[Review]: Introduction to deep learning #25
Comments
|
We're still running a final round of comments for the paper (see carpentries-incubator/deep-learning-intro#364), the plan is to submit the paper on the 15th of September through: https://openjournals.readthedocs.io/en/jose/submitting.html#submitting-your-paper . I'm not sure how that relates to this review, are the 2 independent or should we wait for this review process to finish before submitting to JOSE? |
|
Great to see this submission, @svenvanderburg. As a listed contributor, I have a conflict of interest acting as editor for this one. I am going to find another community member who can fulfill the role for this review, and will post back here when it's ready. To answer your question about review order: we have been asking lesson developers to submit the lesson for review here, before the JOSE review. See #11 and the related review in JOSE for an example. |
|
@tobyhodges any update on finding an editor? |
|
@tobyhodges ? 😇 |
|
I have reached out to a potential guest editor for this review and am waiting for confirmation. Hoping to be able to follow up very soon! |
Perfect, thank you for the update 🙏 |
|
Good news: @brownsarahm has kindly agreed to act as Guest Editor for this review. I am extremely grateful to her for being willing to take this on. |
|
I'll work on this in small bits, but this way it's all in one place and the authors could work on the (very minor) accessibility issues and one small note on setup that I have checked so far. Editor Checklist - Intro to Deep LearningAccessibility
Content
Datasets and licenses
other content notes:
Design
to fix:
RepositoryThe lesson repository includes:
Structure
comment:
Supporting informationThe lesson includes:
other setup note:
General
|
|
@brownsarahm any update on the progress? |
|
@brownsarahm any update? Can you give us an indication when we can expect this to be done? |
|
Hi! Sorry, a bunch of unexpected things happened last fall, and then when you sent the first check-in I was off of work for the holidays. And the second came while I was in a deadline crunch, This is now back in my active queue. I should finish the pre-reviewer stuff within a week and I'm looking for reviewers starting now. |
|
Hi @brownsarahm. Cool, thanks for the update 🤗 |
|
editorial checks are done and @tobyhodges and I are working on finding reviewers next. The comment above has a few things for you all to look at now, but thanks for resolving all of the previously identified ones already! |
|
Thanks @brownsarahm. I have suggested a few reviewers to Sarah but if any of my fellow authors can also suggest anyone they think would be suitable, I am sure it would be helpful. (Please do not tag anyone here by their GitHub handle.) |
|
@svenvanderburg Do you have any updates in response to my final editorial check? In particular, do you have responses to the concerns about:
and ideally before we assign reviewers, it would be nice to resolve, but these are minor:
|
|
Hey @brownsarahm. Sorry, I totally missed that it was final! Thanks for extra pinging me @brownsarahm :) Some answers: Episode lengthsIndeed episode 3 takes a bit longer than the other ones, but not twice longer. In fact, the timing for the other episode is too optimistic: Here is a PR with more realistic timing. In comparison to other lessons the episodes are a bit longer, this is because we want to finish the full deep learning workflow in each episode. When teaching, this is not really a problem though, the workshop is actually pretty balanced in terms of cognitive load because in every episode we go through this deep learning workflow once, and conceptually it makes sense to have the cuts between episodes at these points. What do you think? We could maybe