
Utilities for use with RxJava 1 (see rxjava2-extras for RxJava 2):
Functions.identity, alwaysTrue, alwaysFalse, constant, notActions.setAtomic, doNothing, unsubscribe, increment, decrement, addTo, println, setToTrue, countDown, printStackTraceCheckedprovides lambda helpers for dealing with checked exceptions in functions and actionsTestingHelper.testRetryWhenbuilder for use with.retryWhen(Func1)operatorTransformers.ignoreElementsThenTransformers.mapWithIndexTransformers.matchWithTransformers.orderedMergeWithTransformers.stateMachineTransformers.collectWhileTransformers.toListWhileTransformers.toListUntilChangedTransformers.toListUntilTransformers.collectStatsTransformers.doOnFirstTransformers.doOnNthTransformers.onBackpressureBufferToFile- buffer items to diskTransformers.toOperatorTransformers.windowMin,.windowMaxTransformers.sampleFirstTransformers.decodeTransformers.delayFinalUnsubscribe- to keep a source active for a period after last unsubscribe (useful withrefCount/share)Transformers.repeatLastTransformers.doOnEmptySerialized.read/writeBytes.from- read bytes from resources (InputStream,File)Bytes.unzip- unzips zip archivesBytes.collect- collect bytes into single byte arrayStrings.fromStrings.lines- supports backpressure (not available in rxjava-string 1.0.1)Strings.split- supports backpressure (not available in rxjava-string 1.0.1)PublishSubjectSingleSubscriberOperatorUnsubscribeEagerlyTestingHelper
Status: released to Maven Central
Maven site reports are here including javadoc.
Add this to your pom.xml:
<dependency>
<groupId>com.github.davidmoten</groupId>
<artifactId>rxjava-extras</artifactId>
<version>VERSION_HERE</version>
</dependency>Or add this to your build.gradle:
repositories {
mavenCentral()
}
dependencies {
compile 'com.github.davidmoten:rxjava-extras:VERSION_HERE'
}Use method chaining in your tests (inspired by rxjava 2.x functionality):
Observable.range(1, 1000)
.count()
.to(TestingHelper.test())
.assertValue(1000)
.assertCompleted();Set the initial request like this:
Observable.range(1, 1000)
.to(TestingHelper.testWithRequest(2))
.assertValues(1, 2)
.assertNoTerminalEvent();To ignore the elements of an observable (but wait for completion) and then emit a second observable, use Transformers.ignoreElementsThen:

Maps each item to an item wrapped with a zero-based index:

Finds out-of-order matches in two streams.

You can use Tranformers.matchWith or Obs.match:
Observable<Integer> a = Observable.just(1, 2, 4, 3);
Observable<Integer> b = Observable.just(1, 2, 3, 5, 6, 4);
Obs.match(a, b,
x -> x, // key to match on for a
x -> x, // key to match on for b
(x, y) -> x // combiner
)
.forEach(System.out::println);gives
1
2
3
4
Don't rely on the output order!
Under the covers elements are requested from a and b in alternating batches of 128 by default. The batch size is configurable in another overload.
To merge two (or more) streams in order (according to a Comparator):
source1.compose(Transformers.orderedMergeWith(source2, comparator));
To merge with many:
source1.compose(Transformers.orderedMergeWith(Arrays.asList(source2, source3), comparator));You may want to group emissions from an Observable into lists of variable size. This can be achieved safely using toListWhile.

As an example from a sequence of temperatures lets group the sub-zero and zero or above temperatures into contiguous lists:
Observable.just(10, 5, 2, -1, -2, -5, -1, 2, 5, 6)
.compose(Transformers.toListWhile(
(list, t) -> list.isEmpty()
|| Math.signum(list.get(0)) < 0 && Math.signum(t) < 0
|| Math.signum(list.get(0)) >= 0 && Math.signum(t) >= 0)
.forEach(System.out::println);produces
[10, 5, 2]
[-1, -2, -5, -1]
[2, 5, 6]
Behaves as per toListWhile but allows control over the data structure used.

Accumulate statistics, emitting the accumulated results with each item.

