-
Notifications
You must be signed in to change notification settings - Fork 1
/
writty.sql
262 lines (205 loc) · 172 KB
/
writty.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
# ************************************************************
# Sequel Pro SQL dump
# Version 4529
#
# http://www.sequelpro.com/
# https://github.com/sequelpro/sequelpro
#
# Host: 127.0.0.1 (MySQL 5.6.29)
# Database: writty
# Generation Time: 2016-05-21 17:02:41 +0000
# ************************************************************
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
# Dump of table t_comment
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_comment`;
CREATE TABLE `t_comment` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`pid` varchar(36) NOT NULL DEFAULT '' COMMENT '文章id',
`cid` int(11) DEFAULT NULL COMMENT '评论id',
`uid` int(11) NOT NULL COMMENT '发布评论的用户',
`to_uid` int(11) DEFAULT NULL,
`content` text NOT NULL,
`ip` varchar(255) DEFAULT NULL COMMENT '评论人ip',
`created` int(11) DEFAULT NULL COMMENT '评论时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_comment` WRITE;
/*!40000 ALTER TABLE `t_comment` DISABLE KEYS */;
INSERT INTO `t_comment` (`id`, `pid`, `cid`, `uid`, `to_uid`, `content`, `ip`, `created`)
VALUES
(1,'5f233fbaca',NULL,6,NULL,'11','127.0.0.1',1463765242),
(2,'5f233fbaca',NULL,6,NULL,'2222','127.0.0.1',1463765425);
/*!40000 ALTER TABLE `t_comment` ENABLE KEYS */;
UNLOCK TABLES;
# Dump of table t_favorite
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_favorite`;
CREATE TABLE `t_favorite` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`pid` varchar(64) NOT NULL,
`uid` int(10) NOT NULL,
`created` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# Dump of table t_link
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_link`;
CREATE TABLE `t_link` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '链接名称',
`url` varchar(255) NOT NULL DEFAULT '' COMMENT '链接地址',
`is_new` tinyint(2) NOT NULL COMMENT '是否新窗口打开',
`display_order` int(10) DEFAULT '0' COMMENT '排序',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# Dump of table t_open
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_open`;
CREATE TABLE `t_open` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`open_id` int(11) NOT NULL,
`uid` int(11) NOT NULL,
`created` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_open` WRITE;
/*!40000 ALTER TABLE `t_open` DISABLE KEYS */;
INSERT INTO `t_open` (`id`, `open_id`, `uid`, `created`)
VALUES
(2,3849072,6,1462977008);
/*!40000 ALTER TABLE `t_open` ENABLE KEYS */;
UNLOCK TABLES;
# Dump of table t_options
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_options`;
CREATE TABLE `t_options` (
`okey` varchar(100) NOT NULL DEFAULT '',
`ovalue` text,
PRIMARY KEY (`okey`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='系统配置表';
LOCK TABLES `t_options` WRITE;
/*!40000 ALTER TABLE `t_options` DISABLE KEYS */;
INSERT INTO `t_options` (`okey`, `ovalue`)
VALUES
('site_description',NULL),
('site_favicon',NULL),
('site_keyworlds','写作平台,技术文章,markdown,blade框架'),
('site_title','Writty');
/*!40000 ALTER TABLE `t_options` ENABLE KEYS */;
UNLOCK TABLES;
# Dump of table t_post
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_post`;
CREATE TABLE `t_post` (
`pid` varchar(36) NOT NULL DEFAULT '' COMMENT '文章uuid',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`slug` varchar(255) DEFAULT NULL COMMENT '自定义文章显示名',
`uid` int(11) NOT NULL COMMENT '文章发布人',
`sid` int(11) DEFAULT NULL COMMENT '所属栏目id',
`type` tinyint(2) NOT NULL COMMENT '1:原创 2:转载 3:翻译',
`cover` varchar(255) DEFAULT NULL COMMENT '文章封面图',
`content` text COMMENT '文章内容',
`comments` int(11) DEFAULT '0' COMMENT '文章评论数',
`is_pub` tinyint(2) DEFAULT '0' COMMENT '文章是否已经发布,0草稿1待审核2已发布',
`is_del` tinyint(2) DEFAULT '0' COMMENT '文章是否被删除',
`created` int(11) NOT NULL COMMENT '文章发布时间',
`updated` int(11) NOT NULL COMMENT '最后更新时间',
PRIMARY KEY (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_post` WRITE;
/*!40000 ALTER TABLE `t_post` DISABLE KEYS */;
INSERT INTO `t_post` (`pid`, `title`, `slug`, `uid`, `sid`, `type`, `cover`, `content`, `comments`, `is_pub`, `is_del`, `created`, `updated`)
VALUES
('0c0d2584e0','Tomcat 安装和配置、优化',NULL,6,1002,2,'post/0c0d2584e0.png','## Tomcat 8 安装\r\n\r\n- Tomcat 8 安装\r\n - 官网:<http://tomcat.apache.org/>\r\n - Tomcat 8 官网下载:<http://tomcat.apache.org/download-80.cgi>\r\n - 此时(20160207) Tomcat 8 最新版本为:`apache-tomcat-8.0.32.tar.gz`\r\n - 我个人习惯 `/opt` 目录下创建一个目录 `setups` 用来存放各种软件安装包;在 `/usr` 目录下创建一个 `program` 用来存放各种解压后的软件包,下面的讲解也都是基于此习惯\r\n - 我个人已经使用了第三方源:`EPEL、RepoForge`,如果你出现 `yum install XXXXX` 安装不成功的话,很有可能就是你没有相关源,请查看我对源设置的文章\r\n - Tomcat 8 下载:`wget http://apache.fayea.com/tomcat/tomcat-8/v8.0.32/bin/apache-tomcat-8.0.32.tar.gz`\r\n - 压缩包解压:`tar -zxvf apache-tomcat-8.0.32.tar.gz`\r\n - 移到解压出来文件夹到 /usr 下:`mv apache-tomcat-8.0.32/ /usr/program/`\r\n - 为了方便,修改解压目录的名字:`mv /usr/program/apache-tomcat-8.0.32/ /usr/program/tomcat8/`\r\n- 设置 Iptables 规则(这一步是必须设置的):\r\n - 一种方式:先关闭 iptables,防止出现拦截问题而测试不了:`service iptables stop`\r\n - 一种方式:在 iptables 中添加允许规则(Tomcat 默认端口是 8080):\r\n - 添加规则:`sudo iptables -I INPUT -p tcp -m tcp --dport 8080 -j ACCEPT`\r\n - 保存规则:`sudo /etc/rc.d/init.d/iptables save`\r\n - 重启 iptables:`sudo service iptables restart`\r\n- 测试安装好后的 Tomcat:\r\n - 启动 Tomcat:`sh /usr/program/tomcat8/bin/startup.sh ; tail -200f /usr/program/tomcat8/logs/catalina.out`\r\n - 访问:`http://服务器 IP 地址:8080/`\r\n - 停止 Tomcat:`sh /usr/program/tomcat8/bin/shutdown.sh`\r\n\r\n\r\n## Tomcat 8 配置\r\n\r\n- 设置 Tomcat 相关变量:\r\n - `sudo vim /usr/program/tomcat8/bin/catalina.sh`\r\n - 在配置文件的可编辑内容最上面(98 行开始),加上如下内容(具体参数根据你服务器情况自行修改):\r\n ``` ini\r\n JAVA_HOME=/usr/program/jdk1.8.0_72\r\n CATALINA_HOME=/usr/program/tomcat8\r\n CATALINA_OPTS=\"-server -Xms528m -Xmx528m -XX:PermSize=256m -XX:MaxPermSize=358m\"\r\n CATALINA_PID=$CATALINA_HOME/catalina.pid\r\n ```\r\n- 如果使用 `shutdown.sh` 还无法停止 tomcat,可以修改其配置:`vim /usr/program/tomcat8/bin/shutdown.sh`\r\n - 把最尾巴这一行:`exec \"$PRGDIR\"/\"$EXECUTABLE\" stop \"$@\"`\r\n - 改为:`exec \"$PRGDIR\"/\"$EXECUTABLE\" stop 10 -force`\r\n \r\n \r\n## Tomcat 8 优化\r\n\r\n- Tomcat 6/7/8 的优化参数有点不一样,最好按下面的方式看一下官网这个文档是否还保留着这个参数\r\n- 启动tomcat,访问该地址,下面要讲解的一些配置信息,在该文档下都有说明的:\r\n - 文档:<http://127.0.0.1:8080/docs/config>\r\n - 你也可以直接看网络版本:\r\n - Tomcat 6 文档:<https://tomcat.apache.org/tomcat-6.0-doc/config>\r\n - Tomcat 7 文档:<https://tomcat.apache.org/tomcat-7.0-doc/config/>\r\n - Tomcat 8 文档:<https://tomcat.apache.org/tomcat-8.0-doc/config/>\r\n- 如果你需要查看 Tomcat 的运行状态可以配置tomcat管理员账户,然后登陆 Tomcat 后台进行查看\r\n- 编辑 /opt/tomcat7/bin/conf/tomcat-users.xml 文件,在里面添加下面信息:\r\n``` xml\r\n<role rolename=\"manager\"/>\r\n<role rolename=\"manager-gui\"/>\r\n<role rolename=\"admin\"/>\r\n<role rolename=\"admin-gui\"/>\r\n<user username=\"tomcat\" password=\"tomcat\" roles=\"admin-gui,admin,manager-gui,manager\"/>\r\n```\r\n- 编辑配置文件:`vim /usr/program/tomcat7/conf/server.xml`\r\n - 打开默认被注释的连接池配置:\r\n - 默认值:\r\n ``` xml\r\n <!--\r\n <Executor name=\"tomcatThreadPool\" namePrefix=\"catalina-exec-\"\r\n maxThreads=\"150\" minSpareThreads=\"4\"/>\r\n -->\r\n ```\r\n - 修改为:\r\n ``` xml\r\n <Executor \r\n name=\"tomcatThreadPool\" \r\n namePrefix=\"catalina-exec-\"\r\n maxThreads=\"500\" \r\n minSpareThreads=\"100\" \r\n prestartminSpareThreads = \"true\"\r\n maxQueueSize = \"100\"\r\n />\r\n ```\r\n - 重点参数解释:\r\n - maxThreads,最大并发数,默认设置 200,一般建议在 500 ~ 800,根据硬件设施和业务来判断\r\n - minSpareThreads,Tomcat 初始化时创建的线程数,默认设置 25\r\n - prestartminSpareThreads,在 Tomcat 初始化的时候就初始化 minSpareThreads 的参数值,如果不等于 true,minSpareThreads 的值就没啥效果了\r\n - maxQueueSize,最大的等待队列数,超过则拒绝请求\r\n - 修改默认的链接参数配置:\r\n - 默认值:\r\n ``` xml\r\n <Connector \r\n port=\"8080\" \r\n protocol=\"HTTP/1.1\" \r\n connectionTimeout=\"20000\" \r\n redirectPort=\"8443\" \r\n />\r\n ```\r\n - 修改为:\r\n ``` xml\r\n <Connector \r\n executor=\"tomcatThreadPool\"\r\n port=\"8080\" \r\n protocol=\"org.apache.coyote.http11.Http11Nio2Protocol\" \r\n connectionTimeout=\"20000\" \r\n maxConnections=\"10000\" \r\n redirectPort=\"8443\" \r\n enableLookups=\"false\" \r\n acceptCount=\"100\" \r\n maxPostSize=\"10485760\" \r\n compression=\"on\" \r\n disableUploadTimeout=\"true\" \r\n compressionMinSize=\"2048\" \r\n acceptorThreadCount=\"2\" \r\n compressableMimeType=\"text/html,text/xml,text/plain,text/css,text/javascript,application/javascript\" \r\n URIEncoding=\"utf-8\"\r\n />\r\n ```\r\n - 重点参数解释:\r\n - protocol,Tomcat 8 设置 nio2 更好:org.apache.coyote.http11.Http11Nio2Protocol(如果这个用不了,就用下面那个)\r\n - protocol,Tomcat 6、7 设置 nio 更好:org.apache.coyote.http11.Http11NioProtocol\r\n - enableLookups,禁用DNS查询\r\n - acceptCount,指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理队列中的请求数,超过这个数的请求将不予处理,默认设置 100\r\n - maxPostSize,以 FORM URL 参数方式的 POST 提交方式,限制提交最大的大小,默认是 2097152(2兆),它使用的单位是字节。10485760 为 10M。如果要禁用限制,则可以设置为 -1。\r\n - acceptorThreadCount,用于接收连接的线程的数量,默认值是1。一般这个指需要改动的时候是因为该服务器是一个多核CPU,如果是多核 CPU 一般配置为 2.\r\n - 禁用 AJP(如果你服务器没有使用 Apache) \r\n - 把下面这一行注释掉,默认 Tomcat 是开启的。\r\n ``` xml\r\n <!-- <Connector port=\"8009\" protocol=\"AJP/1.3\" redirectPort=\"8443\" /> -->\r\n ```\r\n\r\n\r\n\r\n## JVM 优化\r\n\r\n- 模型资料来源:<http://xmuzyq.iteye.com/blog/599750>\r\n- Java 的内存模型分为:\r\n - Young,年轻代(易被 GC)。Young 区被划分为三部分,Eden 区和两个大小严格相同的 Survivor 区,其中 Survivor 区间中,某一时刻只有其中一个是被使用的,另外一个留做垃圾收集时复制对象用,在 Young 区间变满的时候,minor GC 就会将存活的对象移到空闲的Survivor 区间中,根据 JVM 的策略,在经过几次垃圾收集后,任然存活于 Survivor 的对象将被移动到 Tenured 区间。\r\n - Tenured,终身代。Tenured 区主要保存生命周期长的对象,一般是一些老的对象,当一些对象在 Young 复制转移一定的次数以后,对象就会被转移到 Tenured 区,一般如果系统中用了 application 级别的缓存,缓存中的对象往往会被转移到这一区间。\r\n - Perm,永久代。主要保存 class,method,filed 对象,这部门的空间一般不会溢出,除非一次性加载了很多的类,不过在涉及到热部署的应用服务器的时候,有时候会遇到 java.lang.OutOfMemoryError : PermGen space 的错误,造成这个错误的很大原因就有可能是每次都重新部署,但是重新部署后,类的 class 没有被卸载掉,这样就造成了大量的 class 对象保存在了 perm 中,这种情况下,一般重新启动应用服务器可以解决问题。\r\n- Linux 修改 /usr/program/tomcat7/bin/catalina.sh 文件,把下面信息添加到文件第一行。Windows 和 Linux 有点不一样的地方在于,在 Linux 下,下面的的参数值是被引号包围的,而 Windows 不需要引号包围。\r\n - 如果服务器只运行一个 Tomcat\r\n - 机子内存如果是 8G,一般 PermSize 配置是主要保证系统能稳定起来就行:\r\n - `JAVA_OPTS=\"-Dfile.encoding=UTF-8 -server -Xms6144m -Xmx6144m -XX:NewSize=1024m -XX:MaxNewSize=2048m -XX:PermSize=512m -XX:MaxPermSize=512m -XX:MaxTenuringThreshold=10 -XX:NewRatio=2 -XX:+DisableExplicitGC\"`\r\n - 机子内存如果是 16G,一般 PermSize 配置是主要保证系统能稳定起来就行:\r\n - `JAVA_OPTS=\"-Dfile.encoding=UTF-8 -server -Xms13312m -Xmx13312m -XX:NewSize=3072m -XX:MaxNewSize=4096m -XX:PermSize=512m -XX:MaxPermSize=512m -XX:MaxTenuringThreshold=10 -XX:NewRatio=2 -XX:+DisableExplicitGC\"`\r\n - 机子内存如果是 32G,一般 PermSize 配置是主要保证系统能稳定起来就行:\r\n - `JAVA_OPTS=\"-Dfile.encoding=UTF-8 -server -Xms29696m -Xmx29696m -XX:NewSize=6144m -XX:MaxNewSize=9216m -XX:PermSize=1024m -XX:MaxPermSize=1024m -XX:MaxTenuringThreshold=10 -XX:NewRatio=2 -XX:+DisableExplicitGC\"`\r\n - 如果是开发机\r\n - `-Xms550m -Xmx1250m -XX:PermSize=550m -XX:MaxPermSize=1250m`\r\n - 参数说明:\r\n ``` nginx \r\n -Dfile.encoding:默认文件编码\r\n -server:表示这是应用于服务器的配置,JVM 内部会有特殊处理的\r\n -Xmx1024m:设置JVM最大可用内存为1024MB\r\n -Xms1024m:设置JVM最小内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。\r\n -XX:NewSize:设置年轻代大小\r\n -XX:MaxNewSize:设置最大的年轻代大小\r\n -XX:PermSize:设置永久代大小\r\n -XX:MaxPermSize:设置最大永久代大小\r\n -XX:NewRatio=4:设置年轻代(包括 Eden 和两个 Survivor 区)与终身代的比值(除去永久代)。设置为 4,则年轻代与终身代所占比值为 1:4,年轻代占整个堆栈的 1/5\r\n -XX:MaxTenuringThreshold=10:设置垃圾最大年龄,默认为:15。如果设置为 0 的话,则年轻代对象不经过 Survivor 区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在 Survivor 区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。\r\n -XX:+DisableExplicitGC:这个将会忽略手动调用 GC 的代码使得 System.gc() 的调用就会变成一个空调用,完全不会触发任何 GC\r\n ```\r\n\r\n\r\n## 其他\r\n\r\n- Tomcat 历史版本下载地址整理(不间断更新):\r\n - **Tomcat 9.0.0.M4**:`wget http://mirror.bit.edu.cn/apache/tomcat/tomcat-9/v9.0.0.M4/bin/apache-tomcat-9.0.0.M4.tar.gz`\r\n - **Tomcat 8.0.32**:`wget http://mirror.bit.edu.cn/apache/tomcat/tomcat-8/v8.0.32/bin/apache-tomcat-8.0.32.tar.gz`\r\n - **Tomcat 7.0.68**:`wget http://apache.fayea.com/tomcat/tomcat-7/v7.0.68/bin/apache-tomcat-7.0.68.tar.gz`\r\n - **Tomcat 6.0.45**:`wget http://mirrors.cnnic.cn/apache/tomcat/tomcat-6/v6.0.45/bin/apache-tomcat-6.0.45.tar.gz`\r\n\r\n## 资料\r\n\r\n- <http://www.jikexueyuan.com/course/2064_3.html?ss=1>\r\n- <http://www.wellho.net/mouth/2163_CATALINA-OPTS-v-JAVA-OPTS-What-is-the-difference-.html>\r\n- <http://blog.csdn.net/sunlovefly2012/article/details/47395165>\r\n- <http://blog.csdn.net/lifetragedy/article/details/7708724>\r\n- <http://ihuangweiwei.iteye.com/blog/1233941>\r\n- <http://www.cnblogs.com/ggjucheng/archive/2013/04/16/3024731.html>\r\n- <https://tomcat.apache.org/tomcat-8.0-doc/config/http.html#Connector_Comparison>\r\n- <http://www.apelearn.com/study_v2/chapter23.html>',0,1,0,1463848272,1463848272),
('0d40e382dd','如何正确地写出单例模式',NULL,6,1008,2,'post/0d40e382dd.png','单例模式算是设计模式中最容易理解,也是最容易手写代码的模式了吧。但是其中的坑却不少,所以也常作为面试题来考。本文主要对几种单例写法的整理,并分析其优缺点。很多都是一些老生常谈的问题,但如果你不知道如何创建一个线程安全的单例,不知道什么是双检锁,那这篇文章可能会帮助到你。\r\n\r\n### 懒汉式,线程不安全\r\n\r\n当被问到要实现一个单例模式时,很多人的第一反应是写出如下的代码,包括教科书上也是这样教我们的。\r\n\r\n```java\r\npublic class Singleton {\r\n private static Singleton instance;\r\n private Singleton (){}\r\n\r\n public static Singleton getInstance() {\r\n if (instance == null) {\r\n instance = new Singleton();\r\n }\r\n return instance;\r\n }\r\n}\r\n```\r\n\r\n这段代码简单明了,而且使用了懒加载模式,但是却存在致命的问题。当有多个线程并行调用 getInstance() 的时候,就会创建多个实例。也就是说在多线程下不能正常工作。\r\n\r\n### 懒汉式,线程安全\r\n\r\n为了解决上面的问题,最简单的方法是将整个 getInstance() 方法设为同步(synchronized)。\r\n\r\n```java\r\npublic static synchronized Singleton getInstance() {\r\n if (instance == null) {\r\n instance = new Singleton();\r\n }\r\n return instance;\r\n}\r\n```\r\n\r\n虽然做到了线程安全,并且解决了多实例的问题,但是它并不高效。因为在任何时候只能有一个线程调用 getInstance() 方法。但是同步操作只需要在第一次调用时才被需要,即第一次创建单例实例对象时。这就引出了双重检验锁。\r\n\r\n### 双重检验锁\r\n\r\n双重检验锁模式(double checked locking pattern),是一种使用同步块加锁的方法。程序员称其为双重检查锁,因为会有两次检查 `instance == null`,一次是在同步块外,一次是在同步块内。为什么在同步块内还要再检验一次?因为可能会有多个线程一起进入同步块外的 if,如果在同步块内不进行二次检验的话就会生成多个实例了。\r\n\r\n```java\r\npublic static Singleton getSingleton() {\r\n if (instance == null) { //Single Checked\r\n synchronized (Singleton.class) {\r\n if (instance == null) { //Double Checked\r\n instance = new Singleton();\r\n }\r\n }\r\n }\r\n return instance ;\r\n}\r\n```\r\n\r\n这段代码看起来很完美,很可惜,它是有问题。主要在于instance = new Singleton()这句,这并非是一个原子操作,事实上在 JVM 中这句话大概做了下面 3 件事情。\r\n\r\n1. 给 instance 分配内存\r\n2. 调用 Singleton 的构造函数来初始化成员变量\r\n3. 将instance对象指向分配的内存空间(执行完这步 instance 就为非 null 了)\r\n\r\n但是在 JVM 的即时编译器中存在指令重排序的优化。也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以线程二会直接返回 instance,然后使用,然后顺理成章地报错。\r\n\r\n我们只需要将 instance 变量声明成 volatile 就可以了。\r\n\r\n```java\r\npublic class Singleton {\r\n private volatile static Singleton instance; //声明成 volatile\r\n private Singleton (){}\r\n\r\n public static Singleton getSingleton() {\r\n if (instance == null) { \r\n synchronized (Singleton.class) {\r\n if (instance == null) { \r\n instance = new Singleton();\r\n }\r\n }\r\n }\r\n return instance;\r\n }\r\n \r\n}\r\n```\r\n\r\n有些人认为使用 volatile 的原因是可见性,也就是可以保证线程在本地不会存有 instance 的副本,每次都是去主内存中读取。但其实是不对的。使用 volatile 的主要原因是其另一个特性:禁止指令重排序优化。也就是说,在 volatile 变量的赋值操作后面会有一个内存屏障(生成的汇编代码上),读操作不会被重排序到内存屏障之前。比如上面的例子,取操作必须在执行完 1-2-3 之后或者 1-3-2 之后,不存在执行到 1-3 然后取到值的情况。从「先行发生原则」的角度理解的话,就是对于一个 volatile 变量的写操作都先行发生于后面对这个变量的读操作(这里的“后面”是时间上的先后顺序)。\r\n\r\n但是特别注意在 Java 5 以前的版本使用了 volatile 的双检锁还是有问题的。其原因是 Java 5 以前的 JMM (Java 内存模型)是存在缺陷的,即时将变量声明成 volatile 也不能完全避免重排序,主要是 volatile 变量前后的代码仍然存在重排序问题。这个 volatile 屏蔽重排序的问题在 Java 5 中才得以修复,所以在这之后才可以放心使用 volatile。\r\n\r\n相信你不会喜欢这种复杂又隐含问题的方式,当然我们有更好的实现线程安全的单例模式的办法。\r\n\r\n### 饿汉式 static final field\r\n\r\n这种方法非常简单,因为单例的实例被声明成 static 和 final 变量了,在第一次加载类到内存中时就会初始化,所以创建实例本身是线程安全的。\r\n\r\n```java\r\npublic class Singleton{\r\n //类加载时就初始化\r\n private static final Singleton instance = new Singleton();\r\n \r\n private Singleton(){}\r\n\r\n public static Singleton getInstance(){\r\n return instance;\r\n }\r\n}\r\n```\r\n\r\n这种写法如果完美的话,就没必要在啰嗦那么多双检锁的问题了。缺点是它不是一种懒加载模式(lazy initialization),单例会在加载类后一开始就被初始化,即使客户端没有调用 getInstance()方法。饿汉式的创建方式在一些场景中将无法使用:譬如 Singleton 实例的创建是依赖参数或者配置文件的,在 getInstance() 之前必须调用某个方法设置参数给它,那样这种单例写法就无法使用了。\r\n\r\n### 静态内部类 static nested class\r\n\r\n我比较倾向于使用静态内部类的方法,这种方法也是《Effective Java》上所推荐的。\r\n\r\n```java\r\npublic class Singleton { \r\n private static class SingletonHolder { \r\n private static final Singleton INSTANCE = new Singleton(); \r\n } \r\n private Singleton (){} \r\n public static final Singleton getInstance() { \r\n return SingletonHolder.INSTANCE; \r\n } \r\n}\r\n```\r\n\r\n这种写法仍然使用JVM本身机制保证了线程安全问题;由于 SingletonHolder 是私有的,除了 getInstance() 之外没有办法访问它,因此它是懒汉式的;同时读取实例的时候不会进行同步,没有性能缺陷;也不依赖 JDK 版本。\r\n\r\n### 枚举 Enum\r\n\r\n用枚举写单例实在太简单了!这也是它最大的优点。下面这段代码就是声明枚举实例的通常做法。\r\n\r\n```java\r\npublic enum EasySingleton{\r\n INSTANCE;\r\n}\r\n```\r\n\r\n我们可以通过EasySingleton.INSTANCE来访问实例,这比调用getInstance()方法简单多了。创建枚举默认就是线程安全的,所以不需要担心double checked locking,而且还能防止反序列化导致重新创建新的对象。但是还是很少看到有人这样写,可能是因为不太熟悉吧。\r\n\r\n### 总结\r\n\r\n一般来说,单例模式有五种写法:懒汉、饿汉、双重检验锁、静态内部类、枚举。上述所说都是线程安全的实现,文章开头给出的第一种方法不算正确的写法。\r\n\r\n就我个人而言,一般情况下直接使用饿汉式就好了,如果明确要求要懒加载(lazy initialization)会倾向于使用静态内部类,如果涉及到反序列化创建对象时会试着使用枚举的方式来实现单例。\r\n\r\n### Read More\r\n\r\n- [Double Checked Locking on Singleton Class in Java](http://javarevisited.blogspot.sg/2014/05/double-checked-locking-on-singleton-in-java.html)\r\n- [http://javarevisited.blogspot.sg/2012/07/why-enum-singleton-are-better-in-java.html](http://javarevisited.blogspot.sg/2012/07/why-enum-singleton-are-better-in-java.html)\r\n- [How to create thread safe Singleton in Java](http://javarevisited.blogspot.com/2012/12/how-to-create-thread-safe-singleton-in-java-example.html)\r\n- [10 Singleton Pattern Interview questions in Java](http://javarevisited.blogspot.com/2011/03/10-interview-questions-on-singleton.html)\r\n\r\n由于作者这篇文章写的非常好,我也就没有重写 [原文出处](http://wuchong.me/blog/2014/08/28/how-to-correctly-write-singleton-pattern/#from=biezhi.me)',0,1,0,1463812815,1463812815),
('2fa29ad674','Maven 安装和配置',NULL,6,1002,2,'post/2fa29ad674.png','## Maven 安装\r\n\r\n- Maven 安装\r\n - 官网:<http://maven.apache.org/>\r\n - 官网下载:<http://maven.apache.org/download.cgi>\r\n - 历史版本下载:<https://archive.apache.org/dist/maven/binaries/>\r\n - 此时(20160208) Maven 最新版本为:**3.3.9**\r\n - Maven 3.3 的 JDK 最低要求是 JDK 7\r\n - 我个人习惯 `/opt` 目录下创建一个目录 `setups` 用来存放各种软件安装包;在 `/usr` 目录下创建一个 `program` 用来存放各种解压后的软件包,下面的讲解也都是基于此习惯\r\n - 我个人已经使用了第三方源:`EPEL、RepoForge`,如果你出现 `yum install XXXXX` 安装不成功的话,很有可能就是你没有相关源,请查看我对源设置的文章\r\n - 下载压缩包:`wget http://mirrors.cnnic.cn/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz`\r\n - 解压:`tar zxvf apache-maven-3.3.9-bin.tar.gz`\r\n - 修改目录名,默认的太长了:`mv apache-maven-3.3.9/ maven3.3.9/`\r\n - 移到我个人习惯的安装目录下:`mv maven3.3.9/ /usr/program`\r\n - 环境变量设置:`vim /etc/profile`\r\n - 在文件最尾巴添加下面内容:\r\n \r\n ``` ini\r\n # Maven\r\n MAVEN_HOME=/usr/program/maven3.3.9\r\n PATH=$PATH:$MAVEN_HOME/bin\r\n MAVEN_OPTS=\"-Xms256m -Xmx356m\"\r\n export MAVEN_HOME\r\n export PATH\r\n export MAVEN_OPTS\r\n ```\r\n\r\n - 刷新配置文件:`source /etc/profile`\r\n - 测试是否安装成功:`mvn -version`\r\n\r\n\r\n## Maven 配置\r\n\r\n- 配置项目连接上私服\r\n- 全局方式配置:\r\n\r\n``` xml\r\n<?xml version=\"1.0\" encoding=\"UTF-8\"?>\r\n\r\n<settings xmlns=\"http://maven.apache.org/SETTINGS/1.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xsi:schemaLocation=\"http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd\">\r\n\r\n <!--本地仓库位置-->\r\n <localRepository>D:/maven/my_local_repository</localRepository>\r\n\r\n <pluginGroups>\r\n </pluginGroups>\r\n\r\n <proxies>\r\n </proxies>\r\n\r\n <!--设置 Nexus 认证信息-->\r\n <servers>\r\n <server>\r\n <id>nexus-releases</id>\r\n <username>admin</username>\r\n <password>admin123</password>\r\n </server>\r\n <server>\r\n <id>nexus-snapshots</id>\r\n <username>admin</username>\r\n <password>admin123</password>\r\n </server>\r\n </servers>\r\n\r\n <!--设置 Nexus 镜像,后面只要本地没对应的以来,则到 Nexus 去找-->\r\n <mirrors>\r\n <mirror>\r\n <id>nexus-releases</id>\r\n <mirrorOf>*</mirrorOf>\r\n <url>http://localhost:8081/nexus/content/groups/public</url>\r\n </mirror>\r\n <mirror>\r\n <id>nexus-snapshots</id>\r\n <mirrorOf>*</mirrorOf>\r\n <url>http://localhost:8081/nexus/content/groups/public-snapshots</url>\r\n </mirror>\r\n </mirrors>\r\n\r\n\r\n <profiles>\r\n <profile>\r\n <id>nexus</id>\r\n <repositories>\r\n <repository>\r\n <id>nexus-releases</id>\r\n <url>http://nexus-releases</url>\r\n <releases>\r\n <enabled>true</enabled>\r\n </releases>\r\n <snapshots>\r\n <enabled>true</enabled>\r\n </snapshots>\r\n </repository>\r\n <repository>\r\n <id>nexus-snapshots</id>\r\n <url>http://nexus-snapshots</url>\r\n <releases>\r\n <enabled>true</enabled>\r\n </releases>\r\n <snapshots>\r\n <enabled>true</enabled>\r\n </snapshots>\r\n </repository>\r\n </repositories>\r\n <pluginRepositories>\r\n <pluginRepository>\r\n <id>nexus-releases</id>\r\n <url>http://nexus-releases</url>\r\n <releases>\r\n <enabled>true</enabled>\r\n </releases>\r\n <snapshots>\r\n <enabled>true</enabled>\r\n </snapshots>\r\n </pluginRepository>\r\n <pluginRepository>\r\n <id>nexus-snapshots</id>\r\n <url>http://nexus-snapshots</url>\r\n <releases>\r\n <enabled>true</enabled>\r\n </releases>\r\n <snapshots>\r\n <enabled>true</enabled>\r\n </snapshots>\r\n </pluginRepository>\r\n </pluginRepositories>\r\n </profile>\r\n </profiles>\r\n\r\n <activeProfiles>\r\n <activeProfile>nexus</activeProfile>\r\n </activeProfiles>\r\n\r\n</settings>\r\n```\r\n\r\n- 项目级别:\r\n\r\n\r\n\r\n\r\n## 资料\r\n\r\n- <http://maven.apache.org/install.html>\r\n- <http://www.tutorialspoint.com/maven/index.htm>\r\n- <http://maven.apache.org/guides/getting-started/maven-in-five-minutes.html>\r\n- <http://maven.apache.org/guides/getting-started/index.html>\r\n- <http://maven.apache.org/general.html>\r\n- <http://stackoverflow.com/questions/6950346/infrastructure-with-maven-jenkins-nexus>\r\n- <http://blog.csdn.net/sxyx2008/article/details/7975129>\r\n- <http://blog.csdn.net/xuke6677/article/details/8482472>',0,1,0,1463848412,1463848412),
('404aaa651e','Ubuntu 介绍',NULL,6,1002,2,'','\r\n- Ubuntu 母公司 Canonical:<http://www.canonical.com/>\r\n- Ubuntu 百科:<http://baike.baidu.com/item/ubuntu>\r\n- Ubuntu Wiki:<http://zh.wikipedia.org/zh/Ubuntu>\r\n- Ubuntu 英文官网:<http://www.ubuntu.com>\r\n- Ubuntu 中文官网:<http://www.ubuntu.org.cn>\r\n- Ubuntu kylin 官网:<http://cn.Ubuntu.com/desktop>\r\n- Ubuntu 标准桌面版下载:<http://www.ubuntu.org.cn/download/desktop>\r\n- Ubuntu 官网回答社区:<http://askubuntu.com/>\r\n- Ubuntu 正式衍生版本:<https://zh.wikipedia.org/zh/Ubuntu#.E5.88.86.E6.94.AF.E7.89.88.E6.9C.AC>\r\n- Ubuntu 非正式衍生版本:<https://zh.wikipedia.org/zh/Ubuntu#.E9.9D.9E.E6.AD.A3.E5.BC.8F.E8.A1.8D.E7.94.9F.E7.89.88.E6.9C.AC>\r\n- Unity 桌面介绍:<https://zh.wikipedia.org/wiki/Unity_(使用者介面)>\r\n- GNOME 桌面介绍:<https://zh.wikipedia.org/wiki/GNOME>\r\n- KDE 桌面介绍:<https://zh.wikipedia.org/wiki/KDE>\r\n\r\n# Ubuntu 原型系统:Debian\r\n\r\n- Debian Wiki:<http://zh.wikipedia.org/zh/Debian>\r\n- Debian 百科:<http://baike.baidu.com/view/40687.htm>\r\n- Debian 官网:<http://www.debian.org/index.zh-cn.html>\r\n- Debian 自我介绍:<https://www.debian.org/intro/about>\r\n - 关键字:\r\n - [Debian 社群契约](https://www.debian.org/social_contract)\r\n - [何谓自由 (Free)? 或者说,何谓自由软件 (Free Software)?](https://www.debian.org/intro/free)\r\n - [什么是自由软件?](http://www.gnu.org/philosophy/free-sw)\r\n - [Debian 历史](https://www.debian.org/doc/manuals/project-history/)\r\n- Debian 的发行版介绍:<https://www.debian.org/releases/>\r\n- Debian 官网稳定版下载 1:<https://www.debian.org/distrib/>\r\n- Debian 官网稳定版下载 2:<https://www.debian.org/CD/http-ftp/#stable>\r\n- Debian 中国镜像 1:<http://mirrors.hust.edu.cn/debian-cd/>\r\n- Debian 中国镜像 2:<ftp://mirrors.sohu.com/debian-cd/>\r\n- Debian 中国镜像 3:<ftp://debian.ustc.edu.cn/debian-cd/>\r\n- Debian 中文安装手册:<https://www.debian.org/releases/stable/amd64/>\r\n- Debian 软件列表:<https://packages.debian.org/stable/>\r\n\r\n',0,1,0,1463847696,1463847696),
('555e12872a','4. 配置设计',NULL,6,1000,1,'','Mario中所有的配置都可以在 `Mario` 全局唯一对象完成,将它设计为单例。\r\n\r\n要运行起来整个框架,Mario对象是核心,看看里面都需要什么吧!\r\n\r\n- 添加路由\r\n- 读取资源文件\r\n- 读取配置\r\n- 等等\r\n\r\n由此我们简单的设计一个Mario全局对象:\r\n\r\n```java\r\n/**\r\n * Mario\r\n * @author biezhi\r\n *\r\n */\r\npublic final class Mario {\r\n\r\n /**\r\n * 存放所有路由\r\n */\r\n private Routers routers;\r\n \r\n /**\r\n * 配置加载器\r\n */\r\n private ConfigLoader configLoader;\r\n \r\n /**\r\n * 框架是否已经初始化\r\n */\r\n private boolean init = false;\r\n \r\n private Mario() {\r\n routers = new Routers();\r\n configLoader = new ConfigLoader();\r\n }\r\n \r\n public boolean isInit() {\r\n return init;\r\n }\r\n\r\n public void setInit(boolean init) {\r\n this.init = init;\r\n }\r\n \r\n private static class MarioHolder {\r\n private static Mario ME = new Mario();\r\n }\r\n \r\n public static Mario me(){\r\n return MarioHolder.ME;\r\n }\r\n \r\n public Mario addConf(String conf){\r\n configLoader.load(conf);\r\n return this;\r\n }\r\n \r\n public String getConf(String name){\r\n return configLoader.getConf(name);\r\n }\r\n \r\n public Mario addRoutes(Routers routers){\r\n this.routers.addRoute(routers.getRoutes());\r\n return this;\r\n }\r\n\r\n public Routers getRouters() {\r\n return routers;\r\n }\r\n \r\n /**\r\n * 添加路由\r\n * @param path 映射的PATH\r\n * @param methodName 方法名称\r\n * @param controller 控制器对象\r\n * @return 返回Mario\r\n */\r\n public Mario addRoute(String path, String methodName, Object controller){\r\n try {\r\n Method method = controller.getClass().getMethod(methodName, Request.class, Response.class);\r\n this.routers.addRoute(path, method, controller);\r\n } catch (NoSuchMethodException e) {\r\n e.printStackTrace();\r\n } catch (SecurityException e) {\r\n e.printStackTrace();\r\n }\r\n return this;\r\n }\r\n \r\n}\r\n```',0,1,0,1463849467,1463849467),
('57e98796d7','Java8简明指南',NULL,6,1005,3,'post/57e98796d7.png','> 欢迎来到Java8简明指南。本教程将一步一步指导你通过所有新语言特性。由短而简单的代码示例,带你了解如何使用默认接口方法,lambda表达式,方法引用和可重复注解。本文的最后你会熟悉最新的API的变化如Stream,Fcuntional,Map API扩展和新的日期API。\r\n\r\n\r\n<!--more-->\r\n\r\n\r\n### 接口的默认方法\r\n在Java8中,利用`default`关键字使我们能够添加非抽象方法实现的接口。此功能也被称为扩展方法,这里是我们的第一个例子:\r\n\r\n```java\r\ninterface Formula {\r\n double calculate(int a);\r\n\r\n default double sqrt(int a) {\r\n return Math.sqrt(a);\r\n }\r\n}\r\n```\r\n除了接口抽象方法`calculate`,还定义了默认方法`sqrt`的返回值。具体类实现抽象方法`calculate`。默认的方法`sqrt`可以开箱即用。\r\n```java\r\nFormula formula = new Formula() {\r\n @Override\r\n public double calculate(int a) {\r\n return sqrt(a * 100);\r\n }\r\n};\r\n\r\nformula.calculate(100); // 100.0\r\nformula.sqrt(16); // 4.0\r\n```\r\n\r\n该公式被实现为匿名对象。这段代码是相当长的:非常详细的一个计算:6行代码完成这样一个简单的计算。正如我们将在下一节中看到的,Java8有一个更好的方法来实现单方法对象。\r\n\r\n### Lambda表达式\r\n\r\n让我们以一个简单的例子来开始,在以前的版本中对字符串进行排序:\r\n```java\r\nList<String> names = Arrays.asList(\"peter\", \"anna\", \"mike\", \"xenia\");\r\n\r\nCollections.sort(names, new Comparator<String>() {\r\n @Override\r\n public int compare(String a, String b) {\r\n return b.compareTo(a);\r\n }\r\n});\r\n```\r\n静态的集合类方法`Collections.sort`,为比较器的给定列表中的元素排序。你会发现自己经常创建匿名比较器并将它们传递给方法。\r\nJava8支持更短的语法而不总是创建匿名对象,\r\n**Lambda表达式:**\r\n```java\r\nCollections.sort(names, (String a, String b) -> {\r\n return b.compareTo(a);\r\n});\r\n```\r\n正如你可以看到的代码更容易阅读。但它甚至更短:\r\n```java\r\nCollections.sort(names, (String a, String b) -> b.compareTo(a));\r\n```\r\n一行方法的方法体可以跳过`{}`和参数类型,使它变得更短:\r\n```java\r\nCollections.sort(names, (a, b) -> b.compareTo(a));\r\n```\r\nJava编译器知道参数类型,所以你可以跳过它们,接下来让我们深入了解lambda表达式。\r\n\r\n### 函数式接口(Functional Interfaces)\r\n如何适应Java lambda表达式类型系统?每个`lambda`由一个指定的接口对应于一个给定的类型。所谓的函数式接口必须包含一个确切的**一个抽象方法声明**。该类型将匹配这个抽象方法每个lambda表达式。因为默认的方法是不抽象的,你可以自由添加默认的方法到你的函数式接口。\r\n\r\n我们可以使用任意的接口为lambda表达式,只要接口只包含一个抽象方法。确保你的接口满足要求,你应该添加`@FunctionalInterface`注解。当你尝试在接口上添加第二个抽象方法声明时,编译器会注意到这个注释并抛出一个编译器错误。\r\n\r\n举例:\r\n```java\r\n@FunctionalInterface\r\ninterface Converter<F, T> {\r\n T convert(F from);\r\n}\r\n```\r\n\r\n```java\r\nConverter<String, Integer> converter = (from) -> Integer.valueOf(from);\r\nInteger converted = converter.convert(\"123\");\r\nSystem.out.println(converted); // 123\r\n```\r\n记住,有`@FunctionalInterface`注解的也是有效的代码。\r\n\r\n### 方法和构造函数引用\r\n上面的例子代码可以进一步简化,利用静态方法引用:\r\n```java\r\nConverter<String, Integer> converter = Integer::valueOf;\r\nInteger converted = converter.convert(\"123\");\r\nSystem.out.println(converted); // 123\r\n```\r\nJava使您可以通过`::`关键字调用引用的方法或构造函数。上面的示例演示了如何引用静态方法。但我们也可以参考对象方法:\r\n```java\r\nclass Something {\r\n String startsWith(String s) {\r\n return String.valueOf(s.charAt(0));\r\n }\r\n}\r\n```\r\n\r\n```java\r\nSomething something = new Something();\r\nConverter<String, String> converter = something::startsWith;\r\nString converted = converter.convert(\"Java\");\r\nSystem.out.println(converted); // \"J\"\r\n```\r\n\r\n让我们来看看如何使用`::`关键字调用构造函数。首先,我们定义一个`Person`类并且提供不同的构造函数:\r\n```java\r\nclass Person {\r\n String firstName;\r\n String lastName;\r\n\r\n Person() {}\r\n\r\n Person(String firstName, String lastName) {\r\n this.firstName = firstName;\r\n this.lastName = lastName;\r\n }\r\n}\r\n```\r\n\r\n接下来,我们指定一个`Person`的工厂接口,用于创建`Person`:\r\n```java\r\ninterface PersonFactory<P extends Person> {\r\n P create(String firstName, String lastName);\r\n}\r\n```\r\n然后我们通过构造函数引用来把所有东西拼到一起,而不是手动实现工厂:\r\n```java\r\nPersonFactory<Person> personFactory = Person::new;\r\nPerson person = personFactory.create(\"Peter\", \"Parker\");\r\n```\r\n我们通过`Person::new`创建一个人的引用,Java编译器会自动选择正确的构造函数匹配`PersonFactory.create`的返回。\r\n\r\n### Lambda作用域\r\n\r\n从lambda表达式访问外部变量的作用域是匿名对象非常相似。您可以从本地外部范围以及实例字段和静态变量中访问`final`变量。\r\n\r\n#### 访问局部变量\r\n我们可以从lambda表达式的外部范围读取`final`变量:\r\n```java\r\nfinal int num = 1;\r\nConverter<Integer, String> stringConverter = (from) -> String.valueOf(from + num);\r\nstringConverter.convert(2); // 3\r\n```\r\n但不同的匿名对象变量`num`没有被声明为`final`,下面的代码也有效:\r\n```java\r\nint num = 1;\r\nConverter<Integer, String> stringConverter = (from) -> String.valueOf(from + num);\r\nstringConverter.convert(2); // 3\r\n```\r\n然而`num`必须是隐含的`final`常量。以下代码不编译:\r\n```java\r\nint num = 1;\r\nConverter<Integer, String> stringConverter = (from) -> String.valueOf(from + num);\r\nnum = 3;\r\n```\r\n在lambda表达式里修改`num`也是不允许的。\r\n\r\n#### 访问字段和静态变量\r\n与局部变量不同,我们在lambda表达式的内部能获取到对成员变量或静态变量的读写权。这种访问行为在匿名对象里是非常典型的。\r\n```java\r\nclass Lambda4 {\r\n static int outerStaticNum;\r\n int outerNum;\r\n\r\n void testScopes() {\r\n Converter<Integer, String> stringConverter1 = (from) -> {\r\n outerNum = 23;\r\n return String.valueOf(from);\r\n };\r\n\r\n Converter<Integer, String> stringConverter2 = (from) -> {\r\n outerStaticNum = 72;\r\n return String.valueOf(from);\r\n };\r\n }\r\n}\r\n```\r\n\r\n#### 访问默认接口方法\r\n记得第一节的`formula`例子吗?接口`Formula`定义了一个默认的方法可以从每个公式实例访问包括匿名对象,\r\n这并没有Lambda表达式的工作。\r\n默认方法**不能**在lambda表达式访问。以下代码不编译:\r\n```java\r\nFormula formula = (a) -> sqrt( a * 100);\r\n```\r\n\r\n### 内置函数式接口(Built-in Functional Interfaces)\r\n\r\nJDK1.8的API包含许多内置的函数式接口。其中有些是众所周知的,从旧版本中而来,如`Comparator`或者`Runnable`。使现有的接口通过`@FunctionalInterface`注解支持Lambda。\r\n\r\n但是Java8 API也添加了新功能接口,使你的开发更简单。其中一些接口是众所周知的[Google Guava](https://code.google.com/p/guava-libraries/)库。即使你熟悉这个库也应该密切关注这些接口是如何延长一些有用的扩展方法。\r\n\r\n#### Predicates(谓词)\r\nPredicates是一个返回布尔类型的函数。这就是谓词函数,输入一个对象,返回true或者false。\r\n在Google Guava中,定义了Predicate接口,该接口包含一个带有泛型参数的方法:\r\n```java\r\napply(T input): boolean\r\n```\r\n```java\r\nPredicate<String> predicate = (s) -> s.length() > 0;\r\n \r\npredicate.test(\"foo\"); // true\r\npredicate.negate().test(\"foo\"); // false\r\n \r\nPredicate<Boolean> nonNull = Objects::nonNull;\r\nPredicate<Boolean> isNull = Objects::isNull;\r\n \r\nPredicate<String> isEmpty = String::isEmpty;\r\nPredicate<String> isNotEmpty = isEmpty.negate();\r\n```\r\n#### Functions(函数)\r\nFunctions接受一个参数,并产生一个结果。默认方法可以将多个函数串在一起(compse, andThen)\r\n```java\r\nFunction<String, Integer> toInteger = Integer::valueOf;\r\nFunction<String, String> backToString = toInteger.andThen(String::valueOf);\r\n\r\nbackToString.apply(\"123\"); // \"123\"\r\n```\r\n#### Suppliers(生产者)\r\nSuppliers产生一个给定的泛型类型的结果。与Functional不同的是Suppliers不接受输入参数。\r\n```java\r\nSupplier<Person> personSupplier = Person::new;\r\npersonSupplier.get(); // new Person\r\n```\r\n#### Consumers(消费者)\r\nConsumers代表在一个单一的输入参数上执行操作。\r\n```java\r\nConsumer<Person> greeter = (p) -> System.out.println(\"Hello, \" + p.firstName);\r\ngreeter.accept(new Person(\"Luke\", \"Skywalker\"));\r\n```\r\n#### Comparators(比较器)\r\nComparators在旧版本Java中是众所周知的。Java8增加了各种默认方法的接口。\r\n```java\r\nComparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);\r\n\r\nPerson p1 = new Person(\"John\", \"Doe\");\r\nPerson p2 = new Person(\"Alice\", \"Wonderland\");\r\n\r\ncomparator.compare(p1, p2); // > 0\r\ncomparator.reversed().compare(p1, p2); // < 0\r\n```\r\n#### Optionals(可选项)\r\nOptionals是没有函数的接口,取而代之的是防止`NullPointerException`异常。这是下一节的一个重要概念,所以让我们看看如何结合Optionals工作。\r\n\r\nOptional is a simple container for a value which may be null or non-null. Think of a method which may return a non-null result but sometimes return nothing. Instead of returning null you return an Optional in Java 8.\r\n\r\nOptional是一个简单的容器,这个值可能是空的或者非空的。考虑到一个方法可能会返回一个non-null的值,也可能返回一个空值。为了不直接返回null,我们在Java 8中就返回一个Optional。\r\n```java\r\nOptional<String> optional = Optional.of(\"bam\");\r\n\r\noptional.isPresent(); // true\r\noptional.get(); // \"bam\"\r\noptional.orElse(\"fallback\"); // \"bam\"\r\n\r\noptional.ifPresent((s) -> System.out.println(s.charAt(0))); // \"b\"\r\n```\r\n\r\n#### Streams(管道)\r\n一个`java.util.Stream`代表一个序列的元素在其中的一个或多个可以执行的操作。流操作是中间或终端。当终端操作返回某一类型的结果时,中间操作返回流,这样就可以将多个方法调用在一行中。流是一个源产生的,例如`java.util.Collection`像列表或设置(不支持map)。流操作可以被执行的顺序或并行。\r\n\r\n让我们先看一下数据流如何工作。首先,我们创建一个字符串列表的数据:\r\n```java\r\nList<String> stringCollection = new ArrayList<>();\r\nstringCollection.add(\"ddd2\");\r\nstringCollection.add(\"aaa2\");\r\nstringCollection.add(\"bbb1\");\r\nstringCollection.add(\"aaa1\");\r\nstringCollection.add(\"bbb3\");\r\nstringCollection.add(\"ccc\");\r\nstringCollection.add(\"bbb2\");\r\nstringCollection.add(\"ddd1\");\r\n```\r\n在Java8中Collections类的功能已经有所增强,你可用调用`Collection.stream()`或`Collection.parallelStream()`。\r\n下面的章节解释最常见的流操作。\r\n\r\n#### Filter\r\nFilter接受一个predicate来过滤流的所有元素。这个中间操作能够调用另一个流的操作(Foreach)的结果。ForEach接受一个消费者为每个元素执行过滤流。它是`void`,所以我们不能称之为另一个流操作。\r\n```java\r\nstringCollection\r\n .stream()\r\n .filter((s) -> s.startsWith(\"a\"))\r\n .forEach(System.out::println);\r\n\r\n// \"aaa2\", \"aaa1\"\r\n```\r\n#### Sorted\r\nSorted是一个中间操作,能够返回一个排过序的流对象的视图。这些元素按自然顺序排序,除非你经过一个自定义比较器(实现Comparator接口)。\r\n```java\r\nstringCollection\r\n .stream()\r\n .sorted()\r\n .filter((s) -> s.startsWith(\"a\"))\r\n .forEach(System.out::println);\r\n\r\n// \"aaa1\", \"aaa2\"\r\n```\r\n要记住,排序只会创建一个流的排序视图,而不处理支持集合的排序。原来string集合中的元素顺序是没有改变的。\r\n```java\r\nSystem.out.println(stringCollection);\r\n// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1\r\n```\r\n#### Map\r\n`map`是一个对于流对象的中间操作,通过给定的方法,它能够把流对象中的每一个元素对应到另外一个对象上。下面的例子将每个字符串转换成一个大写字符串,但也可以使用`map`将每个对象转换为另一种类型。所得到的流的泛型类型取决于您传递给`map`方法的泛型类型。\r\n```java\r\nstringCollection\r\n .stream()\r\n .map(String::toUpperCase)\r\n .sorted((a, b) -> b.compareTo(a))\r\n .forEach(System.out::println);\r\n\r\n// \"DDD2\", \"DDD1\", \"CCC\", \"BBB3\", \"BBB2\", \"AAA2\", \"AAA1\"\r\n```\r\n#### Match\r\n可以使用各种匹配操作来检查某个谓词是否匹配流。所有这些操作都是终止操作,返回一个布尔结果。\r\n```java\r\nboolean anyStartsWithA =\r\n stringCollection\r\n .stream()\r\n .anyMatch((s) -> s.startsWith(\"a\"));\r\n\r\nSystem.out.println(anyStartsWithA); // true\r\n\r\nboolean allStartsWithA =\r\n stringCollection\r\n .stream()\r\n .allMatch((s) -> s.startsWith(\"a\"));\r\n\r\nSystem.out.println(allStartsWithA); // false\r\n\r\nboolean noneStartsWithZ =\r\n stringCollection\r\n .stream()\r\n .noneMatch((s) -> s.startsWith(\"z\"));\r\n\r\nSystem.out.println(noneStartsWithZ); // true\r\n```\r\n#### Count\r\nCount是一个终止操作返回流中的元素的数目,返回`long`类型。\r\n```java\r\nlong startsWithB =\r\n stringCollection\r\n .stream()\r\n .filter((s) -> s.startsWith(\"b\"))\r\n .count();\r\n\r\nSystem.out.println(startsWithB); // 3\r\n```\r\n#### Reduce\r\n该终止操作能够通过某一个方法,对元素进行削减操作。该操作的结果会放在一个Optional变量里返回。\r\n```java\r\nOptional<String> reduced =\r\n stringCollection\r\n .stream()\r\n .sorted()\r\n .reduce((s1, s2) -> s1 + \"#\" + s2);\r\n\r\nreduced.ifPresent(System.out::println);\r\n// \"aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2\"\r\n```\r\n\r\n### Parallel Streams\r\n\r\n如上所述的数据流可以是连续的或平行的。在一个单独的线程上进行操作,同时在多个线程上执行并行操作。\r\n\r\n下面的例子演示了如何使用并行流很容易的提高性能。\r\n\r\n首先,我们创建一个大的元素列表:\r\n```java\r\nint max = 1000000;\r\nList<String> values = new ArrayList<>(max);\r\nfor (int i = 0; i < max; i++) {\r\n UUID uuid = UUID.randomUUID();\r\n values.add(uuid.toString());\r\n}\r\n```\r\n现在我们测量一下流对这个集合进行排序消耗的时间。\r\n#### Sequential Sort\r\n```java\r\nlong t0 = System.nanoTime();\r\n\r\nlong count = values.stream().sorted().count();\r\nSystem.out.println(count);\r\n\r\nlong t1 = System.nanoTime();\r\n\r\nlong millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);\r\nSystem.out.println(String.format(\"sequential sort took: %d ms\", millis));\r\n\r\n// sequential sort took: 899 ms\r\n```\r\n#### Parallel Sort\r\n```java\r\nlong t0 = System.nanoTime();\r\n\r\nlong count = values.parallelStream().sorted().count();\r\nSystem.out.println(count);\r\n\r\nlong t1 = System.nanoTime();\r\n\r\nlong millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);\r\nSystem.out.println(String.format(\"parallel sort took: %d ms\", millis));\r\n\r\n// parallel sort took: 472 ms\r\n```\r\n\r\n你可以看到这两段代码片段几乎是相同的,但并行排序大致是50%的差距。唯一的不同就是把`stream()`改成了`parallelStream()`。\r\n\r\n### Map\r\n正如前面所说的Map不支持流操作,现在的Map支持各种新的实用的方法和常见的任务。\r\n\r\n```java\r\nMap<Integer, String> map = new HashMap<>();\r\n\r\nfor (int i = 0; i < 10; i++) {\r\n map.putIfAbsent(i, \"val\" + i);\r\n}\r\n\r\nmap.forEach((id, val) -> System.out.println(val));\r\n```\r\n\r\n上面的代码应该是不解自明的:putIfAbsent避免我们将null写入;forEach接受一个消费者对象,从而将操作实施到每一个map中的值上。\r\n\r\n这个例子演示了如何利用函数判断或获取Map中的数据:\r\n```java\r\nmap.computeIfPresent(3, (num, val) -> val + num);\r\nmap.get(3); // val33\r\n\r\nmap.computeIfPresent(9, (num, val) -> null);\r\nmap.containsKey(9); // false\r\n\r\nmap.computeIfAbsent(23, num -> \"val\" + num);\r\nmap.containsKey(23); // true\r\n\r\nmap.computeIfAbsent(3, num -> \"bam\");\r\nmap.get(3); // val33\r\n```\r\n接下来,我们将学习如何删除一一个给定的键的条目,只有当它当前映射到给定值:\r\n```java\r\nmap.remove(3, \"val3\");\r\nmap.get(3); // val33\r\n\r\nmap.remove(3, \"val33\");\r\nmap.get(3); // null\r\n```\r\n另一种实用的方法:\r\n```java\r\nmap.getOrDefault(42, \"not found\"); // not found\r\n```\r\nMap合并条目是非常容易的:\r\n```java\r\nmap.merge(9, \"val9\", (value, newValue) -> value.concat(newValue));\r\nmap.get(9); // val9\r\n\r\nmap.merge(9, \"concat\", (value, newValue) -> value.concat(newValue));\r\nmap.get(9); // val9concat\r\n```\r\n合并操作先看map中是否没有特定的key/value存在,如果是,则把key/value存入map,否则merging函数就会被调用,对现有的数值进行修改。\r\n\r\n### Date API\r\nJava8 包含一个新的日期和时间API,在`java.time`包下。新的日期API与[Joda Time](http://www.joda.org/joda-time/)库可以媲美,但它们是不一样的。下面的例子涵盖了这个新的API最重要的部分。\r\n\r\n#### Clock\r\nClock提供访问当前日期和时间。Clock是对当前时区敏感的,可以用来代替`System.currentTimeMillis()`来获取当前的毫秒值。当前时间线上的时刻可以用Instance类来表示。Instance可以用来创建`java.util.Date`格式的对象。\r\n```java\r\nClock clock = Clock.systemDefaultZone();\r\nlong millis = clock.millis();\r\n\r\nInstant instant = clock.instant();\r\nDate legacyDate = Date.from(instant); // legacy java.util.Date\r\n```\r\n\r\n#### Timezones\r\n时区是由`ZoneId`表示,通过静态工厂方法可以很容易地访问。时区还定义了一个偏移量,用来转换当前时刻与目标时刻。\r\n```java\r\nSystem.out.println(ZoneId.getAvailableZoneIds());\r\n// prints all available timezone ids\r\n\r\nZoneId zone1 = ZoneId.of(\"Europe/Berlin\");\r\nZoneId zone2 = ZoneId.of(\"Brazil/East\");\r\nSystem.out.println(zone1.getRules());\r\nSystem.out.println(zone2.getRules());\r\n\r\n// ZoneRules[currentStandardOffset=+01:00]\r\n// ZoneRules[currentStandardOffset=-03:00]\r\n```\r\n\r\n#### LocalTime\r\nLocalTime代表没有时区的时间,例如晚上10点或17:30:15。下面的例子会用上面的例子定义的时区创建两个本地时间对象。然后我们比较两个时间并计算小时和分钟的差异。\r\n```java\r\nLocalTime now1 = LocalTime.now(zone1);\r\nLocalTime now2 = LocalTime.now(zone2);\r\n\r\nSystem.out.println(now1.isBefore(now2)); // false\r\n\r\nlong hoursBetween = ChronoUnit.HOURS.between(now1, now2);\r\nlong minutesBetween = ChronoUnit.MINUTES.between(now1, now2);\r\n\r\nSystem.out.println(hoursBetween); // -3\r\nSystem.out.println(minutesBetween); // -239\r\n```\r\n\r\n#### LocalDate\r\nLocalDate代表一个唯一的日期,如2014-03-11。它是不可变的,完全模拟本地时间工作。此示例演示如何通过添加或减去天数,月数,年来计算新的日期。记住每一个操作都会返回一个新的实例。\r\n```java\r\nLocalDate today = LocalDate.now();\r\nLocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);\r\nLocalDate yesterday = tomorrow.minusDays(2);\r\n\r\nLocalDate independenceDay = LocalDate.of(2014, Month.JULY, 4);\r\nDayOfWeek dayOfWeek = independenceDay.getDayOfWeek();\r\nSystem.out.println(dayOfWeek); // FRIDAY\r\n```\r\n将字符串解析为LocalDate:\r\n```java\r\nDateTimeFormatter germanFormatter =\r\n DateTimeFormatter\r\n .ofLocalizedDate(FormatStyle.MEDIUM)\r\n .withLocale(Locale.GERMAN);\r\n\r\nLocalDate xmas = LocalDate.parse(\"24.12.2014\", germanFormatter);\r\nSystem.out.println(xmas); // 2014-12-24\r\n```\r\n\r\n#### LocalDateTime\r\nLocalDateTime代表日期时间。它结合了日期和时间见上面的部分为一个实例。`LocalDateTime`是不可变的,类似于本地时间和LocalDate工作。我们可以从一个日期时间获取某些字段的方法:\r\n```java\r\nLocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);\r\n\r\nDayOfWeek dayOfWeek = sylvester.getDayOfWeek();\r\nSystem.out.println(dayOfWeek); // WEDNESDAY\r\n\r\nMonth month = sylvester.getMonth();\r\nSystem.out.println(month); // DECEMBER\r\n\r\nlong minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);\r\nSystem.out.println(minuteOfDay); // 1439\r\n```\r\n随着一个时区可以转换为一个即时的附加信息。Instance可以被转换为日期型转化为指定格式的` java.util.Date`。\r\n```java\r\nInstant instant = sylvester\r\n .atZone(ZoneId.systemDefault())\r\n .toInstant();\r\n\r\nDate legacyDate = Date.from(instant);\r\nSystem.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014\r\n```\r\n格式日期时间对象就像格式化日期对象或者格式化时间对象,除了使用预定义的格式以外,我们还可以创建自定义的格式化对象,然后匹配我们自定义的格式。\r\n```java\r\nDateTimeFormatter formatter =\r\n DateTimeFormatter\r\n .ofPattern(\"MMM dd, yyyy - HH:mm\");\r\n\r\nLocalDateTime parsed = LocalDateTime.parse(\"Nov 03, 2014 - 07:13\", formatter);\r\nString string = formatter.format(parsed);\r\nSystem.out.println(string); // Nov 03, 2014 - 07:13\r\n```\r\n不像`java.text.NumberFormat`,新的`DateTimeFormatter`是不可变的,线程安全的。\r\n\r\n### Annotations(注解)\r\n\r\n在Java8中注解是可以重复的,让我们深入到一个示例中。\r\n\r\n首先,我们定义了一个包装的注解,它拥有一个返回值为数组类型的方法Hint:\r\n```java\r\n@interface Hints {\r\n Hint[] value();\r\n}\r\n\r\n@Repeatable(Hints.class)\r\n@interface Hint {\r\n String value();\r\n}\r\n```\r\nJava8使我们能够使用相同类型的多个注解,通过`@Repeatable`声明注解。\r\n\r\n##### 变体1:使用注解容器(老方法)\r\n```java\r\n@Hints({@Hint(\"hint1\"), @Hint(\"hint2\")})\r\nclass Person {}\r\n```\r\n\r\n##### 变体2:使用可重复注解(新方法)\r\n```java\r\n@Hint(\"hint1\")\r\n@Hint(\"hint2\")\r\nclass Person {}\r\n```\r\n\r\n使用变体2隐式编译器隐式地设置了`@Hints`注解。这对于通过反射来读取注解信息是非常重要的。\r\n\r\n```java\r\nHint hint = Person.class.getAnnotation(Hint.class);\r\nSystem.out.println(hint); // null\r\n\r\nHints hints1 = Person.class.getAnnotation(Hints.class);\r\nSystem.out.println(hints1.value().length); // 2\r\n\r\nHint[] hints2 = Person.class.getAnnotationsByType(Hint.class);\r\nSystem.out.println(hints2.length); // 2\r\n```\r\n\r\n虽然在`Person`中从未定义`@Hints`注解,它仍然可读通过`getAnnotation(Hints.class)`读取。并且,getAnnotationsByType方法会更方便,因为它赋予了所有@Hints注解标注的方法直接的访问权限。\r\n\r\n```java\r\n@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})\r\n@interface MyAnnotation {}\r\n```\r\n\r\n欢迎Star我的开源Web框架Blade:[http://github.com/biezhi/blade](http://github.com/biezhi/blade)',0,1,0,1463849012,1463849012),
('5f233fbaca','《看漫画,学 Redux》',NULL,6,1008,2,'post/5f233fbaca.png','> 不写一行代码,轻松看懂 Redux 原理。 原文\r\n> 如果你有任何疑惑,不妨在 Issues 中提出。\r\n\r\nFlux 架构已然让人觉得有些迷惑,而比 Flux 更让人摸不着头脑的是 Flux 与 Redux 的区别。Redux 是一个基于 Flux 思想的新架构方式,本文将探讨它们的区别。\r\n\r\n如果你还没有看过[这篇关于 Flux](https://code-cartoons.com/a-cartoon-guide-to-flux-6157355ab207) 的文章(译者注:也可以参考这篇),你应该先阅读一下。\r\n\r\n## 为什么要改变 Flux?\r\n\r\nRedux 解决的问题和 Flux 一样,但 Redux 能做的还有更多。\r\n\r\n和 Flux 一样,Redux 让应用的状态变化变得更加可预测。如果你想改变应用的状态,就必须 dispatch 一个 action。你没有办法直接改变应用的状态,因为保存这些状态的东西(称为 store)只有 getter 而没有 setter。对于 Flux 和 Redux 来说,这些概念都是相似的。\r\n\r\n那么为什么要新设计一种架构呢?Redux 的创造者 Dan Abramov 发现了改进 Flux 架构的可能。他想要一个更好的开发者工具来调试 Flux 应用。他发现如果稍微对 Flux 架构进行一些调整,就可以开发出一款更好用的开发者工具,同时依然能享受 Flux 架构带给你的可预测性。\r\n\r\n确切的说,他想要的开发者工具包含了代码热替换(hot reload)和时间旅行(time travel)功能。然而要想在 Flux 架构上实现这些功能,确实有些麻烦。\r\n\r\n### 问题1:store 的代码无法被热替换,除非清空当前的状态\r\n\r\n在 Flux 中,store 包含了两样东西:\r\n\r\n1. 改变状态的逻辑\r\n2. 当前的状态\r\n\r\n在一个 store 中同时保存这两样东西将会导致代码热替换功能出现问题。当你热替换掉 store 的代码想要看看新的状态改变逻辑是否生效时,你就丢失了 store 中保存的当前状态。此外,你还把 store 与 Flux 架构中其它组件产生关系的事件系统搞乱了。\r\n\r\n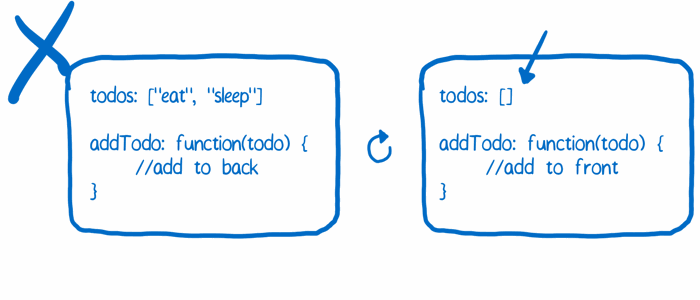\r\n\r\n**解决方案**\r\n\r\n将这两样东西分开处理。让一个对象来保存状态,这个对象在热替换代码的时候不会受到影响。让另一个对象包含所有改变状态的逻辑,这个对象可以被热替换因为它不用关心任何保存状态相关的事情。\r\n\r\n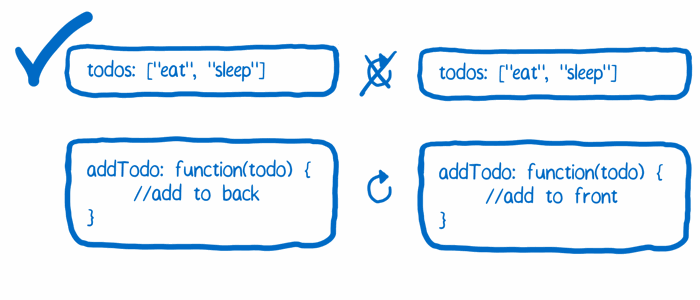\r\n\r\n### 问题2:每次触发 action 时状态对象都被直接改写了\r\n\r\n时间旅行调试法的特性是:你能掌握状态对象的每一次变化,这样的话,你就能轻松的跳回到这个对象之前的某个状态(想象一个撤销功能)。\r\n\r\n要实现这样的功能,每次状态改变之后,你都需要把旧的状态保存在一个数组中。但是由于 JavaScript 的对象引用特性,简单的把一个对象放进数组中并不能实现我们需要的功能。这样做不能创建一个快照(snapshot),而只是创建了一个新的指针指向同一个对象。\r\n\r\n所以要想实现时间旅行特性,每一个状态改变的版本都需要保存在不同的 JavaScript 对象中,这样你才不会不小心改变了某个历史版本的状态。\r\n\r\n\r\n\r\n**解决方案**\r\n要实现这样的特性,Flux 架构需要一个扩展点。\r\n\r\n一个简单的例子就是日志。比如说你希望 console.log() 每一个触发的 action 同时 console.log() 这个 action 被响应完成后的状态。在 Flux 中,你只能订阅(subscribe) dispatcher 的更新和每一个 store 的变动。但是这样就侵入了业务代码,这样的日志功能不是一个第三方插件能够轻易实现的。\r\n\r\n\r\n',2,1,0,1463583004,1463583004),
('65a81ffc26','SVN 安装和配置',NULL,6,1002,2,'post/65a81ffc26.png','# Subversion 1.8 安装\r\n\r\n\r\n## RPM 安装(推荐)\r\n\r\n- wandisco 整理的 RPM 文件官网:<http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/>\r\n- 下载下面几个 RPM 文件:\r\n - 创建目录来保存下载的 RPM:`sudo mkdir -p /opt/setups/subversion/ ; cd /opt/setups/subversion/`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/mod_dav_svn-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/serf-1.3.7-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-gnome-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-javahl-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-perl-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-python-1.8.15-1.x86_64.rpm`\r\n - `wget http://opensource.wandisco.com/centos/6/svn-1.8/RPMS/x86_64/subversion-tools-1.8.15-1.x86_64.rpm`\r\n - 如果上面的 RPM 链接失效,你也可以考虑下载我提供的百度云盘地址:<http://pan.baidu.com/s/1pKnGia3>\r\n \r\n \r\n- 安装下载的 RPM 文件:\r\n - `sudo rpm -ivh *.rpm`\r\n\r\n\r\n- 检查安装后的版本:\r\n - `svn --version`\r\n\r\n\r\n## 编译安装(不推荐)\r\n\r\n- subversion 1.8 编译安装(本人没有尝试成功,所以不推荐,下面内容只供参考)\r\n - 官网安装说明(查找关键字 `Dependency Overview`):<http://svn.apache.org/repos/asf/subversion/trunk/INSTALL>\r\n - 此时 1.8 最新版本为:`subversion-1.8.15.tar.gz`\r\n - 我个人习惯 `/opt` 目录下创建一个目录 `setups` 用来存放各种软件安装包;在 `/usr` 目录下创建一个 `program` 用来存放各种解压后的软件包,下面的讲解也都是基于此习惯\r\n - 我个人已经使用了第三方源:`EPEL、RepoForge`,如果你出现 `yum install XXXXX` 安装不成功的话,很有可能就是你没有相关源,请查看我对源设置的文章\r\n - 安装编译所需工具:\r\n - `sudo yum install -y gcc gcc-c++ autoconf libtool `\r\n - 所需依赖包说明:\r\n - (必要包)apr 和 apr-util 官网地址:<http://archive.apache.org/dist/apr/>\r\n - (必要包)zlib 官网地址:<ttp://www.zlib.net/>\r\n - (必要包)SQLite 官网地址:<http://www.sqlite.org/download.html>\r\n - (必要包)Subversion 官网地址:<https://subversion.apache.org/download.cgi>\r\n - 所需依赖包下载:\r\n - apr 下载:`wget http://archive.apache.org/dist/apr/apr-1.5.2.tar.gz`\r\n - apr-util 下载:`wget http://archive.apache.org/dist/apr/apr-util-1.5.4.tar.gz`\r\n - zlib 下载:`wget http://zlib.net/zlib-1.2.8.tar.gz`\r\n - SQLite 下载:`wget http://www.sqlite.org/2016/sqlite-amalgamation-3100200.zip`\r\n - Subversion 下载:`wget http://apache.fayea.com/subversion/subversion-1.8.15.tar.gz`\r\n - 安装依赖包: \r\n - apr 安装:\r\n - 解压:`tar -zxvf apr-1.5.2.tar.gz`\r\n - 移动到我个人习惯的安装目录下:`mv apr-1.5.2/ /usr/program/`\r\n - 标准的 GNU 源码安装方式:\r\n - `cd /usr/program/apr-1.5.2`\r\n - `./configure`\r\n - `make`\r\n - `make install`\r\n - 安装完得到安装的配置路径:`/usr/local/apr/bin/apr-1-config`,这个需要记下来,下面会用到\r\n - apr-util 安装:\r\n - 解压:`tar -zxvf apr-util-1.5.4.tar.gz`\r\n - 移动到我个人习惯的安装目录下:`mv apr-util-1.5.4/ /usr/program/`\r\n - 标准的 GNU 源码安装方式:\r\n - `cd /usr/program/apr-util-1.5.4/`\r\n - `./configure --with-apr=/usr/local/apr/bin/apr-1-config`\r\n - `make`\r\n - `make install`\r\n - 安装完得到安装的配置路径:`/usr/local/apr/bin/apu-1-config`,这个需要记下来,下面会用到\r\n - zlib 安装:\r\n - 解压:`tar -zxvf zlib-1.2.8.tar.gz`\r\n - 移动到我个人习惯的安装目录下:`mv zlib-1.2.8/ /usr/program/`\r\n - 标准的 GNU 源码安装方式:\r\n - `cd /usr/program/zlib-1.2.8/`\r\n - `./configure`\r\n - `make`\r\n - `make install`\r\n - Subversion 解压:\r\n - 解压:`tar -zxvf subversion-1.8.15.tar.gz`\r\n - 移动到我个人习惯的安装目录下:`mv subversion-1.8.15/ /usr/program/`\r\n - SQLite 安装:\r\n - 解压:`unzip sqlite-amalgamation-3100200.zip`\r\n - 移动到 subversion 目录下:`mv sqlite-amalgamation-3100200/ /usr/program/subversion-1.8.15/`\r\n - Subversion 安装:\r\n - 标准的 GNU 源码安装方式:\r\n - `cd /usr/program/subversion-1.8.15/`\r\n - `./configure --prefix=/usr/local/subversion --with-apr=/usr/local/apr/bin/apr-1-config --with-apr-util=/usr/local/apr/bin/apu-1-config`\r\n - `make`\r\n - `make install`\r\n \r\n \r\n## SVN 配置\r\n\r\n- 在系统上创建一个目录用来存储所有的 SVN 文件:`mkdir -p /opt/svn/repo/`\r\n- 新建一个版本仓库:`svnadmin create /opt/svn/repo/`\r\n - 生成如下目录和文件:\r\n - 目录:`locks`\r\n - 目录:`hooks`\r\n - 目录:`db`\r\n - 目录:`conf`\r\n - 文件:`format`\r\n - 文件:`README.txt`\r\n - 其中,目录 `conf` 最为重要,常用的配置文件都在里面\r\n - `svnserve.conf` 是 svn 服务综合配置文件\r\n - `passwd` 是用户名和密码配置文件\r\n - `authz` 是权限配置文件\r\n\r\n\r\n- 设置配置文件\r\n - 编辑配置文件:`vim /opt/svn/repo/conf/svnserve.conf`\r\n - \r\n - 配置文件中下面几个参数(默认是注释的):\r\n - `anon-access`: 对不在授权名单中的用户访问仓库的权限控制,有三个可选性:`write、read、none`\r\n - `none` 表示没有任何权限\r\n - `read` 表示只有只读权限\r\n - `write` 表示有读写权限\r\n - `auth-access`:对在授权名单中的用户访问仓库的权限控制,有三个可选性:`write、read、none`\r\n - `none` 表示没有任何权限\r\n - `read` 表示只有只读权限\r\n - `write` 表示有读写权限\r\n - `password-db`:指定用户数据配置文件\r\n - `authz-db`:指定用户权限配置文件\r\n - `realm`:指定版本库的认证域,即在登录时提示的认证域名称。若两个版本库的认证域相同,建议使用相同的用户名口令数据文件\r\n - 当前实例的配置内容:`realm = myrepo`\r\n\r\n\r\n- 添加用户\r\n - 编辑配置文件:`vim /opt/svn/repo/conf/passwd`\r\n - \r\n - 添加用户很简答,如上图所示在配置文中添加一个格式为:`用户名 = 密码` 的即可\r\n\r\n\r\n- 设置用户权限\r\n - 编辑配置文件:`vim /opt/svn/repo/conf/authz`\r\n - \r\n - 配置文件中几个参数解释:\r\n - `r` 表示可写\r\n - `w` 表示可读\r\n - `rw` 表示可读可写\r\n - `* =` 表示除了上面设置的权限用户组以外,其他所有用户都设置空权限,空权限表示禁止访问本目录,这很重要一定要加上\r\n - `[groups]` 表示下面创建的是用户组,实际应用中一般我们对使用者都是进行分组的,然后把权限控制在组上,这样比较方便。使用组权限方式:`@组名 = rw` \r\n\r\n\r\n- 启动服务\r\n - `svnserve -d -r /opt/svn/repo/ --listen-port 3690`\r\n - `-d` 表示后台运行\r\n - `-r /opt/svn/repo/` 表示指定根目录\r\n - `--listen-port 3690` 表示指定端口,默认就是 3690,所以如果要用默认端口这个也是可以省略掉的\r\n\r\n- 停止服务\r\n - `killall svnserve`\r\n \r\n \r\n- 测试\r\n - iptables 处理\r\n - 一种方式:先关闭 iptables,防止出现拦截问题而测试不了:`service iptables stop`\r\n - 一种方式:在 iptables 中添加允许规则(svn 默认端口是 3690):\r\n - 添加规则:`sudo iptables -I INPUT -p tcp -m tcp --dport 3690 -j ACCEPT`\r\n - 保存规则:`sudo /etc/rc.d/init.d/iptables save`\r\n - 重启 iptables:`sudo service iptables restart`\r\n - 在 Windows 的 svn 客户端上访问:`svn://192.168.0.110`\r\n\r\n\r\n## SVN 设置提交之后可修改提交的 Message 信息\r\n\r\n- 默认的 SVN 是无法修改提交后的 Message 信息的,修改会报如下错误:\r\n- \r\n- 解决办法:\r\n - 下载我 hooks 文件:<http://pan.baidu.com/s/1c1jtlmw>\r\n - 把 pre-revprop-change 文件放在你的仓库下,比如我仓库地址是:`/opt/svn/repo/hooks`\r\n - 编辑该文件:`vim /opt/svn/repo/hooks/pre-revprop-change`\r\n - 把文件尾巴的这句脚本:`echo \"$1 $2 $3 $4 $5\" >> /opt/svn/repo/logchanges.log`,改为:`echo \"$1 $2 $3 $4 $5\" >> /你的仓库地址/logchanges.log`\r\n - 你在该目录下也可以看到一个文件 `pre-revprop-change.tmpl`,这个其实就是 svn 提供给你模板,其他的那些你有兴趣也可以研究下\r\n\r\n\r\n## 资料\r\n\r\n- <http://tecadmin.net/install-subversion-1-8-on-centos-rhel/>\r\n- <http://svn.apache.org/repos/asf/subversion/trunk/INSTALL>\r\n- <http://chenpipi.blog.51cto.com/8563610/1613007>\r\n- <https://blog.linuxeye.com/348.html>\r\n- <http://jingyan.baidu.com/article/046a7b3efb6a5df9c27fa991.html>\r\n- <http://www.ha97.com/4467.html>\r\n- <http://blog.feehi.com/linux/7.html>\r\n- <http://my.oschina.net/lionel45/blog/298305?fromerr=1NdIndN0>\r\n- <http://www.centoscn.com/CentosServer/ftp/2015/0622/5708.html>\r\n- <http://blog.csdn.net/tianlesoftware/article/details/6119231>\r\n- <http://www.scmeye.com/thread-419-1-1.html>\r\n- <http://m.blog.csdn.net/article/details?id=7908907>\r\n- 设置可编辑提交信息:<http://stackoverflow.com/questions/692851/can-i-go-back-and-edit-comments-on-an-svn-checkin>',0,1,0,1463848135,1463848135),
('6851cf5df6','被子植物APG IV分类法述评',NULL,6,1006,2,'post/6851cf5df6.jpg','百忙之中忽然跑上来冒个泡是因为APG (Angiosperm Phylogeny Group, 被子植物种系发生学组) IV在本月新鲜出炉了。我觉得有必要给大家介绍一下被子植物系统分类学在近六七年间的新进展。\r\n\r\n嘛虽然专栏早就被我玩坏了发到这里显得格格不入,然而我就是这样任性的宝宝惹~\r\n\r\n\r\n\r\n先扔系统树吧,系统学的研究其实看系统树就可以了。\r\n\r\nAPG IV距09年发布的APG III已经有七年之久了,这其间被子植物系统学有了很多新进展,APG IV即是对这几年这些新成果的概括和总结的成果。\r\n\r\n跟APG III相比,APG IV并没有什么博人眼球颠覆性的改变,说明近几年被子植物的系统骨架是趋于稳定的,主要进展是在很多细部上变得更明晰起来。\r\n\r\n这次的主要更新包括:\r\n\r\n\r\n1. 五个新目的成立,这五个新目都是上一版APG中地位未定的类群,这几年的系统学研究可以将它们放置到合理的位置上。这五个新目是:\r\n\r\n\r\n紫草目(Boraginales)\r\n\r\n五桠果目(Dilleniales)\r\n\r\n茶茱萸目(Icacinales)\r\n\r\n\r\n\r\n微花藤(*Iodes cirrhosa*)\r\n\r\n茶茱萸科(Icacinaceae)无疑是APG IV中的明星类群。APG IV的很多新成果都是围绕这一类群的研究展开的。该类群主产于热带,一直没有引起人们研究的重视,其单系性、属系位置和属的构成都相当成问题,是被子植物里面宛如堆满杂物无人问津的地下室一般的存在,分子系统学研究也没有给出高支持率的解决。直到2015年Stull et al.利用叶绿体基因组学系统学才比较确切地将该类群放置于唇形类分支的基部。该科的界限也进一步厘清,所包含的属从54属降到25属。金檀木科(Stemonuraceae)和心翼果科(Cardiopteridaceae)被置于冬青目,Pennantiaceae 被置于伞形目。此外该研究也揭示了下面管花木目的存在。\r\n\r\n管花木目(Metteniusiales)\r\n\r\n\r\n\r\n*Metteniusa tessman*\r\n\r\n管花木科只分布于中南美洲,只有单科单属共七种植物。Stull et al.(2015)的基因组系统学研究将茶茱萸科中的Emmotaceae和柴龙树属(Apodytes)也置于此类群中成立管花木目。\r\n\r\n二歧草目(Vahliales)\r\n\r\n\r\n\r\n*Vahlia capensis*\r\n\r\n二歧草目是一个分布在印度和非洲,只有一科一属5-8种的小类群。Refulio-Rodrıguez & Olmstead (2014)将其作为茄目(Solanales)的姐妹群放置。\r\n\r\n这五个新建立的目除了五桠果目被置于菊类分支(Asterids)外侧以外,其余五个目都位于唇形类分支(Lamiids),这也显示出唇形类植物是现在系统分类比较混乱的研究热点区域,也是这几年系统学成果最集中和令人瞩目的区域。唇形类的分类系统目前还不稳定,以前的唇形科、紫草科、马鞭草科等类群的单系性都很成问题,经常有属的位置的变动。整个唇形类植物的系统学还没有得到满意支持率的解决,亟需重建新的分类系统。\r\n\r\nAPG系统现在总共有64个目和416个科。\r\n\r\n2. 两个APG III未定目的科被合并到临近的目中:\r\n\r\n多须草科(Dasypogonaceae)(澳洲特产)被归入棕榈目(Arecales)\r\n\r\n清风藤科(Sabiaceae)被归入山龙眼目(Proteales)\r\n\r\n这也显示出APG系统在目这一分类阶元上的使用趋于简化和归并的态度。\r\n\r\n3. 两个以前属系不清的寄生类群得到了放置:\r\n\r\n\r\n\r\n欧洲锁阳(*Cynomorium coccineum*)\r\n\r\n锁阳科(Cynomoriaceae)这一污力滔天的类群被放在了虎耳草目(Saxifragales)。\r\n\r\n\r\n\r\n*Pilostyles aethiopica*\r\n\r\n密恐福音离花科(Apodanthaceae)被放置在葫芦目(Cucurbitales)。\r\n\r\n但这两个类群在目中的具体位置还不清楚,有待研究。\r\n\r\n4. 一些科被合并或分拆:\r\n\r\n4.1胡椒目(Piperales)中,最恶心植物菌花科(Hydnoraceae)和短蕊花科( Lactoridaceae)被合并到马兜铃科(Aristolochiaceae)\r\n\r\n\r\n\r\n*Prosopanche americana*\r\n\r\n你要问马兜铃的心理阴影面积?\r\n\r\n\r\n\r\n嘛其实马兜铃也很恶心的惹,真是不是一家人不进一家门。\r\n\r\n4.2 蓝果树科(Nyssaceae)因为跟山茱萸科(Cornales)不呈单系,被单独升级成科((Xiang et al., 2011))\r\n\r\n4.3 其它新承认的科:Maundiaceae(天南星目,从水麦冬科分出),Peraceae(金虎尾目,从大戟科分出),Petenaeaceae(十齿花目),Kewaceae(一个以邱园命名的,特产于南部非洲和圣赫勒拿岛的单属科),Limeaceae, Macarthuriaceae ,Microteaceae,Petiveriaceae(以上石竹目),Mazaceae(唇形目)\r\n\r\n4.4 列当科(Orobanchaceae)现在包含地黄属(Rehmannia)和钟萼花属(*Lindenbergia*)。地黄的内心应该是拒绝的。。。\r\n\r\n\r\n\r\n列当(*Orobanche coerulescens*)\r\n\r\n\r\n\r\n地黄(*Rehmannia glutinosa*)\r\n\r\n作者:林十之\r\n链接:https://zhuanlan.zhihu.com/p/20795367\r\n来源:知乎\r\n著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。\r\n\r\n两者其实看上去还是蛮相似的。。。\r\n\r\n4.5 一些科涉及属的变动,就不赘述了(都是国外产属)。值得一提的是白花菜科(Capparaceae)中的四个属——节蒴木属(Borthwickia),罗志藤属(Stixis),Forchhammeria,Tirania被移到木犀草科(Resedaceae)。\r\n\r\n其它值得注意的地方:\r\n\r\n近年来方法学上的进展是采用大量低拷贝核基因进行构树,Zeng et al. (2014) 和 Wickett et al. (2014)采用59和852个低拷核基因构树,但所涵盖的物种数比较有限(分别为60和37种),可见这一方法在工作量的需要上还是很大的。\r\n\r\n低拷核基因系统学所揭示的系统关系跟之前的研究在大部分位置都没有冲突。但在叶绿体基因系统学中始终位于豆类分支的卫矛目、酢浆草目和金虎尾目分支,在线粒体和核基因系统学中却处于相邻的锦葵类分支。这一冲突可能是由于叶绿体基因组中的古基因水平转移造成的(Sun et al., 2015)\r\n\r\n下面根据不同的类群在进行主要新成果和遗留问题的梳理:\r\n\r\n早期被子植物(Early angiosperm):被子植物最早形成的几个分支。\r\n\r\n早期被子植物的系统跟以前相比保持稳定,依次为:\r\n\r\n互叶梅目(Amborellales)新喀里多尼亚特产单科属种植物,仍然置于整个被子植物的基部。\r\n\r\n睡莲目(Nymphaeales)包括排水草科(澳大利亚和印度特产,我的课题之一)、睡莲科和莼菜科。\r\n\r\n木兰藤目(Austrobaileyales)包括木兰藤科(澳大利亚西北部特有)、早落瓣科(大洋洲东南亚特产)、五味子科(包括八角茴香科)\r\n\r\n木兰类植物(Magnoliids):单子叶植物和真双子叶植物分化之前出现的类群。系统保持稳定,分为四个目:(木兰目、樟目)、(胡椒目和白桂皮目(产于热带非洲和美洲))。\r\n\r\n菌花科(Hydnoraceae)和短蕊花科( Lactoridaceae)被合并到马兜铃科(Aristolochiaceae)\r\n\r\n金粟兰目(Chloranthales):作为位置不确定的类群放在早期被子植物之后。包括一科四属。Wickett et al.,(2014)作为真双子叶植物的姐妹群,Zeng et al., (2014)作为金鱼藻科的姐妹群。APG IV对于该类群的位置持审慎态度,故没有进行放置,有待进一步研究的加强。\r\n\r\n单子叶植物(Monocots):目的水平保持稳定,从演化顺序依次为菖蒲目、泽泻目、(薯蓣目、露兜树目、)、百合目、天门冬目、棕榈目、禾本目、(鸭跖草目、姜目)。\r\n\r\n薯蓣目的科一级的系统不稳定,APG IV维持了APG III的分科系统,但提到菌异养类群水玉簪科(Burmanniaceae)的非单系问题。这也是我的课题之一,已证实水玉簪科非单系,并且情况还要复杂得多。\r\n\r\n禾本目(Poales)中刺鳞草科(Centrolepidaceae)、澳大利亚特产单属科苞穗草科(Anarthriaceae)和帚灯草科(Restionaceae)的关系一直有冲突,APG IV干脆就把它们全部归到帚灯草科(Restionaceae),还很大大落落地说酱紫不过以后的研究有什么成果,至少矛盾都被限制到科水平一类了,从外部矛盾转变成内部矛盾,还是蛮无耻惹(To stabilize the taxonomy of this order, we enlarge Restionaceae to re-include Anarthriaceae and Centrolepidaceae so that, regardless of the outcomes of future studies, the family name will remain the same.)\r\n\r\n金鱼藻目(Ceratophyllales):单科属水生植物,作为整个真双子叶植物的姐妹群。\r\n\r\n基部真双子叶植物(Basal eudicots),即不属于蔷薇类分支和菊类分支的真双子叶演化早期类群。包括毛茛目、山龙眼目(APG IV将清风藤科归于此目)、昆栏树目、洋二仙草目和新承认的五桠果目。但五桠果目的位置不同的研究有冲突,还不明朗,现在作为菊类分支和蔷薇类分支的并系群放置。\r\n\r\n超蔷薇分支(Superrosids)。APG IV提出的新分支,即蔷薇分支加上与其成姐妹群关系的虎耳草目(Saxifragales),锁阳科被放入虎耳草目。\r\n\r\n蔷薇类分支(rosids):目一级保持稳定。蔷薇类分支又分为两个分支:\r\n\r\n豆类分支(fabids) :包括蒺藜目、(卫矛目、(金虎尾目、酢浆草目))、(豆目、蔷薇目(葫芦目、壳斗目))\r\n\r\n离花科加入葫芦目(Filipowicz & Renner, 2010)。\r\n\r\n**锦葵类分支**(malvids):包括(牻牛儿苗目、桃金娘目)、(燧体木目、美洲苦木目、无患子目、十齿花目、(十字花目、锦葵目))\r\n\r\n由于命名上的混乱和纠纷。APG IV牻牛儿苗目(Geraniales)中的几个南美特产的科Bersamaceae,Ledocarpaceae,Rhynchothecaceae, Vivianiaceae一股脑儿合并到花茎草科(Francoaceae)。再次将外部矛盾转移成为科内内部矛盾。\r\n\r\n白花菜科一直在丢属到其它科,APG IV又丢了四个属出去,白花菜科恐成最大输家。\r\n\r\n**超菊分支**(Superasterids):APG IV提出的新概念。即菊类分支加上智利藤目、檀香目和石竹目。\r\n\r\n**檀香目**(Santalales)目以下的系统极不稳定。铁青树科(Olacaceae)被建议拆成八个科,檀香科(Santalaceae)中的七个类群被建议独立成科(Nickrent et al., 2010)。该目亟需进一步厘清。\r\n\r\n**石竹目**(Caryophyllales)仍然有三个系统分类学难题:\r\n\r\n1.紫茉莉科(Nyctaginaceae)和商陆科(Phytolaccaceae)的关系。有研究表明商陆科下的热带美洲产数珠珊瑚亚科(Rivinoideae)跟紫茉莉科形成了姐妹群关系。(Brockington et al., 2009, 2011; Bissinger et al., 2014)\r\n\r\n2.仙人掌科(Cactaceae)和马齿苋科(Portulacaceae)的关系。后者跟仙人掌科会形成并系关系。为了减少建立单属科,APG曾提议将仙人掌科的范围扩大,吞掉一些马齿苋科类群,但网络调查发现这一提议非常不受这一类群的分类学家欢迎(提议者的内心是崩溃的。。。)\r\n\r\n\r\n\r\n3. 粟米草科(Molluginaceae)的非单系问题。为解决这一问题,APG IV建立了一系列新的科。\r\n\r\n菊类分支(asterids): 包括位于基部的山茱萸目、杜鹃花目和两个大类群——唇形分支(lamiids)和桔梗分支(campanulids)\r\n\r\n桔梗分支包括冬青目、菊目、南鼠刺目?、鳞叶树目、伞形目、(川续断目和盔瓣花目)\r\n\r\n唇形分支包括茶茱萸目、管花木目、绞木目、(紫草目?、龙胆目?、二歧草目?、茄目?、唇形目?)\r\n\r\n杜鹃花目中恶心寄生植物帽蕊草科(Mitrastemonaceae)的位置不确定。\r\n\r\n\r\n\r\n奴 草(Mitrastemon yamamotoi)。悄悄问圣僧,女儿美不美?\r\n\r\n山茱萸目中,珙桐、喜树和单室茱萸(Mastixia)构成蓝果树科(Nyssaceae),跟绣球花科、水穗草科和刺莲花科构成姐妹群关系,故不跟山茱萸科呈单系,所以独立成科。(Xiang et al., 2011)\r\n\r\n曾属于玄参科的地黄属(Rehmannia)被发现是列当科(Orobanchaceae)的姐妹群。(Xia, Wang & Smith, 2009; Refulio-Rodrıguez & Olmstead, 2014)。APG IV建议将地黄属并入列当科。\r\n\r\n唇形目跟单子叶植物中的天门冬目是新系统学研究影响最厉害的两个类群,以前的分类系统几乎被完全颠覆。经常有属从原有科变动到其它科,还有很多属的归属仍不清楚,亟需进一步研究。整个唇形目也需要重建分类系统。\r\n\r\n紫草科的位置还不清楚,APG IV索性为它建立了一个单科目。\r\n\r\n地位未定\r\n\r\nAPG III中地位未定的类群只剩下一个属——Gumillea.只有一份在18世纪晚期在秘鲁采到的标本。APG IV又增加了六个地位未定的属:Atrichodendron,Coptocheile,Hirania,Keithia,Poilanedora,Rumphia。都是一些少见或者只剩标本的植物。其中Rumphia只有插图保留。。。简直是山海经级别的神仙植物,饶了它吧。\r\n\r\n题图——《橡树》, 希斯金,1886.',0,1,0,1463158518,1463158518),
('739ffad056','MySQL 安装和配置',NULL,6,1002,2,'post/739ffad056.jpg','## MySQL 安装\r\n\r\n- Mysql 安装\r\n - 官网:<http://www.mysql.com/>\r\n - 官网下载:<http://dev.mysql.com/downloads/mysql/>\r\n - 官网 5.5 下载:<http://dev.mysql.com/downloads/mysql/5.5.html#downloads>\r\n - 官网 5.6 下载:<http://dev.mysql.com/downloads/mysql/5.6.html#downloads>\r\n - 官网 5.7 下载:<http://dev.mysql.com/downloads/mysql/5.7.html#downloads>\r\n - 官网帮助中心:<http://dev.mysql.com/doc/refman/5.6/en/source-installation.html>\r\n - 此时(20160210) Mysql 5.5 最新版本为:**5.5.48**\r\n - 此时(20160210) Mysql 5.6 最新版本为:**5.6.29**\r\n - 此时(20160210) Mysql 5.7 最新版本为:**5.7.11**\r\n - 我个人习惯 `/opt` 目录下创建一个目录 `setups` 用来存放各种软件安装包;在 `/usr` 目录下创建一个 `program` 用来存放各种解压后的软件包,下面的讲解也都是基于此习惯\r\n - 我个人已经使用了第三方源:`EPEL、RepoForge`,如果你出现 `yum install XXXXX` 安装不成功的话,很有可能就是你没有相关源,请查看我对源设置的文章\r\n - Mysql 5.6 下载:`wget http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.29.tar.gz` (大小:31 M)\r\n - Mysql 5.7 下载:`wget http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.11.tar.gz` (大小:47 M)\r\n - 我们这次安装以 5.6 为实例\r\n - 进入下载目录:`cd /opt/setups`\r\n - 解压压缩包:`tar zxvf mysql-5.6.29.tar.gz`\r\n - 移到解压包:`mv /opt/setups/mysql-5.6.29 /usr/program/`\r\n - 安装依赖包、编译包:`yum install -y make gcc-c++ cmake bison-devel ncurses-devel`\r\n - 进入解压目录:`cd /usr/program/mysql-5.6.29/`\r\n - 生成安装目录:`mkdir -p /usr/program/mysql/data`\r\n - 生成配置(使用 InnoDB):`sudo cmake -DCMAKE_INSTALL_PREFIX=/usr/program/mysql -DMYSQL_DATADIR=/usr/program/mysql/data -DMYSQL_UNIX_ADDR=/tmp/mysql.sock -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_EXTRA_CHARSETS:STRING=utf8 -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DENABLED_LOCAL_INFILE=1`\r\n - 更多参数说明可以查看:<http://dev.mysql.com/doc/refman/5.6/en/source-configuration-options.html>\r\n - 编译:`sudo make`,这个过程比较漫长,一般都在 30 分钟左右,具体还得看机子配置,如果最后结果有 error,建议删除整个 mysql 目录后重新解压一个出来继续处理\r\n - 安装:`sudo make install`\r\n - 配置开机启动:\r\n - `sudo cp /usr/program/mysql-5.6.29/support-files/mysql.server /etc/init.d/mysql`\r\n - `sudo chmod 755 /etc/init.d/mysql`\r\n - `sudo chkconfig mysql on`\r\n - 复制一份配置文件: `sudo cp /usr/program/mysql-5.6.29/support-files/my-default.cnf /etc/my.cnf`\r\n - 删除安装的目录:`rm -rf /usr/program/mysql-5.6.29/`\r\n - 添加组和用户及安装目录权限\r\n - `sudo groupadd mysql` #添加组\r\n - `sudo useradd -g mysql mysql -s /bin/false` #创建用户mysql并加入到mysql组,不允许mysql用户直接登录系统\r\n - `sudo chown -R mysql:mysql /usr/program/mysql/data` #设置MySQL数据库目录权限\r\n - 初始化数据库:`sudo /usr/program/mysql/scripts/mysql_install_db --basedir=/usr/program/mysql --datadir=/usr/program/mysql/data --skip-name-resolve --user=mysql`\r\n - 开放防火墙端口:\r\n - `sudo iptables -I INPUT -p tcp -m tcp --dport 3306 -j ACCEPT`\r\n - `sudo service iptables save`\r\n - `sudo service iptables restart`\r\n - 禁用 selinux\r\n - 编辑配置文件:`vim /etc/selinux/config`\r\n - 把 `SELINUX=enforcing` 改为 `SELINUX=disabled`\r\n - 常用命令软连接,才可以在终端直接使用:mysql 和 mysqladmin 命令\r\n - `sudo ln -s /usr/program/mysql/bin/mysql /usr/bin`\r\n - `sudo ln -s /usr/program/mysql/bin/mysqladmin /usr/bin`\r\n\r\n\r\n## MySQL 配置\r\n\r\n- 官网配置参数解释:<http://dev.mysql.com/doc/refman/5.6/en/mysqld-option-tables.html>\r\n- 找一下当前系统中有多少个 my.cnf 文件:`find / -name \"my.cnf\"`,我查到的结果:\r\n\r\n``` nginx\r\n/etc/my.cnf\r\n/usr/program/mysql/my.cnf\r\n/usr/program/mysql/mysql-test/suite/ndb/my.cnf\r\n/usr/program/mysql/mysql-test/suite/ndb_big/my.cnf\r\n.............\r\n/usr/program/mysql/mysql-test/suite/ndb_rpl/my.cnf\r\n```\r\n\r\n\r\n- 保留 **/etc/my.cnf** 和 **/usr/program/mysql/mysql-test/** 目录下配置文件,其他删除掉。\r\n- 我整理的一个单机版配置说明(MySQL 5.6,适用于 1G 内存的服务器):\r\n - [my.cnf](MySQL-Settings/MySQL-5.6/1G-Memory-Machine/my-for-comprehensive.cnf)\r\n\r\n## 修改 root 账号密码\r\n\r\n- 启动 Mysql 服务器:`service mysql start`\r\n- 查看是否已经启动了:`ps aux | grep mysql`\r\n- 默认安装情况下,root 的密码是空,所以为了方便我们可以设置一个密码,假设我设置为:123456\r\n- 终端下执行:`mysql -uroot`\r\n - 现在进入了 mysql 命令行管理界面,输入:`SET PASSWORD = PASSWORD(\'123456\');`\r\n- 修改密码后,终端下执行:`mysql -uroot -p`\r\n - 根据提示,输入密码进度 mysql 命令行状态。\r\n- 如果你在其他机子上连接该数据库机子报:**Access denied for user \'root\'@\'localhost\' (using password: YES)**\r\n - 解决办法:\r\n - 在终端中执行:`service mysql stop`\r\n - 在终端中执行:`/usr/program/mysql/bin/mysqld --skip-grant-tables`\r\n - 此时 MySQL 服务会一直处于监听状态,你需要另起一个终端窗口来执行接下来的操作\r\n - 在终端中执行:`mysql -u root mysql`\r\n - 进入 MySQL 命令后执行:`UPDATE user SET Password=PASSWORD(\'填写你要的新密码\') where USER=\'root\';FLUSH PRIVILEGES;`\r\n - 重启 MySQL 服务:`service mysql restart`\r\n\r\n\r\n\r\n## MySQL 主从复制\r\n\r\n### 环境说明和注意点\r\n\r\n- 假设有两台服务器,一台做主,一台做从\r\n - MySQL 主信息:\r\n - IP:**12.168.1.113**\r\n - 端口:**3306**\r\n - MySQL 从信息:\r\n - IP:**12.168.1.115**\r\n - 端口:**3306**\r\n- 注意点\r\n - 主 DB server 和从 DB server 数据库的版本一致\r\n - 主 DB server 和从 DB server 数据库数据一致\r\n - 主 DB server 开启二进制日志,主 DB server 和从 DB server 的 server-id 都必须唯一\r\n- 优先操作:\r\n - **把主库的数据库复制到从库并导入**\r\n \r\n### 主库机子操作\r\n\r\n- 主库操作步骤\r\n - 创建一个目录:`mkdir -p /usr/program/mysql/data/mysql-bin`\r\n - 主 DB 开启二进制日志功能:`vim /etc/my.cnf`,\r\n - 添加一行:`log-bin = /usr/program/mysql/data/mysql-bin`\r\n - 指定同步的数据库,如果不指定则同步全部数据库,其中 ssm 是我的数据库名:`binlog-do-db=ssm`\r\n - 主库关掉慢查询记录,用 SQL 语句查看当前是否开启:`SHOW VARIABLES LIKE \'%slow_query_log%\';`,如果显示 OFF 则表示关闭,ON 表示开启\r\n - 重启主库 MySQL 服务\r\n - 进入 MySQL 命令行状态,执行 SQL 语句查询状态:`SHOW MASTER STATUS;`\r\n - 在显示的结果中,我们需要记录下 **File** 和 **Position** 值,等下从库配置有用。\r\n - 设置授权用户 slave01 使用 123456 密码登录主库,这里 @ 后的 IP 为从库机子的 IP 地址,如果从库的机子有多个,我们需要多个这个 SQL 语句。\r\n\r\n ``` SQL\r\n grant replication slave on *.* to \'slave01\'@\'192.168.1.135\' identified by \'123456\';\r\n flush privileges;\r\n ```\r\n\r\n\r\n### 从库机子操作\r\n\r\n\r\n- 从库操作步骤\r\n - 从库开启慢查询记录,用 SQL 语句查看当前是否开启:`SHOW VARIABLES LIKE \'%slow_query_log%\';`,如果显示 OFF 则表示关闭,ON 表示开启。\r\n - 测试从库机子是否能连上主库机子:`sudo mysql -h 192.168.1.105 -u slave01 -p`,必须要连上下面的操作才有意义。\r\n - 由于不能排除是不是系统防火墙的问题,所以建议连不上临时关掉防火墙:`service iptables stop`\r\n - 或是添加防火墙规则:\r\n - 添加规则:`sudo iptables -I INPUT -p tcp -m tcp --dport 3306 -j ACCEPT`\r\n - 保存规则:`sudo service iptables save`\r\n - 重启 iptables:`sudo service iptables restart`\r\n - 修改配置文件:`vim /etc/my.cnf`,把 server-id 改为跟主库不一样\r\n - 在进入 MySQL 的命令行状态下,输入下面 SQL:\r\n\r\n ``` SQL\r\n CHANGE MASTER TO\r\n master_host=\'192.168.1.113\',\r\n master_user=\'slave01\',\r\n master_password=\'123456\',\r\n master_port=3306,\r\n master_log_file=\'mysql3306-bin.000006\',>>>这个值复制刚刚让你记录的值\r\n master_log_pos=1120;>>>这个值复制刚刚让你记录的值\r\n ```\r\n\r\n- 执行该 SQL 语句,启动 slave 同步:`START SLAVE;`\r\n- 执行该 SQL 语句,查看从库机子同步状态:`SHOW SLAVE STATUS;`\r\n- 在查看结果中必须下面两个值都是 Yes 才表示配置成功:\r\n - `Slave_IO_Running:Yes`\r\n - 如果不是 Yes 也不是 No,而是 Connecting,那就表示从机连不上主库,需要你进一步排查连接问题。\r\n - `Slave_SQL_Running:Yes`\r\n- 如果你的 Slave_IO_Running 是 No,一般如果你是在虚拟机上测试的话,从库的虚拟机是从主库的虚拟机上复制过来的,那一般都会这样的,因为两台的 MySQL 的 UUID 值一样。你可以检查从库下的错误日志:`cat /usr/program/mysql/data/mysql-error.log`\r\n - 如果里面提示 uuid 错误,你可以编辑从库的这个配置文件:`vim /usr/program/mysql/data/auto.cnf`,把配置文件中的:server-uuid 值随便改一下,保证和主库是不一样即可。\r\n\r\n\r\n## 资料\r\n\r\n- <http://www.cnblogs.com/xiongpq/p/3384681.html>',0,1,0,1463848549,1463848549),
('7ddf070557','代理模式剖析',NULL,6,1008,1,'post/7ddf070557.png','\r\n* [代理模式定义](#代理模式定义)\r\n* [静态代理](#静态代理)\r\n * [代理模式的参与者](#代理模式的参与者)\r\n * [代理模式的实现思路](#代理模式的实现思路)\r\n * [静态代理的实例](#静态代理的实例)\r\n* [动态代理](#动态代理)\r\n* [JDK动态代理源码分析(JDK7)](#JDK动态代理源码分析(JDK7))\r\n * [代理对象是如何创建出来的?](#代理对象是如何创建出来的?)\r\n * [是谁调用了Invoke?](#是谁调用了Invoke?)\r\n* [参考文献](#参考文献)\r\n\r\n## 代理模式定义\r\n\r\n[维基百科](https://zh.wikipedia.org/wiki/%E4%BB%A3%E7%90%86%E6%A8%A1%E5%BC%8F)上是这样描述代理模式的:**所谓代理者是指一个类可以作为其他东西的接口**。代理者可以作任何东西的接口, 例如网络连接,存储器中的大对象,文件或者其他无法复制的资源。\r\n\r\n著名的代理模式的例子就是**引用计数(reference counting)**: 当需要一个复杂对象的多份副本时,代理模式可以结合**享元模式**以减少存储器的用量。典型做法是创建一个复杂对象以及多个代理者,每个代理者会引用到原本的对象。而作用在代理者的运算会转送到原本对象。一旦所有的代理者都不存在时,复杂对象会被移除。\r\n\r\n## 静态代理\r\n\r\n所谓静态代理,就是在编译阶段就生成**代理类**来完成对代理对象的一系列操作。下面是代理模式的结构类图:\r\n\r\n### 代理模式的参与者\r\n\r\n代理模式的角色分四种:\r\n\r\n- 主题接口: 即代理类的所实现的行为接口。\r\n- 目标对象: 也就是被代理的对象。\r\n- 代理对象: 用来封装真是主题类的代理类\r\n- 客户端 \r\n\r\n下面是代理模式的类图结构: \r\n\r\n\r\n\r\n### 代理模式的实现思路\r\n\r\n- **代理对象**和**目标对象**均实现**同一个行为接口**。\r\n- **代理类**和**目标类**分别具体实现接口逻辑。\r\n- 在**代理类**的构造函数中实例化一个**目标对象**。\r\n- 在**代理类**中调用**目标对象**的行为接口。\r\n- **客户端**想要调用**目标对象**的行为接口,只能通过**代理类**来操作。\r\n\r\n### 静态代理的实例\r\n\r\n下面以一个**延迟加载**的例子来说明一下静态代理。我们在启动某个服务系统时,加载某一个类时可能会耗费很长时间。为了获取更好的性能,在启动系统的时候,我们往往不去初始化这个复杂的类,取而代之的是去初始化其**代理类**。这样将耗费资源多的方法使用代理进行分离,可以加快系统的启动速度,减少用户等待的时间。\r\n\r\n- 定义一个主题接口\r\n\r\n```java\r\npublic interface Subject {\r\n public void sayHello();\r\n public void sayGoodBye();\r\n}\r\n```\r\n\r\n- 定义一个目标类, 并实现主题接口\r\n\r\n```java\r\npublic class RealSubject implements Subject {\r\n public void sayHello() {\r\n System.out.println(\"Hello World\");\r\n }\r\n\r\n public void sayGoodBye() {\r\n System.out.println(\"GoodBye World\");\r\n }\r\n}\r\n```\r\n\r\n- 定义一个代理类,来代理目标对象\r\n\r\n```java\r\npublic class StaticProxy implements Subject {\r\n\r\n Private RealSubject realSubject = null;\r\n\r\n public StaticProxy() {}\r\n\r\n public void sayHello() {\r\n //用到时候才加载,懒加载\r\n if(realSubject == null) {\r\n realSubject = new RealSubject();\r\n }\r\n realSubject.sayHello();\r\n }\r\n\r\n //sayGoodbye方法同理\r\n ...\r\n}\r\n```\r\n\r\n- 定义一个客户端\r\n\r\n```java\r\npublic class Client {\r\n public static void main(String [] args) {\r\n StaticProxy sp = new StaticProxy();\r\n sp.sayHello();\r\n sp.sayGoodBye();\r\n }\r\n}\r\n```\r\n\r\n以上就是静态代理的一个简单测试例子。感觉可能没有实际用途。然而并非如此。使用代理我们还可以将目标对象的方法进行改造,比如**数据库连接池**中创建了一系列连接,为了保证不频繁的打开连接,这些连接是几乎不会关闭的。然而我们编程总有习惯去将打开的 `Connection` 去 `close` 。 这样我们就可以利用代理模式来重新代理 `Connection` 接口中的 `close` 方法,改变为**回收到数据库连接池**中而不是真正的执行 `Connection.close` 方法。其他的例子还有很多,具体需要自己体会。\r\n\r\n## 动态代理\r\n\r\n**动态代理**是指在运行时动态生成代理类。即,代理类的字节码将在运行时生成并载入当前代理的 `ClassLoader`。与静态处理类相比,动态类有诸多好处。\r\n\r\n* 不需要为真实主题写一个形式上完全一样的封装类,假如主题接口中的方法很多,为每一个接口写一个代理方法也很麻烦。如果接口有变动,则真实主题和代理类都要修改,不利于系统维护;\r\n* 使用一些动态代理的生成方法甚至可以在运行时制定代理类的执行逻辑,从而大大提升系统的灵活性。\r\n\r\n生成动态代理的方法有很多: **JDK中自带动态代理**,**CGlib**, **javassist**等。这些方法各有优缺点。本文主要探究JDK中的动态代理的使用和源码分析。\r\n\r\n下面用一个实例讲解一下JDK中动态代理的用法:\r\n\r\n```java\r\npublic class dynamicProxy implements InvocationHandler {\r\n\r\n private RealSubject = null;\r\n\r\n public Object invoke(Object proxy, Method method, Object[] args){\r\n if(RealSubject == null) {\r\n RealSubject = new RealSubject();\r\n }\r\n method.invoke(RealSubject, args);\r\n return RealSubject;\r\n }\r\n\r\n}\r\n```\r\n\r\n客户端代码实例\r\n\r\n```java\r\npublic class Client {\r\n public static void main(Strings[] args) {\r\n Subject subject = (Subject)Proxy.newInstance(ClassLoader.getSystemLoader(), RealSubject.class.getInterfaces(), new DynamicProxy());\r\n Subject.sayHello();\r\n Subject.sayGoodBye();\r\n }\r\n}\r\n```\r\n\r\n从上面的代码可以看出,要利用JDK中的动态代理。利用静态方法`Proxy.newInstance(ClassLoader, Interfaces[], InvokeHandler)`可以创建一个动态代理类。 `newInstance`方法有三个参数,分别表示**类加载器**,**一个希望该代理类实现的接口列表**,以及**实现`InvokeHandler`接口的实例**。 动态代理将每个方法的执行过程则交给了Invoke方法处理。\r\n\r\n**JDK动态代理要求,被代理的必须是个接口,单纯的类则不行**。JDK动态代理所生成的代理类都会继承 `Proxy` 类,同时代理类会实现所有你传入的接口列表。因此可以强制类型转换成接口类型。 下面是 `Proxy` 的结构图。\r\n\r\n\r\n\r\n可以看出`Proxy`全是静态方法,因此如果代理类没有实现任何接口,那么他就是`Proxy`类型,没有实例方法。\r\n\r\n当然加入你要是非要代理一个没有实现某个接口的类,同时该类的方法与其他接口定义的方法相同,利用**反射**也是可以轻松实现的。\r\n\r\n```java\r\npublic class DynamicProxy implements InvokeHandler {\r\n\r\n //你想代理的类\r\n private TargetClass targetClass = null;\r\n\r\n //初始化该类\r\n public DynamicProxy(TargetClass targetClass) {\r\n this.targetClass = targetClass;\r\n }\r\n\r\n public Object invoke(Object proxy, Method method, Object[] args) {\r\n //利用反射获取你想代理的类的方法\r\n Method myMethod = targetClass.getClass().getDeclaredMethod(method.getName(), method.getParameterTypes());\r\n myMethod.setAccessible(true);\r\n return myMethod.invoke(targetClass, args);\r\n }\r\n}\r\n```\r\n\r\n## JDK动态代理源码分析(JDK7)\r\n\r\n看了上面的例子,我们只是简单会用动态代理。但是对于代理类是如何创建出来的,是谁调用Invoke方法等还云里雾里。下面通过分析\r\n\r\n### 代理对象是如何创建出来的?\r\n\r\n首先看 `Proxy.newInstance` 方法的源码:\r\n\r\n```java\r\npublic static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException {\r\n\r\n //获取接口信息\r\n final Class<?>[] intfs = interfaces.clone();\r\n final SecurityManager sm = System.getSecurityManager();\r\n if (sm != null) {\r\n checkProxyAccess(Reflection.getCallerClass(), loader, intfs);\r\n }\r\n\r\n //生成代理类\r\n Class<?> cl = getProxyClass0(loader, intfs);\r\n // ...OK我们先看前半截\r\n}\r\n```\r\n\r\n从源码看出代理类的生成是依靠`getProxyClass0`这个方法,接下来看`getProxyClass0`源码:\r\n\r\n```java\r\nprivate static Class<?> getProxyClass0(ClassLoader loader, Class<?>... interfaces) {\r\n\r\n //接口列表数目不能超过0xFFFF\r\n if (interfaces.length > 65535) {\r\n throw new IllegalArgumentException(\"interface limit exceeded\");\r\n }\r\n\r\n //注意这里, 下面详细解释 \r\n return proxyClassCache.get(loader, interfaces);\r\n}\r\n```\r\n\r\n对 `proxyClassCache.get` 的解释是: **如果实现接口列表的代理类已经存在,那么直接从cache中拿。如果不存在,则通过ProxyClassFactory生成一个。**\r\n\r\n在看 `proxyClassCache.get` 源码之前,先简单了解一下 `proxyClassCache`:\r\n\r\n```java\r\nprivate static final WeakCache<ClassLoader, Class<?>[], Class<?>>\r\n proxyClassCache = new WeakCache<>(new KeyFactory(), new ProxyClassFactory());\r\n```\r\n\r\n`proxyClassCache`是一个`WeakCache`类型的缓存,它的构造函数有两个参数,其中一个就是用于生成代理类的`ProxyClassFactory`,下面是`proxyClassCache.get`的源码:\r\n\r\n```java\r\nfinal class WeakCache<K, P, V> {\r\n ...\r\n public V get(K key, P parameter) {}\r\n}\r\n```\r\n\r\n**这里K表示key,P表示parameters, V表示value**\r\n\r\n```java\r\npublic V get(K key, P parameter) {\r\n\r\n // java7 NullObject判断方法,如果parameter为空则抛出带有指定消息的异常。 如果不为空则返回。\r\n Objects.requireNonNull(parameter);\r\n\r\n // 清理持有弱引用的WeakHashMap这种数据结构,一般用于缓存\r\n expungeStaleEntries();\r\n\r\n // 从队列中获取cacheKey\r\n Object cacheKey = CacheKey.valueOf(key, refQueue);\r\n\r\n //利用懒加载的方式填充Supplier,Concurrent是一种线程安全的map\r\n ConcurrentMap<Object, Supplier<V>> valuesMap = map.get(cacheKey);\r\n if (valuesMap == null) {\r\n ConcurrentMap<Object, Supplier<V>> oldValuesMap = map.putIfAbsent(cacheKey, valuesMap = new ConcurrentHashMap<>());\r\n if (oldValuesMap != null) {\r\n valuesMap = oldValuesMap;\r\n }\r\n }\r\n \r\n // create subKey and retrieve the possible Supplier<V> stored by that\r\n // subKey from valuesMap\r\n Object subKey = Objects.requireNonNull(subKeyFactory.apply(key, parameter));\r\n Supplier<V> supplier = valuesMap.get(subKey);\r\n Factory factory = null;\r\n while (true) {\r\n if (supplier != null) {\r\n // 从supplier中获取Value,这个Value可能是一个工厂或者Cache的实\r\n //下面这三句代码是核心代码,返回实现InvokeHandler的类并包含了所需要的信息。\r\n V value = supplier.get();\r\n if (value != null) {\r\n return value;\r\n }\r\n }\r\n\r\n // else no supplier in cache\r\n // or a supplier that returned null (could be a cleared CacheValue\r\n // or a Factory that wasn\'t successful in installing the CacheValue)\r\n //下面这个过程就是填充supplier的过程\r\n if(factory == null) {\r\n //创建一个factory\r\n }\r\n if(supplier == null) {\r\n //填充supplier\r\n }else {\r\n //填充supplier\r\n }\r\n }\r\n}\r\n```\r\n\r\n**while循环**的作用就是不停的获取实现`InvokeHandler`的类,这个类可以是从缓存中拿到,也可是是从`proxyFactoryClass`生成的。 \r\n`Factory`是一个实现了`Supplier<V>`接口的内部类。这个类覆盖了`get`方法,在`get`方法中调用了类型为`proxyFactoryClass`的实例方法`apply`。这个方法才是真正创建**代理类**的方法。下面看`ProxyFactoryClass.apply`方法的源码:\r\n\r\n```java\r\npublic Class<?> apply(ClassLoader loader, Class<?>[] interfaces) {\r\n Map<Class<?>, Boolean> interfaceSet = new IdentityHashMap<>(interfaces.length);\r\n for (Class<?> intf : interfaces) {\r\n /* Verify that the class loader resolves the name of this interface to the same Class object.*/\r\n Class<?> interfaceClass = null;\r\n try {\r\n //加载每一个接口运行时的信息\r\n interfaceClass = Class.forName(intf.getName(), false, loader);\r\n } catch (ClassNotFoundException e) {\r\n }\r\n\r\n //如果使用你自己的classload加载的class与你传入的class不相等,抛出异常\r\n if (interfaceClass != intf) {\r\n throw new IllegalArgumentException(\r\n intf + \" is not visible from class loader\");\r\n }\r\n\r\n //如果传入不是一个接口类型\r\n if (!interfaceClass.isInterface()) {\r\n throw new IllegalArgumentException(\r\n interfaceClass.getName() + \" is not an interface\");\r\n }\r\n\r\n //验证接口是否重复\r\n if (interfaceSet.put(interfaceClass, Boolean.TRUE) != null) {\r\n throw new IllegalArgumentException(\"repeated interface: \" + interfaceClass.getName());\r\n }\r\n }\r\n \r\n String proxyPkg = null; // package to define proxy class in\r\n /* Record the package of a non-public proxy interface so that the proxy class will be defined in the same package. \r\n * Verify that all non-public proxy interfaces are in the same package.\r\n */\r\n //这一段是看你传入的接口中有没有不是public的接口,如果有,这些接口必须全部在一个包里定义的,否则抛异常 \r\n for (Class<?> intf : interfaces) {\r\n int flags = intf.getModifiers();\r\n if (!Modifier.isPublic(flags)) {\r\n String name = intf.getName();\r\n int n = name.lastIndexOf(\'.\');\r\n String pkg = ((n == -1) ? \"\" : name.substring(0, n + 1));\r\n if (proxyPkg == null) {\r\n proxyPkg = pkg;\r\n } else if (!pkg.equals(proxyPkg)) {\r\n throw new IllegalArgumentException(\r\n \"non-public interfaces from different packages\");\r\n }\r\n }\r\n }\r\n if (proxyPkg == null) {\r\n // if no non-public proxy interfaces, use com.sun.proxy package\r\n proxyPkg = ReflectUtil.PROXY_PACKAGE + \".\";\r\n }\r\n /*\r\n * Choose a name for the proxy class to generate.\r\n */\r\n long num = nextUniqueNumber.getAndIncrement();\r\n //生成随机代理类的类名,$Proxy + num\r\n String proxyName = proxyPkg + proxyClassNamePrefix + num;\r\n /*\r\n * 生成代理类的class文件,返回字节流\r\n */\r\n byte[] proxyClassFile = ProxyGenerator.generateProxyClass(proxyName, interfaces);\r\n try {\r\n return defineClass0(loader, proxyName, proxyClassFile, 0, proxyClassFile.length);\r\n } catch (ClassFormatError e) {\r\n //结束\r\n throw new IllegalArgumentException(e.toString());\r\n }\r\n }\r\n }\r\n}\r\n```\r\n\r\n前文提到`ProxyFactoryClass.apply`是真正生成代理类的方法,这其实是不准确的。源代码读到这里,我们会发现`ProxyGenerator.generateProxyClass`才是真正生成代理类的方法。\r\n根据Java class字节码组成来生成相应的Clss文件。具体`ProxyGenerator.generateProxyClass`源码如下:\r\n\r\n```java\r\nprivate byte[] generateClassFile() {\r\n /*\r\n * Step 1: Assemble ProxyMethod objects for all methods to\r\n * generate proxy dispatching code for.\r\n */\r\n //addProxyMethod方法,就是将方法都加入到一个列表中,并与对应的class对应起来 \r\n //这里给Object对应了三个方法hashCode,toString和equals \r\n addProxyMethod(hashCodeMethod, Object.class);\r\n addProxyMethod(equalsMethod, Object.class);\r\n addProxyMethod(toStringMethod, Object.class);\r\n //将接口列表中的接口与接口下的方法对应起来\r\n for (int i = 0; i < interfaces.length; i++) {\r\n Method[] methods = interfaces[i].getMethods();\r\n for (int j = 0; j < methods.length; j++) {\r\n addProxyMethod(methods[j], interfaces[i]);\r\n }\r\n }\r\n /*\r\n * For each set of proxy methods with the same signature,\r\n * verify that the methods\' return types are compatible.\r\n */\r\n for (List<ProxyMethod> sigmethods : proxyMethods.values()) {\r\n checkReturnTypes(sigmethods);\r\n }\r\n /*\r\n * Step 2: Assemble FieldInfo and MethodInfo structs for all of\r\n * fields and methods in the class we are generating.\r\n */\r\n //方法中加入构造方法,这个构造方法只有一个,就是一个带有InvocationHandler接口的构造方法 \r\n //这个才是真正给class文件,也就是代理类加入方法了,不过还没真正处理,只是先加进来等待循环,构造方法在class文件中的名称描述是<init> \r\n try {\r\n methods.add(generateConstructor());\r\n for (List<ProxyMethod> sigmethods : proxyMethods.values()) {\r\n for (ProxyMethod pm : sigmethods) {\r\n //给每一个代理方法加一个Method类型的属性,数字10是class文件的标识符,代表这些属性都是private static的 \r\n fields.add(new FieldInfo(pm.methodFieldName,\r\n \"Ljava/lang/reflect/Method;\",\r\n ACC_PRIVATE | ACC_STATIC));\r\n //将每一个代理方法都加到代理类的方法中 \r\n methods.add(pm.generateMethod());\r\n }\r\n }\r\n //加入一个静态初始化块,将每一个属性都初始化,这里静态代码块也叫类构造方法,其实就是名称为<clinit>的方法,所以加到方法列表 \r\n methods.add(generateStaticInitializer());\r\n } catch (IOException e) {\r\n throw new InternalError(\"unexpected I/O Exception\");\r\n }\r\n //方法和属性个数都不能超过65535,包括之前的接口个数也是这样,\r\n //这是因为在class文件中,这些个数都是用4位16进制表示的,所以最大值是2的16次方-1 \r\n if (methods.size() > 65535) {\r\n throw new IllegalArgumentException(\"method limit exceeded\");\r\n }\r\n if (fields.size() > 65535) {\r\n throw new IllegalArgumentException(\"field limit exceeded\");\r\n }\r\n //接下来就是写class文件的过程,包括魔数,类名,常量池等一系列字节码的组成,就不一一细说了。需要的可以参考JVM虚拟机字节码的相关知识。\r\n cp.getClass(dotToSlash(className));\r\n cp.getClass(superclassName);\r\n for (int i = 0; i < interfaces.length; i++) {\r\n cp.getClass(dotToSlash(interfaces[i].getName()));\r\n }\r\n cp.setReadOnly();\r\n ByteArrayOutputStream bout = new ByteArrayOutputStream();\r\n DataOutputStream dout = new DataOutputStream(bout);\r\n try {\r\n // u4 magic;\r\n dout.writeInt(0xCAFEBABE);\r\n // u2 minor_version;\r\n dout.writeShort(CLASSFILE_MINOR_VERSION);\r\n // u2 major_version;\r\n dout.writeShort(CLASSFILE_MAJOR_VERSION);\r\n cp.write(dout); // (write constant pool)\r\n // u2 access_flags;\r\n dout.writeShort(ACC_PUBLIC | ACC_FINAL | ACC_SUPER);\r\n // u2 this_class;\r\n dout.writeShort(cp.getClass(dotToSlash(className)));\r\n // u2 super_class;\r\n dout.writeShort(cp.getClass(superclassName));\r\n // u2 interfaces_count;\r\n dout.writeShort(interfaces.length);\r\n \r\n // u2 interfaces[interfaces_count];\r\n for (int i = 0; i < interfaces.length; i++) {\r\n dout.writeShort(cp.getClass(\r\n dotToSlash(interfaces[i].getName())));\r\n }\r\n\r\n // u2 fields_count;\r\n dout.writeShort(fields.size());\r\n // field_info fields[fields_count];\r\n for (FieldInfo f : fields) {\r\n f.write(dout);\r\n }\r\n\r\n // u2 methods_count;\r\n dout.writeShort(methods.size());\r\n // method_info methods[methods_count];\r\n for (MethodInfo m : methods) {\r\n m.write(dout);\r\n }\r\n // u2 attributes_count;\r\n dout.writeShort(0); // (no ClassFile attributes for proxy classes)\r\n } catch (IOException e) {\r\n throw new InternalError(\"unexpected I/O Exception\");\r\n }\r\n return bout.toByteArray();\r\n}\r\n```\r\n\r\n经过层层调用,一个代理类终于生成了。\r\n\r\n### 是谁调用了Invoke?\r\n\r\n我们模拟JDK自己生成一个代理类, 类名为**TestProxyGen**:\r\n\r\n```java\r\npublic class TestGeneratorProxy {\r\n public static void main(String[] args) throws IOException {\r\n byte[] classFile = ProxyGenerator.generateProxyClass(\"TestProxyGen\",\r\n Subject.class.getInterfaces());\r\n File file = new File(\"/Users/yadoao/Desktop/TestProxyGen.class\");\r\n FileOutputStream fos = new FileOutputStream(file); \r\n fos.write(classFile); \r\n fos.flush(); \r\n fos.close(); \r\n }\r\n}\r\n```\r\n\r\n用JD-GUI反编译该class文件,结果如下:\r\n\r\n```java\r\nimport java.lang.reflect.InvocationHandler;\r\nimport java.lang.reflect.Method;\r\nimport java.lang.reflect.Proxy;\r\nimport java.lang.reflect.UndeclaredThrowableException;\r\n\r\npublic final class TestProxyGen extends Proxy implements ISubject {\r\n\r\n private static Method m3;\r\n private static Method m1;\r\n private static Method m0;\r\n private static Method m4;\r\n private static Method m2;\r\n\r\n public TestProxyGen(InvocationHandler paramInvocationHandler) throws {\r\n super(paramInvocationHandler);\r\n }\r\n\r\n public final void sayHello() throws {\r\n try {\r\n this.h.invoke(this, m3, null);\r\n return;\r\n } catch (Error|RuntimeException localError) {\r\n throw localError;\r\n } catch (Throwable localThrowable) {\r\n throw new UndeclaredThrowableException(localThrowable);\r\n }\r\n }\r\n\r\n public final boolean equals(Object paramObject) throws {\r\n try {\r\n return ((Boolean)this.h.invoke(this, m1, new Object[] { paramObject })).booleanValue();\r\n } catch (Error|RuntimeException localError) {\r\n throw localError;\r\n } catch (Throwable localThrowable) {\r\n throw new UndeclaredThrowableException(localThrowable);\r\n }\r\n }\r\n \r\n public final int hashCode() throws {\r\n try {\r\n return ((Integer)this.h.invoke(this, m0, null)).intValue();\r\n } catch (Error|RuntimeException localError) {\r\n throw localError;\r\n } catch (Throwable localThrowable) {\r\n throw new UndeclaredThrowableException(localThrowable);\r\n }\r\n }\r\n\r\n public final void sayGoodBye() throws {\r\n try {\r\n this.h.invoke(this, m4, null);\r\n return;\r\n } catch (Error|RuntimeException localError) {\r\n throw localError;\r\n } catch (Throwable localThrowable) {\r\n throw new UndeclaredThrowableException(localThrowable);\r\n }\r\n }\r\n\r\n public final String toString() throws {\r\n try {\r\n return (String)this.h.invoke(this, m2, null);\r\n } catch (Error|RuntimeException localError) {\r\n throw localError;\r\n } catch (Throwable localThrowable) {\r\n throw new UndeclaredThrowableException(localThrowable);\r\n }\r\n }\r\n\r\n static {\r\n try {\r\n m3 = Class.forName(\"com.su.dynamicProxy.ISubject\").getMethod(\"sayHello\", new Class[0]);\r\n m1 = Class.forName(\"java.lang.Object\").getMethod(\"equals\", new Class[] { Class.forName(\"java.lang.Object\") });\r\n m0 = Class.forName(\"java.lang.Object\").getMethod(\"hashCode\", new Class[0]);\r\n m4 = Class.forName(\"com.su.dynamicProxy.ISubject\").getMethod(\"sayGoodBye\", new Class[0]);\r\n m2 = Class.forName(\"java.lang.Object\").getMethod(\"toString\", new Class[0]);\r\n return;\r\n } catch (NoSuchMethodException localNoSuchMethodException) {\r\n throw new NoSuchMethodError(localNoSuchMethodException.getMessage());\r\n } catch (ClassNotFoundException localClassNotFoundException) {\r\n throw new NoClassDefFoundError(localClassNotFoundException.getMessage());\r\n }\r\n }\r\n}\r\n```\r\n\r\n- 首先注意到生成代理类的构造函数,它传入一个实现InvokeHandler接口的类作为参数,并调用父类Proxy的构造器,即将Proxy中的成员变量protected InvokeHander h进行了初始化。\r\n- 再次注意到几个静态的初始化块,这里的静态初始化块就是对代理的接口列表以及hashcode,toString, equals方法进行初始化。\r\n- 最后就是这几个方法的调用过程,全都是回调Invoke方法。\r\n\r\n就此代理模式分析到此结束。\r\n\r\n# 参考文献\r\n\r\n- [代理模式原理及实例讲解](https://www.ibm.com/developerworks/cn/java/j-lo-proxy-pattern/) \r\n- [代理模式学习](http://blog.csdn.net/zuoxiaolong8810/article/details/9026775)',0,1,0,1463846957,1463846957),
('7e20696150','8. 增删改查',NULL,6,1000,1,'','```java\r\n/**\r\n * 用户控制器\r\n */\r\npublic class UserController {\r\n \r\n /**\r\n * 用户列表\r\n * @param request\r\n * @param response\r\n */\r\n public void users(Request request, Response response){\r\n List<User> users = MarioDb.getList(\"select * from t_user\", User.class);\r\n request.attr(\"users\", users);\r\n response.render(\"users\");\r\n }\r\n \r\n /**\r\n * 添加用户界面\r\n * @param request\r\n * @param response\r\n */\r\n public void show_add(Request request, Response response){\r\n response.render(\"user_add\");\r\n }\r\n \r\n /**\r\n * 保存方法\r\n * @param request\r\n * @param response\r\n * @throws ParseException\r\n */\r\n public void save(Request request, Response response) throws ParseException{\r\n String name = request.query(\"name\");\r\n Integer age = request.queryAsInt(\"age\");\r\n String date = request.query(\"birthday\");\r\n \r\n if(null == name || null == age || null == date){\r\n request.attr(\"res\", \"error\");\r\n response.render(\"user_add\");\r\n return;\r\n }\r\n \r\n Date bir = new SimpleDateFormat(\"yyyy-MM-dd\").parse(date);\r\n \r\n int res = MarioDb.insert(\"insert into t_user(name, age, birthday)\", name, age, bir);\r\n if(res > 0){\r\n String ctx = MarioContext.me().getContext().getContextPath();\r\n String location = ctx + \"/users\";\r\n response.redirect(location.replaceAll(\"[/]+\", \"/\"));\r\n } else {\r\n request.attr(\"res\", \"error\");\r\n response.render(\"user_add\");\r\n }\r\n }\r\n \r\n /**\r\n * 编辑页面\r\n * @param request\r\n * @param response\r\n */\r\n public void edit(Request request, Response response){\r\n Integer id = request.queryAsInt(\"id\");\r\n if(null != id){\r\n Map<String, Object> map = new HashMap<String, Object>();\r\n map.put(\"id\", id);\r\n User user = MarioDb.get(\"select * from t_user where id = :id\", User.class, map);\r\n request.attr(\"user\", user);\r\n response.render(\"user_edit\");\r\n }\r\n }\r\n \r\n /**\r\n * 修改信息\r\n * @param request\r\n * @param response\r\n */\r\n public void update(Request request, Response response){\r\n Integer id = request.queryAsInt(\"id\");\r\n String name = request.query(\"name\");\r\n Integer age = request.queryAsInt(\"age\");\r\n \r\n if(null == id || null == name || null == age ){\r\n request.attr(\"res\", \"error\");\r\n response.render(\"user_edit\");\r\n return;\r\n }\r\n \r\n Map<String, Object> map = new HashMap<String, Object>();\r\n map.put(\"id\", id);\r\n map.put(\"name\", name);\r\n map.put(\"age\", age);\r\n \r\n int res = MarioDb.update(\"update t_user set name = :name, age = :age where id = :id\", map);\r\n if(res > 0){\r\n String ctx = MarioContext.me().getContext().getContextPath();\r\n String location = ctx + \"/users\";\r\n response.redirect(location.replaceAll(\"[/]+\", \"/\"));\r\n } else {\r\n request.attr(\"res\", \"error\");\r\n response.render(\"user_edit\");\r\n }\r\n }\r\n \r\n /**\r\n * 删除\r\n * @param request\r\n * @param response\r\n */\r\n public void delete(Request request, Response response){\r\n Integer id = request.queryAsInt(\"id\");\r\n if(null != id){\r\n Map<String, Object> map = new HashMap<String, Object>();\r\n map.put(\"id\", id);\r\n MarioDb.update(\"delete from t_user where id = :id\", map);\r\n }\r\n \r\n String ctx = MarioContext.me().getContext().getContextPath();\r\n String location = ctx + \"/users\";\r\n response.redirect(location.replaceAll(\"[/]+\", \"/\"));\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n+ [演示程序代码](https://github.com/junicorn/mario-sample)\r\n+ [Blade框架](https://github.com/biezhi/blade)',0,1,0,1463849574,1463849574),
('8035ef8e67','java8 foreach',NULL,6,1005,3,'','在这篇文章中我将向你演示如何使用Java8中的`foreach`操作`List`和`Map`\r\n\r\n### 1. Foreach操作Map\r\n1.1 正常方式遍历Map\r\n```java\r\nMap<String, Integer> items = new HashMap<>();\r\nitems.put(\"A\", 10);\r\nitems.put(\"B\", 20);\r\nitems.put(\"C\", 30);\r\nitems.put(\"D\", 40);\r\nitems.put(\"E\", 50);\r\nitems.put(\"F\", 60);\r\n\r\nfor (Map.Entry<String, Integer> entry : items.entrySet()) {\r\n System.out.println(\"Item : \" + entry.getKey() + \" Count : \" + entry.getValue());\r\n}\r\n```\r\n\r\n<!--more-->\r\n\r\n1.2 使用Java8的`foreach`+`lambda`表达式遍历Map\r\n```java\r\nMap<String, Integer> items = new HashMap<>();\r\nitems.put(\"A\", 10);\r\nitems.put(\"B\", 20);\r\nitems.put(\"C\", 30);\r\nitems.put(\"D\", 40);\r\nitems.put(\"E\", 50);\r\nitems.put(\"F\", 60);\r\n\r\nitems.forEach((k,v)->System.out.println(\"Item : \" + k + \" Count : \" + v));\r\n\r\nitems.forEach((k,v)->{\r\n System.out.println(\"Item : \" + k + \" Count : \" + v);\r\n if(\"E\".equals(k)){\r\n System.out.println(\"Hello E\");\r\n }\r\n});\r\n```\r\n\r\n###2. Foreach操作List\r\n2.1 普通方式循环List\r\n```java\r\nList<String> items = new ArrayList<>();\r\nitems.add(\"A\");\r\nitems.add(\"B\");\r\nitems.add(\"C\");\r\nitems.add(\"D\");\r\nitems.add(\"E\");\r\n\r\nfor(String item : items){\r\n System.out.println(item);\r\n}\r\n```\r\n2.2 在Java8中使用`foreach`+`lambda`表达式遍历List\r\n```java\r\nList<String> items = new ArrayList<>();\r\nitems.add(\"A\");\r\nitems.add(\"B\");\r\nitems.add(\"C\");\r\nitems.add(\"D\");\r\nitems.add(\"E\");\r\n\r\n//lambda\r\n//Output : A,B,C,D,E\r\nitems.forEach(item->System.out.println(item));\r\n \r\n//Output : C\r\nitems.forEach(item->{\r\n if(\"C\".equals(item)){\r\n System.out.println(item);\r\n }\r\n});\r\n \r\n//method reference\r\n//Output : A,B,C,D,E\r\nitems.forEach(System.out::println);\r\n\r\n//Steam and filter\r\n//Output : B\r\nitems.stream()\r\n .filter(s->s.contains(\"B\"))\r\n .forEach(System.out::println);\r\n```\r\n\r\n参考资料:\r\n1. [Java 8 Iterable forEach JavaDoc](https://docs.oracle.com/javase/8/docs/api/java/lang/Iterable.html#forEach-java.util.function.Consumer-)\r\n2. [Java 8 forEach JavaDoc](https://docs.oracle.com/javase/8/docs/api/java/util/Map.html#forEach-java.util.function.BiConsumer-)',0,1,0,1463849051,1463849051),
('9e50709d3c','5. 视图设计',NULL,6,1000,1,'','我们已经完成了MVC中的C层,还有M和V没有做呢。这一小节来对视图进行设计,从后台到前台的渲染是这样的\r\n后台给定一个视图位置,输出到前端JSP或者其他模板引擎上,做一个非常简单的接口:\r\n\r\n```java\r\n/**\r\n * 视图渲染接口\r\n * @author biezhi\r\n *\r\n */\r\npublic interface Render {\r\n \r\n /**\r\n * 渲染到视图\r\n * @param view 视图名称\r\n * @param writer 写入对象\r\n */\r\n public void render(String view, Writer writer);\r\n \r\n}\r\n```\r\n\r\n具体的实现我们先写一个JSP的,当你在使用Servlet进行开发的时候已经习惯了这句语法:\r\n\r\n```java\r\nservletRequest.getRequestDispatcher(viewPath).forward(servletRequest, servletResponse);\r\n```\r\n\r\n那么一个JSP的渲染实现就很简单了\r\n\r\n```java\r\n/**\r\n * JSP渲染实现\r\n * @author biezhi\r\n *\r\n */\r\npublic class JspRender implements Render {\r\n \r\n @Override\r\n public void render(String view, Writer writer) {\r\n \r\n String viewPath = this.getViewPath(view);\r\n \r\n HttpServletRequest servletRequest = MarioContext.me().getRequest().getRaw();\r\n HttpServletResponse servletResponse = MarioContext.me().getResponse().getRaw();\r\n try {\r\n servletRequest.getRequestDispatcher(viewPath).forward(servletRequest, servletResponse);\r\n } catch (ServletException e) {\r\n e.printStackTrace();\r\n } catch (IOException e) {\r\n e.printStackTrace();\r\n }\r\n \r\n }\r\n\r\n private String getViewPath(String view){\r\n Mario mario = Mario.me();\r\n String viewPrfix = mario.getConf(Const.VIEW_PREFIX_FIELD);\r\n String viewSuffix = mario.getConf(Const.VIEW_SUFFIX_FIELD);\r\n\r\n if (null == viewSuffix || viewSuffix.equals(\"\")) {\r\n viewSuffix = Const.VIEW_SUFFIX;\r\n }\r\n if (null == viewPrfix || viewPrfix.equals(\"\")) {\r\n viewPrfix = Const.VIEW_PREFIX;\r\n }\r\n String viewPath = viewPrfix + \"/\" + view;\r\n if (!view.endsWith(viewSuffix)) {\r\n viewPath += viewSuffix;\r\n }\r\n return viewPath.replaceAll(\"[/]+\", \"/\");\r\n }\r\n\r\n}\r\n```\r\n\r\n配置 JSP 视图的位置和后缀可以在配置文件或者硬编码中进行,当然这看你的习惯,\r\n默认设置了 JSP 在 `/WEB-INF/` 下,后缀是 `.jsp` 你懂的!\r\n\r\n怎么用可以参考 `mario-sample` 这个项目,因为真的很简单 相信你自己。\r\n\r\n在下一节中我们就要和数据库打交道了,尝试新的旅程吧 :)',0,1,0,1463849501,1463849501),
('a41d15766c','1. 项目规划',NULL,6,1000,1,'','做任何事情都需要做好规划,那么我们在开发博客系统之前,同样需要做好项目的规划,如何设置目录结构,如何理解整个项目的流程图,当我们理解了应用的执行过程,那么接下来的设计编码就会变得相对容易了\r\n\r\n# 创建一个maven项目\r\n\r\n## 约定一下框架基础信息\r\n\r\n* 假设我们的web框架名称是 `mario`\r\n* 包名是 `com.junicorn.mario`\r\n\r\n### 命令行创建\r\n\r\n```sh\r\nmvn archetype:create -DgroupId=com.junicorn -DartifactId=mario -DpackageName=com.junicorn.mario\r\n```\r\n\r\n### Eclipse创建\r\n\r\n\r\n\r\n\r\n\r\n创建好的基本结构是这样的\r\n\r\n\r\n\r\n初始化一下 `pom.xml`\r\n\r\n```xml\r\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\"\r\n xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd\">\r\n <modelVersion>4.0.0</modelVersion>\r\n\r\n <groupId>com.junicorn</groupId>\r\n <artifactId>mario</artifactId>\r\n <version>0.0.1-SNAPSHOT</version>\r\n <packaging>jar</packaging>\r\n\r\n <name>mario</name>\r\n <url>https://github.com/junicorn/mario</url>\r\n\r\n <properties>\r\n <maven.compiler.source>1.6</maven.compiler.source>\r\n <maven.compiler.target>1.6</maven.compiler.target>\r\n <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>\r\n <servlet.version>3.0.1</servlet.version>\r\n </properties>\r\n \r\n <dependencies>\r\n <dependency>\r\n <groupId>javax.servlet</groupId>\r\n <artifactId>javax.servlet-api</artifactId>\r\n <version>3.1.0</version>\r\n <scope>provided</scope>\r\n </dependency>\r\n </dependencies>\r\n \r\n <build>\r\n <plugins>\r\n <plugin>\r\n <groupId>org.apache.maven.plugins</groupId>\r\n <artifactId>maven-compiler-plugin</artifactId>\r\n <version>3.1</version>\r\n <configuration>\r\n <source>1.6</source>\r\n <target>1.6</target>\r\n <encoding>UTF-8</encoding>\r\n </configuration>\r\n </plugin>\r\n </plugins>\r\n </build>\r\n</project>\r\n```\r\n\r\nOK,项目创建好了,这个将是我们的框架。\r\n\r\n# 框架流程\r\n\r\nweb程序是基于 `M(模型)V(视图)C(控制器)` 设计的。MVC是一种将应用程序的逻辑层和表现层进行分离的结构方式。在实践中,由于表现层从 Java 中分离了出来,所以它允许你的网页中只包含很少的脚本。\r\n\r\n* 模型 (Model) 代表数据结构。通常来说,模型类将包含取出、插入、更新数据库资料等这些功能。\r\n* 视图 (View) 是展示给用户的信息的结构及样式。一个视图通常是一个网页,但是在Java中,一个视图也可以是一个页面片段,如页头、页尾。它还可以是一个 RSS 页面,或其它类型的“页面”,Jsp已经很好的实现了View层中的部分功能。\r\n* 控制器 (Controller) 是模型、视图以及其他任何处理HTTP请求所必须的资源之间的中介,并生成网页。\r\n\r\n# 设计思路\r\n\r\nmario 是基于servlet实现的mvc,用一个全局的Filter来做核心控制器,使用sql2o框架作为数据库基础访问。\r\n使用一个接口 `Bootstrap` 作为初始化启动,实现它并遵循Filter参数约定即可。\r\n\r\n建立路由、数据库、视图相关的包和类,下面是结构:\r\n\r\n\r\n',0,1,0,1463849342,1463849342),
('bd73bdf283','如何设计一个JavaWeb MVC框架',NULL,6,1000,1,'','通过使用Java语言实现一个完整的框架设计,这个框架中主要内容有第一小节介绍的Web框架的结构规划,例如采用MVC模式来进行开发,程序的执行流程设计等内容;第二小节介绍框架的第一个功能:路由,如何让访问的URL映射到相应的处理逻辑;第三小节介绍处理逻辑,如何设计一个公共的 `调度器`,对象继承之后处理函数中如何处理response和request;第四小节至第六小节介绍如何框架的一些辅助功能,例如配置信息,数据库操作等;最后介绍如何基于Web框架实现一个简单的增删改查,包括User的添加、修改、删除、显示列表等操作。\r\n\r\n通过这么一个完整的项目例子,我期望能够让读者了解如何开发Web应用,如何搭建自己的目录结构,如何实现路由,如何实现MVC模式等各方面的开发内容。在框架盛行的今天,MVC也不再是神话。经常听到很多程序员讨论哪个框架好,哪个框架不好, 其实框架只是工具,没有好与不好,只有适合与不适合,适合自己的就是最好的,所以教会大家自己动手写框架,那么不同的需求都可以用自己的思路去实现。\r\n\r\n\r\n\r\n- 项目源码:[https://github.com/junicorn/mario](https://github.com/junicorn/mario)\r\n- 示例代码:[https://github.com/junicorn/mario-sample](https://github.com/junicorn/mario-sample)\r\n\r\n欢迎Star我写的一个简洁优雅的MVC框架 [Blade](https://github.com/biezhi/blade) :wink:\r\n\r\n# 目录\r\n\n* [项目规划](a41d15766c)\n* [路由设计](c8c56e9e85)\n* [控制器设计](fe6d15965a)\n* [配置设计](555e12872a)\n* [视图设计](9e50709d3c)\n* [数据库操作](cbe33c2e40)\n* [增删改查](7e20696150)\r\n\r\n接下来开始我们的 [框架之旅](1.plan.md) 吧~',0,1,0,1463578152,1463578152),
('c19519a67d','Linux 介绍',NULL,6,1002,2,'','## Linux 这个名字\r\n\r\nLinux 的 Wiki 介绍:[http://zh.wikipedia.org/zh/Linux](http://http://zh.wikipedia.org/zh/Linux)\r\n\r\nLinux 也称:`GNU/Linux`,而其中 GNU 的全称又是:`Gnu’s Not Unix`。\r\n\r\n其中 GNU 放前面是有原因的,GNU 介绍:[http://zh.wikipedia.org/wiki/GNU](http://zh.wikipedia.org/wiki/GNU)\r\n\r\n对于 Linux 和 GNU/Linux 的两种叫法是有争议,可以看下面文章:[https://zh.wikipedia.org/wiki/GNU/Linux%E5%91%BD%E5%90%8D%E7%88%AD%E8%AD%B0](https://zh.wikipedia.org/wiki/GNU/Linux%E5%91%BD%E5%90%8D%E7%88%AD%E8%AD%B0)\r\n\r\n其实我们可以认为:Linux 本质是指 Linux 内核,而称 GNU/Linux 则代表这是一个系统,所以我认为 Debian 的这个叫法是合理的,但是确实有点不好念和记忆。所以普遍大家直接称作 Linux。\r\n\r\n通过上面的全称和资料其实我们也就了解到,Linux 本质来源不是 Unix,但是它借鉴了 Unix 的设计思想,所以在系统业界上把这种和 Unix 是一致设计思想的系统归为:`类 Unix 系统`。\r\n\r\n类 Unix 系统的介绍:[https://zh.wikipedia.org/wiki/%E7%B1%BBUnix%E7%B3%BB%E7%BB%9F](https://zh.wikipedia.org/wiki/%E7%B1%BBUnix%E7%B3%BB%E7%BB%9F)\r\n\r\n类 Unix 系统,除了我们今天要讲的 Linux,还有大家熟知的 Mac OS X、FreeBSD(这两个是直接从 Unix 系发展过来的,所以相对 Linux 是比较地道的类 Unix 系统)\r\n\r\n- FreeBSD 介绍:[http://zh.wikipedia.org/zh/FreeBSD](http://zh.wikipedia.org/zh/FreeBSD)\r\n- Mac OS X 介绍:[http://zh.wikipedia.org/wiki/OS_X](http://zh.wikipedia.org/wiki/OS_X)\r\n\r\n## Linux 的发行版本\r\n\r\nLinux 的 Wiki 中有这句话:\r\n\r\n> 通常情况下,Linux 被打包成供个人计算机和服务器使用的 Linux 发行版,一些流行的主流 Linux 发布版,包括 Debian(及其派生版本 Ubuntu、Linux Mint)、Fedora(及其相关版本 Red Hat Enterprise Linux、CentOS)和 openSUSE、ArchLinux(这个是我补充的)等。\r\n\r\n**通过上面这句话我做了总结,我个人觉得应该这样分:**\r\n\r\n- Fedora、RHEL、Centos 是一个系,他们的区别:[http://blog.csdn.net/tianlesoftware/article/details/5420569](http://blog.csdn.net/tianlesoftware/article/details/5420569)\r\n- Debian、Ubuntu 是一个系的,他们的区别直接看 Ubuntu 的 Wiki 就可以得知:[http://zh.wikipedia.org/zh/Ubuntu](http://zh.wikipedia.org/zh/Ubuntu)\r\n- ArchLinux 自己一个系:[http://zh.wikipedia.org/wiki/Arch_Linux](http://zh.wikipedia.org/wiki/Arch_Linux)\r\n- openSUSE 自己一个系:[http://zh.wikipedia.org/wiki/OpenSUSE](http://zh.wikipedia.org/wiki/OpenSUSE)\r\n\r\n**根据用途可以再总结:**\r\n\r\n- Fedora 系业界一般用于做服务器\r\n- Debian 系业界一般用于桌面,移动端,TV这一类\r\n- ArchLinux 系,很轻量的Linux,适合有一定Linux基础,并且爱折腾的人使用,用它做桌面或是服务器都行。\r\n- OpenSuse 系,嘛,嗯…人气相对比较差,一般是服务器。\r\n\r\n其实 Linux 的发行版本有太多了,我也只是简单说下常见的而已,具体可以看:[http://zh.wikipedia.org/wiki/Linux%E5%8F%91%E8%A1%8C%E7%89%88%E5%88%97%E8%A1%A8](http://zh.wikipedia.org/wiki/Linux%E5%8F%91%E8%A1%8C%E7%89%88%E5%88%97%E8%A1%A8)\r\n\r\n## Linux 作用\r\n\r\n为什么要用 Linux 系统?大家常看到的说法是这样的:\r\n\r\n> Linux 是一个开源的,有潜力,安全,免费的操作系统\r\n\r\n我觉得这几个点都比较虚, 特别是免费这东西,在景德镇应该算是最不值钱的东西。作为系统的上层使用者来讲,我们之所以喜欢某个操作系统就是因为它可以加快的你生产效率,提高产能。我推荐 Linux 也只是因为它适合常见的编程语言做开发环境,仅此一点。\r\n\r\n**所有,对此我的总结就是:**\r\n\r\n如果你是某种语言的开发者,你从事这个行业,不管你怎么学习下去,Linux 永远绕不开。从简单的各种语言开发,到后期的服务器部署,分布式,集群环境,数据库相关等,Linux 都在等着你。如果你是新手程序员可能还不太懂我这句话,但是我这里可以这样提示:你可以认真去看下各个语言的官网、对应的开发组件官网,看下他们的下载和新手上路相关页面,都会有 Linux 系统对应的介绍,但是不一定有会 Windows。(P.S:微软系、美工等设计系是唯一这个总结之外的人)\r\n\r\n在认识 Linux 作用上我以下面这边文章为结尾。Linux 和 Mac OS X 都是类 Unix 系统,所以这篇文章中基本上的理由都可以用到 Linux 上的。\r\n为什么国外程序员爱用 Mac?[http://www.vpsee.com/2009/06/why-programmers-love-mac/](http://www.vpsee.com/2009/06/why-programmers-love-mac/)\r\n\r\n## 推荐的发行版本\r\n\r\n**Ubuntu:适用于开发机**\r\n\r\n**推荐版本:Ubuntu kylin 15.10**\r\n\r\n- Ubuntu kylin 官网:<http://cn.Ubuntu.com/desktop>\r\n- Ubuntu 英文官网:<http://www.ubuntu.com>\r\n- Ubuntu 中文官网:<http://www.ubuntu.org.cn>\r\n- 网易镜像:<http://mirrors.163.com/ubuntu-releases/>\r\n- 阿里云镜像:<http://mirrors.aliyun.com/ubuntu-releases/>\r\n- Ubuntu kylin 15.10 **64 位**镜像地址:<http://cdimage.ubuntu.com/ubuntukylin/releases/15.10/release/ubuntukylin-15.10-desktop-amd64.iso>\r\n\r\n**推荐理由:**\r\n\r\n我们是要在上面做开发的,不是要把他变成生活用机的,所以你认为自己尝试安装各种中文输入法很爽吗?自己尝试让国际 Ubuntu 版变成又一个符合国情的 kylin 很爽吗?真心别折腾这些没用的东西。就像我以前说的,大学老师让 Java 新手使用记事本写代码就是一种非常 shit 行为,不断地在 Windows 上用 `cmd > javac` 是毫无意义的。\r\n\r\n------\r\n\r\n**CentOS:适用于服务器机**\r\n\r\n**推荐版本:6.7**\r\n\r\n- CentOS 官网:<http://www.centos.org/download/>\r\n- 网易镜像:<http://mirrors.163.com/centos/>\r\n- 阿里云镜像:<http://mirrors.aliyun.com/centos/>\r\n- CentOS 6.7 **64 位**镜像地址:<http://mirrors.163.com/centos/6.7/isos/x86_64/CentOS-6.7-x86_64-bin-DVD1.iso>\r\n\r\n**推荐理由:**\r\n\r\nFedora(CentOS、RHEL) 系,是在国内外,作为企业服务器的系统最多,没有之一。我在 Quora 和知乎上也搜索了下,基本上大家都是赞同这个观点的。',0,1,0,1463847514,1463847514),
('c8c56e9e85','2. 路由设计',NULL,6,1000,1,'','现代 Web 应用的 URL 十分优雅,易于人们辨识记忆。 路由的表现形式如下:\r\n\r\n```\r\n/resources/:resource/actions/:action\r\nhttp://bladejava.com\r\nhttp://bladejava.com/docs/modules/route\r\n```\r\n\r\n那么我们在java语言中将他定义一个 `Route` 类, 用于封装一个请求的最小单元,\r\n在Mario中我们设计一个路由的对象如下:\r\n\r\n```java\r\n/**\r\n * 路由\r\n * @author biezhi\r\n */\r\npublic class Route {\r\n\r\n /**\r\n * 路由path\r\n */\r\n private String path;\r\n\r\n /**\r\n * 执行路由的方法\r\n */\r\n private Method action;\r\n\r\n /**\r\n * 路由所在的控制器\r\n */\r\n private Object controller;\r\n\r\n public Route() {\r\n }\r\n\r\n public String getPath() {\r\n return path;\r\n }\r\n\r\n public void setPath(String path) {\r\n this.path = path;\r\n }\r\n\r\n public Method getAction() {\r\n return action;\r\n }\r\n\r\n public void setAction(Method action) {\r\n this.action = action;\r\n }\r\n\r\n public Object getController() {\r\n return controller;\r\n }\r\n\r\n public void setController(Object controller) {\r\n this.controller = controller;\r\n }\r\n\r\n}\r\n```\r\n\r\n所有的请求在程序中是一个路由,匹配在 `path` 上,执行靠 `action`,处于 `controller` 中。\r\n\r\nMario使用一个Filter接收所有请求,因为从Filter过来的请求有无数,如何知道哪一个请求对应哪一个路由呢?\r\n这时候需要设计一个路由匹配器去查找路由处理我们配置的请求,\r\n有了路由匹配器还不够,这么多的路由我们如何管理呢?再来一个路由管理器吧,下面就创建路由匹配器和管理器2个类:\r\n\r\n```java\r\n/**\r\n * 路由管理器,存放所有路由的\r\n * @author biezhi\r\n */\r\npublic class Routers {\r\n\r\n private static final Logger LOGGER = Logger.getLogger(Routers.class.getName());\r\n \r\n private List<Route> routes = new ArrayList<Route>();\r\n \r\n public Routers() {\r\n }\r\n \r\n public void addRoute(List<Route> routes){\r\n routes.addAll(routes);\r\n }\r\n \r\n public void addRoute(Route route){\r\n routes.add(route);\r\n }\r\n \r\n public void removeRoute(Route route){\r\n routes.remove(route);\r\n }\r\n \r\n public void addRoute(String path, Method action, Object controller){\r\n Route route = new Route();\r\n route.setPath(path);\r\n route.setAction(action);\r\n route.setController(controller);\r\n \r\n routes.add(route);\r\n LOGGER.info(\"Add Route:[\" + path + \"]\");\r\n }\r\n\r\n public List<Route> getRoutes() {\r\n return routes;\r\n }\r\n\r\n public void setRoutes(List<Route> routes) {\r\n this.routes = routes;\r\n }\r\n \r\n}\r\n```\r\n\r\n这里的代码很简单,这个管理器里用List存储所有路由,公有的 `addRoute` 方法是给外部调用的。\r\n\r\n```java\r\n/**\r\n * 路由匹配器,用于匹配路由\r\n * @author biezhi\r\n */\r\npublic class RouteMatcher {\r\n\r\n private List<Route> routes;\r\n\r\n public RouteMatcher(List<Route> routes) {\r\n this.routes = routes;\r\n }\r\n \r\n public void setRoutes(List<Route> routes) {\r\n this.routes = routes;\r\n }\r\n\r\n /**\r\n * 根据path查找路由\r\n * @param path 请求地址\r\n * @return 返回查询到的路由\r\n */\r\n public Route findRoute(String path) {\r\n String cleanPath = parsePath(path);\r\n List<Route> matchRoutes = new ArrayList<Route>();\r\n for (Route route : this.routes) {\r\n if (matchesPath(route.getPath(), cleanPath)) {\r\n matchRoutes.add(route);\r\n }\r\n }\r\n // 优先匹配原则\r\n giveMatch(path, matchRoutes);\r\n \r\n return matchRoutes.size() > 0 ? matchRoutes.get(0) : null;\r\n }\r\n\r\n private void giveMatch(final String uri, List<Route> routes) {\r\n Collections.sort(routes, new Comparator<Route>() {\r\n @Override\r\n public int compare(Route o1, Route o2) {\r\n if (o2.getPath().equals(uri)) {\r\n return o2.getPath().indexOf(uri);\r\n }\r\n return -1;\r\n }\r\n });\r\n }\r\n \r\n private boolean matchesPath(String routePath, String pathToMatch) {\r\n routePath = routePath.replaceAll(PathUtil.VAR_REGEXP, PathUtil.VAR_REPLACE);\r\n return pathToMatch.matches(\"(?i)\" + routePath);\r\n }\r\n\r\n private String parsePath(String path) {\r\n path = PathUtil.fixPath(path);\r\n try {\r\n URI uri = new URI(path);\r\n return uri.getPath();\r\n } catch (URISyntaxException e) {\r\n return null;\r\n }\r\n }\r\n\r\n}\r\n```\r\n\r\n路由匹配器使用了正则去遍历路由列表,匹配合适的路由。当然我不认为这是最好的方法,\r\n因为路由的量很大之后遍历的效率会降低,但这样是可以实现的,如果你有更好的方法可以告诉我 :)\r\n\r\n在下一章节我们需要对请求处理做设计了~',0,1,0,1463849385,1463849385),
('cbe33c2e40','6. 数据库操作',NULL,6,1000,1,'','这一小节是对数据库操作做一个简单的封装,不涉及复杂的事务操作等。\r\n\r\n我选用了Sql2o作为底层数据库框架作为支持,它的简洁易用性让我刮目相看,后面我们也会写如何实现一个ORM框架。\r\n\r\n```java\r\n/**\r\n * 数据库支持\r\n * @author biezhi\r\n *\r\n */\r\npublic final class MarioDb {\r\n \r\n private static Sql2o sql2o = null;\r\n \r\n private MarioDb() {\r\n }\r\n \r\n /**\r\n * 初始化数据库配置\r\n * @param url\r\n * @param user\r\n * @param pass\r\n */\r\n public static void init(String url, String user, String pass){\r\n sql2o = new Sql2o(url, user, pass);\r\n }\r\n \r\n /**\r\n * 初始化数据库配置\r\n * @param dataSource\r\n */\r\n public static void init(DataSource dataSource){\r\n sql2o = new Sql2o(dataSource);\r\n }\r\n \r\n /**\r\n * 查询一个对象\r\n * @param sql\r\n * @param clazz\r\n * @return\r\n */\r\n public static <T> T get(String sql, Class<T> clazz){\r\n return get(sql, clazz, null);\r\n }\r\n \r\n /**\r\n * 查询一个列表\r\n * @param sql\r\n * @param clazz\r\n * @return\r\n */\r\n public static <T> List<T> getList(String sql, Class<T> clazz){\r\n return getList(sql, clazz, null);\r\n }\r\n \r\n /**\r\n * 查询一个对象返回为map类型\r\n * @param sql\r\n * @return\r\n */\r\n public static Map<String, Object> getMap(String sql){\r\n return getMap(sql, null);\r\n }\r\n \r\n /**\r\n * 查询一个列表并返回为list<map>类型\r\n * @param sql\r\n * @return\r\n */\r\n public static List<Map<String, Object>> getMapList(String sql){\r\n return getMapList(sql, null);\r\n }\r\n \r\n /**\r\n * 插入一条记录\r\n * @param sql\r\n * @param params\r\n * @return\r\n */\r\n public static int insert(String sql, Object ... params){\r\n StringBuffer sqlBuf = new StringBuffer(sql);\r\n sqlBuf.append(\" values (\");\r\n \r\n int start = sql.indexOf(\"(\") + 1;\r\n int end = sql.indexOf(\")\");\r\n String a = sql.substring(start, end);\r\n String[] fields = a.split(\",\");\r\n \r\n Map<String, Object> map = new HashMap<String, Object>();\r\n \r\n int i=0;\r\n for(String name : fields){\r\n sqlBuf.append(\":\" + name.trim() + \" ,\");\r\n map.put(name.trim(), params[i]);\r\n i++;\r\n }\r\n \r\n String newSql = sqlBuf.substring(0, sqlBuf.length() - 1) + \")\";\r\n \r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(newSql);\r\n \r\n executeQuery(query, map);\r\n \r\n int res = query.executeUpdate().getResult();\r\n \r\n con.close();\r\n \r\n return res;\r\n }\r\n /**\r\n * 更新\r\n * @param sql\r\n * @return\r\n */\r\n public static int update(String sql){\r\n return update(sql, null);\r\n }\r\n \r\n /**\r\n * 带参数更新\r\n * @param sql\r\n * @param params\r\n * @return\r\n */\r\n public static int update(String sql, Map<String, Object> params){\r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(sql);\r\n executeQuery(query, params);\r\n int res = query.executeUpdate().getResult();\r\n con.close();\r\n return res;\r\n }\r\n \r\n public static <T> T get(String sql, Class<T> clazz, Map<String, Object> params){\r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(sql);\r\n executeQuery(query, params);\r\n T t = query.executeAndFetchFirst(clazz);\r\n con.close();\r\n return t;\r\n }\r\n \r\n @SuppressWarnings(\"unchecked\")\r\n public static Map<String, Object> getMap(String sql, Map<String, Object> params){\r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(sql);\r\n executeQuery(query, params);\r\n Map<String, Object> t = (Map<String, Object>) query.executeScalar();\r\n con.close();\r\n return t;\r\n }\r\n \r\n public static List<Map<String, Object>> getMapList(String sql, Map<String, Object> params){\r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(sql);\r\n executeQuery(query, params);\r\n List<Map<String, Object>> t = query.executeAndFetchTable().asList();\r\n con.close();\r\n return t;\r\n }\r\n \r\n public static <T> List<T> getList(String sql, Class<T> clazz, Map<String, Object> params){\r\n Connection con = sql2o.open();\r\n Query query = con.createQuery(sql);\r\n executeQuery(query, params);\r\n List<T> list = query.executeAndFetch(clazz);\r\n con.close();\r\n return list;\r\n }\r\n \r\n private static void executeQuery(Query query, Map<String, Object> params){\r\n if (null != params && params.size() > 0) {\r\n Set<String> keys = params.keySet();\r\n for(String key : keys){\r\n query.addParameter(key, params.get(key));\r\n }\r\n }\r\n }\r\n}\r\n```\r\n\r\n设计MVC框架部分已经完成,下一节是一个增删改查的例子',0,1,0,1463849529,1463849529),
('d5185dd976','Ubuntu 安装和分区',NULL,6,1002,2,'post/d5185dd976.png','- 先下载该系列教程:<http://pan.baidu.com/s/1gdw7CuJ>\r\n\r\n\r\n\r\n- 找到如图箭头目录上的两个视频,并看完,你对 Ubuntu 的安装就有了一个大概的了解,视频中 Ubuntu 虽然版本较早 13.04 的, 但是没关系,对于 Ubuntu 来讲新旧版本安装基本都一样的,所以别担心,驱动的问题也别担心,我们不是要在 Ubuntu 打游戏的,所以常见驱动系统是已经帮我们集成的不会影响使用。但是分区这一块的话,我个人建议是手工分区,视频中没有最终执行手动分区,只是演示了一下又返回了。 我个人是要求你手动分区的。\r\n\r\n- 但是再讲分区之前,用什么设备安装是第一前提,我这里推荐用 U 盘,你准备一个 4 G 以上的 U 盘,把 Ubuntu 系统进行格式化到里面,用这个 U 盘作为安装盘进行安装。这个过程不难,具体看如下文章:\r\n\r\n - [http://www.Ubuntukylin.com/ask/index.php?qa=jc_1](http://www.Ubuntukylin.com/ask/index.php?qa=jc_1)\r\n - [http://www.wubantu.com/36bc2075036fab76.html](http://www.wubantu.com/36bc2075036fab76.html)\r\n - [http://tieba.baidu.com/p/2795415868](http://tieba.baidu.com/p/2795415868)\r\n - [http://www.Ubuntukylin.com/public/pdf/UK1410install.pdf](http://www.Ubuntukylin.com/public/pdf/UK1410install.pdf)\r\n \r\n- 好了假设你现在已经格式化好 U 盘,现在可以开始讲分区了。这里特别说明的是有多个硬盘的,多块硬盘分区方案就没视频中那么简单,特别是 Linux 的盘符不了解的就更加难了,所以看下图:\r\n\r\n\r\n\r\n- 以我这边为例:我这边机子的硬盘是:一个 128 G 固态 + 500 G 的机械,我给一个分区方案给你们参考。下面的内容需要你先看过视频才能看懂:\r\n\r\n- Linux 一般可分 3 个分区,分别是 `boot 分区`、`swap 分区` 和 `根分区`(根分区也就是斜杠/) boot 是主分区类型,swap 是是逻辑分区,/ 是逻辑分区,其他如果你还想划分的也都是逻辑分区。 最近年代生产的的主板,可能还需要分出一个 EFI 分区启动。EFI 的选择和 swap 一样,都在那个下拉菜单中。 怎么判断你要不要分出一个 EFI 呢?如果你根据我的要求分了 boot,swap,根之后,点击下一步报错,有提示 EFI 相关的错误信息,那就分一个给它,我这边就是有报错的。\r\n\r\n- **120 G 固态硬盘:**\r\n - `/boot` == 1G(主分区),这里为boot单独挂载是有必要的。系统崩溃的时候,损坏的是这个分区。我们重装系统之后,其他分区我们保留下来,重新挂载上去就可以用了。\r\n - `/EFI` == 100M(主分区)(我有提示报错需要分这个,我就分了)\r\n - `/swap` == 12G(逻辑分区)一般大家的说法这个大小是跟你机子的内存大小相关的,也有说法内存大不需要这个,但是还是建议分,我内存是12G,所以我分12G。\r\n - `/` == 100G(逻辑分区)\r\n \r\n- **500 G 机械硬盘:**\r\n - `/home` == 500G(逻辑分区)\r\n \r\n- 分区后的安装都是下一步的,而且 Ubuntu kylin 还是中文的说明,所以没啥难度。 到此假设你给自己的电脑安装了 Ubuntu,那下一讲我将讲 Ubuntu 的相关设置。\r\n\r\n- 如果你想用 VMware 虚拟机安装,这个教程推荐给你,讲得很详细。\r\n - [http://www.jikexueyuan.com/course/1583.html](http://www.jikexueyuan.com/course/1583.html) ',0,1,0,1463847809,1463847809),
('e25541697b','JDK 安装',NULL,6,1002,2,'post/e25541697b.jpg','## CentOS 下过程\r\n\r\n- JDK 在 CentOS 和 Ubuntu 下安装过程是一样的,所以这里不再讲 Ubuntu 系统下的安装\r\n- JDK 1.8 下载\r\n - 此时(20160205)最新版本:`jdk-8u72-linux-x64.tar.gz`\r\n - 官网:<http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html>\r\n - 百度云下载(64 位):<http://pan.baidu.com/s/1eQZffbW>\r\n - 官网压缩包地址:<http://211.138.156.198:82/1Q2W3E4R5T6Y7U8I9O0P1Z2X3C4V5B/download.oracle.com/otn-pub/java/jdk/8u72-b15/jdk-8u72-linux-x64.tar.gz>\r\n - 在命令行模式下下载上面压缩包:\r\n - `cd /opt`\r\n - `sudo wget http://211.138.156.198:82/1Q2W3E4R5T6Y7U8I9O0P1Z2X3C4V5B/download.oracle.com/otn-pub/java/jdk/8u72-b15/jdk-8u72-linux-x64.tar.gz`\r\n\r\n\r\n- 默认 CentOS 有安装 openJDK,建议先卸载掉\r\n - 检查 JDK 命令:`java -version`\r\n - 查询本地 JDK 安装程序情况; `rpm -qa|grep java`\r\n - 我查询出来的结果如下:\r\n \r\n ```\r\n java-1.6.0-openjdk-1.6.0.38-1.13.10.0.el6_7.x86_64\r\n java-1.7.0-openjdk-1.7.0.95-2.6.4.0.el6_7.x86_64\r\n tzdata-java-2015g-2.el6.noarch\r\n ```\r\n\r\n - 卸载上面三个文件(`--nodeps` 的作用:忽略依赖的检查):\r\n - `sudo rpm -e --nodeps java-1.6.0-openjdk-1.6.0.38-1.13.10.0.el6_7.x86_64`\r\n - `sudo rpm -e --nodeps java-1.7.0-openjdk-1.7.0.95-2.6.4.0.el6_7.x86_64`\r\n - `sudo rpm -e --nodeps tzdata-java-2015g-2.el6.noarch`\r\n - 也可以一起卸载:`sudo rpm -e --nodeps java-1.6.0-openjdk-1.6.0.38-1.13.10.0.el6_7.x86_64 java-1.7.0-openjdk-1.7.0.95-2.6.4.0.el6_7.x86_64 tzdata-java-2015g-2.el6.noarch`\r\n\r\n- JDK 1.8 安装\r\n - 我们以安装 `jdk-8u72-linux-x64.tar.gz` 为例\r\n - 我个人习惯 `/opt` 目录下创建一个目录 `setups` 用来存放各种软件安装包;在 `/usr` 目录下创建一个 `program` 用来存放各种解压后的软件包,下面的讲解也都是基于此习惯\r\n - 我个人已经使用了第三方源:`EPEL、RepoForge`,如果你出现 `yum install XXXXX` 安装不成功的话,很有可能就是你没有相关源,请查看我对源设置的文章\r\n - 解压安装包:`sudo tar -zxvf jdk-8u72-linux-x64.tar.gz`\r\n - 移到解压包到我个人习惯的安装目录下:`mv jdk1.8.0_72/ /usr/program/`\r\n - 配置环境变量:\r\n - 编辑配置文件:`sudo vim /etc/profile`\r\n - 在该文件的最尾巴,添加下面内容:\r\n ```\r\n # JDK\r\n JAVA_HOME=/usr/program/jdk1.8.0_72\r\n JRE_HOME=$JAVA_HOME/jre\r\n PATH=$PATH:$JAVA_HOME/bin\r\n CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar\r\n export JAVA_HOME\r\n export JRE_HOME\r\n export PATH\r\n export CLASSPATH\r\n ```\r\n - 执行命令,刷新该配置(必备操作):`source /etc/profile`\r\n - 检查是否使用了最新的 JDK:`java -version`\r\n\r\n\r\n\r\n## 其他\r\n\r\n- JDK 历史版本下载地址整理(不间断更新):\r\n - **JDK 9**:<https://jdk9.java.net/download/>\r\n - **JDK 8**:<http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html>\r\n - **JDK 7**:<http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html>\r\n - **JDK 6**:<http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase6-419409.html>\r\n\r\n\r\n\r\n## 资料\r\n\r\n - <http://www.jikexueyuan.com/course/480_1.html?ss=1>',0,1,0,1463847971,1463847971),
('fe6d15965a','3. 控制器设计',NULL,6,1000,1,'','一个MVC框架里 `C` 是核心的一块,也就是控制器,每个请求的接收,都是由控制器去处理的。\r\n在Mario中我们把控制器放在路由对象的controller字段上,实际上一个请求过来之后最终是落在某个方法去处理的。\r\n\r\n简单的方法我们可以使用反射实现动态调用方法执行,当然这对性能并不友好,你可以用缓存Method或者更高明的技术去做。\r\n在这里我们不提及太麻烦的东西,因为初步目标是实现MVC框架,所以给大家提醒一下有些了解即可。\r\n\r\n控制器的处理部分放在了核心Filter中,代码如下:\r\n\r\n```java\r\n/**\r\n * Mario MVC核心处理器\r\n * @author biezhi\r\n *\r\n */\r\npublic class MarioFilter implements Filter {\r\n \r\n private static final Logger LOGGER = Logger.getLogger(MarioFilter.class.getName());\r\n \r\n private RouteMatcher routeMatcher = new RouteMatcher(new ArrayList<Route>());\r\n \r\n private ServletContext servletContext;\r\n \r\n @Override\r\n public void init(FilterConfig filterConfig) throws ServletException {\r\n Mario mario = Mario.me();\r\n if(!mario.isInit()){\r\n \r\n String className = filterConfig.getInitParameter(\"bootstrap\");\r\n Bootstrap bootstrap = this.getBootstrap(className);\r\n bootstrap.init(mario);\r\n \r\n Routers routers = mario.getRouters();\r\n if(null != routers){\r\n routeMatcher.setRoutes(routers.getRoutes());\r\n }\r\n servletContext = filterConfig.getServletContext();\r\n \r\n mario.setInit(true);\r\n }\r\n }\r\n \r\n private Bootstrap getBootstrap(String className) {\r\n if(null != className){\r\n try {\r\n Class<?> clazz = Class.forName(className);\r\n Bootstrap bootstrap = (Bootstrap) clazz.newInstance();\r\n return bootstrap;\r\n } catch (ClassNotFoundException e) {\r\n throw new RuntimeException(e);\r\n } catch (InstantiationException e) {\r\n e.printStackTrace();\r\n } catch (IllegalAccessException e) {\r\n e.printStackTrace();\r\n }\r\n }\r\n throw new RuntimeException(\"init bootstrap class error!\");\r\n }\r\n \r\n @Override\r\n public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {\r\n HttpServletRequest request = (HttpServletRequest) servletRequest;\r\n HttpServletResponse response = (HttpServletResponse) servletResponse;\r\n \r\n // 请求的uri\r\n String uri = PathUtil.getRelativePath(request);\r\n \r\n LOGGER.info(\"Request URI:\" + uri);\r\n \r\n Route route = routeMatcher.findRoute(uri);\r\n \r\n // 如果找到\r\n if (route != null) {\r\n // 实际执行方法\r\n handle(request, response, route);\r\n } else{\r\n chain.doFilter(request, response);\r\n }\r\n }\r\n \r\n private void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, Route route){\r\n \r\n // 初始化上下文\r\n Request request = new Request(httpServletRequest);\r\n Response response = new Response(httpServletResponse);\r\n MarioContext.initContext(servletContext, request, response);\r\n \r\n Object controller = route.getController();\r\n // 要执行的路由方法\r\n Method actionMethod = route.getAction();\r\n // 执行route方法\r\n executeMethod(controller, actionMethod, request, response);\r\n }\r\n \r\n /**\r\n * 获取方法内的参数\r\n */\r\n private Object[] getArgs(Request request, Response response, Class<?>[] params){\r\n \r\n int len = params.length;\r\n Object[] args = new Object[len];\r\n \r\n for(int i=0; i<len; i++){\r\n Class<?> paramTypeClazz = params[i];\r\n if(paramTypeClazz.getName().equals(Request.class.getName())){\r\n args[i] = request;\r\n }\r\n if(paramTypeClazz.getName().equals(Response.class.getName())){\r\n args[i] = response;\r\n }\r\n }\r\n \r\n return args;\r\n }\r\n \r\n /**\r\n * 执行路由方法\r\n */\r\n private Object executeMethod(Object object, Method method, Request request, Response response){\r\n int len = method.getParameterTypes().length;\r\n method.setAccessible(true);\r\n if(len > 0){\r\n Object[] args = getArgs(request, response, method.getParameterTypes());\r\n return ReflectUtil.invokeMehod(object, method, args);\r\n } else {\r\n return ReflectUtil.invokeMehod(object, method);\r\n }\r\n }\r\n\r\n}\r\n```\r\n\r\n这里执行的流程是酱紫的:\r\n\r\n 1. 接收用户请求\r\n 2. 查找路由\r\n 3. 找到即执行配置的方法\r\n 4. 找不到你看到的应该是404\r\n\r\n看到这里也许很多同学会有点疑问,我们在说路由、控制器、匹配器,可是我怎么让它运行起来呢?\r\n您可说到点儿上了,几乎在任何框架中都必须有配置这项,所谓的零配置都是扯淡。不管硬编码还是配置文件方式,\r\n没有配置,框架的易用性和快速开发靠什么完成,又一行一行编写代码吗? 如果你说机器学习,至少现在好像没人用吧。\r\n\r\n扯淡完毕,下一节来进入全局配置设计 ->',0,1,0,1463849418,1463849418);
/*!40000 ALTER TABLE `t_post` ENABLE KEYS */;
UNLOCK TABLES;
# Dump of table t_special
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_special`;
CREATE TABLE `t_special` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(100) NOT NULL DEFAULT '' COMMENT '分类名称',
`slug` varchar(255) NOT NULL DEFAULT '' COMMENT '分类显示名',
`cover` varchar(255) DEFAULT NULL COMMENT '分类封面',
`description` varchar(1000) DEFAULT NULL COMMENT '分类介绍',
`post_count` int(10) DEFAULT '0' COMMENT '文章数',
`follow_count` int(10) DEFAULT '0' COMMENT '关注数',
`is_del` tinyint(2) DEFAULT '0' COMMENT '专栏是否已经被删除',
`created` int(11) NOT NULL COMMENT '分类创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='专栏';
LOCK TABLES `t_special` WRITE;
/*!40000 ALTER TABLE `t_special` DISABLE KEYS */;
INSERT INTO `t_special` (`id`, `title`, `slug`, `cover`, `description`, `post_count`, `follow_count`, `is_del`, `created`)
VALUES
(1000,'如何设计一个MVC框架','mvc-framework','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517225229029_fD1zstqDSV.png/b24M/4789.png','如何设计一个MVC框架',0,0,0,1463068334),
(1001,'妹子图什么的','meizi','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517231042404_oK2WWHGTuE.jpg/NZ5R/3135.jpg','定期更新各种妹子图。',0,0,0,1463068334),
(1002,'Java程序员眼中的Linux','java-linux','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517231128082_QJAczEFNQX.jpg/1xnv/5861.jpg','Java程序员眼中的Linux',0,0,0,1463068334),
(1003,'7天学会NodeJs','learn-to-nodejs-seven-days','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517230821521_D0RoR8vnMl.jpg/g4HM/6741.jpg','7天学会NodeJs',0,0,0,1463068334),
(1004,'缓存的理解和框架实现','cache-understand-implements','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517231305760_85sVdo06Xg.png/kBYk/3936.png','缓存的理解和框架实现',0,0,0,1463068334),
(1005,'Java8的那点事儿','java8-guide','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517230721284_wG8pEiuszQ.png/cgn8/8394.png','Java8的那点事儿',0,0,0,1463068334),
(1006,'Flask一步一步来','flask-learn','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517230148816_lgl2ToFnMQ.png/vxQ0/2662.png','Flask一步一步来',0,0,0,1463068334),
(1007,'CentOS实战系列','centos-combat','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517225745551_O0DfWpwOpI.jpg/ka7I/5143.jpg','CentOS实战系列',0,0,0,1463068334),
(1008,'设计模式跟我学','design-patterns','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517225624330_1IhcN8puUn.png/g9Bx/8858.png','设计模式跟我学',0,0,0,1463068334),
(1009,'数据结构跟我学','data-structure','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517230026308_6fZFtCXqWp.jpg/K079/1566.jpg','数据结构跟我学',0,0,0,1463068334),
(1010,'手动实现一个IOC','ioc-implments','special//usr/local/apache-tomcat-8.0.32/webapps/writty/static/temp/20160517231539577_RzLl7hgBda.png/0ERa/9477.png','手把手教你实现IOC容器',0,0,0,1463068334);
/*!40000 ALTER TABLE `t_special` ENABLE KEYS */;
UNLOCK TABLES;
# Dump of table t_user
# ------------------------------------------------------------
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`uid` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`user_name` varchar(50) NOT NULL DEFAULT '' COMMENT '登录名',
`pass_word` varchar(64) DEFAULT '' COMMENT '密码',
`nick_name` varchar(50) DEFAULT NULL COMMENT '昵称',
`avatar` varchar(255) DEFAULT NULL COMMENT '用户头像',
`email` varchar(100) DEFAULT NULL COMMENT '邮箱',
`role_id` tinyint(4) DEFAULT '4' COMMENT '1:系统管理员 2:管理员 3:编辑 4:普通会员',
`created` int(11) NOT NULL COMMENT '创建时间',
`updated` int(11) NOT NULL COMMENT '最后修改时间',
`logined` int(11) DEFAULT NULL COMMENT '最后登录时间',
PRIMARY KEY (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
LOCK TABLES `t_user` WRITE;
/*!40000 ALTER TABLE `t_user` DISABLE KEYS */;
INSERT INTO `t_user` (`uid`, `user_name`, `pass_word`, `nick_name`, `avatar`, `email`, `role_id`, `created`, `updated`, `logined`)
VALUES
(1,'biezhi','916a042f1bde53eba1e49cd59cf4eb75','王爵',NULL,'[email protected]',1,1462708055,1462708055,1462708055),
(6,'biezhi','8bb2badf2767e76ba529208763f74208','王爵nice','https://avatars.githubusercontent.com/u/3849072?v=3','[email protected]',3,1462977008,1462977008,NULL);
/*!40000 ALTER TABLE `t_user` ENABLE KEYS */;
UNLOCK TABLES;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;