write this explanation in the introductory instructor notes? Dataset licensesIf I understand correctly, the only problem is with the CIFAR-10 dataset. It is so widely used, but I never realized it doesn't actually have a license judging from the official website. I found a paper that extracts the statement about citation as their license: It is actually a crawled dataset, and in the paper I don't read anything about the crawled images being under open-source license.... Anyway: do you think it is a problem that we use this dataset? It is such a central dataset in the field and so widely used. We would have to change the entire episode if we use a different dataset. We can write a comment about in the instructor notes. Small issuesI resolved the two small issues you referred to, will be reviewed soon by one of my colleagues. We will soon pick up any other remaining issues. Would be good to enter the next phase of reviewing. Let us know what we have to do to help this progress. |
TimingThanks for the explanation. I think at one level your strategy for putting breaks in the content makes sense. I am not certain if your claim about cognitive load is true, but also not certain that it is false. However 3.5 hours without a break is a long time and most instructors will not want to give a break in the middle of an episode. Maybe an instructor note reminding about breaks? (as context, I'm a maintainer on instructor training and we get a lot of complaints about not enough breaks there and we have them ~every 90 minutes). Dataset LicenseIn my understanding of carpentries policy a permissive license is required. Since the dataset was crawled, it likely has zero consent to be using the images from the original owners of the images. I think it probably does not have the same risks as imagenet, but should be checked. On the other hand, this is clearly, to me, an intended use by the people who curated the images into a dataset, despite them not putting a license on it and them possibly not having appropriate rights to the images either. Whether it is okay or not is going to be up to Carpentries policy about the situation where there is no license. @tobyhodges can you help navigate that or let us know who else in the carpentries should be looped in? |
|
Thanks for tagging me @brownsarahm. I need to do a bit more reading and thinking about this, and will come back soon with a full response. |
|
Thanks for your patience while I took some time to read through the relevant pages and documents, and to reflect on the most appropriate course of action. I am sorry to say that I think we should replace the dataset in the lesson. The lack of a license file in the dataset is somewhat problematic, even though the authors clearly intend for the dataset to be re-used and usage in the lesson is within the terms stated on their website. But my biggest concerns are with the unethical way in which the data was "collected." Images were scraped and modified for the dataset without any attempt at seeking permission from the copyright owners or giving them attribution, which feels unethical to me regardless of any arguments over its legality. (I am not a lawyer but it seems like the use may fall under "fair dealing" in Canadian copyright law, where the researchers who published the dataset are based.) In Collaborative Lesson Development Training, alongside considerations of licensing, size, and complexity, we ask lesson developers to consider the ethics of the example datasets they include in their lessons. I would like to apply the same standard to lesson reviews in The Carpentries Lab. I acknowledge that replacing the dataset will require significant new work on the part of the authors, and perhaps I should have noticed sooner and avoided some of this inconvenience. @svenvanderburg for my part, I would like to devote some time in the coming weeks to try to make the necessary changes (as I am already one of the authors). I hope I will be able to propose some alternative datasets soon, and of course it would help to have input from others with more DL experience than I have. However, please also be aware that you can withdraw the lesson from review here if you prefer. Finally, many thanks to @brownsarahm for catching this and looping me into the discussion. |
