.dropright .dropdown-toggle-split::after,.dropup .dropdown-toggle-split::after{margin-left:0}.dropleft .dropdown-toggle-split::before{margin-right:0}.btn-group-sm>.btn+.dropdown-toggle-split,.btn-sm+.dropdown-toggle-split{padding-right:.375rem;padding-left:.375rem}.btn-group-lg>.btn+.dropdown-toggle-split,.btn-lg+.dropdown-toggle-split{padding-right:.75rem;padding-left:.75rem}.btn-group-vertical{-ms-flex-direction:column;flex-direction:column;-ms-flex-align:start;align-items:flex-start;-ms-flex-pack:center;justify-content:center}.btn-group-vertical .btn,.btn-group-vertical .btn-group{width:100%}.btn-group-vertical>.btn+.btn,.btn-group-vertical>.btn+.btn-group,.btn-group-vertical>.btn-group+.btn,.btn-group-vertical>.btn-group+.btn-group{margin-top:-1px;margin-left:0}.btn-group-vertical>.btn-group:not(:last-child)>.btn,.btn-group-vertical>.btn:not(:last-child):not(.dropdown-toggle){border-bottom-right-radius:0;border-bottom-left-radius:0}.btn-group-vertical>.btn-group:not(:first-child)>.btn,.btn-group-vertical>.btn:not(:first-child){border-top-left-radius:0;border-top-right-radius:0}.btn-group-toggle>.btn,.btn-group-toggle>.btn-group>.btn{margin-bottom:0}.btn-group-toggle>.btn input[type=checkbox],.btn-group-toggle>.btn input[type=radio],.btn-group-toggle>.btn-group>.btn input[type=checkbox],.btn-group-toggle>.btn-group>.btn input[type=radio]{position:absolute;clip:rect(0,0,0,0);pointer-events:none}.input-group{position:relative;display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;-ms-flex-align:stretch;align-items:stretch;width:100%}.input-group>.custom-file,.input-group>.custom-select,.input-group>.form-control{position:relative;-ms-flex:1 1 auto;flex:1 1 auto;width:1%;margin-bottom:0}.input-group>.custom-file:focus,.input-group>.custom-select:focus,.input-group>.form-control:focus{z-index:3}.input-group>.custom-file+.custom-file,.input-group>.custom-file+.custom-select,.input-group>.custom-file+.form-control,.input-group>.custom-select+.custom-file,.input-group>.custom-select+.custom-select,.input-group>.custom-select+.form-control,.input-group>.form-control+.custom-file,.input-group>.form-control+.custom-select,.input-group>.form-control+.form-control{margin-left:-1px}.input-group>.custom-select:not(:last-child),.input-group>.form-control:not(:last-child){border-top-right-radius:0;border-bottom-right-radius:0}.input-group>.custom-select:not(:first-child),.input-group>.form-control:not(:first-child){border-top-left-radius:0;border-bottom-left-radius:0}.input-group>.custom-file{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center}.input-group>.custom-file:not(:last-child) .custom-file-label,.input-group>.custom-file:not(:last-child) .custom-file-label::after{border-top-right-radius:0;border-bottom-right-radius:0}.input-group>.custom-file:not(:first-child) .custom-file-label{border-top-left-radius:0;border-bottom-left-radius:0}.input-group-append,.input-group-prepend{display:-ms-flexbox;display:flex}.input-group-append .btn,.input-group-prepend .btn{position:relative;z-index:2}.input-group-append .btn+.btn,.input-group-append .btn+.input-group-text,.input-group-append .input-group-text+.btn,.input-group-append .input-group-text+.input-group-text,.input-group-prepend .btn+.btn,.input-group-prepend .btn+.input-group-text,.input-group-prepend .input-group-text+.btn,.input-group-prepend .input-group-text+.input-group-text{margin-left:-1px}.input-group-prepend{margin-right:-1px}.input-group-append{margin-left:-1px}.input-group-text{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;padding:.375rem .75rem;margin-bottom:0;font-size:1rem;font-weight:400;line-height:1.5;color:#495057;text-align:center;white-space:nowrap;background-color:#e9ecef;border:1px solid #ced4da;border-radius:.25rem}.input-group-text input[type=checkbox],.input-group-text input[type=radio]{margin-top:0}.input-group>.input-group-append:last-child>.btn:not(:last-child):not(.dropdown-toggle),.input-group>.input-group-append:last-child>.input-group-text:not(:last-child),.input-group>.input-group-append:not(:last-child)>.btn,.input-group>.input-group-append:not(:last-child)>.input-group-text,.input-group>.input-group-prepend>.btn,.input-group>.input-group-prepend>.input-group-text{border-top-right-radius:0;border-bottom-right-radius:0}.input-group>.input-group-append>.btn,.input-group>.input-group-append>.input-group-text,.input-group>.input-group-prepend:first-child>.btn:not(:first-child),.input-group>.input-group-prepend:first-child>.input-group-text:not(:first-child),.input-group>.input-group-prepend:not(:first-child)>.btn,.input-group>.input-group-prepend:not(:first-child)>.input-group-text{border-top-left-radius:0;border-bottom-left-radius:0}.custom-control{position:relative;display:block;min-height:1.5rem;padding-left:1.5rem}.custom-control-inline{display:-ms-inline-flexbox;display:inline-flex;margin-right:1rem}.custom-control-input{position:absolute;z-index:-1;opacity:0}.custom-control-input:checked~.custom-control-label::before{color:#fff;background-color:#007bff}.custom-control-input:focus~.custom-control-label::before{box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(0,123,255,.25)}.custom-control-input:active~.custom-control-label::before{color:#fff;background-color:#b3d7ff}.custom-control-input:disabled~.custom-control-label{color:#6c757d}.custom-control-input:disabled~.custom-control-label::before{background-color:#e9ecef}.custom-control-label{position:relative;margin-bottom:0}.custom-control-label::before{position:absolute;top:.25rem;left:-1.5rem;display:block;width:1rem;height:1rem;pointer-events:none;content:"";-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none;background-color:#dee2e6}.custom-control-label::after{position:absolute;top:.25rem;left:-1.5rem;display:block;width:1rem;height:1rem;content:"";background-repeat:no-repeat;background-position:center center;background-size:50% 50%}.custom-checkbox .custom-control-label::before{border-radius:.25rem}.custom-checkbox .custom-control-input:checked~.custom-control-label::before{background-color:#007bff}.custom-checkbox .custom-control-input:checked~.custom-control-label::after{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 8 8'%3E%3Cpath fill='%23fff' d='M6.564.75l-3.59 3.612-1.538-1.55L0 4.26 2.974 7.25 8 2.193z'/%3E%3C/svg%3E")}.custom-checkbox .custom-control-input:indeterminate~.custom-control-label::before{background-color:#007bff}.custom-checkbox .custom-control-input:indeterminate~.custom-control-label::after{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 4 4'%3E%3Cpath stroke='%23fff' d='M0 2h4'/%3E%3C/svg%3E")}.custom-checkbox .custom-control-input:disabled:checked~.custom-control-label::before{background-color:rgba(0,123,255,.5)}.custom-checkbox .custom-control-input:disabled:indeterminate~.custom-control-label::before{background-color:rgba(0,123,255,.5)}.custom-radio .custom-control-label::before{border-radius:50%}.custom-radio .custom-control-input:checked~.custom-control-label::before{background-color:#007bff}.custom-radio .custom-control-input:checked~.custom-control-label::after{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='-4 -4 8 8'%3E%3Ccircle r='3' fill='%23fff'/%3E%3C/svg%3E")}.custom-radio .custom-control-input:disabled:checked~.custom-control-label::before{background-color:rgba(0,123,255,.5)}.custom-select{display:inline-block;width:100%;height:calc(2.25rem + 2px);padding:.375rem 1.75rem .375rem .75rem;line-height:1.5;color:#495057;vertical-align:middle;background:#fff url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 4 5'%3E%3Cpath fill='%23343a40' d='M2 0L0 2h4zm0 5L0 3h4z'/%3E%3C/svg%3E") no-repeat right .75rem center;background-size:8px 10px;border:1px solid #ced4da;border-radius:.25rem;-webkit-appearance:none;-moz-appearance:none;appearance:none}.custom-select:focus{border-color:#80bdff;outline:0;box-shadow:inset 0 1px 2px rgba(0,0,0,.075),0 0 5px rgba(128,189,255,.5)}.custom-select:focus::-ms-value{color:#495057;background-color:#fff}.custom-select[multiple],.custom-select[size]:not([size="1"]){height:auto;padding-right:.75rem;background-image:none}.custom-select:disabled{color:#6c757d;background-color:#e9ecef}.custom-select::-ms-expand{opacity:0}.custom-select-sm{height:calc(1.8125rem + 2px);padding-top:.375rem;padding-bottom:.375rem;font-size:75%}.custom-select-lg{height:calc(2.875rem + 2px);padding-top:.375rem;padding-bottom:.375rem;font-size:125%}.custom-file{position:relative;display:inline-block;width:100%;height:calc(2.25rem + 2px);margin-bottom:0}.custom-file-input{position:relative;z-index:2;width:100%;height:calc(2.25rem + 2px);margin:0;opacity:0}.custom-file-input:focus~.custom-file-label{border-color:#80bdff;box-shadow:0 0 0 .2rem rgba(0,123,255,.25)}.custom-file-input:focus~.custom-file-label::after{border-color:#80bdff}.custom-file-input:lang(en)~.custom-file-label::after{content:"Browse"}.custom-file-label{position:absolute;top:0;right:0;left:0;z-index:1;height:calc(2.25rem + 2px);padding:.375rem .75rem;line-height:1.5;color:#495057;background-color:#fff;border:1px solid #ced4da;border-radius:.25rem}.custom-file-label::after{position:absolute;top:0;right:0;bottom:0;z-index:3;display:block;height:2.25rem;padding:.375rem .75rem;line-height:1.5;color:#495057;content:"Browse";background-color:#e9ecef;border-left:1px solid #ced4da;border-radius:0 .25rem .25rem 0}.custom-range{width:100%;padding-left:0;background-color:transparent;-webkit-appearance:none;-moz-appearance:none;appearance:none}.custom-range:focus{outline:0}.custom-range::-moz-focus-outer{border:0}.custom-range::-webkit-slider-thumb{width:1rem;height:1rem;margin-top:-.25rem;background-color:#007bff;border:0;border-radius:1rem;-webkit-appearance:none;appearance:none}.custom-range::-webkit-slider-thumb:focus{outline:0;box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(0,123,255,.25)}.custom-range::-webkit-slider-thumb:active{background-color:#b3d7ff}.custom-range::-webkit-slider-runnable-track{width:100%;height:.5rem;color:transparent;cursor:pointer;background-color:#dee2e6;border-color:transparent;border-radius:1rem}.custom-range::-moz-range-thumb{width:1rem;height:1rem;background-color:#007bff;border:0;border-radius:1rem;-moz-appearance:none;appearance:none}.custom-range::-moz-range-thumb:focus{outline:0;box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(0,123,255,.25)}.custom-range::-moz-range-thumb:active{background-color:#b3d7ff}.custom-range::-moz-range-track{width:100%;height:.5rem;color:transparent;cursor:pointer;background-color:#dee2e6;border-color:transparent;border-radius:1rem}.custom-range::-ms-thumb{width:1rem;height:1rem;background-color:#007bff;border:0;border-radius:1rem;appearance:none}.custom-range::-ms-thumb:focus{outline:0;box-shadow:0 0 0 1px #fff,0 0 0 .2rem rgba(0,123,255,.25)}.custom-range::-ms-thumb:active{background-color:#b3d7ff}.custom-range::-ms-track{width:100%;height:.5rem;color:transparent;cursor:pointer;background-color:transparent;border-color:transparent;border-width:.5rem}.custom-range::-ms-fill-lower{background-color:#dee2e6;border-radius:1rem}.custom-range::-ms-fill-upper{margin-right:15px;background-color:#dee2e6;border-radius:1rem}.nav{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;padding-left:0;margin-bottom:0;list-style:none}.nav-link{display:block;padding:.5rem 1rem}.nav-link:focus,.nav-link:hover{text-decoration:none}.nav-link.disabled{color:#6c757d}.nav-tabs{border-bottom:1px solid #dee2e6}.nav-tabs .nav-item{margin-bottom:-1px}.nav-tabs .nav-link{border:1px solid transparent;border-top-left-radius:.25rem;border-top-right-radius:.25rem}.nav-tabs .nav-link:focus,.nav-tabs .nav-link:hover{border-color:#e9ecef #e9ecef #dee2e6}.nav-tabs .nav-link.disabled{color:#6c757d;background-color:transparent;border-color:transparent}.nav-tabs .nav-item.show .nav-link,.nav-tabs .nav-link.active{color:#495057;background-color:#fff;border-color:#dee2e6 #dee2e6 #fff}.nav-tabs .dropdown-menu{margin-top:-1px;border-top-left-radius:0;border-top-right-radius:0}.nav-pills .nav-link{border-radius:.25rem}.nav-pills .nav-link.active,.nav-pills .show>.nav-link{color:#fff;background-color:#007bff}.nav-fill .nav-item{-ms-flex:1 1 auto;flex:1 1 auto;text-align:center}.nav-justified .nav-item{-ms-flex-preferred-size:0;flex-basis:0;-ms-flex-positive:1;flex-grow:1;text-align:center}.tab-content>.tab-pane{display:none}.tab-content>.active{display:block}.navbar{position:relative;display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;-ms-flex-align:center;align-items:center;-ms-flex-pack:justify;justify-content:space-between;padding:.5rem 1rem}.navbar>.container,.navbar>.container-fluid{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;-ms-flex-align:center;align-items:center;-ms-flex-pack:justify;justify-content:space-between}.navbar-brand{display:inline-block;padding-top:.3125rem;padding-bottom:.3125rem;margin-right:1rem;font-size:1.25rem;line-height:inherit;white-space:nowrap}.navbar-brand:focus,.navbar-brand:hover{text-decoration:none}.navbar-nav{display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;padding-left:0;margin-bottom:0;list-style:none}.navbar-nav .nav-link{padding-right:0;padding-left:0}.navbar-nav .dropdown-menu{position:static;float:none}.navbar-text{display:inline-block;padding-top:.5rem;padding-bottom:.5rem}.navbar-collapse{-ms-flex-preferred-size:100%;flex-basis:100%;-ms-flex-positive:1;flex-grow:1;-ms-flex-align:center;align-items:center}.navbar-toggler{padding:.25rem .75rem;font-size:1.25rem;line-height:1;background-color:transparent;border:1px solid transparent;border-radius:.25rem}.navbar-toggler:focus,.navbar-toggler:hover{text-decoration:none}.navbar-toggler:not(:disabled):not(.disabled){cursor:pointer}.navbar-toggler-icon{display:inline-block;width:1.5em;height:1.5em;vertical-align:middle;content:"";background:no-repeat center center;background-size:100% 100%}@media (max-width:575.98px){.navbar-expand-sm>.container,.navbar-expand-sm>.container-fluid{padding-right:0;padding-left:0}}@media (min-width:576px){.navbar-expand-sm{-ms-flex-flow:row nowrap;flex-flow:row nowrap;-ms-flex-pack:start;justify-content:flex-start}.navbar-expand-sm .navbar-nav{-ms-flex-direction:row;flex-direction:row}.navbar-expand-sm .navbar-nav .dropdown-menu{position:absolute}.navbar-expand-sm .navbar-nav .nav-link{padding-right:.5rem;padding-left:.5rem}.navbar-expand-sm>.container,.navbar-expand-sm>.container-fluid{-ms-flex-wrap:nowrap;flex-wrap:nowrap}.navbar-expand-sm .navbar-collapse{display:-ms-flexbox!important;display:flex!important;-ms-flex-preferred-size:auto;flex-basis:auto}.navbar-expand-sm .navbar-toggler{display:none}}@media (max-width:767.98px){.navbar-expand-md>.container,.navbar-expand-md>.container-fluid{padding-right:0;padding-left:0}}@media (min-width:768px){.navbar-expand-md{-ms-flex-flow:row nowrap;flex-flow:row nowrap;-ms-flex-pack:start;justify-content:flex-start}.navbar-expand-md .navbar-nav{-ms-flex-direction:row;flex-direction:row}.navbar-expand-md .navbar-nav .dropdown-menu{position:absolute}.navbar-expand-md .navbar-nav .nav-link{padding-right:.5rem;padding-left:.5rem}.navbar-expand-md>.container,.navbar-expand-md>.container-fluid{-ms-flex-wrap:nowrap;flex-wrap:nowrap}.navbar-expand-md .navbar-collapse{display:-ms-flexbox!important;display:flex!important;-ms-flex-preferred-size:auto;flex-basis:auto}.navbar-expand-md .navbar-toggler{display:none}}@media (max-width:991.98px){.navbar-expand-lg>.container,.navbar-expand-lg>.container-fluid{padding-right:0;padding-left:0}}@media (min-width:992px){.navbar-expand-lg{-ms-flex-flow:row nowrap;flex-flow:row nowrap;-ms-flex-pack:start;justify-content:flex-start}.navbar-expand-lg .navbar-nav{-ms-flex-direction:row;flex-direction:row}.navbar-expand-lg .navbar-nav .dropdown-menu{position:absolute}.navbar-expand-lg .navbar-nav .nav-link{padding-right:.5rem;padding-left:.5rem}.navbar-expand-lg>.container,.navbar-expand-lg>.container-fluid{-ms-flex-wrap:nowrap;flex-wrap:nowrap}.navbar-expand-lg .navbar-collapse{display:-ms-flexbox!important;display:flex!important;-ms-flex-preferred-size:auto;flex-basis:auto}.navbar-expand-lg .navbar-toggler{display:none}}@media (max-width:1199.98px){.navbar-expand-xl>.container,.navbar-expand-xl>.container-fluid{padding-right:0;padding-left:0}}@media (min-width:1200px){.navbar-expand-xl{-ms-flex-flow:row nowrap;flex-flow:row nowrap;-ms-flex-pack:start;justify-content:flex-start}.navbar-expand-xl .navbar-nav{-ms-flex-direction:row;flex-direction:row}.navbar-expand-xl .navbar-nav .dropdown-menu{position:absolute}.navbar-expand-xl .navbar-nav .nav-link{padding-right:.5rem;padding-left:.5rem}.navbar-expand-xl>.container,.navbar-expand-xl>.container-fluid{-ms-flex-wrap:nowrap;flex-wrap:nowrap}.navbar-expand-xl .navbar-collapse{display:-ms-flexbox!important;display:flex!important;-ms-flex-preferred-size:auto;flex-basis:auto}.navbar-expand-xl .navbar-toggler{display:none}}.navbar-expand{-ms-flex-flow:row nowrap;flex-flow:row nowrap;-ms-flex-pack:start;justify-content:flex-start}.navbar-expand>.container,.navbar-expand>.container-fluid{padding-right:0;padding-left:0}.navbar-expand .navbar-nav{-ms-flex-direction:row;flex-direction:row}.navbar-expand .navbar-nav .dropdown-menu{position:absolute}.navbar-expand .navbar-nav .nav-link{padding-right:.5rem;padding-left:.5rem}.navbar-expand>.container,.navbar-expand>.container-fluid{-ms-flex-wrap:nowrap;flex-wrap:nowrap}.navbar-expand .navbar-collapse{display:-ms-flexbox!important;display:flex!important;-ms-flex-preferred-size:auto;flex-basis:auto}.navbar-expand .navbar-toggler{display:none}.navbar-light .navbar-brand{color:rgba(0,0,0,.9)}.navbar-light .navbar-brand:focus,.navbar-light .navbar-brand:hover{color:rgba(0,0,0,.9)}.navbar-light .navbar-nav .nav-link{color:rgba(0,0,0,.5)}.navbar-light .navbar-nav .nav-link:focus,.navbar-light .navbar-nav .nav-link:hover{color:rgba(0,0,0,.7)}.navbar-light .navbar-nav .nav-link.disabled{color:rgba(0,0,0,.3)}.navbar-light .navbar-nav .active>.nav-link,.navbar-light .navbar-nav .nav-link.active,.navbar-light .navbar-nav .nav-link.show,.navbar-light .navbar-nav .show>.nav-link{color:rgba(0,0,0,.9)}.navbar-light .navbar-toggler{color:rgba(0,0,0,.5);border-color:rgba(0,0,0,.1)}.navbar-light .navbar-toggler-icon{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg viewBox='0 0 30 30' xmlns='http://www.w3.org/2000/svg'%3E%3Cpath stroke='rgba(0, 0, 0, 0.5)' stroke-width='2' stroke-linecap='round' stroke-miterlimit='10' d='M4 7h22M4 15h22M4 23h22'/%3E%3C/svg%3E")}.navbar-light .navbar-text{color:rgba(0,0,0,.5)}.navbar-light .navbar-text a{color:rgba(0,0,0,.9)}.navbar-light .navbar-text a:focus,.navbar-light .navbar-text a:hover{color:rgba(0,0,0,.9)}.navbar-dark .navbar-brand{color:#fff}.navbar-dark .navbar-brand:focus,.navbar-dark .navbar-brand:hover{color:#fff}.navbar-dark .navbar-nav .nav-link{color:rgba(255,255,255,.5)}.navbar-dark .navbar-nav .nav-link:focus,.navbar-dark .navbar-nav .nav-link:hover{color:rgba(255,255,255,.75)}.navbar-dark .navbar-nav .nav-link.disabled{color:rgba(255,255,255,.25)}.navbar-dark .navbar-nav .active>.nav-link,.navbar-dark .navbar-nav .nav-link.active,.navbar-dark .navbar-nav .nav-link.show,.navbar-dark .navbar-nav .show>.nav-link{color:#fff}.navbar-dark .navbar-toggler{color:rgba(255,255,255,.5);border-color:rgba(255,255,255,.1)}.navbar-dark .navbar-toggler-icon{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg viewBox='0 0 30 30' xmlns='http://www.w3.org/2000/svg'%3E%3Cpath stroke='rgba(255, 255, 255, 0.5)' stroke-width='2' stroke-linecap='round' stroke-miterlimit='10' d='M4 7h22M4 15h22M4 23h22'/%3E%3C/svg%3E")}.navbar-dark .navbar-text{color:rgba(255,255,255,.5)}.navbar-dark .navbar-text a{color:#fff}.navbar-dark .navbar-text a:focus,.navbar-dark .navbar-text a:hover{color:#fff}.card{position:relative;display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;min-width:0;word-wrap:break-word;background-color:#fff;background-clip:border-box;border:1px solid rgba(0,0,0,.125);border-radius:.25rem}.card>hr{margin-right:0;margin-left:0}.card>.list-group:first-child .list-group-item:first-child{border-top-left-radius:.25rem;border-top-right-radius:.25rem}.card>.list-group:last-child .list-group-item:last-child{border-bottom-right-radius:.25rem;border-bottom-left-radius:.25rem}.card-body{-ms-flex:1 1 auto;flex:1 1 auto;padding:1.25rem}.card-title{margin-bottom:.75rem}.card-subtitle{margin-top:-.375rem;margin-bottom:0}.card-text:last-child{margin-bottom:0}.card-link:hover{text-decoration:none}.card-link+.card-link{margin-left:1.25rem}.card-header{padding:.75rem 1.25rem;margin-bottom:0;background-color:rgba(0,0,0,.03);border-bottom:1px solid rgba(0,0,0,.125)}.card-header:first-child{border-radius:calc(.25rem - 1px) calc(.25rem - 1px) 0 0}.card-header+.list-group .list-group-item:first-child{border-top:0}.card-footer{padding:.75rem 1.25rem;background-color:rgba(0,0,0,.03);border-top:1px solid rgba(0,0,0,.125)}.card-footer:last-child{border-radius:0 0 calc(.25rem - 1px) calc(.25rem - 1px)}.card-header-tabs{margin-right:-.625rem;margin-bottom:-.75rem;margin-left:-.625rem;border-bottom:0}.card-header-pills{margin-right:-.625rem;margin-left:-.625rem}.card-img-overlay{position:absolute;top:0;right:0;bottom:0;left:0;padding:1.25rem}.card-img{width:100%;border-radius:calc(.25rem - 1px)}.card-img-top{width:100%;border-top-left-radius:calc(.25rem - 1px);border-top-right-radius:calc(.25rem - 1px)}.card-img-bottom{width:100%;border-bottom-right-radius:calc(.25rem - 1px);border-bottom-left-radius:calc(.25rem - 1px)}.card-deck{display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column}.card-deck .card{margin-bottom:15px}@media (min-width:576px){.card-deck{-ms-flex-flow:row wrap;flex-flow:row wrap;margin-right:-15px;margin-left:-15px}.card-deck .card{display:-ms-flexbox;display:flex;-ms-flex:1 0 0%;flex:1 0 0%;-ms-flex-direction:column;flex-direction:column;margin-right:15px;margin-bottom:0;margin-left:15px}}.card-group{display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column}.card-group>.card{margin-bottom:15px}@media (min-width:576px){.card-group{-ms-flex-flow:row wrap;flex-flow:row wrap}.card-group>.card{-ms-flex:1 0 0%;flex:1 0 0%;margin-bottom:0}.card-group>.card+.card{margin-left:0;border-left:0}.card-group>.card:first-child{border-top-right-radius:0;border-bottom-right-radius:0}.card-group>.card:first-child .card-header,.card-group>.card:first-child .card-img-top{border-top-right-radius:0}.card-group>.card:first-child .card-footer,.card-group>.card:first-child .card-img-bottom{border-bottom-right-radius:0}.card-group>.card:last-child{border-top-left-radius:0;border-bottom-left-radius:0}.card-group>.card:last-child .card-header,.card-group>.card:last-child .card-img-top{border-top-left-radius:0}.card-group>.card:last-child .card-footer,.card-group>.card:last-child .card-img-bottom{border-bottom-left-radius:0}.card-group>.card:only-child{border-radius:.25rem}.card-group>.card:only-child .card-header,.card-group>.card:only-child .card-img-top{border-top-left-radius:.25rem;border-top-right-radius:.25rem}.card-group>.card:only-child .card-footer,.card-group>.card:only-child .card-img-bottom{border-bottom-right-radius:.25rem;border-bottom-left-radius:.25rem}.card-group>.card:not(:first-child):not(:last-child):not(:only-child){border-radius:0}.card-group>.card:not(:first-child):not(:last-child):not(:only-child) .card-footer,.card-group>.card:not(:first-child):not(:last-child):not(:only-child) .card-header,.card-group>.card:not(:first-child):not(:last-child):not(:only-child) .card-img-bottom,.card-group>.card:not(:first-child):not(:last-child):not(:only-child) .card-img-top{border-radius:0}}.card-columns .card{margin-bottom:.75rem}@media (min-width:576px){.card-columns{-webkit-column-count:3;-moz-column-count:3;column-count:3;-webkit-column-gap:1.25rem;-moz-column-gap:1.25rem;column-gap:1.25rem;orphans:1;widows:1}.card-columns .card{display:inline-block;width:100%}}.accordion .card:not(:first-of-type):not(:last-of-type){border-bottom:0;border-radius:0}.accordion .card:not(:first-of-type) .card-header:first-child{border-radius:0}.accordion .card:first-of-type{border-bottom:0;border-bottom-right-radius:0;border-bottom-left-radius:0}.accordion .card:last-of-type{border-top-left-radius:0;border-top-right-radius:0}.breadcrumb{display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;padding:.75rem 1rem;margin-bottom:1rem;list-style:none;background-color:#e9ecef;border-radius:.25rem}.breadcrumb-item+.breadcrumb-item{padding-left:.5rem}.breadcrumb-item+.breadcrumb-item::before{display:inline-block;padding-right:.5rem;color:#6c757d;content:"/"}.breadcrumb-item+.breadcrumb-item:hover::before{text-decoration:underline}.breadcrumb-item+.breadcrumb-item:hover::before{text-decoration:none}.breadcrumb-item.active{color:#6c757d}.pagination{display:-ms-flexbox;display:flex;padding-left:0;list-style:none;border-radius:.25rem}.page-link{position:relative;display:block;padding:.5rem .75rem;margin-left:-1px;line-height:1.25;color:#007bff;background-color:#fff;border:1px solid #dee2e6}.page-link:hover{z-index:2;color:#0056b3;text-decoration:none;background-color:#e9ecef;border-color:#dee2e6}.page-link:focus{z-index:2;outline:0;box-shadow:0 0 0 .2rem rgba(0,123,255,.25)}.page-link:not(:disabled):not(.disabled){cursor:pointer}.page-item:first-child .page-link{margin-left:0;border-top-left-radius:.25rem;border-bottom-left-radius:.25rem}.page-item:last-child .page-link{border-top-right-radius:.25rem;border-bottom-right-radius:.25rem}.page-item.active .page-link{z-index:1;color:#fff;background-color:#007bff;border-color:#007bff}.page-item.disabled .page-link{color:#6c757d;pointer-events:none;cursor:auto;background-color:#fff;border-color:#dee2e6}.pagination-lg .page-link{padding:.75rem 1.5rem;font-size:1.25rem;line-height:1.5}.pagination-lg .page-item:first-child .page-link{border-top-left-radius:.3rem;border-bottom-left-radius:.3rem}.pagination-lg .page-item:last-child .page-link{border-top-right-radius:.3rem;border-bottom-right-radius:.3rem}.pagination-sm .page-link{padding:.25rem .5rem;font-size:.875rem;line-height:1.5}.pagination-sm .page-item:first-child .page-link{border-top-left-radius:.2rem;border-bottom-left-radius:.2rem}.pagination-sm .page-item:last-child .page-link{border-top-right-radius:.2rem;border-bottom-right-radius:.2rem}.badge{display:inline-block;padding:.25em .4em;font-size:75%;font-weight:700;line-height:1;text-align:center;white-space:nowrap;vertical-align:baseline;border-radius:.25rem}.badge:empty{display:none}.btn .badge{position:relative;top:-1px}.badge-pill{padding-right:.6em;padding-left:.6em;border-radius:10rem}.badge-primary{color:#fff;background-color:#007bff}.badge-primary[href]:focus,.badge-primary[href]:hover{color:#fff;text-decoration:none;background-color:#0062cc}.badge-secondary{color:#fff;background-color:#6c757d}.badge-secondary[href]:focus,.badge-secondary[href]:hover{color:#fff;text-decoration:none;background-color:#545b62}.badge-success{color:#fff;background-color:#28a745}.badge-success[href]:focus,.badge-success[href]:hover{color:#fff;text-decoration:none;background-color:#1e7e34}.badge-info{color:#fff;background-color:#17a2b8}.badge-info[href]:focus,.badge-info[href]:hover{color:#fff;text-decoration:none;background-color:#117a8b}.badge-warning{color:#212529;background-color:#ffc107}.badge-warning[href]:focus,.badge-warning[href]:hover{color:#212529;text-decoration:none;background-color:#d39e00}.badge-danger{color:#fff;background-color:#dc3545}.badge-danger[href]:focus,.badge-danger[href]:hover{color:#fff;text-decoration:none;background-color:#bd2130}.badge-light{color:#212529;background-color:#f8f9fa}.badge-light[href]:focus,.badge-light[href]:hover{color:#212529;text-decoration:none;background-color:#dae0e5}.badge-dark{color:#fff;background-color:#343a40}.badge-dark[href]:focus,.badge-dark[href]:hover{color:#fff;text-decoration:none;background-color:#1d2124}.jumbotron{padding:2rem 1rem;margin-bottom:2rem;background-color:#e9ecef;border-radius:.3rem}@media (min-width:576px){.jumbotron{padding:4rem 2rem}}.jumbotron-fluid{padding-right:0;padding-left:0;border-radius:0}.alert{position:relative;padding:.75rem 1.25rem;margin-bottom:1rem;border:1px solid transparent;border-radius:.25rem}.alert-heading{color:inherit}.alert-link{font-weight:700}.alert-dismissible{padding-right:4rem}.alert-dismissible .close{position:absolute;top:0;right:0;padding:.75rem 1.25rem;color:inherit}.alert-primary{color:#004085;background-color:#cce5ff;border-color:#b8daff}.alert-primary hr{border-top-color:#9fcdff}.alert-primary .alert-link{color:#002752}.alert-secondary{color:#383d41;background-color:#e2e3e5;border-color:#d6d8db}.alert-secondary hr{border-top-color:#c8cbcf}.alert-secondary .alert-link{color:#202326}.alert-success{color:#155724;background-color:#d4edda;border-color:#c3e6cb}.alert-success hr{border-top-color:#b1dfbb}.alert-success .alert-link{color:#0b2e13}.alert-info{color:#0c5460;background-color:#d1ecf1;border-color:#bee5eb}.alert-info hr{border-top-color:#abdde5}.alert-info .alert-link{color:#062c33}.alert-warning{color:#856404;background-color:#fff3cd;border-color:#ffeeba}.alert-warning hr{border-top-color:#ffe8a1}.alert-warning .alert-link{color:#533f03}.alert-danger{color:#721c24;background-color:#f8d7da;border-color:#f5c6cb}.alert-danger hr{border-top-color:#f1b0b7}.alert-danger .alert-link{color:#491217}.alert-light{color:#818182;background-color:#fefefe;border-color:#fdfdfe}.alert-light hr{border-top-color:#ececf6}.alert-light .alert-link{color:#686868}.alert-dark{color:#1b1e21;background-color:#d6d8d9;border-color:#c6c8ca}.alert-dark hr{border-top-color:#b9bbbe}.alert-dark .alert-link{color:#040505}@-webkit-keyframes progress-bar-stripes{from{background-position:1rem 0}to{background-position:0 0}}@keyframes progress-bar-stripes{from{background-position:1rem 0}to{background-position:0 0}}.progress{display:-ms-flexbox;display:flex;height:1rem;overflow:hidden;font-size:.75rem;background-color:#e9ecef;border-radius:.25rem}.progress-bar{display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;-ms-flex-pack:center;justify-content:center;color:#fff;text-align:center;white-space:nowrap;background-color:#007bff;transition:width .6s ease}@media screen and (prefers-reduced-motion:reduce){.progress-bar{transition:none}}.progress-bar-striped{background-image:linear-gradient(45deg,rgba(255,255,255,.15) 25%,transparent 25%,transparent 50%,rgba(255,255,255,.15) 50%,rgba(255,255,255,.15) 75%,transparent 75%,transparent);background-size:1rem 1rem}.progress-bar-animated{-webkit-animation:progress-bar-stripes 1s linear infinite;animation:progress-bar-stripes 1s linear infinite}.media{display:-ms-flexbox;display:flex;-ms-flex-align:start;align-items:flex-start}.media-body{-ms-flex:1;flex:1}.list-group{display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;padding-left:0;margin-bottom:0}.list-group-item-action{width:100%;color:#495057;text-align:inherit}.list-group-item-action:focus,.list-group-item-action:hover{color:#495057;text-decoration:none;background-color:#f8f9fa}.list-group-item-action:active{color:#212529;background-color:#e9ecef}.list-group-item{position:relative;display:block;padding:.75rem 1.25rem;margin-bottom:-1px;background-color:#fff;border:1px solid rgba(0,0,0,.125)}.list-group-item:first-child{border-top-left-radius:.25rem;border-top-right-radius:.25rem}.list-group-item:last-child{margin-bottom:0;border-bottom-right-radius:.25rem;border-bottom-left-radius:.25rem}.list-group-item:focus,.list-group-item:hover{z-index:1;text-decoration:none}.list-group-item.disabled,.list-group-item:disabled{color:#6c757d;background-color:#fff}.list-group-item.active{z-index:2;color:#fff;background-color:#007bff;border-color:#007bff}.list-group-flush .list-group-item{border-right:0;border-left:0;border-radius:0}.list-group-flush:first-child .list-group-item:first-child{border-top:0}.list-group-flush:last-child .list-group-item:last-child{border-bottom:0}.list-group-item-primary{color:#004085;background-color:#b8daff}.list-group-item-primary.list-group-item-action:focus,.list-group-item-primary.list-group-item-action:hover{color:#004085;background-color:#9fcdff}.list-group-item-primary.list-group-item-action.active{color:#fff;background-color:#004085;border-color:#004085}.list-group-item-secondary{color:#383d41;background-color:#d6d8db}.list-group-item-secondary.list-group-item-action:focus,.list-group-item-secondary.list-group-item-action:hover{color:#383d41;background-color:#c8cbcf}.list-group-item-secondary.list-group-item-action.active{color:#fff;background-color:#383d41;border-color:#383d41}.list-group-item-success{color:#155724;background-color:#c3e6cb}.list-group-item-success.list-group-item-action:focus,.list-group-item-success.list-group-item-action:hover{color:#155724;background-color:#b1dfbb}.list-group-item-success.list-group-item-action.active{color:#fff;background-color:#155724;border-color:#155724}.list-group-item-info{color:#0c5460;background-color:#bee5eb}.list-group-item-info.list-group-item-action:focus,.list-group-item-info.list-group-item-action:hover{color:#0c5460;background-color:#abdde5}.list-group-item-info.list-group-item-action.active{color:#fff;background-color:#0c5460;border-color:#0c5460}.list-group-item-warning{color:#856404;background-color:#ffeeba}.list-group-item-warning.list-group-item-action:focus,.list-group-item-warning.list-group-item-action:hover{color:#856404;background-color:#ffe8a1}.list-group-item-warning.list-group-item-action.active{color:#fff;background-color:#856404;border-color:#856404}.list-group-item-danger{color:#721c24;background-color:#f5c6cb}.list-group-item-danger.list-group-item-action:focus,.list-group-item-danger.list-group-item-action:hover{color:#721c24;background-color:#f1b0b7}.list-group-item-danger.list-group-item-action.active{color:#fff;background-color:#721c24;border-color:#721c24}.list-group-item-light{color:#818182;background-color:#fdfdfe}.list-group-item-light.list-group-item-action:focus,.list-group-item-light.list-group-item-action:hover{color:#818182;background-color:#ececf6}.list-group-item-light.list-group-item-action.active{color:#fff;background-color:#818182;border-color:#818182}.list-group-item-dark{color:#1b1e21;background-color:#c6c8ca}.list-group-item-dark.list-group-item-action:focus,.list-group-item-dark.list-group-item-action:hover{color:#1b1e21;background-color:#b9bbbe}.list-group-item-dark.list-group-item-action.active{color:#fff;background-color:#1b1e21;border-color:#1b1e21}.close{float:right;font-size:1.5rem;font-weight:700;line-height:1;color:#000;text-shadow:0 1px 0 #fff;opacity:.5}.close:focus,.close:hover{color:#000;text-decoration:none;opacity:.75}.close:not(:disabled):not(.disabled){cursor:pointer}button.close{padding:0;background-color:transparent;border:0;-webkit-appearance:none}.modal-open{overflow:hidden}.modal{position:fixed;top:0;right:0;bottom:0;left:0;z-index:1050;display:none;overflow:hidden;outline:0}.modal-open .modal{overflow-x:hidden;overflow-y:auto}.modal-dialog{position:relative;width:auto;margin:.5rem;pointer-events:none}.modal.fade .modal-dialog{transition:-webkit-transform .3s ease-out;transition:transform .3s ease-out;transition:transform .3s ease-out,-webkit-transform .3s ease-out;-webkit-transform:translate(0,-25%);transform:translate(0,-25%)}@media screen and (prefers-reduced-motion:reduce){.modal.fade .modal-dialog{transition:none}}.modal.show .modal-dialog{-webkit-transform:translate(0,0);transform:translate(0,0)}.modal-dialog-centered{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;min-height:calc(100% - (.5rem * 2))}.modal-content{position:relative;display:-ms-flexbox;display:flex;-ms-flex-direction:column;flex-direction:column;width:100%;pointer-events:auto;background-color:#fff;background-clip:padding-box;border:1px solid rgba(0,0,0,.2);border-radius:.3rem;outline:0}.modal-backdrop{position:fixed;top:0;right:0;bottom:0;left:0;z-index:1040;background-color:#000}.modal-backdrop.fade{opacity:0}.modal-backdrop.show{opacity:.5}.modal-header{display:-ms-flexbox;display:flex;-ms-flex-align:start;align-items:flex-start;-ms-flex-pack:justify;justify-content:space-between;padding:1rem;border-bottom:1px solid #e9ecef;border-top-left-radius:.3rem;border-top-right-radius:.3rem}.modal-header .close{padding:1rem;margin:-1rem -1rem -1rem auto}.modal-title{margin-bottom:0;line-height:1.5}.modal-body{position:relative;-ms-flex:1 1 auto;flex:1 1 auto;padding:1rem}.modal-footer{display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;-ms-flex-pack:end;justify-content:flex-end;padding:1rem;border-top:1px solid #e9ecef}.modal-footer>:not(:first-child){margin-left:.25rem}.modal-footer>:not(:last-child){margin-right:.25rem}.modal-scrollbar-measure{position:absolute;top:-9999px;width:50px;height:50px;overflow:scroll}@media (min-width:576px){.modal-dialog{max-width:500px;margin:1.75rem auto}.modal-dialog-centered{min-height:calc(100% - (1.75rem * 2))}.modal-sm{max-width:300px}}@media (min-width:992px){.modal-lg{max-width:800px}}.tooltip{position:absolute;z-index:1070;display:block;margin:0;font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,sans-serif,"Apple Color Emoji","Segoe UI Emoji","Segoe UI Symbol";font-style:normal;font-weight:400;line-height:1.5;text-align:left;text-align:start;text-decoration:none;text-shadow:none;text-transform:none;letter-spacing:normal;word-break:normal;word-spacing:normal;white-space:normal;line-break:auto;font-size:.875rem;word-wrap:break-word;opacity:0}.tooltip.show{opacity:.9}.tooltip .arrow{position:absolute;display:block;width:.8rem;height:.4rem}.tooltip .arrow::before{position:absolute;content:"";border-color:transparent;border-style:solid}.bs-tooltip-auto[x-placement^=top],.bs-tooltip-top{padding:.4rem 0}.bs-tooltip-auto[x-placement^=top] .arrow,.bs-tooltip-top .arrow{bottom:0}.bs-tooltip-auto[x-placement^=top] .arrow::before,.bs-tooltip-top .arrow::before{top:0;border-width:.4rem .4rem 0;border-top-color:#000}.bs-tooltip-auto[x-placement^=right],.bs-tooltip-right{padding:0 .4rem}.bs-tooltip-auto[x-placement^=right] .arrow,.bs-tooltip-right .arrow{left:0;width:.4rem;height:.8rem}.bs-tooltip-auto[x-placement^=right] .arrow::before,.bs-tooltip-right .arrow::before{right:0;border-width:.4rem .4rem .4rem 0;border-right-color:#000}.bs-tooltip-auto[x-placement^=bottom],.bs-tooltip-bottom{padding:.4rem 0}.bs-tooltip-auto[x-placement^=bottom] .arrow,.bs-tooltip-bottom .arrow{top:0}.bs-tooltip-auto[x-placement^=bottom] .arrow::before,.bs-tooltip-bottom .arrow::before{bottom:0;border-width:0 .4rem .4rem;border-bottom-color:#000}.bs-tooltip-auto[x-placement^=left],.bs-tooltip-left{padding:0 .4rem}.bs-tooltip-auto[x-placement^=left] .arrow,.bs-tooltip-left .arrow{right:0;width:.4rem;height:.8rem}.bs-tooltip-auto[x-placement^=left] .arrow::before,.bs-tooltip-left .arrow::before{left:0;border-width:.4rem 0 .4rem .4rem;border-left-color:#000}.tooltip-inner{max-width:200px;padding:.25rem .5rem;color:#fff;text-align:center;background-color:#000;border-radius:.25rem}.popover{position:absolute;top:0;left:0;z-index:1060;display:block;max-width:276px;font-family:-apple-system,BlinkMacSystemFont,"Segoe UI",Roboto,"Helvetica Neue",Arial,sans-serif,"Apple Color Emoji","Segoe UI Emoji","Segoe UI Symbol";font-style:normal;font-weight:400;line-height:1.5;text-align:left;text-align:start;text-decoration:none;text-shadow:none;text-transform:none;letter-spacing:normal;word-break:normal;word-spacing:normal;white-space:normal;line-break:auto;font-size:.875rem;word-wrap:break-word;background-color:#fff;background-clip:padding-box;border:1px solid rgba(0,0,0,.2);border-radius:.3rem}.popover .arrow{position:absolute;display:block;width:1rem;height:.5rem;margin:0 .3rem}.popover .arrow::after,.popover .arrow::before{position:absolute;display:block;content:"";border-color:transparent;border-style:solid}.bs-popover-auto[x-placement^=top],.bs-popover-top{margin-bottom:.5rem}.bs-popover-auto[x-placement^=top] .arrow,.bs-popover-top .arrow{bottom:calc((.5rem + 1px) * -1)}.bs-popover-auto[x-placement^=top] .arrow::after,.bs-popover-auto[x-placement^=top] .arrow::before,.bs-popover-top .arrow::after,.bs-popover-top .arrow::before{border-width:.5rem .5rem 0}.bs-popover-auto[x-placement^=top] .arrow::before,.bs-popover-top .arrow::before{bottom:0;border-top-color:rgba(0,0,0,.25)}.bs-popover-auto[x-placement^=top] .arrow::after,.bs-popover-top .arrow::after{bottom:1px;border-top-color:#fff}.bs-popover-auto[x-placement^=right],.bs-popover-right{margin-left:.5rem}.bs-popover-auto[x-placement^=right] .arrow,.bs-popover-right .arrow{left:calc((.5rem + 1px) * -1);width:.5rem;height:1rem;margin:.3rem 0}.bs-popover-auto[x-placement^=right] .arrow::after,.bs-popover-auto[x-placement^=right] .arrow::before,.bs-popover-right .arrow::after,.bs-popover-right .arrow::before{border-width:.5rem .5rem .5rem 0}.bs-popover-auto[x-placement^=right] .arrow::before,.bs-popover-right .arrow::before{left:0;border-right-color:rgba(0,0,0,.25)}.bs-popover-auto[x-placement^=right] .arrow::after,.bs-popover-right .arrow::after{left:1px;border-right-color:#fff}.bs-popover-auto[x-placement^=bottom],.bs-popover-bottom{margin-top:.5rem}.bs-popover-auto[x-placement^=bottom] .arrow,.bs-popover-bottom .arrow{top:calc((.5rem + 1px) * -1)}.bs-popover-auto[x-placement^=bottom] .arrow::after,.bs-popover-auto[x-placement^=bottom] .arrow::before,.bs-popover-bottom .arrow::after,.bs-popover-bottom .arrow::before{border-width:0 .5rem .5rem .5rem}.bs-popover-auto[x-placement^=bottom] .arrow::before,.bs-popover-bottom .arrow::before{top:0;border-bottom-color:rgba(0,0,0,.25)}.bs-popover-auto[x-placement^=bottom] .arrow::after,.bs-popover-bottom .arrow::after{top:1px;border-bottom-color:#fff}.bs-popover-auto[x-placement^=bottom] .popover-header::before,.bs-popover-bottom .popover-header::before{position:absolute;top:0;left:50%;display:block;width:1rem;margin-left:-.5rem;content:"";border-bottom:1px solid #f7f7f7}.bs-popover-auto[x-placement^=left],.bs-popover-left{margin-right:.5rem}.bs-popover-auto[x-placement^=left] .arrow,.bs-popover-left .arrow{right:calc((.5rem + 1px) * -1);width:.5rem;height:1rem;margin:.3rem 0}.bs-popover-auto[x-placement^=left] .arrow::after,.bs-popover-auto[x-placement^=left] .arrow::before,.bs-popover-left .arrow::after,.bs-popover-left .arrow::before{border-width:.5rem 0 .5rem .5rem}.bs-popover-auto[x-placement^=left] .arrow::before,.bs-popover-left .arrow::before{right:0;border-left-color:rgba(0,0,0,.25)}.bs-popover-auto[x-placement^=left] .arrow::after,.bs-popover-left .arrow::after{right:1px;border-left-color:#fff}.popover-header{padding:.5rem .75rem;margin-bottom:0;font-size:1rem;color:inherit;background-color:#f7f7f7;border-bottom:1px solid #ebebeb;border-top-left-radius:calc(.3rem - 1px);border-top-right-radius:calc(.3rem - 1px)}.popover-header:empty{display:none}.popover-body{padding:.5rem .75rem;color:#212529}.carousel{position:relative}.carousel-inner{position:relative;width:100%;overflow:hidden}.carousel-item{position:relative;display:none;-ms-flex-align:center;align-items:center;width:100%;transition:-webkit-transform .6s ease;transition:transform .6s ease;transition:transform .6s ease,-webkit-transform .6s ease;-webkit-backface-visibility:hidden;backface-visibility:hidden;-webkit-perspective:1000px;perspective:1000px}@media screen and (prefers-reduced-motion:reduce){.carousel-item{transition:none}}.carousel-item-next,.carousel-item-prev,.carousel-item.active{display:block}.carousel-item-next,.carousel-item-prev{position:absolute;top:0}.carousel-item-next.carousel-item-left,.carousel-item-prev.carousel-item-right{-webkit-transform:translateX(0);transform:translateX(0)}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.carousel-item-next.carousel-item-left,.carousel-item-prev.carousel-item-right{-webkit-transform:translate3d(0,0,0);transform:translate3d(0,0,0)}}.active.carousel-item-right,.carousel-item-next{-webkit-transform:translateX(100%);transform:translateX(100%)}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.active.carousel-item-right,.carousel-item-next{-webkit-transform:translate3d(100%,0,0);transform:translate3d(100%,0,0)}}.active.carousel-item-left,.carousel-item-prev{-webkit-transform:translateX(-100%);transform:translateX(-100%)}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.active.carousel-item-left,.carousel-item-prev{-webkit-transform:translate3d(-100%,0,0);transform:translate3d(-100%,0,0)}}.carousel-fade .carousel-item{opacity:0;transition-duration:.6s;transition-property:opacity}.carousel-fade .carousel-item-next.carousel-item-left,.carousel-fade .carousel-item-prev.carousel-item-right,.carousel-fade .carousel-item.active{opacity:1}.carousel-fade .active.carousel-item-left,.carousel-fade .active.carousel-item-right{opacity:0}.carousel-fade .active.carousel-item-left,.carousel-fade .active.carousel-item-prev,.carousel-fade .carousel-item-next,.carousel-fade .carousel-item-prev,.carousel-fade .carousel-item.active{-webkit-transform:translateX(0);transform:translateX(0)}@supports ((-webkit-transform-style:preserve-3d) or (transform-style:preserve-3d)){.carousel-fade .active.carousel-item-left,.carousel-fade .active.carousel-item-prev,.carousel-fade .carousel-item-next,.carousel-fade .carousel-item-prev,.carousel-fade .carousel-item.active{-webkit-transform:translate3d(0,0,0);transform:translate3d(0,0,0)}}.carousel-control-next,.carousel-control-prev{position:absolute;top:0;bottom:0;display:-ms-flexbox;display:flex;-ms-flex-align:center;align-items:center;-ms-flex-pack:center;justify-content:center;width:15%;color:#fff;text-align:center;opacity:.5}.carousel-control-next:focus,.carousel-control-next:hover,.carousel-control-prev:focus,.carousel-control-prev:hover{color:#fff;text-decoration:none;outline:0;opacity:.9}.carousel-control-prev{left:0}.carousel-control-next{right:0}.carousel-control-next-icon,.carousel-control-prev-icon{display:inline-block;width:20px;height:20px;background:transparent no-repeat center center;background-size:100% 100%}.carousel-control-prev-icon{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' fill='%23fff' viewBox='0 0 8 8'%3E%3Cpath d='M5.25 0l-4 4 4 4 1.5-1.5-2.5-2.5 2.5-2.5-1.5-1.5z'/%3E%3C/svg%3E")}.carousel-control-next-icon{background-image:url("data:image/svg+xml;charset=utf8,%3Csvg xmlns='http://www.w3.org/2000/svg' fill='%23fff' viewBox='0 0 8 8'%3E%3Cpath d='M2.75 0l-1.5 1.5 2.5 2.5-2.5 2.5 1.5 1.5 4-4-4-4z'/%3E%3C/svg%3E")}.carousel-indicators{position:absolute;right:0;bottom:10px;left:0;z-index:15;display:-ms-flexbox;display:flex;-ms-flex-pack:center;justify-content:center;padding-left:0;margin-right:15%;margin-left:15%;list-style:none}.carousel-indicators li{position:relative;-ms-flex:0 1 auto;flex:0 1 auto;width:30px;height:3px;margin-right:3px;margin-left:3px;text-indent:-999px;cursor:pointer;background-color:rgba(255,255,255,.5)}.carousel-indicators li::before{position:absolute;top:-10px;left:0;display:inline-block;width:100%;height:10px;content:""}.carousel-indicators li::after{position:absolute;bottom:-10px;left:0;display:inline-block;width:100%;height:10px;content:""}.carousel-indicators .active{background-color:#fff}.carousel-caption{position:absolute;right:15%;bottom:20px;left:15%;z-index:10;padding-top:20px;padding-bottom:20px;color:#fff;text-align:center}.align-baseline{vertical-align:baseline!important}.align-top{vertical-align:top!important}.align-middle{vertical-align:middle!important}.align-bottom{vertical-align:bottom!important}.align-text-bottom{vertical-align:text-bottom!important}.align-text-top{vertical-align:text-top!important}.bg-primary{background-color:#007bff!important}a.bg-primary:focus,a.bg-primary:hover,button.bg-primary:focus,button.bg-primary:hover{background-color:#0062cc!important}.bg-secondary{background-color:#6c757d!important}a.bg-secondary:focus,a.bg-secondary:hover,button.bg-secondary:focus,button.bg-secondary:hover{background-color:#545b62!important}.bg-success{background-color:#28a745!important}a.bg-success:focus,a.bg-success:hover,button.bg-success:focus,button.bg-success:hover{background-color:#1e7e34!important}.bg-info{background-color:#17a2b8!important}a.bg-info:focus,a.bg-info:hover,button.bg-info:focus,button.bg-info:hover{background-color:#117a8b!important}.bg-warning{background-color:#ffc107!important}a.bg-warning:focus,a.bg-warning:hover,button.bg-warning:focus,button.bg-warning:hover{background-color:#d39e00!important}.bg-danger{background-color:#dc3545!important}a.bg-danger:focus,a.bg-danger:hover,button.bg-danger:focus,button.bg-danger:hover{background-color:#bd2130!important}.bg-light{background-color:#f8f9fa!important}a.bg-light:focus,a.bg-light:hover,button.bg-light:focus,button.bg-light:hover{background-color:#dae0e5!important}.bg-dark{background-color:#343a40!important}a.bg-dark:focus,a.bg-dark:hover,button.bg-dark:focus,button.bg-dark:hover{background-color:#1d2124!important}.bg-white{background-color:#fff!important}.bg-transparent{background-color:transparent!important}.border{border:1px solid #dee2e6!important}.border-top{border-top:1px solid #dee2e6!important}.border-right{border-right:1px solid #dee2e6!important}.border-bottom{border-bottom:1px solid #dee2e6!important}.border-left{border-left:1px solid #dee2e6!important}.border-0{border:0!important}.border-top-0{border-top:0!important}.border-right-0{border-right:0!important}.border-bottom-0{border-bottom:0!important}.border-left-0{border-left:0!important}.border-primary{border-color:#007bff!important}.border-secondary{border-color:#6c757d!important}.border-success{border-color:#28a745!important}.border-info{border-color:#17a2b8!important}.border-warning{border-color:#ffc107!important}.border-danger{border-color:#dc3545!important}.border-light{border-color:#f8f9fa!important}.border-dark{border-color:#343a40!important}.border-white{border-color:#fff!important}.rounded{border-radius:.25rem!important}.rounded-top{border-top-left-radius:.25rem!important;border-top-right-radius:.25rem!important}.rounded-right{border-top-right-radius:.25rem!important;border-bottom-right-radius:.25rem!important}.rounded-bottom{border-bottom-right-radius:.25rem!important;border-bottom-left-radius:.25rem!important}.rounded-left{border-top-left-radius:.25rem!important;border-bottom-left-radius:.25rem!important}.rounded-circle{border-radius:50%!important}.rounded-0{border-radius:0!important}.clearfix::after{display:block;clear:both;content:""}.d-none{display:none!important}.d-inline{display:inline!important}.d-inline-block{display:inline-block!important}.d-block{display:block!important}.d-table{display:table!important}.d-table-row{display:table-row!important}.d-table-cell{display:table-cell!important}.d-flex{display:-ms-flexbox!important;display:flex!important}.d-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}@media (min-width:576px){.d-sm-none{display:none!important}.d-sm-inline{display:inline!important}.d-sm-inline-block{display:inline-block!important}.d-sm-block{display:block!important}.d-sm-table{display:table!important}.d-sm-table-row{display:table-row!important}.d-sm-table-cell{display:table-cell!important}.d-sm-flex{display:-ms-flexbox!important;display:flex!important}.d-sm-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}}@media (min-width:768px){.d-md-none{display:none!important}.d-md-inline{display:inline!important}.d-md-inline-block{display:inline-block!important}.d-md-block{display:block!important}.d-md-table{display:table!important}.d-md-table-row{display:table-row!important}.d-md-table-cell{display:table-cell!important}.d-md-flex{display:-ms-flexbox!important;display:flex!important}.d-md-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}}@media (min-width:992px){.d-lg-none{display:none!important}.d-lg-inline{display:inline!important}.d-lg-inline-block{display:inline-block!important}.d-lg-block{display:block!important}.d-lg-table{display:table!important}.d-lg-table-row{display:table-row!important}.d-lg-table-cell{display:table-cell!important}.d-lg-flex{display:-ms-flexbox!important;display:flex!important}.d-lg-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}}@media (min-width:1200px){.d-xl-none{display:none!important}.d-xl-inline{display:inline!important}.d-xl-inline-block{display:inline-block!important}.d-xl-block{display:block!important}.d-xl-table{display:table!important}.d-xl-table-row{display:table-row!important}.d-xl-table-cell{display:table-cell!important}.d-xl-flex{display:-ms-flexbox!important;display:flex!important}.d-xl-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}}@media print{.d-print-none{display:none!important}.d-print-inline{display:inline!important}.d-print-inline-block{display:inline-block!important}.d-print-block{display:block!important}.d-print-table{display:table!important}.d-print-table-row{display:table-row!important}.d-print-table-cell{display:table-cell!important}.d-print-flex{display:-ms-flexbox!important;display:flex!important}.d-print-inline-flex{display:-ms-inline-flexbox!important;display:inline-flex!important}}.embed-responsive{position:relative;display:block;width:100%;padding:0;overflow:hidden}.embed-responsive::before{display:block;content:""}.embed-responsive .embed-responsive-item,.embed-responsive embed,.embed-responsive iframe,.embed-responsive object,.embed-responsive video{position:absolute;top:0;bottom:0;left:0;width:100%;height:100%;border:0}.embed-responsive-21by9::before{padding-top:42.857143%}.embed-responsive-16by9::before{padding-top:56.25%}.embed-responsive-4by3::before{padding-top:75%}.embed-responsive-1by1::before{padding-top:100%}.flex-row{-ms-flex-direction:row!important;flex-direction:row!important}.flex-column{-ms-flex-direction:column!important;flex-direction:column!important}.flex-row-reverse{-ms-flex-direction:row-reverse!important;flex-direction:row-reverse!important}.flex-column-reverse{-ms-flex-direction:column-reverse!important;flex-direction:column-reverse!important}.flex-wrap{-ms-flex-wrap:wrap!important;flex-wrap:wrap!important}.flex-nowrap{-ms-flex-wrap:nowrap!important;flex-wrap:nowrap!important}.flex-wrap-reverse{-ms-flex-wrap:wrap-reverse!important;flex-wrap:wrap-reverse!important}.flex-fill{-ms-flex:1 1 auto!important;flex:1 1 auto!important}.flex-grow-0{-ms-flex-positive:0!important;flex-grow:0!important}.flex-grow-1{-ms-flex-positive:1!important;flex-grow:1!important}.flex-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.flex-shrink-1{-ms-flex-negative:1!important;flex-shrink:1!important}.justify-content-start{-ms-flex-pack:start!important;justify-content:flex-start!important}.justify-content-end{-ms-flex-pack:end!important;justify-content:flex-end!important}.justify-content-center{-ms-flex-pack:center!important;justify-content:center!important}.justify-content-between{-ms-flex-pack:justify!important;justify-content:space-between!important}.justify-content-around{-ms-flex-pack:distribute!important;justify-content:space-around!important}.align-items-start{-ms-flex-align:start!important;align-items:flex-start!important}.align-items-end{-ms-flex-align:end!important;align-items:flex-end!important}.align-items-center{-ms-flex-align:center!important;align-items:center!important}.align-items-baseline{-ms-flex-align:baseline!important;align-items:baseline!important}.align-items-stretch{-ms-flex-align:stretch!important;align-items:stretch!important}.align-content-start{-ms-flex-line-pack:start!important;align-content:flex-start!important}.align-content-end{-ms-flex-line-pack:end!important;align-content:flex-end!important}.align-content-center{-ms-flex-line-pack:center!important;align-content:center!important}.align-content-between{-ms-flex-line-pack:justify!important;align-content:space-between!important}.align-content-around{-ms-flex-line-pack:distribute!important;align-content:space-around!important}.align-content-stretch{-ms-flex-line-pack:stretch!important;align-content:stretch!important}.align-self-auto{-ms-flex-item-align:auto!important;align-self:auto!important}.align-self-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-end{-ms-flex-item-align:end!important;align-self:flex-end!important}.align-self-center{-ms-flex-item-align:center!important;align-self:center!important}.align-self-baseline{-ms-flex-item-align:baseline!important;align-self:baseline!important}.align-self-stretch{-ms-flex-item-align:stretch!important;align-self:stretch!important}@media (min-width:576px){.flex-sm-row{-ms-flex-direction:row!important;flex-direction:row!important}.flex-sm-column{-ms-flex-direction:column!important;flex-direction:column!important}.flex-sm-row-reverse{-ms-flex-direction:row-reverse!important;flex-direction:row-reverse!important}.flex-sm-column-reverse{-ms-flex-direction:column-reverse!important;flex-direction:column-reverse!important}.flex-sm-wrap{-ms-flex-wrap:wrap!important;flex-wrap:wrap!important}.flex-sm-nowrap{-ms-flex-wrap:nowrap!important;flex-wrap:nowrap!important}.flex-sm-wrap-reverse{-ms-flex-wrap:wrap-reverse!important;flex-wrap:wrap-reverse!important}.flex-sm-fill{-ms-flex:1 1 auto!important;flex:1 1 auto!important}.flex-sm-grow-0{-ms-flex-positive:0!important;flex-grow:0!important}.flex-sm-grow-1{-ms-flex-positive:1!important;flex-grow:1!important}.flex-sm-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.flex-sm-shrink-1{-ms-flex-negative:1!important;flex-shrink:1!important}.justify-content-sm-start{-ms-flex-pack:start!important;justify-content:flex-start!important}.justify-content-sm-end{-ms-flex-pack:end!important;justify-content:flex-end!important}.justify-content-sm-center{-ms-flex-pack:center!important;justify-content:center!important}.justify-content-sm-between{-ms-flex-pack:justify!important;justify-content:space-between!important}.justify-content-sm-around{-ms-flex-pack:distribute!important;justify-content:space-around!important}.align-items-sm-start{-ms-flex-align:start!important;align-items:flex-start!important}.align-items-sm-end{-ms-flex-align:end!important;align-items:flex-end!important}.align-items-sm-center{-ms-flex-align:center!important;align-items:center!important}.align-items-sm-baseline{-ms-flex-align:baseline!important;align-items:baseline!important}.align-items-sm-stretch{-ms-flex-align:stretch!important;align-items:stretch!important}.align-content-sm-start{-ms-flex-line-pack:start!important;align-content:flex-start!important}.align-content-sm-end{-ms-flex-line-pack:end!important;align-content:flex-end!important}.align-content-sm-center{-ms-flex-line-pack:center!important;align-content:center!important}.align-content-sm-between{-ms-flex-line-pack:justify!important;align-content:space-between!important}.align-content-sm-around{-ms-flex-line-pack:distribute!important;align-content:space-around!important}.align-content-sm-stretch{-ms-flex-line-pack:stretch!important;align-content:stretch!important}.align-self-sm-auto{-ms-flex-item-align:auto!important;align-self:auto!important}.align-self-sm-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-sm-end{-ms-flex-item-align:end!important;align-self:flex-end!important}.align-self-sm-center{-ms-flex-item-align:center!important;align-self:center!important}.align-self-sm-baseline{-ms-flex-item-align:baseline!important;align-self:baseline!important}.align-self-sm-stretch{-ms-flex-item-align:stretch!important;align-self:stretch!important}}@media (min-width:768px){.flex-md-row{-ms-flex-direction:row!important;flex-direction:row!important}.flex-md-column{-ms-flex-direction:column!important;flex-direction:column!important}.flex-md-row-reverse{-ms-flex-direction:row-reverse!important;flex-direction:row-reverse!important}.flex-md-column-reverse{-ms-flex-direction:column-reverse!important;flex-direction:column-reverse!important}.flex-md-wrap{-ms-flex-wrap:wrap!important;flex-wrap:wrap!important}.flex-md-nowrap{-ms-flex-wrap:nowrap!important;flex-wrap:nowrap!important}.flex-md-wrap-reverse{-ms-flex-wrap:wrap-reverse!important;flex-wrap:wrap-reverse!important}.flex-md-fill{-ms-flex:1 1 auto!important;flex:1 1 auto!important}.flex-md-grow-0{-ms-flex-positive:0!important;flex-grow:0!important}.flex-md-grow-1{-ms-flex-positive:1!important;flex-grow:1!important}.flex-md-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.flex-md-shrink-1{-ms-flex-negative:1!important;flex-shrink:1!important}.justify-content-md-start{-ms-flex-pack:start!important;justify-content:flex-start!important}.justify-content-md-end{-ms-flex-pack:end!important;justify-content:flex-end!important}.justify-content-md-center{-ms-flex-pack:center!important;justify-content:center!important}.justify-content-md-between{-ms-flex-pack:justify!important;justify-content:space-between!important}.justify-content-md-around{-ms-flex-pack:distribute!important;justify-content:space-around!important}.align-items-md-start{-ms-flex-align:start!important;align-items:flex-start!important}.align-items-md-end{-ms-flex-align:end!important;align-items:flex-end!important}.align-items-md-center{-ms-flex-align:center!important;align-items:center!important}.align-items-md-baseline{-ms-flex-align:baseline!important;align-items:baseline!important}.align-items-md-stretch{-ms-flex-align:stretch!important;align-items:stretch!important}.align-content-md-start{-ms-flex-line-pack:start!important;align-content:flex-start!important}.align-content-md-end{-ms-flex-line-pack:end!important;align-content:flex-end!important}.align-content-md-center{-ms-flex-line-pack:center!important;align-content:center!important}.align-content-md-between{-ms-flex-line-pack:justify!important;align-content:space-between!important}.align-content-md-around{-ms-flex-line-pack:distribute!important;align-content:space-around!important}.align-content-md-stretch{-ms-flex-line-pack:stretch!important;align-content:stretch!important}.align-self-md-auto{-ms-flex-item-align:auto!important;align-self:auto!important}.align-self-md-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-md-end{-ms-flex-item-align:end!important;align-self:flex-end!important}.align-self-md-center{-ms-flex-item-align:center!important;align-self:center!important}.align-self-md-baseline{-ms-flex-item-align:baseline!important;align-self:baseline!important}.align-self-md-stretch{-ms-flex-item-align:stretch!important;align-self:stretch!important}}@media (min-width:992px){.flex-lg-row{-ms-flex-direction:row!important;flex-direction:row!important}.flex-lg-column{-ms-flex-direction:column!important;flex-direction:column!important}.flex-lg-row-reverse{-ms-flex-direction:row-reverse!important;flex-direction:row-reverse!important}.flex-lg-column-reverse{-ms-flex-direction:column-reverse!important;flex-direction:column-reverse!important}.flex-lg-wrap{-ms-flex-wrap:wrap!important;flex-wrap:wrap!important}.flex-lg-nowrap{-ms-flex-wrap:nowrap!important;flex-wrap:nowrap!important}.flex-lg-wrap-reverse{-ms-flex-wrap:wrap-reverse!important;flex-wrap:wrap-reverse!important}.flex-lg-fill{-ms-flex:1 1 auto!important;flex:1 1 auto!important}.flex-lg-grow-0{-ms-flex-positive:0!important;flex-grow:0!important}.flex-lg-grow-1{-ms-flex-positive:1!important;flex-grow:1!important}.flex-lg-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.flex-lg-shrink-1{-ms-flex-negative:1!important;flex-shrink:1!important}.justify-content-lg-start{-ms-flex-pack:start!important;justify-content:flex-start!important}.justify-content-lg-end{-ms-flex-pack:end!important;justify-content:flex-end!important}.justify-content-lg-center{-ms-flex-pack:center!important;justify-content:center!important}.justify-content-lg-between{-ms-flex-pack:justify!important;justify-content:space-between!important}.justify-content-lg-around{-ms-flex-pack:distribute!important;justify-content:space-around!important}.align-items-lg-start{-ms-flex-align:start!important;align-items:flex-start!important}.align-items-lg-end{-ms-flex-align:end!important;align-items:flex-end!important}.align-items-lg-center{-ms-flex-align:center!important;align-items:center!important}.align-items-lg-baseline{-ms-flex-align:baseline!important;align-items:baseline!important}.align-items-lg-stretch{-ms-flex-align:stretch!important;align-items:stretch!important}.align-content-lg-start{-ms-flex-line-pack:start!important;align-content:flex-start!important}.align-content-lg-end{-ms-flex-line-pack:end!important;align-content:flex-end!important}.align-content-lg-center{-ms-flex-line-pack:center!important;align-content:center!important}.align-content-lg-between{-ms-flex-line-pack:justify!important;align-content:space-between!important}.align-content-lg-around{-ms-flex-line-pack:distribute!important;align-content:space-around!important}.align-content-lg-stretch{-ms-flex-line-pack:stretch!important;align-content:stretch!important}.align-self-lg-auto{-ms-flex-item-align:auto!important;align-self:auto!important}.align-self-lg-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-lg-end{-ms-flex-item-align:end!important;align-self:flex-end!important}.align-self-lg-center{-ms-flex-item-align:center!important;align-self:center!important}.align-self-lg-baseline{-ms-flex-item-align:baseline!important;align-self:baseline!important}.align-self-lg-stretch{-ms-flex-item-align:stretch!important;align-self:stretch!important}}@media (min-width:1200px){.flex-xl-row{-ms-flex-direction:row!important;flex-direction:row!important}.flex-xl-column{-ms-flex-direction:column!important;flex-direction:column!important}.flex-xl-row-reverse{-ms-flex-direction:row-reverse!important;flex-direction:row-reverse!important}.flex-xl-column-reverse{-ms-flex-direction:column-reverse!important;flex-direction:column-reverse!important}.flex-xl-wrap{-ms-flex-wrap:wrap!important;flex-wrap:wrap!important}.flex-xl-nowrap{-ms-flex-wrap:nowrap!important;flex-wrap:nowrap!important}.flex-xl-wrap-reverse{-ms-flex-wrap:wrap-reverse!important;flex-wrap:wrap-reverse!important}.flex-xl-fill{-ms-flex:1 1 auto!important;flex:1 1 auto!important}.flex-xl-grow-0{-ms-flex-positive:0!important;flex-grow:0!important}.flex-xl-grow-1{-ms-flex-positive:1!important;flex-grow:1!important}.flex-xl-shrink-0{-ms-flex-negative:0!important;flex-shrink:0!important}.flex-xl-shrink-1{-ms-flex-negative:1!important;flex-shrink:1!important}.justify-content-xl-start{-ms-flex-pack:start!important;justify-content:flex-start!important}.justify-content-xl-end{-ms-flex-pack:end!important;justify-content:flex-end!important}.justify-content-xl-center{-ms-flex-pack:center!important;justify-content:center!important}.justify-content-xl-between{-ms-flex-pack:justify!important;justify-content:space-between!important}.justify-content-xl-around{-ms-flex-pack:distribute!important;justify-content:space-around!important}.align-items-xl-start{-ms-flex-align:start!important;align-items:flex-start!important}.align-items-xl-end{-ms-flex-align:end!important;align-items:flex-end!important}.align-items-xl-center{-ms-flex-align:center!important;align-items:center!important}.align-items-xl-baseline{-ms-flex-align:baseline!important;align-items:baseline!important}.align-items-xl-stretch{-ms-flex-align:stretch!important;align-items:stretch!important}.align-content-xl-start{-ms-flex-line-pack:start!important;align-content:flex-start!important}.align-content-xl-end{-ms-flex-line-pack:end!important;align-content:flex-end!important}.align-content-xl-center{-ms-flex-line-pack:center!important;align-content:center!important}.align-content-xl-between{-ms-flex-line-pack:justify!important;align-content:space-between!important}.align-content-xl-around{-ms-flex-line-pack:distribute!important;align-content:space-around!important}.align-content-xl-stretch{-ms-flex-line-pack:stretch!important;align-content:stretch!important}.align-self-xl-auto{-ms-flex-item-align:auto!important;align-self:auto!important}.align-self-xl-start{-ms-flex-item-align:start!important;align-self:flex-start!important}.align-self-xl-end{-ms-flex-item-align:end!important;align-self:flex-end!important}.align-self-xl-center{-ms-flex-item-align:center!important;align-self:center!important}.align-self-xl-baseline{-ms-flex-item-align:baseline!important;align-self:baseline!important}.align-self-xl-stretch{-ms-flex-item-align:stretch!important;align-self:stretch!important}}.float-left{float:left!important}.float-right{float:right!important}.float-none{float:none!important}@media (min-width:576px){.float-sm-left{float:left!important}.float-sm-right{float:right!important}.float-sm-none{float:none!important}}@media (min-width:768px){.float-md-left{float:left!important}.float-md-right{float:right!important}.float-md-none{float:none!important}}@media (min-width:992px){.float-lg-left{float:left!important}.float-lg-right{float:right!important}.float-lg-none{float:none!important}}@media (min-width:1200px){.float-xl-left{float:left!important}.float-xl-right{float:right!important}.float-xl-none{float:none!important}}.position-static{position:static!important}.position-relative{position:relative!important}.position-absolute{position:absolute!important}.position-fixed{position:fixed!important}.position-sticky{position:-webkit-sticky!important;position:sticky!important}.fixed-top{position:fixed;top:0;right:0;left:0;z-index:1030}.fixed-bottom{position:fixed;right:0;bottom:0;left:0;z-index:1030}@supports ((position:-webkit-sticky) or (position:sticky)){.sticky-top{position:-webkit-sticky;position:sticky;top:0;z-index:1020}}.sr-only{position:absolute;width:1px;height:1px;padding:0;overflow:hidden;clip:rect(0,0,0,0);white-space:nowrap;border:0}.sr-only-focusable:active,.sr-only-focusable:focus{position:static;width:auto;height:auto;overflow:visible;clip:auto;white-space:normal}.shadow-sm{box-shadow:0 .125rem .25rem rgba(0,0,0,.075)!important}.shadow{box-shadow:0 .5rem 1rem rgba(0,0,0,.15)!important}.shadow-lg{box-shadow:0 1rem 3rem rgba(0,0,0,.175)!important}.shadow-none{box-shadow:none!important}.w-25{width:25%!important}.w-50{width:50%!important}.w-75{width:75%!important}.w-100{width:100%!important}.w-auto{width:auto!important}.h-25{height:25%!important}.h-50{height:50%!important}.h-75{height:75%!important}.h-100{height:100%!important}.h-auto{height:auto!important}.mw-100{max-width:100%!important}.mh-100{max-height:100%!important}.m-0{margin:0!important}.mt-0,.my-0{margin-top:0!important}.mr-0,.mx-0{margin-right:0!important}.mb-0,.my-0{margin-bottom:0!important}.ml-0,.mx-0{margin-left:0!important}.m-1{margin:.25rem!important}.mt-1,.my-1{margin-top:.25rem!important}.mr-1,.mx-1{margin-right:.25rem!important}.mb-1,.my-1{margin-bottom:.25rem!important}.ml-1,.mx-1{margin-left:.25rem!important}.m-2{margin:.5rem!important}.mt-2,.my-2{margin-top:.5rem!important}.mr-2,.mx-2{margin-right:.5rem!important}.mb-2,.my-2{margin-bottom:.5rem!important}.ml-2,.mx-2{margin-left:.5rem!important}.m-3{margin:1rem!important}.mt-3,.my-3{margin-top:1rem!important}.mr-3,.mx-3{margin-right:1rem!important}.mb-3,.my-3{margin-bottom:1rem!important}.ml-3,.mx-3{margin-left:1rem!important}.m-4{margin:1.5rem!important}.mt-4,.my-4{margin-top:1.5rem!important}.mr-4,.mx-4{margin-right:1.5rem!important}.mb-4,.my-4{margin-bottom:1.5rem!important}.ml-4,.mx-4{margin-left:1.5rem!important}.m-5{margin:3rem!important}.mt-5,.my-5{margin-top:3rem!important}.mr-5,.mx-5{margin-right:3rem!important}.mb-5,.my-5{margin-bottom:3rem!important}.ml-5,.mx-5{margin-left:3rem!important}.p-0{padding:0!important}.pt-0,.py-0{padding-top:0!important}.pr-0,.px-0{padding-right:0!important}.pb-0,.py-0{padding-bottom:0!important}.pl-0,.px-0{padding-left:0!important}.p-1{padding:.25rem!important}.pt-1,.py-1{padding-top:.25rem!important}.pr-1,.px-1{padding-right:.25rem!important}.pb-1,.py-1{padding-bottom:.25rem!important}.pl-1,.px-1{padding-left:.25rem!important}.p-2{padding:.5rem!important}.pt-2,.py-2{padding-top:.5rem!important}.pr-2,.px-2{padding-right:.5rem!important}.pb-2,.py-2{padding-bottom:.5rem!important}.pl-2,.px-2{padding-left:.5rem!important}.p-3{padding:1rem!important}.pt-3,.py-3{padding-top:1rem!important}.pr-3,.px-3{padding-right:1rem!important}.pb-3,.py-3{padding-bottom:1rem!important}.pl-3,.px-3{padding-left:1rem!important}.p-4{padding:1.5rem!important}.pt-4,.py-4{padding-top:1.5rem!important}.pr-4,.px-4{padding-right:1.5rem!important}.pb-4,.py-4{padding-bottom:1.5rem!important}.pl-4,.px-4{padding-left:1.5rem!important}.p-5{padding:3rem!important}.pt-5,.py-5{padding-top:3rem!important}.pr-5,.px-5{padding-right:3rem!important}.pb-5,.py-5{padding-bottom:3rem!important}.pl-5,.px-5{padding-left:3rem!important}.m-auto{margin:auto!important}.mt-auto,.my-auto{margin-top:auto!important}.mr-auto,.mx-auto{margin-right:auto!important}.mb-auto,.my-auto{margin-bottom:auto!important}.ml-auto,.mx-auto{margin-left:auto!important}@media (min-width:576px){.m-sm-0{margin:0!important}.mt-sm-0,.my-sm-0{margin-top:0!important}.mr-sm-0,.mx-sm-0{margin-right:0!important}.mb-sm-0,.my-sm-0{margin-bottom:0!important}.ml-sm-0,.mx-sm-0{margin-left:0!important}.m-sm-1{margin:.25rem!important}.mt-sm-1,.my-sm-1{margin-top:.25rem!important}.mr-sm-1,.mx-sm-1{margin-right:.25rem!important}.mb-sm-1,.my-sm-1{margin-bottom:.25rem!important}.ml-sm-1,.mx-sm-1{margin-left:.25rem!important}.m-sm-2{margin:.5rem!important}.mt-sm-2,.my-sm-2{margin-top:.5rem!important}.mr-sm-2,.mx-sm-2{margin-right:.5rem!important}.mb-sm-2,.my-sm-2{margin-bottom:.5rem!important}.ml-sm-2,.mx-sm-2{margin-left:.5rem!important}.m-sm-3{margin:1rem!important}.mt-sm-3,.my-sm-3{margin-top:1rem!important}.mr-sm-3,.mx-sm-3{margin-right:1rem!important}.mb-sm-3,.my-sm-3{margin-bottom:1rem!important}.ml-sm-3,.mx-sm-3{margin-left:1rem!important}.m-sm-4{margin:1.5rem!important}.mt-sm-4,.my-sm-4{margin-top:1.5rem!important}.mr-sm-4,.mx-sm-4{margin-right:1.5rem!important}.mb-sm-4,.my-sm-4{margin-bottom:1.5rem!important}.ml-sm-4,.mx-sm-4{margin-left:1.5rem!important}.m-sm-5{margin:3rem!important}.mt-sm-5,.my-sm-5{margin-top:3rem!important}.mr-sm-5,.mx-sm-5{margin-right:3rem!important}.mb-sm-5,.my-sm-5{margin-bottom:3rem!important}.ml-sm-5,.mx-sm-5{margin-left:3rem!important}.p-sm-0{padding:0!important}.pt-sm-0,.py-sm-0{padding-top:0!important}.pr-sm-0,.px-sm-0{padding-right:0!important}.pb-sm-0,.py-sm-0{padding-bottom:0!important}.pl-sm-0,.px-sm-0{padding-left:0!important}.p-sm-1{padding:.25rem!important}.pt-sm-1,.py-sm-1{padding-top:.25rem!important}.pr-sm-1,.px-sm-1{padding-right:.25rem!important}.pb-sm-1,.py-sm-1{padding-bottom:.25rem!important}.pl-sm-1,.px-sm-1{padding-left:.25rem!important}.p-sm-2{padding:.5rem!important}.pt-sm-2,.py-sm-2{padding-top:.5rem!important}.pr-sm-2,.px-sm-2{padding-right:.5rem!important}.pb-sm-2,.py-sm-2{padding-bottom:.5rem!important}.pl-sm-2,.px-sm-2{padding-left:.5rem!important}.p-sm-3{padding:1rem!important}.pt-sm-3,.py-sm-3{padding-top:1rem!important}.pr-sm-3,.px-sm-3{padding-right:1rem!important}.pb-sm-3,.py-sm-3{padding-bottom:1rem!important}.pl-sm-3,.px-sm-3{padding-left:1rem!important}.p-sm-4{padding:1.5rem!important}.pt-sm-4,.py-sm-4{padding-top:1.5rem!important}.pr-sm-4,.px-sm-4{padding-right:1.5rem!important}.pb-sm-4,.py-sm-4{padding-bottom:1.5rem!important}.pl-sm-4,.px-sm-4{padding-left:1.5rem!important}.p-sm-5{padding:3rem!important}.pt-sm-5,.py-sm-5{padding-top:3rem!important}.pr-sm-5,.px-sm-5{padding-right:3rem!important}.pb-sm-5,.py-sm-5{padding-bottom:3rem!important}.pl-sm-5,.px-sm-5{padding-left:3rem!important}.m-sm-auto{margin:auto!important}.mt-sm-auto,.my-sm-auto{margin-top:auto!important}.mr-sm-auto,.mx-sm-auto{margin-right:auto!important}.mb-sm-auto,.my-sm-auto{margin-bottom:auto!important}.ml-sm-auto,.mx-sm-auto{margin-left:auto!important}}@media (min-width:768px){.m-md-0{margin:0!important}.mt-md-0,.my-md-0{margin-top:0!important}.mr-md-0,.mx-md-0{margin-right:0!important}.mb-md-0,.my-md-0{margin-bottom:0!important}.ml-md-0,.mx-md-0{margin-left:0!important}.m-md-1{margin:.25rem!important}.mt-md-1,.my-md-1{margin-top:.25rem!important}.mr-md-1,.mx-md-1{margin-right:.25rem!important}.mb-md-1,.my-md-1{margin-bottom:.25rem!important}.ml-md-1,.mx-md-1{margin-left:.25rem!important}.m-md-2{margin:.5rem!important}.mt-md-2,.my-md-2{margin-top:.5rem!important}.mr-md-2,.mx-md-2{margin-right:.5rem!important}.mb-md-2,.my-md-2{margin-bottom:.5rem!important}.ml-md-2,.mx-md-2{margin-left:.5rem!important}.m-md-3{margin:1rem!important}.mt-md-3,.my-md-3{margin-top:1rem!important}.mr-md-3,.mx-md-3{margin-right:1rem!important}.mb-md-3,.my-md-3{margin-bottom:1rem!important}.ml-md-3,.mx-md-3{margin-left:1rem!important}.m-md-4{margin:1.5rem!important}.mt-md-4,.my-md-4{margin-top:1.5rem!important}.mr-md-4,.mx-md-4{margin-right:1.5rem!important}.mb-md-4,.my-md-4{margin-bottom:1.5rem!important}.ml-md-4,.mx-md-4{margin-left:1.5rem!important}.m-md-5{margin:3rem!important}.mt-md-5,.my-md-5{margin-top:3rem!important}.mr-md-5,.mx-md-5{margin-right:3rem!important}.mb-md-5,.my-md-5{margin-bottom:3rem!important}.ml-md-5,.mx-md-5{margin-left:3rem!important}.p-md-0{padding:0!important}.pt-md-0,.py-md-0{padding-top:0!important}.pr-md-0,.px-md-0{padding-right:0!important}.pb-md-0,.py-md-0{padding-bottom:0!important}.pl-md-0,.px-md-0{padding-left:0!important}.p-md-1{padding:.25rem!important}.pt-md-1,.py-md-1{padding-top:.25rem!important}.pr-md-1,.px-md-1{padding-right:.25rem!important}.pb-md-1,.py-md-1{padding-bottom:.25rem!important}.pl-md-1,.px-md-1{padding-left:.25rem!important}.p-md-2{padding:.5rem!important}.pt-md-2,.py-md-2{padding-top:.5rem!important}.pr-md-2,.px-md-2{padding-right:.5rem!important}.pb-md-2,.py-md-2{padding-bottom:.5rem!important}.pl-md-2,.px-md-2{padding-left:.5rem!important}.p-md-3{padding:1rem!important}.pt-md-3,.py-md-3{padding-top:1rem!important}.pr-md-3,.px-md-3{padding-right:1rem!important}.pb-md-3,.py-md-3{padding-bottom:1rem!important}.pl-md-3,.px-md-3{padding-left:1rem!important}.p-md-4{padding:1.5rem!important}.pt-md-4,.py-md-4{padding-top:1.5rem!important}.pr-md-4,.px-md-4{padding-right:1.5rem!important}.pb-md-4,.py-md-4{padding-bottom:1.5rem!important}.pl-md-4,.px-md-4{padding-left:1.5rem!important}.p-md-5{padding:3rem!important}.pt-md-5,.py-md-5{padding-top:3rem!important}.pr-md-5,.px-md-5{padding-right:3rem!important}.pb-md-5,.py-md-5{padding-bottom:3rem!important}.pl-md-5,.px-md-5{padding-left:3rem!important}.m-md-auto{margin:auto!important}.mt-md-auto,.my-md-auto{margin-top:auto!important}.mr-md-auto,.mx-md-auto{margin-right:auto!important}.mb-md-auto,.my-md-auto{margin-bottom:auto!important}.ml-md-auto,.mx-md-auto{margin-left:auto!important}}@media (min-width:992px){.m-lg-0{margin:0!important}.mt-lg-0,.my-lg-0{margin-top:0!important}.mr-lg-0,.mx-lg-0{margin-right:0!important}.mb-lg-0,.my-lg-0{margin-bottom:0!important}.ml-lg-0,.mx-lg-0{margin-left:0!important}.m-lg-1{margin:.25rem!important}.mt-lg-1,.my-lg-1{margin-top:.25rem!important}.mr-lg-1,.mx-lg-1{margin-right:.25rem!important}.mb-lg-1,.my-lg-1{margin-bottom:.25rem!important}.ml-lg-1,.mx-lg-1{margin-left:.25rem!important}.m-lg-2{margin:.5rem!important}.mt-lg-2,.my-lg-2{margin-top:.5rem!important}.mr-lg-2,.mx-lg-2{margin-right:.5rem!important}.mb-lg-2,.my-lg-2{margin-bottom:.5rem!important}.ml-lg-2,.mx-lg-2{margin-left:.5rem!important}.m-lg-3{margin:1rem!important}.mt-lg-3,.my-lg-3{margin-top:1rem!important}.mr-lg-3,.mx-lg-3{margin-right:1rem!important}.mb-lg-3,.my-lg-3{margin-bottom:1rem!important}.ml-lg-3,.mx-lg-3{margin-left:1rem!important}.m-lg-4{margin:1.5rem!important}.mt-lg-4,.my-lg-4{margin-top:1.5rem!important}.mr-lg-4,.mx-lg-4{margin-right:1.5rem!important}.mb-lg-4,.my-lg-4{margin-bottom:1.5rem!important}.ml-lg-4,.mx-lg-4{margin-left:1.5rem!important}.m-lg-5{margin:3rem!important}.mt-lg-5,.my-lg-5{margin-top:3rem!important}.mr-lg-5,.mx-lg-5{margin-right:3rem!important}.mb-lg-5,.my-lg-5{margin-bottom:3rem!important}.ml-lg-5,.mx-lg-5{margin-left:3rem!important}.p-lg-0{padding:0!important}.pt-lg-0,.py-lg-0{padding-top:0!important}.pr-lg-0,.px-lg-0{padding-right:0!important}.pb-lg-0,.py-lg-0{padding-bottom:0!important}.pl-lg-0,.px-lg-0{padding-left:0!important}.p-lg-1{padding:.25rem!important}.pt-lg-1,.py-lg-1{padding-top:.25rem!important}.pr-lg-1,.px-lg-1{padding-right:.25rem!important}.pb-lg-1,.py-lg-1{padding-bottom:.25rem!important}.pl-lg-1,.px-lg-1{padding-left:.25rem!important}.p-lg-2{padding:.5rem!important}.pt-lg-2,.py-lg-2{padding-top:.5rem!important}.pr-lg-2,.px-lg-2{padding-right:.5rem!important}.pb-lg-2,.py-lg-2{padding-bottom:.5rem!important}.pl-lg-2,.px-lg-2{padding-left:.5rem!important}.p-lg-3{padding:1rem!important}.pt-lg-3,.py-lg-3{padding-top:1rem!important}.pr-lg-3,.px-lg-3{padding-right:1rem!important}.pb-lg-3,.py-lg-3{padding-bottom:1rem!important}.pl-lg-3,.px-lg-3{padding-left:1rem!important}.p-lg-4{padding:1.5rem!important}.pt-lg-4,.py-lg-4{padding-top:1.5rem!important}.pr-lg-4,.px-lg-4{padding-right:1.5rem!important}.pb-lg-4,.py-lg-4{padding-bottom:1.5rem!important}.pl-lg-4,.px-lg-4{padding-left:1.5rem!important}.p-lg-5{padding:3rem!important}.pt-lg-5,.py-lg-5{padding-top:3rem!important}.pr-lg-5,.px-lg-5{padding-right:3rem!important}.pb-lg-5,.py-lg-5{padding-bottom:3rem!important}.pl-lg-5,.px-lg-5{padding-left:3rem!important}.m-lg-auto{margin:auto!important}.mt-lg-auto,.my-lg-auto{margin-top:auto!important}.mr-lg-auto,.mx-lg-auto{margin-right:auto!important}.mb-lg-auto,.my-lg-auto{margin-bottom:auto!important}.ml-lg-auto,.mx-lg-auto{margin-left:auto!important}}@media (min-width:1200px){.m-xl-0{margin:0!important}.mt-xl-0,.my-xl-0{margin-top:0!important}.mr-xl-0,.mx-xl-0{margin-right:0!important}.mb-xl-0,.my-xl-0{margin-bottom:0!important}.ml-xl-0,.mx-xl-0{margin-left:0!important}.m-xl-1{margin:.25rem!important}.mt-xl-1,.my-xl-1{margin-top:.25rem!important}.mr-xl-1,.mx-xl-1{margin-right:.25rem!important}.mb-xl-1,.my-xl-1{margin-bottom:.25rem!important}.ml-xl-1,.mx-xl-1{margin-left:.25rem!important}.m-xl-2{margin:.5rem!important}.mt-xl-2,.my-xl-2{margin-top:.5rem!important}.mr-xl-2,.mx-xl-2{margin-right:.5rem!important}.mb-xl-2,.my-xl-2{margin-bottom:.5rem!important}.ml-xl-2,.mx-xl-2{margin-left:.5rem!important}.m-xl-3{margin:1rem!important}.mt-xl-3,.my-xl-3{margin-top:1rem!important}.mr-xl-3,.mx-xl-3{margin-right:1rem!important}.mb-xl-3,.my-xl-3{margin-bottom:1rem!important}.ml-xl-3,.mx-xl-3{margin-left:1rem!important}.m-xl-4{margin:1.5rem!important}.mt-xl-4,.my-xl-4{margin-top:1.5rem!important}.mr-xl-4,.mx-xl-4{margin-right:1.5rem!important}.mb-xl-4,.my-xl-4{margin-bottom:1.5rem!important}.ml-xl-4,.mx-xl-4{margin-left:1.5rem!important}.m-xl-5{margin:3rem!important}.mt-xl-5,.my-xl-5{margin-top:3rem!important}.mr-xl-5,.mx-xl-5{margin-right:3rem!important}.mb-xl-5,.my-xl-5{margin-bottom:3rem!important}.ml-xl-5,.mx-xl-5{margin-left:3rem!important}.p-xl-0{padding:0!important}.pt-xl-0,.py-xl-0{padding-top:0!important}.pr-xl-0,.px-xl-0{padding-right:0!important}.pb-xl-0,.py-xl-0{padding-bottom:0!important}.pl-xl-0,.px-xl-0{padding-left:0!important}.p-xl-1{padding:.25rem!important}.pt-xl-1,.py-xl-1{padding-top:.25rem!important}.pr-xl-1,.px-xl-1{padding-right:.25rem!important}.pb-xl-1,.py-xl-1{padding-bottom:.25rem!important}.pl-xl-1,.px-xl-1{padding-left:.25rem!important}.p-xl-2{padding:.5rem!important}.pt-xl-2,.py-xl-2{padding-top:.5rem!important}.pr-xl-2,.px-xl-2{padding-right:.5rem!important}.pb-xl-2,.py-xl-2{padding-bottom:.5rem!important}.pl-xl-2,.px-xl-2{padding-left:.5rem!important}.p-xl-3{padding:1rem!important}.pt-xl-3,.py-xl-3{padding-top:1rem!important}.pr-xl-3,.px-xl-3{padding-right:1rem!important}.pb-xl-3,.py-xl-3{padding-bottom:1rem!important}.pl-xl-3,.px-xl-3{padding-left:1rem!important}.p-xl-4{padding:1.5rem!important}.pt-xl-4,.py-xl-4{padding-top:1.5rem!important}.pr-xl-4,.px-xl-4{padding-right:1.5rem!important}.pb-xl-4,.py-xl-4{padding-bottom:1.5rem!important}.pl-xl-4,.px-xl-4{padding-left:1.5rem!important}.p-xl-5{padding:3rem!important}.pt-xl-5,.py-xl-5{padding-top:3rem!important}.pr-xl-5,.px-xl-5{padding-right:3rem!important}.pb-xl-5,.py-xl-5{padding-bottom:3rem!important}.pl-xl-5,.px-xl-5{padding-left:3rem!important}.m-xl-auto{margin:auto!important}.mt-xl-auto,.my-xl-auto{margin-top:auto!important}.mr-xl-auto,.mx-xl-auto{margin-right:auto!important}.mb-xl-auto,.my-xl-auto{margin-bottom:auto!important}.ml-xl-auto,.mx-xl-auto{margin-left:auto!important}}.text-monospace{font-family:SFMono-Regular,Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace}.text-justify{text-align:justify!important}.text-nowrap{white-space:nowrap!important}.text-truncate{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}.text-left{text-align:left!important}.text-right{text-align:right!important}.text-center{text-align:center!important}@media (min-width:576px){.text-sm-left{text-align:left!important}.text-sm-right{text-align:right!important}.text-sm-center{text-align:center!important}}@media (min-width:768px){.text-md-left{text-align:left!important}.text-md-right{text-align:right!important}.text-md-center{text-align:center!important}}@media (min-width:992px){.text-lg-left{text-align:left!important}.text-lg-right{text-align:right!important}.text-lg-center{text-align:center!important}}@media (min-width:1200px){.text-xl-left{text-align:left!important}.text-xl-right{text-align:right!important}.text-xl-center{text-align:center!important}}.text-lowercase{text-transform:lowercase!important}.text-uppercase{text-transform:uppercase!important}.text-capitalize{text-transform:capitalize!important}.font-weight-light{font-weight:300!important}.font-weight-normal{font-weight:400!important}.font-weight-bold{font-weight:700!important}.font-italic{font-style:italic!important}.text-white{color:#fff!important}.text-primary{color:#007bff!important}a.text-primary:focus,a.text-primary:hover{color:#0062cc!important}.text-secondary{color:#6c757d!important}a.text-secondary:focus,a.text-secondary:hover{color:#545b62!important}.text-success{color:#28a745!important}a.text-success:focus,a.text-success:hover{color:#1e7e34!important}.text-info{color:#17a2b8!important}a.text-info:focus,a.text-info:hover{color:#117a8b!important}.text-warning{color:#ffc107!important}a.text-warning:focus,a.text-warning:hover{color:#d39e00!important}.text-danger{color:#dc3545!important}a.text-danger:focus,a.text-danger:hover{color:#bd2130!important}.text-light{color:#f8f9fa!important}a.text-light:focus,a.text-light:hover{color:#dae0e5!important}.text-dark{color:#343a40!important}a.text-dark:focus,a.text-dark:hover{color:#1d2124!important}.text-body{color:#212529!important}.text-muted{color:#6c757d!important}.text-black-50{color:rgba(0,0,0,.5)!important}.text-white-50{color:rgba(255,255,255,.5)!important}.text-hide{font:0/0 a;color:transparent;text-shadow:none;background-color:transparent;border:0}.visible{visibility:visible!important}.invisible{visibility:hidden!important}@media print{*,::after,::before{text-shadow:none!important;box-shadow:none!important}a:not(.btn){text-decoration:underline}abbr[title]::after{content:" (" attr(title) ")"}pre{white-space:pre-wrap!important}blockquote,pre{border:1px solid #adb5bd;page-break-inside:avoid}thead{display:table-header-group}img,tr{page-break-inside:avoid}h2,h3,p{orphans:3;widows:3}h2,h3{page-break-after:avoid}@page{size:a3}body{min-width:992px!important}.container{min-width:992px!important}.navbar{display:none}.badge{border:1px solid #000}.table{border-collapse:collapse!important}.table td,.table th{background-color:#fff!important}.table-bordered td,.table-bordered th{border:1px solid #dee2e6!important}.table-dark{color:inherit}.table-dark tbody+tbody,.table-dark td,.table-dark th,.table-dark thead th{border-color:#dee2e6}.table .thead-dark th{color:inherit;border-color:#dee2e6}}
+/*# sourceMappingURL=bootstrap.min.css.map */
\ No newline at end of file
diff --git a/plugins/bootstrap/bootstrap.min.js b/plugins/bootstrap/bootstrap.min.js
new file mode 100644
index 00000000..9e495539
--- /dev/null
+++ b/plugins/bootstrap/bootstrap.min.js
@@ -0,0 +1,13 @@
+/*
+ Copyright (C) Federico Zivolo 2018
+ Distributed under the MIT License (license terms are at http://opensource.org/licenses/MIT).
+ */(function (e, t) { 'object' == typeof exports && 'undefined' != typeof module ? module.exports = t() : 'function' == typeof define && define.amd ? define(t) : e.Popper = t() })(this, function () { 'use strict'; function e(e) { return e && '[object Function]' === {}.toString.call(e) } function t(e, t) { if (1 !== e.nodeType) return []; var o = getComputedStyle(e, null); return t ? o[t] : o } function o(e) { return 'HTML' === e.nodeName ? e : e.parentNode || e.host } function n(e) { if (!e) return document.body; switch (e.nodeName) { case 'HTML': case 'BODY': return e.ownerDocument.body; case '#document': return e.body; }var i = t(e), r = i.overflow, p = i.overflowX, s = i.overflowY; return /(auto|scroll|overlay)/.test(r + s + p) ? e : n(o(e)) } function r(e) { return 11 === e ? re : 10 === e ? pe : re || pe } function p(e) { if (!e) return document.documentElement; for (var o = r(10) ? document.body : null, n = e.offsetParent; n === o && e.nextElementSibling;)n = (e = e.nextElementSibling).offsetParent; var i = n && n.nodeName; return i && 'BODY' !== i && 'HTML' !== i ? -1 !== ['TD', 'TABLE'].indexOf(n.nodeName) && 'static' === t(n, 'position') ? p(n) : n : e ? e.ownerDocument.documentElement : document.documentElement } function s(e) { var t = e.nodeName; return 'BODY' !== t && ('HTML' === t || p(e.firstElementChild) === e) } function d(e) { return null === e.parentNode ? e : d(e.parentNode) } function a(e, t) { if (!e || !e.nodeType || !t || !t.nodeType) return document.documentElement; var o = e.compareDocumentPosition(t) & Node.DOCUMENT_POSITION_FOLLOWING, n = o ? e : t, i = o ? t : e, r = document.createRange(); r.setStart(n, 0), r.setEnd(i, 0); var l = r.commonAncestorContainer; if (e !== l && t !== l || n.contains(i)) return s(l) ? l : p(l); var f = d(e); return f.host ? a(f.host, t) : a(e, d(t).host) } function l(e) { var t = 1 < arguments.length && void 0 !== arguments[1] ? arguments[1] : 'top', o = 'top' === t ? 'scrollTop' : 'scrollLeft', n = e.nodeName; if ('BODY' === n || 'HTML' === n) { var i = e.ownerDocument.documentElement, r = e.ownerDocument.scrollingElement || i; return r[o] } return e[o] } function f(e, t) { var o = 2 < arguments.length && void 0 !== arguments[2] && arguments[2], n = l(t, 'top'), i = l(t, 'left'), r = o ? -1 : 1; return e.top += n * r, e.bottom += n * r, e.left += i * r, e.right += i * r, e } function m(e, t) { var o = 'x' === t ? 'Left' : 'Top', n = 'Left' == o ? 'Right' : 'Bottom'; return parseFloat(e['border' + o + 'Width'], 10) + parseFloat(e['border' + n + 'Width'], 10) } function h(e, t, o, n) { return $(t['offset' + e], t['scroll' + e], o['client' + e], o['offset' + e], o['scroll' + e], r(10) ? o['offset' + e] + n['margin' + ('Height' === e ? 'Top' : 'Left')] + n['margin' + ('Height' === e ? 'Bottom' : 'Right')] : 0) } function c() { var e = document.body, t = document.documentElement, o = r(10) && getComputedStyle(t); return { height: h('Height', e, t, o), width: h('Width', e, t, o) } } function g(e) { return le({}, e, { right: e.left + e.width, bottom: e.top + e.height }) } function u(e) { var o = {}; try { if (r(10)) { o = e.getBoundingClientRect(); var n = l(e, 'top'), i = l(e, 'left'); o.top += n, o.left += i, o.bottom += n, o.right += i } else o = e.getBoundingClientRect() } catch (t) { } var p = { left: o.left, top: o.top, width: o.right - o.left, height: o.bottom - o.top }, s = 'HTML' === e.nodeName ? c() : {}, d = s.width || e.clientWidth || p.right - p.left, a = s.height || e.clientHeight || p.bottom - p.top, f = e.offsetWidth - d, h = e.offsetHeight - a; if (f || h) { var u = t(e); f -= m(u, 'x'), h -= m(u, 'y'), p.width -= f, p.height -= h } return g(p) } function b(e, o) { var i = 2 < arguments.length && void 0 !== arguments[2] && arguments[2], p = r(10), s = 'HTML' === o.nodeName, d = u(e), a = u(o), l = n(e), m = t(o), h = parseFloat(m.borderTopWidth, 10), c = parseFloat(m.borderLeftWidth, 10); i && 'HTML' === o.nodeName && (a.top = $(a.top, 0), a.left = $(a.left, 0)); var b = g({ top: d.top - a.top - h, left: d.left - a.left - c, width: d.width, height: d.height }); if (b.marginTop = 0, b.marginLeft = 0, !p && s) { var y = parseFloat(m.marginTop, 10), w = parseFloat(m.marginLeft, 10); b.top -= h - y, b.bottom -= h - y, b.left -= c - w, b.right -= c - w, b.marginTop = y, b.marginLeft = w } return (p && !i ? o.contains(l) : o === l && 'BODY' !== l.nodeName) && (b = f(b, o)), b } function y(e) { var t = 1 < arguments.length && void 0 !== arguments[1] && arguments[1], o = e.ownerDocument.documentElement, n = b(e, o), i = $(o.clientWidth, window.innerWidth || 0), r = $(o.clientHeight, window.innerHeight || 0), p = t ? 0 : l(o), s = t ? 0 : l(o, 'left'), d = { top: p - n.top + n.marginTop, left: s - n.left + n.marginLeft, width: i, height: r }; return g(d) } function w(e) { var n = e.nodeName; return 'BODY' === n || 'HTML' === n ? !1 : 'fixed' === t(e, 'position') || w(o(e)) } function E(e) { if (!e || !e.parentElement || r()) return document.documentElement; for (var o = e.parentElement; o && 'none' === t(o, 'transform');)o = o.parentElement; return o || document.documentElement } function v(e, t, i, r) { var p = 4 < arguments.length && void 0 !== arguments[4] && arguments[4], s = { top: 0, left: 0 }, d = p ? E(e) : a(e, t); if ('viewport' === r) s = y(d, p); else { var l; 'scrollParent' === r ? (l = n(o(t)), 'BODY' === l.nodeName && (l = e.ownerDocument.documentElement)) : 'window' === r ? l = e.ownerDocument.documentElement : l = r; var f = b(l, d, p); if ('HTML' === l.nodeName && !w(d)) { var m = c(), h = m.height, g = m.width; s.top += f.top - f.marginTop, s.bottom = h + f.top, s.left += f.left - f.marginLeft, s.right = g + f.left } else s = f } return s.left += i, s.top += i, s.right -= i, s.bottom -= i, s } function x(e) { var t = e.width, o = e.height; return t * o } function O(e, t, o, n, i) { var r = 5 < arguments.length && void 0 !== arguments[5] ? arguments[5] : 0; if (-1 === e.indexOf('auto')) return e; var p = v(o, n, r, i), s = { top: { width: p.width, height: t.top - p.top }, right: { width: p.right - t.right, height: p.height }, bottom: { width: p.width, height: p.bottom - t.bottom }, left: { width: t.left - p.left, height: p.height } }, d = Object.keys(s).map(function (e) { return le({ key: e }, s[e], { area: x(s[e]) }) }).sort(function (e, t) { return t.area - e.area }), a = d.filter(function (e) { var t = e.width, n = e.height; return t >= o.clientWidth && n >= o.clientHeight }), l = 0 < a.length ? a[0].key : d[0].key, f = e.split('-')[1]; return l + (f ? '-' + f : '') } function L(e, t, o) { var n = 3 < arguments.length && void 0 !== arguments[3] ? arguments[3] : null, i = n ? E(t) : a(t, o); return b(o, i, n) } function S(e) { var t = getComputedStyle(e), o = parseFloat(t.marginTop) + parseFloat(t.marginBottom), n = parseFloat(t.marginLeft) + parseFloat(t.marginRight), i = { width: e.offsetWidth + n, height: e.offsetHeight + o }; return i } function T(e) { var t = { left: 'right', right: 'left', bottom: 'top', top: 'bottom' }; return e.replace(/left|right|bottom|top/g, function (e) { return t[e] }) } function C(e, t, o) { o = o.split('-')[0]; var n = S(e), i = { width: n.width, height: n.height }, r = -1 !== ['right', 'left'].indexOf(o), p = r ? 'top' : 'left', s = r ? 'left' : 'top', d = r ? 'height' : 'width', a = r ? 'width' : 'height'; return i[p] = t[p] + t[d] / 2 - n[d] / 2, i[s] = o === s ? t[s] - n[a] : t[T(s)], i } function D(e, t) { return Array.prototype.find ? e.find(t) : e.filter(t)[0] } function N(e, t, o) { if (Array.prototype.findIndex) return e.findIndex(function (e) { return e[t] === o }); var n = D(e, function (e) { return e[t] === o }); return e.indexOf(n) } function P(t, o, n) { var i = void 0 === n ? t : t.slice(0, N(t, 'name', n)); return i.forEach(function (t) { t['function'] && console.warn('`modifier.function` is deprecated, use `modifier.fn`!'); var n = t['function'] || t.fn; t.enabled && e(n) && (o.offsets.popper = g(o.offsets.popper), o.offsets.reference = g(o.offsets.reference), o = n(o, t)) }), o } function k() { if (!this.state.isDestroyed) { var e = { instance: this, styles: {}, arrowStyles: {}, attributes: {}, flipped: !1, offsets: {} }; e.offsets.reference = L(this.state, this.popper, this.reference, this.options.positionFixed), e.placement = O(this.options.placement, e.offsets.reference, this.popper, this.reference, this.options.modifiers.flip.boundariesElement, this.options.modifiers.flip.padding), e.originalPlacement = e.placement, e.positionFixed = this.options.positionFixed, e.offsets.popper = C(this.popper, e.offsets.reference, e.placement), e.offsets.popper.position = this.options.positionFixed ? 'fixed' : 'absolute', e = P(this.modifiers, e), this.state.isCreated ? this.options.onUpdate(e) : (this.state.isCreated = !0, this.options.onCreate(e)) } } function W(e, t) { return e.some(function (e) { var o = e.name, n = e.enabled; return n && o === t }) } function B(e) { for (var t = [!1, 'ms', 'Webkit', 'Moz', 'O'], o = e.charAt(0).toUpperCase() + e.slice(1), n = 0; n < t.length; n++) { var i = t[n], r = i ? '' + i + o : e; if ('undefined' != typeof document.body.style[r]) return r } return null } function H() { return this.state.isDestroyed = !0, W(this.modifiers, 'applyStyle') && (this.popper.removeAttribute('x-placement'), this.popper.style.position = '', this.popper.style.top = '', this.popper.style.left = '', this.popper.style.right = '', this.popper.style.bottom = '', this.popper.style.willChange = '', this.popper.style[B('transform')] = ''), this.disableEventListeners(), this.options.removeOnDestroy && this.popper.parentNode.removeChild(this.popper), this } function A(e) { var t = e.ownerDocument; return t ? t.defaultView : window } function M(e, t, o, i) { var r = 'BODY' === e.nodeName, p = r ? e.ownerDocument.defaultView : e; p.addEventListener(t, o, { passive: !0 }), r || M(n(p.parentNode), t, o, i), i.push(p) } function I(e, t, o, i) { o.updateBound = i, A(e).addEventListener('resize', o.updateBound, { passive: !0 }); var r = n(e); return M(r, 'scroll', o.updateBound, o.scrollParents), o.scrollElement = r, o.eventsEnabled = !0, o } function F() { this.state.eventsEnabled || (this.state = I(this.reference, this.options, this.state, this.scheduleUpdate)) } function R(e, t) { return A(e).removeEventListener('resize', t.updateBound), t.scrollParents.forEach(function (e) { e.removeEventListener('scroll', t.updateBound) }), t.updateBound = null, t.scrollParents = [], t.scrollElement = null, t.eventsEnabled = !1, t } function U() { this.state.eventsEnabled && (cancelAnimationFrame(this.scheduleUpdate), this.state = R(this.reference, this.state)) } function Y(e) { return '' !== e && !isNaN(parseFloat(e)) && isFinite(e) } function j(e, t) { Object.keys(t).forEach(function (o) { var n = ''; -1 !== ['width', 'height', 'top', 'right', 'bottom', 'left'].indexOf(o) && Y(t[o]) && (n = 'px'), e.style[o] = t[o] + n }) } function K(e, t) { Object.keys(t).forEach(function (o) { var n = t[o]; !1 === n ? e.removeAttribute(o) : e.setAttribute(o, t[o]) }) } function q(e, t, o) { var n = D(e, function (e) { var o = e.name; return o === t }), i = !!n && e.some(function (e) { return e.name === o && e.enabled && e.order < n.order }); if (!i) { var r = '`' + t + '`'; console.warn('`' + o + '`' + ' modifier is required by ' + r + ' modifier in order to work, be sure to include it before ' + r + '!') } return i } function G(e) { return 'end' === e ? 'start' : 'start' === e ? 'end' : e } function z(e) { var t = 1 < arguments.length && void 0 !== arguments[1] && arguments[1], o = me.indexOf(e), n = me.slice(o + 1).concat(me.slice(0, o)); return t ? n.reverse() : n } function V(e, t, o, n) { var i = e.match(/((?:\-|\+)?\d*\.?\d*)(.*)/), r = +i[1], p = i[2]; if (!r) return e; if (0 === p.indexOf('%')) { var s; switch (p) { case '%p': s = o; break; case '%': case '%r': default: s = n; }var d = g(s); return d[t] / 100 * r } if ('vh' === p || 'vw' === p) { var a; return a = 'vh' === p ? $(document.documentElement.clientHeight, window.innerHeight || 0) : $(document.documentElement.clientWidth, window.innerWidth || 0), a / 100 * r } return r } function _(e, t, o, n) { var i = [0, 0], r = -1 !== ['right', 'left'].indexOf(n), p = e.split(/(\+|\-)/).map(function (e) { return e.trim() }), s = p.indexOf(D(p, function (e) { return -1 !== e.search(/,|\s/) })); p[s] && -1 === p[s].indexOf(',') && console.warn('Offsets separated by white space(s) are deprecated, use a comma (,) instead.'); var d = /\s*,\s*|\s+/, a = -1 === s ? [p] : [p.slice(0, s).concat([p[s].split(d)[0]]), [p[s].split(d)[1]].concat(p.slice(s + 1))]; return a = a.map(function (e, n) { var i = (1 === n ? !r : r) ? 'height' : 'width', p = !1; return e.reduce(function (e, t) { return '' === e[e.length - 1] && -1 !== ['+', '-'].indexOf(t) ? (e[e.length - 1] = t, p = !0, e) : p ? (e[e.length - 1] += t, p = !1, e) : e.concat(t) }, []).map(function (e) { return V(e, i, t, o) }) }), a.forEach(function (e, t) { e.forEach(function (o, n) { Y(o) && (i[t] += o * ('-' === e[n - 1] ? -1 : 1)) }) }), i } function X(e, t) { var o, n = t.offset, i = e.placement, r = e.offsets, p = r.popper, s = r.reference, d = i.split('-')[0]; return o = Y(+n) ? [+n, 0] : _(n, p, s, d), 'left' === d ? (p.top += o[0], p.left -= o[1]) : 'right' === d ? (p.top += o[0], p.left += o[1]) : 'top' === d ? (p.left += o[0], p.top -= o[1]) : 'bottom' === d && (p.left += o[0], p.top += o[1]), e.popper = p, e } for (var J = Math.min, Q = Math.round, Z = Math.floor, $ = Math.max, ee = 'undefined' != typeof window && 'undefined' != typeof document, te = ['Edge', 'Trident', 'Firefox'], oe = 0, ne = 0; ne < te.length; ne += 1)if (ee && 0 <= navigator.userAgent.indexOf(te[ne])) { oe = 1; break } var i = ee && window.Promise, ie = i ? function (e) { var t = !1; return function () { t || (t = !0, window.Promise.resolve().then(function () { t = !1, e() })) } } : function (e) { var t = !1; return function () { t || (t = !0, setTimeout(function () { t = !1, e() }, oe)) } }, re = ee && !!(window.MSInputMethodContext && document.documentMode), pe = ee && /MSIE 10/.test(navigator.userAgent), se = function (e, t) { if (!(e instanceof t)) throw new TypeError('Cannot call a class as a function') }, de = function () { function e(e, t) { for (var o, n = 0; n < t.length; n++)o = t[n], o.enumerable = o.enumerable || !1, o.configurable = !0, 'value' in o && (o.writable = !0), Object.defineProperty(e, o.key, o) } return function (t, o, n) { return o && e(t.prototype, o), n && e(t, n), t } }(), ae = function (e, t, o) { return t in e ? Object.defineProperty(e, t, { value: o, enumerable: !0, configurable: !0, writable: !0 }) : e[t] = o, e }, le = Object.assign || function (e) { for (var t, o = 1; o < arguments.length; o++)for (var n in t = arguments[o], t) Object.prototype.hasOwnProperty.call(t, n) && (e[n] = t[n]); return e }, fe = ['auto-start', 'auto', 'auto-end', 'top-start', 'top', 'top-end', 'right-start', 'right', 'right-end', 'bottom-end', 'bottom', 'bottom-start', 'left-end', 'left', 'left-start'], me = fe.slice(3), he = { FLIP: 'flip', CLOCKWISE: 'clockwise', COUNTERCLOCKWISE: 'counterclockwise' }, ce = function () { function t(o, n) { var i = this, r = 2 < arguments.length && void 0 !== arguments[2] ? arguments[2] : {}; se(this, t), this.scheduleUpdate = function () { return requestAnimationFrame(i.update) }, this.update = ie(this.update.bind(this)), this.options = le({}, t.Defaults, r), this.state = { isDestroyed: !1, isCreated: !1, scrollParents: [] }, this.reference = o && o.jquery ? o[0] : o, this.popper = n && n.jquery ? n[0] : n, this.options.modifiers = {}, Object.keys(le({}, t.Defaults.modifiers, r.modifiers)).forEach(function (e) { i.options.modifiers[e] = le({}, t.Defaults.modifiers[e] || {}, r.modifiers ? r.modifiers[e] : {}) }), this.modifiers = Object.keys(this.options.modifiers).map(function (e) { return le({ name: e }, i.options.modifiers[e]) }).sort(function (e, t) { return e.order - t.order }), this.modifiers.forEach(function (t) { t.enabled && e(t.onLoad) && t.onLoad(i.reference, i.popper, i.options, t, i.state) }), this.update(); var p = this.options.eventsEnabled; p && this.enableEventListeners(), this.state.eventsEnabled = p } return de(t, [{ key: 'update', value: function () { return k.call(this) } }, { key: 'destroy', value: function () { return H.call(this) } }, { key: 'enableEventListeners', value: function () { return F.call(this) } }, { key: 'disableEventListeners', value: function () { return U.call(this) } }]), t }(); return ce.Utils = ('undefined' == typeof window ? global : window).PopperUtils, ce.placements = fe, ce.Defaults = { placement: 'bottom', positionFixed: !1, eventsEnabled: !0, removeOnDestroy: !1, onCreate: function () { }, onUpdate: function () { }, modifiers: { shift: { order: 100, enabled: !0, fn: function (e) { var t = e.placement, o = t.split('-')[0], n = t.split('-')[1]; if (n) { var i = e.offsets, r = i.reference, p = i.popper, s = -1 !== ['bottom', 'top'].indexOf(o), d = s ? 'left' : 'top', a = s ? 'width' : 'height', l = { start: ae({}, d, r[d]), end: ae({}, d, r[d] + r[a] - p[a]) }; e.offsets.popper = le({}, p, l[n]) } return e } }, offset: { order: 200, enabled: !0, fn: X, offset: 0 }, preventOverflow: { order: 300, enabled: !0, fn: function (e, t) { var o = t.boundariesElement || p(e.instance.popper); e.instance.reference === o && (o = p(o)); var n = B('transform'), i = e.instance.popper.style, r = i.top, s = i.left, d = i[n]; i.top = '', i.left = '', i[n] = ''; var a = v(e.instance.popper, e.instance.reference, t.padding, o, e.positionFixed); i.top = r, i.left = s, i[n] = d, t.boundaries = a; var l = t.priority, f = e.offsets.popper, m = { primary: function (e) { var o = f[e]; return f[e] < a[e] && !t.escapeWithReference && (o = $(f[e], a[e])), ae({}, e, o) }, secondary: function (e) { var o = 'right' === e ? 'left' : 'top', n = f[o]; return f[e] > a[e] && !t.escapeWithReference && (n = J(f[o], a[e] - ('right' === e ? f.width : f.height))), ae({}, o, n) } }; return l.forEach(function (e) { var t = -1 === ['left', 'top'].indexOf(e) ? 'secondary' : 'primary'; f = le({}, f, m[t](e)) }), e.offsets.popper = f, e }, priority: ['left', 'right', 'top', 'bottom'], padding: 5, boundariesElement: 'scrollParent' }, keepTogether: { order: 400, enabled: !0, fn: function (e) { var t = e.offsets, o = t.popper, n = t.reference, i = e.placement.split('-')[0], r = Z, p = -1 !== ['top', 'bottom'].indexOf(i), s = p ? 'right' : 'bottom', d = p ? 'left' : 'top', a = p ? 'width' : 'height'; return o[s] < r(n[d]) && (e.offsets.popper[d] = r(n[d]) - o[a]), o[d] > r(n[s]) && (e.offsets.popper[d] = r(n[s])), e } }, arrow: { order: 500, enabled: !0, fn: function (e, o) { var n; if (!q(e.instance.modifiers, 'arrow', 'keepTogether')) return e; var i = o.element; if ('string' == typeof i) { if (i = e.instance.popper.querySelector(i), !i) return e; } else if (!e.instance.popper.contains(i)) return console.warn('WARNING: `arrow.element` must be child of its popper element!'), e; var r = e.placement.split('-')[0], p = e.offsets, s = p.popper, d = p.reference, a = -1 !== ['left', 'right'].indexOf(r), l = a ? 'height' : 'width', f = a ? 'Top' : 'Left', m = f.toLowerCase(), h = a ? 'left' : 'top', c = a ? 'bottom' : 'right', u = S(i)[l]; d[c] - u < s[m] && (e.offsets.popper[m] -= s[m] - (d[c] - u)), d[m] + u > s[c] && (e.offsets.popper[m] += d[m] + u - s[c]), e.offsets.popper = g(e.offsets.popper); var b = d[m] + d[l] / 2 - u / 2, y = t(e.instance.popper), w = parseFloat(y['margin' + f], 10), E = parseFloat(y['border' + f + 'Width'], 10), v = b - e.offsets.popper[m] - w - E; return v = $(J(s[l] - u, v), 0), e.arrowElement = i, e.offsets.arrow = (n = {}, ae(n, m, Q(v)), ae(n, h, ''), n), e }, element: '[x-arrow]' }, flip: { order: 600, enabled: !0, fn: function (e, t) { if (W(e.instance.modifiers, 'inner')) return e; if (e.flipped && e.placement === e.originalPlacement) return e; var o = v(e.instance.popper, e.instance.reference, t.padding, t.boundariesElement, e.positionFixed), n = e.placement.split('-')[0], i = T(n), r = e.placement.split('-')[1] || '', p = []; switch (t.behavior) { case he.FLIP: p = [n, i]; break; case he.CLOCKWISE: p = z(n); break; case he.COUNTERCLOCKWISE: p = z(n, !0); break; default: p = t.behavior; }return p.forEach(function (s, d) { if (n !== s || p.length === d + 1) return e; n = e.placement.split('-')[0], i = T(n); var a = e.offsets.popper, l = e.offsets.reference, f = Z, m = 'left' === n && f(a.right) > f(l.left) || 'right' === n && f(a.left) < f(l.right) || 'top' === n && f(a.bottom) > f(l.top) || 'bottom' === n && f(a.top) < f(l.bottom), h = f(a.left) < f(o.left), c = f(a.right) > f(o.right), g = f(a.top) < f(o.top), u = f(a.bottom) > f(o.bottom), b = 'left' === n && h || 'right' === n && c || 'top' === n && g || 'bottom' === n && u, y = -1 !== ['top', 'bottom'].indexOf(n), w = !!t.flipVariations && (y && 'start' === r && h || y && 'end' === r && c || !y && 'start' === r && g || !y && 'end' === r && u); (m || b || w) && (e.flipped = !0, (m || b) && (n = p[d + 1]), w && (r = G(r)), e.placement = n + (r ? '-' + r : ''), e.offsets.popper = le({}, e.offsets.popper, C(e.instance.popper, e.offsets.reference, e.placement)), e = P(e.instance.modifiers, e, 'flip')) }), e }, behavior: 'flip', padding: 5, boundariesElement: 'viewport' }, inner: { order: 700, enabled: !1, fn: function (e) { var t = e.placement, o = t.split('-')[0], n = e.offsets, i = n.popper, r = n.reference, p = -1 !== ['left', 'right'].indexOf(o), s = -1 === ['top', 'left'].indexOf(o); return i[p ? 'left' : 'top'] = r[o] - (s ? i[p ? 'width' : 'height'] : 0), e.placement = T(t), e.offsets.popper = g(i), e } }, hide: { order: 800, enabled: !0, fn: function (e) { if (!q(e.instance.modifiers, 'hide', 'preventOverflow')) return e; var t = e.offsets.reference, o = D(e.instance.modifiers, function (e) { return 'preventOverflow' === e.name }).boundaries; if (t.bottom < o.top || t.left > o.right || t.top > o.bottom || t.right < o.left) { if (!0 === e.hide) return e; e.hide = !0, e.attributes['x-out-of-boundaries'] = '' } else { if (!1 === e.hide) return e; e.hide = !1, e.attributes['x-out-of-boundaries'] = !1 } return e } }, computeStyle: { order: 850, enabled: !0, fn: function (e, t) { var o = t.x, n = t.y, i = e.offsets.popper, r = D(e.instance.modifiers, function (e) { return 'applyStyle' === e.name }).gpuAcceleration; void 0 !== r && console.warn('WARNING: `gpuAcceleration` option moved to `computeStyle` modifier and will not be supported in future versions of Popper.js!'); var s, d, a = void 0 === r ? t.gpuAcceleration : r, l = p(e.instance.popper), f = u(l), m = { position: i.position }, h = { left: Z(i.left), top: Q(i.top), bottom: Q(i.bottom), right: Z(i.right) }, c = 'bottom' === o ? 'top' : 'bottom', g = 'right' === n ? 'left' : 'right', b = B('transform'); if (d = 'bottom' == c ? -f.height + h.bottom : h.top, s = 'right' == g ? -f.width + h.right : h.left, a && b) m[b] = 'translate3d(' + s + 'px, ' + d + 'px, 0)', m[c] = 0, m[g] = 0, m.willChange = 'transform'; else { var y = 'bottom' == c ? -1 : 1, w = 'right' == g ? -1 : 1; m[c] = d * y, m[g] = s * w, m.willChange = c + ', ' + g } var E = { "x-placement": e.placement }; return e.attributes = le({}, E, e.attributes), e.styles = le({}, m, e.styles), e.arrowStyles = le({}, e.offsets.arrow, e.arrowStyles), e }, gpuAcceleration: !0, x: 'bottom', y: 'right' }, applyStyle: { order: 900, enabled: !0, fn: function (e) { return j(e.instance.popper, e.styles), K(e.instance.popper, e.attributes), e.arrowElement && Object.keys(e.arrowStyles).length && j(e.arrowElement, e.arrowStyles), e }, onLoad: function (e, t, o, n, i) { var r = L(i, t, e, o.positionFixed), p = O(o.placement, r, t, e, o.modifiers.flip.boundariesElement, o.modifiers.flip.padding); return t.setAttribute('x-placement', p), j(t, { position: o.positionFixed ? 'fixed' : 'absolute' }), o }, gpuAcceleration: void 0 } } }, ce });
+//# sourceMappingURL=popper.min.js.map
+
+/*!
+ * Bootstrap v4.1.1 (https://getbootstrap.com/)
+ * Copyright 2011-2018 The Bootstrap Authors (https://github.com/twbs/bootstrap/graphs/contributors)
+ * Licensed under MIT (https://github.com/twbs/bootstrap/blob/master/LICENSE)
+ */
+!function (t, e) { "object" == typeof exports && "undefined" != typeof module ? e(exports, require("jquery"), require("popper.js")) : "function" == typeof define && define.amd ? define(["exports", "jquery", "popper.js"], e) : e(t.bootstrap = {}, t.jQuery, t.Popper) }(this, function (t, e, c) { "use strict"; function i(t, e) { for (var n = 0; n < e.length; n++) { var i = e[n]; i.enumerable = i.enumerable || !1, i.configurable = !0, "value" in i && (i.writable = !0), Object.defineProperty(t, i.key, i) } } function o(t, e, n) { return e && i(t.prototype, e), n && i(t, n), t } function h(r) { for (var t = 1; t < arguments.length; t++) { var s = null != arguments[t] ? arguments[t] : {}, e = Object.keys(s); "function" == typeof Object.getOwnPropertySymbols && (e = e.concat(Object.getOwnPropertySymbols(s).filter(function (t) { return Object.getOwnPropertyDescriptor(s, t).enumerable }))), e.forEach(function (t) { var e, n, i; e = r, i = s[n = t], n in e ? Object.defineProperty(e, n, { value: i, enumerable: !0, configurable: !0, writable: !0 }) : e[n] = i }) } return r } e = e && e.hasOwnProperty("default") ? e.default : e, c = c && c.hasOwnProperty("default") ? c.default : c; var r, n, s, a, l, u, f, d, _, g, m, p, v, E, y, T, C, I, A, D, b, S, w, N, O, k, P, L, j, R, H, W, M, x, U, K, F, V, Q, B, Y, G, q, z, X, J, Z, $, tt, et, nt, it, rt, st, ot, at, lt, ht, ct, ut, ft, dt, _t, gt, mt, pt, vt, Et, yt, Tt, Ct, It, At, Dt, bt, St, wt, Nt, Ot, kt, Pt, Lt, jt, Rt, Ht, Wt, Mt, xt, Ut, Kt, Ft, Vt, Qt, Bt, Yt, Gt, qt, zt, Xt, Jt, Zt, $t, te, ee, ne, ie, re, se, oe, ae, le, he, ce, ue, fe, de, _e, ge, me, pe, ve, Ee, ye, Te, Ce, Ie, Ae, De, be, Se, we, Ne, Oe, ke, Pe, Le, je, Re, He, We, Me, xe, Ue, Ke, Fe, Ve, Qe, Be, Ye, Ge, qe, ze, Xe, Je, Ze, $e, tn, en, nn, rn, sn, on, an, ln, hn, cn, un, fn, dn, _n, gn, mn, pn, vn, En, yn, Tn, Cn = function (i) { var e = "transitionend"; function t(t) { var e = this, n = !1; return i(this).one(l.TRANSITION_END, function () { n = !0 }), setTimeout(function () { n || l.triggerTransitionEnd(e) }, t), this } var l = { TRANSITION_END: "bsTransitionEnd", getUID: function (t) { for (; t += ~~(1e6 * Math.random()), document.getElementById(t);); return t }, getSelectorFromElement: function (t) { var e = t.getAttribute("data-target"); e && "#" !== e || (e = t.getAttribute("href") || ""); try { return 0 < i(document).find(e).length ? e : null } catch (t) { return null } }, getTransitionDurationFromElement: function (t) { if (!t) return 0; var e = i(t).css("transition-duration"); return parseFloat(e) ? (e = e.split(",")[0], 1e3 * parseFloat(e)) : 0 }, reflow: function (t) { return t.offsetHeight }, triggerTransitionEnd: function (t) { i(t).trigger(e) }, supportsTransitionEnd: function () { return Boolean(e) }, isElement: function (t) { return (t[0] || t).nodeType }, typeCheckConfig: function (t, e, n) { for (var i in n) if (Object.prototype.hasOwnProperty.call(n, i)) { var r = n[i], s = e[i], o = s && l.isElement(s) ? "element" : (a = s, {}.toString.call(a).match(/\s([a-z]+)/i)[1].toLowerCase()); if (!new RegExp(r).test(o)) throw new Error(t.toUpperCase() + ': Option "' + i + '" provided type "' + o + '" but expected type "' + r + '".') } var a } }; return i.fn.emulateTransitionEnd = t, i.event.special[l.TRANSITION_END] = { bindType: e, delegateType: e, handle: function (t) { if (i(t.target).is(this)) return t.handleObj.handler.apply(this, arguments) } }, l }(e), In = (n = "alert", a = "." + (s = "bs.alert"), l = (r = e).fn[n], u = { CLOSE: "close" + a, CLOSED: "closed" + a, CLICK_DATA_API: "click" + a + ".data-api" }, f = "alert", d = "fade", _ = "show", g = function () { function i(t) { this._element = t } var t = i.prototype; return t.close = function (t) { var e = this._element; t && (e = this._getRootElement(t)), this._triggerCloseEvent(e).isDefaultPrevented() || this._removeElement(e) }, t.dispose = function () { r.removeData(this._element, s), this._element = null }, t._getRootElement = function (t) { var e = Cn.getSelectorFromElement(t), n = !1; return e && (n = r(e)[0]), n || (n = r(t).closest("." + f)[0]), n }, t._triggerCloseEvent = function (t) { var e = r.Event(u.CLOSE); return r(t).trigger(e), e }, t._removeElement = function (e) { var n = this; if (r(e).removeClass(_), r(e).hasClass(d)) { var t = Cn.getTransitionDurationFromElement(e); r(e).one(Cn.TRANSITION_END, function (t) { return n._destroyElement(e, t) }).emulateTransitionEnd(t) } else this._destroyElement(e) }, t._destroyElement = function (t) { r(t).detach().trigger(u.CLOSED).remove() }, i._jQueryInterface = function (n) { return this.each(function () { var t = r(this), e = t.data(s); e || (e = new i(this), t.data(s, e)), "close" === n && e[n](this) }) }, i._handleDismiss = function (e) { return function (t) { t && t.preventDefault(), e.close(this) } }, o(i, null, [{ key: "VERSION", get: function () { return "4.1.1" } }]), i }(), r(document).on(u.CLICK_DATA_API, '[data-dismiss="alert"]', g._handleDismiss(new g)), r.fn[n] = g._jQueryInterface, r.fn[n].Constructor = g, r.fn[n].noConflict = function () { return r.fn[n] = l, g._jQueryInterface }, g), An = (p = "button", E = "." + (v = "bs.button"), y = ".data-api", T = (m = e).fn[p], C = "active", I = "btn", D = '[data-toggle^="button"]', b = '[data-toggle="buttons"]', S = "input", w = ".active", N = ".btn", O = { CLICK_DATA_API: "click" + E + y, FOCUS_BLUR_DATA_API: (A = "focus") + E + y + " blur" + E + y }, k = function () { function n(t) { this._element = t } var t = n.prototype; return t.toggle = function () { var t = !0, e = !0, n = m(this._element).closest(b)[0]; if (n) { var i = m(this._element).find(S)[0]; if (i) { if ("radio" === i.type) if (i.checked && m(this._element).hasClass(C)) t = !1; else { var r = m(n).find(w)[0]; r && m(r).removeClass(C) } if (t) { if (i.hasAttribute("disabled") || n.hasAttribute("disabled") || i.classList.contains("disabled") || n.classList.contains("disabled")) return; i.checked = !m(this._element).hasClass(C), m(i).trigger("change") } i.focus(), e = !1 } } e && this._element.setAttribute("aria-pressed", !m(this._element).hasClass(C)), t && m(this._element).toggleClass(C) }, t.dispose = function () { m.removeData(this._element, v), this._element = null }, n._jQueryInterface = function (e) { return this.each(function () { var t = m(this).data(v); t || (t = new n(this), m(this).data(v, t)), "toggle" === e && t[e]() }) }, o(n, null, [{ key: "VERSION", get: function () { return "4.1.1" } }]), n }(), m(document).on(O.CLICK_DATA_API, D, function (t) { t.preventDefault(); var e = t.target; m(e).hasClass(I) || (e = m(e).closest(N)), k._jQueryInterface.call(m(e), "toggle") }).on(O.FOCUS_BLUR_DATA_API, D, function (t) { var e = m(t.target).closest(N)[0]; m(e).toggleClass(A, /^focus(in)?$/.test(t.type)) }), m.fn[p] = k._jQueryInterface, m.fn[p].Constructor = k, m.fn[p].noConflict = function () { return m.fn[p] = T, k._jQueryInterface }, k), Dn = (L = "carousel", R = "." + (j = "bs.carousel"), H = ".data-api", W = (P = e).fn[L], M = { interval: 5e3, keyboard: !0, slide: !1, pause: "hover", wrap: !0 }, x = { interval: "(number|boolean)", keyboard: "boolean", slide: "(boolean|string)", pause: "(string|boolean)", wrap: "boolean" }, U = "next", K = "prev", F = "left", V = "right", Q = { SLIDE: "slide" + R, SLID: "slid" + R, KEYDOWN: "keydown" + R, MOUSEENTER: "mouseenter" + R, MOUSELEAVE: "mouseleave" + R, TOUCHEND: "touchend" + R, LOAD_DATA_API: "load" + R + H, CLICK_DATA_API: "click" + R + H }, B = "carousel", Y = "active", G = "slide", q = "carousel-item-right", z = "carousel-item-left", X = "carousel-item-next", J = "carousel-item-prev", Z = { ACTIVE: ".active", ACTIVE_ITEM: ".active.carousel-item", ITEM: ".carousel-item", NEXT_PREV: ".carousel-item-next, .carousel-item-prev", INDICATORS: ".carousel-indicators", DATA_SLIDE: "[data-slide], [data-slide-to]", DATA_RIDE: '[data-ride="carousel"]' }, $ = function () { function s(t, e) { this._items = null, this._interval = null, this._activeElement = null, this._isPaused = !1, this._isSliding = !1, this.touchTimeout = null, this._config = this._getConfig(e), this._element = P(t)[0], this._indicatorsElement = P(this._element).find(Z.INDICATORS)[0], this._addEventListeners() } var t = s.prototype; return t.next = function () { this._isSliding || this._slide(U) }, t.nextWhenVisible = function () { !document.hidden && P(this._element).is(":visible") && "hidden" !== P(this._element).css("visibility") && this.next() }, t.prev = function () { this._isSliding || this._slide(K) }, t.pause = function (t) { t || (this._isPaused = !0), P(this._element).find(Z.NEXT_PREV)[0] && (Cn.triggerTransitionEnd(this._element), this.cycle(!0)), clearInterval(this._interval), this._interval = null }, t.cycle = function (t) { t || (this._isPaused = !1), this._interval && (clearInterval(this._interval), this._interval = null), this._config.interval && !this._isPaused && (this._interval = setInterval((document.visibilityState ? this.nextWhenVisible : this.next).bind(this), this._config.interval)) }, t.to = function (t) { var e = this; this._activeElement = P(this._element).find(Z.ACTIVE_ITEM)[0]; var n = this._getItemIndex(this._activeElement); if (!(t > this._items.length - 1 || t < 0)) if (this._isSliding) P(this._element).one(Q.SLID, function () { return e.to(t) }); else { if (n === t) return this.pause(), void this.cycle(); var i = n < t ? U : K; this._slide(i, this._items[t]) } }, t.dispose = function () { P(this._element).off(R), P.removeData(this._element, j), this._items = null, this._config = null, this._element = null, this._interval = null, this._isPaused = null, this._isSliding = null, this._activeElement = null, this._indicatorsElement = null }, t._getConfig = function (t) { return t = h({}, M, t), Cn.typeCheckConfig(L, t, x), t }, t._addEventListeners = function () { var e = this; this._config.keyboard && P(this._element).on(Q.KEYDOWN, function (t) { return e._keydown(t) }), "hover" === this._config.pause && (P(this._element).on(Q.MOUSEENTER, function (t) { return e.pause(t) }).on(Q.MOUSELEAVE, function (t) { return e.cycle(t) }), "ontouchstart" in document.documentElement && P(this._element).on(Q.TOUCHEND, function () { e.pause(), e.touchTimeout && clearTimeout(e.touchTimeout), e.touchTimeout = setTimeout(function (t) { return e.cycle(t) }, 500 + e._config.interval) })) }, t._keydown = function (t) { if (!/input|textarea/i.test(t.target.tagName)) switch (t.which) { case 37: t.preventDefault(), this.prev(); break; case 39: t.preventDefault(), this.next() } }, t._getItemIndex = function (t) { return this._items = P.makeArray(P(t).parent().find(Z.ITEM)), this._items.indexOf(t) }, t._getItemByDirection = function (t, e) { var n = t === U, i = t === K, r = this._getItemIndex(e), s = this._items.length - 1; if ((i && 0 === r || n && r === s) && !this._config.wrap) return e; var o = (r + (t === K ? -1 : 1)) % this._items.length; return -1 === o ? this._items[this._items.length - 1] : this._items[o] }, t._triggerSlideEvent = function (t, e) { var n = this._getItemIndex(t), i = this._getItemIndex(P(this._element).find(Z.ACTIVE_ITEM)[0]), r = P.Event(Q.SLIDE, { relatedTarget: t, direction: e, from: i, to: n }); return P(this._element).trigger(r), r }, t._setActiveIndicatorElement = function (t) { if (this._indicatorsElement) { P(this._indicatorsElement).find(Z.ACTIVE).removeClass(Y); var e = this._indicatorsElement.children[this._getItemIndex(t)]; e && P(e).addClass(Y) } }, t._slide = function (t, e) { var n, i, r, s = this, o = P(this._element).find(Z.ACTIVE_ITEM)[0], a = this._getItemIndex(o), l = e || o && this._getItemByDirection(t, o), h = this._getItemIndex(l), c = Boolean(this._interval); if (t === U ? (n = z, i = X, r = F) : (n = q, i = J, r = V), l && P(l).hasClass(Y)) this._isSliding = !1; else if (!this._triggerSlideEvent(l, r).isDefaultPrevented() && o && l) { this._isSliding = !0, c && this.pause(), this._setActiveIndicatorElement(l); var u = P.Event(Q.SLID, { relatedTarget: l, direction: r, from: a, to: h }); if (P(this._element).hasClass(G)) { P(l).addClass(i), Cn.reflow(l), P(o).addClass(n), P(l).addClass(n); var f = Cn.getTransitionDurationFromElement(o); P(o).one(Cn.TRANSITION_END, function () { P(l).removeClass(n + " " + i).addClass(Y), P(o).removeClass(Y + " " + i + " " + n), s._isSliding = !1, setTimeout(function () { return P(s._element).trigger(u) }, 0) }).emulateTransitionEnd(f) } else P(o).removeClass(Y), P(l).addClass(Y), this._isSliding = !1, P(this._element).trigger(u); c && this.cycle() } }, s._jQueryInterface = function (i) { return this.each(function () { var t = P(this).data(j), e = h({}, M, P(this).data()); "object" == typeof i && (e = h({}, e, i)); var n = "string" == typeof i ? i : e.slide; if (t || (t = new s(this, e), P(this).data(j, t)), "number" == typeof i) t.to(i); else if ("string" == typeof n) { if ("undefined" == typeof t[n]) throw new TypeError('No method named "' + n + '"'); t[n]() } else e.interval && (t.pause(), t.cycle()) }) }, s._dataApiClickHandler = function (t) { var e = Cn.getSelectorFromElement(this); if (e) { var n = P(e)[0]; if (n && P(n).hasClass(B)) { var i = h({}, P(n).data(), P(this).data()), r = this.getAttribute("data-slide-to"); r && (i.interval = !1), s._jQueryInterface.call(P(n), i), r && P(n).data(j).to(r), t.preventDefault() } } }, o(s, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return M } }]), s }(), P(document).on(Q.CLICK_DATA_API, Z.DATA_SLIDE, $._dataApiClickHandler), P(window).on(Q.LOAD_DATA_API, function () { P(Z.DATA_RIDE).each(function () { var t = P(this); $._jQueryInterface.call(t, t.data()) }) }), P.fn[L] = $._jQueryInterface, P.fn[L].Constructor = $, P.fn[L].noConflict = function () { return P.fn[L] = W, $._jQueryInterface }, $), bn = (et = "collapse", it = "." + (nt = "bs.collapse"), rt = (tt = e).fn[et], st = { toggle: !0, parent: "" }, ot = { toggle: "boolean", parent: "(string|element)" }, at = { SHOW: "show" + it, SHOWN: "shown" + it, HIDE: "hide" + it, HIDDEN: "hidden" + it, CLICK_DATA_API: "click" + it + ".data-api" }, lt = "show", ht = "collapse", ct = "collapsing", ut = "collapsed", ft = "width", dt = "height", _t = { ACTIVES: ".show, .collapsing", DATA_TOGGLE: '[data-toggle="collapse"]' }, gt = function () { function a(t, e) { this._isTransitioning = !1, this._element = t, this._config = this._getConfig(e), this._triggerArray = tt.makeArray(tt('[data-toggle="collapse"][href="#' + t.id + '"],[data-toggle="collapse"][data-target="#' + t.id + '"]')); for (var n = tt(_t.DATA_TOGGLE), i = 0; i < n.length; i++) { var r = n[i], s = Cn.getSelectorFromElement(r); null !== s && 0 < tt(s).filter(t).length && (this._selector = s, this._triggerArray.push(r)) } this._parent = this._config.parent ? this._getParent() : null, this._config.parent || this._addAriaAndCollapsedClass(this._element, this._triggerArray), this._config.toggle && this.toggle() } var t = a.prototype; return t.toggle = function () { tt(this._element).hasClass(lt) ? this.hide() : this.show() }, t.show = function () { var t, e, n = this; if (!this._isTransitioning && !tt(this._element).hasClass(lt) && (this._parent && 0 === (t = tt.makeArray(tt(this._parent).find(_t.ACTIVES).filter('[data-parent="' + this._config.parent + '"]'))).length && (t = null), !(t && (e = tt(t).not(this._selector).data(nt)) && e._isTransitioning))) { var i = tt.Event(at.SHOW); if (tt(this._element).trigger(i), !i.isDefaultPrevented()) { t && (a._jQueryInterface.call(tt(t).not(this._selector), "hide"), e || tt(t).data(nt, null)); var r = this._getDimension(); tt(this._element).removeClass(ht).addClass(ct), (this._element.style[r] = 0) < this._triggerArray.length && tt(this._triggerArray).removeClass(ut).attr("aria-expanded", !0), this.setTransitioning(!0); var s = "scroll" + (r[0].toUpperCase() + r.slice(1)), o = Cn.getTransitionDurationFromElement(this._element); tt(this._element).one(Cn.TRANSITION_END, function () { tt(n._element).removeClass(ct).addClass(ht).addClass(lt), n._element.style[r] = "", n.setTransitioning(!1), tt(n._element).trigger(at.SHOWN) }).emulateTransitionEnd(o), this._element.style[r] = this._element[s] + "px" } } }, t.hide = function () { var t = this; if (!this._isTransitioning && tt(this._element).hasClass(lt)) { var e = tt.Event(at.HIDE); if (tt(this._element).trigger(e), !e.isDefaultPrevented()) { var n = this._getDimension(); if (this._element.style[n] = this._element.getBoundingClientRect()[n] + "px", Cn.reflow(this._element), tt(this._element).addClass(ct).removeClass(ht).removeClass(lt), 0 < this._triggerArray.length) for (var i = 0; i < this._triggerArray.length; i++) { var r = this._triggerArray[i], s = Cn.getSelectorFromElement(r); if (null !== s) tt(s).hasClass(lt) || tt(r).addClass(ut).attr("aria-expanded", !1) } this.setTransitioning(!0); this._element.style[n] = ""; var o = Cn.getTransitionDurationFromElement(this._element); tt(this._element).one(Cn.TRANSITION_END, function () { t.setTransitioning(!1), tt(t._element).removeClass(ct).addClass(ht).trigger(at.HIDDEN) }).emulateTransitionEnd(o) } } }, t.setTransitioning = function (t) { this._isTransitioning = t }, t.dispose = function () { tt.removeData(this._element, nt), this._config = null, this._parent = null, this._element = null, this._triggerArray = null, this._isTransitioning = null }, t._getConfig = function (t) { return (t = h({}, st, t)).toggle = Boolean(t.toggle), Cn.typeCheckConfig(et, t, ot), t }, t._getDimension = function () { return tt(this._element).hasClass(ft) ? ft : dt }, t._getParent = function () { var n = this, t = null; Cn.isElement(this._config.parent) ? (t = this._config.parent, "undefined" != typeof this._config.parent.jquery && (t = this._config.parent[0])) : t = tt(this._config.parent)[0]; var e = '[data-toggle="collapse"][data-parent="' + this._config.parent + '"]'; return tt(t).find(e).each(function (t, e) { n._addAriaAndCollapsedClass(a._getTargetFromElement(e), [e]) }), t }, t._addAriaAndCollapsedClass = function (t, e) { if (t) { var n = tt(t).hasClass(lt); 0 < e.length && tt(e).toggleClass(ut, !n).attr("aria-expanded", n) } }, a._getTargetFromElement = function (t) { var e = Cn.getSelectorFromElement(t); return e ? tt(e)[0] : null }, a._jQueryInterface = function (i) { return this.each(function () { var t = tt(this), e = t.data(nt), n = h({}, st, t.data(), "object" == typeof i && i ? i : {}); if (!e && n.toggle && /show|hide/.test(i) && (n.toggle = !1), e || (e = new a(this, n), t.data(nt, e)), "string" == typeof i) { if ("undefined" == typeof e[i]) throw new TypeError('No method named "' + i + '"'); e[i]() } }) }, o(a, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return st } }]), a }(), tt(document).on(at.CLICK_DATA_API, _t.DATA_TOGGLE, function (t) { "A" === t.currentTarget.tagName && t.preventDefault(); var n = tt(this), e = Cn.getSelectorFromElement(this); tt(e).each(function () { var t = tt(this), e = t.data(nt) ? "toggle" : n.data(); gt._jQueryInterface.call(t, e) }) }), tt.fn[et] = gt._jQueryInterface, tt.fn[et].Constructor = gt, tt.fn[et].noConflict = function () { return tt.fn[et] = rt, gt._jQueryInterface }, gt), Sn = (pt = "dropdown", Et = "." + (vt = "bs.dropdown"), yt = ".data-api", Tt = (mt = e).fn[pt], Ct = new RegExp("38|40|27"), It = { HIDE: "hide" + Et, HIDDEN: "hidden" + Et, SHOW: "show" + Et, SHOWN: "shown" + Et, CLICK: "click" + Et, CLICK_DATA_API: "click" + Et + yt, KEYDOWN_DATA_API: "keydown" + Et + yt, KEYUP_DATA_API: "keyup" + Et + yt }, At = "disabled", Dt = "show", bt = "dropup", St = "dropright", wt = "dropleft", Nt = "dropdown-menu-right", Ot = "position-static", kt = '[data-toggle="dropdown"]', Pt = ".dropdown form", Lt = ".dropdown-menu", jt = ".navbar-nav", Rt = ".dropdown-menu .dropdown-item:not(.disabled):not(:disabled)", Ht = "top-start", Wt = "top-end", Mt = "bottom-start", xt = "bottom-end", Ut = "right-start", Kt = "left-start", Ft = { offset: 0, flip: !0, boundary: "scrollParent", reference: "toggle", display: "dynamic" }, Vt = { offset: "(number|string|function)", flip: "boolean", boundary: "(string|element)", reference: "(string|element)", display: "string" }, Qt = function () { function l(t, e) { this._element = t, this._popper = null, this._config = this._getConfig(e), this._menu = this._getMenuElement(), this._inNavbar = this._detectNavbar(), this._addEventListeners() } var t = l.prototype; return t.toggle = function () { if (!this._element.disabled && !mt(this._element).hasClass(At)) { var t = l._getParentFromElement(this._element), e = mt(this._menu).hasClass(Dt); if (l._clearMenus(), !e) { var n = { relatedTarget: this._element }, i = mt.Event(It.SHOW, n); if (mt(t).trigger(i), !i.isDefaultPrevented()) { if (!this._inNavbar) { if ("undefined" == typeof c) throw new TypeError("Bootstrap dropdown require Popper.js (https://popper.js.org)"); var r = this._element; "parent" === this._config.reference ? r = t : Cn.isElement(this._config.reference) && (r = this._config.reference, "undefined" != typeof this._config.reference.jquery && (r = this._config.reference[0])), "scrollParent" !== this._config.boundary && mt(t).addClass(Ot), this._popper = new c(r, this._menu, this._getPopperConfig()) } "ontouchstart" in document.documentElement && 0 === mt(t).closest(jt).length && mt(document.body).children().on("mouseover", null, mt.noop), this._element.focus(), this._element.setAttribute("aria-expanded", !0), mt(this._menu).toggleClass(Dt), mt(t).toggleClass(Dt).trigger(mt.Event(It.SHOWN, n)) } } } }, t.dispose = function () { mt.removeData(this._element, vt), mt(this._element).off(Et), this._element = null, (this._menu = null) !== this._popper && (this._popper.destroy(), this._popper = null) }, t.update = function () { this._inNavbar = this._detectNavbar(), null !== this._popper && this._popper.scheduleUpdate() }, t._addEventListeners = function () { var e = this; mt(this._element).on(It.CLICK, function (t) { t.preventDefault(), t.stopPropagation(), e.toggle() }) }, t._getConfig = function (t) { return t = h({}, this.constructor.Default, mt(this._element).data(), t), Cn.typeCheckConfig(pt, t, this.constructor.DefaultType), t }, t._getMenuElement = function () { if (!this._menu) { var t = l._getParentFromElement(this._element); this._menu = mt(t).find(Lt)[0] } return this._menu }, t._getPlacement = function () { var t = mt(this._element).parent(), e = Mt; return t.hasClass(bt) ? (e = Ht, mt(this._menu).hasClass(Nt) && (e = Wt)) : t.hasClass(St) ? e = Ut : t.hasClass(wt) ? e = Kt : mt(this._menu).hasClass(Nt) && (e = xt), e }, t._detectNavbar = function () { return 0 < mt(this._element).closest(".navbar").length }, t._getPopperConfig = function () { var e = this, t = {}; "function" == typeof this._config.offset ? t.fn = function (t) { return t.offsets = h({}, t.offsets, e._config.offset(t.offsets) || {}), t } : t.offset = this._config.offset; var n = { placement: this._getPlacement(), modifiers: { offset: t, flip: { enabled: this._config.flip }, preventOverflow: { boundariesElement: this._config.boundary } } }; return "static" === this._config.display && (n.modifiers.applyStyle = { enabled: !1 }), n }, l._jQueryInterface = function (e) { return this.each(function () { var t = mt(this).data(vt); if (t || (t = new l(this, "object" == typeof e ? e : null), mt(this).data(vt, t)), "string" == typeof e) { if ("undefined" == typeof t[e]) throw new TypeError('No method named "' + e + '"'); t[e]() } }) }, l._clearMenus = function (t) { if (!t || 3 !== t.which && ("keyup" !== t.type || 9 === t.which)) for (var e = mt.makeArray(mt(kt)), n = 0; n < e.length; n++) { var i = l._getParentFromElement(e[n]), r = mt(e[n]).data(vt), s = { relatedTarget: e[n] }; if (r) { var o = r._menu; if (mt(i).hasClass(Dt) && !(t && ("click" === t.type && /input|textarea/i.test(t.target.tagName) || "keyup" === t.type && 9 === t.which) && mt.contains(i, t.target))) { var a = mt.Event(It.HIDE, s); mt(i).trigger(a), a.isDefaultPrevented() || ("ontouchstart" in document.documentElement && mt(document.body).children().off("mouseover", null, mt.noop), e[n].setAttribute("aria-expanded", "false"), mt(o).removeClass(Dt), mt(i).removeClass(Dt).trigger(mt.Event(It.HIDDEN, s))) } } } }, l._getParentFromElement = function (t) { var e, n = Cn.getSelectorFromElement(t); return n && (e = mt(n)[0]), e || t.parentNode }, l._dataApiKeydownHandler = function (t) { if ((/input|textarea/i.test(t.target.tagName) ? !(32 === t.which || 27 !== t.which && (40 !== t.which && 38 !== t.which || mt(t.target).closest(Lt).length)) : Ct.test(t.which)) && (t.preventDefault(), t.stopPropagation(), !this.disabled && !mt(this).hasClass(At))) { var e = l._getParentFromElement(this), n = mt(e).hasClass(Dt); if ((n || 27 === t.which && 32 === t.which) && (!n || 27 !== t.which && 32 !== t.which)) { var i = mt(e).find(Rt).get(); if (0 !== i.length) { var r = i.indexOf(t.target); 38 === t.which && 0 < r && r-- , 40 === t.which && r < i.length - 1 && r++ , r < 0 && (r = 0), i[r].focus() } } else { if (27 === t.which) { var s = mt(e).find(kt)[0]; mt(s).trigger("focus") } mt(this).trigger("click") } } }, o(l, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return Ft } }, { key: "DefaultType", get: function () { return Vt } }]), l }(), mt(document).on(It.KEYDOWN_DATA_API, kt, Qt._dataApiKeydownHandler).on(It.KEYDOWN_DATA_API, Lt, Qt._dataApiKeydownHandler).on(It.CLICK_DATA_API + " " + It.KEYUP_DATA_API, Qt._clearMenus).on(It.CLICK_DATA_API, kt, function (t) { t.preventDefault(), t.stopPropagation(), Qt._jQueryInterface.call(mt(this), "toggle") }).on(It.CLICK_DATA_API, Pt, function (t) { t.stopPropagation() }), mt.fn[pt] = Qt._jQueryInterface, mt.fn[pt].Constructor = Qt, mt.fn[pt].noConflict = function () { return mt.fn[pt] = Tt, Qt._jQueryInterface }, Qt), wn = (Yt = "modal", qt = "." + (Gt = "bs.modal"), zt = (Bt = e).fn[Yt], Xt = { backdrop: !0, keyboard: !0, focus: !0, show: !0 }, Jt = { backdrop: "(boolean|string)", keyboard: "boolean", focus: "boolean", show: "boolean" }, Zt = { HIDE: "hide" + qt, HIDDEN: "hidden" + qt, SHOW: "show" + qt, SHOWN: "shown" + qt, FOCUSIN: "focusin" + qt, RESIZE: "resize" + qt, CLICK_DISMISS: "click.dismiss" + qt, KEYDOWN_DISMISS: "keydown.dismiss" + qt, MOUSEUP_DISMISS: "mouseup.dismiss" + qt, MOUSEDOWN_DISMISS: "mousedown.dismiss" + qt, CLICK_DATA_API: "click" + qt + ".data-api" }, $t = "modal-scrollbar-measure", te = "modal-backdrop", ee = "modal-open", ne = "fade", ie = "show", re = { DIALOG: ".modal-dialog", DATA_TOGGLE: '[data-toggle="modal"]', DATA_DISMISS: '[data-dismiss="modal"]', FIXED_CONTENT: ".fixed-top, .fixed-bottom, .is-fixed, .sticky-top", STICKY_CONTENT: ".sticky-top", NAVBAR_TOGGLER: ".navbar-toggler" }, se = function () { function r(t, e) { this._config = this._getConfig(e), this._element = t, this._dialog = Bt(t).find(re.DIALOG)[0], this._backdrop = null, this._isShown = !1, this._isBodyOverflowing = !1, this._ignoreBackdropClick = !1, this._scrollbarWidth = 0 } var t = r.prototype; return t.toggle = function (t) { return this._isShown ? this.hide() : this.show(t) }, t.show = function (t) { var e = this; if (!this._isTransitioning && !this._isShown) { Bt(this._element).hasClass(ne) && (this._isTransitioning = !0); var n = Bt.Event(Zt.SHOW, { relatedTarget: t }); Bt(this._element).trigger(n), this._isShown || n.isDefaultPrevented() || (this._isShown = !0, this._checkScrollbar(), this._setScrollbar(), this._adjustDialog(), Bt(document.body).addClass(ee), this._setEscapeEvent(), this._setResizeEvent(), Bt(this._element).on(Zt.CLICK_DISMISS, re.DATA_DISMISS, function (t) { return e.hide(t) }), Bt(this._dialog).on(Zt.MOUSEDOWN_DISMISS, function () { Bt(e._element).one(Zt.MOUSEUP_DISMISS, function (t) { Bt(t.target).is(e._element) && (e._ignoreBackdropClick = !0) }) }), this._showBackdrop(function () { return e._showElement(t) })) } }, t.hide = function (t) { var e = this; if (t && t.preventDefault(), !this._isTransitioning && this._isShown) { var n = Bt.Event(Zt.HIDE); if (Bt(this._element).trigger(n), this._isShown && !n.isDefaultPrevented()) { this._isShown = !1; var i = Bt(this._element).hasClass(ne); if (i && (this._isTransitioning = !0), this._setEscapeEvent(), this._setResizeEvent(), Bt(document).off(Zt.FOCUSIN), Bt(this._element).removeClass(ie), Bt(this._element).off(Zt.CLICK_DISMISS), Bt(this._dialog).off(Zt.MOUSEDOWN_DISMISS), i) { var r = Cn.getTransitionDurationFromElement(this._element); Bt(this._element).one(Cn.TRANSITION_END, function (t) { return e._hideModal(t) }).emulateTransitionEnd(r) } else this._hideModal() } } }, t.dispose = function () { Bt.removeData(this._element, Gt), Bt(window, document, this._element, this._backdrop).off(qt), this._config = null, this._element = null, this._dialog = null, this._backdrop = null, this._isShown = null, this._isBodyOverflowing = null, this._ignoreBackdropClick = null, this._scrollbarWidth = null }, t.handleUpdate = function () { this._adjustDialog() }, t._getConfig = function (t) { return t = h({}, Xt, t), Cn.typeCheckConfig(Yt, t, Jt), t }, t._showElement = function (t) { var e = this, n = Bt(this._element).hasClass(ne); this._element.parentNode && this._element.parentNode.nodeType === Node.ELEMENT_NODE || document.body.appendChild(this._element), this._element.style.display = "block", this._element.removeAttribute("aria-hidden"), this._element.scrollTop = 0, n && Cn.reflow(this._element), Bt(this._element).addClass(ie), this._config.focus && this._enforceFocus(); var i = Bt.Event(Zt.SHOWN, { relatedTarget: t }), r = function () { e._config.focus && e._element.focus(), e._isTransitioning = !1, Bt(e._element).trigger(i) }; if (n) { var s = Cn.getTransitionDurationFromElement(this._element); Bt(this._dialog).one(Cn.TRANSITION_END, r).emulateTransitionEnd(s) } else r() }, t._enforceFocus = function () { var e = this; Bt(document).off(Zt.FOCUSIN).on(Zt.FOCUSIN, function (t) { document !== t.target && e._element !== t.target && 0 === Bt(e._element).has(t.target).length && e._element.focus() }) }, t._setEscapeEvent = function () { var e = this; this._isShown && this._config.keyboard ? Bt(this._element).on(Zt.KEYDOWN_DISMISS, function (t) { 27 === t.which && (t.preventDefault(), e.hide()) }) : this._isShown || Bt(this._element).off(Zt.KEYDOWN_DISMISS) }, t._setResizeEvent = function () { var e = this; this._isShown ? Bt(window).on(Zt.RESIZE, function (t) { return e.handleUpdate(t) }) : Bt(window).off(Zt.RESIZE) }, t._hideModal = function () { var t = this; this._element.style.display = "none", this._element.setAttribute("aria-hidden", !0), this._isTransitioning = !1, this._showBackdrop(function () { Bt(document.body).removeClass(ee), t._resetAdjustments(), t._resetScrollbar(), Bt(t._element).trigger(Zt.HIDDEN) }) }, t._removeBackdrop = function () { this._backdrop && (Bt(this._backdrop).remove(), this._backdrop = null) }, t._showBackdrop = function (t) { var e = this, n = Bt(this._element).hasClass(ne) ? ne : ""; if (this._isShown && this._config.backdrop) { if (this._backdrop = document.createElement("div"), this._backdrop.className = te, n && Bt(this._backdrop).addClass(n), Bt(this._backdrop).appendTo(document.body), Bt(this._element).on(Zt.CLICK_DISMISS, function (t) { e._ignoreBackdropClick ? e._ignoreBackdropClick = !1 : t.target === t.currentTarget && ("static" === e._config.backdrop ? e._element.focus() : e.hide()) }), n && Cn.reflow(this._backdrop), Bt(this._backdrop).addClass(ie), !t) return; if (!n) return void t(); var i = Cn.getTransitionDurationFromElement(this._backdrop); Bt(this._backdrop).one(Cn.TRANSITION_END, t).emulateTransitionEnd(i) } else if (!this._isShown && this._backdrop) { Bt(this._backdrop).removeClass(ie); var r = function () { e._removeBackdrop(), t && t() }; if (Bt(this._element).hasClass(ne)) { var s = Cn.getTransitionDurationFromElement(this._backdrop); Bt(this._backdrop).one(Cn.TRANSITION_END, r).emulateTransitionEnd(s) } else r() } else t && t() }, t._adjustDialog = function () { var t = this._element.scrollHeight > document.documentElement.clientHeight; !this._isBodyOverflowing && t && (this._element.style.paddingLeft = this._scrollbarWidth + "px"), this._isBodyOverflowing && !t && (this._element.style.paddingRight = this._scrollbarWidth + "px") }, t._resetAdjustments = function () { this._element.style.paddingLeft = "", this._element.style.paddingRight = "" }, t._checkScrollbar = function () { var t = document.body.getBoundingClientRect(); this._isBodyOverflowing = t.left + t.right < window.innerWidth, this._scrollbarWidth = this._getScrollbarWidth() }, t._setScrollbar = function () { var r = this; if (this._isBodyOverflowing) { Bt(re.FIXED_CONTENT).each(function (t, e) { var n = Bt(e)[0].style.paddingRight, i = Bt(e).css("padding-right"); Bt(e).data("padding-right", n).css("padding-right", parseFloat(i) + r._scrollbarWidth + "px") }), Bt(re.STICKY_CONTENT).each(function (t, e) { var n = Bt(e)[0].style.marginRight, i = Bt(e).css("margin-right"); Bt(e).data("margin-right", n).css("margin-right", parseFloat(i) - r._scrollbarWidth + "px") }), Bt(re.NAVBAR_TOGGLER).each(function (t, e) { var n = Bt(e)[0].style.marginRight, i = Bt(e).css("margin-right"); Bt(e).data("margin-right", n).css("margin-right", parseFloat(i) + r._scrollbarWidth + "px") }); var t = document.body.style.paddingRight, e = Bt(document.body).css("padding-right"); Bt(document.body).data("padding-right", t).css("padding-right", parseFloat(e) + this._scrollbarWidth + "px") } }, t._resetScrollbar = function () { Bt(re.FIXED_CONTENT).each(function (t, e) { var n = Bt(e).data("padding-right"); "undefined" != typeof n && Bt(e).css("padding-right", n).removeData("padding-right") }), Bt(re.STICKY_CONTENT + ", " + re.NAVBAR_TOGGLER).each(function (t, e) { var n = Bt(e).data("margin-right"); "undefined" != typeof n && Bt(e).css("margin-right", n).removeData("margin-right") }); var t = Bt(document.body).data("padding-right"); "undefined" != typeof t && Bt(document.body).css("padding-right", t).removeData("padding-right") }, t._getScrollbarWidth = function () { var t = document.createElement("div"); t.className = $t, document.body.appendChild(t); var e = t.getBoundingClientRect().width - t.clientWidth; return document.body.removeChild(t), e }, r._jQueryInterface = function (n, i) { return this.each(function () { var t = Bt(this).data(Gt), e = h({}, Xt, Bt(this).data(), "object" == typeof n && n ? n : {}); if (t || (t = new r(this, e), Bt(this).data(Gt, t)), "string" == typeof n) { if ("undefined" == typeof t[n]) throw new TypeError('No method named "' + n + '"'); t[n](i) } else e.show && t.show(i) }) }, o(r, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return Xt } }]), r }(), Bt(document).on(Zt.CLICK_DATA_API, re.DATA_TOGGLE, function (t) { var e, n = this, i = Cn.getSelectorFromElement(this); i && (e = Bt(i)[0]); var r = Bt(e).data(Gt) ? "toggle" : h({}, Bt(e).data(), Bt(this).data()); "A" !== this.tagName && "AREA" !== this.tagName || t.preventDefault(); var s = Bt(e).one(Zt.SHOW, function (t) { t.isDefaultPrevented() || s.one(Zt.HIDDEN, function () { Bt(n).is(":visible") && n.focus() }) }); se._jQueryInterface.call(Bt(e), r, this) }), Bt.fn[Yt] = se._jQueryInterface, Bt.fn[Yt].Constructor = se, Bt.fn[Yt].noConflict = function () { return Bt.fn[Yt] = zt, se._jQueryInterface }, se), Nn = (ae = "tooltip", he = "." + (le = "bs.tooltip"), ce = (oe = e).fn[ae], ue = "bs-tooltip", fe = new RegExp("(^|\\s)" + ue + "\\S+", "g"), ge = { animation: !0, template: '', trigger: "hover focus", title: "", delay: 0, html: !(_e = { AUTO: "auto", TOP: "top", RIGHT: "right", BOTTOM: "bottom", LEFT: "left" }), selector: !(de = { animation: "boolean", template: "string", title: "(string|element|function)", trigger: "string", delay: "(number|object)", html: "boolean", selector: "(string|boolean)", placement: "(string|function)", offset: "(number|string)", container: "(string|element|boolean)", fallbackPlacement: "(string|array)", boundary: "(string|element)" }), placement: "top", offset: 0, container: !1, fallbackPlacement: "flip", boundary: "scrollParent" }, pe = "out", ve = { HIDE: "hide" + he, HIDDEN: "hidden" + he, SHOW: (me = "show") + he, SHOWN: "shown" + he, INSERTED: "inserted" + he, CLICK: "click" + he, FOCUSIN: "focusin" + he, FOCUSOUT: "focusout" + he, MOUSEENTER: "mouseenter" + he, MOUSELEAVE: "mouseleave" + he }, Ee = "fade", ye = "show", Te = ".tooltip-inner", Ce = ".arrow", Ie = "hover", Ae = "focus", De = "click", be = "manual", Se = function () { function i(t, e) { if ("undefined" == typeof c) throw new TypeError("Bootstrap tooltips require Popper.js (https://popper.js.org)"); this._isEnabled = !0, this._timeout = 0, this._hoverState = "", this._activeTrigger = {}, this._popper = null, this.element = t, this.config = this._getConfig(e), this.tip = null, this._setListeners() } var t = i.prototype; return t.enable = function () { this._isEnabled = !0 }, t.disable = function () { this._isEnabled = !1 }, t.toggleEnabled = function () { this._isEnabled = !this._isEnabled }, t.toggle = function (t) { if (this._isEnabled) if (t) { var e = this.constructor.DATA_KEY, n = oe(t.currentTarget).data(e); n || (n = new this.constructor(t.currentTarget, this._getDelegateConfig()), oe(t.currentTarget).data(e, n)), n._activeTrigger.click = !n._activeTrigger.click, n._isWithActiveTrigger() ? n._enter(null, n) : n._leave(null, n) } else { if (oe(this.getTipElement()).hasClass(ye)) return void this._leave(null, this); this._enter(null, this) } }, t.dispose = function () { clearTimeout(this._timeout), oe.removeData(this.element, this.constructor.DATA_KEY), oe(this.element).off(this.constructor.EVENT_KEY), oe(this.element).closest(".modal").off("hide.bs.modal"), this.tip && oe(this.tip).remove(), this._isEnabled = null, this._timeout = null, this._hoverState = null, (this._activeTrigger = null) !== this._popper && this._popper.destroy(), this._popper = null, this.element = null, this.config = null, this.tip = null }, t.show = function () { var e = this; if ("none" === oe(this.element).css("display")) throw new Error("Please use show on visible elements"); var t = oe.Event(this.constructor.Event.SHOW); if (this.isWithContent() && this._isEnabled) { oe(this.element).trigger(t); var n = oe.contains(this.element.ownerDocument.documentElement, this.element); if (t.isDefaultPrevented() || !n) return; var i = this.getTipElement(), r = Cn.getUID(this.constructor.NAME); i.setAttribute("id", r), this.element.setAttribute("aria-describedby", r), this.setContent(), this.config.animation && oe(i).addClass(Ee); var s = "function" == typeof this.config.placement ? this.config.placement.call(this, i, this.element) : this.config.placement, o = this._getAttachment(s); this.addAttachmentClass(o); var a = !1 === this.config.container ? document.body : oe(this.config.container); oe(i).data(this.constructor.DATA_KEY, this), oe.contains(this.element.ownerDocument.documentElement, this.tip) || oe(i).appendTo(a), oe(this.element).trigger(this.constructor.Event.INSERTED), this._popper = new c(this.element, i, { placement: o, modifiers: { offset: { offset: this.config.offset }, flip: { behavior: this.config.fallbackPlacement }, arrow: { element: Ce }, preventOverflow: { boundariesElement: this.config.boundary } }, onCreate: function (t) { t.originalPlacement !== t.placement && e._handlePopperPlacementChange(t) }, onUpdate: function (t) { e._handlePopperPlacementChange(t) } }), oe(i).addClass(ye), "ontouchstart" in document.documentElement && oe(document.body).children().on("mouseover", null, oe.noop); var l = function () { e.config.animation && e._fixTransition(); var t = e._hoverState; e._hoverState = null, oe(e.element).trigger(e.constructor.Event.SHOWN), t === pe && e._leave(null, e) }; if (oe(this.tip).hasClass(Ee)) { var h = Cn.getTransitionDurationFromElement(this.tip); oe(this.tip).one(Cn.TRANSITION_END, l).emulateTransitionEnd(h) } else l() } }, t.hide = function (t) { var e = this, n = this.getTipElement(), i = oe.Event(this.constructor.Event.HIDE), r = function () { e._hoverState !== me && n.parentNode && n.parentNode.removeChild(n), e._cleanTipClass(), e.element.removeAttribute("aria-describedby"), oe(e.element).trigger(e.constructor.Event.HIDDEN), null !== e._popper && e._popper.destroy(), t && t() }; if (oe(this.element).trigger(i), !i.isDefaultPrevented()) { if (oe(n).removeClass(ye), "ontouchstart" in document.documentElement && oe(document.body).children().off("mouseover", null, oe.noop), this._activeTrigger[De] = !1, this._activeTrigger[Ae] = !1, this._activeTrigger[Ie] = !1, oe(this.tip).hasClass(Ee)) { var s = Cn.getTransitionDurationFromElement(n); oe(n).one(Cn.TRANSITION_END, r).emulateTransitionEnd(s) } else r(); this._hoverState = "" } }, t.update = function () { null !== this._popper && this._popper.scheduleUpdate() }, t.isWithContent = function () { return Boolean(this.getTitle()) }, t.addAttachmentClass = function (t) { oe(this.getTipElement()).addClass(ue + "-" + t) }, t.getTipElement = function () { return this.tip = this.tip || oe(this.config.template)[0], this.tip }, t.setContent = function () { var t = oe(this.getTipElement()); this.setElementContent(t.find(Te), this.getTitle()), t.removeClass(Ee + " " + ye) }, t.setElementContent = function (t, e) { var n = this.config.html; "object" == typeof e && (e.nodeType || e.jquery) ? n ? oe(e).parent().is(t) || t.empty().append(e) : t.text(oe(e).text()) : t[n ? "html" : "text"](e) }, t.getTitle = function () { var t = this.element.getAttribute("data-original-title"); return t || (t = "function" == typeof this.config.title ? this.config.title.call(this.element) : this.config.title), t }, t._getAttachment = function (t) { return _e[t.toUpperCase()] }, t._setListeners = function () { var i = this; this.config.trigger.split(" ").forEach(function (t) { if ("click" === t) oe(i.element).on(i.constructor.Event.CLICK, i.config.selector, function (t) { return i.toggle(t) }); else if (t !== be) { var e = t === Ie ? i.constructor.Event.MOUSEENTER : i.constructor.Event.FOCUSIN, n = t === Ie ? i.constructor.Event.MOUSELEAVE : i.constructor.Event.FOCUSOUT; oe(i.element).on(e, i.config.selector, function (t) { return i._enter(t) }).on(n, i.config.selector, function (t) { return i._leave(t) }) } oe(i.element).closest(".modal").on("hide.bs.modal", function () { return i.hide() }) }), this.config.selector ? this.config = h({}, this.config, { trigger: "manual", selector: "" }) : this._fixTitle() }, t._fixTitle = function () { var t = typeof this.element.getAttribute("data-original-title"); (this.element.getAttribute("title") || "string" !== t) && (this.element.setAttribute("data-original-title", this.element.getAttribute("title") || ""), this.element.setAttribute("title", "")) }, t._enter = function (t, e) { var n = this.constructor.DATA_KEY; (e = e || oe(t.currentTarget).data(n)) || (e = new this.constructor(t.currentTarget, this._getDelegateConfig()), oe(t.currentTarget).data(n, e)), t && (e._activeTrigger["focusin" === t.type ? Ae : Ie] = !0), oe(e.getTipElement()).hasClass(ye) || e._hoverState === me ? e._hoverState = me : (clearTimeout(e._timeout), e._hoverState = me, e.config.delay && e.config.delay.show ? e._timeout = setTimeout(function () { e._hoverState === me && e.show() }, e.config.delay.show) : e.show()) }, t._leave = function (t, e) { var n = this.constructor.DATA_KEY; (e = e || oe(t.currentTarget).data(n)) || (e = new this.constructor(t.currentTarget, this._getDelegateConfig()), oe(t.currentTarget).data(n, e)), t && (e._activeTrigger["focusout" === t.type ? Ae : Ie] = !1), e._isWithActiveTrigger() || (clearTimeout(e._timeout), e._hoverState = pe, e.config.delay && e.config.delay.hide ? e._timeout = setTimeout(function () { e._hoverState === pe && e.hide() }, e.config.delay.hide) : e.hide()) }, t._isWithActiveTrigger = function () { for (var t in this._activeTrigger) if (this._activeTrigger[t]) return !0; return !1 }, t._getConfig = function (t) { return "number" == typeof (t = h({}, this.constructor.Default, oe(this.element).data(), "object" == typeof t && t ? t : {})).delay && (t.delay = { show: t.delay, hide: t.delay }), "number" == typeof t.title && (t.title = t.title.toString()), "number" == typeof t.content && (t.content = t.content.toString()), Cn.typeCheckConfig(ae, t, this.constructor.DefaultType), t }, t._getDelegateConfig = function () { var t = {}; if (this.config) for (var e in this.config) this.constructor.Default[e] !== this.config[e] && (t[e] = this.config[e]); return t }, t._cleanTipClass = function () { var t = oe(this.getTipElement()), e = t.attr("class").match(fe); null !== e && 0 < e.length && t.removeClass(e.join("")) }, t._handlePopperPlacementChange = function (t) { this._cleanTipClass(), this.addAttachmentClass(this._getAttachment(t.placement)) }, t._fixTransition = function () { var t = this.getTipElement(), e = this.config.animation; null === t.getAttribute("x-placement") && (oe(t).removeClass(Ee), this.config.animation = !1, this.hide(), this.show(), this.config.animation = e) }, i._jQueryInterface = function (n) { return this.each(function () { var t = oe(this).data(le), e = "object" == typeof n && n; if ((t || !/dispose|hide/.test(n)) && (t || (t = new i(this, e), oe(this).data(le, t)), "string" == typeof n)) { if ("undefined" == typeof t[n]) throw new TypeError('No method named "' + n + '"'); t[n]() } }) }, o(i, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return ge } }, { key: "NAME", get: function () { return ae } }, { key: "DATA_KEY", get: function () { return le } }, { key: "Event", get: function () { return ve } }, { key: "EVENT_KEY", get: function () { return he } }, { key: "DefaultType", get: function () { return de } }]), i }(), oe.fn[ae] = Se._jQueryInterface, oe.fn[ae].Constructor = Se, oe.fn[ae].noConflict = function () { return oe.fn[ae] = ce, Se._jQueryInterface }, Se), On = (Ne = "popover", ke = "." + (Oe = "bs.popover"), Pe = (we = e).fn[Ne], Le = "bs-popover", je = new RegExp("(^|\\s)" + Le + "\\S+", "g"), Re = h({}, Nn.Default, { placement: "right", trigger: "click", content: "", template: '' }), He = h({}, Nn.DefaultType, { content: "(string|element|function)" }), We = "fade", xe = ".popover-header", Ue = ".popover-body", Ke = { HIDE: "hide" + ke, HIDDEN: "hidden" + ke, SHOW: (Me = "show") + ke, SHOWN: "shown" + ke, INSERTED: "inserted" + ke, CLICK: "click" + ke, FOCUSIN: "focusin" + ke, FOCUSOUT: "focusout" + ke, MOUSEENTER: "mouseenter" + ke, MOUSELEAVE: "mouseleave" + ke }, Fe = function (t) { var e, n; function i() { return t.apply(this, arguments) || this } n = t, (e = i).prototype = Object.create(n.prototype), (e.prototype.constructor = e).__proto__ = n; var r = i.prototype; return r.isWithContent = function () { return this.getTitle() || this._getContent() }, r.addAttachmentClass = function (t) { we(this.getTipElement()).addClass(Le + "-" + t) }, r.getTipElement = function () { return this.tip = this.tip || we(this.config.template)[0], this.tip }, r.setContent = function () { var t = we(this.getTipElement()); this.setElementContent(t.find(xe), this.getTitle()); var e = this._getContent(); "function" == typeof e && (e = e.call(this.element)), this.setElementContent(t.find(Ue), e), t.removeClass(We + " " + Me) }, r._getContent = function () { return this.element.getAttribute("data-content") || this.config.content }, r._cleanTipClass = function () { var t = we(this.getTipElement()), e = t.attr("class").match(je); null !== e && 0 < e.length && t.removeClass(e.join("")) }, i._jQueryInterface = function (n) { return this.each(function () { var t = we(this).data(Oe), e = "object" == typeof n ? n : null; if ((t || !/destroy|hide/.test(n)) && (t || (t = new i(this, e), we(this).data(Oe, t)), "string" == typeof n)) { if ("undefined" == typeof t[n]) throw new TypeError('No method named "' + n + '"'); t[n]() } }) }, o(i, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return Re } }, { key: "NAME", get: function () { return Ne } }, { key: "DATA_KEY", get: function () { return Oe } }, { key: "Event", get: function () { return Ke } }, { key: "EVENT_KEY", get: function () { return ke } }, { key: "DefaultType", get: function () { return He } }]), i }(Nn), we.fn[Ne] = Fe._jQueryInterface, we.fn[Ne].Constructor = Fe, we.fn[Ne].noConflict = function () { return we.fn[Ne] = Pe, Fe._jQueryInterface }, Fe), kn = (Qe = "scrollspy", Ye = "." + (Be = "bs.scrollspy"), Ge = (Ve = e).fn[Qe], qe = { offset: 10, method: "auto", target: "" }, ze = { offset: "number", method: "string", target: "(string|element)" }, Xe = { ACTIVATE: "activate" + Ye, SCROLL: "scroll" + Ye, LOAD_DATA_API: "load" + Ye + ".data-api" }, Je = "dropdown-item", Ze = "active", $e = { DATA_SPY: '[data-spy="scroll"]', ACTIVE: ".active", NAV_LIST_GROUP: ".nav, .list-group", NAV_LINKS: ".nav-link", NAV_ITEMS: ".nav-item", LIST_ITEMS: ".list-group-item", DROPDOWN: ".dropdown", DROPDOWN_ITEMS: ".dropdown-item", DROPDOWN_TOGGLE: ".dropdown-toggle" }, tn = "offset", en = "position", nn = function () { function n(t, e) { var n = this; this._element = t, this._scrollElement = "BODY" === t.tagName ? window : t, this._config = this._getConfig(e), this._selector = this._config.target + " " + $e.NAV_LINKS + "," + this._config.target + " " + $e.LIST_ITEMS + "," + this._config.target + " " + $e.DROPDOWN_ITEMS, this._offsets = [], this._targets = [], this._activeTarget = null, this._scrollHeight = 0, Ve(this._scrollElement).on(Xe.SCROLL, function (t) { return n._process(t) }), this.refresh(), this._process() } var t = n.prototype; return t.refresh = function () { var e = this, t = this._scrollElement === this._scrollElement.window ? tn : en, r = "auto" === this._config.method ? t : this._config.method, s = r === en ? this._getScrollTop() : 0; this._offsets = [], this._targets = [], this._scrollHeight = this._getScrollHeight(), Ve.makeArray(Ve(this._selector)).map(function (t) { var e, n = Cn.getSelectorFromElement(t); if (n && (e = Ve(n)[0]), e) { var i = e.getBoundingClientRect(); if (i.width || i.height) return [Ve(e)[r]().top + s, n] } return null }).filter(function (t) { return t }).sort(function (t, e) { return t[0] - e[0] }).forEach(function (t) { e._offsets.push(t[0]), e._targets.push(t[1]) }) }, t.dispose = function () { Ve.removeData(this._element, Be), Ve(this._scrollElement).off(Ye), this._element = null, this._scrollElement = null, this._config = null, this._selector = null, this._offsets = null, this._targets = null, this._activeTarget = null, this._scrollHeight = null }, t._getConfig = function (t) { if ("string" != typeof (t = h({}, qe, "object" == typeof t && t ? t : {})).target) { var e = Ve(t.target).attr("id"); e || (e = Cn.getUID(Qe), Ve(t.target).attr("id", e)), t.target = "#" + e } return Cn.typeCheckConfig(Qe, t, ze), t }, t._getScrollTop = function () { return this._scrollElement === window ? this._scrollElement.pageYOffset : this._scrollElement.scrollTop }, t._getScrollHeight = function () { return this._scrollElement.scrollHeight || Math.max(document.body.scrollHeight, document.documentElement.scrollHeight) }, t._getOffsetHeight = function () { return this._scrollElement === window ? window.innerHeight : this._scrollElement.getBoundingClientRect().height }, t._process = function () { var t = this._getScrollTop() + this._config.offset, e = this._getScrollHeight(), n = this._config.offset + e - this._getOffsetHeight(); if (this._scrollHeight !== e && this.refresh(), n <= t) { var i = this._targets[this._targets.length - 1]; this._activeTarget !== i && this._activate(i) } else { if (this._activeTarget && t < this._offsets[0] && 0 < this._offsets[0]) return this._activeTarget = null, void this._clear(); for (var r = this._offsets.length; r--;) { this._activeTarget !== this._targets[r] && t >= this._offsets[r] && ("undefined" == typeof this._offsets[r + 1] || t < this._offsets[r + 1]) && this._activate(this._targets[r]) } } }, t._activate = function (e) { this._activeTarget = e, this._clear(); var t = this._selector.split(","); t = t.map(function (t) { return t + '[data-target="' + e + '"],' + t + '[href="' + e + '"]' }); var n = Ve(t.join(",")); n.hasClass(Je) ? (n.closest($e.DROPDOWN).find($e.DROPDOWN_TOGGLE).addClass(Ze), n.addClass(Ze)) : (n.addClass(Ze), n.parents($e.NAV_LIST_GROUP).prev($e.NAV_LINKS + ", " + $e.LIST_ITEMS).addClass(Ze), n.parents($e.NAV_LIST_GROUP).prev($e.NAV_ITEMS).children($e.NAV_LINKS).addClass(Ze)), Ve(this._scrollElement).trigger(Xe.ACTIVATE, { relatedTarget: e }) }, t._clear = function () { Ve(this._selector).filter($e.ACTIVE).removeClass(Ze) }, n._jQueryInterface = function (e) { return this.each(function () { var t = Ve(this).data(Be); if (t || (t = new n(this, "object" == typeof e && e), Ve(this).data(Be, t)), "string" == typeof e) { if ("undefined" == typeof t[e]) throw new TypeError('No method named "' + e + '"'); t[e]() } }) }, o(n, null, [{ key: "VERSION", get: function () { return "4.1.1" } }, { key: "Default", get: function () { return qe } }]), n }(), Ve(window).on(Xe.LOAD_DATA_API, function () { for (var t = Ve.makeArray(Ve($e.DATA_SPY)), e = t.length; e--;) { var n = Ve(t[e]); nn._jQueryInterface.call(n, n.data()) } }), Ve.fn[Qe] = nn._jQueryInterface, Ve.fn[Qe].Constructor = nn, Ve.fn[Qe].noConflict = function () { return Ve.fn[Qe] = Ge, nn._jQueryInterface }, nn), Pn = (on = "." + (sn = "bs.tab"), an = (rn = e).fn.tab, ln = { HIDE: "hide" + on, HIDDEN: "hidden" + on, SHOW: "show" + on, SHOWN: "shown" + on, CLICK_DATA_API: "click" + on + ".data-api" }, hn = "dropdown-menu", cn = "active", un = "disabled", fn = "fade", dn = "show", _n = ".dropdown", gn = ".nav, .list-group", mn = ".active", pn = "> li > .active", vn = '[data-toggle="tab"], [data-toggle="pill"], [data-toggle="list"]', En = ".dropdown-toggle", yn = "> .dropdown-menu .active", Tn = function () { function i(t) { this._element = t } var t = i.prototype; return t.show = function () { var n = this; if (!(this._element.parentNode && this._element.parentNode.nodeType === Node.ELEMENT_NODE && rn(this._element).hasClass(cn) || rn(this._element).hasClass(un))) { var t, i, e = rn(this._element).closest(gn)[0], r = Cn.getSelectorFromElement(this._element); if (e) { var s = "UL" === e.nodeName ? pn : mn; i = (i = rn.makeArray(rn(e).find(s)))[i.length - 1] } var o = rn.Event(ln.HIDE, { relatedTarget: this._element }), a = rn.Event(ln.SHOW, { relatedTarget: i }); if (i && rn(i).trigger(o), rn(this._element).trigger(a), !a.isDefaultPrevented() && !o.isDefaultPrevented()) { r && (t = rn(r)[0]), this._activate(this._element, e); var l = function () { var t = rn.Event(ln.HIDDEN, { relatedTarget: n._element }), e = rn.Event(ln.SHOWN, { relatedTarget: i }); rn(i).trigger(t), rn(n._element).trigger(e) }; t ? this._activate(t, t.parentNode, l) : l() } } }, t.dispose = function () { rn.removeData(this._element, sn), this._element = null }, t._activate = function (t, e, n) { var i = this, r = ("UL" === e.nodeName ? rn(e).find(pn) : rn(e).children(mn))[0], s = n && r && rn(r).hasClass(fn), o = function () { return i._transitionComplete(t, r, n) }; if (r && s) { var a = Cn.getTransitionDurationFromElement(r); rn(r).one(Cn.TRANSITION_END, o).emulateTransitionEnd(a) } else o() }, t._transitionComplete = function (t, e, n) { if (e) { rn(e).removeClass(dn + " " + cn); var i = rn(e.parentNode).find(yn)[0]; i && rn(i).removeClass(cn), "tab" === e.getAttribute("role") && e.setAttribute("aria-selected", !1) } if (rn(t).addClass(cn), "tab" === t.getAttribute("role") && t.setAttribute("aria-selected", !0), Cn.reflow(t), rn(t).addClass(dn), t.parentNode && rn(t.parentNode).hasClass(hn)) { var r = rn(t).closest(_n)[0]; r && rn(r).find(En).addClass(cn), t.setAttribute("aria-expanded", !0) } n && n() }, i._jQueryInterface = function (n) { return this.each(function () { var t = rn(this), e = t.data(sn); if (e || (e = new i(this), t.data(sn, e)), "string" == typeof n) { if ("undefined" == typeof e[n]) throw new TypeError('No method named "' + n + '"'); e[n]() } }) }, o(i, null, [{ key: "VERSION", get: function () { return "4.1.1" } }]), i }(), rn(document).on(ln.CLICK_DATA_API, vn, function (t) { t.preventDefault(), Tn._jQueryInterface.call(rn(this), "show") }), rn.fn.tab = Tn._jQueryInterface, rn.fn.tab.Constructor = Tn, rn.fn.tab.noConflict = function () { return rn.fn.tab = an, Tn._jQueryInterface }, Tn); !function (t) { if ("undefined" == typeof t) throw new TypeError("Bootstrap's JavaScript requires jQuery. jQuery must be included before Bootstrap's JavaScript."); var e = t.fn.jquery.split(" ")[0].split("."); if (e[0] < 2 && e[1] < 9 || 1 === e[0] && 9 === e[1] && e[2] < 1 || 4 <= e[0]) throw new Error("Bootstrap's JavaScript requires at least jQuery v1.9.1 but less than v4.0.0") }(e), t.Util = Cn, t.Alert = In, t.Button = An, t.Carousel = Dn, t.Collapse = bn, t.Dropdown = Sn, t.Modal = wn, t.Popover = On, t.Scrollspy = kn, t.Tab = Pn, t.Tooltip = Nn, Object.defineProperty(t, "__esModule", { value: !0 }) });
+//# sourceMappingURL=bootstrap.min.js.map
\ No newline at end of file
diff --git a/plugins/filterizr/jquery.filterizr.min.js b/plugins/filterizr/jquery.filterizr.min.js
new file mode 100644
index 00000000..af5c9e60
--- /dev/null
+++ b/plugins/filterizr/jquery.filterizr.min.js
@@ -0,0 +1 @@
+!function(t){function e(i){if(r[i])return r[i].exports;var n=r[i]={i:i,l:!1,exports:{}};return t[i].call(n.exports,n,n.exports,e),n.l=!0,n.exports}var r={};e.m=t,e.c=r,e.d=function(t,r,i){e.o(t,r)||Object.defineProperty(t,r,{configurable:!1,enumerable:!0,get:i})},e.n=function(t){var r=t&&t.__esModule?function(){return t.default}:function(){return t};return e.d(r,"a",r),r},e.o=function(t,e){return Object.prototype.hasOwnProperty.call(t,e)},e.p="",e(e.s=4)}([function(t,e,r){"use strict";r.d(e,"b",function(){return n}),r.d(e,"h",function(){return o}),r.d(e,"i",function(){return s}),r.d(e,"g",function(){return a}),r.d(e,"e",function(){return l}),r.d(e,"j",function(){return u}),r.d(e,"f",function(){return c}),r.d(e,"k",function(){return f}),r.d(e,"c",function(){return p}),r.d(e,"d",function(){return h}),r.d(e,"l",function(){return d}),r.d(e,"a",function(){return v});var i="function"==typeof Symbol&&"symbol"==typeof Symbol.iterator?function(t){return typeof t}:function(t){return t&&"function"==typeof Symbol&&t.constructor===Symbol&&t!==Symbol.prototype?"symbol":typeof t},n=function(t,e){for(var r=0;rn?1:0}}(e))},p=function(t,e,r,n,o){if(void 0!==e){var s=new Error('Filterizr: expected type of option "'+t+'" to be "'+r+'", but its type is: "'+(void 0===e?"undefined":i(e))+'"'),a=!1,l=!1,u=r.includes("array");if((void 0===e?"undefined":i(e)).match(r)?a=!0:!a&&u&&(l=Array.isArray(e)),!a&&!u)throw s;if(!a&&u&&!l)throw s;var c=function(t){return t?" For further help read here: "+t:""};if(Array.isArray(n)){var f=!1;if(n.forEach(function(t){t===e&&(f=!0)}),!f)throw new Error('Filterizr: allowed values for option "'+t+'" are: '+n.map(function(t){return'"'+t+'"'}).join(", ")+'. Value received: "'+e+'".'+c(o))}else if(n instanceof RegExp){var p=e.match(n);if(!p)throw new Error('Filterizr: invalid value "'+e+'" for option "'+t+'" received.'+c(o))}}},h=/(^linear$)|(^ease-in-out$)|(^ease-in$)|(^ease-out$)|(^ease$)|(^step-start$)|(^step-end$)|(^steps\(\d\s*,\s*(end|start)\))$|(^cubic-bezier\((\d*\.*\d+)\s*,\s*(\d*\.*\d+)\s*,\s*(\d*\.*\d+)\s*,\s*(\d*\.*\d+)\))$/,d="\n webkitTransitionEnd.Filterizr \n otransitionend.Filterizr \n oTransitionEnd.Filterizr \n msTransitionEnd.Filterizr \n transitionend.Filterizr\n",v={IDLE:"IDLE",FILTERING:"FILTERING",SORTING:"SORTING",SHUFFLING:"SHUFFLING"}},function(t,e,r){"use strict";function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}var n=r(2),o=r(0),s=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:".filtr-container",r=arguments[1];i(this,t),this.$node=a(e),this.$node.css({padding:0,position:"relative",width:"100%",display:"flex","flex-wrap":"wrap"}),this.props={FilterItems:this.getFilterItems(r),w:this.getWidth(),h:0},this.updateFilterItemsDimensions()}return s(t,[{key:"destroy",value:function(){this.$node.attr("style","").find(".filtr-item").attr("style",""),this.unbindEvents()}},{key:"getFilterItems",value:function(t){return a.map(this.$node.find(".filtr-item"),function(e,r){return new n.a(a(e),r,t)})}},{key:"push",value:function(t,e){var r=this.props.FilterItems;this.$node.append(t);var i=r.length,o=new n.a(t,i,e);this.props.FilterItems.push(o)}},{key:"calcColumns",value:function(){return Math.round(this.props.w/this.props.FilterItems[0].props.w)}},{key:"updateFilterItemsTransitionStyle",value:function(t,e,r,i){this.props.FilterItems.forEach(function(n){return n.$node.css({transition:"all "+t+"s "+e+" "+n.calcDelay(r,i)+"ms"})})}},{key:"updateHeight",value:function(t){this.props.h=t,this.$node.css("height",t)}},{key:"updateWidth",value:function(){this.props.w=this.getWidth()}},{key:"updateFilterItemsDimensions",value:function(){this.props.FilterItems.forEach(function(t){return t.updateDimensions()})}},{key:"getWidth",value:function(){return this.$node.innerWidth()}},{key:"bindTransitionEnd",value:function(t,e){this.$node.on(o.l,Object(o.e)(function(){t()},e))}},{key:"bindEvents",value:function(t){this.$node.on("filteringStart.Filterizr",t.onFilteringStart),this.$node.on("filteringEnd.Filterizr",t.onFilteringEnd),this.$node.on("shufflingStart.Filterizr",t.onShufflingStart),this.$node.on("shufflingEnd.Filterizr",t.onShufflingEnd),this.$node.on("sortingStart.Filterizr",t.onSortingStart),this.$node.on("sortingEnd.Filterizr",t.onSortingEnd)}},{key:"unbindEvents",value:function(){this.$node.off(o.l+"\n filteringStart.Filterizr \n filteringEnd.Filterizr \n shufflingStart.Filterizr \n shufflingEnd.Filterizr \n sortingStart.Filterizr \n sortingEnd.Filterizr")}},{key:"trigger",value:function(t){this.$node.trigger(t)}}]),t}();e.a=l},function(t,e,r){"use strict";function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}var n=r(0),o=function(){function t(t,e){for(var r=0;r0?r[0]:a.a;this._fltr=new n.a(e,o)}else if(r.length>=1&&"string"==typeof r[0]){var s=r[0],l=Array.prototype.slice.call(r,1),c=this._fltr;switch(s){case"filter":return c.filter.apply(c,i(l)),this;case"insertItem":return c.insertItem.apply(c,i(l)),this;case"toggleFilter":return c.toggleFilter.apply(c,i(l)),this;case"sort":return c.sort.apply(c,i(l)),this;case"shuffle":return c.shuffle.apply(c,i(l)),this;case"search":return c.search.apply(c,i(l)),this;case"setOptions":return c.setOptions.apply(c,i(l)),this;case"destroy":return c.destroy.apply(c,i(l)),delete this._fltr,this;default:throw new Error("Filterizr: "+s+" is not part of the Filterizr API. Please refer to the docs for more information.")}}return this}}(f),e.default=c,r(16)},function(t,e,r){"use strict";function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}var n=r(7),o=r(1),s=r(8),a=r(3),l=r(0),u=function(){function t(t,e){for(var r=0;r0&&void 0!==arguments[0]?arguments[0]:".filtr-container",r=arguments[1];i(this,t),this.options=Object(l.i)(a.a,r);var s=new o.a(e,this.options);if(!s.$node.length)throw new Error("Filterizr: could not find a container with the selector "+e+", to initialize Filterizr.");new n.a(this,this.options.controlsSelector),this.props={filterizrState:l.a.IDLE,searchTerm:"",sort:"index",sortOrder:"asc",FilterContainer:s,FilterItems:s.props.FilterItems,FilteredItems:[]},this.bindEvents(),this.filter(this.options.filter)}return u(t,[{key:"filter",value:function(t){var e=this.props,r=e.searchTerm,i=e.FilterContainer,n=e.FilterItems;i.trigger("filteringStart"),this.props.filterizrState=l.a.FILTERING,t=Array.isArray(t)?t.map(function(t){return t.toString()}):t.toString();var o=this.searchFilterItems(this.filterFilterItems(n,t),r);this.props.FilteredItems=o,this.render(o)}},{key:"destroy",value:function(){var t=this.props.FilterContainer,e=this.options.controlsSelector;t.destroy(),c(window).off("resize.Filterizr"),c(e+"[data-filter]").off("click.Filterizr"),c(e+"[data-multifilter]").off("click.Filterizr"),c(e+"[data-shuffle]").off("click.Filterizr"),c(e+"[data-search]").off("keyup.Filterizr"),c(e+"[data-sortAsc]").off("click.Filterizr"),c(e+"[data-sortDesc]").off("click.Filterizr")}},{key:"insertItem",value:function(t){var e=this.props.FilterContainer,r=t.clone().attr("style","");e.push(r,this.options);var i=this.filterFilterItems(this.props.FilterItems,this.options.filter);this.render(i)}},{key:"sort",value:function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:"index",e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"asc",r=this.props,i=r.FilterContainer,n=r.FilterItems;i.trigger("sortingStart"),this.props.filterizrState=l.a.SORTING,this.props.FilterItems=this.sortFilterItems(n,t,e);var o=this.filterFilterItems(this.props.FilterItems,this.options.filter);this.props.FilteredItems=o,this.render(o)}},{key:"search",value:function(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:this.props.searchTerm,e=this.props.FilterItems,r=this.searchFilterItems(this.filterFilterItems(e,this.options.filter),t);this.props.FilteredItems=r,this.render(r)}},{key:"shuffle",value:function(){var t=this.props,e=t.FilterContainer,r=t.FilteredItems;e.trigger("shufflingStart"),this.props.filterizrState=l.a.SHUFFLING;var i=this.shuffleFilterItems(r);this.props.FilteredItems=i,this.render(i)}},{key:"setOptions",value:function(t){Object(l.c)("animationDuration",t.animationDuration,"number"),Object(l.c)("callbacks",t.callbacks,"object"),Object(l.c)("controlsSelector",t.controlsSelector,"string"),Object(l.c)("delay",t.delay,"number"),Object(l.c)("easing",t.easing,"string",l.d,"https://www.w3schools.com/cssref/css3_pr_transition-timing-function.asp"),Object(l.c)("delayMode",t.delayMode,"string",["progressive","alternate"]),Object(l.c)("filter",t.filter,"string|number|array"),Object(l.c)("filterOutCss",t.filterOutCss,"object"),Object(l.c)("filterInCss",t.filterOutCss,"object"),Object(l.c)("layout",t.layout,"string",["sameSize","vertical","horizontal","sameHeight","sameWidth","packed"]),Object(l.c)("multifilterLogicalOperator",t.multifilterLogicalOperator,"string",["and","or"]),Object(l.c)("setupControls",t.setupControls,"boolean"),this.options=Object(l.i)(this.options,t),(t.animationDuration||t.delay||t.delayMode||t.easing)&&this.props.FilterContainer.updateFilterItemsTransitionStyle(t.animationDuration,t.easing,t.delay,t.delayMode),(t.callbacks||t.animationDuration)&&this.rebindFilterContainerEvents(),t.filter&&this.filter(t.filter),t.multifilterLogicalOperator&&this.filter(this.options.filter)}},{key:"toggleFilter",value:function(t){var e=this.options.filter;"all"===e?e=t:Array.isArray(e)?e.includes(t)?(e=e.filter(function(e){return e!==t}),1===e.length&&(e=e[0])):e.push(t):e=e===t?"all":[e,t],this.options.filter=e,this.filter(this.options.filter)}},{key:"filterFilterItems",value:function(t,e){var r=this.options.multifilterLogicalOperator;return"all"===e?t:t.filter(function(t){var i=t.getCategories();return Array.isArray(e)?"or"===r?Object(l.g)(i,e).length:Object(l.b)(e,i):i.includes(e)})}},{key:"sortFilterItems",value:function(t){var e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"index",r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:"asc",i=Object(l.k)(t,function(t){return"index"!==e&&"sortData"!==e?t.props.data[e]:t.props[e]});return"asc"===r?i:i.reverse()}},{key:"searchFilterItems",value:function(t){var e=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.props.searchTerm;return e?t.filter(function(t){return t.contentsMatchSearch(e)}):t}},{key:"shuffleFilterItems",value:function(t){for(var e=Object(l.j)(t);t.length>1&&Object(l.f)(t,e);)e=Object(l.j)(t);return e}},{key:"render",value:function(t){var e=this,r=this.options,i=r.filter,n=r.filterInCss,o=r.filterOutCss,a=r.layout,u=r.multifilterLogicalOperator;this.props.FilterItems.filter(function(t){var r=t.getCategories(),n=Array.isArray(i),o=t.contentsMatchSearch(e.props.searchTerm);return!(n?"or"===u?Object(l.g)(r,i).length:Object(l.b)(i,r):r.includes(i))||!o}).forEach(function(t){t.filterOut(o)});var c=Object(s.a)(a,this);t.forEach(function(t,e){t.filterIn(c[e],n)})}},{key:"onTransitionEndCallback",value:function(){var t=this.props,e=t.filterizrState,r=t.FilterContainer;switch(e){case l.a.FILTERING:r.trigger("filteringEnd");break;case l.a.SORTING:r.trigger("sortingEnd");break;case l.a.SHUFFLING:r.trigger("shufflingEnd")}this.props.filterizrState=l.a.IDLE}},{key:"rebindFilterContainerEvents",value:function(){var t=this,e=this.props.FilterContainer,r=this.options,i=r.animationDuration,n=r.callbacks;e.unbindEvents(),e.bindEvents(n),e.bindTransitionEnd(function(){t.onTransitionEndCallback()},i)}},{key:"bindEvents",value:function(){var t=this,e=this.props.FilterContainer;this.rebindFilterContainerEvents(),c(window).on("resize.Filterizr",Object(l.e)(function(){e.updateWidth(),e.updateFilterItemsDimensions(),t.filter(t.options.filter)},250))}}]),t}();e.a=f},function(t,e,r){"use strict";function i(t,e){if(!(t instanceof e))throw new TypeError("Cannot call a class as a function")}var n=r(0),o=function(){function t(t,e){for(var r=0;r1&&void 0!==arguments[1]?arguments[1]:"";i(this,t),this.props={Filterizr:e,selector:r},this.setupFilterControls(),this.setupShuffleControls(),this.setupSearchControls(),this.setupSortControls()}return o(t,[{key:"setupFilterControls",value:function(){var t=this.props,e=t.Filterizr,r=t.selector;s(r+"[data-filter]").on("click.Filterizr",function(t){var r=s(t.currentTarget),i=r.attr("data-filter");e.options.filter=i,e.filter(e.options.filter)}),s(r+"[data-multifilter]").on("click.Filterizr",function(t){var r=s(t.target),i=r.attr("data-multifilter");e.toggleFilter(i)})}},{key:"setupShuffleControls",value:function(){var t=this.props,e=t.Filterizr,r=t.selector;s(r+"[data-shuffle]").on("click.Filterizr",function(){e.shuffle()})}},{key:"setupSearchControls",value:function(){var t=this.props,e=t.Filterizr,r=t.selector;s(r+"[data-search]").on("keyup.Filterizr",Object(n.e)(function(t){var r=s(t.target),i=r.val();e.props.searchTerm=i.toLowerCase(),e.search(e.props.searchTerm)},250))}},{key:"setupSortControls",value:function(){var t=this.props,e=t.Filterizr,r=t.selector;s(r+"[data-sortAsc]").on("click.Filterizr",function(){var t=s(r+"[data-sortOrder]").val();e.props.sortOrder="asc",e.sort(t,"asc")}),s(r+"[data-sortDesc]").on("click.Filterizr",function(){var t=s(r+"[data-sortOrder]").val();e.props.sortOrder="desc",e.sort(t,"desc")})}}]),t}();e.a=a},function(t,e,r){"use strict";var i=r(9),n=r(10),o=r(11),s=r(12),a=r(13),l=r(14),u=function(t,e){switch(t){case"horizontal":return Object(i.a)(e);case"vertical":return Object(n.a)(e);case"sameHeight":return Object(o.a)(e);case"sameWidth":return Object(s.a)(e);case"sameSize":return Object(a.a)(e);case"packed":return Object(l.a)(e);default:return Object(a.a)(e)}};e.a=u},function(t,e,r){"use strict";var i=function(t){var e=t.props,r=e.FilterContainer,i=e.FilteredItems,n=0,o=0,s=i.map(function(t){var e=t.props,r=e.w,i=e.h,s={left:n,top:0};return n+=r,i>o&&(o=i),s});return r.updateHeight(o),s};e.a=i},function(t,e,r){"use strict";var i=function(t){var e=t.props,r=e.FilterContainer,i=e.FilteredItems,n=0,o=i.map(function(t){var e=t.props.h,r={left:0,top:n};return n+=e,r});return r.updateHeight(n),o};e.a=i},function(t,e,r){"use strict";var i=function(t){var e=t.props,r=e.FilterContainer,i=e.FilteredItems,n=r.props.w,o=i[0].props.h,s=0,a=0,l=i.map(function(t){var e=t.props.w;a+e>n&&(s++,a=0);var r={left:a,top:o*s};return a+=e,r});return r.updateHeight((s+1)*i[0].props.h),l};e.a=i},function(t,e,r){"use strict";function i(t){if(Array.isArray(t)){for(var e=0,r=Array(t.length);e=s&&a++;var c=e-s*a;return l[c]+=u,{left:c*i,top:o(n,s,e)}});return r.updateHeight(Math.max.apply(Math,i(l))),u},o=function(t,e,r){if(e<=0)return 0;var i=0;if(r=0;)i+=t[r].props.h,r-=e;return i};e.a=n},function(t,e,r){"use strict";var i=function(t){var e=t.props,r=e.FilterContainer,i=e.FilteredItems,n=r.calcColumns(),o=0,s=i.map(function(t,e){return e%n==0&&e>=n&&o++,{left:(e-n*o)*t.props.w,top:o*t.props.h}}),a=i[0]&&i[0].props.h||0;return r.updateHeight((o+1)*a),s};e.a=i},function(t,e,r){"use strict";var i=function(t){var e=t.props,r=e.FilterContainer,i=e.FilteredItems,o=new n(r.props.w),s=i.map(function(t){var e=t.props;return{w:e.w,h:e.h}});o.fit(s);var a=s.map(function(t){var e=t.fit;return{left:e.x,top:e.y}});return r.updateHeight(o.root.h),a},n=function(t){this.init(t)};n.prototype={init:function(t){this.root={x:0,y:0,w:t}},fit:function(t){var e,r,i,n=t.length,o=n>0?t[0].h:0;for(this.root.h=o,e=0;ethis.length)&&-1!==this.indexOf(t,e)}),Array.prototype.includes||Object.defineProperty(Array.prototype,"includes",{value:function(t,e){if(null==this)throw new TypeError('"this" is null or not defined');var r=Object(this),i=r.length>>>0;if(0===i)return!1;for(var n=0|e,o=Math.max(n>=0?n:i-Math.abs(n),0);oli{position:relative}.fa-li{position:absolute;left:-2.14285714em;width:2.14285714em;top:.14285714em;text-align:center}.fa-li.fa-lg{left:-1.85714286em}.fa-border{padding:.2em .25em .15em;border:solid .08em #eee;border-radius:.1em}.fa-pull-left{float:left}.fa-pull-right{float:right}.fa.fa-pull-left{margin-right:.3em}.fa.fa-pull-right{margin-left:.3em}.pull-right{float:right}.pull-left{float:left}.fa.pull-left{margin-right:.3em}.fa.pull-right{margin-left:.3em}.fa-spin{-webkit-animation:fa-spin 2s infinite linear;animation:fa-spin 2s infinite linear}.fa-pulse{-webkit-animation:fa-spin 1s infinite steps(8);animation:fa-spin 1s infinite steps(8)}@-webkit-keyframes fa-spin{0%{-webkit-transform:rotate(0deg);transform:rotate(0deg)}100%{-webkit-transform:rotate(359deg);transform:rotate(359deg)}}@keyframes fa-spin{0%{-webkit-transform:rotate(0deg);transform:rotate(0deg)}100%{-webkit-transform:rotate(359deg);transform:rotate(359deg)}}.fa-rotate-90{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=1)";-webkit-transform:rotate(90deg);-ms-transform:rotate(90deg);transform:rotate(90deg)}.fa-rotate-180{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=2)";-webkit-transform:rotate(180deg);-ms-transform:rotate(180deg);transform:rotate(180deg)}.fa-rotate-270{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=3)";-webkit-transform:rotate(270deg);-ms-transform:rotate(270deg);transform:rotate(270deg)}.fa-flip-horizontal{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=0, mirror=1)";-webkit-transform:scale(-1, 1);-ms-transform:scale(-1, 1);transform:scale(-1, 1)}.fa-flip-vertical{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=2, mirror=1)";-webkit-transform:scale(1, -1);-ms-transform:scale(1, -1);transform:scale(1, -1)}:root .fa-rotate-90,:root .fa-rotate-180,:root .fa-rotate-270,:root .fa-flip-horizontal,:root .fa-flip-vertical{filter:none}.fa-stack{position:relative;display:inline-block;width:2em;height:2em;line-height:2em;vertical-align:middle}.fa-stack-1x,.fa-stack-2x{position:absolute;left:0;width:100%;text-align:center}.fa-stack-1x{line-height:inherit}.fa-stack-2x{font-size:2em}.fa-inverse{color:#fff}.fa-glass:before{content:"\f000"}.fa-music:before{content:"\f001"}.fa-search:before{content:"\f002"}.fa-envelope-o:before{content:"\f003"}.fa-heart:before{content:"\f004"}.fa-star:before{content:"\f005"}.fa-star-o:before{content:"\f006"}.fa-user:before{content:"\f007"}.fa-film:before{content:"\f008"}.fa-th-large:before{content:"\f009"}.fa-th:before{content:"\f00a"}.fa-th-list:before{content:"\f00b"}.fa-check:before{content:"\f00c"}.fa-remove:before,.fa-close:before,.fa-times:before{content:"\f00d"}.fa-search-plus:before{content:"\f00e"}.fa-search-minus:before{content:"\f010"}.fa-power-off:before{content:"\f011"}.fa-signal:before{content:"\f012"}.fa-gear:before,.fa-cog:before{content:"\f013"}.fa-trash-o:before{content:"\f014"}.fa-home:before{content:"\f015"}.fa-file-o:before{content:"\f016"}.fa-clock-o:before{content:"\f017"}.fa-road:before{content:"\f018"}.fa-download:before{content:"\f019"}.fa-arrow-circle-o-down:before{content:"\f01a"}.fa-arrow-circle-o-up:before{content:"\f01b"}.fa-inbox:before{content:"\f01c"}.fa-play-circle-o:before{content:"\f01d"}.fa-rotate-right:before,.fa-repeat:before{content:"\f01e"}.fa-refresh:before{content:"\f021"}.fa-list-alt:before{content:"\f022"}.fa-lock:before{content:"\f023"}.fa-flag:before{content:"\f024"}.fa-headphones:before{content:"\f025"}.fa-volume-off:before{content:"\f026"}.fa-volume-down:before{content:"\f027"}.fa-volume-up:before{content:"\f028"}.fa-qrcode:before{content:"\f029"}.fa-barcode:before{content:"\f02a"}.fa-tag:before{content:"\f02b"}.fa-tags:before{content:"\f02c"}.fa-book:before{content:"\f02d"}.fa-bookmark:before{content:"\f02e"}.fa-print:before{content:"\f02f"}.fa-camera:before{content:"\f030"}.fa-font:before{content:"\f031"}.fa-bold:before{content:"\f032"}.fa-italic:before{content:"\f033"}.fa-text-height:before{content:"\f034"}.fa-text-width:before{content:"\f035"}.fa-align-left:before{content:"\f036"}.fa-align-center:before{content:"\f037"}.fa-align-right:before{content:"\f038"}.fa-align-justify:before{content:"\f039"}.fa-list:before{content:"\f03a"}.fa-dedent:before,.fa-outdent:before{content:"\f03b"}.fa-indent:before{content:"\f03c"}.fa-video-camera:before{content:"\f03d"}.fa-photo:before,.fa-image:before,.fa-picture-o:before{content:"\f03e"}.fa-pencil:before{content:"\f040"}.fa-map-marker:before{content:"\f041"}.fa-adjust:before{content:"\f042"}.fa-tint:before{content:"\f043"}.fa-edit:before,.fa-pencil-square-o:before{content:"\f044"}.fa-share-square-o:before{content:"\f045"}.fa-check-square-o:before{content:"\f046"}.fa-arrows:before{content:"\f047"}.fa-step-backward:before{content:"\f048"}.fa-fast-backward:before{content:"\f049"}.fa-backward:before{content:"\f04a"}.fa-play:before{content:"\f04b"}.fa-pause:before{content:"\f04c"}.fa-stop:before{content:"\f04d"}.fa-forward:before{content:"\f04e"}.fa-fast-forward:before{content:"\f050"}.fa-step-forward:before{content:"\f051"}.fa-eject:before{content:"\f052"}.fa-chevron-left:before{content:"\f053"}.fa-chevron-right:before{content:"\f054"}.fa-plus-circle:before{content:"\f055"}.fa-minus-circle:before{content:"\f056"}.fa-times-circle:before{content:"\f057"}.fa-check-circle:before{content:"\f058"}.fa-question-circle:before{content:"\f059"}.fa-info-circle:before{content:"\f05a"}.fa-crosshairs:before{content:"\f05b"}.fa-times-circle-o:before{content:"\f05c"}.fa-check-circle-o:before{content:"\f05d"}.fa-ban:before{content:"\f05e"}.fa-arrow-left:before{content:"\f060"}.fa-arrow-right:before{content:"\f061"}.fa-arrow-up:before{content:"\f062"}.fa-arrow-down:before{content:"\f063"}.fa-mail-forward:before,.fa-share:before{content:"\f064"}.fa-expand:before{content:"\f065"}.fa-compress:before{content:"\f066"}.fa-plus:before{content:"\f067"}.fa-minus:before{content:"\f068"}.fa-asterisk:before{content:"\f069"}.fa-exclamation-circle:before{content:"\f06a"}.fa-gift:before{content:"\f06b"}.fa-leaf:before{content:"\f06c"}.fa-fire:before{content:"\f06d"}.fa-eye:before{content:"\f06e"}.fa-eye-slash:before{content:"\f070"}.fa-warning:before,.fa-exclamation-triangle:before{content:"\f071"}.fa-plane:before{content:"\f072"}.fa-calendar:before{content:"\f073"}.fa-random:before{content:"\f074"}.fa-comment:before{content:"\f075"}.fa-magnet:before{content:"\f076"}.fa-chevron-up:before{content:"\f077"}.fa-chevron-down:before{content:"\f078"}.fa-retweet:before{content:"\f079"}.fa-shopping-cart:before{content:"\f07a"}.fa-folder:before{content:"\f07b"}.fa-folder-open:before{content:"\f07c"}.fa-arrows-v:before{content:"\f07d"}.fa-arrows-h:before{content:"\f07e"}.fa-bar-chart-o:before,.fa-bar-chart:before{content:"\f080"}.fa-twitter-square:before{content:"\f081"}.fa-facebook-square:before{content:"\f082"}.fa-camera-retro:before{content:"\f083"}.fa-key:before{content:"\f084"}.fa-gears:before,.fa-cogs:before{content:"\f085"}.fa-comments:before{content:"\f086"}.fa-thumbs-o-up:before{content:"\f087"}.fa-thumbs-o-down:before{content:"\f088"}.fa-star-half:before{content:"\f089"}.fa-heart-o:before{content:"\f08a"}.fa-sign-out:before{content:"\f08b"}.fa-linkedin-square:before{content:"\f08c"}.fa-thumb-tack:before{content:"\f08d"}.fa-external-link:before{content:"\f08e"}.fa-sign-in:before{content:"\f090"}.fa-trophy:before{content:"\f091"}.fa-github-square:before{content:"\f092"}.fa-upload:before{content:"\f093"}.fa-lemon-o:before{content:"\f094"}.fa-phone:before{content:"\f095"}.fa-square-o:before{content:"\f096"}.fa-bookmark-o:before{content:"\f097"}.fa-phone-square:before{content:"\f098"}.fa-twitter:before{content:"\f099"}.fa-facebook-f:before,.fa-facebook:before{content:"\f09a"}.fa-github:before{content:"\f09b"}.fa-unlock:before{content:"\f09c"}.fa-credit-card:before{content:"\f09d"}.fa-feed:before,.fa-rss:before{content:"\f09e"}.fa-hdd-o:before{content:"\f0a0"}.fa-bullhorn:before{content:"\f0a1"}.fa-bell:before{content:"\f0f3"}.fa-certificate:before{content:"\f0a3"}.fa-hand-o-right:before{content:"\f0a4"}.fa-hand-o-left:before{content:"\f0a5"}.fa-hand-o-up:before{content:"\f0a6"}.fa-hand-o-down:before{content:"\f0a7"}.fa-arrow-circle-left:before{content:"\f0a8"}.fa-arrow-circle-right:before{content:"\f0a9"}.fa-arrow-circle-up:before{content:"\f0aa"}.fa-arrow-circle-down:before{content:"\f0ab"}.fa-globe:before{content:"\f0ac"}.fa-wrench:before{content:"\f0ad"}.fa-tasks:before{content:"\f0ae"}.fa-filter:before{content:"\f0b0"}.fa-briefcase:before{content:"\f0b1"}.fa-arrows-alt:before{content:"\f0b2"}.fa-group:before,.fa-users:before{content:"\f0c0"}.fa-chain:before,.fa-link:before{content:"\f0c1"}.fa-cloud:before{content:"\f0c2"}.fa-flask:before{content:"\f0c3"}.fa-cut:before,.fa-scissors:before{content:"\f0c4"}.fa-copy:before,.fa-files-o:before{content:"\f0c5"}.fa-paperclip:before{content:"\f0c6"}.fa-save:before,.fa-floppy-o:before{content:"\f0c7"}.fa-square:before{content:"\f0c8"}.fa-navicon:before,.fa-reorder:before,.fa-bars:before{content:"\f0c9"}.fa-list-ul:before{content:"\f0ca"}.fa-list-ol:before{content:"\f0cb"}.fa-strikethrough:before{content:"\f0cc"}.fa-underline:before{content:"\f0cd"}.fa-table:before{content:"\f0ce"}.fa-magic:before{content:"\f0d0"}.fa-truck:before{content:"\f0d1"}.fa-pinterest:before{content:"\f0d2"}.fa-pinterest-square:before{content:"\f0d3"}.fa-google-plus-square:before{content:"\f0d4"}.fa-google-plus:before{content:"\f0d5"}.fa-money:before{content:"\f0d6"}.fa-caret-down:before{content:"\f0d7"}.fa-caret-up:before{content:"\f0d8"}.fa-caret-left:before{content:"\f0d9"}.fa-caret-right:before{content:"\f0da"}.fa-columns:before{content:"\f0db"}.fa-unsorted:before,.fa-sort:before{content:"\f0dc"}.fa-sort-down:before,.fa-sort-desc:before{content:"\f0dd"}.fa-sort-up:before,.fa-sort-asc:before{content:"\f0de"}.fa-envelope:before{content:"\f0e0"}.fa-linkedin:before{content:"\f0e1"}.fa-rotate-left:before,.fa-undo:before{content:"\f0e2"}.fa-legal:before,.fa-gavel:before{content:"\f0e3"}.fa-dashboard:before,.fa-tachometer:before{content:"\f0e4"}.fa-comment-o:before{content:"\f0e5"}.fa-comments-o:before{content:"\f0e6"}.fa-flash:before,.fa-bolt:before{content:"\f0e7"}.fa-sitemap:before{content:"\f0e8"}.fa-umbrella:before{content:"\f0e9"}.fa-paste:before,.fa-clipboard:before{content:"\f0ea"}.fa-lightbulb-o:before{content:"\f0eb"}.fa-exchange:before{content:"\f0ec"}.fa-cloud-download:before{content:"\f0ed"}.fa-cloud-upload:before{content:"\f0ee"}.fa-user-md:before{content:"\f0f0"}.fa-stethoscope:before{content:"\f0f1"}.fa-suitcase:before{content:"\f0f2"}.fa-bell-o:before{content:"\f0a2"}.fa-coffee:before{content:"\f0f4"}.fa-cutlery:before{content:"\f0f5"}.fa-file-text-o:before{content:"\f0f6"}.fa-building-o:before{content:"\f0f7"}.fa-hospital-o:before{content:"\f0f8"}.fa-ambulance:before{content:"\f0f9"}.fa-medkit:before{content:"\f0fa"}.fa-fighter-jet:before{content:"\f0fb"}.fa-beer:before{content:"\f0fc"}.fa-h-square:before{content:"\f0fd"}.fa-plus-square:before{content:"\f0fe"}.fa-angle-double-left:before{content:"\f100"}.fa-angle-double-right:before{content:"\f101"}.fa-angle-double-up:before{content:"\f102"}.fa-angle-double-down:before{content:"\f103"}.fa-angle-left:before{content:"\f104"}.fa-angle-right:before{content:"\f105"}.fa-angle-up:before{content:"\f106"}.fa-angle-down:before{content:"\f107"}.fa-desktop:before{content:"\f108"}.fa-laptop:before{content:"\f109"}.fa-tablet:before{content:"\f10a"}.fa-mobile-phone:before,.fa-mobile:before{content:"\f10b"}.fa-circle-o:before{content:"\f10c"}.fa-quote-left:before{content:"\f10d"}.fa-quote-right:before{content:"\f10e"}.fa-spinner:before{content:"\f110"}.fa-circle:before{content:"\f111"}.fa-mail-reply:before,.fa-reply:before{content:"\f112"}.fa-github-alt:before{content:"\f113"}.fa-folder-o:before{content:"\f114"}.fa-folder-open-o:before{content:"\f115"}.fa-smile-o:before{content:"\f118"}.fa-frown-o:before{content:"\f119"}.fa-meh-o:before{content:"\f11a"}.fa-gamepad:before{content:"\f11b"}.fa-keyboard-o:before{content:"\f11c"}.fa-flag-o:before{content:"\f11d"}.fa-flag-checkered:before{content:"\f11e"}.fa-terminal:before{content:"\f120"}.fa-code:before{content:"\f121"}.fa-mail-reply-all:before,.fa-reply-all:before{content:"\f122"}.fa-star-half-empty:before,.fa-star-half-full:before,.fa-star-half-o:before{content:"\f123"}.fa-location-arrow:before{content:"\f124"}.fa-crop:before{content:"\f125"}.fa-code-fork:before{content:"\f126"}.fa-unlink:before,.fa-chain-broken:before{content:"\f127"}.fa-question:before{content:"\f128"}.fa-info:before{content:"\f129"}.fa-exclamation:before{content:"\f12a"}.fa-superscript:before{content:"\f12b"}.fa-subscript:before{content:"\f12c"}.fa-eraser:before{content:"\f12d"}.fa-puzzle-piece:before{content:"\f12e"}.fa-microphone:before{content:"\f130"}.fa-microphone-slash:before{content:"\f131"}.fa-shield:before{content:"\f132"}.fa-calendar-o:before{content:"\f133"}.fa-fire-extinguisher:before{content:"\f134"}.fa-rocket:before{content:"\f135"}.fa-maxcdn:before{content:"\f136"}.fa-chevron-circle-left:before{content:"\f137"}.fa-chevron-circle-right:before{content:"\f138"}.fa-chevron-circle-up:before{content:"\f139"}.fa-chevron-circle-down:before{content:"\f13a"}.fa-html5:before{content:"\f13b"}.fa-css3:before{content:"\f13c"}.fa-anchor:before{content:"\f13d"}.fa-unlock-alt:before{content:"\f13e"}.fa-bullseye:before{content:"\f140"}.fa-ellipsis-h:before{content:"\f141"}.fa-ellipsis-v:before{content:"\f142"}.fa-rss-square:before{content:"\f143"}.fa-play-circle:before{content:"\f144"}.fa-ticket:before{content:"\f145"}.fa-minus-square:before{content:"\f146"}.fa-minus-square-o:before{content:"\f147"}.fa-level-up:before{content:"\f148"}.fa-level-down:before{content:"\f149"}.fa-check-square:before{content:"\f14a"}.fa-pencil-square:before{content:"\f14b"}.fa-external-link-square:before{content:"\f14c"}.fa-share-square:before{content:"\f14d"}.fa-compass:before{content:"\f14e"}.fa-toggle-down:before,.fa-caret-square-o-down:before{content:"\f150"}.fa-toggle-up:before,.fa-caret-square-o-up:before{content:"\f151"}.fa-toggle-right:before,.fa-caret-square-o-right:before{content:"\f152"}.fa-euro:before,.fa-eur:before{content:"\f153"}.fa-gbp:before{content:"\f154"}.fa-dollar:before,.fa-usd:before{content:"\f155"}.fa-rupee:before,.fa-inr:before{content:"\f156"}.fa-cny:before,.fa-rmb:before,.fa-yen:before,.fa-jpy:before{content:"\f157"}.fa-ruble:before,.fa-rouble:before,.fa-rub:before{content:"\f158"}.fa-won:before,.fa-krw:before{content:"\f159"}.fa-bitcoin:before,.fa-btc:before{content:"\f15a"}.fa-file:before{content:"\f15b"}.fa-file-text:before{content:"\f15c"}.fa-sort-alpha-asc:before{content:"\f15d"}.fa-sort-alpha-desc:before{content:"\f15e"}.fa-sort-amount-asc:before{content:"\f160"}.fa-sort-amount-desc:before{content:"\f161"}.fa-sort-numeric-asc:before{content:"\f162"}.fa-sort-numeric-desc:before{content:"\f163"}.fa-thumbs-up:before{content:"\f164"}.fa-thumbs-down:before{content:"\f165"}.fa-youtube-square:before{content:"\f166"}.fa-youtube:before{content:"\f167"}.fa-xing:before{content:"\f168"}.fa-xing-square:before{content:"\f169"}.fa-youtube-play:before{content:"\f16a"}.fa-dropbox:before{content:"\f16b"}.fa-stack-overflow:before{content:"\f16c"}.fa-instagram:before{content:"\f16d"}.fa-flickr:before{content:"\f16e"}.fa-adn:before{content:"\f170"}.fa-bitbucket:before{content:"\f171"}.fa-bitbucket-square:before{content:"\f172"}.fa-tumblr:before{content:"\f173"}.fa-tumblr-square:before{content:"\f174"}.fa-long-arrow-down:before{content:"\f175"}.fa-long-arrow-up:before{content:"\f176"}.fa-long-arrow-left:before{content:"\f177"}.fa-long-arrow-right:before{content:"\f178"}.fa-apple:before{content:"\f179"}.fa-windows:before{content:"\f17a"}.fa-android:before{content:"\f17b"}.fa-linux:before{content:"\f17c"}.fa-dribbble:before{content:"\f17d"}.fa-skype:before{content:"\f17e"}.fa-foursquare:before{content:"\f180"}.fa-trello:before{content:"\f181"}.fa-female:before{content:"\f182"}.fa-male:before{content:"\f183"}.fa-gittip:before,.fa-gratipay:before{content:"\f184"}.fa-sun-o:before{content:"\f185"}.fa-moon-o:before{content:"\f186"}.fa-archive:before{content:"\f187"}.fa-bug:before{content:"\f188"}.fa-vk:before{content:"\f189"}.fa-weibo:before{content:"\f18a"}.fa-renren:before{content:"\f18b"}.fa-pagelines:before{content:"\f18c"}.fa-stack-exchange:before{content:"\f18d"}.fa-arrow-circle-o-right:before{content:"\f18e"}.fa-arrow-circle-o-left:before{content:"\f190"}.fa-toggle-left:before,.fa-caret-square-o-left:before{content:"\f191"}.fa-dot-circle-o:before{content:"\f192"}.fa-wheelchair:before{content:"\f193"}.fa-vimeo-square:before{content:"\f194"}.fa-turkish-lira:before,.fa-try:before{content:"\f195"}.fa-plus-square-o:before{content:"\f196"}.fa-space-shuttle:before{content:"\f197"}.fa-slack:before{content:"\f198"}.fa-envelope-square:before{content:"\f199"}.fa-wordpress:before{content:"\f19a"}.fa-openid:before{content:"\f19b"}.fa-institution:before,.fa-bank:before,.fa-university:before{content:"\f19c"}.fa-mortar-board:before,.fa-graduation-cap:before{content:"\f19d"}.fa-yahoo:before{content:"\f19e"}.fa-google:before{content:"\f1a0"}.fa-reddit:before{content:"\f1a1"}.fa-reddit-square:before{content:"\f1a2"}.fa-stumbleupon-circle:before{content:"\f1a3"}.fa-stumbleupon:before{content:"\f1a4"}.fa-delicious:before{content:"\f1a5"}.fa-digg:before{content:"\f1a6"}.fa-pied-piper-pp:before{content:"\f1a7"}.fa-pied-piper-alt:before{content:"\f1a8"}.fa-drupal:before{content:"\f1a9"}.fa-joomla:before{content:"\f1aa"}.fa-language:before{content:"\f1ab"}.fa-fax:before{content:"\f1ac"}.fa-building:before{content:"\f1ad"}.fa-child:before{content:"\f1ae"}.fa-paw:before{content:"\f1b0"}.fa-spoon:before{content:"\f1b1"}.fa-cube:before{content:"\f1b2"}.fa-cubes:before{content:"\f1b3"}.fa-behance:before{content:"\f1b4"}.fa-behance-square:before{content:"\f1b5"}.fa-steam:before{content:"\f1b6"}.fa-steam-square:before{content:"\f1b7"}.fa-recycle:before{content:"\f1b8"}.fa-automobile:before,.fa-car:before{content:"\f1b9"}.fa-cab:before,.fa-taxi:before{content:"\f1ba"}.fa-tree:before{content:"\f1bb"}.fa-spotify:before{content:"\f1bc"}.fa-deviantart:before{content:"\f1bd"}.fa-soundcloud:before{content:"\f1be"}.fa-database:before{content:"\f1c0"}.fa-file-pdf-o:before{content:"\f1c1"}.fa-file-word-o:before{content:"\f1c2"}.fa-file-excel-o:before{content:"\f1c3"}.fa-file-powerpoint-o:before{content:"\f1c4"}.fa-file-photo-o:before,.fa-file-picture-o:before,.fa-file-image-o:before{content:"\f1c5"}.fa-file-zip-o:before,.fa-file-archive-o:before{content:"\f1c6"}.fa-file-sound-o:before,.fa-file-audio-o:before{content:"\f1c7"}.fa-file-movie-o:before,.fa-file-video-o:before{content:"\f1c8"}.fa-file-code-o:before{content:"\f1c9"}.fa-vine:before{content:"\f1ca"}.fa-codepen:before{content:"\f1cb"}.fa-jsfiddle:before{content:"\f1cc"}.fa-life-bouy:before,.fa-life-buoy:before,.fa-life-saver:before,.fa-support:before,.fa-life-ring:before{content:"\f1cd"}.fa-circle-o-notch:before{content:"\f1ce"}.fa-ra:before,.fa-resistance:before,.fa-rebel:before{content:"\f1d0"}.fa-ge:before,.fa-empire:before{content:"\f1d1"}.fa-git-square:before{content:"\f1d2"}.fa-git:before{content:"\f1d3"}.fa-y-combinator-square:before,.fa-yc-square:before,.fa-hacker-news:before{content:"\f1d4"}.fa-tencent-weibo:before{content:"\f1d5"}.fa-qq:before{content:"\f1d6"}.fa-wechat:before,.fa-weixin:before{content:"\f1d7"}.fa-send:before,.fa-paper-plane:before{content:"\f1d8"}.fa-send-o:before,.fa-paper-plane-o:before{content:"\f1d9"}.fa-history:before{content:"\f1da"}.fa-circle-thin:before{content:"\f1db"}.fa-header:before{content:"\f1dc"}.fa-paragraph:before{content:"\f1dd"}.fa-sliders:before{content:"\f1de"}.fa-share-alt:before{content:"\f1e0"}.fa-share-alt-square:before{content:"\f1e1"}.fa-bomb:before{content:"\f1e2"}.fa-soccer-ball-o:before,.fa-futbol-o:before{content:"\f1e3"}.fa-tty:before{content:"\f1e4"}.fa-binoculars:before{content:"\f1e5"}.fa-plug:before{content:"\f1e6"}.fa-slideshare:before{content:"\f1e7"}.fa-twitch:before{content:"\f1e8"}.fa-yelp:before{content:"\f1e9"}.fa-newspaper-o:before{content:"\f1ea"}.fa-wifi:before{content:"\f1eb"}.fa-calculator:before{content:"\f1ec"}.fa-paypal:before{content:"\f1ed"}.fa-google-wallet:before{content:"\f1ee"}.fa-cc-visa:before{content:"\f1f0"}.fa-cc-mastercard:before{content:"\f1f1"}.fa-cc-discover:before{content:"\f1f2"}.fa-cc-amex:before{content:"\f1f3"}.fa-cc-paypal:before{content:"\f1f4"}.fa-cc-stripe:before{content:"\f1f5"}.fa-bell-slash:before{content:"\f1f6"}.fa-bell-slash-o:before{content:"\f1f7"}.fa-trash:before{content:"\f1f8"}.fa-copyright:before{content:"\f1f9"}.fa-at:before{content:"\f1fa"}.fa-eyedropper:before{content:"\f1fb"}.fa-paint-brush:before{content:"\f1fc"}.fa-birthday-cake:before{content:"\f1fd"}.fa-area-chart:before{content:"\f1fe"}.fa-pie-chart:before{content:"\f200"}.fa-line-chart:before{content:"\f201"}.fa-lastfm:before{content:"\f202"}.fa-lastfm-square:before{content:"\f203"}.fa-toggle-off:before{content:"\f204"}.fa-toggle-on:before{content:"\f205"}.fa-bicycle:before{content:"\f206"}.fa-bus:before{content:"\f207"}.fa-ioxhost:before{content:"\f208"}.fa-angellist:before{content:"\f209"}.fa-cc:before{content:"\f20a"}.fa-shekel:before,.fa-sheqel:before,.fa-ils:before{content:"\f20b"}.fa-meanpath:before{content:"\f20c"}.fa-buysellads:before{content:"\f20d"}.fa-connectdevelop:before{content:"\f20e"}.fa-dashcube:before{content:"\f210"}.fa-forumbee:before{content:"\f211"}.fa-leanpub:before{content:"\f212"}.fa-sellsy:before{content:"\f213"}.fa-shirtsinbulk:before{content:"\f214"}.fa-simplybuilt:before{content:"\f215"}.fa-skyatlas:before{content:"\f216"}.fa-cart-plus:before{content:"\f217"}.fa-cart-arrow-down:before{content:"\f218"}.fa-diamond:before{content:"\f219"}.fa-ship:before{content:"\f21a"}.fa-user-secret:before{content:"\f21b"}.fa-motorcycle:before{content:"\f21c"}.fa-street-view:before{content:"\f21d"}.fa-heartbeat:before{content:"\f21e"}.fa-venus:before{content:"\f221"}.fa-mars:before{content:"\f222"}.fa-mercury:before{content:"\f223"}.fa-intersex:before,.fa-transgender:before{content:"\f224"}.fa-transgender-alt:before{content:"\f225"}.fa-venus-double:before{content:"\f226"}.fa-mars-double:before{content:"\f227"}.fa-venus-mars:before{content:"\f228"}.fa-mars-stroke:before{content:"\f229"}.fa-mars-stroke-v:before{content:"\f22a"}.fa-mars-stroke-h:before{content:"\f22b"}.fa-neuter:before{content:"\f22c"}.fa-genderless:before{content:"\f22d"}.fa-facebook-official:before{content:"\f230"}.fa-pinterest-p:before{content:"\f231"}.fa-whatsapp:before{content:"\f232"}.fa-server:before{content:"\f233"}.fa-user-plus:before{content:"\f234"}.fa-user-times:before{content:"\f235"}.fa-hotel:before,.fa-bed:before{content:"\f236"}.fa-viacoin:before{content:"\f237"}.fa-train:before{content:"\f238"}.fa-subway:before{content:"\f239"}.fa-medium:before{content:"\f23a"}.fa-yc:before,.fa-y-combinator:before{content:"\f23b"}.fa-optin-monster:before{content:"\f23c"}.fa-opencart:before{content:"\f23d"}.fa-expeditedssl:before{content:"\f23e"}.fa-battery-4:before,.fa-battery:before,.fa-battery-full:before{content:"\f240"}.fa-battery-3:before,.fa-battery-three-quarters:before{content:"\f241"}.fa-battery-2:before,.fa-battery-half:before{content:"\f242"}.fa-battery-1:before,.fa-battery-quarter:before{content:"\f243"}.fa-battery-0:before,.fa-battery-empty:before{content:"\f244"}.fa-mouse-pointer:before{content:"\f245"}.fa-i-cursor:before{content:"\f246"}.fa-object-group:before{content:"\f247"}.fa-object-ungroup:before{content:"\f248"}.fa-sticky-note:before{content:"\f249"}.fa-sticky-note-o:before{content:"\f24a"}.fa-cc-jcb:before{content:"\f24b"}.fa-cc-diners-club:before{content:"\f24c"}.fa-clone:before{content:"\f24d"}.fa-balance-scale:before{content:"\f24e"}.fa-hourglass-o:before{content:"\f250"}.fa-hourglass-1:before,.fa-hourglass-start:before{content:"\f251"}.fa-hourglass-2:before,.fa-hourglass-half:before{content:"\f252"}.fa-hourglass-3:before,.fa-hourglass-end:before{content:"\f253"}.fa-hourglass:before{content:"\f254"}.fa-hand-grab-o:before,.fa-hand-rock-o:before{content:"\f255"}.fa-hand-stop-o:before,.fa-hand-paper-o:before{content:"\f256"}.fa-hand-scissors-o:before{content:"\f257"}.fa-hand-lizard-o:before{content:"\f258"}.fa-hand-spock-o:before{content:"\f259"}.fa-hand-pointer-o:before{content:"\f25a"}.fa-hand-peace-o:before{content:"\f25b"}.fa-trademark:before{content:"\f25c"}.fa-registered:before{content:"\f25d"}.fa-creative-commons:before{content:"\f25e"}.fa-gg:before{content:"\f260"}.fa-gg-circle:before{content:"\f261"}.fa-tripadvisor:before{content:"\f262"}.fa-odnoklassniki:before{content:"\f263"}.fa-odnoklassniki-square:before{content:"\f264"}.fa-get-pocket:before{content:"\f265"}.fa-wikipedia-w:before{content:"\f266"}.fa-safari:before{content:"\f267"}.fa-chrome:before{content:"\f268"}.fa-firefox:before{content:"\f269"}.fa-opera:before{content:"\f26a"}.fa-internet-explorer:before{content:"\f26b"}.fa-tv:before,.fa-television:before{content:"\f26c"}.fa-contao:before{content:"\f26d"}.fa-500px:before{content:"\f26e"}.fa-amazon:before{content:"\f270"}.fa-calendar-plus-o:before{content:"\f271"}.fa-calendar-minus-o:before{content:"\f272"}.fa-calendar-times-o:before{content:"\f273"}.fa-calendar-check-o:before{content:"\f274"}.fa-industry:before{content:"\f275"}.fa-map-pin:before{content:"\f276"}.fa-map-signs:before{content:"\f277"}.fa-map-o:before{content:"\f278"}.fa-map:before{content:"\f279"}.fa-commenting:before{content:"\f27a"}.fa-commenting-o:before{content:"\f27b"}.fa-houzz:before{content:"\f27c"}.fa-vimeo:before{content:"\f27d"}.fa-black-tie:before{content:"\f27e"}.fa-fonticons:before{content:"\f280"}.fa-reddit-alien:before{content:"\f281"}.fa-edge:before{content:"\f282"}.fa-credit-card-alt:before{content:"\f283"}.fa-codiepie:before{content:"\f284"}.fa-modx:before{content:"\f285"}.fa-fort-awesome:before{content:"\f286"}.fa-usb:before{content:"\f287"}.fa-product-hunt:before{content:"\f288"}.fa-mixcloud:before{content:"\f289"}.fa-scribd:before{content:"\f28a"}.fa-pause-circle:before{content:"\f28b"}.fa-pause-circle-o:before{content:"\f28c"}.fa-stop-circle:before{content:"\f28d"}.fa-stop-circle-o:before{content:"\f28e"}.fa-shopping-bag:before{content:"\f290"}.fa-shopping-basket:before{content:"\f291"}.fa-hashtag:before{content:"\f292"}.fa-bluetooth:before{content:"\f293"}.fa-bluetooth-b:before{content:"\f294"}.fa-percent:before{content:"\f295"}.fa-gitlab:before{content:"\f296"}.fa-wpbeginner:before{content:"\f297"}.fa-wpforms:before{content:"\f298"}.fa-envira:before{content:"\f299"}.fa-universal-access:before{content:"\f29a"}.fa-wheelchair-alt:before{content:"\f29b"}.fa-question-circle-o:before{content:"\f29c"}.fa-blind:before{content:"\f29d"}.fa-audio-description:before{content:"\f29e"}.fa-volume-control-phone:before{content:"\f2a0"}.fa-braille:before{content:"\f2a1"}.fa-assistive-listening-systems:before{content:"\f2a2"}.fa-asl-interpreting:before,.fa-american-sign-language-interpreting:before{content:"\f2a3"}.fa-deafness:before,.fa-hard-of-hearing:before,.fa-deaf:before{content:"\f2a4"}.fa-glide:before{content:"\f2a5"}.fa-glide-g:before{content:"\f2a6"}.fa-signing:before,.fa-sign-language:before{content:"\f2a7"}.fa-low-vision:before{content:"\f2a8"}.fa-viadeo:before{content:"\f2a9"}.fa-viadeo-square:before{content:"\f2aa"}.fa-snapchat:before{content:"\f2ab"}.fa-snapchat-ghost:before{content:"\f2ac"}.fa-snapchat-square:before{content:"\f2ad"}.fa-pied-piper:before{content:"\f2ae"}.fa-first-order:before{content:"\f2b0"}.fa-yoast:before{content:"\f2b1"}.fa-themeisle:before{content:"\f2b2"}.fa-google-plus-circle:before,.fa-google-plus-official:before{content:"\f2b3"}.fa-fa:before,.fa-font-awesome:before{content:"\f2b4"}.fa-handshake-o:before{content:"\f2b5"}.fa-envelope-open:before{content:"\f2b6"}.fa-envelope-open-o:before{content:"\f2b7"}.fa-linode:before{content:"\f2b8"}.fa-address-book:before{content:"\f2b9"}.fa-address-book-o:before{content:"\f2ba"}.fa-vcard:before,.fa-address-card:before{content:"\f2bb"}.fa-vcard-o:before,.fa-address-card-o:before{content:"\f2bc"}.fa-user-circle:before{content:"\f2bd"}.fa-user-circle-o:before{content:"\f2be"}.fa-user-o:before{content:"\f2c0"}.fa-id-badge:before{content:"\f2c1"}.fa-drivers-license:before,.fa-id-card:before{content:"\f2c2"}.fa-drivers-license-o:before,.fa-id-card-o:before{content:"\f2c3"}.fa-quora:before{content:"\f2c4"}.fa-free-code-camp:before{content:"\f2c5"}.fa-telegram:before{content:"\f2c6"}.fa-thermometer-4:before,.fa-thermometer:before,.fa-thermometer-full:before{content:"\f2c7"}.fa-thermometer-3:before,.fa-thermometer-three-quarters:before{content:"\f2c8"}.fa-thermometer-2:before,.fa-thermometer-half:before{content:"\f2c9"}.fa-thermometer-1:before,.fa-thermometer-quarter:before{content:"\f2ca"}.fa-thermometer-0:before,.fa-thermometer-empty:before{content:"\f2cb"}.fa-shower:before{content:"\f2cc"}.fa-bathtub:before,.fa-s15:before,.fa-bath:before{content:"\f2cd"}.fa-podcast:before{content:"\f2ce"}.fa-window-maximize:before{content:"\f2d0"}.fa-window-minimize:before{content:"\f2d1"}.fa-window-restore:before{content:"\f2d2"}.fa-times-rectangle:before,.fa-window-close:before{content:"\f2d3"}.fa-times-rectangle-o:before,.fa-window-close-o:before{content:"\f2d4"}.fa-bandcamp:before{content:"\f2d5"}.fa-grav:before{content:"\f2d6"}.fa-etsy:before{content:"\f2d7"}.fa-imdb:before{content:"\f2d8"}.fa-ravelry:before{content:"\f2d9"}.fa-eercast:before{content:"\f2da"}.fa-microchip:before{content:"\f2db"}.fa-snowflake-o:before{content:"\f2dc"}.fa-superpowers:before{content:"\f2dd"}.fa-wpexplorer:before{content:"\f2de"}.fa-meetup:before{content:"\f2e0"}.sr-only{position:absolute;width:1px;height:1px;padding:0;margin:-1px;overflow:hidden;clip:rect(0, 0, 0, 0);border:0}.sr-only-focusable:active,.sr-only-focusable:focus{position:static;width:auto;height:auto;margin:0;overflow:visible;clip:auto}
diff --git a/plugins/fontawesome/fonts/FontAwesome.otf b/plugins/fontawesome/fonts/FontAwesome.otf
new file mode 100644
index 00000000..401ec0f3
Binary files /dev/null and b/plugins/fontawesome/fonts/FontAwesome.otf differ
diff --git a/plugins/fontawesome/fonts/fontawesome-webfont.eot b/plugins/fontawesome/fonts/fontawesome-webfont.eot
new file mode 100644
index 00000000..e9f60ca9
Binary files /dev/null and b/plugins/fontawesome/fonts/fontawesome-webfont.eot differ
diff --git a/plugins/fontawesome/fonts/fontawesome-webfont.svg b/plugins/fontawesome/fonts/fontawesome-webfont.svg
new file mode 100644
index 00000000..855c845e
--- /dev/null
+++ b/plugins/fontawesome/fonts/fontawesome-webfont.svg
@@ -0,0 +1,2671 @@
+
+
+
diff --git a/plugins/fontawesome/fonts/fontawesome-webfont.ttf b/plugins/fontawesome/fonts/fontawesome-webfont.ttf
new file mode 100644
index 00000000..35acda2f
Binary files /dev/null and b/plugins/fontawesome/fonts/fontawesome-webfont.ttf differ
diff --git a/plugins/fontawesome/fonts/fontawesome-webfont.woff b/plugins/fontawesome/fonts/fontawesome-webfont.woff
new file mode 100644
index 00000000..400014a4
Binary files /dev/null and b/plugins/fontawesome/fonts/fontawesome-webfont.woff differ
diff --git a/plugins/fontawesome/fonts/fontawesome-webfont.woff2 b/plugins/fontawesome/fonts/fontawesome-webfont.woff2
new file mode 100644
index 00000000..4d13fc60
Binary files /dev/null and b/plugins/fontawesome/fonts/fontawesome-webfont.woff2 differ
diff --git a/plugins/google-map/gmap.js b/plugins/google-map/gmap.js
new file mode 100644
index 00000000..d7c9e98e
--- /dev/null
+++ b/plugins/google-map/gmap.js
@@ -0,0 +1,80 @@
+window.marker = null;
+
+function initialize() {
+ var map;
+ var latitude = $('#map_canvas').attr('data-latitude');
+ var longitude = $('#map_canvas').attr('data-longitude');
+ var mapMarker = $('#map_canvas').attr('data-marker');
+ var mapMarkerName = $('#map_canvas').attr('data-marker-name');
+ var nottingham = new google.maps.LatLng(latitude, longitude);
+ var style = [{
+ "featureType": "road",
+ "elementType": "geometry",
+ "stylers": [{
+ "lightness": 100
+ },
+ {
+ "visibility": "simplified"
+ }
+ ]
+ },
+ {
+ "featureType": "water",
+ "elementType": "geometry",
+ "stylers": [{
+ "visibility": "on"
+ },
+ {
+ "color": "#C6E2FF"
+ }
+ ]
+ },
+ {
+ "featureType": "poi",
+ "elementType": "geometry.fill",
+ "stylers": [{
+ "color": "#C5E3BF"
+ }]
+ },
+ {
+ "featureType": "road",
+ "elementType": "geometry.fill",
+ "stylers": [{
+ "color": "#D1D1B8"
+ }]
+ }
+ ];
+ var mapOptions = {
+ center: nottingham,
+ mapTypeId: google.maps.MapTypeId.ROADMAP,
+ backgroundColor: "#000",
+ zoom: 15,
+ panControl: false,
+ zoomControl: true,
+ mapTypeControl: false,
+ scaleControl: false,
+ streetViewControl: false,
+ overviewMapControl: false,
+ zoomControlOptions: {
+ style: google.maps.ZoomControlStyle.LARGE
+ }
+ }
+ map = new google.maps.Map(document.getElementById('map_canvas'), mapOptions);
+ var mapType = new google.maps.StyledMapType(style, {
+ name: "Grayscale"
+ });
+ map.mapTypes.set('grey', mapType);
+ map.setMapTypeId('grey');
+ var marker_image = mapMarker;
+ var pinIcon = new google.maps.MarkerImage(marker_image, null, null, null, new google.maps.Size(46, 58));
+ marker = new google.maps.Marker({
+ position: nottingham,
+ map: map,
+ icon: pinIcon,
+ title: mapMarkerName
+ });
+}
+var map = document.getElementById('map_canvas');
+if (map != null) {
+ google.maps.event.addDomListener(window, 'load', initialize);
+}
\ No newline at end of file
diff --git a/plugins/jQuery/jquery.min.js b/plugins/jQuery/jquery.min.js
new file mode 100644
index 00000000..a967467b
--- /dev/null
+++ b/plugins/jQuery/jquery.min.js
@@ -0,0 +1,2 @@
+/*! jQuery v3.3.1 | (c) JS Foundation and other contributors | jquery.org/license */
+!function (e, t) { "use strict"; "object" == typeof module && "object" == typeof module.exports ? module.exports = e.document ? t(e, !0) : function (e) { if (!e.document) throw new Error("jQuery requires a window with a document"); return t(e) } : t(e) }("undefined" != typeof window ? window : this, function (e, t) { "use strict"; var n = [], r = e.document, i = Object.getPrototypeOf, o = n.slice, a = n.concat, s = n.push, u = n.indexOf, l = {}, c = l.toString, f = l.hasOwnProperty, p = f.toString, d = p.call(Object), h = {}, g = function e(t) { return "function" == typeof t && "number" != typeof t.nodeType }, y = function e(t) { return null != t && t === t.window }, v = { type: !0, src: !0, noModule: !0 }; function m(e, t, n) { var i, o = (t = t || r).createElement("script"); if (o.text = e, n) for (i in v) n[i] && (o[i] = n[i]); t.head.appendChild(o).parentNode.removeChild(o) } function x(e) { return null == e ? e + "" : "object" == typeof e || "function" == typeof e ? l[c.call(e)] || "object" : typeof e } var b = "3.3.1", w = function (e, t) { return new w.fn.init(e, t) }, T = /^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g; w.fn = w.prototype = { jquery: "3.3.1", constructor: w, length: 0, toArray: function () { return o.call(this) }, get: function (e) { return null == e ? o.call(this) : e < 0 ? this[e + this.length] : this[e] }, pushStack: function (e) { var t = w.merge(this.constructor(), e); return t.prevObject = this, t }, each: function (e) { return w.each(this, e) }, map: function (e) { return this.pushStack(w.map(this, function (t, n) { return e.call(t, n, t) })) }, slice: function () { return this.pushStack(o.apply(this, arguments)) }, first: function () { return this.eq(0) }, last: function () { return this.eq(-1) }, eq: function (e) { var t = this.length, n = +e + (e < 0 ? t : 0); return this.pushStack(n >= 0 && n < t ? [this[n]] : []) }, end: function () { return this.prevObject || this.constructor() }, push: s, sort: n.sort, splice: n.splice }, w.extend = w.fn.extend = function () { var e, t, n, r, i, o, a = arguments[0] || {}, s = 1, u = arguments.length, l = !1; for ("boolean" == typeof a && (l = a, a = arguments[s] || {}, s++), "object" == typeof a || g(a) || (a = {}), s === u && (a = this, s--); s < u; s++)if (null != (e = arguments[s])) for (t in e) n = a[t], a !== (r = e[t]) && (l && r && (w.isPlainObject(r) || (i = Array.isArray(r))) ? (i ? (i = !1, o = n && Array.isArray(n) ? n : []) : o = n && w.isPlainObject(n) ? n : {}, a[t] = w.extend(l, o, r)) : void 0 !== r && (a[t] = r)); return a }, w.extend({ expando: "jQuery" + ("3.3.1" + Math.random()).replace(/\D/g, ""), isReady: !0, error: function (e) { throw new Error(e) }, noop: function () { }, isPlainObject: function (e) { var t, n; return !(!e || "[object Object]" !== c.call(e)) && (!(t = i(e)) || "function" == typeof (n = f.call(t, "constructor") && t.constructor) && p.call(n) === d) }, isEmptyObject: function (e) { var t; for (t in e) return !1; return !0 }, globalEval: function (e) { m(e) }, each: function (e, t) { var n, r = 0; if (C(e)) { for (n = e.length; r < n; r++)if (!1 === t.call(e[r], r, e[r])) break } else for (r in e) if (!1 === t.call(e[r], r, e[r])) break; return e }, trim: function (e) { return null == e ? "" : (e + "").replace(T, "") }, makeArray: function (e, t) { var n = t || []; return null != e && (C(Object(e)) ? w.merge(n, "string" == typeof e ? [e] : e) : s.call(n, e)), n }, inArray: function (e, t, n) { return null == t ? -1 : u.call(t, e, n) }, merge: function (e, t) { for (var n = +t.length, r = 0, i = e.length; r < n; r++)e[i++] = t[r]; return e.length = i, e }, grep: function (e, t, n) { for (var r, i = [], o = 0, a = e.length, s = !n; o < a; o++)(r = !t(e[o], o)) !== s && i.push(e[o]); return i }, map: function (e, t, n) { var r, i, o = 0, s = []; if (C(e)) for (r = e.length; o < r; o++)null != (i = t(e[o], o, n)) && s.push(i); else for (o in e) null != (i = t(e[o], o, n)) && s.push(i); return a.apply([], s) }, guid: 1, support: h }), "function" == typeof Symbol && (w.fn[Symbol.iterator] = n[Symbol.iterator]), w.each("Boolean Number String Function Array Date RegExp Object Error Symbol".split(" "), function (e, t) { l["[object " + t + "]"] = t.toLowerCase() }); function C(e) { var t = !!e && "length" in e && e.length, n = x(e); return !g(e) && !y(e) && ("array" === n || 0 === t || "number" == typeof t && t > 0 && t - 1 in e) } var E = function (e) { var t, n, r, i, o, a, s, u, l, c, f, p, d, h, g, y, v, m, x, b = "sizzle" + 1 * new Date, w = e.document, T = 0, C = 0, E = ae(), k = ae(), S = ae(), D = function (e, t) { return e === t && (f = !0), 0 }, N = {}.hasOwnProperty, A = [], j = A.pop, q = A.push, L = A.push, H = A.slice, O = function (e, t) { for (var n = 0, r = e.length; n < r; n++)if (e[n] === t) return n; return -1 }, P = "checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|ismap|loop|multiple|open|readonly|required|scoped", M = "[\\x20\\t\\r\\n\\f]", R = "(?:\\\\.|[\\w-]|[^\0-\\xa0])+", I = "\\[" + M + "*(" + R + ")(?:" + M + "*([*^$|!~]?=)" + M + "*(?:'((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\"|(" + R + "))|)" + M + "*\\]", W = ":(" + R + ")(?:\\((('((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\")|((?:\\\\.|[^\\\\()[\\]]|" + I + ")*)|.*)\\)|)", $ = new RegExp(M + "+", "g"), B = new RegExp("^" + M + "+|((?:^|[^\\\\])(?:\\\\.)*)" + M + "+$", "g"), F = new RegExp("^" + M + "*," + M + "*"), _ = new RegExp("^" + M + "*([>+~]|" + M + ")" + M + "*"), z = new RegExp("=" + M + "*([^\\]'\"]*?)" + M + "*\\]", "g"), X = new RegExp(W), U = new RegExp("^" + R + "$"), V = { ID: new RegExp("^#(" + R + ")"), CLASS: new RegExp("^\\.(" + R + ")"), TAG: new RegExp("^(" + R + "|[*])"), ATTR: new RegExp("^" + I), PSEUDO: new RegExp("^" + W), CHILD: new RegExp("^:(only|first|last|nth|nth-last)-(child|of-type)(?:\\(" + M + "*(even|odd|(([+-]|)(\\d*)n|)" + M + "*(?:([+-]|)" + M + "*(\\d+)|))" + M + "*\\)|)", "i"), bool: new RegExp("^(?:" + P + ")$", "i"), needsContext: new RegExp("^" + M + "*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\\(" + M + "*((?:-\\d)?\\d*)" + M + "*\\)|)(?=[^-]|$)", "i") }, G = /^(?:input|select|textarea|button)$/i, Y = /^h\d$/i, Q = /^[^{]+\{\s*\[native \w/, J = /^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/, K = /[+~]/, Z = new RegExp("\\\\([\\da-f]{1,6}" + M + "?|(" + M + ")|.)", "ig"), ee = function (e, t, n) { var r = "0x" + t - 65536; return r !== r || n ? t : r < 0 ? String.fromCharCode(r + 65536) : String.fromCharCode(r >> 10 | 55296, 1023 & r | 56320) }, te = /([\0-\x1f\x7f]|^-?\d)|^-$|[^\0-\x1f\x7f-\uFFFF\w-]/g, ne = function (e, t) { return t ? "\0" === e ? "\ufffd" : e.slice(0, -1) + "\\" + e.charCodeAt(e.length - 1).toString(16) + " " : "\\" + e }, re = function () { p() }, ie = me(function (e) { return !0 === e.disabled && ("form" in e || "label" in e) }, { dir: "parentNode", next: "legend" }); try { L.apply(A = H.call(w.childNodes), w.childNodes), A[w.childNodes.length].nodeType } catch (e) { L = { apply: A.length ? function (e, t) { q.apply(e, H.call(t)) } : function (e, t) { var n = e.length, r = 0; while (e[n++] = t[r++]); e.length = n - 1 } } } function oe(e, t, r, i) { var o, s, l, c, f, h, v, m = t && t.ownerDocument, T = t ? t.nodeType : 9; if (r = r || [], "string" != typeof e || !e || 1 !== T && 9 !== T && 11 !== T) return r; if (!i && ((t ? t.ownerDocument || t : w) !== d && p(t), t = t || d, g)) { if (11 !== T && (f = J.exec(e))) if (o = f[1]) { if (9 === T) { if (!(l = t.getElementById(o))) return r; if (l.id === o) return r.push(l), r } else if (m && (l = m.getElementById(o)) && x(t, l) && l.id === o) return r.push(l), r } else { if (f[2]) return L.apply(r, t.getElementsByTagName(e)), r; if ((o = f[3]) && n.getElementsByClassName && t.getElementsByClassName) return L.apply(r, t.getElementsByClassName(o)), r } if (n.qsa && !S[e + " "] && (!y || !y.test(e))) { if (1 !== T) m = t, v = e; else if ("object" !== t.nodeName.toLowerCase()) { (c = t.getAttribute("id")) ? c = c.replace(te, ne) : t.setAttribute("id", c = b), s = (h = a(e)).length; while (s--) h[s] = "#" + c + " " + ve(h[s]); v = h.join(","), m = K.test(e) && ge(t.parentNode) || t } if (v) try { return L.apply(r, m.querySelectorAll(v)), r } catch (e) { } finally { c === b && t.removeAttribute("id") } } } return u(e.replace(B, "$1"), t, r, i) } function ae() { var e = []; function t(n, i) { return e.push(n + " ") > r.cacheLength && delete t[e.shift()], t[n + " "] = i } return t } function se(e) { return e[b] = !0, e } function ue(e) { var t = d.createElement("fieldset"); try { return !!e(t) } catch (e) { return !1 } finally { t.parentNode && t.parentNode.removeChild(t), t = null } } function le(e, t) { var n = e.split("|"), i = n.length; while (i--) r.attrHandle[n[i]] = t } function ce(e, t) { var n = t && e, r = n && 1 === e.nodeType && 1 === t.nodeType && e.sourceIndex - t.sourceIndex; if (r) return r; if (n) while (n = n.nextSibling) if (n === t) return -1; return e ? 1 : -1 } function fe(e) { return function (t) { return "input" === t.nodeName.toLowerCase() && t.type === e } } function pe(e) { return function (t) { var n = t.nodeName.toLowerCase(); return ("input" === n || "button" === n) && t.type === e } } function de(e) { return function (t) { return "form" in t ? t.parentNode && !1 === t.disabled ? "label" in t ? "label" in t.parentNode ? t.parentNode.disabled === e : t.disabled === e : t.isDisabled === e || t.isDisabled !== !e && ie(t) === e : t.disabled === e : "label" in t && t.disabled === e } } function he(e) { return se(function (t) { return t = +t, se(function (n, r) { var i, o = e([], n.length, t), a = o.length; while (a--) n[i = o[a]] && (n[i] = !(r[i] = n[i])) }) }) } function ge(e) { return e && "undefined" != typeof e.getElementsByTagName && e } n = oe.support = {}, o = oe.isXML = function (e) { var t = e && (e.ownerDocument || e).documentElement; return !!t && "HTML" !== t.nodeName }, p = oe.setDocument = function (e) { var t, i, a = e ? e.ownerDocument || e : w; return a !== d && 9 === a.nodeType && a.documentElement ? (d = a, h = d.documentElement, g = !o(d), w !== d && (i = d.defaultView) && i.top !== i && (i.addEventListener ? i.addEventListener("unload", re, !1) : i.attachEvent && i.attachEvent("onunload", re)), n.attributes = ue(function (e) { return e.className = "i", !e.getAttribute("className") }), n.getElementsByTagName = ue(function (e) { return e.appendChild(d.createComment("")), !e.getElementsByTagName("*").length }), n.getElementsByClassName = Q.test(d.getElementsByClassName), n.getById = ue(function (e) { return h.appendChild(e).id = b, !d.getElementsByName || !d.getElementsByName(b).length }), n.getById ? (r.filter.ID = function (e) { var t = e.replace(Z, ee); return function (e) { return e.getAttribute("id") === t } }, r.find.ID = function (e, t) { if ("undefined" != typeof t.getElementById && g) { var n = t.getElementById(e); return n ? [n] : [] } }) : (r.filter.ID = function (e) { var t = e.replace(Z, ee); return function (e) { var n = "undefined" != typeof e.getAttributeNode && e.getAttributeNode("id"); return n && n.value === t } }, r.find.ID = function (e, t) { if ("undefined" != typeof t.getElementById && g) { var n, r, i, o = t.getElementById(e); if (o) { if ((n = o.getAttributeNode("id")) && n.value === e) return [o]; i = t.getElementsByName(e), r = 0; while (o = i[r++]) if ((n = o.getAttributeNode("id")) && n.value === e) return [o] } return [] } }), r.find.TAG = n.getElementsByTagName ? function (e, t) { return "undefined" != typeof t.getElementsByTagName ? t.getElementsByTagName(e) : n.qsa ? t.querySelectorAll(e) : void 0 } : function (e, t) { var n, r = [], i = 0, o = t.getElementsByTagName(e); if ("*" === e) { while (n = o[i++]) 1 === n.nodeType && r.push(n); return r } return o }, r.find.CLASS = n.getElementsByClassName && function (e, t) { if ("undefined" != typeof t.getElementsByClassName && g) return t.getElementsByClassName(e) }, v = [], y = [], (n.qsa = Q.test(d.querySelectorAll)) && (ue(function (e) { h.appendChild(e).innerHTML = "", e.querySelectorAll("[msallowcapture^='']").length && y.push("[*^$]=" + M + "*(?:''|\"\")"), e.querySelectorAll("[selected]").length || y.push("\\[" + M + "*(?:value|" + P + ")"), e.querySelectorAll("[id~=" + b + "-]").length || y.push("~="), e.querySelectorAll(":checked").length || y.push(":checked"), e.querySelectorAll("a#" + b + "+*").length || y.push(".#.+[+~]") }), ue(function (e) { e.innerHTML = ""; var t = d.createElement("input"); t.setAttribute("type", "hidden"), e.appendChild(t).setAttribute("name", "D"), e.querySelectorAll("[name=d]").length && y.push("name" + M + "*[*^$|!~]?="), 2 !== e.querySelectorAll(":enabled").length && y.push(":enabled", ":disabled"), h.appendChild(e).disabled = !0, 2 !== e.querySelectorAll(":disabled").length && y.push(":enabled", ":disabled"), e.querySelectorAll("*,:x"), y.push(",.*:") })), (n.matchesSelector = Q.test(m = h.matches || h.webkitMatchesSelector || h.mozMatchesSelector || h.oMatchesSelector || h.msMatchesSelector)) && ue(function (e) { n.disconnectedMatch = m.call(e, "*"), m.call(e, "[s!='']:x"), v.push("!=", W) }), y = y.length && new RegExp(y.join("|")), v = v.length && new RegExp(v.join("|")), t = Q.test(h.compareDocumentPosition), x = t || Q.test(h.contains) ? function (e, t) { var n = 9 === e.nodeType ? e.documentElement : e, r = t && t.parentNode; return e === r || !(!r || 1 !== r.nodeType || !(n.contains ? n.contains(r) : e.compareDocumentPosition && 16 & e.compareDocumentPosition(r))) } : function (e, t) { if (t) while (t = t.parentNode) if (t === e) return !0; return !1 }, D = t ? function (e, t) { if (e === t) return f = !0, 0; var r = !e.compareDocumentPosition - !t.compareDocumentPosition; return r || (1 & (r = (e.ownerDocument || e) === (t.ownerDocument || t) ? e.compareDocumentPosition(t) : 1) || !n.sortDetached && t.compareDocumentPosition(e) === r ? e === d || e.ownerDocument === w && x(w, e) ? -1 : t === d || t.ownerDocument === w && x(w, t) ? 1 : c ? O(c, e) - O(c, t) : 0 : 4 & r ? -1 : 1) } : function (e, t) { if (e === t) return f = !0, 0; var n, r = 0, i = e.parentNode, o = t.parentNode, a = [e], s = [t]; if (!i || !o) return e === d ? -1 : t === d ? 1 : i ? -1 : o ? 1 : c ? O(c, e) - O(c, t) : 0; if (i === o) return ce(e, t); n = e; while (n = n.parentNode) a.unshift(n); n = t; while (n = n.parentNode) s.unshift(n); while (a[r] === s[r]) r++; return r ? ce(a[r], s[r]) : a[r] === w ? -1 : s[r] === w ? 1 : 0 }, d) : d }, oe.matches = function (e, t) { return oe(e, null, null, t) }, oe.matchesSelector = function (e, t) { if ((e.ownerDocument || e) !== d && p(e), t = t.replace(z, "='$1']"), n.matchesSelector && g && !S[t + " "] && (!v || !v.test(t)) && (!y || !y.test(t))) try { var r = m.call(e, t); if (r || n.disconnectedMatch || e.document && 11 !== e.document.nodeType) return r } catch (e) { } return oe(t, d, null, [e]).length > 0 }, oe.contains = function (e, t) { return (e.ownerDocument || e) !== d && p(e), x(e, t) }, oe.attr = function (e, t) { (e.ownerDocument || e) !== d && p(e); var i = r.attrHandle[t.toLowerCase()], o = i && N.call(r.attrHandle, t.toLowerCase()) ? i(e, t, !g) : void 0; return void 0 !== o ? o : n.attributes || !g ? e.getAttribute(t) : (o = e.getAttributeNode(t)) && o.specified ? o.value : null }, oe.escape = function (e) { return (e + "").replace(te, ne) }, oe.error = function (e) { throw new Error("Syntax error, unrecognized expression: " + e) }, oe.uniqueSort = function (e) { var t, r = [], i = 0, o = 0; if (f = !n.detectDuplicates, c = !n.sortStable && e.slice(0), e.sort(D), f) { while (t = e[o++]) t === e[o] && (i = r.push(o)); while (i--) e.splice(r[i], 1) } return c = null, e }, i = oe.getText = function (e) { var t, n = "", r = 0, o = e.nodeType; if (o) { if (1 === o || 9 === o || 11 === o) { if ("string" == typeof e.textContent) return e.textContent; for (e = e.firstChild; e; e = e.nextSibling)n += i(e) } else if (3 === o || 4 === o) return e.nodeValue } else while (t = e[r++]) n += i(t); return n }, (r = oe.selectors = { cacheLength: 50, createPseudo: se, match: V, attrHandle: {}, find: {}, relative: { ">": { dir: "parentNode", first: !0 }, " ": { dir: "parentNode" }, "+": { dir: "previousSibling", first: !0 }, "~": { dir: "previousSibling" } }, preFilter: { ATTR: function (e) { return e[1] = e[1].replace(Z, ee), e[3] = (e[3] || e[4] || e[5] || "").replace(Z, ee), "~=" === e[2] && (e[3] = " " + e[3] + " "), e.slice(0, 4) }, CHILD: function (e) { return e[1] = e[1].toLowerCase(), "nth" === e[1].slice(0, 3) ? (e[3] || oe.error(e[0]), e[4] = +(e[4] ? e[5] + (e[6] || 1) : 2 * ("even" === e[3] || "odd" === e[3])), e[5] = +(e[7] + e[8] || "odd" === e[3])) : e[3] && oe.error(e[0]), e }, PSEUDO: function (e) { var t, n = !e[6] && e[2]; return V.CHILD.test(e[0]) ? null : (e[3] ? e[2] = e[4] || e[5] || "" : n && X.test(n) && (t = a(n, !0)) && (t = n.indexOf(")", n.length - t) - n.length) && (e[0] = e[0].slice(0, t), e[2] = n.slice(0, t)), e.slice(0, 3)) } }, filter: { TAG: function (e) { var t = e.replace(Z, ee).toLowerCase(); return "*" === e ? function () { return !0 } : function (e) { return e.nodeName && e.nodeName.toLowerCase() === t } }, CLASS: function (e) { var t = E[e + " "]; return t || (t = new RegExp("(^|" + M + ")" + e + "(" + M + "|$)")) && E(e, function (e) { return t.test("string" == typeof e.className && e.className || "undefined" != typeof e.getAttribute && e.getAttribute("class") || "") }) }, ATTR: function (e, t, n) { return function (r) { var i = oe.attr(r, e); return null == i ? "!=" === t : !t || (i += "", "=" === t ? i === n : "!=" === t ? i !== n : "^=" === t ? n && 0 === i.indexOf(n) : "*=" === t ? n && i.indexOf(n) > -1 : "$=" === t ? n && i.slice(-n.length) === n : "~=" === t ? (" " + i.replace($, " ") + " ").indexOf(n) > -1 : "|=" === t && (i === n || i.slice(0, n.length + 1) === n + "-")) } }, CHILD: function (e, t, n, r, i) { var o = "nth" !== e.slice(0, 3), a = "last" !== e.slice(-4), s = "of-type" === t; return 1 === r && 0 === i ? function (e) { return !!e.parentNode } : function (t, n, u) { var l, c, f, p, d, h, g = o !== a ? "nextSibling" : "previousSibling", y = t.parentNode, v = s && t.nodeName.toLowerCase(), m = !u && !s, x = !1; if (y) { if (o) { while (g) { p = t; while (p = p[g]) if (s ? p.nodeName.toLowerCase() === v : 1 === p.nodeType) return !1; h = g = "only" === e && !h && "nextSibling" } return !0 } if (h = [a ? y.firstChild : y.lastChild], a && m) { x = (d = (l = (c = (f = (p = y)[b] || (p[b] = {}))[p.uniqueID] || (f[p.uniqueID] = {}))[e] || [])[0] === T && l[1]) && l[2], p = d && y.childNodes[d]; while (p = ++d && p && p[g] || (x = d = 0) || h.pop()) if (1 === p.nodeType && ++x && p === t) { c[e] = [T, d, x]; break } } else if (m && (x = d = (l = (c = (f = (p = t)[b] || (p[b] = {}))[p.uniqueID] || (f[p.uniqueID] = {}))[e] || [])[0] === T && l[1]), !1 === x) while (p = ++d && p && p[g] || (x = d = 0) || h.pop()) if ((s ? p.nodeName.toLowerCase() === v : 1 === p.nodeType) && ++x && (m && ((c = (f = p[b] || (p[b] = {}))[p.uniqueID] || (f[p.uniqueID] = {}))[e] = [T, x]), p === t)) break; return (x -= i) === r || x % r == 0 && x / r >= 0 } } }, PSEUDO: function (e, t) { var n, i = r.pseudos[e] || r.setFilters[e.toLowerCase()] || oe.error("unsupported pseudo: " + e); return i[b] ? i(t) : i.length > 1 ? (n = [e, e, "", t], r.setFilters.hasOwnProperty(e.toLowerCase()) ? se(function (e, n) { var r, o = i(e, t), a = o.length; while (a--) e[r = O(e, o[a])] = !(n[r] = o[a]) }) : function (e) { return i(e, 0, n) }) : i } }, pseudos: { not: se(function (e) { var t = [], n = [], r = s(e.replace(B, "$1")); return r[b] ? se(function (e, t, n, i) { var o, a = r(e, null, i, []), s = e.length; while (s--) (o = a[s]) && (e[s] = !(t[s] = o)) }) : function (e, i, o) { return t[0] = e, r(t, null, o, n), t[0] = null, !n.pop() } }), has: se(function (e) { return function (t) { return oe(e, t).length > 0 } }), contains: se(function (e) { return e = e.replace(Z, ee), function (t) { return (t.textContent || t.innerText || i(t)).indexOf(e) > -1 } }), lang: se(function (e) { return U.test(e || "") || oe.error("unsupported lang: " + e), e = e.replace(Z, ee).toLowerCase(), function (t) { var n; do { if (n = g ? t.lang : t.getAttribute("xml:lang") || t.getAttribute("lang")) return (n = n.toLowerCase()) === e || 0 === n.indexOf(e + "-") } while ((t = t.parentNode) && 1 === t.nodeType); return !1 } }), target: function (t) { var n = e.location && e.location.hash; return n && n.slice(1) === t.id }, root: function (e) { return e === h }, focus: function (e) { return e === d.activeElement && (!d.hasFocus || d.hasFocus()) && !!(e.type || e.href || ~e.tabIndex) }, enabled: de(!1), disabled: de(!0), checked: function (e) { var t = e.nodeName.toLowerCase(); return "input" === t && !!e.checked || "option" === t && !!e.selected }, selected: function (e) { return e.parentNode && e.parentNode.selectedIndex, !0 === e.selected }, empty: function (e) { for (e = e.firstChild; e; e = e.nextSibling)if (e.nodeType < 6) return !1; return !0 }, parent: function (e) { return !r.pseudos.empty(e) }, header: function (e) { return Y.test(e.nodeName) }, input: function (e) { return G.test(e.nodeName) }, button: function (e) { var t = e.nodeName.toLowerCase(); return "input" === t && "button" === e.type || "button" === t }, text: function (e) { var t; return "input" === e.nodeName.toLowerCase() && "text" === e.type && (null == (t = e.getAttribute("type")) || "text" === t.toLowerCase()) }, first: he(function () { return [0] }), last: he(function (e, t) { return [t - 1] }), eq: he(function (e, t, n) { return [n < 0 ? n + t : n] }), even: he(function (e, t) { for (var n = 0; n < t; n += 2)e.push(n); return e }), odd: he(function (e, t) { for (var n = 1; n < t; n += 2)e.push(n); return e }), lt: he(function (e, t, n) { for (var r = n < 0 ? n + t : n; --r >= 0;)e.push(r); return e }), gt: he(function (e, t, n) { for (var r = n < 0 ? n + t : n; ++r < t;)e.push(r); return e }) } }).pseudos.nth = r.pseudos.eq; for (t in { radio: !0, checkbox: !0, file: !0, password: !0, image: !0 }) r.pseudos[t] = fe(t); for (t in { submit: !0, reset: !0 }) r.pseudos[t] = pe(t); function ye() { } ye.prototype = r.filters = r.pseudos, r.setFilters = new ye, a = oe.tokenize = function (e, t) { var n, i, o, a, s, u, l, c = k[e + " "]; if (c) return t ? 0 : c.slice(0); s = e, u = [], l = r.preFilter; while (s) { n && !(i = F.exec(s)) || (i && (s = s.slice(i[0].length) || s), u.push(o = [])), n = !1, (i = _.exec(s)) && (n = i.shift(), o.push({ value: n, type: i[0].replace(B, " ") }), s = s.slice(n.length)); for (a in r.filter) !(i = V[a].exec(s)) || l[a] && !(i = l[a](i)) || (n = i.shift(), o.push({ value: n, type: a, matches: i }), s = s.slice(n.length)); if (!n) break } return t ? s.length : s ? oe.error(e) : k(e, u).slice(0) }; function ve(e) { for (var t = 0, n = e.length, r = ""; t < n; t++)r += e[t].value; return r } function me(e, t, n) { var r = t.dir, i = t.next, o = i || r, a = n && "parentNode" === o, s = C++; return t.first ? function (t, n, i) { while (t = t[r]) if (1 === t.nodeType || a) return e(t, n, i); return !1 } : function (t, n, u) { var l, c, f, p = [T, s]; if (u) { while (t = t[r]) if ((1 === t.nodeType || a) && e(t, n, u)) return !0 } else while (t = t[r]) if (1 === t.nodeType || a) if (f = t[b] || (t[b] = {}), c = f[t.uniqueID] || (f[t.uniqueID] = {}), i && i === t.nodeName.toLowerCase()) t = t[r] || t; else { if ((l = c[o]) && l[0] === T && l[1] === s) return p[2] = l[2]; if (c[o] = p, p[2] = e(t, n, u)) return !0 } return !1 } } function xe(e) { return e.length > 1 ? function (t, n, r) { var i = e.length; while (i--) if (!e[i](t, n, r)) return !1; return !0 } : e[0] } function be(e, t, n) { for (var r = 0, i = t.length; r < i; r++)oe(e, t[r], n); return n } function we(e, t, n, r, i) { for (var o, a = [], s = 0, u = e.length, l = null != t; s < u; s++)(o = e[s]) && (n && !n(o, r, i) || (a.push(o), l && t.push(s))); return a } function Te(e, t, n, r, i, o) { return r && !r[b] && (r = Te(r)), i && !i[b] && (i = Te(i, o)), se(function (o, a, s, u) { var l, c, f, p = [], d = [], h = a.length, g = o || be(t || "*", s.nodeType ? [s] : s, []), y = !e || !o && t ? g : we(g, p, e, s, u), v = n ? i || (o ? e : h || r) ? [] : a : y; if (n && n(y, v, s, u), r) { l = we(v, d), r(l, [], s, u), c = l.length; while (c--) (f = l[c]) && (v[d[c]] = !(y[d[c]] = f)) } if (o) { if (i || e) { if (i) { l = [], c = v.length; while (c--) (f = v[c]) && l.push(y[c] = f); i(null, v = [], l, u) } c = v.length; while (c--) (f = v[c]) && (l = i ? O(o, f) : p[c]) > -1 && (o[l] = !(a[l] = f)) } } else v = we(v === a ? v.splice(h, v.length) : v), i ? i(null, a, v, u) : L.apply(a, v) }) } function Ce(e) { for (var t, n, i, o = e.length, a = r.relative[e[0].type], s = a || r.relative[" "], u = a ? 1 : 0, c = me(function (e) { return e === t }, s, !0), f = me(function (e) { return O(t, e) > -1 }, s, !0), p = [function (e, n, r) { var i = !a && (r || n !== l) || ((t = n).nodeType ? c(e, n, r) : f(e, n, r)); return t = null, i }]; u < o; u++)if (n = r.relative[e[u].type]) p = [me(xe(p), n)]; else { if ((n = r.filter[e[u].type].apply(null, e[u].matches))[b]) { for (i = ++u; i < o; i++)if (r.relative[e[i].type]) break; return Te(u > 1 && xe(p), u > 1 && ve(e.slice(0, u - 1).concat({ value: " " === e[u - 2].type ? "*" : "" })).replace(B, "$1"), n, u < i && Ce(e.slice(u, i)), i < o && Ce(e = e.slice(i)), i < o && ve(e)) } p.push(n) } return xe(p) } function Ee(e, t) { var n = t.length > 0, i = e.length > 0, o = function (o, a, s, u, c) { var f, h, y, v = 0, m = "0", x = o && [], b = [], w = l, C = o || i && r.find.TAG("*", c), E = T += null == w ? 1 : Math.random() || .1, k = C.length; for (c && (l = a === d || a || c); m !== k && null != (f = C[m]); m++) { if (i && f) { h = 0, a || f.ownerDocument === d || (p(f), s = !g); while (y = e[h++]) if (y(f, a || d, s)) { u.push(f); break } c && (T = E) } n && ((f = !y && f) && v-- , o && x.push(f)) } if (v += m, n && m !== v) { h = 0; while (y = t[h++]) y(x, b, a, s); if (o) { if (v > 0) while (m--) x[m] || b[m] || (b[m] = j.call(u)); b = we(b) } L.apply(u, b), c && !o && b.length > 0 && v + t.length > 1 && oe.uniqueSort(u) } return c && (T = E, l = w), x }; return n ? se(o) : o } return s = oe.compile = function (e, t) { var n, r = [], i = [], o = S[e + " "]; if (!o) { t || (t = a(e)), n = t.length; while (n--) (o = Ce(t[n]))[b] ? r.push(o) : i.push(o); (o = S(e, Ee(i, r))).selector = e } return o }, u = oe.select = function (e, t, n, i) { var o, u, l, c, f, p = "function" == typeof e && e, d = !i && a(e = p.selector || e); if (n = n || [], 1 === d.length) { if ((u = d[0] = d[0].slice(0)).length > 2 && "ID" === (l = u[0]).type && 9 === t.nodeType && g && r.relative[u[1].type]) { if (!(t = (r.find.ID(l.matches[0].replace(Z, ee), t) || [])[0])) return n; p && (t = t.parentNode), e = e.slice(u.shift().value.length) } o = V.needsContext.test(e) ? 0 : u.length; while (o--) { if (l = u[o], r.relative[c = l.type]) break; if ((f = r.find[c]) && (i = f(l.matches[0].replace(Z, ee), K.test(u[0].type) && ge(t.parentNode) || t))) { if (u.splice(o, 1), !(e = i.length && ve(u))) return L.apply(n, i), n; break } } } return (p || s(e, d))(i, t, !g, n, !t || K.test(e) && ge(t.parentNode) || t), n }, n.sortStable = b.split("").sort(D).join("") === b, n.detectDuplicates = !!f, p(), n.sortDetached = ue(function (e) { return 1 & e.compareDocumentPosition(d.createElement("fieldset")) }), ue(function (e) { return e.innerHTML = "", "#" === e.firstChild.getAttribute("href") }) || le("type|href|height|width", function (e, t, n) { if (!n) return e.getAttribute(t, "type" === t.toLowerCase() ? 1 : 2) }), n.attributes && ue(function (e) { return e.innerHTML = "", e.firstChild.setAttribute("value", ""), "" === e.firstChild.getAttribute("value") }) || le("value", function (e, t, n) { if (!n && "input" === e.nodeName.toLowerCase()) return e.defaultValue }), ue(function (e) { return null == e.getAttribute("disabled") }) || le(P, function (e, t, n) { var r; if (!n) return !0 === e[t] ? t.toLowerCase() : (r = e.getAttributeNode(t)) && r.specified ? r.value : null }), oe }(e); w.find = E, w.expr = E.selectors, w.expr[":"] = w.expr.pseudos, w.uniqueSort = w.unique = E.uniqueSort, w.text = E.getText, w.isXMLDoc = E.isXML, w.contains = E.contains, w.escapeSelector = E.escape; var k = function (e, t, n) { var r = [], i = void 0 !== n; while ((e = e[t]) && 9 !== e.nodeType) if (1 === e.nodeType) { if (i && w(e).is(n)) break; r.push(e) } return r }, S = function (e, t) { for (var n = []; e; e = e.nextSibling)1 === e.nodeType && e !== t && n.push(e); return n }, D = w.expr.match.needsContext; function N(e, t) { return e.nodeName && e.nodeName.toLowerCase() === t.toLowerCase() } var A = /^<([a-z][^\/\0>:\x20\t\r\n\f]*)[\x20\t\r\n\f]*\/?>(?:<\/\1>|)$/i; function j(e, t, n) { return g(t) ? w.grep(e, function (e, r) { return !!t.call(e, r, e) !== n }) : t.nodeType ? w.grep(e, function (e) { return e === t !== n }) : "string" != typeof t ? w.grep(e, function (e) { return u.call(t, e) > -1 !== n }) : w.filter(t, e, n) } w.filter = function (e, t, n) { var r = t[0]; return n && (e = ":not(" + e + ")"), 1 === t.length && 1 === r.nodeType ? w.find.matchesSelector(r, e) ? [r] : [] : w.find.matches(e, w.grep(t, function (e) { return 1 === e.nodeType })) }, w.fn.extend({ find: function (e) { var t, n, r = this.length, i = this; if ("string" != typeof e) return this.pushStack(w(e).filter(function () { for (t = 0; t < r; t++)if (w.contains(i[t], this)) return !0 })); for (n = this.pushStack([]), t = 0; t < r; t++)w.find(e, i[t], n); return r > 1 ? w.uniqueSort(n) : n }, filter: function (e) { return this.pushStack(j(this, e || [], !1)) }, not: function (e) { return this.pushStack(j(this, e || [], !0)) }, is: function (e) { return !!j(this, "string" == typeof e && D.test(e) ? w(e) : e || [], !1).length } }); var q, L = /^(?:\s*(<[\w\W]+>)[^>]*|#([\w-]+))$/; (w.fn.init = function (e, t, n) { var i, o; if (!e) return this; if (n = n || q, "string" == typeof e) { if (!(i = "<" === e[0] && ">" === e[e.length - 1] && e.length >= 3 ? [null, e, null] : L.exec(e)) || !i[1] && t) return !t || t.jquery ? (t || n).find(e) : this.constructor(t).find(e); if (i[1]) { if (t = t instanceof w ? t[0] : t, w.merge(this, w.parseHTML(i[1], t && t.nodeType ? t.ownerDocument || t : r, !0)), A.test(i[1]) && w.isPlainObject(t)) for (i in t) g(this[i]) ? this[i](t[i]) : this.attr(i, t[i]); return this } return (o = r.getElementById(i[2])) && (this[0] = o, this.length = 1), this } return e.nodeType ? (this[0] = e, this.length = 1, this) : g(e) ? void 0 !== n.ready ? n.ready(e) : e(w) : w.makeArray(e, this) }).prototype = w.fn, q = w(r); var H = /^(?:parents|prev(?:Until|All))/, O = { children: !0, contents: !0, next: !0, prev: !0 }; w.fn.extend({ has: function (e) { var t = w(e, this), n = t.length; return this.filter(function () { for (var e = 0; e < n; e++)if (w.contains(this, t[e])) return !0 }) }, closest: function (e, t) { var n, r = 0, i = this.length, o = [], a = "string" != typeof e && w(e); if (!D.test(e)) for (; r < i; r++)for (n = this[r]; n && n !== t; n = n.parentNode)if (n.nodeType < 11 && (a ? a.index(n) > -1 : 1 === n.nodeType && w.find.matchesSelector(n, e))) { o.push(n); break } return this.pushStack(o.length > 1 ? w.uniqueSort(o) : o) }, index: function (e) { return e ? "string" == typeof e ? u.call(w(e), this[0]) : u.call(this, e.jquery ? e[0] : e) : this[0] && this[0].parentNode ? this.first().prevAll().length : -1 }, add: function (e, t) { return this.pushStack(w.uniqueSort(w.merge(this.get(), w(e, t)))) }, addBack: function (e) { return this.add(null == e ? this.prevObject : this.prevObject.filter(e)) } }); function P(e, t) { while ((e = e[t]) && 1 !== e.nodeType); return e } w.each({ parent: function (e) { var t = e.parentNode; return t && 11 !== t.nodeType ? t : null }, parents: function (e) { return k(e, "parentNode") }, parentsUntil: function (e, t, n) { return k(e, "parentNode", n) }, next: function (e) { return P(e, "nextSibling") }, prev: function (e) { return P(e, "previousSibling") }, nextAll: function (e) { return k(e, "nextSibling") }, prevAll: function (e) { return k(e, "previousSibling") }, nextUntil: function (e, t, n) { return k(e, "nextSibling", n) }, prevUntil: function (e, t, n) { return k(e, "previousSibling", n) }, siblings: function (e) { return S((e.parentNode || {}).firstChild, e) }, children: function (e) { return S(e.firstChild) }, contents: function (e) { return N(e, "iframe") ? e.contentDocument : (N(e, "template") && (e = e.content || e), w.merge([], e.childNodes)) } }, function (e, t) { w.fn[e] = function (n, r) { var i = w.map(this, t, n); return "Until" !== e.slice(-5) && (r = n), r && "string" == typeof r && (i = w.filter(r, i)), this.length > 1 && (O[e] || w.uniqueSort(i), H.test(e) && i.reverse()), this.pushStack(i) } }); var M = /[^\x20\t\r\n\f]+/g; function R(e) { var t = {}; return w.each(e.match(M) || [], function (e, n) { t[n] = !0 }), t } w.Callbacks = function (e) { e = "string" == typeof e ? R(e) : w.extend({}, e); var t, n, r, i, o = [], a = [], s = -1, u = function () { for (i = i || e.once, r = t = !0; a.length; s = -1) { n = a.shift(); while (++s < o.length) !1 === o[s].apply(n[0], n[1]) && e.stopOnFalse && (s = o.length, n = !1) } e.memory || (n = !1), t = !1, i && (o = n ? [] : "") }, l = { add: function () { return o && (n && !t && (s = o.length - 1, a.push(n)), function t(n) { w.each(n, function (n, r) { g(r) ? e.unique && l.has(r) || o.push(r) : r && r.length && "string" !== x(r) && t(r) }) }(arguments), n && !t && u()), this }, remove: function () { return w.each(arguments, function (e, t) { var n; while ((n = w.inArray(t, o, n)) > -1) o.splice(n, 1), n <= s && s-- }), this }, has: function (e) { return e ? w.inArray(e, o) > -1 : o.length > 0 }, empty: function () { return o && (o = []), this }, disable: function () { return i = a = [], o = n = "", this }, disabled: function () { return !o }, lock: function () { return i = a = [], n || t || (o = n = ""), this }, locked: function () { return !!i }, fireWith: function (e, n) { return i || (n = [e, (n = n || []).slice ? n.slice() : n], a.push(n), t || u()), this }, fire: function () { return l.fireWith(this, arguments), this }, fired: function () { return !!r } }; return l }; function I(e) { return e } function W(e) { throw e } function $(e, t, n, r) { var i; try { e && g(i = e.promise) ? i.call(e).done(t).fail(n) : e && g(i = e.then) ? i.call(e, t, n) : t.apply(void 0, [e].slice(r)) } catch (e) { n.apply(void 0, [e]) } } w.extend({ Deferred: function (t) { var n = [["notify", "progress", w.Callbacks("memory"), w.Callbacks("memory"), 2], ["resolve", "done", w.Callbacks("once memory"), w.Callbacks("once memory"), 0, "resolved"], ["reject", "fail", w.Callbacks("once memory"), w.Callbacks("once memory"), 1, "rejected"]], r = "pending", i = { state: function () { return r }, always: function () { return o.done(arguments).fail(arguments), this }, "catch": function (e) { return i.then(null, e) }, pipe: function () { var e = arguments; return w.Deferred(function (t) { w.each(n, function (n, r) { var i = g(e[r[4]]) && e[r[4]]; o[r[1]](function () { var e = i && i.apply(this, arguments); e && g(e.promise) ? e.promise().progress(t.notify).done(t.resolve).fail(t.reject) : t[r[0] + "With"](this, i ? [e] : arguments) }) }), e = null }).promise() }, then: function (t, r, i) { var o = 0; function a(t, n, r, i) { return function () { var s = this, u = arguments, l = function () { var e, l; if (!(t < o)) { if ((e = r.apply(s, u)) === n.promise()) throw new TypeError("Thenable self-resolution"); l = e && ("object" == typeof e || "function" == typeof e) && e.then, g(l) ? i ? l.call(e, a(o, n, I, i), a(o, n, W, i)) : (o++ , l.call(e, a(o, n, I, i), a(o, n, W, i), a(o, n, I, n.notifyWith))) : (r !== I && (s = void 0, u = [e]), (i || n.resolveWith)(s, u)) } }, c = i ? l : function () { try { l() } catch (e) { w.Deferred.exceptionHook && w.Deferred.exceptionHook(e, c.stackTrace), t + 1 >= o && (r !== W && (s = void 0, u = [e]), n.rejectWith(s, u)) } }; t ? c() : (w.Deferred.getStackHook && (c.stackTrace = w.Deferred.getStackHook()), e.setTimeout(c)) } } return w.Deferred(function (e) { n[0][3].add(a(0, e, g(i) ? i : I, e.notifyWith)), n[1][3].add(a(0, e, g(t) ? t : I)), n[2][3].add(a(0, e, g(r) ? r : W)) }).promise() }, promise: function (e) { return null != e ? w.extend(e, i) : i } }, o = {}; return w.each(n, function (e, t) { var a = t[2], s = t[5]; i[t[1]] = a.add, s && a.add(function () { r = s }, n[3 - e][2].disable, n[3 - e][3].disable, n[0][2].lock, n[0][3].lock), a.add(t[3].fire), o[t[0]] = function () { return o[t[0] + "With"](this === o ? void 0 : this, arguments), this }, o[t[0] + "With"] = a.fireWith }), i.promise(o), t && t.call(o, o), o }, when: function (e) { var t = arguments.length, n = t, r = Array(n), i = o.call(arguments), a = w.Deferred(), s = function (e) { return function (n) { r[e] = this, i[e] = arguments.length > 1 ? o.call(arguments) : n, --t || a.resolveWith(r, i) } }; if (t <= 1 && ($(e, a.done(s(n)).resolve, a.reject, !t), "pending" === a.state() || g(i[n] && i[n].then))) return a.then(); while (n--) $(i[n], s(n), a.reject); return a.promise() } }); var B = /^(Eval|Internal|Range|Reference|Syntax|Type|URI)Error$/; w.Deferred.exceptionHook = function (t, n) { e.console && e.console.warn && t && B.test(t.name) && e.console.warn("jQuery.Deferred exception: " + t.message, t.stack, n) }, w.readyException = function (t) { e.setTimeout(function () { throw t }) }; var F = w.Deferred(); w.fn.ready = function (e) { return F.then(e)["catch"](function (e) { w.readyException(e) }), this }, w.extend({ isReady: !1, readyWait: 1, ready: function (e) { (!0 === e ? --w.readyWait : w.isReady) || (w.isReady = !0, !0 !== e && --w.readyWait > 0 || F.resolveWith(r, [w])) } }), w.ready.then = F.then; function _() { r.removeEventListener("DOMContentLoaded", _), e.removeEventListener("load", _), w.ready() } "complete" === r.readyState || "loading" !== r.readyState && !r.documentElement.doScroll ? e.setTimeout(w.ready) : (r.addEventListener("DOMContentLoaded", _), e.addEventListener("load", _)); var z = function (e, t, n, r, i, o, a) { var s = 0, u = e.length, l = null == n; if ("object" === x(n)) { i = !0; for (s in n) z(e, t, s, n[s], !0, o, a) } else if (void 0 !== r && (i = !0, g(r) || (a = !0), l && (a ? (t.call(e, r), t = null) : (l = t, t = function (e, t, n) { return l.call(w(e), n) })), t)) for (; s < u; s++)t(e[s], n, a ? r : r.call(e[s], s, t(e[s], n))); return i ? e : l ? t.call(e) : u ? t(e[0], n) : o }, X = /^-ms-/, U = /-([a-z])/g; function V(e, t) { return t.toUpperCase() } function G(e) { return e.replace(X, "ms-").replace(U, V) } var Y = function (e) { return 1 === e.nodeType || 9 === e.nodeType || !+e.nodeType }; function Q() { this.expando = w.expando + Q.uid++ } Q.uid = 1, Q.prototype = { cache: function (e) { var t = e[this.expando]; return t || (t = {}, Y(e) && (e.nodeType ? e[this.expando] = t : Object.defineProperty(e, this.expando, { value: t, configurable: !0 }))), t }, set: function (e, t, n) { var r, i = this.cache(e); if ("string" == typeof t) i[G(t)] = n; else for (r in t) i[G(r)] = t[r]; return i }, get: function (e, t) { return void 0 === t ? this.cache(e) : e[this.expando] && e[this.expando][G(t)] }, access: function (e, t, n) { return void 0 === t || t && "string" == typeof t && void 0 === n ? this.get(e, t) : (this.set(e, t, n), void 0 !== n ? n : t) }, remove: function (e, t) { var n, r = e[this.expando]; if (void 0 !== r) { if (void 0 !== t) { n = (t = Array.isArray(t) ? t.map(G) : (t = G(t)) in r ? [t] : t.match(M) || []).length; while (n--) delete r[t[n]] } (void 0 === t || w.isEmptyObject(r)) && (e.nodeType ? e[this.expando] = void 0 : delete e[this.expando]) } }, hasData: function (e) { var t = e[this.expando]; return void 0 !== t && !w.isEmptyObject(t) } }; var J = new Q, K = new Q, Z = /^(?:\{[\w\W]*\}|\[[\w\W]*\])$/, ee = /[A-Z]/g; function te(e) { return "true" === e || "false" !== e && ("null" === e ? null : e === +e + "" ? +e : Z.test(e) ? JSON.parse(e) : e) } function ne(e, t, n) { var r; if (void 0 === n && 1 === e.nodeType) if (r = "data-" + t.replace(ee, "-$&").toLowerCase(), "string" == typeof (n = e.getAttribute(r))) { try { n = te(n) } catch (e) { } K.set(e, t, n) } else n = void 0; return n } w.extend({ hasData: function (e) { return K.hasData(e) || J.hasData(e) }, data: function (e, t, n) { return K.access(e, t, n) }, removeData: function (e, t) { K.remove(e, t) }, _data: function (e, t, n) { return J.access(e, t, n) }, _removeData: function (e, t) { J.remove(e, t) } }), w.fn.extend({ data: function (e, t) { var n, r, i, o = this[0], a = o && o.attributes; if (void 0 === e) { if (this.length && (i = K.get(o), 1 === o.nodeType && !J.get(o, "hasDataAttrs"))) { n = a.length; while (n--) a[n] && 0 === (r = a[n].name).indexOf("data-") && (r = G(r.slice(5)), ne(o, r, i[r])); J.set(o, "hasDataAttrs", !0) } return i } return "object" == typeof e ? this.each(function () { K.set(this, e) }) : z(this, function (t) { var n; if (o && void 0 === t) { if (void 0 !== (n = K.get(o, e))) return n; if (void 0 !== (n = ne(o, e))) return n } else this.each(function () { K.set(this, e, t) }) }, null, t, arguments.length > 1, null, !0) }, removeData: function (e) { return this.each(function () { K.remove(this, e) }) } }), w.extend({ queue: function (e, t, n) { var r; if (e) return t = (t || "fx") + "queue", r = J.get(e, t), n && (!r || Array.isArray(n) ? r = J.access(e, t, w.makeArray(n)) : r.push(n)), r || [] }, dequeue: function (e, t) { t = t || "fx"; var n = w.queue(e, t), r = n.length, i = n.shift(), o = w._queueHooks(e, t), a = function () { w.dequeue(e, t) }; "inprogress" === i && (i = n.shift(), r--), i && ("fx" === t && n.unshift("inprogress"), delete o.stop, i.call(e, a, o)), !r && o && o.empty.fire() }, _queueHooks: function (e, t) { var n = t + "queueHooks"; return J.get(e, n) || J.access(e, n, { empty: w.Callbacks("once memory").add(function () { J.remove(e, [t + "queue", n]) }) }) } }), w.fn.extend({ queue: function (e, t) { var n = 2; return "string" != typeof e && (t = e, e = "fx", n--), arguments.length < n ? w.queue(this[0], e) : void 0 === t ? this : this.each(function () { var n = w.queue(this, e, t); w._queueHooks(this, e), "fx" === e && "inprogress" !== n[0] && w.dequeue(this, e) }) }, dequeue: function (e) { return this.each(function () { w.dequeue(this, e) }) }, clearQueue: function (e) { return this.queue(e || "fx", []) }, promise: function (e, t) { var n, r = 1, i = w.Deferred(), o = this, a = this.length, s = function () { --r || i.resolveWith(o, [o]) }; "string" != typeof e && (t = e, e = void 0), e = e || "fx"; while (a--) (n = J.get(o[a], e + "queueHooks")) && n.empty && (r++ , n.empty.add(s)); return s(), i.promise(t) } }); var re = /[+-]?(?:\d*\.|)\d+(?:[eE][+-]?\d+|)/.source, ie = new RegExp("^(?:([+-])=|)(" + re + ")([a-z%]*)$", "i"), oe = ["Top", "Right", "Bottom", "Left"], ae = function (e, t) { return "none" === (e = t || e).style.display || "" === e.style.display && w.contains(e.ownerDocument, e) && "none" === w.css(e, "display") }, se = function (e, t, n, r) { var i, o, a = {}; for (o in t) a[o] = e.style[o], e.style[o] = t[o]; i = n.apply(e, r || []); for (o in t) e.style[o] = a[o]; return i }; function ue(e, t, n, r) { var i, o, a = 20, s = r ? function () { return r.cur() } : function () { return w.css(e, t, "") }, u = s(), l = n && n[3] || (w.cssNumber[t] ? "" : "px"), c = (w.cssNumber[t] || "px" !== l && +u) && ie.exec(w.css(e, t)); if (c && c[3] !== l) { u /= 2, l = l || c[3], c = +u || 1; while (a--) w.style(e, t, c + l), (1 - o) * (1 - (o = s() / u || .5)) <= 0 && (a = 0), c /= o; c *= 2, w.style(e, t, c + l), n = n || [] } return n && (c = +c || +u || 0, i = n[1] ? c + (n[1] + 1) * n[2] : +n[2], r && (r.unit = l, r.start = c, r.end = i)), i } var le = {}; function ce(e) { var t, n = e.ownerDocument, r = e.nodeName, i = le[r]; return i || (t = n.body.appendChild(n.createElement(r)), i = w.css(t, "display"), t.parentNode.removeChild(t), "none" === i && (i = "block"), le[r] = i, i) } function fe(e, t) { for (var n, r, i = [], o = 0, a = e.length; o < a; o++)(r = e[o]).style && (n = r.style.display, t ? ("none" === n && (i[o] = J.get(r, "display") || null, i[o] || (r.style.display = "")), "" === r.style.display && ae(r) && (i[o] = ce(r))) : "none" !== n && (i[o] = "none", J.set(r, "display", n))); for (o = 0; o < a; o++)null != i[o] && (e[o].style.display = i[o]); return e } w.fn.extend({ show: function () { return fe(this, !0) }, hide: function () { return fe(this) }, toggle: function (e) { return "boolean" == typeof e ? e ? this.show() : this.hide() : this.each(function () { ae(this) ? w(this).show() : w(this).hide() }) } }); var pe = /^(?:checkbox|radio)$/i, de = /<([a-z][^\/\0>\x20\t\r\n\f]+)/i, he = /^$|^module$|\/(?:java|ecma)script/i, ge = { option: [1, ""], thead: [1, "", "
"], col: [2, "", "
"], tr: [2, "", "
"], td: [3, "", "
"], _default: [0, "", ""] }; ge.optgroup = ge.option, ge.tbody = ge.tfoot = ge.colgroup = ge.caption = ge.thead, ge.th = ge.td; function ye(e, t) { var n; return n = "undefined" != typeof e.getElementsByTagName ? e.getElementsByTagName(t || "*") : "undefined" != typeof e.querySelectorAll ? e.querySelectorAll(t || "*") : [], void 0 === t || t && N(e, t) ? w.merge([e], n) : n } function ve(e, t) { for (var n = 0, r = e.length; n < r; n++)J.set(e[n], "globalEval", !t || J.get(t[n], "globalEval")) } var me = /<|&#?\w+;/; function xe(e, t, n, r, i) { for (var o, a, s, u, l, c, f = t.createDocumentFragment(), p = [], d = 0, h = e.length; d < h; d++)if ((o = e[d]) || 0 === o) if ("object" === x(o)) w.merge(p, o.nodeType ? [o] : o); else if (me.test(o)) { a = a || f.appendChild(t.createElement("div")), s = (de.exec(o) || ["", ""])[1].toLowerCase(), u = ge[s] || ge._default, a.innerHTML = u[1] + w.htmlPrefilter(o) + u[2], c = u[0]; while (c--) a = a.lastChild; w.merge(p, a.childNodes), (a = f.firstChild).textContent = "" } else p.push(t.createTextNode(o)); f.textContent = "", d = 0; while (o = p[d++]) if (r && w.inArray(o, r) > -1) i && i.push(o); else if (l = w.contains(o.ownerDocument, o), a = ye(f.appendChild(o), "script"), l && ve(a), n) { c = 0; while (o = a[c++]) he.test(o.type || "") && n.push(o) } return f } !function () { var e = r.createDocumentFragment().appendChild(r.createElement("div")), t = r.createElement("input"); t.setAttribute("type", "radio"), t.setAttribute("checked", "checked"), t.setAttribute("name", "t"), e.appendChild(t), h.checkClone = e.cloneNode(!0).cloneNode(!0).lastChild.checked, e.innerHTML = "", h.noCloneChecked = !!e.cloneNode(!0).lastChild.defaultValue }(); var be = r.documentElement, we = /^key/, Te = /^(?:mouse|pointer|contextmenu|drag|drop)|click/, Ce = /^([^.]*)(?:\.(.+)|)/; function Ee() { return !0 } function ke() { return !1 } function Se() { try { return r.activeElement } catch (e) { } } function De(e, t, n, r, i, o) { var a, s; if ("object" == typeof t) { "string" != typeof n && (r = r || n, n = void 0); for (s in t) De(e, s, n, r, t[s], o); return e } if (null == r && null == i ? (i = n, r = n = void 0) : null == i && ("string" == typeof n ? (i = r, r = void 0) : (i = r, r = n, n = void 0)), !1 === i) i = ke; else if (!i) return e; return 1 === o && (a = i, (i = function (e) { return w().off(e), a.apply(this, arguments) }).guid = a.guid || (a.guid = w.guid++)), e.each(function () { w.event.add(this, t, i, r, n) }) } w.event = { global: {}, add: function (e, t, n, r, i) { var o, a, s, u, l, c, f, p, d, h, g, y = J.get(e); if (y) { n.handler && (n = (o = n).handler, i = o.selector), i && w.find.matchesSelector(be, i), n.guid || (n.guid = w.guid++), (u = y.events) || (u = y.events = {}), (a = y.handle) || (a = y.handle = function (t) { return "undefined" != typeof w && w.event.triggered !== t.type ? w.event.dispatch.apply(e, arguments) : void 0 }), l = (t = (t || "").match(M) || [""]).length; while (l--) d = g = (s = Ce.exec(t[l]) || [])[1], h = (s[2] || "").split(".").sort(), d && (f = w.event.special[d] || {}, d = (i ? f.delegateType : f.bindType) || d, f = w.event.special[d] || {}, c = w.extend({ type: d, origType: g, data: r, handler: n, guid: n.guid, selector: i, needsContext: i && w.expr.match.needsContext.test(i), namespace: h.join(".") }, o), (p = u[d]) || ((p = u[d] = []).delegateCount = 0, f.setup && !1 !== f.setup.call(e, r, h, a) || e.addEventListener && e.addEventListener(d, a)), f.add && (f.add.call(e, c), c.handler.guid || (c.handler.guid = n.guid)), i ? p.splice(p.delegateCount++, 0, c) : p.push(c), w.event.global[d] = !0) } }, remove: function (e, t, n, r, i) { var o, a, s, u, l, c, f, p, d, h, g, y = J.hasData(e) && J.get(e); if (y && (u = y.events)) { l = (t = (t || "").match(M) || [""]).length; while (l--) if (s = Ce.exec(t[l]) || [], d = g = s[1], h = (s[2] || "").split(".").sort(), d) { f = w.event.special[d] || {}, p = u[d = (r ? f.delegateType : f.bindType) || d] || [], s = s[2] && new RegExp("(^|\\.)" + h.join("\\.(?:.*\\.|)") + "(\\.|$)"), a = o = p.length; while (o--) c = p[o], !i && g !== c.origType || n && n.guid !== c.guid || s && !s.test(c.namespace) || r && r !== c.selector && ("**" !== r || !c.selector) || (p.splice(o, 1), c.selector && p.delegateCount-- , f.remove && f.remove.call(e, c)); a && !p.length && (f.teardown && !1 !== f.teardown.call(e, h, y.handle) || w.removeEvent(e, d, y.handle), delete u[d]) } else for (d in u) w.event.remove(e, d + t[l], n, r, !0); w.isEmptyObject(u) && J.remove(e, "handle events") } }, dispatch: function (e) { var t = w.event.fix(e), n, r, i, o, a, s, u = new Array(arguments.length), l = (J.get(this, "events") || {})[t.type] || [], c = w.event.special[t.type] || {}; for (u[0] = t, n = 1; n < arguments.length; n++)u[n] = arguments[n]; if (t.delegateTarget = this, !c.preDispatch || !1 !== c.preDispatch.call(this, t)) { s = w.event.handlers.call(this, t, l), n = 0; while ((o = s[n++]) && !t.isPropagationStopped()) { t.currentTarget = o.elem, r = 0; while ((a = o.handlers[r++]) && !t.isImmediatePropagationStopped()) t.rnamespace && !t.rnamespace.test(a.namespace) || (t.handleObj = a, t.data = a.data, void 0 !== (i = ((w.event.special[a.origType] || {}).handle || a.handler).apply(o.elem, u)) && !1 === (t.result = i) && (t.preventDefault(), t.stopPropagation())) } return c.postDispatch && c.postDispatch.call(this, t), t.result } }, handlers: function (e, t) { var n, r, i, o, a, s = [], u = t.delegateCount, l = e.target; if (u && l.nodeType && !("click" === e.type && e.button >= 1)) for (; l !== this; l = l.parentNode || this)if (1 === l.nodeType && ("click" !== e.type || !0 !== l.disabled)) { for (o = [], a = {}, n = 0; n < u; n++)void 0 === a[i = (r = t[n]).selector + " "] && (a[i] = r.needsContext ? w(i, this).index(l) > -1 : w.find(i, this, null, [l]).length), a[i] && o.push(r); o.length && s.push({ elem: l, handlers: o }) } return l = this, u < t.length && s.push({ elem: l, handlers: t.slice(u) }), s }, addProp: function (e, t) { Object.defineProperty(w.Event.prototype, e, { enumerable: !0, configurable: !0, get: g(t) ? function () { if (this.originalEvent) return t(this.originalEvent) } : function () { if (this.originalEvent) return this.originalEvent[e] }, set: function (t) { Object.defineProperty(this, e, { enumerable: !0, configurable: !0, writable: !0, value: t }) } }) }, fix: function (e) { return e[w.expando] ? e : new w.Event(e) }, special: { load: { noBubble: !0 }, focus: { trigger: function () { if (this !== Se() && this.focus) return this.focus(), !1 }, delegateType: "focusin" }, blur: { trigger: function () { if (this === Se() && this.blur) return this.blur(), !1 }, delegateType: "focusout" }, click: { trigger: function () { if ("checkbox" === this.type && this.click && N(this, "input")) return this.click(), !1 }, _default: function (e) { return N(e.target, "a") } }, beforeunload: { postDispatch: function (e) { void 0 !== e.result && e.originalEvent && (e.originalEvent.returnValue = e.result) } } } }, w.removeEvent = function (e, t, n) { e.removeEventListener && e.removeEventListener(t, n) }, w.Event = function (e, t) { if (!(this instanceof w.Event)) return new w.Event(e, t); e && e.type ? (this.originalEvent = e, this.type = e.type, this.isDefaultPrevented = e.defaultPrevented || void 0 === e.defaultPrevented && !1 === e.returnValue ? Ee : ke, this.target = e.target && 3 === e.target.nodeType ? e.target.parentNode : e.target, this.currentTarget = e.currentTarget, this.relatedTarget = e.relatedTarget) : this.type = e, t && w.extend(this, t), this.timeStamp = e && e.timeStamp || Date.now(), this[w.expando] = !0 }, w.Event.prototype = { constructor: w.Event, isDefaultPrevented: ke, isPropagationStopped: ke, isImmediatePropagationStopped: ke, isSimulated: !1, preventDefault: function () { var e = this.originalEvent; this.isDefaultPrevented = Ee, e && !this.isSimulated && e.preventDefault() }, stopPropagation: function () { var e = this.originalEvent; this.isPropagationStopped = Ee, e && !this.isSimulated && e.stopPropagation() }, stopImmediatePropagation: function () { var e = this.originalEvent; this.isImmediatePropagationStopped = Ee, e && !this.isSimulated && e.stopImmediatePropagation(), this.stopPropagation() } }, w.each({ altKey: !0, bubbles: !0, cancelable: !0, changedTouches: !0, ctrlKey: !0, detail: !0, eventPhase: !0, metaKey: !0, pageX: !0, pageY: !0, shiftKey: !0, view: !0, "char": !0, charCode: !0, key: !0, keyCode: !0, button: !0, buttons: !0, clientX: !0, clientY: !0, offsetX: !0, offsetY: !0, pointerId: !0, pointerType: !0, screenX: !0, screenY: !0, targetTouches: !0, toElement: !0, touches: !0, which: function (e) { var t = e.button; return null == e.which && we.test(e.type) ? null != e.charCode ? e.charCode : e.keyCode : !e.which && void 0 !== t && Te.test(e.type) ? 1 & t ? 1 : 2 & t ? 3 : 4 & t ? 2 : 0 : e.which } }, w.event.addProp), w.each({ mouseenter: "mouseover", mouseleave: "mouseout", pointerenter: "pointerover", pointerleave: "pointerout" }, function (e, t) { w.event.special[e] = { delegateType: t, bindType: t, handle: function (e) { var n, r = this, i = e.relatedTarget, o = e.handleObj; return i && (i === r || w.contains(r, i)) || (e.type = o.origType, n = o.handler.apply(this, arguments), e.type = t), n } } }), w.fn.extend({ on: function (e, t, n, r) { return De(this, e, t, n, r) }, one: function (e, t, n, r) { return De(this, e, t, n, r, 1) }, off: function (e, t, n) { var r, i; if (e && e.preventDefault && e.handleObj) return r = e.handleObj, w(e.delegateTarget).off(r.namespace ? r.origType + "." + r.namespace : r.origType, r.selector, r.handler), this; if ("object" == typeof e) { for (i in e) this.off(i, t, e[i]); return this } return !1 !== t && "function" != typeof t || (n = t, t = void 0), !1 === n && (n = ke), this.each(function () { w.event.remove(this, e, n, t) }) } }); var Ne = /<(?!area|br|col|embed|hr|img|input|link|meta|param)(([a-z][^\/\0>\x20\t\r\n\f]*)[^>]*)\/>/gi, Ae = /\s*$/g; function Le(e, t) { return N(e, "table") && N(11 !== t.nodeType ? t : t.firstChild, "tr") ? w(e).children("tbody")[0] || e : e } function He(e) { return e.type = (null !== e.getAttribute("type")) + "/" + e.type, e } function Oe(e) { return "true/" === (e.type || "").slice(0, 5) ? e.type = e.type.slice(5) : e.removeAttribute("type"), e } function Pe(e, t) { var n, r, i, o, a, s, u, l; if (1 === t.nodeType) { if (J.hasData(e) && (o = J.access(e), a = J.set(t, o), l = o.events)) { delete a.handle, a.events = {}; for (i in l) for (n = 0, r = l[i].length; n < r; n++)w.event.add(t, i, l[i][n]) } K.hasData(e) && (s = K.access(e), u = w.extend({}, s), K.set(t, u)) } } function Me(e, t) { var n = t.nodeName.toLowerCase(); "input" === n && pe.test(e.type) ? t.checked = e.checked : "input" !== n && "textarea" !== n || (t.defaultValue = e.defaultValue) } function Re(e, t, n, r) { t = a.apply([], t); var i, o, s, u, l, c, f = 0, p = e.length, d = p - 1, y = t[0], v = g(y); if (v || p > 1 && "string" == typeof y && !h.checkClone && je.test(y)) return e.each(function (i) { var o = e.eq(i); v && (t[0] = y.call(this, i, o.html())), Re(o, t, n, r) }); if (p && (i = xe(t, e[0].ownerDocument, !1, e, r), o = i.firstChild, 1 === i.childNodes.length && (i = o), o || r)) { for (u = (s = w.map(ye(i, "script"), He)).length; f < p; f++)l = i, f !== d && (l = w.clone(l, !0, !0), u && w.merge(s, ye(l, "script"))), n.call(e[f], l, f); if (u) for (c = s[s.length - 1].ownerDocument, w.map(s, Oe), f = 0; f < u; f++)l = s[f], he.test(l.type || "") && !J.access(l, "globalEval") && w.contains(c, l) && (l.src && "module" !== (l.type || "").toLowerCase() ? w._evalUrl && w._evalUrl(l.src) : m(l.textContent.replace(qe, ""), c, l)) } return e } function Ie(e, t, n) { for (var r, i = t ? w.filter(t, e) : e, o = 0; null != (r = i[o]); o++)n || 1 !