This document describes the architecture design and implementation of OpenCensus Agent and OpenCensus Collector.
- Allow enabling/configuring of exporters lazily. After deploying code, optionally run a daemon on the host and it will read the collected data and upload to the configured backend.
- Binaries can be instrumented without thinking about the exporting story. Allows open source binary projects (e.g. web servers like Caddy or Istio Mixer) to adopt OpenCensus without having to link any exporters into their binary.
- Easier to scale the exporter development. Not every language has to implement support for each backend.
- Custom daemons containing only the required exporters compiled in can be created.
On a typical VM/container, there are user applications running in some processes/pods with OpenCensus Library (Library). Previously, Library did all the recording, collecting, sampling and aggregation on spans/stats/metrics, and exported them to other persistent storage backends via the Library exporters, or displayed them on local zpages. This pattern has several drawbacks, for example:
- For each OpenCensus Library, exporters/zpages need to be re-implemented in native languages.
- In some programming languages (e.g Ruby, PHP), it is difficult to do the stats aggregation in process.
- To enable exporting OpenCensus spans/stats/metrics, application users need to manually add library exporters and redeploy their binaries. This is especially difficult when there’s already an incident and users want to use OpenCensus to investigate what’s going on right away.
- Application users need to take the responsibility in configuring and initializing exporters. This is error-prone (e.g they may not set up the correct credentials\monitored resources), and users may be reluctant to “pollute” their code with OpenCensus.
To resolve the issues above, we are introducing OpenCensus Agent (Agent). Agent runs as a daemon in the VM/container and can be deployed independent of Library. Once Agent is deployed and running, it should be able to retrieve spans/stats/metrics from Library, export them to other backends. We MAY also give Agent the ability to push configurations (e.g sampling probability) to Library. For those languages that cannot do stats aggregation in process, they should also be able to send raw measurements and have Agent do the aggregation.
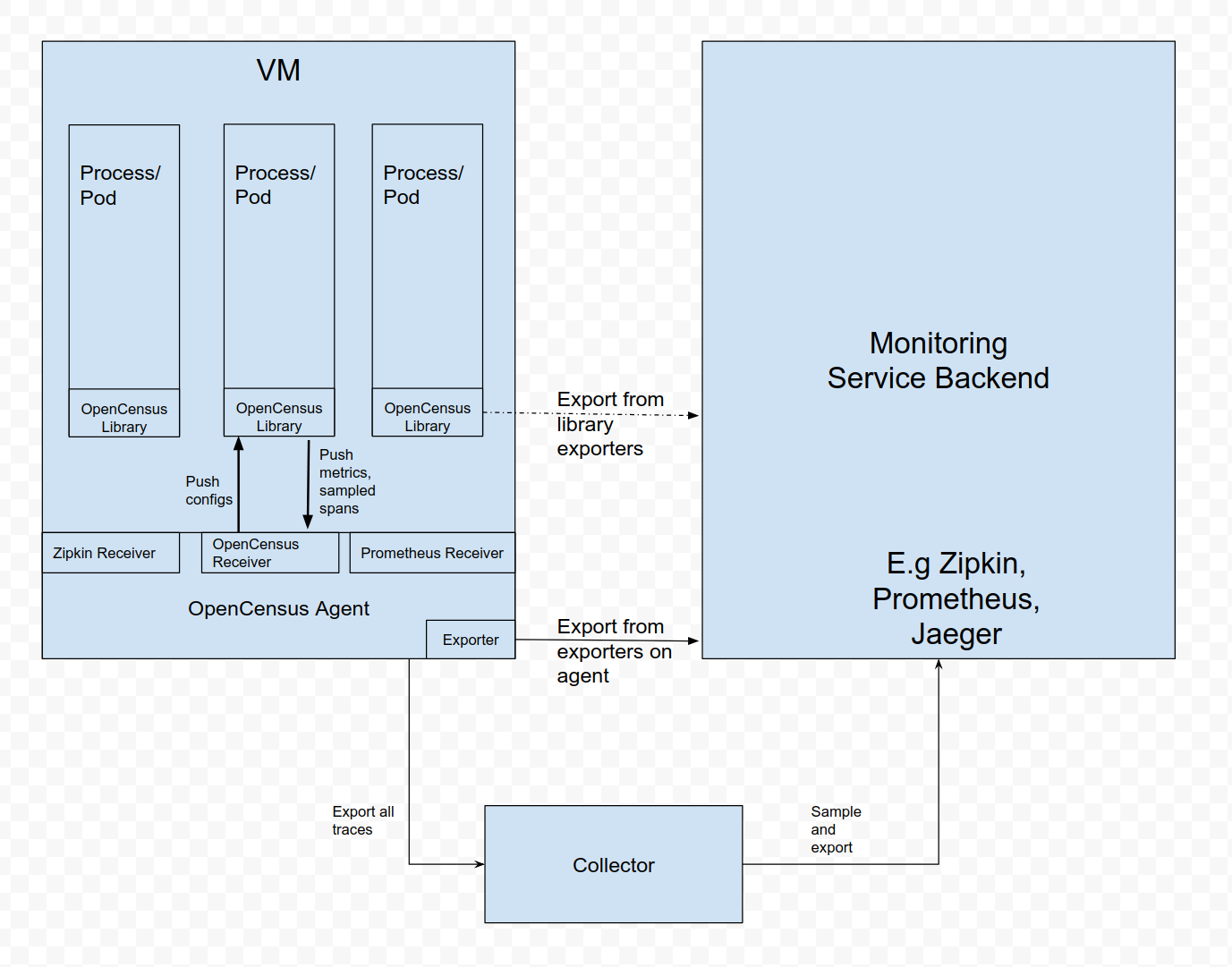
For developers/maintainers of other libraries: Agent can also be extended to accept spans/stats/metrics from other tracing/monitoring libraries, such as Zipkin, Prometheus, etc. This is done by adding specific recevers. See Receivers for details.