TimingHa, no 3,5 hour teaching without breaks is absurd! At the Netherlands eScience Center we usually teach in a schedule like [for this recently taught workshop](this https://esciencecenter-digital-skills.github.io/2024-02-05-ds-dl-intro/#schedule). Never more than 90 minutes of teaching! And I think beta pilots copied that schedule in rough lines. It doesn't matter that it is in the middle of an episode. In addition, we swap instructors halfway the episodes which makes teaching load lighter as well. See carpentries-incubator/deep-learning-intro#446 for addressing this, do you agree @brownsarahm ? And thanks for bringing this up, this is a great outcome of the review. Since we always use the same schedule no matter what lesson material we use we had a blind spot here. LicenseThanks @tobyhodges for digging into the CIFAR10 license. I agree we should change it, indeed it goes against everything the Carpentries stands for... So, the remaining issues to fix before the review are:
(and some more small comments from Sarah that we will definitely pick up the coming period but are not essential to do before the review) Can you confirm this @brownsarahm ? |
|
Yes, this is correct, these two issues would get it to a point where it is ready for review. |
|
Wow, you're so sharp @brownsarahm! I was already planning on using the dollarstreet dataset as example to open up a discussion on ethical AI next time we teach the lesson. I'm really happy that we use this dataset now. Great, we're looking forward to the review! |
|
@likeajumprope thank you for volunteering to review lessons for The Carpentries Lab. Please can you confirm if you are happy to review this Introduction to Deep Learning lesson? You can read more about the lesson review process in our Reviewer Guide. |
Yes I am happy to accept the invitation for review. |
|
@mike-ivs thank you for volunteering to review lessons for The Carpentries Lab. Please can you confirm if you are happy to review this Introduction to Deep Learning lesson? You can read more about the lesson review process in our Reviewer Guide. |
Happy to review the lesson. We'll actually be teaching the beta lesson again next week! |
|
@svenvanderburg we have moved to the next phase! I think we expect the reviews within about 6 weeks. |
|
Hi all, I'm still working through the review and have currently gone through all of the supplementary material (instructor notes/glossary/references/etc) and the Summary&Setup, episode 1, and episode 2. I hope to get through the remaining episodes by the end of next week. I'm pretty happy overall with the lesson, but will wait to post the "reviewer checklist" summary until i've finished all the episodes. In the meantime i'll post my comments/etc here so that there's something to get started with. And of course, some of the comments are suggestions/questions so feel free to answer as you wish! Most of my comments are clarity/cognitive load related which is inevitable given the topic, but I do think the lesson does a stellar job of teaching Deep Learning already! supplementary material (i.e. bonus material, instructor notes, references, etc)
Summary and Setup
Episode 1 - IntroductionOverview questions & objectives
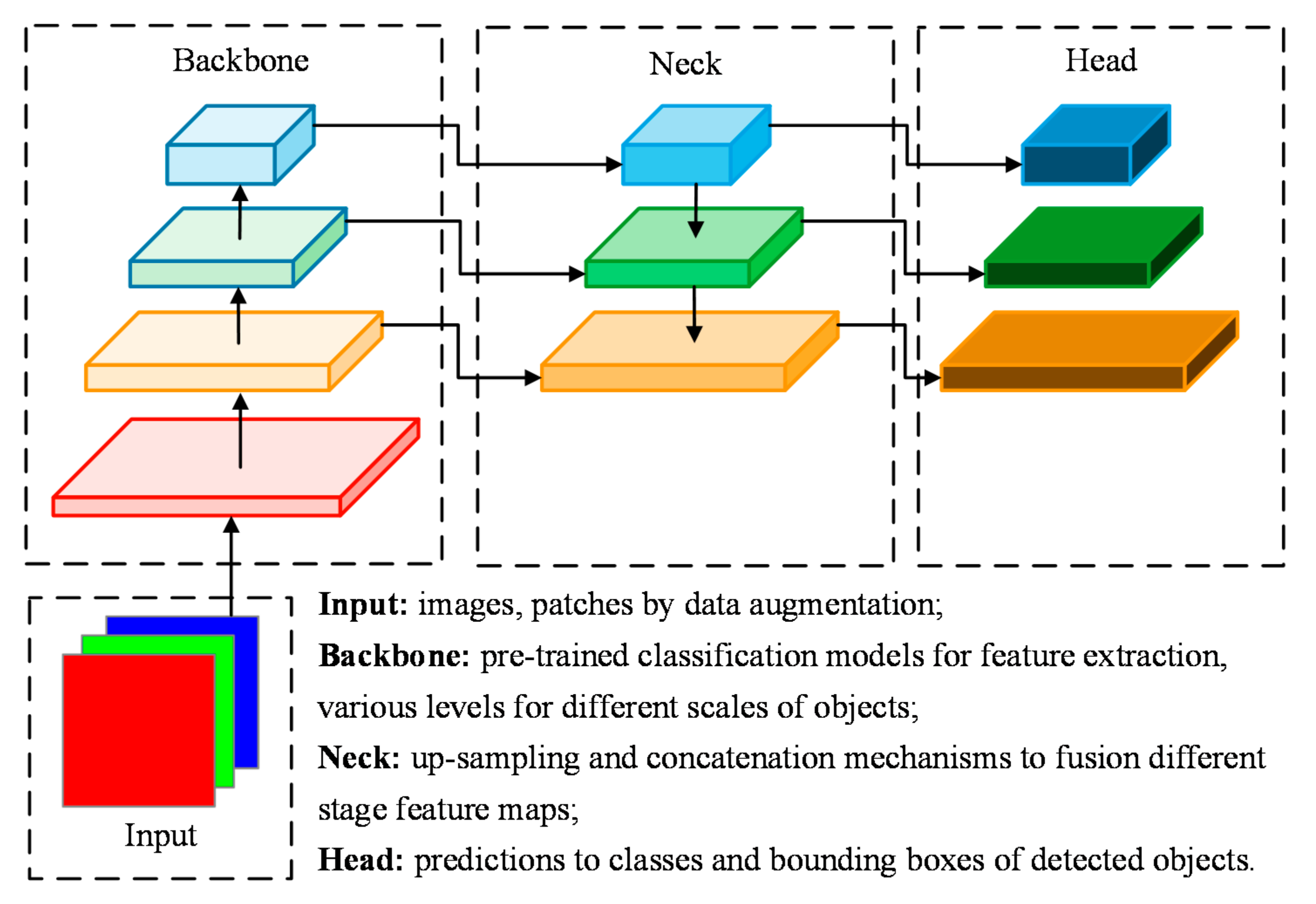
Figure
|
|
@mike-ivs thank for your comments so far! Super useful. 🙏 Looking forward to the rest! |
|
Hi all,
Just to chime in: I am on it 😊
Feedback coming soon.
Best,
Johanna
From: Sven van der Burg ***@***.***>
Date: Tuesday, 9 July 2024 at 07:57
To: carpentries-lab/reviews ***@***.***>
Cc: Johanna Bayer ***@***.***>, Mention ***@***.***>
Subject: Re: [carpentries-lab/reviews] [Review]: Introduction to deep learning (Issue #25)
@mike-ivs<https://github.com/mike-ivs> thank for your comments so far! Super useful. 🙏 Looking forward to the rest!
—
Reply to this email directly, view it on GitHub<#25 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AFVBFNU5TDJ6YLAEHUVGGRLZLN3T5AVCNFSM6AAAAAA4HVHIKOVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMZDEMJWGYZTQMBWG4>.
You are receiving this because you were mentioned.Message ID: ***@***.***>
|
|
Checking in @likeajumprope and @mike-ivs, could you each provide an updated ETA for your review this week(or the review itself if you happen to be done)? |
|
My apologies, life got in the way since my last post! I've had a look at the changes so far (carpentries-incubator/deep-learning-intro#482) and am very happy with them :) I'll submit my relevant link/typo PRs shortly. (PR here). In terms of ETAs I aim to get the rest of the review finished up by the 2nd August at the latest, hopefully by the end of this week. |
|
@mike-ivs no worries. Looking forward to the rest of your comments :) |
|
As promised, here's the remaining comments. I'll post the reviewer checklist after this along with overall comments/summary. Again, i've very happy with the lesson and most of my comments are aimed at improving the clarity / further reducing the cognitive-load of a fairly heavy topic! (the lesson does a very good job already). Episode 3 - Monitor the training process2) Identify inputs and outputs
4) Choose a pretrained model or start building architecture from scratch
6) Train the model
9) Refine the model
Episode 4: Advanced layer typesDropout
|
{kind=link}
SummaryVery happy with lesson overall and I would say it is pretty much ready to graduate beyond the incubator. Quite a few of my comments are suggestions, and mostly aimed at improving clarity / reducing cognitive load on an inescapably concept-heavy topic. The lesson contributors+maintainers+testers have done a great job! Reviewer ChecklistAccessibility
* To view the alternative text of an image, we recommend using Content
Design
Supporting information
|
|
Great! @mike-ivs thank you for your review! 🙏 |
|
Hi @likeajumprope checking in for n ETA on your review |
Happy belated 1 year anniversary! 🎉On the 1st of September we had our anniversary celebrating that we are now 1 year under review 🎉🙈😂 Sorry for the sarcasm ;) If we can do anything to speed up the process (also for future reviews), please let us know. Thanks again everyone for your valuable input to the lesson! |
Hi, I have been invited to the project end of May this year. I know that this is also quite a stretch, but this is free labor that I am doing in addition to my work. :) I am 3/4 done and will send a summary asap. |
|
Thank you for keeping us updated, @likeajumprope. I want to stress how much we appreciate the time and effort that you, @mike-ivs, @brownsarahm, and others are volunteering to make this review happen. We could not do it without you and I recognise that activities like this one always compete for time with many other things that often must take higher priority. Please let me or @brownsarahm know if there is anything that we can do to support you. @svenvanderburg I understand your frustration but please remain respectful in your communications. Everyone is trying their best while faced with many competing priorities. Consider for