If a stream has elements and completes then the last element is repeated.

source.compose(Transformers.repeatLast());Performs an action only if a stream completes without emitting an item.
source.compose(Transformers.doOnEmpty(action));Custom operators are difficult things to get right in RxJava mainly because of the complexity of supporting backpressure efficiently. Transformers.stateMachine enables a custom operator implementation when:
- each source emission is mapped to 0 to many emissions (of a different type perhaps) to downstream but those emissions are calculated based on accumulated state

An example of such a transformation might be from a list of temperatures you only want to emit sequential values that are less than zero but are part of a sub-zero sequence at least 1 hour in duration. You could use toListWhile above but Transformers.stateMachine offers the additional efficiency that it will immediately emit temperatures as soon as the duration criterion is met.
To implement this example, suppose the source is half-hourly temperature measurements:
static class State {
final List<Double> list;
final boolean reachedThreshold;
State(List<Double> list, boolean reachedThreshold) {
this.list = list;
this.reachedThreshold = reachedThreshold;
}
}
int MIN_SEQUENCE_LENGTH = 2;
Transformer<Double, Double> trans = Transformers
.stateMachine()
.initialStateFactory(() -> new State(new ArrayList<>(), false))
.<Double, Double> transition((state, t, subscriber) -> {
if (t < 0) {
if (state.reachedThreshold) {
if (subscriber.isUnsubscribed()) {
return null;
}
subscriber.onNext(t);
return state;
} else if (state.list.size() == MIN_SEQUENCE_LENGTH - 1) {
for (Double temperature : state.list) {
if (subscriber.isUnsubscribed()) {
return null;
}
subscriber.onNext(temperature);
}
return new State(null, true);
} else {
List<Double> list = new ArrayList<>(state.list);
list.add(t);
return new State(list, false);
}
} else {
return new State(new ArrayList<>(), false);
}
}).build();
Observable
.just(10.4, 5.0, 2.0, -1.0, -2.0, -5.0, -1.0, 2.0, 5.0, 6.0)
.compose(trans)
.forEach(System.out::println);A common use case for .retry() is some sequence of actions that are attempted and then after a delay a retry is attempted. RxJava does not provide
first class support for this use case but the building blocks are there with the .retryWhen() method. RetryWhen offers static methods that build a Func1 for use with Observable.retryWhen().
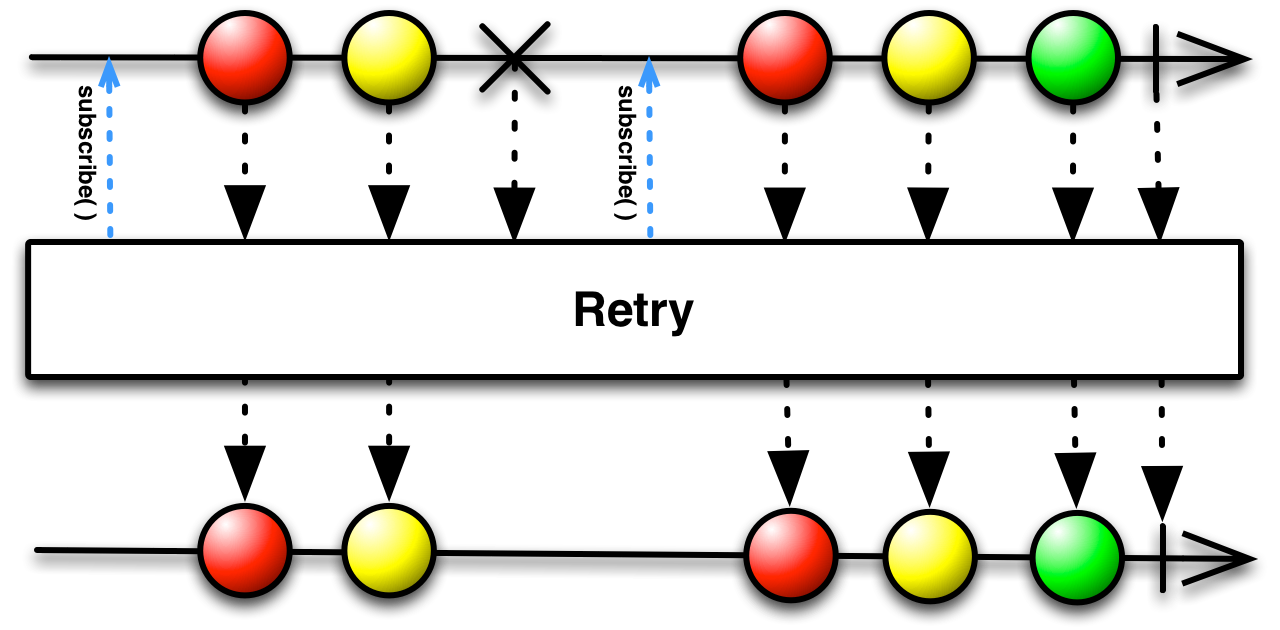
observable.retryWhen(
RetryWhen.delay(10, TimeUnit.SECONDS).build());observable.retryWhen(
RetryWhen.delay(10, TimeUnit.SECONDS)
.maxRetries(10).build());//the length of waits determines number of retries
Observable<Long> delays = Observable.just(10L,20L,30L,30L,30L);
observable.retryWhen(
RetryWhen.delays(delays, TimeUnit.SECONDS).build());//the length of waits determines number of retries
observable.retryWhen(
RetryWhen.exponentialBackoff(delay, TimeUnit.SECONDS).build());You can cap the delay:
//the length of waits determines number of retries
observable.retryWhen(
RetryWhen.exponentialBackoff(delay, maxDelay, TimeUnit.SECONDS).build());The default backoff factor is 2 (the delay doubles on each consecutive failure). You can customize this value with another overload:
//the length of waits determines number of retries
observable.retryWhen(
RetryWhen.exponentialBackoff(delay, maxDelay, TimeUnit.SECONDS, 1.5).build());observable.retryWhen(
RetryWhen.retryWhenInstanceOf(IOException.class)
.build());As of 0.7.2, you can offload an observable's emissions to disk to reduce memory pressure when you have a fast producer + slow consumer (or just to minimize memory usage).

If you use the onBackpressureBuffer operator you'll know that when a stream is producing faster than the downstream operators can process (perhaps the producer cannot respond meaningfully to a slow down request from downstream) then onBackpressureBuffer buffers the items to an in-memory queue until they can be processed. Of course if memory is limited then some streams might eventually cause an OutOfMemoryError. One solution to this problem is to increase the effectively available memory for buffering by using disk instead (and small in-memory read/write buffers). That's why Transformers.onBackpressureBufferToFile was created.
Internally one queue corresponds to a sequence of files (each with <=M entries). A read position and a write position for the file are maintained and relate to byte positions in files in the sequence. Naturally enough the write position will always be >= the read position. As the read position advances past the end of a file to the next file in the sequence the previous file is closed and deleted. Any files between the read position and the write position are closed (not referenced by open file descriptors) and are opened when the read position advances to it. The read position can advance beyond the last position in the last file into the write buffer (but will always be before or at the write position).

Note that new files for a file buffered observable are created for each subscription and thoses files are in normal circumstances deleted on unsubscription (triggered by onCompleted/onError termination or manual unsubscription).
Here's an example:
// write the source strings to a
// disk-backed queue on the subscription
// thread and emit the items read from
// the queue on the computation() scheduler.
Observable<String> source =
Observable
.just("a", "b", "c")
.compose(
Transformers.onBackpressureBufferToFile(
DataSerializers.string(),
Schedulers.computation()));This example does the same as above but more concisely and uses standard java IO serialization (normally it will be more efficient to write your own DataSerializer):
Observable<String> source =
Observable
.just("a", "b", "c")
.compose(Transformers.<String>onBackpressureBufferToFile());An example with a custom serializer:
// define how the items in the source stream would be serialized
DataSerializer<String> serializer = new DataSerializer<String>() {
@Override
public void serialize(DataOutput output, String s) throws IOException {
output.writeUTF(s);
}
@Override
public String deserialize(DataInput input, int availableBytes) throws IOException {
return input.readUTF();
}
};
Observable
.just("a", "b", "c")
.compose(
Transformers.onBackpressureBufferToFile(
serializer, Schedulers.computation()))
...You can configure various options:
Observable
.just("a", "b", "c")
.compose(
Transformers.onBackpressureBufferToFile(
serializer,
Schedulers.computation(),
Options
.fileFactory(fileFactory)
.bufferSizeBytes(1024)
.rolloverEvery(10000)
.rolloverSizeBytes(10000000)
.delayError(false)
.build()))
...Options.fileFactory(Func0<File>) specifies the method used to create the root temporary file used by the queue storage mechanism (MapDB). The default is a factory that calls Files.createTempFile("bufferToFileDB", "").
Rollover (via Options.rolloverEvery(long) and/or Options.rolloverSizeBytes(long)) is an important option for long running/infinite streams. The strategy used to reclaim disk space is to create a new file based queue every N emissions and/or on the file size reaching a threshold. Writing will occur to the latest created queue and reading will be occuring on the earliest non-closed queue. Once a queue instance is read fully and it is not the last queue it is closed and its file resources deleted. The abstraction used internally to handle these operations is RollingQueue.
- If you have a long running stream (or just a lot of data going through in terms of MB) then be sure to specify a value for
rolloverEveryorrolloverSizeBytes
There are some inbuilt DataSerializer implementations:
DataSerializers.string()DataSerializers.integer()DataSerializers.byteArray()DataSerializers.javaIO()- uses standard java serialization (ObjectOutputStreamand such)
Using default java serialization you can buffer array lists of integers to a file like so:
Observable.just(1, 2, 3, 4)
//accumulate into sublists of length 2
.buffer(2)
.compose(
Transformers.<List<Integer>>onBackpressureBufferToFile())In the above example it's fortunate that .buffer emits ArrayList<Integer> instances which are serializable. To be strict you might want to .map the returned list to a data type you know is serializable:
Observable.just(1, 2, 3, 4)
.buffer(2)
.map(list -> new ArrayList<Integer>(list))
.compose(
Transformers.<List<Integer>>onBackpressureBufferToFile())Throughput writing to spinning disk (and reading straight away with little downstream processing cost) on an i7 with Options.bufferSizeBytes=1024:
rate = 42.7MB/s (1K messages, no rollover, write only)
rate = 42.2MB/s (1K messages, rollover, write only)
rate = 37.4MB/s (1K messages, no rollover)
rate = 37.3MB/s (1K messages, rollover)
rate = 15.2MB/s (4B messages, no rollover)
rate = 9.3MB/s (4B messages, rollover)
I wouldn't be surprised to see significant improvement on some of these benchmarks in the medium term (perhaps using memory-mapped files). There are at least a couple of java file based implementations out there that have impressive throughput using memory-mapped files.
Checked exceptions can be annoying. If you are happy to wrap a checked exception with a RuntimeException then the function and action helpers in Checked are great:
Instead of
OutputStream os = ...;
Observable<String> source = ...;
source.doOnNext(s -> {
try {
os.write(s.getBytes());
} catch (IOException e) {
throw new RuntimeException(e);
}
})
.subscribe();you can write:
source.doOnNext(Checked.a1(s -> os.write(s.getBytes())))
.subscribe();To read serialized objects from a file:
Observable<Item> items = Serialized.read(file);To write an Observable to a file:
Serialized.write(observable, file).subscribe();Serialized also has support for the very fast serialization library kryo. Unlike standard Java serialization Kryo can also serialize/deserialize objects that don't implement Serializable.
Add this to your pom.xml:
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>3.0.3</version>
</dependency>For example,
To read:
Observable<Item> items = Serialized.kryo().read(file);To write:
Serialized.write(observable, file).subscribe();You can also call Serialized.kryo(kryo) to use an instance of Kryo that you have configured specially.
To read bytes from an InputStream in chunks:
Observable<byte[]> chunks = Bytes.from(inputStream, chunkSize);To read bytes from a File in chunks:
Observable<byte[]> chunks = Bytes.from(file, chunkSize);Suppose you have a a zip file file.zip and you want to stream the lines of the file doc.txt extracted from the archive:
Observable<String> lines =
Bytes.unzip(new File("file.zip"))
.filter(entry -> entry.getName().equals("doc.txt"))
.concatMap(entry -> Strings.from(entry.getInputStream()))
.compose(o-> Strings.split(o, "\n"));Note that above you don't need to worry about closing entry.getInputStream() because it is handled in the unsubscribe of the Bytes.unzip source.
You must process the emissions of ZippedEntry synchronously (don't replace the concatMap() with a flatMap(... .subscribeOn(Schedulers.computation()) for instance. This is because the InputStream of each ZippedEntry must be processed fullly (which could mean ignoring it of course) before moving on to the next one.
Given a stream of byte arrays this is an easy way of collecting those bytes into one byte array:
Observable<byte[]> chunks = ...
byte[] allBytes = chunks.compose(Bytes::collect).toBlocking().single();For a given named test the following variations are tested:
- without backpressure
- intiial request maximum, no further request
- initial request maximum, keep requesting single
- backpressure, initial request 1, then by 0 and 1
- backpressure, initial request 1, then by 1
- backpressure, initial request 2, then by 2
- backpressure, initial request 5, then by 5
- backpressure, initial request 100, then by 100
- backpressure, initial request 1000, then by 1000
- backpressure, initial request 2, then Long.MAX_VALUE-1 (checks for request overflow)
Note that the above list no longer contains a check for negative request because that situation is covered by Subscriber.request throwing an IllegalArgumentException.
For each variation the following aspects are tested:
- expected onNext items received
- unsubscribe from source occurs (for completion, error or explicit downstream unsubscription (optional))
- unsubscribe from downstream subscriber occurs
onCompletedcalled (if unsubscribe not requested before completion and no errors expected)- if
onCompletedexpected is only called once onErrornot called unless error expected- if error expected
onCompletednot called afteronError - should not deliver more than requested
An example that tests all of the above variations and aspects for the Observable.count() method:
import junit.framework.TestCase;
import junit.framework.TestSuite;
import rx.Observable;
import com.github.davidmoten.rx.testing.TestingHelper;
public class CountTest extends TestCase {
public static TestSuite suite() {
return TestingHelper
.function(o -> o.count())
// test empty
.name("testCountOfEmptyReturnsZero")
.fromEmpty()
.expect(0)
// test error
.name("testCountErrorReturnsError")
.fromError()
.expectError()
// test error after some emission
.name("testCountErrorAfterTwoEmissionsReturnsError")
.fromErrorAfter(5, 6)
.expectError()
// test non-empty count
.name("testCountOfTwoReturnsTwo")
.from(5, 6)
.expect(2)
// test single input
.name("testCountOfOneReturnsOne")
.from(5)
.expect(1)
// count many
.name("testCountOfManyDoesNotGiveStackOverflow")
.from(Observable.range(1, 1000000))
.expect(1000000)
// get test suites
.testSuite(TestingHelperCountTest.class);
}
public void testDummy() {
// just here to fool eclipse
}
}When you run CountTest as a JUnit test in Eclipse you see the test variations described as below:

