diff --git a/k8s-yuan-ma-ren-cai-fu-hua-xun-lian-ying/di-wu-zhang-apimachinery/5.10-k8s-api-zu-he-ban-ben-kong-zhi-chu-tan.md b/k8s-yuan-ma-ren-cai-fu-hua-xun-lian-ying/di-wu-zhang-apimachinery/5.10-k8s-api-zu-he-ban-ben-kong-zhi-chu-tan.md
index 9f4b66d..fddad2f 100644
--- a/k8s-yuan-ma-ren-cai-fu-hua-xun-lian-ying/di-wu-zhang-apimachinery/5.10-k8s-api-zu-he-ban-ben-kong-zhi-chu-tan.md
+++ b/k8s-yuan-ma-ren-cai-fu-hua-xun-lian-ying/di-wu-zhang-apimachinery/5.10-k8s-api-zu-he-ban-ben-kong-zhi-chu-tan.md
@@ -14,11 +14,15 @@ Kubernetes 支持多个 API 版本,每个版本位于不同的 API 路径,
API 资源通过其 API 组、资源类型、名字空间(用于名字空间作用域的资源)和名称来区分。 API 服务器透明地处理 API 版本之间的转换:所有不同的版本实际上都是相同持久化数据的呈现,即底层数据是同一份数据。 API 服务器可以通过多个 API 版本提供相同的底层数据,但是根据调用 API 的版本不同,可以转换成对应版本的资源对象。
-例如,假设针对相同的资源有两个 API 版本:`v1` 和 `v1beta1`。 如果你最初使用其 API 的 `v1beta1` 版本创建了一个对象, 你稍后可以使用 `v1beta1` 或 `v1` API 版本来读取、更新或删除该对象, 直到 `v1beta1` 版本被废弃和移除为止。此后,你可以使用 `v1` API 继续访问和修改该对象。其实这个特性完全是为了保持API的兼容而设计的,正常情况下,没有人会混着版本去用,它发挥作用的地方主要在升级迭代时,要知道随着API的迭代开发,API 会逐渐 GA 进入到稳定版本,那 beta 版,以及 alpha 版则会在某一个阶段被移除,这时候,你用beta版API创建的资源对象,仍然能够用稳定版 API 来操作,这样就实现了无缝升级。
+例如,假设针对相同的资源有两个 API 版本:`v1` 和 `v1beta1`。 如果你最初使用其 API 的 `v1beta1` 版本创建了一个对象, 你稍后可以使用 `v1beta1` 或 `v1` API 版本来读取、更新或删除该对象, 直到 `v1beta1` 版本被废弃和移除为止。此后,你可以使用 `v1` API 继续访问和修改该对象。其实这个特性完全是为了保持API的兼容而设计的,正常情况下,没有人会混着版本去用,它发挥作用的地方主要在`升级迭代`,要知道随着API的迭代开发,API 会逐渐 GA 进入到稳定版本,那 beta 版,以及 alpha 版则会在某一个阶段被移除,这时候,你用beta版API创建的资源对象,仍然能够用稳定版 API 来操作,这样就实现了无缝升级。
-我们来举个例子体验下,在1.30 版本的Kubernetes中,有一个用来做流控的API,叫FlowSchema,目前有四个版本,v1,v1beta1,v1beta2和v1beta3,我们以v1beta2创建一个FlowSchema对象,然后使用v1beta2和v1beta3分别将这个对象读出来:
+我们来举个例子体验下,在1.30 版本有一个用来做流控的 API,叫 `FlowSchema`,目前有四个版本,v1, v1beta1, v1beta2 和 v1beta3,我们以 v1beta2 创建一个FlowSchema 对象,然后使用 v1beta2 和 v1beta3分别将这个对象读出来:
-1\. 使用v1beta2 api创建该对象:
+1\. 使用 v1beta2 创建该对象:
+
+```bash
+kubectl apply -f flowschema.yml
+```
```yaml
apiVersion: flowcontrol.apiserver.k8s.io/v1beta2
@@ -43,11 +47,7 @@ spec:
name: "system:unauthenticated"
```
-```bash
-kubectl apply -f flowschema.yml
-```
-
-2\. 使用v1beta2读取:
+2\. 使用 v1beta2 读取:
```bash
kubectl get flowschema.v1beta2.flowcontrol.apiserver.k8s.io test -o yaml
@@ -98,7 +98,7 @@ status:
type: Dangling
```
-3\. 使用v1beta3读取:
+3\. 使用 v1beta3 读取:
```bash
kubectl get flowschema.v1beta3.flowcontrol.apiserver.k8s.io test -o yaml
