title : Data Munging in Python using Pandas description : Pandas is at the heart of data analysis in Python. This chapter gets you started with Data Munging in Python using Pandas
--- type:NormalExercise lang:python xp:100 skills:2, 4, 8 key:af2f6f90f3
Rarely is the data captured perfectly in real world. People might not disclose few details or those details might not be available in the first place. This data set is no different. There are missing values in variables.
We need to first find out which variables have missing values, and then see what is the best way to handle these missing values. The way to handle a missing value can depend on the number of missing values, the type of variable and the expected importance of those variables.
So, let's start by finding out whether variable "Credit_history" has missing values or not and if so, how many observations are missing.
train['Credit_History'].isnull().sum()
- isnull() helps to check the observation has missing value or not (It returns a boolean value TRUE or FALSE)
- sum() used to return the number of records have missing values
*** =instructions
- Apply isnull() to check the observation has null value or not
- Check number of missing values is greater than 0 or not
*** =hint Use sum() with train['Self_Employed'].isnull() to check number of missing values
*** =pre_exercise_code
# The pre-exercise code runs code to initialize the user's workspace. You can use it for several things:
# Import library pandas
import pandas as pd
# Import training file
train = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/train.csv")
# Import testing file
test = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/test.csv")
*** =sample_code
# How many missing values in variable "Self_Employed" ?
n_missing_value_Self_Employed = train['Self_Employed']._____.sum()
# Variable Loan amount has missing values or not?
LoanAmount_have_missing_value = train['LoanAmount'].isnull().sum() > ____
*** =solution
# How many missing values in variable "Self_Employed" ?
n_missing_value_Self_Employed = train['Self_Employed'].isnull().sum()
# Variable Loan amount has missing values or not?
LoanAmount_have_missing_value = train['LoanAmount'].isnull().sum() > 0
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package. Documentation can also be found at github.com/datacamp/pythonwhat/wiki
# How many missing values in variable "Self_Employed" ?
test_object("n_missing_value_Self_Employed", incorrect_msg='Have you checked the missing values?')
# Variable Loan amount has missing values or not?
test_object("LoanAmount_have_missing_value", incorrect_msg='Have you checked the column has missing value or not?')
success_msg("Great work!")
--- type:NormalExercise lang:python xp:100 skills:2, 4, 8 key:4abbcb0b8d
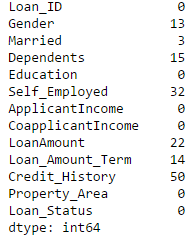
Till now, we have checked the variable has missing value or not? Next action is to check how many variables have missing values. One way of doing this check would be to evaluate each individual variable. This would not be easy if we have hundred of columns. This action can be performed simply by using isnull() on dataframe object.
train.isnull().sum()
This statement will return the column names with the number of observation that have missing (null) values.
*** =instructions Apply isnull().sum() with test dataset
*** =hint Use train.isnull().sum() to check number of missing values in train data set
*** =pre_exercise_code
# The pre-exercise code runs code to initialize the user's workspace. You can use it for several things:
# Import library pandas
import pandas as pd
# Import training file
train = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/train.csv")
# Import testing file
test = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/test.csv")
*** =sample_code
# Check variables have missing values in test data set
number_missing_values_test_data = test.isnull()._____()
*** =solution
# Check variables have missing values in test data set
number_missing_values_test_data = test.isnull().sum()
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package. Documentation can also be found at github.com/datacamp/pythonwhat/wiki
# Check variables have missing values in test data set
test_object("number_missing_values_test_data", incorrect_msg='Have you count the number of missing values in each variable of test data set?')
success_msg("Great work!")
--- type:NormalExercise lang:python xp:100 skills:2, 4, 8 key:fd3cdcb726
There are multiple ways to fill the missing values of continuous variables. You can replace them with mean, median or estimate values based on other features of the data set.
For the sake of simplicity, we would impute the missing values of LoanAmount by mean value (Mean of available values of LoanAmount).
train['LoanAmount'].fillna(train['LoanAmount'].mean(), inplace=True)
*** =instructions Impute missing values with a specific value 168
*** =hint Use dataframe['missingcol'].fillna(225, inplace=True) to impute missing value of column 'missingcol' with 225
*** =pre_exercise_code
# The pre-exercise code runs code to initialize the user's workspace. You can use it for several things:
# Import library pandas
import pandas as pd
# Import training file
train = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/train.csv")
# Import testing file
test = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/test.csv")
*** =sample_code
# Impute missing value of LoanAmount with 168 for test data set
test['LoanAmount'].fillna(______, inplace=True)
*** =solution
# Impute missing value of LoanAmount with 168 for test data set
test['LoanAmount'].fillna(168, inplace=True)
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package. Documentation can also be found at github.com/datacamp/pythonwhat/wiki
# Impute missing value of LoanAmount with 168 for test data set
test_data_frame("test", columns=["LoanAmount"], incorrect_msg='Did you impute missing value with 168?')
success_msg("Great work!")
--- type:NormalExercise lang:python xp:100 skills:2, 4, 8 key:ca19896cae
Similarly, to impute missing values of Categorical variables, we look at the frequency table. The simplest way is to impute with value which has highest frequency because there is a higher probability of success.
For example, if you look at the distribution of SelfEmployed 500 out of 582 which is ~86% of total values falls under the category "No". Here we will replace missing values of SelfEmployed with "No".
train['Self_Employed'].fillna('No',inplace=True)
*** =instructions
- Impute missing values with more frequent category of Gender and Credit History
- Use value_counts() to check more frequent category of variable
*** =hint
- Male is more frequent in Gender
- 1 is more frequent in Credit_History
*** =pre_exercise_code
# The pre-exercise code runs code to initialize the user's workspace. You can use it for several things:
# Import library pandas
import pandas as pd
# Import training file
train = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/train.csv")
# Import testing file
test = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/test.csv")
*** =sample_code
# Impute missing value of Gender (Male is more frequent category)
train['Gender'].fillna(_____,inplace=True)
# Impute missing value of Credit_History ( 1 is more frequent category)
train['Credit_History'].fillna(_____,inplace=True)
*** =solution
# Impute missing value of LoanAmount with median for test data set
train['Gender'].fillna('Male',inplace=True)
# Impute missing value of Credit_History
train['Credit_History'].fillna(1,inplace=True)
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package. Documentation can also be found at github.com/datacamp/pythonwhat/wiki
# Impute missing value of LoanAmount with median for test data set
test_data_frame("train", columns=["Gender"], incorrect_msg='Did you impute missing value of Gender with Male?')
# Impute missing value of Credit_History
test_data_frame("train", columns=["Credit_History"], incorrect_msg='Did you impute missing value of Credit_History with 1?')
success_msg("Great work!")
--- type:NormalExercise lang:python xp:100 skills:2, 4, 8 key:2607b0ce32
Let’s analyze LoanAmount first. Since the extreme values are practically possible, i.e. some people might apply for high-value loans due to specific needs.
train ['LoanAmount'].hist(bins=20)
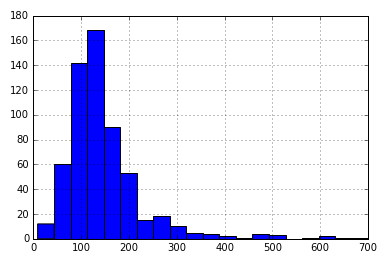
So instead of treating them as outliers, let’s try a log transformation to nullify their effect:
import numpy as np
train ['LoanAmount_log'] = np.log(train['LoanAmount'])
train ['LoanAmount_log'].hist(bins=20)
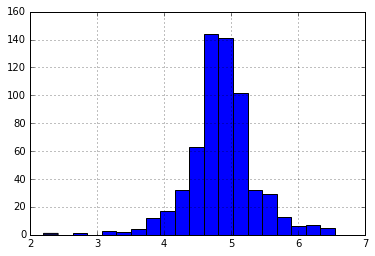
Now the distribution looks much closer to normal and effect of extreme values has been significantly subsided.
*** =instructions
- Add both ApplicantIncome and CoapplicantIncome as TotalIncome
- Take log transformation of TotalIncome to deal with extreme values
*** =hint
- Add both train['ApplicantIncome'] and train['CoapplicantIncome']
- Take log of df['TotalIncome']
*** =pre_exercise_code
# The pre-exercise code runs code to initialize the user's workspace. You can use it for several things:
# Import library pandas
import pandas as pd
import numpy as np
# Import training file
train = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/train.csv")
# Import testing file
test = pd.read_csv("https://s3-ap-southeast-1.amazonaws.com/av-datahack-datacamp/test.csv")
train['TotalIncome'] = train['ApplicantIncome'] + train['CoapplicantIncome']
*** =sample_code
# Training and Testing datasets are loaded in variable train and test dataframe respectively
# Add both ApplicantIncome and CoapplicantIncome to TotalIncome
train['TotalIncome'] = train['ApplicantIncome'] + train[_________]
# Perform log transformation of TotalIncome to make it closer to normal
train['TotalIncome_log']= np.____(train['TotalIncome'])
*** =solution
# Training and Testing datasets are loaded in variable train and test dataframe respectively
# Add both ApplicantIncome and CoapplicantIncome to TotalIncome
train['TotalIncome'] = train['ApplicantIncome'] + train['CoapplicantIncome']
# Perform log transformation of TotalIncome to make it closer to normal
train['TotalIncome_log'] = np.log(train['TotalIncome'])
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package. Documentation can also be found at github.com/datacamp/pythonwhat/wiki
# Add both ApplicantIncome and CoapplicantIncome to TotalIncome
test_data_frame("train", columns=["TotalIncome"], incorrect_msg='Have you added both ApplicantIncome and CoapplicantIncome?')
# Perform log transformation of TotalIncome to make it closer to normal
test_data_frame("train", columns=["TotalIncome_log"], incorrect_msg='Have you taken log of TotalIncome?')
success_msg("Great work!")
--- type:MultipleChoiceExercise lang:python xp:50 skills:2 key:9a8fd577a9
The Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, machine learning and much more.
We have shared the Jupyter notebook for your reference here
Download the jupyter notebook from here. Have you downloaded the jupyter notebook?
*** =instructions
- Yes, I have downloaded the notebook
- No, I am not able to
*** =hint Click on the link and download the Jupyter notebook.
*** =sct
# The sct section defines the Submission Correctness Tests (SCTs) used to
# evaluate the student's response. All functions used here are defined in the
# pythonwhat Python package
msg1 = "Awesome! You can proceed to model building now!"
msg2 = "Check the link provided and download the file from there."
# Use test_mc() to grade multiple choice exercises.
# Pass the correct option (Action, option 2 in the instructions) to correct.
# Pass the feedback messages, both positive and negative, to feedback_msgs in the appropriate order.
test_mc(1, [msg1, msg2])