আমরা মেশিন লার্নিংয়ের একদম শেষ পর্বে চলে এলাম। আগের পর্বেই মোটামুটি দেখেছিলাম মডেল ভাল পারফর্ম না করলে অথবা অন্য মডেল আদৌ ভাল পারফর্ম করছে কিনা সেটা জানার জন্য কীভাবে কাজ আগাতে হয়।
- টেস্ট ডেটার মাধ্যমে মডেল এভালুয়েশন
- রেজাল্ট ইন্টারপ্রিটেশন
- অ্যাকুরেসি বাড়ানো
- কনফিউশন ম্যাট্রিক্স
- Recall
- Precision
- AUC (Area Under Curve)
- ROC (Receiver Operating Characteristics) - Curve
- ওভারফিটিং
- মডেল হাইপারপ্যারামিটার
- ওভারফিটিং মিনিমাইজেশন
- K-Fold / N-Fold Cross-validation
- Bias-Variance Trade Off
- ভাল পারফর্মেন্সের জন্য পার্ফেকশন ছাড় দেওয়া
আমরা এখনো এই ধাপে,

ROC বোঝার আগে অবশ্যই Confusion Matrix সম্পর্কে জানতে হবে, না জানলে আগের পর্ব থেকে পড়ে নিন।
ROC স্পেসে ROC কার্ভ আঁকার জন্য X-axis এ FPR (False Positive Rate) ও Y-axis এ TPR (True Positive Rate) বসাতে হয়।
তারমানে কনফিউশন ম্যাট্রিক্স থেকে প্রাপ্ত TPR ও FPR রেট বসালে আমরা একটা পয়েন্ট পাব, এভাবে একই ডেটাসেটের উপর প্রয়োগকৃত যতগুলা মডেল নিয়ে আমরা কাজ করব সেগুলোর প্রতিটি থেকে একটি করে পয়েন্ট পাব।
এই পয়েন্টগুলো যোগ করে দিয়ে গ্রাফ আঁকলেই আপনি পেয়ে যাবেন আপনার আকাঙ্ক্ষিত ROC কার্ভ।
একটা পার্ফেক্ট ক্লাসিফায়ারের TPR হয় 1 এবং FPR হয় 0।
একটি উদাহরণ দিয়েই ROC বোঝা যায়।
একটা সিনারিও দেখা যাক,
আমি একটা ডায়বেটিস ডেটাসেট নিলাম, ডেটাসেট এ Observation আছে 1000 টা, আমি এটাকে 80%-20% এ ভাগ করলাম। তারমানে 80% ডেটা হল ট্রেইনিং ডেটা, 20% ডেটা হল টেস্টিং ডেটা।
আবার ধরুন, 200 টা টেস্টিং ডেটার মধ্যে 100 টা হল Positive (মানে আউটপুট পজিটিভ আরও সহজভাবে বললে ঔ ১০০ টা ডেটার আউটকাম হল ডায়বেটিস হয়েছে)। এবং 100 টা Negative।
আমি চারটা মডেল তৈরি করলাম, এই মডেল চারটা আমি ট্রেইন করব ও তাদের পারফর্মেন্স টেস্ট করব। চারটা মডেল হল,
- Gaussian Naive Bayes Model
- Logistic Regression Model
- Random Forest Model
- Artificial Neural Network Model
আমরা এখনো Artificial Neural Network দেখি নাই এবং এটা সম্পর্কে না জানলেও সমস্যা নেই।
আমি আগের পর্বের মত করে প্রতিটা মডেলকে ট্রেইন করে তারপর তাদের Confusion Matrix বের করতে পারি, তাই না? ঠিক সেভাবেই আমি 80% ডেটাসেট দিয়ে মডেলগুলোকে শিখিয়ে পড়িয়ে মানুষ করব তারপর তাদের পারফর্মেন্স টেস্ট করার জন্য পড়া ধরব। (কনফিউশন ম্যাট্রিক্স বের করব)।
আরও মনে করতে থাকেন, প্রতিটি মডেলের Confusion Matrix ও পাশাপাশি তাদের TPR, FPR বের করলাম।
| TP = 63 | FP = 28 |
|---|---|
| FN = 37 | TN = 72 |
TPR = 0.63
FPR = 0.28
| TP = 77 | FP = 77 |
|---|---|
| FN = 23 | TN = 23 |
TPR = 0.77
FPR = 0.77
| TP = 24 | FP = 88 |
|---|---|
| FN = 76 | TN = 12 |
TPR = 0.24
FPR = 0.88
| TP = 76 | FP = 12 |
|---|---|
| FN = 24 | TN = 88 |
TPR = 0.76
FPR = 0.12
আমরা আগেই জেনেছি ROC Curve এর ক্ষেত্রে Y-axis এ থাকে TPR এবং X-axis এ থাকে FPR। তাহলে আমরা এই চারটা Coordinate সহজেই ROC Space এ বসাতে পারি।
Coordinate গুলো
Coordinate -> Model (X, Y)
--------------------------------------
G point -> Gaussian Naive (0.28, 0.63)
L point -> Logistic Regression (.77, .77)
R point -> Random Forest (.88, .24)
A point -> Artificial Neural Network (.76, .12)
এই পয়েন্টগুলো আমরা এখন প্লট করব।
import numpy as np
import matplotlib.pyplot as plt
# fpr, tpr
naive_bayes = np.array([0.28, 0.63])
logistic = np.array([0.77, 0.77])
random_forest = np.array([0.88, 0.24])
ann = np.array([0.12, 0.76])
# plotting
plt.scatter(naive_bayes[0], naive_bayes[1], label = 'Naive Bayes', facecolors='black', edgecolors='orange', s=300)
plt.scatter(logistic[0], logistic[1], label = 'Logistic Regression', facecolors='orange', edgecolors='orange', s=300)
plt.scatter(random_forest[0], random_forest[1], label = 'Random Forest', facecolors='blue', edgecolors='black', s=300)