example that delays on my part have contributed considerably more to the extended duration of the process -- and I am one of the authors, plus compensated for the time I spend on it! We cannot say the same for the guest editor or reviewers. I note also that although the process may be slower than you might like, the duration of this review has been fairly typical of what we have seen so far on the Lab and at other places that operate open peer review. Writing as an author of the lesson, instead of focusing on the time it can take to get reviewer feedback I choose to reflect on how valuable the input we have received so far has been. For example, the editorial comments from @brownsarahm have helped us make a big improvement to the example data used in the lesson. And @mike-ivs has provided a pretty forensic analysis of how the order and emphasis of our lesson content could be adjusted to make it flow as well as possible. I am looking forward to finding out how @likeajumprope's comments will help us make the lesson even better! |
|
Thanks @tobyhodges for your kind and mediating words. Sorry if this came across as disrespectful, it was not ment that way, but I can see how it can feel like that. Like my wife says (who is a primary school teacher): It's only funny if everyone can laugh about it. I think I should have put a bit more emphasis on that I really appreciate everyone's valuable time spent, also yours @likeajumprope 🙏 I'm looking forward to your comments @likeajumprope :) |
|
@likeajumprope can you update us on the progress of your review? (Where no progress is also a valid update 😉 ) |
|
@likeajumprope Do you have progress on this? Even an incomplete review helps the authors improve the lesson and then you can update after. |
Reviewer ChecklistAccessibility
Content
Design
Supporting information
General
|
|
Almost done - in general the lesson is super nice and I think I can check most boxes above. Will fill in the general section with my notes in the next few days |
|
Great @likeajumprope 🎉 Looking forward to your notes 😺 |
|
@likeajumprope any update on this? 😽 |
Lesson Title
Introduction to deep learning
Lesson Repository URL
https://github.com/carpentries-incubator/deep-learning-intro
Lesson Website URL
https://carpentries-incubator.github.io/deep-learning-intro/
Lesson Description
This is a hands-on introduction to the first steps in Deep Learning, intended for researchers who are familiar with (non-deep) Machine Learning.
The use of Deep Learning has seen a sharp increase of popularity and applicability over the last decade. While Deep Learning can be a useful tool for researchers from a wide range of domains, taking the first steps in the world of Deep Learning can be somewhat intimidating. This introduction aims to cover the basics of Deep Learning in a practical and hands-on manner, so that upon completion, you will be able to train your first neural network and understand what next steps to take to improve the model.
We start with explaining the basic concepts of neural networks, and then go through the different steps of a Deep Learning workflow. Learners will learn how to prepare data for deep learning, how to implement a basic Deep Learning model in Python with Keras, how to monitor and troubleshoot the training process and how to implement different layer types such as convolutional layers.
Author Usernames
@dsmits @psteinb @cpranav93 @colinsauze @CunliangGeng
Zenodo DOI
10.5281/zenodo.8308392
Differences From Existing Lessons
No response
Confirmation of Lesson Requirements
JOSE Submission Requirements
paper.mdandpaper.bibfiles as described in the JOSE submission guide for learning modulesPotential Reviewers
No response
The text was updated successfully, but these errors were encountered: