- Single responsibility principle simply means giving only one responsibility to a component and letting it execute it perfectly, be it saving data, running the application logic or ensuring the delivery of the messages throughout the system. This approach gives us a lot of flexibility and makes management easier.
- Separation of concerns kind of means the same thing, be concerned about your work only and stop worrying about the rest of the stuff. Keeping the components separate makes them reusable.
REST stands for Representational State Transfer. It’s a software architectural style for implementing web services. Web services implemented using the REST architectural style are known as the RESTful Web services.
REST为表现层状态转换,是一种构建网络服务的软件架构风格,符合这种风格的网络服务就叫RESTful网络服务
- Requirements clarifications. 明确需求
- Back-of-the-envelope estimation.It is always a good idea to estimate the scale of the system we’re going to design. 粗略评估
- System interface definition.Define what APIs are expected from the system. 定义系统接口
- Defining data model.The ata model will clarify how data will flow between different system components. Later, it will guide for data partitioning and management.(e.g. storage, transportation, encryption)定义数据模型
- High-level design.Design the core components of our system.We should identify enough components that are needed to solve the actual problem from end to end.
- Detailed design.There is no single answer,the only important thing is to consider Tradeoffs between different options while keeping system constraints in mind.细节设计
- Identifying and resolving bottlenecks.找到并解决系统瓶颈
- Is there any single point of failure in our system.
- How are we monitoring the performance of our service.
- Scalability
- Horizontal: add more servers. scale by adding more servers into pool of resources. 水平增加机器
- Vertical: add more resources to the same server. scale by adding more power (CPU, RAM, Storage, etc.) to an existing server. 提高单机性能
- Reliability.keeps delivering its services even when one or several of its software or hardware components fail
- Availability.is the percentage of time that some service or infrastructure is accessible to clients and is operated upon under normal conditions.
- Efficiency.
- response time (or latency) that denotes the delay to obtain the first item
- the throughput (or bandwidth) which denotes the number of items delivered in a given time unit (e.g., a second)
- Manageability.how easy it is to operate and maintain
- Write-through cache: Under this scheme, data is written into the cache and the corresponding database simultaneously. 缓存与库同时写
- we will have complete data consistency between the cache and the storage.
- this scheme has the disadvantage of higher latency for write operations.
- Write-around cache: This technique is similar to write-through cache, but data is written directly to permanent storage, bypassing the cache.只写库不写缓存
- This can reduce the cache being flooded with write operations that will not subsequently be re-read
- disadvantage that a read request for recently written data will create a “cache miss” and must be read from slower back-end storage and experience higher latency.
- Write-back cache: Data is written to cache alone, and completion is immediately confirmed to the client.The write to the permanent storage is done after specified intervals or under certain conditions.只写缓存不写库
- low-latency and high-throughput for write-intensive applications.
- risk of data loss because the only copy of the written data is in the cache.
- First In First Out (FIFO): The cache evicts the first block accessed first without any regard to how often or how many times it was accessed before.
- Last In First Out (LIFO): The cache evicts the block accessed most recently first without any regard to how often or how many times it was accessed before.
- Least Recently Used (LRU): Discards the least recently used items first.
- Most Recently Used (MRU): Discards, in contrast to LRU, the most recently used items first.
- Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
- Random Replacement (RR): Randomly selects a candidate item and discards it to make space when necessary.
- man errno
- EAGAIN Resource temporarily unavailable (may be the same value as EWOULDBLOCK) (this error can be ignore e.g. ZeroMQ).
- EWOULDBLOCK Operation would block (may be same value as EAGAIN) (POSIX.1-2001).
###Debug
- C++服务调试工具及步骤【无需coredump文件生成】
- 涉及工具 gdb、addr2line、objdump、objcopy、valgrind等。
- 服务编译时增加指定编译选项 -O0 -g -rdynamic -fPIC 。编译优化要关闭
- 单独线程内开启 ::backtrace(frame, max_frames)、::backtrace_symbols(frame, nptrs)等保证有问题 能输出必要信息
- objdump -Slt mian 打印服务相关汇编信息。
- addr2line -fCe main 0xfff(由backtrace生成的 相关地址信息) 打印运行当前输出的内容
- A high-performance asynchronous messaging library,It provides a message queue.
- ZeroMQ supports common messaging patterns (pub/sub, request/reply, client/server and others) over a variety of transports (TCP, in-process, inter-process, multicast, WebSocket and more), making inter-process messaging as simple as inter-thread messaging.
- The inter-process transport passes messages between local processes using a system-dependent IPC mechanism.
- The in-process transport passes messages via memory directly between threads sharing a single ØMQ context.
- A ZeroMQ message is a discrete unit of data passed between applications or components of the same application.
- Reactor is an event handling design pattern for handling service requests
Reactor是处理事件驱动的设计模式,用于同步的处理服务的高并发请求。 用来处理IO密集的高性能网络服务的设计模式
- Resources: 任何能读写的文件资源。Any resource that can provide input to or consume output from the system.
- Synchronous Event Demultiplexer: 同步事件发生器。
- Dispatcher: 注册或注销请求,并将I/O从事件发生器分发给指定处理程序。For registering, removing, and dispatching Event Handlers. Handles registering and unregistering of request handlers. Dispatches resources from the demultiplexer to the associated request handler.
- Request Handler: I/O处理程序。 An application defined request handler and its associated resource.
- Proactor 也是处理事件驱动的设计模式,相当于Reactor的异步版本。是Asynchronous Event demultiplexer异步事件发生器。Proactor is a software design pattern for event handling in which long running activities are running in an asynchronous part.
- 序号发生器 INCR key
- 滑动窗口 API限流(使用Sorted Set配合zadd,zremrankbyscore,zcard)
AOF(Append Only File)通过保存Redis的写命令来保存数据库状态。具体通过命令追加、文件写入同步三个步骤实现持久化
命令追加: 每个写命令都会以协议格式追加到aof_buf缓冲区。
文件写入同步:Redis服务进程就是一个事件循环,处理文件事件、时间事件等。在写的文件事件循环结束前,都会调用flushAOF函数来将aof_buf中的数据写入和保存到
AOF文件中。同时根据appedfsync选项对写入命令进行实际文件同步落盘操作。
- appendfsync: always(可能丢失一个事件内的的所有写命令)、everysec(会丢失一秒钟数据)、no(文件同步操作由操作系统决定,Redis重启会丢失数据)
- AOF有文件重写功能以压缩日益膨胀的aof文件体积
- AOF保存写命令过程,数据恢复速度较慢
RDB(Redis Data Binary)使用键值对的压缩二进制文件保存数据库状态。
- 通过SAVE和BGSAVE两种命令创建RDB文件,前者创建时会阻塞工作进程,而后者则另起一个子进程做创建工作不会阻塞Redis工作进程。
- Redis周期性操作函数serverCron,定期检查是否满足RDB操作条件(save 600 3. 600秒内至少操作了3次修改)。如果满足则进行RDB相关操作。类似定时器操作所以较容易丢失数据
- RDB紧凑的单文件保存数据快照,易于传输且数据恢复速度快
- In theory, for asynchronous replication, there is no guarantee to prevent data loss. 理论上,异步数据复制无法保证数据不丢失
- However, this is an extremely low probability scenario as described above.但是可以极大减少出现的概率
- 数据丢失问题。如Svr1 和 Svr2通过redis list结构互联,Svr1push 到list里。 Svr2从list里pop数据。现在Svr2没收到某个数据,Svr1认为已经写入redis了。问Svr1 和 Svr2 怎么定位具体问题。{查看rdb 或者 aof文件即可。}
- 一份变量 一线程写 多线程读。 怎样保证正确读写操作。
- Difference between a
Referencevariable and aPointerin C++? A pointer stores the address of the variable whereas a reference variable is just an alias for that variable.
- Factory Method Pattern is defined as providing an interface for object creation but delegating the actual instantiation of objects to subclasses.工厂模式 为对象的创建提供一个接口,但将对象实例化委托给子类。
- Abstract factory pattern is defined as defining an interface to create families of related or dependent objects without specifying their concrete classes. 虚拟工厂模式 定义一个接口来创建相关或依赖对象的家族,而不用指定它们的具体类。
- Observer Pattern is defined as a one to many dependency between objects so that when one object changes state all the dependents are notified.观察者模式 定义了一对多的类关系。当一个subject状态发生变化时,所有observe能够感知到。
- State Pattern is defined as allowing an object to alter behavior when its internal state changes so that it appears to change its class. 状态模式 允许对象在其内部状态发生变化时,改变其行为。看上去就像改变了自身所属类一样。
- Prototype Pattern is a creational design pattern that lets you copy existing objects without making your code dependent on their classes.是一种创建模式。允许在不依赖其他类的前提下复制此类对象。
- Adapter Pattern is defined as allowing incompatible classes to work together by converting the interface of one class into another expected。适配器模式 让多个不兼容的类可以共同工作。

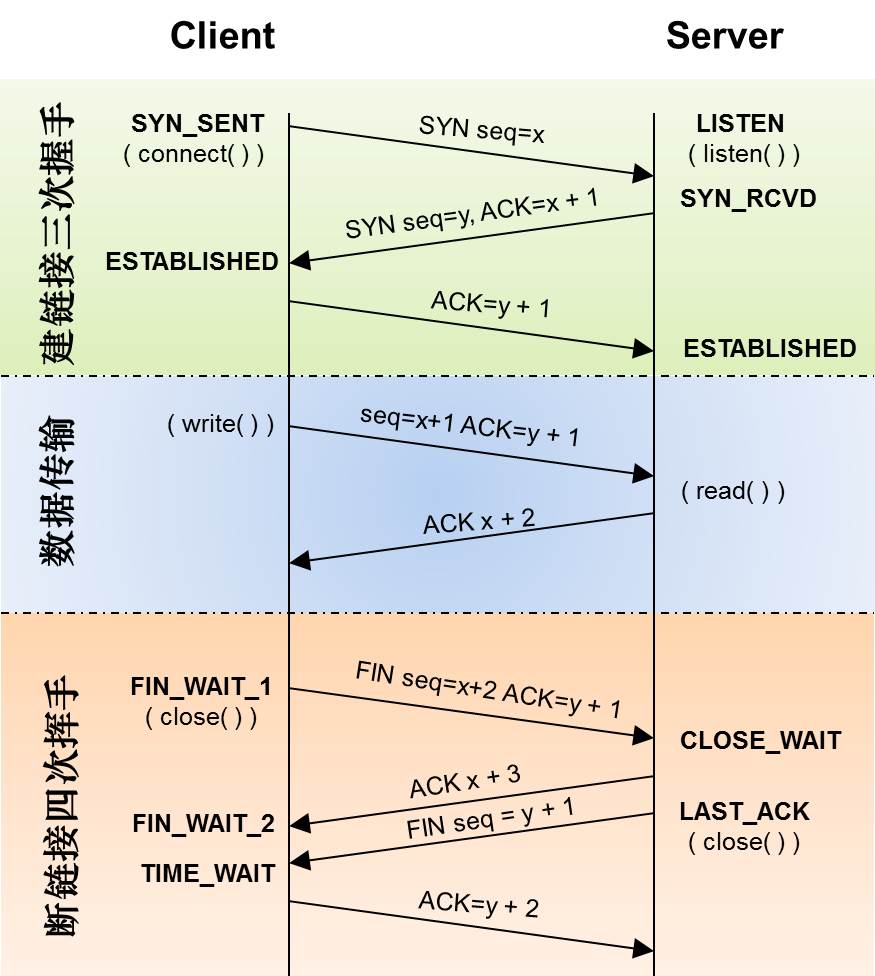
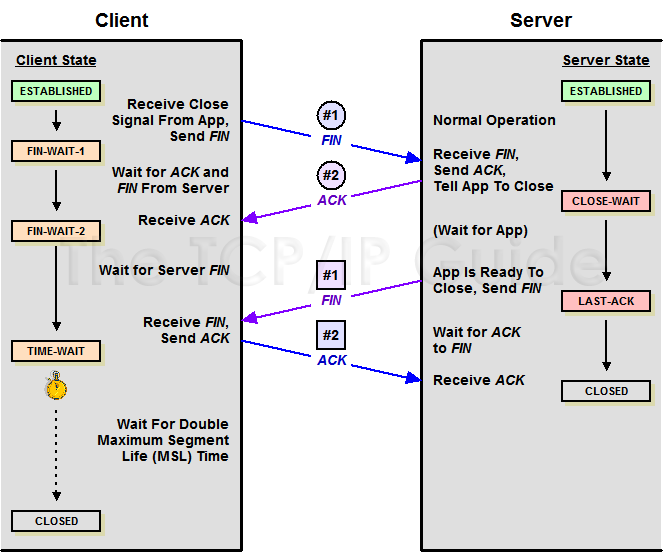
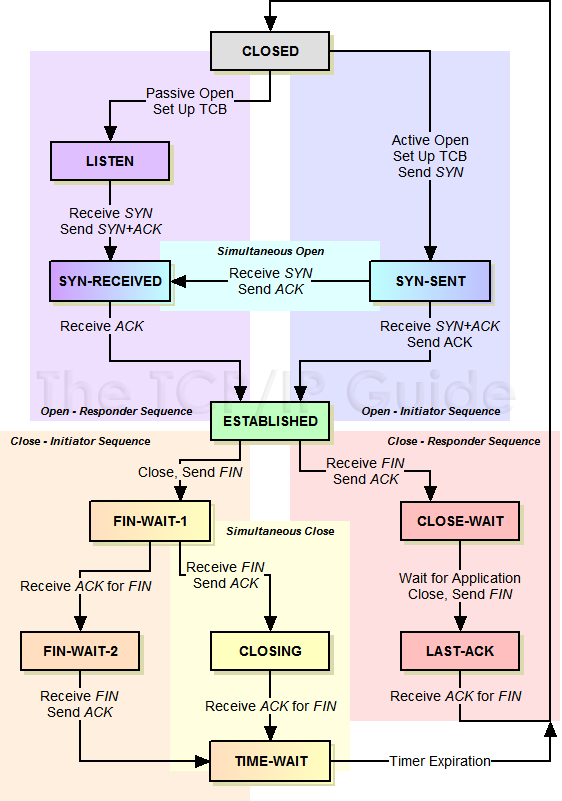
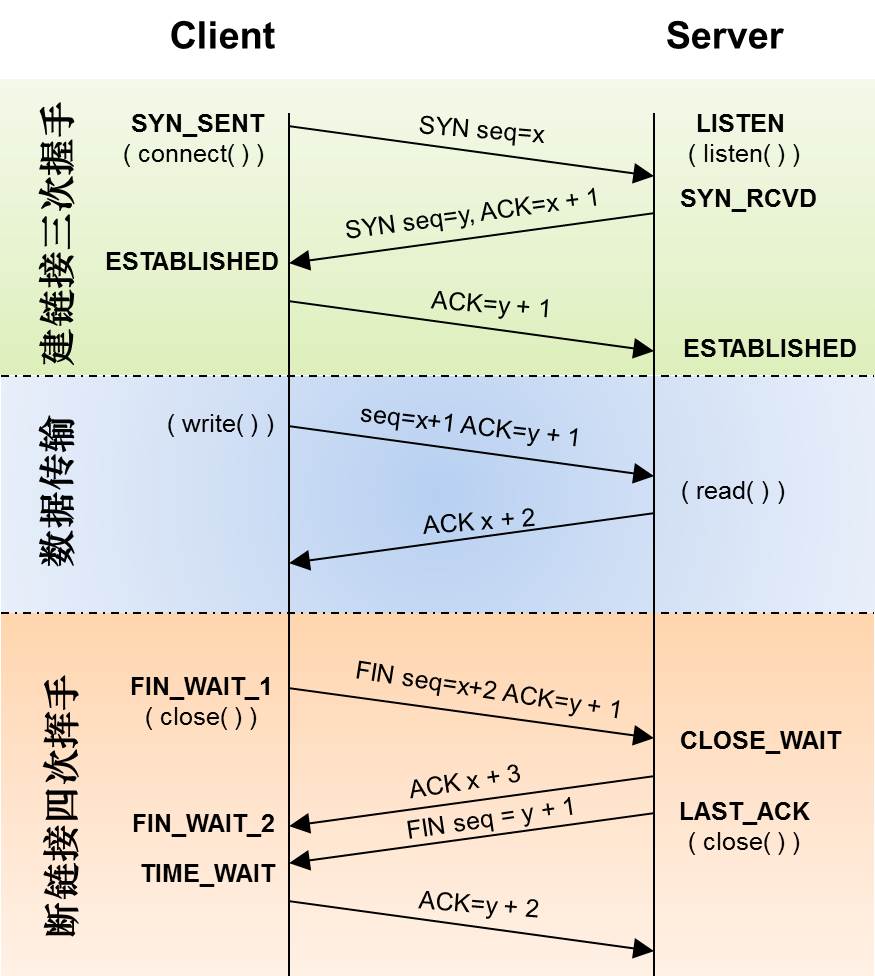
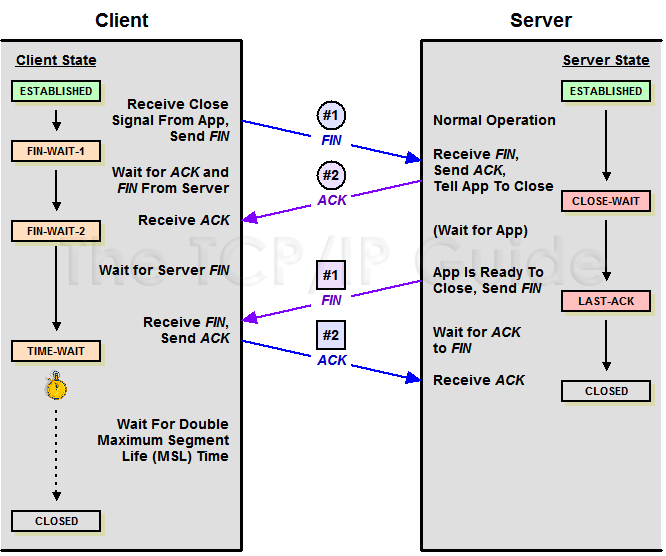
- 从TIME_WAIT状态到CLOSED状态,有一个超时设置是 2*MSL(RFC793)为什么要这有TIME_WAIT?为什么不直接给转成CLOSED状态呢?主要有两个原因:
- 1)TIME_WAIT确保有足够的时间让对端收到ACK,能够安全正确的关闭双全工TCP连接。如果被动关闭的那方没有收到ACK就会触发被动端重发FIN,一来一去正好2个MSL。
- 2)防止旧链接的迷走segment(e.g. 迷走就是由于路由协议的问题,TCP分组被路由器A转发给路由器B,随后又被路由器B转发给路由器A),影响新连接(新旧链接相同四元组)。
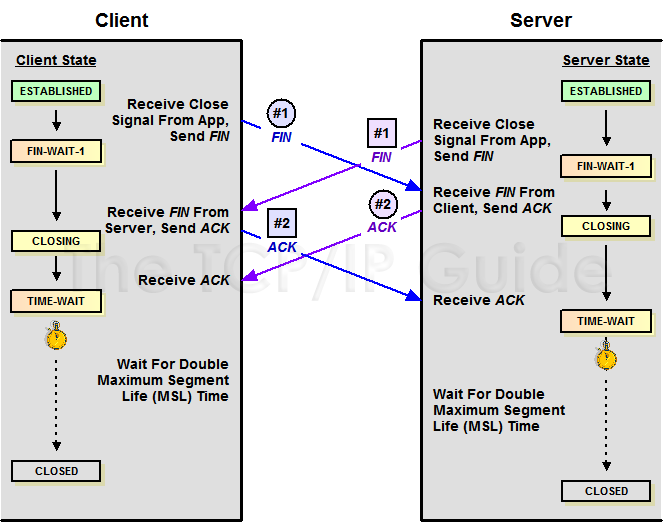
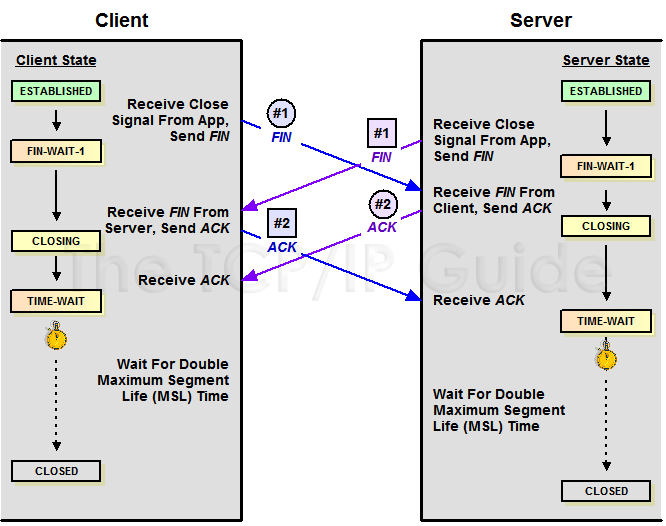
- 如果两边同时断连接,那两边就都会就进入到CLOSING状态,然后到达TIME_WAIT状态。下图是双方同时断连接的示意图。
How does HTTPS work?
Hypertext Transfer Protocol Secure (HTTPS) is an extension of the Hypertext Transfer Protocol (HTTP.) HTTPS transmits encrypted data using Transport Layer Security (TLS.) If the data is hijacked online, all the hijacker gets is binary code.
Step 1 - The client (browser) and the server establish a TCP connection.创建TCP连接
Step 2 - The client sends a “client hello” to the server. The message contains a set of necessary encryption algorithms(cipher suites) , the latest TLS version it can support and client random.