== r.nodeType || w.cleanData(ye(r)), r.parentNode && (n && w.contains(r.ownerDocument, r) && ve(ye(r, "script")), r.parentNode.removeChild(r)); return e } w.extend({ htmlPrefilter: function (e) { return e.replace(Ne, "<$1>") }, clone: function (e, t, n) { var r, i, o, a, s = e.cloneNode(!0), u = w.contains(e.ownerDocument, e); if (!(h.noCloneChecked || 1 !== e.nodeType && 11 !== e.nodeType || w.isXMLDoc(e))) for (a = ye(s), r = 0, i = (o = ye(e)).length; r < i; r++)Me(o[r], a[r]); if (t) if (n) for (o = o || ye(e), a = a || ye(s), r = 0, i = o.length; r < i; r++)Pe(o[r], a[r]); else Pe(e, s); return (a = ye(s, "script")).length > 0 && ve(a, !u && ye(e, "script")), s }, cleanData: function (e) { for (var t, n, r, i = w.event.special, o = 0; void 0 !== (n = e[o]); o++)if (Y(n)) { if (t = n[J.expando]) { if (t.events) for (r in t.events) i[r] ? w.event.remove(n, r) : w.removeEvent(n, r, t.handle); n[J.expando] = void 0 } n[K.expando] && (n[K.expando] = void 0) } } }), w.fn.extend({ detach: function (e) { return Ie(this, e, !0) }, remove: function (e) { return Ie(this, e) }, text: function (e) { return z(this, function (e) { return void 0 === e ? w.text(this) : this.empty().each(function () { 1 !== this.nodeType && 11 !== this.nodeType && 9 !== this.nodeType || (this.textContent = e) }) }, null, e, arguments.length) }, append: function () { return Re(this, arguments, function (e) { 1 !== this.nodeType && 11 !== this.nodeType && 9 !== this.nodeType || Le(this, e).appendChild(e) }) }, prepend: function () { return Re(this, arguments, function (e) { if (1 === this.nodeType || 11 === this.nodeType || 9 === this.nodeType) { var t = Le(this, e); t.insertBefore(e, t.firstChild) } }) }, before: function () { return Re(this, arguments, function (e) { this.parentNode && this.parentNode.insertBefore(e, this) }) }, after: function () { return Re(this, arguments, function (e) { this.parentNode && this.parentNode.insertBefore(e, this.nextSibling) }) }, empty: function () { for (var e, t = 0; null != (e = this[t]); t++)1 === e.nodeType && (w.cleanData(ye(e, !1)), e.textContent = ""); return this }, clone: function (e, t) { return e = null != e && e, t = null == t ? e : t, this.map(function () { return w.clone(this, e, t) }) }, html: function (e) { return z(this, function (e) { var t = this[0] || {}, n = 0, r = this.length; if (void 0 === e && 1 === t.nodeType) return t.innerHTML; if ("string" == typeof e && !Ae.test(e) && !ge[(de.exec(e) || ["", ""])[1].toLowerCase()]) { e = w.htmlPrefilter(e); try { for (; n < r; n++)1 === (t = this[n] || {}).nodeType && (w.cleanData(ye(t, !1)), t.innerHTML = e); t = 0 } catch (e) { } } t && this.empty().append(e) }, null, e, arguments.length) }, replaceWith: function () { var e = []; return Re(this, arguments, function (t) { var n = this.parentNode; w.inArray(this, e) < 0 && (w.cleanData(ye(this)), n && n.replaceChild(t, this)) }, e) } }), w.each({ appendTo: "append", prependTo: "prepend", insertBefore: "before", insertAfter: "after", replaceAll: "replaceWith" }, function (e, t) { w.fn[e] = function (e) { for (var n, r = [], i = w(e), o = i.length - 1, a = 0; a <= o; a++)n = a === o ? this : this.clone(!0), w(i[a])[t](n), s.apply(r, n.get()); return this.pushStack(r) } }); var We = new RegExp("^(" + re + ")(?!px)[a-z%]+$", "i"), $e = function (t) { var n = t.ownerDocument.defaultView; return n && n.opener || (n = e), n.getComputedStyle(t) }, Be = new RegExp(oe.join("|"), "i"); !function () { function t() { if (c) { l.style.cssText = "position:absolute;left:-11111px;width:60px;margin-top:1px;padding:0;border:0", c.style.cssText = "position:relative;display:block;box-sizing:border-box;overflow:scroll;margin:auto;border:1px;padding:1px;width:60%;top:1%", be.appendChild(l).appendChild(c); var t = e.getComputedStyle(c); i = "1%" !== t.top, u = 12 === n(t.marginLeft), c.style.right = "60%", s = 36 === n(t.right), o = 36 === n(t.width), c.style.position = "absolute", a = 36 === c.offsetWidth || "absolute", be.removeChild(l), c = null } } function n(e) { return Math.round(parseFloat(e)) } var i, o, a, s, u, l = r.createElement("div"), c = r.createElement("div"); c.style && (c.style.backgroundClip = "content-box", c.cloneNode(!0).style.backgroundClip = "", h.clearCloneStyle = "content-box" === c.style.backgroundClip, w.extend(h, { boxSizingReliable: function () { return t(), o }, pixelBoxStyles: function () { return t(), s }, pixelPosition: function () { return t(), i }, reliableMarginLeft: function () { return t(), u }, scrollboxSize: function () { return t(), a } })) }(); function Fe(e, t, n) { var r, i, o, a, s = e.style; return (n = n || $e(e)) && ("" !== (a = n.getPropertyValue(t) || n[t]) || w.contains(e.ownerDocument, e) || (a = w.style(e, t)), !h.pixelBoxStyles() && We.test(a) && Be.test(t) && (r = s.width, i = s.minWidth, o = s.maxWidth, s.minWidth = s.maxWidth = s.width = a, a = n.width, s.width = r, s.minWidth = i, s.maxWidth = o)), void 0 !== a ? a + "" : a } function _e(e, t) { return { get: function () { if (!e()) return (this.get = t).apply(this, arguments); delete this.get } } } var ze = /^(none|table(?!-c[ea]).+)/, Xe = /^--/, Ue = { position: "absolute", visibility: "hidden", display: "block" }, Ve = { letterSpacing: "0", fontWeight: "400" }, Ge = ["Webkit", "Moz", "ms"], Ye = r.createElement("div").style; function Qe(e) { if (e in Ye) return e; var t = e[0].toUpperCase() + e.slice(1), n = Ge.length; while (n--) if ((e = Ge[n] + t) in Ye) return e } function Je(e) { var t = w.cssProps[e]; return t || (t = w.cssProps[e] = Qe(e) || e), t } function Ke(e, t, n) { var r = ie.exec(t); return r ? Math.max(0, r[2] - (n || 0)) + (r[3] || "px") : t } function Ze(e, t, n, r, i, o) { var a = "width" === t ? 1 : 0, s = 0, u = 0; if (n === (r ? "border" : "content")) return 0; for (; a < 4; a += 2)"margin" === n && (u += w.css(e, n + oe[a], !0, i)), r ? ("content" === n && (u -= w.css(e, "padding" + oe[a], !0, i)), "margin" !== n && (u -= w.css(e, "border" + oe[a] + "Width", !0, i))) : (u += w.css(e, "padding" + oe[a], !0, i), "padding" !== n ? u += w.css(e, "border" + oe[a] + "Width", !0, i) : s += w.css(e, "border" + oe[a] + "Width", !0, i)); return !r && o >= 0 && (u += Math.max(0, Math.ceil(e["offset" + t[0].toUpperCase() + t.slice(1)] - o - u - s - .5))), u } function et(e, t, n) { var r = $e(e), i = Fe(e, t, r), o = "border-box" === w.css(e, "boxSizing", !1, r), a = o; if (We.test(i)) { if (!n) return i; i = "auto" } return a = a && (h.boxSizingReliable() || i === e.style[t]), ("auto" === i || !parseFloat(i) && "inline" === w.css(e, "display", !1, r)) && (i = e["offset" + t[0].toUpperCase() + t.slice(1)], a = !0), (i = parseFloat(i) || 0) + Ze(e, t, n || (o ? "border" : "content"), a, r, i) + "px" } w.extend({ cssHooks: { opacity: { get: function (e, t) { if (t) { var n = Fe(e, "opacity"); return "" === n ? "1" : n } } } }, cssNumber: { animationIterationCount: !0, columnCount: !0, fillOpacity: !0, flexGrow: !0, flexShrink: !0, fontWeight: !0, lineHeight: !0, opacity: !0, order: !0, orphans: !0, widows: !0, zIndex: !0, zoom: !0 }, cssProps: {}, style: function (e, t, n, r) { if (e && 3 !== e.nodeType && 8 !== e.nodeType && e.style) { var i, o, a, s = G(t), u = Xe.test(t), l = e.style; if (u || (t = Je(s)), a = w.cssHooks[t] || w.cssHooks[s], void 0 === n) return a && "get" in a && void 0 !== (i = a.get(e, !1, r)) ? i : l[t]; "string" == (o = typeof n) && (i = ie.exec(n)) && i[1] && (n = ue(e, t, i), o = "number"), null != n && n === n && ("number" === o && (n += i && i[3] || (w.cssNumber[s] ? "" : "px")), h.clearCloneStyle || "" !== n || 0 !== t.indexOf("background") || (l[t] = "inherit"), a && "set" in a && void 0 === (n = a.set(e, n, r)) || (u ? l.setProperty(t, n) : l[t] = n)) } }, css: function (e, t, n, r) { var i, o, a, s = G(t); return Xe.test(t) || (t = Je(s)), (a = w.cssHooks[t] || w.cssHooks[s]) && "get" in a && (i = a.get(e, !0, n)), void 0 === i && (i = Fe(e, t, r)), "normal" === i && t in Ve && (i = Ve[t]), "" === n || n ? (o = parseFloat(i), !0 === n || isFinite(o) ? o || 0 : i) : i } }), w.each(["height", "width"], function (e, t) { w.cssHooks[t] = { get: function (e, n, r) { if (n) return !ze.test(w.css(e, "display")) || e.getClientRects().length && e.getBoundingClientRect().width ? et(e, t, r) : se(e, Ue, function () { return et(e, t, r) }) }, set: function (e, n, r) { var i, o = $e(e), a = "border-box" === w.css(e, "boxSizing", !1, o), s = r && Ze(e, t, r, a, o); return a && h.scrollboxSize() === o.position && (s -= Math.ceil(e["offset" + t[0].toUpperCase() + t.slice(1)] - parseFloat(o[t]) - Ze(e, t, "border", !1, o) - .5)), s && (i = ie.exec(n)) && "px" !== (i[3] || "px") && (e.style[t] = n, n = w.css(e, t)), Ke(e, n, s) } } }), w.cssHooks.marginLeft = _e(h.reliableMarginLeft, function (e, t) { if (t) return (parseFloat(Fe(e, "marginLeft")) || e.getBoundingClientRect().left - se(e, { marginLeft: 0 }, function () { return e.getBoundingClientRect().left })) + "px" }), w.each({ margin: "", padding: "", border: "Width" }, function (e, t) { w.cssHooks[e + t] = { expand: function (n) { for (var r = 0, i = {}, o = "string" == typeof n ? n.split(" ") : [n]; r < 4; r++)i[e + oe[r] + t] = o[r] || o[r - 2] || o[0]; return i } }, "margin" !== e && (w.cssHooks[e + t].set = Ke) }), w.fn.extend({ css: function (e, t) { return z(this, function (e, t, n) { var r, i, o = {}, a = 0; if (Array.isArray(t)) { for (r = $e(e), i = t.length; a < i; a++)o[t[a]] = w.css(e, t[a], !1, r); return o } return void 0 !== n ? w.style(e, t, n) : w.css(e, t) }, e, t, arguments.length > 1) } }); function tt(e, t, n, r, i) { return new tt.prototype.init(e, t, n, r, i) } w.Tween = tt, tt.prototype = { constructor: tt, init: function (e, t, n, r, i, o) { this.elem = e, this.prop = n, this.easing = i || w.easing._default, this.options = t, this.start = this.now = this.cur(), this.end = r, this.unit = o || (w.cssNumber[n] ? "" : "px") }, cur: function () { var e = tt.propHooks[this.prop]; return e && e.get ? e.get(this) : tt.propHooks._default.get(this) }, run: function (e) { var t, n = tt.propHooks[this.prop]; return this.options.duration ? this.pos = t = w.easing[this.easing](e, this.options.duration * e, 0, 1, this.options.duration) : this.pos = t = e, this.now = (this.end - this.start) * t + this.start, this.options.step && this.options.step.call(this.elem, this.now, this), n && n.set ? n.set(this) : tt.propHooks._default.set(this), this } }, tt.prototype.init.prototype = tt.prototype, tt.propHooks = { _default: { get: function (e) { var t; return 1 !== e.elem.nodeType || null != e.elem[e.prop] && null == e.elem.style[e.prop] ? e.elem[e.prop] : (t = w.css(e.elem, e.prop, "")) && "auto" !== t ? t : 0 }, set: function (e) { w.fx.step[e.prop] ? w.fx.step[e.prop](e) : 1 !== e.elem.nodeType || null == e.elem.style[w.cssProps[e.prop]] && !w.cssHooks[e.prop] ? e.elem[e.prop] = e.now : w.style(e.elem, e.prop, e.now + e.unit) } } }, tt.propHooks.scrollTop = tt.propHooks.scrollLeft = { set: function (e) { e.elem.nodeType && e.elem.parentNode && (e.elem[e.prop] = e.now) } }, w.easing = { linear: function (e) { return e }, swing: function (e) { return .5 - Math.cos(e * Math.PI) / 2 }, _default: "swing" }, w.fx = tt.prototype.init, w.fx.step = {}; var nt, rt, it = /^(?:toggle|show|hide)$/, ot = /queueHooks$/; function at() { rt && (!1 === r.hidden && e.requestAnimationFrame ? e.requestAnimationFrame(at) : e.setTimeout(at, w.fx.interval), w.fx.tick()) } function st() { return e.setTimeout(function () { nt = void 0 }), nt = Date.now() } function ut(e, t) { var n, r = 0, i = { height: e }; for (t = t ? 1 : 0; r < 4; r += 2 - t)i["margin" + (n = oe[r])] = i["padding" + n] = e; return t && (i.opacity = i.width = e), i } function lt(e, t, n) { for (var r, i = (pt.tweeners[t] || []).concat(pt.tweeners["*"]), o = 0, a = i.length; o < a; o++)if (r = i[o].call(n, t, e)) return r } function ct(e, t, n) { var r, i, o, a, s, u, l, c, f = "width" in t || "height" in t, p = this, d = {}, h = e.style, g = e.nodeType && ae(e), y = J.get(e, "fxshow"); n.queue || (null == (a = w._queueHooks(e, "fx")).unqueued && (a.unqueued = 0, s = a.empty.fire, a.empty.fire = function () { a.unqueued || s() }), a.unqueued++ , p.always(function () { p.always(function () { a.unqueued-- , w.queue(e, "fx").length || a.empty.fire() }) })); for (r in t) if (i = t[r], it.test(i)) { if (delete t[r], o = o || "toggle" === i, i === (g ? "hide" : "show")) { if ("show" !== i || !y || void 0 === y[r]) continue; g = !0 } d[r] = y && y[r] || w.style(e, r) } if ((u = !w.isEmptyObject(t)) || !w.isEmptyObject(d)) { f && 1 === e.nodeType && (n.overflow = [h.overflow, h.overflowX, h.overflowY], null == (l = y && y.display) && (l = J.get(e, "display")), "none" === (c = w.css(e, "display")) && (l ? c = l : (fe([e], !0), l = e.style.display || l, c = w.css(e, "display"), fe([e]))), ("inline" === c || "inline-block" === c && null != l) && "none" === w.css(e, "float") && (u || (p.done(function () { h.display = l }), null == l && (c = h.display, l = "none" === c ? "" : c)), h.display = "inline-block")), n.overflow && (h.overflow = "hidden", p.always(function () { h.overflow = n.overflow[0], h.overflowX = n.overflow[1], h.overflowY = n.overflow[2] })), u = !1; for (r in d) u || (y ? "hidden" in y && (g = y.hidden) : y = J.access(e, "fxshow", { display: l }), o && (y.hidden = !g), g && fe([e], !0), p.done(function () { g || fe([e]), J.remove(e, "fxshow"); for (r in d) w.style(e, r, d[r]) })), u = lt(g ? y[r] : 0, r, p), r in y || (y[r] = u.start, g && (u.end = u.start, u.start = 0)) } } function ft(e, t) { var n, r, i, o, a; for (n in e) if (r = G(n), i = t[r], o = e[n], Array.isArray(o) && (i = o[1], o = e[n] = o[0]), n !== r && (e[r] = o, delete e[n]), (a = w.cssHooks[r]) && "expand" in a) { o = a.expand(o), delete e[r]; for (n in o) n in e || (e[n] = o[n], t[n] = i) } else t[r] = i } function pt(e, t, n) { var r, i, o = 0, a = pt.prefilters.length, s = w.Deferred().always(function () { delete u.elem }), u = function () { if (i) return !1; for (var t = nt || st(), n = Math.max(0, l.startTime + l.duration - t), r = 1 - (n / l.duration || 0), o = 0, a = l.tweens.length; o < a; o++)l.tweens[o].run(r); return s.notifyWith(e, [l, r, n]), r < 1 && a ? n : (a || s.notifyWith(e, [l, 1, 0]), s.resolveWith(e, [l]), !1) }, l = s.promise({ elem: e, props: w.extend({}, t), opts: w.extend(!0, { specialEasing: {}, easing: w.easing._default }, n), originalProperties: t, originalOptions: n, startTime: nt || st(), duration: n.duration, tweens: [], createTween: function (t, n) { var r = w.Tween(e, l.opts, t, n, l.opts.specialEasing[t] || l.opts.easing); return l.tweens.push(r), r }, stop: function (t) { var n = 0, r = t ? l.tweens.length : 0; if (i) return this; for (i = !0; n < r; n++)l.tweens[n].run(1); return t ? (s.notifyWith(e, [l, 1, 0]), s.resolveWith(e, [l, t])) : s.rejectWith(e, [l, t]), this } }), c = l.props; for (ft(c, l.opts.specialEasing); o < a; o++)if (r = pt.prefilters[o].call(l, e, c, l.opts)) return g(r.stop) && (w._queueHooks(l.elem, l.opts.queue).stop = r.stop.bind(r)), r; return w.map(c, lt, l), g(l.opts.start) && l.opts.start.call(e, l), l.progress(l.opts.progress).done(l.opts.done, l.opts.complete).fail(l.opts.fail).always(l.opts.always), w.fx.timer(w.extend(u, { elem: e, anim: l, queue: l.opts.queue })), l } w.Animation = w.extend(pt, { tweeners: { "*": [function (e, t) { var n = this.createTween(e, t); return ue(n.elem, e, ie.exec(t), n), n }] }, tweener: function (e, t) { g(e) ? (t = e, e = ["*"]) : e = e.match(M); for (var n, r = 0, i = e.length; r < i; r++)n = e[r], pt.tweeners[n] = pt.tweeners[n] || [], pt.tweeners[n].unshift(t) }, prefilters: [ct], prefilter: function (e, t) { t ? pt.prefilters.unshift(e) : pt.prefilters.push(e) } }), w.speed = function (e, t, n) { var r = e && "object" == typeof e ? w.extend({}, e) : { complete: n || !n && t || g(e) && e, duration: e, easing: n && t || t && !g(t) && t }; return w.fx.off ? r.duration = 0 : "number" != typeof r.duration && (r.duration in w.fx.speeds ? r.duration = w.fx.speeds[r.duration] : r.duration = w.fx.speeds._default), null != r.queue && !0 !== r.queue || (r.queue = "fx"), r.old = r.complete, r.complete = function () { g(r.old) && r.old.call(this), r.queue && w.dequeue(this, r.queue) }, r }, w.fn.extend({ fadeTo: function (e, t, n, r) { return this.filter(ae).css("opacity", 0).show().end().animate({ opacity: t }, e, n, r) }, animate: function (e, t, n, r) { var i = w.isEmptyObject(e), o = w.speed(t, n, r), a = function () { var t = pt(this, w.extend({}, e), o); (i || J.get(this, "finish")) && t.stop(!0) }; return a.finish = a, i || !1 === o.queue ? this.each(a) : this.queue(o.queue, a) }, stop: function (e, t, n) { var r = function (e) { var t = e.stop; delete e.stop, t(n) }; return "string" != typeof e && (n = t, t = e, e = void 0), t && !1 !== e && this.queue(e || "fx", []), this.each(function () { var t = !0, i = null != e && e + "queueHooks", o = w.timers, a = J.get(this); if (i) a[i] && a[i].stop && r(a[i]); else for (i in a) a[i] && a[i].stop && ot.test(i) && r(a[i]); for (i = o.length; i--;)o[i].elem !== this || null != e && o[i].queue !== e || (o[i].anim.stop(n), t = !1, o.splice(i, 1)); !t && n || w.dequeue(this, e) }) }, finish: function (e) { return !1 !== e && (e = e || "fx"), this.each(function () { var t, n = J.get(this), r = n[e + "queue"], i = n[e + "queueHooks"], o = w.timers, a = r ? r.length : 0; for (n.finish = !0, w.queue(this, e, []), i && i.stop && i.stop.call(this, !0), t = o.length; t--;)o[t].elem === this && o[t].queue === e && (o[t].anim.stop(!0), o.splice(t, 1)); for (t = 0; t < a; t++)r[t] && r[t].finish && r[t].finish.call(this); delete n.finish }) } }), w.each(["toggle", "show", "hide"], function (e, t) { var n = w.fn[t]; w.fn[t] = function (e, r, i) { return null == e || "boolean" == typeof e ? n.apply(this, arguments) : this.animate(ut(t, !0), e, r, i) } }), w.each({ slideDown: ut("show"), slideUp: ut("hide"), slideToggle: ut("toggle"), fadeIn: { opacity: "show" }, fadeOut: { opacity: "hide" }, fadeToggle: { opacity: "toggle" } }, function (e, t) { w.fn[e] = function (e, n, r) { return this.animate(t, e, n, r) } }), w.timers = [], w.fx.tick = function () { var e, t = 0, n = w.timers; for (nt = Date.now(); t < n.length; t++)(e = n[t])() || n[t] !== e || n.splice(t--, 1); n.length || w.fx.stop(), nt = void 0 }, w.fx.timer = function (e) { w.timers.push(e), w.fx.start() }, w.fx.interval = 13, w.fx.start = function () { rt || (rt = !0, at()) }, w.fx.stop = function () { rt = null }, w.fx.speeds = { slow: 600, fast: 200, _default: 400 }, w.fn.delay = function (t, n) { return t = w.fx ? w.fx.speeds[t] || t : t, n = n || "fx", this.queue(n, function (n, r) { var i = e.setTimeout(n, t); r.stop = function () { e.clearTimeout(i) } }) }, function () { var e = r.createElement("input"), t = r.createElement("select").appendChild(r.createElement("option")); e.type = "checkbox", h.checkOn = "" !== e.value, h.optSelected = t.selected, (e = r.createElement("input")).value = "t", e.type = "radio", h.radioValue = "t" === e.value }(); var dt, ht = w.expr.attrHandle; w.fn.extend({ attr: function (e, t) { return z(this, w.attr, e, t, arguments.length > 1) }, removeAttr: function (e) { return this.each(function () { w.removeAttr(this, e) }) } }), w.extend({ attr: function (e, t, n) { var r, i, o = e.nodeType; if (3 !== o && 8 !== o && 2 !== o) return "undefined" == typeof e.getAttribute ? w.prop(e, t, n) : (1 === o && w.isXMLDoc(e) || (i = w.attrHooks[t.toLowerCase()] || (w.expr.match.bool.test(t) ? dt : void 0)), void 0 !== n ? null === n ? void w.removeAttr(e, t) : i && "set" in i && void 0 !== (r = i.set(e, n, t)) ? r : (e.setAttribute(t, n + ""), n) : i && "get" in i && null !== (r = i.get(e, t)) ? r : null == (r = w.find.attr(e, t)) ? void 0 : r) }, attrHooks: { type: { set: function (e, t) { if (!h.radioValue && "radio" === t && N(e, "input")) { var n = e.value; return e.setAttribute("type", t), n && (e.value = n), t } } } }, removeAttr: function (e, t) { var n, r = 0, i = t && t.match(M); if (i && 1 === e.nodeType) while (n = i[r++]) e.removeAttribute(n) } }), dt = { set: function (e, t, n) { return !1 === t ? w.removeAttr(e, n) : e.setAttribute(n, n), n } }, w.each(w.expr.match.bool.source.match(/\w+/g), function (e, t) { var n = ht[t] || w.find.attr; ht[t] = function (e, t, r) { var i, o, a = t.toLowerCase(); return r || (o = ht[a], ht[a] = i, i = null != n(e, t, r) ? a : null, ht[a] = o), i } }); var gt = /^(?:input|select|textarea|button)$/i, yt = /^(?:a|area)$/i; w.fn.extend({ prop: function (e, t) { return z(this, w.prop, e, t, arguments.length > 1) }, removeProp: function (e) { return this.each(function () { delete this[w.propFix[e] || e] }) } }), w.extend({ prop: function (e, t, n) { var r, i, o = e.nodeType; if (3 !== o && 8 !== o && 2 !== o) return 1 === o && w.isXMLDoc(e) || (t = w.propFix[t] || t, i = w.propHooks[t]), void 0 !== n ? i && "set" in i && void 0 !== (r = i.set(e, n, t)) ? r : e[t] = n : i && "get" in i && null !== (r = i.get(e, t)) ? r : e[t] }, propHooks: { tabIndex: { get: function (e) { var t = w.find.attr(e, "tabindex"); return t ? parseInt(t, 10) : gt.test(e.nodeName) || yt.test(e.nodeName) && e.href ? 0 : -1 } } }, propFix: { "for": "htmlFor", "class": "className" } }), h.optSelected || (w.propHooks.selected = { get: function (e) { var t = e.parentNode; return t && t.parentNode && t.parentNode.selectedIndex, null }, set: function (e) { var t = e.parentNode; t && (t.selectedIndex, t.parentNode && t.parentNode.selectedIndex) } }), w.each(["tabIndex", "readOnly", "maxLength", "cellSpacing", "cellPadding", "rowSpan", "colSpan", "useMap", "frameBorder", "contentEditable"], function () { w.propFix[this.toLowerCase()] = this }); function vt(e) { return (e.match(M) || []).join(" ") } function mt(e) { return e.getAttribute && e.getAttribute("class") || "" } function xt(e) { return Array.isArray(e) ? e : "string" == typeof e ? e.match(M) || [] : [] } w.fn.extend({ addClass: function (e) { var t, n, r, i, o, a, s, u = 0; if (g(e)) return this.each(function (t) { w(this).addClass(e.call(this, t, mt(this))) }); if ((t = xt(e)).length) while (n = this[u++]) if (i = mt(n), r = 1 === n.nodeType && " " + vt(i) + " ") { a = 0; while (o = t[a++]) r.indexOf(" " + o + " ") < 0 && (r += o + " "); i !== (s = vt(r)) && n.setAttribute("class", s) } return this }, removeClass: function (e) { var t, n, r, i, o, a, s, u = 0; if (g(e)) return this.each(function (t) { w(this).removeClass(e.call(this, t, mt(this))) }); if (!arguments.length) return this.attr("class", ""); if ((t = xt(e)).length) while (n = this[u++]) if (i = mt(n), r = 1 === n.nodeType && " " + vt(i) + " ") { a = 0; while (o = t[a++]) while (r.indexOf(" " + o + " ") > -1) r = r.replace(" " + o + " ", " "); i !== (s = vt(r)) && n.setAttribute("class", s) } return this }, toggleClass: function (e, t) { var n = typeof e, r = "string" === n || Array.isArray(e); return "boolean" == typeof t && r ? t ? this.addClass(e) : this.removeClass(e) : g(e) ? this.each(function (n) { w(this).toggleClass(e.call(this, n, mt(this), t), t) }) : this.each(function () { var t, i, o, a; if (r) { i = 0, o = w(this), a = xt(e); while (t = a[i++]) o.hasClass(t) ? o.removeClass(t) : o.addClass(t) } else void 0 !== e && "boolean" !== n || ((t = mt(this)) && J.set(this, "__className__", t), this.setAttribute && this.setAttribute("class", t || !1 === e ? "" : J.get(this, "__className__") || "")) }) }, hasClass: function (e) { var t, n, r = 0; t = " " + e + " "; while (n = this[r++]) if (1 === n.nodeType && (" " + vt(mt(n)) + " ").indexOf(t) > -1) return !0; return !1 } }); var bt = /\r/g; w.fn.extend({ val: function (e) { var t, n, r, i = this[0]; { if (arguments.length) return r = g(e), this.each(function (n) { var i; 1 === this.nodeType && (null == (i = r ? e.call(this, n, w(this).val()) : e) ? i = "" : "number" == typeof i ? i += "" : Array.isArray(i) && (i = w.map(i, function (e) { return null == e ? "" : e + "" })), (t = w.valHooks[this.type] || w.valHooks[this.nodeName.toLowerCase()]) && "set" in t && void 0 !== t.set(this, i, "value") || (this.value = i)) }); if (i) return (t = w.valHooks[i.type] || w.valHooks[i.nodeName.toLowerCase()]) && "get" in t && void 0 !== (n = t.get(i, "value")) ? n : "string" == typeof (n = i.value) ? n.replace(bt, "") : null == n ? "" : n } } }), w.extend({ valHooks: { option: { get: function (e) { var t = w.find.attr(e, "value"); return null != t ? t : vt(w.text(e)) } }, select: { get: function (e) { var t, n, r, i = e.options, o = e.selectedIndex, a = "select-one" === e.type, s = a ? null : [], u = a ? o + 1 : i.length; for (r = o < 0 ? u : a ? o : 0; r < u; r++)if (((n = i[r]).selected || r === o) && !n.disabled && (!n.parentNode.disabled || !N(n.parentNode, "optgroup"))) { if (t = w(n).val(), a) return t; s.push(t) } return s }, set: function (e, t) { var n, r, i = e.options, o = w.makeArray(t), a = i.length; while (a--) ((r = i[a]).selected = w.inArray(w.valHooks.option.get(r), o) > -1) && (n = !0); return n || (e.selectedIndex = -1), o } } } }), w.each(["radio", "checkbox"], function () { w.valHooks[this] = { set: function (e, t) { if (Array.isArray(t)) return e.checked = w.inArray(w(e).val(), t) > -1 } }, h.checkOn || (w.valHooks[this].get = function (e) { return null === e.getAttribute("value") ? "on" : e.value }) }), h.focusin = "onfocusin" in e; var wt = /^(?:focusinfocus|focusoutblur)$/, Tt = function (e) { e.stopPropagation() }; w.extend(w.event, { trigger: function (t, n, i, o) { var a, s, u, l, c, p, d, h, v = [i || r], m = f.call(t, "type") ? t.type : t, x = f.call(t, "namespace") ? t.namespace.split(".") : []; if (s = h = u = i = i || r, 3 !== i.nodeType && 8 !== i.nodeType && !wt.test(m + w.event.triggered) && (m.indexOf(".") > -1 && (m = (x = m.split(".")).shift(), x.sort()), c = m.indexOf(":") < 0 && "on" + m, t = t[w.expando] ? t : new w.Event(m, "object" == typeof t && t), t.isTrigger = o ? 2 : 3, t.namespace = x.join("."), t.rnamespace = t.namespace ? new RegExp("(^|\\.)" + x.join("\\.(?:.*\\.|)") + "(\\.|$)") : null, t.result = void 0, t.target || (t.target = i), n = null == n ? [t] : w.makeArray(n, [t]), d = w.event.special[m] || {}, o || !d.trigger || !1 !== d.trigger.apply(i, n))) { if (!o && !d.noBubble && !y(i)) { for (l = d.delegateType || m, wt.test(l + m) || (s = s.parentNode); s; s = s.parentNode)v.push(s), u = s; u === (i.ownerDocument || r) && v.push(u.defaultView || u.parentWindow || e) } a = 0; while ((s = v[a++]) && !t.isPropagationStopped()) h = s, t.type = a > 1 ? l : d.bindType || m, (p = (J.get(s, "events") || {})[t.type] && J.get(s, "handle")) && p.apply(s, n), (p = c && s[c]) && p.apply && Y(s) && (t.result = p.apply(s, n), !1 === t.result && t.preventDefault()); return t.type = m, o || t.isDefaultPrevented() || d._default && !1 !== d._default.apply(v.pop(), n) || !Y(i) || c && g(i[m]) && !y(i) && ((u = i[c]) && (i[c] = null), w.event.triggered = m, t.isPropagationStopped() && h.addEventListener(m, Tt), i[m](), t.isPropagationStopped() && h.removeEventListener(m, Tt), w.event.triggered = void 0, u && (i[c] = u)), t.result } }, simulate: function (e, t, n) { var r = w.extend(new w.Event, n, { type: e, isSimulated: !0 }); w.event.trigger(r, null, t) } }), w.fn.extend({ trigger: function (e, t) { return this.each(function () { w.event.trigger(e, t, this) }) }, triggerHandler: function (e, t) { var n = this[0]; if (n) return w.event.trigger(e, t, n, !0) } }), h.focusin || w.each({ focus: "focusin", blur: "focusout" }, function (e, t) { var n = function (e) { w.event.simulate(t, e.target, w.event.fix(e)) }; w.event.special[t] = { setup: function () { var r = this.ownerDocument || this, i = J.access(r, t); i || r.addEventListener(e, n, !0), J.access(r, t, (i || 0) + 1) }, teardown: function () { var r = this.ownerDocument || this, i = J.access(r, t) - 1; i ? J.access(r, t, i) : (r.removeEventListener(e, n, !0), J.remove(r, t)) } } }); var Ct = e.location, Et = Date.now(), kt = /\?/; w.parseXML = function (t) { var n; if (!t || "string" != typeof t) return null; try { n = (new e.DOMParser).parseFromString(t, "text/xml") } catch (e) { n = void 0 } return n && !n.getElementsByTagName("parsererror").length || w.error("Invalid XML: " + t), n }; var St = /\[\]$/, Dt = /\r?\n/g, Nt = /^(?:submit|button|image|reset|file)$/i, At = /^(?:input|select|textarea|keygen)/i; function jt(e, t, n, r) { var i; if (Array.isArray(t)) w.each(t, function (t, i) { n || St.test(e) ? r(e, i) : jt(e + "[" + ("object" == typeof i && null != i ? t : "") + "]", i, n, r) }); else if (n || "object" !== x(t)) r(e, t); else for (i in t) jt(e + "[" + i + "]", t[i], n, r) } w.param = function (e, t) { var n, r = [], i = function (e, t) { var n = g(t) ? t() : t; r[r.length] = encodeURIComponent(e) + "=" + encodeURIComponent(null == n ? "" : n) }; if (Array.isArray(e) || e.jquery && !w.isPlainObject(e)) w.each(e, function () { i(this.name, this.value) }); else for (n in e) jt(n, e[n], t, i); return r.join("&") }, w.fn.extend({ serialize: function () { return w.param(this.serializeArray()) }, serializeArray: function () { return this.map(function () { var e = w.prop(this, "elements"); return e ? w.makeArray(e) : this }).filter(function () { var e = this.type; return this.name && !w(this).is(":disabled") && At.test(this.nodeName) && !Nt.test(e) && (this.checked || !pe.test(e)) }).map(function (e, t) { var n = w(this).val(); return null == n ? null : Array.isArray(n) ? w.map(n, function (e) { return { name: t.name, value: e.replace(Dt, "\r\n") } }) : { name: t.name, value: n.replace(Dt, "\r\n") } }).get() } }); var qt = /%20/g, Lt = /#.*$/, Ht = /([?&])_=[^&]*/, Ot = /^(.*?):[ \t]*([^\r\n]*)$/gm, Pt = /^(?:about|app|app-storage|.+-extension|file|res|widget):$/, Mt = /^(?:GET|HEAD)$/, Rt = /^\/\//, It = {}, Wt = {}, $t = "*/".concat("*"), Bt = r.createElement("a"); Bt.href = Ct.href; function Ft(e) { return function (t, n) { "string" != typeof t && (n = t, t = "*"); var r, i = 0, o = t.toLowerCase().match(M) || []; if (g(n)) while (r = o[i++]) "+" === r[0] ? (r = r.slice(1) || "*", (e[r] = e[r] || []).unshift(n)) : (e[r] = e[r] || []).push(n) } } function _t(e, t, n, r) { var i = {}, o = e === Wt; function a(s) { var u; return i[s] = !0, w.each(e[s] || [], function (e, s) { var l = s(t, n, r); return "string" != typeof l || o || i[l] ? o ? !(u = l) : void 0 : (t.dataTypes.unshift(l), a(l), !1) }), u } return a(t.dataTypes[0]) || !i["*"] && a("*") } function zt(e, t) { var n, r, i = w.ajaxSettings.flatOptions || {}; for (n in t) void 0 !== t[n] && ((i[n] ? e : r || (r = {}))[n] = t[n]); return r && w.extend(!0, e, r), e } function Xt(e, t, n) { var r, i, o, a, s = e.contents, u = e.dataTypes; while ("*" === u[0]) u.shift(), void 0 === r && (r = e.mimeType || t.getResponseHeader("Content-Type")); if (r) for (i in s) if (s[i] && s[i].test(r)) { u.unshift(i); break } if (u[0] in n) o = u[0]; else { for (i in n) { if (!u[0] || e.converters[i + " " + u[0]]) { o = i; break } a || (a = i) } o = o || a } if (o) return o !== u[0] && u.unshift(o), n[o] } function Ut(e, t, n, r) { var i, o, a, s, u, l = {}, c = e.dataTypes.slice(); if (c[1]) for (a in e.converters) l[a.toLowerCase()] = e.converters[a]; o = c.shift(); while (o) if (e.responseFields[o] && (n[e.responseFields[o]] = t), !u && r && e.dataFilter && (t = e.dataFilter(t, e.dataType)), u = o, o = c.shift()) if ("*" === o) o = u; else if ("*" !== u && u !== o) { if (!(a = l[u + " " + o] || l["* " + o])) for (i in l) if ((s = i.split(" "))[1] === o && (a = l[u + " " + s[0]] || l["* " + s[0]])) { !0 === a ? a = l[i] : !0 !== l[i] && (o = s[0], c.unshift(s[1])); break } if (!0 !== a) if (a && e["throws"]) t = a(t); else try { t = a(t) } catch (e) { return { state: "parsererror", error: a ? e : "No conversion from " + u + " to " + o } } } return { state: "success", data: t } } w.extend({ active: 0, lastModified: {}, etag: {}, ajaxSettings: { url: Ct.href, type: "GET", isLocal: Pt.test(Ct.protocol), global: !0, processData: !0, async: !0, contentType: "application/x-www-form-urlencoded; charset=UTF-8", accepts: { "*": $t, text: "text/plain", html: "text/html", xml: "application/xml, text/xml", json: "application/json, text/javascript" }, contents: { xml: /\bxml\b/, html: /\bhtml/, json: /\bjson\b/ }, responseFields: { xml: "responseXML", text: "responseText", json: "responseJSON" }, converters: { "* text": String, "text html": !0, "text json": JSON.parse, "text xml": w.parseXML }, flatOptions: { url: !0, context: !0 } }, ajaxSetup: function (e, t) { return t ? zt(zt(e, w.ajaxSettings), t) : zt(w.ajaxSettings, e) }, ajaxPrefilter: Ft(It), ajaxTransport: Ft(Wt), ajax: function (t, n) { "object" == typeof t && (n = t, t = void 0), n = n || {}; var i, o, a, s, u, l, c, f, p, d, h = w.ajaxSetup({}, n), g = h.context || h, y = h.context && (g.nodeType || g.jquery) ? w(g) : w.event, v = w.Deferred(), m = w.Callbacks("once memory"), x = h.statusCode || {}, b = {}, T = {}, C = "canceled", E = { readyState: 0, getResponseHeader: function (e) { var t; if (c) { if (!s) { s = {}; while (t = Ot.exec(a)) s[t[1].toLowerCase()] = t[2] } t = s[e.toLowerCase()] } return null == t ? null : t }, getAllResponseHeaders: function () { return c ? a : null }, setRequestHeader: function (e, t) { return null == c && (e = T[e.toLowerCase()] = T[e.toLowerCase()] || e, b[e] = t), this }, overrideMimeType: function (e) { return null == c && (h.mimeType = e), this }, statusCode: function (e) { var t; if (e) if (c) E.always(e[E.status]); else for (t in e) x[t] = [x[t], e[t]]; return this }, abort: function (e) { var t = e || C; return i && i.abort(t), k(0, t), this } }; if (v.promise(E), h.url = ((t || h.url || Ct.href) + "").replace(Rt, Ct.protocol + "//"), h.type = n.method || n.type || h.method || h.type, h.dataTypes = (h.dataType || "*").toLowerCase().match(M) || [""], null == h.crossDomain) { l = r.createElement("a"); try { l.href = h.url, l.href = l.href, h.crossDomain = Bt.protocol + "//" + Bt.host != l.protocol + "//" + l.host } catch (e) { h.crossDomain = !0 } } if (h.data && h.processData && "string" != typeof h.data && (h.data = w.param(h.data, h.traditional)), _t(It, h, n, E), c) return E; (f = w.event && h.global) && 0 == w.active++ && w.event.trigger("ajaxStart"), h.type = h.type.toUpperCase(), h.hasContent = !Mt.test(h.type), o = h.url.replace(Lt, ""), h.hasContent ? h.data && h.processData && 0 === (h.contentType || "").indexOf("application/x-www-form-urlencoded") && (h.data = h.data.replace(qt, "+")) : (d = h.url.slice(o.length), h.data && (h.processData || "string" == typeof h.data) && (o += (kt.test(o) ? "&" : "?") + h.data, delete h.data), !1 === h.cache && (o = o.replace(Ht, "$1"), d = (kt.test(o) ? "&" : "?") + "_=" + Et++ + d), h.url = o + d), h.ifModified && (w.lastModified[o] && E.setRequestHeader("If-Modified-Since", w.lastModified[o]), w.etag[o] && E.setRequestHeader("If-None-Match", w.etag[o])), (h.data && h.hasContent && !1 !== h.contentType || n.contentType) && E.setRequestHeader("Content-Type", h.contentType), E.setRequestHeader("Accept", h.dataTypes[0] && h.accepts[h.dataTypes[0]] ? h.accepts[h.dataTypes[0]] + ("*" !== h.dataTypes[0] ? ", " + $t + "; q=0.01" : "") : h.accepts["*"]); for (p in h.headers) E.setRequestHeader(p, h.headers[p]); if (h.beforeSend && (!1 === h.beforeSend.call(g, E, h) || c)) return E.abort(); if (C = "abort", m.add(h.complete), E.done(h.success), E.fail(h.error), i = _t(Wt, h, n, E)) { if (E.readyState = 1, f && y.trigger("ajaxSend", [E, h]), c) return E; h.async && h.timeout > 0 && (u = e.setTimeout(function () { E.abort("timeout") }, h.timeout)); try { c = !1, i.send(b, k) } catch (e) { if (c) throw e; k(-1, e) } } else k(-1, "No Transport"); function k(t, n, r, s) { var l, p, d, b, T, C = n; c || (c = !0, u && e.clearTimeout(u), i = void 0, a = s || "", E.readyState = t > 0 ? 4 : 0, l = t >= 200 && t < 300 || 304 === t, r && (b = Xt(h, E, r)), b = Ut(h, b, E, l), l ? (h.ifModified && ((T = E.getResponseHeader("Last-Modified")) && (w.lastModified[o] = T), (T = E.getResponseHeader("etag")) && (w.etag[o] = T)), 204 === t || "HEAD" === h.type ? C = "nocontent" : 304 === t ? C = "notmodified" : (C = b.state, p = b.data, l = !(d = b.error))) : (d = C, !t && C || (C = "error", t < 0 && (t = 0))), E.status = t, E.statusText = (n || C) + "", l ? v.resolveWith(g, [p, C, E]) : v.rejectWith(g, [E, C, d]), E.statusCode(x), x = void 0, f && y.trigger(l ? "ajaxSuccess" : "ajaxError", [E, h, l ? p : d]), m.fireWith(g, [E, C]), f && (y.trigger("ajaxComplete", [E, h]), --w.active || w.event.trigger("ajaxStop"))) } return E }, getJSON: function (e, t, n) { return w.get(e, t, n, "json") }, getScript: function (e, t) { return w.get(e, void 0, t, "script") } }), w.each(["get", "post"], function (e, t) { w[t] = function (e, n, r, i) { return g(n) && (i = i || r, r = n, n = void 0), w.ajax(w.extend({ url: e, type: t, dataType: i, data: n, success: r }, w.isPlainObject(e) && e)) } }), w._evalUrl = function (e) { return w.ajax({ url: e, type: "GET", dataType: "script", cache: !0, async: !1, global: !1, "throws": !0 }) }, w.fn.extend({ wrapAll: function (e) { var t; return this[0] && (g(e) && (e = e.call(this[0])), t = w(e, this[0].ownerDocument).eq(0).clone(!0), this[0].parentNode && t.insertBefore(this[0]), t.map(function () { var e = this; while (e.firstElementChild) e = e.firstElementChild; return e }).append(this)), this }, wrapInner: function (e) { return g(e) ? this.each(function (t) { w(this).wrapInner(e.call(this, t)) }) : this.each(function () { var t = w(this), n = t.contents(); n.length ? n.wrapAll(e) : t.append(e) }) }, wrap: function (e) { var t = g(e); return this.each(function (n) { w(this).wrapAll(t ? e.call(this, n) : e) }) }, unwrap: function (e) { return this.parent(e).not("body").each(function () { w(this).replaceWith(this.childNodes) }), this } }), w.expr.pseudos.hidden = function (e) { return !w.expr.pseudos.visible(e) }, w.expr.pseudos.visible = function (e) { return !!(e.offsetWidth || e.offsetHeight || e.getClientRects().length) }, w.ajaxSettings.xhr = function () { try { return new e.XMLHttpRequest } catch (e) { } }; var Vt = { 0: 200, 1223: 204 }, Gt = w.ajaxSettings.xhr(); h.cors = !!Gt && "withCredentials" in Gt, h.ajax = Gt = !!Gt, w.ajaxTransport(function (t) { var n, r; if (h.cors || Gt && !t.crossDomain) return { send: function (i, o) { var a, s = t.xhr(); if (s.open(t.type, t.url, t.async, t.username, t.password), t.xhrFields) for (a in t.xhrFields) s[a] = t.xhrFields[a]; t.mimeType && s.overrideMimeType && s.overrideMimeType(t.mimeType), t.crossDomain || i["X-Requested-With"] || (i["X-Requested-With"] = "XMLHttpRequest"); for (a in i) s.setRequestHeader(a, i[a]); n = function (e) { return function () { n && (n = r = s.onload = s.onerror = s.onabort = s.ontimeout = s.onreadystatechange = null, "abort" === e ? s.abort() : "error" === e ? "number" != typeof s.status ? o(0, "error") : o(s.status, s.statusText) : o(Vt[s.status] || s.status, s.statusText, "text" !== (s.responseType || "text") || "string" != typeof s.responseText ? { binary: s.response } : { text: s.responseText }, s.getAllResponseHeaders())) } }, s.onload = n(), r = s.onerror = s.ontimeout = n("error"), void 0 !== s.onabort ? s.onabort = r : s.onreadystatechange = function () { 4 === s.readyState && e.setTimeout(function () { n && r() }) }, n = n("abort"); try { s.send(t.hasContent && t.data || null) } catch (e) { if (n) throw e } }, abort: function () { n && n() } } }), w.ajaxPrefilter(function (e) { e.crossDomain && (e.contents.script = !1) }), w.ajaxSetup({ accepts: { script: "text/javascript, application/javascript, application/ecmascript, application/x-ecmascript" }, contents: { script: /\b(?:java|ecma)script\b/ }, converters: { "text script": function (e) { return w.globalEval(e), e } } }), w.ajaxPrefilter("script", function (e) { void 0 === e.cache && (e.cache = !1), e.crossDomain && (e.type = "GET") }), w.ajaxTransport("script", function (e) { if (e.crossDomain) { var t, n; return { send: function (i, o) { t = w("
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Following the 1st International workshop on Benchmarking RDF Systems (BeRSys 2013) the aim of the BeRSys 2014 workshop is to provide a discussion forum where researchers and industrials can meet to discuss topics related to the performance of RDF systems. BeRSys 2014 is the only workshop dedicated to benchmarking different aspects of RDF engines - in the line of TPCTC series of workshops.The focus of the workshop is to expose and initiate discussions on best practices, different application needs and scenarios related to different aspects of RDF data management.
+More at: http://events.sti2.at/bersys2014/
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+  +
+