![]()
![]()
A Minecraft server written in COBOL. It supports Minecraft 1.21.4 (the latest version at time of writing).
- +The following features are already working:
- infinite terrain generation and dynamic chunk loading @@ -50,7 +50,7 @@
- trapdoors (including interaction)
- beds
A Minecraft server written in COBOL
CobolCraft was developed using GnuCOBOL and is meant to be run on Linux. Support for other operating systems such as Windows has not been tested. However, it is possible to use Docker for a platform-independent deployment.
@@ -101,7 +101,7 @@A Minecraft server written in COBOL
To make it accessible from the outside (your local network, via VPN, port forwarding, on a rented server, ...), you can start the Docker container like this:docker run --rm -it -p 0.0.0.0:25565:25565 meyfa/cobolcraft
Well, there are quite a lot of rumors and stigma surrounding COBOL. This intrigued me to find out more about this language, which is best done with some sort of project, in my opinion. You heard right - I had no prior COBOL experience going into this.
@@ -115,18 +115,18 @@A Minecraft server written in COBOL
https://gnucobol.sourceforge.io/HTML/gnucobpg.htmlTo learn more about the Minecraft protocol, you can refer to https://wiki.vg/Protocol. In some cases, it may be helpful to look at real server traffic to better understand the flow of information.
- +This section provides a high-level overview of CobolCraft from a software design viewpoint.
- +The program entrypoint is main.cob.
The remaining COBOL sources are located in the src/ directory, including src/server.cob, which contains the bulk
of CobolCraft.
These sources are located in the cpp/ directory and get compiled into a shared library (.so on Linux).
TCP sockets are managed by the CBL_GC_SOCKET socket library located in the CBL_GC_SOCKET/ directory.
CobolCraft makes use of network data captured from an instance of the official server application via Wireshark.
This data is located in the blobs/ directory and is decoded at run-time.
The official Minecraft (Java Edition) server and client applications contain large amounts of data such as:
- block and item types @@ -137,7 +137,7 @@
- The content had become bloated with topics that weren't really suitable for beginner web developers — either they were too advanced, or they were out of scope altogether. +
- Beginners tend to want a robust pathway they can follow to get the knowledge they need, rather than being expected to figure out what to learn and when. +
- Learners these days tend to want interactive multimedia content, not just text. +
- The articles now follow the same structure as the curriculum, with useful background and environment setup information in Getting started, the web fundamentals everyone should know in Core, and optional extra topics in Extensions. There is a clear pathway to follow between each article in the first two major sections, so readers know what to learn next at each stage. +
- In some cases, content was deemed not suitable for a beginner audience and has been repurposed as extensions/additional articles or migrated to other parts of MDN. +
- The specific learning outcomes detailed in the curriculum have been added to the top of the Getting started, Core, and some of the Extension articles, to match the learning outcomes detailed in the Curriculum. +
- Other features from the Curriculum have been migrated across to the Learn Web Development section, such as the About page and Resources for educators. +
401for expired jwt token
+ 403for not enough access
+ 418for banned users
+401is for expired jwt token //🧠+, ok just temporary remember it
+ 403is for not enough access //🧠++
+ 418is for banned users //🧠+++
+- Our architecture is a standard CRUD app architecture, a Python monolith on top of Postgres +
- How Instagram scaled to 14 million users with only 3 engineers +
- The companies where we were like ”woah, these folks are smart as hell” for the most part failed +
- One function that wires up the entire system. If you want to know how the system works - go read it +
-
Embedding Proof-oriented Programming Languages in F*)
-
-
- Online lectures at the Oregon Programming Language Summer School (2021): Lecture notes, slides, code +
- Online lectures at the Oregon Programming Language Summer School (2021): Lecture notes, slides, code
-
Formal Verification with F* and Meta-F*
-
-
- Lectures and tutorial at ECI 2019: Lecture notes, slides, code +
- Lectures and tutorial at ECI 2019: Lecture notes, slides, code
-
Verifying Low-Level Code for Correctness and Security
-
-
- Lectures at the Oregon Programming Language Summer School (2019): Lecture notes, slides, code +
- Lectures at the Oregon Programming Language Summer School (2019): Lecture notes, slides, code
@@ -135,7 +135,7 @@ - Why build an electrically heated table?
- The table
@@ -82,24 +74,24 @@
The heated table is an excellent example of our ancestors’ energy-efficient way of warming: heating people, not spaces. Historically, glowing charcoal from the fireplace heated the space under the table. While that provided sufficient warmth, it also carried a significant risk of fire and carbon monoxide poisoning. Nowadays, we can use electric heating technology instead. For example, the Japanese kotatsu is still in use, but it’s now working with a small electric heater fixed under the table surface.
- Extra insulation material (I used cork)
- Heating people, not spaces.
A Minecraft server written in COBOL
The CobolCraftMakefile has a target that downloads the .jar and extracts the JSON data from it.
The JSON files are evaluated at runtime using a custom-built generic JSON parser, such that CobolCraft can
inter-operate successfully with the Minecraft client without distributing potentially copyrighted material.
-
+
This project (except 3rd-party contents as stated below) is licensed under the MIT License. See LICENSE for further information.
This project includes the 3rd-party CBL_GC_SOCKET shared library, licensed under the LGPL v3. diff --git a/docs/posts/a-new-learning-experience-on-mdn.html b/docs/posts/a-new-learning-experience-on-mdn.html new file mode 100644 index 00000000000..166edc59511 --- /dev/null +++ b/docs/posts/a-new-learning-experience-on-mdn.html @@ -0,0 +1,53 @@ + + +
+ + + +A new learning experience on MDN
+ +
A major update to the MDN Learn Web Development section started in November 2024 and was finally published in December 2024. +To summarize, the MDN Curriculum has been merged into Learn Web Development. +This post looks at the background leading up to this decision being made, what the changes mean specifically, and what updates you can expect to see in the future.
Overview of learning material on MDN
We originally launched the MDN Learn Web Development section in 2016 with the aim of making MDN more accessible to non-experts and helping to take new web developers from "beginner to comfortable".
+The content was pretty successful — by 2019 it was being used by over a million people per month to learn web development topics. +However, it was noted that the structure was sub-par:
+-
+
Developing the MDN curriculum
To solve the second issue highlighted above, we created a resource to help guide people towards learning a better skillset, making them more employable, and enabling them to build a better, more accessible, more responsible web of tomorrow.
+As part of this project, we did substantial research to find out exactly what skills are seen as essential in new hires, and what the most common knowledge gaps are. +The resulting curriculum was intended to be useful as a study guide for self-learners, and a syllabus for educators to base courses on. +We also used it as a place to experiment with including interactive multimedia content via our learning partner, Scrimba. +We launched the MDN Curriculum in early 2024.
Why the update?
The curriculum was well-received by educators, but we quickly received feedback that users found it confusing having two learning resources on MDN, with the curriculum/learning pathway in one place and the learning content in another place.
+In addition, the pathway was just a curriculum; learners still had to figure out what content to look at to achieve the learning objectives. And it did nothing to solve the first issue listed above — the content was still bloated.
The new state of learning material on MDN
To provide a less confusing, more streamlined learning experience, we decided to merge the curriculum pathway into the MDN Learn Web Development section, restructuring it in the process. The results can be seen at the following new URL — developer.mozilla.org/
The most significant changes are as follows:
+-
+
Initially, the Curriculum section will stay, however it will be merged into the Learn area over the next few iterations of this work and will be removed when it is felt the time is right. +We will keep a downloadable version as a resource for educators.
What's next for learners on MDN
Moving forward, we will continue to update the content and design to make Learn Web Development even more useful to learners and educators.
+We are intending to give the article content a significant overhaul as we move into 2025. A lot of the content is timeless and does a good job of teaching the fundamentals, but the pacing is uneven, some of the articles are pretty long (which can be intimidating for beginners), and some of the challenges and examples have been around for a long time. Inspired by resources such as the content produced by our learning partner, Scrimba, we intend to shake our content up a bit to make it more fun, bite-size, and digestible.
+We are also looking at improving the design of our learning pages, to echo the bright bold design we used on the curriculum and improve the experience further. +You can expect to see regular iterative improvements going forward, so watch this space.
Summary
We hope you find the new Learn Web Development content structure useful — have a look around and let us know what you think.
+If you still have unanswered questions or wish to report issues, please get in touch via the usual communication channels. +If your issue concerns a specific piece of content, you might want to file a GitHub issue.
Previous Post Countdown to the holidays with daily coding challenges
bad research idea: false statements in e-graphs
OK after much squinting at the progression of rewrite rules... I think I have found an example of where the logic goes wrong.
Can you spot the error?
- +
+
The issue here is that the empty int list TupleInt.EMPTY is unified with TupleInt(0, partial(lambda i, self, j: Int.if_(j == self.length(), i, self[j])), 101, TupleInt.empty) aka TupleInt(0, lambda j: Int.if_(j == 0, 101, TupleInt.EMPTY[j])))
Now let's say we do a naive index the empty list like TupleInt.EMPTY[0]. We could say this incorrect, or how we can represent it is that it unifies with Int.NEVER. But it can show up in the e-graph, because in if_ conditionals, the false branch can end up doing indexing that is not allowed. So we want it to not mess things up.
And in this case then, it will evaluate to (lambda j: Int.if_(j == 0, 101, TupleInt.EMPTY[j])))(0) which is Int.if_(0 == 0, 101, TupleInt.EMPTY[0])) which is 101... So then what we get is that 101 is unified with Int.NEVER which... isn't good! Is really bad! Because it means all numbers can be unified together basically, i.e. false is true whatever.
Cognitive load is what matters
+ +
The logo image was taken from Reddit.
+It is a living document, last update: November 2024. Your contributions are welcome!
++ Introduction +
+There are so many buzzwords and best practices out there, but let's focus on something more fundamental. What matters is the amount of confusion developers feel when going through the code.
+Confusion costs time and money. Confusion is caused by high cognitive load. It's not some fancy abstract concept, but rather a fundamental human constraint.
+Since we spend far more time reading and understanding code than writing it, we should constantly ask ourselves whether we are embedding excessive cognitive load into our code.
++ Cognitive load +
+++Cognitive load is how much a developer needs to think in order to complete a task.
+
When reading code, you put things like values of variables, control flow logic and call sequences into your head. The average person can hold roughly four such chunks in working memory. Once the cognitive load reaches this threshold, it becomes much harder to understand things.
+Let's say we have been asked to make some fixes to a completely unfamiliar project. We were told that a really smart developer had contributed to it. Lots of cool architectures, fancy libraries and trendy technologies were used. In other words, the author had created a high cognitive load for us.
+
We should reduce the cognitive load in our projects as much as possible.
++ Types of cognitive load +
+Intrinsic - caused by the inherent difficulty of a task. It can't be reduced, it's at the very heart of software development.
+Extraneous - created by the way the information is presented. Caused by factors not directly relevant to the task, such as smart author's quirks. Can be greatly reduced. We will focus on this type of cognitive load.
+
Let's jump straight to the concrete practical examples of extraneous cognitive load.
+We will refer to the level cognitive load as follows:
+++Our brain is much more complex and unexplored, but we can go with this simplistic model.
+
+ Complex conditionals +
+if val > someConstant
+ && (condition2 || condition3)
+ && (condition4 && !condition5) {
+ ...
+}
+Introduce intermediate variables with meaningful names:
+isValid = val > someConstant
+isAllowed = condition2 || condition3
+isSecure = condition4 && !condition5
+
+if isValid && isAllowed && isSecure {
+ ...
+}
++ Nested ifs +
+if isValid {
+ if isSecure {
+ stuff // 🧠+++
+ }
+}
+Compare it with the early returns:
+if !isValid
+ return
+
+if !isSecure
+ return
+
+
+
+stuff
+We can focus on the happy path only, thus freeing our working memory from all sorts of preconditions.
++ Inheritance nightmare +
+We are asked to change a few things for our admin users: 🧠
AdminController extends UserController extends GuestController extends BaseControllerOhh, part of the functionality is in BaseController, let's have a look: 🧠+
Oh, wait, there's SuperuserController which extends AdminController. By modifying AdminController we can break things in the inherited class, so let's dive in SuperuserController first: 🤯
Prefer composition over inheritance. We won't go into detail - there's plenty of material out there.
++ Too many small methods, classes or modules +
+++Method, class and module are interchangeable in this context
+
Mantras like "methods should be shorter than 15 lines of code" or "classes should be small" turned out to be somewhat wrong.
+Deep module - simple interface, complex functionality
+
Having too many shallow modules can make it difficult to understand the project. Not only do we have to keep in mind each module responsibilities, but also all their interactions. To understand the purpose of a shallow module, we first need to look at the functionality of all the related modules. 🤯
++Information hiding is paramount, and we don't hide as much complexity in shallow modules.
+
I have two pet projects, both of them are somewhat 5K lines of code. The first one has 80 shallow classes, whereas the second one has only 7 deep classes. I haven't been maintaining any of these projects for one year and a half.
+Once I came back, I realised that it was extremely difficult to untangle all the interactions between those 80 classes in the first project. I would have to rebuild an enormous amount of cognitive load before I could start coding. On the other hand, I was able to grasp the second project quickly, because it had only a few deep classes with a simple interface.
+++The best components are those that provide powerful functionality yet have simple interface.
+
The interface of the UNIX I/O is very simple. It has only five basic calls:
+open(path, flags, permissions)
+read(fd, buffer, count)
+write(fd, buffer, count)
+lseek(fd, offset, referencePosition)
+close(fd)
+A modern implementation of this interface has hundreds of thousands of lines of code. Lots of complexity is hidden under the hood. Yet it is easy to use due to its simple interface.
+++This deep module example is taken from the book A Philosophy of Software Design by John K. Ousterhout. Not only does this book cover the very essence of complexity in software development, but it also has the greatest interpretation of Parnas' influential paper On the Criteria To Be Used in Decomposing Systems into Modules. Both are essential reads. Other related readings: It's probably time to stop recommending Clean Code, Small Functions considered Harmful.
+
P.S. If you think we are rooting for bloated God objects with too many responsibilities, you got it wrong.
++ Shallow modules and SRP +
+All too often, we end up creating lots of shallow modules, following some vague "a module should be responsible for one, and only one, thing" principle. What is this blurry one thing? Instantiating an object is one thing, right? So MetricsProviderFactoryFactory seems to be just fine. The names and interfaces of such classes tend to be more mentally taxing than their entire implementations, what kind of abstraction is that? Something went wrong.
+++Jumping between such shallow components is mentally exhausting, linear thinking is more natural to us humans.
+
We make changes to our systems to satisfy our users and stakeholders. We are responsible to them.
+++A module should be responsible to one, and only one, user or stakeholder.
+
This is what this Single Responsibility Principle is all about. Simply put, if we introduce a bug in one place, and then two different business people come to complain, we've violated the principle. It has nothing to do with the number of things we do in our module.
+But even now, this interpretation can do more harm than good. This rule can be understood in as many different ways as there are individuals. A better approach would be to look at how much cognitive load it all creates. It's mentally demanding to remember that change in one module can trigger a chain of reactions across different business streams. And that's about it.
++ Too many shallow microservices +
+This shallow-deep module principle is scale-agnostic, and we can apply it to microservices architecture. Too many shallow microservices won't do any good - the industry is heading towards somewhat "macroservices", i.e., services that are not so shallow (=deep). One of the worst and hardest to fix phenomena is so-called distributed monolith, which is often the result of this overly granular shallow separation.
+I once consulted a startup where a team of five developers introduced 17(!) microservices. They were 10 months behind schedule and appeared nowhere close to the public release. Every new requirement led to changes in 4+ microservices. Diagnostic difficulty in integration space skyrocketed. Both time to market and cognitive load were unacceptably high. 🤯
Is this the right way to approach the uncertainty of a new system? It's enormously difficult to elicit the right logical boundaries in the beginning. The key is to make decisions as late as you can responsibly wait, because that is when you have the most information on which to base the decision. By introducing a network layer up front, we make our design decisions hard to revert right from the start. The team's only justification was: "The FAANG companies proved microservices architecture to be effective". Hello, you got to stop dreaming big.
+The Tanenbaum-Torvalds debate argued that Linux's monolithic design was flawed and obsolete, and that a microkernel architecture should be used instead. Indeed, the microkernel design seemed to be superior "from a theoretical and aesthetical" point of view. On the practical side of things - three decades on, microkernel-based GNU Hurd is still in development, and monolithic Linux is everywhere. This page is powered by Linux, your smart teapot is powered by Linux. By monolithic Linux.
+A well-crafted monolith with truly isolated modules is often much more flexible than a bunch of microservices. It also requires far less cognitive effort to maintain. It's only when the need for separate deployments becomes crucial, such as scaling the development team, that you should consider adding a network layer between the modules, future microservices.
++ Feature-rich languages +
+We feel excited when new features got released in our favourite language. We spend some time learning these features, we build code upon them.
+If there are lots of features, we may spend half an hour playing with a few lines of code, to use one or another feature. And it's kind of a waste of time. But what's worse, when you come back later, you would have to recreate that thought process!
+You not only have to understand this complicated program, you have to understand why a programmer decided this was the way to approach a problem from the features that are available. 🤯
These statements are made by none other than Rob Pike.
+++Reduce cognitive load by limiting the number of choices.
+
Language features are OK, as long as they are orthogonal to each other.
+Thoughts from an engineer with 20 years of C++ experience ⭐️
+I was looking at my RSS reader the other day and noticed that I have somewhat three hundred unread articles under the "C++" tag. I haven't read a single article about the language since last summer, and I feel great!
+I've been using C++ for 20 years for now, that's almost two-thirds of my life. Most of my experience lies in dealing with the darkest corners of the language (such as undefined behaviours of all sorts). It's not a reusable experience, and it's kind of creepy to throw it all away now.
+Like, can you imagine, the token || has a different meaning in requires ((!P<T> || !Q<T>)) and in requires (!(P<T> || Q<T>)). The first is the constraint disjunction, the second is the good-old logical or operator, and they behave differently.
You can't allocate space for a trivial type and just memcpy a set of bytes there without extra effort - that won't start the lifetime of an object. This was the case before C++20. It was fixed in C++20, but the cognitive load of the language has only increased.
Cognitive load is constantly growing, even though things got fixed. I should know what was fixed, when it was fixed, and what it was like before. I am a professional after all. Sure, C++ is good at legacy support, which also means that you will face that legacy. For example, last month a colleague of mine asked me about some behaviour in C++03. 🤯
There were 20 ways of initialization. Uniform initialization syntax has been added. Now we have 21 ways of initialization. By the way, does anyone remember the rules for selecting constructors from the initializer list? Something about implicit conversion with the least loss of information, but if the value is known statically, then... 🤯
This increased cognitive load is not caused by a business task at hand. It is not an intrinsic complexity of the domain. It is just there due to historical reasons (extraneous cognitive load).
+I had to come up with some rules. Like, if that line of code is not as obvious and I have to remember the standard, I better not write it that way. The standard is somewhat 1500 pages long, by the way.
+By no means I am trying to blame C++. I love the language. It's just that I am tired now.
++ Business logic and HTTP status codes +
+On the backend we return: +-
+
The guys on the frontend use backend API to implement login functionality. They would have to temporarily create the following cognitive load in their brains:
+-
+
Frontend developers would (hopefully) introduce some kind numeric status -> meaning dictionary on their side, so that subsequent generations of contributors wouldn't have to recreate this mapping in their brains.
