Kernel Breakdown by Annotation Range #180
Labels
Comments
|
@jeromeku Are you expecting something like a kernel_dataframe with a call_stack column = ["aten:op1_", "aten:op", "module name"..] Does the call_stack logic help to achieve something similar to your request? It should be able to link from the kernel up to the operators (and likely user annotations like profiler.profile) |
|
Something like the "Events" view in Essentially what you see when you do
|
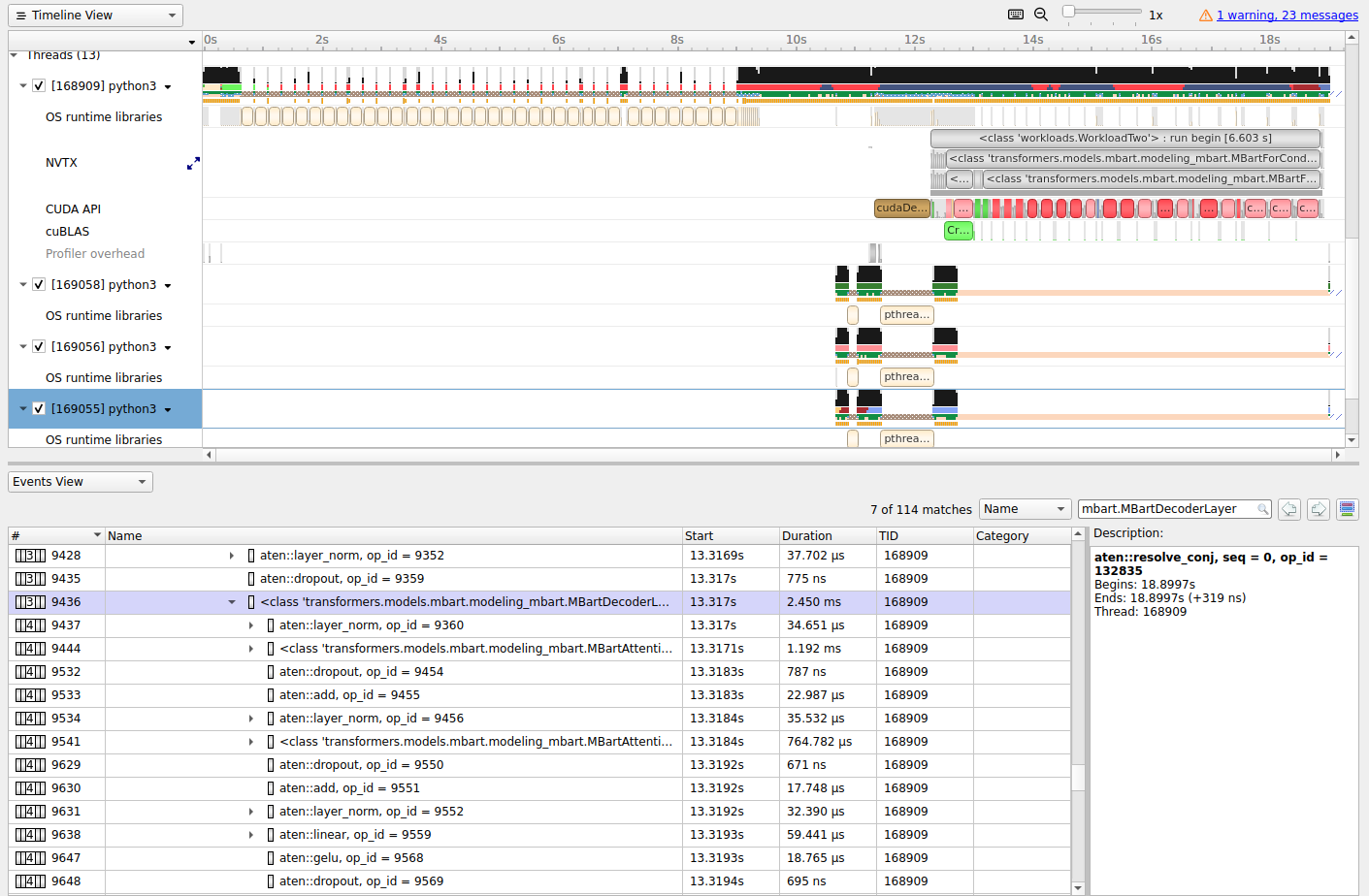{kind=link}
|
Same question |
8 tasks
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
🚀 Motivation and context
Is it possible to correlate kernel distribution with ranges annotated either through
torch.cuda.nvtxortorch.profiler.profile?The use case is model architecture optimization. I'd like a to understand where the bottlenecks are in a model forward / backwards and where the opportunities are for kernel fusion, cuda graphs, etc. Exporting a chrome / tensorboard trace can be helpful for visualizing such areas when model regions are annotated with
torch.profiler.record_function(ornvtx) but it would be helpful to have this information available for further analysis as a dataframe.Description
It would be useful to have kernel breakdown by annotation range aggregated into a dataframe to further investigate problematic modules and layers within the model:
aten/torchops that dispatched these kernelsAlternatives
No response
Additional context
No response
The text was updated successfully, but these errors were encountered: