import json
import re
import openpyxl
import requests
from lxml import etree
import csv
cookies = {
'SUB': '_2AkMRcyacf8NxqwFRmfsQxG3lb4t3wwrEieKnL9dHJRMxHRl-yT9vqhA7tRB6OvMIc71hiVugltoaHcZ3tShbEbigs6j1',
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWlN0z94LR6Vq-2CZGGpQC7',
'XSRF-TOKEN': 'ALBZ5zY_YLCch7bfNKBZmnqA',
'WBPSESS': 'gJ7ElPMf_3q2cdj5JUfmvOmOpSk7C1JxpzOkDaH8sK1Kcrj3y9bjLcsXbcXwDAKNQ5BVj_MmHDUbEie0S_8hpMBP57KXkPC2z7FS_xrFiJH7jJhopjBRFKQtskOuMVg8',
'_s_tentry': 'weibo.com',
'Apache': '9474795353437.963.1714399695446',
'SINAGLOBAL': '9474795353437.963.1714399695446',
'ULV': '1714399695470:1:1:1:9474795353437.963.1714399695446:',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'client-version': 'v2.45.7',
# 'cookie': 'SUB=_2AkMRcyacf8NxqwFRmfsQxG3lb4t3wwrEieKnL9dHJRMxHRl-yT9vqhA7tRB6OvMIc71hiVugltoaHcZ3tShbEbigs6j1; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWlN0z94LR6Vq-2CZGGpQC7; XSRF-TOKEN=ALBZ5zY_YLCch7bfNKBZmnqA; WBPSESS=gJ7ElPMf_3q2cdj5JUfmvOmOpSk7C1JxpzOkDaH8sK1Kcrj3y9bjLcsXbcXwDAKNQ5BVj_MmHDUbEie0S_8hpMBP57KXkPC2z7FS_xrFiJH7jJhopjBRFKQtskOuMVg8; _s_tentry=weibo.com; Apache=9474795353437.963.1714399695446; SINAGLOBAL=9474795353437.963.1714399695446; ULV=1714399695470:1:1:1:9474795353437.963.1714399695446:',
'priority': 'u=1, i',
'referer': 'https://weibo.com/newlogin?tabtype=weibo&gid=102803&openLoginLayer=0&url=https%3A%2F%2Fwww.weibo.com%2F',
'sec-ch-ua': '"Chromium";v="124", "Microsoft Edge";v="124", "Not-A.Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'server-version': 'v2024.04.29.1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0',
'x-requested-with': 'XMLHttpRequest',
'x-xsrf-token': 'ALBZ5zY_YLCch7bfNKBZmnqA',
}
url = requests.get('https://weibo.com/ajax/side/hotSearch', cookies=cookies, headers=headers)
# print(url.text)
ws=[]
ws.append(['顺序','热搜分类','热搜关键词'])
data = json.loads(url.text)['data']['realtime']
for i in data:
try:
print(f'热搜:{i["realpos"]}, 热搜分类[{i["category"]}], 热搜关键词:{i["word"]}')
ws.append([i["realpos"],i["category"],i["word"].replace(' ','')])
except:
pass
with open("热搜.csv", 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for i in ws:
writer.writerow(i)
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
from PIL import Image
import jieba.analyse
from pprint import pprint
import numpy as np
from wordcloud import WordCloud
from snownlp import SnowNLP
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib.dates as mdates
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置显示中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号
my_font = FontProperties(fname=r"/Users/easyo/Library/Fonts/方正像素16.ttf", size=12)
# 请求头
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更换cookie,否则location爬不到
'cookie': "buvid3=400B449F-552C-4641-2982-7A9D4008CE3D06541infoc; b_nut=1713932206; _uuid=F41AF179-6FB2-6FE9-F898-E5D46565D77202875infoc; enable_web_push=DISABLE; FEED_LIVE_VERSION=V_WATCHLATER_PIP_WINDOW3; buvid4=A926CCEE-259E-5574-F40D-6A4529C094C708059-024042404-8M%2Fk2zYeusDF%2FagXt%2FweLhkVEVvdqLmWsrQNaxTc8cqHcQKXI6g%2Br0n2Iy%2BS4hA7; CURRENT_FNVAL=4048; rpdid=0zbfVFVf3J|CY59vGJe|41u|3w1RZu3X; bsource=search_sougo; header_theme_version=CLOSE; DedeUserID=44780233; DedeUserID__ckMd5=a3f833e80f6ac30a; home_feed_column=5; fingerprint=6bc4ba3263b0340544fd36f78b75cdca; buvid_fp_plain=undefined; buvid_fp=6bc4ba3263b0340544fd36f78b75cdca; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MTQzMTQ5NzksImlhdCI6MTcxNDA1NTcxOSwicGx0IjotMX0.y8ksDiq8et6P8vEePKcXDScX32YUtTCQFhCIlSVIHLs; bili_ticket_expires=1714314919; browser_resolution=1708-818; SESSDATA=206ce534%2C1729749695%2Cf9ef4%2A41CjDNW93e15MamYUOxdoJjwGBTp0griKXnb-tskr20ghsRvgwLTPT7mQ8jof1k7j0wD8SVkpZSUllT3MxUGE4NVFNZ3pTeVVRNE9GMVV1ajc3MkpCcElRZTlGYUdlTmNtTWdIbGdPZ3dQVDJDRHd1UDdqWWdDMFU5ME1VWDd1RXVrbW1KWUtpOGpBIIEC; bili_jct=c32cacedc61a1ed9fb9313455af62794; sid=788cfgno; bp_video_offset_44780233=925053543733264419; b_lsid=101052C68B_18F1FB82769; PVID=4",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
def bv2av(bid):
"""把哔哩哔哩视频的bv号转成av号"""
table = 'fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF'
tr = {}
for i in range(58):
tr[table[i]] = i
s = [11, 10, 3, 8, 4, 6]
r = 0
for i in range(6):
r += tr[bid[s[i]]] * 58 ** i
aid = (r - 8728348608) ^ 177451812
return aid
def get_comment(v_aid, v_bid):
"""
爬取B站评论数据
:param v_aid: B站视频的aid号
:param v_bid: B站视频的bid号
:return: None
"""
# 循环页码爬取评论
for i in range(max_page):
try:
sleep(random.uniform(0, 5)) # 随机等待,防止反爬
url = "https://api.bilibili.com/x/v2/reply/wbi/main?oid=1752243679&type=1&mode=3&pagination_str=%7B%22offset%22:%22%7B%5C%22type%5C%22:1,%5C%22direction%5C%22:1,%5C%22session_id%5C%22:%5C%221755366185780515%5C%22,%5C%22data%5C%22:%7B%7D%7D%22%7D&plat=1&web_location=1315875&w_rid=3bf0582b0eb173e9b202b9dadd0e8b97&wts=1714224814".format(
i, v_aid) # 请求地址
response = requests.get(url, headers=headers, ) # 发送请求
data_list = response.json()['data']['replies'] # 解析评论数据
print('正在爬取B站评论[{}]: 第{}页,共{}条评论'.format(bid, i + 1, len(data_list)))
comment_list = [] # 评论内容
location_list = [] # IP属地
time_list = [] # 评论时间
user_list = [] # 评论作者
like_list = [] # 点赞数
# 循环爬取每一条评论数据
for a in data_list:
# 评论内容
comment = a['content']['message']
comment_list.append(comment)
# IP属地
try:
location = a['reply_control']['location']
except:
location = ""
location_list.append(location.replace("IP属地:", ""))
# 评论时间
time = trans_date(a['ctime'])
time_list.append(time)
# 评论作者
user = a['member']['uname']
user_list.append(user)
# 点赞数
like = a['like']
like_list.append(like)
# 把列表拼装为DataFrame数据
df = pd.DataFrame({
'视频链接': 'https://www.bilibili.com/video/' + v_bid,
'评论页码': (i + 1),
'评论作者': user_list,
'评论时间': time_list,
'IP属地': location_list,
'点赞数': like_list,
'评论内容': comment_list,
})
if os.path.exists(outfile):
header = False
else:
header = True
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
except Exception as e:
print('爬评论发生异常: {},继续..'.format(str(e)))
if __name__ == '__main__':
print('爬虫开始执行!')