plt.scatter(ann[0], ann[1], label = 'Artificial Neural Network', facecolors='red', edgecolors='black', s=300)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc='lower center')
plt.show()
উদাহরণটি উইকিপিডিয়া থেকে নেয়া, উইকিপিডিয়ার ROC কার্ভে অতিরিক্ত কিছু জিনিস পয়েন্ট আউট করে দেওয়া আছে,
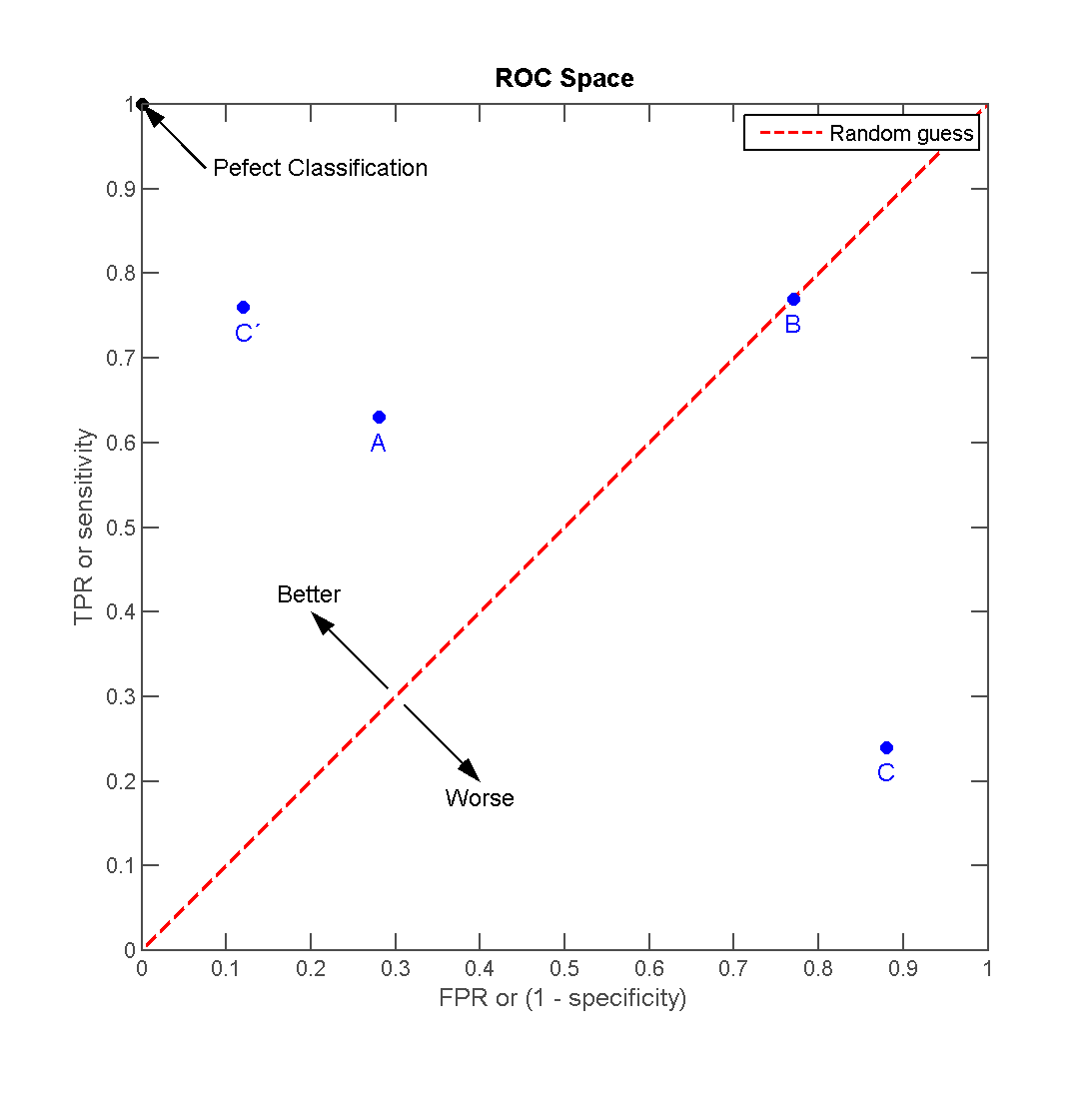
আমি এখানে প্রতিটি পয়েন্ট বোঝানোর জন্য আলাদা ভাবে স্ক্যাটার প্লট করেছি। আপনার যদি মডেল অনেকগুলো হয় কিংবা, একই মডেলের প্যারামিটার পরিবর্তনভিত্তিক পারফর্মেন্স যদি আপনি প্লট করেন তাহলে আপনার প্লট করা ROC কার্ভ হবে এইরকম।

আমার এখানে মডেল মাত্র ৪ টা, তাই এখানে লাইন প্লট করলে বোঝা যাবে না তাই, স্ক্যাটার প্লট করা হল।
100% Accurate Model এর FPR = 0 এবং TPR = 1। এটাকে আইডিয়াল ধরে সহজেই বোঝা যাচ্ছে ANN মডেল হিসেবে সবেচেয়ে ভাল, তারপর Naive Bayes, তারপর Logistic Regression এবং সবার শেষে Random Forest পারফর্ম করেছে।
আগেই (এবং আবারো) বলে রাখি, সবসময় ANN > NB > LR > RF এইরকম হবে তা নয়, ডেটাসেট ও প্রবলেমের ধরণ অনুযায়ী এক এক মডেলের পারফর্মেন্স একেক রকম। আমি এখানে পুরো ব্যাপারটা কল্পনা করেছি।
মাঝখান দিয়ে যে ড্যাশড লাইন কোণাকুণি বরাবর গিয়েছে তাকে বলে Line of no-discrimination। পয়েন্ট যত এই লাইনের উপরে থাকবে তত ভাল এবং নিচে থাকলে ততটাই খারাপ।
উপরে একটা ROC Curve দেখছেন নিশ্চয়? সেখানে ROC কার্ভ যতটা Area কভার করে ততটাই ভাল। 100% Accurate Model এর AUC হল TPR * FPR বা পুরো গ্রাফের ক্ষেত্রফল।
AUC দিয়ে পারফর্মেন্স পরিমাপ করা নিয়ে অনেক প্রশ্ন উঠেছে বর্তমানে, সবাই কমবেশি ROC প্রেফার করে । তাই AUC নিয়ে কথা বাড়ালাম না।
আগেও বলা হয়েছিল, কোন কোন সময় মডেলের পারফর্মেন্স এতটাই ভাল হয় যে Training Data এর ক্ষেত্রে Accuracy Rate প্রায় 95-99% হয়। কিন্তু Testing Data তে প্রেডিক্ট করতে দিলে 40% Accuracy Rate ও হয় না।
প্রশ্ন হচ্ছে, এটা কেন হয়?
আসলে আমরা যে ডেটাসেট দিয়ে ট্রেইন করি, সেখানে আসল ডেটার পাশাপাশি Noise ও থাকে। অর্থাৎ, 100% Pure Dataset আপনি কখনোই পাবেন না।
একটা ক্লাসিক এক্সাম্পল হতে পারে, আমি কিছু ডেটাসেট জোগাড় করলাম, কয় ঘণ্টা পড়ি আর কয় ঘণ্টা ঘুমাই তার উপর কত মার্কস পাই। এখন আমি এই ডেটাসেট এর উপরে মডেল ট্রেইন করে প্রেডিক্ট করতে বসে যাই এবং যদি কোনভাবে দেখি, পড়া কমিয়ে ঘুমালে মার্কস বেশি আসছে, এবং সেটার উপর ভিত্তি করে আমি পরবর্তী পরীক্ষার আগে ঘুমায়ে কাটালাম কিন্তু পড়লাম না একটুও (কারণ আমার তৈরি A.I বলেছে ঘুমালে মার্কস বেশি পাওয়া যাবে)। তাতে ফলাফল কী আসবে সেটা বোঝাই যাচ্ছে।
তাহলে এই যে ভুলভাল প্রেডিকশন দিচ্ছে, তার কারণ কী? দুইটা কারণ, (১) পর্যাপ্ত পরিমাণ ডেটা নাই, (২) ডেটাসেট এ কলামের সংখ্যা (ভ্যারিয়েবল, এখানে যেমন কয় ঘণ্টা পড়ি আর কয় ঘণ্টা ঘুমাই) কম। মার্কস ভাল আসার অনেক কারণ থাকতে পারে, পরীক্ষা যদি MCQ হয় আর তাতে ঝড়ে বক দিয়ে ভাল পরিমাণ দাগিয়ে ফেললাম, অথবা প্রশ্ন অনেক সহজ হল ইত্যাদি। তাহলে এগুলোতো আমি ইনপুট এ না দিয়েই ট্রেইন করেছি, তাই মডেল স্বভাবতই সেই ? কারণ গুলো না জেনেই আমার দেওয়া ডেটাসেট এর সাথে নিজেকে এমন ভাবে খাপ খাওয়াবে তাতে Error সবচেয়ে কম থাকে।
মডেল ট্রেইন মানে হচ্ছে Error কমানো, আর Error কমানোর জন্য প্রতিটি মডেলের হাইপারপ্যারামিটার গুলো ম্যাথেমেটিক্যাল অ্যানালাইসিস অনুযায়ী সেট হয়। যে হাইপারপ্যারামিটার ব্যবহার করলে Error সবচেয়ে কম হবে সেটাই মডেল ব্যবহার করবে (এটাই স্বাভাবিক)। কিন্তু Error কম করতে গিয়ে যদি Model, ডেটাসেটের Noise এর সাথে খাপ খাইয়ে নেয় তাহলে যথেষ্ট ঝামেলা হবে।
ওভারফিটিং সম্পর্কে পরবর্তীতে আমরা আরও বিস্তারিত দেখব কয়েকটি ধাপে।
ওভারফিটিং কমানোর জন্য যেটা করা যায় সেটা হচ্ছে, ডেটা জোগাড় করা এবং কলামের সংখ্যা বাড়ানো। যতটা পিওর সম্ভব ততটা পিওর ডেটাসেট ও ভাল প্রেডিকশন রেজাল্ট দিতে পারে। এটাতো গেল ডেটাসেট এ কি করবেন। চাইলে অ্যালগরিদম টিউন করেও ভাল রেজাল্ট বের করা সম্ভব। আমরা একটা মেথড দেখব।
একটা অ্যালগরিদম কীভাবে শিখবে সেটা আমরা চাইলে কন্ট্রোল করতে পারি। মেশিন লার্নিং অ্যালগরিদম মানেই তার পিছনে কোন না কোন ম্যাথমেটিক্যাল মডেল কাজ করছে, তাই সেই ম্যাথমেটিক্যাল মডেলের লার্নিং মেকানিজম চাইলে কিছু নির্দিষ্ট প্যারামিটার দিয়ে কন্ট্রোল করা যায়।
ধরি কোন একটি মডেল আউটপুট বের করে এই সূত্র দিয়ে,
আমরা এর লার্নিং কন্ট্রোল করার জন্য, Regularized Model তৈরি করতে পারি,
এখানে,$$\lambda$$ ই হল Regularization Hyperparameter।
লক্ষণীয়,
যখনই মডেলটা এরর কমানোর জন্য ডেটাসেট এর সাথে খাপ খাওয়াতে যাবে, ওমনি lambda তাকে পেনাল্টি দিয়ে দূরে সরিয়ে দেবে। আমাদের আল্টিমেট কাজ হবে এই lambda কে এমন ভাবে টিউন করা যাতে Testing Dataset এ অ্যাকুরেসি ভাল আসে। Training Dataset এ অ্যাকুরেসি গোল্লায় যাক :P
টপিকের টাইটেল একটু বড় হয়ে গেল। একটু আগে আমরা জানলাম, ম্যাথমেটিক্যাল মডেল হ্যাক করে আমরা Regularization এর মাধ্যমে মডেলের ওভারফিটিং কমাতে পারি। মডেল ভিত্তিক Regularization Hyperparameter বিভিন্ন হয়। সাইকিট লাইব্রেরিতে অলরেডি Logistic Regression এর মডেলের কোড করে দেওয়া আছে এবং তারা Regularization Hyperparameter চেঞ্জ করার জন্য সুবিধাজনক ইন্টারফেসও দিয়েছে।
আমাদের কাজ হবে, Regularization Hyperparameter এর মান পরিবর্তন করে প্রেডিকশন স্কোর সংগ্রহ করা। তারপর যে Hyperparameter Value তে প্রেডিকশনের অ্যাকুরেসি সর্বোচ্চ হবে সেটা স্টোর করে রাখা।
থিওরি দেখলাম, এবার প্র্যাক্টিক্যাল দেখার পালা। এখন আপনাকে অবশ্যই নোটবুক বের করে কোড লিখতে হবে।

from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression(C=0.7, random_state=42)
lr_model.fit(X_train, y_train.ravel())
lr_predict_test = lr_model.predict(X_test)
# training metrics
print "Accuracy : {0:.4f}".format(metrics.accuracy_score(y_test, lr_predict_test))
print "Confusion Matrix"
print metrics.confusion_matrix(y_test, lr_predict_test, labels=[1, 0])
print ""
print "Classification Report"
print metrics.classification_report(y_test, lr_predict_test, labels=[1, 0])Accuracy : 0.7446
Confusion Matrix
[[ 44 36]
[ 23 128]]
Classification Report
precision recall f1-score support
1 0.66 0.55 0.60 80
0 0.78 0.85 0.81 151
avg / total 0.74 0.74 0.74 231
এই কাজগুলো আমরা নাইভ বেয়েস মডেলের জন্য করেছিলাম। এখানে C হচ্ছে আমাদের সেই Regularization Hyperparameter, শুরুতে ধরে নিলাম
C_start = 0.1
C_end = 5
C_inc = 0.1
C_values, recall_scores = [], []
C_val = C_start
best_recall_score = 0
while (C_val < C_end):
C_values.append(C_val)
lr_model_loop = LogisticRegression(C=C_val, random_state=42)
lr_model_loop.fit(X_train, y_train.ravel())
lr_predict_loop_test = lr_model_loop.predict(X_test)
recall_score = metrics.recall_score(y_test, lr_predict_loop_test)
recall_scores.append(recall_score)
if (recall_score > best_recall_score):
best_recall_score = recall_score
best_lr_predict_test = lr_predict_loop_test
C_val = C_val + C_inc
best_score_C_val = C_values[recall_scores.index(best_recall_score)]
print "1st max value of {0:.3f} occured at C={1:.3f}".format(best_recall_score, best_score_C_val)
%matplotlib inline
plt.plot(C_values, recall_scores, "-")
plt.xlabel("C value")
plt.ylabel("recall score")যেহেতু Regularization Hyperparameter C, আর আমি বিভিন্ন C এর মানের জন্য recall_scores দেখতে চাচ্ছি (recall_score যত বেশি তত ভাল), তাই C_start = 0.1 নিলাম, C_end = 5 নিলাম, আর লুপে C এর মান 0.1 করে বৃদ্ধি করলাম।
আর প্রতি C এর ভ্যালুর জন্য প্রেডিক্টেড ডেটাসেট দিয়ে অ্যাকুরেসি চেক করলাম, যখনই recall এর মান আগেরটার চেয়ে বেশি হবে তখনই best_recall_score এ recall_score অর্থাৎ বর্তমান স্কোর অ্যাসাইন হবে।
আগের বিষয়গুলো বুঝতে পারলে কোডটা কঠিন কিছু নয়।
C_values এবং recall_scores নামের দুইটা লিস্ট রাখলাম ভ্যালু স্টোরের জন্য
C এর মান বৃদ্ধির সাথে কীভাবে পারফর্মেন্স পরিবর্তন হচ্ছে তার গ্রাফ।

C এর মান যখন 2-3 এর মধ্যে তখন Recall Score সবচেয়ে বেশি, C এর মান 4-5 এবং 0-1 এর মধ্যে কম।
Regularization Hyperparameter একটাই হবে তার কোন কারণ নেই, একাধিক থাকতে পারে। একটু আগে আমরা C এর মান বের করেছিলাম। এখন আমরা আরেকটি প্যারামিটার (class_weight) কে balanced দিয়ে দেখব পারফর্মেন্স কিরকম দিচ্ছে।
class_weight = 'balanced' রেখে C এর মান পরিবর্তন করে পারফর্মেন্স বের করাই হবে মূল উদ্দেশ্য।
C_start = 0.1
C_end = 5
C_inc = 0.1
C_values, recall_scores = [], []
C_val = C_start
best_recall_score = 0
while (C_val < C_end):
C_values.append(C_val)
lr_model_loop = LogisticRegression(C=C_val, class_weight="balanced", random_state=42)
lr_model_loop.fit(X_train, y_train.ravel())
lr_predict_loop_test = lr_model_loop.predict(X_test)
recall_score = metrics.recall_score(y_test, lr_predict_loop_test)
recall_scores.append(recall_score)
if (recall_score > best_recall_score):
best_recall_score = recall_score
best_lr_predict_test = lr_predict_loop_test
C_val = C_val + C_inc
best_score_C_val = C_values[recall_scores.index(best_recall_score)]
print "1st max value of {0:.3f} occured at C={1:.3f}".format(best_recall_score, best_score_C_val)
%matplotlib inline
plt.plot(C_values, recall_scores, "-")
plt.xlabel("C value")
plt.ylabel("recall score")
ক্লাস ওয়েট balanced দেওয়াতে দেখা যাচ্ছে Recall Score বেড়ে 0.73+ হয়েছে, definitely what we were looking for!
কনফিউশন ম্যাট্রিক্স
কোড:
from sklearn.linear_model import LogisticRegression
lr_model =LogisticRegression( class_weight="balanced", C=best_score_C_val, random_state=42)
lr_model.fit(X_train, y_train.ravel())
lr_predict_test = lr_model.predict(X_test)
# training metrics
print "Accuracy: {0:.4f}".format(metrics.accuracy_score(y_test, lr_predict_test))
print metrics.confusion_matrix(y_test, lr_predict_test, labels=[1, 0])
print ""
print "Classification Report"
print metrics.classification_report(y_test, lr_predict_test, labels=[1,0])
print metrics.recall_score(y_test, lr_predict_test)Accuracy: 0.7143
[[ 59 21]
[ 45 106]]
Classification Report
precision recall f1-score support
1 0.57 0.74 0.64 80
0 0.83 0.70 0.76 151
avg / total 0.74 0.71 0.72 231
0.7375
Regularization এর মাধ্যমে এভাবে আমরা অ্যাকুরেসি বাড়াতে পারি (ওভারফিটিং কমিয়ে)।
ওভারফিটিং কমানোর আরেকটি ইফেক্টিভ অ্যালগরিদম হল K-Fold Cross-validation। নামটা অনেক কঠিন শোনালেও কাজ খুবই সহজ।
আমাদের ডায়বেটিস ডেটাসেট এ কিন্তু নেগেটিভ উত্তর বেশি (মানে ডায়বেটিস হয় নাই)। যেখানে ডেটাসেট এর ব্যালেন্স কম থাকবে সেসব ক্ষেত্রে K-Fold Cross-validation খুবই ভাল অ্যাকুরেসি দিতে সাহায্য করে।
