Replica propagation times systematically change in cyclic patterns that may slow simulations #613
Comments
|
@hannahbrucemacdonald : If you have a chance before I do, here’s what I was doing to look into the variable timing issue. I edited multistatesampler.py and inserted the following at the end of This should write the output of The relevant numbers are |
|
Did you only see this in complex, or solvent and vacuum too? |
|
Hey - I've got so far as to run a short bit of complex with Thrombin and here are the minimal plots. Looks like we have oscillations not correlated to the GPU temp. It looks like it's stabilising around 80C which should be fine. I will have a go with the other parameters that you've suggested too System: Thrombin
(edited to fix x-axis labels) |


|
Fan speed is quite variable, but also doesn't seem to correlate |

|
Are you plotting this every iteration or every replica propagation time? I was hoping to get more fine grained information by printing the output of nvidia-smi every replica propagation substep |
|
Ahhhh I see what you mean, I have that I think - give me a min. |
|
Ok so I have the time of each replica iteration from the nvidia-smi output, but it's in seconds, while each replica propogation is ~1 second. I can't see anything useful about each replica taking longer or not because of the rounding
Unless I'm getting the wrong end of the stick. I can increase the amount of MD (~factor 10?) per step to push this up? We currently do... 250*4 fs per replica per iteration (1 picosecond). |

@hannahbrucemacdonald : Great question! I used this jupyter notebook to generate this plot for all phases from GitHub seems to have trouble with image uploads right now, but check out the notebook:
|
|
That temperature plot looks suspicious to me. Temp throttling can definitely happen at intervals. Some data pulled from this article:
So we might be hitting 80ºC, decreasing performance to "calm down" (but keeping the temperature just a bit below 80ºC!), then we think we can use more power and hit 80ºC, chill down, etc. |
|
Power usage might give more details. |
|
Sorry got a little further --- but not much - I can expand biggest addition is looking at timestep is still too small to really see the finetooth timing... I'll run something slower in the same directory - hopefully it will be there for european morning time! |
|
Hopefully there is some more output in |
This is my hypothesis exactly! |
|
It really looks like the temperature is causing the driver to throttle the speed here: Could you also pull the node name(s), the driver version, and GPU type? Once we have some good data compiled, we can ask the sysadmins to tweak the driver settings a bit to minimize this. |


|
There's more info on There are some useful options here: @jaimergp suggests that we especially want to monitor the The sysadmins have control over the power profile to modify the policy used to change power states. |

|
Cool thanks - I'll look into
|
|
Back working on this now Lilac is back --- Power state is depreciated and now called Performance state. It seems at first glance to always be at |
|
@hannahbrucemacdonald : and look at these things:
There is useful info on ensuring we can get maximum performance here: |
|
Note that step 1---just looking to make sure we are always in P0---may be sufficient here! If we're not, we should post on the HPC slack and have them fix this. |
|
^ I'm saying that we are always in P2 i.e. from the first step |
|
From my reading, I've determined
|
|
Here's what I've found so far:
rmmod nvidia; modprobe nvidia NVreg_RegistryDwords="RMForcePstate=0"; nvidia-smi -pm 1; sleep 30; nvidia-smi Edit: It appears that this is described as an option for the windows-only nvidiaInspector, but the above presents a way to do this in linux.
|
|
Just had a chat with Sam Ellis (MolSSI) about this --- he suggested that we try run with OpenCL to just sanity check if it's a cuda issue or not? He wasn't sure, but seeing as we've tried it on a few different hardwares, he said it might be worth narrowing down if it's more on the software side of things. Also - I haven't run this since upgrading to cuda/10.1 and openmm 7.4.1, which I guess you have been running? |
|
@peastman : This is fantastic! This makes a great deal of sense, and I think fully explains the odd behavior we've observed. Is there a way to trigger the reordering via the API? If so, we could call this every time we call If not, we might be able to restructure the calculations to try to use a separate |
|
@peastman : It looks like |
|
@peastman : Thanks so much for identifying this!
Atom reordering seems quite expensive, so although this might remove the cycling problem, the average iteration time will probably be much longer, right?
This seems like a better solution
I think it reorders atoms if void ComputeContext::reorderAtoms() {
atomsWereReordered = false;
if (numAtoms == 0 || !getNonbondedUtilities().getUseCutoff() || stepsSinceReorder < 250) {
stepsSinceReorder++;
return;
}
atomsWereReordered = true;
stepsSinceReorder = 0;
if (getUseDoublePrecision())
reorderAtomsImpl<double, mm_double4, double, mm_double4>();
else if (getUseMixedPrecision())
reorderAtomsImpl<float, mm_float4, double, mm_double4>();
else
reorderAtomsImpl<float, mm_float4, float, mm_float4>();
} |
|
@peastman These are great points you are making. It makes a lot of sense. Was this sampling algorithm something that has been changed in the dev version of Openmm? Or in other words, why is this issue not being shown in the current 7.7 release? On the other hand, there used to be a time when if we specified a |
I think by "sampling algorithm", he means the details of how we are running repex, which is outside of openmm (in openmmtools). But Iván does raise a good point -- are there any changes to atom reordering that were added between 7.7 and 7.7.0.dev1? If not, then I wonder if there is a different change that is causing the difference in behaviors between the two openmm versions (when using 2 MPI processes)? |
We have two separate stages:
If the atoms are not reordered after the new replica positions are set, some fraction of those steps will be taken with bad atom orderings, resulting in slow dynamics. In the worst case, all steps will be slow. If we're using a separate For energy computation, we currently use the idiom This is means that energy evaluation will also take longer since we're always using the suboptimal atom orderings. Instead, we should invert this order, or cache a separate context for each replica.
Running up to 250 steps with bad atom orderings might be much more expensive than reordering atoms once at the beginning and using the optimal atom ordering for the replica propagation. |
|
@peastman : One other thought: Why fix the atom reordering interval at all? If it can have such a big impact on performance, wouldn't a simple heuristic to auto-tune the atom reordering interval have the potential for significant performance impact? |
|
Triggering the reordering of atoms does work around the issue. I tried what @jchodera suggested in this comment and the results are as follow. Sorry for the crowded plot but I think it's readable enough. The localbuild is openmm at the commit @zhang-ivy pointed in a previous comment, which corresponds to her environment and to the |