bid_list = ['BV1sx421Q7nb', 'BV1Hz421Q7Wf', 'BV1Jt421V7dE']
# 评论最大爬取页(每页20条评论)
max_page = 10
# 获取当前时间戳
now = time.strftime("%Y%m%d%H%M%S", time.localtime())
# 输出文件名
outfile = 'b站评论_{}.csv'.format(now)
# 循环爬取这几个视频的评论
for bid in bid_list:
# 转换aid
aid = bv2av(bid=bid)
# 爬取评论
get_comment(v_aid=aid, v_bid=bid)
print('爬虫正常结束!')
# 去除重复
df = pd.read_csv(outfile)
# 去重
df.drop_duplicates(subset=['评论作者','评论时间','评论内容'], inplace=True, keep='first')
# 再次保存csv文件
df.to_csv('最新的评论数据.csv' , index=False, encoding='utf_8_sig')
print('数据清洗完成')
# 情感分析打标
def sentiment_analyse(v_cmt_list):
"""
情感分析打分
:param v_cmt_list: 需要处理的评论列表
:return:
"""
score_list = [] # 情感评分值
tag_list = [] # 打标分类结果
pos_count = 0 # 计数器-积极
neg_count = 0 # 计数器-气愤
nog_count = 0 # 计数器-焦虑
for comment in v_cmt_list:
tag = ''
sentiments_score = SnowNLP(str(comment)).sentiments
if sentiments_score<0.1:
tag = '气愤'
neg_count += 1
else:
if sentiments_score<0.4:
tag = '焦虑'
nog_count += 1
else:
neg_count += 1
tag = '积极'
pos_count += 1
score_list.append(sentiments_score) # 得分值
tag_list.append(tag) # 判定结果
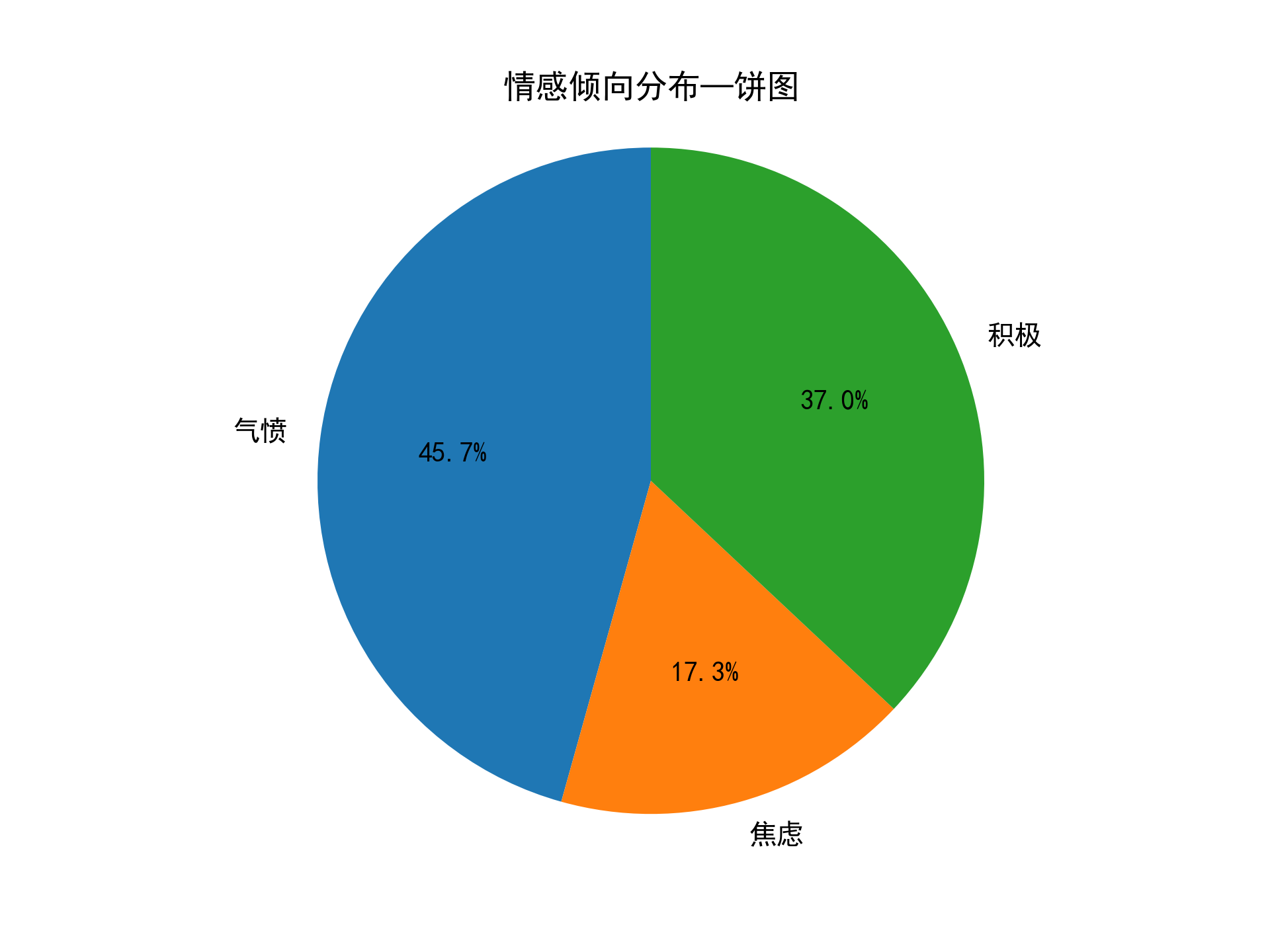
print('积极评价占比:', round(pos_count / (pos_count + neg_count + nog_count), 4))
print('焦虑评价占比:', round(nog_count / (pos_count + neg_count + nog_count), 4))
print('气愤评价占比:', round(neg_count / (pos_count + neg_count + nog_count), 4))
df['情感得分'] = score_list
df['分析结果'] = tag_list
# 把情感分析结果保存到excel文件
df.to_excel('关于提案_情感评分结果.xlsx', index=True)
print('情感分析结果已生成:关于提案_情感评分结果.xlsx')
# 把情感分析结果保存到excel文件
df.to_excel('关于提案_情感评分结果.xlsx', index=None)
print('情感分析结果已生成:关于提案_情感评分结果.xlsx')
labels=['气愤','焦虑','积极']
sizes=[neg_count,nog_count,pos_count]
plt.pie(sizes,labels=labels,autopct='%1.1f%%',startangle=90)
plt.axis('equal')
plt.title('情感倾向分布—饼图')
plt.savefig('情感倾向分布-饼图.png',dpi=300)
plt.show()
plt.close()
def make_wordcloud(v_str, v_stopwords, v_outfile):
"""
绘制词云图
:param v_str: 输入字符串
:param v_stopwords: 停用词
:param v_outfile: 输出文件
:return: None
"""
print('开始生成词云图:{}'.format(v_outfile))
try:
stopwords = v_stopwords # 停用词
backgroud_Image = np.array(Image.open('47.png')) # 读取背景图片
wc = WordCloud(
background_color="white", # 背景颜色
width=1500, # 图宽
height=1200, # 图高
max_words=1000, # 最多字数
font_path="C:\Windows\Fonts\simhei.ttf", # 字体文件路径,根据实际情况(Windows)替换
stopwords=stopwords, # 停用词
mask=backgroud_Image, # 背景图片
)
jieba_text = " ".join(jieba.lcut(v_str)) # jieba分词
wc.generate_from_text(jieba_text) # 生成词云图
wc.to_file(v_outfile) # 保存图片文件
print('词云文件保存成功:{}'.format(v_outfile))
except Exception as e:
print('make_wordcloud except: {}'.format(str(e)))
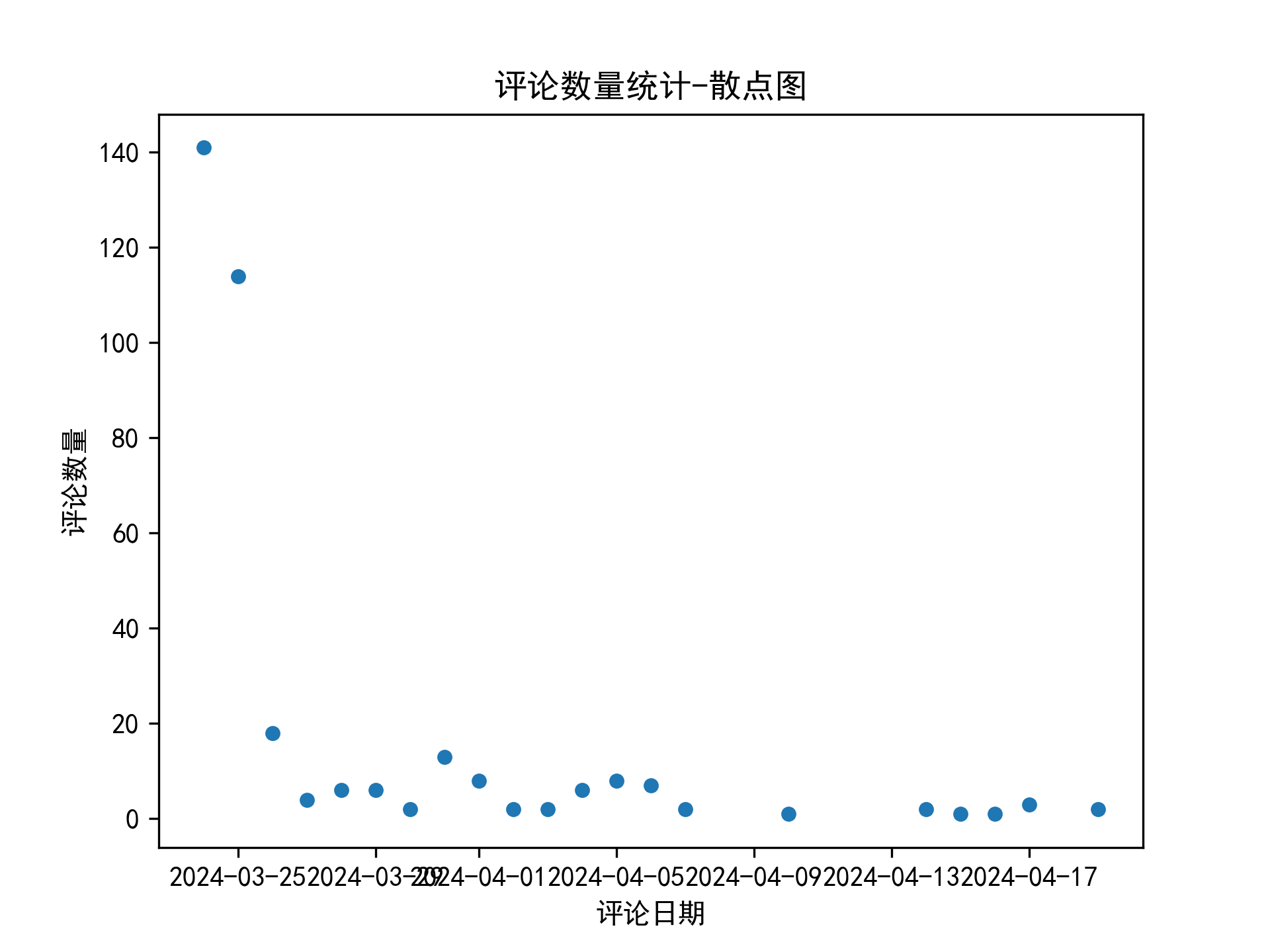
def plot(df_cmt_date):
df_cmt_date.columns = ['评论日期', '评论数量']
import matplotlib.dates as mdates
df_cmt_date.plot('评论日期', '评论数量', kind='scatter')
plt.title('评论数量统计-散点图')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.savefig('评论数量统计-散点图.png', dpi=300)
plt.show()
if __name__ == '__main__':
df =pd.read_csv('最新的评论数据.csv' )
df['评论时间2'] = pd.to_datetime(df['评论时间'])
df['评论日期'] = df['评论时间2'].dt.date
df_cmt_date = df['评论日期'].value_counts()
df_cmt_date = df_cmt_date.reset_index()
v_cmt_list=df["评论内容"].values.tolist()
print('length of v_cmt_list is:{}'.format(len(v_cmt_list)))
sentiment_analyse(v_cmt_list=v_cmt_list)
v_cmt_str=' '.join(str(i) for i in v_cmt_list)
keywords_top20=jieba.analyse.extract_tags(v_cmt_str,withWeight=True,topK=20)
print('top20关键词及权重:')
pprint(keywords_top20)
make_wordcloud(v_str=v_cmt_str,v_stopwords=['有','13','21','50'],v_outfile='提案_词云图.jpg')
plot(df_cmt_date)

import requests
import json
import pandas as pd
url = 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all'
headers = {
'Referer': 'https://www.bilibili.com/v/popular/rank/all/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
data = json.loads(response.text)
video_list = data['data']['list']
rank_list = []
title_list = []
play_cnt_list = []
danmu_cnt_list = []
coin_cnt_list = []
author_list = []
video_url = []
for idx, video in enumerate(video_list):
rank_list.append(idx + 1)
title_list.append(video['title'])
play_cnt_list.append(video['stat']['view'])
danmu_cnt_list.append(video['stat']['danmaku'])
coin_cnt_list.append(video['stat']['coin'])
author_list.append(video['owner']['name'])
video_url.append(f'https://www.bilibili.com/video/{video["bvid"]}')
df = pd.DataFrame({
'排行': rank_list,
'视频标题': title_list,
'视频地址': video_url,
'作者': author_list,
'播放数': play_cnt_list,
'弹幕数': danmu_cnt_list,
'硬币数': coin_cnt_list,
})
df.to_csv('/users/easyo/B站热榜.csv', index=False, encoding="utf_8_sig")
import requests # 发送请求
import random
from time import sleep # 设置等待,防止反爬
import time
import pandas as pd # 保存csv
import datetime
import os
def trans_date(v_timestamp):
"""13位时间戳转换为时间字符串"""
v_timestamp = int(str(v_timestamp)[:10])
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
# 当前时间戳
now = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
# 爬取目标
page_id = '5d2dc8564c11180001712db3'
# 保存文件名
result_file = '小红书TAG_{}_{}.csv'.format(page_id, now)
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
# 初始化页码
page = 1
while True:
title_list = [] # 笔记标题
note_id_list = [] # 笔记id
note_url_list = [] # 笔记链接
likes_list = [] # 点赞数
author_name_list = [] # 作者昵称
author_id_list = [] # 作者id
author_url_list = [] # 作者链接
create_time_list = [] # 发布时间
# 随机等待,防止反爬
sleep(random.uniform(0, 2))
# 判断是否首页
if page == 1:
url = 'https://www.xiaohongshu.com/web_api/sns/v3/page/notes?page_size=6&sort=hot&page_id={}&sid=&limit=false'.format(
page_id)
else:
url = 'https://www.xiaohongshu.com/web_api/sns/v3/page/notes?page_size=6&sort=hot&page_id={}&sid=&cursor={}&limit=false'.format(
page_id, next_cursor)
# 发送请求
r = requests.get(url, headers=h1)
# 解析数据
json_data = r.json()
note_num = len(json_data['data']['notes'])
print('开始爬第{}页,笔记数量:{}'.format(page, note_num))
# 解析
for i in json_data['data']['notes']:
# 笔记标题
title = i['title']
title_list.append(title)
# 笔记id
note_id = i['id']
note_id_list.append(note_id)
# 笔记链接
note_url_list.append('https://www.xiaohongshu.com/explore/' + note_id)
# 点赞数
like_count = i['likes']
likes_list.append(like_count)
# 作者昵称
author_name = i['user']['nickname']
author_name_list.append(author_name)
# 作者id
author_id = i['user']['userid']
author_id_list.append(author_id)
# 作者链接
author_url_list.append('https://www.xiaohongshu.com/user/profile/' + author_id)
# 发布时间
create_time = trans_date(i['create_time'])
create_time_list.append(create_time)
# 保存数据到DF
df = pd.DataFrame(
{
'页码': page,
'笔记标题': title_list,
'笔记id': note_id_list,
'笔记链接': note_url_list,
'点赞数': likes_list,
'作者昵称': author_name_list,
'作者id': author_id_list,
'作者链接': author_url_list,
'发布时间': create_time_list,
}
)
# 设置csv文件表头
if os.path.exists(result_file):
header = False
else:
header = True
# 保存到csv
df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')
print('文件保存成功:', result_file)
# 判断终止条件
next_cursor = json_data['data']['cursor']
if not json_data['data']['has_more']:
print('没有下一页了,终止循环!')
break
page += 1
import requests
from lxml import etree
#import pandas as pd
#import time
def page(url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:109.0) Gecko/20100101 Firefox/116.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
# 'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Referer': 'https://movie.douban.com/',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Dest': 'iframe',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'cross-site',
'Cookie': 'll="118381"; bid=u8W938yW3Rw; __utma=30149280.1427340690.1714406596.1714476685.1714485673.6; __utmz=30149280.1714485673.6.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; dbcl2="230302338:Y8MCu494BKI"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.23030; __gads=ID=20dba742ff0011d4:T=1714406703:RT=1714485675:S=ALNI_MZz8jZp982rT48QdQdDBjh5a_vi0w; __gpi=UID=00000dff8c542177:T=1714406703:RT=1714485675:S=ALNI_MZxicDjcSAMi_pdkeduQ3otQCutaQ; __eoi=ID=4874846fe6a3305c:T=1714406703:RT=1714485675:S=AA-Afjb2qzoXLCtivOMEIgch2k1e; __utmc=30149280; ck=mJ0K; frodotk_db="f723232f0ba97d93e569698d22fc78b9"; __utmb=30149280.2.10.1714485673; ap_v=0,6.0; __utmt=1',
}
response= requests.get(url=url ,headers=headers)
c_html = response.content
return c_html
def next_p(c_html,base_url):
link = None
html_n = etree.HTML(c_html)
lu_next = html_n.xpath('//div[@id="paginator"]/a[@class="next"]/@href')
if lu_next:
link = base_url + lu_next[0]
# time.sleep(5)
return link
def pin(c_html):
#print(c_html)
et_html= etree.HTML(c_html)
lujing = et_html.xpath("/html/body/div[3]/div[1]/div/div[1]/div[4]/div/div[2]/p/span")
return lujing
'''for i in lujing:
return i.text'''
def tol():
base_url = 'https://movie.douban.com/subject/4321270/comments'
link = base_url
while link:
c_html = page(link)
data=[]
for j in pin(c_html):
data.append(j.text)
print(data)
link=next_p(c_html,base_url)
return data
if __name__ == '__main__':
#df = pd.DataFrame(tol())
#df.to_csv('output.csv',index = False, encoding='utf-8')
tol()