@@ -149,7 +149,7 @@ status:
type: Dangling
```
-可以看到,使用两个版本读出来的对象,几乎完全一样,除了`apiVersion`字段有区别,`metadata`字段中的`resourceVersion`和`uid`字段都一样,说明他们其实是同一个对象,我们可以直接查看etcd的数据库来确认下:
+可以看到,使用两个版本读出来的对象,几乎完全一样,除了`apiVersion`字段有区别,`metadata`字段中的`resourceVersion`和`uid`字段都一样,说明他们其实是同一个对象,我们可以直接查看 etcd 来确认下:
```bash
# etcdctl --endpoints http://127.0.0.1:2379 get / --prefix --keys-only | grep test
@@ -182,9 +182,9 @@ DanglingFal"Found*]This FlowSchema references the PriorityLevelConfiguration obj
可以看到存到数据库中实际上只有一条记录,但是却可以读出来两个不同的版本,说明在调用不同版本的API读取对象时,肯定是经历了某种转换。
-这个例子其实还不太好,因为两个版本的 FlowSchema 对象的字段是完全一样的,如果两个版本之间有字段的差异,可能更能说明问题,但是由于现在 Kubernetes 发展的已经很成熟了,各个API都已经趋于成熟,都逐渐的把beta版的API给移除了,或者beta版跟ga版几乎没有差异,beta的存在仅仅是为了能够兼容一下旧版本的应用,还有一些组是有alpha版本的,但是它是用来孵化新功能的,还没有成熟到进入beta或者ga的阶段,所以在beta或者ga版本的API中,还不存在alpha版中的对象,可以使用较旧版本的Kubernetes,肯定会有同一个对象在不同版本中同时存在的情况,而且可能会有字段的差异,或者关注下当前版本的alpha功能,未来肯定会经历beta, ga的迭代。
+这个例子其实还不太好,因为两个版本的 FlowSchema 对象的字段是完全一样的,如果两个版本之间有字段的差异,可能更能说明问题,但是由于现在 Kubernetes 发展的已经很成熟了,各个API都已经趋于成熟,都逐渐的把 beta 版的API给移除了,或者 beta 版跟 GA 版几乎没有差异,beta 的存在仅仅是为了能够兼容一下旧版本的应用。
-通过上面的例子,我们大概感受了下API多版本的功能,此外,还有个多协议的功能点,即用户可以选择API返回的数据的格式,比如上例中,我们通过命令行的-o选项或者api请求的Accept Header参数,来指定了希望返回yaml格式的数据,于是apiserver会将API资源给序列化成yaml格式返回给客户端,除了yaml格式,apiserver还支持序列化成json以及protobuf格式,例如:
+通过上面的例子,我们大概感受了下 API 多版本的功能,此外,还有个多协议的功能点,即用户可以选择API返回的数据的格式,比如上例中,我们通过命令行的 -o 选项或者 api请求的Accept Header参数,来指定了希望返回 yaml 格式的数据,于是 apiserver 会将 API 资源给序列化成 yaml 格式返回给客户端,除了yaml 格式,apiserver 还支持序列化成 json 以及 protobuf 格式,例如:
```bash
curl -H "Accept: application/json" http://127.0.0.1:8001/apis/flowcontrol.apiserver.k8s.io/v1beta3/flowschemas/test
@@ -216,7 +216,7 @@ system:unauthenticated
DanglingFal"Found*]This FlowSchema references the PriorityLevelConfiguration object named "exempt" and it exists"
```
-从上面的功能介绍来看,Kubernetes能够做到这个程度的API兼容,真的是很良心的,难怪它会一统江湖,Kubernetes社区将API的兼容性看得很重要,除了每个API都有一个进化迭代的过程之外,一旦API进入到GA稳定版阶段,后续对它的修改一定是不能破坏兼容性的,关于API兼容性的更多内容,可以阅读下社区的这个文档:[Changing the API](https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api\_changes.md)
+从上面的功能介绍来看,k8s 社区将API 的兼容性看得很重要,能够做到这个程度的 API 兼容,真的是很良心的,难怪它会一统江湖,除了每个API都有一个进化迭代的过程之外,一旦API进入到GA稳定版阶段,后续对它的修改一定是不能破坏兼容性的,关于API兼容性的更多内容,可以阅读下社区的这个文档:[Changing the API](https://github.com/kubernetes/community/blob/master/contributors/devel/sig-architecture/api\_changes.md)
OK,看了上面的功能介绍和示例,我们心里可能会有一些困惑:
@@ -230,11 +230,11 @@ OK,看了上面的功能介绍和示例,我们心里可能会有一些困惑
主要来说说版本是怎么转换的,为了方便各个版本之间互相转换,APIServer引入了一个`内部版本`的概念,每个API对象都有一个对应的内部版本,它是一个特殊的版本,是在APIServer内部对各个API对象进行处理时使用的数据结构(Struct),而不是使用的某个具体版本的数据结构(Struct),当该API对象跟外部交互时,则会从内部版本转换成对应的具体版本,我们称之为`外部版本`,这个“外部”其实包含两个地方:一个是通过HTTP协议跟客户端交互时,会将其转换成客户端请求的版本,一个是将该对象存储到数据库时,数据库会将其保存成某个版本的数据结构(Struct)。这个`内部版本`,有点类似于`中间版本`的概念,不论你请求的是哪个版本,都是那个版本跟`内部版本`之间互相转换,具体版本之间是不会直接进行转换的,这样就将一个网状的结构,转换成了星状的结构,减少了数据处理的维度,每个版本的API对象,只需要申明自己怎么跟`内部版本`进行转换就可以了。
-还有就是将某个对象存储到数据库时,并不是存储的`内部版本`的数据结构,而是存储的某个具体版本的数据结构,一般是该API对象最稳定版本的数据结构,比如某个API对象同时有两个版本,v1和v1beta1,那么不论通过哪个版本请求过来的,最终存储到数据库中的,都是v1版本对应的数据结构,反过来,当你从数据库读出来对应的数据之后,APIServer则首先会将其从`v1版本`转换成`内部版本`,然后再进行其他的处理。当然,也有可能存储的不是最稳定的版本,而是某个中间版本,比如v1, v1beta1, v1beta2,可能它存的是v1beta2版本的数据结构,即次稳定版本,这种情况,一般都处在升级迭代的过程中,保证应用的兼容性,经历几个版本迭代之后,还是最终切到v1版本的数据结构上去。
+还有就是将某个对象存储到数据库时,并不是存储的`内部版本`的数据结构,而是存储的某个具体版本的数据结构,一般是该API对象最稳定版本的数据结构,比如某个API对象同时有两个版本,v1和v1beta1,那么不论通过哪个版本请求过来的,最终存储到数据库中的,都是v1版本对应的数据结构,反过来,当你从数据库读出来对应的数据之后,APIServer则首先会将其从`v1版本`转换成`内部版本`,然后再进行其他的处理。当然,也有可能存储的不是最稳定的版本,而是某个中间版本,比如v1, v1beta1, v1beta2,可能它存的是 v1beta2 版本的数据结构,即次稳定版本,这种情况,一般都处在升级迭代的过程中,保证应用的兼容性,经历几个版本迭代之后,还是最终切到v1版本的数据结构上去。
OK,我们还是以上面的`FlowSchema`为例,来看看它不同版本之间转换的一个过程,先来看看`FlowSchema`各个版本的数据结构定义:
-v1beta2的数据结构:
+v1beta2 的数据结构:
```go
# k8s.io/api/flowcontrol/v1beta2/types.go
@@ -327,7 +327,7 @@ type FlowSchemaSpec struct {
内部结构
-```yaml
+```go
# kubernetes/pkg/apis/flowcontrol/types.go
type FlowSchema struct {
@@ -370,25 +370,19 @@ type FlowSchemaSpec struct {
}
```
-从上面的代码可以看到,v1beta2和v1beta3目前的数据结构是一模一样的,并且都位于`k8s.io/api`这个第三方库中,只是所在的目录不同而已,而内部版本的数据结构的字段跟他们也是一样的,只是没有带用来做序列化的tag,并且内部结构是位于kubernetes本身的代码目录树中的,并没有以第三方库的形式暴露出去。
+从上面的代码可以看到,v1beta2 和v1beta3 目前的数据结构是一模一样的,并且都位于`k8s.io/api`这个第三方库中,只是所在的目录不同而已,而内部版本的数据结构的字段跟他们也是一样的,只是没有带用来做序列化的 tag,并且内部结构是位于 kubernetes 本身的代码目录树中的,并没有以第三方库的形式暴露出去。
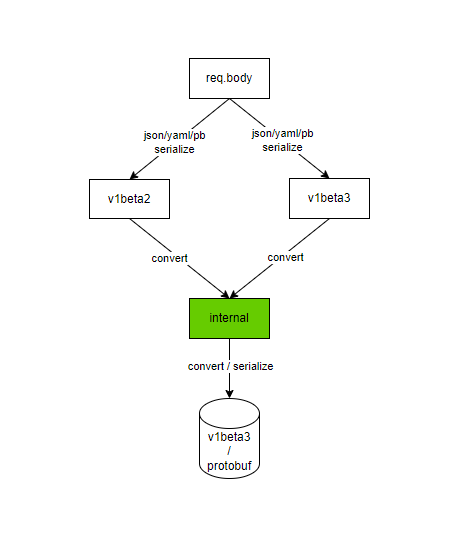
OK,我们先来看下创建过程中的版本转换以及序列化过程,如下图:
-[](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_create.png)
+ -[kubernetes\_versioning\_flowcontrol\_create](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_create.png)
-
-HTTP请求到了APIServer,会由该资源API对应的Handler来处理,第一步就是根据HTTP请求的`Content-Type Header`中标记的数据类型,比如是json还是protobuf,来将字节类型的 `req.body` 反序列化为对应版本的数据结构的对象实例,第二步,又会将具体版本的对象转换成内部版本的对象,第三步,在存数据库的时候,又将内部版本的对象转换成了稳定版本的数据结构的对象实例,并且将其序列化为protobuf格式的数据,将其存到数据库中。在存数据库的时候,默认是使用protobuf格式,可以通过配置项 `--storage-media-type` 来更改存储的格式,支持 `json/yaml/protobuf` 三种格式。
+HTTP请求到了APIServer,会由该资源API对应的Handler来处理,第一步就是根据HTTP请求的`Content-Type Header`中标记的数据类型,比如是 json还 是 protobuf,来将字节类型的 `req.body` 反序列化为对应版本的数据结构的对象实例,第二步,又会将具体版本的对象转换成内部版本的对象,第三步,在存数据库的时候,又将内部版本的对象转换成了稳定版本的数据结构的对象实例,并且将其序列化为protobuf格式的数据,将其存到数据库中。在存数据库的时候,默认是使用protobuf格式,可以通过配置项 `--storage-media-type` 来更改存储的格式,支持 `json/yaml/protobuf` 三种格式。
再来看看读取的过程,如下图:
-[](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_get.png)
-
-[kubernetes\_versioning\_flowcontrol\_get](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_get.png)
+
-[kubernetes\_versioning\_flowcontrol\_create](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_create.png)
-
-HTTP请求到了APIServer,会由该资源API对应的Handler来处理,第一步就是根据HTTP请求的`Content-Type Header`中标记的数据类型,比如是json还是protobuf,来将字节类型的 `req.body` 反序列化为对应版本的数据结构的对象实例,第二步,又会将具体版本的对象转换成内部版本的对象,第三步,在存数据库的时候,又将内部版本的对象转换成了稳定版本的数据结构的对象实例,并且将其序列化为protobuf格式的数据,将其存到数据库中。在存数据库的时候,默认是使用protobuf格式,可以通过配置项 `--storage-media-type` 来更改存储的格式,支持 `json/yaml/protobuf` 三种格式。
+HTTP请求到了APIServer,会由该资源API对应的Handler来处理,第一步就是根据HTTP请求的`Content-Type Header`中标记的数据类型,比如是 json还 是 protobuf,来将字节类型的 `req.body` 反序列化为对应版本的数据结构的对象实例,第二步,又会将具体版本的对象转换成内部版本的对象,第三步,在存数据库的时候,又将内部版本的对象转换成了稳定版本的数据结构的对象实例,并且将其序列化为protobuf格式的数据,将其存到数据库中。在存数据库的时候,默认是使用protobuf格式,可以通过配置项 `--storage-media-type` 来更改存储的格式,支持 `json/yaml/protobuf` 三种格式。
再来看看读取的过程,如下图:
-[](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_get.png)
-
-[kubernetes\_versioning\_flowcontrol\_get](https://hackerain.github.io/assets/kubernetes\_versioning\_flowcontrol\_get.png)
+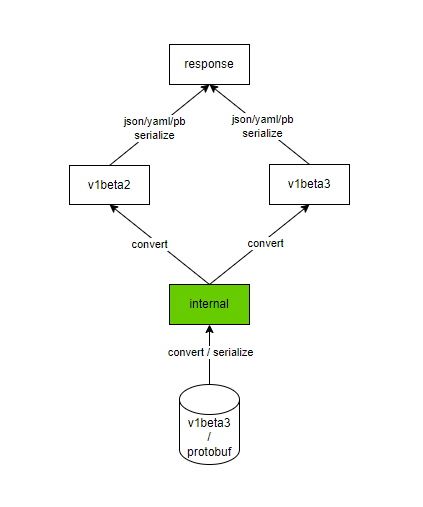 读的过程,其实正好跟写的过程相反,当请求某一个版本的API对象时,首先会从数据库中读出字节类型的数据,然后将其反序列化为内部数据结构的对象实例,然后再转换成对应的版本,然后再根据请求中的`Accept Header`来决定将其序列化为哪种数据格式,返回给客户端。
-在创建时,因为要把创建结果返回给客户端,其实也走了一遍读的流程,跟单独去读过程是类似的,上面没有再画出来了。
-
读的过程,其实正好跟写的过程相反,当请求某一个版本的API对象时,首先会从数据库中读出字节类型的数据,然后将其反序列化为内部数据结构的对象实例,然后再转换成对应的版本,然后再根据请求中的`Accept Header`来决定将其序列化为哪种数据格式,返回给客户端。
-在创建时,因为要把创建结果返回给客户端,其实也走了一遍读的流程,跟单独去读过程是类似的,上面没有再画出来了。
-