+Then QA people come into play:
+ "Hey, I got 403 status, is that expired token or not enough access?"
+ QA people can't jump straight to testing, because first they have to recreate the cognitive load that the guys on the backend once created.
Why hold this custom mapping in our working memory? It's better to abstract away your business details from the HTTP transfer protocol, and return self-descriptive codes directly in the response body:
+{
+ "code": "jwt_has_expired"
+}
+Cognitive load on the frontend side: 🧠 (fresh, no facts are held in mind)
The same rule applies to all sorts of numeric statuses (in the database or wherever) - prefer self-describing strings. We are not in the era of 640K computers to optimise for memory.
+++People spend time arguing between
+401and403, making decisions based on their own mental models. New developers are coming in, and they need to recreate that thought process. You may have documented the "whys" (ADRs) for your code, helping newcomers to understand the decisions made. But in the end it just doesn't make any sense. We can separate errors into either user-related or server-related, but apart from that, things are kind of blurry.
P.S. It's often mentally taxing to distinguish between "authentication" and "authorization". We can use simpler terms like "login" and "permissions" to reduce the cognitive load.
++ Abusing DRY principle +
+Do not repeat yourself - that is one of the first principles you are taught as a software engineer. It is so deeply embedded in ourselves that we can not stand the fact of a few extra lines of code. Although in general a good and fundamental rule, when overused it leads to the cognitive load we can not handle.
+Nowadays, everyone builds software based on logically separated components. Often those are distributed among multiple codebases representing separate services. When you strive to eliminate any repetition, you might end up creating tight coupling between unrelated components. As a result changes in one part may have unintended consequences in other seemingly unrelated areas. It can also hinder the ability to replace or modify individual components without impacting the entire system. 🤯
In fact, the same problem arises even within a single module. You might extract common functionality too early, based on perceived similarities that might not actually exist in the long run. This can result in unnecessary abstractions that are difficult to modify or extend.
+Rob Pike once said:
+++A little copying is better than a little dependency.
+
We are tempted to not reinvent the wheel so strong that we are ready to import large, heavy libraries to use a small function that we could easily write by ourselves.
+All your dependencies are your code. Going through 10+ levels of stack trace of some imported library and figuring out what went wrong (because things go wrong) is painful.
+ ++ Tight coupling with a framework +
+There's a lot of "magic" in frameworks. By relying too heavily on a framework, we force all upcoming developers to learn that "magic" first. It can take months. Even though frameworks enable us to launch MVPs in a matter of days, in the long run they tend to add unnecessary complexity and cognitive load.
+Worse yet, at some point frameworks can become a significant constraint when faced with a new requirement that just doesn't fit the architecture. From here onwards people end up forking a framework and maintaining their own custom version. Imagine the amount of cognitive load a newcomer would have to build (i.e. learn this custom framework) in order to deliver any value. 🤯
By no means do we advocate to invent everything from scratch!
+We can write code in a somewhat framework-agnostic way. The business logic should not reside within a framework; rather, it should use the framework's components. Put a framework outside of your core logic. Use the framework in a library-like fashion. This would allow new contributors to add value from day one, without the need of going through debris of framework-related complexity first.
++ Why I Hate Frameworks ++
+ Layered architecture +
+There is a certain engineering excitement about all this stuff.
+I myself was a passionate advocate of Hexagonal/Onion Architecture for years. I used it here and there and encouraged other teams to do so. The complexity of our projects went up, the sheer number of files alone had doubled. It felt like we were writing a lot of glue code. On ever changing requirements we had to make changes across multiple layers of abstractions, it all became tedious. 🤯
Abstraction is supposed to hide complexity, here it just adds indirection. Jumping from call to call to read along and figure out what goes wrong and what is missing is a vital requirement to quickly solve a problem. With this architecture’s layer uncoupling it requires an exponential factor of extra, often disjointed, traces to get to the point where the failure occurs. Every such trace takes space in our limited working memory. 🤯
This architecture was something that made intuitive sense at first, but every time we tried applying it to projects it made a lot more harm than good. In the end, we gave it all up in favour of the good old dependency inversion principle. No port/adapter terms to learn, no unnecessary layers of horizontal abstractions, no extraneous cognitive load.
+If you think that such layering will allow you to quickly replace a database or other dependencies, you're mistaken. Changing the storage causes lots of problems, and believe us, having some abstractions for the data access layer is the least of your worries. At best, abstractions can save somewhat 10% of your migration time (if any), the real pain is in data model incompatibilities, communication protocols, distributed systems challenges, and implicit interfaces.
++++With a sufficient number of users of an API,
+
We did a storage migration, and that took us about 10 months. The old system was single-threaded, so the exposed events were sequential. All our systems depended on that observed behaviour. This behavior was not part of the API contract, it was not reflected in the code. A new distributed storage didn't have that guarantee - the events came out-of-order. We spent only a few hours coding a new storage adapter. We spent the next 10 months on dealing with out-of-order events and other challenges. It's now funny to say that layering helps us replace components quickly.
+So, why pay the price of high cognitive load for such a layered architecture, if it doesn't pay off in the future? Plus, in most cases, that future of replacing some core component never happens.
+These architectures are not fundamental, they are just subjective, biased consequences of more fundamental principles. Why rely on those subjective interpretations? Follow the fundamental rules instead: dependency inversion principle, cognitive load and information hiding. Discuss.
+Do not add layers of abstractions for the sake of an architecture. Add them whenever you need an extension point that is justified for practical reasons. Layers of abstraction aren't free of charge, they are to be held in our working memory.
++ DDD +
+Domain-driven design has some great points, although it is often misinterpreted. People say "We write code in DDD", which is a bit strange, because DDD is about problem space, not about solution space.
+Ubiquitous language, domain, bounded context, aggregate, event storming are all about problem space. They are meant to help us learn the insights about the domain and extract the boundaries. DDD enables developers, domain experts and business people to communicate effectively using a single, unified language. Rather than focusing on these problem space aspects of DDD, we tend to emphasise particular folder structures, services, repositories, and other solution space techniques.
+Chances are that the way we interpret DDD is likely to be unique and subjective. And if we build code upon this understanding, i.e., if we create a lot of extraneous cognitive load - future developers are doomed. 🤯
+ Examples +
+-
+
+ These architectures are quite boring and easy to understand. Anyone can grasp them without much mental effort. +
+ ++ Involve junior developers in architecture reviews. They will help you to identify the mentally demanding areas. +
+ ++ Cognitive load in familiar projects +
+++The problem is that familiarity is not the same as simplicity. They feel the same — that same ease of moving through a space without much mental effort — but for very different reasons. Every “clever” (read: “self-indulgent”) and non-idiomatic trick you use incurs a learning penalty for everyone else. Once they have done that learning, then they will find working with the code less difficult. So it is hard to recognise how to simplify code that you are already familiar with. This is why I try to get “the new kid” to critique the code before they get too institutionalised!
+It is likely that the previous author(s) created this huge mess one tiny increment at a time, not all at once. So you are the first person who has ever had to try to make sense of it all at once.
+In my class I describe a sprawling SQL stored procedure we were looking at one day, with hundreds of lines of conditionals in a huge WHERE clause. Someone asked how anyone could have let it get this bad. I told them: “When there are only 2 or 3 conditionals, adding another one doesn’t make any difference. By the time there are 20 or 30 conditionals, adding another one doesn’t make any difference!”
+There is no “simplifying force” acting on the code base other than deliberate choices that you make. Simplifying takes effort, and people are too often in a hurry.
+Thanks to Dan North for his comment.
+
If you've internalized the mental models of the project into your long-term memory, you won't experience a high cognitive load.
+
The more mental models there are to learn, the longer it takes for a new developer to deliver value.
+Once you onboard new people on your project, try to measure the amount of confusion they have (pair programming may help). If they're confused for more than ~40 minutes in a row - you've got things to improve in your code.
+If you keep the cognitive load low, people can contribute to your codebase within the first few hours of joining your company.
+ ++ Conclusion +
+Imagine for a moment that what we inferred in the second chapter isn’t actually true. If that’s the case, then the conclusion we just negated, along with the conclusions in the previous chapter that we had accepted as valid, might not be correct either. 🤯
Do you feel it? Not only do you have to jump all over the article to get the meaning (shallow modules!), but the paragraph in general is difficult to understand. We have just created an unnecessary cognitive load in your head. Do not do this to your colleagues.
+ +
We should reduce any cognitive load above and beyond what is intrinsic to the work we do.
+ ++ + + + + +
CRT Simulation in a GPU Shader, Looks Better Than Black Frame Insertion
- -Please enable cookies.
-- -
You are unable to access blurbusters.com
- - - - -Why have I been blocked?
- -This website is using a security service to protect itself from online attacks. The action you just performed triggered the security solution. There are several actions that could trigger this block including submitting a certain word or phrase, a SQL command or malformed data.
-What can I do to resolve this?
- -You can email the site owner to let them know you were blocked. Please include what you were doing when this page came up and the Cloudflare Ray ID found at the bottom of this page.
-- Cloudflare Ray ID: 8f82b4577f1acf25 - • - - Performance & security by Cloudflare - -
- - -F*: A proof oriented general purpose programming language
An online - book Proof-oriented + book Proof-oriented Programming In F* is being written and regular updates are posted online. You probably want to read it while trying out examples and exercises in your browser by clicking the image below.
-  +
+ 
Low*
We also have a
@@ -68,21 +68,21 @@
F* is an active topic of research, both in the programming languages and formal methods community,
as well as from an application perspective in the security and systems communities.
- We list a few of them below, with full citations to these papers available in this bibliography.
+ We list a few of them below, with full citations to these papers available in this bibliography.
If you would like your paper included in this list, please contact fstar-maintainers@googlegroups.com.
diff --git a/docs/posts/how-to-build-an-electrically-heated-table.html b/docs/posts/how-to-build-an-electrically-heated-table.html
index bc128f52409..edee60192c1 100644
--- a/docs/posts/how-to-build-an-electrically-heated-table.html
+++ b/docs/posts/how-to-build-an-electrically-heated-table.html
@@ -18,40 +18,32 @@
+
View original image
-
+
View dithered image
- In this manual, I will walk you through the making of an electrically heated work desk for one person. I have built the table for myself in the co-working space in Barcelona where I have my office now. The building, an old industrial warehouse, has very high ceilings, no insulation, and little sun in winter. It can get very cold here and conventional heating systems don’t work. My heated table turns out to be a perfect solution. I can power it with a solar panel, a wind turbine, a bike generator, or a battery. I can also plug it into the power grid.
+
View original image
-
+
View dithered image
- A heated table offers exceptional comfort. The lower part of your body gets immersed in heat as if you are baking in the sun or sitting in a hot bath. The warmth quickly spreads to the rest of your body through the bloodstream. During a week of experiments in December 2024, with indoor air temperatures of 12-14°C (53-57°F), I recorded very low energy use for my freshly built heated table: between 50 and 75 watt-hours per hour. 1 Compare that to a conventional electric portable heater, which easily consumes 1,500 watt-hours per hour (and does not guarantee thermal comfort). My heated table uses as little electricity as charging a laptop or heating two liters of water for a hot water bottle (58 watt-hours per hour, assuming you reheat the water every two hours).
+
View original image
-
+
View dithered image
-
+
View original image
-
+
View dithered image
-
+
View original image
-
+
View dithered image
- This manual concerns a table for only one person - my writing desk. Unlike the Japanese and Middle Eastern examples, my table is adapted to a Western-style sitting position: not on the floor but on a chair. You can turn any table into a personal heat source, but some are better suited than others. Most importantly, you should be able to screw a flat heating foil (step 2) under the table. However, structural elements may complicate that, as is the case for my table (see the image below).
+
View original image
-
+
View dithered image
- I solved this by installing the heating foil on a thin wooden board which I then screwed against the supporting elements. However, for some other tables, this may not work. Choose a wooden table. Wood insulates relatively well, so a wooden table top already provides some of the insulation you need to maximize heat production. It’s easy to screw things onto a wooden table as well. You can build a larger heated table that can seat more people, but in that case, you will have to connect several heating foils (step 2) and stitch several blankets (step 8) together. Low-tech Magazine will build a large heated table for several people during a workshop in Barcelona on January 25, 2025. The best heating element for an electrically heated table - and the one I am using in this manual - is carbon or infrared heating film. These very thin heating foils are primarily meant for electric floor and wall heating in buildings and vehicles, for protecting batteries or water tanks against the cold, or for warming beehives and terrariums. Infrared heating films are low-temperature, large-surface heaters, so there’s no risk of burns or fire through direct contact with skin or clothes. They are meant to operate at a maximum temperature of 40-45°C (104-113°F).
+
View original image
-
+
View dithered image
- Carbon heating foils come in different voltages: 12V, 24V, and 110/220V. I chose a 12V heating foil to make my table compatible with my 12V solar installations and bike generator. If you have a 24V renewable power system, opt for a 24V heating foil. The thermostat is connected between the heating foil and the power source, as shown in the illustration below. The wiring may be different for other thermostat models.
+
View original image
-
+
View dithered image
- Your cables must be thick enough for the current that flows through them. Infrared heating foils are sold with thick electric cables included, and they are often much longer than you need them to be. You can cut them shorter and use the rest to wire the whole system. If you want to use other cables, then use a multimeter to measure the current that the heating film draws. For example, my 12V heat foil requires 6.6 Amps, so my cables - in the complete circuit - should have a conductor cross-section of at least 2.63 mm2 (that’s 13 AWG gauge, check this chart). Before you start wiring the system, decide where your thermostat goes, because it will determine the length of the cables you need. I have my thermostat installed under the table, hidden under the blankets. Once programmed, there’s no need to access it regularly (see further). Having the thermostat on top of the table means that you need a hole in your blanket for all the cables to go through. It also complicates the adding and removing of blankets.
+
View original image
-
+
View dithered image
- To program the thermostat, connect it to the power source. First, select the “heating” function. My thermostat’s default setting was “cooling” and I struggled to make it work at first. Here’s the steps to follow: The energy efficiency and thermal comfort of an electrically heated table are in large part determined by the type and size of the blankets you put over it. The blankets form part of the heat film insulation layer, but if they are long enough to reach the ground they also trap warm air under the table. Radiant heating systems transfer energy to surfaces - including your body - and do not warm up the air directly. However, the air temperature under the table will slowly increase indirectly due to the higher surface temperatures of the blankets, the table, the carpet, and the person who sits at the table. During the experiments, the air temperature below my table at 25 cm above the floor increased by about 10°C (18°F).
+
View original image
-
+
View dithered image
- Choose a wool blanket. Wool traps heat very efficienctly, is much more flame-resistant than other textile materials, doesn’t get dirty or smelly easily, regulates humidity, and purifies the air. 4 New wool blankets can be pricey at hundreds of euros for the size we need. However, I purchased four second-hand wool blankets for 90 euros, two of them large enough to reach the ground. If you find a wool blanket that is ugly or stained, simply layer it with a nicer and cheaper cotton blanket. Although it feels nice to work on a wool or cotton surface in winter, you can also put a wooden board on top of the blanket, cut to size, in order to protect the blanket from wear and dirt. Or, you drape a cotton tablecloth over the blanket, which is easier to wash than wool.
+
View original image
-
+
View dithered image
- Any heating system must be able to be adjusted to achieve the desired comfort. For a central heating system, that happens by manipulating the thermostat. However, that doesn’t work so well for a heated table, because the temperature range of the carbon heating film is limited. Going below 38°C (100°F) will not provide a pleasant sensation of warmth, while prolonged heating above 45°C (113°F) may damage the heating film and make it too hot to touch. However, you can adjust thermal comfort in a wide range of air temperatures by “dressing” and “undressing” the table: by adding and removing textile layers, and by using them in different ways.
+
View original image
-
+
View dithered image
-
+
View original image
-
+
View dithered image
- However, as you add more blankets, the textile layer becomes increasingly heavy, and it takes more time to get in and out - to “dress” and “undress”. Consequently, a lighter cover is preferable if it provides sufficient comfort. On a chilly spring evening, one or two shorter blankets may be sufficient to keep you comfortable. I have tested the table like that and it did almost as good as with a large blanket. Energy use was somewhat higher and thermal comfort somewhat lower - I especially noted cold feet. However, should it be a bit warmer, I would prefer this setup because it’s more practical to get up from the desk. Overheating can be solved without reaching for the thermostat as well: lift a corner of the carpet with your foot and let some heat escape, or remove one of the blankets. It would be more energy-efficient to turn down the thermostat, but the energy use of a heated table is already so low that there is room for some convenience. The comfort of a heated table can be further improved by a heated chair or bench, or by putting a screen behind your chair, covered with heat foil on one side and with insulation on the other side. That’s something for a future manual.
+
View original image
-
+
View dithered image
- Course Material
Project Everest
How to Build an Electrically Heated Table?
 -
+
-
+
 -
+
-
+The manual
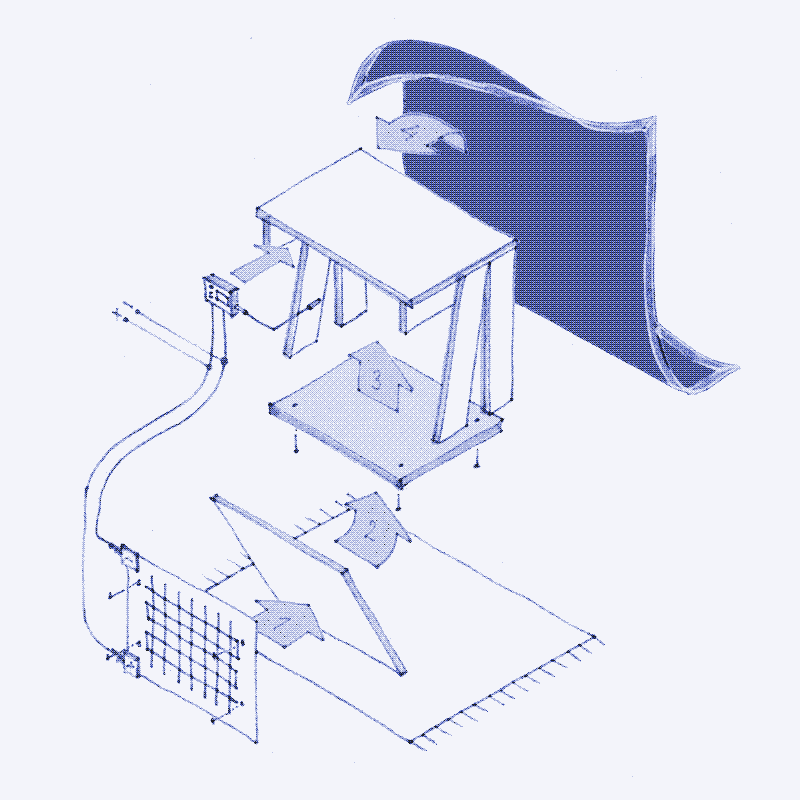 -
+
-
+ -
+
-
+ -
+
-
+Step 1: Get a table
 -
+
-
+Ste
Carbon heating film
 -
+
-
+Voltage
Step 3:
Step 4: Wire everything together
 -
+
-
+Cable size
Temperature sensor
Where does the thermostat go?
 -
+
-
+Step 5: Program the thermostat
Step 8: Find
 -
+
-
+Wool
Blanket size
Work surface
 -
+
-
+Dressing and undressing the table
-
 -
+
-
+ -
+
-
+Relevant books:
 -
+
-
+