To support Agent, Library should have “agent exporters”, similar to the existing exporters to other backends. There should be 3 separate agent exporters for tracing/stats/metrics respectively. Agent exporters will be responsible for sending spans/stats/metrics and (possibly) receiving configuration updates from Agent.
Communication between Library and Agent should use a bi-directional gRPC stream. Library should initiate the connection, since there’s only one dedicated port for Agent, while there could be multiple processes with Library running. By default, Agent is available on port 55678.
- Library will try to directly establish connections for Config and Export streams.
- As the first message in each stream, Library must send its identifier. Each identifier should
uniquely identify Library within the VM/container. If there is no identifier in the first message,
Agent should drop the whole message and return an error to the client. In addition, the first
message MAY contain additional data (such as
Spans). As long as it has a valid identifier assoicated, Agent should handle the data properly, as if they were sent in a subsequent message. Identifier is no longer needed once the streams are established. - On Library side, if connection to Agent failed, Library should retry indefintely if possible, subject to available/configured memory buffer size. (Reason: consider environments where the running applications are already instrumented with OpenCensus Library but Agent is not deployed yet. Sometime in the future, we can simply roll out the Agent to those environments and Library would automatically connect to Agent with indefinite retries. Zero changes are required to the applications.) Depending on the language and implementation, retry can be done in either background or a daemon thread. Retry should be performed at a fixed frequency (rather than exponential backoff) to have a deterministic expected connect time.
- On Agent side, if an established stream were disconnected, the identifier of the corresponding Library would be considered expired. Library needs to start a new connection with a unique identifier (MAY be different than the previous one).
This section describes the in-process implementation details of OC-Agent.

Note: Red arrows represent RPCs or HTTP requests. Black arrows represent local method invocations.
The Agent consists of three main parts:
- The receivers of different instrumentation libraries, such as OpenCensus, Zipkin, Istio Mixer, Prometheus client, etc. Receivers act as the “frontend” or “gateway” of Agent. In addition, there MAY be one special receiver for receiving configuration updates from outside.
- The core Agent module. It acts as the “brain” or “dispatcher” of Agent.
- The exporters to different monitoring backends or collector services, such as Omnition Collector, Stackdriver Trace, Jaeger, Zipkin, etc.
Each receiver can be connected with multiple instrumentation libraries. The
communication protocol between receivers and libraries is the one we described in the
proto files (for example trace_service.proto). When a library opens the connection with the
corresponding receiver, the first message it sends must have the Node identifier. The
receiver will then cache the Node for each library, and Node is not required for
the subsequent messages from libraries.
Most functionalities of Agent are in Agent Core. Agent Core's responsibilies include:
- Accept
SpanProtofrom each receiver. Note that theSpanProtos that are sent to Agent Core must haveNodeassociated, so that Agent Core can differentiate and groupSpanProtos by eachNode. - Store and batch
SpanProtos. - Augment the
SpanProtoorNodesent from the receiver. For example, in a Kubernetes container, Agent Core can detect the namespace, pod id and container name and then add them to its record of Node from receiver - For some configured period of time, Agent Core will push
SpanProtos (grouped byNodes) to Exporters. - Display the currently stored
SpanProtos on local zPages. - MAY accept the updated configuration from Config Receiver, and apply it to all the config service clients.
- MAY track the status of all the connections of Config streams. Depending on the language and implementation of the Config service protocol, Agent Core MAY either store a list of active Config streams (e.g gRPC-Java), or a list of last active time for streams that cannot be kept alive all the time (e.g gRPC-Python).
Once in a while, Agent Core will push SpanProto with Node to each exporter. After
receiving them, each exporter will translate SpanProto to the format supported by the
backend (e.g Jaeger Thrift Span), and then push them to corresponding backend or service.
The OpenCensus Collector runs as a standalone instance and receives spans and metrics exporterd by one or more OpenCensus Agents or Libraries, or by tasks/agents that emit in one of the supported protocols. The Collector is configured to send data to the configured exporter(s). The following figure summarizes the deployment architecture:

The OpenCensus Collector can also be deployed in other configurations, such as receiving data from other agents or clients in one of the formats supported by its receivers.