这是一个 PaddlePaddle 实现的 ConvNeXt。
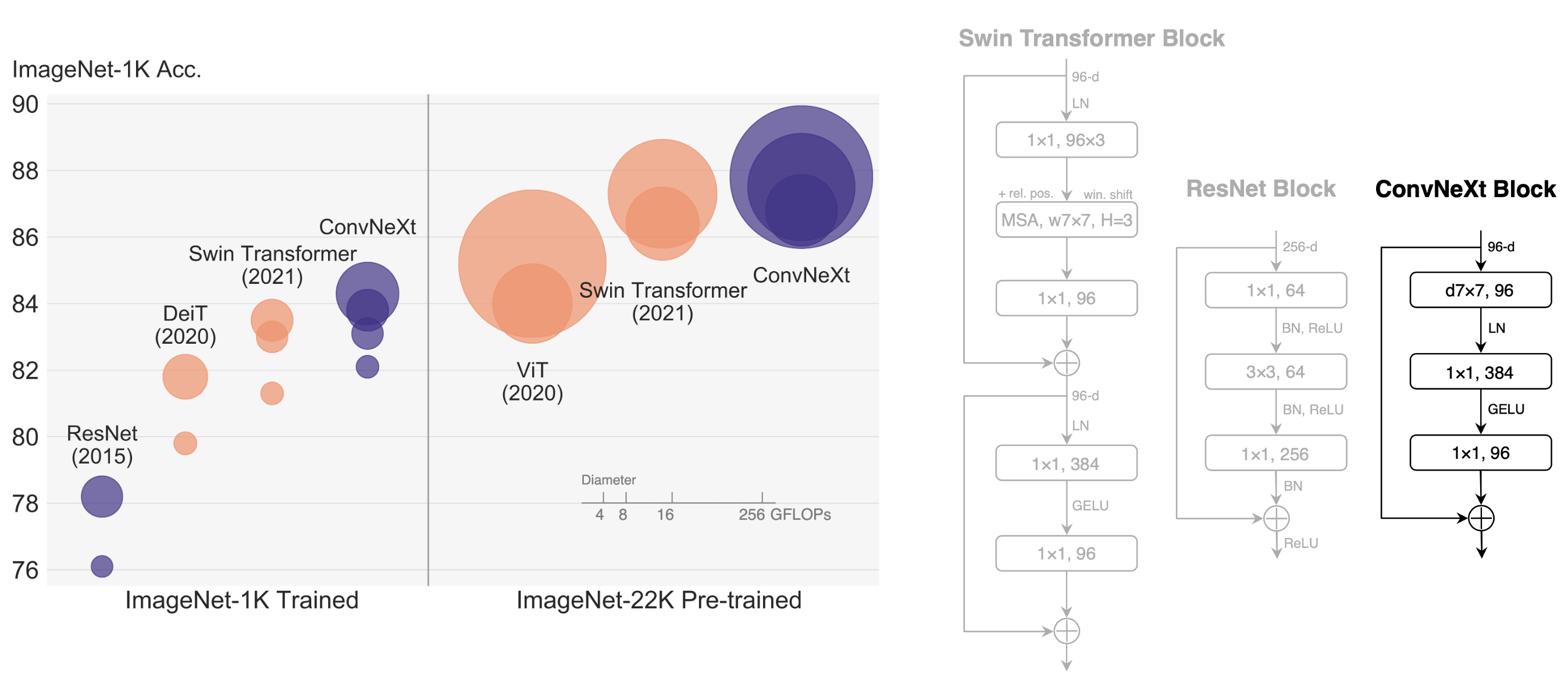
参考repo: ConvNeXt
在此非常感谢s9xie、HannaMao和liuzhuang13等人贡献的ConvNeXt,提高了本repo复现论文的效率。
数据集为ImageNet,训练集包含1281167张图像,验证集包含50000张图像。
│imagenet/
├──train/
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├──val/
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
您可以从ImageNet 官网申请下载数据。
| 模型 | top1 acc (参考精度) | top1 acc (复现精度) | 权重 | 训练日志 |
|---|---|---|---|
| convnext_tiny | 0.821 | 0.821 | checkpoint-best.pd | log.txt |
权重及训练日志下载地址:百度网盘
硬件和框架版本等环境的要求如下:
- 硬件:4 * RTX3090
- 框架:
- PaddlePaddle >= 2.2.0
- 安装paddlepaddle
# 需要安装2.2及以上版本的Paddle,如果
# 安装GPU版本的Paddle
pip install paddlepaddle-gpu==2.2.0
# 安装CPU版本的Paddle
pip install paddlepaddle==2.2.0更多安装方法可以参考:Paddle安装指南。
- 下载代码
git clone https://github.com/flytocc/ConvNeXt-paddle.git
cd ConvNeXt-paddle- 安装requirements
pip install -r requirements.txt如果您已经ImageNet1k数据集,那么该步骤可以跳过,如果您没有,则可以从ImageNet官网申请下载。
- 单机多卡训练
python -m paddle.distributed.launch --gpus=0,1,2,3 \
train.py \
/path/to/imagenet/ \
--config configs/train/cvt/cvt_13_224x224.yaml \
# --log_wandb --wandb_project MobileNeXt_100 \
# --cls_label_path_train /path/to/train_list.txt \
# --cls_label_path_val /path/to/val_list.txt \ps: 如果未指定cls_label_path_train/cls_label_path_val,会读取data_path下train/val里的图片作为train-set/val-set。
部分训练日志如下所示。
[11:46:22.948892] Epoch: [96] [ 840/2502] eta: 0:15:25 lr: 0.003310 loss: 3.6854 (3.5704) time: 0.5759 data: 0.0005
[11:46:33.860486] Epoch: [96] [ 860/2502] eta: 0:15:14 lr: 0.003310 loss: 3.6475 (3.5700) time: 0.5454 data: 0.0005
python eval.py \
/path/to/imagenet/ \
# --cls_label_path_val /path/to/val_list.txt \
--model convnext_tiny \
--batch_size 128 \
--interpolation bicubic \
--resume $TRAINED_MODELps: 如果未指定cls_label_path_val,会读取data_path/val里的图片作为val-set。
python predict.py \
--infer_imgs ./demo/ILSVRC2012_val_00020010.JPEG \
--model convnext_tiny \
--interpolation bicubic \
--resume $TRAINED_MODEL
最终输出结果为
[{'class_ids': [178, 211, 85, 236, 246], 'scores': [0.8764122724533081, 0.0005400953232310712, 0.00053271499928087, 0.00046646789996884763, 0.0004493726301006973], 'file_name': './demo/ILSVRC2012_val_00020010.JPEG', 'label_names': ['Weimaraner', 'vizsla, Hungarian pointer', 'quail', 'Doberman, Doberman pinscher', 'Great Dane']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.8764122724533081。
python export_model.py \
--model convnext_tiny \
--output /path/to/save/export_model/ \
--resume $TRAINED_MODEL
python infer.py \
--interpolation bicubic \
--model_file /path/to/save/export_model/model.pdmodel \
--params_file /path/to/save/export_model/model.pdiparams \
--input_file ./demo/ILSVRC2012_val_00020010.JPEG输出结果为
[{'class_ids': [178, 211, 85, 236, 246], 'scores': [0.876124918460846, 0.0005408982397057116, 0.0005338677437976003, 0.0004670215421356261, 0.0004502409719862044], 'file_name': './demo/ILSVRC2012_val_00020010.JPEG', 'label_names': ['Weimaraner', 'vizsla, Hungarian pointer', 'quail', 'Doberman, Doberman pinscher', 'Great Dane']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.876124918460846。与predict.py结果的误差在正常范围内。
This project is released under the MIT license.
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- ConvNeXt: https://github.com/facebookresearch/ConvNeXt
再次感谢s9xie、HannaMao和liuzhuang13等人贡献的ConvNeXt,提高了本repo复现论文的效率。
@Article{liu2022convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
}