K-Fold বা N-Fold Cross-validation একই জিনিস যখন k=N! বা K = Number of observation।
k-Fold Cross-validation এ যেটা করা হয়, সম্পূর্ণ ডেটাসেটকে k equal sized এ সাবস্যাম্পল করা হয়।
এবার এই k সংখ্যক সাবস্যাম্পল থেকে একটা একটা করে ডেটা নেয়া হয় টেস্টিং এর জন্য।
যেমন, আমার কাছে 25 টা অবসার্ভেশনের ডেটাসেট আছে, আমি এদেরকে ৫ টা গ্রুপে ভাগ করলাম।
তারমানে প্রতিগ্রুপে ডেটাসেট থাকল ৫ টা করে। এবার এই পাঁচটা গ্রুপের প্রথম গ্রুপ আমি Hold করলাম বাকিগুলো ট্রেইনিংয়ে দিলাম, Hold করা ডেটাসেট দিয়ে টেস্ট করলাম।
দ্বিতীয় Pass এ দ্বিতীয় গ্রুপ Hold করব (ট্রেনিংয়ে পাঠাব না), আর বাকিগুলো Training এ পাঠাব।
ঠিক একই ভাবে চতুর্থ এবং পঞ্চম Pass এ ঔ পজিশনাল গ্রুপটি Hold করে বাকিটা পাঠাব ট্রেইনিংয়ে।
এভাবে 5 বার 5-Fold এ ট্রেইন করব। যেহেতু প্রতি গ্রুপে Observation 5 টা এবং গ্রুপ সংখ্যা ৫ টা তাই এর নাম হবে 5-Fold Cross-validation।
ক্রস ভ্যালিডেশন এনাবলড মডেল সাইকিটে বানানোই আছে, যেকোন নরমাল মডেল এর সাথে CV লাগিয়ে দিলেই Cross-validation Enabled Model পেয়ে যাবেন।
যেমন, LogisticRegression এর Cross-validation Enabled মডেল হবে LogisticRegressionCV, এভাবে বাকিগুলোর জন্যও সত্য।
চলুন এটার পারফর্মেন্স দেখা যাক,
from sklearn.linear_model import LogisticRegressionCV
lr_cv_model = LogisticRegressionCV(n_jobs=-1, random_state=42, Cs=3, cv=10, refit=False, class_weight="balanced")
# set number of jobs to -1 which uses all cores to parallelize
lr_cv_model.fit(X_train, y_train.ravel())
lr_cv_predict_test = lr_cv_model.predict(X_test)
# training metrics
print "Accuracy: {0:.4f}".format(metrics.accuracy_score(y_test, lr_cv_predict_test))
print metrics.confusion_matrix(y_test, lr_cv_predict_test, labels=[1, 0])
print ""
print "Classification Report"
print metrics.classification_report(y_test, lr_cv_predict_test, labels=[1,0])Accuracy: 0.7100
[[ 55 25]
[ 42 109]]
Classification Report
precision recall f1-score support
1 0.57 0.69 0.62 80
0 0.81 0.72 0.76 151
avg / total 0.73 0.71 0.72 231
10-Fold ক্রস ভ্যালিডেশনে পারফর্মেন্স খারাপ আসে নি!
অনেক বড় হয়ে গেল চ্যাপ্টারটা, তবুও Bias-Variance টা বাদ থেকে গেল। পরবর্তী অন্য কোন পর্বে আমরা দেখব Bias-Variance Trade-off কী জিনিস এবং এর ইম্প্যাক্ট কতখানি।
ডেটাসেট থেকে অ্যালগো সিলেকশনের উপরে সাইকিটের নিজস্ব একটা চিটশিট আছে। খুবই ইফেক্টিভ,

- টেস্ট ডেটার মাধ্যমে মডেল এভালুয়েশন
- রেজাল্ট ইন্টারপ্রিটেশন
- অ্যাকুরেসি বাড়ানো
- কনফিউশন ম্যাট্রিক্স
- Recall
- Precision
- AUC (Area Under Curve)
- ROC (Receiver Operating Characteristics) - Curve
- ওভারফিটিং
- মডেল হাইপারপ্যারামিটার
- ওভারফিটিং মিনিমাইজেশন
- K-Fold / N-Fold Cross-validation
- Bias-Variance Trade Off
- ভাল পারফর্মেন্সের জন্য পার্ফেকশন ছাড় দেওয়া