An asynchronous example with OperatorMerge is below. Note the specific control of the wait times. For synchronous transformations the wait times can be left at their defaults:
public class TestingHelperMergeTest extends TestCase {
private static final Observable<Integer> MERGE_WITH =
Observable.from(asList(7, 8, 9)).subscribeOn(Schedulers.computation());
public static TestSuite suite() {
return TestingHelper
.function(o->o.mergeWith(MERGE_WITH).subscribeOn(Schedulers.computation())
.waitForUnsubscribe(100, TimeUnit.MILLISECONDS)
.waitForTerminalEvent(10, TimeUnit.SECONDS)
.waitForMoreTerminalEvents(100, TimeUnit.MILLISECONDS)
// test empty
.name("testEmptyWithOtherReturnsOther")
.fromEmpty()
.expect(7, 8, 9)
// test error
.name("testMergeErrorReturnsError")
.fromError()
.expectError()
// test error after items
.name("testMergeErrorAfter2ReturnsError")
.fromErrorAfter(1, 2)
.expectError()
// test non-empty count
.name("testTwoWithOtherReturnsTwoAndOtherInAnyOrder")
.from(1, 2)
.expectAnyOrder(1, 7, 8, 9, 2)
// test single input
.name("testOneWithOtherReturnsOneAndOtherInAnyOrder").from(1)
.expectAnyOrder(7, 1, 8, 9)
// unsub before completion
.name("testTwoWithOtherUnsubscribedAfterOneReturnsOneItemOnly").from(1, 2)
.unsubscribeAfter(1).expectSize(1)
// get test suites
.testSuite(TestingHelperMergeTest.class);
}
public void testDummy() {
// just here to fool eclipse
}
}Observable<T> o;
Observable<T> stream =
o.lift(OperatorUnsubscribeEagerly.<T>instance());