The server responds with a “server hello” so the browser knows whether it can support the algorithms(cipher algorithms) and TLS version and server random.The server then sends the SSL certificate to the client. The certificate contains the public key, host name, expiry dates, etc. The client validates the certificate.客户端与服务段相互发送hello,用以确定加密算法和TLS版本。确定好后服务段发送证书给客户端,证书中包含公钥、过期时间和域名。
Step 3 - After validating the SSL certificate, the client generates a pre-master secret and encrypts it using the public key. The server receives the encrypted pre-master secret and decrypts it with the private key.客户端校验完证书正确后生成pre-master secret,并用证书加密后发给服务端,服务端用私钥解密得到pre-master secret。
Step 4 - Now both the client and the server calculate the session key (symmetric encryption) using the client random, server random, and the pre-master secret. They both will obtain the same session key. The encrypted data is transmitted in a secure bi-directional channel.客户端和服务端通过session key对数据进行对称加密。
Why does HTTPS switch to symmetric encryption during data transmission? There are two main reasons:
- Security: The asymmetric encryption goes only one way. This means that if the server tries to send the encrypted data back to the client, anyone can decrypt the data using the public key.
- Server resources: The asymmetric encryption adds quite a lot of mathematical overhead. It is not suitable for data transmissions in long sessions.
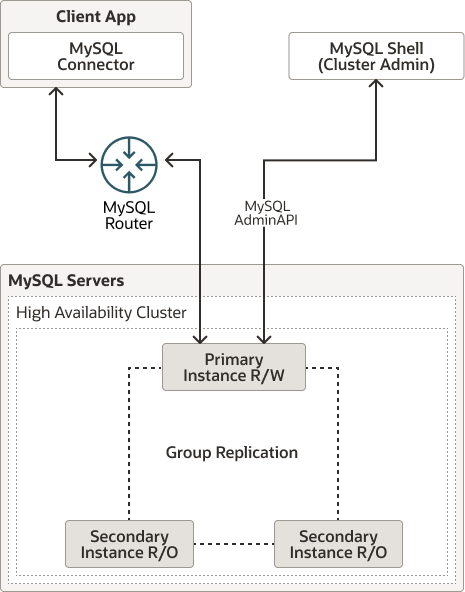
- MySQL InnoDB Cluster provides a complete high availability solution for MySQL. Each MySQL server instance in an InnoDB Cluster runs MySQL Group Replication, which provides the mechanism to replicate data within an InnoDB Cluster, with built-in failover.
- MySQL Router can automatically configure itself based on the cluster you deploy, connecting client applications transparently to the server instances.
- In the default Single-Primary mode, an InnoDB Cluster has a single Read-Write server instance - the Primary. Multiple secondary server instances are replicas of the primary. If the primary fails, a secondary is automatically promoted to the role of primary.
- follow diagram show an overview of how the technologies work together:
- MySQL Master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL Slave 向Master发送dump协议,Master收到dump请求后向Slave推送bin log。
- MySQL Slave 将binary log events 拷贝到它的中继日志(Relay log)。
- MySQL Slave 重放 relay log 中事件,将数据变更反映它自己的数据。
Indexes are a data structure that helps decrease the look-up time of requested data.
- Consistency ( C ): All users see the same data at the same time.
- Availability ( A ): System continues to function even with node failures.
- Partition tolerance ( P ): System continues to function even if the communication fails between nodes.
Replication refers to keeping multiple copies of the data at various nodes (preferably geographically distributed) to achieve availability, scalability, and performance.
Additional complexities that could arise due to replication are as follows:
- How do we keep multiple copies of data consistent with each other?
- How do we deal with failed replica nodes?
- Should we replicate synchronously or asynchronously?
- How do we deal with replication lag in case of asynchronous replication?
- How do we handle concurrent writes?
- What consistency model needs to be exposed to the end programmers?
- Single leader or primary-secondary replication
In primary-secondary replication, data is replicated across multiple nodes. One node is designated as the primary. It’s responsible for processing any writes to data stored on the cluster. It also sends all the writes to the secondary nodes and keeps them in sync.Primary-secondary replication is appropriate when our workload is read-heavy.
There are many different replication methods in primary-secondary replication:
- Statement-based replication
- Write-ahead log (WAL) shipping
- Logical (row-based) replication
- Multi-leader replication There are multiple primary nodes that process the writes and send them to all other primary and secondary nodes to replicate. Multi-leader replication gives better performance and scalability than single leader replication, but it also has a significant disadvantage. Since all the primary nodes concurrently deal with the write requests, they may modify the same data, which can create a conflict between them. For example, suppose the same data is edited by two clients simultaneously. In that case, their writes will be successful in their associated primary nodes, but when they reach the other primary nodes asynchronously, it creates a conflict. There are many topologies through which multi-leader replication is implemented, The most common is the all-to-all topology. - circular topology - star topology - all-to-all topology
- Peer-to-peer or leaderless replication
The act of distributing data across a set of nodes is called data partitioning.
- Vertical sharding
We might break a table into multiple tables so that some columns are in one table while the rest are in the other. Often, vertical sharding is used to increase the speed of data retrieval from a table consisting of columns with very wide text or a binary large object (blob). In this case, the column with large text or a blob is split into a different table.
- Horizontal sharding
- Key-range based sharding In the key-range based sharding, each partition is assigned a continuous range of keys.
Sometimes, a database consists of multiple tables **bound by foreign key relationships**. In such a case, the horizontal partition is performed using the same partition key on all tables in a relation. Tables (or subtables) that belong to the same partition key are distributed to one database shard. The following figure shows that several tables with the same partition key are placed in a single database shard:

- Hash based sharding Consistent Hash: is a special kind of hashing such that when a hash table is re-sized and consistent hashing is used, only
$k/n$ keys need to be remapped on average, where$k$ is the number of keys, and$n$ is the number of slots(Each slot is represented by a server in a distributed system or cluster).一致哈希是一个hash环,key映射到环的某个位置后,由指定的node(也就是服务器)负责。当node增加或删除后
- only a small set of keys move when servers are added or removed.
- This scheme can result in non-uniform data and load distribution(HotKeys).First, it is impossible to keep the same size of partitions on the ring for all servers considering a server can be added or removed.Second, it is possible to have a non-uniform key distribution on the ring. However solves these issues with the help of Virtual Nodes.Adding replicas reduces the load on hot shards. Another way to handle the hotkeys problem is to do further sharding within the range of those keys. 增加slot可以缓解热key的问题,还有一种方法就是为每个key继续划分virtual node。为每个slot 继续划分 virtual node,数据通过哈希值分配至对应virtual node后进而找到真实slot node。当slot失效后多个virtual也失效,从而使多个相邻真实slot节点负载失效节点压力。当然virtual node数量远远大于 slot node数量从而使压力基本均衡。


Rate limiter is used to control the rate of traffic sent by a client or a service.
**Rule database**: This is the database, consisting of rules defined by the service owner. Each rule specifies the number of requests allowed for a particular client per unit of time. **Rules retriever**: This is a background process that periodically checks for any modifications to the rules in the database. The rule cache is updated if there are any modifications made to the existing rules. **Throttle rules cache**: The cache consists of rules retrieved from the rule database. The cache serves a rate-limiter request faster than persistent storage. As a result, it increases the performance of the system. So, when the rate limiter receives a request against an ID (key), it checks the ID against the rules in the cache. **Decision-maker**: This component is responsible for making decisions against the rules in the cache. This component works based on one of the rate-limiting algorithms that are token bucket,leaking bucket etc. **Client identifier builder**: This component generates a unique ID for a request received from a client. This could be a remote IP address, login ID, or a combination of several other attributes, due to which a sequencer can’t be used here. This ID is considered as a key to store the user data in the key-value database. So, this key is passed to the decision-maker for further service decisions.

Include Token bucket, Leaking bucket, Fixed window counter, Sliding window log, Sliding window counter.
Sliding Windows with Redis backend. (使用Sorted Set配合zadd,zremrankbyscore,zcard)实现全局限流器。Local rate limiting can be used in conjunction with global rate limiting to reduce load on the global rate limit service. Thus, the rate limit is applied in two stages. The initial coarse grained limiting is performed by the token bucket limit before a fine grained global limit finishes the job.可以配合本地限流器吸收绝大部分流量以保护全局限流器。所以限流器可以用两步实现。在细颗粒度的全局限流器完成工作之前,初始的粗颗粒度的限制由令牌桶执行。
Token Bucket algorithm can sometimes suffer from overrunning the limit at the edges. 会出现边界超限的问题. Token Bucket with Redis

- A client has to send 18 MB of data at a rate of 6 Mbps (megabits per second) to a server. Let’s assume that the server processes data at a rate of 4 Mbps. If the leaky bucket algorithm is used at the server end, how much capacity must the queue hold so as not to discard any data? seconds taken to transmit
$18MB$ :$18MB / 6Mbps = 24s$ , server can process data in$24s$ :$4Mbps * 24s = 12MB$ . bucket queue size:$18MB - 12MB = 6MB$.- In the event of a failure where a rate limiter is unable to perform the task of throttling, the request should be accepted. This approach ensures that the system remains available and fault-tolerant, adhering to non-functional requirements. It’s important because there are usually multiple rate limiters at different service levels, and even if a specific rate limiter fails, other mechanisms like load balancers can still manage the load to some extent. However, it’s crucial for the engineering team to quickly address the failure, as rate limiting is a critical component of a system’s infrastructure to prevent overloading.