It is a lot of work, but I've seen other MD engines auto-tune the neighbor list parameters, the advantage of auto-tuning is that there are many choices in neighbor list parameters that are very system dependent. |
Not that I know of. Clearly something changed, since the behavior is slightly different. But it seems to be a change for the better, since average performance is now slightly faster than before.
The challenge is to come up with a heuristic that's efficient in all cases, or at least not too horribly inefficient. And of course, that requires prioritizing which use cases are most important and which are less important.
In this case, the thing we need to adapt to is the pattern of what methods you invoke in what order. When it's just a matter of looking at simulation settings, you can analyze them and try to pick optimal parameters. But each time you call The current behavior compromises between the two. It will do at most 250 inefficient steps before reordering again. Unfortunately, that just happens to be the exact number of steps the above script executes before switching replicas, which is maybe the worst possible choice. If it did 1000 steps then at least 75% of steps would be guaranteed to have an efficient ordering. The question is whether we can find a different behavior that makes this particular use case faster without making a more important use case slower, or making a less important but still relevant use case dramatically slower. |
|
It sounds like it would be more performant to keep track of the number of steps of dynamics since the last Even better would be to auto-tune based on the number of steps of dynamics since the last It could potentially be useful to use total atomic displacements, or pairlist updates, but it might be hard to find a universal heuristic for those. Just auto-tuning based on number of steps since last |
|
Some notes from our perses dev sync this past Monday: What are we going to do about repex cycling issue?
I tried the last option, and here are the results: In each of the above experiments, I am running t-repex on barnase:barstar using 2 GeForce RTX 2080 Ti and n_replicas = 24 with OpenMM 7.7.0.dev1. Though using 24 MPI processes causes the cycling problem to disappear, it seems like the overhead of using so many processes causes a slowdown that is not worth it. |

|
As a short term workaround, is it reasonable to increase the number of steps per iteration? Was 250 chosen for a good reason, or is it arbitrary? A larger number would reduce the impact of reordering and lead to faster overall performance. |
|
It's a reasonable suggestion to try for now. We could try 1250
steps/iteration (5 ps/iteration).
This will reduce the number of exchange attempts by ~5x, however, and there
is excellent evidence in the literature that the benefits of replica
exchange are maximized by exchanging as frequently as possible to allow the
best mixing among replicas. We'd probably get some improvement in aggregate
simulation time per day, but the loss in efficiency (how much variance is
reduced by a given wall clock time) may not be worth it.
Thanks for doing these experiments, @zhang-ivy! I'll look into suggesting
how we can restructure the inner propagation and energy computation for
MultiStateSampler in the meantime.
@peastman: I'm happy to try to contribute a PR to OpenMM if you have an
idea of what solution you think is optimal. I do think it would be sensible
to consider switching to counting number of dynamics steps instead of
number of calls to reorderAtoms to determine when to reorder, and forcing
reordering on the first dynamics step if the positions have just been
updated since it is very likely that many steps will be taken and the
efficiency boost will be worth it.
If might also be useful to add a method to allow manual triggering of atom
reordering, and to make the hard-coded 250 steps between reordering
something that can be set as a platform parameter.
|
|
I have some preliminary ideas about how to address this. I want to take a little more time to let them solidify. Before implementing anything, we need to identify all relevant use cases and make sure we have good benchmarks for them. We need to be sure we don't accidentally make something slower. I think these are the main cases to consider.
|
This list looks reasonable to me! I'll tag @mikemhenry @ijpulidos @zhang-ivy @dominicrufa in case they have anything to add. |
|
That list covers all the cases I'm interested in -- the last case is something we do in our repex code as well -- for each iteration, we compute the potential energy of each replica at each state. And the first case also covers nonequilibrium switching. |
|
Ok, thanks. I think the behavior we want is something like this.
|
|
This sounds eminently reasonable. Any thoughts on allowing the reordering interval to be set manually as a platform property? That should be relatively straightforward and help us discover if auto-tuning would provide significant advantages. It would still be nice to have a manual way to force reordering via the API, but given this is a platform implementation detail, it doesn't seem like there is a clean way to introduce this into the (platform-agnostic) OpenMM API. |
Let's first see if we can make it work well without the need for that. When you expose an internal detail like that, it becomes harder to change the implementation later. And then people specify a value for it without understanding what it does, just because they saw someone else do it in a script, and they get worse performance because of it. |
|
I implemented the logic described above in #613 (comment). It mostly works, but it ends up having unintended consequences. Every time the barostat runs, it triggers a call to |
|
Closed via openmm/openmm#3721 |
In plotting the total replica propagation time per iteration from one of @hannahbrucemacdonald's experiments (

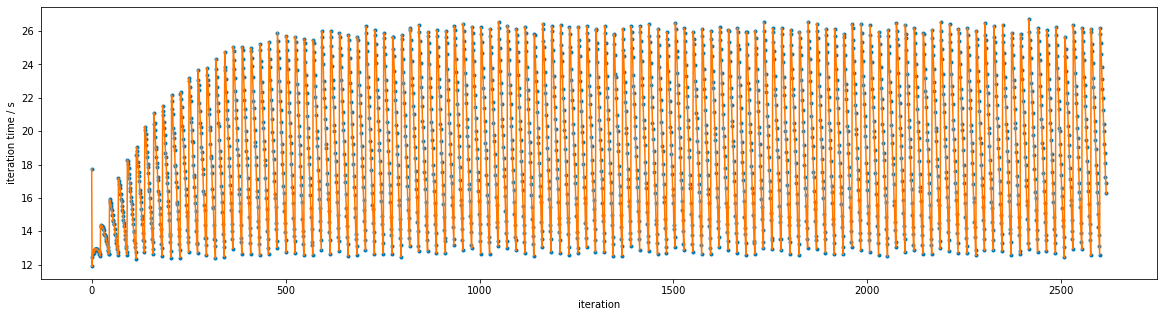
/data/chodera/brucemah/relative_paper/dec/jnk1/lig20to8/complex_0.stderr), it appears that there is a pattern:Connecting successive iterations with lines reveals a clearer pattern:
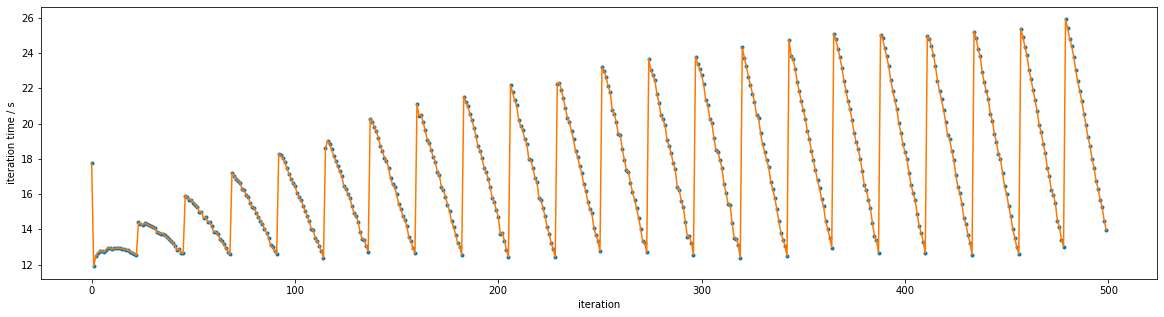
Zooming in shows the pattern more clearly:
This is currently just something intriguing, but something we should investigate in the new year since it may lead to speed improvements if we can understand what is going on here.
The text was updated successfully, but these errors were encountered: