From aee9acb30307a7f794fddd77fb8f3e95f40c9bb1 Mon Sep 17 00:00:00 2001
From: Yuwen Hu <54161268+Oscilloscope98@users.noreply.github.com>
Date: Mon, 2 Dec 2024 17:03:10 +0800
Subject: [PATCH] Add NPU QuickStart & update example links (#12470)
* Add initial NPU quickstart (c++ part unfinished)
* Small update
* Update based on comments
* Update main readme
* Remove LLaMA description
* Small fix
* Small fix
* Remove subsection link in main README
* Small fix
* Update based on comments
* Small fix
* TOC update and other small fixes
* Update for Chinese main readme
* Update based on comments and other small fixes
* Change order
---
README.md | 27 +--
README.zh-CN.md | 30 ++--
docs/mddocs/Quickstart/README.md | 1 +
docs/mddocs/Quickstart/npu_quickstart.md | 155 ++++++++++++++++++
docs/mddocs/README.md | 1 +
.../HF-Transformers-AutoModels/LLM/README.md | 2 +-
.../Multimodal/README.md | 1 +
.../NPU/HF-Transformers-AutoModels/README.md | 2 +-
8 files changed, 192 insertions(+), 27 deletions(-)
create mode 100644 docs/mddocs/Quickstart/npu_quickstart.md
diff --git a/README.md b/README.md
index fe58a8419eb..9aa8530ab5b 100644
--- a/README.md
+++ b/README.md
@@ -185,6 +185,7 @@ Please see the **Perplexity** result below (tested on Wikitext dataset using the
- [VSCode on GPU](docs/mddocs/DockerGuides/docker_run_pytorch_inference_in_vscode.md): running and developing `ipex-llm` applications in Python using VSCode on Intel GPU
### Use
+- [NPU](docs/mddocs/Quickstart/npu_quickstart.md): running `ipex-llm` on Intel **NPU** in both Python and C++
- [llama.cpp](docs/mddocs/Quickstart/llama_cpp_quickstart.md): running **llama.cpp** (*using C++ interface of `ipex-llm`*) on Intel GPU
- [Ollama](docs/mddocs/Quickstart/ollama_quickstart.md): running **ollama** (*using C++ interface of `ipex-llm`*) on Intel GPU
- [PyTorch/HuggingFace](docs/mddocs/Quickstart/install_windows_gpu.md): running **PyTorch**, **HuggingFace**, **LangChain**, **LlamaIndex**, etc. (*using Python interface of `ipex-llm`*) on Intel GPU for [Windows](docs/mddocs/Quickstart/install_windows_gpu.md) and [Linux](docs/mddocs/Quickstart/install_linux_gpu.md)
@@ -252,13 +253,13 @@ Please see the **Perplexity** result below (tested on Wikitext dataset using the
## Verified Models
Over 50 models have been optimized/verified on `ipex-llm`, including *LLaMA/LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM2/ChatGLM3, Baichuan/Baichuan2, Qwen/Qwen-1.5, InternLM* and more; see the list below.
-| Model | CPU Example | GPU Example |
-|------------|----------------------------------------------------------------|-----------------------------------------------------------------|
-| LLaMA *(such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.)* | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](python/llm/example/GPU/HuggingFace/LLM/vicuna)|
-| LLaMA 2 | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link](python/llm/example/GPU/HuggingFace/LLM/llama2) |
-| LLaMA 3 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3) |
+| Model | CPU Example | GPU Example | NPU Example |
+|------------|----------------------------------------------|----------------------------------------------|----------------------------------------------|
+| LLaMA | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](python/llm/example/GPU/HuggingFace/LLM/vicuna)|
+| LLaMA 2 | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link](python/llm/example/GPU/HuggingFace/LLM/llama2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
+| LLaMA 3 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| LLaMA 3.1 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3.1) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.1) |
-| LLaMA 3.2 | | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.2) |
+| LLaMA 3.2 | | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| LLaMA 3.2-Vision | | [link](python/llm/example/GPU/PyTorch-Models/Model/llama3.2-vision/) |
| ChatGLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm) | |
| ChatGLM2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2) | [link](python/llm/example/GPU/HuggingFace/LLM/chatglm2) |
@@ -276,13 +277,13 @@ Over 50 models have been optimized/verified on `ipex-llm`, including *LLaMA/LLaM
| Phoenix | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix) | |
| StarCoder | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder) | [link](python/llm/example/GPU/HuggingFace/LLM/starcoder) |
| Baichuan | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan) |
-| Baichuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan2) |
+| Baichuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM) |
| InternLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm) | [link](python/llm/example/GPU/HuggingFace/LLM/internlm) |
| InternVL2 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/internvl2) |
| Qwen | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen) |
| Qwen1.5 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen1.5) |
-| Qwen2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen2) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2) |
-| Qwen2.5 | | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2.5) |
+| Qwen2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen2) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
+| Qwen2.5 | | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2.5) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| Qwen-VL | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl) | [link](python/llm/example/GPU/HuggingFace/Multimodal/qwen-vl) |
| Qwen2-VL || [link](python/llm/example/GPU/PyTorch-Models/Model/qwen2-vl) |
| Qwen2-Audio | | [link](python/llm/example/GPU/HuggingFace/Multimodal/qwen2-audio) |
@@ -324,13 +325,15 @@ Over 50 models have been optimized/verified on `ipex-llm`, including *LLaMA/LLaM
| CodeGemma | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma) | [link](python/llm/example/GPU/HuggingFace/LLM/codegemma) |
| Command-R/cohere | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere) | [link](python/llm/example/GPU/HuggingFace/LLM/cohere) |
| CodeGeeX2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegeex2) | [link](python/llm/example/GPU/HuggingFace/LLM/codegeex2) |
-| MiniCPM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm) | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm) |
+| MiniCPM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm) | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| MiniCPM3 | | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm3) |
| MiniCPM-V | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V) |
| MiniCPM-V-2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm-v-2) | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2) |
-| MiniCPM-Llama3-V-2_5 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-Llama3-V-2_5) |
-| MiniCPM-V-2_6 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm-v-2_6) | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2_6) |
+| MiniCPM-Llama3-V-2_5 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-Llama3-V-2_5) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
+| MiniCPM-V-2_6 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm-v-2_6) | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2_6) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
| StableDiffusion | | [link](python/llm/example/GPU/HuggingFace/Multimodal/StableDiffusion) |
+| Bce-Embedding-Base-V1 | | | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
+| Speech_Paraformer-Large | | | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
## Get Support
- Please report a bug or raise a feature request by opening a [Github Issue](https://github.com/intel-analytics/ipex-llm/issues)
diff --git a/README.zh-CN.md b/README.zh-CN.md
index 05ce48bcf1f..1740299492c 100644
--- a/README.zh-CN.md
+++ b/README.zh-CN.md
@@ -185,6 +185,7 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
- [VSCode on GPU](docs/mddocs/DockerGuides/docker_run_pytorch_inference_in_vscode.md): 在 Intel GPU 上使用 VSCode 开发并运行基于 Python 的 `ipex-llm` 应用
### 使用
+- [NPU](docs/mddocs/Quickstart/npu_quickstart.md): 在 Intel **NPU** 上运行 `ipex-llm`(支持 Python 和 C++)
- [llama.cpp](docs/mddocs/Quickstart/llama_cpp_quickstart.zh-CN.md): 在 Intel GPU 上运行 **llama.cpp** (*使用 `ipex-llm` 的 C++ 接口*)
- [Ollama](docs/mddocs/Quickstart/ollama_quickstart.zh-CN.md): 在 Intel GPU 上运行 **ollama** (*使用 `ipex-llm` 的 C++ 接口*)
- [PyTorch/HuggingFace](docs/mddocs/Quickstart/install_windows_gpu.zh-CN.md): 使用 [Windows](docs/mddocs/Quickstart/install_windows_gpu.zh-CN.md) 和 [Linux](docs/mddocs/Quickstart/install_linux_gpu.zh-CN.md) 在 Intel GPU 上运行 **PyTorch**、**HuggingFace**、**LangChain**、**LlamaIndex** 等 (*使用 `ipex-llm` 的 Python 接口*)
@@ -252,13 +253,13 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
## 模型验证
50+ 模型已经在 `ipex-llm` 上得到优化和验证,包括 *LLaMA/LLaMA2, Mistral, Mixtral, Gemma, LLaVA, Whisper, ChatGLM2/ChatGLM3, Baichuan/Baichuan2, Qwen/Qwen-1.5, InternLM,* 更多模型请参看下表,
-| 模型 | CPU 示例 | GPU 示例 |
-|------------|----------------------------------------------------------------|-----------------------------------------------------------------|
-| LLaMA *(such as Vicuna, Guanaco, Koala, Baize, WizardLM, etc.)* | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](python/llm/example/GPU/HuggingFace/LLM/vicuna)|
-| LLaMA 2 | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link](python/llm/example/GPU/HuggingFace/LLM/llama2) |
-| LLaMA 3 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3) |
+| 模型 | CPU 示例 | GPU 示例 | NPU 示例 |
+|----------- |------------------------------------------|-------------------------------------------|-------------------------------------------|
+| LLaMA | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/vicuna) |[link](python/llm/example/GPU/HuggingFace/LLM/vicuna)|
+| LLaMA 2 | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama2) | [link](python/llm/example/GPU/HuggingFace/LLM/llama2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
+| LLaMA 3 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| LLaMA 3.1 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/llama3.1) | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.1) |
-| LLaMA 3.2 | | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.2) |
+| LLaMA 3.2 | | [link](python/llm/example/GPU/HuggingFace/LLM/llama3.2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| LLaMA 3.2-Vision | | [link](python/llm/example/GPU/PyTorch-Models/Model/llama3.2-vision/) |
| ChatGLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm) | |
| ChatGLM2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/chatglm2) | [link](python/llm/example/GPU/HuggingFace/LLM/chatglm2) |
@@ -276,15 +277,16 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
| Phoenix | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/phoenix) | |
| StarCoder | [link1](python/llm/example/CPU/Native-Models), [link2](python/llm/example/CPU/HF-Transformers-AutoModels/Model/starcoder) | [link](python/llm/example/GPU/HuggingFace/LLM/starcoder) |
| Baichuan | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan) |
-| Baichuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan2) |
+| Baichuan2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/baichuan2) | [link](python/llm/example/GPU/HuggingFace/LLM/baichuan2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM) |
| InternLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/internlm) | [link](python/llm/example/GPU/HuggingFace/LLM/internlm) |
| InternVL2 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/internvl2) |
| Qwen | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen) |
| Qwen1.5 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen1.5) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen1.5) |
-| Qwen2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen2) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2) |
-| Qwen2.5 | | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2.5) |
+| Qwen2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen2) | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
+| Qwen2.5 | | [link](python/llm/example/GPU/HuggingFace/LLM/qwen2.5) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| Qwen-VL | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/qwen-vl) | [link](python/llm/example/GPU/HuggingFace/Multimodal/qwen-vl) |
| Qwen2-VL || [link](python/llm/example/GPU/PyTorch-Models/Model/qwen2-vl) |
+| Qwen2-Audio | | [link](python/llm/example/GPU/HuggingFace/Multimodal/qwen2-audio) |
| Aquila | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila) | [link](python/llm/example/GPU/HuggingFace/LLM/aquila) |
| Aquila2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/aquila2) | [link](python/llm/example/GPU/HuggingFace/LLM/aquila2) |
| MOSS | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/moss) | |
@@ -323,13 +325,15 @@ See the demo of running [*Text-Generation-WebUI*](https://ipex-llm.readthedocs.i
| CodeGemma | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma) | [link](python/llm/example/GPU/HuggingFace/LLM/codegemma) |
| Command-R/cohere | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere) | [link](python/llm/example/GPU/HuggingFace/LLM/cohere) |
| CodeGeeX2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegeex2) | [link](python/llm/example/GPU/HuggingFace/LLM/codegeex2) |
-| MiniCPM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm) | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm) |
+| MiniCPM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm) | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM), [C++ link](python/llm/example/NPU/HF-Transformers-AutoModels/LLM/CPP_Examples) |
| MiniCPM3 | | [link](python/llm/example/GPU/HuggingFace/LLM/minicpm3) |
| MiniCPM-V | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V) |
-| MiniCPM-V-2 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2) |
-| MiniCPM-Llama3-V-2_5 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-Llama3-V-2_5) |
-| MiniCPM-V-2_6 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2_6) |
+| MiniCPM-V-2 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm-v-2) | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2) |
+| MiniCPM-Llama3-V-2_5 | | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-Llama3-V-2_5) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
+| MiniCPM-V-2_6 | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/minicpm-v-2_6) | [link](python/llm/example/GPU/HuggingFace/Multimodal/MiniCPM-V-2_6) | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
| StableDiffusion | | [link](python/llm/example/GPU/HuggingFace/Multimodal/StableDiffusion) |
+| Bce-Embedding-Base-V1 | | | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
+| Speech_Paraformer-Large | | | [Python link](python/llm/example/NPU/HF-Transformers-AutoModels/Multimodal) |
## 官方支持
- 如果遇到问题,或者请求新功能支持,请提交 [Github Issue](https://github.com/intel-analytics/ipex-llm/issues) 告诉我们
diff --git a/docs/mddocs/Quickstart/README.md b/docs/mddocs/Quickstart/README.md
index 49a839c2d00..c214e3e15a2 100644
--- a/docs/mddocs/Quickstart/README.md
+++ b/docs/mddocs/Quickstart/README.md
@@ -13,6 +13,7 @@ This section includes efficient guide to show you how to:
## Inference
+- [Run IPEX-LLM on Intel NPU](./npu_quickstart.md)
- [Run Performance Benchmarking with IPEX-LLM](./benchmark_quickstart.md)
- [Run Local RAG using Langchain-Chatchat on Intel GPU](./chatchat_quickstart.md)
- [Run Text Generation WebUI on Intel GPU](./webui_quickstart.md)
diff --git a/docs/mddocs/Quickstart/npu_quickstart.md b/docs/mddocs/Quickstart/npu_quickstart.md
new file mode 100644
index 00000000000..0d220ee18bc
--- /dev/null
+++ b/docs/mddocs/Quickstart/npu_quickstart.md
@@ -0,0 +1,155 @@
+# Run IPEX-LLM on Intel NPU
+
+This guide demonstrates:
+
+- How to install IPEX-LLM for Intel NPU on Intel Core™ Ultra Processers (Series 2)
+- Python and C++ APIs for running IPEX-LLM on Intel NPU
+
+> [!IMPORTANT]
+> IPEX-LLM currently only supports Windows on Intel NPU.
+
+## Table of Contents
+
+- [Install Prerequisites](#install-prerequisites)
+- [Install `ipex-llm` with NPU Support](#install-ipex-llm-with-npu-support)
+- [Runtime Configurations](#runtime-configurations)
+- [Python API](#python-api)
+- [C++ API](#c-api)
+- [Accuracy Tuning](#accuracy-tuning)
+
+## Install Prerequisites
+
+> [!NOTE]
+> IPEX-LLM NPU support on Windows has been verified on Intel Core™ Ultra Processers (Series 2) with processor number 2xxV (code name Lunar Lake).
+
+### Update NPU Driver
+
+> [!IMPORTANT]
+> If you have NPU driver version lower than `32.0.100.3104`, it is highly recommended to update your NPU driver to the latest.
+
+To update driver for Intel NPU:
+
+1. Download the latest NPU driver
+
+ - Visit the [official Intel NPU driver page for Windows](https://www.intel.com/content/www/us/en/download/794734/intel-npu-driver-windows.html) and download the latest driver zip file.
+ - Extract the driver zip file
+
+2. Install the driver
+
+ - Open **Device Manager** and locate **Neural processors** -> **Intel(R) AI Boost** in the device list
+ - Right-click on **Intel(R) AI Boost** and select **Update driver**
+ - Choose **Browse my computer for drivers**, navigate to the folder where you extracted the driver zip file, and select **Next**
+ - Wait for the installation finished
+
+A system reboot is necessary to apply the changes after the installation is complete.
+
+### (Optional) Install Visual Studio 2022
+
+> [!NOTE]
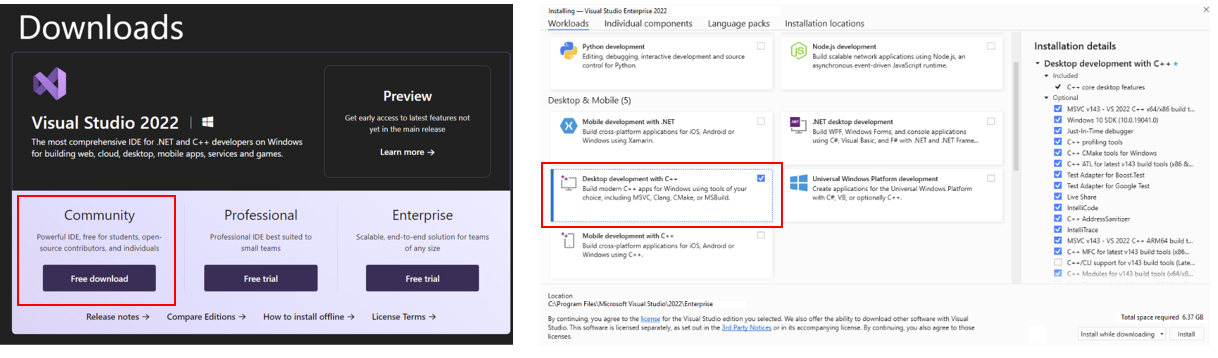
+> To use IPEX-LLM **C++ API** on Intel NPU, you are required to install Visual Studio 2022 on your system. If you plan to use the **Python API**, skip this step.
+
+Install [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) Community Edition and select "Desktop development with C++" workload:
+
+
+
+
+

+