RPC (Remote Procedure Call) is called “𝐫𝐞𝐦𝐨𝐭𝐞” because it enables communications between remote services when services are deployed to different servers. From the user’s point of view, it acts like a local function call.让远程服务器上的不同服务间进行通讯,从用户角度看就像调用本地函数一样。


Kafka was created at LinkedIn around 2010 to track various events, such as page views, messages from the messaging system, and logs from various services. A Kafka server is called Broker. Brokers are responsible for reliably storing data provided by the producers and making it available to the consumers.Kafka divides its messages into categories called Topics. In simple terms, a topic is like a table in a database, and the messages are the rows in that table.As topics can get quite big, they are split into partitions of a smaller size for better performance and scalability.Kafka guarantees that all messages inside a partition are stored in the sequence they came in. Ordering of messages is maintained at the partition level, not across the topic.By using consumer groups, consumers can be parallelized so that multiple consumers can read from multiple partitions on a topic, allowing a very high message processing throughput.
A leader is the node responsible for all reads and writes for the given partition. Every partition has one Kafka broker acting as a leader.To handle single point of failure, Kafka can replicate partitions and distribute them across multiple broker servers called followers.
To handle split-brain (where we have multiple active controller brokers), Kafka uses ‘epoch number,’ which is simply a monotonically increasing number to indicate a server’s generation.This epoch is included in every request that is sent from the Controller to other brokers.This way, brokers can easily differentiate the real Controller by simply trusting the Controller with the highest number. This epoch number is stored in ZooKeeper.
- How can a producer know that the data is successfully stored at the leader or that the followers are keeping up with the leader?生产者保证数据写入成功的几种方式
Async: Producer sends a message to Kafka and does not wait for acknowledgment from the server. Committed to Leader: Producer waits for an acknowledgment from the leader. Committed to Leader and Quorum: Producer waits for an acknowledgment from the leader and the quorum.
- What message-delivery guarantees does Kafka provide to consumers? kafka怎样保证消费者消费到数据。
At-most-once: Messages may be lost but are never redelivered.Consumers commit message offsets before they process them.消费者先commit offset再处理消息。 At-least-once: Messages are never lost but may be redelivered.Consumer can process the message first and then commit the offset. 消费者先处理消息再commit offset。 Exactly-once: Each message is delivered once and only once. Tags every message with a sequence number. In this way, the broker can keep track of the largest number per PID and reject duplicates.
- 消息的保序
- 消息的保持 事件回溯模式
Why is Kafka fast?

Quorum consensus can guarantee consistency for both read and write operations.The configuration of
$N$ = The number of replicas.$W$ = A write quorum of size$W$ . For a write operation to be considered as successful, write operation must be acknowledged from$W$ replicas.$R$ = A read quorum of size$R$ . For a read operation to be considered as successful, read operation must wait for responses from at least$R$ replicas.
Bloom Filter how to make a valid choice of parameter.here
$n$ number of items in the filter.$m$ number of bits in the filter.$k$ number of hash functions.$p$ probability of False Positives. fraction between 0 and 1 or a number indicating$1$ -in-$p$.
证券公司使用的核心交易系统,其基本的核心组件、数据流向、系统边界基本一致。通过系统的参考架构示意图,对核心交易系统进行整体说明。核心交易系统参考架构图,如图1。
 核心交易系统的核心组件包括接入网关、交易引擎、报盘通道、行情模块及账户、清算等,其中接入网关负责外围接入系统报入订单的接收及路由,交易引擎负责订单检查及处理,报盘通道将订单报送到交易所进行撮合处理,行情模块负责接收交易所行情信息并进行行情处理,账户、清算等模块负责开户、清算文件处理等。清算模块就是把交易的钱券算准确后更新到资金表和股份表,这一天交易就结束了。美股是上手IB,港股是CCASS,A股是中国登记结算中心。
核心交易系统的核心组件包括接入网关、交易引擎、报盘通道、行情模块及账户、清算等,其中接入网关负责外围接入系统报入订单的接收及路由,交易引擎负责订单检查及处理,报盘通道将订单报送到交易所进行撮合处理,行情模块负责接收交易所行情信息并进行行情处理,账户、清算等模块负责开户、清算文件处理等。清算模块就是把交易的钱券算准确后更新到资金表和股份表,这一天交易就结束了。美股是上手IB,港股是CCASS,A股是中国登记结算中心。